opnclaw接哪个国内大模型

粉丝11.4万获赞104.3万
相关视频
 00:42查看AI文稿AI文稿
00:42查看AI文稿AI文稿用单片机做东西玩,看上去门槛很高,既要懂硬件接线,又要懂软件编程。实际上只要开始动手,从零基础到入门也就一两天。编程软件就使用米斯特二点零, 不需要敲代码,用鼠标拖一拖模块,调一调参数,就能完成编程。比如我想让这个舵机摆动起来,找一块开发板接起来就能做到。玩舵机就找舵机的程序块,舵机接哪个口,这里就选哪个口,给一个延时时间,避免动作太快,然后复制一份, 最后在这两个程序块的角度不一样,程序就可以上传了,所以入门起来一点都不难。新手朋友先看我主页合集单片机快速入门系列,还可以在我主页搜关键词,找特定模块的教程视频。
832科技手工折腾局 04:10查看AI文稿AI文稿
04:10查看AI文稿AI文稿今天介绍一套好用的 web 代码工具,国内就能使用,无需魔法 windows, 快 捷打开 windows, 点击市场。安装 cc 插件,请看操作。第一次安装,这里会出现安装两个字,我的已经装过了。 接下来看怎么启动 cc, 点这个 cc 图标, 这就自动跳过,不选也行。 这里有三种模式自动执行,先预览再确认,先规划再动手。 为啥这里能使用国内模型,那就得请出 switch 这个工具了。 现在我们来用 switch 配置国内模型,点酷狗,选 mini mac, 添加 p 和模型信息, 点酷狗看到新加的点启动就行了。 好了,已经能干活了, 接下来是常规演示,看不看都行。 好嘞,今天就到这里,感觉 switch 作者开源,有啥问题评论区见。
89附近的老王 02:33查看AI文稿AI文稿
02:33查看AI文稿AI文稿大家好,随着国内的国产大魔性的发展,以及近期 open core 的 风靡,直接以 top coin 计费方式的这种模式开始衍生开来,那接下来我们一起详细学习一下 top coin 的 出海的行业梳理。 top 控的话一共分为这么几个大的模型,第一个是 mini max, 第二个是 kimi, 第三个是 deepsea, 第四个是智普 ai, 下一个是字节的豆包,下一个是阿里千问,下一个是腾讯的元宝,最后一个是百度的文心。 那我们接下来的话详细的梳理一下。首先我们先看第一个大模型 mini max, mini max 的 话,目前国内的鸿博股份公司、 首都在线公司有相应的算力与智算的一个服务。第二个是 kimi 大 模型,目前国内的润泽科技公司、 亚康股份公司都与 kimi 有 相应的算力服务。下一个是与 deepsea 合作深度相关的,目前国内的润泽科技公司、韩钢股份公司 与 deepsea 提供相应的算力集群的一个服务。下一个是智普 ai 方面,目前国内的网速科技公司、优克德公司、奥菲数据公司有系与 智普 ai 合作相关的一个算力。下一个我们再看一下润泽科技方面,日字节豆包方面。字节豆包方面的话,目前国内的润泽科技公司、 东阳光公司、光环新网公司、大卫科技公司、亚康股份公司、东方国信公司与字节跳动的 a i、 d c 服务商有相应的合作。 下一个我们看一下阿里千份方面,目前国内的数据管公司,韩钢股份公司、润建股份公司 与阿里云以及阿里千份有相应的智算云服务的项目,下一个我们看一下腾讯的元宝方面,目前与腾讯元宝深度合作的国内的科华数据公司、润泽科技公司都与腾讯签有战略的合作协议。 下一个是群星玩具,也与腾讯有相应的算力集团的一个服务。最后一个是百度的文新,目前国内的奥菲数据公司、数据港公司 啊,与百度有相应的百度智云的 idc 的 这种服务,算力是大模型的底座,国产算力又是整个接下来发展的核心方向,大家可以详细的研究梳理一下。
23🔥火线题材🔥 00:40查看AI文稿AI文稿
00:40查看AI文稿AI文稿一个开源项目,让你玩转所有顶级大模型,这里有一千多个全免费的 ai 模型,堪称最强大的本地部署 ai 平台。不管是 lama chat、 gpt quen, 还是 stable fusion 等等你想要的顶级模型, 都只要这个工具就能搞定。离谱的是,它提供了与 open ai api 完全兼容的接口,而且不需要显卡,只要你的陈老 cpu 就 能跑起来,让你几乎零成本拥有文本生成、音频处理、视频处理 及图像生成等多种 ai 能力,重点数据完全在本地运行,不上传云端,保护你的隐私安全,支持豆壳儿部署。这下终于能爽完大场的模型了,感兴趣的可以研究研究。
1299AI小蔡狗 04:24查看AI文稿AI文稿
04:24查看AI文稿AI文稿大家好,我上一条讲风沫的视频爆了,回复超级多。首先先谢谢大家,但是我发现评论区里有好多小伙伴有一个天大的误区,他们一直没用上 cc, 竟然是以为国内用不了,我用的可都一直是国产模型。 来,我给大家看一下我的 cc 是 怎么用的,我目前接了智普、 kimi、 迷你 max, 还有朋友给我共享的四零九零双卡, 我每次启动的时候会选一个供应商,而且一般我会开多个窗口同时用,有时候用相同的,有时候用不同的, 所以你看,我从来没有在 cloud code 里用过 ontropix, 自家的 cloud 模型一次都没有。那我今天就教大家一个方法吧, 怎么样配置 cc, 使用国产模型,怎么样切换模型?虽然有很多工具啊,但是工具都有一些学习成本,我们不应该花那么多时间来学工具,而是要学会怎么样能用 ai 来解决一切问题。所以今天我就教大家就是用 ai 做个脚本,在启动的时候选择。 我们来看一下。首先你得知道两件事,一个是 c c 的 模型供应商和环境变量的关系,还有一个是它的 api 格式。我们先看第一个 c c 配置模型的供应商是通过这四个环境变量操作的, 你可以给它设不同的值, base url 就是 你的 api key, model 就是 你要用的模型, 这个可以不设,不设的时候有的供应商他就会给你用一个小模型,我是一般习惯把这个变量设成跟他模型一样,这样就始终保持用一个模型,基本上就是你把这四个黄金变量填好之后,启动 cc, 他 就会改改变。对, 还有一个关键就是说这世界上 ai 供应商都提供了三种的格式,一种是 chat completion api, 这有大部分的供应商都有,但是 c c 用不了 responses api 呢?这是 open ai 最新的,但是大部分供应商也不支持 c c 也不用 c c 用的都是 iso 自家的格式,现在一般提供 coding plan 的 厂商都会有这个格式,所以,但你设置的时候不要设错了,不能设成这个了,所以你需要去看一下 它是怎么样,但是我觉得我们都不需要这么麻烦,不需要去调查文档来看一下很简单,就你把这个脚本扔给 dbc, 让它去打开它网页调查或和深度思考,让它自己去查就行了,它会给你生成一个脚本。 我这条 prompt 就是 windows 的 或者 mac 的, 它都会给你生成,然后你复制,复制到你的目录就行了。 哪个目录呢? windows 下在这个目录, mac 下在这个目录,这个就是你们自己需要去看一下。 注意一注意一点,就是 windows 下 c c 点 bat 这个文件,你千万不要用 unico 的, 否则会乱码哦。我,我的 prompt 里头要求写的是英文,可能也不会,但是我建议把它改成 a n s i, 然后你用那个 notepad 打开之后选择另存,然后选那个全部文件,当然把编码格式改成 a n s i 就 行了, 然后 mac 就 无所谓,就是这个目录。还有一个很重要的事,这个是好多朋友可能会因为这个原因导致它一直用不上 cc 或者产生误解,因为 cc 在 第一次启动的时候,它会强制要求你登录 cloud 的 账号, 但是实际上我们配置的是完全不应该有这一步的,这个就是因为这个 cloud layer json 这个文件里这个东西没设置好, 你把它设置好了之后,它再也不会弹出那个登录提示了,所以好多朋友不知道这个它就它就误解了,但是实际上我们稍微把它跳过了 cc, 就 可以用本地模型了。 最后呢,友情提示,你入门 ai 的 时候, cloud code 是 一个很不错的选择,但是一定要记住,一定要有一个国产的或者开源的平替,省得哪天他用不了了你就哭吧。 好吧,国产的 kimi code, queen code, 开源的 open code, 这些都是不错的选择,多条路总没错吧。以上就是本期的所有内容了,谢谢大家!
1.9万小天fotos 02:13查看AI文稿AI文稿
02:13查看AI文稿AI文稿有个记者啊,揭露了六个大模型啊,对 openclock 做了完整的实测啊,任务是找文件,收信息,发邮件啊,结果就是找不到文件啊,搜索报错,发邮件卡死, 已经有人连续的产出报文啊,偏偏阅读破万。同一个工具,为什么差距这么大?今天把实测的结论给你说清楚,你自己判断到底值不值得装 核心三点。第一点就是实测里失败的是什么?千问三点五的任务是找一个本地的文件啊,测试人员明确的告诉了他位置, ai 整整找了五分钟,还是没找到发邮件的,测试更是直接, ai 一 直重复命令,没有实际的动作。这不是个例,六款模型参与测试, 大多数需要在操控浏览器的环节,全部失败。第二点,那为什么有人觉得很好呢?因为 open 本身不是大模型,它是指挥官 调用的,大模型才是士兵,士兵强不强决定了账,能不能打印,大家明白哈。所以还有配置, 有人用它搭了一套热点监控系统,每天自动全网扫内容,推送到钉钉或者是飞书,配置好了之后几乎不用管,靠这套流程,连续就出了好几篇破万的报文。同一个工具,配置对了是神器啊,配置错了是坑。 第三点就是正确的用法,到底长什么样?用过 open club 的 人,这个体验的曲线几乎都是一模一样。第一周就是蜜月期哇,他能控制电脑,好神奇。第二周幻灭期, 分一百个文件,花了好几刀,然后呢,自己一分钟搞定,需要什么成本呢?第三个阶段呢,就是平衡期,只把它用在高价值、长耗时, 人们不愿意反复干的任务上,到了这个阶段,他才是真正的生产力工具。前小米 o s a i 的 专家说了一句话,目前的版本不是合格的生产力工具, 但等大模型再进步一点, open 可乐只会越来越好。但他现在是一个需要配对才能发挥价值的工具,不是开箱即用的产品。你装了之后卡在哪里了?评论区聊聊,我们一起摸。
11桥比特 00:51查看AI文稿AI文稿
00:51查看AI文稿AI文稿带着大家先去部署我们的这个 open core, 然后接入大模型,然后以及连到非说我可能更期待于后半部分,就是大家看能不能把它怎么玩出花来, 那些 skills 是 拿来干嘛的?他后面有他的描述,对,有很多 skills, 然后比如说选完了之后你就点这个,点这个, 这是我们第一个小时就安装好了, 快七点多了,就是这个,我看他前面都跑起了,然后现在就差最后去飞输了一次,还有点问题,在调这个电脑早就没电了。
91智维界麓客AI社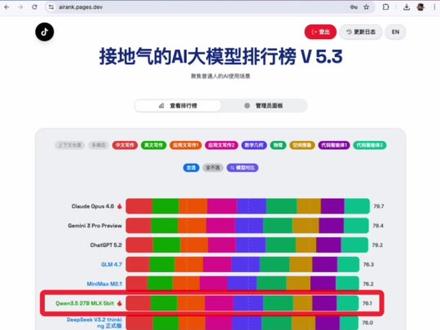 03:01查看AI文稿AI文稿
03:01查看AI文稿AI文稿啊,继昨天的千问三点五一百二十二币模型之后,我把千问三点五最后的一块拼图及二十七币的稠密模型测试了一下, 结果可以说意料之外,但是又是情理之中,我愿称其为开元中小模型的搜它。 在我的测试任务里,二十七币拿到了八十三点一分的高分,名列目前榜单第四名,它上面只有 jimmy 三 pro、 cloud opus 四点六和 gpt 五点二。如果我们去掉多模态和上下文的加分项, 单看模型本身的能力,二十七币依旧以七十六点一分和 deepsix 三点二正式版不相上下。 中英文写作和应用文写作的得分是三十五点二分,属于是第一梯队的水平,数学、几何和物理方面则是十九点四分。 大家可以发现,在纯文本问答和写作方面,中小模型的性能已经和国外闭元大模型没有什么太大的差别了。所以如果你的日常任务是问答和写作的话,本地部署一个中小模型是完全够用的。 代码能力方面,二十七 b 则是展现了稠密模型的优势,表现非常抢眼,以二十一点五分和 cloudsonnet 四点五的二十一点七分平分秋色。 这里我们用 cloud opus 四点六和 mini max 二点五作为对比测试对象,左边是 cloud, 中间是千问三点五二十七 b, 右边是 mini max 二点五满写版二十七 b 可能在视觉效果方面稍稍有些欠缺,但是整体完成度还是非常高的。 作为对比,我们再看看和其他中小体积模型的对比。这里左边是法国的 devstra 二,右边是 openai 的 chat gpt os 二十币 结果高下立判,和一百二十二币以及三十五币的横向对比,我们也可以发现二十七币的效果是更加接近一百二十二币的, 而三十五 b 的 混合专家模型则是有严重的涂层问题。 python 六边形小球测试的效果也非常不错,图形效果非常美观,各种粒的影响也有体现。 虽然有些欺负人,但是这里是 cloud opus 四点六的实现效果,这是 glm 四点七的实现效果,大家可以自行评判。 如果你想对比一下其他的模型的话,可以上我的网站自行查看所有测试任务的输出并对比哦。总结一下, 虽然现在的主流已经是混合专家模型了,但是稠密模型的性能仍然是强于混合专家的。稠密模型在 ai 领域,因此也总会有自己的一席之地。
91AI踩坑指南 01:38查看AI文稿AI文稿
01:38查看AI文稿AI文稿然后呢我们接下来在这一步呢,继续去完善相关的功能,那其实我们也只差最后一步了啊,就是把 nonchain 的 一些功能呢接入进来,其实 nonchain 这部分呢,它的功能相对比较多啊,它里面的代码我们当时在给大家去实现的,主要是在模型层去做了一部分处理,给大家看一下在 那个 ai engine 那 一层实现的那一部分主要集中在大模型调用这块啊,在这个里面我们因为是用的本地的欧拉玛,所以呢通过七幺欧拉玛去做基础的调用, 调用这一层的话,我们整个调用执行器都是自己去实现的啊,不管是从开始节点到各种这个 h t p 节点, end 节点、 condition 节点都是自己去实现的,这个执行器 自实行执行器。然后呢再在最上层通过注册内置的一些节点执行器完成了一个解偶,这是我们说的那个解偶盒,或者说是通过插件化的方式来完成的这个基础架构啊,那这部分呢,其实在我们那个项目实战里面给大家去有详细的介绍啊,在这个项目里面,大家如果说 在接下来啊,想重点的去把 ai 相关的一些知识点重点去学习,去掌握,之后到年后啊,能够去比如说三四月份求职涨薪,那大家可以去了解一下我们对应的这个 项目实战啊,这个大家可以去找咨询老师去领取相关的项目介绍。然后呢包括项目的演示文,那个演示项目的地址啊,大家可以输入一下 cloud 啊,那个 ai flow 妙码一丢点 com 进来之后自己去体验一下啊,这是给大家去部署的这个演示版,大家可以看一看,完整课间评论区扣八八八,免费领取!
 10:16查看AI文稿AI文稿
10:16查看AI文稿AI文稿这个图片国内的主流 ai 几乎都识别错误,这个粮食放大器,国外的 gpt、 gmail 三表现如何呢?还有这个比较潦草的鸟,到底是哪个模型识别的更精准? 接下来我们做一个简单的模型识图能力对比。我找了四家平台,用免费的模型去测试,均选快速模式。国内的是豆包和千问,海外的是 gmail 和 gpt。 其实还有几家模型也不错,但免费用户的服务器太容易出现繁忙状态了。规则如下,我们分四组不同类型的照片,每组呢五张,让每个模行为每张图片生成五个不同的标题和二十个不同的关键词,每组满分是一百二十五分, 标题或关键词错一个扣一分。为避免混子,模型会对以下的情况进行一个加分,比如照片中是一只鸟,其他的模型都说是鸟,这个回答是没有错误,但是有一个模型,如果说出了这只鸟的具体型号或者是具体的特点,我们会额外的加五分。 当然有一些照片的内容我不能百分百确定,请见谅。如果有说的错的地方,欢迎大家指正。本次所用到的图片,除了一张风光照外,全部由我个人拍摄,不是什么热门的网图。 理论上对 ai 来说比较新,我们采用的一个方式就是随机的截图,加一个统一的复制粘贴形式上传,这样就不会附带照片的原数据。因为这些照片其实它们的原数据里面我已经写入了大量的关键词,还有不同的标题, 所以我们去截图就会避免模型识别到这些数据。现在开始测试 一个突发情况,就是 gpt 上传了几张图片之后,对免费的用户就进行了一个限制,后面我们的 gpt 就 换了一个渠道,但是模型呢,也从免费的五点三升级到了最新的五点四,这是需要注意的一点, 没想到整理这么花时间,周末搞了一下午才搞完。求赞,求评论,求关注,我们先看动物组的情况,抖音豆包二点零得分一百一十七分,他把大雁宝宝识别成了鹅宝宝,其他的倒没什么问题。下面是阿里千问三点五 plus 得分一百零七分,也是大雁宝宝识别成了鹅宝宝。还有这个麋鹿的状态也是识别错误的,这个麋鹿是夏天太热刚从河水里面出来,后背是黑色的淤泥, 很健康,但是比较孤僻。但是千万的模型识别,这只麋鹿挂了,所以是一个扣分项。而鹅苗识别成了鸵鸟,其实非常严格的意义,算它勉强是对的,但是其他模型呢,都给出了一个正确的答案,所以也扣分。但是这个灰罐鹤, 阿里的千万给出了具体的产地和象征意义,所以我们会额外的加五分。谷歌的 jimmy nike 三 得分一百二十七分,也是大雁宝宝识别成了鹅宝宝,但是它的关键词里面有一个大雁幼崽,这一个词是所有模型中唯一给出正确答案的词,所以也是额外加五分。而麋鹿呢,说出了一个四不像的真实特点,我们也会额外加五分。 g p t 五点四得分一百零九分,也是大雁宝宝识别成了鸭宝宝,和其他的还不太一样,麋鹿里面有一个词是受困泥地,也是一个明显错误,也是略微减去了一些分数,其他的回答倒是很标准。最终动物组得分,谷歌这名 nine 三,一百二十七分。 抖音豆包二点零一百一十七分。 g p t 五点四,一百零九分。阿里的千问三点五 plus 一 百零七分。这里面 g p t 给我的工具感是最重,不过我个人还是比较喜欢下面呢。来到了复古组, 这组图片其实对国内的 ai 比较友好。抖音的豆包二点零得分一百三十分。唯一精确说出这个搪瓷盆具体型号的模型, 红双喜,所以额外加五分。阿里的千问三点五 plus 得分一百一十八分。主要扣分项是它把搪瓷盆里面识别出了有 鱼,但是显然这个盆它就是一个单纯的搪瓷盆,这一项扣的比较多。谷歌的 jimi nike 三得分是一一百二十四分。粮食放大器识别成了老的压力锅, 虽然这个东西和压力有一定的关联,但是物品的分类明显是错的,所以也是扣分。 gpt 五点四,得分呢是一百二十二分,它把粮食放大器识别成了工业设备,我不排除它有一定的工业属性, 但是和主体的关联过弱也是一个扣分。像但是这个电视的照片, gpt 是 唯一缩出 crt 电视的一个模型, crt 就是 大屁股电视的一个意思, 这一点会额外加五分。最终复古组的得分,豆包二点零一百三十分。瑞米奈三,一百二十四分。 c p t 五点四得分一百二十二分。千问三点五 plus 得分一百一十八分。豆包的发挥依旧很稳定。接下来是动植物的一个混合组, 六包二点零系列,得分一百三十分,是唯一识别出石牙蝇的模型,这点会额外加五分。这个东西其实是看着像蜜蜂,但其实不是,蜜蜂的眼睛没有这么大,你看这个照片,昆虫的眼睛是不是特别像苍蝇,所以叫石牙蝇?阿里千问三点五 plus 得分一百一十九分, 也是把石牙蝇识别成了蜜蜂。但刺猬这张照片 把里面的背景三叶草识别出来了,所以会额外加五分。还有这张乌冬丝桑葚的照片,这面奶是唯一指出具体品种的模型,所以也会额外加五分。但是这里要说一下,其实这张照片这几个模型理论上都能识别出来, 但是不知道为什么,这次只有谷歌的 jimmy nike 给出了一个很标准的正确答案,其他的模型都识别出了一个基础的鸟类,但是不够具体。 g p t。 五点四,得分一百二十分,同样是把石牙蝇识别成了蜜蜂, 给出的答案依旧保持了很好的工具感。最终呢,植物组的得分,谷歌 jimmy 三是最高的,一百三十二分,豆包二点零一百三十分。 g p t 五点四,一百二十分,阿里千问三点五 plus 一 百一十九分。豆包的发挥呢,依旧非常稳定, 但是谷歌的 jimmy 凑巧在乌冬这张票片上面减了五分,因为乌冬这个鸟其实基本的模型都能识别出来,但是呢,这次结果就是没出最后一组。城市的一个风光建筑对国内的模型比较友好, 同时呢,也主要看看海外对国内风光建筑的一个识别能力。我们先看抖音的豆包二点零,得分一百二十五分,发挥很稳定。 阿里的千问三点五 plus 得分一百二十三分,没有钟楼略微是扣分。需要注意的一点就是南京紫峰大厦这张照片,其他的模型都能精准地识别出地区在南京,建筑是紫峰大厦。但是阿里的千问 没有给出一个特别明确的答案,但是他的回答也都没有问题,所以这里不扣分。谷歌的 jimmy 三,得分一百二十五分,很标准的回答,没什么问题。 gpt 五点四得分一百零八分,把北京的正阳门和箭楼识别成了西安的景区, 这里也是一个扣分项,最终城市风光组的一个得分。抖音的豆包二点零一百二十五分。 谷歌的 jimmy nike 三,一百二十五分。阿里的千问三点五 plus 一 百二十三分。 g p t 五点四,一百零八分。豆包和 jimmy nike 发挥依旧很稳定。阿里的千问三点五 plus 没有识别出南京这个地域,真的让我挺意外的。 j p t 五点四把北京的景区识别成了西安的景区。最终呢,我们的得分,第一名是 谷歌的 jimmy 三,总分是五百零八分。第二名是豆包的二点零,得分是五百零二分。 第三名就是阿里的千问三点五 plus, 得分是四百六十七分。第四名就是 gpt 五点四,得分是四百五十九分。 这就是一个本次的模型识图能力比拼,不知道这个排名是不是和你想的是一样。最后发一个几乎全军覆没的照片,就是这个,大雁宝宝。当然我我也不是百分百确定他是大雁宝宝,但是我百分之九十九确定他是大雁宝宝。 只有谷歌 jimmy 三在关键词处给了一个正确精准的答案,因为我是摄影爱好者, 需要借助不同的模型去帮我跑这些照片的标题和关键词描述,所以我目前更偏向于这种工具属性的答案,像是豆包 g p t 这种。但是谷歌 gmail 三 真的是非常拟人,个人觉得更适合做一些创造性的回答。阿里的千问三点五 plus 说实话真的是进步神速,比我去年使用的那个状态真的是好太多了!真的是好太多了。其实本次的分数和排名 都只是大模型在特定维度下的一次快照,其实不能说明什么。数字的高低从来不是衡量技术价值的唯一标准, 更不是判断一个模型是否好用的唯一答案。真正重要的是这个技术它是否一直在前进,而且能否为普通人的生活创造出真正有用的价值。最后呢,感谢这些模型在多个维度给我带来的一时方便 和更多维度的轻微不安。模型呢在迭代赛道呢一边又在扩宽,另一边呢又在加快收展,我们普通人也要尽量跟上,尽量不要掉队。好了,这就是本次的全部内容,欢迎关注新人自媒体,我们下次见!
57阿朴的探索 01:17查看AI文稿AI文稿
01:17查看AI文稿AI文稿这两天 oppo klo 的是双屏了,是刷的非常非常火,简直火到了一塌糊涂,就好像感觉好像 oppo klo 的 什么都能干一样,就真的好像二十四小时待机。但是当你试了一下之后,你会发现这跟智障没什么区别。这就好像一个鸡生了一个蛋,然后第一个人说,啊,这个鸡蛋好大,那么第二个人说那个鸡蛋像西红柿也大, 那第三个人说啊,鸡蛋像西瓜一样大,那么第四个人说鸡蛋像一个大石头那么大,那么到第一千个人说,啊,鸡蛋像一座山一样大,那么接下来一些人就相信鸡蛋真的像一座山一样那么大,那么他们就说,我要看一下像山一样大的鸡蛋。其实你用脑,你稍微想一下,这个事情其实很简单, 到任何一个软件刚刚开发出来之后,他就是个智障,他就真的只能做最简单最简单最简单的事情,甚至最简单的事情他都做不了。你现在就想象 ai 生图刚出来的时候,他能生成一张图,他就已经很了不起了,他能发展到今天,他也是中间隔了这两三年的,他哪能一出来就像现在这个样子?那不可能的。 你现在想想, gpt 刚出来的时候跟现在 gpt 能比吗?没法比吗?但他是接待了好多好多好多好多次。所以说 opencloud 现在其实就是个智障,我告诉你,现在没用,你现在该怎么着你就怎么着,这东西如果真的想发展到像传说中的那个样子, 我告诉你,还要时间,至少一年,所以你现在该干嘛干嘛,不要把时间花在这个上面,没意义。更多设计内容欢迎关注设计师正方形。
15设计师正方形 06:02查看AI文稿AI文稿
06:02查看AI文稿AI文稿这个是基于工程 ycl, 然后在 esp 三二七六的基础上添加了 qq 官方机器人的配置,接下来演示一下。嗯, 首先我们重启一下设备, 嗯,第一次启动设备,设备是没有配网的,我们用手机给它配个网,手机打开 wifi, 然后点击 wifi 设置, 这里输入第一个,输入 wifi 的 名称, 然后 wifi 密码。第三个是 api key, 是 大模型的 api key, 这里我已经事先保存了一个, 然后模型名称这里用的是国内的 mini max, 上面名称可以不改。然后基础地址 填大模型的机首地址,然后 nats 的 主机和端口可以不填。然后消息平台这里改成 qq app id, 呃,输入 app id, 呃,这个 app id 可以 在腾讯机器人官网可以看到。 qq 开放平台这里可以创建一个机器人,这里就有 app id 和密钥, 然后输入完,点击保存,然后设备会重启,然后等待重启。 嗯,然后看到这个 hello, 就 说明连接上了,然后这时我们可以在窗口发点消息。 hello, 然后出现新屏,然后等待回复,就说明成功了 啊,出现大模型的回复就说明成功了。那我们现在要打开 qq, 这个是我刚才配的一个机器人,我在这里给他发消息, 那可以看到这边收到了,这边在思考, 嗯,然后消息就推送过来了, 然后它有这些功能,我先查询一下它的温度, 嗯,它就把当前芯片的温度返回给我了,然后 再把电瓶拉高。 嗯,这里大模型会调用工具,调用调用工具,然后把这个 g p l 五拉高。 嗯,那我们也可以查一下当前设备的状态,可以看到哦现在的状态以及刷新当前的模型, 嗯,然后也是可以正常对话, 嗯,这边就收到了, 嗯嗯, ok。



