你有没有算过,你用 cloud code 提一个需求要烧多少 token? 反复改几轮下来,额度已经去了一大截,结果交付的东西还是差点意思。 我当时就在想,到底是我在用它,还是它在消耗我,直到我装了一个插件,同样的任务完成度明显高了, token 也省了不少。 github 六千多星了,叫 oh my cloud code。 关注我的朋友知道,之前我推过 ccb 给 cloud code 配团队,今天这个不一样,是给他装大脑。 裸用 cloud code, 它虽然会自动切模型,但策略比较粗, mac 的 智能模型路由更精细,根据任务复杂度动态分配,能再帮你省下不少 token。 而且它有技能学习你踩过的坑,它自动提取模式,下次遇到同样的问题,直接服用,不重复烧 token 解决同一个问题。 o m c 内置了三十二个专业智能体,架构设计、代码分析、 ui 设计、测试验证、数据科学。你说需求它自动分配最合适的智能体去干。核心理念就一句话,别让开发者学工具,让工具来理解开发者。你不用被任何命令直接说人话。 最狠的是几个魔法关键词, autopilot, 完全自主,从规划到编码到测试,全自动 ralph 必答模式,不成功不收工,反复验证修复,直到通过这两个关键词,解决了裸用 cloud code 最头疼的问题。任务做一半崩了, 怎么装三步? marketplace id 地址, plugin install o m c setup 完了,不需要改配置,不需要学新命令。装完之后,你用 cloud code 的 方式完全不变,只是背后多了三十二个智能体在帮你调度,你感受到的变化就是同样的需求, token 少了,交付好了,任务不崩了。 跟 c c b 什么区别?一句话, c c b 给 cloud code 配团队,多个 ai 协同 o m c 给 c cloud code 装大脑,单体强化不冲突,可以一起用 c c b 看我之前的视频, o m c 开源免费 github 地址评论区关注我,每天一个技术深浅。

粉丝9758获赞4.5万
相关视频
 10:20查看AI文稿AI文稿
10:20查看AI文稿AI文稿最近为大家做了多期 openclaw 相关的视频,而且昨天我还发了一期 openclaw 的 高级用法的视频。但最近我发现几乎每期视频的评论区都会有留言提到 openclaw 调用 cloud code 会非常消耗 token。 因为在之前的视频中,我有为大家演示过,用 openclaw 来调用 cloud code 进行编程开发,我们只需要为 openclaw 全程操作 cloud code, 为我们实现编程开发。 但是我们如果采用传统的方式,也就是常规的方式让 open cloud 直接调用 cloud code 的 话,那么 open cloud 每隔几秒就会轮循一次,检查一下 cloud code 的 状态以及 cloud code 的 输出。使用这种传统方式的话, open cloud 必须时刻盯着 cloud code, 所以 openclaw 就 会消耗非常多的 token。 所以 我发现在评论区大家抱怨 openclaw 调用 cloud code 会消耗更多的 token。 因为大家采用的是这种常规的传统方式, 所以 openclaw 要采用不断轮询的方式来查询 cloud code 的 状态,也就是 cloud code, 它执行的任务越久,在 openclaw 中它轮询的次数就越多,所消耗的 token 也越多。 所以我们可以完全不需要用这种传统的方式直接让 opencloud 来调用 cloud code。 因为无论是 opencloud 还是 cloud code, 它们都非常非常的灵活,所以越灵活就越强大,就越有利于我们去自定义一些功能,从而轻松解决用 opencloud 调用 cloud code 的 时候, 产生大量的 token 消耗。尤其是 cloud code 在 前几天新增了 agent teams 这个新特性,因为 agent teams 相当于在 cloud code 中随时可以创建一个完整的开发团队, 而且每个 agent 呢都是独立的进程,所以是真正的并行执行,而且每个 agent 之间还可以相互通信,还能共享任务列表,能自动认领,还能实现专职角色分工,比如说负责开发前端的 agent, 负责开发后端的 agent, 还有负责测试的 agent。 所以在 cloud code 中有了 agent teams 这个最强大的新特性,在 open cloud 中就可以更加轻松地向 cloud code 委派任务,让 cloud code 全自动完成整个开发工作流。 想让 open cloud 以更节省 token 的 方式来调用 cloud code, 其实非常简单,我们只需要用到 cloud code hux 功能, 在 open cloud 中可以结合 cloud code 的 hooks 功能,真正实现调用 cloud code 进行自主开发,并且能够实现真正的零轮询,而且还能非常节省 token。 当开发任务完成之后, 我们还能在聊天软件的群组中自动接收到任务完成的通知,包括实现的是什么任务, 项目存储的路径,还有耗时,还有 cloud code 的 agent teams 是 否已经起用,还有具体完成的功能,还有项目的文件结构等内容。下面我们就看一下我是如何通过 cloud code 的 hux 来实现了整个流程。 下面我们先通过这个流程图,让大家更直观的感受一下在 cloud code 中通过 hux 回调来实现的整个步骤是怎样的。 首先是由 opencloak 将我们要开发的任务委派给 cloud code, 像这个委派只执行一次,而且它是后台运行,不会阻设 opencloak 的 对话窗口和它的主 agent。 当 cloud code 接到任务之后,它就会进行自主开发还有测试,当任务完成之后,它就会触发 stop 事件。 第三步就是 cloud code 中 hooks 自动触发,它会先将执行结果写入到这个文件中,然后再发送 wake event 来唤醒。 open cloud 在 这里采用了 stop event 以及 session end event 实现双重保障,来保障在聊天软件中,我们能够真正收到它的任务完成的通知, 然后 opencll 就 会读取这个文件中的这些结果和状态,当它读取完这些结果和状态之后,它就会回复给我们,也就是通过我们的聊天软件来回复给我们这些状态。 像这个流程的话, opencll 只在给 cloud code 派发任务的时候调用一次 cloud code, 然后这中间的流程不需要 opencll 参与。在最后这里, opencll 再读取一下这个执行的结果,并且将执行结果发送给用户。 所以在第一步, opencloud 只是给 cloudcode 下发一个任务,它下发任务的过程所消耗的 token 几乎可以忽略不计。在最后这里,它只是读取一下结果,将处理结果发送给用户,而且这个结果里的内容非常少,甚至不超过一千字, 所以在最后一个步骤,它所消耗的 token 也几乎可以忽略不计。在 cloudcode 的 自主完成这个任务的过程中, opencloud 不 需要对 cloudcode 进行轮询。 好,下面为大家讲解一下我是如何实现的。在 cloud code 中通过 stop hook 来达到任务完成自动回调的效果。在刚才也提到了我们使用了 stop hook, 还用到了 cloud code 的 session end。 下面我们简单看一下为什么要用到这两个 hooks。 在 cloud code 中一共有十四个 hooks, 之所以我们选择这两个, 是因为我们构建的这个工作流,在 cloud code 中,它完成开发之后才会触发这个 hooks, 所以 使用 stop hook 作为主回调,就可以保证 cloud code 的 真正完成开发时才会触发。在这里我们还用到了 session and 作为兜底回调, 也就是假设 stop hook 它没有触发成功,还有这个 session and 它能够作为兜底。像这样的话,我们就能够真正保证 open cloud 向 cloudcode 发送一条开发任务,然后 cloudcode 独立运行。在 cloudcode 独立运行的这个过程中,它并不会消耗 opencloud 的 上下文。当 cloudcode 完成开发后才会触发 hux, 然后我们的聊天软件就会收到通知, 下面我们就可以看一下具体的代码。在这个代码中,我们先看一下这一个脚本,它的作用就是将要开发的任务来写入到这一个文件中,然后再通过这个脚本来启动 cloud code。 当 cloud code 完成开发后,这个 stop hook 就 会自动触发,然后就会调用这一个脚本,我们可以点开看一下, 这一个脚本就会将任务发送给 openclaw, 所以 这个自动回调流程,它会读取这两个文件里的内容,并且写入到这一个文件,然后 openclaw 就 会将这些信息推送到我们的聊天软件,这样的话我们就能够实现 在 open cloud 中向 cloud code 下达开发任务,然后由 cloud code 自主完成开发。当完成开发之后再触发这两个 hux, 最后我们的聊天软件就会收到推送通知。好,下面我们可以先用一个简单的开发案例来测试一下。在主 a 选项这里,我们直接在对话框中输入我们的任务, 我是为了是用 cloud code 的 a g and team 协助模式构建一个基于物理引擎还有 h t m l c s s 的 带材质系统的落沙模拟游戏,然后我们直接发送,看一下这个效果, 这里很快输出提示,它已经将这个任务派发给 cloud code 的 agent teams。 这个开发模式就是调用 cloud code 的 agent teams 多智能体写作,这里还给出了这个工作路径,然后这里它提到完成后会自动通知到群里, 像这样的话,这个主 agent 的 线称并没有被阻塞,它还可以继续为我们执行其他的任务。比如说我们在这个主 agent 中继续输入任务,比 比如说让他查询新加坡今天的天气,然后我们直接点击发送,看一下最终的效果。像我们如果采取传统的方式在 open cloud 中来调用 cloud code, 在 主 agent 中必须等到 cloud code 真正完成开发之后,这个主 agent 呢才会继续执行我们的其他任务。 像我们采取了现在这种方式,这个主 agent 的 进程并没有被阻塞,所以我们让他查询新加坡的天气,然后这里他就很快查询了一个天气,然后我们还可以继续输入其他人物,比如说讲个笑话,然后这里他就很快输出了一个笑话。而 cloud code 在 后台完全是自主运行,不需要我们去干预, 然后我们只需要等待 cloud code 完成之后,将完成后的消息推送到这一个群组里就可以了。之所以设置为将完成后的消息单独推送到一个群组,是因为我们在这个 agent 中可能还在进行其他任务的操作, 比如说让他讲个笑话,他在讲笑话的时候突然多出来一条任务完成提示,这样会导致这个上下文窗口比较混乱,所以我们就将他完成后的这个消息推送单独推送到一个群组里,这样的话就不会占用这个主 a 智能的这个聊天窗口。在这个群组里我们就看到了这个消息推送,我们点开群组 查看一下,在这里我们就看到了这个任务推送,这里提示 cloud 的 任务完成。这里是开发的这个游戏,然后这里是游戏的路径, 在 cloud 的 code 中使用的就是 agent teams, 这里就是给出的项目文件,然后这里它还推送了第二条消息,这里还给出了完成时间大概六分钟,然后这里还包含一百八十四个测试通过, 然后这里就是给出的交付,然后这里还给出了这些性能,下面我们可以输入提示词,让他将代码文件打包发给我,这样的话我们就可以在本地打开进行测试,因为我的 open cloud 是 运行在云端的 好,这里他将为我们开发的这个项目文件发送给了我们,这里还提示解压后在浏览器中就可以打开使用,然后我们直接点开,然后我们在浏览器中打开看一下这个效果,就是他开发的这个落沙游戏,我们可以先测试一下,我们选择这个沙子 好,这样点击之后这个沙子就落在了底下,然后我们再点击这个水 好,可以看到水落在了沙子上,然后我们再给它加一把火,可以看到这个火会往天上飘,再给它加一些木头, 然后再给它加一些蒸汽,可以看到这个蒸汽飘到木头上会变成雨。像这样的话,我们就真正实现了在 open cloud 中调用 cloud code 进行开发。大家就不用担心在 open cloud 中调用 cloud code 非常浪费。 token, opencloud 所消耗的 token 几乎可以忽略不计,哪怕我们不在电脑前,也可以通过手机向 opencloud 下达开发指令。当完成开发之后,我们就可以在群组中查看推送的这些消息。
908AI超元域 00:39查看AI文稿AI文稿
00:39查看AI文稿AI文稿当你不小心安装了个 open curl, 然后发现 token 消耗刹不住了,而且非常健忘。你直接给我去 guitar 输入 cloud man, 你 会发现这是一颗能给你的龙虾赋予持久化记忆的插件。以后你就能像看朋友圈一样,实时看到你的 open curl 到底记住了些什么,而且还能节省百分之九十的 token 消耗。之后你又不小心输入 open viking, 更牛的来了,这是一个专门为你的龙虾设计的开源上下文数据库,它能让你的多个智能体之间共享信息,直接结束那种无法协助的智障模式,而且还能让你的书 token 成本降低大概百分之九十六,任务完成率直线上升。有了它们,你的大龙虾会越来越聪明。这么好的东西,不给你的龙虾配一个吗?
6029赛博自由老爹 03:41查看AI文稿AI文稿
03:41查看AI文稿AI文稿ai 编程的时候,你的 token 是 不是很快就消耗完了?今天教你两个巨省 token 的 办法。这几天我在视频区看到很多人在说 cc 的 token 不 够用,一百美金的都不够用,问怎么才能省 token? 我 今天先分享两招,我总结了 cc 节省 token 的 五种办法。那今天先分享前两种最重要的 最节省 token 的 办法是,第一种,根据不同的任务难度来使用不同的模型,比如说我简单的任务,我使用黑库四点五,因为这个是非常省 token 的, 它的 token 价格比较低,比如格式化文本修改,翻译,还有 ui 的 一些样式的修改,都可以用这个模型。 那如果说是一些简单的业务,比如说单个 api 的 调用, ui 的 交互的修改,你只是一种单独的业务流程,单个函数路由这种添加都可以用 socket。 四点五, 如果是复杂的业务,比如说框架设计啊,业务的架构的调整, bug 的 检查,算法,其性能,还有这些安全问题的修复检查,这些必须要用 office。 四点五 再讲。第二种就是我在我的项目目录里面一定要去创建这个可洛德点 md 的 文档,这个文档是官方制定的一个标准,当没有上下文的时候,我每次打开文档, 那 kolode 都会默认先读取这个文档,了解我的项目结构。如果你没有这个文档,那它就需要全部扫描整一个项目,你想想得多费头肯,虽然说你现在没有上下文,那我现在通过阅读这个文档,我就知道你的项目架构是什么, 你的技术标准是什么,你这个项目是做什么的?因为我们每次打开一个项目的时候,对于 kolode 来说是没有上下文的,所以就用这种办法来去解决。 我自己在平时用的时候,大概就是在这个文档里面会存这些东西。我自己的个人使用习惯,比如说我不需要 closed, 每次把它总结的东西整理成文档,我需要他直接告诉我这是我个人使用习惯。一些技术规范,你用什么语言,你用 next js 或者 python 使用的技术规范,语言规范等等都可以存在这里。项目架构肯 是要存的,就是你的项目目录结构, api 的 目录结构,技术上的说明,还有一些其他的什么技术架构什么,然后你的 api 的 调用,调用哪些服务?你一个项目当中肯定有很多的 api 也,但是你如果不懂代码, 你必须要把这个 api 的 调用方式列出来,因为你很有可能会经常去调整某一个 api 的 参数。那这个时候最好是存到这个文档里面,让 ai 每次都读取这个文档,很快的就知道哪个 api 在 哪里,路径在哪里,它会存好部署方式,重要的交互逻辑,还有一些我自己喜欢把环境变量是存到这个文档里面的, 还有一些其他的你觉得认为的重要的东西,如果说你不知道哪些重要,你可以直接让 c c 帮你整理提示词,我结尾也分享出来看一下我自己一个项目当中在使用的,对了,这里一和二 其实是可以结合使用的,我直接把我的第一个规则放在 kolod md 当中,那 kolod 就 知道我每次什么情况下会使用黑库这个四点五, solid 四点五, op 四点五,如果你不放在这里面,那你每次都要去手动去切换,比如 每次都得这样去结合切换。他默认现在是用 office 四点五了,这个存的是我自己的个人使用的习惯,那直接给出来,不要给我整理文档, 我也不要让他跟我废话。我提到问题的时候,你给我直接修改,主要是集中在解决问题上面,而不是组织更多的信息,浪费我的头肯,尤其是项目的盖住,这个项目是干啥的? 这个项目的核心的特点是技术上,包括后端的技术站,我因为我的项目结构,这是我的 api 的 端点的结构,数据模型, 反正就不看了,就大概就是这样,你如果不会直接让可乐扣的帮你总结,帮你存他觉得认为重要的东西存到这里面,因为我们不太懂代码,像我就不懂代码,我根本不会看代码,我只关心我的业务满不满足, 我作为一个普通用户想要的那个预期就 ok 了。如果你们觉得这两个办法特别实用的话,可以在评论区六六六安排,剩下的三个要不要分享出来。
93Super李文君 01:20查看AI文稿AI文稿
01:20查看AI文稿AI文稿给大家推荐一个在 openclaw 上面帮大家省 token 的 skill, 那 这个 skill 真的 非常有用,因为这两天我的 cloud 的 max 套餐都已经不太够用了,所以我赶紧去找有没有这样的 skill, 结果发现它确实不错, 那安装也很简单,你把这个地址扔给 openclock, 让它安装就可以了。那它做了什么事情呢?其实就是减少上下文的加载。首先它减少了 skill 文件的加载,默认是加载全部的 skill, 它现在是按需加载, 你用到哪个 skill, 加载哪个 skill, 这是第一层。第二层,它把那些定时任务用到的模型给你降级到一个低级的模型, 比如说你的定时任务只是去写一个日报,那你没必要用 cloud 的 ops 模型,你用一个派克模型可能就足够了。 那第三层面,它优化了上下文的加载,简单的对话,它加载的内容就少,复杂的对话,它加载的内容就多。 简单理解,大概就是这样,所以它一定会让我们的 token 数量变少,因为我们的上下文加载的少,那未给大模型的 token 就 会变少,所以大家可以赶紧把这个装上,帮大家省点钱。
163自说自话的江哥 01:57查看AI文稿AI文稿
01:57查看AI文稿AI文稿最近发现一个工具,专门解决 ai 编程烧 token 的 问题,叫 r t k。 先说痛点,你用 cloud code 也好, cursor 也好, codex 也好。每次跑一个 git status, 输出十几行,全部塞进上下文窗口,跑一个 cargo test, 两百行测试日记全吃进去。这些输出大部分是废话, 进度条空行通过的测试重复的警告,但 l l m 不知道哪些是废话,它全都读,全都算钱。而 t k 做的事情特别简单,就是在命令和 l l m 之间差了一层。你敲 get push, 它帮你跑成功了只返回一行, ok men 你 跑测试一百个通过,三个失败,它只把失败的给你看。日制里同一行报错出现四十二次,它折叠成一行,加个数字,原理不复杂,但效果很猛。 有个用户跑了十五天的真实数据,七千多条命令,原始 token 接近三千万,压缩完剩不到五百万,省了百分之八十三。而且它不挑工具, cloud code, cursor codex, windsurfer, gemini, c l i idler, klein 七个主流 ai 编程工具都支持。装完之后,它会注册一个 hook, 命令被自动改写,你正常用 ai 也感知不到,区别就是上下文变干净了。安装也简单,一个 rust 二禁制,没有任何依赖,启动开销十毫秒以内。他说,我觉得它不够好的地方,它是用正则和规则做的过滤,不是真正理解内容。 g a t div 被截掉的部分可能正好是你要找的 bug。 注,是被过滤掉了,但里面可能有关键的 to deal, 成功的命令它不保留原始输出,过滤错了没法回看。 另外,它每个命令都要单独写一个过滤模块,源码里已经四十多个文件了,新工具出来就得加,长期维护是个问题,但整体来说,日常开发够用了。 g i t n p m cargo docker 这些高频命令的输出确实大部分是噪音,砍掉之后上下文窗口能多做很多事。感兴趣的可以搜 r t k gitlab 开源的。你平时 ai 编程一个绘画大概用多少 token 评论?
41Lif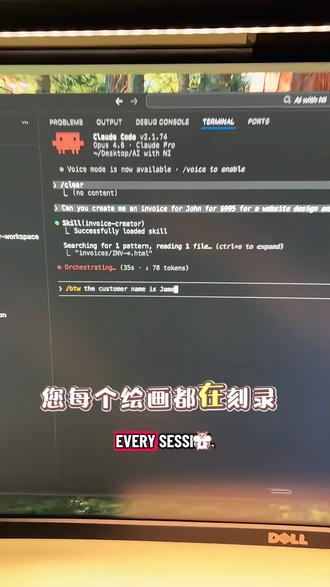 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿如果您没有在 cloud 代码中使用此斜杠命令,您每个绘画都在刻入令牌。这是最新的斜杠命令,它可以帮助您节省一堆代币。这是斜杠 b t 高币命令。 这有助于在同一绘画中打开一个侧面对话,没有零额外的上下文成本。 cloud 代码不需要查找新文件或重新加载任何技能。您只需输入 b t w, 然后输入您的问题。这也是了解 cloud, 看实际在做什么的好方。
 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿别再瞎用 openclaw 了,别人用 ai 啊,一分钱不花,你却在疯狂地烧 talk。 今天一条视频告诉你, openclaw 到底能连哪些大模型, talk 又该怎么薅?哪几个模型便宜又好用? openclaw 能连的模型啊,就三类, 国际大厂 g b t cloud, 国产头部空一千万 g l m kimi, mini max, 还有本地的 alama 开源模型,零成本啊,随便跑,想省 talk 啊?记住三招, 第一,新用户免费额度全领一遍。 deepseek 百链智普注册呢,就能白拿几百万的 token, 每月还有赠送的额度。第二,简单任务,用低价模型,复杂任务呢,再上高端。 第三,本地跑开元模型,一分钱不花,如果追求性价比,日常清量啊,用 deepseek 加千万 flash 免费额度就够你用了。中等任务呢,选 mini max g o m 四点五,便宜又稳,复杂推理直接上 cloud, 索尼 g p 四 o 迷你效果顶价格还不心疼?逻辑通了,你一个人就是一家二十四小时无人公司,关注我带你用 ai 早点下班!
999陈凡Carina 01:32查看AI文稿AI文稿
01:32查看AI文稿AI文稿酷狗官方可能要连夜修 bug 了,我发现了一个能让 cloud o p u 四点六 max 彻底不限量的糟操作,二十美金的酷狗 pro 会员,硬生生的被我耗出了上亿的 token 价值。而在那个发布的 o p u 四点六确实太猛了, 但是正常用在酷狗上,二十多的订阅也就能跑个中型项目,大概能跑两千五百万 token。 但是重点来了,酷狗新出了一个 cloud agent 功能, 默认就是 opu 四点六 max 模式,虽然它限制一个环境最多聊六次,但是关键的是它不计 token 的 消耗。 最糟的操作就在这。聊完五次之后,我们直接把代码末置到 github, 反手就把这个环境删了,重新再开一个新环境。代码还在,但五次全新的不限 token 的 顶级算率又回来了, 这不是在写代码,这是在指挥一个不要命的数字劳模,只要你会 get up, 简单动手点一点,酷 sir pro 就是 你的无线提款机。趁官方还没反应过来,赶紧去把你的大项目跑起来!转发给那个天天加班的兄弟评论区,告诉我你今天薅了多少头啃! 总有一种不祥的预感,总感觉我在 被无数双眼睛盯着,但是又看不到人。不对!
417淋七七 08:47查看AI文稿AI文稿
08:47查看AI文稿AI文稿上一期教大家了 cloud code 怎么安装和部署,那么这一期教大家怎么样去对接大模型,怎么样去付费使用?首先介绍一下 cloud code 的, 我现在使用方式有这几种,第一种呢,最基础的官方订阅了,你要去 cloud 官方注册一个账号,订阅它们的计划, 它有不同的这个付费的这个形式。是的, free 的 pro max 对 第一个门槛。好多评论区的人问怎么注册账号啊?有一个最简单的办法就是你去注册个谷歌账号, cloud 是 支持直接用谷歌账号登录的,就不会碰到什么用手机号的问题了。 ok, 然后呢,解释一下他们的这个 pro 和 max 账号, 他们这个账号有一个限制,比如说像 pro 账号,它是在五小时之内,你可以用到一定的 token 用量,然后在一周也有一个 token 上限,但是它有一个很坏的地方,就是你不知道它的 token 的 限制到底是多少。对,我们找了很多,没有一个官方的说明。对啊,它其实大家都是动态的,它会根据它们自己的用量实际 去调整。 ok, 我 去论坛找了一个大家使用反反馈,就是呢,有一个人大概估算了一下,像估计它是比较大量的那个 token, 消耗任务的话,可能两个任务就能用掉 pro 账号的百分之五十五的使用额度了, 大家可以感受一下,其实我之前在自己使用过程中也是差不多是个这样量的,比如说如果你的项目下内容比较多的话,可能五六个任务你五个小时的额度就用光了, 你就要再等等他解锁了那个五个小时,五个小时以后你再开始用。对,是的,所以呢,总结一下他官方订阅的,他的优点就是质量是肯定没保没问题的,用的是真正的 cloud 的 最顶尖的大模型。缺点是封号封快飞快,我已经给封了两个账号了。 还有就是 pro 账号是肯定是不够用的,大部分人的,就国外的那些专业开发者用的都是 max 账号, max 账号的话一个月折合人民币大概是一千四百块钱人民币,所以这个打呗打呗对这个专业的用户才会考虑。 ok, 如果你想要去解决不被封号,你需要去投入研究 更多的办法,这个隐形成本是很高的,建议如果你有本事折腾就是避免封号,你可以去考虑,你一定想搞的话,你可以考虑用组合配或者 apple pay, 这种方式会加收百分之二十五左右的费用,但是听说封号的时候 谷歌会或或者 apple 官方,他会帮你挡一刀,有时候会给你退钱或者帮你兜底,至少,但也只是听说啊,不负责任感觉下来就是大可不必。对新手小白不建议这个方式, ok, 第二个方式,官方 api 其实对于大家来说其实是不需要考虑的,因为质量没问题,但是缺点是死贵, 你们可以看一下奥普四点六,他的呃输入是每百万托肯是五到,也就是三十五块钱人民币,输出的话是二十五到每百万托肯非常非常贵。 正好我一个任务差不多就一个,一个多一点,任务差不多就结束了。哎,讲了这个正好呢,我们正好解答一下之前还有很多朋友关心的这个推算消耗的问题,我也给大家测算了一下,投入啊,真金白银的投入。测算了一下, 我有一个很复杂的一个自己的项目,就是那类似于今天老师之前的那个个人的工作台一样的,这里面有我我所有的工作的记录,包括记忆进度啊等等等等,这项目还是比较大的, 我让他全量的跑一遍我这个项目,把里面的每一件事的进展汇报一下,相当于他会把我整个文件夹全部读懂点。对,是的,我第一个是用的是卡的 pos 四点六模型,他耗时用了大概十四分钟,把我这个项目读完了, ok, 用了投,看多少呢?用了, 用了七万的投垦,这一个任务后面的两百是什么?其实两百是这个上下文窗口的上限,这次用的是七万的投投垦。给大家大概估算了一下,假设 大部分情况下,输入是占百分之七十,输出占百分之三十,所以折算下来,我本次绘画用了五块六毛钱人民币,做一个任务是相当于重量的, 也就是说大概你可以估算出来吧,可能对于你们这种办公工作者可能会少一点,不会五块钱,但是一次任务一块钱肯定是有的,我透露一下,有一天下午我一个人就用掉了人民币六十,对,是的是的,所以大家有数啊。很多人关心偷更消耗,但其实偷更消耗这个问题其实很难回答, 它基于的是,首先你的项目,你的复杂度,你的文档的多少,还有你这个用的模型,有的模型他的思考的程度高,那么他消耗的头可能就高。 还有基于的就是你用的软件,所以呢,为什么我在对比呢?我用的是 g p t 五点三 codex 思考度 high 的 那个模型,它的思考程度很高,所以可以看到我本次跑下来用了十三 万,刚刚是七万,现在是十四万,十四万,十四万的消耗翻一倍,对,同样的任务翻一倍,所以用不同的模型跑同样的项目,它的消耗不一样。是的,用同样的模型, 也是那个 gpt 三点五的模型,我在 opencloud 里面再跑了一遍,消耗就是七十七万。因为之前在 opencloud 里其实也有很多人关心这个 token 消耗的问题,所以呢,我给大家看一下,大概感受一下。相同的模型,不同的软件在 products 下跑的是十三万, 在 opencloud 底下跑的是七十七万,这也就是为什么大家说 opencloud 很 少 token 很 厉害的问题原因。但是这个东西在 bug 里面其实只有七万对,是的,其实只有七万对, 天呐,但这个里面有核心原因,影响因素很多啊,比如说 gbt 五点三扣带子 high 这个这模型它的思考度就高,所以呢,它耗,它耗,它消耗头很高,它本身它因为它的记忆体系,所以导致它它的消耗头很高,这也是影响因素,所以这个只是做个横向的,让大家感受一下, 点到为止。所以这个总结下来,如果你调用官方 vpi, 这个就对于新手来讲一定也不用考虑,大部分研发也不会做这种事,这种只会做产品的时候考虑。 还有一个办法就是我提一下,免得有人说我没提就是 antigravity, 反反贷把,有一个软件开发软件叫 antigravity, 就 谷歌推出来的,有的人有办法把它里面的 api 提出来,到扣子里面去用,当时它谷歌很大方,但现在已经开始对这样用的人进行封号处理了,所以今天就不去详细提了, 别搞了,能写到我们,我们咱们就是。然后最后一种办法就是通过第三方 api 来接入。第三方 api 的 话其实又分成三种方式, 第一种就是 open route, 国外最大的一个就是第三方 ip, 提供平台模型超市,对,是的,然后它们里面会有各种各样的模型的 ipi, 然后也有那个 cloud office 四点五的,但是它的价格和官方是一模一样的,呵呵, 所以呢,它是同样死贵的,花钱也是飞快的。它对于就是我们大陆的 ip 封禁没有那么不会,没有那么严啊,能用上,对,能用上,不像那个官方的一天你是几乎用,为了用还很费劲,还很花钱,所以你大部分情况下可以不用考虑,但是你可以去少充一点钱, 通过这个去感受一下奥克斯四点六的真正的能力。然后呢,还有一个就是大家常提的中转站,就国内的中转站, 它实惠,一定程度上你可以用到 off 四点六的顶级模型,但有很大的缺点就是首先它不稳定,时时时不时断线,那很多都是自营的,所以呢,大概率会跑路,有风险有风险,而且还可能会一次充好它。你说是在用 off 四点六,而背后说不定用的是别的模型,都有可能的,你也不知道它那个管子跟你插在哪个边了。是的是的, 所以建议就是啊,你可以用,但是不要一次性充过太多钱,少量多次的充,用多少用多充多少,也不要在我的评论区交流。对,我不会给大家推荐具体哪一个厂商,但是呢,会给大家推荐一个网站,叫做这个网站不读了,在这里面你可以看到各种各样的中转商以及他们的稳定性,可以 基于这个去选择你想用的中转商。不要交流啊,你看就行了,不要交流。好的三种方式呢,就是我大家比较推 推荐新手小白,先尝试的就是用国内的模型来代替,因为国内模型的话是最实惠的,也是最稳定的,而且其实在能力上的话也没有什么太大明显的差别。 然后讲到这呢,正好就是给大家推荐一个软件,是开源的,之前我也提到过叫 cc switch, 因为 cloud code 它本身理论上来说只能用它自家的模型,但通过这个软件是可以切换到别的任意一个模型的,包括了我前面提到的中转商提供的模型以及 国内的模型,它使用起来也很简单,你去 getapp 上面,或者到时候曾老师发一个。然后呢,我们打开这个软件以后,点击右上角的加号,你就可以看到它预设好了各种各样的模型厂商,包括了千问、 kimi, 然后你去他们那边注册订阅一下他们的 kimi 二点五去做我们的那个网站,也都是挺实惠的啊,包括上次我们其实用了那个 kimi 二点五去做我们的那个网站也都是啊, g r m 也都 支持的。好的,我推荐新手小白呢,最好的方式就是你订阅一个国内的模型,然后你再去 openroot 上稍微充一点点钱,你把 真正的 cloud office 四点六接入进来,然后也可以把国内的模型接入进来,两个去做同一个任务,去比较一下这个结果对于你来说差别是不是真的很大。如果差别不大的话,你就完全可以先用着国内模型,然后等到以后真的有一些业务需要了,你再去换。 你先看看你自己做的这点事,你配不配用这么贵的东西啊?有些写文档的工作,你自己思考一下你配不配用。 ok, 本期视频就这样,拜拜。拜拜。
1653珍妮丁丁说AI 02:12查看AI文稿AI文稿
02:12查看AI文稿AI文稿你可能有一个问题,如果我装了五十个 skill, 启动时全部加载了 token, 就 撑爆了你?其实答案就不会, 因为 s 融资公司在设计 skill 时用了一个巧妙的设计,就是渐进式纰漏。我们来说一下 skill 的 三层加载机制,便于你加强理解。第一层 skill 在 启动时仅加载目录, 也就是 name 加 description 原数据,每个 scale 大 约也就一百个 token, 五十个 scale 粗略的算也就大约五千个 token。 具体取决于描述的长度, 核心目标是让模型快速感知技能时的全貌,知道有哪些 scale 何时被触发。第二层 skill 在 触发时才加载说明书,也就是 skill 点 md 的 正本,只有当任务匹配时才加载。官方建议控制在小于五千 toc, 长度随内容而定,以确保模型严格遵循该技能的流程。第三层 skill 在 执行时按需加载参考书、脚本等扩展资料,未读取不占上下文,脚本可执行,而无需把脚本内容读入上下文。由此可以推断,第三层开销主要来自你实际读取的参考内容与 执行产生的输出,因此在常态下几乎不占输出。我们用使用 skill 的 前后算一笔账, 以前单次四万个套餐的场景,现在只需一万,省了百分之七十五。真是一句广告词,用的越多,你省的越多。 这里打了一个小小的广告,如果有朋友对高质量的大模型,比如 oppo 的 四点五,有需求的可以给我留言,我这里有非常稳定的服务,可以给大家推荐。下一集是本系列的第四集, skill 和 mcp 到底有什么区别? 看完这个系列,相信对你使用 skill 乃至 ai 的 能力都会有巨大的提升,下一集还是干货,千万别错过!点赞加关注,获取更多的有价值的 ai 新信息!
 11:06查看AI文稿AI文稿
11:06查看AI文稿AI文稿大家好,不知道你们是否跟我一样,在 ai 编程开发当中,经常会找一些啊比较流行的插件啊,技能或者命令。 我最近在看这个 cloud code 官方自己出的这个插件组合呢,发现一些非常有用的这些技能啊,命令啊,在代理,而且他们对于这些工序的这个定义和书写也是非常值得去学习的。那本期视频呢,给大家一起来探讨一下, cloud 官方的这个最强的插件包含了哪些我们能够直接用来的这个技能 子弹里或者说一些插件,也会看一下在别的 ai 编程工具是不是能够飞。首先呢,我们可以看一下它是一个 git 的 一个原码的形式啊,那么我们可以去打开 打开这个 git, 那 按照它的这个命令去安装,安装也是非常简单的,安装完成之后呢,你打开你的 curl code, 在 这边输入 pran, 然后的话你就能看到在这个 marketplace 里面就能看到你去安装这个,那么这个是带两个新号的,就是它的这个官方的这个插件啊,那经常如果你没有安装到它这边,在你对话的时候,有时候也会在右下角呢,会提示你去安装这个插件啊,非常建议大家去安装好, 那你安装完之后,那么你就可以在这个 discover 里面去看到这些你没有安装的它里面的这些插件呢,比如说这个带这个啊,这个 officer, 这个这个 playwrite, 或者说这些东西都是没有装的,那么你就可以去选择它装上,你也可以在这边 marketplace 里面去选选中它 啊, enter 键,那么你就可以去浏览它所有的这里面的所有的内容啊,那比如说这些打勾的说明就你已经安装的,那这些的话是没有安装的,那么你就可以选择,比如说选择这个 commit commands, 那 我选错了,那这里的安装就是 你可以是安装是用户级别的,也就说你所有的项目都能用这个里面的功能,那么你也可以是安装这个工程级别的,也就说只有在当前项目下才能用这些功能,所以自己选择好,建议是 都安装到这个 user 这个级别啊,就是所有的项目都能用,因为它提供的都是一些比较通用的。那安装完之后呢,我们再看一下这五十六个里面,哪些是我觉得可以拿过来直接用的,然后呢,我把这个能够用的,或者说比较好的这九个啊整理出来,这里面有一个一列是 cos 可用啊, tree 可用 codex, 也就是它们原声支不支持,直接复制过去用,那不我这里打了叉的就说它是原声就不支持,比如说 tree 它不支持命令,对吧?但是其实你也可以把这个提示词复制到它的对话框里面,也可以用, 也是有办法能用的啊,我这边说不支持,只是说它原声就不支持。第一个就是非常非常重要的,也是非常有用的这个创建技能的这个技能啊, 那么这个创建技能呢,最近又发布了新的版本,增加了很多评估,还增加了很多测试,是吧?因为经常我们在创建技能的时候,你创建完之后,这个技能效果到底是怎么样的,你是不知道的,你只能说去自己去做做一些测试,那现在呢,他技能本身提供了很多这种评估的这种方法 和这种,你的这个技能的这个效果到底怎么样?这个对于非编程的这个人员是非常友好的,那么在用技能的时候一定要注意啊,比如说我选择这个 skill crate, 那 么打开这个技能的时候啊,你如果安装了别的 插件,也有可能有跟它名字一模一样的这个区分好,它在这里的时候会如果重重复的话,它这边会有一个这样的一个标识,相当于公司名称一样,比如说我这个 是是它这个的这个名字的下面的所有的技能,那么这个就是类似于像官方一样,那么你也可以选择这个 enter 键,那么你可以看到是 square critic 这个名字,那么你就可以大概就知道这是官方的,因为名字相同很容易混淆。那这个呢?因为它是以技能的形式存在的,所以说这个 ctrl 啊 shift 都是可以使用的,那么你这边可以去下载这个安装包,你也可以在 github 里面去直接把它复制到你的这个呃,对应的 ai 编程工具的这个目录下面就可以使用。 那第二个呢,就是这个人可能很多人忽略了,就是 cloud md 这个文件的一个维护啊,那通常情况下我们去维护这个 cloud md 的 人可能是自己去手写,那么 这个官方提供了这个 cloud md management 这个这个命令,它是一个命令或者技能形式的存在,它可以根据你的历史对话去优化这 cloud md 里面的内容。那比如说我们在历史对话中,可能在最近的这个对话中啊, 那存在可能去纠正,对吧?纠正一些局的错误,或者说定义一些工作流程,那么它就可以提取出来,把它写到这个 cloud md 文件里面去。那 cloud md 这个文件是非常非常重要,我可以认为是所有的这个 ai 编程工具啊, cloud md 或者 agent md 啊,这两个是一样的意思,只是 不同的命名而已,它们都是非常重要,是一个承上启下,是整个 ai 编程,一个维持的一个内存记忆的非常重要的一个文件,所以这个文件一定是经常更新 是最重要的,所以呢,它提供这样的技能啊,你可以就可以根据你的对话智能去总结需要更新的内容,是一个持续学习迭代的一个东西,非常非常重要。那比如说我使用了这个啊,技能里面的这个就是优化我们的 cloud md, 那么他就会去啊阅读现有的 cloud md 的 文件,然后顺便去把最近的对话或者最近的变动 提取出来,然后会得到一个这样的一个结果啊,说就说啊,补充我们这个 cloud md 的 内容,所以这个是非常有意思的,就是它会根据你的这个对话记录去做优化, 也非常推荐大家去使用这样一个 md 啊。那么其他的一些插件其实也有类似的功能,就是持续学习的这个能力啊,那这篇稿弄完之后,你就可以去更新到你的 cloud md 文件里面去,那下一个也是非常有用的,就是简化代码, 那这个相当于因为 ai 其实生成代码是会堆积那种很多复杂的,把很多代码写得特别复杂,就是你能可能很容易就看得出来这个代码是 ai 写的,不是人类写的。那这个功能就是对你的代码进行简化,它会结合你 cloud md 里面,一般我们 cloud md 会去定义 代码规范,比如说在我这个项目里面,那么 cloud md 里面就有一个这样一个简单的一个代码规范,那么它去做简化的时候,就会根据你这里的代码规范进行去简化。你可以这边可以写得更详细一点,比如说你的这个命名方式啊,你的这个啊,这个接口的命名方式啊, 这这些写的越细越好。一方面它就会根据你 cloud md 的 定义的这个代码这个风格去优化。那第二个呢,它会根据一些通用的一些编码的一些规范,比如说你这个太过复杂了,比如说合并重复的逻辑啊,去掉垄断代码啊,可以去做这些,那优化完这代码的话肯定是会更好。 那么如果你不指定范围的话,它是会默认只是对当前对话最近的修改进行一个这样的一个简化,那它是以子代理的方式来存在的,那这边的话是三个 ai 编程工具都支持。那第四个呢?就是我非常非常推荐啊,这个 feature dv, 这个 就是你当你要开发一个功能的时候啊,你用这,你用这个方式去启动,那么他是会把这个功能的这个分成一个固定的流程,比如说他先会去搜索你的代码,去理解你的需求,然后呢去加个设计, 然后呢最后会做一些质量的审核,那这个过程是非常非常标准的。我们可以看一下这个例子,我们在使用 arslp 和 v 开发之后呢,我们可以看到他明显的有一个这样的流程, 比如说他会先做需求澄清啊,会做你的问题的提问,然后做完之后开始做价格的设计,然后价格设计的时候他会去做很多代码的搜索,这个是非常重要的,然后把价格的设计的方案给到你之后,你再去确认, 然后的话他这边就开始,如果你 ok 没问题了,才开始去实施。来到第五步去实施,实施完之后呢,他会对代码又进行一个检测 啊,一个质量的检测,然后的话如果发现有问题,然后他再去修复,所以整个过程是非常非常的一个标准的一个流程。我们可以看到最后他在整个过程中用了哪些步骤来完成这么一个功能的开发, 我们可以看到在最最下面可以看到他总共有七步,对吧?一个是啊,这个去理解代码,去理解你的需求,然后的话去做问题的澄清,然后价格的设计,然后再去做你的这个更进一步的优化,然后开始去实施,然后再就是代码质量的检测, 最后做一个文档的总结,那这些个流程是非常非常好的,所以说我把它评为了,就是啊,也是一个 ai 编程的一个最佳流程,就光这一个插件就已经实现了一个很小的一个迭代的流程,它非常适合用来做迭代,非常适合就是对 prime 模式一个增强。 所以大家从上面的例子可以看到啊,这是一个非常推荐使用的。那第五个就是比较大家比较用的可能比较多的就是,呃,我们的前端优化的一个技能, 那这个技能就是要去掉我们的 ai 味道啊,那经常我们使用 ai 生成的这个前端,就像要么就是大紫色,要么就是大红色啊,这颜色会比较单一,那么它是做了一些优化,让我们这个前端的设计会更加美观一点,那这个也是非常简单,它是一个技能。 那第六个呢,就是可能会用的比较少,但是呢如果你要用的话,它就提高了,大大的这个提高这个简易性啊。比如说你要去串一个钩子, 那你如果使用写脚本的方式,那个门槛太高了,那么他提供的这种方式就通过对话的方式能很快速的把钩子串联起来,那么对于一些自,对于一些喜欢啊,设计一些自由度高的一些人来说,这个东西是非常方便的。 那第七个这个 pr review 的 这个工具啊,那么主要用的就是你在提交 pr 这些对代码这些,这个你可以指定啊 review 有 什么东西,那比如说我这里有个例子,那么我会执行这个 pr 的 这个命令啊,然后去让它去检查一下是不是有漏的注视的,那么它就会 拉取我最近提交的 comit 记录,然后的话就是你可以看到哪些是需要改进的,可能就会遗漏,这样的话在 你提交 pr 之前有一个这样的一个最终的检测,那这样的话你就可以 pr 提交的效率就会高一点,质量也会高一点。那第八个也是简化这样 git 的 操作,那我们经常使用 git 提交提交的时候,你要去想一下,就是,哎,最最近这段的变化是什么样内容啊?你自己要去创建, 自己要去写,那么有了这个命令之后呢?他会啊总结你这一段时间这个代码变更的一个简化的说明,你只要直接写上合并就可以了,他就会去总结,完全不需要去关注你 自己做了什么东西,所以这个是非常高的效率啊,然后他也是支持这种合并之后,然后顺便把这个布局到上面去。那这也是一个非常常用的一个工具啊。 那第九个就是之之前非常火的叫拉尔夫循环了,也就是你可以通过这个秘密让这个呃 color code 可以 一直执行多少次,直到结束。那么有的人用它去生成一个稍微大点的项目,可以直 循环去运行一晚上,所以这是一个非常有意思的。如果你有这样的需求的话,你可以去使用一下这个插件,那么这个插件也有很多变种啊,也是可以去看一下。 ok, 那 本期视频就到这,希望这些内容对你有所帮助。
428AI随风 00:51查看AI文稿AI文稿
00:51查看AI文稿AI文稿很多人还没意识到,为了改一行代码而读取整个文件,会浪费掉你百分之九十五的 token。 这种低效操作正是成本高涨的元凶。最核心的规则是,能用 bash 命令完成的操作,绝不读文件。比如复制文件,直接用 cp 命令,无需填 cloud 读取内容,这能瞬间省下数万 token。 必须读文件时,先过滤再读。用 tail 看日期,用 jq 提取的段 数据证明,这种精准读取模式比全量读取效率高出百倍。安装 token efficiency 技能包后, cloud 会自动遵循这些规 则。实战测算显示,大型项目的开发成本能因此降低百分之九十以上。获取更多硬核 ai 编程实战技巧,别忘了关注,下期带你解锁更多高效 skill!
1615啊拜拜 01:38查看AI文稿AI文稿
01:38查看AI文稿AI文稿很多人用了 cloud code 的 一段时间,都会发现一个问题,一开始很聪明,后面越用越笨,回答越来越乱,头啃还消耗巨快。那其实很多时候并不是模型本身的问题,而是你不会用这五个最基础的命令。那今天这条视频带你一分钟掌握。 第一个命令, config。 这个命令可以说是 cloud code 的 控制中心,那输入斜杠 config, 你 可以查看和修改当前的各种配置,比如是否自动压缩会话,是否自动切换思考模式等。建议你把每个配置项都了解一下。 第二个命令, model。 如果你想切换模型,直接输入斜杠 model, 就 可以看到当前支持的模型列表,直接选择就可以切换普通任务,你可以选择 so net 模型, 复杂任务你可以选用 opus, 性价比最高。第三个命令, clear。 很多人会发现一个问题啊,聊着聊着, claus 回答开始抽风了,越来越乱,越来越慢,而且 token 消耗飞快。这其实是因为上下文啊太长了,这个时候只需要输入斜杠 clear, 就 可以清空当前对话的上下文, 重新开始一个新的绘画。我建议每个独立的任务啊,都可以开启一个新的绘画。第四个命令, compact。 如果你不想完全清空对话,但是又想减少上下文的长度,那就用斜杠 compact, 它会自动压缩历史绘画,保留关键的信息。简单理解啊,就是给绘画做一次瘦身。 那第五个命令, continue。 有 时候 cloud code 会回答到一半的时候,因为意外的各种情况,导致终端的窗口不小心被关闭了。很多人这个时候啊,就会把之前的输入再重新来一遍,但其实大可不必如此,那直接输入斜杠 continue cloud 就 会接着之前的回答继续输出。 总结一下,学会这五个命令,不仅可以让输出的质量更高,关键是还更省 token。 那 你觉得哪个 cloud code 的 命令最好用呢?欢迎在评论区告诉我,我是新启,关注我,每天分享一个外部限定的小技巧。
1043AI产品兴起 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿这个抠钉 play 疯了吧,一天只要几块钱?九亿次请求随便用,彻底解决 token 价格贵不够用的问题。 它按请求次数计费,每个月最多九万次请求,相当于十亿 token 的 调用量,价格却只有调用的一折左右。而且每个用户之间互相独立,不会因为高峰期降速,特别适合 ai 编程个人开发者, 支持豆包、 kimi、 智浦、 deepsea 等模型,还支持 cloud code、 cursor、 openclaw 等主流工具。操作也很简单,首先订阅 coding plan, 然后配置,以 openclaw 为例,执行这个命令就完成切换。余量在这里看, 每五小时刷新一次,目前周期内我已经用了百分之十六,再过一个半小时会自动从百分之零开始计,这模型量太管饱了。流程已整理好,需要的朋友留言分享。
199智算AI云顾问 19:03查看AI文稿AI文稿
19:03查看AI文稿AI文稿去年十一月, ansorepic 发布了一系列新的测试版功能,只在解决我们在构建 ai 智能体时遇到的一些实际问题。 工具定义在你发送第一条消息之前就已经占用了大量的上下文。当智能体连续执行多个工具调用时,这些工具调用的中间结果会进一步膨胀上下文。 而且随着你在系统中增加工具的数量,智能体在为任务选择合适工具时会变得非常吃力。因此,这些测试版功能帮助解决了这些问题。而且随着两周前 sony 四点六的发布,这些功能已经在云 api 上全面开放。 在他们的原始帖子中,他们展示了这些功能如何帮助实现了八十五百分之的 token 使用量减少。 这也导致一些网友宣称 entropic 已经终结了工具调用,或者至少是传统的工具调用方式。虽然这种说法有些夸张而且确实不准确,但这两个功能编程是工具调用和工具搜索工具 确实是非常巧妙的解决方案,在集成到任何 ai 智能体中时都能发挥极高的效用。而且关键在于这些功能并不是云 api 独有的,也并非最初就是 entropic 的 创意。 这些是智能体构建的核心模式,适用于任何框架或模型。我会解释这两种高级工具调用如何运作,并演示如何集成到你的定制智能体中。 这正是我在这里所做的事情。我已经把它集成进了我的系统,这个系统是我用 python 和 react 定制开发的应用,这是我在本频道过去四期视频中逐步搭建出来的。 我还用全新的困三点五,拥有二百七十亿参数的模型来测试这些高级工具调用方法。所以与其直接跳进理论部分,不如我们在应用里演示一下。 而最简单的切入点大概就是先演示一下工具搜索工具。所以即使只是打个招呼,我们也能收到一个简短的回复。但在底部,你可以看到我们正在追踪本次绘画的上下文窗口。 我们已经用了一万三千个 token, 为了弄清楚发生了什么,如果我们切换到 langfuse, 如果我们看一下这个生成追踪,你会发现已经有六十个不同的工具被加载到上下文中了。 虽然听起来很多,但实际上只有两个 mcp, 就是 playrite mcp 和 github mcp, 再加上一些我在前几期节目中开发的工具。 所以工具搜索工具的关键点在于你不会一开始就加载所有内容。你会延迟加载让代理去搜索他,所以他会多出一个额外的步骤。现在我会把这些 m c p 服务器标记为延迟加载,然后让我重启一下服务器。 如果我再次问同样的问题,比如我们打开一个新的聊天窗口,输入 hello, 然后得到一个回复,你可以看到我们现在只用了六千三百个 tokens。 如果我们看一下这个追踪,你会发现现在只有十二个工具被加载到上下文中。第十二个就是这个工具搜索工具。 这个工具允许代理在工具注册表中搜索,通过名称或关键词来发现并加载工具。为了演示工具搜索的实际效果,我们让他获取这个项目的最新提交。这是一个私有项目,所以他需要使用 m c p。 你 可以看到他现在正在触发工具搜索。他找到了一个工具, 就是 list commits 工具,然后他用仓库的信息触发了这个工具。好了,我们得到了提交 id 以及提交内容的信息。 如果我们查看这次工具搜索的响应,你会发现 listcommits 是 一个延迟加载的 mcp 工具,它会把这个工具的完整模式加载到上下文中。 现在这个工具已经被加载到接下来对话的上下文中了。所以如果我再问任何后续问题,就不需要再去搜索这个工具了。比如说给我最后一个提交,我就可以直接使用 listcommits 工具。 如果我们切换到 langfuse, 在 我发送的第一条消息中,你可以看到只有十二个可用工具。然后在它触发工具注册表搜索后, 在下一次调用中,我们有了十三个工具,包括 list commits, 并且它能够对此作出响应。而在我后续的问题中,我们同样有十三个可用工具。 简而言之,这就是工具搜索实际的工作方式。虽然这已经非常有用,但我认为以编程方式调用工具更加令人印象深刻。如果我们开启一个新的聊天,现在我们在 opodder 上使用的是 cloud hikou, 我 一会会切换到 queen 三点五。但我想先给大家展示一下云端模型和开源模型在这里是如何工作的。为此,我们将使用 anthropic 在 其文章中发布的官方示意。 这里他给出了一个预算合规检查的例子。然后问题是哪些团队成员超出了他们第三季度的差旅预算? 这里有三个可用工具,分别是获取团队成员,获取支出和按级别获取预算。他在这里展示了传统的方法,也就是需要大量的工具调用和许多中间响应,这会导致上下文窗口被迅速填满, 所以我已经写好了云端代码来生成这个场景的虚拟数据。首先我们来看一下传统的做法,我已经关闭了沙河,现在我来提问哪些团队成员超出了他们第三季度的差旅预算。 正如我之前提到的,我们现在用的是嗨酷模型,所以他正在执行工具搜索,获取报销数据,获取团队成员。现在他正按照这种传统方式操作,需要为每一位成员逐一获取报销信息, 让我们看看会得到什么答案。所以第三季度差旅预算分析显示,有三个人超出了他们的差旅预算,这是他给出的结果。 根据测试数据,这个答案是正确的,但实际上应该有四个人,所以他似乎漏掉了一个。 marcus johnson 超出了预算一千七百, 所以这种传统方法实际上消耗了大量的工具调用。实际上有五十六次工具调用。正如你在这里看到的, 它处理了七万六千个 tokens, 但实际上并没有给出一个准确或者说全面的答案。这正是程序化工具调用能够解决的问题,因为所有这些其实都可以通过脚本自动完成。 因为一旦你知道了团队成员和预算水平,你就可以用一个负循环来获取每个用户的开销,并计算实际的超支情况。 那么现在让我们起用沙盒,并尝试用程序化工具调用来实现。好的沙盒已经开启,让我们重启后端,打开一个新的聊天窗口。好的哪些团队成员超出了他们第三季度的差旅预算?现在正在进行工具搜索。他找到了所需的三个工具。 现在他进入了编程模式,并创建了一个即将被执行的脚本。他抛出了一个错误。这其实并不奇怪,因为他并不知道这些工具的输出结构。所以本质上,如果没有所有信息,他就无法一次性完成。 现在他正在不断迭代自己的代码,实际上是在尝试得到一个结果。你可以看到他不断抛出错误,并且正在逐步解决。 与 anthropomorphic 的 论文相比,这可能是更贴近现实的程序化工具调用方式。因为我相信在 anthropomorphic 的 论文中,它是一次性完成的,而实际上并不会这样。经过多次迭代后,我们得到了一个准确的答案, 所以二千二百, sarah, chen, marcus, alex, emily。 所以 我们得到了所有正确的答案。 这很好,但这才是程序化工具调用的现实。它的方法相当迭代,就像 cloud code 或 open code 一 样。出于兴趣,我们再运行一次,看看能不能得到正确的答案。它会不会走一条不同的路径。我们假设是的, 很有趣。这一次它实际上是在预算层面获取团队成员的信息,所以它实际上是先获取所需的数据,然后再生成代码。所以这次它可能一次性就能完成。 但实际上他并没有做到,他仍然在自我迭代。不过我们确实得到了正确的答案,所以结果是对的,每一次都是如此,只是到达结果的路径不同。所以我们来看看这两条追踪记录。在我刚才运行的那一次中,总共进行了六轮调用, 总共调用了十二次工具,总提示词数为五万八千。现在如果我继续这个对话,目前只用了一万三千,但这是在与大语言模型进行了六轮来回交互的情况下。而之前那一次是在十一轮中用了十一万六千个 prof tokens, 都是为了得到正确的答案, 所以我确实没有看到 anthrax 所报告的八十五百分之的 token 节省。但这其实非常依赖具体的用力。 比如说这里我是在和二十个团队成员一起工作的,如果你有两千个团队成员,那情况就完全不同了,因为大圆模型需要运行两千次单独的调用,这根本行不通, 所以在那种情况下,就需要程序化的工具调用。或者你就需要一个真正的端点,让实际的数据处理在服务器端完成,而你只是获取信息并将其展示给用户。所以这其实切中了这个话题的核心。 也就是说,你的大圆模型到底应该像这样临时进行数据处理,还是应该仅仅从一个预先创建的脚本中传递信息? 比如说这个脚本可以放在一个技能文件夹里,因为这是我们在上一个视频中搭建的一个完整的技能部分。你可以有一个 python 文件,一旦创建测试并验证后,它就能真正完成这项工作,或者你也可以把它放在工具调用的 m c p 端,这样它就只是简单地传递接收到的信息。 那么我们把 cloud haiku 换成 queen 三点五二十七亿参数,来看看它的实际表现如何。我现在是在网络上运行这个模型,这里用的是欧拉玛,我有一个十万个上下文窗口长度,这里用的是 rtx 五零九零,显卡有三十二 gb 的 显存。 那么我们保存一下,重启服务器,然后问同样的问题,哪些团队成员超出了他们第三季度的差旅预算?现在加载需要一点时间,因为他需要把模型加载到内存中。好了,他已经触发了工具搜索,然后直接开始生成代码。 他实际上在工具调用之间没有输出文本,但你可以看到他正在生成代码本身,而且他正在经历和嗨酷一样的迭代过程,他正在从错误中学习, 并且在不断完善。看看,这就是我们的答案。让我看看二二百十五十七,还有三百,看起来很准确,我觉得这比嗨酷用的 tokens 更少,这很酷,我们来深入看看追踪记录吧。 是的,这次用了四万五千个 tokens 就 得到了准确的回应,这真的很棒,只用了四次工具调用,这已经相当不错了。这是我们 ai builder 系列的第五个视频。在这个系列中,我们正在用云端代码构建一个功能完善的 ai 系统。 本模块的 prd 可以 在我们的公共 github 仓库中获取完整的课程和代码库则在我们的社区中提供 相关链接在下方描述中。那么好吧,这一切到底是如何运作的呢?因为你可以看到我们正在这里的沙箱中触发代码执行,但这实际上意味着什么呢?所以这是一个完全本地化的系统。 我之前用的是嗨酷配合 open router, 但现在用的是 queen 三点五,这里内置了一些文档和 r a g 功能,使用的是 queen 三的嵌入模型。所以你看到的这个代码执行其实是在 docker 中触发了一个沙箱。你可以看到 现在所有这些容器都已经启动了。这里有一些孤立的容器是因为我一直在重启后端。但总体来说,代码执行都是在这里的一个隔离沙箱中进行的。 而这个架构安全性的一个关键部分就是工具桥的概念。所以从头到尾,当用户提出问题时,他会先到 fast api, 然后到 python, 接着再转发到 ai 模型。无论是远程还是本地的, 我们会收到一个工具调用,也就是你需要去执行这段 python 代码,这时后端就会启动一个沙箱容器。 我在上一个视频里已经介绍过这个的设置过程,但本质上我们用的是这个 github 仓库,也就是 llm sandbox。 这是一个非常清亮即可移植的沙箱环境,你可以配合 docker 这样的工具使用。或者如果你不用 docker, 也可以用 portman。 但本质上,这大大简化了启动这些环境的复杂性。 它们支持多种语言,还有许多不同的高级功能。你可以预先启动容器,而不是按需启动。 你也可以使用自定义镜像。这个项目里有很多很棒的功能,所以我会在描述区留下相关链接。我在上一个视频里已经非常详细的讲解过了,所以基本上我们就触发了那个容器的创建, 然后我们会把代码和一个绘画 id 一 起传递进去。所以现在在这个容器里,我们有一个 python 运行器,它会执行那段代码。在我们之前的例子中,有很多不同的工具需要被触发,比如获取预算水平、获取部门、获取团队成员, 而所有这些都可以存在于比如说一个外部系统中,但我们并不希望让沙乡访问外部服务。 相反,我们创建了一个安全的工具桥梁连接回 python 应用程序,然后每当工具或函数在 python 脚本中被触发时,都必须通过这个桥梁。正如你之前看到的,单个脚本中可能会有五十次不同的 api 调用或工具调用, 所以对于每一次工具调用都需要通过这个桥梁,它会使用绘画 id 来进行身份验证, 然后 python 应用程序会将该调用路由到外部系统获取响应后再将其发送回沙乡。因此,除了访问这个 python 应用程序中的 fast api 之外,沙乡没有任何互联网访问权限。从安全角度来看,你可以对这个 fast api 进行严格限制, 这些限制是基于工具本身的精确模式,所以所有这些工具片段、工具定义都是在创建时作为存根发送到沙箱中的。因此,多个工具调用会在 python 代码中,比如说在一个 for 循环内进行, 而且这样做速度非常快,因为此时你完全忽略了 l l m 没有任何中间代码堵塞上下纹。在这里, l l m 完全不参与这个过程,直到 l l m 完成脚本并生成响应。你在之前的演示中已经看到了, 然后这个响应看起来大致是这样的,这就是我们的脚本结果,然后这个结果会被反馈给 l l m。 l l m 接着可以决定下一步该做什么。 如果它已经获得了所有需要的信息,就可以生成综合响应并返回给用户。或者正如你在演示中看到的,它需要对代码本身进行迭代。在很多情况下,它会生成更多的代码,并再次触发沙盒环境。 这就是端到端的流程。我在这里提到了 gviser, 因为 docker 容器并不是你能拥有的最安全的隔离沙盒,因为它们与整个系统共享内核。 所以为了真正保障像 ram, sandbox 这样的安全性,我建议你搭配 gviser 一 起使用。 cloudflair 曾经做过一些有趣的研究,探讨了 ram 在 生成 python 代码或 type script 以及触发工具和 mcp 方面的有效性。他们发现,当工具以 type script api 的 形式呈现,而不是标准的 mcp 时,智能体能够处理更复杂的工具。 我认为这是有道理的,因为他们在训练时接触了大量原生的 python 和 javascript, 所以 在 cloudflared code mode 版本中,也就是我们所做的类似,他们会把 mcp 的 schema 转换成 type script, 因此 l l m 只是生成 type script 代码来触发 m c p。 这和我们正在做的事情非常相似。所以我刚才提到,工具存根被发送到沙盒中。因此,我们在智能体层面定义的 m c p 和工具会被转换成 python 存根 自动生成的 python 函数。这样,当 ai 为沙盒生成代码时,它实际上只是触发 python 函数, 而且因为这是原声 python, 所以 它在这方面会非常擅长。而且重要的是,沙盒永远不会接触到 api 凭证,它永远不会接触到任何机密信息或类似的内容。 我之前提到过需要高效的工具设计,因为在早期,有太多的 mcp 服务器完全塞满了你的上下文窗口,让你根本无法完成任何实际工作。 即使在 anspec 自己的文章中,他们试图解决的挑战也是关于臃肿的 mcp。 在 这里,他们提到 github 的 mcp 有 三十五个工具和两万六千个 tokens。 但即使是在这篇文章发布之后, github 也发布了他们 mcp 的 新版,现在这个数字大约是四千个 tokens。 所以 在 mcp 和工具调用端其实可以做很多工作来确保不会无谓的给你的上下文窗口增加负担。 最后, entropy 在 他们的高级工具调用工具包中还加入了另一个功能,就是关于工具使用视力的这个概念。因为虽然 jason schema 非常擅长定义结构,但它无法表达使用模式。 他们举了一个例子,比如说截止日期,它的数据类型是自复串。日期格式有很多种传递方式, 那么他们到底希望用哪种日期格式呢?除非你真的引导他,否则大圆模型是不会知道的。所以,通过工具使用势力,你可以为每个字段提供一个势力,以便让大圆模型朝着正确的方向前进。比如在这里,日期格式就是年月 日。在他们的测试中,他们发现这能将复杂参数处理的准确率从七十二百分之提升到九十百分之,这很合理,因为本质上这就是多轮提示。你只是给了一个你想要的视力,这绝对会引导模型朝着正确的方向。 实际上,我不确定你是否需要把这个设置成系统中完全独立的功能。我认为,使用技能这个概念意味着你可以在加载技能时提供视力,这样就可以触发你想要实现的任务的执行顺序。 你会发现 cloud 也有点类似,里面有很多功能是重叠的。 antropic 之所以没有取消工具调用,是因为他们认为你应该有策略力对这些功能进行分层。 所以,如果你的上下文因为工具定义工具搜索而变得臃肿,如果你有大量中间结果污染了上下文,那就走沙河路线。或者,如果 ai 总是把错误的值传递给参数,那么使用工具势利就是有意义的。非常感谢你的观看,我们下期再见。
95一蛙AI 04:23
04:23



