MATLAB设置时长

粉丝4085获赞7782
相关视频
 01:12查看AI文稿AI文稿
01:12查看AI文稿AI文稿哈喽,大家好,今天我们来演示怎么使用 markup 软件。运行代码是一个通用模板,在控制台输入 cd 之后,在英文状态下输入括号,在里面输入单引号, 在电脑打开你的项目就是项目所在的根目录,点击上方的目录框,复制该路径之后回到代码,粘贴到单引号里面,然后回车 markup 工具左边就出现你的项目了,之后打开点飞对应的点亮文件, 打开之后点击上方的运行即可,是不是很简单无脑教会你运行 matlab 项目到此结束。 注意,我的所有项目需要在 matlab 二零二二版本及以上运行,出现各种报错,要么就是 matlab 版本不对,或者安装时候忘记勾选需要的工具包。很多同学都是这个问题,解决方法就是重新安装 matlab 软件,看我之前有一期手把手的安装视频, 如果是深度学习的项目运行报错的话,需要单独安装对应深度学习工具包,前提是 matlab 软件也是二零二二级以上的,这个在购买时候附件有解决文档,自行下载,后续也会更新。深度学习项目运行报错通用解决方法的视频教学。
48孤独的根号三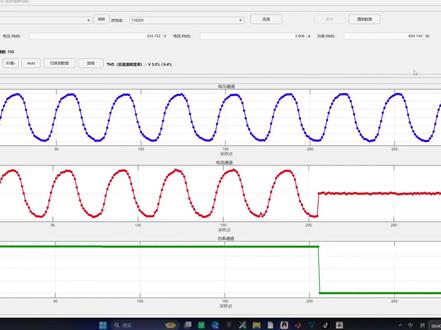 03:02查看AI文稿AI文稿
03:02查看AI文稿AI文稿大家好,最近我用这个 metlab app 做了一个上位机界面,用于适配我们的产品。然后它主要就是有三路,这个电压、电流和功率的一个显示,然后呢可以切换到频域, 有一个连续频谱的一个分析,当然功率就没有这个频率的分析。然后我们把这个鼠标点在设置上面的每一个点,它都可以显示它的一个 x y 轴,然后我们可以换回这个 切换到这个数据的一个页面,它把我们的数据都存储了起来,然后上面是电压的有效值,电流有效值和功率有效值,这里可以选择波特率,然后我们这里试一下连接, 然后现在开始刷波形,我们摁一下一键 auto, 然后我切换副本, 然后我们可以再切换到频域看一下,当我覆盖发生变化的时候,它的一个频谱在后台做这个快速复列变换, 然后我们切换回时域 auto, 调节它的一个彩虹绿,可以写成双色。然后我们在测量的过程中,它这个 t h d 总斜波基频率、电压和电流的在这里一直显示。 我们支持的这个数据格式是那个 firewater, 因为我们一开始以前用的都是这个 v o f 一 加的这个协议,这个协议就是电压值逗号,电流那个电压值逗号,然后后面结尾的话是反斜杠 n 这样的一个格式,大家可以看一下这个 这个格式,然后可以看一下我们这个视频,就是之前我们做的就是给大家展示一下我们现在做的这个和 v o f a 家的格式一样的, 然后我们这个还可以变成一个桌面的 app, 不 用基于 my lab, 我 只需要在这里选择一下我的一个,上传一下我这个文件,然后本地部署一下,这边打包, 然后就可以在这里生成一个这个桌面文件,我们只需要点开,不需要打开那个 mytime 就 可以运行了 啊,就像这样子。
41傅里叶不是天才 01:36查看AI文稿AI文稿
01:36查看AI文稿AI文稿啊,大家好啊,今天我们介绍一下基于狐狸优化算法的 l s t n 网络异为时间训练预测算法。首先我们将当前文件夹窗口定位到程序所在路径。 啊,定位之后的话可以看到有这一些文件。首先这个的话是 l s t n 网络模型的训练和预测,这个的话是通过狐狸优化算法优化 l s t n 网络的操参数,然后再进行训练和预测, 然后这两个模型它们的训练误差和结果会保存到 r 一 和 r 二这两个 m a t 文件里面。全部运行完之后,我们打开 ctrl pad, 点击运行啊, ctrl pad 的 话可以得到这么三个图,我们依次来看一下。 首先这个第一个的话是训练和预测的啊损失值以及 训练误差对比,可以看到通过 fox 优化之后,它的损失值和误差值收敛速度更快,值也更小,然后这个的话是 fox 适应度值的一个收敛曲线。 啊,这个的话是啊,训练和预测误差对比优化前是三点六四,优化之后三点一九,可以看到性能得到的提升。 好,就大概这么一个效果演示完毕,谢谢大家。
 02:04查看AI文稿AI文稿
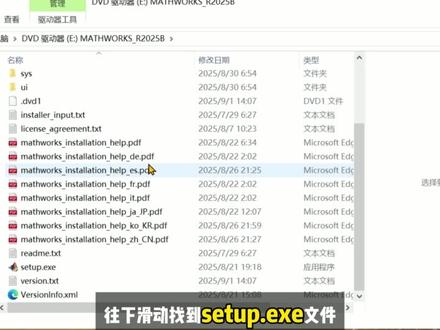
02:04查看AI文稿AI文稿很多同学安装 mate 六的时候,经常遇到激活失败,安装卡顿、路径报错的问题,这期视频两分钟手把手教大家一次性安装和激活软件。安装包我放评论区里了,需要的宝可以自取。 首先我们把 mate 六安装包下载到本地文件夹,右击点击解压到 mate 六二零二五 b 文件夹。安装包跟解压的文件夹体积比较大,电脑磁盘至少要预留五十 g 的 空间, 要是磁盘仍然紧张,解压后删除压缩包就能省出十几个 g 的 空间。解压完之后,打开文件夹,找到这个 iso 文件,并打开 往下滑,找到已在文件,这里划重点,一定要右键选择,以管理员身份运行。弹出确认框后点击式,现在安装界面出来了,我们点击右上角高级选项,选择我有文件安装密匙,勾选接受许可条款后点下一步,把我们的安装密令粘贴进去, 再点下一步。接下来需要许可证文件的完整路径,这个路径就在我们下载的括号文件夹里,右击点击文件显属性,在安全里复制完整路径,粘贴过来就行。然后点击下一步安装路径,建议大家选 d 盘的文件夹, 这里我们选 matelab 文件夹,在下一步主键方面直接全选就可以。接着勾选添加桌面快捷方式,继续点下一步,这里可以看到需要安装二十四句,大家一定要确认此盘空间足够,点击开始安装即可, 安装完成后还没结束,最后一步激活很关键。回到下载的文件夹,打开 crack 文件夹,复制里面的 bing 文件夹,再打开刚刚下载到 d 盘的文件夹,把 bing 文件夹粘贴进去,选择替换目标中的文件,到这里就全部搞定了。我们打开软件,看看 能否正常启动,还能运行代码,说明安装激活都成功了。掌握这套方法,两分钟理清步骤,一小时做的安装完成,再也不用反复折腾了。觉得有用的话,别忘了下面知识呀!关注我,解锁更多软件安装的使用技巧!
63云顶科研 01:32查看AI文稿AI文稿
01:32查看AI文稿AI文稿啊,大家好,今天我们介绍一下基于海洋捕食算法的 l s t n 网络时间系列预测 my table 仿真。首先我们将啊当前文件夹窗口定位到程序所在路径, 然后看到有这些文件。啊,这个方形文件夹里面是啊字函数,然后这个的话是空 p r 的 对比,然后这个的话是 l s t n。 网络的训练和预测。啊,这个的话是通过海洋捕食者算法优化 l s t n。 网络超参数,然后再进行训练和预测, 那这个的话是训练样本,然后这个和这个文件运行后的结果的话,会保存到 r 一 和 r 二这两个 m a t 里面。最后的运行完之后,我们再打开 ctrl 啊进行对比, 可以看到这么一个效果,首先这个的话是 m p a 捕食者算法的一个适应度子的收敛曲线, 然后这个的话是预测对比,可以看到预优化前误差是三点六四,优化后四三点零 e, 然后这个的话是收敛曲线, 可以看到通过优化算法 l s t。 网的训练损失值和误差值,收敛速度更快,值也更小。好,大概这么一个效果演示完毕,谢谢大家。
 02:41查看AI文稿AI文稿
02:41查看AI文稿AI文稿啊,大家好,今天我们介绍一下基于海象优化算法的 l s、 t 网络异为时间虚列预测算法。首先我们将当前文件在窗口定位到程序所在路径,啊,定位之后的话我们可以看到有这些文件, 然后这个的话是啊海象优化算法的一个优化和测试,我们首先打开它好点击运行, 然后这个时候的话程序进入一个优化状态,这个 t 的 话表示当前的优化迭代次数,然后我们这里设置总群规模是三十,迭代次数的话是啊,也是三十,那这个 t 的 话是当前迭代次数,然后这里的话我们稍微耐心等待一下, 看 好现在迭代三十次。迭代三十次之后的话,网系统啊得到优化结果,这里的话我们优化的是 l s t n 网络的, l s t 网络的是隐含成数量, 优化之后引函数数量最优值是五十八,也就是这个值。然后的话通过优化后的网络参数再进行 l s、 t n 网络训练,这个就训练曲线好,训练之后的话我们再打开这 compare。 啊,对比结果 好,可以看到这个的话是海枪优化算火的受练曲线,那这个的话是对比优化前的话误差三点六,油耗的误差四二点八九,那这个的话是啊训练曲线的损失值和误差值的一个对比,可以看到通过海上优化优化之后 它的受练值。啊,受练速度啊更快,受练值也更小。好,大概就这么一个效果演示完毕,谢谢大家。
 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿啊,大家好,今天我们介绍一下距 w a 近于优化的 l s, t n 网络模型文本分类算法啊, matlab 仿真。首先我们将当前文件夹窗口定位到程序所在路径定位之后,我们看到有这些文件 风雪里面的话是子函数啊,这些子函数的话是不用管它在运行的时候会自动调用,然后这个的话是一个数据库,里面包括不同的新闻内容,然后这个的话是提取 跟读取啊新闻的数据啊,然后进行一个格式化的训练,将文本啊训练成啊网络模型可以识别的啊向量数据 啊,也就是我们所说的词欠录训练,然后词欠录训练完成之后,它的结果会保存到这个 word embedded 的 meta 里面,然后分别通过 l, s, t, n 网络啊进行训练和预测,然后通过金鱼优化啊算法优化 l s t n 网络,再进行训练和预测, 两者之间的结果会保存到 r 一 和 r 二中啊,这里的话训练时间比较久,我这里就啊不演示,然后我们直接看结论,点击 ctrl 啊运行 啊,可以看到最后结果降呢。首先这个的话是 w a 的 啊适应度值的一个收敛曲线啊,这个的话是网络模型的损失值对比和精度训练精度对比,以及最后的 视频率对比,可以看到优化前视被率百分七十五,优化后视被率百分之八十五。 好,大概这么一个效果,好,演示完毕,好,谢谢大家。
 06:08查看AI文稿AI文稿
06:08查看AI文稿AI文稿哈喽,大家好,好久没给大家攒配置了啊。就是放假了吗?好多这个亲戚朋友,他们家小孩,他们看了这个 春晚啊,发现好多机啊,机器人在这个春晚上,然后他们就想让他们的小孩将来学这个啊,自动化专业啊,机械制造专业,然后还有这个什么 什么什么,具体不清楚,反正就跟跟这个相关的啊,不育儿童就是因为他们知道我。我以前卖电脑的嘛,虽然我现在不卖了啊,我现在上班去,哎,就等弄弄一个什么什什么电脑能能够将来能够从事这个行业, 其实挺简单的啊。没没没那么复杂,就是他无论什么样的机器人,限阶段他都是都是人做的,都是人做的 人就是用软件在电脑上做出来,其中最重要的一个软件叫 matelab。 matelab 啊,就这个软件,就基本上你学自动化的,学这个机械工程机械的都都会用到的。一个一个软件他需要一个什么配置呢? 官网的配置要求就是一个四核以上的处理器,然后一 gb 以上的显卡就就够用了,当然那是最低的配置,你如果就是大学四年 想完完整整的就是一点也不卡动的,想要学学这个软件,其实要求并不低。 并不低?那你怎么选一个?就是五年不过时的电脑,而且大学生嘛,上学肯定得玩玩点游戏。 嗯,这套配置呢,我跟大家讲就是我今天也是刚在腾讯上看 啊,发现一个很神奇的现象,就是现在内存在涨,硬盘在涨,就是 cpu 好 像降价了啊,尤其是 amd 的 cpu 好 像降价了,现在你买一个最新款的九七零零叉的板优套装大概多少钱?一千七百五十块钱,在闲鱼上一千七百五十块钱, 它的性能就是民用八核处理器里面最强的啊,最强的什么英特尔,什么这个那个,它就是最强的,大家记住它就是最强的,五年不过时,哎。然后那个 内存,大家最关心的内存也不像年前那么就是炒的那么厉害了,年前十六 g 的 内存基本上炒在一千块钱以上了,现在你只要不是买那种一线的牌子,买个二三线的牌子凑合用,十六 g 的 大概也就八九百块钱, 这两个加起来也就两千五百块钱,满用内存三千多号你就都有了。然后啊,像 mate lab, 它主要是数学计算嘛,它对显卡的要求其实并不高。那当然也不能太低啊,因为现在小伙,对吧,你上大学总得玩点游戏嘛,对吧? 嗯,我们就按这个游戏机的这个配置来算,大家觉得这个 ps 四 pro 这款游戏机,它的显卡是个什么显卡呢?它的显卡是 rx 四八零的水平啊,就是它都不到五八零,所以你花个三四百块钱弄个四八零,弄个五八零, 未来五年不,不敢说多了,未来五年基本上所有的游戏你都能进去看一眼,网游的话基本上通吃,你就放心大胆的玩就行了,什么吃鸡什么三角洲,你就放心大胆玩就行。但是你不能追追求太高的帧数啊,哎,不过也可以也可以,因为这个处理器很强劲,他的处理器性能就是帧数仅仅 仅比这个九七零叉三 d, 可能比一般的处理器要牛逼多了,九七零叉三 d 嘛,毕竟是。 嗯,打网游的话证书会好很多,所以你不需要配太好的显卡,但是你如果想就是我还想玩一些很好的单机,很牛逼的单机,那你就四零六零五零六零五零五零。现在价格可能会稍微贵一点,但是两千块钱你能拿下,你要是没有两千块钱,你就三百块钱 整一个五八零,玩五年玩到大学毕业,一点毛病没有。好不好,你要求不太高。嗯,硬盘的话其实怎么说呢,你要是因为硬盘现在也也涨价了,尤其是固固态硬盘。所以你 我的理解啊,我的理解就是你买一个小容量的硬盘,你玩游戏的时候,你玩软件的话,他不需要太大的硬盘的容量。真的啊,上过学的都知道不需要太大的硬盘啊。那个 你要你要是玩游戏的话,那你就玩一个删一个,玩一个删一个吧,对吧?这个五百 g 的 也也凑合凑合够用,然后以后有钱了你再往上加,你一个主机里头平均能加六块硬盘。就那种标准主机啊,不是那种小主机,你就慢慢往上加就行了。等等降价的时候慢慢加,现在先将将用 够,够你装个系统,装一两个游戏。行了啊,要求别太高,两三百块钱,然后剩下的就是你也别搞什么光污染,别搞什么这个风扇,那个这个散热,跟你风扇多少没关系,它是跟风道有关系啊,你就选一个风道好一点的机箱,一百多块钱的。 嗯,弄一个散热器也别弄什么水冷,就弄个风冷就行了,风冷还稳定,毕竟你要用好几年呢嘛。 呃,这套配置的话可能对电源要求的稍微高一点。那也不用太高,就六百五十八左右,七百五十八左右,电源大概一百五十块钱差不多,总共算下来就是差不多四千五百块钱。成本啊。成本?四千五百块钱 你就可以拿它做机器人了啊?就充满那机器人就是拿这种人做的。啊哈,不要不要,太神秘。就是,我们还是要相信人的力量。他再牛逼的东西,哪怕是 ai 现在也是人开发的对吧?他 ai 也做不到自己开发自己。没没,还没那么智能。
14狗提督小车车 01:51查看AI文稿AI文稿
01:51查看AI文稿AI文稿啊,大家好,我是简简单单做断法啊,今天我们介绍基于 pso 优化的 lstm 长短记忆网络模型文本分类算法啊,首先我们将当前文记在窗口定位到程序所在路径啊定位之后的话有三个程序,首先我们看这个程序 啊,这个程序的话我们主要验证的是词啊欠录训练得到词欠录训练之后的一个模型,这里的话我们使用的 matlab 自带的诗音无二的 embedded 这个程序, 然后将磁切入训练之后的模型保存到啊这个 m a t 文件里面,然后分别通过 l s, t n 网络以及 p s o, l s e 网络调用这个磁切入训练之后模型进行训练,训练之后的两个网络模型等。 啊精度和误差会保存到阿林和阿 e 里面。最后的话我们再打开这孔片的进行对比。 好,最后结结果,对比结果是这样的,首先这个的话是啊他的啊训练损失值的对比,然后这个的话是他的训练精度的一个对比。 好,最后的话是将两个网络模型的啊测试样本进行啊测试,最后的话 p s o 加 l s t m, 它的测试结果的精度在百分之啊八十八左右,然后直接通过 l s t m 网络进行测试,它精确率在百分之八十一二左右。 好啊,但还就是这么一个效果,演说完毕,谢谢大家。
12简简单单做算法 01:24查看AI文稿AI文稿
01:24查看AI文稿AI文稿啊,大家好,今天我们介绍一下基于虎鲸优化算法的 l s t n。 网络的模型啊,意味时间虚列预测满台,来吧,仿真。首先我们将当前文记在窗口定位到程序所在路径 啊,定位之后的话看到有这些文件啊,第一个的话是 l s t n。 网络的训练和测试啊,第二个的话是通过虎鲸优化算法对 l s t n。 网络进行训练和诱使测试,然后这两个程序它的呢结果会保存到 r 一 和 r 二这两个 m a t。 文件里面 啊,全部运行完之后,我们可以打开 ctrl pad 的 进行对比, 全部运行完之后,我们可以去打开 ctrl pad 的 进行对比。 首先第一个的话是 l s t m。 网络训练损失值和训练精度啊,训练误差的一个对比,可以看到通过虎鲸优化算法之后 l s t。 网络它的训练啊收敛值和啊收敛速度更快也更低。 然后这个的话是 ps 啊,虎鲸优化算法的适应度值得收敛曲线啊。最后是训练误差对比啊,优化之前它的误差是三点六,优化之后误差是三点一。好,大概这么一个效果演示完毕,谢谢大家。
23软件算法开发 03:41查看AI文稿AI文稿
03:41查看AI文稿AI文稿好,现在我们来看八点二点三频域分析法,那在讲频域分析法之前啊,先给大家来表述一下啊,微分方程伏立叶变换和拉普拉斯变换之间的关系。 为什么这么说呢?因为我们可以看到伏立呃,这个奈奎斯特曲线是吧?它是 j j omega 等于什么什么什么吧,但是呢,这有个前提,它是 j j omega, 这跟我们所一般题目上给的 g s 是 有的不太一样的地方, 它是 j o m d, 它是 s, 那 么 s 呢?一般是什么呢?它等于 a 加 b i, 它,它一般就是 会有这个复数,但是呢,这个呢是虚数,复数跟虚数其实呢就对应了我们。呃,这个就是拉普拉斯变换,那这个呢,就是拉普拉斯变换的一种特殊的形式,就是令十步等于零,那么这个呢就是浮力表, 这是两种不同的表现形式。那么为什么我们在频域分析法的时候需要用到的浮力变化,也就是需要令这个实部等于零呢?这是因为我们需要 这个虚部啊,虚部是更有利于我们去分析啊,它的稳态的频率。 可以这么理解,所以说当我们用频域分析法的时候,实际上我们想要的是更精确的,或者这么说就是我们如果只看这个虚步的话,是想要求这个系统准更快,那么如果说这个实步的话,是想要看他的稳 啊,所以拉普拉斯的话包含的是稳准、快,因为他有实步,有虚步。但是呃,频域分析法就是当我们用到弗利叶的话,他是求我们准更快, 这么理解大家就更好理解了。然后微分方程呢,实际上是我们去描述我们的现实的世界嘛,是吧? 所以这个就是他们的关系。然后例八杠十一的话给,一般呀,都是给我们一个开环转函数, 开环转函数 g s 等于 s 加一分之一一阶惯性环节。让你求一下这个奈克斯的曲线是什么? 然后频域分析法的话,它还包括了两种,一种是耐克斯特,一种是博德图,在我们的电机控制里头的话,更常见的用的是博德图。嗯,所以这个耐克斯特比较常用的话是在考研的时候啊,那我们针对这个再理一下,就是 微分方程还有拉 plus 变换,还有这个,呃,浮力变换,他们之间的关系啊,微分方程的话是很好理解的物理物理的定律啊,然后建立一个数学模型,这个就是我们的微分方程,把微分方程求出来之后,但是它是有这个 微积分的,我们想让他更简单一点,这个时候就用到了拉 plus 变换,就是把一些微分积分变成了乘除加减这样的方式,这是一个数学公式,数学工具,就拉 plus 变换就起到这样一个作用,就简化我们的预算。然后呢 又想更精确的因为拉普拉斯变换,它里面包含了太多的信息,稳、准、快他都有,但是呢,如果我们到平移分析法的话,我们只分析他的快跟准啊,那就需要用到负离子变换,把他的实部给它去掉,只看虚部啊, 这就是整体的这个关系,所以这是我们要学的这个目的。运行之后呢啊,你可以看到这个代码也很简单啊,就是我们把数学模型建立起来,然后调用一下奈克斯的这个函数就可以了,直接把进行一个传参,然后绘制 啊,这个就是我们的 nexus 图,它结构非常简单,所以各位如果想绘制 nexus 的 时候,嗯,不妨先利用一下这个 my lab 来去绘一下,看看你的期望是不是相符的。横坐标的话就是 omega 啊,纵坐标的话就是这集 omega。
 06:16查看AI文稿AI文稿
06:16查看AI文稿AI文稿啊,大家好,今天我们就按控制器啊第一章学习教程的第一章啊,基于强化 q 热点强化协时 啊的实现做一个简单的讲解,那么这里主要讲解 q 热点强化协时啊训练部分的程序,我们打开程序,然后将簿册中的程序复制进来,整个程序的结构是这样的,我们逐个讲解一下, 这里我们主要是训练一个智能控制智能体控制小车移动啊,使小车啊上的一个啊倒立摆保持平衡,它还这么有功能。 然后我们首先看啊程序的第一滑第一个部分啊,这一期的滑式系统的一些参数定义,我们这里都有一些注示 啊,包括正的状态的话,主要三个啊,车速啊,改的偏角啊,改角的速度啊这三个变量。 然后的话我们定了车速的一个啊,控制的,控制之后的一个最大行驶的一个范围啊,它是往左或往右啊,分别定义啊,最大值是十,所以是啊负十到十, 然后感的偏角也是负三十度到正三十度啊,这些的话,可以在啊 q 能力强化学习训练过程中保证啊训练后的这些参数在我们所规定的范围之内。 然后这个的话是我们电影的控制指控制级啊,也可以也可以理解为动作空间啊,主要是用于控制小车向左或者向右。 好,以下是强化学习的一些啊,残数这些的话都是固定的,我们就不介绍了。然后进入一个逐题程序 啊,首先的话还是一个初识化的过程 啊,这个初识化过程主要我们定义了一个啊,小车的一个啊,初识状态啊,包括位移啊,第一个是位移,第二个是车数,第三个是 啊啊摆角的随机值,第四个的话是角数度啊,这四个变量,我们啊定一台一个出式值,然后再啊对其状态进行离散化处理,然后再出式化奖励值, 然后这里面的话是一个啊单步的时间啊循环啊。首先我们通过一个 appsono 贪心策略啊进行动作选择,我们定义了一个随机数,如果这个随机数小于这个参数,那么进行一个随机的动作选择,否则的话啊从 啊啊 q 值中的最大值所对应的缩影啊作为当前的动作值啊,这个的话是标准的一个弹性车轮啊选的动作方法啊,是一个固定的一个啊算法, 然后我们根据得它的动作值获得啊实际的啊啊选择,然后将这个选择后的动作和环境进行交互,那么这个环境的话,我们主要定的是一个车辆的动力学方程, 根据这个动力学方程以及我们所产生的动作啊完成一个啊环境交互,它主要是自信动作获取啊小车的状态,然后获得当前动作上所对应的奖励值这么一个过程。 然后的话就是 q 值的更新,这里的话我们定义了两组 q 值啊,这里两组 q 值的话啊,它的主要功能是这样的,这里我们哈设置了一个随机值,如果这个随机值小于百分之五十,那么我们更新第一个 q 值, 用 q 值第一个 q 值 a 啊搜索下一个状态的最右的动作,然后结合 q 至 b 记成标值,如果啊随机值大于百分之五十,那么就用 q 至 b 来啊,找到最右动作,然后来结合 q 至 a 计算所对应的啊 q 值, 那么这种交替的方式方法还可以避免单独一个 q 值啊,过估计的一个问题,让得到的 q 值更加接近啊实际值啊,大概这么过程,然后啊完成 q 值更新之后,我们就累积本轮的一个奖励 啊,然后每一次累积奖励啊,在啊当前轮次啊训练之后,它会清零 啊,同时呢记录每一轮啊假例,它的平均假例用于后期的格式化处理,也就是这个步骤。 好,大概的话就是这么一个过程,所以说啊,基于 q 啊冷凝强化学习的 一个空系统,他啊其实比较简单,首先我们通过啊策略啊,结合贪心策略以及搜索 q 子最大值,获得当前的一个动作,然后将这个动作作用到啊环境中,实现环境交互 啊,完成环境交互之后,我们更新假立值,然后进入下一轮的一个啊训练啊,就是这么一个过程。 好,这里的话我们已经训练好了啊,训练完之后的话,他的奖励收啊收敛值是这么一个曲线,可以看到随着啊训练次数增加,奖励值啊逐渐收敛好,大概就这么一个效果,讲解完毕,谢谢大家。
24可编程芯片开发 57:02查看AI文稿AI文稿
57:02查看AI文稿AI文稿下面呢我们将会为大家结合这个算法本身的一个代码,然后去进行一个实操。 我们在这个地方呢,可以看到我们的算法呢,其实就是采用 matlab 编程的一个方式去实现的。 那在正式介绍我们的代码之前呢,我们这个地方是给大家去准备了一些资料啊,顺便给大家去介绍一下,最基本的就是一个 ppt 的 一个资料,其次呢就是我们的一个图片的一些资料,那当中呢就包含了我们一个遗传优化算法的一个代码框架。 为了大家更方便地去理解啊,我们这个算法的一个代码框架呢,我就用 xmind 这个思维导图给大家去做了一个 代码框架的一个思维导图,那内容是非常精简的啊,很多时候我们很多同学他拿到代码之后,大部分情况下是很懵的一个状态,原因很简单,因为这些英文第一个不认识,第二个是这个 每个算法呢,它的一个实现是什么样子的?先有哪些,再有哪些他很多时候是找不到。一般而言,我们拿到代码之后呢,我们都是通常运行一个主函数,也就是 main 函数,那在这一份代码而言呢,它就是一个两个部分, unit 就是 我们的一个基因的意思。 还有一个是工具箱 example 二,就是我们采用工具箱的一个编码的一个方式来进行一个编码。大家可以看到在这个算法 这里,我们可以看到它是有两个代码,一个是 generate, 就是 我们的一个自编码的一个方式啊,这是一份开源的一个代码资源。那第二部分呢,则是一个 example 二,这采用调用工具箱的一种方式去实现,两者之间有什么区别呢?其实第一种呢,就是 调用字编辑的一些函数,来去完成我们的一个一一川优化算法的编写。而第二种呢则是使用我们已有的一些啊 maclab 的 工具箱,通过调用工具箱的一些函数来去实现我们遗传优化算法, 因为我们遗传优化算法它的时间其实是非常久的,一九七五年提出到现在呢已经是五十年左右了, 刚今年刚好是五十年,那五十年的一个时间呢?呃,中间就有很多学者在不断的对它进行优化以及研究,因此呢他们就去封装了一些工具箱,那么这个工具箱呢,我们在这个地方也是有去给到大家在代码资料里面, 我们这一次是 maclab 版本,就包含了一个是一串优化算法,这些就是我们的一个自编写的一个函数,而这一个呢就是我们的一些工具箱的一些内容。 那在这个地方的工具箱啊,就放在这个地方给大家去简单去查看一下我们一个 d o c 文档啊,这也是一份开源的资料啊,本身呢里面可能是英文的,大家可以放到翻译器里面去简单查看一下啊,查阅一下。 那么在这个基础上面呢,我们来去看一下,我们这一次呢,一个是字编辑,一个是调用工具箱,那这两种呢,都是我们这个主函数,比如说我们这个地方给大家去运行一下啊,先使用这个 lection, 然后点击运行这个地方就添加路径就可以了,然后它就会自动计算,算完了之后呢就会出来两张图,一张图呢就是我们的一个函数的一个曲线图,它随着迭代次数变化,我们函数找到最小啊,最大值的一个数值变化的一个情况,那就是这一个函数曲线图。 另一部分呢,则是我们的一个函数的一个啊,它的一个函数的一个示意图。那在这张函数图当中,我们可以看到它在这个负二到二这个区间上面呢,它是函数图,大概是长这个样子,那同时我们可以看到是不是这个地方有一个三角的点,然后我们可以去 稍微点击一下,可以看看它的一个大概位置,坐标的一个位置呢,基本上是一致的。所以说这个三角形的一个 图啊,三角形的这个点呢,其实就是我们找到的当前的一个最大值,当前的一个最大值,因为我们算法本身是具有一个随机性的,因此它每一次运行它的结果都不一样,我们这个地方呢,可以再给大家再运行一次, 我们可以再运行一次,那大家会发现我们数值上来讲跟刚才的是有所区别,我们可以再点击一次运行, 你可以看到它的数值又会变化,所以说它本身是有一个非常强的一个随机性。嗯,我们对于当前这个迭代次数和它的一个, 比如说种群数量等等而言,都是没有改变过的。而我们再次运行的时候就会发现,哎,它的效果有时候会有个很明显的波动,对吧? 因此呢,这个一串优化算法呢,本身是有一个非常强的随机性,那如何去把这种随机性控制好,就是我们需要去做一些算法改进了,那对于这个案例而言呢,我们更多是理解它基础的一个框架是怎么实现的, 那紧接着我们来去看一下调用工具箱它运行出来是什么样的效果。那么大家可以看到啊,目前来讲呢,就是在这个运行, 那么这个地方呢,可能是有一个报错啊,稍后呢等一下我们可以再去看一下,重新去添加一下我们的一些工具箱等等啊,这部分呢大家不用担心,给到大家手上呢,肯定是能够正常运行的啊。 那对于这部分而言,我们本次的一个课程而言呢,更多的时间精力就是放在我们这一一系列的函数呢,我已经给大家去做了非常详细的一个批注,大家只需要去拿到手上去看一下就可以了。 而对于工具箱这部分而言呢,很多时候都是调用现有一些函数,两者之间的框架上是完全一致,只是一个是自编写的一个方式实现,一个是调用工具箱的一个方式实现。那么在正式看代码之前呢,我们要去了解一下遗传优化算法的代码框架, 那第一部分就是我们的主函数,一个是自编写的 gradient, 一个是工具箱 example 二,那随后呢则是我们一个编码的一个过程, 我们这个编码呢,其实就是去促使生成一些生成这个染色体啊。我们第一部分呢则是 code c o d, code 表示我们染色体的一个初识化的生成啊,生促使生成一些染色体,那我们生成这些染色体之后,它可能就会 超出我们设定一些边界,因此呢,我们就要去进行一个检测边界范围,那这个函数就是 t s t test 啊,去进行一下检测,检测一下我们 code 这个里面生成的染色体是否超出边界,如果超出边界的话,我们返回到边界以内啊,重新再进行一个个体的一个调整, 这就是编码的两个函数,那随后呢,就是我们进行一个适应度的计算,我们生成了这些初识的函数之后啊,初识的这个染色体之后,我们需要去计算一下它的适应度值是否符合我们的当前需求。那比如说我们这个目标函数呢,就是设为 f u n f, 那么这个放呢,其实就是方选的一个缩写,那对于我们这个案例而言呢,我们的这个函数其实就是我们刚才在 ppt 里面当中设计了 f x y 等于 y 三二拍 x 加上 x cosine 二拍 y, 那 对于这部分的一个函数,我们将它设为目标函数,寻找它的一个最大值啊,寻找它的一个最大值。随后呢则是我们遗传优化算法最经典的三个操作,分别是选择交叉以及变异。 对于选择操作而言呢,则是选择优秀的染色体进行基因的一个遗传,那我们这部分的函数则是 select, s, e, l, e, c, t select。 而交叉呢则是进行交叉染色体把它的基因进行一个交换 啊,生成我们的一个新的子代,那这时候呢,它的代码则是 cos 这一部分, cos 这份代码 变异呢,则是这个啊,对染色体进行变异操作,那代码呢也是 m k 这个文件啊,随后呢则是要进行一个适应度的再次计算啊,我们这时候呢就需要去再次调用目标函数 f u n f, 那么在这过程当中呢,我们也有一个精英保留策略给大家去拓展一下,那么精英保留策略则是更新历史最优,那么采用历史最优的一个数值去替换当前最差的一个个体啊,这就是我们一个精英保留的一个策略, 那换句话说呢,就是把最差的一些个体呢给逐渐的淘汰掉,就是这样的一个思路。最后我们则是进行一个基本的一个绘图啊,这是我们整个代码的一个框架的一个介绍,那接下来呢,我们对应到我们的 maclab 这个代码里面也是一样的,我们就包括了 genesis code, fun, test, select course, 然后 rotation, 这也就是我们的一个变异的一个操作,那所以说从左往右是依次过来啊,进行一个 调用啊,那当然我们具体调用的时候呢就是呃,可以看一下我们的主函数,主函数的一份代码,那下面呢,我们则是从这个主函数的 heredity 字边写的这份代码开始去给大家去介绍一下。 在第一行代码呢,我们就是进行一个清空环境啊, clc 和 clear, 这是我们常规的一个清空变量以及清空工作区间的一个环境, 那这时候我们可以点击一下运行,那么就会把刚才的一个啊函数值以及变量的一个结果呢进行一个清空,而后面呢则是一个遗传算法的参数设定,我们最基本的就是 总和种群的一个迭代次数啊,最大迭代次数是一千,我目前设为了一千,而种群数量呢,设为了一百啊,这是我们的一个基本的一个规模。而在这个基本上面呢,我们后面就会有三大操作的一个一些算子的一个设计,比如说我们交叉的概率设为零点七, 变异的一个概率则设为零点零一,也是百分之一的概率进行一个变异。还有一个就是我们那个变量自串的一个长度,因为我们这一次问题呢,它是优化两个参数, 一个是 x, 一个是 y, 那 它的一个自自数复串的一个长度呢?其实就是一个 x 和 y, 就是 一和一, 那本身呢,并没有一个多维空间,或者说是一个多层的一个变量啊,维度没有去进一步的增加,所以说我们就是一个变量的一个长度呢,就设为了一和一啊,分别去存储 x 和 y 的 一个长度。 紧接着就是我们一个参数变量的一个范围,我们在负二到二这个区间上面进行一个参数的一个调优,因此呢我们这个 bug 区间范围就设为了负二到二,负二到二分别对应的是 x 和 y 两个参数的一个取值范围,共有两行数据啊,存储着我们各优化参数的一个下限以及上限,那当然大家如果感兴趣的话,我们也可以去略微的去调整一下,修改一下。 紧接着呢就是我们的一个初识化的一个述组,那在这个过程当中呢,我们 individuals 就是 我们的一个个体,那在这个过程当中,我们就是一个种群的一个初识结构啊,我们这个 strike 就是 我们的一个结构啊,构成了一个渗入度,它的一个呃, 零矩阵啊,我们构成一个零矩阵,以及它的一些适应度值。个体啊,一个是适应度值,然后生成相应的一个矩阵去构建,然后后面的则是它的个体,这里是构成一个空的数组啊,作为一个存储, 后面的则是一些比如说种群的平均适应度,种群的最佳适应度值以及适应度最好的一个染色体,他们的一个 数值的一个初实化。因为在这个过程当中呢,我们要先构成一个空的数组,随后呢我们将这些数值不断的放在放入我们这些空的数组当中进行存储,所以说在这个地方呢,就是一个数组的一个初实化, 随后呢才是我们的一个种群初实化,那在这过过程当中,我们采用 for 循环 for i, 从一到这个种群的一个数量进行一个循环,那在这时候呢,我们调用编码方法 code 去随机产生个体,然后传递个体的一些数据啊,从 individuals 的 一个框,也是它的一个数值传递到这个 x, 随后我们调用函数去进行一个计算啊,调用函数放去计算它个体的一个适应度值,那这三行代码呢?对应的事情我们在后面也有去进行一个批注, 紧接着我们完成了一个种群的初识化之后呢,我们则需要去寻找一下最优的一个染色体, 那在这个过程当中呢,我们根据适应度的一个值提取出锁影值 index, 那 所以说一个是最优适应度的本身的一个数值,一个是它的一个位置啊,我这个适应度 值具体在排第几?它的一个排序我们也叫做缩影度值 index, 我 们根据这个排序,也就是缩影值 index 去匹配出我们最优的一个染色体。然后呢去计算一下啊,染色体的一个平均适应度情况,那在 这个过程当中就是去寻找出它的一个最有染色体的一个过程。紧接着呢,我们要去初识画一下数组,记录一下每一代进化当中最好的适应度值以及平均适应度值啊,那这个时候呢,其实就是为了方便我们后续画图啊,做一个数据的一个记录与存储。 下面呢则是进化开始的一个过程, for i, 从这个 e 一 直到 max 进行一个迭代循环。我们可以看到 individuals 则是当前种群包含了一个染色体眶以及适应度 fitness 一 部分是染色体本身的一个个体的一个数值,另一个是这个数值所对应的一个适应度啊,它的一个优劣程度的一个指标。 sizeport 就是 我们的一个种群大小, 也就表述了我们一个个体的数量,那这时候就是我们的一个选择操作。那下面呢则是它的一个基本情况,下面呢则是计算当前种群的一个平均适应度值啊,这个地方就是求和,并且进行一个除以它的一个数值,得到一个平均数, 紧接着则是它的一个交叉操作,我们在这个过程当中呢,呃,它这个交叉概率呢,就是这个, 这个 pcos 就是 我们的一个交叉概率。然后后面呢则是一个 lancon, 就是 我们的染色体的一个长度,也就是我们的一个变量维度,然后比如说对于我们这个 染色体的长度而言呢,应该就是二啊,应该就是二,我们因为只有两个参数,对吧?然后它的一个长度本身就是一一,那棒呢就是我们一个变量的取值范围,也是它的一个约束范围,在哪个范围内进行一个参数询优,那我们也给他进行一个缩影,那对于这个案例就是负二到二这个区间上, 那随后呢我们就是调用这个交叉的一个函数进行一个操作, 那在这个时候呢,我们就可以看到一个是 slack, 一个是 course course, 一个是 slack, 一个是 course, 那 对于我们的函数的编写呢,也就是在后面 slack 和 course 在 后面,稍后呢我会给大家去一一介绍。那最后呢第三个操作则是变异操作,那同样的把我们的一个 当前代数以及最大的迭代次数啊放导入进去,并且呢将我们变异概率呢进行一个传递,传递之后呢我们则是进行一个变异操作,同样也去调用我们便携的一个变异函数的操作, 那至此呢,我们就完成了三大操作,选择、交叉以及变异,分别调用我们已有的这个便携好的函数,紧接着就去进行一个适应度的计算,要去更新一下,哎,我们这一个这一轮迭代之后,我们适应度值都怎么样啊?它的效果怎么样? 紧接着我们就是进行一个操作,叫做基因保留,这时候呢其实就是找到最小和最大的适应度的一个染色体,提取出种群的一个位置, 那么如果说当代的最优是硬度值,比历史最优更好,那我们就更新一下,把这个最优染色体呢进行一个更新啊,这时候呢就是进行一个覆盖与更新了,更新一下最优的是硬度值,对吧?然后呢再更新一下最优的染色体,它的一个参数级, 随后呢我们用这个历史最优解,然后去替代当前的一个最大最差的一个个体啊,最差的一个个体,保证最优解呢,不会被交叉或者破坏啊,变异破坏,那这就是我们的一个精英保留的一个策略啊,基本的一个策略。 那么这个过程当中呢,我们还要去进行一个记录,就是记录一下我们进化的一个过程,比如说我们最优的染色体是谁,然后每一代进化当中平均的一个适应度值,以及最优的一个适应度值都是进行一个数据的一个存储,方便我们后续进行一个画图。 那至此呢,我们进化也就结束了,那就是我们整一个过程分为包括了啊,选择交叉变异,适应度计算,进行保留,最后呢再进行记录,这就是它整个循环的一个过程。 在我们完成所有的循环之后呢,我们就要进行一个绘图显示,那这时候呢,其实就是获取矩阵的一个行数和列数,来去进行一个 绘图,方便我们后续进行绘图,然后绘制收敛的一个曲线,那这个时候呢, figure 一 就是创建一个新的图形窗口,将我们的参数进行传递,去绘制我们的一个啊函数曲线的一个变化,我们最优值的一个变化, 那在这个过程当中呢,这括号一冒号 r 就是 我们 x 轴的一个数据,表示的一到总代数 r 的 一个列向量啊,从一到这个总代数的一个 r 的 列向量,就一二三,一直到这个 r 的 一个呃,总代数的一个 排序,它一个数量,它的一个列向量,那么 trace 这个部分呢,则是它的一个 y 轴数据。 那么第二列呢,我们可以看到在这个地方啊,在这个地方就是我们的 best fitness, 其实就是记录着我们每一代的最优函数值的一个变化,它是一列数,我们用这一列数呢来去判呃去进行一个绘图,绘图绘制一下我们最优值的一个变化, 而这个 b 呢则是表示的是蓝色虚线的一个样式啊,这是我们一个格式的一个选择。随后呢则是进行一些标题的一个设置, x 轴的设置以及它的一些 啊其他的设置,比如说我们这个地方是啊网格的一个打开啊,方便我们去衡量一下它的一个数值的一个空间上平面图当中那个位置。 随后呢我们还要再去画制第二张图,那第二张图呢,就是我们的一个函数图,那其实就设设定了一下我们函数的一个取值范围,并且把我们这个函数进行一个导入, 画出我们的一个函数的一个曲线。同样的我们要把这个点每代的最优点呢也进行一个绘制,绘制完了之后再把网格打开,我们这个地方呢也可以给大家去跑一下。那这时候呢,其实就是第一张图就是我们的这个部分, figure e 这一部分去绘制了我们的第一张图, 而第二张图呢就是我们的函数的一个最优值的一个情况。我们可以看到在这个 在这个图像上面就会有个三角点,其实就是我们这一轮啊计算当中他的一个 最优值啊,最大值的一个具体点位,同时这个本身也是一个函数的一个空间的一个图啊,去方便我们去理解啊,我们这个最优值在这个函数上面他是怎么样子分布的我们的一个具体的一个情况, 那以上呢就是我们这个自编写代码的一个 joint 题的一个基本的一个介绍,这是它一个主函数,那相比之下呢,我们这个 example two 呢也是完全一致的,那我们这个 地方呢,由于时间关系啊,我们其实就没有必要去深入太多,那刚才呢,我们也给大家去运行了一下,嗯,这时候呢就是需要去给大家说一下,要将我们的这些函数给到大家这个函数工具箱呢进行一个调用。因为刚才呢这个地方其实就是我们去 路径没有进行一个设置,比如说我们这个地方可以去添加一下浏览文件夹,我们工具箱的这个文件夹下, 点击选择文件夹,那么它就会自动找到这个文件夹的位置,我们在运行的时候呢,它就会发现这些我们工具箱那些 文件或者是代码,然后呢就会自动进行调用,就不会出错。如果说你运行的时候会报错,那很有可能就是我们这个地方没有把路径添加进来,或者说函数 在运行的时候呢,它找不到你之前编辑的这些工具箱的文件,所以说就会导致报错,那也就给大家去解释一下, 那整一个过程当中呢,其实是完全一致的啊,呃,就说白了,这个地方呢其实没有什么太大区别,唯一的区别就是什么呢? 就是我们这个地方调用的时候呢,是采用工具箱的一个方式去进行调用,所以这就是唯一的一个区别。呃,具体的一些数值啊,还有一些含义啊,我们在这个地方给大家去已经批注好了,就是大家啊自己去看一下就行了,那么这就是我们的两个主函数。那紧接着呢,我们要去给大家去介绍一下 后面的一些其他子函数的一些具体编写内容啊,方便大家去理解。这也是我们本节课这个案例代码的一个最重要的地方,因为很多同学他拿到这个代码就是看不懂,对吧?那我们就给大家去解释一下。 那首先呢是我们一个 code, 就是 我们的编码的一个部分,那么这个函数呢,就是将变量编成一个染色体,然后用于随机抽象一个种群,那这时候我们可以看到 learn code, 就是 我们那个染色体的长度, bang 的 就是我们的变量的一个取值范围,那对于这个函数变呃这个案例而言就是负二到二这个区间, rat 就是 我们的一个输出,染色体的一个编码制,所以说我们输入分别是染色体的长度以及它的一个取值范围。输出呢则是具体的一个染色体的编码,大家可以看到两个输入, 紧接着呢就是它的最后是一个输出 red, 在 这我们在这个地方呢 flag 设为零,它其实就是一个标志,我们开始使这个 while 循环, 在开始 while 循环的时候呢,我们它的条件就是要进行一个设置,直到生成有效的染色体, flag 等于一的时候,它才会去退出我们的一个整个循环。那 pick 就是 表示我们随机生成一个向量 pick, 它的长度呢是与 length 相同,元素值在零到一之间进行一个均匀分布,那这个过程当中其实就是生成了一个零到一之间的一个随机数, 那么我们通过限性差值的一个方式,将随机数映射到变量的一个取值范围内,那么这个过程当中其实就是我们进行一个映射,那大家可以看到这个其实就是我们的一个边界,而这一个部分呢就是它一个边界范围再乘上一个随机数。那么我们这时候呢,可以去 把我们的 ppt 再找到,将我们这个 ppt 呢可以看到这个随机部分,这就是我们一个种群啊,边界范围内随机生成后选解的一个公式。那其实刚才的这个编码的一个过程,生成出式解的一个过程,就是我们的一个 公式啊,两个就是公式是能够完全一一对应上的啊,就是通过限行差值将随机数印刷到变量的一个取值范围内, 紧接着呢就是去进行一个检验以及测试,检验一下我们染色体是否可行啊,调用此函数这个 test 进行检查 我们生成的染色体是否在允许的范围内,也就说是否在我们的边界范围内,如果说超出这个边界的话,那我们可能就要把这个染色体丢弃,或者是说重新生成一次啊,生成到一个边界范围内的染色体就是它的一个使用, 那么这个函数呢,其实本身也比较简单,那在这个过程当中它就嵌套了一个染色体,从 code 又调用一下 test, 那 我们来看一下 test 这个函数它有什么内容。 那么这个测试函数呢,其实就是检查染色体是否有效,我们的一个输入呢也是一样,染色体的长度,变量的取值范围,以及最后输出它的一个染色体的编码值,进行一个返回, 那这时候呢,我们这个返回呢,其实就是一个 flag, 那 这时候我们可以看到前面底已经调用了一下它返回值, flag 无外乎就是零或者一, 如果说是零的话呢啊说明我们这个染色体呢就是无效的,如果说是一的话呢,说明我们染色体是有效的,它就会退出循环啊,会退出这个循环, 那这时候呢,我们可以看到它的一个检验,它会检验一下初识化呢为一,假设染色体是有效的,我们去获取一下染色体编码的一个尺寸,随后呢我们可以去看一下,嗯,判断一下这个 它的一个下限与上限,把这个数值取出来,如果说变量超出对应的一个取值范围,那我们就将这个 flag 设为零,如果说没有的话呢,我们就去设定为这个一, 就是去进行一个检验,就说这个地方呢,其实就是检验一下我们染色体是否有效,如果说有效呢,那我们就返回一把,这个循环呢就退出来了,这时候染色体编码也就编码完成,基本上就生成了一个边界范围内的啊编码或说是一个染色体。 而如果说当我们这个检验的时候发现,哎,他已经超出了下线,或者是超出了上限的一个情况下,那就超出边界了,我们这个时候染色体就是无效的,他就会自动再重新执行一次这个代码,然后直到生成有效的染色体,边界范围内的染色体才会跳出循环, 就是我们的 code 以及 test 这两个函数,紧接着呢就是我们的一个放函数,那么这个放函数呢,其实就是我们的一个适应度值的一个函数,那 y 等于放 x, 那 这时候呢, x 呢,就表示为 x 一 以及 x 二两个部分,那大家可以看到 x 二乘上三 二派 x 一, 加上 x 一 乘上一个 q 三二派 x 二,那大家会发现是不是和我们这个 ppt 当中最后的这一部分, 我们案例实操的这个函数是 f 二是完全一致的,对吧?那它其实就是换了一种编码形式,我在这个地方呢,其实就是方便大家理解,就采用了 f x y 的 一个形式,分别是 y 和 x, 方便大家做一个区分。 那在代码里面呢,我们就是比较简单了, y 呢就是我们的输出变量下面有 x 一 和 x 二两个不同维度的 x, 来进行一个参数的一个搜索,这就是我们适应度函数值,在我们的矩阵体里面呢,是有去调用它进行一个函数的一个评价指标,我们可以看到 在这个地方呢是一个适应度函数计算,我们可以看到这地方就是一个放 x, 把 x 传递进去之后,我们就可以输出一它的一个适应度值啊,这就是我们那个最后算出来其实就是函数的一个最大值,也就是函数的一个值, 那这时候呢,就是进行一个参数的一个调用,或者说是函数的一个调用,我们的放在进行一个评价指标计算的时候都会去调用它,那如果说后面还有的话呢,我们可以再去找一找,如果说没有的话呢,应该就是在这个地方去进行一个适应度的一个计算, 那紧接着呢,我们就是去进行下一部分的,看看一下它的子函数代码,那剩下的部分呢则是我们的 select, cause rotation 就是 我们这个 三个部分,一个是选择交叉以及它的变异,那么对于这一部分呢,我们就是可以去看一下它具体 在这个地方呢? function write 就 等于 select, 我 们的输入呢分别是 individuals 以及 size plus, 那 么这个函数就是对每一代种群中的染色体进行选择,以进行后面的交叉以及变异。 那其中呢, individuals input 就是 我们的一个种群信息,种群信息,而 size plus 就是 我们的一个种群规模, o p t s 则是它的一个方法的一个选择, arite 就是 我们的一个经过选择后的一个种群,那这个地方呢,也大家要去注意一下,这个 o p t s 就是 我们方法选择呢。呃,其实就是说我们选择的方式呢,也是有很多种的啊,也是有很多种,那在这一个案例当中呢, 我们就是采用轮盘读法进行一个选择,就和我们前面讲的 ppt 内容是完全一致的, 下面呢我们来去看一下它的一个具体内容,这个是它的一个总的一个适应度函数值,我们可以看到它要去计算一下当前种群所有个体的适应度之合,也就是 some fitness, 对 所有适应度值进行一个求和,我们将个体的适应度值全部取出,然后进行求和,求和完了之后呢,我们需要进行一个单独计算,比如说当前个体的适应度数值, 然后除以总的一个适应度数值,就可以计算出每个个体的一个啊选择概率,换句话说也就是适应度值的一个占比,比如说算下来其实就是一个权重, 零点一,零点三,零点六等等,那本质上呢,权重也可以看作是一个概率,对吧?那这时候呢,就是在零到一之间的一个数,表示的我们这个概体,我们这个个体能够被选中中的一个概率, 呃,当它的一个适应度值越优的时候,它的概率呢也就会越大,那就是它的一个点。紧接着呢,我们来看一下它有一个初设化的一个数值 index, 记录一下我们的一个缩影位置, 下面呢则是它的一个循环, for i in e, 在 这个 sizepos 当中进行一个循环, 也就是说我们要去转多次轮盘,那这个 sizepos 就是 我们的一个种群规模,我们要转很多次轮盘, 那这时候可以去想象一下,想象一个轮盘每个个体占据的面积呢,与其适应度值是成正比的,那这时候我们也可以去回到我们的 ppt 当中来去回顾一下这个图。大家可以看到啊,每一次转动轮盘,每个个体去转动轮盘,那大家可以看到它是不是 个体的一个概率和它的一个面积占比啊,是成正比的。就比如说我们这个蓝色区域呢,就是这样子一个大概区域,它的概率是四十二,它的一个占比面积就非常大啊,被选中的概率也就非常高, 那这时候就是我们啊转多次轮盘的一个含义,那么具体要转多少次,就是根据我们的种群规模去定 每一轮叠带当中有多少的数量,我们就断转多少次,进行一个选择。随后呢我们就去随机扔一个球 来去看一下这个球落在哪个区域,我们就选中对应的个体,那这时候这个 round 本质上来讲它就是一个随机数, pick 呢就是我们选中的一个 随机数值,我们来去进行一个确定。那在这下面呢,我们又看到是有一个循环的一个函数,那个追呢,就是从一到这个总行数当中进行一个循环, 我们来去看一下 pick 这个变量呢,则是进行一个计算,它减去当前个体的一个概率 进行一个计算。如果说 pick 小 于零,说明我们当前这个概率呢小于我们当前这个个体的一个概率,那么 pick 小 于零的话,就说明我们落入了当前个体的一个区间,换句话说,我们这个轮盘这一次转就已经啊转到了这个个体的一个区间之内, 我们就去记录一下被选中的个体的一个缩影序号,方便什么?方便我们后续去把这个数给它取出来,或者说是把这个个体给它找到,那随后呢我们去寻找落入的区间, 此此次转轮盘呢,选中了染色体 i, 那 这时候呢,需要去注意一下适应度高的个体呢,也有机会啊,就是说我们的一个点 啊,你不管你的概率有多大还是多小,那么本质上来讲呢,你都是有机会被选中,只是可能性高还是低,那并不是说低就完全不会选中啊,这就是我们一个要注意的点。第二个点呢,则是他可能会重复选择某些优质的染色体, 比如说就,呃,像我们刚才 ppt 当中啊,这个四十二这个概率最大的这个面积,它肯定会多次去选中这样的一个个体,为什么?因为它的面积足够的大,那每次选的时候呢,它其实就是可以去重复选择它, 这样子呢也去表示了什么?表示了一个点叫做适者生存啊,体现了我们这个一串优化算法适者生存的一个原则,那这就是我们一个选择的一个函数, 那么根据 index, 我 们把这个锁影值啊,把这个锁影值记录下来之后,根据这个锁影值去从原种群当中提取出被选中的个体,然后呢去形成新一代的一个种群。 那在这个过程当中呢,其实就是去进行调用,根据这个 index 这个序号找到这些染色体,把它 进行一个参数传递,传递完了之后呢,我们这个适应度值也进行一个传递,就说更新了两个部分,一个是染色体本身,一个是我们的 相对应的一个染色体的适应度数值,它的优劣程度都进行了一个更新。最后呢我们再将 individuals, 也就是我们这个染色体的一个群体呢进行一个返回,这样子就构成了一个新的一个种群,这是我们一个选择的一个过程啊,选择的一个过程,我们就包括了 整一个的一个适应度的一个啊概率的一个计算以及丢轮盘。最后呢我们来判断是否选中,如果选中这个地方也注意了是 if, 如果选中的话呢啊就说明我们要去记录一下个体,如果没有选中的话,我们就不做相应的其他操作,进入到下一个循环,就是说我们那个核心内容。 以上就是选择的一个概念,接下来呢则是我们的一个交叉的一个操作,那么这个方选 right 等于 cos, 那 这过程当中 p cos 就是 我们的一个概率,也是我们交叉的一个概率,这个地方是交叉的概率。 learn compound 就是 我们的染色体的一个长度, compound 就是 我们染色体的一个种群,而 sizepop 就是 我们的种群规模有多大。 rat 就是 我们交叉之后的一个染色体,所以说前四者呢都是输入啊,只有最后这一个 rat 就是 我们的输出。 同样的我们进入到这个循环当中来去看一下它具体的操作。 for i 等于这个一到 n, 也就是说我们这个一到这个 size pop 总行数量当中进行循环。那在这个时候呢,我们随机选择两个染色体进行交叉,我们这个地方呢就是 rand 一 和二,也就是生成两个随机数, pick 呢,就等于 r 一 和 r 二,它的取值范围呢是在零到一之间, y 就是 表示当我们的这个 r 一 或者 r 二为零的时候呢,我们就重新生成,那这时候其实就是避免了一个情况,避免了缩影值为零的一种情况啊,这个时候呢,它就会重新生成, 直到啊出现一个非零的一个情况,我们就是进入到下面的循环下面的一个内容,通过这个函数啊, c i l 这个函数呢,将随机数映射到这个种群当中, 那么有的同学呢,可能是第一次见到这个 c i l, 它本质上来讲就是一个向上取值啊,向上取整的一个呃,函数。那这时候呢,其实就是我们将随机数乘上我们的一个种群数量, 然后就可以找到两个个体的一个缩影值 index, 就 把这两个缩影值的一个位置找到,换句话说找到两个染色体的一个位置, 将它们呢作为我们要交叉的两个染色体啊,要交叉的两个染色体就是这行代码的一个含义。那这时候呢,我们就会有一个概率的一个问题,那交叉概率呢,就会决定我们是否进行交叉, 那这时候呢,我们就去生成一个随机数, rand 它取值范围依然是在零到一之间啊,同样的我们要去避免什么?避免生成为零,然后 pick 等于 rand 重新再生成一次这个呃随机数, 如果说当我们现在这个生成的随机数大于我们的一个这个交叉的概率呢?我们就跳过交叉,不执行后续的一个操作, 面前的 flag 就 进进入到下面的一个操作,然后我们后面的操作呢就不进入了,我们的 continue 呢,就是表示跳过本次循环啊, 完了,跳过本次循环的后续所有操作,那么这后面那些所有操作啊,这些操作都不要了啊,都不要了,不执行了,然后直接进入到第二次循环,或者说下一次循环当中,这就是我们的一个概率的一个问题。 那反过来讲,如果说当我们的 pick 小 于等于 pick cos 的 时候,就是表示我们这一次呢要进行交叉,那这时候呢,这行代码呢?我们可以看到就基本上 执行完了,我们不执行这个 continue, 不 跳过这一次本循环,我们就直接进入到后面的 flag 等于零。所以说这个地方呢,则是进行一个交叉概率进行判断,判断我们本次循环当中是否执行交叉的一个过程。 接下来我们去看一下我们默认的 flag 是 等于零,它其实就是表示尚未生成有效的一个交叉结果。 while 这个我们的呃 flag 等于等于零的时候呢,我们去执行下面一个代码, 直到我们生成一个有效的交叉结果,我们才退出循环,那这时候也是一样,我们先去随机选择一个交叉的位置, pick 等于 run, 然后 看一下,这时候呢就会有一个位置的一个选择 post 等于 c i l, 然后 pick 乘上一个 sun, 然后取值是 lun 框,那这是什么意思呢?其实就是随机选择进行交叉的一个位置,也就是说选择第几个基因位置进行一个交叉,那本质上来讲呢, 然后这个 learn compound 就是 我们的一个染色体的一个长度,对它进行一个求和,再乘上这个随机数,并且向上取整。那本质上来讲,这一系列的操作其实就是去找到了一个染色体交叉的一个位置,选择我们第几个染色体之后进行交叉。 我们这个地方呢,是可以去找一下我们的前面的一个图,在这个地方啊,在这个地方其实本质上来讲就是找到我们一个染色体的一个长度,对吧?我们染色体长度是多少?然后乘上一个随机数,哎,选中了,选中了,比如说我们这个地方就是选中四这个地方作为随机选择的一个交叉点, 然后执行后续的一个操作,那这个地方的缩影值,呃,比如说我们从零开始,零一二三,这个缩影值就是三,哎, 我们这个基因四对应所对应的这个缩影值就是序号三啊,序列值是三,把这个序列三呢给它取出来,这就是我们刚才这一段代码 pose 啊, pose 等于 c、 e、 l 这段代码的一个基本含义。 那在下面我们需要去注意两个点,那么第一个点就是两个染色体交叉呢,它的位置是相同的啊,并不是。说什么啊,并不是说我们这个染色体, 染色体的一个位置一个是四,而另一个位置是其他地方,不是的啊,更多的时候是什么?是我们从这个地方这个位置开始就要进行一个交叉啊,进行一个交叉,两个位置是一致的啊, 这个地方就是两个位置是一致的,大家就是知道就行。那随后呢,我们还有一个点,就是 cel 函数呢,是向上趋整数, 那这个部分呢,是将随机数 pick 啊映射到呃,我们的一个啊染色体长度的一个范围,那因为这个部分呢,其实就是对染色体的长度进行求和,那本质上来讲就是一个区间范围零到染色体的长度,其实就是我们 去确定染色体它整个长度的一个范围,因为我们如果只有一个长度是不够去乘上它的一个数的,我们要有一个区间零,比如说我们这个地方是八这样的一个区间,再乘上一个随机数,比如说是 rand 啊, a n d, rand 就是 我们的一个随机数,把这个随机数确定下来之后,就可以得到我们随机寻找的一个呃切染色体的一个点,进行一个交叉交换,我们的基因 就是这串代码的一个含义。那很多同学呢,拿到代码有时候看不懂,就是一两句可能看不懂,导致我们整个代码看的比较云里雾里,这很正常。那接下来呢,我们就是去看一下 pick 等于 rand 的 话呢,就是交叉开始,然后就要去更新一下随机数, 那在这个过程当中呢,我们需要去看一下,它采用的是一种算数交叉生成子弹。 那这个地方呢,我们其实就是新的一种交叉方式,我们之前也说了交叉的方式其实有很多种,那在这个地方呢,给大家去再拓展一种,因为这个代码呢,是使用这种算术交叉去生成一个子弹。 那比如说我们直接看后面的一个批注的案例就好了啊,因为你看前面的一个这个部分呢,可能还不一定好懂,对,我们看代码的话呢,其实直接看备注懂它的意思就可以了。那在这个地方呢,我们给大家去看一下附带一呢,比如说它的一个 染色体呢,就是一三五,附带二呢染色体就是二四六。那这时候呢,我们只带一去选中一个位置, 选中一个位置呢,就是 pick 乘上一个 v 二啊,我们的再加上 e 减, pick 乘上一个 v 一, 也就是说我们这个地方呢啊,找到它一个要交叉的一个点啊,要交叉的一个点,然后进行一个数值上的一个计算,比如说我们这中间这个点啊,中间这个点, 我们这个地方呢可以去看一下,我们这地方可以去看一下。呃,这里呢可以是这样子,先是一三五,再就是二四六这两个部分,我们假设刚才这个地方是已经去确定了一个随机数,假设我们是选中了随机第二个基因,进行一个 算术交叉进行生成子弹。那这时候呢,我们还有一个是什么它的一个交叉系数,这个地方其实是一个交叉系数, 比如说是零点三,确定下来之后呢,我们再来去看一下它的一个内容。那这时候呢,我们可以去 给大家去计算一下,比如说我们刚才说的是第一个是三点零点三,是它的一个交叉系数啊,乘上,呃,一个是 v 二,比如说是四,再加上呢是零点七啊,一减零点七,一减零点三,等于零点七,再乘上是我们的三, 就可以最后得到我们的一个基本的数值,就是我们基本的一个数值,三七二十一、三四十二,然后就是三点三啊,就是我们的一个数值,所以说这时候我们第一个个体的中间这个交叉的数值呢,就是三点三点三啊,从这里变成了一个三点三,就是它的一个基本数值。 而后续的另一个公式呢,也是一样。因此呢我们这个地方子代一的值呢,就是等于 pick, 也就是我们的一个系数零点三乘上四,那就是一点二, 然后我们这个一减零点三,就是零点七乘上一个三。好,我们就是 v v 一 的一个值就是三,那就是二点一,那最后算下的话就是我们三点三,这就是它一个算数交叉生成的一个基因位的一个数值,那最后我们生成的一个子代一的话呢,其实就是一三点三, 然后还有就是五,这就是我们子代一,那同样的子代二的一个计算公式呢,也是一样的啊,就是方便大家去理解,给大家去举了一个非常具体的例子。 那这个时候呢,大家肯定会有点绕晕,那其实就是两个地方,第一个是它这个随机上的随机位置,这有一个随机,第二个是它这个, 呃,交叉系数也是一个随机啊,也是一个随机,所以说这两个随机呢,就是会导致,哎,我们刚才不是生成了一个随机位置,一个是确定它的位置,一个是它确定它的一个交叉系数 啊,我们乘上多少系数去进行一个数值上的更新,所以说这种就是我们一个算数交叉的一个啊,基本的一个含义给大家去解释了一下, 那为什么不在 ppt 去讲呢?因为我们这个地方的内容还是很多种多样的,很多时候呢,像单点交叉,双点交叉、部分匹配交叉等等,很多时候呢, 呃,就有很多种多样,我们就要去根据实际案例去进行啊了解。那这个时候呢,我们就是给大家去解释了一下算术交叉生成的一个子代,它是什么样子的,紧接着呢,我们交叉完了之后,生成了两个子代,对吧?那这时候要去检验一下这个 test, 去测试一下我们这个染色体是否是可行的,换句话说有没有超出边界,如果不小心超出边界的话呢,那我们可能就需要去重新生成, 那么这时候呢,我们就要去规避一下它的一个数值就是零,我们可以看到 flag 一 乘上一个 flag 二等于零,那这时候呢,我们这个染色体就是什么? 就是不可信的。那所以说这时候呢,如果说我们这个染色体有问题的话呢,超出了边界范围内,它就会生成一个零值,那这时候呢,就会让我们这个循环呢持续下去,表示什么?没有生成有效的交叉结果啊, 它就会再一次执行一次交叉,直到生成一个呃,有有效的一个交叉结果,然后跳出我们的循环, 这个地方也就去写了。如果说两个染色体都不是可行的啊,我们则需要去重新交叉,就是它的一个基本含义,最后呢则是返回出它的一个交叉的一个染色体,进行一个返回,就是我们这个交叉函数的一个内容。 紧接着呢,我们来看到变异的一个操作,那么变异操作呢?呃,我们可以看到它本身是有一个变异的概率,染色体的长度,染色体的一个种群数量,种群规模以及 当前种群的进化代数和最大进化代数的一个信息啊,这基本上就是一个呃信息的一个记录, 最后输出的则是变异后的一个染色体。同样的我们开始进行一个循环,在这个过程当中去生成一个随机数啊,随机去选择一个染色体进行变异,把它的一个位置给它缩影出来,把这个染色体给它找到, 找到了之后呢,我们根据这个变异概率去决定本轮循环呢是否进行一个变异。那如果说当这个随机数啊,比我们的变异概率要大的话呢,表示我们就是跳过变异,这一次呢就不进行一个变异了, 代码呢就会跳过后续的一些操作,进入到下一轮循环。那如果说我们这个随机数小于我们的概率,比如说这个概率是零点零一百分之一,小于百分之一的情况下呢,我们就执行后续的操作,完成后续的一个变异的一个循环。 在下面呢我们来去看一下,这时候呢 flag 是 默认为零,表示未完成变异操作的一个循环。紧接着呢我们去看一下它的一个变异位置,这时候要去随机生成一个变异位置 啊,通过生成一个随机数,在零到一范围内的一个随机数,去找到它的一个变异的一个位置,紧接着随机选择 d p o s depos 个变量进行一个变异,换句话说就是我们去找到一个啊 depos 个基因的一个位置进行一个变异,那么根据当前的一个基因值, 然后进行找到一个呃它的一个下界以及上界的一个距离,我们可以看到这个地方呢,其实就是它的一个位置,把这个当前基因值的位置找到,随后呢根据它的一个边界范围, 当前值到下界的一个距离,以及当前值到上界的一个距离进行一个计算,把它一个距离给它计算出来, 紧接着我们就是进行开始变异,然后生成一个变异方向的一个系数,来去决定变异的一个方向。那么如果说当这个 pick 大 于零点五的时候啊,我们呢就是进行一个咨询下面的一个操作, pop 一 呢表示是当前的一个袋鼠, pop 二呢表示是最大的一个袋鼠,那么这个 pop 一 就是当前的迭代次数, pop 二呢则是最大迭代次数。那对于我们呃之前学过的同学呢,其实就是大概知道它是大 t 分 子小 t, 那么随着叠代次数不断的增加呢,它就会越来越趋近于一啊,从零趋近于一,那这时候呢,它会有一个一减这个过程啊,我们有一个这么一个一减的这个过程,那本质上来讲它其实是什么意思呢啊?就是从一减去大题,分成小题,随着叠代次数不断增加, 那么这个数值会从一一直趋向于零啊,这就是我们这一个啊部分的一个公式的一个基本含义啊,这个就是从一趋近于零, 这部分公式就会从一趋近于零,这就会使得我们变异的一个幅度 dalt 啊,会随着迭代次数的一个增加而减小,那这样的好处是什么?它就能实现一个效果,叫做早期呢?呃,大范围的探索,而后期呢,是进行一个小范围的微调,这是它的一个区别。 那么当我们的 pick 接近于零的时候呢,我们雕塔的数值就会接近最大值 v 一 或者 v 二。那么大家可以看到,在这个地方,如果 pick 等于零的话呢,后面基本上就没有了,那这时候其实变成了 v 二乘上一,那这时候基本上就是雕塔就等于 v 二, 同样的后面呢,下面这个部分呢,公式是完全一致的,只是这个地方换成了 v 一 啊 v 一, 所以说 delta 呢,就会趋近于这个 v 一 或者 v 二,当 peak 接近于零的时候, delta 接近这个最大值 v 一 或者 v 二。那有的同学问了,哎,这两个公式有什么区别呢?那本质上来讲, peak 大 于零点五或者小于零点五,它只是决定了一个变异的一个方向,对吧?它本身就是一个变异的一个方向, 去看一下它的一个距离,往哪个方向去进行一个变异,这就是我们的一个基本的一个基本情况。 在完成变异之后呢啊,我们的一个 flag 呢,就是等于 test 进行一个检测,检测一下,哎,我们这个染色体变异之后呢,这个个体是否仍在这个变量范围内?最后呢,再返回我们种群啊,变异后的一个种群,进行一个数值上的一个返回,这就是我们的一个变异的一个基本操作。 那么我们在这个变异里面呢,其实有的同学可能会说,哎,我这个变异的一个向上和向下啊,可能没有太懂,其实我们可以去画一些啊,最基本一些图来去表示,比如说它的一个边界啊,是在这样子,这个的是下,这边呢是上, 那这时候呢,我对于当前位置而言呢,我这个基因选择的一个位置呢,他离下边界是非常近,那这时候我们就要去判断一下,他是不是往这个什么往上边界这个方向去变异 啊,去随机选择一个位置,对吧?我们这个数值呢,可以去往上边界去靠拢,这样子呢,他寻找到最优解的可能性会更高一些,对吧? 呃,这就是我们向上变异的一个意思,它就会决定了一个变异的方向。如果你当前这个数值在,比如说我们对于这道题而言,或者说这个案例而言,它的边界取值范围是负二到二之间。我们当前数值可能比如说一点七 啊,负一点七离负二非常近了,那我这时候肯定是往上边界这个方向去靠,或者说是去变异随机去取一个值,比如说是一啊,这样子的话呢,能够更容易的去找到最优解,这也是我们变异能够呃 向上进行一个波动,然后去寻找到最优解的一个效果。这就是我们去呃,给大家去解释一下,这为什么是这个地方是有一个决定变异方向的一个内容。 因为我们一般来讲呢,我们算法在迭代后期的时候呢,它可能会卡在这个局部最优,对吧?我们这个地方是局部的一个最优, 而在后面呢,我们可能就会想要让它跳到这个最呃全区最优解的一个情况下,那因此呢,我们这个变异方向呢,就会去进行一个判判断,或者说是选择。 如果说对于我当前这个数值而言啊,已经离下边界非常近了,我再往下边界去探索的话呢,可能并不会有更好的结果。那相比之下呢,我往上边界去犒劳啊,去变异,那这时候呢,可能就会找到一个局部最优 啊,找到全区最优的一个解的一个位置,这就是我们这个变异方向的一个含义。那当然了,我们刚才也去说了,随着迭代次数增加,对吧?我们整一个探索范围呢,也是在不断变化,早期呢是主这个扩大探索的一个范围,后期呢则是进行一个局部范围这个 微小范围的微调,这是它整体一个策略。所以说变异这一块呢,一个是方向还比较难懂,我们刚才也去解释一下,它根据当前位置离边界范围的一个距离 来去,往反方向啊,往往远的那一侧的边界去靠拢啊,去变异。那另一个范围呢,就是我们随着迭代次数增大,对吧?我们的一个探索的一个幅度是有变化的, 前期那就是浮动,浮动呢就是会比较大一些,主探索后期呢,这个浮动就会小一些,主这个微调啊,主这个局部的开发 就是我们的变异的一个补充。那至此呢,我们整一个代码的一个讲解呢,基本上就过了下来,那内容呢还是比较多一些。呃,不过大家跟下来之后,我们再结合着这个批注啊,我们这些批注做的非常多,看一下的话呢,基本上就没有什么问题了, 那最后呢,我们再去拿 example 二,然后再剪辑运行一下,看一下它的一个运行效果。那一般来讲呢,我们可以看到,在这个地方呢,我们多次运行 example 二之后,它的一个效果呢,往往会稳定一些啊,注意是稳定一点。 而相比之下呢,我们这个使用 genit, 它的一个效果呢,可能就相对来讲不是那么稳定了啊,这是它的一个小问题, 那大家可以看到啊,基本上是会有一些小问题。呃,目前来讲这个效果呢,并不是很好啊,多次运行呢,可能没有达到三点七五这个 g u 值附近。 而我们这个调用工具箱呢,它的一个效果呢,基本上是比较稳定的啊,多次运行是比较稳定,这也是我们的一个对比。那最后呢,我们这个呃再简单过一下,代码的一个框架啊,主函数呢就是呃包括的两个部分,一个是字边写的 janity, 一个是调用工具箱的 example two。 那其次呢,就是我们的一个编码,编码就包括了生成染色体的 code 以及检测边界范围的 test, 随后则是计算适应度函数,目标函数放那,紧接着就是选择交叉变异,分别是 slack, cause 和 mortation, 那 就是我们三个操作的一个代码, 代码块或者说是函数。紧接着就是重复了,给大家去再反复一下,按着流程图去反复一下。 随后呢则是进行一个精英保留的一个策略,更新一下我们的历史最优,然后用历史最优去替换当前最差,最后再绘图显示一下,把我们这个曲线进行一个绘图显示,这就是我们整一个代码层次的一个框架。 那最后呢,我们也去给大家啊,去介绍一下整一个流程内容。那在这个地方呢,我们是 交叉选择,选择的话呢,介绍了一个是轮盘读法,一个是锦标赛选择,随后呢交叉则是单点交叉, 还有一个是两点交叉,以及部分匹配交叉,那变异呢?就并并没有去啊,介绍一个气体啊,具体的一个变异策略。那么在后续的一个课程的视频当中呢, 我们会给大家进行一个案例的一个应用,比如说我们去用这个 ga 遗传优化算法去优化一下我们的 lstm 神经网络,对它的超参数进行一个优化, 那这时候呢,它的一个案例呢会更加的明确一些,那因此呢,需要大家先学好我们一个遗传优化算法的一个基础内容, 把这些基本的原理概念基本上懂了之后,我们再去学后面的一个呃易创优化,这个神经网络的一个参数调优的时候就会更加的清晰明了。那么在那一部分内容,我们会采用这个 python 的 一个编码,那现在呢是 matlab 啊,对于一个简单的函数进行优化,那在下一部分课程当中, 我们会采用 python 编码的一个方式,进行神经网络的一个参数调优。那这时候呢,我们的选择, 我们选择依然是轮盘读法,但是它的交叉以及变异呢,我们会给大家去介绍一些新的啊,新的一些方式啊,或者说是操作。 那这时候呢,就希望大家先把这次课程呢啊学好,看懂,学会,然后如果有任何问题,我们也可以去评论区交流。那以上呢,就是我们本次课程的一个内容,也就是遗传优化算法的基础版本的一个内容,希望大家能够有所帮助啊,谢谢大家。
18数模加油站




