runpod部署模型教程

粉丝995获赞1.6万
相关视频
 01:16
01:16 02:36查看AI文稿AI文稿
02:36查看AI文稿AI文稿家人们阿里达摩院 rainbring 巨深智能大模型来了!基于通用千问 qwn 三 v l 统一视觉语言架构,看图看视频,多模态直接输出 两点框物体,多点圈区域能识别操作能预判轨迹,第一人称视角细力度视频理解, ocr 技术全能搞定,空间定位加语言推理, 给机器人下达更精准指令,有多种版本,还做了轻量化优化,省显存好部署。聚深智能机器人视觉导航,面向真实物理世界的开放基础模型打开整合包,点击 run demo, 进入程序, 点击上传一张图片提示词,输入为图片里有什么内容,点击提交,运行速度很快,二三秒就能出结果,占用显存八 g 左右。可以看到模型详细描述了图片的全部内容, 模型还可以根据选定区域识别出这一区域的内容。我们把领结用矩形圈点一下,先在领结的左上角用鼠标点一下,屏幕出现绿点,点击 add point, 绿点就变成红点,然后在右下角点一下, 点击 at point, 就 出现一个红色矩形框,点击 at point prompt, 就 会把矩形的坐标添加到提示词位置了,在后面填上这是什么?点击提交,模型返回,这是一个领结。 总之模型的识别能力非常强大,这里就不一一测试了,感兴趣的可自行测试。我们测试一下模型的视频识别能力。上传一段视频,视频装入后,自动在左面生成一组图片,它会每秒抽取两帧的图片放在一起,可以用滑条选择要处理的帧数。 我们在提示词写上视频里是什么内容,点击提交,大概等待二十秒左右,系统就能返回结果。我们再输入视频,第五秒发生了什么事?稍等一会,系统就返回了正确答案。 我们选择一针来识别一下,我们选择脸部区域提示词,输入这是什么表情,点击提交稍等,系统就回答是微笑的表情。 系统还有很多功能,大家可以自行测试。整合包,包括全部原代码整合包解压即用。我把软件的获取办法放到简介里了,今天的视频就到这里,我们下期再见。
 01:22查看AI文稿AI文稿
01:22查看AI文稿AI文稿嗯,最近有不少朋友在问怎么去配这个本地的大模型啊?这边简单讲解一下,首先的话进入这个网站奥 利马点 com, 然后他这有这个教程啊,然后我们只需要把这段话给复制下来,然后下载到本地,也就是在 哦这个位置我这下载,下载了之后呢就下载把程序,下载之后呢我们去呃,用这个指令点微信去查看我们有没有把这个本地部署大模型的这个软件给部署好, 如果说能看见他的微信的话,就说明这个软件我们已已经下载成功了。然后后面的话我们就可以直接去奥利马点 run, 这 run 的 话你可以随便选择模型啊, run 的 时候他会帮你把这个模型给下载好,下载好之后顺便就跑这个模型,然后跑了这个模型之后,你就可以一对一的跟他进行通话,然后这个模型的话你也可以在这个网站点这个 modos, 在这进行去找那个啊你需要的模型,我这边的话是用的那个纤维衫,然后这边的话还有其他的很多模型,而你都可以选,要根据自己的硬件配置的话,选择更多的模型,然后部署到本地。以上就是这个的一个简单的流程。
32神秘人类 06:17查看AI文稿AI文稿
06:17查看AI文稿AI文稿嗨,大家好,在本视频中我们将向您展示如何在 windows 十一上安装 openclaw, 以及如何让 openclaw 使用本地模型,以便您可以完全免费使用 openclaw。 接下来让我们开始 首先在 bios 中设置性能模式,让机器发挥最佳性能,并且把显存设置为九十六 gb。 更高的固定显存分配有助于提高 gpu 密集型工作覆盖焊本地推理的稳定性。 将 windows 电源模式设置为最佳性能以及永不睡眠,避免运行时掉线。 将您的 imd 显卡驱动程序更新至二六点二点二版本,然后重启电脑,确保 gpu 计算时获得最佳性能。 opencore 强烈建议 windows 用户在 wsl 下运行,以获得更一致的 linux 运行时环境。接下来我们将安装 wsl 函数。 现在我们使用官方安装脚本安装 open claw, 这是推荐的方法。 然后运行 on board 的 命令启动并配置 open claw。 这里我们先不配置本地模型, 至此基本安装完成。接下来开始配置本地模型。在 windows 系统上,我们建议安装 lm studio 进行模型管理和下载,然后启动本地服务器,通常是本地 ip 一 千两百三十四为一。 最后将 open curl 连接到本地模型服务器。 如果遇到模型上下文窗口过小错误,请修改 open curl。 四文件中的以下设置, context window 二十五万六千, max tokens 两万,然后重启网关。 最后测试一下本地对话,看工具调用是否正常。 i love you!
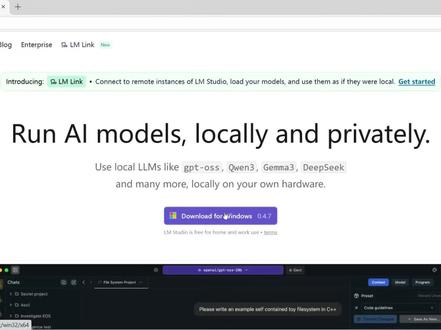 02:21查看AI文稿AI文稿
02:21查看AI文稿AI文稿大模型都不会装,为什么不跟 d t 学,难道是怕 d t 坑你吗?首先让我们打开网站 l m studio, 点 ai, 找到 download for windows 按钮,点击下载下载安装后打开 l m s t u d i o 软件,可以看到它是这样的一个界面, 我们找到左侧第四个按钮, model search, 点击打开模型列表,最上面的推荐模型是可以在我们显卡上运行的模型,这个右侧显示绿色的提示就是告诉我们这个模型可以在我们的机器上运行,灰色则是需要卸载,可能会有些慢, 我们找一个我们可以运行的模型进行点击下载,等待下载完成。 在右上角有一个下载图标,点击以后可以查看下载进度,这里面包含模型和需要用到的依赖软件。下载完成后,我们点击左侧的第三个图标 my models, 可以 看到我们已经下载好的模型。 我们对模型进行一些简单的微调,不配置用默认参数也是可以的。 这个上下文长度如果显卡允许,尽量设置为二零零零零,这样方便下龙虾的上下文,防止超长导致内容中断。 点击软件左侧的第二个按钮, developer, 打开软件 open ip 接口配置界面,点蓝色 load model 按钮,选择我们刚才下载的模型,它会自动载入, 载入完成后,点击 server settings 按钮, server port 设置为一二三四,其他按照我们的设置勾选即可。点击 top 的 右侧的按钮,启动 api 服务, 点击 info 按钮,查看模型基本信息,可以看到模型的 api 端点地址和模型的 id, 方便我们用来进行 open ip 接口的配置。加油哦家人们!
17程序员DT 02:31查看AI文稿AI文稿
02:31查看AI文稿AI文稿首先我们第一步安装欧拉玛,大家下去之后呢,可以看这个视频回放来操作啊,因为我可能讲解的速度呢,相对来说快一些,所以大家如果说跟不上的话,可以稍后下去之后再来去看。 呃, olamar 的 安装比较简单,直接大家打开 olamar 点 com 官网点击下载,点这个 download 就 可以了啊。如果说你是呃 windows 的 同学也是点这啊,因为它不管是苹果系统, linux 或者是 windows 都是完全支持的啊,你直接点一下 download 就 可以了。点 download 之后,我这边呢就直接可以打开这个 olamar, 我那么打开以后呢,在这啊,就是一个羊驼的图标,现在我是我是已经安装好并且打开了。打开了之后呢,我们接下来就想要去安装模型,模型的选择大家可以点一下这个 models, 点 models 之后,大家可以看到排的第一的就是 deepsea 二一啊,我们今天用的呢也是它,并且大家可以看到它的热度,这是九点四兆 plus, 拿取的人非常多啊,我们也就选用这个,大家直接点进去看这个地方呢,有一个选择。呃,具体的这个 选择呢,我们可以选择稍微小一点的啊,就比如说七 b 或者一点五 b, 反正你就选择一下之后去用一下啊,正常情况下,满血版的六七六百七十一 b 的 这个呢?四百多 g, 这个一般同学们的电脑是不用不用去试的啊,基本上试不了的, 你可以点一下这个 view wall, 下面这些呢,其实都是他的啊,对应那些模型 tag 啊,打的 tag, 我 们可以选择七 b 或者是 nattest, 我 们现在呢就选择 nattest 啊,选择这个 nattest, 然后我们打开这个命令行工具,因为我们其实已经安装了 alama, alama 安装好之后,你就可以直接在这 搜索啊,或者说去看 alama 有 哪些命令,比如说杠 h 回车,你就能够看到所有关于 alama 的 提供给大家的一些命令啊,比如说有 serve, create, show, run 等等。其他这些命令呢,我不跟大家去介绍了,我们直接来把 deep seek 跑起来啊,那么我们这里跑呢,就直接 deep seek r e 冒号 nast 回车,这个其实跑起来比较简单呢,就是几行命令的事情, 好,启动的时候相对比较慢哎,大家可以看到现在就启动好了啊,现在启动好以后,其实我现在就可以对他呃发送命令,他就可以帮我去回答了,比如说你好,或者说给我的给我直播间的同学前端同学打个招呼, 好,这 sink 的 这一部分呢,其实就是它的思考,然后后面就提示出来了啊,你好呀,直播间的前的同学们,呃,很高兴能够在直播间见到大家啊,大家新年快乐,如果有任何问题和想法的随时跟我互动啊,这样就这个模型其实就已经跑起来了啊,完整课间评论区扣八八八,免费领取!
 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿准备好,你即将在几分钟内拥有一个你随时可以访问的私有免费大模型。第一步,下载欧拉玛。欧拉玛呢是最火的专门为本地运行和部署的开源大模型设计的工具,下载完它呢,只需要输入一句, 欧拉玛瑙某某某开源大模型就任你用。第一步呢,我们打开欧拉玛的官网,然后点击他主页的下载,跳转进去之后呢, 选择适合你的系统,比如说我这里的系统是 windows, 下载好之后继续跟着它的步骤去安装。第二步,按住键盘上的 win 加 r, 在 这里输入 cmd 回车。在终端输入我们唯一的一条命令,欧拉玛 run 拉玛三点一,让欧拉玛帮你运行拉玛三点一的模型,现在他就开始下载模型了。下载完成之后呢,你就看到这个提示, 你已经可以成功的在本地运行这个大模型了,然后你就可以直接开始对话了。第三步,首先 ctrl 加 d 或者直接输入 by 就 可以退出对话啦。 我们打开欧拉玛的官网,看到右上角的这个 models 点进去,这里几乎有所有的前沿大模型,我们想要哪个模型点进去拷贝他的口令?比如我们再来一个最近登顶世界之最的千万大模型,欧拉玛万千万拷贝过去,回车 搞定。现在呢,你就可以像普通 ai 客户端那样去对话了。如果我们要读取网页链接的话,在这个网页链接之前加一个井号就可以了。如果要上传文件的话,就点击对话框左边的这个加号就可以上传了。再设定一个提示词,让他永远回复中文。 好啦,拥有一个运行在自己电脑上随时可以访问的大模型,就是这么简单!关注皮皮,每天解锁一个逆袭小技巧!
1542072皮皮 27:5713深度云创科技
27:5713深度云创科技 00:33查看AI文稿AI文稿
00:33查看AI文稿AI文稿做跨境 p u d 鼠标垫的老板,您还在手动截图、手动抠图吗?效率太慢了!试一下印花克隆,六秒钟就可以把您的素材图变成您需要的平面高清印刷图,效果又快又好。支持百万级别算力机房升图一千张仅需 一小时,套图一千张一分钟左右就可以完成,且平台不用部署,有网就能用,一个人就可以完成一整条链接的全部图文信息制作,包括像工厂图、场景图、英文标题等都是一次全出,全品类覆盖,跨境小白也可以轻松上手,做跨境更轻松、更省心。
 02:38查看AI文稿AI文稿
02:38查看AI文稿AI文稿今天运行 call pro 遇到一个问题哈,就是这个定时任务啊,在这个定时任务里呢?呃,这一项,后面这一项哈向后拖啊,有一个, 这个叫 run time out second 哈,还有个 run time misfire grace second 啊,这两个时间呢对应的是什么呢?就是说让这个 定时任务他自动运行的时候啊,他也有一个超时的这个概念,就是说默认呢是一百二和六十。什么意思呢?就是说啊, 我这个定时任务我向模型发消息,然后呢?比如说我想查什么或者干什么,如果说你的模型性能比较弱的话,或者说性能模型比较繁忙的话啊,服务器繁忙,那么可能一百二十秒这个时间就不够 啊,你像我呢,我是本地 lm still 部署的哈,本机性能呢有限,它在处理上下文的时候呢?长上下文的时候啊,它呢就会这个很长时间哈,没有响应,甚至四五分钟啊,这就导致什么呢? 啊?这就导致呢?我的任务会自动被这个 call pro 给终止掉啊,就会导致什么呢? lm studio 啊,它会接到一个消息。 说什么啊?我这里没有哈,因为已经刷掉了哈。消息原文的意思呢?就是说什么呢?说啊, 客户端啊,关闭了这个链接,怎么怎么回事的?原因呢?就是在这个时间这个地方啊,一个是连接超,一个是这个运行超时,一个是这个是什么呢?这个是啊,叫什么来着啊? 就是比如说我定时是四点半运行的,但是四点半的时候他没有运行,我可以延迟啊,延迟,比如说我容忍他十分钟后就是六百秒,十分钟后再重新运行这个任务 啊,这两个东西一个是运行中超时,一个是啊,可容忍的延迟超时啊。这样子 啊,这两个值呢?我建议是调大一点啊,因为像我们这种单机用户哈,像我们这种单机就是部署这个大模型用户啊, 他的电脑性能可能有限,处理长上下纹的时候呢,他这个性能可能就跟不上啊,时间会长一些。所以呢,要放宽这个实线,让这个大模型呢有处理的时间空间啊。
7半两啤啤









