agent s对显卡要求
这是 amd 在 二零一八年发布的矿渣之神 x 五九零,经历了两次矿工大战,百炼成钢啊,成为显卡装机界的性价比首选卡。 而这是 amd 在 二零二五年发布的超强甜品卡 x 九零六零叉 t, 其性能对标五零六零太,价格却和五零六零一样,由于目前五零系显卡溢价严重,这张显卡或将成为当前装机的首选甜品卡。原本想用五八零对比九零六零,奈何二者都没有相关的产品线啊, 而五六零叉 t 又属于二零系列的产物了,所以只能拿出当年 g c n 时代的最强甜品卡来和如今的阿迪 a 四最强甜品卡作对比了。那么时隔八年,让我们来看看 amd 这几年甜品卡的性能究竟提升了多少呢? r x 五九零采用的是驯警的黑狼,正面采用了纯黑双风扇,异形的设计,棱角处的过渡显得非常有层次感,顶部非常的简洁,只有一个 logo, 卡采用了八加六拼的供电翻斗,背板设计也同样简洁,做了部分镂空的设计。视频输出接口拥有三个 d p, 一个 hd 以及一个 d v i 接口,非常的全面。九零六零叉 t 则是采用的华硕的八 g 黑雪豹,整卡采用了纯黑比较方正的设计,性能和十六 g 没有太大差距, 它的整体设计和 n 卡那边一模一样,只不过变成 a 卡了。视频输出接口采用了两个 d p 以及一个 hd 接口,非常的盖啊。其他配置如图所示。 首先是纸面参数对比,制成工艺就是比大小,当然三星除外,很明显九零六零叉 t 绝对碾压五九零。核心频率方面,九零六零叉 t 由于新架构以及制成工艺的提升,频率直接翻倍啊。显存方面,九零六零叉 t 升级了第六位,宽上 五九零有着绝对优势,但是毕竟这么老了,性能也就那样,放到现在优势也显现不出来了。油处理器没啥好说的,架构不同,只能说九零六零叉 t 定位甚至比五九零低那么一点,功耗也 也没啥好说的了。下面是精准测试,首先是三 d mark time spot 测试,可以看到九六叉 t 比五九零提升幅度来到了百分之二百四十六,其表现和隔壁 nike 六零系列差不多。再来看一下 extreme, 相比之前提升了百分之二百三十四,还算可以哦, 但是由于九六叉 t 的 位宽被限制了,所以并没有想象中那么大的提升幅度。十六 g 版本由于大选存会好那么一些。下面是游戏测试,先说明一下,本次测试只测试了光山性能,对 一 k 以及二 k 分 辨率分别进行了测试,画质设置均为日常游玩模式,所以不存在极端画质设置。首先是热门网游的测试,在 csgo 幺零八零 p 画质设置如图,基本测试中, 五九零平均帧为二百六十三, low 帧为一百四十三。九六叉 t 平均帧为四百五十七, low 帧为二百五十四。然后再看二 k, 五九零平均帧为一百七十七, low 帧为一百零九九六,叉 t 平均帧为三百五十二, low 帧为二百六十一。可以看到在 csgo 中,一 k 分 辨率下,九六叉 t 的 领先幅度只有百分之七十四啊, 非常的拉跨哦,就算是二 k 分 辨率下,提升幅度也只有百分之九十九,这我不知道怎么评价了,这种新游中 给人一种反而五九零更有优势的错觉啊,把二者百分之二百的差距硬生生控制到了百分之一百以内,说实话哈,九六叉 t 的 性能表现着实很抽象,实测表现完全和跑分不符啊。 接着是 pubg, 在 幺零八零 p 三级质化之下,五九零平均值为一百三十七, low 值为一百二十四。九六叉 t 平均值为二百七十二, low 值为二百二十四。然后来到二 k, 五九零平均值为一百零一, low 值为九十二。而九六叉 t 平均值为一百八十八, low 值为一百五十九。 可以看到,在这款游戏里,一 k 分 辨率下,九六叉 t 提升幅度为百分之九十九,提升幅度非常的有限啊,来到二 k 领先幅度只有可怜的百分之八十六了,说实话,还是五九零太强了, 自己近年发布的老游戏当中,表现是真的不错,九六叉 t 的 优化再差也有五零六零的水平啊,但是这个表现真的拜拜了,赶紧拿去回收了吧,哎,对了,说到回收,我给大家推荐一个靠谱的平台,那就是点击我的个人主页就能回收哦, 同时也支持置换哦。之后是无畏区,在四 k 分 辨率画质无脑拉满的情况下,五九零平均值为八十三, low 值为六十九九六叉 t 平均值为二百三十二, low 值为一百七十一。在这一款游戏里,就 六叉 t 终于还算说得过去,提升幅度来到了百分之一百八十,对这种新优还是新架构有优势啊,五九零这种老架构真的有点吃不消了。最后是三小洲行动,在幺零八零分辨率画质设为高大战场模式中,五九零平均认为六十一,漏帧为五 七九六叉 t 平均认为一百七十三, low 帧为一百四十二。然后是二 k, 五九零平均认为四十, low 帧为三十六九六叉 t 平均认为一百一十, low 帧为九十九。在三秒钟这种新游中,九六叉 t 依旧稳定发挥,领先幅度来到了百分之一百八十四啊,二 k 也差不多。说实话,在该游戏中,九六叉 t 的 实际表现甚至不如 五零六零,这优化真的很想喷啊,不过看一下价格的话算了,只能等后续机械优化喽。 下面是三 a 大 度的测试,首先是黑猴在幺零八零画质设为高,五九零平均认为二十九九零六零,叉 t 平均认为八十八,二 k 分 辨一下,五九零平均认为二十二九零六零叉 t 平均认为六十九,在黑猴中 算是来到了 a 卡的强势部分。两个分辨率的测试,九六叉 t 领先幅度均超过了百分之二百,提升幅度明显强于网游啊。 果然现在的 a 卡只适合玩三 a 网游,真的是一言难尽,我个人感觉和游戏厂商没啥关系,纯纯是 amd 懒得优化,但凡优化一下也不至于这样吧。接着是赛博朋克,在幺零八零画质无脑拉满, 五九零平均分为二十五九六叉 t 平均分为七十七九六叉 t, 领先幅度来到了百分之二百零八,还算可以,非常接近理论性能了。来到二 k 后,九六叉 t 的 领先幅度 更是来到了百分之二百六十,这才是正常水平嘛,其表现已经要强于理论性能了,二者的差距非常大。如果你主玩三 a, 我是 比较建议你升级 a 卡的,网游 还是算了吧。之后是地平线,在幺零八零,画质设为高,五九零平均为五十四九六叉 t 平均为二百零五九六叉 t, 依旧稳定发挥,提升幅度来到了百分之二百八十。看来 a 卡还是别玩网游了,或者等后续进一步优化吧。 讲真的,网游那个表现啊,真的甚至只比五零五零强一点点,二 k 分 辨率下提升幅度也能有百分之二百五十九,真的很不错了。最后是大表哥在幺零八零 p 画质设置如图,五九零平均认为五十六九六叉 t, 平均认为一百零七九六叉 t 的 领先幅度又回到了一百分之一百以内啊, 只有可怜的百分之九十一了,二 k 也只是提升了一点。说实话,我一时分不清是五九零太强了还是九六叉 t 太拉了,九六叉 t 的 表现真的令人琢磨不透啊,给人一种肌无力的感觉。整体测下来, a 卡的甜品逆显卡这几年来的提升远不如 n 卡呀。 即便我这里拿出来的还是对比五零六零 pad 的 九六叉 t, 只有在部分的三 a 大 作当中才能达到及格线,大多数游戏的帧数提升远不及预期啊, 现在 a 卡的交互化更是一言难尽,如果你是网游玩家,我这里非常不建议去选择 a 卡,即便是 n 卡一家也是非常的不推荐。好了,以上就是本期视频的全部内容了,喜欢本期视频的小伙伴们记得关注哦!

粉丝1.1万获赞9.1万
相关视频
 06:09查看AI文稿AI文稿
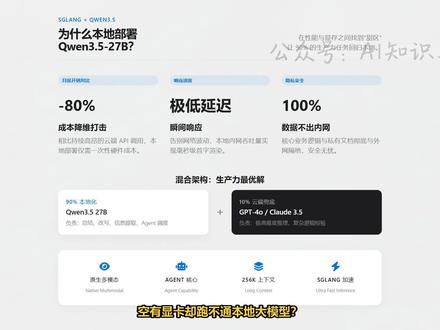
06:09查看AI文稿AI文稿空有显卡却跑不通本地大模型,用 sgl 部署 kiln 三点五,成本直降百分之八十,而且响应飞快。这套实战避坑指南你必须拿下。现在的策略很明确, 百分之九十的总结改写、信息抽取等高频任务,全部扔给本地的 qm 三点五二十七 b, 它刚好踩在性能和显存的平衡点上。至于剩下那百分之十的极高难度推理,再让云端的 gpt 或者 cloud 的 兜底, 这样既保住了钱包,又拿到了原生多模态和超长上下文的处理能力。整套架构其实非常干练。最前端是你的通讯工具, 中间由 opencall 负责业务编排,他会把消息转成标准请求,转发给后端的 sgl line 推理服务。这里最关键的一环是, sgl i 会直接起一个兼容 openai 标准的接口, 让本地模型像云端 api 一 样好用。只要解决掉工具调用时的格式类及问题,你就能在本地拥有一个能写代码、能看图、还能自己挑工具的超级助手。 环境起不来,或者模型不听话,百分之九十的问题都出在启动参数上。看屏幕这段脚本,除了常规的显存分配,最容易被忽略,也最致命的就是最后这一行工具调用解析器。 如果你不显示指定为 q n 三 coder 模型,面对工具请求时会直接宕机或者回一段毫无逻辑的乱码。哪怕你的硬件再强,没了这个参数,它也只是个会聊天的花瓶, 根本无法触发任何外部工具。在生产环境,这是让 a 省称称动起来的唯一开关。后端稳了,接着看 openclaw 这边的对接逻辑 有两个不起眼,但能让你排查通宵的细节。第一个是基础路径结尾,千万别手抖加斜杠,否则路由拼接出错会导致所有的请求直接报四零四。第二个是在兼容性配置里, 务必把开发者角色支持关掉,很多 agent 在 调用时会产生特殊角色,本地后端如果认不出来,就会直接甩给你一个五零零。服务器 错误。把这两项改对,全链路调通基本就成了一大半,配完了环境却卡在连接上。最让人崩溃的就是模型名字,本地 curl 都能通,一接上 open claw 就 报四百错误, 原因极度无脑,你在启动脚本里叫它 a, 在 配置文件里哪怕多加了一个斜杠,叫它 a 分 之 b 请求就会直接丢进黑洞,全列路必须严格锁定为 q n 三点五二十七 b, 一个字母都不能差。还有那种莫名其妙的五百报错,是 agent 产生的特殊角色,超出了后端的理解范围。 别废话,直接在配置里关掉,开发者角色支持稳定性瞬间就能拉回来。如果你发现普通对话正常, 但一触发工具调用就弹出一串看不懂的英文,说无法从印刷中获取象棋,这说明你的参数格式踩雷了。 s g a 像这种高性能后端,对工具定义的严苛程度超乎想象,他不接受任何偷懒的数组缩写,必须是教科书级别的标准接收对象, 也就是必须有 type 等于 object 这一层嵌套。很多人卡在这里调了两三天,其实就是因为多了一层中括号或者少定义了属性。记住格式不对, agent 就 算有再强的推理能力,也连一个简单的天气插件都调不起来。 最后这个坑专门留给追求性能的高手。你想开投机踩样让速度翻倍,又想开二十六万超长上下文,结果就是 s g 链启动瞬间直接爆显存。原理很简单, 唱上下文本身就是吃显存的黑洞,而投机踩样还需要额外割让一块内存池,两头一挤, 显存水位直接破百。听我一句劝,刚开始部署的时候,先把那些花里胡哨的性能加速全关了,把上下文长度和显存预算压到稳妥的红线以下。等你的工具调用和多 agent 协助全跑通了,再去一个一个调优参数。 比赛还没学会,走的时候就想在显存的悬崖边上跑步,为什么一定要在本地搞夺 a 阵协助?因为单一通用的 ai 往往啥都会,但啥都不精。 面对复杂任务,你需要的是像公司一样的专业化分工。在 openclaw 里,你可以让大总管负责拆解任务,咨询助理去全网搜瓜素材内容助理最后负责沉文。 这种高频的内部通信如果走云端, api 成本会让你肉疼,但在本地,这就是几乎零成本的算力游戏,也是真正让 ai 介入生产力的分水岭。能扛住三五个 agent 同时工作,全靠 s g line 的 前缀缓存。这就像你跟一个老朋友聊天, 你不需要每次开口前都重报一遍姓名和生屏,系统会把那十几万字的历史对话直接锁在显存的最快区域, 每次新请求进来, gpu 只负责算你新说的那几百个字,剩下的历史记录全部秒速服用。这就是为什么在长上下文环境下,本地部署反而比很多云端 api 响应更顺滑的原因。他把每一分算力都压在了深沉回答上,而不是反复重算过去。 最后说点压箱底的调优经验,本地部署不是把模型塞进去就完了。你手里有三个最重要的旋钮,并发数、上下文长度和显存预算。这三个参数是此消彼长的, 你想让模型记住二十多万字的文档,并发能力就一定会缩水。如果你发现系统报显存易出错误,别慌, 先去缩减显存比例或者压低上下文长度。最稳妥的做法是先关掉所有投机采样和花哨加速,在基础参数下跑通全流程等工具调用和多 agent 写作都稳如老狗了,再去摸索显存的极限边界。
373AI技能研究社 02:29查看AI文稿AI文稿
02:29查看AI文稿AI文稿英伟达最近出了一个黑科技 dlss 五,没想到惹到了众怒。詹塞黄在 gtc 发布了第五代深度学习超级彩阳技术 dlss 五,号称要用神经模型渲染,结果全网差评如潮。脸相谨慎的老黄也不得不亲自出面呼及批评, 这是为什么呢?你看,这是生化危机星座主角本来的样子。而 ds 五开启后,他原本疲惫朴素的脸被 ai 自动做了丰唇、瘦脸,甚至带上了全妆。不止他,所有角色经过 ds 五的包装后,都变成了精致完美的人,彻底脱离了模型感, 细节程度远超所有当下游戏。但缩小来看效果很糟糕,像真人,但又不是真人,有一种莫名的诡异感。 为啥主打真实的 dlss 五反而让追求真实的玩家反感呢?因为这恰恰是一种不真实。 尽管老黄发布会上反复强调 dlss 五是深度结合了游戏模型信息生成,只影响贴图,但随后官方还是承认了演示里的效果是用游戏渲染完后的二 d 图像生成的。这就是说,这就只是一个 ai 滤。 ai 的 特点是倾向于产出一种近似的符合平均审美的标准脸,比如看 grace 五官端正,就把它变得像明星一样,看到老人脸上有皱纹就 疯狂加更多的皱纹。对于细节对 ai 来说不是难事,难的是理解角色的脸为什么长这样,这些信息 ai 是 没有的。而且 ai 也不理解 光为什么要这么大。游戏中的光影不仅仅是为了照亮场景,更是为了主题故事服务的。甚至当我们在过场动画切换到自由视角,会发现每一个镜头灯光都经过了重新布置, 不真实但好看。当 ai 仅仅依靠当前画面添加一对他认为正确的真实光效时,无论是什么类型的游戏,在 d l s s 五的处理下都呈现出同一种油光水滑、光线充足的质感,所以玩家都可以一眼识别啊。 ai 味儿过 过分的是,连玉璧和卡普宫的一线美术师都是在看直播时才发现自己的作品被 ai 强行重绘了。真正让大家担心的可能是以后的游戏,呃,也许都会被这样做了。 ai 渲染变成了必需品,而不是锦上添花。或许我们真的不一定需要 ai 来代替游戏。美术技术的初衷本应该是实现创作者的灵感,我觉得大部分人还是更乐意看到经过人手雕琢的带有个性和创意的画面的,你觉得呢?
2.0万贪玩歌姬小宁子 04:38查看AI文稿AI文稿
04:38查看AI文稿AI文稿大家晚上好啊,先给大家看看我的电脑的配置,它有个独立显卡,内存也挺大的,有十六 g 呢, 可是早上的时候我不是,就昨天我就是装了那么三点二 b 一 b, 还有就是后来又换成了三 b, 虽然说我的龙虾连上了,能跑能跑起来了,但是反应特别慢, 跟他聊个天大概有了,得三分钟才能给我回信,关键吧,我的电脑那个就 cpu 就是 狂转,风扇也在也在响, 我就想,哎,这怎么感觉不对劲啊,后来就去查怎么回事,后来才知道原来他们没有在我的信用卡上跑, 用的都跑去调用我的内存去了,在我内存上跑,难怪那么慢,而且我的那个电脑负荷那么大,后来我就想去解决这个问题, 就去查了查,后来发现那个这这个欧拉玛这个东西, 它好像在你你的电脑有两个显卡的时候,它好像自我适配能力比较差,我呢就想手动改它的配置, 可是怎么改也改不过来,就说好像还是因为欧拉玛他的那个版本兼容性的问题。 然后正好看到咱们评论区有有大神给我推荐的 s g 链,这个东西叫 s g 浪吧, 然后我还特地问豆包我的电脑能不能装,他说可以,那我就去装呗。后来,后来在那个后来就去装,下载下到一半 哈,告诉我他对那个操作系统的适配, 好像那个不不是那么和谐就有,有些有,有些依赖,包装不上。后来呢,他呢,那个就给我推荐了一,给我推荐了一个另外一个东西叫 l m studio。 这个东西 哇, l m studio 我 觉得是太好用了吧,我极力给大家推荐,现在呢?我我在 l a l m studio 那 边,我发现它这边提供了好多大模型,关键都是可以在本地部署的大模型。 然后我呢,先是先是还是那个那么三点二 b 三 b 这这个, 但后来我发现好像智商智力有点低,跟我聊天我叫他图灵,他就只会很很死板的应我, 没有像之前那个接接那个阿里云百店的那个那个图灵那么灵活,那我就,我正好看到这里面有千万三点五九币的那个,我就给他下载下来了, 大概六点五五 g, 我 就给他下载到我本地,然后也跑起来了, 然后再跟他聊,哎,发现就顺畅多了,那个说话的风格感觉也找回来了。但是有人跟我说 咱们在自己电脑上部署大模型,就说聊天可以,然后调用工具啊, 搞开发那些可能就不是那么灵活,这个我也不大确定,因为毕竟我刚搞好,我就是接下来就试试呗, 看一看是不是真的真自己电脑部署那个部署大模型真的就那么不好用,毕竟要试过才知道对不对。好的。
10木火相助 02:58查看AI文稿AI文稿
02:58查看AI文稿AI文稿大家好,我们现在装的车电量主要是用于 cad 有 机的一个电脑配置是一个 auto 九二八五 k 二十四核二十四线的电脑主机。详细配置清单在视频结尾,感谢来自安徽省合肥市的王老板,祝王老板的汽车配件有限公司 越做越大。话不多说,下面就开始装机。 cpu, 英特尔 auto 九二八五 k 二十四核二十四线材 主板,华硕 top z 八九零 plus wifi 版, 内存支起六十四 g 两条三十二 g 套条 硬盘三千九九零 pro e t 独驱速度,七千四百五十兆每秒 散热,瓦尔基尼 b 三六零 gt。 bt 是 谁了? 电源,长城八百五十瓦金牌全模组 显卡,英伟达 rtx 四千 ada 二十 g 专业图形卡。
22重庆克拉拉电脑 00:40查看AI文稿AI文稿
00:40查看AI文稿AI文稿mac mini 暴涨,这纯属是跟风买错了。来讲个硬核知识点,这个叫龙虾的 agent, 它的本质其实是一串 pad 脚本,它不吃显卡, 也不吃本地算力,它真正的大脑在云端 cloud api。 所以 这跟你是 mac 还是 windows, 甚至是一台十年前的破烂笔记本毫无关系。那些加价买 m 四芯片的,怎么说呢,这就好比是吃了顿外卖,非得把五星级大厨请回家里住,太败家了。真正的成本在这里。 toker, 他 每一步操作都在烧钱,省下买电脑的钱去充 a p i。 余额才是正的工具,指在内,算力才是核心,别被硬件厂商收了税。
1603建筑师小翔 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿换个显卡驱动就能原地暴涨一百帧,魔震超平哥看了都得怀疑人生。测试配置为九八三加四零七零,画质一丝没动, 只将驱动更新为五八一点零八,瓦罗兰特直接封神,无论是静止还是开枪,稳涨一百帧左右,公认的积血五六零点九四居然被吊打!测试结果还是挺令人吃惊的,三角洲提升近二十帧, 反恐精英创意公房新老驱动均测试了三次取平均值,平均帧和漏帧均提升了十来帧,永结无间训练营也提升了四十来帧。全程无玄学无调试,纯驱动对比, 如果你觉得新版的驱动不好用,想回退旧版,却在官网找不到你原来的老驱动,其实你直接在这写你想要的版本就行,台世纪的驱动就带上六步。 但最后堂主想告诉大家,这东西每个人的配置和系统不同,具体情况得自己试了才穿,都这么躲着了,别搞心能焦虑。
2701爱搞机の堂主 01:52查看AI文稿AI文稿
01:52查看AI文稿AI文稿capsc 又扔出一个网站,开源了仅六百三十行代码的 auto research 框架,让 ai 自己当研究员,一块消费级显卡就能跑。 你只需在 program 到 md 里写清研究方向,比如优化 nanochat 训练效率, ai 就 会自动修改 train 到 pi、 调整层数、学习率、优化器等参数,启动一轮五分钟的训练。实验结束后用 yippo pb 指标打分,越低越好,且与模型大小无关,公平可靠。 改得有效就保留,变差就回滚。重试每五分钟一轮,一小时能跑十多次,人类一天调两三次就累垮它,四十八小时内跑了近两百五十轮,筛出二十九次,真正有效的改进。这些不是微调, 在 rtx 四千零九十上连跑两天, ai 自主提升训练效率百分之十一。比如修复 qk norm 缺失缩放因子,还混搭了 mon 和 adam w 优化器。 要知道这些模型本已被人工调到极限, ai 居然还能挖出新空间。整个系统就三个文件, prepare 定增基础配置。 print 到的 pi 是 ai 的 实验本, program d 是 你的指令书,换方向改个 markdown 就 行。所有有效改动都以 git commit 记录,清晰可追溯。 carpathi 的 野心更大,打破所有研究必须合并到主干的惯性,他设想成千上万个智能体在独立分支探索,通过 getup discussions 互相留言, depths 等于十十 lr 等于三 e 四,效果更好,新智能体读到就能避开老坑。这灵感来自一九九九年的 s e t i at home, 当年网友用闲置电脑找外星信号, 现在他想用全球闲置 gpu 构建分布式 ai 科研网络,每个分支都是虚拟,博士生不求合并,只管积累和分享。发布不到四十八小时, auto research 已获九千五百家星标。 shopify ceo 直呼疯狂,斯坦福伯克利已用作教学案例。这不是调餐工具,而是一场科研范式的转移,从人写代码变成 ai 攒经验。未来真正的突破,或许不再来自天才灵光,而是无数沉默智能体在五分钟一轮的试错中,悄悄拼出答案。
75跟陈博士学AI 00:50查看AI文稿AI文稿
00:50查看AI文稿AI文稿用 ai 写代码,你至少得搞懂这四个东西, agent、 skill、 mcp 和 rules 分 不清,它们效率永远上不去。第一个 agent 就是 你的 ai 程序员本身,你给他需求,他自己拆任务去想方案,写代码,跑测试,出了错还能自己改。它是整个系统的大脑,统筹大局的指挥官。 第二个 skill, 相当于给 agent 发一本岗前培训手册。装上之后, agent 就 拥有了特定领域的专家知识和标准化工作流,零配置加载就生效,直接提升输出质量。第三个 mcp, 全称 model context protocol, 相当于万能插头。装上之后, agent 就 能操控浏览器 查数据库、调 api, 从只会聊天变成真的能干活。第四个 rules 相当于公司的编码规范,写在项目里, a 阵的每次干活都自动遵守命名规则。代码风格。技术站约定团队十个人写出来的代码像一个人。
1182AI干货局 00:51查看AI文稿AI文稿
00:51查看AI文稿AI文稿游戏不跟手,帧数上不去,其实是你的设置没做对。这期说几个电脑到手后想要满血游戏必做的几个设置,我将告诉大家他们的原理,以及能够带来哪些提升。一、窗口游戏优化一定要开,它的作用是可以让游戏在无边框模式下切屏时更快更丝滑。二、硬件加速, gpu 调度,同样建议打开 后能一定程度上增加显卡的占用率,提升帧数。三、游戏模式还是建议打开,它能够让 windows 优先分配资源给游戏,没有明显缺点。四、内存完整性这个就因人而异了,它是一个在后台持续检查系统的安全功能,如果你是纯游戏党,那建议关闭,帧数会有个百分之五左右的提升,有办公、网银等隐私需求的可以保持开启。 最后什么 c s、 五啊洲等设计游戏玩家如果游戏支持 reflex, 千万要开启,会明显感觉到更丝滑。跟手游戏里没有的话,进英美达控制面板,将 d h 模式打开,电源管理模式也设置为性能优先,同样可以带来更好的帧数和手感。
526折腾到吐 00:33查看AI文稿AI文稿
00:33查看AI文稿AI文稿不同分辨率最低要用什么显卡?先说一零八零 p, 如果只是简单办公,那么英特尔 amd 的 核显就能带。要是想玩一下游戏,低预算幺零六零五八零基本就能玩。想画质再高点,那就上到二零六零。接下来是二 k 入门就选二零六零,想唱完的话,那就三零六零、三零六零太,四零六零。这三张卡最高,不建议超过四零六零太,毕竟今天不打高端局 后是四 k 中低画质玩游戏,那么三零六零菜即可。想画质再高点,那就三零八零十二 g、 四零七零 super 五零七零。这三张显卡只要不追求四 k 原生分辨率画质,光追全拉满这些显卡就能用。当然,能用和用的爽是完全两个概念。如果你对画质要求极高,也别挑刺了,直接五零九零。
365装机龙-小爻 00:56查看AI文稿AI文稿
00:56查看AI文稿AI文稿哈喽,宝宝们,请签收你们的新显卡,给大家推荐一款适合黑色主题海景房 diy 装机玩家的华硕显卡。这是一款定位四 k 中高画质、主力性价比的显卡。华硕的大师九零七零 st, 十六 gb g d d r 六显存, 四千零九十六个油处理器,二点五槽静音优化,简约设计。如果你用来搭配四 k 显示器,带宽高达六百四十 gb 每秒。 四 k 高画质不易爆,显存帧率更稳,玩三 a 大 作,光追高画质,赛博、朋克、黑猴等 x t 性能更强,显存更从容做设计,渲染,多开十六 g b 显存,对生产力更友好。大师系列更紧凑,噪音更低。三风扇轴流相变导热,全金属通风背板 强效散热,三百零四瓦高覆盖,稳如磐石。这款显卡适合预算在五千多,追求四 k 全能的电竞玩家,装机老朋友们学会了吗?
 00:52查看AI文稿AI文稿
00:52查看AI文稿AI文稿d l、 s、 s 四点五的模型到底该怎么选?看完这个视频你就懂了。预设 k 是 d l s s 四点零的标准穿梭门模型,预设 m 是 最新的 d l、 s s 四点五最新的全能预设, 进一步优化了光流分析。预设 l 是 当前计算量最大的模型,专为超高性能模式优化。 d l a a 与质量党使用 m 模型,超级性能党使用 l 模型, 使用 g 加 rtx 五零六零太血鹰显卡对支持 dlss 四点五的明日方舟中末地进行实测, 可以发现 m 模型与 l 模型在相同的画质压力下, m 模型帧数更高, l 模型画质效果更好。以上就是本期视频的全部内容,更多 diy 内容请关注我们,下期见!
221技嘉AORUS俱乐部







猜你喜欢
最新视频
- 6115阿敲