NMF模型怎么用Python做
我们这时候进入到大模型应用开发,就使用这个 login 这框架嘛,那什么叫大模型应用开发呢? 那既要开发一个完整的应用嘛,就不仅仅是说学大模型了,因为大模型本身还是擅长于对自然元的理解和生成。当然了,现在不光局限于自然元了,包括对图片的视频、音频的理解和生成,大模型都可以搞。 但是我们开发一个 app, 一个应用嘛,还有其他很多功能需要完成。比如说我希望他能够自动的去上网查询一下最新信息,希望他能够完成一个文档解析,希望他能够去搜索浏览商品,然后呢帮我自动的去下单 等等。这类功能我们通通称之为工具。那么工具的实现其实还是传统方式嘛,你要去掉各种各样的接口,比如说你要去掉淘宝的一个搜索接口,去掉支付宝的微信的支付接口。 所以在大冒险出现之前,这些功能该怎么写,现在还怎么写?只不过呢,现在我们要把这些功能和大冒险融合在一起,共同开发一个 app 时, 那么就有了朗庆这样一个框架。在朗庆框架里面虽然说包含了大模型和工具两部分,但它还是以大模型为核心展开的, 我们还通过这个 pickin store 去安装一下我们的朗庆。那现在呢,已经到了这个一点二点一了,这边还强调一下,就之前的话都是零点几、零点几, 那零点零几就表示这个版本还不够成熟,还在频繁的变化当中。而一旦升级到一点几的话,就意味着他会比较稳定, 轻易不会再改变了,那就算有新的功能加进来,他也是去升级这个次版本号啊。主版本号最前面这个一是轻易不会变的, 只要主编码号这个一不变,就意味着它始终是向前兼容的。就说我们现在这个课程呢,是按照一点二点一来讲,那么将来就算它升级到了一点九,一点十,咱们现在讲的所有的 api 在 将来依然是可以直接使用的, 这叫兼容嘛。但如果说将来主编码号变成二了,那么之前在一里面的某些 api 它可能就不再支持了。 那么第一节课咱们先通过浪清这个框架来调几个大模型感受感受。第一个我们先调这个 deepsea, 我 们打开 deepsea 官网,当然了本节课我所讲的所有的网址都会出现在我的代码的注示里面,或者出现在我的文档里面,大家拿到代码,把那个 u r 从代码里面拷贝出来就可以了。这边我们点这个 api 开放平台,这边需要注册个账号, 然后的话这边有一个 api k 的 管理,我创建一个自己的 api k, 你 后续所有的 deep 调用都需要把这个 k 呢作为参数传过去,这边可以查看这个用量信息。 我当时充了十块钱,现在还剩下七点八四元,所以十块钱其实可以用很长时间,待会呢我们也可以去调用字节的这个火山引擎, 这个链接也在我们的代码里面有。这边有一个模型列表,现在是豆包的一点八,在公测当中往下翻,咱们点这个豆包 c 的 一八,那么就跳转到了火山方舟的管理控制台左侧这边我们往下翻, 有一个系统管理,开通管理,开通管理下面的话,这边有一些模型,语言模型、语音模型、视觉模型、向量模型和智能路由模型。那么语言模型呢, 你可以选一个点击开通服务就可以了。我现在是开通了这个豆包 c 的 一点八,大家你也可以多开通几个。另外的话强调一下,就这个向量模型这边呢, 我们也需要开通一个,那我开通的是这个豆包 ambidi, 因为后面课程我们需要去调用这个 ambidi 能力。那这个模型开通之后的话,开始呢是免费的, 比如它这边有多少 token 的 这个免费使用额度嘛?包括这边这个豆包一点八也有这么多的免费使用额度,所以大家可以放心使用。然后这边有一个 api k 的 管理,当然了你也需要先注册一个开发账号,然后呢生成一个 api k, 我呢是把这些 api k 都放到了我的环境变量里面去,将来我在代码里面呢,直接从环境变量里面读取 api k 作为参数,传给对应的后端就可以了。 当然了,你也可以把这个 api k 呢存到你的配置文件里面都行。然后在朗清里面,为了去调用各个模型呢,我们需要去安装一些工具,比如调 deepsafe, 我 们需要去 piping store 这个 long chain deepsafe 这边我来写一个函数,我要去创建一个 deep seek 的 模型, create deep seek chat model 这边我已经引入了 chat deep seek, 所以呢这边我来一个 i r m, 等于这个 chat deep seek 好 看,参数怎么传? 第一个需要把你的 api key 传过去,这是当初你在 deepsea 高网上这边创建好的,这个 key 我 不是已经放到我的环境变量里面去了吗?这边的话,我直接读取我的环境变量 get in, 输入环境变量对应的那个名称, 这个都是你自己配置的啊。第二个参数,指定 model name, 我 们调的是这个 dipstick chat 模型。好,这两个是必须真的。然后还有一些可选参数,比如说指定一个温度 temperature, 这个温度呢?取值是零到二,那么温度越高,它会越发散,温度越低会越冷静,越聚焦。比如说数理化类的,你可以把温度设到低点零点五,零点三, 而文艺创作类的,可以把温度设高一点一点五,一点八,对不对?咱们取一个中间值一点零。 max tokens 表示你想控制大模型返回的这个文本长度, 因为它返回的特殊越多,那么你的金额消耗就越多嘛。想控制一下边,我控制成三千吧,还可以控制一个 timeout。 每次用大模型,你的最大等待时间是多长? pass 里面时间都是以秒回单位的,这边呢,我最大等待二十秒,超过二十秒还没返回结果。那么呢,本次调用就直接以一个异常就结束了, 还可以指定一个最大的重试次数,假如第一次失败了,你是否允许他再重试第二次?好,最后我去返回这个 l m, 所以 这一些参数都是可选的,可以指定也可以不指定。我们来试一下 model, 等于调这个模型, 然后我们看一下这个模型的名称, model name, 通过这个 model 点, model name 可以 答出来,然后我们问他一个问题, model 点掉他的 in book 函数,好问一个问题,今天是几号? 把它赋给一个变量 completion, 等于它,然后来打印这个 completion 看一看,好跑一下,那么这个模型调用还是比较慢的,需要等个十秒左右看这个结果。模型名称是 dipschat, 就是我们刚才在这个地方指定的模型名称嘛。那么这个 inlook 函数返回值呢?它应该是一个类,一个 class, class 里面它对应了一个 content, 它返回这样一句话。还有很多的其他信息,比如这边啊, to cost 表示调用了几个工具嘛?目前的话,我没有调用任何工具,所以工具调用为空。 这边还有一个关于 token 的 使用状况,输入七个 token, 突出了二十个 token, 总共消耗是二十七个 token, 那 么他这个时间呢?二零二五年的一月二十四号肯定是错的,就说大模型他不可能知道这些事实的信息。 如大模型是二零二四年六月一号训练好的,那么二零二四年六月一号之后发生的事情,他肯定是一概不知的, 所有跟当前时间是相关信息他都不知道,所以呢,他这个时间会是错的。那么将来我们通过自己写一个函数,就写一个工具嘛,来告诉大漠新当前的时时间是什么?好,不管怎么说吧,这个接口是能够调通的。 那么我们再来换一个模型,看一下火山方舟豆包模型怎么调?我来创建一个 ark chat model, 这个 ark 表示的是火山方舟 i o m。 等于 啊,刚才咱们调这个 chat deep secret 嘛,但是对于这个豆包模型来说啊,官方并没有去维护一个 room 下面的可用的一个库, 因为我们知道豆包是自结的吗?而字节它是用的构源,字节有一个 i n o 框架,专门是用来做构源的大模型应用开发的, 所以呢,它们目前还没有去对接这个 python 语言,那目前我们还是需要通过这个 open ai 的 方式, 通过它的 api 来调用火山模型。那怎么调呢?我们看一下,这边是 chat open ai 啊,很关键一点,我们要指定一个 ul, 这个 ul 呢,定到 ark, 就是 这样一个 ul 啊,目前需要写死, 然后的话跟刚才一样,指定一个 api k, 指定一个 model 名称, api k 呢?我还是去读我的环境变量,而这个模型名称呢?模型名称我们还是来到后台这个地方, 比如说这个豆包一点八,我们点进去,然后往下翻,这边有一个调用时历。好,那这个时历里面的话,我们看到 这是那个模型名称,我们把这个字母串呢拷贝过来,拷贝过来粘贴在代码的这个地方。 ok, 这个是豆包一点八对应的完整的模型名称。那么同理你也可以额外的配置一下其他参数,我们呢就不再配置了, 所以这三个是 b 一 倍函数,然后返回 i r m。 好, 我们把这个模型替换一下,这一次我替换成 arc, 那 么再来运行一下,开始它也会很慢。这个是模型名称 啊,豆包呢,就比较诚实,他说我无法获得当前时间,让我去查手机,查电脑。而这个 deepx 呢,就很自信的告诉了一个错的时间,它也包含了其他信息, 比如说这个工具掉了哪些,然后用量啊?输入了五十一个透坑,然后返回的是一百零九个透坑,总共消耗是一百六十个透坑。 就说虽然你问的这个话是一模一样的,今天是几号,但是呢,不同的模型,它这个 token 的 计算方式是不一样的。 deepsea 认为我只输入了七个 token, 而这个豆包呢,它认为我输入了五十一个 token。 所以 你要衡量一下这边给出的免费使用额度,五十万个 token, 它可能并不是你想的那么多。然后其实我们还可以在运行时就调这个 inlook 的 时候来指定这一些参数,指这边我指定一个 config, 这边一个 dict 来一个 configurable, 它对应的 value 呢?又是一个 dict 的, 这里面我另外的指定一个 timeout, 超时时间 为三十吧。另外指定一个 temperature, 温度,比如说是一点五吧,一点五。好,就说当初我去创建模型时,我指定的超时呢是二十秒,温度是一点零, 这是跟这个模型绑定的。但是说对于某一次具体的 invoke 来说,我可以临时的再去换一个参数配置, 那么如果指定配置了,就以这里面的配置为准。如果 invoc 时没有指定相关配置的话,那么就以当初创建模型时指定的配置为准。 然后的话,我们也可以一次性的问大模型多个问题。那么在廊城内部呢,它可以开辟多个县城并行的去调用大模型, 因为我们知道大模型词调用很慢嘛,当你问题比较多时,你可以搞并行,这边我来演示一下。 好,假如说你有多个问题,这是一个 list messages 需要问的话,那么第一步跟刚才一样,先创建模型,然后呢,这边通过调 byte。 注意啊,刚才是调的 invoke 一个问题,现在多个问题的话,你需要通过调这个 byte, 哎,把这个问题列表 list 传递了,当然你也可以通过 config 来进行一些配置, 那么这种情况下,你这边传几个消息,他就会开几个县城。那假如说你传了一百个消息呢,他就要开一百个县城,那为了控制住这个最大的县城数目啊,你可以在这边加一个参数,是吧? max concurrence 最大的变化度嘛, 配置为五,那最多就只会开五个县城。先把前五个处理完,然后再接着处理后五个,这样逐步逐步地把这些个 messages 全部处理完, 那么对应的它返回的这个 responses 也是一个 list 嘛?这边呢,咱们把原始的问题和 response, 哎,通过 zip 把两个集合呢给拼起来, 打印出对应的问题和对应的答案。就这个 content, 因为我们只关心 content 这一部分嘛,后面的暂时不打印好。那么这边呢,我准备了三个问题, 让柄形地去掉大模型,看看效果,再来 pass 一下,好,打印 message, 这是原始的问题,打印 response content, 这个呢,它对应答案,这个是一个问题,这个是个答案,这个是一个问题,这个是对应答案。好,这节课呢,咱们就讲一些通过朗讯去调用各个大模型。

粉丝1.6万获赞3.0万
相关视频
 06:26查看AI文稿AI文稿
06:26查看AI文稿AI文稿ai 和机器人会淘汰很多的人,两种人淘汰不了。第一个你跟着老师学中文 python, 人工智能编程的人淘汰不了,对不对?因为机器人还是人工智能都是有人在开发的软件啊。 第二类人就是善于,善于什么,善于利用 ai 的 人,那教大家指标公式, 这都是小儿科,教大家编程都是 ai, 做的都是小儿科。现在给大家讲讲 ai 在 怎么做,因为在我们这里面有很多的插件,老师提供了所有的全球市场的行情和交易接口,所以我们这轻轻松松能接 小白量化,能跟跟全球市场交易,港股、美股、数字币,什么都能做下来。我们讲我们有下载 f 十,批量下载 f 十的信息, 对不对?我们点开始下载,让它下载,我们不管它了,我们刚才给大家讲了,我们正在下载, 我们还是这个大魔星还在,我们不管它了,我们还正在下载数据。哦,看一下,我们下载 f 十,已经下载了七百六十个票了,这个票里面放到我们哪里?小白 date 二点 base 目录下 这里面,我们看看这里面放的是什么?所有的新闻,我们看一下它像是我们股票的 f 十资料,你看这个是三月十七号的,我们再看一下其他的,对不对?都是最新的信息,这是三月十七号, 也是三月十七号的,有没有新的数据呢?肯定是有新数据,我们随便找一个看看有没有,我们看一下最上面的,我们把所有的 f 十都爬出来了, 这不三月十八号越红眼,因为他有信息变化,他就会更新的,你到哪去爬这些数据去?这里面包括财务分析, 每一年每一季度的营收情况,你要是懂财务,你慢慢去研究。这里边对老师来讲,老师就喜欢研究股东,研研究老师就关注 最近的机构投资者有没有,你看流通大股东有没有人增仓,哎,这是自然,人增仓我就不感兴趣了,对不对?这不这个新界,哎,这是机构银行吗? 有限公司,对不对?它在增长,这个个人我就不感兴趣,你看这个没变,我们就喜欢研究股东,研究下来怎么办呢?我们让 ai 编了个程序,我们的征程序在哪里?我们给大家读一下, 连接本地大模型,通过财务数据选股。我们给大家讲这实际上是一个规则,我们利用本地的大模型,你看见没?我们用这规则找到了以后一些,主要是找增持比例, 这是不是用本地的大模型?千万八币?当然我可以用更高级的,越高级分析的越准,但是对这这种来说,这种八币的大模型的够用了,因为他很简单,不像做软件、做指标,他要求高智商的这种普通的就够了,你知道不? 所以我们要求分析股东的数据,找机构基金公司、计划投资类的股东,因为我们刚才打开这个文件,对不对?我们刚打开这个文件,看到了什么呢? 我们打开这个小白 data 二,这是贝斯,这相当于 f 十资料,我们随便读一个,我们看到了,因为这里面都可研究,我们老师研究的是股东研究,股东研究,我们把它放大,大家可以看到 这里面有什么,你比如说银行,对吧?我们没有查,你比如说 资产管理,你看管理这就是属于公司吗?有限公司,对吧? 集理财指数基金理财计划,因为公银行他就叫理财计划 或者投资计划,你知道吧?他就是这些都属于机构,我们找这些机构,你看这个在减少,你比如说这个他在卖出减少,我们找增加的,你看这个 公司在增加,对吧?这些在减少,他会把这些增减做一个统计,然后汇总,根据汇总来找最近 持仓比例增加的前二百名。那我们分,我们找个快速分析的,我们运行一下啊。你看 他在筛选,现在已经下载总共有五千只股票,我可能下载了一千多只,很多人说爬买数据,我那自己在我们这里从来都不需要 这个速度快,不然后他把这个所以分析完了后,取前二百只排序,这排前二百只。但是我们仅仅是给大家讲一种方式,因为 f 十的资料多了, 你看他里边有,你还可以研究懂财务的研究,他追求利润的研究,他 追求智商智智理的找,他还可以追求热点的一个研究报告,经营分析、热点题材、行业分析,这都是你研究的概念吗?你看他所属的板块,零零零二所属的板块有多少? 什么 h 股、体育养老、智能机器人,粤港澳,他占这么多板块,还指数类、中证一百、深圳这些东西都是你能用 o、 a、 l 来提取的 信息,都给你了全部的资讯,最新的三月十八号最新的信信息,他给我选了,你看我在现有的里面搜索了一下机构增仓的一些股票,比如说。
12小白量化 00:39查看AI文稿AI文稿
00:39查看AI文稿AI文稿这是一个人人都能训练的小模型,在 github 上斩获了四十一点六 k 的 四大,并且还登上川定榜单,因为他会教你怎么用三块钱花两个小时训练出仅有二十五点八 m 的 超小语言模型库。主打的是极其轻量化, 只有两千五百万个参数,最小版本体积只有 gpt 三的七千分之一。项目开源了 tokenizer 分 磁器训练,包含 pretrain、 sft 等全过程训练代码, 甚至拓展了视觉多模态的 mini mangley。 所有训练脚本均为 p i t o x 原生框架,兼容了 m o e 混合专家模型架构,麻雀虽小,五脏俱全,实现了对大语言模型全阶段开源赋现,是入门 l l m 的 绝佳教程。
6140AI小蔡狗 00:46查看AI文稿AI文稿
00:46查看AI文稿AI文稿传统边缘 ai 部署算法工程师天天崩溃,不会 c 加加环境搭建三天起步模型部署直接聚集项目永远卡在最后一步。试试 r k n n toky 的 light。 二 瑞星微官方出品的轻量级工具包,支持纯 python, 几行代码搞定。 tensor flow pie torch 模型推理,专为二 v 一 一二六 b 等二 k 芯片 npu 优化,支持预加载模型一键推理,完美解决算法开发者痛点。 欢迎访问 e c i 灵眸智能官网,获取完整教程与详细文档。
 00:45查看AI文稿AI文稿
00:45查看AI文稿AI文稿我现在正在给大家搭建一个是用本地 ai 大 模型做的翻译的。啊,这么一个啊,本地部署 就说现在用的是一个开源的,叫做什么东西?我也搞不懂啊?你看你们看一下啊,就是这个啊,现在正在下载啊自字体翻译模型, 就是他支持全国,就是全球二十多个国家的语言。然后啊,比如说你们要做这个跨境电商啊,这种啊,双语字幕啊这些啊, 就完全不用花钱,对吧?那个就是你们那种做一条视频可能要几块钱,但是我们做这个视频成本就很低啊。
6羞羞老牛 16:56
16:56 02:15查看AI文稿AI文稿
02:15查看AI文稿AI文稿你们连大模型学啥都不知道,就要学大模型了?哎呀,我是真的不知道怎么回复了,我的宝子呢。大模型这东西呢,先看要学数据结构、 python 语法和数据分析三剑客,然后还有 ninux 语句。这个阶段是比较简单的,你哪怕让艺术生来学,他都能学会。 第二阶段就要上强度了,要学深度学习,继续学习 n l p 相关的 transformer 加固这些东西。说白了,这玩意你只要学好了,就能复个 type c。 一 般普本同学呢,这个阶段完全是听天书听个响,也就九二的能够听得懂。 第三阶段一般就要开始上项目落地了,学学微调啊,学学多模态呀,学学 ray 相关内容。说人话,就是能把你公司内部数据文档融合到 ai 里,把通用大模型改造成你们专用大模型,这样既能保证公司的隐私安全,也能让业务落地,帮助又有发展。 多模态就是大模型,不仅仅能读文字,还能看图片,接收文件内容。最后学学智能体相关的,教你怎么样把模型包装成好用的产品。一般大模型就学这些东西, 比较推教,双一流以上学学习。如果二本去学,那你也得数学和逻辑比较好,因为这里边它涉及到推导数学公式啥的。想学这个方向肯定要科班的,或者是和数学挂科的。理工科专业 文科生、艺术生就不要想了,咱们不能没苦硬吃。如果你是普本就想在二三线城市发展就业的,咱就踏踏实实学个 java 加 ai。 it 运界最新消息,头部机构已经放弃纯 java 路线了,因为在实践中,纯 java 路线它就是不好就业的,尤其是应届生,你凑个小招, 基本上都要包装两年经验。现在招聘更讲究 java 加 ai。 因为中小公司成员呢,一般都是 java 出身的, 所以机构的课程进化成了 java 加 ai 加 python。 目前只有头部机构有这样的课程,绝大多数机构还没有跟进。这也是我经常说如果学 java 肯定要去头部机构的原因,他们的课程能用 ai, 地方都用 ai 了,然后再学学 python, 搭建智能体, 普本学大模型本身就学不会,再者,大模型最次也是细分化行业头部机构了,普本进入的机会不多,考虑到一些同学还想去二三线城市工作的,所以普本尽量还是学加号加 ai, 别拿自己的短板去碰别人长处,选对路,才能吃到 ai 的 红利。
65计算机圆圆 16:56
16:56 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿周五天气如何?用数据分析模型告诉你答案?今天的结果大幅低于预期,但是事出有因,兄弟们,我们一起来看周五,把今天的数据带入 python 数据分析模型计算,麻烦大家顺手点赞支持一下,谢谢了!来看计算结果,我们先看随机森林模型的结果,从结果来看,周五天晴的可能性极大。 把数据带入时间序列模型计算,这是计算结果,周五是红色,欢迎大家一起来验证,感谢点赞关注, respect!
293陈汼汼 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿今天给大家利用 ai 开发一套拍蛋的必设项目,基于改进食言人的菌种图像分类与识别平台设计与实现。下面是我的 ai 开发提示词,我们可以把它复制到 ai 开发工具里面,然后进行开发。 这里我们跳过 ai 开发的融资过程,进行我们的项目演示,启动拍摄后端与小程序,前端看数据库,整体可以看到 ai 开发的项目非常不错,符合我们的要求。项目是进行深度学习训练的七 k 张卷内的图片,为了确保我们训练卷内正确的效果,这里我们演示, 选择我们下载的图片进行识别。 这里开始识别,可以看到我们训练的训练模型非常准确。大家有什么需要开发的项目可以点赞关注我,在评论区评论出你要的项目安排开发。
38程序员-⑩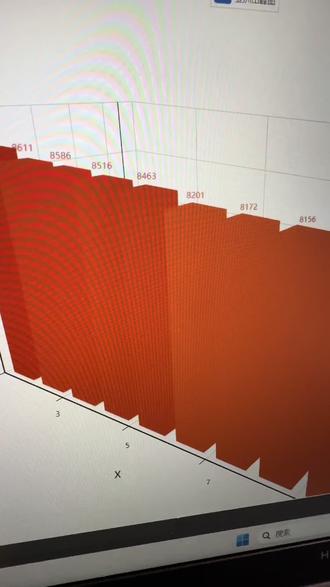 00:37查看AI文稿AI文稿
00:37查看AI文稿AI文稿哇,这是什么?这是我们的看亚洲山峰图啊。嗯,哇,好牛啊,它是立体的,看这个眉形渲染出来的。亚洲、北美、南美洲、北美洲、欧洲,这是他们各山峰的高度。嗯,好看好看,让他转一下看看。 嗯,这是用代码打出来的。对啊,可以给你看看代码。嗯,好哦,这这这这么多哎, 好长的代码呀。
12是小泽泽呀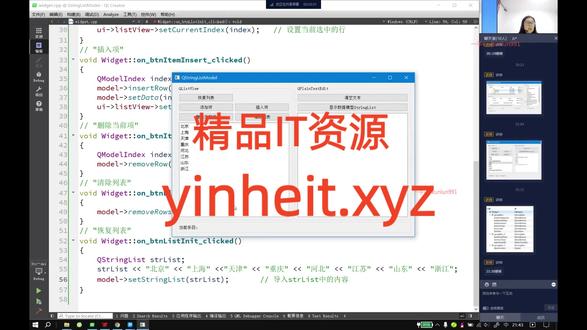 00:54查看AI文稿AI文稿
00:54查看AI文稿AI文稿也是这些功能吧,我们但是呢,那时候做的时候呢,都是挨个呢去创建 q list widget item 的, 对吧?那时呢数据和控件是绑定到一起的,真的是一个一个添加项,但是我们在这里边所谓的添加删除等等,其实操作的都是模型, 每一个啊都是你看模型插入,然后呢模型删除,对吧?模型删除多行,那么模型的插入全是这个吧,其实都是模型的操作 啊,这个呢,应该就是我们这里边啊,使用这个 item 维五和那个 item widget 的 时候,它们这两类控件啊,最根本性的差别就是使用那些 widget 的, 它的数据和控件呢是一体的, 用于呢出示一些简单的那样的数据,但是呢,我们这个使用。
1入机的课 00:35查看AI文稿AI文稿
00:35查看AI文稿AI文稿周末在家无聊,我花二点五小时我用 python 手搓了一个 ai agent 智能体,好用到爆。早就想搭建一个专属的 ai 智能体了,但平时工作太忙没时间,放假在家终于彻底开干了。我知道很多朋友一听到搭建就头大,全是代码怎么搞?我没基础能行吗? 别担心,我熬夜把整个过程梳理成了一份文字版保姆级教程,哪怕是纯小白,跟着步骤一步步来,也能搭建出来。如果你也想玩装 ai, 走在时代前沿,这份教程应该能帮上大忙,留下学习,双手抱走。
 06:41查看AI文稿AI文稿
06:41查看AI文稿AI文稿哈喽,大家好,这里陈一元,今天呢给大家录制一期,这个还是关于模型类的,我们打开一张图片看一下啊, 这个我们来去做一个练手的一个项目,大家可以看到这个在这张图片里面呢,散落了很多张扑克,而他有倾斜角度,有被遮挡的,有倾斜角度,有的呢只漏出来一点点, 打比方来说,这个八啊,右下角他只漏了一点点出来,还有这个十 啊,我们怎么去训练模型,让他把这每一张是什么,或者说至少把漏出来的数字啊,都能识别,正常的识别到,我们这边现在已经有一个出版的了, 把图片稍微放大一点,我们这边点击一下识别。好,大家可以看到啊, 现在呢还是在做这个数据标注啊。嗯,我们看一下他这个第一版第一个模型的识别成功率啊, 勾十 k 七圈八圈,勾十七三,这个这个三是有错的啊,这个应该是一张二啊,这个是二十,错的应该是有三。 然后其他的再看一下 s 群,像这个,你像这个群,它就基本上快值了百分之五十,超百分之五十了吧已经啊,也是能够正常的识别的到 好,其他就基本上没有错的了啊,其他基本上就没有错的了,那这个时候呢,我们就把这个给它保存到军事文件啊,再看,再来再来一张看一下, 依旧是把图片放大,然后利用 i 识别。嗯,我们在训练的时候呢,还是要尽量避免这种比较差的数据啊,你像这个, 这是是应该是一张七啊,猜测是一张七,他猜的也好像也是七啊,看一下网址里面 删除二十一啊,这这里没有,没有说具体是多少,看一下,其他也没错的啊。 大家看一下,这里有一个区域,他把这一个区域直接识别成了一个数字啊,包括这两个区域,这个是错误的。我们现在呢就是对于二点零版本的模型呢,就是一些保值,保留他一些质量比较高的这个数据, 其他的都是没有错,但是这个也是这个二也是纯靠猜的,这个二也是纯靠猜的,给他删掉。 还有这一张也是猜的,也是猜的啊,也给他删掉。其他的呢?基本上都是对的啊,也都能找出来。但是现在呢有一个比较严峻的问题啊,是什么问题呢?就是, 嗯,大家看刚才可能看看到了,就是这一幅图里面这一个三,很明显的三他会识别错啊,或者说在这个之前,在这个一点点版本之前还有个零点五的版本,还有零点五的版本,零点五的那个版本, 零点五的那个版本。还有一个问题,就是他会把这个特别明显的一个数字把他误认为背景了啊,就是觉得他是个背景,我就没有去识别他 啊。大家有如果觉得有这方面好的建议啊,可以提出来算法方面,这个是哪一部分的原因 导致他把特别清晰的一个数字识别成背景了?你不会像现在这种特别清晰的这个一个二他可能会识别成三,我们再来看着。 嗯呐,这里你看特别清晰的一个三他会识别成二, 然后这个圈的话,这个数据就没有必要,没有必要保留了,这个删掉, 其他都是对的啊,其他都是对的,你像这个五知道大概百分之三十左右吧,也是能知道它的识别 啊,根据其他特征能识别,现在希望大家提一点好的建议,我感觉现在可能是联想的这个有点过分了 啊,有点太太多过于联想了,所以以至于他导致会把中间的花色啊,会也会识别成扑克,也会识别成数字啊,不过把一些这个嗯 q 啊,他只露了一半,他这里正正常就不应该识别了,但是他也会识别啊,大家如果是有什么好的算法优化方面的方案,大家可以提出来,大家一起讨论一下。这期呢就给大家录制在这里,这个做完呢, 大家也可以自己尝试去做一下,在杂乱的这个摆放当中去找一些目标啊,大家也不一定非要用牌去做,你用其他的,但其他的物体呢,就没有这么好训练, 没有这么容易去去去做了,其他的物体,他可能每个都长得差不多啊,也没有什么 太大的具体差别。扑克呢是大家很好作为一个练手,练做模型啊,做算法是比较好练手的一个,这个工具啊, 这期视频呢就给大家录制到这里,如果大家需要这个模型啊,模型的定制啊,算法的定制啊,包括一些协议类的,工具类的,都都可以在后台私信我们,感谢大家观看。
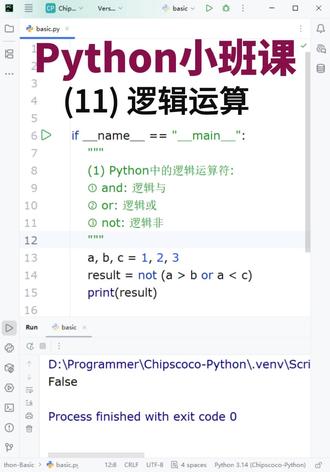 02:25查看AI文稿AI文稿
02:25查看AI文稿AI文稿薯条老师的 python 小 班课,跟薯条老师系统学 python 数据分析与高级爬虫 ai 大 模型算法。线上线下小班课, 我们这节课来学习 python 中的逻辑运算。逻辑运算用来计算真或假,在条件判断的场景中非常有用。要掌握逻辑运算,我们得先掌握逻辑运算符。逻辑运算包括以下三种,第一种是 end, 表示逻辑与表达并列的关系,所有值都为真实,结果才为真。 第二种是 or 表示逻辑或逻辑,或是只要一个值为真,最终的结果就为真。最后一个是逻辑非,非真就是假,非假就是真。我们接下来写代码,先定义三个变量, a、 b、 c, 并分别赋值为一、二、三。 接着写一个逻辑语的表达式,判断 a 是 否大于 b, 且 a 是 否大于 c。 最后调用 print 函数输出逻辑运算的结果。 在这个逻辑语的表达式中,需要所有值都为真实,结果才为真。由于 a 不 大于 b, a 也不大于 c, 所以 最终的结果一定是假值。 逻辑与运算其实只要其中一个为假,那最终的结果就一定为假。我们接下来按快捷键 ctrl 加 shift 加 f 幺零执行这个 python 程序,程序执行之后发现返回的的确是假值 false。 我们接下来把逻辑改成逻辑,或并把表达式 a 大 于 c 改成 a 小 于 c。 在 这个逻辑或表达式中, a 大 于 b 是 不成立的,而 a 小 于 c 是 成立的。逻辑或是只要其中一个为真,最终的结果就为真。 我们执行程序,发现表达式返回的的确是真值处。我们最后来理解逻辑非,逻辑非使用的计算符是 not, 逻辑非可以理解为取反。我们把这个表达式括起来,然后使用逻辑非来取反。由于这个逻辑或的结果是真值,取反之后返回的就一定是假值。 我们执行修改后的程序,发现返回的果然是假值 false。 今天这节课就上到这里,跟薯条老师系统学 python 数据分析与高级爬虫 ai 大 模型算法线上线下小班课。
16薯条老师教算法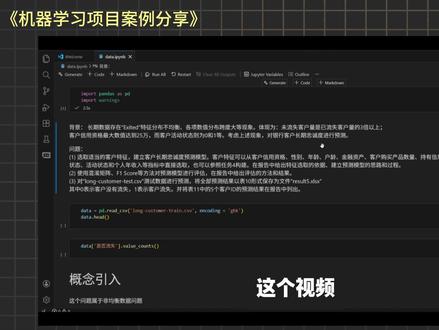 07:51查看AI文稿AI文稿
07:51查看AI文稿AI文稿这个视频给大家分享一个继续学习的案例,背景的话就是有一个数据,然后他存在啊,结果的一个特征分布不均衡,然后导致他的跨度特别的大,出现的未流失客户的量是已流失客户量的三倍以上。那我们的问题呢,是需要选举一些指标,然后构建一个模型,进行一个预测。 然后第二个的话,我们需要使用一些评价体系,比如说混淆矩阵、 f 值等等,因为我们之前讲的评价体系是那个长仓吗?第三个就是我们训练出来的模型要用到这个数据集上面。然后呢我们现在看一下背景讲的这个数据不均衡的情况是什么样的。首先我们先导入一下这个 数据,那我们首先去判断一下这个是否流失的一个比例是怎么样的,我们可以用这个方式去看一下,零代表的就是流失,一代表的是没有流失,确实跟我们 问题里面讲的是一模一样的,就是一比三的一个关系。那这里引入一个概念,就是这个问题属于非均衡数据的一个问题。非均衡数据的处理方法主要有两种,一个叫增加数据,另外一个是改进算法。那数据类型的模型主要有两大类,一个叫欠产量,一个叫过产量。他们的基本思想就是欠产量呢,他就是对,比如这里的零, 他就少产一点,比如说你这里有七千多个,他可能就采个一千多个跟他一样的量级,然后拿这个数据去预测,这个就是欠产量的一个基本原理。那 过彩样呢?就是反过来的,他就通过这个数据的分布去生成多几千个这个一的类别的数据出来,然后我们再去预测他的一个结果,那他们的模型具体上有哪一些呢?就是下面举例的这一些。然后第二个就是改进算法的一个模型,那主要有这一类的模型,所有的模型建立的前提 一定是先对数据进行一个清洗,首先呢我们会对模型和特征进行转换和筛选。然后我们之前讲过呢,比如回归式内它分为离散型和连续型嘛,像性别它的磁卡状态以及活动状态这种就是属于离散型。比如性别就是男和女嘛,就两种状态。 然后信用卡持有状态就是要么持有,要么不持有,所以它都是存在某种状态。然后其他特征的话可以认为是一个连续性的变量。然后对于定性变量的话,我们一般会采用主流编码处理, 比如说这里男和女,他的结果就是一零和零一。这里我们看一下具体的一个代码实现。首先我们先对这个理想和连续性的数据称一下,我们从 sk 任里面导入这个独热编码处理的这个方法。然后我们接着就是来实现这个数据增加的模型。 首先 x 和 y 就是 我们构建模型使用的数据,那我们这里因为独热编码之后,它的数据类型发生了变化,所以这里用到一个 ctrl, 然后我们就获取它的一个标签,然后这里面的话就是模型训练,首先我们做模型训练之前还会做一个动作,叫数据集划分,那我们这里划分的话是用到这个 tran task lee 的 方法,然后它会传入四个参数,一个叫自变量,一个叫因变量。 然后就是你划分的一个比例,那比如说我这里写零点三,那就是百分之七十的训练级以及百分之三十的测试级。这个 red state 呢是一个随机种子,比如说你不指定的情况下,那它划分的百分之七十和百分之三十的这个训练级以及测试级,在第二次执行的时候,它的样本可能是不一样的, 因为他这个随机种子在变,但如果说你同一个模型,同一个随机种子下,他说出来的结果一定是一样的。然后我们用这个随机森林先做一个初步的预测,那我们先看一下结果吧。我们刚刚题目里面讲到的要用混淆矩阵还有 f 一 去看这个值啊,这个函数它的作用就是这个混淆矩阵 得到的,你看这个结果就像一个矩阵一样。那首先我们看 f 值啊,对零这个类别的一个预测结果是百分之十四的一个准确率,所以这个结果是比较低的。 那另外一个我们可以看一下模型整体的一个准确率只有百分之七十八,那就意味着这个模型其实大部分都是在预测零这个结果 就是他能保证这个零一定大概率被预测。对,但是一他无法保证剩下两个结果呢?一个叫红光,一个叫加权的 a、 b、 g, 那它的结果是比较低的,比如说这个百分之五十一,那你剪刀、石头布擦一下,你可能都比这个高,对吧?这个就是在这个数据机下,我们用这个模型训练之后的它的一个结果,那我们要优化这个结果,这里我们用这五种方法,先对数据进行一个过产样增加数据的方法,然后呢这里面我定义了一个函数,大家可以参考一下, 那后面自己可以去实现一下,那这里有个 x 和 y, 就是 你传入的自变量和变量,拿这个是方法名, 然后这个参数呢是你要不要把它填补的数据进行一个删除?首先你就是通过这个模型里面的废的函数对它进行一个不裁样,然后裁样完之后呢,你就会把这个数据进行一个转化,然后我们还是会去分这个数据集, 分完之后呢,这里会有一个填补信息剔除的一个判断标准,就我们为了去控制这个变量的一个结果。 然后呢我们用随机森林,就是一个默认参数的随机森林进行训练,看这些过材料的方法,他们的一个最终的结果是怎么样的。然后这里就是传入他们具体的一个方法。 首先呢是我们先去建一个实力嘛,就是把这些模型给它创建出来,然后我们去便利这些模型,把它传进去啊,进行一个预测, 那这两个值呢?一个是对零类的一个预测的 f 值,以及对于一类的一个 f 一 的一个值。首先我们讲一下 f 值吧,我们这里可以看到一个结果,这个是刚刚讲过,这个是反向矩阵,然后这个是 f 值,然后它里面会传一个参数,就是你的测试级的 y 值以及你的预测值进行一个对比。然后呢参数这里面的话就是指定的你的一个预测值进行一个对比, 然后呢参数这里面的话就是指定的你的一个预测值进行一个对比,然后呢参数这里面的话就是指定的你的一个预测值进行一个对比,然后呢参数这里面的话就是二分类,除此之外还有一些宏观、 微观,还有加权平均的这些呃指标。然后 pos 的 label 呢?就是我们指定要预测哪一类,然后我们用这个格式化的方式给大家展示一下。首先就是我们发现这五种方法 对于一的一个预测标准其实是非常高的,我们刚刚也说过最简单的模型下面没有做过任何修正的。 我们刚刚讲过在基本模型的处理下,对于零类的预测值也有百分之八十七,但对一类的只有百分之十七,但在这里的话它的结果就从百分之十七变成了百分之三十,其实是有提升的一个效果,那就是证明这个模型它是有用的。我们刚刚讲过 这个模型在基本模型的训练下,结果对于零类的预测结果有比较高的一个准确率,但是对于第一类的一个预测结果只有 百分之十三的一个效果,但是我们在这里预测之后,你会发现它的结果变成了二十多三十,就证明这个过产量的方法其实是有用的。那我们这里控制的是同一个模型用的不同的采样方法,接着我们去用同一个采样方法,用不同的模型去实现, 这里我们选了随机森林叉、 g box 以及极限提升数作为一个参考。然后我们其实也可以发现在这一个产量数据下,模型的表现也其实还可以,像这个叉 g box 的 综合表现是比较好的。我们刚才讲这个函数里面其实有一个参数,就是你要不要剔除掉这个填补后的数据, 原因是如果我们不删除增加的填补数据,它的结果会变成这个样子,就是很夸张。叉 g box 的 一个分类去对于两个类别的分类都是百分之八十多,也就意味着 这个模型对于这两个类别都能比较好的识别出来。但是问题就是补进去的这些第一类的数据,它真的符合我们的实际业务场景的数据要求吗?这个是我们没法保证的。第二个板块就是我们看一下算法改进的一个模型的训练结果, 首先我们先用末日超速进行训练,然后我们发现这个效果其实也蛮不错的,虽然说一类的预测结果变低了,但是对第零类的预测结果其实变高了,所以这里我们可以看出来,其实它更多的是针对于预测结果的一个权重分配,你会发现第一类的下降了,第零类的升高了, 都会有这么样的一个结果。然后接着呢我们对模型进行一个调差,然后这里的调差是比较简单的,就是我们得到了这些参数,你会发现它的结果它提升会非常的大,就是我们不改变数据的情况下,通过模型改进之后也能得到一个比较好的结果。通过这个案例就是大家可以 去学到这个模型它怎么去落地,怎么去建,然后怎么去预测,以及它在这种问题背景下面有哪些的问题?如果想要本期案例,可以评论区留言,我要数据。如果觉得本期视频对你有帮助,记得点赞、收藏,关注三连,我们下期再见!
 01:55查看AI文稿AI文稿
01:55查看AI文稿AI文稿好的,欢迎回来,我们介绍完了 i m s 归一化旋转位置编码和注意力机制啊,现在我们来聊聊乾坤神经网络 f f n 和 sweet g l u 激活函数。 ok, 首先呢,前面还是一样,就是继承这个 n n 点魔九。好,这里有个重要的环节,就是隐藏层,隐藏层膨胀的维度设置为这个三分之八倍的就是单位选,就是三分之八乘五百一十二。然后我们还要确保一件事是 multiple of 的 倍数啊, multiple of 是 什么意思呢?就是 他这个数字就是二五六啊,这个东西就是二五六,为什么要这个量?他是不等于二的八次方,他对于显卡来说是一张非常友好啊,训练和推理经常要分到不同显卡上去进行操作,如果分成二的八次方的话,除以三十二,除以十六,他都是二的倍数啊,这是一个比较理想的量,如果你不是一个完整的量的话,显卡计算效率会严重大打折扣,所以我们要让这个维度数尽可能对齐这个二的八次方。 ok, 好 的啊,那我们看一下,就是如果你直接四乘五百一十二乘三分之二的倍数,所以我们要去乘一个二百五十六的最小膨胀系数。 哎,他这一行东西他就在做这么一件事情啊,就是计算一个上向上取整数的操作,最终得到应该是六倍乘二五六,所以得到是一五三六。 ok, 好, 现在我们要实现 sweet g l u, 对 吧?我们要我们里面有三个矩阵,一个是 w up 升为矩阵, w c 内容矩阵,一个 w down 是 降为矩阵。哎,那这里全部都定义好了,跟前面是一模一样的啊,这个东西也可以被参数更新, ok, 我 们继续往下看,这边的话直接一步就完成了,直接就是啊,四 f 点 w, 二 f 点 s s u f 就是 不需要参数的函数 放在这个 f 里面啊, f 点 sol, sol 函数就是这个东西,它会返回啊, sol x 会返回 x 除以一加一的负 x 方, ok, 然后 它内部是不是就是 x 乘 w up 呀?就 w 一 是 w 的 矩阵,升为矩阵,这一块是门控分支,然后乘法,这是族元素乘法,对吧?这就是进行一个直接乘就行了,不用矩阵乘法,然后 x 乘 w c, 我 们看一下维度数啊, x 是 不是五一二乘五一二,它前面还有个那个 batch 数,当然我们可以不用考虑,因为只考虑后面两者, ok, wup 呢?是不是五一二乘一,一五三六啊?就是就是,深维嘛,对吧?这是深厚的维度,然后 xc 呢? wc 也是同理啊,就是这个 w 三,然后降维,是不是从一五三六变成五一二啊?就是这个 w 档, ok, 直接一行就返回出来这个最终的结果。
105别闹了!小周同志 05:00查看AI文稿AI文稿
05:00查看AI文稿AI文稿在配置小龙虾的时候,这里有不同的模型可以供我们选择,但是呢大多数都是国外的模型, 那很多小伙伴说我更喜欢使用 deep seek 模型,要如何配置呢? ok, 那 这个视频中咱们就手把手教大家如何在 opencloud 小 龙虾中配置 deep seek 模型。好,我们看到当前这个页面就是我们之前配置好的小龙虾的 web 页面, 在这里面我们输入任何聊天内容,它都会返回一个错误信息,这是因为这个模型 and topic 咱们没有配置,我们要配置的是 deep sec。 那 怎么配置呢?接下来跟着我的流程。首先我们在这个页面中找到这里的设置,这里有个配置, 然后我们找到模型在这里 models, 那 么配置方式有两种,如果你会编程的话,你直接找到这个路径,在这个接私文件中进行配置。我先给大家演示一下, 直接打开你电脑中的访达,然后点击这里前往粘贴一下这里的路径。好,现在就已经找到这个文件了,然后打开你的一个编辑器, 比如说我这里就使用文本编辑 sublime, 这是每一项配置,比如说 agent tools, message 等等等等,咱们就给它添加,到最后这里添加一个逗号。接下来就是咱们的 provider 模型的设置,这里呢给大家准备了一个文档,大家可以直接粘过来, 直接把这个文件全部粘过来,这是一个新的一项叫做 models, 那粘过来以后,我们会发现这里有一个 api key, 它是 deepseek 的 api key, 那 么我们需要访问 deepseek 的 网址,查看一下它的后台, 找到 api 开放平台,充值完成以后,这里有一个 api keys, 点击它,然后点击新建 api keys, 输入一个名称,比如说我们就叫做这个 open crawl, 直接复制它,然后把它保存到一个地方,然后把你的 api key 添加到这里,保存这个文件就 ok 了,这是你会编辑代码的情况下, ok, 我 们还原回去。 那小伙伴说如果不会写代码,不会这么操作怎么办?非常简单,我们直接就在这个配置页面中来进行添加。 ok, 那 接下来咱们看一下怎么添加。首先咱们找到配置,找到 models, 然后这里 model parameter 模型提供商,点击它, 点击这里的 a, d, d entry 添加试卷,咱们就在这里进行添加,其实无外乎就是把刚才内容这里添加了一遍,咱们叫做 deep seek, 起个名字, 然后这里选择模型,选择模型的时候呢,这里没有 deep seek, 咱们可以选择这个 open ai competition, 因为什么呢?因为 deep seek 它是兼容 open i 的, 所以说你选择它是没有问题的。接下来这里填写 api key, 也就是我们刚才在 deep seek 中复制的那个 api key, 把它填到这里,好,下一项,这里咱们选择 api key 的 形式, 接下来这里有个 base ui 二, base ui 二,我们应该填写这个 base ui 二, 这样的话它就会请求 deep seek 的 这个 api, 然后继续 model list, 这里是额外的选项,咱们点击 a d, d, a, p i, 选择这里,我们还是选择 open a i, 然后继续 content window, 这是文本长度,对应的就是它,把它拷贝过来,然后点击 cost, 这些全部设置为零。 id, 这个 id 呢,咱们就叫做 deep seek chat input, 点击 a, d, d, 然后选择文本形式 t y 七 ok, 最大的 token 这里咱们设置为八幺九二 name, 这个 name 呢,咱们就叫做 deep seek chat。 好,全部填写完成以后,点击这里的 save, 现在呢就保存成功了。保存成功以后,咱们再回到聊天系统这里,那此时它的回复是,我是 deepsafe chat 模型, 这也说明咱们现在 deepsafe 配置成功了。如果你在配置过程中遇到任何问题,请在评论区告诉我,关注我,带你玩转小龙虾!


