火山 api 的收费标准是怎样的?
一块钱一秒钟字节跳动的 cds 二点零视频大模型终于公布了 a p i 底价,纯文字或图片生视频只要四十六元一百万 tokens, 折算下来,这差不多就是一块钱一秒。必须承认,在目前的画质和时空一致性表现下,这是一个极具杀伤力的价格点, 成行业级的效率神器。很多人惊呼,视频生产的白菜价来了,人人都是大导演的时代终于降临,但别急着沸腾,在真实的商业管线拍 plan 里,咱们得把这笔账算透。表面上看是一块钱一秒,但做 ai 视频最大的隐形黑洞是什么?是抽卡你脑子里的绝妙分镜。 ai 哪怕懂了百分之九十,剩下的百分之十也可能给你整出物理崩坏 人物脸部肌变。为了得到那完美的可以直接上用的一秒钟,你可能需要重跑五次、十次甚至二十次。这就叫花钱容易抽卡难。你以为付的是单行道的过路费,实际上是在玩一台吞食 tokens 的 老虎机。表面的低价一旦成,以高昂的费片率,真实的可用单秒成本会瞬间让你肉疼。看透了抽卡成本, 你就能明白这套 a p i 背后的真实受众。它根本不是给普通人准备的民用剪刀,而是一台名副其实的工业重型机械。对于大型广告公司和影视特效团队来说,它们原本的实拍和 c g i 渲染成本极高,所以完全有预算取海量抽卡。 这台重型机械对它们而言,确实能极大提升生产力,是降本增效的利器。所以总结一下 c 单词二点零的定价非常聪明,它在加速影视工业体系 的重构。但对于追求极致投入产出比的独立创作者,或者致力于低成本运作的自媒体人来说,这台重型机械和咱们的关系暂时不大,强行接入高能耗的 a p i 大 概率会被抽卡,成本直接拖垮。面对技术狂欢,捂紧钱包,看清投入产出比。已在下注,锐禾智库出品。

粉丝28获赞196
相关视频
 01:25查看AI文稿AI文稿
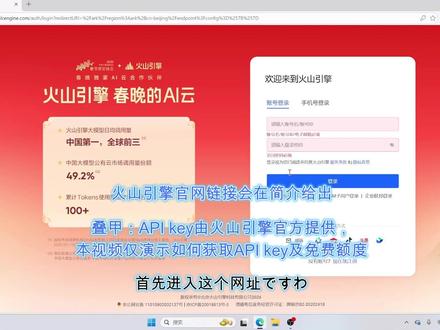
01:25查看AI文稿AI文稿首先进入这个王者的死亡,可以用抖音直接扫码登录,火山引擎的广告稍微有点多,叫 cosette's death one, 然后找到系统管理,点击右边的倒三角,找到 apik 咖喱的阿比特,然后点击创建 apik 名称随便取一个就可以,其余的配置不用动,直接点击创建,然后点击那一大串信号,旁边的小眼睛显示一大串乱码,之后点击旁边的小书,看到复制变为已复制就好了。 点击它的小到三九,然后找到并点击在线推理,点击创建,随你随意的等的,什么名称随便起一个就好,其他的设置不用动,然后随便选一个字节跳动或者深度求索的大语言模型。 切,这些都是由火山引擎官方免费赠送的,五十万的看字的,选好了就点击确定,稍微看一下火山引擎赠送的免费额度,够用很久了。 然后找到名称下面的 id, 找到后面的小书,点击发现复制变成已复制就好了。接下来的深度求索模型开通同理稍微演示一遍。
26見月 01:31查看AI文稿AI文稿
01:31查看AI文稿AI文稿大家好啊,现在市面上企业接入国内大模型 a p i 的 渠道特别多,那我今天就和大家汇报总结一下不同渠道的特点。首先呢是火山引擎的豆包系列和 deepsea 系列产品, 那他们的特点是限流的额度最高,基本上不会打满他们的 tpm 和 rpm。 原因是因为火山之前囤了很多英伟达的卡, 所以它背后的推理集群资源特别充足。那价格上呢,它的折扣力度相对比较小,如果不是特别大的客户的话,官方渠道最多是给七折,火山销售的业绩压力也很大,基本上每个人单单大模型都要背至少一千万的业绩。 其次呢是阿里云的千位系列和 deepsea 系列产品,那它的优点是单价最低,而且阿里云内部最近在打大模型战役, 千万系列模型的折扣根据用量呢,从五折到三折不等。但是缺点呢是背后的集群资源相对来说没有那么充足,如果遇到大客户重保的话,比如说 b 站跨年晚会,那资源就会更紧俏一些。 百度的大模型呢,目前基本上是卖三方的 deepsea 和其他模型为主,他们自己家的文心妍用的客户相对少一些,但是百度的折扣政策一般来说是还不错的。然后就是各种各样的大模型中转站了,比如说三零二点、 ai 云雾、 api 等等的平台, 这些平台的价格浮动会比较大,而且折扣普遍会比原厂高一些。但是有些厂商的模型可以做到特别低的价格,这种情况下呢,一般是做了逆向账号之类的方式,他们能够保证低价,但是不保证可用性。最后呢,如果您希望低价进入国内主流的大模型 api, 可以 后台私信我,我有靠谱的渠道。
400奥开花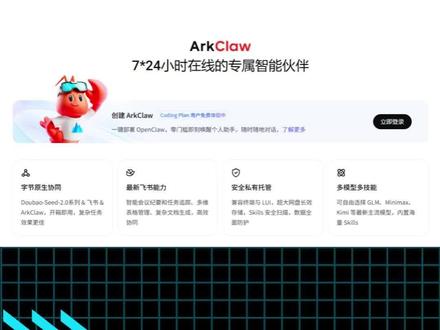 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿ai 编程与智能体赛道再出重磅产品,火山引擎 coding plan、 arc claw、 open claw 和豆包 app 常被混淆,本视频一次性讲清定位、用法与选型,零基础也能快速上手 四大产品。一句话分清, coding plan 是 大脑, open claw 是 本地身体, arc claw 是 云端身体,豆包是独立聊天工具。 coding plan 多模型 api 订阅智能体大脑新用户 light 版首月九点九元,适配主流编程与智能体工具 rcl 云端 sas 版 opencl 零部署网页,非书即用,七乘二十四小时后台运行。 opencl 开源本地智能体框架,隐私性强,但部署繁琐,关机即停止任务。 豆包 app 字节 c 端免费 ai 对 话工具,仅客户端可用,无 api 与火山额度不互通,而且豆包无 api, 无法用于智能体,仅能聊天付费组合可自动写代码部署项目数据爬取后台执行,算力专属更稳定。具体选型可以直接参考如下图片, 九点九元解锁顶级模型加七乘二十四云端智能体,低成本开启 ai 提效时代,学生开发者、职场人都适用。如您有云服务器及选型需求,欢迎留言,我们提供免费技术支持,记得点赞关注哦!
 04:29查看AI文稿AI文稿
04:29查看AI文稿AI文稿ai 大 模型呢,为什么要按照托肯收费?同样是一百万的托肯呢?为什么价格能差三十倍?等等,你可能会说啊,我们平时用的豆包啊,元宝啊,也没交过钱啊。没错,咱们平时用的网页版或者 app 呢,确实是免费的,那是大厂为了抢占市场给的福利。 但如果你是专业用,或者是使用最近爆火的小龙虾,那就必须通过 api 接口来调用大模型,按量付费,烧起钱来也是非常吓人的。那这些钱到底烧在哪了? 当模型正式发布后呢?它的使用成本其实由两个部分组成。第一部分呢,是固定成本,也就是模型上线前已经砸下去的钱, 包括前期的研发与训练投入,还有算力基础设施的建设,像建机房,采购显卡,配齐内存和硬盘。最近大家可能也注意到了,显卡和内存价格是一路上涨,很大程度就是因为 ai 需求暴增呢,把硬件价格也推高了。但这些成本呢,有个特点,它是沉没的, 在模型发布前呢,就已经支出了,随着用户越来越多,这部分费用呢,会被不断贪薄,贪到每一次调用上呢,它的占比会越来越低,甚至低到可以忽略不计。 那第二部分呢,是动态成本,也就是每一次调用模型实打实消耗掉的东西,每次计算都要消耗电力,还需要占用内存, 数据在传输过程中呢,也需要消耗网络流量。而所有这些消耗呢,都和 token 的 数量呢,直接相关。这里呢,快速同步一个概念。到底什么是 token? token 的 中文呢,可以翻译为词源,可以是一个字,一个词,一个分词,甚至一个字节。在大模型中呢,被表达为一组数字序列,用于计算下一个 token。 token 越多呢,模型的计算的时间就越长,占用的算力和资源呢,自然就越多。所以,按照 token 数量收费,本质上是一个多用多付少用呢少付的计费方式, 非常直观呢,也非常合理。这像什么呢?就像我们每个月交的水电气一样。从这个角度看呢, ai 正悄悄完成一个转变,它正从一项技术、产品呢,演变成一种基础服务。我们想要获得智力呢,就需要购买算力。 说不定以后每个月的水电账单旁边呢,就会多出一行 token 费用。那既然都是按 token 收费呢,为什么不同大模型的价格差这么多?比如你输入一百万 token, deepsea v 三的收费呢,是零点二八美元,而 g p t 模型呢,要二点五美元。如果是输出 token 呢,差距更夸张, deepsea 呢是零点四二美元, g p t 呢是十五美元,整整差了三十多倍。 同样都是 token 呢,为什么价格能差出这么多?其实 token 的 价格呢,主要是由两个因素决定的。第一,电力和人工成本不同。在美国、中国、中东等不同地区,电价运为成本,人力成本差异非常大,而这些呢,最终都会反映到价格里。第二呢,算法不同。 好的算法呢,就像一台省油的发动机,同样是跑一百公里啊,有的车呢,只需要三升油,而有的车呢,却要烧掉十升。大模型也是一样,算法呢,设计的越巧妙呢,达到同样质量的输出,消耗,算力呢就越少。所以优化算法是模型研发人员最最重要的任务之一。 算法越高效,成本就越低,价格自然就更有优势。在这方面呢,有很多创新的工作,比如 deepstack 引入的 mo 机制,想了解的朋友可以翻看我之前的这期视频。 那为什么输出托管的价格比输入托管贵这么多?原因呢?很简单,输入和输出呢,干的活不一样。输入的托管呢,是你的提示词, 模型可以一次性全部读取参与计算,多一个少一个呢,对显卡的负担影响呢,是有限的。但输出 token 就 不一样了,它是一个接一个逐自生成的,每生成一个 token 呢,模型都要重新算一次。输的 token 是 配角,输出的 token 呢是主角,所以给出的片酬呢,就不一样。 具体的技术原理呢,也可以看我这期视频,理解注意力机制对托根计算量的影响。这里呢,再顺便澄清一个常见的误解,托根的发明初衷呢,不是为了计费。 托根是纯粹的算法创新和工程发明,是为了把人类的语言翻译成机械能听懂的数学坐标。 只是后来大家发现呢,托管的数量呢,恰好决定了计算量,这才顺理成章的用它来计费,绝不是因为要收钱才搞出来这么个复杂的概念。当这里可以像自来水一样按量计费,一个属于算力文明的时代就真正开始了。
940陈兴AI 04:40
04:40 02:52
02:52 01:55查看AI文稿AI文稿
01:55查看AI文稿AI文稿家人们是不是都好奇, ai 大 魔行为啥非要按 token 收费?同样是一百万 token, 有 的便宜的巨贵,价格能差出三十倍。今天用大白话 一次性给你讲明白,咱们平时用豆包、元宝这些全都免费,这可不是 ai 不 花钱,而是大厂抢市场给的福利。但只要你是专业用户,或者用那些爆火的 ai 工具屌用 api 接口,那就得按量付费,烧钱速度真的超乎想象。那这些钱到底花在哪了? 其实模型成本就两部分,第一是固定成本,研发训练、买显卡进机房,这些钱前期就砸完了,用户越多越贪保,单次调用几乎可以忽略。第二是动态成本,这才是收费的关键。每调用一次 i 就 要耗电,占内存,耗网络流量,而所有消耗全都和托肯直接挂钩。很多人问, token 到底是啥?简单说就是 ai 处理员的最小单位,一个字一个词一个符号都算 token。 token 越多,模型算得越久,耗的算力就越多。所以按 token 收费,就跟咱们交水电费一模一样,多用多付,少用少付, 特别公平。哎,也从一个技术产品,慢慢变成了像水电一样的基础服务。那问题来了,同样一百万 toc, 为啥价格能差三十倍?核心就两个原因,一是地区成本不一样,不同国家的店家人工运维成本天差地别,最终都算在价格里。二是算法效率不同, 好算法就像省油的车,同样的效果,算力耗得更少,成本自然低。还有个细节,为啥输出 token 比输入贵这么多?因为输入是一次性读完,对显卡负担很小,但输出是一个字一个字逐次生成,每出一个 token 都要重新计算一遍,工作量完全不在一个级别, 价格自然更高。最后澄清一个误区, token 根本不是为了收费发明的,它是纯算法创新,只是刚好 token 数量决定了计算量,才被用来计费。等到算力真的像自来水一样随用随满按量计费,一个属于算力文明的新时代就真的来了。关注我,一起看清 ai 发展,跟上 ai 教播!
26瞪大眼看AI












