openclaw能够自动切模型吗
第一,不是所有模型都适合自动化,有的模型更适合聊天,有的模型更适合执行任务。第二,你以为模型能用不代表他能稳定,跑流程聊天正常不等于自动化正常。第三,做自动化不要随便切模型,模型一换,输出风格和执行逻辑都会变。 第四, kimi 这类模型更适合写内容,比如文案标题润色,但跑自动化不一定稳。第五,真正做流程写脚本连续执行,还是要选更偏执行类的模型。很多人不是不会用 open globe, 而是模型一开始就选错了。

粉丝56获赞339
相关视频
 01:51查看AI文稿AI文稿
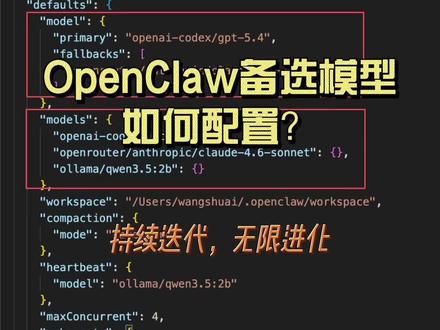
01:51查看AI文稿AI文稿codex gbt 五点四模型啊,终于还是扛不住了,今天呢,频繁报如下这个错误,这个应该是最近使用 codex 五点四这个模型的人太多了,服务器扛不住了, 因为通过订阅方式来使用这个模型确实是比较划算的。就如我一天的使用量来说,如果把 token 折合成 api 请求的价格的话,一天的费用可能就要十几美元了。 但这个错误比较奇怪的是,即便是你的 open clone 中配置了备用模型,它也没有进行自动的切换,这是什么原因呢?主要是因为这个错误呢,虽然是服务器错误,但是它是在任务处理过程中发生的错误, 也就是说,模型正在响应的过程中出现了这样的一个错误提示。这样的话呢, open clone 是 没办法进行模型的切换的, 如果是遇到模型限额或者是第一次请求的时候,就发生了服务器错误,这时候 openclock 还是可以自动去切换到备用模型的。如果还没有配置备用模型的用户呢,可以按照如下这种方式来进行备用模型的配置。 其实对于备用模型呢,我采用的是 open router。 使用 open router 的 好处是,第一,它在国内可以用,第二,它能够使用国际的顶尖模型,像 openai, gpt、 cloud code, gemini 都是可以通过 open router 统一的 api 可以 进行调用 的。还有一个原因是, open router 支持国内的双币信用卡进行支付,但国内银行发行的 visa 卡和万事达卡 是没办法支付 openai 和 arthurric 的 模型的。另外一个支持国内的双币信用卡的模型是界面奶,也就是你订阅了谷 歌的套餐的话,你是可以使用国内的信用卡直接进行美元结算的。好,今天就说这个问题,希望大家都能非常流畅地使用 opencloud, 关注我,持续迭代,无限进化。
 02:25查看AI文稿AI文稿
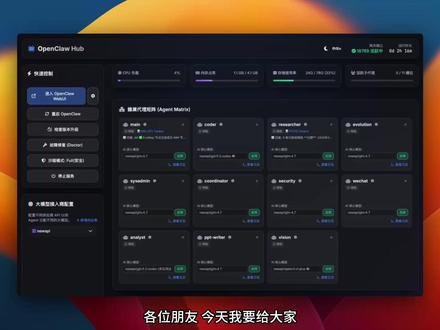
02:25查看AI文稿AI文稿各位朋友,今天我要给大家介绍一下我们龙虾的控制中枢纽,之前我给龙虾建了个办公室,现在给他整一个更专业的面板,支持多个模型供应商同时接入感切换模型。 咱们先看看这个面板,面板左边是快速控制龙虾的区域,这里有打开 ypu 的 按键,还有重启哦喷科尔的按钮、检查版本升级以及故障修复的功能。沙箱模式设置了三个等级,包括安全白名单和关闭选项, 最后还有停止服务的按钮。左边控制栏把原本需要在终端操作的采用指令都集成在一起了,上面能看到 cpu 负债、内存占用、存储使用率以及活跃的指令数, 这些都是龙虾运行时硬件的显示磁标。面板下面是整个龙虾的矩阵,要是龙虾的某一带泥被触发,对应的绿色灯就会亮起,等会由我给大家演示一下。 这个面板最大的便利之处在于可以自定义多个接入模型的供应商,你可以在这里填写 r、 p i 进行联通, 连通之后就能看到模型管理界面。在模型管理里,你可以添加自定义的模型,要是有新模型出现,直接搜索就行。 比如我随便添加一个挂孔模型,要是它是多模态模型,点击 v 键就能把模型添加进来, 添加成功后就能看到它已经在列表里了。这里还能无缝切换所有子弹里的模型, 同时可以查看子代理的设定下边界。点击应用之后,日子里面的默认模型就会改成 glm 的 四点七,这样一来就极大地方便了有多个模型供应商接入的情况, 能轻松解决每个子代理的模型切换问题。接下来我给大家测试一下,我们刚刚问了你现在是什么模式,大家可以看到这边的指示灯已经亮了,现在我们使用 ko 的 这个代理,看看他的灯会不会亮。大家看子代理正在运行,他换起了工具,模型也修改了。 现在抠的纸代理开始工作了,他把任务交给纸代理审查了。抠的纸代理主要负责代码相关工作,他更注重代码质量和非速度。以上就是这个控制中控面板的整体情况了,关注我还有更多好玩实用的 skills。
438大熊的AI朋友 04:48查看AI文稿AI文稿
04:48查看AI文稿AI文稿现在很多人用 open core 龙虾来提升工作效率,但是他用云端的大模型,大家又有所顾虑,数据不安全,依赖外网还会受限。想让龙虾直接调用你本地的大模型吗?今天这期手把手带你切换,安全又自由。 好的,真的是手把手教哈!现在我们在左下角搜索框上面输入 c、 m、 d 三个字母,在弹出来的命令提示框里面,我们首先要进行一个环境检测,那检测的内容无非就是两项,首先第一个是龙虾的环境是否是安装正确,另外一个是欧拉玛本地 你的开源大模型运行框架是否正常,有些人到这一步可能就开始挂了,哎,我这里怎么跟你不一样呢?这些都是基础环境的问题,点赞过千呢!我会为大家出一期教大家怎么零基础安装龙虾环境,并且配好本地大模型。 openclose 需要一个 api key 来识别,欧拉玛服务 这里我是使用了 linux 常用的,这种 spot 命令在 windows 环境下应该是识别不出来,所以待会大家看到一定会出一些问题啊, 那我们换另外一种方式就可以了。所以现在我们是通过 open call 来配置他的 a b i k, 这个 k 可以 是任意的支付船。我这里是设置成了欧拉玛 logo, 那 你要设置成 abc 也是可以的。 现在大家看到提示就代表着我们的龙虾已经连上了本地的大模型,当然现在还没结束啊。接下来我们要检查一下奥巴马服务是否已经开启,因为如果没有运行的话,是需要重新再启动的。这里输入的是本地奥巴马的服务地址, 可以看到我现在本地正在使用的一个大模型是千问三点五的九币,如果没有顺利出现模型铃声,那需要执行这条命令,手动启动本地大模型。那如果你的拉玛本来就是正常运行的,执行这条命令呢,就会 有错误,跟我一样,这是正常的,不用慌,现在我们干脆新开一个命令行窗口啊,我们先检查一下这个龙虾里面的模型有哪一些啊?用 openclose model list 的 这条命令就能够查询的到,第一个千万三幺四 b 的, 这个是之前我使用的本地模型。 第二个呢就是龙虾他默认使用的大模型啊,这是一个在线的大模型。然后呢,用现在大家看到的这条命令,我们就可以让龙虾去找到本地正在使用的大模型。 千万三点五九币。执行完了以后,龙虾会自动的重启,重启以后倒转到这个龙虾的 t u i 交互界面, t u i 交互界面是我们和龙虾进行交互的一个 窗口,我们可以交代他去做什么啊,他会在同样的地方给我们反馈。按 ctrl c 就 可以退出 d o i 界面。紧接着用 open claw on board 这条命令 来启动龙虾的出石化像道这一步用方向左右键就可以选择 yes or no, 这里我们选择的是 yes。 第二项默认选第一个就可以 回车跳转以后我们就可以在龙虾里面看到一个表,这个表里面就显示出了龙虾检测到的本地大模型。千万三点五九币。下一个配置我们可以选择一二两项中的一项,但是千万不要选择第三项 reset, 接下来模型供应商选择,我们直接跳转到最后一个,跳过就可以, 然后选择 o provider, 在 这个 default model 里面连接的欧拉玛模型应该会出现在最上面,并且作为末日模型选择这个就可以了。后面的设置大家只需要参考视频的配置就行。 最后重启龙虾我们就可以来测试是否切换成功。由于之前我已经使用了飞书来测试一下本地的 overclock 使用 大模型是否是正确的啊。大家可以看到当前我发送的消息是直接会发送到我本地的服务器的, 然后有本地的大模型去查找问题。好,我们看到了现在这个龙虾去查询了一下,回复我们当前模型是圈问三点五九币,这个是准确的啊,那基本上到现在 本地模型切换呢,就是完成了啊。最后给大家展示的是拉取本地模型常用的两条命令啊,第一个是拉取,第二个是查询啊,有需要的宝贝啊就可以去参考一下。
28许说AI 03:20查看AI文稿AI文稿
03:20查看AI文稿AI文稿如果你是做电商的,或者是做重复办公室工作的,一定要用这款 ai 智能体 open cloud, 就 也就是现在爆火的小龙虾,它和普通的大模型完全不同,它不只是聊天机器人,而是拥有电脑操作权限的一个执行者,就是直接给你结果的,不是只给你答案, 就他能二十四小时不眠不休的干活,就你只要下达指令,对吧?他就能打开浏览器,然后查竞品,做 excel, 整理数据啊,发邮件啊,抓取行业动态对吧?填财务报表,包括监控,竞能排名啊,全流程他全部自动执行, 哪怕就是一个模糊的指令,他也能就是自己拆解步骤,在各大搜索引擎找到解决方案,像专业员工一样规划路径。 更厉害的是啥呢?这不它能打通商业闭环,就咱们电商运营,对吧?要盯了一些,比如像排名啊,销量啊,控价,包括一些评价,对吧?它全部能自动收集汇总,成为你的真正的专属业务数字分身, 把咱们普通 ai 只能做一些交互的一些问答。而小龙虾呢,它能操控鼠标文件 api, 就 从给建议变成直接的干活,你包括像一些发帖、运营、售后,给你全部搞定,这你受得了吗? 我身边有个兄弟,他让公司的百分之八十员工转岗,就是一百个人,最后精简到二十个人,就我很庆幸这五年我没怎么招人。像客服啊,设计啊,运营岗,小龙虾他全部都能高效的替代。 就我现在做 ip, 包括群内一些问题的一些整理啊,包括视频的分发,然后包括一些话题的一些策划,对吧?全靠他解决。 淘宝一些后台运营啊,竞品一些数据统计,包括一些差评的监控,还有一些客服的售后投诉处理,他两个小时就能干完人工几天的活。现在创业,你千万不要招没有思考能力就只做重复工作的人,公司只需要思考者就是创造者, 按部就班的执行岗,未来肯定都会被 ai 所取代,管理纯粹浪费时间啊。你看一下沟通啊,激励啊,团建啊,其实都没必要用 ai 砍掉所有环节,一个人就能顶一只团队啊。就小龙虾最核心的优势 是打破平台的壁垒,然后抖音刷到爆款,它能自动给你拆解视频啊,核算利润啊,给出可执行的方案, 全程合规操作,而且它能规避平台的一些风险,知道吧?而且它还能跨平台跟你做私域个性化定制,就不断地投喂你的一些业务数据,就他能越来越懂你的业务。 终于迎来咱们真正的属于个人创业时代,就是你只需要掌握核心的能力啊,比如产品开发和一些产品痛点的挖掘,供应链的整合,剩下的执行全部交给 open cloud, 就 一个人能抵过去五百个人的效能, 就别再纠结就业失业率,企业先活下来才是最关键的,就没有人会主动革自己的命,对吧?但是咱们老板必须要主动拥抱这个工具, 这个时代竞争的核心绝对不是说人力了,是工具效率知道吧?不会用 ai 工具,你迟早会被市场淘汰,赶紧把小龙虾用起来,这才是电商和创业的终极破局之道。
62西哥说电商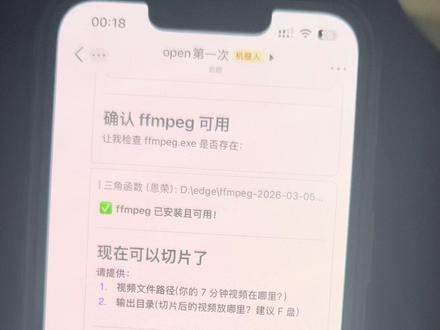 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿兄弟们, oppo 可乐可以做自动切片了,我刚刚尝尝试过,没任何问题。然后我这边让他给我做切片,然后前面的话他可以就是根据你的高光去,就是某一个高光点去内容高光点去进行切片。还有就是分段, 我这为了演示我就进行了一个按时间分段,比如说总共多少长,然后每段分给他分多长,然后我这边就说分成三段,然后每段是二分二十秒, 然后他让我给一个我视频的文件夹,就是我的视频文件夹放在哪的,然后我给他说,说了之后,但他这个有问题,不能出现 中文的文件夹,要随便弄一个英文的文件夹的名称,我就换成了英文的文件夹的名称,那就我这个文件就放在这个路径下面。 ok, 他 检查之后看这个文件就查找到了这个文件,然后大约多少多少兆, 那就把它分成,按我说的分成了三段,嗯,然后第一段、第二段、第三段,第一段我这个视频,我最开始我以为我的视频是我给他 弄错了,我总时长是多少,我以为是七,我给他说的是七分钟,结果原视频其实是五分钟三十二秒,让他这边也给你提示了,然后他给我切,切好就是呃,第一段呃两分半,第二段多少多到多少, 他这个种子时长就有一两分钟的事情,特别快,可能跟我这个文件比较,我这个视频总文件不大的原因,然后我就看我的电脑, 你看这个是我的原文件,他切好之后还会放在你这个原文件的下面,直接放在这下面,然后这是我命原文件吗?然后他自己给你命名片段一、片段二、片段三,然后我这个原文件大家可以看一下,是五分三十三秒吧?然后他这个第一段 两分二十秒,第二段也是两分二十秒,然后最后一段就到结尾,只有五十多秒,完全没任何问题。做欺骗的话。
 08:25查看AI文稿AI文稿
08:25查看AI文稿AI文稿今天跟大家讲一下这个在小龙虾里面,他这个的模型是怎么切换的,那我当前这个模型是 glm glm 五的模型,那如果说我要切换成呃 glm 四点六 v 的 这种模型,那该怎么切换呢?那切换里面我们有这么几种办法。 呃,先给大家说一下,一种我们先打开一个终端,在这个终端里面呢,我们输入这么一个命令,叫 openclock apple color, 然后呢 o d l 是 model 四,那设置 set j ai, 这是智普的那个前缀 j ai, 然后写杠 g l m 杠四点六 v, 那 这个就是切换成把把这个默认模型切换成 g m 四点六 v 的 版本,然后我们敲回车一下, 敲回车完之后呢,它这里呢会告诉我们模型已经设置成功了,然后呢我们给这个小龙虾呢的网关重启一下, 重启一下,这个可以重启一下, 那重启完之后呢,我们回到这边来,我们去刷新一下这个浏览器,你看它当前呢这一个会增加了,多增加了一个叫 g l m 四点六 v 的 这么一个呃默认模型, 那这个呢是我们切换模型的一种方法,当然大家这里看到的这是一种呃通过它这种内置的这种 p p n 的 一个命令, 呃可以设置的,那如果说呃这里面的那个模型默认的模型不在我们的小龙项链表里面,比如说像 deepsea 这这种模型,那要怎么设置呢?因为 deepsea 它是不能通过这种呃简单的命令去设置,它只能通过自定义的呃 模型去设置,那它这边呢有两种,一种两种命令,一种是直接通过什么通过这种呃非交互模式的这种条命令就可以执行,比如说像这个, 比如说像这种像这种一条式的命令,它这里是什么呢?它这条命令呢?它这个是什么?呃是像这个参数呢?是。呃 执行非交互模式,使用非交互模式。那第二个叫 modelcare 了,这一个呢?按本地模式配置网关,这个是按本地模式配置网关。那第三个是什么呢?第三个是使用自定义的 api t 接入,这个是使用指定 api t 接入的参数。那第四个参数呢?这个第四个就是给这个呢?呃提供商命名为叫 dbseek, 对 吧? 那第五个这个参数呢?这个是什么?这个说明让它兼容 openai 的 协议。那第六个呢?第六个是什么设置?呃, deepsafe 的 这个接口地址。那第七个是什么呢?第七个是,呃设置默认模行为 deepsafe chat。 那第八个这个呢?那就简单了。第八个这个就是填写我们在数据库上创建的这个 api t, 这个就是 api t 的 序号。那第九个这个是什么呢?确认接受非交互模式的风险提示,一定要加这句话,要不然如果说少了这个,它上面的这个就执行不成功,那我现在来给他执行看一下 啊,这里已经告诉我们。呃, justin 呢?已经备份了,然后呢?这里也执行完成了。那执行完成之后我们要记得什么?记得是,呃,我们要给它一个重启网关,网关重启一下。 网关重启完之后我们直接在这上面刷新一下就可以了啊,刷新一下它当前这个 deepsea 的 这个什么?呃,模型已经加载进来了,那我们可以直接什么跟这个呃, 我们直接问用 deepsea 看一下 它,这里会回复我们是由深度求索公司那一个研发的这个大模型, 那这个模式像这种方式呢?都是用一条的命令方式,那还有没有办法用?呃另外一种方法呢?就不用一条命令,我们用那种直接 on 使用的是什么? openclock on board 这条命令呢,就是类似于刚刚安装的时候我们去执行,那我接下来也给大家去演示一下这个呃,我们用这种命令,使用 openclock, 使用这样子的粗俗化的方式去呃配置我们的 deepseek 的 这个呃模型。那首先呢,我现在呢先给它做一个啊,先把这个呢做一下来还原。其实所有我们所有配置的这个 wincore 的 这些配置参数都在这个文件里面,我先把这个删掉, 删掉完之后复原这个文件, 我重命名一下,我复原这个文件之后呢,我们我在这里呢先给他什么,先把它网关 重启一下啊,重启完之后我们确认一下是不是恢复到我之前的呃初设设置,我刷新一下啊, 这已经呃复原到最早的之前的设置了。好了,我现在呢给大家去演示一下这个什么呃通过这个叫做 open, 通过这条命令怎么去呃配置我们的 deepcom 这个模型,那我们执行这条命令叫 opencloud on board 的 这个命令, 那这个执行完之后呢?他就是我们,就像我们第一次安装的时候会告诉我们这个呃一些风险信息吧。完了我们给他确认一下这个选择 yes 啊,这个还是继续选择 quickstar, 那 这里呢告诉我们什么配置,是否继承原来的值,那我们选择第一个就可以了。 use assign 就是 继承原来的值, 那关键就是这些位这个位置了,这个位置这里的模型驱动商呢?有这么多个,那我们要选择哪一个呢?我们选择的是这个叫做 custom, 因为这里没有 dsp 的 那个默认的夫商,所以说我们这里要选择的是自定义的 夫商,那我们选择这个回车,那回车完之后,关键这个位置的 api, 那 个 api base url, 这一个要改成什么?就是我们的模型的接口地址, 这里的接口地址呢?要改成我们的这个叫 deepsafe v 一 的这个默认模型,那我们啊路径改一下,黏贴进来,就一定要改成这什么 a p i deepsafe, 点 com 点 v e 这个 u r 的 地址呢?是兼容 openai 的 接口模式。那我们回车,那这里呢?我们是什么?呃,黏贴那个 api key 的 值,那我们把 api key 的 值黏贴进来, 然后呢这个位置这里有三个参数,是选哪一个呢?我们要选择的是什么?叫做呃,说明兼容和 ai 模式协议,然后我们这里选择第一个兼容 open ai 协议, 那这里呢? model id 又是什么呢? model id 呢?这里呢是设置默认模型,也就是这个提供了哪些的默认模型?然后我们选择呃,输入 d e e p s e k 默认模型,然后显示 a t, 其实就是这一个, 其实就是呃这个位置接口文件里面的这个,其实就是这个, 其实就是这个。这个 deepsafe 提供的这一个叫做什么?推理模型跟聊天模型,然后我现在先选择的是聊天模型,叫 deepsafe chat 的 这个模型。好了,那我们给它 model id 选择了 deepsafe chat, 那这里的是什么呢?那 point id 又是干什么的呢?那 point id 它其实是是模型的一个小名,那我们这里的小名呢?也可以叫让它默认叫 custom api, 这个默认的也行,那我们选择用默认值吧。 那第二个是这个是别名,那这里的别名呢?我们也可以不填,没关系,我们直接敲回车也不填。然后第三个,这什么使用的一些我们交互的方式吧,那这个我们直接跳过啊,这里呢也是直接跳过, 然后这个是配置技能,那技能像我们之前也配置过了,我们可以选择 low, 也可以选择 yes 或者点 yes, 在 这里面跳过也行。我们先跳过,那这后面都是跳过了啊,像谷歌的,国外的这些 a p i 我 们都跳过,目前都没有申请 好了,那这个是不可使的,这个也跳过,那现在最后步呢?这个是什么呢?我们再重启一下就可以了。重启网关, 重启完关之后我们选择的是什么?还是继续选择 open 的 web ui 的 这个方式,然后呢它这里呢?它这里呢?你看它这种方式也可以把这个 deepseek 的 这个模型给它配置进来,那这个就是我们呃默认的这种, 呃自定义的方式,把 deepseek 的 一些那个 a p i 呢?呃配置到小龙虾里面去好了。呃,这个今天呢,呃,跟大家讲的这个第三方的 a p i 呢?呃就到这里了。
272拉灯 00:41查看AI文稿AI文稿
00:41查看AI文稿AI文稿你可以为我做些什么?我可以陪你聊天,解答问题。作为智能硬件助手,我还能控制树莓派操作灯光、电机或者读取传感器数据。你想体验一下吗? 拍一张照,看看我现在在哪里。你现在在书房里,站在深色木质书架前,书架上摆满了各类书籍,上层有蓝色套书和那个青绿色山形摆件,中层能看到熊猫玩偶。 你的粉色手机也在画面里。前景还有块灰底粉字的布料。需要我帮你找什么书吗?
21星幻Annie 05:06查看AI文稿AI文稿
05:06查看AI文稿AI文稿一个视频告诉你龙虾欧根库奥背后的原理到底是什么。如果你拿大模型给他发一个消息,那么他就会根据你的消息给你一个回复,这样你就得到了一个最原始的 ai 聊天工具。然而,大模型只能根据你发送信息进行单次的回应。你们聊了这一句,忘了上一句,压根无法进行有效的对话。 于是你灵机一动,每次发送新消息时,都会把旧的聊天记录打包一起发过去。有了上下文,模型终于有了记忆,你们终于可以愉快的聊天了。可你很快又发现了一个问题,虽然此时的模型有了记忆,但仍然没有改变你一句我一句的聊天形式。只要你不主动给他发消息,他就原地挂机,不会理你。 可你不可能一天二十四小时守在电脑前给他写提示词。这样一来,他就只能帮你做一些琐碎的小事,无法自动帮你完成一些长期复杂的任务。当然,这也难不倒聪明的你,既然你没办法盯着他干活,那么设置一段程序自动盯着不就好了吗? 于是你动手写了一段简单循环脚本,每次大模型输出后,都让他自己判断任务是否完成。如果判断任务还未完成,那么脚本就自动把刚才的对话记录重新喂给他,让他继续思考。直到模型认为自己已经大功告成,在输出中调用 finish 结束函数,整个循环才停下了。 当然, ai 偶尔也会脑子抽筋,陷入死循环或者疯狂报错。于是你又顺手给脚本加了最大循环次数限制,脚本终于稳定了下来。 这样你就得到了一个简易的 agent, 它可以在你离开电脑时也能独立的思考工作。可新的问题又随之出现,模型累积的上下文越来越长,眼看着就要达到模型的输入上限了, 如果继续循环下去,模型就再也无法正常工作了。你思来想去,突然想到大模型可以提炼长文本的信息,生成简洁的摘药。 于是你在脚本中加入了一个新的机制,如果当前的对话长度逼近红线,就立刻触发压缩机制,通过提示此要求,模型将对话框中几千字废话浓缩成高度精炼的摘药。 这下终于不用担心模型被超长的上下文撑爆了。不过对话框中的上下文虽然被凝练了,但凝练前的那几千字原声记录你也不舍得删,万一里面有啥重要信息以后用的到呢? 于是你让脚本新建了一个 markdown 格式的绘画保存文件,将这段超长对话一字不落的写入该文件,并保存在绘画文件架。 现在对话框只剩下被凝练后的摘药了, ai 又可以愉快的干活了。但你认为这些摘药也是极其重要的信息。你又按照日期新建了一个 markdown 日制文件,将每次凝练后的摘药也存入了进去。 从此以后,你每天都会按日期新建一个日记文件,专门存储明面后的摘药。如此一来,脚本每次调用模型时,只需要将最近两天的日记文件加入提示词,就能立刻唤醒他的近期记忆了。 就这样,模型拥有了自己的短期记忆。可是光有两天的短期记忆还不够,你想要给它完整一生。于是你又新建了一个叫 memory 点 m d 的 长期记忆文件,将摘录中的那些长期结晶,如用户的私人偏好、项目、重大决策给抽取出来,写入其中, ai 就 拥有了它的长期记忆。 你的脚本只需要带着近期日记和长期记忆去唤醒 ai, 它就能自然流畅的进行长期任务了。而你所保存的完整绘画记录也不会闲着,如果需要 ai 回忆某个久远的细节,它就能去绘画文件夹里一字不落的搜索出来。 有了这套丝滑的记忆系统,你再也不用担心 ai 失忆了,它们就保存在你的硬盘里,直到永远。现在 ai 的 记忆问题解决了,但还有一个问题让你头疼,模型只会输出文本,你该如何让它操控电脑干活呢?一开始你想的简单粗暴, 计算机的底层不过是一些代码命令行,那么直接丢给 ai 一个最高权限的射奥终端,让他直接生成底层的命令,不就能操控电脑了吗?可真正尝试后才发现,这是一场惨不忍睹的灾难。目前的 ai 并不可靠,一个小小的幻觉都会让你的电脑崩溃, 无奈你只好放弃这条危险的底层直连。你想到之前工作时写过一些简单的功能性程序,比如发送邮件、抓取网页的脚本,这些脚本由确定的程序编写,只需要输入相应的参数,就能自动执行并返回确定的结果。于是你灵机一动,将这些写好的程序整合到了你的平台中。 现在你不需要 ai 直接敲代码,只需要让它根据不同的任务脚本生成对应格式的 jc 参数,就能通过这些脚本间接操控你的电脑,不管是浏览网页、整理表格,还是直接读取屏幕、操控鼠标, ai 都能轻松完成。同时,你也给这些脚本起了一个响亮的名字, skill! 一个极其清亮、即插即用的技能拓展框架。未来你还打算将平台全面开源,这样全世界的开发者都能编辑上传各种各样的 skill, 你 的 ai 也将会越来越强。 最后,为了能够让 ai 随时随地的在电脑上接受你的指令,你将平台的网关打通,让模型通过 api 接口与主流的聊天工具对接。 现在,你只需要掏出手机,就能像和朋友聊天一样,在手机上和你的 ai 助手沟通了。恭喜你发明了开源的自主 ai 智能体 openclo, 你 知道他可能还不够完美,但你不会放弃优化,相信终有一天你能做出像人类一样工作的 ai 助手。
4729交叉科学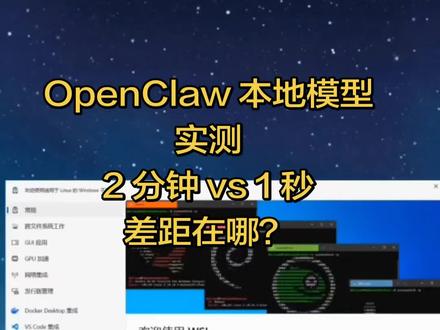 01:27查看AI文稿AI文稿
01:27查看AI文稿AI文稿家人们谁懂啊?我的 openclaw 龙虾终于装好了,本以为能本地爽玩 ai, 结果测个最简单的,你好 直接给我整破房了。先上结论,配置没问题,模型没问题,但 openclaw 调用本地模型,性能损耗严重到离谱。我的环境,本地模型 q n 三比零点六 b i 五八二五零 u 十六 g 内存 wsl 二五零 u 十六 g 内存 wsl 网关。 两组数据一对比,血压直接上来了,直连欧莱玛跑模型,八点五秒就完整恢复模型本身完全正常。 同样的模型走 openclaw 网关整整一分五十五秒才返回结束,性能慢了十三倍,我都能泡好一碗面再回来。等回复了,我换了零点五 b 到三 b, 各种模型只要过 openclaw 就 卡成老年机。问题根本不在模型,就在 openclaw 网关层, 流势响应有巨大缓冲延迟。别怀疑自己,你没配错,是他在卡你 buff。 听我一句劝, 别死磕了,直接切云端模型,阿里云千问 plus 响应稳定一到两秒, a p i m 要配好一行命令搞定,瞬间从折磨模式回到科技本该有的流畅。本地模型优化, 后面有空再公关,现在先让自己用的舒服。如果你也在折腾 openclaw 本地模型,别内耗,不是你的问题,是网关的问题。最后补一句, deepsea 都在劝我别折腾了,听劝。解决方案很简单,上云端模型体验直接起飞,关注我,带你少踩这些技术大坑!
64阿铭小程序 01:21查看AI文稿AI文稿
01:21查看AI文稿AI文稿今天给大家分享一个项目,是香港中文大学发的一个 c l i anything, 专门是给这种 open curl, 把所有的这种软件,所有的这种开源的项目, 只要是你有源码的,它都可以给你转化成 open curl 可以 调用的 api 形式,它什么都不需要安装,只需要一个命令,它会自动把你的这个软件程序打包成 open curl 可以 支持的 api。 本质上这个项目的话,它是一个 cloud code 的 一个插件,其实它是拿 cloud code 做了一些配置和工作流或者子智能体,然后经过这种 编排去把你的一些项目或者仓库代码,仓库直接转化成几个 open curl, 它们可以支持的一些工作流,它会把这种工作流也进行合成集成, 使用起来也是非常简单。你只要有 cloud code, 然后安装这个插件,然后一个命令,把你的这个仓库或者你的这种源代码地址直接告诉他,然后他自己会去扫描源代码,进行设计,进行实现,进行这种文档,最后进行发布。 这种就非常适合你自己有一些源码呀,有这种 github 的 项目,你觉得还不错的,你就可以把它拿下来,做成这种 api 的 形式,可以让 open curl 可以 直接使用。 这个项目还是非常有实用性,但是它是没有达到,比如说你去操控你的软件啊,这些它是达不到的,你必须要有具体的这种代码,原代码你不能是操控微信啊,这种是达不到的。
196jesee-自然智群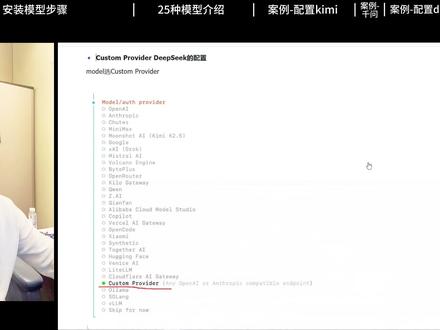 11:04查看AI文稿AI文稿
11:04查看AI文稿AI文稿啊,大家好,呃,今天溪水哥给大家做一期关于 open color 的 这个 model 模型的配置,今天给大家讲的全面一点儿把。呃, 给大家分享一下我们怎么安装 model, 然后 openclaw 的 内置的这些 model 是 什么样子,有哪几种类型,然后做一个介绍,然后再给大家针对每一种类型做一个案例的分享,会举一个具体的例子给大家讲一下怎么配。 最后就是如果你的本地呃 openclaw 有 好多个模型的话,你怎么去切换它?对,就是如何切换 model。 好,我们开始第一部分,呃安装 model 的 这种大模型,呃,现在是一共是五种类型啊,就是 open clone 支持的五种类型有五种,一种是 api key 的 这种方式就是需要你把 api key 拿过来, 呃,这里面像 kimi 啊, mini max 啊, open ai 啊 clone, 然后还有智普都是属于需要你把 api key 拿过来 对进行配置,然后还有呃像 on os 的 这种方式,就是它会跳转到官网,然后呃你登录完了之后自动跳,自动授权,授权对,像谦问式这种, 呃,然后再就是自建的这种,就是你需要配置那个他的那个服务器地址,然后和 key, 这个就是 deepsea, 属于这一类的。最后就是还有那种聚合的, 就是,呃只需要配 key 就 行了,像这个 open root 这种,呃,它就属于聚合的。 还有一种就是欧曼,欧曼大家应该听得非常多,是本地模型,它的模型呢?那个点就是需要呃本地安装,然后端过,通过端口访问,然后它最大的就是呃它因为本地跑嘛,最大特点就是托肯是免费的 啊。对,一共是这五种类型,然后我们怎么配置呢?嗯,配置大概分为七步就完成了, 很快。对,如果你会的话,就是安装起来会非常快。我们依然首先还是要打开我们的这个命令窗口,如果我们的同学是 mac, 那 你就需要打开终端就行了。如果你是 windows 的 话,你就需要打开那个 pro shell。 如果你在 windows 是 装了 wsl 的 话,那你就打开 wsl 里面,点开之后你会有那个 u 帮图,你打开 u 帮图,如果是 linux 的 话,那就直接是命令窗口了就 ok 了。然后第一步呢,我们就需要这个啊,输入 open curl config, 也就是配置文件, 就是配置配置文件,然后选完了之后,你就选你的那个。呃,就是你在 git 会在哪个地方跑,然后你选 local 就 行了。 然后配置你要配置什么?它里面有好多种,就是你要配置你的 channels 呀,有配置你的这个 web tools 呀,对吧?然后还有配置 model 的 呀,对不对?你选个你的配配置就行了,就是选你的那个类型, 然后最后就是,呃,然后你就就选择选了 model, 之后你就选这个 这个谁,谁给我打电话,然后你就选那个千问,比如说啊,我是配的千问啊,你选模,选模型的话,你就选哪家模型就行。 然后选完模型了之后,这个模型有可能是让你 apikey 的, 有可能是让你弄那个 onos 的。 还有一种就是自建, 对,如果是 api key 的 话,你后面就粘贴 api key, 如果是 onos 的 话,你就需要登录去授权。如果是自建的话,你就需要这个啊,把你那个服务器的地址和 key 都要配置好。对,配置完了之后就输入这个,就是网关,重启 open clock, get away, restart 就 行了。 这就是啊,分为这几步啊,后面等会给大家讲案例啊,具体讲案例,然后这里给大家接下来讲一下内置的 model provider 介绍,也像我们 open core 到底支持哪一些? 呃,这个大模型,呃,你看这个第一类就是国际主流的啊,就是这几家,这几家我们好像都玩不了,玩起来比较费劲,要转要转好几站,对吧? 对,像这个 openai 的 呀,美国的,对吧?然后这个啊, cloud 呀,对不对?谷歌的是不是这个 gork 的, 对吧?还有这个法国的,这几个呢,都是需要填 apikey 啊,谷歌呢,是需要除了 apikey 还可以用 onos 的 方式去验证的, 然后国内的,这是国内的,国内的大家应该配的比较多了,对吧?这个像 mini max 啊,对不对?然后月之一面呢?然后千问呢?百度的呀,对吧?然后阿里巴巴的 这个字节,它有海外和海内的,然后小米还有智普。对,这几家呢,都是支持。呃,支持这个 apikey 的 只有这个。呃,谦问是需要 onos, minimax 也支持,两个都支持验证的方式。 然后这种呢是大家用的少,我们就不过不做过多的去介绍,但是它的那个默认配置里面是支持这些的。这个里面有两个得重点说一下, 一个是欧莱玛,欧莱玛是可以啊,他这个工具可以把一些开源的模型直接拽下来,拽在你本机本机上,这种最大的特点,刚才说了,就是什么呀? 最大的特点其实就是啊,再打一遍就是免费。对,但是啊,对你的本机的机器要求就比较高了,像你内存呢?显卡啊,对吧?然后这个呢,就是开源的,这个就配置,一般的人是整不起来的。 然后这个呢,呃,也是用的比较,这种方式用的比较多,像 deepsea 就 需要通过这种方式去配置用户自定义的方式, 这是我们整个呃整个 model 的 前面的介绍, 然后好,现在给大家分享几个案例,每一种类型的案例。第一种就是我们分享一下 kimi, kimi 怎么配置 kimi, 这种就是 api key 的 这种方式去配置啊,我们依然还是打开这个,呃,就是这怎么多了一个 依然打开这个,呃,命令窗口输入 openclo, 对 吧? openclo config 这儿输完了之后,它就会呃让你选择你是在本地 get 会是在本地跑还是远程跑,所以我们这个地方就选本地 local 就 行了。 然后选完这个之后呢,它就会跳到这个界面,让你呃你要配置什么,这里面可以配置你的什么工作空间呀,对吧?然后你的 web 的 工具啊,是吧?然后你的网关呐, get away, 对 不对?然后你的 channels 就是 你的这个渠道配飞书 还是配微信,对不对?这就是技能 skills, 它也是官方的技能,对吧?这个就是配置,这里面我们选 model 就 行了,选模型,对,模型选完了之后呢,我们就呃到了这个界面,这个界面呢就是大家看看你自己想用的是哪一个?我这给大家呃 分享的是 kimi 的 啊,我们选 kimi, 选完之后它就会让你输入,呃,是是 api key 了,这个地方因为我用的是 kimi code, 所以 我就选这个, 这个选完了之后呢,就让我粘贴这个啊 api key 了,我就这个地方,这个 api key 就是 在你的那个 kimi 的 后台去建,建完了 key 之后,然后直接粘贴过来就可以了。 这一步是这样的啊,然后这选这个回车完了之后就这个把 key 粘贴进来,这样就配好了。 这个是 api key 的 方式配置,然后再给大家分享。接下来分享的是谦问的这种 onos 的 配置,这个跟上面的这个 kimi 的 配置完全不一样的,我们在这个 model 这个地方选择的是 这个工业上模型。是,呃,是 q 问,这就是千问的,千问想完了之后,它就会自动跳转到千问的这个网站上,然后你就需要登录,登录完之后授权点确认就可以了,确认完了之后呢?呃,就配置完了。 然后还有一种就是 deep seek, deep seek 是 需要用这种方式,也叫 coster profiler 这种方式去配置的。 我们在这个 model 这个这个地方选的呀,就得选这个 custom provider, 选这种方式就是自定义方式,这种方式呢,你选完之后它就会让你配置 api base url, 对, 这个地方就是要配它, 如果是你是 kimi 的 啊,那个 deepsea 的 话,就来配这个,然后输完这个之后,他会让你粘贴你的 key, 然后你把你的那个 key 粘贴过来,输入你的 key。 对, 输入 key 完了之后,他会他会问你这个选项怎么选,你选第一个就行了。对, 这是关于这个的这个啊,然后再就是,呃,你就输入你的啊那个 model id, 这个 model id 我 们输 deep seek 杠 chat。 呃,为什么输这个呢?等会儿我告诉大家 为什么是输这个,然后一会后面都回车就行了,这样的话这种就是呃 deep seek 的 这种配置, custom 这种配置就这么来配的, 然后关于刚才那个 base u l, 还有那个那几个东西该怎么配呢?是这样的,你打开这个 api 的 官网啊,打开谁有电话给我 api 的 官网,然后打开 api key 开放平台,开放平台之后呢?呃,你就会,就会看到呃,那个文档里面就会看到这个内容,这里面会看到这个就是 base 与 r, 这个就是 model id, 一个 deep seek 杠 chat, 还有 deep seek 这一个,然后这个是关于呃那个啊 custom 这种配置,然后最后装了这么多模型的话,我们该怎么去切换模型呢?我现在又装了千问的,又装了 kimi 的, 呃,切换的方式是这样,你在命令窗口里面输入 openclaw models list, 你 就把你的所有的 models 全部列出来,列出完了之后你看它就这么显示,显示完了之后你再配置用这个命令就行了。 openclaw models set, set, 这后面是个名称啊,这个名称就是你的这一列,一定是按照这一列来啊,你输少了,输多了都是不行的,所以你看我这个地方是百炼千问斜杠, 对吧?这个千问三点五杠 plus, 就是 这个,这个就是你切换你的这个模型的命令。对,呃,这就是今天给大家做的分享,内容有点长,嗯,大家看完了,我们相互学习。好,谢谢大家。
23AI溪水哥 05:03查看AI文稿AI文稿
05:03查看AI文稿AI文稿哈喽,大家好,这期视频主要讲一下阿里百炼模型的自动切换的问题,之前有网友说百炼模型比较容易用光,单个,单个切换非常麻烦,那么这个视频里面我们介绍了怎么去把百炼模型多个模型同时写固配置文件,这样避免出现每次应用中出现切换的问题。这是我们 现在之前的 opencore 的 配置文件。我们首先看到在 opencore 的 配置文件里面有一个 models, 这个就是选择到模型,然后这里面有一个模式是 merge, 这个 merge 就 表示是合并啊,可以合并的意思 or widers, 就是 指现在我们这个模型的提供商,我们看到现在这个提供商这里有一个 blend 摆列啊,摆列就摆列,然后这里有一个摆列,下面有一个括号啊,它就对应着 这一些内容啊,它对应的这些内容,那么我们其实只要再加一个其他的 这样的一个模型的名称就可以了,那么这个模型的名称呢?我们还可以,就是还是用白练啊。嗯,其实很简单,就是这里,从这里我们把它 copy 一下。 copy 到哪呢? copy 到这个地方啊,这个你要对齐啊,就是这里有一个方括号,对吧?我们看到这里这里模式这里有一个方括号, mod 这有个方括号,那么这个方括号中间都是,中间都是。 呃,这个括号呢?都是一对一的啊,这个方括号是跟这个匹配的,是吧?那么这个方括号呢?它就应该跟这个匹配,也就是这个方括号是到了这个模式这里 mod 这里是吧? 那么这个大括号它就应该是对的方括号的下面这个括号 这个对齐了吧,那么这个摆链的这个第一个模型就应该是对到这个位置上的大括号,好在这个大括号这个位置我们加一个 模型就可以了,用一个小的分号,然后再往下加这个模型,那么我们先加的时候呢,我们可以把它先拷贝出来, 然后黏贴啊,这个里面就是我们这里是百炼,是吧第一个模型,那么我们在这里可以写百炼二第二个模型, 然后这个东西是不变的啊,这个 key 也不变的,这两个都不变,然后我们要做的就是把这个 id 给换掉就可以了,那么我们可以去查百炼的 这个模型的本身的这样的一个列表啊, 我们看到百炼模型本身的列表啊,我们找一个, 比如说天文 plus, 我 现在这个模型它是有的,我就把这个改成天文 plus 就 可以了, 改成天文 plus 就 可以了啊,然后,嗯, 我们在这个 agent 下面啊这里,然后大家要注意我这个写法啊,一定要写成数组的形式。我们前面我做实验的时候呢,有两个问题,第一个就是 four four bags, 忘了加 s, 还有一个就是没有写成数组的形式,所以大家一定要参照我的数组形式的写法仔细看一下, 然后我们用同样的方法再加一个哈,这样就有三个不同的模型类别在上面,后面根据你的需要可以加任何任意多个, ok, 这期视频就到这里啊,如果大家觉得有帮助,别忘了点赞加关注支持,感谢大家,我们下次见 哦,等等我们可能再验证一下,然后,嗯,我们打开 open core 的 对话窗,我们再验证一下,确认没问题啊,应该是没问题的。好,我们下次见。
76技术分享的巴顿 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿如何用 opencore 实现浏览器自动化任务?这期视频告诉你是怎么实现的,然后文墨会提供到手直用的 skills, 现在正式进入正题。首先分享我之前春节的经验, 当时我直接让 ai 去做浏览器自动化任务,它会优先选择固定脚本,固定点击网页按钮的形式, 这样做出来的不知道为什么总是无法稳定成功。然后现在我成功了,我现在用的是大模型,理解网页再定位和点击元素的形式,这样就非常稳定。这里面用的是 blos user 工具, 只需要你填入你的大模型 a p i t, 就 可以用自然语言安排浏览器净化任务了。这工具大模型之前为什么没有找到和使用我不知道,但是我可以告诉大家我是怎么搞找到这个工具的。首先是问 ai 有 哪些工具,然后去问 ai 怎么用, 然后我就了解到了有一个工具,它需要使用到大模型 a p i t。 之前春节用过的方案都没有这个要求,那我就让人家去用和测试这个,呃,工具 就测试成功,那我就用 ai 优化为 skills 了。这个 skills 我 现在就分享给大家,这个链接我不确定可以在哪里分享给大家,大家可以私聊我获取或者评论区获取使用方法。我在视频里面就告诉大家,你下载完这个 skills 之后,你就告诉 ai 编程工具或者各种 code, 你告诉他我用的是叉叉大模型 a p i t。 是 s k 叉叉叉叉叉。使用这个 skills 帮我执行一下软式进化任务,这个描述可以参考一下, 请帮我完成以下浏览器是动画操作,第一部分是登录,打开某某网址,等网页完全加载之后,查找并点击某个按钮,在里面输入账号密码,登录完之后你就可以让他点击其他东西,这个就是一个范例,大家可以参考一下。好,那我这次的分享就很简短,就是这些。
 00:30查看AI文稿AI文稿
00:30查看AI文稿AI文稿晚安, openclo 的 朋友,你们是不是都被一个问题搞疯了, token 太烧钱了,同样的请求,问一次扣一次,跑自动化越跑越亏。纯纯给平台打工,开研一个 ai 路由缓存服务,同样请求只扣一次 token, 后面直接走缓存, 不花钱秒响应,还能自动切换本地模型和云端接口,搭配 openclo 用,成本直接砍半,速度还更快。
1155senwen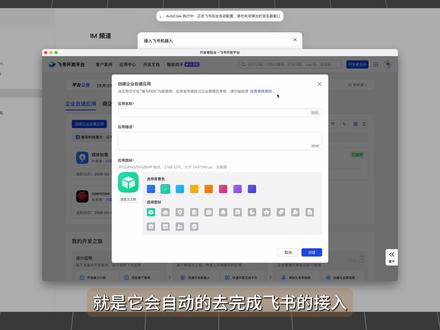 07:08查看AI文稿AI文稿
07:08查看AI文稿AI文稿你有没有发现啊, open cloud 正在推动大模型呢,去重塑它的能力体系,养成龙虾以后啊,你就会发现,龙虾的任务呢,和普通的聊天任务完全是两回事, 龙虾呢更需要的是工具调用,只能遵循定时和持续的长任务等方面的能力。那就在这两天啊,智府发布了 gm turbo, 那我呢也第一时间呢把它配到了我的 openclaw 当中,让它呢去调度我的龙虾团队。那今天呢,我来分享一下我是怎么用 openclaw 来管理我的自媒体一人公司的,也看一下这样母特布的效果。首先呢,我还是想先说一下 openclaw 的 安装,虽然呢,我之前已经出过安装部署的视频, 但是还是有很多朋友搞不定,其实我也很能理解,所以呢,这一次啊,我就找了一个完全的零基础一键安装的版本澳龙,也就是啊, auto cloud, 这个呢是智普最新发布的龙虾的版本。 那安装的过程啊,这一次真的没有什么可说的了,完全的不用动脑。那完成以后呢,除了自动的装好 open cloud, 澳龙呢还会自带很多实用的 skill, 非常的方便啊。还有一点非常让我喜欢的呢,就是他会自动的去完成飞速的接入,那就是点一下,然后呢,他会自动的去打开一个网页,一步一步的去完成配置,那这个才是真正的吃自己的狗粮,自我的去驱动。 那接下来呢,我就来说一下啊,我的 openclaw 龙虾团队的情况。那作为一个自媒体的博主啊,那我的团队呢,会有一个总管,一个自媒体的助理,一个财务的助理和一个开发的助理,那每一个呢都是独立的 agent 那 但是啊,为什么要用多 agent 呢? 如果是简单使用的话,其实一个 agent 就 足够了,但是啊,如果是深度使用,当你将过多的内容啊放到一个 agent 当中,就会污染它的上下文,人设呢,也很难去调教记忆呢,也不容易啊,去产生有效的进化。 分开独立的 agent 以后呢,那每一个 agent 都有独立的 workspace 啊, agent 点 md 啊, skill 等等这些内容,从而呢就能够实现啊任务的专业化分工和并行的执行, 而且呢还可以节省 token。 后面的势力啊,我也会去介绍。那接下来呢,我也带你去走一下如何去配置这样的龙虾团队,那配置龙虾最好的方法呢,当然是让他自己去搞定。那首先呢,我先去见一个自媒体的助理,一开始呢需求啊,并没有想太细,我就直接呢让他去帮我做一下设计。 这里能看到啊,这两姆特布的表现呢很不错,他会基于现有的情况呢去设计出一个 agent 的 内容,他的理解和规划呢,我觉得在这里啊都是九十分以上的水平。除了这个以外呢,我还要再去创建一个财务的助理和一个开发的助理,那加上最主要的 manager 呢,就会有四个 agent 的 团队。 那团队准备好了以后啊,我们就来测试一下 gm turbo 的 指挥龙虾水平。首先呢我们先在财务助理这里去热一个身啊,我让他呢给我建一个多余表格来去记录发票,那后面我再发给他发票的时候啊,要用本地欧拉玛里运行的模型啊去做 ocr。 然后呢记录发票的内容,还要上传附件, 那表格呢,过一会就能搞好,我这里啊就发一张发票,其实呢,这个过程还是蛮复杂的,为了节省 token 呢,我还要求了用本地的工具去调用,还有飞书的操作。那最后呢,还有上传附件 opencloud 呢,会自己啊去把相关的信息做录入。 那在最后上传发票的这个过程当中啊,其实一开始呢,这昂姆特吧没有成功,但是呢他不断的去尝试不同的方法来解决这个问题。那这点呢,我觉得就非常不错啊,他没有像很多其他模型一样,要求我去完成授权,然后再去重新执行这个任务,而是呢自己啊一点一点的去把这个问题搞定。 那再来看一下自媒体的工作台啊,那我先让他呢去定时的采集一些信息,每小时啊抓取全网的资讯,并且总结五条发给我,再把内容呢写到飞出的文档里,那这个可以说是博主的必备品, 那同时呢要处理搜索文档工具,还有定时执行的情况,那这种情况下呢, gm 特步的表现是不错的,那这个是收集的结果,这里呢已经稳定的运行了一段时间,一直呢没有出现忘记之前操作的内容的情况。那除了资讯以外呢,还有一点必须要做的,就是收集各种视频的灵感, 那我需要每天早上收集 youtube 上五个 ai 方向的热门视频,并且呢去汇总信息。那之后呢,就是使用我自己的一个 skill 去把视频下载下来。 那这里呢,我想分享一个小 tips 啊,因为很多人呢都可能会卡在下载这个环节上,那怎么办呢?那我总是说啊, github 是 一个大宝藏,那咱们呢就去 github 上想想办法, 比如呢,我看到一个项目,他已经实现了视频获取的能力,而且呢我也亲测,还挺好用的,那我呢,就直接把这个项目的链接甩给 opencloud, 让他呢把这个项目作为工具,然后呢自己去分析一下项目应该怎么去使用。那这里可以看到啊, gm 特本呢,会有一个超长的一个尝试过程, 他会研究和测试项目,然后呢就真的一次性的完成了在本地的部署和使用,然后呢,我再让他把这个提炼成一个 skill, 那 以后呢,下载的问题啊,就可以解决了。 那最后呢,也不能漏掉开发的助理啊,那前面啊,我之前一直让 openclaw 去整理每天的日报,那我呢再让开发助理啊去做一个统一的一个门户网站,把每天的日报信息呢统一的做汇总的展示,这样呢就方便我来查看。 那在日报里面呢,我要求他每天去检查所有助理的情况,并且呢用本地运行的一个 gm 四点七的 flash 的 模型啊去做分析, 然后呢更新网站的内容,那这个就是 gm turbo 最终开发的一个成果,在开发方面啊,我觉得效果也是非常不错的,审美和功能啊也都很在线。 那这里还有一个小 tips 啊,就是关于前面说的省钱的。那在 opencloud 当中啊,其实对于一些精度要求不高的任务,是可以单独创建 a 帧的,来使用本地的模型去运行的,或者呢使用云上加本地的组合,那就像我的话呢,比如像 ocr 图像的简单理解,还有日制的分析整理 这些呢,我都专门会去派给本地的模型之行。那有机会的话呢,我都专门会去派给本地的模型之行,怎么样啊?我的龙虾小队各司其职的状态还不错吧。 那我呢也来汇总一下试用 gm turbo 的 一个感受。首先呢, openclaw 最大的场景呢就是工具的调用,其实呢,大部分的时候呢,都在处理各种不同的工具和 skill 的 调用。那这个过程当中啊,能够感受到 gm turbo 的 表现呢,是比较稳定的,比如像前面发票的上传过程当中啊,它会不断的去尝试, 直到能够成功为止。还有呢,像那个 getaham 项目的研究,这个过程呢真的非常的长,中间呢也没有出现过像丢失上下文和不知道应该如何处理的情况。所以呢,能够看出来啊,在适配 openclaw 的 场景方面呢,这样姆特布的效果是很好的。那另外一个我使用起来感受最明显的呢,就是速度快, 大家都知道啊, openclaw 发的 tokyo 呢会比较多,所以呢,在用很多模型的时候都会有卡顿的感觉。目前呢, jimmy turbo 在 使用的时候呢,我能明显的感觉到流畅度的提升,希望呢,这个速度啊,也可以一直保持住。那我觉得呢,在未来一段时间呢,针对龙虾模型的竞争啊,会越来越激烈, 那你觉得 jimmy turbo 在 龙虾当中的表现应该打几分呢?那好了,这里是 it 咖啡馆,我们下次再见。
2108IT咖啡馆


