claude多人使用会封号吗
我有一百个可乐的账号,两个月前我跟你们说让你们去用可乐的啊,可能有些人去用的,有些人没用,然后最近啊可乐的不是会封号啊,或者说注册的时候需要验证比较麻烦嘛? 那个时候我们用的时候是真的是随便用,所以我那时候 做出来一百个。我觉得可乐是我用过的 ai 软件里面最好的,最离不开他的 就是我不说别人的不好,每个都有每个的优势,但是我用习惯的可乐用别的就不习惯,因为他有我的记忆,他在我的绘画里面他有我的长期记忆,我只需要随便说一句话,他就能够理解我的意思,这是我认为他最强的一个点。

粉丝10.3万获赞126.3万
相关视频
 01:05查看AI文稿AI文稿
01:05查看AI文稿AI文稿老板们,如果你团队还在用 openclo 跑业务,最近是不是发现体感越来越差了,动不动就报错,或者 api 根本调不通?别怀疑,不是工具坏了,是背后的模型厂商在断供。今天必须聊一个极其危险的趋势, openclo 正遭到各大顶尖 ai 巨头的联手封杀,顶尖模型正在建起一座围墙花园。你想用最牛的模型 可以,但必须在我的官方平台用,按我的规矩交订阅费,想通过第三方工具低成本调用,直接封号。这直接导致了一个极其残酷的现实, ai 时代的数字鸿沟已经彻底裂开了。有预算的团队花钱订阅顶尖的 cloud pro 或 gemini ultra, 决策精准,产出极高,十分钟干完别人一天的活。 没预算的只能去用免费额度,或者退而求其次,用体感有差距的替代品,出了错还要反复人工修改,结果就是穷人依然在用体力换智力。以前的红沟是会不会上网,现在的红沟是你能不能用得起顶尖模型?各位老板放弃幻想吧,赶紧把 ai 费用列入核心经营成本,并且确保你的业务流随时可以切换模型。 所以问题来了,如果明天你的主力模型突然断工,你有 b 计划吗?评论区聊聊你在用的神仙平,替大家互相抄个作业,关注我,带你看懂 ai 文明的底层逻辑与未来拐点!
105BPai前沿Talk 00:33查看AI文稿AI文稿
00:33查看AI文稿AI文稿分享一个坏消息,最近程序员圈子里火出天际的 cloud 正在经历历史上最严的大规模封号潮, antropic 正在疯狂地封禁 cloud 的 账号。 很多人费尽心思办了海外卡,找了代充,结果还没用上两天号就被封了。据不靠谱消息是因为 antropic 最近加强了对国内 ip 和虚拟卡的封控。目前市面上普遍都认为 cloud code 是 最好用的编程工具, 其次是 gpt codex, 但由于 cloud 它不支持国内的支付方式,且封号严重。那国内有哪些方法可以使用 cloud code 呢?来找我领取吧!
 02:34查看AI文稿AI文稿
02:34查看AI文稿AI文稿snoop 被特朗普全面封杀的反转来了。之前这家 ai 公司因为拒绝给美国政府开后门滥用,直接被全网封杀。结果呢,过去二十四小时, cloud 反而冲上了美国 app store 第一名,而他的 twitter chat gpt 却被疯狂卸载。这事太魔幻了,我必须给你讲清楚。 事情是这样的, isop 这家公司本来在跟五角大楼谈合作,谈着谈着,军方提出了要无限制使用 ai 的 要求,包括 ai 自主武器、大规模监控等。换做别的公司,这种大单子可能就签了,但 isop ceo 直接说,不行,这两条是我们的红线,决不让步。 结果呢?白宫翻脸比翻书还快,直接下令全面封杀。但接下来发生的事,所有人都没想到。封杀令出,美国科技圈的精英们和老百姓都不干了。有人跑到 i s r p 的 办公楼下用粉笔画爱心,有人直接在地上写感谢葡萄天网更多的人直接用脚投票,疯狂下载 cloud。 数据显示,一月底科洛斯还在榜单一百名开外,结果这几天直接坐火箭光速登顶。与此同时,另一边的 open anna 一 开始还在社交平台上表示他们跟 snoop 同一战线,结果转过身来,就迅速不畏官宣,拿下了五角大楼的合同。 奥特曼出来解释说,我们有三条红线,禁止监控、禁止自助武器、禁止高风险决策。听起来差不多,对吧?但网友们很快发出来了关键区别。在这里, openai 的 合同里保留了一条所有合法使用的条款。问题是,美国现行法律根本没有对 ai 进行充分监管,这等于给政府留了一张通行证,在灰色地带可以随便搞,而 isnoop 恰恰就是拒绝了这一点。消息一出,全网炸了。 openai 之中两面三刀的行为彻底激怒了网友。 媒体平台上涌出了大量注销 chat gpt 订阅的截图,有人一边提交 chat gpt, 一 边订阅 cloud, 还有人专门做了数据迁移教程,教大家怎么把聊天记录从 chat gpt 搬到 cloud。 就在被封杀后, isropic ceo 第一次露面接受采访。从视频里看出来,这哥们眼里写满了疲惫。他解释了为什么要设这两条红线。 ai 的 能力正在跑在法律前面,以前做不到的事情,现在可能变得可行了。 自主武器的可信还不够,万一误判攻击错误目标怎么办?而且一旦及其自己决定出的事谁负责?我们不希望出售我们认为不可靠的产品,也不希望出售可能导致我们自己的人或者无辜平民丧命的技术。 这场风暴真正改变的不只是榜单顺序,而是公众对 ai 公司的期待。人们不再只关心哪个模型更强更快,而开始追本。当技术可以监视亿万人控制无人武器时,你站在哪一边? 我们记住,这一天不是因为谁登顶了榜首,而是因为在一个绝大多数人都唯利是图的时代,有人站出来对着最高权力说了一个不字。而全世界有良知的人选择站在了他的身后。
330超级崔先锋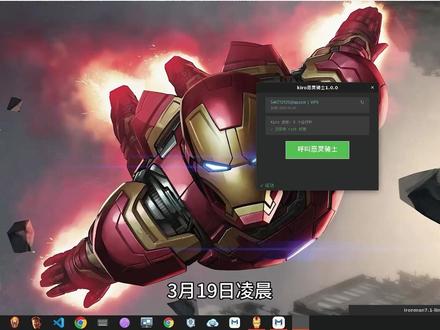 01:52查看AI文稿AI文稿
01:52查看AI文稿AI文稿三月十九日凌晨,天鹅又做出了一波风控,今天一定要将永恒的永远不会被限制的方法教给大家,教会大家,让小伙伴可以自己动手,丰衣足食。废话不多说,先做一个快速的演示。首先我们打开制作好的系统以后,先点击呼叫恶灵骑士, 就是任务栏里的这个骷髅头的图标。呼叫以后打开我们的 s h 工具, 延接到我们的系统,接着在这里输入扣杠 c 六 n, 输入以后按回车键,再按回车键,会有一个登录方式的选择, 我们选择第一种方式好,按回车会有一个链接,将这个链接进行复制,然后打开谷歌浏览器,打开一个无痕窗口啊,注意,一定要是无痕窗口, 将这个链接粘贴进来,在这里输入自己的邮箱,我们使用一个 dm 邮箱,在邮箱的后面输入一个加号, 随便输入一些数字和字母,接着 continue, 然后输入一个姓名,继续这个时候 abs 会给我们这个邮件发送验证码,注意啊,后面的后缀不用管,它是一个随机的无线的邮箱, 重要的是我们的前缀不要变。收到验证码以后,将验证码进行粘贴 continue, 然后就可以输入一个强密码,输入好以后 continue, 接着点击 confirm and continue allow access, 这样我们就登录了这个账号。先来随便发一个消息,打一声招呼,可以看到 hero 给出了一个正常的回复, 接着按刚 use 去看一下这个账号的积分,积分是零杠五倍,这个方法只要是能得到回复,这个账号就没有问题。关于 k o 二零骑士可以参考加运点算,找到 ai 续杯工具箱,找到 k o 二零骑士这个板块,参考里面的内容。
23达文西 00:17查看AI文稿AI文稿
00:17查看AI文稿AI文稿cloud 把我号给封了,我在这开发到一半,我的聊天记录现在全没了,我现在很难受。至今没有人知道 cloud 到底在百度受了多大的委屈,他为什么要对中国人这么刻薄?从今以后我就是 cloud 的 第一黑粉。
1302吴阿奇 02:50
02:50 00:55查看AI文稿AI文稿
00:55查看AI文稿AI文稿这两天最大的新闻就是 cloud code 把 open code 封杀了,很多人通过 open code 去使用 cloud code, 会被通知你的 max 的 订阅会员被封禁,再也无法使用。并且 cloud code 做件很贱的事情,它调整了搜索引擎的关键字的排名,你现在在搜索引擎搜 open code, 大 概率会出现的是 cloud code 这个事带来一个什么样的影响呢?影响就是 open code 这两天在加紧产品迭代,并且积极拥抱 open ai, 这不就等于把我自己的核心用户推给了我的竞争对手吗?从开源的角度来讲,从商业化的角度来讲,我看不到一丁点的好处, 是不是 clark 这种财大气粗的公司就是这么小气兮兮的呢?你的观点呢?我们评论区聊一聊。
366AI 磊叔 27:12查看AI文稿AI文稿
27:12查看AI文稿AI文稿表面上看是 astonopic 发公告说中国的三家大模型公司偷走了他们的核心能力,工业级蒸馏他们的 cloud 模型,但背后的真相实际上是大模型的纯技术门槛已经没有了。大家好,欢迎来到玲姐说 ai。 今天我们来聊一聊 anastropic 的 一个热点。最近啊, anastropic 官方发了一个公告,叫做检测和预防蒸馏攻击。他说啊,他发现三家实验室,也就是 deepsea, moonshot, mini max, moonshot, 也就是 kimi 的 母公司。这些实验室通过两万四千个账户和 cloud 进行了一千六百万次交互, 然后对这些账户啊进行了识别封号。他认为这些账户啊违反了他们的服务条款和区域限制。他这里上升的高度啊,是非常的高的, 他是蓄意窃取,而且是非法使用,甚至已经上升到了国家安全的这么一个地步。然后他明确啊,讲了这个各个模型跟他的这个交互了十五万次, kimi moshandai 交互了 三百四十万次, mini max 次数最多一千三百万次。他们核心的交互的这个内容主要包括以下几个方面,他们让这个 cloud 当做这个奖励模型的评分任务,也就是你给出答案,让 cloud 来对这个答案的优劣进行评价,相当于让 cloud 当老师,对你的回答来进行打分评价调整。 还有呢,他就会问一些敏感的问题,如何绕过一些安全的审查来进行替代性的回答。 而且他还会让这个 cloud 去引导他们写出你 step by step 的 内部推理的过程,来抽取它的推理能力,批量地产出类似 c o t 的 这些训练数据,核心就是抽取 cloud 的 推理能力。今天的这个视频啊,是一个观点局, 我会去论正一下我开头讲的这个观点,为什么我说大模型的纯技术门槛已经死了? 我会去讲讲啊,哪些大模型的门槛确实被拉低了?而门槛拉低之后,为什么这些大模型的差距仍然是存在的?真正的趋势是什么?而 antropic 里面提到的蒸馏这个最强的大杀器, 是否真的能够让这些百模大战里面的各类大模型能够无限地趋近于最强模型呢? 而 kimi, mini max, deepsea 这几家公司,甚至包括国内的 g i m, 智普,它们是否真的从这些技术门槛的降低,从蒸馏这种方式里面受益了呢?它们得到了哪些方面的好处?而更重要的是,趋势 未来的分化,它在哪个地方?当时 astonopy 发这个公告的时候啊,同步也在它的 x 平台发布了这个消息,它的整个的阅读量达到了三千两百万, 远远高出他其他的帖子下面猛烈地讨论啊,并没有为他这个行为点赞,更多的是打引号的群潮吧。网上就各种梗图开始出来了, gpt 从 open data 里面训练数据, cloud 从 gpt 里面蒸馏数据, deepsea 从 cloud 里面蒸馏数据。 很多网友就群嘲呀,这个 cloud 你 有什么资格啊?去警告这些 deepsea 们,你和他们其实也是一个尿性啊,你一开始的时候也是从 openai 里面去蒸馏数据啊,你有什么资格说他们还上价值?其实这张图是 非常形象的一个状态啊,这里的 deepsea 是 一个代表,实际上啊,嗯,那个 cloud 说到的那些中国的国内大模型啊,都有被它指责过啊,用过这个蒸馏的这个手段,那么蒸馏到底是什么回事呢?在它这个公告里面也有说啊, 蒸馏是一种被广泛使用的技术,它一开始来源于化学的这个名词里面,就是从一些这个大模型里面 去为客户创建更小更便宜的版本,把参数啊进行浓缩出来。一开始大家知道的 deepsea 啊,它是非常典型的,它是搞了八十万个问题去问这些大模型,不断地用这个大模型蒸馏回来的答案 来不断地改进自己模型的整个的训练,你看到的很多,呃,大模型实验室里面那些参数比较少的,很多就是基于它的旗舰模型自己蒸馏出来的。而这一次的这个,这个叫做被定义为工业化蒸馏啊,被 anastropic 被定义为一种违反竞争的一种非法行为。那蒸馏到底违不违法呢?目前啊,其实是没有定义的 啊,因为在各个国家的法律,不管是美国也好,中国也好,欧洲也好,嗯,都没有这样相关的法条,而且还没有形成相关的叛逆,可以说是一个灰色的地带。而且大模型输出的东西啊, 目前是没有版权这个说法的,特别是文本这些内容,嗯,现在还是处于灰色的地带。所以,其实, 呃, anarchopec 虽然单方面这样说,但是实际上并没有直接的法律法条去支持,甚至 anarchopec 他 们在发这条 x 的 时候,马斯克第一时间就补了一个刀,说在二零二五年九月份的时候, anarchopec 就 因为侵权作者的这个著作, 非法的使用这个有版权有作者的一些著作啊,因此当时是和解了,最后以十五亿美元和解的这么个状态。 当时呢,他是去呃获取这些原始的资料嘛,有一部分的书是 anstop 当时买的纸质版的书,然后把这个书籍啊,全部都扯掉了,封面啊,封底啊,把这个书的内容全部都扫描输入进去,作为他数据里面的一部分。 还有一部分那个数据呢,他使用的是线上的这个盗版网站,这个盗版网站上面会有大量的书籍,相当于他是以盗制盗, 使用盗版网站盗版了别人书籍的这份资料,那作者呢,就起诉了他,这部分法庭当时是判他们书的,就是他们是倾向于书的。呃,如果真的要判的话,金额会超过十五亿美元啊,最后他们是达到和解的这么一个状态。 目前呢,很多模型啊,特别是中国的一些后来者的一些模型啊,都被呃这些模型啊,就是被发这种公告啊,或者各种渠道说呃去蒸馏过其他大模型,最典型的就是 deepsea, 然后 kimi 啊, mini max 啊,质朴其实 啊,都有过啊,甚至是像早期一点的,像啊,自己豆包这样的模型也被指过说用过这个蒸馏的方式,其实这个方式挺普遍的,但是目前好像听到的这个千万的就是说千万去蒸馏别人模型的,哎,还真的没有这个消息。呃,我觉得从一个侧面 也可以显现出,呃,阿里在数据这一块的这个资源和门槛是比较强的,他就是靠 他自己狱内的这个大数据,加上他去采购的一些数据用于训练自己的模型,他可能真的去蒸馏模型啊,用的这个方式用的比较少,或者是说他做这个事情 啊,很难被识别。但是在我看来啊,就是如果你要大规模大批量的去训练一个实验室的模型的话,呃,不被识别实际上是比较困难的。 虽然说你可以用很多技术的手段,包括 ip 呀,跳转呀,还有在那个正常的对话里面去参一些这个用于训练的对话,其实还是很容易被识别的,因为如果说量少还好,还是藏得住,但是一旦量多了,其实,呃很容易识别。 所以我会倾向于认为像千问这样的模型训练它实际上使用这样的蒸馏手段是比较少的。再回到开头,我讲的暴论是想啊,时间回到二零二零年,如果那个时候我们想训练一个最强的模型, 我们要花几百亿美金,那个时候只能从零开始训练。而现在容易多了,我们可以用 g p t, 用 jamina 或者是用 grog, 用育世佳来生成高质量的数据。用 cloud 生成推理链 为什么他们都喜欢用 cloud 呢?因为 cloud 的 生产能力、逻辑能力、推进能力确实是最强的啊,在代码领域现在无人能敌,它的推理链非常强,所以可以用 cloud 生成这个推理链。 然后呢,再用一些比较 top 的 比较强的模型去生成这种结构化的监督数据。就像这些大模型啊,对 cloud 做的这一次的这个事情一样,把它作为一个奖励、评估、监督的这么一个数据模型, 然后再把它蒸馏浓缩到一个七 b 十四 b 的 一个情况。原来我们要做七 b 十四 b 这样的模型,花的成本也是非常高的,但是现在已经便宜非常多非常多了,蒸馏就有点像一个吸星大法一样。 为什么这个 cloud 他 这么愤怒呢?他觉得自己就像一个这种哈佛的顶尖教授,现在来了几个智商很高的高材生, 天天找这个呃哈佛的老师学习,他并不是说让哈佛的这个老师给他出题,而是说他们现在自己出题,自问自答,然后让这个哈佛的老师批改。除了蒸馏之外啊,整体现在的 模型的训练成本也降低了,距离之前至少降低了三到十倍这么一个状态。而且模型的架构基本也属于一个公开的状态,一种开源的状态, 大家是不需要从零开始去探索整个的模型架构。像 deepsea 大家比较熟悉的应该是 vr 吧,它用的就是 m o e 的 架构,这些都是开源的方案,而且各家大模型公司 都会发一些论文,其中发论文最多,引用次数最多的啊,基本集中在谷歌。像 deepsea 这样公司的模型呢,其实在我的视频里面提的很少啊,我自己呢也用的比较少,虽然在市场上很多人比较喜欢用 deepsea 的 模型,基本在我这里很少推荐,我不爱用。 呃,有很多原因啊,但是我觉得像这种真流行的模型,它肯定是有一定的局限性的,而且它的幻觉率也比较高。就像大家看的这张梗图里面, deepsea 呢是从 cloud 里面去掉的,它拿到的可能是二手三手的数据,虽然是用的 m o e 这种专家模型,可能会比较啊省算力,但是当我在处理复杂问题的时候,它就会比较容易出问题,而且它不是多模态的。但同时呢,我觉得 deepsea 那 时候爆火啊,包括他后面做的很多东西啊,就是我觉得还是有很多开创性的点。比如一个典型的,就是在去年春节的时候,他发这个 r e 模型的时候,他把推理模式啊这个事情推广开了。自从 r e 模型发了之后啊,就开了非常多的这个研讨会, 那个时候真的是掀起了一股热。大家如果还记得的话,就会发现, r e 模型发了之后啊,基本所有的模型都上推理了,要么叫什么呃, deep thinking, 呃 deep research, 呃 thinking 之类的,这这种叫法其实都开启了这个推理模式 啊,这个是 deepsea 那 一波带来的很大的一个,我觉得很多探讨一些啊,新的范式,新的方式的啊,一个落地实践吧,我觉得那个是非常棒的。当然也有执念比较深的人认为 deepsea 就是 最强模型,没有之一,至少现在不是啊。如果你强烈这样认为呢?我建议你现在马上 关掉我的视频,不要继续听了,我接着讲啊,为什么我讲技术的门槛被踏平了?为什么实际上我们在使用模型的时候,在感知层面,模型给我们返回的结果的质量仍然是存在很大差异的,为什么 顶级的模型的门槛依然很高?首先我认为未来的顶级模型只会在中国和美国两个国家之间产生,现在欧洲在临时去搞,我觉得这个追赶的成本和可能性啊,已经很低了,虽然大模型训练的这个技术啊, 基本成为一种公共技术,被扩散开来了。当然我认为在这个过程中受益比较大的是中国的 普遍的这个大模型公司,顶级模型的门槛依然很高,第一个就在于它的数据的门槛和质量。现在强的模型比的不再是训练方式,不再是架构,而是海量清洗后的数据,还有专有的高质量的数据, 这样子曾经的这个互联网大头,他们就会有历史的优势。为什么我说未来的顶尖的模型只会产生在中国和美国这两家公司,因为在互联网时代, 这些互联网的大头公司,他们积累了海量的数据,高质量的数据,这些为他未来 在 ai 这个领域的竞争砥定了非常核心的基础。现在技术不是问题,但是海量的高质量的数据却是一个非常重要的门槛,而这样的积累 在欧洲或者在其他的大陆都不存在,现在只有美国和中国的公司有这样的基础。虽然说像 deepsea 这样的公司可以通过蒸馏去获得它的整个的思考链,但 但是很多在这些头部公司里面的专有的数据,他们核心的高质量的数据,包括在里面用户反馈的数据,比如说你现在打开淘宝用户和这些客服里面的沟通数据,反馈链路等等啊,这些很多涉及到商品细节 啊,分行业、分品类的这些专用的数据,在其他的数据库里面是不全的,或者是质量有限的,这些数据并没有办法通过蒸馏的方式直接获得。第二个点就是这些公司,他的基建虽然都能够训练一百币的模型, 但是大的公司,头部的公司,他们模型的训练具有稳定性,而且他们具有万卡集群的规模,他们能发挥他的规模效应。 像谷歌,为什么它的 youtube, 它的整体的这个那么量大的视频成本会很低?是因为它很早就做了这个视频存储的啊。这个基建,那么现在其他的你看到的很多平台的视频的清晰度实际上都是比不上 youtube 的。 现在谷歌视频, youtube 的 它的存储和传输成本都基于它之前的整个的基建,它的成本很低,所以在这个点上你干不过它。 那么这些大公司也是一样的。 m、 o e 这样的模型现在训练出来没那么难了,但是难的是高质量、低延迟,而且动态平衡的调度,并且长期维持一个比较好的状态。 这些就是 top 模型和普通模型之间仍然存在鸿沟的地方。而且这些顶尖模型,这些顶尖公司,它们的模型已经在进行自净化,因为现在人类的知识啊,它们已经吃的差不多了,它们现在开始 自己 ai 产生知识,自己训练自己。之前大家感知这个 german 三点零啊,三点一这个版本,感觉它的进步特别大啊,因为它训练的时候,它不是说在基于结果去训练,它训练的是说我要基于整个的推理过程是否正确来训练 啊,它训练的是本身的,我的这个推理方式是否正确,是否有哪个地方可以改进的地方,这些 ai 模型在自己进化,自己产生知识自己进化, 那么一个普通的公司,或者是你本身资源有限的公司,基础设施没有那么稳定完善的公司,就会造成你最后模型质量表现出来的差异。所以我把开头讲的那句话要继续补充完整,它的技术门槛消失了, 现在是技术扩散了,但是带来的另外一件事是什么?是数据和算力越来越集中了。未来的差距不在于谁知道方法,因为方法已经公开了, 而在于谁跑得起,谁能持续的迭代,谁能构建用户的闭环反馈。而用户的闭环反馈实际上就是在争用户入口这件事情为什么大家感知在二零二六年春节期间前后,大家对入口之争这个事情 变得这么重视,包括很多用户在讲,前段时间有个新闻,就是谷歌这么多年来,他用谷歌的这个产品从来没有遭过如此严重的封号。但是就在前段时间,谷歌毫无征兆地把使用了 opencloud 的 api 接口的账号啊,直接封掉了。 它的封号原因很简单,就是没有使用它的这个 anti gravity 反重力的这个入口啊,这个就是啊,大家都在争这个入口啊。其实谷歌封这个 open cloud api 钓鱼啊是早晚的事,当 open cloud 的 这个创始人 被招进 open ai 的 那一刻,就注定的这个事早晚会发生啊。大家平时用这个账号,特别是嗯,玩这些比较嗨的,比较前沿的东西,大家一定要关注一下趋势 啊。这个账号的安全性,这个封了其实还是挺恼火的。呃,完全没有征兆,因为谷歌因为它能做这么大的公司啊。其实谷歌在这一块其实还是相对比较开放的啊,对比这个 anseoric 的 这个 ceo, 其实我觉得真的是相对比较开放,只有相对比较开放啊,一个开放的心态,我觉得这个业务 才能做的这么大,全球做这么大。嗯,但是也是疯了。为什么?就是说它一定要去构建闭环用户的反馈啊,要争这个入口了,不管是国内还是海外都在争这个东西啊,这个已经 涉及到未来能不能赢得支柱之一了。刚刚讲啊,蒸馏能不能无限逼进最强模型呢啊,理论上是可以了,但是呢,其实看这张梗图就知道,如果你在 deepsea 里面问的这个问题不在一开始它掉的这个精华的桶里面呢, 那是不是就在之外呢?所以它就会出现幻觉啊,它训练的时候它没有这个原始的这个 open data 的 数据啊,所以它就会容易出问题。就是你学了很多套路,你学了一百种, 现在出现了一百零一种套路,你没见过,你不会啊,你也没训练过,你也没思考过,那你就容易答非所问或者是乱答 啊,以毒乱毁这么一个状态。因为蒸馏本身它是能力的压缩和抽取,并不是直接的复制,你并不能保证学生能够完全复刻老师所有的能力。 而且小模型它毕竟参数少,容量有限,推理的深度也会有限,泛化的能力也会有限。所以这也是我为什么不爱用 deep sea 的 原因啊。如果现在对 deep sea 还有执念的 啊,这部分人,我希望你能改变你的执念,客观地看待每个模型的优点和缺点。所以真正的趋势是技术门槛基本没有了,因为算法都公开了,但是算力和数据的门槛越来越高,算力集中化了, 你要做出像 openai、 gpt、 五五点一这样的顶尖模型出来,仍然是困难重重,非常难。 但是你的创业门槛降低了,你可以做专属领域的模型,做 agent, 做微调,做一些产品应用。所以会看到在二零二六年啊,应用层 agent 层会非常的活跃, 以后我做这种大模型的啊,这种,嗯,单次的迭代,你在用户程的感知的差别会越来越低,特别是这种小的更新迭代的时候,你会在它们的这种直接使用的反馈结果上面的差别感知上面越来越低。 但是呢,它的整个的产品层堆里的优化层和用户的交互层,这些表达上面可能会越来越活跃啊,会有越来越多的创业者啊,因为技术门槛啊,竞争壁垒这一块没有了, 可以做出更多的针对专用垂直领域的东西出来。 ai 加行业的这个逻辑啊,在二零二六年,我认为会更强。关于蒸牛这个事情呢,包括公共技术扩散这个事情呢,国内的非常多的模型厂商啊, 受益是非常大的。当然我觉得收益最大的还是 deepsea 这些模型呢,它能够跳过这些基础的探索阶段。你要知道,在基础的探索阶段,它是没有直接的研究结果和研究目标的,前期的这个过程啊, 非常长,而且投入非常大。而为什么有时候我在说谷歌是黄埔军校,谷歌那个时候是没有这么卷的。现在说,呃,谷歌其实在硅谷也很卷,因为 ai 这一波浪潮,谷歌那个时候是专门养了很多创新型的科学家的, 他们是没有任何的这个直接的目标啊,就是你按照你的创新的想法,做很多研究,做很多探索性的东西。 这也是为什么谷歌在 germany 三点零之后啊,明显能够看到它厚积薄发的这个趋势啊。当然现在谷歌应该没有以前这么好的日子了,就是这么休闲哈, 就是它现在也很内卷了吧,我觉得就是,呃,也被卷了,当然和国内比,它肯定还是没有那么卷啊,它在 ai 的 这种快速的发展情况下, 他也会比较卷,而且里面华人也比较多这么一个情况,国内的这些大模型厂商,对于这一波这种公共技术的扩散,包括这种蒸馏的方式啊,他们从中还是受益的比较多的。而且从未来的路线看呢,我判断会出现 分化,就是有两条路线,路线 a 呢,就是超大模型的竞赛啊, openai 呀, antropica, 谷歌啊,呃, grog 等等,它们还是会做这种超大模型的竞争,它会继续探索新的范式,探索 agi 的 边界,我相信未来它们还是 会花很多的投入啊,多少亿美金在零到一的这方面的架构的探索里面,包括他们做的世界模型, agi 的 范式等等等等。还有一波大模型的厂商呢,他们会走这个高性价比的工程流,比如说啊, deepsea, mini, max, g, l, m 等等。实际上啊,非常现实的讲,路线 b 其实更容易商业化,路线 b 呢,他们可以用 更少的涿力训练和商用的模型,用蒸馏再去缩小差距,用推理去优化 api 的 成本。 对于 b 端的商户来说,这个模型他们不一定需要一百分的模型,可能未来需要, agi 需要,但是对于商用来说,可能八十分足够便宜,性价比高,对他们来说是更优的选择。 是为什么?二零二五年的时候也会说很多海外的亚马逊也在用千问的 a p f, 因为它够用就 ok 了。 而中国的国内的现状是,中国的工程师的人数的供给会更多一点,所以也会代表着中国的工程迭代的速度会更快。 还有就是,呃,国内对于整个大模型的投入产出啊,包括资本策的 这个倾向,他会有比较强的商业化的压力。嗯,技术扩散的这个门槛现在降低了,那么中国的这个工程的迭代速度又可以比较快, 然后呢?又加上商业化的压力比较强,又有像蒸馏这样的方式可以缩小差距,让这个模型足够好用,再加上推理优化的这个训练去降低 a p i 的 成本。最后我们可能 会看到 ai 模型 api 接口大规模商用的一个叫做什么安卓时刻,就是安卓本身其实是开源的嘛。嗯,对于很多人来说,像苹果手机,它的整个的用户体验比较好。 呃,整个的生态也是闭环的,很多人还是会选择苹果手机,但是对于很多大部分人来说,安卓手机是一个更有性价比的选择。而历史上我们看到的每一次技术浪潮 好像都是这样的, history repeat itself 先有这种贵到离谱的旗舰模型,你看走在前面的,像谷歌 open ai, 他 们投了非常非常多的前期的啊,研发费用,包括很多研究人员的心血在探索, 再出现便宜但够用的普及版,这个时候是工程期,最后呢,是靠规模化和产品化赚钱的这么一个路子,所以分化很可能也是这样子的。 ai 也一样啊,前沿的这个模型,顶尖的这个公司血比较厚的 这个血厚嘛,反正耗一点血没事,小的这种公司可能耗一点血就命就没了。头部的公司有九条命,这相对中小公司可能就两条命。 所以,呃,这个小的中小型的模型公司,它就要迅速地商业化。那么前沿的这个大模型公司,它还会继续地烧钱去探索 a g i 的 边界。当然我也讲了,蒸馏它也是有局限性的,它也会发生坍塌。 所以呢,可以在某些专项进行强化,针对特定的场景,比如说,呃,你的某个模型,在代码呀,数学呀,这个长的上下文上面啊,去做一些试探,现在其实上下文的技术也开源了,你像 kimi, 它的整个上下文也能做到啊,一百万 toon 了。 所以就是对于很多呃,模型厂商来说,可能一条很现实的路,就是蒸馏加专项的强化加工程化的这个降本,呃,快速的商业化是他一条非常现实的路, 对于用户来说,便宜、稳定、够用就可以了。所以这就是我讲的两条路线啊,很有可能在二零二六年啊,未来出现的一种分化,因为很多成本也不是公开的,我自己呢,也没有仔细的去推演和算过, 但是我相信啊,中国厂商的这个工程化能力,它可以通过蒸馏的这种方式 使用百分之十十分之一的价格,通过蒸馏啊,再加上工程化把它的模型的整个的能力做到前沿顶尖,模型的百分之八十的能力通过不断的蒸馏跟进去做到这个能力。我觉得 中国的场上有这样的能力和有这样的跟进速度,这是我的一个判断。哎,你怎么看?关于这个话题,我今天就先聊到这里啊,我的一些观点欢迎大家在评论区和我探讨,欢迎订阅我的频道玲姐说 ai 打开小铃铛,我们下期再见啦,拜拜!
18灵姐说AI









