atokens输入跟输出怎么算
大家好,我是破旺这个系列呢,我用同一个问题讲了十七个 ai 的 概念,就是用这个年夜饭吃上。 今天呢,我把这十七个概念串一遍,替你系统的梳理一下它们的脉络,看完你会发现,哎,这些的概念并不是孤立的,它有一条血脉,以后再碰到呃,什么新的概念,也能顺着这条脉络摸清楚它在哪里,是干什么的。咱们从最简单的任务开始 啊,你跟 ai 说年夜饭吃啥? ai 说到这句话呢,它会先切成一小块一小块的碎片, 这个碎片呢,就叫 token, 年夜饭吃啥可能会被切成年夜饭吃啥,那还有问号这四个 token。 然后呢, ai 会去查每个 token 跟谁关系近,那年夜饭关系近的有春节初期饺子吃,关系近的有饭,饺子,汤圆等等。 那 token 的 关系网里面呢,就会发现哦,饺子出现的比较多,那 ai 就 知道该往这个方向走,那这个查关系的能力就是 embedding。 然后呢,大摩羯就开始干活了,拿着这些的关系预测下一个 token 最可能的是什么?一个一个往下写,那从饺子,然后汤圆,然后红烧肉等等等等。那这个呢,就是 ai 最底层的运作方式。 toker 呢,是输入的基础单元, in binding 呢,是各个单元之间的关系网,大模型呢,是反复运作这个单元,预测下一个的机器,那后面所有的概念呢,其实都是在这个基础上长出来的。 但大模型有两个问题要说清楚,第一,它的目标是写的像,而不是事实对, 那说错了呢,也会显得很自信,这就是人们常说的一本正经的胡说八道,也是 ai 幻觉。第二个呢,他也不会想清楚,列完菜呢,他就完事了,没有考虑有几个人,预算多少,有没有过敏等等,这些任务稍微复杂一点,他就不够用了,那怎么办呢?就让他多运作几轮, 那我们可以看下一张图,那这个呢,其实就是若干个基础单元出来的, 那先让他运作一轮,你做好年夜饭啊,年夜饭吃啥?做好年夜饭都需要考虑哪些呢?那他会返回了啊,我要考虑菜系,要考虑忌口,要考虑价格,加工市场等等等等, 然后呢再运作一轮,那菜系呢?都有哪些?然后忌口呢?都常见的有哪些价格呢?常见的哪些加工市场等等等等,他就会一点一点的进行输出, 输出之后,然后大模型再进行最终的一个整合,整合了之后发现检查一下,哎,合不合适,那他就会输,做出一个最终的一个回复,那整个这个过程呢,就叫思维链, 那思维链的本质呢?就是让 token 的 一个基础单元多跑了几遍,先练要点,再写答案,而且在给答案之前,运作的轮数越大,那么也就是所谓的思考越深,这就是 deepsea 二一带火的这个深度思考的这样一个模式。 那想清楚了,答案出来了,那么给 ai 的是一段话,人能看得懂,但是程序它就不好处理。那这个时候怎么办呢?就是用结构化输出, 那也就是在最终输出之前,先套一个结构化输出的这样的一个小的运作循环, 那在输出之前,提前告诉 ai, 你 下一个 token 只能在啊这个 json 格式里面去进行一个挑选,那其实呢,本质上还是 token 在 运作,只不过是套了一个格式的一个模具,套了这样一个模具进行一个输出而已, 那格式有了,但是它里面具体的一个价格呢?拆价实际上是瞎拆了。比如说 ai 训练的数据的时效性, 他不知道今天的猪肉大概多少钱一斤,他只能凭借着印象,然后写那么一个猪肉的一个价格。所以呢,光靠 token 的 续写,永远解决不了查询真实数据的这样的一个问题, 那得让 ai 能够查询外部的一个数据,那怎么调呢?那我们现在已经知道了, ai 可以 进行结构化的输出,就是输出一个接收串,而接收串是我们系统是可以识别识别出来的,那么在这种情况下,我们只要中间加这么一步, 就是它输出的这样的一个结构化的一个输出,然后给到我们的一个系统,就比如说一个 api 接口,那我们 a api 接口返回,然后又作为它的思维链当中的一个输入的 token 输入进来,再进行整合回应,那这个时候 ai 就 知道了一个真实的一个数据是什么样的。那在中间的这个过程,我们就管它叫工具调用,也就是托靠 那工具多了,每个工具的接口格式可能都不一样,比如说查菜价那盒马有一套,美团有一套,叮咚有一套, 那每接一个新的工具就给重新写代码,就像 type c 出来之前,手机、平板、相机各自都是一个接口,那换个设备就要换线,而 m c p 就是 ai 世界的 type c 全网统一的一套标准接口,那所有的工具呢?都按 m c p 的 格式注册啊,自己能干什么?参数参数怎么传? ai 只要按照 m c p 的 一个格式发出调用,不管对接的是哪个平台,规则都是一样的,即插即用, m c p 就是 托靠的全网通用升级版。人们口中所说的找个 m c p, 实际上是找一个支持 m c p 格式的一个工具, 那么菜价查到了,菜单也出来了,但是 ai 给你的答案呢,质量全靠缘分。 有的时候呢,它推荐川菜,有的时候呢,它推荐粤菜,有的时候呢,它会给你列二十多道菜,但是呢,因为你只是说了年夜饭吃法,没有做一些其他的一个规则。那这个时候呢, ai 写的东西就完全像抽卡一样, 那本质上是因为我们并没有去约束 ai 的 续写方向, ai 输出什么,完全是靠当时 ai 思维链当中抽到了什么,那他就给我们写什么,这也就是我们没有写清楚相应的一个描述, 所以呢,我们要把需求写清楚再给他。比如说家里有六个人,预算三百,不要海鲜,要八道菜,用这层格式输出这一道精心组织的输入,就是 promenade 的 一个组织,就是提示词组织。 那本质呢,是你提前安排好了 token 的 一个输入,输入的越精准呢,它续写的方向呢,就是越靠谱。说白了, promenade 不是 玄学,而是科学。 那有了 problem, 然后 ai 按照你的要求去做了啊,八道菜,然后但是一会你又不满意了,你就说海鲜太贵啊,换成便宜的,那 ai 这个时候他就会蒙了, 那蒙了之后怎么办呢?因为他不知道前面他推荐了什么海鲜,也不知道为什么要提这个海鲜,是你是打算做这个海鲜的批发贩卖吗?那解决办法呢?就是把多轮的对话就是给它拼接进去, 那也就是说每一轮在对话之前,我们不仅仅是把它的规范提示放进来,还要把历史上的一些的对话也要放进来。这个时候 ai 才知道啊,我之前是推荐了这样的一些的东西,那他才知道这里面的海鲜可能是指 清蒸鱼三十元和大虾,大虾四十五元。那本质呢,这个 palmer 的 这个 token 输入,它会不断地变成,因为它的对话越来越多,但是聊得久了,那 palmer 呢?里面的对话就会特别多,那 里面的呃,这个 token 多了,那它就会变得贵,同时呢运行起来也会慢,那有的时候呢,还会超出 ai 的 处理上限,这个时候呢,就会删除一些之前的一个对话。 那三这个时候我们就发现 ai 已经开始忘记了前面说的一些的内容,也就是大家常说的,哎,我聊着聊着忘了, 那这就需要呢, content 工程,那在 content 工程当中呢,它会主动管理朋友们的里面的各种各样的 token, 比如说把好的明白了就是等等这些的废话的 token 统统都给删掉。那把菜单呢,可能改在第一版,第二版,第三版,那这个过程 完全压缩成一个最终版本的一个菜单,那把关键条件呢?六人预算三百,不要海鲜等等这些东西始终保留管理好整个的 token 的 一个输入的长度和质量,让 ai 始终保持一个 呃好的一个状态,那这个也是人们常说的 context 管理,上下文管理当中的一个压缩对话这个东西, 那瘦完身。还有一个问题就是有的一些的信息,你压根就装不进整个的这个 public 提示词里面,比如说你五加你家五年 年益汉的一个记录,一千多个收藏的菜谱,各地的饮食习俗等等等等,包括有可能是几十万只这个提示词根本就装不下。那这个时候呢,就需要 r g 这个技术, 那 r g 这个技术呢?其实就是在 ai 外部建立一个资料库,用户一问,把问题先进行资料库里面进行一个查找,那查找了之后呢?然后再把它拼接到这个 problem 里, 那拼接了之后,然后再进行呃后续的一个运转,那由于是这个插入,先查找再插入,那么就相当于是在给 ai d 小 抄,让它从 闭卷变成开卷。同时呢,讲这次对话没关系的,那几十万字的一个资料就隔离在 problem 的 之外,大幅度地节约了整个的一个 token。 那 到这里面呢, ai 想清楚,能查数据,能记得住对话,能翻海量的一个资料,但这些的能力呢,它都是分散的。比如说查菜价是一个工具,翻菜谱又是另一个工具,那 调到底决定哪个先调用,后哪个后调用,然后呢我们再把结果拼起来,那如果是自己干,那就累死了。

粉丝199获赞826
相关视频
 04:00查看AI文稿AI文稿
04:00查看AI文稿AI文稿一个视频讲清楚输入托肯和输出托肯到底差在哪?为什么回复越长,花的钱越多? 输入托肯是你给 ai 看的内容,输出托肯是 ai 生成的,回复大模型的输入托肯和输出托肯的价格是不一样的。输出托肯通常比输入托肯贵三到十五倍,因为生成比读取更耗算力。具体怎么理解, 你可以把 ai 想象成一个打字员,输入托肯就是你给他看的参考资料,他只需要读一遍,速度快,成本低。 输出托肯是他一个字一个字敲出来的,回复每敲一个字,都要思考、预测生成,耗时耗力,所以贵。举个真实例子, 你用 g p t 五点二问了一个问题,输入了一百个托肯,大约七十五个中文字, ai 回复了五百个托肯,大约三百七十五个中文字。按二零二六年二月的价格,输入托肯价格是一点七五美元,百万个托肯,输出托肯是十四美元,百万个托肯。 你这次对话的成本是,输入零点零零零一七五美元,输出零点零零七美元,总共零点零零七一七五美元,约合人民币零点零五二元。 看起来不多,但如果你每天让 ai 生成长文章、写代码、做翻译,输出托肯动不动就上万,一个月下来可能大几百、上千、上万的钱就花出去了。有时候没有控制好费用,说不定一晚上就得卖车卖房抵债了。 为什么输出托肯这么贵?因为 ai 生成每个字的时候,都要做一次完整的推理计算,它不是提前写好答案,而是根据你的问题和前面已经生成的内容, 实时预测下一个最合适的字,这个过程需要调用整个模型的参数,计算量是输入托肯的好几倍。 而输入托肯只是把你的问题读进去,做一次编码,不需要反复生成,所以便宜。再说个边界, 不是所有 ai 服务都明码标价输入输出托肯,有些产品按对话次数收费,有些按月订阅,但底层逻辑都一样, 输出越多成本越高。如果你用的是 api 接口,账单会直接显示输入输出托管数量和费用,这时候你就能清楚看到差别。 如果你用的是 chatgptplus 这种包月服务,虽然不按托管计费,但平台也会限制你的使用量,本质上还是在控制输出托管的总量。 所以怎么省钱?第一,问题尽量精准,别让 ai 生成一堆废话。第二啊,如果只是想要个思路或关键点,明确告诉 ai 简短回复或只给要点。 第三,别把 ai 当聊天对象闲聊,每一轮对话的历史记录都会算进输入托肯,对话越长,输入成本也会涨。 最后一个常见误区,有人以为输入长文档让 ai 总结很贵,其实不一定。 如果你输入五千个托肯, ai 只输出二百个托肯的总结总成本可能比你输入五百个托肯,让 ai 输出两千个托肯的详细分析报告还便宜。关键不是输入多少,而是输出多少。 所以真正决定 ai 使用成本的,不是你问了多少问题,而是你让 ai 生成了多少回复。
33AI编程小白 03:28查看AI文稿AI文稿
03:28查看AI文稿AI文稿五分钟 ai 知识点学到 token, 这是大模型最基础也最重要的概念。 token 就是 大模型处理文本的最小单元,如同原子构成物质, token 构成语言模型理解的文本世界, 它可以是单词、子词、汉字或标点。掌握 token 就 握住了 l l m 的 算力方向盘,精准控制输入,预测成本,优化生成效果。 token 有 三个核心特性,第一,非固定长度,一个 token 不 等于一个字,比如中文人工智能可能拆为两个 token, 人工智能也可能是四个 token。 人工智能 第二,数值化表示每个 token 映设唯一 id, 如 ai 对 应数字三一九二四,再转为向量输入神经网络。第三,计费机制, api 调用,按输入输出 token 量收费,比如每百万 token 收费一元 token 计算,等于提问给大模型的输入加大模型的输出。关键机制有中英文差异,一个中文制服约等于零点六个 token, 一个英文制服约等于零点三个 token。 上下文窗口模型单次处理 token 上线,比如 gpt 四 turbo 支持一百二十八 k token 约六点五万汉字。为什么要学会 token 约等于 money 调用?所有付费大模型 api 都是基于 token 数计费模式。 我们来看一个实际场景,用户提问,订单号滴滴,二零二四零八一五,何时发货?第一步,使用 deepseek 分 词器拆分为七个 token。 订单号 滴滴,二零二四零八十五,何时发货?第二步,模型回复订单,已发货物流单号 s f, 一 二三四五六拆分为六个 token。 第三步,计算成本,输入七 token 加输出六 token 等于总十三 token 按 deepseek v 三定价输入,每百万 token 收费零点一元,成本等于十三乘以零点零零零零等于零点零零零零一三元。 行业真相,克服系统月耗千万 token, 优化分词规则,可降本百分之二十。动域模型采用不同的分词策略。 chat gpt 使用 bpe 算法,长词猜分准,人工智能猜为二个 token。 deep seek 使用 word piece 算法,词缀捕捉强学习能力,猜为学习加能力。 阿里 quinn 使用 sentence piece 算法,生僻词支持优氪氪金保留为一个 token 选择,建议六十四 k 选 quinn, 七 b 开元免费获 gpt。 四 turbo 多模态 六十四 k 到二百 k 用 cloud 三点七长文本理解强大于二百 k 选 gmail 一 点五 pro 需要高预算。 最后分享几个冷知识,第一,训练数据规模, gpt 三吃下三千亿 token, 约等于人类三百万年阅读量。第二,一百二十八 k 上下文威力,可一次性处理整本三体约六点五万汉字。 第三,中文的 token 税,同一段信息,中文消耗 token 数比英文多百分之四十到百分之一百。 第四, emoji 的 拆解,诅咒爱心表情被拆为心脏符号加修饰符共两个 token, 若用于情感分析,可能被误判五分。
 00:42查看AI文稿AI文稿
00:42查看AI文稿AI文稿别再乱划 talking 了,百分之九十的人都用错了。 talking 到底是什么?其实就是 ai 算字数的计算单位。一句人话讲透,不是你会不会被收费,而是你输入的字, ai 输出的字都会被拆开来计算。消耗不是按对话次数来算,而是按字 词一点一点扣额度。你问的越啰嗦,他回答的越长,消耗额度就越快。所以额度突然没了,不是出错,也不是坑人,是字数堆出来太多了。 这就记住这句话就够了。 talking 等于 ai 用掉你的次数,懂这个再也不会背,突然没额度搞心态,记得关注再走哦!
14同桌小溢聊AI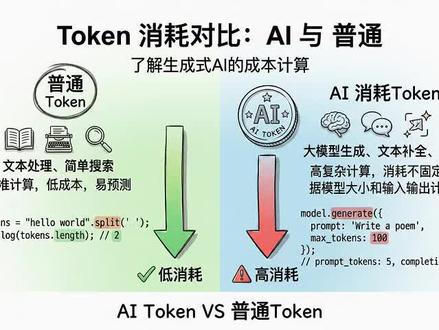 04:28查看AI文稿AI文稿
04:28查看AI文稿AI文稿写了三年代码才发现, ai 消耗的 token 和普通 token 根本不是一回事儿。今天三分钟讲透核心区别。通用 token 是 计算机系统里广泛使用的权限或身份凭证,本质是一串加密深沉的自复串,类似日常用的门禁卡、演唱会电子票本身携带了持有者的身份权限范围、有效期信息, 常见用在用户登录太校验、开放接口调用健全等场景。比如刷短视频 app 不 用每次输密码就是本地存了有效的登录 token。 要注意,这是通用语境下的 token 定义,和 ai 领域的 token 是 完全独立的两个概念,不要一开始就混淆。和 通用语境的 token 完全不同。 ai 领域提到的 token 是 大语言模型处理文本的最小计量单位,和全线凭证没有任何关系,类似印刷厂排版用的单个活字块。 不管是用户输入的提示词,还是模型深层的回答内容,都会先被拆分成一个个 token 单元再做计算。不同大模型的分词规则略有差异,但核心作用都是统计模型的文本处理量,和常说的字数功能类似,但拆分逻辑更符合模型的运算特性。 搞清楚两者的本质区别后,我们再来看他们的核心用途差异。通用 token 的 唯一作用是做身份和权限校验,核心解决的是安全问题,避免每次请求都传递账号密码这类敏感信息。 ai token 的 唯一作用是计量模型的算力消耗,核心解决的是成本核算问题, 两者的用途完全没有重叠,就像小区门禁卡和快递寄费的重量单位,只是刚好都用了 token 这个名字,实际功能使用逻辑没有任何关联。接下来我们先拆解通用 token 的 生成逻辑,它通常是服务端用非对称加密算法生成的随机字母串, 会和用户 id 权限列表、有效期、时间戳绑定,类似游乐场入场时给你发的 rfid 万代,扫一下就能知道你买的是通票还是单项目票,无法被伪造篡改。 通用 token 只有有效和无效两种状态,不存在消耗多少的说法,只要在有效期内全线匹配就可以反复使用,不会因为使用次数多而失效。 而 ai token 的 计算逻辑则完全不同,它的计算完全基于文本内容,不同语言的拆分规则不同。中文平均一个汉字对应一点五个 token, 英文平均四个字母对应一个 token, 标点、空格、换行符都会被记入 token 数量,就像打印店按打印的字数收费,不管你写的内容是什么,只看最终拆分出来的 token 总数。大部分大模型平台会把输入和输出的 token 分 开计费,通常输出 token 的 单价要高于输入 token。 我们再来看两者的使用逻辑区别。先说通用 token, 使用时只需要在每次发起请求时把它带在请求头里,服务端会先叫验 token 的 合法性、有效期权限范围叫验,通过就会处理你的请求。类似进写字楼,每次进门都刷一下工牌,只要工牌没过期,是本楼的员工就可以正常进入。 通用 token 不 会因为调用次数增加而减少,除非用户主动登出服务端手动作废或者到了有效期才会无法使用。和通用 token 可反复使用的特性不同, ai token 是 典型的消耗品,每次调用大模型接口都会产生实际消耗。比如你输入的提示词拆分后是八百 token, 模型深沉的回答拆分后是六百 token, 这次调用就总共消耗了一千四百 token。 类似去店完成玩游戏,每玩一个项目就消耗对应的游戏币,用完就需要再充值。 哪怕两次调用的输入内容完全一致,每次调用都会重新计算消耗,不会因为之前调用过就洁面。 正是因为两者同名,很多初学者刚接触大模型接口时,容易走入混淆误区,会把调用接口用的 api 密钥和 api token 搞混。 实际上, api 密钥属于通用 token 的 一种,作用是叫验你有没有调用接口的权限,不会产生消耗。而你请求里的文本拆分出来的计量单位才是 ai token, 每次调用都会扣减额度, 两者是同时存在的,一个管你能不能用,一个管你用一次要花多少成本,不要把两者的功能搞混。 最后,我们从工程设计的角度来看两者的意义差异。通用 token 的 设计初衷是降低身份叫院的安全风险,适合所有需要权限控制的系统,不管是电商平台还是内部办公系统都能用到,和 ai 没有任何绑定关系。 ai token 的 设计初衷是统一大模型算力消耗的计量标准,方便平台定价和用户预估成本,只有在涉及大模型文本处理的场景才会用到,两者的应用边界非常清晰,只是重名而已。
546小猿星星(接单中) 07:43查看AI文稿AI文稿
07:43查看AI文稿AI文稿hello, 大家好,我是算力基建狂魔。今天我们来聊一个 ai 时代最基础但也最核心的概念, token。 如果你用过 chat、 gpt、 文心一言或者豆包一定见过这个词,但可能一直没搞明白 token 到底是什么?它和算力有什么关系? 为什么说 token 正在成为数字经济的硬通货?先来破除一个最大的误区, ai 里的 token 和区块链加密货币中的代币完全不是一回事。在 ai 的 世界里, token 是 大模型处理文本时的最小语义与运算单元, 你可以把它理解为 ai 用来读懂和表达语言的积木块。我们人类交流时,会把语言拆分成字、词、句子,再组合起来表达意思。 但 ai 没有人类的思维,无法直接理解完整的文字,它只能把文本拆分成一个个可识别、可计算的片段,这个片段就是 token。 举个例子,中文场景下,人工智能通常被拆分为两个 token, 我 爱 ai 科普会被拆成四个 token, 我 爱 ai 科普注意,标点空格换行也会单独算作一个 token。 英文场景下,长单词 un 加 believable 三个 token, hello world 则是两个 token。 简单来说, token 就是 ai 的 语言单位,它把我们的自然语言翻译成了 ai 能看懂并进行计算的机器语言。 那么 token 和算力到底是什么关系?这才是今天最核心的部分。你可以把 token 理解为 ai 算力消耗的计量单位,就像我们用电按度计费,用水按立方米计费一样, ai 的 算力消耗就是按 token 来计量的。 更形象的比喻是, ai 的 算力就像一台发动机,而 token 就是 这台发动机的工作量单位,每处理一个 token, 就 相当于发动机完成了一次完整的做工模型,需要调用 gpu、 服务器等硬件资源进行一次复杂的数学运算, 这个过程会消耗电力、占用显存,也就是实实在在的算力消耗。这里面有三个关键逻辑, 第一, token 数量越多,算力消耗越大。 ai 处理的 token 越多,需要进行的运算次数就越多,计算量会呈指数级增长,大致遵循 o n 平方规律。比如处理一千个 token 的 算力消耗远小于处理一万个 token。 第二,算力越强,处理 token 效率越高。如果 ai 的 算力越强,比如用更先进的 gpu、 更多的服务器集群,单位时间内能够处理的 token 数量就越多,我们使用 ai 时,等待回复的时间就越短,处理长文本的能力也越强。 第三, token 是 算力与用户体验的桥梁。我们使用 ai 时,输入的提问、粘贴的文本都是输入 token, ai 生成的回复是输出 token, 输入加输出的总 token 数量,直接决定了这次使用消耗的算力,也决定了计费金额和回复速度。说到计费,这就引出了 token 的 第一个核心作用, ai 服务的算力货币。 目前几乎所有主流 ai 大 模型,包括 gbt、 文心妍、 cloud 等,都是按输入加输出总 token 来计费的。 token 就 相当于 ai 服务的货币。我们用 token 购买 ai 的 算力服务, 不同模型的计费标准略有差异,但整体规律一致。输入 token 约零点零一到零点零三元,每一千个输出 token 约零点零三到零点零八元,每一千个输出需要模型主动生成内容,算力消耗更高,所以更贵。 举个实际例子,我们用 ai 写一篇一千字的文案,输入的需求约两百个 token, 输出的文案约一千个 token, 总 token 约一千两百个,费用大概在零点一元左右。 token 的 第二个核心作用是定义 ai 的 记忆力上限,也就是上下文窗口。 我们和 ai 聊天时, ai 能记住我们之前说过话,这种记忆能力就是由 token 数量决定的,行业里称之为上下文窗口,本质上就是 ai 单次能处理的最大 token 总量。不同模型的上下文窗口大小不同,对应的记忆能力也不同。 八 k token, 约等于六千个汉字,相当于一篇中等长度的文章,适合日常聊天。短文案生成。 三十二 ktoken, 约等于二点四万个汉字,相当于一本短篇小说,适合处理长文档多轮复杂对话。 一百二十八 ktoken, 约等于九点六万个汉字,相当于一整本三体第一部,适合处理书籍、报告代码等超长文本。 如果我们的对话或输入文本超出了 ai 的 上下文窗口 token 限制, ai 就 会忘记前面的内容,甚至无法继续生成回复。这也是为什么有时候我们和 ai 聊太久,它会出现答非所问的情况。 token 的 第三个核心作用,也是当前最受关注的一点,它是 ai 产业竞争的核心抓手,正在重塑整个产业链的价值分配逻辑。 英伟达 ceo 黄仁勋在最近的 gtc 大 会上提出,未来市战术中心不再是存储文件的仓库,而是生产 token 的 工厂,在既定的电力预算下,谁的梅瓦特 token 吞档最高,谁的盈利能力就越强。 这意味着行业竞争从比拼模型参数转向优化单 token 成本和美瓦特 token 产出率。中国厂商在这方面表现尤为突出,凭借绿电成本和算法优化 token 身品成本压制海外模型的十分之一甚至更低, 推动中国大模型全球 token 调用量占比达到百分之六十一。更深远的是, token 正在成为数字经济的新硬通货。 黄仁勋预测, token 可能像电力一样,成为数字经济的通用计价单位。企业为员工发放 token 额度,作为福利开发者按 token 消耗核算 ai 应用成本,云厂商按 token 吞吐量重构商业模式。 那么,作为普通用户,了解 token 有 什么实际用处呢?最直接的就是省钱和提效物。我们可以通过优化提示词、精简输入内容、控制输出长度等方式,减少不必要的 token 消耗,从而降低使用成本,提高响应速度。 比如,与其说你好,我想请问一下,我现在有一个问题,就是我想知道怎么写一篇关于 ai 的 文章,不如直接说写一篇 ai 文章大纲,前者可能消耗三十到四十个 token, 后者只需五到六个 token, 效率提升六到八倍,成本也相应降低。 总结一下, token 看似微小,却是 ai 理解世界、生成内容、创造价值的基石,它是技术的最小单元,也是产业的核心变量。 从语言积木到算力货币,从印记单位到硬通货, token 正在定义 ai 时代的生产关系和经济逻辑。谁掌握了 token 的 效率与成本优势,谁就掌握了 ai 产业竞争的主动权。 在算力基建狂魔看来,读懂 token 才能真正看懂大模型,用好 ai, 把握智能时代的底层逻辑。好了,今天的分享就到这里,我是算力基建狂魔,我们下期再见!
11算力基建狂魔 04:03查看AI文稿AI文稿
04:03查看AI文稿AI文稿如果你在用 openclaw 或任何 ai 自动化工具,却不懂 token 的 计费逻辑,你的信用卡随时会报。今天不讲故事,只讲三个核心事实, token 怎么算钱? openclaw 哪里在偷偷扣费?未来会更便宜吗? 看完这三分钟,帮你省下真金白银。第一部分, token 是 什么? token 就是 ai 把人类语言翻译成它自己能消化的数字之前的最小切分单位。 token 不 等于字,也不等于词, 它是介于字和词之间的一种智能切片。 ai 不 认识字,它只认 token。 想象语言是一张大披萨, token 就是 切好的小块。英文 pizza 切法比较规则, 通常一个单词约等于一点三个 token。 例如 hello 是 一个 running, 可能被切分为 run 加 name 就是 两个 token。 中文披萨切法比较碎,通常一个汉字约等于一点五到两个 token。 比如这个词,人工智能可能被切成人工加智能,可能会计算成七到九个 token。 第二部分,收费标准与三大致命坑,这里有三个烧钱的坑 坑一,输出比输入贵三到五倍。 ai 读你的话很便宜,但写出回答很贵, 无论模型多便宜,输出永远更贵。 g p d 四,输出是输入的三倍, cloud 甚至高达五倍,对测试永远加上限制,比如限一百字坑二,隐形消耗巨大 system prompt 每轮对话必收 我们普通的聊天室,你问一句,我答一句。但在 openclo 里,每次对话都会自动打包三样东西,第一是系统指令,告诉 ai 它是谁。第二是历史记忆,就是你过去的聊天记录。第三才是你提出的问题, 哪怕你只是和 openclo 打个招呼,发了你好两个字, openclo 后台可能已经偷偷发送了三千到一万五千个 token 的 背景信息给 ai, 这意味着你还没开始聊就已经欠费了。 对策,定期清理记忆库,别让书包太重坑。三、自动化死循环这是最可怕的,如果你的脚本出错,陷入到死循环,即 ai 生成代码,到运行报错,再到 ai 修复之后系统再报错, ai 再修复, 有用户脚本死循环,一周跑出一点八亿 token 的 天价账单。更有 ai 后台崩溃,重洗四千六百七十一次,主人却完全不知情,你没操作,电脑在空转,钱在狂烧。 对策,必须设置每日消费上限。第三部分,未来 token 会便宜吗?结论,单价必跌,总账难审,为什么跌?因为以后算法会更强,芯片会更便宜,大厂会进行价格战,现在价格已经是两年前的百分之一。 那为什么总账难审?因为杰文斯贝论越便宜,你用的越疯。以前只敢问一句话,以后会让 ai 读完整个图书馆,结果单个托肯像自来水一样便宜,但你家的水费账单反而更高了,别指望免费,要指望控制用量。 第四部分,立刻执行的四条止损指令,一、切换模型简单任务,如翻译总结,强制使用经济型模型,如 deepsea quiz。 问 turbo, 别用旗舰版杀机二、设置应限额,去云厂商后台设置 daily budget, 每日预算超支自动停机。 三、限制输出长度,在所有提示词末尾加上回答,严格控制在两百字以内。四、清理上下文,每周清理一次 opencloud 的 长期机密库,减小背景包体积,不做这四步,你的下一次账单爆炸只是时间问题。 节语 token 是 ai 时代的电费, opencloud 给了你超级算力,但也给了你超级账单的风险。懂规则才能驾驭它,不懂规则就是为它收割。觉得有用点赞收藏,转给你那个正在乱用 ai 的 朋友。
57没几个为什么 05:42查看AI文稿AI文稿
05:42查看AI文稿AI文稿那么第一个对于第一个规律就是他经常会把本过程的输入和输出混淆,就是他不会牵涉到特别多其他的子过程,他仅仅只考自己这个子过程内容,但是他会把输入和输出跟你做一个混合的错误选项,放在这个题目当中,你把它选出来就行了。所以在整个备考过程当中,我们首先需要的是对一些非常重要的子过程,你一定要把它的输入输出要把它去背一下的。 我们来看一下这道题目啊,以下哪一个不是收集需求的输入?很明显考的就是范围管理,收集需求这个子过程,那么收集需求有两个非常重要的输出,一个我们叫做需求文件, 还有一个就叫做需求跟踪矩阵。好,这两个呢是非常重要的两个,因为这两个输出仅仅只在这一个子过程当中出现过,其他所有的四十八个子过程都没有,那么你就需要把它给背下来。 好,所以这个地方哪一个不是他的输入?你说,哎,我也没有背那么多输入,但没有关系,他的错误选项常常在输出当中输出就两个呀,这个是可以背下来的,所以 d 选项需求跟踪矩阵就不是他的输入,你说 abc 我 背了没有啊?你不记得就不记得,但是 d 你 能够选出来,所以这一个是在我们这个子过程当中,他经常把输入输出混合起来做一个选项出现。 第二个规划质量管理的输入不包括什么,那么规划质量管理它有几个比较重要的输出?一个是我们的质量管理计划,我相信大家计划并不会陌生,每一个知识领域的第一个都有一个计划,第二个就是它的一个叫做测量指标,这个是很重要的一个输出,为什么?因为这个指标只在这一个字上出现过,所以我们要把它背一下,那么它既然是输出,它就一定不会输入,所以 a 选项就不正确, 所以为什么这个比较好选出来?也是我们在论文课当中也收到过,你再去写质量管理论文,你的第一个字过程一定要用质量测量指标去做,举例,比如说我这个服务器要同时能够接受一万个人进行访问,这个一万就是我们的测量指标,我这服务器呢?我这我这个系统信息化系统要能够去运行二十四个小时不死机,那么这二十四个小时也是指标,所以它是非常独一无二的输出,把它 背下来。第三个以下哪一个不是规划甘肃人管理的输入?那么同样的在这个子库当中,它有一个独一无二的输出,我们叫做甘肃人参与计划,那么这个是要把它背下来的,所以 d 选项你要把它选出来,你说它是独一无二的输出,其他的输入要不要背啊?输入太多了,对吧?特别是它当中特别容易出现的项目管理、项目文件,项目文件又包含哪些呢?这些东西根本背不下来,但是对于有一些独一无二的输出背下来, 所以这样子对于这一种,第一个规律啊,在本过程当中出现的容易混淆的应该是没太大问题的。第二个我们来看一看啊, 它就是会在多个子过程当中混淆出混淆这个作为答案出现,但是呢,它虽然出现在多个子过程当中,也是比较容易把多个子过程当中的独一无二的给你放在一起去,你看一下以下哪一个是定义范围的输入,对吧?那么定义范围它的这个输出是什么?输出就是我们的 范围说明书,这是最重要的对不对?那么我们回顾一下,我们在讲范围管理的时候,我们是不是首先规划范围管理,然后收集需求,然后定义范围,然后创建 wbs。 那 么在创建 wbs 的 时候,有一个非常重要的输出叫做范围精准,首先大家都可能记得对不对?所以这个什么范围精准,工作分解结构肯定都不是他输入,因为是先定义范围再创建 wbs, 甚至包括验收的可交成果,更不可能了,这个也是一个独一无二的输出,它在哪里?它在我们确认范围这一章,因为确认范围是由客户和发起人去验收,那么验收了就是我们这个确认范围嘛, 所以这个 d 也是要把它背下来的,就是在这个比较重要的子过程中把它背下来,那么 abd 能排除掉,我们只有 c 选项啊,所以是需求文件。这是第一种解法,就是你把其他每个子过程独一无二的优先给背下来,因为四十九个子过程设计的 itto 太多了,你不可能全部背,那我就把独一无二的把它先给背下来。第二个就是 上一个子过程的输出,有可能会成为下一个子过程的输入,比如说我们首先这个实物矩阵图大家是肯定晓得的,范围管理它就是规划范围管理,然后再就是收集需求,然后是定义范围创建 w s。 那 么在定义范围之前有谁啊?有两个子过程,一个是规划范围管理,一个是收集需求,那么收集需求它有一个输出,刚讲过需求文件,所以这个也能把 c 给选出来,所以通过逻辑去帮助我们做好这个选项。 第二个,哪一个不是制定项目章程的依据,那么不是章程的依据,来看一下口头协议管理计划、商业认证工作说明书,那么项目章程是我们学到的,第一个项目的文件就是你进入项目的文件就是章程,那么章程之后才会去制定项目管理计划,所以按照这个逻辑来说的话,章程之前一定不会有项目管理计划,所以 b 选项我们就能把它给选出来, 所以通过去把实物矩阵图背下来,以及它之间的逻辑关系理清楚,那么这种题目也是能够选出的啊,并不需要说你一定要把它背下来,你原封不动的把这么多 it 背下来,你自己头就是脑袋都要爆炸掉了,所以还是要通过理解的逻辑上把它选出来 好,这是第二个规律,然后是第三个规律,我们来讲讲考工具啊,因为前面两个规律呢,都是去讲的,如何去考他的输入和输出,那么下一个呢?是考这个工具和技术啊,那么工具和技术第一个考他的基本定义,这个呢考到的是一些送分题了,那就是你知道这个工具是怎么定义他的,你就能把它选出来,比如说第一个,哪一个是通过与江西人直接交谈获得他的 或者是方法,那么直接交谈我们叫做访谈。所以 a 选项考基本定义对吧?那么头脑风暴呢?那么是大家集思广益对吧?快速获取大量需求,不论对错。那么民意小组呢?是把头脑风暴进行排序,是这个叫做民意小组。清河图是把大量的创意,我按照他的这个呃直观的进行逻辑分类,所以清河图它是会先分类,分完类之后再进行分析, 这些都是工具的基本含义嘛,这个是不容易搞混淆的,就是理解就行了,所以第一个选 a, 第二个是一种特殊形式的条形图,用于描述集中趋势,分散程度等等,那么这个我们选的是 d 脂肪图,同样的基本概念理解透就行了。 好,所以如果考到规律三这么一个基本定义,大家不要把这个分给丢掉了。第四个呢,就是他可能会在多个子过程当中对工具进行混淆,那么这个混淆也是一样,对于独一无二的工具,一定要把它给记下来就是了。经常会问我到底要背哪些啊?是不是一定要把独一无二的最优先把它给背下来? 你看一下哪一个不是收集需求的工具?收集需求会有非常多的工具对不对?那么表格对照明细表格的都是分解,不是分解是什么概念上去理解,分解是把一个大的分解为小的吧,所以我们在创建 w s 时候才用到分解,那么收集工具它更多强调是怎么去把这个需求给收集起来,所以 d 选项它就不是第二个,哪一个不是管理质量的工具?那么质量管理就有三个词,过程规划、质量管理、管理、 管理质量和控制质量。那么这个地方我们要是把这个控制图经常考到,把它给背下来,控制图是我们控制质量的工具,对不对?那么它就是不属于我们的管理质量,所以 d 选项能够选出来,那么 abc 自然就知道了。 那么第三个,哪一个不是制定进度计划的工具和技术?同样看到这种题目,不用担心去看打去看选项啊,假设经典分析、蒙特卡洛快速跟进、类比估估算,哪一个不是制定这个计划呢?很明显是我们的类比算法吧,它是干嘛估算估算?它是去估算活动的持续时间的呀, 它跟制定进度计划就没有了,因为我们制定进度计划在去做这个子部分之前,我已经要得到每一个活动的时间,所以类比估算是在之前,所以这个是他的低选项。
 01:52查看AI文稿AI文稿
01:52查看AI文稿AI文稿ai 领域常说的 tokens 到底是什么意思?这个视频彻底给你讲清楚。 token 是 ai 大 模型处理文本的最小单位,也是 ai 大 模型的最小计费单位。 一个汉字,一个单词,一个标点符号都是一个 token。 一 段文本会被大模型分成多个 token, 我 们称之为分词。不同的大模型会有不同的分词方式。以 gpt 五为例, how are you 被分成四个 token, 三个单词加一个问号,这是 gpt 五的计费表格。注意,这是每百万个 token 对 应的价格。你可以算算向 gpt 五输入这么一句话需要多少钱。 我们再看看中文如何分词。黄仁勋是我表舅,这句话被分成了九个头肯。明明七个字,怎么就九个头肯呢?这是因为常见汉字在训练语料中出现频率较高,被完整收入进词表向我表示,黄仁这五个字,一个字对应一个头肯, 而就勋这两个字在训练语料中出现频率较低,每个字被拆分成了两个 token, 这些加起来刚好九个 token。 而且那些更不常见的汉字,一个字会被拆分成三个 token。 有 人就又问了,我用豆包 deep sync 元宝也没收费啊? 注意,你用的不论是 app 还是网页端,它们本质上都是 agent, 用户与 agent 交互,而 agent 调用大模型, agent 调用大模型必然消耗 tokens。 不 过这几个产品调用的都是自家的大模型, 而 agent 面向用户可以免费,也可以像拆拆 gpt 那 样分为免费订户和按月订阅收费用户。现在大火的 open call 也是, agent 只是调用哪个大门型需要自己配置,你如果调用服务商提供的大门型,就要按照所消耗的 tokens 付费。 当然,你如果调用的是自己部署的大门型,也会消耗 tokens, 但不计费就是了。最后,关注我,带你了解更多 ai 知识!
39程序员铭哥 09:05查看AI文稿AI文稿
09:05查看AI文稿AI文稿同学们大家好,欢迎来到系统集成冲刺课堂,我是刀刀老师啊,继续输入输出逻辑秒杀法,看逻辑时输出成果包含的内容就是输出 啊,比如说项目章程的内容,它包含了有相关的成功标准,那么这个相关的成功标准就是制定项目章程的输出。 那又比如说进度管理计划的内容包含了控制临界值,那么控制临界值就是规划进度管理的输出。 又比如识别风险,它会输出风险登记册,那么风险登记册里边包含的这三个内容也是识别风险的输出。 就是大家知道我们现在考试他会考的比较细,是不是啊?所以他考到细节就是这些内容的时候啊,你就要稍微的去注意一下,相对来说会比较难啊。逻辑师,那我们要把这些内容记住, 怎么记呢?哎,我们记他常考的一些内容来看,常考的啊,那第一个就是项目章程的内容,主要包括 记关键词、整体标准、高层级、关键目标、里程碑要求资源两职权。 那整体就是整体项目风险标准呢?相关的成功标准啊,然后是退出标准,高层级,两个高层级,那关键是关键干信人名单,目标、项目目标, 还有这个目的也可以跟目标一起啊,一起记里程碑是总体里程碑、进度计划要求、审批要求,然后是资源、财务资源啊,两个职权。你看我们把这个关键词记住 是吧?你遇到了这个项目章程主要内容的选择题,其实我们也可以选出来,那你遇到了他输入输出考这个内容的,是不是也可以选出来啊, 甚至于在案例里边啊,遇到问答题要你去默写项目章程的内容,那我们用这个关键词,你应该也可以想起来一些,是吧?好,所以他这个用途比较多。 第二个进度管理计划的内容,单位模型、临界值格式规则、死长度。那单位指的是计量单位模型、进度模型,还有这个模型的维护, 临界值是控制临界值,那格式是报告格式,然后是绩效测量规则 死长度,这个死就是 w b s 的 这个 s 啊,长度,迭代长度和准确度两个度啊,一个是迭代长度,一个是准确度。 好,还有一个跟进度管理计划内容很像的,就是成本管理计划的内容,因为他们有重合的。那我们来看,成本管理计划的内容就是单位链接、临界值格式规则、精准度啊,你看同样是有计量单位是吧? 啊,链接是组织程序链接,同样有控制临界值,那同样有测量规则,而这个测量规则呢,它通常又会考细一点点,把这个正值规则记住, 那格式就是报告格式啦,精准度就是精确度和准确度啊,两个合并在一起叫做精准度。 第四是风险管理计划的主要内容有跟踪、报告人才时方略偏好、影响类啊,跟踪就是啊,这跟踪报告报告格式, 人才时指的是啊,你看人就是角色,是不是人呐,是吧?还有职责也是指的是人的职责嘛,所以这个我们记人就可以了。财就是指的是人的职责嘛,所以这个我们记人就资金,是不是钱呐,就是财嘛。 啊,时就是时间啊,就是时间,所以人才时指的是这三个, 然后方略就方法论,还有是风险管理策略,这叫方略偏好,是干细人风险的偏好,然后影响 两个影响风险概率和影响概率和影响矩阵啊。类就是风险类别。那跟踪报告人才时方略偏好影响类 就是我做这个方略的时候啊,我比较偏好于啊这个去研究有影响的这些类别 好。第五,识别风险呢?会输出风险登记册。风险登记册的内容呢?主要包括三个, 这也是常考的啊,就是潜在清单,潜在两个潜在嘛,潜在风险责任人和潜在的风险应对措施清单,然后清单,已识别风险的清单, 或者你这两个清单是吧,也可以这样子记,反正两个潜在两个清单,但是合并在一起其实是三个。好,那么我们做题巩固一下来。一、哪个不是制定项目章程的输入呢? 成功标准,成功标准是项目章程的内容,所以是它的输出, 选 d 啊。第二,哪个不是它的输出? 那是的,挑出来嘛。哎,高层级是不是有啊,标准是不是有啊?里程碑是不是有啊?所以你看我们记关键词就可以了。所以 b 江西人登记册就不是它的输出,选 b。 选项 三,风险识别的输出,那风险识别它会得到风险登记册,风险登记册包括潜在清单是吧,那清单呢?选 b。 第四,哪个不是规划项目进度管理过程的输入?哪个不是进度模型,选 c。 第五,哪个属于规划项目进度管理过程的输出?你看刚才就选不是,现在又选是了,临界值好,选 d。 其实这道题还有另外一个解法,其实也很快。排除法嘛,你看像项目管理计划、项目章程、事业环境因素,不是通常都作为输入吗?是吧?嗯,所以你看就也可以排除出来啊。 第六,规划成本管理的依据不包括啊,正值规则不是选 d, 这是它的输出。 第七,哪个不属于风险管理计划编制的成果?那就方略偏好影响类。它是属于风险管理计划的内容,方略 偏好影响类,是吧?所以 a、 b、 c 都是它的成果,就 d 不是, 所以我们选 d 选项。 第八啊,不属于识别风险过程的输入啊,潜在清单你看潜在看清单都可以是它的输出,选 a。 老师给大家整理了输入输出专题练习,已上传到问卷心,有需要的同学可以找我啊,谢谢大家!
2叨叨老师 01:44查看AI文稿AI文稿
01:44查看AI文稿AI文稿ai 圈最近有个词特别火, token。 今年三月,国家数据局在官方发布中给他定了个中文名词源。同一个月,国内日军 token 调用量冲到了一百四十万亿次。 token 到底是什么?简单说,它是大模型处理信息的最小计量单位, 人类读写以字为单位,大模型输入输出则以 token 为单位。一个 token 可能对应半个中文词、一个英文单词,也可能只是一个标点或数字。它有点像 ai 时代的流量计费单位,你用哪家模型,就按消耗了多少 token 来算账。 过去几个月,智能体应用爆发,全球 token 用量直线上升。但这一轮有个明显变化,中国大模型的日军 token 调用量首次超过了美国。全球开发者为什么开始用?中国的 token 不是 凭空变出来的, 它背后是 gpu 跑运算,烧电发热,经过数千亿次计算才生成。每吐出一个 token, 都对应着真实的电费和算力开销。中国能把 token 价格压下来,靠的是两样东西,一是电,二是技术。 先说电,国内电力基础设施比较完善,西部的新能源绿电正加快与数据中心融合,西部的风光资源正被转化成 ai 时代可被调用的算力服务。 再说技术,这几年国内在推理芯片、模型架构、系统优化上进步不小。面对同样的问题,能用更少的算力、更短的时间算出结果,单位成本自然就下来了。这也催生了一个新现象,偷啃出海。一个美国开发者调用中国模型的 api 请求,从加州出发,经海底光缆传到国内数据中心, gpu 在 这头完成推理,再把结果返回大洋彼岸,整个过程看不见、摸不着,但电力在烧,算力在跑, token 在 流动。有人说, token 正在变成 ai 时代的新型能源单位。在这场看不见的 token 跨境流动背后,电力算力正以一种新的方式参与着全球数字服务的分工。
169并购赋能指南 01:50查看AI文稿AI文稿
01:50查看AI文稿AI文稿原版阅读读了很多书,怎么样从输入转为输出?其实原版阅读的核心就是大量的输入,但是输入的再多,没有最后的输出也是白读,所以很多家长就会很担心这个问题。那今天我来教大家几 个小办法啊,来从原版阅读的输入转向输出。那第一种输出类型就是跟读加复述 reading a to z 的 书读完了以后,我们都会有一个环节,让孩子来跟读这本书,大声的朗读 这本书的内容,那这个就是一种输出。第二就是复述这本书的内容。在我的别的视频里面,包括在我的课程里面,都有教小朋友怎么样来一步一步 把这个书的内容输出。当他能够复述这本书的内容以后,就已经是最高级别的输出了。那除了这个比较难一点的输出之外,其实还有一种类型的输出,叫做句型的替换使用。比如说我们在书里面读到了 i like apples, 那 很简单, 当他有一天看到 i like bananas, i like oranges, 他 会把这个句型替换上去使用,甚至他说 i like my mom, i like my dad, 这个就是一种 句型上的转换输出,这也是成功输出的一种标志。第三,在书里面情景地在运用。比如说这个书里面小朋友去上学了,他说 let's go, let's go to school, 那他在真实生活中能够把这个句型使用出来,这也是另外一种类型的输出。那第四种,我们可以用读到的这些内容 来写一个小小的日记。比如说今天读了一本跟猫有关的书,那他在他的小日记里面可能画了一个小小的猫,说 i like cats, cats are cute, 那 这种就 是一种书写型的输出。以上几种类型的输出只要能够成功的做到一到两点,就是一个能力的迁徙,从大量的输入内化语言,把这个语言能够使用出来,这就是阅读成功的地方。
 04:07查看AI文稿AI文稿
04:07查看AI文稿AI文稿分享了很多期关于 oppo 可乐的,我们今天来说一个热点词汇啊, token, 我 们来看一下什么是 token? token 其实最早的理解就是词源啊,其实按照我们中文来说就是最小的语义单元,其实它就是一个词组,我想我想去北京啊,这就可以变成三个, 这是三个偷看啊,这就是偷看的最早的定义。那么偷看是怎么产生的?只要我们跟大模型进行交互,不管是输入和输出,它都会产生偷看。那么最近为什么大家会疯狂的在说偷看的词语呢?因为偷看已经发生了本质上的变化,现在的偷看等于等于模型能力加 算力综合投入,其实它是 ai 时代的计价与结算单元,也其实是 ai 时代的通用货。模型能力是指的什么呢?就是算法体系啊,回答的精准度啊,那算力的综合投入呢?包括了我们常见的基建了,机房了,贷款了,包括芯片里边 gpu, tpu, 包括 所指的电力啊,这些都是算力的综合投入,其实抽根等于模型能力加算力的综合投入。我们来 呃看一下目前 tok 的 这个提供商呢?都有哪些呢?一种是模型原厂,咱们也可以叫它原声 tok, 再来就是算力厂商或算力集成商,那么模型的原厂呢?有哪些厂家呢?就大家耳熟能详的,比如说 gopro, gpt 啊, 吉米尼啊,可沃达等等,这些模型厂家产出的模型呢,相对来说质量是比较高的,当然也包括我们国内的天安门,豆包,他们相对来说因为一直在对模型不停的进行升级、优化和训练,那么他回答的这个精准度啊,包括质量都是非常高的。 还有一种就是算力厂商和算力集成商,那么比如说我们现在知道的像亚马逊,阿里啊,华为啊,英伟达这些都属于算力厂商,因为他们直接生产的是芯片啊。还有一些就是算力集成商,比如说我们知道的国内的浪潮啊,或三大运营商,因为他们本本质上他们不生产芯片, 他们是将所有的这个算力做成集权,那么他们是将所有的这个算力做成集权,那么他们是将所有的算力千万的 太原的各个版本的模型,那么他们主打的是什么呢?性价比,尤其是这个算力集成商,因为他们自己本身不生产模型,也不生产芯片啊,他们只是把这些算力齐全在一起,那么他们输出的就是这种透肯呢,可能从质量上 并没有原生模型的透肯的质量高,但是相对来说就比较便宜啊。那么来看一下国家最近在鼓励的所谓的透肯出海啊。透肯出海是什么意思呢?就是因为 整个全世界目前在 ai 上投入的最大的两个国家,人工智能这块真正竞产生竞争的其实就是中美啊。那么为什么我们要通过出海呢?本质上约等于电力出海啊,为什么这么说呢?我们来看一下,其实我们国内的整个基础配套设施是比较发达的啊,也比较完善, 尤其是什么我们店里的价格非常低,因为我们大量的发展这个光伏发电和风力发展,所以呢我们整体的价格是比较低的,所以我们通过偷啃出海的方式呢? 其实也是店里出海,国内的模型跟国外的模型有没有差距?我们要客观的承认是存在差距的。但是 针对一般型的企业,国内的模型比如说像通一千,他其实已经可以满足大部分企业的日常使用,其实我们出海还是非常具备竞争力的。那么最后来看一下 hokken 竞赛,其实就是中美的竞赛,那么后期呢?可能美国呢?主要是以什么以模型能力为他的进化方向。那么我们国内呢?其实就是在酸利成本上我们不停的去 优化啊,还是有很大很大的优势,那么包括我们也在不停的去升级优化训练我们现有的模型, 后期的主要竞争就是这两块。呃,最近不管是各大厂商也也罢,还是厂家也罢,都在说 top, 包括黄仁勋近一次的发布会也在说到 top 就是 未来时代的结算货币。今天我的分享就结束。
17请叫我薛师 01:28查看AI文稿AI文稿
01:28查看AI文稿AI文稿很多人一听到 token, 第一反应就是虚拟币,今天我用一分钟时间让你彻底搞懂它。 token 是 ai 里最小的语言单位,你可以把它想象成搭建 ai 语言世界的文字积木。无论是你向 ai 提出问题,还是让它拣写文案 进行数字人直播,所有输入和输出的文字都会被拆分成一个个小块,每一个小块就是一个 token。 这里有个简单的换算关系,可以记住,一千个 token 大 约相当于六百五十到七百五十个汉字。你发给 ai 的 内容所包含的 token 叫输入 token, ai 回复内容里的 token 则是输出 token, 而且输出 token 的 成本更高。你使用 ai 的 时间越长,内容篇幅越长,消耗的 token 就 越多。这也意味着对应的算力成本、 gpu 消耗以及电费都会大幅增加。简单来说, token 代表着 ai 的 工作量,而这背后关联的就是你实实在在要花出去的钱。 不管是运行大模型、开展数字人业务,还是开启 ai 自动化流程,计费都是按照 token 的 使用量来计算的。只有真正理解了 token, 你才能精准控制成本,合理计算报价,有效对接算力,甚至从中赚取差价。如果觉得我的分享对你有帮助,麻烦动动您高贵的手,点赞关注一下。以后再有人和你聊起 token, 你 就知道它可不是什么虚拟币,而是 ai 行业的硬通货,是衡量算力的重要计量单位。
 02:16查看AI文稿AI文稿
02:16查看AI文稿AI文稿同学们大家好,欢迎来到系统集成冲刺课堂,我是刀刀老师,我们继续输入输出逻辑秒杀法, 看逻辑。四,预算出精准,它指的是制定预算会输出成本精准啊,就这一句话很好用,那我们来做一下题。一,制定预算的输入不包括, 那输入啊,预算出基准,成本基准是它的输出,所以选低选项。 二,成本管理计划的内容不包括啊,预算出基准,这成本基准是制定预算会得到的,所以它不是成本管理计划的内容啊。选 a。 第三,关于制定项目成本管理计划的描述不正确的是, 那你看 b 选项,项目成本精准,在成本管理计划中记录不是是吧,它是制定预算才会得到的啊,在成本管理计划当中还没有,所以选 b。 第四,以下哪个过程会建立成本基础?预算出基准 第第五,关于成本估算和预算的描述不正确的是 a, 估算成本的输出除了包括成本基准外,还应有估算依据。那我们说预算才出基准啊,是不是所以前半句就错了啊? 那选 a 选项第六,估算成本输出不包括哎,不包括成本基准,因为是预算出基准, 老师给大家整理了输入输出专题练习,已上传到问卷心,有需要的同学可以找我,谢谢大家!
18叨叨老师 04:52查看AI文稿AI文稿
04:52查看AI文稿AI文稿同学们好,欢迎来到系统集成冲刺课堂,我是刀刀老师,那我们继续输入输出逻辑、秒杀法 逻辑三,可交付成果的变形计,看结论,干活出成果,质检再核实确认后,验收结束得最终。 那我们指导和管理项目工作就是在干活,那只要你干活,无论这个活干的好不好,哎,都会得到一个成果,就是可交付成果。 所以指导和管理项目工作,他会输出可交付成果,这就是干活出成果啊。那这个成果能不能直接交给客户呢? 啊?不行啊,我们得自己先检查一遍,是不是啊?所以呢,是通过质量控制这个过程做质检,这也是自己在做检查 啊,就是自己先核实一遍,没问题了,你再把它交出去,所以这个可交付成果是质量控制这个过程的输入。 好,那么我们检查核实过后就会得到什么呀?就得到了核实的可交付成果吗?因为你核实过了是不是?那质检其实就是在核实,核实过后就会得到核实的可交付成果。 那核实过后,哎,那我们呢,就把这个可以交给客户了。那给客户干什么呀?去验收吗?是不是?那就是确认范围,其实就是在做验收啊,所以核实的可交付成果是确认范围的输入, 那验收通过就是得到了验收的可交付成果。你看,只要你验收了,就得到了验收的可交付成果,这就是确认后验收。 那么我们的可交付成果其实有很多个嘛,那你验收的可交付成果是不是也有很多个呀? 哎,那我们最后就是通过结束项目或阶段,这些验收的可交付成果全部,哎,收集起来是不是把它 形成一个最终的产品、服务或成果?所以验收的可交付成果它是结束项目或阶段的输入啊,最终它会得到就是最终的产品、服务或成果 啊,所以这是结束的最终。好,那么我们来做题巩固一下。 一、核实的可交付成果属于哪个过程的输出呢?那就是质检再核实,所以控制质量啊。选 c。 二、项目范围确认的依据不包括看,看到确认就想到再做验收是吧?那它对应的得到的就是验收的可交付成果,所以 d 验收的可交付成果是它的输出,是它的成果啊,不是依据,选 d。 选项。 第三,验收的可交付成果属于项目范围管理当中的哪个过程的输出啊?那验收对应的就是确认范围吧,所以选 d。 在项目整合过程中,哪一个不属于结束项目过阶段过程的输入 输入,我们说结束得最终是吧?那你最终产品服务过程果它是它的输出啊, 所以 b 选项就不吃了。第五,结束项目过阶段的输出不包括,那你看,我们结束得最终,所以 b 最终报告是他的输出, 那待更新的一般是作为输出的,所以排除法就选 a。 或者我们记住验收对应的就是确认后验收嘛,那这样子也很快,那就 a 就是 确认范围的输出,而不是结束项目过阶段的输出。嗯,所以选 a。 好, 那么逻辑三给大家讲到这里,谢谢大家。
8叨叨老师


