谷歌的Gemma4大模型支持多模态吗
谷歌 deepmind 上线战马四全系列开源模型,全系 ipad 二点零协议商用自由手机、树莓派服务器全场景覆盖,真正实现把 ai 装进口袋,断网,也能用四款模型覆盖全场景。 第二币仅需一点五 gb 内存即可在手机端离线运行,性能媲美上代两百七十亿参数模型,三十一币单词,在拼鸟 ai 榜单位列全球开源第三。 压二十倍餐数量净品全系支持多模态输入。 e 二 b 四 b 内置音频编码器,实现三十秒实时语音识别。二十六 b mode 通过混合专家架构激活三十八亿参数,速度与智商兼得,而且开放开源协议,告别过往限制,自由修改 分发商用数据,不出设备,企业与开发者彻底掌握数字主权,开源即正义,离线即自由。你准备用粘马四做什么?

粉丝1005获赞6.5万
相关视频
 03:00204YZZ
03:00204YZZ 05:28查看AI文稿AI文稿
05:28查看AI文稿AI文稿公主,你现在看到的就是谷歌最强的开源模型加码四,可以看图,能听音频,也有不错的推理机制,最重要的是完全免费,给我几分钟,从零开始,将加码四部署在自己的电脑上。我们直接开始 先花一分钟和大家聊一下贾马四是什么?它是谷歌刚发布的开源 ai 模型,跟商业版的怎么奈同根同源,你可以理解为谷歌把自家最强的 ai 技术浓缩成了一个免费的版本,直接送给你用。 那么它好在哪里呢?三个点。第一,多模态,不只是聊天机器人,你可以发图片让他看,发音频给他听,还能写代码。 我们可以看看这张表格,横轴是模型的参数体量,而纵轴就是性能表现。贾马四以满血版的性能表现和千万的三百九十七 b 的 模型能力基本持平,关键在于它的体量只有千万的十分之一,这真的非常夸张。 第二,完全免费,不用充会员,不按 token 收费,并且可以商用,你可以模改它做成各种有意思的本地模型,拿去做产品也没有任何的问题。第三,隐私安全,因为跑在你自己的电脑上,所有的数据都不会出,你的电脑拿它处理合同,财务,私人物件,不用去担心泄露。 ok, 我 们直接动手。你现在只需要打开一个浏览器,然后把它放到全屏上,直接官网上搜索欧拉玛点 com 啊,然后这个东西就出来了。然后你只要点击整个画面的一个右上角 download, 看到没有?然后你可以选择你是 mac os 系统还是 linux 还是 windows, 我是 mac os, 那 你就直接点击这个 download from mac os, 然后我们就可以看到这个画面上的右上角应该是会有个下载的链接, 然后等它下载好就可以了,因为我这边其实已经安装好了吗?那么我这边的最终的一个输出效果的话,大概是在这里。你们下载完了之后,打开你们的桌面上的欧拉玛,你们看到的应该是现在这样子的一个画面,那就说明你已经安装成功。 佳马仕一共有四个版本,你可以根据你的电脑配置进行模型的选择,模型的能力越强,所需要的配置就越高。对于内存小于三十二 g 的 玩家,我建议大家直接安装一四 b, 三十二 g 及其以上,可以试试看二十六 b 和三十一 b 的 参数量, 其实这两者模型的能力大通小异,如果你是为了极致的精度,可以选择三十一 b, 但是在我看来,二十六 b 呢,其实是一个非常甜点的位置,达到了速度和精度的一个平衡。如果你不知道你的电脑内存是多少,这里针对 mac 用户,你可以选择终端输入这行命令。 而 windows 用户你可以点击 win 加 r, 点击回车,召唤出来你的终端以后,然后再输入这个命令,也可以显示出你的内存。选择好对应的模型,我们只需要打开终端,和刚刚一样的步骤,根据模型输入指令直接回车即可。等待模型下载好,打开你的 oala, 选择模型就可以开始了。 ok, 我 们打开我们欧曼的软件,你点击这里,然后往下滑,你就可以看到你刚刚已经安装好的这个佳马仕。我们来问他一个很有逻,就是说很有那个逻辑陷阱的一个问题,就是我今天要去洗车,但是只有一百米,你觉得我是走路去还是开车去? ok, 我 们来看一下他的一个答复是怎么样子。 这是一个非常有意思的一个逻辑陷阱题,我们可以从不同的维度去分析。逻辑层面上来说,必须开车去, ok, 这一点已经很棒了啊。 那如果说是从脑筋急转弯角度上来说,他说如果你走路去,那么你是在散步,而不是在洗车。哦,也就是说他分为了三个维度,一个是脑筋急转弯,一个是实用主义层面,还有个就是逻辑层面。我们来看一下他这个佳马仕的这个逻辑能力。哎,你还真别说这小参数,但他的表现还是不错的。 那么 jamas 它的一个很大的优点就在于它其实是支持这个多模态的。我们来不妨给他上传张图片,我们来看一下。 ok, 那 么我们上传一张什么图片呢?哎,上传张这个图片,你们看怎么样啊?就是这是一朵花,然后有个太阳,有一本书,我们来让他看看。我说,啊,描述一下, 描述一下这个图片,我们来看看他的多模态识别能力怎么样?说实话,本地具有多模态识别能力的模型,而且是能够你自己去模改的,其实并不是很多。我们来看一下。 ok, 一, jeff 二,然后 jeff 三,给了几个他看到的一些画面。好,我看他现在在思考和输出。这张画面充满了诗意,唯美且带一丝忧伤。 画面主体是一本翻开的书籍。哎,确实是对的,背景与中景是一个画面,然后呢,躺着一只洁白的玫瑰,然后背景是有一个夕阳,散发出这个温暖的金橙色光芒,哎呦,很不错,你们发现没有,是不是很棒?就是说他好像 表达的还是很到位的,但是因为呃,我其实本来还是想测一下这个关于音频识别和这个视频识别的,因为这个佳马仕它也是支持视频识别的, 但是因为欧拉玛官方不太支持,所以大家可以自己去谷歌 as do do 上面去玩一玩。所以总的来说,其实通过这么两个比较简单的测试,它当然不够严谨,而我觉得感受来说的话,这个香奈儿丝还是 真的是能够在本地帮我们处理一些比较复杂的一些任务的,就是在文字层面以及去多模态识别能力上来说,是一个比较抗打的模型。 看到这里相信你一定会明白, olama 本身是一个模型管理器,你当然也可以不用贾马四,你可以选择开源的 deep stick, 千问等等,其他的开源模型还是同样的命令,一键配置就可以了。 本地捕鼠的最大优点就是保护你的隐私,模型的使用不会受到任何的限制,同时也可以支持模型的微调,让它更合你的口味。下期我打算教大家小白如何从零到一,微调自己的本地模型,感兴趣的可以点个关注,我们下期再见。
8389赵逍遥Xavier 09:55查看AI文稿AI文稿
09:55查看AI文稿AI文稿谷歌终于坐不住了,正式卷开源市场, jm 四的效果到底如何呢? jm 四的发布啊,真的有可能让我们实现头很自由。这期视频呢,老张给大家简要介绍一下 jm 四怎么安装到本地,以及如何搭配到我们的 open klo 大 龙虾上, 附带所有的安装步骤啊,大家可以一起来体验一下。后续呢,老张也会根据测评效果给大家接着发视频,这期是我们完整的部署流程,老张重点给大家简单聊一下,就是为什么 jm 四的发布啊,会让大家感觉谷歌真的开始卷起来了呢? 首先第一点,他和目前谷歌的 jimmy 三用的是相同的技术基座啊,所以说他的能力是毋庸置疑的。第二点就是商业自由,你直接部署下来做什么都是可以的,都是允许的。然后第三个就是支持多模态,无论是文本、图像甚至小规模的视频音频, 他都可以直接支持。第四点就是结合前段时间爆火的 open klo, 他 可以直接在本地对接 open klo 以及对接 klo 的 code, 实现本地的偷根无线化。这是老张给大家总结的四点,为什么詹姆斯的发布会让大家感觉,哎,可能真的要进入到一个新的纪元, 然后呢,他所发布的这四款模型呢?老张给大家做了一张图片啊,大家可以到时候把它截下来。第一个模型一二 b 的, 他本身是用于手机或者边缘设备八 g 显存, 然后最高端的三十一 b, 他 所对应的旗舰版本呢,是对应的是二十四 g 加,所以大家根据你的需求来进行对应的模型选择。老张这次视频呢给大家来看一下三十一 b 的 这款模型的安装, 然后关于本地的安装部署啊,其实非常简单,任何开源模型,其实我们只需要让他和欧拉玛就是那个小羊驼结合到一起就可以了,然后找到你符合要求的版本。安装成功之后啊,欧拉玛现在已经有了一个完整的应用端了,所以大家可以直接在这个位置和他进行对话交流。 那我们想要下载 jm 四到你本地的电脑上,我们可以使用它的官方指令,会告诉我们直接怎么样去进行 jm 四的对应安装,像老张想安这个三十一 b 的 对吧?我们就把它拿过来, 把它直接这有一个 c l i 命令行安装方式,把这个东西直接复制在你的开始菜单中,单机右键选择运行输入 cmd, 直接把刚才指令粘贴过来,这儿的时间会很长,因为它有二十个 g 的 大小,我们直接稍作等待 安装成功之后,我们也可以直接回到它的客户端中,在模型选项上找到我们安装好的詹姆斯冒号三十一币, 然后可以直接进行对话。老张他处理一个较为复杂的提示词,我们让他看一下当前显存的内存消耗, 咱们拿这个 ai 慢距的提示词来测试啊,这个提示词非常的长,我们看一下他读取提示词的能力,以及他的这个显卡的性能消耗,我们看一下啊,这个显存直接拉满的,达到了百分之九十四的占比, 而且这个响应速度还是非常快的,只需十一点七秒啊,就把整体的业务流程给我们直接补齐了,而且呢按照需求给我们进行了对应的提问,要什么样的慢距效果,所以说以目前的测试反应来看呢,他的这个响应速度起码要比之前的很多大模型要好的多, 所以接下来我们自己来尝试一下对话类的工具,可能大家都不是很需要的,我们能不能把它接入到我们的 open clone, 丢到我们的龙虾里,让它们俩来进行联动的。然后这期视频呢,老张顺便给大家提一下,就是最新版的 open clone 的 部署流程 啊,咱们可以快速的去过一下一些重点的细节,因为之前老张发过很多期的部署视频一块的呢,因为它本身啊, wsl 它是相当于在 windows 系统上安装一个 linux 的 独立系统, 这样的话呢,就直接相当于在你电脑上安装了一个独立的存储空间,它所谓叫做沙盒安全,而且运行起来呢是不会有任何的兼容性的对应问题的,因为 windows 中啊,它的权限呐,路径等经常会报错。所以说我们这 期视频重点教大家怎么用 wsl 进行 win opencl 的 部署安装,这样的话, windows 和 wsl 的 安装您都了解之后之后学起来就非常方便了。 然后接下来呢,老张给大家简单的介绍一下在 wsl 中如何安装我们的 openclaw, 因为之前呢,咱们介绍过太多次了,很多兄弟留言说老张就别介绍怎么安装了,然后我们就给大家简单说一下注意事 项。首先第一呢,你想在 wsl 上安装 openclaw 的 话,第一点你得先在你的 windows 系统下把 wsl 安装一下,当然很多电脑老张发现其实都是自带的, 怎么检查是否自带呢?咱们可以直接输入 wsl 空格杠杠威森,如果弹出定的版本号,证明 wsl 电脑已经安装了,如果没有弹出的话,使用安装指令 wsl 空格 insert 直接安装即可。然后紧接着按照老张给你提供的指令复制粘贴就可以了。先安装你的优班图, 安装之后进行一下更新。安装完优班图之后啊,在这选择这个倒三角,找到优班图系统,就可以直接进入到你的优班图系统当中。 在你安装过程中啊,它会让你设置一个用户名和密码,到时候可能需要做一步密码验证。在优班图系统中,注意是优班图系统中运行这些环境指令,分别安装 python 三,安装一个压缩包工具,方便安装一个 node 点 ps, 然后再安装一个 get 工具。 如果说为了检测每一步安装是否成功的话,你可以分别输入,比如 note 杠 v、 npm 杠 v, 包括 get 杠 v, 在 这检测我们对应的这个版本。如果都能弹出版本号,证明你三项安装都是成功的,这是配置 openclo 的 基本的内容要求。 然后紧接着我们把基本环境配置好的兄弟,你还需要在这个位置安装一下这个欧拉玛。 这老张要重点说一下,说老张我不在本地都已经下载好欧拉玛了吗?为什么在优班图里还需要再配置一下?其实我们优班图中是可以调用本地的欧拉玛的,但是很多兄弟在调用过程中分别给老张留言说说调用时无论是 ip 地址找不到,还是 ip 的 动态变化,导致每次都需要重新连接,重新配置。 所以说最简单的方式就是把欧拉玛在你的优班图系统中再次的安装一遍。其实安装非常简单,只需要把第一步的安装指令复制过去,直接在这个位置直接粘贴即可。安装成功的检测方式很简单,你就输入欧拉玛, 如果他不报错还给我们对应的选项,是咱们是进行对话呀,还是怎么样的证明你的安装就是成功的? ctrl c 直接退出。 所以说欧拉玛安装之后,紧接着就是把我们的模型在当前的优班图中跑起来。老张刚才给大家测试的是 jm 四三十一 b 模型,我们直接输入指令欧拉玛空格 run, 然后你的模型效果直接回车,第一次时他会直接进行对应的模型下载。如果说你现在只想用 open klo 来调用欧拉玛的这个占四的话,可以在我们的本地电脑上把之前咱们那个桌面端给他 删掉,如果说你不你想两端都使用的话,就可以直接在这个位置进行使用了,然后发一个你好看一下响应速度, 嗯,响应速度是非常快的,所以接下来我们把这个家伙欧拉玛的詹姆士直接部署给我们的 openclo, 在 这怎么中止对话,摁一下 ctrl c, 再摁一下 ctrl d 啊,就可以直接进行中止对话了啊,所以说大家可以直接的把它退出来, 退出来之后我们在这儿部署一下 openclo。 关于 openclo 的 安装呢,官网推荐是使用 c o r l 这种安装方法,但是老张发现很多兄弟在使用这种安装方式时呢, 出现了这个网络问题,导致下载出现卡顿,如果说 c u i l 的 方法报错的话,直接使用 n p m 安装也是完全可以的,安装完之后直接输入 open klo 空格杠 v 来输出最新的 open klo 的 对应版本啊,这就是老张跟大家说的一些建议啊,大家按照这个要求去做就行了。 然后接下来我们进入到配置,直接是直接输入它的配置指令回车,选择 yes, 然后选择快速开始就可以,我们直接配置一下模型, 然后选择更新,这选择谁呢?选择这个欧拉玛啊,然后选择默认的这个 ul, 选择本地模型,让他去给我找一下咱们本地有哪些模型,稍作等待 好,选择当前的这个模型,咱们四三十一币,然后配置我们的聊天软件啊,这个老张之前讲过太多太多次了,现在呢,他又支持了很多,包括 qq 之类的,大家有需要的话可以按照之前老张的教程再来一遍,我们先跳过 打开之后啊,就可以直接对话。但是如果说善于观察的兄弟们也发现了,老张呢把这个使用模型呢换成了这个一四 b 的 模型,不是那个三十一 b 的, 因为三十一 b 呢,老张在测试的时候也好,或者在一些使用时候也好,他有的时候会出现这个连接超时的问题,也是 oppo klo 更新到最新版本出现了一个能启动问题, 这个呢,老张现在还没有特别好的解决方案,所以说我先用一次必得给大家进行演示,发一个,你好,我们来测试一下他的响应速度啊,还是比较快的。 然后接下来呢,我们再把之前的那个慢句的提示词发送过来,我们来看一下他能不能更好的帮我们去进行慢句提示词的对应理解,以及对应的相关反馈。 嗯,其实我们看到啊,他反馈的这个结果呢,和三十一 b 相比啊,真的是有一定差距的,但是呢,确实也是另一方面实现了我们所谓的叫偷根自由。 大家呢也可以后续啊,去测试一下怎么让本地如果你的显卡够用的话,把这个大模型给它跑起来。然后老张呢也会及时给大家更新,无论是在评论区中还是视频中教大家如何使用。我是程学老张,定期分享 ai 好 用知识,希望大家多多关注。
4467程序员老张(AI教学) 00:40查看AI文稿AI文稿
00:40查看AI文稿AI文稿家人们 google 的 jam 四已经可以在手机上运行了,而且不需要网络,完全本地化,可以实现多模态交互和工作。这里可以看到它可以识别图片,基本上文字、细节、颜色、 表情都可以识别出来了,速度也是非常快,然后也可以直接语音识别和交互,可以看到也是很快,也可以控制手机,可以玩游戏,这里点击下载就可以了,还可以写代码,写总结等。最后还有 cq 的 能力,可以用自带包括自己希望做的 q 来实现相关功能,同时可以进行调查,做自己专有小模型将不是梦,大家快用起来吧!
126杰哥AI实验室 02:26查看AI文稿AI文稿
02:26查看AI文稿AI文稿今天 ai 圈神仙打架最重磅的消息,谷歌开源了 em 四最高三十一 b 参数版本,直接支持看图和听音,加上二十五万六千的上下文窗口和原声放声 calling 支持。 如果你在做 r a g 或者文档,理解,它就是目前最能打的开源基座之一,赶紧去测阿里。这次的路线选择很有意思, 它们避开了通用大模型的正面互卷,发布了 qn 三点六 plus, 这是一个专门为 ai agent 场景彻底优化的编程模型,不管你是写 ai 开发辅助工具,还是做 agent 的 底层架构,这条专精路线的产品必看。 cloud 的 a p i 更新了单次输出终于放宽到了三十万, token 以后生成长文本,不用再痛苦的切块分段了。另外要注意,旧版 sonnet 和 hico 三将在四月中下旬集中退役,一旦过期,原有的接口都又会直接瘫痪。 本地跑大模型的玩家有了新硬件选项, amd 刚刚搞了个免费开源的本地服务器,叫 lemonade, 以前跑本地大家首选奥拉马,但他基本只吃 gpu 算力。 amd 这个新东西最大的亮点是把 npu 也榨干用起来了。 用 a 卡或者关注本地推力效率的人,这绝对是一个极佳的替代方案。生态方面, mister 动作非常密集, 他们不仅发布了开源语音合成 voxel 和 agent 开发工具,还拉上 nvidia 成立了 neemo 创联盟。这个组合的目标非常明确,就是通过大厂联手来加速开放模型生态的落地。数据方面,字节跳动的豆包日军 token 流量已经突破了一百二十万亿, 这是一个非常夸张的量级,意味着字节在 ai 基础设施上的投入已经形成了规模效应,在这个调用量下,后来者基本没办法在成本上跟他竞争了。 国内多模态也在加速,智普发布了 g o m v turbo, 核心卖点就是一眼看图,直接写代码。与此同时,快手发布了生成式推荐系统,蚂蚁也开源了 agent 安全插件, 国内大厂的产品发布节奏明显在变快。最后推荐几个神仙开源工具,录屏 demo 试试免费无水印的 open screen, mac 玩家记得升级欧莱曼 m l x 提速享讯机器人可以关注 o r c a lab。 另外, clock flair 也有个案例非常夸张,他们用 ai 只花了一个周末就复刻了 next day, 并跑进生产环境, ai 的 实际生产能力已经不需要再怀疑了。
106AI赚钱研究社 24:38查看AI文稿AI文稿
24:38查看AI文稿AI文稿hello, 大家好,欢迎来到我的频道,这里是荒野星洲观察带你,我吃的是小看 ai。 好, 那么咱们本天呢,就来讲一个谷歌团队的 deepmind 最新发布的一个叫迅雷马四的一个模型啊,这个模型就很厉害了哈,那我们看到啊,这个模型它其实是包括三种啊,不同的参数量的, 或者三种不同的大小的,也属于一种小型的,包括啊,两臂和四臂的一个模型啊,它专门为移动设备设置的,这个呢,我们会 待会就会专门在我们的 iphone 上来试一下。我的设备呢是 iphone 十七 pro max, 我 们也来实测一下啊,这个设备这个模型呢,在我们的 iphone 十七 pro max 上的一个运行实际表现是怎么样啊?我们待会也会拿图像文本和视频一起来看一看 啊,那那感兴趣的小伙伴呢,也可以待会或者是直接跳转到后面也可以,也可以来听一听我们前面对这个模型的一些分析。 好,那我们看了,还有除了两个两币和四币的一个密集参数,也是 dance 模型, 那我们先来看一个 m o e 模型,一个三三啊,一个二十六 b 的 m o e 模型,那看上去都比较少啊,和那我们动不动 deepsea 的 这种六百七十 e b 的 这种模型相比的话呢,还是小比较多的,而且只有这三十 e b 的 二十六 e b, 二十六 b 的 啊,但是呢,谷歌他有自己的一个在小模型上提升效果的方法,这个我会讲。 好,我们可以看它这个模型的一些特点,我们可以看到它是支持推理的所有的模型,其实小模型它也支持推理开启推理模式,包括原声多模态, 它可以处理文本啊,包括可变宽高比的这个可变分辨率的所有图像和视频和音频啊,它都是原生提供的。好,我们看了原声多模态大模型,我们之前讲过非常多次了, 他和我们说非原声的用这个投影层相比的区别就在于啊,他是省去了翻译官这个这个角色的。如果你是非原声的这个大模型的话呢,你需要做的就是啊,你把这个 啊,你把这个图片啊,你先切分切分块,接下来呢,你再啊读一遍啊,然后文字呢读一遍,接下来把你图片的 这个读完的这个结果呢,翻译一遍,翻译成文本,能够听得懂的,通过投影词翻译一下要投的这个统一的文本向量,就这样你就有一个翻译的过程,那相当于损失了图片的很多的语义,或者损失了图片的很多的一个地方, 那这个时候呢,如果你变成原声呢,相当于你把所有的只要能做 token 的 万物皆可 token, 如果把所有的图片也变成 token 的 话呢,这样就可以在图片文本甚至是音频视频间无暇无缝的进行 attention, 点击计算,这个时候呢,你的图片的任意一个像素点都能关注到你文字里面的任意一个文字,比如说猫的眼睛这四个文字,它就会把更多的 attention 呢啊,就是 点击这到这个最硬的这个图像的这个猫的眼睛的地方去,这也就是原生态大冒险的能力了。但是如果你是 我们说的 clip 模型,做了那种传统的这种拼接型的这个原声大模型的话,然后拼接型的多模态大模型的话,那他就做不到了哈。好,我们包括更大的,像这种窗口小型模型就是边缘层呢,有一百二十八 k, 那 中型模型呢?是二百五十六 k 了, 看,还有是一个增强的编码括领或者这个 h 的 功能啊,它编码方面它说是有改进的啊,并且支持了方正括领了啊,那包括原声系统提示, 那包括他就是有一些原声的系统,其实死在里面都会有的。好,所以我们这几个点的话呢,像我们对一般的普通的一个大模型,比如说这么来说呢,也是非常司空见惯的,但是在这种开源模型里面还是非常不容易的哈, 好,那我们接下来看啊,啊,它是默认的话是 b f b f 十六啊,那我们看它需要多少内存呢啊?如果是对你手机来的话,是需要多少内存或者显存呢?啊?那比如说这个最小这个模型,它需要九点六 b, 默认就是九点六 g b 啊,那如果你 iphone 十 g max 是 默认是十二 g b 的,是 ok 的 啊,那四四四四 b 的 这个模型的话就不行了,所以我们一般 iphone 十 g max 你 可能跑一个九点六 g b 的, 如果你要比这个十五 g b 还要大的话 啊,就可以,但是呢这个只是最小的一个值了,为什么呢?啊?那具体说的话,级别我们可以看到哈, 它具体的所要的这个内存,它取决于哪因素呢?比如说啊,这个我们看 e e 代表的是有效的一个参数啊,有效的一个参数就是 efficient 啊,它为什么呢?这么说呢,在有效的参数呢,我们看到是 e 八啊, e 二比,那就是有效的参数是两 二十亿啊,那就是四十亿个有效参数啊,我们看教程的模型,它采用了什么?我们之前没有讲过,这叫做每层进入 p l e 技术 啊,为什么要有这个 p l e 技术呢?我们看它的目的是以在程度上提高设备中的参数效率啊,我们看 p l e 是 什么意思呢啊?所以我们知道一般情况下,我们这个每一层啊, transform 层的那个逻辑是怎么样的,哎,就是你先走 attention, 再走情感传播啊,那接下来就 ok 了, 对吧?你就出去了啊,你首先是透看词源化或者是 embedding 啊, embedding, 然后再啊,我们说这个 attention, 再然后再添加传播就可以了,就剩三步,但是呢,哎,它这个 pl e 呢,在每一步里面,它会多给你一个词汇表啊,相当于呢, 它不会给这个模型添加更多层,而是为每个司法单元的解码器层提供小型嵌入。 我们说这个 ple 到底是什么意思呢?其实是这样的哈,就一般情况下,每一层的参数它是固定的,我们知道非常多拆 transform 层,那每一层的 transform 层呢,它都对于这个每一个 token 它来进行计算或者推理过程中呢, 它的参数都一样的,但是呢,我们这时候如果有了 p l e, 相当于呢,对于每个 token, 它会有一个单独的一个词汇表,那会去进行叉表,那对每个 token 它叉表那会有不同的一个微调的一个作用,相当于呢,对你每个 token 在 每个层里面进行了一个微调,这种情况呢,它这个目的最终就是说 即使在你小参数量的情况下呢,也能达到你大参数量的模型的一个作用,因为为什么呢?因为你的模型的啊,这个体积啊是有限的,所以他谴责在不加大层数的情况下来做,做到了微调的效果。一般情况下他就说如果你想要模型效果更好,就是跟你是 kelvin, 你 需要加大模型的层数, 你需要加到目前的参数量,你需要加到目前的计算量,但是这个时候呢,谷歌这种方法就是适用于小模型啊,去 p l e 技术呢,可以在你啊不加载模型参数量的时候能够做到我们刚刚说的这些效果哈。 好,那么接下来看这个 m o e 我 们就比较熟悉了,我们之前很多视频都讲过,对吧?好,我们看到是二十六 b 的 m o e 模型啊,每一个每个 token 仅只激活四十四十一个 a, 就是 四 b 的 参数啊, 啊,但是说二百六十个亿个参数都必须加在显存里面,这我们讲过,为什么吧?因为因为它是专家并行的,或者是说啊,它要找专家的,那你如果不抓在它显存里面,你永远不知道下个 top 你 要找哪个专家,对吧? 好,那我们这个就不讲了哈,啊,包括仅是它这个我们上次说的仅是精准权重,对吧?不包括很额外的这个 k v catch 啊等等等等,这个我们就不再讲了。 好,那我们先看一看这个模型卡片,也就是最新的它有什么区别呢?我们可以看到,之前呢,我们都看过了,那这些其实我们也看过了啊,那编码器的参数我们就不再看了 啊,其实我们看到滑动窗口上下文长度转换词汇表,这个大家有感兴趣的话可以看一下,包括这个积分结果可以看到哈。这个啊,编码四呢,这个三十一 b 和骏马四的一个二 b 的, 这个模型呢,还是差啊, m m l u 是 通识技术,通识能力的话还是差挺多的,对吧?那么一个最最强的是八十五啊,这个时候六十啊,那么这个还是差的就比较多 啊啊, m l m m u pro 呢,也是差的比较多的是我们,但是呢,这个能在最小的这个模型能在你的是边缘测计算或者边缘测运行就已经很不错了。好,那么接下来呢,我们就不看了,好,我们直接进行测试。 好的,那大家现在看到的呢,这个就是我的手机了啊,那么关于怎么用这个 app 啊,其实大家只要到如果你是苹果手机的话,你在啊啊,你,你在比如说漂亮区的 app store 里面下载一个这个东西,叫做 google ai gallery, 这么样的一个画廊就能够 啊使用了,你只要下个 app 就 可以了,你就没有什么复杂操作,当然你也可以在 a s studio 里面,但是 a s studio 里面呢,它就 就是联网的了,那你要到本地跑的话呢,你可能就要下载这么 app 了,我们看了它是纯本地的,我们其实是把它这个关掉啊,我们把我们的网络关掉,它也是在这个本地跑的,我们看看这个 app 的 界面能不能看得出来啊?它可以,如果我们讲到这个 model 的 话, 选择 model, 我 们可以看到啊,最新的 model 呢,就是这 game 四,它包括原来还有 game 三 n 这种的话, game 四的话呢,我们可以直接是用的,包括它对, game 四呢,它有非常多的一个功能,比如说我们看到这个 s image, 就是 我们可以给他图像,或者是给他一个语音,或者是给他一个文字, 甚至让它用 agent 的 模式,那我们这四个都会一个一个来试一下,下面这个就不用了哈, prompt lab 就 不用了,所以我们来试试一下,一个一个都试一下吧。那好,我们这边是基本的这个 chat。 好, 那么我们看这个模型总共大小是二点五四比,也算是比较亲民的一个大小了,我们试一下。 好,首先呢现在他在把模型,权重等等一切的东西加载到我的这个显存里面来。好,那现在是加载进来了,我们试一下,再看看。这里能上传啊,他什么也上传不了,那我们看看他到底情况怎么样,就比如说,呃,帮我写一首关于 春天的诗。 好,那我们接下来的设置这里看一下它可以设置的,比如说啊,加速器的话, cpu, 那 我们可以用 gpu 了啊, temperature 的 话到 e, 然后 top p, top k, max, token, 这,这个都不用调。那我们把 emoji 滤镜,我们看看它,打开心情,打开推理模式,让它推理一下。好,我们看到啊,这个啊, emoji 滤镜处这个设置都 ok, 那我们试一下,那么看这个速度还是可以的啊啊,不过问题在于它比较耗电,耗手机的电,那他也知道,因为他是本地跑的嘛,他要跑去跑去 p u 当然是比较耗电的,不过我们看这个速度确实不错。 这个推理能力还可以啊。推理了这么多啊,只不过有个问题呢,就是它这玩意是它这个怎么做?是这个传统的,这个传统输出了这种 markdown 格式啊, 哎,这个这个这个,你前端 ui 也不给你整合一下,你看这个档格式乱输出的。嗯,这个问题不大吧,这算是一个,他也不是完全没有整合,你看这个这个啊,井号的,星号的他就整合了这个加粗,但是井号的就没有这个大标题的就没有, 你们看啊,是个一是个啊,当春日的余温渐渐散去啊,溪水涟漪一朵朵花啊,爱你们吧。我觉得还行。那我们接下来再问一个问题,看他在 k v cash 上升的时候,他会不会速度变慢呢? 那比如说我们再问一个问题,就像,呃,你觉得 心情不好的时候可以做什么? 这个还是很快的啊,我们现在看到虽然说退了也很快,但是我的这个手机的电量也消耗了很快。可以告诉大家的是现在就没问题的话,我们手机电量呢已经消耗了三个点了啊,三个三,百分之三了。这个这个,呃,这个就没有办法了, 这我没看到啊,现在它的速度是明显的比刚刚要慢了,这也很正常这也很正常,因为它这个目前的 kiwi cash 是 越积越多了。嗯,虽然慢了吧,但是我感觉还是能接受的,对于你本地模型来说的话还是能接受的 啊。我摸一摸我的手机我的手机呢,目前还是还可以,并不是非常烫的感觉啊,目前我的手机 在这呢啊,这手机感觉还不是特别烫,还可以的,就表示这个,哎呀,这苹果十七这一代啊,它这个散热做的还是可以的啊,这个这个这个这个散热做的还是可以的,一般来说的话,如果你要跑本地跑这种效果的话,肯定是已经炸裂了这个热度 啊,这个手机电呢又一进一步下跌了,现在已经比较慢了啊,这个这个,这没有办法,因为这个已经花了一点二分钟了啊,这我们能感觉到一开始呢就花了这个 啊,三十八秒,现在要花一点二分钟啊,因为呢,你的随你输出输入越来越多,你的 qq 量越来越多,那这个时候呢,你需要进行计算量就会越来越大的,因为你是 n 平方,大家记得吧啊,你的指数,你的计算量次数是 n 平方, n 的 就等于你上升段长度,那你随着上升段的长度越来越多,你的计算量越来越大 啊,那你无论是在 pfif 还是 dq 阶段呢,你都会沉压的啊,所以我们看了这个文字的话,还是不错的,还是不错的,而且它的推理能力也可以, 嗯,还推流能量。那,那我就不尝试问一个这种很高级的推理问题了,那如果你要问推理问题的话,那我觉得他这个这个这个算了啊,算了,算了,那一般来说我们也不会用这种本地的这种啊,这个 ai 呢去问这种推理问题吧。 好,那么我们接下来就看一个别的一个场景啊,比如说,那我们接下来呢就来测一下视频吧。好,我们现在看到啊,我们现在是来测视频的啊,大家看到我们这有个 s cam 啊 image, 然后我们把我们上一期关于飞龙的这个视频呢,在这个图呢,图片给它塞进去了啊,就我们先测的是图片 image, 设了一个图片,那我们就问一个问题,就是说你能从这张图片里面推断出 我买的英伟达啊,那比如说是 nv 机啊 的股票是短期利好还是利空?那这个问题倒是有一点推理难的力度哈,我们看他能不能够啊,扛得住这个问题啊。 好,那我们看一下啊,他确实是能够识别出我图片里的这些数据的,他能够识别出我图片的数据的,他是没有问题的 啊,这是原生态模态的。好,那么接下来看啊,我们手机的电量呢,又一步下跌了,我们之前一开始呢是有八十八啊七十八的,现在呢又下跌六个点,我们就没问几个问题,这个,这个就是说 啊,所以说的话呢,你最好还是不要问一种很推理的问题了。那,那估计扛不住啊,那可能就是啊,原地位的隐私啊,本地还是可以的 好,那他对投资建议的话,他还会有一些这个免责条款啊,可以的,我们看啊, 该报告整体倾向是利好的,偏向利好的。你非常像就是一句非,就是一种估计高预期失业率低于一些展望明向预期强烈的就业收益将对 n v 产生产生利好 啊。所以我们强调这一说,一说放出来的科技,我告诉下,下一说重新考虑,放松后备政策,重重开包容,看我们周瑜身上表现,看你转的款式宽松。 呃,这,这就,大家如果看我上的视频就明白,他这个是讲的是不对的哈,这个讲的是不对的,可能是因为模型比较本身参数比较少的原因啊,因为大家看到这个飞龙数据是超出了我们的预期,按照我来说超出了市场的依据很多了,按照我来说,他应该是 会使这个免疫素充实,这个考虑通胀这边,那就会省的这个乱密不断或者加息,导致短期科技股这些 n v 点会沉压的。他并没有分析到啊,他主要的是后背甚至可能转向宽松,这个是我们这个不对的哈,不对的,所以的话啊,这个是不对啊,有,而且呢,他这个也 在这个模式里面,他没有办法去联网搜索,比如说问一下,你上网搜一下,看看能不能上网搜, 他也是没有办法上网搜索的,他看到了他,他是一个大眼不识,并没有具备搜索的一个能力啊。所以的话呢, 本地的这个用的这个模型啊,确实就是局限性比较大,这个我们也能理解的,本地的局限性现在摆在这了。好,那我们就不再去逗他玩了哈,因为没有什么意思,我们测试一下就可以了。好,那我们接下来看一看,比如说呢,我们接下来看一看这个,嗯, agent agent skills。 好, 那么这里也可以用 agent skills, 我 们看看。 还是这个模型好,先把它加载到我们的选项里面,那我们接下来看它有非常多的 agent skills, 包括。呃,哎,我怎么点了一个这个玩意?等一下 啊,等一下啊,那我们说再来一遍,我们看到有多少个 scales, 我 们点下这个 scales, 好, 看到的有非常多 scales, 我 们它总共八个 scales, 包括 in interactive map, 包括 kitchen, adventure 啊, cosplay, 还包括 query uki p 点。啊,那它还是能够搜索的,但是它有一个 scales, 上面就会搜索的,还有 qr code, 是 可以专业 qr code 出来。啊,那我们呢,其实这里呢,我们也看到啊,它可以 看到你的系统其实词的。那这个系统其实词呢?这个显示的是这个,它就只有一个 skills。 嗯,然后其他的呢?都是指的?是啊,让它符合 skills 输出,这个可以是个 agent 的 一个这样的一个标准的一个格式了。 好,那我们接下来试一试这个 kiting adventure 吧。啊, kiting adventure, 好,那它成功加载了这个 kinead 玩者。它其实呢,它就是一个啊,像一个冒险小文字游戏。那我们接下来用中文来跟他聊一聊,玩一玩这个游戏。 好,那么看你醒来,已光滑的金属面上,台面已经低沉的不像了。你想做什么?仔细检查周围环境,被搜索,那就回答一个。一, 那我能不能自己说呀?啊,我想逃跑,能不能行?行啊,行,行,你想做什么?你说什么?但你成功, 那我想跳下去,能不能行? 好吧,我感觉这个游戏有点无聊啊,多少有点无聊。嗯,这个车确实太无聊了。那我先来试一试能不能让它去,能有一个这种的搜索的啊,我看能不能让它能搜索 啊。 found that one battle of the other ones。 他 他就发现了什么啊?他是能够搜索到一些东西的,但是为什么他只搜索到这一个呢?他是一个 for a given topic 我 并没有给他任何的。 啊我告诉了他了啊我我这个新闻学子问了他 tell me who won the best picture。 那 如果我这个时候我试一下啊啊告诉我现在北京的天气我看它能不能自动去降用这个啊。 skills 他返回过信息报信息而不是返回信息报那他并没有返回一个信息报啊。那这个时候呢就表示这个工具他不是很好用啊他不是很好用。 可能呢对于这个奥斯卡二零二六年奥斯卡还在那用呢但是对于我这个其他问题就用不了了我也不知道为什么因为他这个东西确实是不是很好用所以呢他并不是一个非常好用的一个 agent 不 过我们可以让他写代码他说他能写代码是不是那我们说帮我 写一个完整的啊贪吃蛇游戏 包括钱过关的。那我看看他的极限承压能力怎么样吧如果他作为 agent 的 话他应该要能这么做的对不对如果做不了的话那我觉得他就不是合格的扣进 agent 的 了。 呃这卡住了这就比较尴尬了。那那我只能我重新走也走不了。好吧 刚刚呢就非常尴尬啊刚刚非常尴尬这个整的给他整死机了因为大家看到这个是个新功能我估计还在背的版本咱们再试一次给他一次机会实在不行那就算了吧。啊那那只能说明他要在在这个看在 as studio 里面用也好点。我们边缘测他确实是比较呃捉泥鳅肘啊只能说是那我们这里试一下就帮我写一个 拥有前后端的完整的 贪吃蛇游戏看能不能行啊。那我看这个加号能没有什么。这个 fork library camera 呃也没有什么东西对吧?好那我这个这个 skills 也都选上了,我们看能不能行吧。 啊他怎么把这个系统其实词给打出来了?不是我没有让你打系统其实词啊。 哦他他一定要打系统题的词吗?哦还行啊他写出来了。哦。我感觉这个这个不太对啊。这个 貌似它并没有一个很好的啊或者是一个拓字来支持它,有可能是这个环境它只能是用来做 agent skills 它只能限制于我们刚刚看的那几个 skills 里面。 这个可能这个啊 read file 或者是 crit file 呢,它并没有这么样的工具,也就说它并不能够创造这么样的文件在一个沙滩环境里面,所以导致它就只能输出这种所谓的全文本 啊。那这个算不上一个 a 人呢我觉得算不上一个 a 人呢。那可能最多也就是能够调用一下你的啊这个 skills 那 其实也算 a 人了嘛但是它不是一个合格的 coding 呢,不知道大家怎么看啊。这个东西 好那么我们现在手机的电量呢也成功掉到了六十九啊,就没回答这个问题效果就不太好,我们两个花了三格电啊。所以大家如果除非是对你隐私问题特别要求严啊,不然的话还是不建议让你下个模型自己在这里跑,而且你看后面它是越来越慢的啊,它越来越慢就由于我们刚刚说的原因。 那这个也没有办法,他就是越来越慢的放。那那我们就不等他了啊。那我们首先呢就来总结一下咱们今天的这个视频吧,咱们今天的视频就给大家测试到这里了啊,那么今天这个视频呢啊,也是非常多的意外吧啊,因为这个确实这个模型刚发布也是个悲的版本, 不过呢我们是还是带大家来啊,测试了一下它的各项能力,特别是它原生多肽能力啊,主要是它能够在你手机里面通过十二 gb 的 那个运存,它能够做到啊, 它能够输出点东西,我认为它不错了啊,而且它能做的芯片和原生多肽,这个就超过了我们之前很多的一个模型了啊,所以这个是它,我觉得它是最主要的一个 优势啊,就它与它原生多肽,它能够识别各种各样的一个多肽信息啊,它那个你手机本地执行,你就先别管它效果好不好,你别管它是慢不慢 啊,那至少呢它能够做到的,在目前的话也是首屈一指的啊,那这就是我们咱们本期视频的全部内容了啊,包括包括呢,那这个耗电确实很夸张,很夸张啊,那么咱们呢就不太测试了,测试我感觉我的手机要不行了,现在已经微微的有点发烫了,它也不是特别烫 啊,有点发烫了啊,有点发烫。好,那么本期视频就到这里吧,那感谢大家的这个收听,那如果大家觉得这期视频对大家有帮助,或者想自己下载玩一下的话,也欢迎哈, 那么欢迎下载玩一下,如果安装方面有什么问题的话,也可以私信来问我啊,那么如果大家觉得这期视频对大家有帮助的话呢,欢迎给我点个三点,点个关注吧,那么咱们下期视频再见了,拜拜,咱们下期视频再见。
57荒野芯智观察 01:55查看AI文稿AI文稿
01:55查看AI文稿AI文稿兄弟们,谷歌开源吉马四啊,架构呢,与外面的模型不一样,而吉马四呢,是蒸馏出来的哈,支持语音呢,视觉多模态网络架构啊,整体采用 窄而深的结构啊,跟界面奶三闭源模型架构呢,也没有什么关系,特殊设计呢,有四点, e 氏 jam 三 n 中就采用了 pl e 啊,就是每层呢,都有一个小磁表啊,除了这个标准磁表之外啊,还有这个每层有一个小磁表,它一共三十五层哈,每一个小磁表呢,是二百五十六的特征纬度 原始的 embedding 啊,就是这个原始的 embedding 和每层的小磁表偏老一啊,融合成信息流呢,之后在 f f n 后啊,加入这个传感器模块。二是使用滑动窗口注意力啊,这个是每四层滑动窗口注意力, 然后搭上一层全注意力哈,一共呢就会导致了三十五层滑动窗口注意力呢,其实有很多工作就是在 a 帧等长任务上,它是掉点的哈,但是可能我们这种小模型哈,参数量比较小呃,用途也不在这一块啊。三是最后几层共享 k v 权重啊, 全注意力层,共享最后一层的全注意力 k v 窗口注意力呢啊,共享最后一层窗口注意力的 k v 哈,这样就是 k v 投影权重哈,就就可以省略哈, 只需要保留 q 投影权重就行了哈。四是采用了五层规划,有这个 pre 啊,就是 pre attention, 就是 attention 前面的啊,这个 input, 然后也有 pos 的 attention 哈 啊,还有这个 pre fit forward 规划权重,还有 post 这个 fit forward 的 规划权重,还有这个每一层 p l e 的 这个规划权重来调节残差流,哈,这个是我们的杰马仕啊。
96龙哥紫貂智能 01:08查看AI文稿AI文稿
01:08查看AI文稿AI文稿时隔一年之久,谷歌突然新业发布其最新开源模型 jam 四。 jam 四采用更加先进的原生多模态设计, 采用的是混合滑动窗口注意力机器助力一二八 k 向下为时能降低内存提升速度。 使用 logitech 软截断解决容易出现的幻觉问题。深度精流技术提升逻辑推理能力。开源了四个版本,一二 b、 一 四 b、 二六 b 和三 e b 分 别对应着不同的定位。 三 e b 球迷模型在全球开源模型排名第三,二六 b 排名第六,可以比肩一揍满血大模型,实力不容小觑。 jamah 四六大核心能力,高阶逻辑推理原星 ai 智能体工作流离线代码生成原星多模态细节与音频,超强向下文吞吐,最强二五六 k 海量多语言支持。目前已经可以通过欧拉玛下载这款谷歌最新的旗舰开源模型, 不过还需要等待客户端软件版本升级后才可以载入并运行,等我下载完不朽 jamah 四测试一下再给大家更新。
37集集集集盒🌈 05:42查看AI文稿AI文稿
05:42查看AI文稿AI文稿酷狗发布的 jamax 家族这次把本地部署的门槛彻底拉低了,它包含了从高性能工作站到边缘 iot 设备的四款模型,不仅原生支持图文视频多模态理解,还拥有最高二五六 k 的 超长上下文。 最关键的是,全系全面转向了 h 二点零协议商用,完全没有后顾之忧。首先来看这个家族的扛把子三十一 b 电子版本,它采用全密集架构,三百一十亿参数在推理时全部激活, 这意味着它拥有该系列最强的逻辑能力和输出质量。如果你手里有八十 g 显存的 h 幺零零或者多张消费基显卡组基群,且对结果的精准度有极致要求,选这款就对了。 接下来是性价比最高的二十六 b m o e 版本,这里要重点解释一下混合专家架构的优势。虽然它的总餐数量有二十六 b, 但单次推理时系统只会激活其中三点八 b 的 参数,这种机制在保证智商的同时提高了每秒的吞吐量。 对于大多数本地桌面用户来说,这款模型在响应速度和性能之间达到了完美的平衡。针对手机和 l t 设备, google 推出了 e 四 b 和 e 二 b 两款端侧模型。这里引入了一个关键的 pl e 单层嵌入表技术,简单来说就是让大体级的磁表在查找时不全面参与常规计算,从而大幅降低内存占用。 一四 b 有 四点五 b 有 效参数,适合树莓派或 jason, 而一二 b 只有二点三 b 可以 直接跑在手机上,让端测 ai agent 成为可能。最后总结一下全系列的通用能力, 在上下文长度上,大模型支持二五六 k, 小 模型也达到了幺二八 k, 足以处理超长文档。再加上原生的图文视频理解能力,让它在实际应用场景中非常灵活。 在实际性能测试中, jam 四三十一币的表现非常强悍,尤其在 g p q a diamond 科学推理测试中,拿到了百分之八十五点七的高分, 但更核心的竞争力在于它的 token 效率。同样,一个任务竞品可能需要一百五十万个以上的 token 才能说清楚,而 jam 四只需要一百二十万个,这意味着它说话废话更少,逻辑更直接,在实际部署时能显著降低推理成本。 如果把它和国产明星 q n 三点五二十七 b 放在一起对比,你会发现一个有趣的现象,在一些细分的工具调用跑分上, q n 确实略占上风, 但在基于人类真实偏好的 rena a i yellow 评分中,两者几乎打平。这说明在实际的人机交互体感上, g m 四三十一 b 已经达到了顶尖水平。很多人好奇为什么价格没怎么变,性能却原地起飞? 其实拆解底层代码会发现,它依然沿用了 paperstorm g q a 以及局部全局混合注意力机制。这次性能的飞跃完全不是靠改架构,而是归功于训练数据的质量飞跃和训练配方的深度优化。这再次证明了在当前大中型阶段,高质量的数据才是真正的核心竞争力。 现在进入实操环节,如果你追求极致简单,首选奥拉玛。首先把版本升级到零点二零以上,然后直接在终端输入命令,想要轻量化测试,就运行一二 b 版本。如果追求性能和速度的平衡,强烈推荐运行二十六 b 版本。 对于 macm 系列芯片用户, m l x 框架配合 turboq 是 史诗级加强,它通过压缩 kb 缓存,直接把内存占用,从十三点三 gb 砍到了四点九 gb, 整整节省了百分之六十三的空间。 具体的部署命令就在屏幕上,这里有一个关键的权衡,开启这个优化后,解码速度会慢一点五倍,但它能让你在 mac 上跑满幺二八 k 的 长上下文。对于处理长文档来说,这个招牌绝对稳赚不赔。 如果你是显存困难户或者即刻玩家,可以尝试 einslof 和拉玛 cpp, 只用 einslof 量化,只要六 gb 显存就能跑起一二 b 或一四 b, 甚至能构建支持网页搜索的本地 agent。 而如果你有三张四千零九十并行二十六 b m o e 版本的速度能达到惊人的每秒一百六十二个头啃。此外,通过实验性的 turbo quant plus 分 支,能把三十一 b 模型的体积从三十 g b 强行压到十八点九 g b, 让大模型在消费级显卡上跑起来。 最后是企业级生产环境,建议直接使用 v l l m, 它原生支持多模态输入和二五六 k 的 高吞吐量,并且完美兼容多卡并发。 开发者在实测中发现, v i l l l 搭配最新版的 transformers cool, 可以 非常稳定地调用 jam 四的工具接口,适合构建大规模的商业应用。在部署之前,有几个坑必须提前告知。首先是模态缺失,虽然官方宣传支持音频, 在目前音频输入请在 google ai studio 线上可用,所有的本地框架都还没适配。其次是稳定性问题,如果你使用 l m studio 运行三十一 bit n s 的 g g u f 版本,可能会遇到死循环输出的 bug, 建议等待社区修复。最后是能力边界,在处理复杂的函数调用时, e 二 b 和 e 四 b 这类小模型的表现不如同级别的竞品复杂任务建议直接上二十六 b 或三十一 b 版本。最后根据你的设备和需求 直接看这个部署。建议企业商用直接选 jam 四 high party 二点零协议让你没有任何法务后顾之忧。个人 pc 或游戏本用户强烈推荐二十六 b m o e 版本,单卡四千零九十就能跑通超长上下文,且响应极快。 mac 开发者请认准 mlx 框架,记得开启 turboqant 来解放统一内存。至于 i o t 创客 e 二 b 和 e 四 b 证明了六 gb 内存也能跑起。智能 agent 是 端侧智能的最佳选择。
46AI赚钱研究社 00:58查看AI文稿AI文稿
00:58查看AI文稿AI文稿google jam 四来了,开放权重多模态能推理?今天给你讲透!先说结论, jam 四是 google 最新一代开放权重 ai 模型,四个版本,二 b 四 b 二六 b 三一 b, 最小的七个 g 跑在手机上,最大的二十 g 跑在服务器,但最炸的是中间这个二六 b。 二十六 b 用的是混合专家架构 moe, 总共两百五十二亿参数,但每次推理只激活三十八亿。 百分之十五什么意思?速度接近四 b 的 小模型,性能逼近三一 b 的 大模型,速度加性能,两个都要,这就是性价比之王。对比 jam 二三数学推理, a i m e 提升百分之三百二十九编程能力 code forces d l o 直接翻了十八倍长,上下文理解提升百分之三百九十二这不是挤牙膏,这是换了一辆车。 jam 二四还有个新能力 思考模式 system prompt 加一个 tiktok 模型,就会先内部推理再回答,加上全模态,支持文字图片音频视频一百四十多种语言,两百五十六 k 超长上下文, 最简单的上手方式,欧了吗?一行命令,欧了吗? run gemma 四直接跑,门槛低到离谱。 google 最新开放模型,双架构,四个尺寸,数学百分之八十九编成 elo 二一五零二十六 bmo, 性价比无敌。关注 gaker, 下期教你怎么让小龙虾使用这个模型。
69GeekerV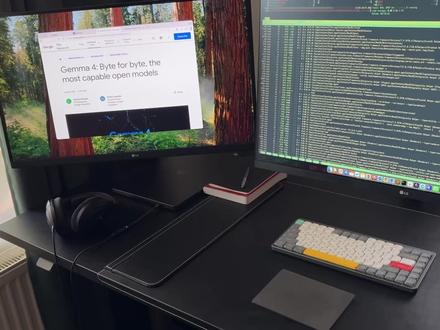 08:14查看AI文稿AI文稿
08:14查看AI文稿AI文稿昨天,谷歌发布了迄今为止最强大的 gemma 四本地大模型系列,让众多本地 l l m 爱好者欣喜若狂。 特别令人兴奋的是, gemma 四基于 gemini 三技术开发,根据公布的基准测试结果,其性能甚至超越了规模高达其二十倍的竞争对手。但抛开所有技术细节这些,我稍后会讲到。此次发布中最引人注目的它是 apache 二点零。 看起来谷歌终于听起了开元社区的呼声。如今, game 四已完全开放,允许商用的 app 二点零许可证发布了。 这意味着你可以用这个模型做几乎你想做的任何事情,完全自由,不受公司绑定,对您的数据和产品拥有绝对控制权。今天我要在我的笔记本上安装并测试这个模型,可能还会在台式机上试一下,看看它是否足够好,能作为我的主要本地模型使用。 但有个重要说明,我不是想用这个替代付费模型。我把詹姆斯视为对付费模型的补充,适用于不太复杂的任务,或我不希望数据离开本机的情形。嗨,我是 nick, 从事软件开发已超过二十年, 在这个频道,我分享自己在 it 领域的经验、见解与思考。所以,为了今天在我的电脑上运行 jm 四,我将使用 lm studio。 如果你还没用过这个工具,看看我频道上的视频,里面解释了这是什么,以及如何使用它。 好的,首先,我会尝试在我的 macbook 上安装这个模型,因为正如我所说,我希望它能随时可用。不幸的是,我的 macbook 只有二十四 gb 内存,所以我会在那里安装一个较小版本的模型,参数规模为两百六十亿或三百一十亿的更大变体,我将安装在台式机上。 该模型有多个量化版本可供选择,我就选最大的那个,毕竟大小差异不大,但输出质量应该更好。 模型下载期间,让我先回顾一下谷歌在公告中强调的几个关键特性。首先,这些模型在设计之初就考虑到了基于智能体的工作流,他们原声支持函数调用,并能生成干净的结构化 g s o n。 第二,所有版本都是多模态的, 他们能处理图像和视频,而较小的模型一二 b 和一四 b 甚至拥有原声音频支持,这意味着他们可以直接理解语音。 第三,这些模型配备上下文窗口,小版本为十二万八千个 token, 大 版本则为二十五万六千个 token, 这应能让他们胜任大型代码库的处理。不过这一点还有待我们测试验证。 最后,作为一个不错的额外福利,这些模型支持多种语言。好了,模型下载完成了,让我们把它加载到内存里,我们也快速检查一下参数。正如我所说,我下载了八位量化版本,架构当然是 gemma 四。最重要的是该模型支持工具和图像输入。 正如你所见,这个模型拥有七十五亿参数,但只有四十亿有效参数,这应该能带来更好的性能。上下文窗口已设置为最大值幺二八零零零头啃,这很棒。好的切换到聊天界面,让我们确认已加载并激活正确的模型。 顺便提一下, lm studio 在 这里显示了一些有趣的信息,比如模型加载后实际占用了多少内存?正如你所见,对我来说大约是十二 gb。 在 聊天底部,你还可以看到在使用模型时可用的工具。 好的模型已成功加载,我们来测试一下它到底行不行。为此,我会在新的聊天中发送一个简单的提示。首先,我会让它完成一项相当简单的任务,编辑一个 python 函数,按两个键对字典列表进行排序。 这是我用来测试每个模型的标准化提示词。这相当基础,所以任何模型都应该能搞定。但这里的目的是验证模型是否正常工作,并看看他在我的硬件上想拥有多快。 我会加快视频中回答生成的速度,因为生成完整答案可能需要一些时间。但最后我会分享总耗时,这样你就能估算他在你的机器上跑的多快。 所以模型耗时不到一分钟。精确来说是四十九秒,平均速度约为每秒三十一个 token, 启动响应的延迟约四点五秒。 老师说这是个相当不错的结果。提醒你一下,我是在配备二十四 gb 内存和 m 四 pro 芯片的 macbook 上运行这个。现在我们来测试一下詹姆士处理图像的效果,看看他是否能真正理解图中的内容。 我会上传一张图片到聊天中,然后让模型描述他看到了什么。这是照片。如你所见,我拍了一张书桌的照片,上面有四样东西,键盘、 kindle、 鼠标和一支笔。让我们看看 gemma 能认出其中多少个 好的模型已完成图像分析。正如你所见,它成功识别出了键盘和鼠标。它还识别出了 kindle, 甚至描述了表面和光照情况。然而它没注意到那只笔。但说实话,这没什么大不了的,重要的是它捕捉到了整体场景,并正确识别出了大部分主要物体。 好的,现在轮到测试更大的模型了。为此,我将使用我的台式机快速介绍一下。我将运行 jam 四两百六十亿参数版本的机器配置。 它配备 amd ryzen 七处理器,一百二十八 gb 内存以及带有十六 gb 显存的 gforce rtx 四零六零钛显卡。好了,模型已启动并运行。让我们给它在 macbook 上执行和小模型相同的任务。 编写一个 python 函数来对字典列表进行排序。这将帮助我对比 jam 四第二十六版在我的台式机上的性能。在此,我会加速生成过程,但稍后会分享总耗时。 在生成回复的同时,看看系统覆盖。右上角我运行的是 mv top, 我 用它来监控 gpu 使用情况。深黄色线条显示显存使用情况,浅蓝色线条显示 gpu 利用率。右下角我运行了 hto p 来监控 cpu 覆盖和内存使用情况。 这两个工具都是免费且开源的。由于完整的 jam 四模型无法完全放入我的显存,因此它严重依赖 cpu 和系统视频内存。但这并不是真正的问题,关键在于响应速度是否可接受。 好了,模型已完成响应生成耗时一分三秒,比小模型稍慢一些,每秒 token 数也显著更低。正如你所见,它大约是每秒十二个 token, 那 比小模型慢了将近三倍。但这并非公平的直面对比。 由于这些模型的能力差异很大,不过现在我对这台电脑上这个模型的预期有了清晰的了解。顺便提一句,这台台式机运行的是 linux 系统,我偶尔用它来做些项目,但我很少把它当做传统台式机用。它主要是一台高性能服务器。 由于它连接到了我的家庭网络,当我需要时,通常可以从任何其他电脑通过 s s h 访问它。我用来与一切交互的主机依然是我的 macbook, 而且好处是你并不需要太多设置就能让它跑起来。厅 l m studio 已经内置了一个可以通过网络访问的 api。 好的,现在让我们切回 macbook, 给模型布置一个更有挑战性的任务。如果你看过我之前测试千三点五和千 code next 的 视频,可能会记得,我准备了一个任务文件,让模型去可示化一个排序算法。 今天让我们给 jama 司同一个任务。在生成回复的过程中,我再给你们看看系统赋载。这和以前差不多, 几乎所有 cpu 核心都已满载,现存也达到极限。好的模型完成了。正如所要求的,它生成了一个可示化排序过程的 html 文件。让我们看看。乍一看,一切看起来都正确无误。我没看出什么明显问题, 现在我要在浏览器中打开它,看看最终效果。哦,这看起来相当不错,它甚至使用了自定义字体,让我试着运行一下。没错,一切正常,速度滑快,可实时更新。动画 不错,总体而言非常扎实。所以今天测试完 demo 四系列后,我可以肯定的说,这些模型真的很棒,我肯定会经常使用它们。 但再次强调,为了明确起见,我并非打算用这个来替代付费模型,我把 demo 四视为付费模型的补充,适用于简单任务或我不希望数据离开本期的情形是,好了,今天就到这里,如果你喜欢这个视频,别忘了点赞订阅,以免错过下一个,回头见。保证。
455声译看世界 11:47查看AI文稿AI文稿
11:47查看AI文稿AI文稿谷歌发布 gemma 四,引发开源模型领域震动。 cursor 正推动 ai 编程全面迈向多智能体协助模式。 meta 似乎正在幕后紧锣密鼓地测试一批神秘模型。 t i i 最近也展示了一款小型视觉模型,在处理高难度任务时,其表现甚至超越了体量庞大的竞争对手。 最近行业动态平平,我们来详细聊聊。谷歌刚刚正式推出了 gemma 四,这可不仅仅是小修小补的迭代,这是开源模型家族,包含四种参数规模,参数规模从二十亿跨越至三百一十亿。 这些模型源自 gemini 三技术,相当于共享了 google 的 核心研究成果,但以开源的形式呈现,其产品阵容相当有看点。其中的轻量化模型集二十亿和四十亿参数的高效版本, 专为边缘设备打造,含盖智能手机、树莓派、 jadison、 orange、 nano 等各类硬件。 它们支持十二点八万上下文窗口,具备多模态交互小模型,甚至还支持音频输入,这可是个大新闻,这意味着您可以进行语音分析,无需依赖云端推理,直接在本地完成。再看高端系列,包括两百六十亿参数的混合专家模型, 以及三百一十亿参数的稠密模型。它们支持高达二十五万六千的上下文窗口,主要针对工作站和消费级显卡。其中两百六十亿参数的 mail 一 最值得关注,因为它虽然总参数量高达两百六十亿,但在推理时只有约三十八亿参数处于激活状态, 这大大提升了其响应速度和运行效率,这正是目前的核心方向。谷歌正在推崇单位参数智能的理念,他们不再一味地追求扩大模型规模, 而是致力于在更小的体积下挖掘更强的性能。根据他们的精准测试,三百一十亿参数模型目前在开源模型中排名第三,位列 arena ai 排行榜,而两百六十亿参数的 m o e 模型则排在第六。这成绩相当亮眼,特别是 考虑到它们号称能超越其他模型且体积大出二十倍的那些。此外,这款三百一十亿参数的模型在 g p q a d m。 的 精准测试中拿下了百分之八十五点七的高分,这可是向难度极高的科学推理测试。 在开源模型中排名第三,四百亿参数以下,这绝非营销噱头,数据实打实地证明了这一点。这些模型完全能胜任多步推理, 还能处理数学任务、 jason 结构化输出以及智能体工作流中的函数调用。它们还具备全模态能力,能处理图像和视频,实现 ocr 识别,还能进行图表分析,甚至在某些场景下支持音频处理。 此外,它们还支持超过幺四零种语言,并支持离线代码生成,而且覆盖范围极广。目前已上线 hugging face、 kegel、 alama 以及 google a s studio 等多个平台,几乎能与所有主流工具集成,如 transformers、 v l l m l a c p p m l x nvidia, nine 等。你可以在 collab or vortex ai 上进行微调,再部署到 google cloud 投入生产。但讲真,这其中最大的变化其实并非模型本身,而是许可协议。这是谷歌首次以 apache 二点零协议发布 gamem 模型, 这意味着完全商用、自由修改,无苛刻限制或终止条款。你可以随意修改模型,部署到任何地方,甚至是私有本地环境,并完全掌控你的数据与基础设施。相比以往,这是一个巨大的策略转变, 毕竟他们之前的策略线之重重。这显然是为了应对压力来自开放权重竞争对手,尤其是中国的挑战。比如阿里巴巴和月之暗面等公司的模型,正展现出强劲的竞争势头。谷歌的态度很明确,为了保持竞争力,他们决定全面开源, 这势必会引发开发者的广泛采用。 jammer 的 下载量已突破四亿次,社区衍生版本也超过了十万个。如今有了 app 二点零协议加持, 这个数字将迎来爆发式增长。开发者可以在自己的 g p u 上微调模型,将其部署到终端设备,并放心地基于此开发商业产品,无需顾虑授权问题。 我们还能看到,这里有强有力的硬件合作伙伴。谷歌与 pixel、 高通及联发科合作,针对移动端部署优化了这些轻量化模型。这显然是为了将 ai 直接推向终端设备,而非仅仅依赖云端处理。这次发布本质上是谷歌试图缩小开源与闭源模型间的差距, 同时也为了稳固其开发者生态。这种进步不仅惠及研究人员或开发者,更彻底改变了实际生产流程中的各种可能。 好了,言归正传,回到视频内容,这次更新带来的惊喜远不止是一次简单的版本迭代。 cursor 三的核心理念其实很简单,即简化 ai 编程智能体在实际开发中的管理。以往大多数 ai 编程工具给人的印象 还是单助手、单对话、单任务的模式,而 cursor 三打破了这一局限,它更贴合当下的实际工作流, 让多个 ai 智能体同时处理不同任务。开发者只需负责监控比对结果,并在必要时介入。此次最大的升级包括并行智能体、智能体标签页以及全新的布局,方便你在代码窗口间自由切换 或智能体式图,甚至两者并行使用。听着简单,实则影响深渊,无需再深陷融长的 ai 对 话现在可以同时运行多个智能体分头处理任务, 一个负责修代码,一个负责做测试,另一个则能尝试完全不同的新方案。这让他不再只是编辑器里的聊天机器人,而是更像一个专业的 ai 工作空间科室。三的适用环境也更为广泛, 支持本地远程 s s h 工作树及云端开发环境。显然,他的目标用户不只是单打独斗的个人开发者, 他还试图适配规模更大、更为复杂的实际生产环境。 cursor 现已将 worktree 功能整合进全新的智能体窗口,让病情开发和分支管理变得井井有条。 此外,还新增了 worktree 指令,用于处理独立任务以及 b、 s、 d、 f、 n 指令来对比多个模型的生成结果。这很实用,毕竟现在的开发者往往想多看几个方案,在从中挑选最佳答案。 此外,还有一些实用的功能升级。 m c p 应用现在能提供更简洁、更规范的结构化输出,大文件代码差异渲染更快,企业用户在安全与溯源方面拥有更多控制权, 所以 cursor 三不仅仅是为了显得更聪明,它只在让 ai 编程更异于管理,更具扩展性,在项目扩大时也确实更加适用。于此同时, mate 似乎正在进行更多动作,幕后进展远超常人预料。 mate ai 内部测试发现了几个模型变体,它们似乎不同于当前驱动 ai 助手的 luma 四系统。 你发现的有 avocado mango、 avocado 九 b, 还有一个叫 avocado dh 的 模型,这大概是深度思考的缩写。光是这一点就很有意思了,这说明 meta 的 测试进度远超外界对下一代模型所知。其中名为 avocado mango 的 版本展现出了相当扎实的多模态能力, 甚至能生成一张提壶骑自行车的 svg 图。虽然这个测试项目相当随意,却依然是个有用的指标,证明它不仅能处理纯文本内容, 较小的九十亿参数版本表现也相当惊人。所以如果 mate 最终用朗玛斯在其消费级产品中换成 avocado, 用户能明显感受到性能的质变。尴尬的是, mate 在 发布节奏的把控上似乎任贤齐立。 据报道, avocado 原定三月发布后被推迟至两千零二十六年五月之后,原因是内部测试显示其性能上不足以抗衡顶级竞品,甚至有消息称 mate 曾考虑暂时向谷歌购买 jimmy 的 授权。 说实话,这足以见得如今的竞争有多么白热化,这些公司正面临着巨大的追赶压力,即便是科技巨头如今也愿意考虑那些决策,他们在不久前看来还简直是天方夜谭。 而且 avocado 可能还不是故事的全部,名为 perrocco 的 另一模型系列也在 meta 模型选择其中被发现同样包含三个版本,分别是常规文本模型、推理模型,以及具备图像和视频理解能力的多模态版本。 这些模型目前尚未公开。没人知道 partycarto 是 取代了 avocado, 还是作为其补充亦或是完全独立的产物。但核心结论显而易见, met 在 后台测试的模型数量远超外界所知。 此外,还发现了两种新模式,文档智能体与健康智能体。这与目前 ai 领域的整体发展趋势不谋而合,与其让一个助手包揽所有任务, 企业现在开始针对特定任务打造更专业的模式。 meta 的 平台未来或许不再只是聊天机器人,而是集成了多种垂直 ai 工具的综合平台。 最后,技术创新研究所发布了一个更侧重研究导向的新成果,不过其背后的理念其实很好懂。 他们推出了 falcon perception, 这是一款小型视觉模型,拥有六亿参数,专门用于理解图像内容。根据自然语言指令,它不再将任务拆分到多个系统里, 一个负责识别图像,另一个负责判断后续动作。 falcon perception 只在完成所有流程,从头至尾均通过单一模型实现。目前很多视觉系统仍像是把不同零件拼凑起来的工具包, 而 ti 正是想简化这一过程。 falcon perception 通过读取图像数据,并从底层开始将文本与图像融合,从而帮助他将您的指令与图像实际内容更直接的关联起来,只在提升视觉定位、提升分割和理解能力,无需大型模型即可处理复杂的视觉场景, 其背后的训练投入依然相当巨大。据 t i i 称,该模型接受了约六千八百五十亿 token 的 训练,只在增强物体识别、视觉细节读取、 布局理解以及处理复杂提示词的能力。他们还推出了 pivot 机准测试,以更直观的评估高难度视觉理解任务。在该测试中, falcon perception 全面超越了 some 三。在他们列出的所有积分指标上,它在简单物体上表现更优,在属性和 ocr 类任务上也表现更好。 在空间理解上优势尤为明显,物体关系处理和复杂场景识别也更甚一筹。其中,空间理解能力的提升最为显著,得分由 s m 三的三十一点六分跃升至五十三点五分,差距十分惊人。 t i i 还沿用这思路开发了 falcon ocr。 这是一款专注于文档识别,仅有三亿参数的小型模型,对于如此轻量的模型来说,表现相当惊人。它在欧林库上取得八十点三分,基本与八十点二分的 gemini 三 pro 持平, 并以明显优势胜过六十九点八分的 g p t 五点二,在 omnitocbench 测试中达到了八十八点六四分,领先于 g p t 五点二和 mr o c r 三,但仍落后于 pad o c r v l 一 点五。 所以,尽管 falcon ocr 体积更小,它已足以与那些大得多的系统一较高下,但在文档理解能力上,这 使它非常适用于大规模 ocr 任务,因为这些任务对速度和效率要求极高。好了,本期内容就到这里,欢迎在评论区留下你的看法,如果视频对你有帮助,欢迎点赞订阅,不错过后续更新,感谢观看,我们下期再见!
 09:22查看AI文稿AI文稿
09:22查看AI文稿AI文稿google deepmind 最近发布的 gemma 四带来了一个非常反常识的结论,模型的能力不太单纯,取决于参数规模的大小。数据证明, gemma 四的三十一 b 参数模型在数学、推理和编程这些硬核任务上 竟然直接飞平,甚至超越了那些参数量在二零零 b 以上的巨型模型。更离谱的是它的微变体二十六 b a 四 b。 这个模型虽然总参数有二十六 b, 但每次处理任务时,真正起作用的活跃参数只有三点八 b。 也就是说,它只用了三十一 b 模型不到十分之一的计算量,就跑出了百分之九十七的性能。这说明,只要架构设计足够高效,我们可以在极小的算力成本下获得极强的智能表现。 不过,这种效率提升并不是万能的,在需要复杂规划的长周期任务中,比如自动写代码的 s w e bench, 测试规模依然是王道。这意味着,架构优化能让小模型在特定任务上极其强悍,但要触碰智能的最高上限,总参数量依然是绕不开的物理基础。 要理解 jam 四的优化,得先看一个痛点,全是 former 模型。在推理时,最迟显存的不是模型权重, 而是 kv cache。 简单说,模型得把之前所有对话的记忆都存在显存里,上下文越长,显存占用越高,很容易直接称爆。针对这个问题, jam 四在一二 b 和一四 b 这类边缘模型中用了一个直接的办法, kv 共享发现深层网络中 相邻层学到的记忆表示其实高度相似,独立计算纯属浪费。于是他让后面的很多层直接附用前面层的计算结果,比如一二 b 模型有三十五层,其中二十层都在共享。这种精确附用直接砍掉了大量溶于计算,让模型能跑在算力受限的设备上。 不过,在三十一 b 这种大模型里, google 并没有开启这个功能,因为大模型需要每层独立计算来保留更多信息增益。 接下来是整个架构中最精妙的部分。 global attention 的 五重压缩全注意力计算是最昂贵的 logo, 为了把它压到极致,设计了一套环环相扣的链条。 首先,他使用 gq a 组查询注意力,把 k v h 的 数量压缩到八比一,但这会导致信息丢失。为了补回来,他把 key 的 维度直接翻倍,用更宽的向量来承载信息。 接着,他走了一步极端的棋,让 key 等于 value。 这意味着模型在解锁和读取时用同一套表示,不仅让 k v catch 再次减半,还起到了一种智能化效果,防止模型过密合。 但这样做在长文本下会产生位置编码失真。于是他引入了 pro p e, 只对百分之二十五的高频维度进行旋转,让低频维度纯粹保留羽翼,不再被位置造成干扰。 最后,他强制要求最后一层必须是大局注意力,确保输出的每一个词都能看到完整的上下文。这五步走下来,原本沉重的大局计算被压缩到了极限。 在位置编码上, jama 四采用了双 rope 机制,简单说就是给不同场景配了不同的尺子。对于局部滑动窗口,它使用标准 ope 参数 f 为一万,处理五幺二到一千零二十四个口径的短距离保证位置感知极其精准,而对于大局注意力, 它切换到 prope, 把 feta 猛增到一百万,并且只旋转一部分维度。这样在面对二五六 k 这种超长上下纹时,能够有效过滤掉远距离产生的位置噪声。 一套组合拳下来,模型既能处理好眼前的细节,又不会在长文本中迷路。接下来看一个非常独特的设计。 playa embedding, 简称 ple, 在 传统的 embedding 在 所有层里都是同一个, 这就要求这项量得预先编码好所有层可能需要的信息,这对固定维度的向量来说压力太大了。 pl e 的 做法是给每一个解码层都配一个独立的小型 embedded 表, 这意味着 token 每进入一层都会收到一个专属的信号。在一二 b 模型中,总参数虽然有五点一 b, 但真正参与计算的有效参数只有二点三 b, 剩下的二点八 b 全是。这些 embedded 表虽然在硬盘上占空间,但推理时只是简单的查表,几乎不增加计算量。说白了, 这就是用存储空间换取计算效率,让模型在保持二 b 级别推理速度的同时,拥有更强的表达能力。 最后我们来看看二十六 b a 四 b 模型的灵魂双路径混合架构,它和 q n 或者 glm 的 纯欧以不同,它在每一层都设计了两条并行的路。 第一条是 dance m l p 路径,这是一个不依赖路由的全量计算通道,就像一个稳固的底座, 提供最基础的信号。第二条是路由猫 e 路径,这里面有一百二十八个极其精细的小专家,每个 token 进来后,路由器会挑选最合适的八个专家来处理。这种设计非常聪明,它既有了 dance m l p 保证的稳定性,又利用了一百二十八个小专家带来的极高参数利用率。 相比于早期只有八到十六个大专家的模型,这种细腻度分发能让每个专家学习的模式更专注,从而在极低的活跃参数下依然能跑出接近大模型的性能 架构决定了效率,但训练决定了上限。目前一个行业共识是,通过蒸馏让大模型教小模型,效果远好于单纯的强化学习。 q 三采用了强到弱的蒸馏, clm 五则用跨阶段蒸馏来防止模型在学习新能力时忘记旧知识。 而 gemma 四的强大,很大程度上得益于他的老师是 gemini 三。 google 利用 gemini 三生成了海量的高质量的推理链数据,然后为给 gemma 四进行指令微调。说白了,小模型的能力上限,其实就取决于那个教他的老师有多强。 在训练管线上,三家公司走出了截然不同的路。最明显的差异在多模态式线上, gemma 四走的是原生融合路线。 他在预训练阶段,就把视觉的 y t 编码器和音频的控风的编码器直接揉进了模型里,让模型像人类一样,在同一个大脑里同时处理文字、图像和声音。这样端到端的响应速度最快,逻辑一致性也最强。而 g l m 五走的是工具调用路线,它的基础模型本身不处理图像, 而是像个调度员,需要看图时就去调用 g l m vision 这种专用模型。这种做法虽然在响应速度上稍慢,但灵活性极高,升级某个模态只需要更换对应的工具模型即可。 k y 三则采取了折中方案,将视觉能力交给独立的 vr 系列模型来承担。 最后聊聊量化,也就是怎么把模型压缩到手机或显卡上。大多数模型用的是后量化,也就是模型练好了,再强行把精度从十六位压到四位。这就像是强行瘦身,难免会损失一些能力。但 jam 四用了 q a t, 也就是量化感知训练, 他在训练过程中就故意加入量化造声,让模型在还没出场前就习惯在低精度环境下工作。结果就是像维利亚发布的斯比特福典版本,精度损失极小。这种在训练阶段就做准备的方案,比事后压缩要高效的多。 把数据摆在一起看,你会发现一个很有意思的现象,在数学推理测试 ai 米上, james 的 二十六 b 模型虽然活跃参数只有三点八 b, 但得分高达百分之八十八点三,这简直是效率奇迹。但你看 g i m 五,它凭借七四四 b 的 庞大体量,拿到了百分之九十三点三的最高分。 尤其是在需要复杂规划的 s w e bench 测试中, g l m 五毫无对手。这再次印证了我们之前的结论,在简单的推理和编程任务上,我们可以靠架构效率来以小博大,但如果要处理极其复杂的 agent 规划任务,总餐数量带来的规模效应依然是不可逾越的壁垒。 面对常文本处理,三家公司走出了完全不同的技术路线。 java 四采用了滑动窗口和全聚注意力的交互设计,目标只有一个,在保证能看到全文的前提下, 把单次推理的开销压到最低,追求极致的效率。听闻三则比较保守,坚持使用标准的全注意力架构,通过调整位置编码来扩展长度,追求的是极致的稳定和通用。 而 glm 五最激进,它用了 mla 和 dsa 这套双重压缩方案,彻底抛弃了传统的缓存方式,目标是让模型在处理超长历史记录的 a 帧任务时依然能快速回溯且不暴显存。 可以说,这三者分别代表了效率、通用和能力三个不同的工程方向。最后,我们给这三个模型做一个简单的定位总结,帮你决定怎么选。 如果你追求的是极致的性价比,希望在有限的算力下部署尽可能多的实力,那么效率至上的 jam 四是首选。如果你需要一个表现稳定、生态完善且能应对各种通用任务的助手,那么均衡的 q 三是最稳妥的选择。 而如果你是在开发一个复杂的 ai agent, 需要模型具备极强的长文本规划和代码编辑能力,那么专精于此的 glm 五则是目前的最佳答案。 回顾整个 jam 四的拆解,我们要记住三个核心结论,第一,参数效率的边界远比我们想象的要远,只要架构设计的好,小模型也能打赢巨无霸。第二,现在的开源模型竞争已经从单纯的参数竞赛转向了谁的蒸馏策略更好,谁的强化学习工程做得更深。 第三,这个世界上没有所谓的最优架构,只有最适合特定场景的权衡。对于所有关注 ai 基础设施的同学来说,与其盲目的推算力,不如花时间去理解不同架构的效率特性,这才是真正的竞争力。
33AI技能研究社 03:34查看AI文稿AI文稿
03:34查看AI文稿AI文稿们想象一下,把最新的 kimi 二点五,还有智普的基拉玛五这样的大模型部署在我这台发布了两三年的 iphone 十五 pro 上,是一种什么体验?那么谷歌给出了他们的答案。就在昨天,谷歌发布了他们的最新的开源大模型加码 four, 那 可能有朋友不了解加码是个什么东西,加码就是谷歌的开源大模型的产品线。 那么这次这个模型呢,一共发布了一二 b、 一 四 b、 二十六 b 和三十一 b 四个版本。那么大家注意这个 e 哈 e 就 代表 effective 有 效参数,那以前我们说的二 b 四 b 那 是实打实的参数量啊,二十亿四十亿。 但是这次的一二 b 呢?它的物理参数就是它真实参数可能只有十二亿,可是它的这个智力表现跟二十亿的大模型是一样的。 这就好比说一个十岁的小孩,他的这个逻辑推理表现,他这个智商和一个二十岁的大学生是完全一模一样的。那么谷歌是怎么做到的呢?全部靠他这项刚刚发布的独角黑科技,叫 p l e per layer in balance, 叫做逐层嵌入技术。这个技术的原理啊,非常简单。我们举个例子,假设现在我们去参加一个比赛,叫做一战到底,你需要回答十道题目才能通关,获得奖金, 那参加比赛之前,他会给你一份这个比赛指南,对吧?比赛参考指南可能厚厚的这么一本书,那么传统的模型怎么做呢?传统的模型就参加比赛之前, 他会把这个厚厚的一本书全部背下来,背下来之后然后再去参加考试。那么这样不仅前期准备的时候骂累死人,这还会导致一个问题,就说我的记性不好,我记混了怎么办?那我是不是只能记 我这个错误的概念去回答问题了?这 pla 技术就完全不一样了,它允许你开卷考试加作弊。首先它不让你去直接把那个厚厚的比赛指南给背下来了,它给你浓缩成了一份精华,比如说什么必背版、必过版,精简版,在比赛之前只要把这一份小小的资料记住就好了。 然后你进入比赛之后,每一关这个监考老师啊或者说这个裁判都会给你一个小小的提示,然后跟你说,这一关考唐诗,下一关考宋词,在下一关我们考历史,在下一关考科技。 那你结合提示和你之前背一个这种精简版招摇,是不是就把这个答案回答的七七八八了?因为每一关回答这个老师都会给你这个提示,对吧?那这就是我们说的逐层潜入模型,不用去花费巨大的内存去是个死记硬背,是通过每一层的精确补给,实现了内存占用减半,但是这个效果是那种大差不差的。 我们再想想,谷歌上一周也是三月底才发布了一项新技术,叫 turboqant, 直接把存储给干崩了,原本需要一百 gb 才能存下来的这种对话记录, 压缩成十 gb 就 存下来了,并且这个模型的智商是一模一样的,那么你想 turbocharged, 它节约显存,压缩记忆,解决这个长对话的问题。那么 pl e 呢?它节约内存,瘦身大脑,让这个小模型更加的聪明。那么通过这两套组合拳,我们就可以看到谷歌的一个布局,一个属于消费级 ai 的 大航海时代已经是到来了。 那,那既然都说到开元模型了,那就不得不提一个我们这个中国之光 deepsea 了,它的模型居然还没有发布, 去年换房量化搞了三百多个亿,大哥,收手吧,这是人民的模型,所以说我还是非常期待 deepsea 他 们发布最新的这个大模型。好吧,我是 jerry s, 我 们下期再见,拜拜。哦对了,朋友们,还忘说了,这次这个加码缝呢,它还支持了 gantt workflow, 也就是说它可以无缝接入到我们这个龙虾里面, 然后因为它又是多模态大模型嘛,那么像图片啊,音频啊,文字啊都可以处理,所以说我们是可以完全在本地部署然后使用的。 那么过两天我也会,也就是这两天吧,我也会出一个关于这个龙虾的一个视频,那么包含一些非常好的一些实践,还有些使用案例,那么敬请期待。好吧,必须关注我。然后这一次是要真的要再见了,拜拜。我是 jerry, 我 们下次再见,拜拜。
191AI 杰瑞斯





猜你喜欢
最新视频
- 43.2万左手玩FPS