三国演义立体怎么写

粉丝1.2万获赞1.3万
相关视频
 02:12查看AI文稿AI文稿
02:12查看AI文稿AI文稿三国演义立体手抄报制作材料清单放视频末尾。白卡纸打印现稿,涂色多用渐变色和叠色更好看。不想涂色可以直接打印彩色现稿。 高光笔提亮装饰, 沿着线稿把所有素材剪下来,留点白边更好看。 红卡纸打底,对比标题描一圈要比标题大一圈,然后剪下来用泡沫胶贴一起。 黄绿卡纸打印波浪线扇形线稿中间掏空剪掉。白卡纸打底,用泡沫胶依次贴上。绿黄卡纸 还是用泡沫胶把所有素材贴上去,注意素材层次,泡沫胶越厚立体感越好。 高光笔装饰一下,写上文案,完成下课。
143嘟妈手工 02:05查看AI文稿AI文稿
02:05查看AI文稿AI文稿三国演义立体手抄报制作材料清单放视频末尾。白坯纸打印线稿涂色多用渐变色和叠色更好看。不想涂色可以直接打印彩色线稿。 高光笔提亮装饰, 沿着线稿把所有素材剪下来,留点白边更好看。 红卡尺打底对比标题描一圈要比标题大一圈,然后剪下来用泡沫胶贴一起。黄绿卡尺打印线条,线稿中间掏空剪掉。 白卡纸打底,用泡沫胶依次贴上。绿黄卡纸还是用泡沫胶把所有素材贴上去,注意素材层次,泡沫胶越厚立体感越好。 高光笔装饰一下, 你学会了吗?
46嘟妈手工 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿三国演义手工立体绘本,绘本每一页都是立体展示内容,一共七张,绘本尺寸为封面 a 四,那页展开 a 三尺寸,也可以制作封面 a 五,那页展开 a 四尺寸,现搞电子档保存打印图色就可以制作了。
76初心美学馆 00:27查看AI文稿AI文稿
00:27查看AI文稿AI文稿画个吕布,为什么罗贯中要把吕布捧成神而不是关羽呢?好多人觉得吕布就是个反复无常的小人,天天拎个方天画戟到处认干爹,然后又翻脸不认人。但你仔细想想,这位也草根出身, 二十几岁就已经威震边疆,打得外族哭爹喊娘,他手下高顺张辽全都是一等一的狠人,更夸张的是,他就带着几千杂牌军,居然敢硬刚曹操和刘备的精锐联军,把曹操打的差点老家不保。
231一纸斑斓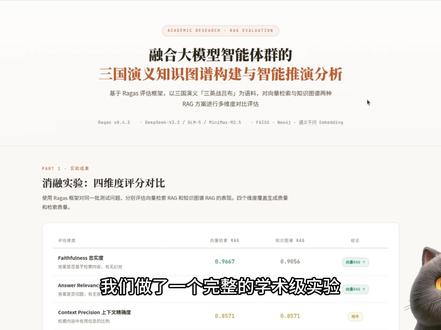 05:36查看AI文稿AI文稿
05:36查看AI文稿AI文稿我们做了一个完整的学术级实验,用三国演义的三音架吕布作为语料,分别搭建向量剪辑和知识图谱两套 r a g 系统,然后用一个专业的评估框架来对比它们到底谁表现更好。 这个实验的完整流程,从数据准备、系统搭建到最终评分,我们全部跑通了。如果你正在做 rex 相关的研究,或者论文里需要做类似的笑容实验,这期视频会非常有参考价值。我们先看结果,再讲工具。最后说过程。对比结果,我们用了四个维度,满分是一分。 第一个维度, freeformess, 忠实度向量解锁拿到零点九七,知识图谱零点九一都很高。这说明两套系统在回答问题时基本没有瞎编, 答案都是基于解锁到的内容生成的。第二个 answerrelevancy, 答案相关性向量解锁零点八八,知识图谱零点八二,向量解锁略像,因为它解锁到的原文段落信息量更丰富, l a l m, 生成答案时能更精准地切题。 第三个 context precision, 上下文精确度两者完全持平,都是零点八六,说明两种解锁方式回来的内容质量差不多,噪音比例相当。重点看第四个 context recall 上下文召回率,这个差距非常大。向量解锁零点七四,知识图谱只有零点一八,为什么差这么多?原因很直观, 向量剪索直接返回的是原文段落,信息是完整的,但知识图谱返回的是三元组。比如吕布使用武器方天画戟这种压缩后的碎片化信息,很多蓄势细节都丢了,所以标准答案需要的信息,它根本召回不全。这告诉我们一个重要结论,对于蓄势类长文本的 red 场景 向量剪索在信息完整性上有天然优势。知识图谱更适合的是结构化查询和跨文档推理的场景。这是我们用 d p c 归三点二 从原文中自动抽取三元组后,在 neo 四 j 里的格式化效果。一共抽取出四十二个实体节点,九十七条关系。可以看到吕布、曹操、袁绍、刘备这几个核心人物的节点连接最密集,准确反映了原文的蓄势中心 关系类型,包括使用武器、担任官职、参与战役、斩杀校中等。我们还做了一个对比实验,用三个不同的大模型对同一段文本做三元组抽取,看看谁抽的更多更全。 deep sea 非三点二排第一, 总共抽取了四百五十个三元组,平均每个文本快十七点三个, g l m 五居中,三百六十八个, mini max 二点五最少两百九十五个。不过需要注意,数量多不一定代表质量好, 有的模型倾向于拆分的更细,有的倾向于合并与异相近的三元组。实际使用中还需要结合去重后的有效信息量来综合评判。刚才的评分结果是用一个叫 rogas 的 框架跑出来的。 这部分我来介绍一下这个工具。 rogas 是 一个 python 评估框架, p i p install rogas 一 行命令就能装,但它不只是一个工具包,它更重要的价值在于定义了一整套评估大模型应用的标准化流程指标和理论体系。它要解决的核心问题就一句话, 如何客观地衡量 rack 系统回答得好不好? rugas 最核心的创新是分解再判断这个评估流程。比如评估忠实度的时候,他不是直接让 l l m 打个分就完了,他会先把答案拆成一条一条的原子命题,比如吕布使用方天画戟,吕布骑赤兔马, 然后逐条去判断这个命题能不能从绞索到的上下文中找到依据,能找到就是一,找不到就是零。最后算比例得出忠实度,分数 写在 rags 源码的下划线 facebook 点 p y 里,拆解命题加逐条判断。 rags 有 三个核心功能,第一,多维度客观评估指标。当前版本内置了三十多个指标,我们今天用的四个是最经典的。针对生成阶段有 facebook 忠实度和 answer relevancy 答案相关性,前者检测幻觉,后者检测答非所问。针对解锁阶段,有 context precision 上下文精确度 和 context recall 上下文照回率,前者看解锁回来的内容有没有噪音,后者看关键信息有没有漏掉。多维度评估指标出在 matrix 目录,每个指标一个文件。第二,自动生成测试数据级。 这个功能非常实用,我们这个实验里只需要给 roggs 一 篇三国演义原文,它就能自动生成问题标准答案和参考上下文,不需要人工标注,大幅降低了构建评测精准的成本。我们实验的第一步用的就是这个功能, 在源码 test site 目录里体现。第三,无缝集成主流 l l m 生态,它能直接和 l l m 这些框架配合使用,还能接入 l l m 这类监控平台,在生产环境里持续跑。评估 出处在 integrations 目录。最后讲一下整个实验是怎么设计的,一共五步,每一步独立成一个脚本。第一步,用 rags 从三国演义原文自动生成问答集, rags 会对文档做切片,构建知识图谱,然后基于单跳和多跳策略生成问答队,输出一个 test site json。 第二步,构建 face 向量锁影, 把原文切成大约三百字一块的文本块,用切入模型做向量化存进 face。 第三步,用 l l m 从原文中抽取三元组,存进 n o 四 g 图数据库。这一步可以替换不同的 l l m 来做对比实验,只需要改制一个脚本,其他步骤完全不用动。第四步,把第一步生成的问题分别喂给两套 r a g 系统 向量 r a g 用 face 剪索原文段落,拼接上下文图谱, r a g 用关键词查 n o 四 g 三元组作为上下文,然后各自调 l l m 生成答案。第五步,把两份答案都交给 ragas 评分,四个维度分别打分,输出我们刚才看到的那张对比表。 为什么选这两种方案作对比?因为它们代表了当前 r a g 最主流的两条技术路线。向量剪辑,基于语义相似度做稠密剪索 知识图谱,基于结构化知识做精确查询。在同一数据集、同一评估框架下做受控实验,能客观揭示两条路线各自的优势和短板,这也是学术论文中最常见的消融实验设计范式。 以上就是这次完整实验的全部内容,总结一下我们做了三件事,用 raga 自动生成测试级,搭建了两套不同技术路线的 rack 系统,然后用四个维度对比了它们的表现。如果你在做 r a g 相关的研究或者论文里需要做类似的评估实验,欢迎联系我们,我们可以提供技术支持和实验协助。感谢观看,我们下期见。
 00:33
00:33













