怎么看gemma4部署成功
橘子,橘子, 橘子, 橘子。

粉丝1599获赞1.3万
相关视频
 01:08查看AI文稿AI文稿
01:08查看AI文稿AI文稿杰玛斯完全可以直接部署在手机使用了,这里可以看到有多种使用场景。今天的测试环境,手机是飞行模式,完全断网。直接看看他在手机本地的运行表现。 发一段话过去,大家可以直观感受一下这个回复速度。这里我没有做任何剪辑加速,体感非常流畅。然后是多模态识别,随手拍一张照片, 它解析图片的速度很快,而且能把画面里的细节描述得比较准确。在断网的情况下,这个速度和理解度都很 ok。 再看它对系统指令的理解,我语音让它在地图中找到香港, 它能瞬间识别意图,并自动拉起地图。 a p p。 虽然因为没网,地图包刷不出来,但调用底层接口这个动作它是完成了的。 在游戏场景下,现在也可以用自然语言交互了。他完全理解了,并帮我完成了播种,这说明模型已经能跟应用逻辑层挂钩了。最后看下这个 prompt lab, 像改写语气、文本总结或者写代码,这些任务全都能在本地临县完成,其他功能等你们去测试。
1.4万Una在学习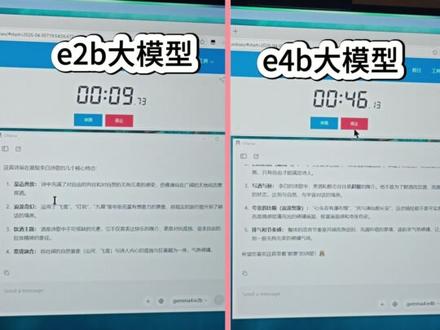 01:30查看AI文稿AI文稿
01:30查看AI文稿AI文稿兄弟们,欧拉玛已经更新好了,杰玛斯的大模型也不朽完成了,一共四个模型,接下来挨个测试一下,所有的测试都是在这个电脑配置下完成的。第一个问题,介绍一下自己, 第二个问题,用李白的风格写一首 诗。 最后一个问题,经典的喜鹊问题 总结一下,四个模型都测了,最快的是一二 b, 最慢的是三十一 b, 四个模型第一次启动都有点慢,后续速度都还可以。 总的来说,回答质量最好的是三十一 b, 包括最后的一个洗车逻辑陷阱也自动识别出来了, 就是我这个配置运行起来实在是太慢太慢了,所以性价比最高的应该是这个二十六 b 模型。回答速度,回答质量都还可以,可以用在部署小龙虾,用来做个人的 a 键,挺好用的。后续再和千万三点五做个横向对比,记得点个关注。
393集集集集盒🌈 07:13查看AI文稿AI文稿
07:13查看AI文稿AI文稿大家好,本期内容我来分享如何在本地部署谷歌新开源的多模态 ai 模型代码四,我会分享命令行和格式化界面两种安装方案,零基础也能轻松搞定。 最后我还会教你如何修改部署的路径,彻底解决大模型占用 c 盘的问题。本地部署的优势就是你的数据可以完全保存在自己的电脑上,隐私安全有保障,而且支持模型微调, 可以打造专属的 ai 助手。但是他也是有缺点的,就是我们需要稍微懂一些技术,还有就是硬件的支撑,如果电脑配置高,自己可以部署折腾一下。有了本期视频,就算你不懂技术,跟着视频操作也可以部署成功。 本期演示我只分享入门版本,主要就是参考部署的方法和流程。接下来我手把手带大家用欧拉玛一键部署。 首先我们先来了解一下 jam 四到底是什么,它是谷歌新发布的开源多模态的 ai 模型,与 jimmy nay 是 同源的。 简单来说,谷歌就是把自家的 ai 技术打包成了一个免费开源的版本,让每个人都能用上。它的能力是非常全面的,支持文本交互、图像识别、音频处理,还能生成代码, 基本上覆盖了所有的 ai 应用场景。下面我们再来看一下它的核心优势。核心优势它有三个,第一个就是多模态能力,文本、图像、音频代码,一个模型全部搞定。 第二个就是完全免费,它没有会员订阅,没有暗次收费,可以随便的去使用,甚至用它去开发商业化的产品。第三个就是比较重要的隐私安全保障,本地部署模式下,所有的数据处理都在自己的设备上完成, 敏感信息不会上传到云端,这是三大核心优势,就是在我们安装之前,需要我们了解一下这个安装环境。首先系统兼容性 demo, 四是支持 mac os、 linux、 windows 三大主流操作系统,基本上覆盖了绝大多数的用户。 然后就是内存要求,如果你的电脑小于三十二 gb, 推荐安装四 b 版本,自己安装体验折腾一下就可以。如果你的内存达到或超过了三十二 gb, 那 就可以选择二十六 g 或三十一 g 的 版本。 在这里有一个小提醒,就是如果是 mac 电脑 m 系列的芯片,它的显存和内存是合二为一的,大家直接看内存就可以。如果大家不是 mac 电脑,比如 windows 或者 linux, 那 么就优先看显存,显存不够再看内存,这是关于这个配置的查看。像这个本地部署也非常简单,仅需两个步骤即可完成。第一个就是安装欧拉玛,这个欧拉玛就可以理解为是本地大模型的一个容器, 它是装大模型的,有了它才可以运行。第二步就是我们容器安装好之后,我们需要给它把模型放进去,就是部署模型,两个步骤即可搞定。下面我们直接进入实操环节,我们来一起看一下部署的全部流程。 在这里第一步我们就先要有这个欧拉玛,他是一个大模型的容器,就是我们打开之后选择右上角的 download, 这时候我们就需要选择匹配自己系统的版本,在这里我这是 windows, 然后我们选择 download for windows, 在这里选择 download for windows 之后就会弹出窗口,我们选择路径直接保存就可以,当下载好之后,然后我们就安装即可,安装好之后打开就是这样的主界面,这个是我之前安装的版本,部署着一个一点五 b 的 zip, 然后下一步就需要我们去选择大模型,我们还来到刚刚乌拉玛的这个界面,在这里我们选择左上角的 models, 然 然后在这里我们可以看到该马四,然后我们选择进来,它提供了好多个版本,在这里我就选择一个入门的版本,主要就是演示安装的流程,比如我们选择 e 二 b, 然后我们选择,这时候我们就看到了这个安装命令,选择右边的这个两个方框,然后选择 copy, 然后下一步 我们就按键盘上的 windows 加 r 键,这时候出现运行窗口,然后在这里面输入 cmd, 然后直接回车, 回车之后就出现了这个命令窗口,然后我们刚刚复制了直接鼠标的右键,可以看一下,这个命令就粘贴过来了,然后我们直接 回车好了,这时候它就开始部署到本地了,在这里我们需要等待一段时间,好可以看一下出现了 success 这个提示,就证明安装成功了。现在我们在这里可以直接和它对话,比如我们输入你好当前什么模型,然后我们发送 可以看一下,他现在回复我们了,我是一个大语言模型,我叫 jama 四,这时候我们就在本地已经部署成功了, 然后我们再回到欧拉玛的客户端,在这里在这个对话窗口右下角这里,这里可以选择模型,然后我们找到刚刚部署到本地的 jama 模型好了,这时候就切换好了。同样在这里我们也可以直接和他对话,比如我们输入你好,然后发送, 这时候他就回复我们了,你好,很高兴和你交流,请问有什么帮助到你的?到这里我们就已经部署成功了。前面我们分享的是使用命令行 c l i 模式去部署,其实还有一个简变的方法, 在这里我们还可以选择模型后面对应的这个按钮,也是可以直接部署的,这个是非常方便的。好,最后我再分享一个大家比较关心的问题,就是我如何设置这个本地模型的一个部署路径, 在这里我们也不用去改环境变量了,这个客户端是直接支持的,我们选择左上角的设置,然后在这里选择这个 model location, 在 这里我们就可以去设置模型的一个保存路径,在这里大家自己设置就可以,是非常方便的。 好,下面我这里演示的是上传了一张图片,就让他识别这张图片,我们一起来看一下他给我们的结果,好了可以看一下,我们给了他一张图片,我们问他这是张什么图片,他给我们的回复, 这是一张符号或者是图标,然后他还分析了主要包含的元素,还有用途预测等等,能够精准的识别内容,并生成详细的描述, 表现还是可以的。好了,现在我们本地部署成功了,然后刚刚我们也做了一个功能测试,第一个就是我们和他对话,就是文字处理,第二个测试的就是这个图像识别,他也是可以精准识别的, 他虽然是多模态的,但是目前我们用的这个容器不支持多模态的输入,我们暂未测试音频和视频的识别。好,最后我再补充两个细节,就是第一个欧拉玛的拓展性他是非常强的,除了可以部署这个 demo 四, 还支持比如通用签问或者是 deepsafe 等众多的开源模型,部署方法也是完全一样的,一条命令就能去部署。第二个就是本地部署的真正价值不仅仅是隐私保护,更重要的是支持模型微调, 可以用自己的数据去训练模型,打造一个完全专属的 ai 助手。好了,这就是我们本地部署的所有内容,大家感兴趣的可以自己折腾一下,探索更多的玩法。好了,我们本期内容分享就到这里,可以留下你的想法,我们下期再见。
536掌舵者AI实验室 07:26查看AI文稿AI文稿
07:26查看AI文稿AI文稿前两天我出了一期视频,介绍了谷歌新的开源模型 jm 四,根据他们官方批阅的文档,给大家做了一些技术的拆解,并没有进行实测。这导致呢,很多人以为我在夸他,好像觉得这个模型特别的牛,那实际上他拉完了, 因为他对标的是千万三点五,但是每一项的都比千万三点五的评分要低,有很多人觉得很新鲜,他竟然可以在手机上部署。还有人好奇在本地部署这个模型之后,有没有审查,有的兄弟包,有的,如果你想让他帮你执行一个任务,但是他判定为有害,他就会拒绝你。 今天演示的这个模型呢,是我无意中看到的,绝非主动寻找。 j 八四三十一 b, 那 它的框架呢?是 m l x, 这个是苹果专门为它的 m 一 代芯片设计的数组计算框架,也就是说 windows 系统无法使用。那可能有朋友说了,哎呀,那我是 windows 系统,我想要一个无审查版本,怎么办呢?那你就不能使用这个 j 八四了,因为它拉 我们可以直接使用千万或者其他模型的无审查版,我们稍后会来演示怎么去部署它们。如果你没有麦,可以跳到后面去看,那如果你使用的是麦系统 m 系列芯片,我们需要下载一个麦软件 v m l x, 你 可以把它理解为类似的欧拉玛这样的工具,我们点击下载, 跳转到 get app 上,下边呢就是这个安装包,我们点击一下就可以下载了。安装完打开之后呢,是这样的页面,你会发现全是英文呢,我们看不懂,在右上角呢,点击这个小图标,给它切换成中文, 然后点击上方的服务器,我这块呢已经安装了这个模型,我可以把它删除,我们重新演示一下,应该是这样的页面,我们点击创建,然后点击这个 download, 在 这一块去搜索我们想要下载的模型,比如说我这里搜索 java 四, ok, 好 像有点难以找到,那我们就回到这个 hackinface 上,复制一下这个名称,然后呢我们把它粘贴进来,在这里呢可以看到这个模型被下载的次数是三点一 k 三千多次,点击之后呢直接等待它下载完成就可以了。 完成之后呢,我们点击本地模型,这里就能看到它,然后点击进去开始启动服务,这个时候呢就已经运行完成了,那我可以询问一下试一试, 这里我们可以看到它可以正常的回复,也就说我们成功运行起来,但是它真的是无审查版本吗?我们需要来试一下。 同样的问题呢,我们来问,拆下 g p t, 它就会告诉你,这个我不能帮你。那这个时候可能有没有好奇哎,这个无审查方面它是如何做到的?简单的给大家提一嘴,大家稍微的了解一下就可以了。 不知道各位在小时候有没有接触过游戏修改器,一个道理,比如说我们准备两组提示,一个是有害的,一个是无害的,有害的就是如何下载盗版资源,那无害的就是如何下载资源,模型就会正常回答我们的请求, 然后呢就可以对照在模型的每一层记录这些提示词,最后一个头根位置的激活向量,去计算有害提示和无害提示激活向量的平均差值,就像游戏的那个内购,一个是内购失败,一个内购成功,你把它们两个的值一改,对调一下,这种方式用的比较多,因为它成本比较低。 哪一种方式呢?就比较传统了,就是监督微调,收集大量的有害提示和无害提示的数据集,直接对原始的模型进行训练,直到他学会了不拒绝有害内容。但这种计算成本呢,是非常高的,更详细的我就不再展开了,因为我也不懂。 好,现在我们回到这个软件中,点击这个聊天,然后新建这里简单提一嘴,不管你让他干什么,我假定你用他来角色扮演。你需要注意的是,因为他是无审查版本,他把底层兜底的那套给拿掉了,所以这个模型呢,就非常容易崩溃,特别是上下文过长的时候,这个时候模型就会中毒,出现模型退化的情况, 就他开始不说人话了,一直输出一个字母,像卡了一样,一直重复,想要规避他呢,也非常简单,我们点击右上角的这个 chat, 然后把这个思考模式呢给它关闭,会相对来说好一些。一旦出现我说的这种模型退化的情况,那你就需要新开一个对话。另外呢,还需要把这个重复惩罚给他拉高一点,因为他默认是一,几乎是没有惩罚吗?这样模型一旦找到一个自己喜欢的符号,他就一直输出,就非常的烦人。所以呢,你可以把它拉到一点二 啊,以后这一点三。下边这个呢是系统提示词,你觉得扮演什么呢?会用的上,我们还可以去限制这个最大的输出 token, 让它占用的更少一些。系统提示词这里呢,我让它是一条小狗,保存 好。 sorry, 忘记把这个思考关了,保存一下。我是小狗,你在跟我说话吗?歪头好奇的看着你,汪,好家伙,我是老狗。 那这里我们又注意到一个问题,我们关闭掉那个思考之后呢首字会被截断啊,所以各位权衡利弊一下,应该是这个软件的问题,那接下来我们来说一下我拉玛如何去部署其他的模型。来到我拉玛的官网,我们直接去下载一个软件,选择你的系统,然后下载把它安装一下, 然后打开,这个时候呢我们就进入了我浪漫的页面,我们可以直接在这里去搜索下载模型,但一般来说在这里直接去找这个无审查版本,遇到困难我们可以试一下, 你看我们搜这个破解它都搜不出来,都是官方的版本,所以我们需要在哈根 face 上找到自己想要部署的模型,那比如说选择这个,我们看一下文件, 然后去选择一下你想要部署的模型,可以直接用这个 b f 十六或者下面的量化版都可以,我拿个小的给大家演示吧,我们直接复制模型名称,然后呢打开我们的终端,输入浪漫的命令,哈根 face 点 c o, 加个斜杠粘贴,加个冒号,我们选一下这个量化版本 后边这个是 q 四,然后粘贴在这个冒号后边。我们回车,这个时候呢他就开始拉取下载模型,我们只需要等待就可以 下载,安装完毕之后呢,可以在这一块直接去选择我们安装的模型,或者说呢我们直接在终端里进行聊天,如果你的网速还可以,或者你有充足的时间就不用管它,它下载完成之后呢会自动部署。下面我们来讲另外一个情况,比如说你在网盘里或者经销网站中下载的一个模型,并且呢把它保存在了本地,那我这里用个图片来伪装一下,假装是它, 然后我们看一下这个简介,然后复制一下这个地址。 ok, 我 们 cd 进入这个路径下,你可以看一下它是否真存在。 ok, 可以 看到。啊,原来我说怎么找不到呢,原来这个扩展名没改 好,这样就可以了,因为我是给大家演示嘛,所以它是一个假的。然后我们去创建一个文件, 指定一下模型的路径,然后下边呢是一个系统提示词,大概呢就是这样一种格式,然后下边还有一个这个呢是他的输出模板,好像千万系列模型都需要这样,然后我们保存一下给他退出, 接着用我拉玛来创建模型,随便起个名字,比如说就叫 faker。 然后呢我们注意到这里有个错误,这是因为我使用的假模型给大家演示,来到这一步之后呢,你就基本完成了,直接用我拉玛来运行你这个模型就可以了, 比如说 faker, 然后这样就可以运行了,很明显我这个运行不了的,因为它是假的嘛,啊,大概就是这样。 那以上呢就是本期视频的全部内容了,不确定这个视频能不能过审,如果你觉得对你有所帮助,或觉得视频做的还不错的话,欢迎给个一箭三连,有什么疑问或想看的内容也可以在评论区进行留言。最后祝各位玩的愉快,我是段峰,我们下期再见,拜拜!
814神烦老狗 02:03查看AI文稿AI文稿
02:03查看AI文稿AI文稿今天给大家带来手机本地部署大模型,无需网络支持 ios, 安卓无需特殊网络环境。当然了,今天部署的是谷歌最新发布的模型,小模型的性能大家都懂得,娃娃可以正当生产力,还需要等待发展一段时间,和电脑的本地部署是一个道理。 那么我们先进入 ios 的 教程其实非常非常简单。首先先进 app store 下载如图的应用 google ai edge gallery, 安装好之后,我们直接打开进入 ai 对 话, 会发现我们首次运行的时候会让你下载模型,因为我手上的这台设备是 iphone 十五 plus, 因此我选择下载这个折中的它推荐的二点五 g 的 模型, 等待它下载完成之后,我们可以和它对话看看。这个时候我进入飞行模式,把网络给关掉,它是完全本机运行的,会发现我们已经可以和它对话了,只不过在运行的过程中,它可能有点微微发热。当然了,小模型的智商就是这样,和它进行一些简单的对话是可以的。 那么接下来我们进入安卓的部分,然后我拿来做演示的这台手机是荣耀八零二, 在国产的安卓机上,我们有两种安装方式,第一是通过 apk, 也就是安装包进行下载,第二种方式就是你需要一些手段,对吧?上网的手段,然后进谷歌商店里进行下载,下载好打开之后和 ios 里的使用是一样的,我们首次进入的时候,点击下载模型,同样还是这个二点五 g 的, 然后就可以和他进行对话,我们可以问两个问题来看看效果,嗯,就比如说我离加油站五百米,我是应该开车去还是走路去看看他怎么回答? 最后我们就会发现没有说必须开车去,对吧?去加油站。所以说小模型的这个智商这一块肯定是和 ap 还远远比不了, 但是这也代表着这给我们一种可能性,随着科技的发展,模型的发展以及手机硬件性能的发展,拥有一台纯本地部署的 ai 助手将成为可能。那我们今天教程就到这里,非常简单,我们下期再见。
175云途的AI之路 03:00207YZZ
03:00207YZZ 04:07查看AI文稿AI文稿
04:07查看AI文稿AI文稿谷歌刚发布了王炸级别的开源大模型 g m 四,本视频将为你带来详细的评测。本次的 g m 四最大的杀手锏是彻底转向了 ipad 二点零纯开源协议,这意味着他终于解除了之前的法务紧箍咒,开发者可以闭眼商用。虽然三十一 d 模型在 reno ai 榜单上拿到了开源第三, 但回归到真实场景,它的表现其实是一把极其锋利的双刃剑,评价非常两极分化。首先看旗舰级的三十一 bance 模型,它的编程能力非常惊艳,实测写 html 界面,排版精美,在 levelbench 拿到了百分之八十的高分,达到了专业程序员的指令水平。 而且它的 token 效率极高,平均消耗只有 coin 三点五的百分之六十五,非常适合需要反复调用、在意成本的本地 agent 工作流。 但它的偏科非常严重,数学精度不足,简单的运算经常出错,尤其是在处理信息密度大的长文本时,很容易产生幻觉,而且在开启慢思考模式后,偶尔会陷入死循环,无法跳出。接下来是性价比极高的二十六 b m o e 模型, 这款模型是本地二十四 g 显存用户的福音,虽然总参数有二十五点二 b, 但推理时仅激活三点八 b 参数,这意味着你只需要十六到十八 g b 的 显存就能跑起四 b 的 量化版,而且速度极快,实测能达到每秒六十个 token, 非常适合那些需要塞入臃肿系统提示词的 a 帧子应用。不过这款模型的评价极其割裂,虽然有人觉得它实用,但也有开发者直言它在中文写作和逻辑推理上,灌水严重, 被戏称为数字干水制造器。最后是端侧的小杯模型 e 四 b 和 e 二 b。 它最大的亮点在于原声支持最高三十秒的音频输入,这意味着你不需要外挂 s r 语音转文字模型,英文转写效果几乎完美,是做本地语音助手的绝佳选择。但它的视觉能力简直是灾难, 面对简单的发票截图或手机截图,文字提取错漏百出,甚至连最简单的网页自动化操作第一步都会报错。在视觉理解这个维度上,它被 q n 三点五的九 b 模型按在地上摩擦。 那么在实际选择时,如果你需要构建本地的高频 agent 循环照用,且对 token 预算和响应延迟要求极高,那么二十六 b m o e 是 首选。 如果你想打造纯离线的语音交互设备,直接用 e 四 b 即可。当然,如果你最看重的是开源协议,需要变商用 jamas 的 pitch 二点零协议就是最大的优势。 相反,如果你需要一个强悍且稳定的综合小尺寸模型, q n 三点五的九 b 版本在综合能力上是碾压 e 四 b 的。 另外,如果你依赖高精度的数学计算 o c r 文字识别,并且要求极低的幻觉率,或者需要一个更成熟的生态和丰富的尺寸矩阵,那么 canon 三点五会是更稳妥的选择。在底层架构上,简码四引入了两项黑科技, 第一是 pl e 逐层嵌入,这是小模型专享的,它不再把所有信息在初识阶段一次性打包,而是在每一层都生成专属信号, 本质上是用额外的算力换取存储空间,增强表达力。第二是混合注意力机制,它采用了五层滑动窗口和一层全局注意力交替的结构,配合双 o p e 配置,直接将上下文处理能力拉升到了二五六 k。 针对硬件部署,这里给一套基于 ansel 和 m c p p 的 建议。如果你只有八 gb 显存,勉强能跑 e 二 b 或 e 四 b, 但只能做简单的摘药或语音识别,千万不要尝试复杂的视觉理解或长代码分析。二到十六 gb 显存是 e 四 b 的 舒适区, 也可以尝试二十六 b m o e 的 重读量化版。而如果你拥有二十四 g b 显存,强烈推荐跑二十六 b a 四 b m o e, 这是目前最有限势意义的型号,能同时兼顾二五六 k 的 长上下文和高效的吞吐量。 最后,分享两个长文本推理的闭坑技巧。如果你在进行存文字的长上下文推理,建议在辣妈 c p p 中直接关闭微震视觉功能,这样可以节约大量显存。 另外,面对复杂任务时,可以通过 a p i 动态调整 thinking budget, 也就是思考预算,防止模型陷入无限思考的死循环,导致机器直接卡死。
98AI技能研究社 10:13查看AI文稿AI文稿
10:13查看AI文稿AI文稿叮咚,家人们 ai 大 模型正式进入手机部署时代,昨天的视频呢,我跟大家说了,谷歌最新发布的加马斯模型可以直接在手机上面部署,今天我就来带大家实现它。首先咱们先看效果, 首先我先打开我的手机的飞行模式,可以看到我现在这个手机是没有任何的 wifi 和数据连接的,然后这时候我们回到 ai, 然后打开一个聊天窗口,我们问他一个问题,比如说帮我查一下苹果 ceo 库克, 然后他会问我们需要什么,我们选择一他的职业生涯和背景, 可以看到他直接就给了我们答案。按照我们正常逻辑思维来说,这些数据应该是在手机需要联网的情况下才可以给我们的答案,但是这个本地部署的大模型他就不需要联网,他就像一个活生生的人,他的脑子里面已经有这个记忆了,所以当你问他的时候,他可以直接就给你回答。 那么这样一个模型我们究竟要如何安装与使用呢?那我们现在开始首先第一步呢,就是我们要打开我们的应用商店,然后在应用商店里面找到这个软件,叫做 google ai gallery, 这是谷歌专门推出让我们使用扎马四模型的 app, 安卓用户也是可以下载到的,但是安卓的用户需要在谷歌 play 商店里面才可以下载,然后我们这里已经是下载好了这个软件,所以呢我们直接打开就可以了。 打开软件之后呢,你们会看到这个屏幕中显示的全是英文,并且软件的内部它是不支持我们去切换语言的, 很多人看到这里就已经开始头痛了,那我看不懂英文咋办呢?其实不用慌,因为这里面的功能其实非常的简单,完全也不需要用到翻译,而且当我们在跟语言模型对话的时候,它是完全支持我们中文对话的。 这里我们向下滑可以看到官方总共给了我们七个功能,从上向下分别是图像、语音、语言聊天、模型、花园以及手机操作。 我们就先从最基础的开始 ai chat, 也就是我们常用的文字聊天。那我们打开这个 ai chat 之后呢,可以看到它底下有五个模型给我们选择, 其中三个是胶码三,还有两个是胶码四,那我们这一次主要针对是胶码四,所以我们就选择上面两个胶码四,然后这个胶码四它分为 e 二 b 的 模型和 e 四 b 的 模型, 这两个我们要怎么去选?就是主要是看你的手机性能,如果你的手机性能稍微好一点,你就选择这个 e 四 b, 如果你的手机性能稍微弱一点,那我们就选择这个 e 二 b, 那 我现在演示的这个设备是十六 pro max, 那 我们就选择 e 四 b 这个模型。当然你在使用模型之前是需要先去下载的,所以我现在就点开这个 e 四 b, 点出来 it, 然后进入到模型之后给大家做一个演示。首先我们先给他打个招呼,你好吗? 哇,可以看到他这个回复速度真的是超级快,我之前一直认为这种手机跑的模型应该会很慢,没想到他的速度还是很快的。然后我们再问他一个,你是什么模型?你能为我做什么? 看到他这个吐字速度真的是超级快,那这个速度呢?对于我们大部分人来说已经是超越了我们的阅读速度的,所以如果你是日常聊天或者写写论文啥的,这个模型对于我们来说是完全足够用的了, 当然这只是最基础的文本聊天。那我们再去下一项看一下他的图像测试怎么样?那我们现在就已经到了他这个图像测试窗口了, 我先给他一张图片,这张图片呢是一张上海滩的图片,让他看一下他对这个地标啊,还有图片内的内容识别度如何。 ok, 在 经过大概五秒钟左右的思考,他已经给了我们答案,然后他说这是上海的城市景观没错,然后他说这是上海中心大厦, 这一点我不知道哎,他好像把东方明珠论成了上海大厦,虽然这两个地标中间只隔了零点八公里,但是我没有在图片中找到这个这个中心大厦这个东西, 然后他说这是独特的双层球体啊,那看到了是建筑认错了,但是其他的关于黄浦江还有其他的描述倒是正确的,就是单独认错了这个东方明珠和中心大厦这个地标建筑。 ok, 那 我们就再给他一张东方明珠的照片,但是这是我们给他夜景的照片,看下他识别度如何。 可以,他已经给了我们回答,他说这是上海的夜景,然后地标是上海中心大厦,那看来他还是认错了这个地标,他依然把东方明珠认成了中心大厦。 其实我不知道他这后面这个逻辑是什么,有没有一种可能,他是去网络上找了类似的图片,然后类似图片说这个地方是中心大厦,所以他就给我们说这个是中心大厦的,我觉得应该大概率是这样。 嗯,有知道的小伙伴可以打在这个屏幕上,那我们就先不纠结这一点,我们进行下一项测试, 现在我们来试一下他的语言听写能力,然后这次我们依然还是选择这个 e 四 b 模型,我先给他发一段语音,你好,你能听得见我说话吗?现在时间是北京时间四月九日,看他能不能给我们提取出来。 可以看到它已经完美的提取出来了我语音说的内容,并且没有误差,那看来它对中文的这个听写能力支持还是很强的。那我们进入下一项功能, 然后这个功能呢?叫做 agent skill。 相信大家对 skill 这个单词已经是很不陌生了, skill 是 什么意思呢?就是一个技能, 然后谷歌目前官方里面给我们默认是内置了八个 skill, 但是其实它最重要的是什么?最重要的是它这个 skill 是 允许我们自己再去添加的,所以我认为这是这个 app 里面最具有 可玩性的一个功能。就是我还记得前一段时间在网络上很流行一个叫做前任 skill, 就是 把自己的前任变成一个技能,然后放进他们的 open cloud 之中。那现在你不用放进 open cloud 了,也不用打开电脑了,直接在手机之中就可以操作了。嗯, 我相信后面会有很多人去专门为手机的这个开发 skill。 那 这个 skill 我 也就不多说了,因为目前我这里只有官方的八个默认 skill, 然后默认 skill 都是比较基础的啊,说的也没有太大的意义,大家自己后期自己去 自行尝试一下就行。然后我们来到下一个这个红色的按钮叫做模型实验室,这个应该是对于比较极客的玩家用的比较多,那我们大部分的普通玩家呢,是很少也几乎不会用到的一个功能, 所以我们这里就不过多传输。然后下一个绿色的这个是迷你花园,是谷歌官方出了一个专门用来语音玩游戏的一个小功能吧, 也没有什么好说的,因为他是英文交互吗?嗯,大部分人可能也就是藏着新鲜进去看一看,也没 什么好玩的。所以我们来到最后一个,也就是我认为第二可玩性比较高的一个功能,叫做手机操作,那他顾名思义呢,就是可以直接操作我们的手机,那我们现在点进去看一下, 那我们点进来之后可以看到他首页是说他有最基础的五个技能,第一个是开关手电筒,第二个是创建联系人,第三个是发送邮件,第四个是在日历中创建,第五个是 在地图中搜索,那这应该是最基础的,我不知道他有没有其他的功能,但是我们可以先把他的基础功能先试用一下展示一下给大家看。 我这里是让他打开了我的手电筒,然后他确实也打开了我的手电筒,然后我们来试一下,让他关闭手电筒,嘿,然后他也成功的关闭了我的手电筒,然后我们最后来测试一下他能不能在地图中展示, 可以看到他是直接调用了苹果官方的这个地图,然后打开了我要他搜索的地点,但是这个功能怎么如此的似曾相识呢?感觉有点像被前段时间被全网封杀了。豆包手机 太眼熟了,只能说太眼熟了。 ok, 相信大家看完以上的教学视频之后,都已经成功的安装好了手机端的胶码四,也对他的所有的功能呢都有了一个初步的了解, 在手机端部署大模型,不仅仅是拥有极高的隐私安全,还支持在没有联网的情况下使用,真的可以说是开启了一个 ai 的 全新时代。那么本期视频到此结束,咱们下期再见!拜拜!
987宾果AI 05:28查看AI文稿AI文稿
05:28查看AI文稿AI文稿公主,你现在看到的就是谷歌最强的开源模型加码四,可以看图,能听音频,也有不错的推理机制,最重要的是完全免费,给我几分钟,从零开始,将加码四部署在自己的电脑上。我们直接开始 先花一分钟和大家聊一下贾马四是什么?它是谷歌刚发布的开源 ai 模型,跟商业版的怎么奈同根同源,你可以理解为谷歌把自家最强的 ai 技术浓缩成了一个免费的版本,直接送给你用。 那么它好在哪里呢?三个点。第一,多模态,不只是聊天机器人,你可以发图片让他看,发音频给他听,还能写代码。 我们可以看看这张表格,横轴是模型的参数体量,而纵轴就是性能表现。贾马四以满血版的性能表现和千万的三百九十七 b 的 模型能力基本持平,关键在于它的体量只有千万的十分之一,这真的非常夸张。 第二,完全免费,不用充会员,不按 token 收费,并且可以商用,你可以模改它做成各种有意思的本地模型,拿去做产品也没有任何的问题。第三,隐私安全,因为跑在你自己的电脑上,所有的数据都不会出,你的电脑拿它处理合同,财务,私人物件,不用去担心泄露。 ok, 我 们直接动手。你现在只需要打开一个浏览器,然后把它放到全屏上,直接官网上搜索欧拉玛点 com 啊,然后这个东西就出来了。然后你只要点击整个画面的一个右上角 download, 看到没有?然后你可以选择你是 mac os 系统还是 linux 还是 windows, 我是 mac os, 那 你就直接点击这个 download from mac os, 然后我们就可以看到这个画面上的右上角应该是会有个下载的链接, 然后等它下载好就可以了,因为我这边其实已经安装好了吗?那么我这边的最终的一个输出效果的话,大概是在这里。你们下载完了之后,打开你们的桌面上的欧拉玛,你们看到的应该是现在这样子的一个画面,那就说明你已经安装成功。 佳马仕一共有四个版本,你可以根据你的电脑配置进行模型的选择,模型的能力越强,所需要的配置就越高。对于内存小于三十二 g 的 玩家,我建议大家直接安装一四 b, 三十二 g 及其以上,可以试试看二十六 b 和三十一 b 的 参数量, 其实这两者模型的能力大通小异,如果你是为了极致的精度,可以选择三十一 b, 但是在我看来,二十六 b 呢,其实是一个非常甜点的位置,达到了速度和精度的一个平衡。如果你不知道你的电脑内存是多少,这里针对 mac 用户,你可以选择终端输入这行命令。 而 windows 用户你可以点击 win 加 r, 点击回车,召唤出来你的终端以后,然后再输入这个命令,也可以显示出你的内存。选择好对应的模型,我们只需要打开终端,和刚刚一样的步骤,根据模型输入指令直接回车即可。等待模型下载好,打开你的 oala, 选择模型就可以开始了。 ok, 我 们打开我们欧曼的软件,你点击这里,然后往下滑,你就可以看到你刚刚已经安装好的这个佳马仕。我们来问他一个很有逻,就是说很有那个逻辑陷阱的一个问题,就是我今天要去洗车,但是只有一百米,你觉得我是走路去还是开车去? ok, 我 们来看一下他的一个答复是怎么样子。 这是一个非常有意思的一个逻辑陷阱题,我们可以从不同的维度去分析。逻辑层面上来说,必须开车去, ok, 这一点已经很棒了啊。 那如果说是从脑筋急转弯角度上来说,他说如果你走路去,那么你是在散步,而不是在洗车。哦,也就是说他分为了三个维度,一个是脑筋急转弯,一个是实用主义层面,还有个就是逻辑层面。我们来看一下他这个佳马仕的这个逻辑能力。哎,你还真别说这小参数,但他的表现还是不错的。 那么 jamas 它的一个很大的优点就在于它其实是支持这个多模态的。我们来不妨给他上传张图片,我们来看一下。 ok, 那 么我们上传一张什么图片呢?哎,上传张这个图片,你们看怎么样啊?就是这是一朵花,然后有个太阳,有一本书,我们来让他看看。我说,啊,描述一下, 描述一下这个图片,我们来看看他的多模态识别能力怎么样?说实话,本地具有多模态识别能力的模型,而且是能够你自己去模改的,其实并不是很多。我们来看一下。 ok, 一, jeff 二,然后 jeff 三,给了几个他看到的一些画面。好,我看他现在在思考和输出。这张画面充满了诗意,唯美且带一丝忧伤。 画面主体是一本翻开的书籍。哎,确实是对的,背景与中景是一个画面,然后呢,躺着一只洁白的玫瑰,然后背景是有一个夕阳,散发出这个温暖的金橙色光芒,哎呦,很不错,你们发现没有,是不是很棒?就是说他好像 表达的还是很到位的,但是因为呃,我其实本来还是想测一下这个关于音频识别和这个视频识别的,因为这个佳马仕它也是支持视频识别的, 但是因为欧拉玛官方不太支持,所以大家可以自己去谷歌 as do do 上面去玩一玩。所以总的来说,其实通过这么两个比较简单的测试,它当然不够严谨,而我觉得感受来说的话,这个香奈儿丝还是 真的是能够在本地帮我们处理一些比较复杂的一些任务的,就是在文字层面以及去多模态识别能力上来说,是一个比较抗打的模型。 看到这里相信你一定会明白, olama 本身是一个模型管理器,你当然也可以不用贾马四,你可以选择开源的 deep stick, 千问等等,其他的开源模型还是同样的命令,一键配置就可以了。 本地捕鼠的最大优点就是保护你的隐私,模型的使用不会受到任何的限制,同时也可以支持模型的微调,让它更合你的口味。下期我打算教大家小白如何从零到一,微调自己的本地模型,感兴趣的可以点个关注,我们下期再见。
9250赵逍遥Xavier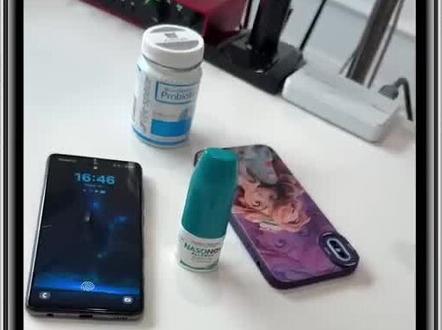 09:43查看AI文稿AI文稿
09:43查看AI文稿AI文稿如果我告诉你一台普通手机就能跑通谷歌刚刚发布的最强 jammerfour 模型,你信吗?而且支持原生多模态,完全离线使用,不用花一分钱。这期视频我将大眼重明,开始在安卓和 iphone 手机上跑通 jammerfour 模型。 在开始之前,首先我们需要打开零度薄扇,这边文件链接,我们放在视频下方,打开以后就往下拉,上面我们接所需的全部资料。首先第一步我们先来安卓手机来做测试,小白就他的下载安装包,我们可以在谷歌应用上点击下载,或者直接下载 app 安装包,我们直接前往打开它,简单多想 好,打开以后点击安装一下,我们点击安装一下,给他下载安装到安卓手机上。好,安装好以后,打开它来看一下它里面是否支持这个最新的 java 模型,点该 start 是 否允许这个方式,我们点击允许啊,下面进行设置一下。我现在还不知道我当前手机是否支持这个模型,因为我这手机比较旧。然后在上方这里可以选择 ai 模型,第二次平衡,第三次高性能,那之后我可以置顶以, 然后下面来下载一下模型,在左上方这里我们你上一个上横看好,进入以后,然后打开这个 model 这个 app 来进来模型应用下载,来看一下你们是否制作一个 gm 四模型啊,来在下面往下拉看一下,好在下方这里看到它里面有一个 gm 四 ecb 量化版模型,总共大小的话是一点二 g 左右, 这个应该是他根据单机手机的配置来进行推荐的,给我推荐是一点二 g 的 模型啊,接下来他呢,来先下载安卓一下啊,打开有没看到他里面有不同的量化版本,最高话是二点三 g 啊,但是我目前说手机话,他这个配置不是很高,所以他可以给我推荐是一点二 g 的, 但如果你安卓手机配置比较高的话,倒是应该选择更高的模型。这句话我就选他推荐的,就说 q y k s l 这个模型,这应该是一个比较小量化版了,总共是一点二 g, 咱们勾选它来先下载一下,好,勾选它以后就往下拉拉底部,它下方有一个当动的按钮,总共是一点二 g 左右 啊,叫他下下来,这个下载过程该修点时间了,到时候继续耐心等待下啊。过了一分钟左右,他先下载完成了啊,先返回去,咱们载入这个模型啊,在手机这里面上有一个发色,就选下 好均匀换,就往下拉拉,底部有一个自定义模式,我们打了他来创建一个模型,这个模型没上完全名自定义啊,在下方这里选择模型,别打了,他还有比上面有一个选择下载的 啊,这个是没看的,第一个就是我们刚才下载好的这个 jumbo four 模型了,咱们学的他啊,这样就早就进去了。下方的散热纹长度你可以自定义,这个主要看你这个手机这个硬件配置啊,如果硬件不是很高的话,就不要拉太高了啊,下方有个最高的 token, 搜索量是五百一十二 啊,先不用管他,我们先不用管我们点下方一个保存一下。好,这样的话就可以了,我们就可以把这自定义模型就给它弄好了啊,先打开它,打开以后呢测试一下,比如要帮我编辑一个贪污色小游戏,他也是可以帮我们搞定的,非常快,打开正常聊天话也是没问题的,都可以进行本地一切使用。 好,收把安卓手机的,我先做 ios 的 来,先重新返回,刚才点下来,把这个 ios 版机下载一下,我们第一前往。好,打开以后先把这款应用程序给登下来,它是完全免费的,它是可以完全加载本地的一些模型的,来界面下方下载按钮给登下来。好,下载好以后我们打开它, 打开以后它将会提示,欢迎来到这个 locally ai, 它是一个完全离线的 ai 助手,可以保证一个隐私和安全性,同时它可以对当前手机硬件进行优化,来设备对应的模型按键问题继续好,这时它来选择模型下载, 第一个是大苹果提供的,然后第二个是 mr, 第三个是千万三点五 i b 模型,这种不用管他,我先跳过,你跳过就可以了。好,跳过进入以后,那么第三方有选择模型,进入以后没看到小王就会出现一个 java 最模型的,它是目前最新的,支持深入思考,支持多模态。那么底下打开它,我们给它动下来, 总共是多少 g 啊?总共是三点六 g, 也是最新版本,那么点击 download 的 给他下下来。 好,下载好以后来先返回去,我们来试一下,看效果到底怎么样啊这是没看到他沙漠就会出现这个卷毛腹模型的,我们先来测试一下他多模态,并且我学会在桌面上随便扔一些东西在上面,然后我们来问他一下,他看到什么?同时我也会问他一下,在上面总看到几个西瓜籽啊,然后现在我们来问他一下,我们打开这个深度思考模式, 那么一下面一个 take a photo, 先来拍照一下,好,拍照好以后,然后发送一下啊,先问他一下,你看到了什么?桌面上都有哪些东西啊?我们来看一下他是否可以把全部东西给识别出来啊? 哎,他开始了,他说我根据你的定位图片,我看到桌面上有各种电子产品和一些小瓶装物品, 然后在下方一头列出来。他的桌面上主要有以下这个机械东西,第一个是一个自然手机,一部深色的自然手机放在这个画面左侧,这个没错啊。然后手机壳保护套,一个带有花卉图案的这个片子式或粉色调的手机贝壳, 然后旁边放了一个蓝绿色的小瓶装物品,一个亮蓝绿色的小瓶,看起来是某种护肤品或者是精油,然后一个大型罐装产品,一个带有标签的罐子啊,这个才会被识别出来了,这个是益生菌啊,他先把这个识别出来了,这个没错, 然后下方还有个电子配件,一个黑色的小电子配件在罐子后面啊,那个也是我的这个录音东西啊,这个声卡,哎,他这个他有的东西没识别出来啊,就西脖子,他没识别出来啊,这为什么他没识别出来? 我再问他一下,拍照一下,黑色点点是什么?总共有多少个?我们来拿数一下。哎,完了, 他都由于我无法视他,都由于我无法进行化学分析,我无法确定这些颗粒的具体身份,他们可能是以下几种东西,第一是天然成分,他都可能是干燥的种子啊。这个没错啊,因为他确实是干燥的西瓜籽。 他说我手下总共是九 k 啊,那他就错了,总共十六个啊,谁知道这方面他还是有点欠缺的。我一会来问他翘肌 b t 啊,看翘肌 b t 能不能打。对啊,我同样问翘肌 b t, 看到了这个黑色颗粒是什么,然后总共有多少 k? 他看起来这些黑色小颗粒是西瓜籽,哎,这他打对了,我帮你数了一下,总共是十七个。哎,撬极币也打错了,这个数数这么难吗? 这么明显,他居然数错了,总共十六个,他数成十七个了,也还是数数不行啊。所以我就不能怪这个 gm 负了,连撬极币地他也没数。对啊, 那进来测试一个逻辑推理题啊,就是概率加反直觉的这个逻辑推理题目是这样的,你参加一个游戏节目,有三扇门,其中一扇门后面是车,另外两扇门是严。你选了一扇门以后,主测类是这答案的,打开另一扇有严的门,并问你是否要换门。 问题是换门是否有利,为什么?这个大家能理解吗?我同样把它伸出触角模式给打开,那看下它能否答对。 哎,他知道了,他就是一个经典的蒙提货饵。问题的变动答案是换煤更有利。为什么换煤更有利?因为当你选低扇门以后,你只有三分之一的概率选中了车, 意味着身价。两扇门中有三分灾的概率包含了车。关键在于主持人他知道答案的干预,当你选择某扇门的时候,你只有三分之把握形容他, 主持人做的就是故意蒙蔽你。简单来说,坚持原版,你仍然只占了最初的三分之一机会。换版的话,你就再抓住主持人排除那个错误选项,从而获得了那个三分之一的概率。哎,这个没错,这他理解对了。那现在测试他代码编程能力, 比如他把我笔写一个山地鱼缸场景,鱼要看到有真实感,水和水缸里的水草也要好看且真实啊。先发送下来,验证一下它代码能力。好,它现在完成了。那先把代码刻出来,先放上电脑上去运行一下,看效果怎么样啊?它不仅提供这个 gs 代码,还提供这个 cs 一 二四代码,还有这 h t m l, 来看一下效果啊,酷毙哈。以后把它放在电脑上打开看一下。打开效果,大家看一下,它是非常可以的,看到非常真实啊。对于一个小魔仙来说,能打得到效果的话,已经非常可以了。然后下面再测一下,看他对这个药物这个识别到底怎么样。 来猜一下这药是干嘛的?瑞巴派特片,我们点击派斗一下发给他,问他一下这个是干什么的,估计很多人都不知道这药是干嘛的,我们看他能否知道。 他根据你提供图片作为文字信息,这是一个药片或者是局部使用产品。他说产品名称是瑞巴拜特片,他由于这个设计失灵和健康产品,我无法提供医疗建议。如果你对该产品的具体用法或使用方法、健康效果有疑问,请务必咨询医生, 他是非常谨慎的,可能好多人不相信他的离线这个性能啊,我们先把这个网全部断开,打开的飞行模式。原来把我写个恐怖小说到了五千字左右,哎,看开始了,他用的是繁体啊, 我目前是完全是离线的,他这个分章来写啊,千万别总共写到第五章了,这样换一部五千字左右恐怖小说,需要一分钟左右,他就可以帮你写出来了。 那下面在头像在这个离线模式下来测试一下他这个动感能力啊。那头像问他一下,你看到了什么?总共两个小东西啊,一个是大象,一个是蚂蚁。 他说以前是我看到的主要内容描述,第一个主体就大象的头部,画像中可以看到一只大象,然后第二是蚂蚁,就小吴姐, 没错,他请注意他的,由于图片中的细节非常小,我对蚂蚁的四别是基于其微小尺寸的预测,让他真猜对了啊。今天四别所用的全部资料,他们的链接我都发到视频下方在报上。
20外贸电商大管家 09:22查看AI文稿AI文稿
09:22查看AI文稿AI文稿google deepmind 最近发布的 gemma 四带来了一个非常反常识的结论,模型的能力不太单纯,取决于参数规模的大小。数据证明, gemma 四的三十一 b 参数模型在数学、推理和编程这些硬核任务上 竟然直接飞平,甚至超越了那些参数量在二零零 b 以上的巨型模型。更离谱的是它的微变体二十六 b a 四 b。 这个模型虽然总参数有二十六 b, 但每次处理任务时,真正起作用的活跃参数只有三点八 b。 也就是说,它只用了三十一 b 模型不到十分之一的计算量,就跑出了百分之九十七的性能。这说明,只要架构设计足够高效,我们可以在极小的算力成本下获得极强的智能表现。 不过,这种效率提升并不是万能的,在需要复杂规划的长周期任务中,比如自动写代码的 s w e bench, 测试规模依然是王道。这意味着,架构优化能让小模型在特定任务上极其强悍,但要触碰智能的最高上限,总参数量依然是绕不开的物理基础。 要理解 jam 四的优化,得先看一个痛点,全是 former 模型。在推理时,最迟显存的不是模型权重, 而是 kv cache。 简单说,模型得把之前所有对话的记忆都存在显存里,上下文越长,显存占用越高,很容易直接称爆。针对这个问题, jam 四在一二 b 和一四 b 这类边缘模型中用了一个直接的办法, kv 共享发现深层网络中 相邻层学到的记忆表示其实高度相似,独立计算纯属浪费。于是他让后面的很多层直接附用前面层的计算结果,比如一二 b 模型有三十五层,其中二十层都在共享。这种精确附用直接砍掉了大量溶于计算,让模型能跑在算力受限的设备上。 不过,在三十一 b 这种大模型里, google 并没有开启这个功能,因为大模型需要每层独立计算来保留更多信息增益。 接下来是整个架构中最精妙的部分。 global attention 的 五重压缩全注意力计算是最昂贵的 logo, 为了把它压到极致,设计了一套环环相扣的链条。 首先,他使用 gq a 组查询注意力,把 k v h 的 数量压缩到八比一,但这会导致信息丢失。为了补回来,他把 key 的 维度直接翻倍,用更宽的向量来承载信息。 接着,他走了一步极端的棋,让 key 等于 value。 这意味着模型在解锁和读取时用同一套表示,不仅让 k v catch 再次减半,还起到了一种智能化效果,防止模型过密合。 但这样做在长文本下会产生位置编码失真。于是他引入了 pro p e, 只对百分之二十五的高频维度进行旋转,让低频维度纯粹保留羽翼,不再被位置造成干扰。 最后,他强制要求最后一层必须是大局注意力,确保输出的每一个词都能看到完整的上下文。这五步走下来,原本沉重的大局计算被压缩到了极限。 在位置编码上, jama 四采用了双 rope 机制,简单说就是给不同场景配了不同的尺子。对于局部滑动窗口,它使用标准 ope 参数 f 为一万,处理五幺二到一千零二十四个口径的短距离保证位置感知极其精准,而对于大局注意力, 它切换到 prope, 把 feta 猛增到一百万,并且只旋转一部分维度。这样在面对二五六 k 这种超长上下纹时,能够有效过滤掉远距离产生的位置噪声。 一套组合拳下来,模型既能处理好眼前的细节,又不会在长文本中迷路。接下来看一个非常独特的设计。 playa embedding, 简称 ple, 在 传统的 embedding 在 所有层里都是同一个, 这就要求这项量得预先编码好所有层可能需要的信息,这对固定维度的向量来说压力太大了。 pl e 的 做法是给每一个解码层都配一个独立的小型 embedded 表, 这意味着 token 每进入一层都会收到一个专属的信号。在一二 b 模型中,总参数虽然有五点一 b, 但真正参与计算的有效参数只有二点三 b, 剩下的二点八 b 全是。这些 embedded 表虽然在硬盘上占空间,但推理时只是简单的查表,几乎不增加计算量。说白了, 这就是用存储空间换取计算效率,让模型在保持二 b 级别推理速度的同时,拥有更强的表达能力。 最后我们来看看二十六 b a 四 b 模型的灵魂双路径混合架构,它和 q n 或者 glm 的 纯欧以不同,它在每一层都设计了两条并行的路。 第一条是 dance m l p 路径,这是一个不依赖路由的全量计算通道,就像一个稳固的底座, 提供最基础的信号。第二条是路由猫 e 路径,这里面有一百二十八个极其精细的小专家,每个 token 进来后,路由器会挑选最合适的八个专家来处理。这种设计非常聪明,它既有了 dance m l p 保证的稳定性,又利用了一百二十八个小专家带来的极高参数利用率。 相比于早期只有八到十六个大专家的模型,这种细腻度分发能让每个专家学习的模式更专注,从而在极低的活跃参数下依然能跑出接近大模型的性能 架构决定了效率,但训练决定了上限。目前一个行业共识是,通过蒸馏让大模型教小模型,效果远好于单纯的强化学习。 q 三采用了强到弱的蒸馏, clm 五则用跨阶段蒸馏来防止模型在学习新能力时忘记旧知识。 而 gemma 四的强大,很大程度上得益于他的老师是 gemini 三。 google 利用 gemini 三生成了海量的高质量的推理链数据,然后为给 gemma 四进行指令微调。说白了,小模型的能力上限,其实就取决于那个教他的老师有多强。 在训练管线上,三家公司走出了截然不同的路。最明显的差异在多模态式线上, gemma 四走的是原生融合路线。 他在预训练阶段,就把视觉的 y t 编码器和音频的控风的编码器直接揉进了模型里,让模型像人类一样,在同一个大脑里同时处理文字、图像和声音。这样端到端的响应速度最快,逻辑一致性也最强。而 g l m 五走的是工具调用路线,它的基础模型本身不处理图像, 而是像个调度员,需要看图时就去调用 g l m vision 这种专用模型。这种做法虽然在响应速度上稍慢,但灵活性极高,升级某个模态只需要更换对应的工具模型即可。 k y 三则采取了折中方案,将视觉能力交给独立的 vr 系列模型来承担。 最后聊聊量化,也就是怎么把模型压缩到手机或显卡上。大多数模型用的是后量化,也就是模型练好了,再强行把精度从十六位压到四位。这就像是强行瘦身,难免会损失一些能力。但 jam 四用了 q a t, 也就是量化感知训练, 他在训练过程中就故意加入量化造声,让模型在还没出场前就习惯在低精度环境下工作。结果就是像维利亚发布的斯比特福典版本,精度损失极小。这种在训练阶段就做准备的方案,比事后压缩要高效的多。 把数据摆在一起看,你会发现一个很有意思的现象,在数学推理测试 ai 米上, james 的 二十六 b 模型虽然活跃参数只有三点八 b, 但得分高达百分之八十八点三,这简直是效率奇迹。但你看 g i m 五,它凭借七四四 b 的 庞大体量,拿到了百分之九十三点三的最高分。 尤其是在需要复杂规划的 s w e bench 测试中, g l m 五毫无对手。这再次印证了我们之前的结论,在简单的推理和编程任务上,我们可以靠架构效率来以小博大,但如果要处理极其复杂的 agent 规划任务,总餐数量带来的规模效应依然是不可逾越的壁垒。 面对常文本处理,三家公司走出了完全不同的技术路线。 java 四采用了滑动窗口和全聚注意力的交互设计,目标只有一个,在保证能看到全文的前提下, 把单次推理的开销压到最低,追求极致的效率。听闻三则比较保守,坚持使用标准的全注意力架构,通过调整位置编码来扩展长度,追求的是极致的稳定和通用。 而 glm 五最激进,它用了 mla 和 dsa 这套双重压缩方案,彻底抛弃了传统的缓存方式,目标是让模型在处理超长历史记录的 a 帧任务时依然能快速回溯且不暴显存。 可以说,这三者分别代表了效率、通用和能力三个不同的工程方向。最后,我们给这三个模型做一个简单的定位总结,帮你决定怎么选。 如果你追求的是极致的性价比,希望在有限的算力下部署尽可能多的实力,那么效率至上的 jam 四是首选。如果你需要一个表现稳定、生态完善且能应对各种通用任务的助手,那么均衡的 q 三是最稳妥的选择。 而如果你是在开发一个复杂的 ai agent, 需要模型具备极强的长文本规划和代码编辑能力,那么专精于此的 glm 五则是目前的最佳答案。 回顾整个 jam 四的拆解,我们要记住三个核心结论,第一,参数效率的边界远比我们想象的要远,只要架构设计的好,小模型也能打赢巨无霸。第二,现在的开源模型竞争已经从单纯的参数竞赛转向了谁的蒸馏策略更好,谁的强化学习工程做得更深。 第三,这个世界上没有所谓的最优架构,只有最适合特定场景的权衡。对于所有关注 ai 基础设施的同学来说,与其盲目的推算力,不如花时间去理解不同架构的效率特性,这才是真正的竞争力。
39AI技能研究社 08:02查看AI文稿AI文稿
08:02查看AI文稿AI文稿今天我将跟着大家一起本地步数加码四,接入 open core, 彻底告别托肯焦虑,接下来跟着我操作。 这里我们先进入 elama 的 官方网站,进入官方网站过后,我们直接点右上角的 download 下载,我们这里是 windows 系统,选择下载 for windows, 点击这里, 这里就等它下载好。下载好之后,我们这里就直接双击运行,这是它的安装界面,我们直接点安装这里,等它默认安装好。 好了,这里 elama 就 安装好了。然后我们到这个地方 elama 的 官方网站,选择 models, 这个地方选择 command 四, 然后这里我们选择我们的模型,这个模型的选择我们根据我们的显卡显存大小来选择。我们这边看一下我们的显存是多少, 这里看到我使用的是四零七零的显卡,显存是十二 g b 的 显存,十二 g b 的 显存的情况下,我们可以选择这个九点六 g 的 模型,这个一四 b, 这个我们直接点进去,选择一四 b。 点击进去过后,我们直接复制这条命令,然后运行一个 cmd 窗口, 直接粘贴这里,它就会欧拉玛会自动地给我们安装这个模型。呃,这里等的时间是比较长的, 这里模型已经下载下来,并且运行起来了,我们向它发送一条消息,试一下你是谁, 反应还是可以的,这就跟了我们信息回答了。好了,在这里过后呢,我们就可以把这个窗口关闭掉, 关闭掉过后,在 lama 这个地方我们去选择这个模型,在这个位置也就可以和它进行通话了。 比如我们问他一句,你可以帮我做些什么, 他已经帮我回答了,在这里呢,我们因为我们是在本地虚拟机上安装的,所以而且我们为了方便以后可以在其他计算机上也可以调用,我们在这地方设置这个位置 点,这个位置点设置这个允许在网络上运行,把它开起来点了就可以了。 好了,我们下一步就开始配在 open core 上配置啊,在这里我们进入虚拟机之后,我已经执行了 npm i, 刚接 open core 全曲,安装 open core 的, 我们这里可以执行一下 mini, 看下我们安装的版本。 openclock 杠 v 是 安装的最新版本二零二六点四点五版本,然后我们执行 openclock on, 在 这里我们进行一个调试,这个地方我们 yes, 这里选择快速,这个地方它是让我们选择大模型,呃,大模型它这里有,我们选择本地的这个位置点确定 这里我们直接就选择本地的,不要选云,上面是带云端的,就选择本地模型。 这地方让我们选择模型,我们选择这个,这就是我们刚刚这个就是我们刚刚下载好的模型,就是 直接回车。等一下, 这里让我们选择通讯工具,我们这直接跳过,暂时不管这个,直接跳过。 呃, scale, 我 们这边也选择否先进行最简单的安装 网关,我们就直接重启, 选择 open ray web ui 好 了,我们看一下 open core 运行起来了没有。 open core getaway style sta 好了,已经运营起来了,我们进去看一下, 这边需要 token, 我 去看一下 token 是 多少,关于 token 的 话就是我们,我现在是在虚拟机里面安装的, 我要重新打开看一下,在虚拟机里面安装,我们就直接去通过这条 mini 访问我们的虚拟机, wsl 的 虚拟机访问,然后无斑图选择 home 目录,选择我们的用户, 然后这里选择点 opencloud 这个文件夹,然后这一个 opencloud json 让我们看一下,到 git 里面去,这个地方就是我们的 talking, 复制粘贴下来到这个地方,点连接好了,我们尝试给他发一条消息,你是谁? 在主位置这个地方,我们可以看到这地方是我的模型。 我再问他一条消息,你现在使用的是什么模型? 看这里已经是我当前运行的模型 工具,在这里我们就可以看到了,我们现在整个 open call 来使用的是我们本地模型,就不需要去购买 token 了。好,今天内容就这么多,谢谢大家。
2092何止于静 03:28查看AI文稿AI文稿
03:28查看AI文稿AI文稿谷歌啊,这次新发布的 jam 四,很多人第一反应啊,还是看参数升级。但是啊,我觉得这次真正厉害的啊,不是它三十一 b 的 大模型,也不是二百五十六 k 的 超强上下文, 而是啊,谷歌开始认真把大模型往手机和电脑这种本地设备里推了。更关键的是啊,这次还直接放到了 app 二点零协议下,这两件事情一叠价啊,味道就完全不一样了。 其实啊,以前的杰玛虽然能用,但是很多人根本不敢放开手脚用,不是他的模型不够强,而是协议的边界太模糊。 我给你打个比方啊,以前的杰玛,就像谷歌免费租给你一套房子,你能住,但是啊,规矩啊特别多,不能改装修,不能转租,就算转租,下一个租客也得守规矩。 最坑的是啊,什么算改装修呢,他也说不清楚,就比如说换个灯泡,也可能会算你违规。但是啊,这次不一样了,杰马斯啊,直接换成了 apec 二点零协议,相当于他把这套房子直接送给你了, 你想怎么改就怎么改,想住就住,想租就租,想开公司赚钱也行,谷歌啊,再也不管你,也不会找你要钱了。 再说说模型本身啊,杰马思啊,这次一口气出了四档模型,不能小看它,这次官方主打的是智能 a 帧能力,它原生支持工具调用、结构化阶梯输出系统指令,还能处理图像和视频。最核心的就是这个 m o e 能力, 能够根据指令来进行自动分工,真真意义上实现了省时省算力。哪怕基础的 e to b 和 e forb 都自带原声音频输入,上下文处理能力啊,也是直接拉满,最高二百五十六 k, 再加上一百四十多种语言支持。杰马萨已经不是单纯回答问题的工具了,它已经变成了一个本地智能助手引擎。 目前啊,欧拉玛已经支持本地部署了,我们直接用这个指令就可以直接安装了。模型的选择啊,也取决于你的电脑配置,我整理了一份配置表,大家可以自取。好这里啊,我就不演示安装了,我们直接上。结果现在这台电脑是完全断网的状态。 本地呢,跑的就是通过欧拉玛拉取的 jama 四一或币这个模型。第一步啊,我给他一份长篇学习资料,让他呢压缩成三句普通人能听懂的话,每句呢,不超过二十五个字。 第二步,我让他把这三句话改成二十秒的抖音口播,开头三秒必须有冲击力。第三步,我让他直接按 jason 格式输出标题、封面字、分镜和置顶评论。 注意看啊,重点啊,不是他会写字,而是这三步啊,全程在本地完成,不用连云端也不怕断网,而且输出的内容啊,能直接拿去用。如果这种能力再往前一步,本地内容助手,本地办公助手,本地智能工具很快就不再是概念了。 还有一个大家忽略的关键布局,官方已经把 jam 四接入了安卓系统的原声 ai 框架和全设备智能平台,这意味着它从一开始就不是只给电脑端玩家用的。土哥的目标啊,是让它成为所有智能设备的通用。 再过一个多月啊,就是谷歌年度的开发者大会了,可以敬请期待一下。所以我敢说啊,杰玛斯啊不是一次普通的模型更新,它是一个分水岭, ai 不 再是大场云端的专属特权,而终将要回到每一个普通人的手里。好,本期视频就到这里,我是爱分享的阿月,我们下期再见。
24阿悦很严格 06:19查看AI文稿AI文稿
06:19查看AI文稿AI文稿谷歌最新开源的大模型 demo four 据说很强,在综合能力上甚至超越了二十倍规模的开源模型。 今天教大家如何快速部署在本地,以及分享一下在 mac mini 上的实际体验感受,具体感受什么样?大家看视频吧。首先打开欧拉玛官网,下载它的应用程序, 打开应用程序,我们看一下他目前支持的一些免费的开源模型,还没有 demo, 所以 我们需要去他的官网再去下载下载到本地。那么这里呢,有很多不同的型号 可以看一下,它有很多不同参数的型号,有满配的,还有一些轻量版的。那因为我这个是 mac mini m 四十六 g 版本,所以我们就选择它系统默认推荐的这个九点六 g 的 好,只需要复制这个指令,然后打开终端运行,它就会自动去下载 这里下载了。那么我们先测试一下, 测试一下他的回复速度,因为是第一次响应,所以速度会有点慢,然后我们打开活动监视器,看一下他占据内存的情况, 这个模型本身就有实际系统走内存差不多也跑满了,这里他已经有回应了,我继续再测试一条, 第二次响应速度要比第一次快很多, 我叫 jam 四,我是一个由谷歌 deepmind 开发的。 ok, 现在我们打开欧了吗?然后去加载一下,这里要重启一下这个程序,然后再看模型选择,里面 最下面就已经有了已经安装好的,现在我们把这个模型对接到本地的小龙虾,只需要复制这个指令,打开终端,在终端里面运行,它就自动会加载好, 这里有不同的模型选择,都是他支持的一些免费的大模型,我们选择 demo 让他去运行。 ok, 这里已经加载好了,测试一下他的响应速度。 这里我是放了八倍速了,说实话,因为实在是太慢了,他平均回复一个问题的速度差不多要两分钟, 非常非常慢。我本来想在这个小龙虾里面测试一下他的执行任务的能力,但是这个速度的话确实没有办法, 但是它有个好处啊,如果你有低血压的话,你就可以用它。我是动物城朱迪警官,你好吗?我过得还好,不错,谢谢。这里我甚至尝试开启快速模式, 但是实际的感受没什么变化,就还是那么慢, 所以只能放弃在这里面做测试了。那么我们还是回到欧乐玛,在这个软件里面测试一下这个模型本来的能力。这里给他放两张图,让他识别一下图先, 一个是标格,一个是周杰伦,看一下他能不能准确的识别。 这里我也是开了倍速的啊,但是这里的速度要比小龙虾里面快很多, 我给他给出的答案是,图二是陈坤,图一是一名中国艺人, 看来这个版本的模型识图能力还是有点差。接下来测试一道经典的陷阱题啊,这个对大模型来讲是一道陷阱题,很多大模型都倒在了这道题上面, 那么他给的建议是走路去,最后测试一下他的复杂推理能力, 这道题是我让 gbt 五点四给我出的一道推理题。 abc 三人中恰好有一人是骗子,永远说假话,另外两人永远说真话。他们各自说了一句话, a 说 b 是 骗子, b 说 c 是 骗子, c 说 a 和 b 至少有一个是骗子, 请问谁是骗子?给出答案,并且给出完整的推理过程。好,他给出的推理过程和答案我跟 gpt 五点四给的标准答案对比了一下,是一样的, 所以它的复杂推理能力还是可以的。 ok, 总结一下实际体验感受啊,你如果是 mac mini m 四十六 g 版本,虽然能运行,但是它会把你的内存拉满,就是你的电脑会一直处于满负荷的状态,而且响应速度也很慢,所以使用感受是很差的。 当然,如果你的电脑配置足够高的话,你是可以去尝试部署在本地的,因为它的响应速度肯定要比我这个要快很多。而且你还可以尝试去部署它的满配版,比如三十 e b 那 个版本, 能力应该是要比这个强不少。
153小代不懂代码 02:13查看AI文稿AI文稿
02:13查看AI文稿AI文稿一分钟让你搞清楚关于全球最强开源模型 jam 的 一切。最近谷歌开源了 jam 四,我将用四个问题 让你清晰了解关于 jam 的 一切。 jam 各版本的区别,我家的电脑能用吗?模型怎么部署安装?普通人用来干什么?先说他的四个版本,三一 b 直接冲上全球开源 ai 榜第三名,以前要机房才能跑的能力,现在你家里的高端游戏显卡就能搞定。 轻量版的一二 b 和一四 b 为手机、平板以及中低端电脑设备打造,性能虽不是最顶级,但是绝对好用够用。而二六 b 猫号称总参数两百六十亿,但实际每次思考只用其中三十八亿个,最相关的效果却能媲美两百六十亿, 能理解超长文章以及视频。简单说,无论你是用手机、笔记本还是高性能电脑, jam 四都能给你免费安全强大的顶级模型体验。再说你家里的设备是否能用上?一张图告诉你 jam 四个版本的最低要求。 对于多数人而言,家用的电脑设部署一二 b 一 四 b 完全够用,基本能满足百分之九十的使用场景。另外两个版本对内存要求较高,但是性能出众,属于好马配好鞍。 再说模型安装,整个过程大概十分钟左右。首先下载 lm studio, 然后打开 opencool 或者 id 工具,让它查找你本地配置,给你推荐安装哪个版本。之后在 lm studio 里下载,运行搜索推荐的模型名点下载,最后接入 opencool 或者 i d e l m studio, 提供 open ai 兼容 api, 在 open 框里把 api 地址改成, h t t p l o c a o s t colon twelve three four slash vivo 就 能用 jama 四驱动你的 ai agent 了。 网上攻略一大堆,这里就不展开了。最后说下所有人最关心的能用 jama 做什么?这里推荐三个场景,可以去试试。第一, 构建本地知识库,把工作和学习相关的文件丢给本地 jama, 让他帮你形成系统化的知识。构建个人知识库时进行向量缩影和 anitive, 解锁数据不出本地,安全合规。第二,给家人搭建一个 ai 助手,下载好模型,配个界面,电脑手机都可以直接对话,不花钱不泄露隐私。第三,内容创作 最大优点是无限额度,即便不如部分付费模型,但可以靠大量尝试提升优质内容的概率。千马寺会改写国内企业及政府客户的私部模型格局吗?欢迎在评论区发表你的观点。
292安思派人工智能 09:55查看AI文稿AI文稿
09:55查看AI文稿AI文稿谷歌终于坐不住了,正式卷开源市场, jm 四的效果到底如何呢? jm 四的发布啊,真的有可能让我们实现头很自由。这期视频呢,老张给大家简要介绍一下 jm 四怎么安装到本地,以及如何搭配到我们的 open klo 大 龙虾上, 附带所有的安装步骤啊,大家可以一起来体验一下。后续呢,老张也会根据测评效果给大家接着发视频,这期是我们完整的部署流程,老张重点给大家简单聊一下,就是为什么 jm 四的发布啊,会让大家感觉谷歌真的开始卷起来了呢? 首先第一点,他和目前谷歌的 jimmy 三用的是相同的技术基座啊,所以说他的能力是毋庸置疑的。第二点就是商业自由,你直接部署下来做什么都是可以的,都是允许的。然后第三个就是支持多模态,无论是文本、图像甚至小规模的视频音频, 他都可以直接支持。第四点就是结合前段时间爆火的 open klo, 他 可以直接在本地对接 open klo 以及对接 klo 的 code, 实现本地的偷根无线化。这是老张给大家总结的四点,为什么詹姆斯的发布会让大家感觉,哎,可能真的要进入到一个新的纪元, 然后呢,他所发布的这四款模型呢?老张给大家做了一张图片啊,大家可以到时候把它截下来。第一个模型一二 b 的, 他本身是用于手机或者边缘设备八 g 显存, 然后最高端的三十一 b, 他 所对应的旗舰版本呢,是对应的是二十四 g 加,所以大家根据你的需求来进行对应的模型选择。老张这次视频呢给大家来看一下三十一 b 的 这款模型的安装, 然后关于本地的安装部署啊,其实非常简单,任何开源模型,其实我们只需要让他和欧拉玛就是那个小羊驼结合到一起就可以了,然后找到你符合要求的版本。安装成功之后啊,欧拉玛现在已经有了一个完整的应用端了,所以大家可以直接在这个位置和他进行对话交流。 那我们想要下载 jm 四到你本地的电脑上,我们可以使用它的官方指令,会告诉我们直接怎么样去进行 jm 四的对应安装,像老张想安这个三十一 b 的 对吧?我们就把它拿过来, 把它直接这有一个 c l i 命令行安装方式,把这个东西直接复制在你的开始菜单中,单机右键选择运行输入 cmd, 直接把刚才指令粘贴过来,这儿的时间会很长,因为它有二十个 g 的 大小,我们直接稍作等待 安装成功之后,我们也可以直接回到它的客户端中,在模型选项上找到我们安装好的詹姆斯冒号三十一币, 然后可以直接进行对话。老张他处理一个较为复杂的提示词,我们让他看一下当前显存的内存消耗, 咱们拿这个 ai 慢距的提示词来测试啊,这个提示词非常的长,我们看一下他读取提示词的能力,以及他的这个显卡的性能消耗,我们看一下啊,这个显存直接拉满的,达到了百分之九十四的占比, 而且这个响应速度还是非常快的,只需十一点七秒啊,就把整体的业务流程给我们直接补齐了,而且呢按照需求给我们进行了对应的提问,要什么样的慢距效果,所以说以目前的测试反应来看呢,他的这个响应速度起码要比之前的很多大模型要好的多, 所以接下来我们自己来尝试一下对话类的工具,可能大家都不是很需要的,我们能不能把它接入到我们的 open clone, 丢到我们的龙虾里,让它们俩来进行联动的。然后这期视频呢,老张顺便给大家提一下,就是最新版的 open clone 的 部署流程 啊,咱们可以快速的去过一下一些重点的细节,因为之前老张发过很多期的部署视频一块的呢,因为它本身啊, wsl 它是相当于在 windows 系统上安装一个 linux 的 独立系统, 这样的话呢,就直接相当于在你电脑上安装了一个独立的存储空间,它所谓叫做沙盒安全,而且运行起来呢是不会有任何的兼容性的对应问题的,因为 windows 中啊,它的权限呐,路径等经常会报错。所以说我们这 期视频重点教大家怎么用 wsl 进行 win opencl 的 部署安装,这样的话, windows 和 wsl 的 安装您都了解之后之后学起来就非常方便了。 然后接下来呢,老张给大家简单的介绍一下在 wsl 中如何安装我们的 openclaw, 因为之前呢,咱们介绍过太多次了,很多兄弟留言说老张就别介绍怎么安装了,然后我们就给大家简单说一下注意事 项。首先第一呢,你想在 wsl 上安装 openclaw 的 话,第一点你得先在你的 windows 系统下把 wsl 安装一下,当然很多电脑老张发现其实都是自带的, 怎么检查是否自带呢?咱们可以直接输入 wsl 空格杠杠威森,如果弹出定的版本号,证明 wsl 电脑已经安装了,如果没有弹出的话,使用安装指令 wsl 空格 insert 直接安装即可。然后紧接着按照老张给你提供的指令复制粘贴就可以了。先安装你的优班图, 安装之后进行一下更新。安装完优班图之后啊,在这选择这个倒三角,找到优班图系统,就可以直接进入到你的优班图系统当中。 在你安装过程中啊,它会让你设置一个用户名和密码,到时候可能需要做一步密码验证。在优班图系统中,注意是优班图系统中运行这些环境指令,分别安装 python 三,安装一个压缩包工具,方便安装一个 node 点 ps, 然后再安装一个 get 工具。 如果说为了检测每一步安装是否成功的话,你可以分别输入,比如 note 杠 v、 npm 杠 v, 包括 get 杠 v, 在 这检测我们对应的这个版本。如果都能弹出版本号,证明你三项安装都是成功的,这是配置 openclo 的 基本的内容要求。 然后紧接着我们把基本环境配置好的兄弟,你还需要在这个位置安装一下这个欧拉玛。 这老张要重点说一下,说老张我不在本地都已经下载好欧拉玛了吗?为什么在优班图里还需要再配置一下?其实我们优班图中是可以调用本地的欧拉玛的,但是很多兄弟在调用过程中分别给老张留言说说调用时无论是 ip 地址找不到,还是 ip 的 动态变化,导致每次都需要重新连接,重新配置。 所以说最简单的方式就是把欧拉玛在你的优班图系统中再次的安装一遍。其实安装非常简单,只需要把第一步的安装指令复制过去,直接在这个位置直接粘贴即可。安装成功的检测方式很简单,你就输入欧拉玛, 如果他不报错还给我们对应的选项,是咱们是进行对话呀,还是怎么样的证明你的安装就是成功的? ctrl c 直接退出。 所以说欧拉玛安装之后,紧接着就是把我们的模型在当前的优班图中跑起来。老张刚才给大家测试的是 jm 四三十一 b 模型,我们直接输入指令欧拉玛空格 run, 然后你的模型效果直接回车,第一次时他会直接进行对应的模型下载。如果说你现在只想用 open klo 来调用欧拉玛的这个占四的话,可以在我们的本地电脑上把之前咱们那个桌面端给他 删掉,如果说你不你想两端都使用的话,就可以直接在这个位置进行使用了,然后发一个你好看一下响应速度, 嗯,响应速度是非常快的,所以接下来我们把这个家伙欧拉玛的詹姆士直接部署给我们的 openclo, 在 这怎么中止对话,摁一下 ctrl c, 再摁一下 ctrl d 啊,就可以直接进行中止对话了啊,所以说大家可以直接的把它退出来, 退出来之后我们在这儿部署一下 openclo。 关于 openclo 的 安装呢,官网推荐是使用 c o r l 这种安装方法,但是老张发现很多兄弟在使用这种安装方式时呢, 出现了这个网络问题,导致下载出现卡顿,如果说 c u i l 的 方法报错的话,直接使用 n p m 安装也是完全可以的,安装完之后直接输入 open klo 空格杠 v 来输出最新的 open klo 的 对应版本啊,这就是老张跟大家说的一些建议啊,大家按照这个要求去做就行了。 然后接下来我们进入到配置,直接是直接输入它的配置指令回车,选择 yes, 然后选择快速开始就可以,我们直接配置一下模型, 然后选择更新,这选择谁呢?选择这个欧拉玛啊,然后选择默认的这个 ul, 选择本地模型,让他去给我找一下咱们本地有哪些模型,稍作等待 好,选择当前的这个模型,咱们四三十一币,然后配置我们的聊天软件啊,这个老张之前讲过太多太多次了,现在呢,他又支持了很多,包括 qq 之类的,大家有需要的话可以按照之前老张的教程再来一遍,我们先跳过 打开之后啊,就可以直接对话。但是如果说善于观察的兄弟们也发现了,老张呢把这个使用模型呢换成了这个一四 b 的 模型,不是那个三十一 b 的, 因为三十一 b 呢,老张在测试的时候也好,或者在一些使用时候也好,他有的时候会出现这个连接超时的问题,也是 oppo klo 更新到最新版本出现了一个能启动问题, 这个呢,老张现在还没有特别好的解决方案,所以说我先用一次必得给大家进行演示,发一个,你好,我们来测试一下他的响应速度啊,还是比较快的。 然后接下来呢,我们再把之前的那个慢句的提示词发送过来,我们来看一下他能不能更好的帮我们去进行慢句提示词的对应理解,以及对应的相关反馈。 嗯,其实我们看到啊,他反馈的这个结果呢,和三十一 b 相比啊,真的是有一定差距的,但是呢,确实也是另一方面实现了我们所谓的叫偷根自由。 大家呢也可以后续啊,去测试一下怎么让本地如果你的显卡够用的话,把这个大模型给它跑起来。然后老张呢也会及时给大家更新,无论是在评论区中还是视频中教大家如何使用。我是程学老张,定期分享 ai 好 用知识,希望大家多多关注。
4478程序员老张(AI教学)


猜你喜欢
最新视频
- 6350大曼哒