lm studio远程使用教程
全网最简单的免费使用各种 l l m 模型教程,如果你想使用人工智能产品帮助提升工作效率,但是又没有米,不会魔法,不会拍摄,也不懂如何配置环境,那么这个视频教程绝对适合你。 今天这个视频主要给大家分享一款免费开源的 l m 软件, l m to deal。 l m to deal 是一个易于使用且功能强大的本地机,可在 windows 和 macos 上使用,并具有 gpu 加速功能,支持很多主流 l l m 模型, 比如辣妈 m p t replate 等。下面给大家讲一下如何使用以及使用过程中的注意细节。首先要在官网下载 l m studio 软件, 我们先测试一下 windows 系统下的使用体验,下载后直接装机就可以打开软件, 这就是软件的主页面,在主页中会有一些推荐的模型,可以在推荐项中选中直接下载,也可以点击详情更加精细的筛选,选择适合自己机器配置的模型。 页面最右侧会有每个模型所需的内存要求,找到合适的模型后点击下载。 下载完成后切换到聊天页面,就可以在模型选择这里看到刚才下载好的模型,点击想要使用的模型,等待加载完成就可以对话了。 在对话栏下方可以看到推理的一些性能参数,每秒十个 token, 速度还是可以 在页面右侧是一些推理设置参数,自定义 proper 及硬件配置等。注意要关闭 tp entire modeling rem 选项,不然推理速度会很慢。如果电脑有 gpu, 可以在这里开启 epu 加速,可以提高推理速度。该软件也支持本地 server 模式启动,并支持 opiapi, 方便开发下游应用调试。 最后一个 type 式模型文件管理可以在这里配置模型的默认下载路径,以及查找删除模型、配置模型预设等。以上就是在 windows 加使用 l f to deal 的主要流程下, 下面讲一下在 macos 下使用 lfgodo 的注意点。我这台电脑是 mr pro, 十六 g 内存可以运行十六 g 以下的模型。因为苹果 m 系列处理器是共享内存,所以十六 g 内存就相当于十六 g 现存,也支持 gpu 加速, 前提是要在这里打开 gpu 加速选项,可以在参数栏看到推理性能,每秒生成十三点七三个 token, 真是不得了。 其他配置都是和 windows 保持一致,这里就不再赘述了。如果这个视频对你有帮助,就点赞关注吧,谢谢观看!

粉丝2658获赞1.2万
相关视频
 03:41查看AI文稿AI文稿
03:41查看AI文稿AI文稿今天 lm studio 团队发布了他们最新的零点四点五版本,这个版本加入了 lm link 的 功能,可以让安装了 lm studio 的 设备之间远程互相访问大模型,并使用远程设备推理, 这是什么意思呢?比如你有一台安装了 lm studio 的 一百二十八 g 的 macbook pro, 然后你的另外一台设备是安装了 lm studio 的 一台极显笔记本,你可以从这台极显笔记本远程访问你的 macbook pro, 把 macbook pro 当做一台大模型推理服务器来使用,这样你在这台极显笔记本上也可以进行高效的大模型推理了。 lm link 是 lm studio 团队和 tail scale 一 起开发的,如果你不知道 tail scale 是 什么的话,你可以简单的看做一个设备到设备之间的 vpn 即可, 这并不是仅限局域网哦,而是可以穿透内网,让你在任何地点都可以访问远程设备推理大模型哦,使用也是超级简单。我们只需要注册一个 lm studio 的 账户,然后点击这里创建一个 link。 由于我已经创建好了,所以进来之后可以直接看到我已经加入的两台设备,一台是 m 三 max 的 macbook pro, 一 台就是 dinkpad p 十六 v 键。二,目前有五台设备的上线,点击这里的三个点,可以选择删除已经加入的设备, 然后来到 lm studio, 首先确保更新到了最新的零点四点五版本,更新到最新版本后,在左下角就可以看到一个 lm link 的 图标,点击就能看到目前加入的设备和链接情况,这里显示的是当前设备,而这里则是你加入远程设备 中间,这里则是显示远程设备信息,我们可以看到 macbook pro m 三 max 右侧则是该设备上的模型,目前显示已经加载了千万三点五二十七币的稠密模型, 点击三个点可以远程卸载模型,然后点击任何的模型就可以加载模型了。这个加载界面和本地加载是完全一模一样的。点击加载,此时远程在我的 macbook 上也可以看到远程设备发来的模型加载请求。 加载完毕后就可以来到聊天界面选择加载的模型,然后开始愉快的聊天啦。怎么样,是不是非常简单,速度也完全不用担心,七十三个 tokens, 每秒和本地推理速度一模一样。 来到模型加载界面的话,你会发现操作和本地模型几乎一模一样。远程设备的模型会在名字前面显示一个图标,点击加载的话也是和本地体验完全一致的。 最后,既然模型加载的体验上和本地完全一致的话,那 open code 的 这些支持 l m studio 的 代码智能体也是可以完美运行的哟! 体验上和本地模型完全没有区别。选择 l m studio, 然后选择模型。这里以 g p t o s s 二十 b 为例, 我们可以看到 open code 的 推理完全是通过远程模型完成的。现在你可以非常方便的构建一套家庭 ai 工作平台了, 只需要一台 m 四的 mac mini, 六十四 g, 装上 lm studio 后直接以无头模式运行,你就拥有了一台百分百完全私人的在哪里都可以访问的 ai 推理服务器啦!
98AI踩坑指南 03:31查看AI文稿AI文稿
03:31查看AI文稿AI文稿尝试在这台老爷机上部署千万三点五,处理器是 i 五四五七零八 g, 内存无读写,我用的是 rms 对 d l 进行部署,打开官网下载安装即可。安装好之后下载千万三点五模型, 我们直接进行搜索,模型越大就越聪明,但是配置要求也越高,我就下载零点八 b 模型来演示,大家可以根据自己的需求和配置进行下载, 下载好模型就可以进行载入了,载入时可以设置上下横,长度也是根据自己的配置和需求设置, 到这里模型已经可以跑起来了,如果不需要联网搜索和本地知识库,做到这一步就行。如果需要联网搜索,就打开浏览器的插件中心搜索,配置 sis 插件进行安装, 然后打开插件设置,把语言改成中文, 搜索引擎可以改成百度搜索,结果按需修改,改好后记得点保存。然后回到 r m, 打开网络服务, 再回到插件,设置了 api 添加供应商, 选择 r m studio 保存即可。点击新聊天,选择千吻模型就可以在网页里进行对话了, 需要联网搜索就打开下面的开关,点击引用的网页就可以看到千吻通过网络搜索到的内容。 然后是建立本地知识库,先在设置里选择文本切入模型,那么会自动帮我们下载好,下了菜单里没有的话就等一会, 记得点保存。现在就可以在知识管理上传我们自己的知识库了, 等状态变成已完成,就能在对话里调用知识点进行回答,点击输入框下方的知识点,选择刚刚上传的知识点即可。
364看到什么我就吃什么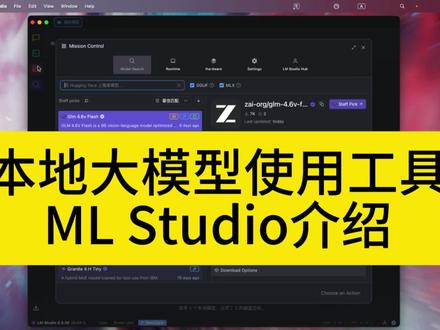 03:54查看AI文稿AI文稿
03:54查看AI文稿AI文稿今天给大家介绍一下我在 mac 上经常用到的一些 ai 相关的一些开发和学习的一些工具啊。嗯,首先我们来看一下这个 m l studio, m l studio 是 一个可以说是图形化的一个一个这个界面啊,可以帮助你能运用本地的大模型。你先看打开这呃页面以后呢,会发现这个空无一物啊,我们可以看到左边有个按钮,可以看我们 这个你的设备所支持的这个所有的模型,这些都是它列出的一些模型,我们可以在里面看千问的这个 vi 的 八 b 的 模型, 还有这千问三的这个模型,四 b 的是四 b 的 都可以进行下载。选中任何一个模型呢,都给你看它的这个适不适合你这个机器啊,可不可以完全加载到你的 gpu 里面去,它下载大小是多少? 一个模型的详细资料在这边都是有显示,像 deepsea 这个,根据千问三这个蒸馏的八 b 的 这个模型也是可以下载的。 那选好模型呢,我们可以进行下载,比如说我们千问十四 b 的 这个模型,我们看下载, 我们就可以在这个下载这个窗口里看到这个你的程序正在进行下载这个模型啊,模型下载完成以后呢,它自己就会进行解压。好,这样我们回到聊天的这个界面的时候呢,我们选择要加载的模型,比如说我们刚才下载这个 d p c 这个模型, 看模型正在加载啊,我们还可以进行这个手动调餐啊,我们调它的上下文的这个长度啊,及它的这一些高级的一些微微的缓存量化等等这些参数啊,但一般我们是用的不到啊,我们加载完成以后,我们可以试一下啊,比如说介绍一下 m l studio, 你 看这个,这就是我们本地跑的这个 deepsea 的 一个根据千万生流出来的八 b 的 一个模型啊,它也是在本地运行,我这个电脑呢是 macbook air, 它六 g 的 内存, 然后本地呢加载这种八 b 模型是完全没有问题的啊,我们也可以选择另外的一个千万十四 b 的 一个模型, 先把这个模型退出,然后把千万十四 b 加载上去,就是说你可以选择你自己喜欢的模型,或者在不同的需求下用不同的模型。十四 b 要比八 b 肯定要慢一些哈,因为参数会更多,它运行起来会更 更慢一些,他的推理的会慢一些,这就是他一个模型的一个加载和使用啊,我们在右边也可以看到,他可以设置对你的模型的进行一个温度的设置啊,海量的设置啊,一结构化输出的一些设置 啊。好,回答也出来了,我们看一下啊,这是这是用中文的回答的,我看十四亿的模型要比刚才八 b 要慢一些,因为它推理它用到的这个硬件的要求就会更高一些。还有上一个视频介绍的 mac mini pro 那 个环境下呢,是三十二 b 模型是没有问题的,也是十分流畅的, 我们看到这个功能还十分强大的啊,我们还可以对这个模型进行这啊远程提供一些服务啊,提供网络上一些服务,所以 mr steadon 呢,可以说是本地运行大模型,在你非常关注你的数据的这个隐私性的一些情况下, 我们就可以这对,这就可以使用这种图形化的这种界面啊,比欧伽玛要稍微简单一些,不需要更多的配置你就可以使用哈。不联网的情况下,我们的数据保证安全的情况下。好,结果出来,我们看这个是这 m 三的 啊,四 b 的 这个模型,我们的 token 大 概是在九点六一个啊,也还是可用的,在十六 g 的 这个 macbook air 的 环境下是没有问题的。 好,今天先介绍这么多,如果大家对这对其他工具有兴趣的话,可以给我留言讨论啊,也可以一起学习如何运用一些打磨性的工具啊,提高我们的一些生产效率以及一些生活的乐趣啊。好,关注探长优质前沿技术资源,不错过。
145AI探长 01:09查看AI文稿AI文稿
01:09查看AI文稿AI文稿到底有没有一个完全免费的本地运行的 ai 代理?阿里推出 co pub, 让担心使用成本和数据安全的朋友们得偿所愿, 今天就用一分钟带大家体验吧。首先是下载和本地部署模型,先安装 almas studio, 需要教程的进主页查看置顶视频。 接下来在 musego 搜索 copart 杠 fresh 要选择 g g f 格式,一般就是极显,选四 b 杠 two 四独显且显存大于六 g 的 可选九 b 杠 two 四 下载到本地,打开 lms。 二 d o 就是 配置模型参数,加载模型并开启服务,然后去官网下载安装 copart, 然后它支持多种方式安装电脑没有 python 的 选择就是一键安装, 否则使用 p i p 安装成功。启动后在浏览器打开网址,进入 cocore 的 web 界面, opencore 有 的功能 cocore 基本都有, 而且界面配置对新手来说更友好。接下来开始配置模型,右上角切换到中文,左侧点模型,选 l i s studio, 然后发现模型,然后测试连接这个配置成功后可以聊天,开启愉快的玩耍吧!
 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿我一直以为用跟 ai 聊天的方式操控电脑离我们还有一些距离,直到 opencloud 的 出现,这玩意能 ai 自动化各种我们的个人工作流。 dehub 的 新处也是突破了十七万, 我们在 opencloud 中可以选择通过 api 接入任意国内 lm, 也可以用 lm studio 进行本地部署。 现在已经有各种成熟的工作流了,有人拿它当一个个人新闻广播,每天早上定时定点的把新东西通过聊天软件推送到手机上。甚至还有人用它全自动的点了外卖送到家,外卖小哥都蒙了,合着我是在给 ai 打工呢? 我也是在第一时间在本地装了这只小龙虾,它的自主性和记忆力确实太惊艳了,对个人工作者的效率提升又进行了一次质的飞跃。 那么想看更多关于 opencloud 的 安装使用场景演示,关注熊仔学长,让我们一同成长。
34熊崽学长 14:37查看AI文稿AI文稿
14:37查看AI文稿AI文稿哈喽哈喽,我是大海,很高兴又和大家见面了。那很多朋友反馈,大海之前教的大家的本地养虾 open club 里头呢,用的大模型欧拉玛比较卡顿,那今天呢,大海就给大家推荐一个全新的 本地大模型引擎啊,比这个欧拉玛要好用一些,我们用来替换他。在开始咱们今天介绍新的大模型框架之前呢,咱们先给大家解决几个之前视频里头很多朋友提到的问题。 首先第一个呢是这个登录,有些人登录这个 openclo 的 时候,就是没用大海的那个一键安装包,自己去虚拟机平台搭建的,然后登录的时候输入了密码之后还是登录不了,他问你要那个 token, 这个 token 呢?如果说你呃 安装的时候没有复制他那个带 token 的 链接,大家可以自己去提取一下,用这个命令,我已经在我的这个 文档里头更新过了,就是在 power 里头用这条命令啊,很简单,我们用这条命令啊,直接给他回车,他就会直接给你返回一个 token 值,你把这个 token 值复制一下,然后去咱们小龙虾的那个登录界面,然后去黏贴进去,再加上你的登录密码一起啊,他就能够进行登录了。 那还有些朋友反映说呢,自己去连接了这个自己本地的大模型之后呢,这个和大模型说话他反应比较慢,或者说他压根跟他说了话不回话, 那我到底是大模型连接正确没有,还是因为他反应慢了?其实最简单的方法就是你切换一个云端的大模型,因为我给大家讲的时候就是说,呃,咱们既有本地大模型,也注册了那个欧拉玛的官方账号,你可以去用他的云端大模型,比如说这里呢,我这里切换云端大模型啊,你和他说话, 如果云端大模型他能够快速的回复你啊,你好,在的有什么可以帮你的吗?那就说明了这个连接欧拉玛是没问题的 啊,有两种可能,第一种可能呢,就是你本地的这个大模型呢,处理的速度比较慢,比如说像,像现在大海这个就是本地大模型,处理速度很慢,对吧?你可能需要等好久,他这个东西会一直跳跳跳,等好久他才会弹出来,最后解决的这个问题,哎,你看我这里也返回了,再的有什么可以帮你,对吧? 那么还有一种可能呢,就是你这个欧拉玛这里设置的上下纹长度的, 咱们的 open clock, 它在实际使用过程中至少也得十六啊,三十二,当然这个官方推荐的长度是六十四 k 的 这个上下文长度,它才能够,呃,有一个前后很好的关联,帮你去回答问题,解决问题。 如果说你这个设置的太低的话,他回复不了的就是那个上下文长度不够,你看比如说我这里把它调成一个十六 k 的 上下文长度,然后再给它保存,保存了这个上下文长度之后呢,我们可以再来这试一下。你好,你是, 你看还是要等很久,就是你把这个欧拉玛的上下文长度调高之后呢,他的反应就会越高,反应会越慢, 但是呢,你低还不行,低他回回复不了话,所以整体上呢,这个欧拉玛的综合性呢,还是不够强。那么有些朋友说是我直接在欧拉玛里头和他对话的时候,这个速度是很好的,基本上一问一答没问题, 而是因为在欧拉玛里头,他不会调用那么长的上下文长度,而在 open call 里头,他会调用那个上下文长度,所以说在 open call 里回复慢是非常正常。那么还有一些朋友说是在使用了欧拉玛之后,有一个问题,就是这个欧拉玛是开机自启动对吧?会占用我电脑的很多性能,那我不希望他开机自启动,我用的时候自己去手动启动, 这个怎么办呢?也非常简单,右键我们的这个工具栏,然后选择任务管理器,然后呢你在这个左侧呢,你给他选启动应用, 然后在这里头你去找到奥拉玛,把它去禁用,那么奥拉玛就不会开机启动了。而且大家也可以用这个小方法去把自己这个启动应用启动里头这些项啊,自己认为没有用的,你去给它全部关闭。当然大家注意,如果这个名字你认识,你就给他决定禁用或者不禁用,如果这个名字你不认识,你最好不要禁用, 因为如果你有一些这个系统服务呃应用,如果你给他禁用的话,可能你这个系统一开机他就打不开了啊,很可能开不了机。由于咱们今天呢要给大家推荐新的这个 大模型的本地框架,所以说咱们还要给欧拉马进行一个测速,咱们看一下相同大模型下,哪一个获得的结果会更快一些啊?我这里呢给他准备了一个数学题,我给他复制一下啊,然后我先发到这, 然后呢我给他开一个,来一个秒表,对吧?哎,我这头点了启动,这头点发送,然后看看他多长时间能把咱们最后这个最终答案得出啊?我这里点启动 发送好完成,咱们就有个大概时间就行了,就是一分十三,算是他这个得出结论,时间是一分十三。咱们现在呢,咱们这个欧拉玛就用不上了,给大家正好演示一下咱们欧拉玛如何的卸载, 我这里呢专门写了个小短片的话,告别欧拉玛,这里大海推荐大家卸载软件,用这个即可。大海在我的这个使用的电脑软件推荐这个系列视频里头给大家推荐过,非常的好用, 他在卸载一个软件的时候可以帮助你去卸,不光能卸载这个软件,而且还能清理残留,对吧?残留的,呃,这个注册列表啊,相关这些东西都非常的好用,那么接下来咱们就用它卸载一下, 这个卸载软件非常的小啊,你去点击登录的,他有两个版本,免费和收费,咱们直接下载这个免费的就行,点出来之后你就会发现他是一个单文件啊,放在哪里都可以。然后呢在卸载之前呢,我们先把这个奥拉玛给他关掉, 去给他退出,紧跟的呢,我们去点击这个即可,然后呢找到我们的奥拉玛,双击他, 然后点击试,然后呢我们直接给他卸载啊,卸载完成了,然后完成之后他还会去扫描你留下这个东西啊,如果没有他就未发现痕迹,对吧?那么接下来呢,进入咱们今天的正片给大家今天推荐的是这个 lm studio 啊,呃,他也是一个本地格式化的这个大模型的引擎啊,而且呢在使用方面呢也非常的方便啊,大海就不多说,咱们直接来下载,然后去给他安装啊,首先呢是去他的官网 下载对应的软件啊,直接下载这个 for windows 版本就可以,大海这里已经下载好了,我就不下载就是这个啊,然后我们直接双击它进行安装,点击我同意,然后呢仅为我安装下一步 安装。然后呢我们去点击完成,我们直接开始就行,然后他推荐咱们安装一个模型,对吧?根据咱们电脑推荐,咱们这里直接跳过啊,然后直接咱们点击康提扭,然后呢咱们首次这个登录的时候呢,咱们点击这个设置,把这里的语言先改一下,至少给咱们改成一个中文的,对吧? 连体中文好,然后接下来呢我们就可以在搜索这里呢去下载我们想要的模型,由于这个 l m c 六六它内置了这个爆脸上头的所有的模型,所以使用起来非常的方便,想要什么模型直接搜啊用就行了,我这里给他搜一个千问 咱们刚才要测试的这个千万二点五,然后给他来个够的,再输一个七币,可以看到你输了对应的模型之后呢,他会给你展现这个模型他是什么时候上传的,并且下载量是多少?呃,咱们就选择这个点赞最多的这个吧,二百零九个点赞点击他。 然后接下来呢咱们选择 down load 的 就可以,也是非常好用的,而且爆脸的这个上头的模型下载速度也是比较快。好,现在咱们这个模型已经下载好了,显示下载完毕。然后咱们这里呢,直接去给他点击柚子 in the new chat 啊,就是在新的窗口去和他对话, 然后啊新模型加载成功,咱们把这里关掉。再说一句,你好,你是什么?可以看他这个速度还是很不错的啊。 嗯,可以看到它这个反应速度,呃,我觉得可能比在欧莱玛里头还再快一点啊,这个对话的这个感觉好像还更快一些,然后接下来呢,咱们不在这里浪费时间啊。当然如果大家想,呃 在本地使用打模型的话,用它这个对话窗口敢说也是很不错的。接下来呢,咱们直接去给它配置这个服务。 首先呢咱们是要在这个 server setting 这里去配置一下,咱们要把这个地方给它开启,在网络中提供服务。 如果你这不开启,在网络中提供服务,他只能在本地访问,那么你的虚拟机里头的那个 open, 它相当于是另一台电脑,它就不属于是本地访问了,大家知道吧?所以这个地方必须开,开了之后呢,咱们这里呢去把这个地方打开,象征着咱们这个服务的开启啊,允许。 那么这个地方我们再点击加载模型,然后在这个模型里头呢,你要把之前已经加载过的这两个给他删掉啊,然后重新呢去给他选一个,然后这个地方咱们给他调成十六 k, 然后这个地方我们点击重新加载已应用,更改好没问题,这又重新加载好了。 然后呢,我们需要点击下面的这个支持的端点,咱们首先是把这个地址给他复制一下啊,然后在我们的浏览器里头去访问一下这个地址, 然后,哎,它会打印这样一个结果,对吧?然后呢接下来我们再回到这个里头,这个上头呢,咱们选择 open ai 兼容的这个,把后头这个给它复制一下,哎,就是 v e 再加上 models, 然后呢给它黏贴到这个刚才的链接后面,然后我们去回车,它就会给我们打印一个模型的 id 啊,一会咱们会用到这个模型的 id。 这个地方结束了之后呢,咱们去重新配置咱们的 open klo 啊,回到我们的这个,呃,管理 open klo 的 终端里,我们去呢 使用我们管理 open klo 的 这个命令。呃,如果说你是第一次看大海的视频,你需要去看大海前几天发的这一期视频,对吧?呃,然后去看那个详细的配置流程,这里大海不再演示,太复杂了 啊,这个地方呢,我们去用这条命令直接回车给它重新配置一下,这里呢我们用键盘上的左键选择 yes, 然后选择 quick start, 就 快速开始,然后呢我们选择,呃,第一个。 好,接下来呢,咱们这里就选择模型这个地方呢,我们就要选择这个,这个地方,意思就是和 open ai 模型的那个输出方式一样的模型都可以用这个来使用啊,就是一个通用的,我们来选择这个在欧莱玛上面,然后地址这里呢,我们把这里删掉,咱们选择给他用这个地址, 注意不能带后头的 models, 就是 到 v 一 这个地方就结束了,有的朋友说咱们之前这个地址不是用的那个,呃, vm net 八那个地址吗?也可以,对吧?这里呢,咱们用一个 cmd 方口,然后给他来一个 ip config, 对 吧? 然后,哎,咱们用这个地址也可以啊。 vm net 八,他是二四七点一,对吧?我们这里呢,给他改成个二四七点一 啊,它结果是一样的啊。然后呢,咱们还是把这个给它复制一下这个地方,哎,我重给它配置一下啊,给它删除掉, 哎,右键粘贴上去,二四七点一幺二三四,斜杠为一。好,没问题。然后回车,然后呢这个地方输入一个 ati 的 密钥,这个可以随便输,因为它咱们本地是没有设置过的,所以随便输啊。然后呢使用的这个模型的方式,咱们肯定是选择 open ai 的 啊, 然后接下来呢这个模型的 id, 哎,这个非常重要,我们必须去复制咱们刚才访问的这个链接下的这个 id, 然后这里给它黏贴进去,然后回车,然后后面的就全部回车就可以啊。 然后接下来咱们把剩下的配置给他跳过这里,我弄,然后呢空格给他倒过,最后呢啊,重启一下网关,然后接下来咱们还是继续啊, 不配置好,这就完成了,然后你会看到咱们这里呢,还是同样的界面,咱们去把它刷新一下, 然后这里有呢,我们就可以选择这个,这个是我们刚刚配置的这个模型的吧,那么,呃,他这里会显示 十四点六 k, 十六 k, 就是 说咱们这个上下文长度快用完了,呃,这里呢,为了保证这个测试的公平起见呢,咱们先给他来一个清理记忆文件,清理记忆文件和缓存,重新 开启对话。好,他说好的,我将清理记忆文件并重新开启对话,请问有什么需要我帮助的吗?这个地方呢,咱们就还是和刚才一样,对吧?把它放在左边,右边呢,咱们选择刚才那个秒表计时器,依旧是用咱们刚才这道数学题,对吧?把它复制一下, 放到咱们 open 可乐里。我还是啊,这里启动,这里我给他先重置一下啊,咱们刚才是一分十三秒,我直接给他重置一下,这里点启动,这里点发送啊。启动发送 好,可以看到他很快,刚才八九秒啊,十秒的样子他就完成了,而且刚才没有给大家打开这个界面给大家看,我给大家看一下这个东西呢,是能看到他的这个推理的过程的啊, 我给大家增加一条命令,然后让大家看一下这个推给过程。因为他这个反应速度太快了,所以就来不及给大家打开看啊。这个地方我说帮我写一个 p y 什么 python 代码 啊,检验这个结果大家看到没有,这个地方他是可以看到他是怎么跑出来这个东西的,知道吧?他会告诉你这个头肯是怎么花掉的,然后最后结果是什么? 所以说整体而言呢,我觉得用这个 lm studio 比起咱们那个欧拉玛效果要好啊,最后得出的效果要好,刚才得出的这个结论都是错的啊,要凑出一双同色的袜子,最少要四只袜子然后要凑出三只同色的袜子呢?最少要七只袜子。 这个所以他这个答案都是错的,这上头这应该是四只,下头是七只,虽然他最后得出这个结论是错的啊。呃,这个计算结果是错的,但是呢, 人家这个输出速度还是相对会快一些,而且也让大家看到这个模型计算的这个过程,也就说当你这卡住的时候,你可以来你的模型这里看一下,对吧?它是正在计算呢,还是真的卡住了,对吧?能验证你这个模型联通是不是正确。那么我认为呢,你跑本地大模型可能用 l m studio 这个 工具是更好的,当然你要想最后的推理效果好,得出正确结论,相关的这些东西,你应该去下载更大的模型,对吧?这这个地方大家可以用这个呃搜索,然后去找 适合自己大模型,而且他这里呢还能看到最新出来的热热度模型,对吧?呃,大家可以去试一试。我觉得像目前他这个反应速度大海的这台机器,安装一个千万三点五九币可能效果会更好一些。 那么希望大家呢,也能找到自己适合自己机器的这个框架,然后同时去安装最适合自己机器的大模型,然后来本地运行我们的 open color 养虾。好吧,那我们下期视频再见,拜拜。拜拜。
185大海资源 03:18查看AI文稿AI文稿
03:18查看AI文稿AI文稿还在担心云端 api token 太贵?今天教你在 windows 电脑上用 lm studio 一 键运行本地大模型,零代码,不花钱断网也能用。 第一步,下载安装 lm studio, 打开浏览器,进入 lm studio 官网,点击右上角下载,选择 windows 版本,双击安装包,一路点下一步,等待安装完成就好。 第二步,打开 lm studio, 建议先更新下运行环境,更新好之后,在这里选择下起用模式,有独立显卡的优先选择独立显卡,没有的选择 cpu general, 这里可以选择语言为中文 hardware, 这里可以看到独立显卡支持情况。第三步,点击 model search 搜索安装下载模型支持众多开源的模型,例如 cuan 三点五、 g l m 四点七,大家可以根据自己的配置来选择模型。下载搜索模型后,在这里会有推荐标志。本次下载一个零点八 b 的 小模型来演示, 如果显示完全加载进 gpu 显存,运行模型可以说毫无压力,不推荐下载过大的模型会导致回复 token 速度很慢,用起来并不舒服。 可以通过 model cart 到 hugen face 中查看模型的详细介绍,也可以在 hugen face 中找你需要的模型。 第四步,加载模型,等待模型下载完成。点击选择要加载的模型,选中刚才下载的零点八 b 模型 参数,这里可以使用推荐参数,然后点击加载模型,等待模型加载完成。点击 newchat, 现在就可以使用本地模型了。零点八 b 的 速度非常快,用作本地 ocr、 网页摘要、翻译都很好用。 本地模型的优势是隐私安全、低延迟离线可用、自主可控、成本可控,大模型越发展越强,本地小模型也会越来越强,越来越好用。 在 developer 中可以开启 api 访问, 就可以用其他应用调用本地模型了,支持多种格式。好了,本期视频就到这里,你也快去试试部署吧!
42北酒北 05:24查看AI文稿AI文稿
05:24查看AI文稿AI文稿大家好,欢迎来到本地 ai 推理平台系列,我正在开发一个开源项目。嗯,这是一个可以在本地运行大模型 agent workflow 各种 ai 工具并进行工程化编排的 ai 平台。呃,这个系列会持续记录这个项目的设计实现以及真实的工程实践。呃,很多人在做本地 ai 时会遇到一个问题,模型跑在另外一台 gpu 服务器上, 或者在局域网里的另一台电脑。嗯,本机只是一个源,或者是 agent 控制端。那问题来了,嗯, agent 怎么调用这些远程模型?这期我们就来解决这个问题。嗯,在我们这个平台里面,模型并不一定是要运行在本机的。呃,我们可以把 嗯,呃,局网中的 l m studio 或者是欧拉玛作为远程推理节点接入进来,你接入之后,所有远程模型都统一进入。嗯,统一的那个 model register, 你 可以被 chat editor flow 统一调用 支持。呃,接入远程的那个 i m studio 或者是欧莱玛啊,这是我已经配好的几个,来看一下。 嗯,这三个啊,都是。嗯,配好在远程的机。呃,在那个局网机器里面配好的。呃, i m studio 和欧莱玛的一些模型啊,那我们来演示一下吧。 啊,先看一个最简单的例子。呃,让我们来演示一下吧。现在用的是那个 嗯, gptos 一 百二十 b 的 模型,重新开一个对话。 嗯,这是部署在局域网里面的,然后我问他一些问题吧,稍微难一点的 帮我解释一下 transform 的 基本结构 啊。 ok, 它的速度还是很快的。 那然后我们再来试一个例子吧,就是用 edit 来调用那个远程的模型, 看一下有没有改啊?我,我已经改好了那个模型,我用的已经是。 那改好了,已经是那个 g 网里面的那个欧拉玛了 啊。 ok, 他 已经给我回复了,而且速度是很快的。 呃,可以看到 agent 在 执行过程中调用的那个模型。呃,在。呃,实际推理发生在远程的节点返回的结果,呃。后,呃,返回结果,然后会执执行后续的一些步骤。呃, 嗯,最,嗯,最关键的一点是, agent 并不关心模型是在哪台机器上,是在云端还是在本机还是在局域网里的哪台机器,他只关心当前有哪些能力可用,这些能力,呃,都是通过那个 model register 来来来进行管理的。 嗯,这其实是一个很重要的变化。从系统角度看,呃,模型可以分布在不同机器,推理可以在不同节点执行, agent 只负责调度,这意味着 ai 系统开始具备分布式推。呃,执行能力 啊,这一期我们做的其实是一个非常基础但关键的能力。远程模型接入,接下来后续我会继续扩展。呃,如果你对本地 ai agent 或 ai 系统开发感兴趣,欢迎关注这个系列项目已经开源在那个 github 了。呃,也欢迎。 嗯,那个 star 或 tenn。 呃,参与这个项目。呃,下一期我们继续。
22Tony沈哲











