如何通过token提取图案
一个月时间带你彻底理解 ai。 今天我们讲 token 是 ai 运作的底层基础,执意是待毙。在今年三月,全国科学技术名词委员会正式设立了它的中文名词源。 token 是 ai 世界里的最小单位, 大模型做的就是经过计算给出最优解。举个例子,你问他今天天气,大模型会把这句话拆分成若干个 token 去理解,然后基于海量训练数据中的统计规律,预测下一个最可能出现的字。 因为训练资料里今天天气后面最强根的系怎么样,所以他就预测出了怎么样,然后继续请求回答,告诉你今天天气晴。 每家大模型对 token 的 划分都不太一样,一般一个英文单词约为一点三个 token, 而一个 token 大 约能对应一点五到二个中文字母。 也就是说,同样一段话,中文消耗的 token 通常比英文更多,而一些词语也能叫做 token, 比如冰淇淋就是一个 token。 总结, token 就是 你给大模型的工资,它们不认黄金珠宝,有了 token, 大模型才能工作。 token 的 星球需要消耗算力,所以买 token 本迹象是在为 ai 的 计算服务付费,就像用电按度计费一样, token 就是 ai 服务里的那个度。

粉丝4500获赞77.2万
相关视频
 03:40查看AI文稿AI文稿
03:40查看AI文稿AI文稿哈喽,大家好,我是 paper, 那 今天我们来说一下我们最常用的 token 本地模型和外部的模型该怎么样去使用?就是 token, token 是 什么呢?一方面它是有这个最小计算机处理文本单元, 另一方面它也是其他的,还有很多身份认证啊,指令串密密实都百度的话,你要使用在我们的 ai 大 模型中,你就记录这个最小文本处理单元就可以了。我们再来看这个本地模型去哪里找啊?一般的话,像这个最常见的开源社区 hackin face, 我们在这里面去找本地模型,我们登录进来,然后找到这个 browser two m 加 models, 或者说你直接在搜索栏中搜索对应的名称,像这个主页,它这个首页里已经有这些,比如说像这个 minimax 的 二点一,千万的三点三,还有一些各种各样的 模型, open i 的 gptos 啊,你可以或者说这个 kimi 二点五等等,你可以点击这里去我们要找的像一些文本到图片的模型, 就是 ai 绘画模型,还有像这个文本到视频的模型啊, text to video, 还有像这个文本到文本,也就是我们的语言模型,就像豆包,千文,这些都是语言模型,我们只要去搜一下这个 text generation 文本生成,我们就可以在这里看到有千文,三点五啊,还有各种各样的 emoji 三啊,各种各样的 mini max 等等啊,只要是你所熟悉大厂,那基本他发了都在这里面啊。你看这个 b 嘛, 这个币数越大,比如十七币,八十币,三十二币,一百九,十九币,甚至这个二十八币,或者说这个四币的,这肯定效果没有那么好,是吧?那因为达到六十七币,一二一百二十四币都很大, 这东西像这个 mini max, 二点五,二点二十九币啊,二百二十九币,这个更大,这个你要是下下来,你会发现 你可能你的电脑用不了啊,就是这么简单哈。 ok, 我 们再看这个像一些其他的开放的 a p i 怎么去使用?那这里我以这个 g m 举例啊,我们直接去找到 a p i k, 点一下就进入到这个页面了, 这个页面就是你的 a p i 密匙了,我们在这个项目管理 a p i key 中找到它,像这个已经有的 a p i, 你 用到别的地方可以去,这样子你也可以直接删除,我们再可以添加个新的 a p i, 比如说你这个 a p i, 你 要去用到自己的 call 啊,那么龙虾上我们就点击 call, 然后把它复制过来,然后粘到这个 call 里,你就给它充钱就可以了哈。 你还想还想要再用一个 a p i 去做别的项目,那比如说我这个叫这个 agent agent, 那 这个 a p i 呢?我们给它复制过来,去放到别别的调用的端口里给它充钱就可以了哈。 像这个 open a d b c 的 a p i 啊,页面也差不多哈,你可以在这里点击 create new c c 啊,你也可以在这里点一样的啊,这里 name 我 写 call 啊。这个 project 你 可以放到你的默认 project 里,不过一般只有一个啊,点击 quit 就 可以了哈, 配置完之后呢,一样的,你就给自己的套餐充钱就可以了。那这个 api 呢?它不同于你的和你的传统的大模型,你直接问它那种网页对答模型不一样的啊,因为 api 呢?它 是啊, api 它是实时计费的,就说你要是用的话,你可以用到很多层面上不同,不停去调用这个模型。而你的网页因为问答呢,只要你这个模型啊,只要你这个网页关了,你就用不了了,是吧?你要是想用它,你是不是得二十四小时数在电脑前啊?你在电脑前你才能用它,但 api 不 一样,你可以做成全自动化的东西, 这样子呢,它的费用就会很高了。所以说 a p i 是 单独收费的啊。 ok, 那 今天呢,学完这课,咱们这个玩龙虾啊,或者说玩什么都会更轻松一些哈。咱们就先到这里啊, ai 啊,一定要去关注这些啊,最基础的东西,如果说这些基础东西你都不知道,那你去你就很难玩得转这些东西哈。
74Paper朱 03:29查看AI文稿AI文稿
03:29查看AI文稿AI文稿大家好,今天咱们来聊聊一个特别重要的概念, token。 你 可能经常听说这个词,但它到底是什么呢?其实啊, token 就是 大语言模型处理文本时的基本积木块。想象一下,我们搭积木最小的那块零件就是 token, 模型就是用这些小零件来理解和生成文字的。那这些积木块是怎么来的呢?其实啊, token 就是 大语言都记的向量,最后模型会把这个向量和词表里所有 token 的 向量比对,找出最相似的,这就要靠分词器了。分词器会把我们输入的文本切成一个一个的 token, 不 过 切分方式可不是固定的哦,它可能是一个完整的单词,也可能是一个字,甚至是一个字母。具体怎么切要看模型的规则。 比如说中文人工智能,有的模型可能切成人工和智能两个 token, 有 的可能切成人工智能四个字。中文就更直观了,像 i like apples 这句话,通常会被切成 i like apples 和这四个 token。 了解了 token 是 什么,咱们再来看看它是怎么工作的。当你给模型输入一段文字,比如问个问题, 模型首先会把这段文字切成 token, 然后给每个 token 分 配一个独一无二的数字 id, 就 像给每个积木块贴个标签,接着模型会根据这些 id 从词嵌入矩阵里,找到对应的向量。这就像积木块的说明书,告诉模型这个 token 代表什么意思, 光有意思还不够,模型还得知道这些 token 的 顺序,所以会给他们加上位置编码,这样模型才明白谁先谁后。然后就是模型内部的 transformer 大 显身手了,经过一系列复杂计算,生成一个预期的向量。最后,模型会把这个向量和词表里所有 token 的 向量对准,找出最相似的那个 token 作为输出,然后重复这个过程,直到生成完整的回答。说到这里,就不得不提上下文窗口了, 这就像模型的工作记忆,指的是模型一次性能处理的最大偷坑数量。如果你的输入太长,超过了这个窗口的容量,模型就会记不住前面的内容,就像我们脑子一下子塞太多东西会混乱一样。而且这个窗口也不是一成不变的, 有的模型会动态滑动,更关注最新的信息。但总的来说,窗口越大,模型能记住的东西越多,但计算成本也越高。那 token 和我们的钱包有什么关系呢?当然有关系啦,用 api 调用大模型的时候, token 数量可是计费的关键。 一般来说, api 成本就是 token 数量乘以单价,再乘以调用次数。这里要注意的是,输入的 token 和输出的 token 都会算钱哦。而且中文和英文消耗的 token 数量还不一样,中文通常更费 token 大 概一到两个汉字就相当于一个 token, 而英文呢,差不多四个字母才。 所以学会省 token 就 等于省钱了。给大家几个实用小技巧,首先,指令一定要精确,别啰嗦,直接说重点。其次, 提供信息的时候只给关键的,别把整个文档都粘贴进去,模型也看不过来。还有,如果开启新话题,最好新建一个绘画,这样可以避免之前的荣誉信息占用 token。 最后,如果你对回答长度没特别要求,可以限制一下输出长度。好了,今天关于 token 的 知识就讲到这里,相信现在你对 token 是 什么,怎么工作,为什么重要,以及怎么省 token 都有了一定的了解。 那么问题来了,你平时在使用 ai 工具的时候,有没有注意过 token 的 消耗呢?或者你还有哪些关于 token 的 疑问,欢迎在评论区告诉我,我们一起讨论。
25知识小分享 01:17查看AI文稿AI文稿
01:17查看AI文稿AI文稿我用大公司的偷坑,是不是我的隐私就都被大公司看到了?那当然是了,你让人家帮忙处理问题,不把内容告诉对方,对方又怎么帮你处理呢?今天我就用科普的方式来讲讲什么是偷坑,它到底能做什么?最近很火的龙虾,大家都在搭建着玩过程中就发现一个问题, 我们要么去大公司购买一些偷坑,要么自己搭建一个模型,那这个偷坑到底是什么呢?我用一个浅显的例子来解释,当然这种说法并不严谨,只是方便大家理解。你现在打开微信,对着朋友说谎, 假如对话的对象是大模型,那你说的话其实就是 toker, 我 们估且算一个字是一个 toker, 十个字就是十个 toker。 你 打开自己搭建的龙虾模型,运行指令,输入一句你好, 其实就是把你好转化成 toker, 再传输到服务器,服务器再根据你输入的 toker 返回你想要的结果。至于为什么要用 toker 的 形式,而不是直接用铭文传输到服务器,这就和 toker 的 优化机制有关吗?这里再举个例子, 你收到一条短信,对方自称是秦始皇的子孙,说自己有钥匙要办,让你转一笔钱,时成之后会加倍返还。而负责 toc 优化的工程师 为了让你少花费费用,会想方设法精简自负数量,比如把这段融长的内容精简成我秦始皇打钱,这样也能避免算力被浪费。所以说,使用大公司的 toc 必然会涉及隐私问题,但大公司算力强,价格低,还是很值得使用的。
194包罗one象 02:20查看AI文稿AI文稿
02:20查看AI文稿AI文稿最近 token 被翻译成词源这个事情相信大家都听说了吧,那么很多人可能不知道 token 究竟是什么?就是我们每天看哎呀我们 ai, 然后花费了多少 token, 然后是多少钱, 这是你要付的账单。但事实上很有意思的一点是,因为中文它是在语言学里面叫做独立语 isolated language, 什么意思呢?它一个字,它其实是一个最小意思单元, 所以感觉好像在中文在 ai 然后把它 token 来的过程当中,它是一个字,一个字,似乎是一个 token, 但是未必是这样一回事。 其实计算机它的理解 token 呢?它其实先是把人类的自然语言把它拆拆成,你可以理解为一串数字,比如说 我吃饭了,那么我它会最后变成一串数字,一个四位数的数字或者是多少的数字,然后吃饭它可能是一起的,它变成了一个头啃,然后把它又是一串数字, 然后它通过这这个数字的排列,然后再根据它的这个语料。我们不是经常看说多少多少 b 的 大模型吗?比如说七十 b 大 模型,这个就是指它这个模型吃了多少语料, 他这个吃的这个东西越多,他就你可以理解为他的知识库越丰富。然后他后面他其实是根据我看了这么多的信息之后,我去猜下一个字可能是什么,他其实是一个预测的模型, 然后他就会说我吃饭了,然后可能是个句号,然后这然后再反过来, ok, 他 预测出来最后一个可能是个句号,或者是我吃饭了的那个了,然后是一串数字嘛,然后再把它翻译,然后变成了或者是一个句号,那整一个过程就是就是输出啊,就是你有输入,然后把它 tokenize, 然后再输出, 然后所以我觉得词源这个翻译其实还蛮恰当的,但是我会觉得有一点点拗口,我不知道你怎么想。如果你想要知道其他的跟 ai 相关的有一些名词解释啊,或者是有一些科普相关的,想要知道什么也可以在底下的评论区告诉我。 那么如果问的人多的话,我也会考虑做一期专门的科普视频,来跟大家讲讲这个 ai 的 一些名词,它到底是怎么样回事。那么以上就是本期视频的全部内容了,然后我是独立开发者,四 s g, 我 们下期视频再见。拜拜!
34SlashZ 04:28查看AI文稿AI文稿
04:28查看AI文稿AI文稿大模型是怎么识别这些文字的?它要把这些所有的文字用一种切割的方式把它变成 token。 tokenization 文字的切割啊,也就是我们如何把我们看到的文字,不管你是中文还是英文,还是意大利文,泰文,最终大模型是怎么识别这些文字的? 它要把这些所有的文字用一种切割的方式把它变成 token。 而 token 这个词呢,我们现在用的非常多,特别是这个龙虾火了以后,大家都说烧 token, 对 吧?这个 token 就是 我们今天给大家介绍的这个 token, 所以 讲了今天的课程以后,大家就大家就知道了,到底这个每天我们烧的 token, 中国的 token 便宜,外国的 token 贵啊,它是为什么?到底是怎么回事?是怎么去计算的啊?大家就清楚了, 所以呢,我们为了让大家更好的去理解呢,呃呃,我们先来看一个实力吧,先来看一个实力啊,呃,假设海南麒麟瓜这五个字,那么在我们人去读他的时候,那就是五个字喽, 而这五个字,如果让大模型去看他的时候,他是什么样子呢?等于什么样的 token 呢?好,我们实际带入我们就会发现,海 他是一个头啃,南他是一个头啃,而麒麟瓜分别是每个都是三个头啃啊,这是一个很有意思的事情, 这实际上是由于编码的方式,像这两个常见字,我们就通常给他按照一个头啃,但是麒麟呢,他是比较这个生僻的一些字,我们就会成三个头啃,所以这五个汉字呢,我们最终是大模型把它变成了十一个头啃, 那这种 token 的 编码方式呢,实际上是我们的算法工程师给它人为去设定的,那不同的模型呢,其实它的 token 的 数量是不同 的啊,因为国外的模型呢,通常来讲它对汉字来说呢,它的 token 的 数量就比较多啊,但是我们国内自研的模型,比如说像 deepsea 啊 啊,有阿里千问啊这样的一些模型呢,他的头肯就不像这个海外的这些模型啊,数量那么多,他就会精简和压缩了更多的一些编码方式,因为我们国人所做的大模型,他更对中文有更好的一个理解, 那有了这些头肯以后呢,计算机才能更好的去识别啊。呃,我们举个例子而言, token 的 过程,把把文字变成 token 的 过程,就像厨师切食材的一个比喻, 我们厨师在炒菜之前呢,肯定要把食材的这个切成标准的大小啊,所以它就像 gpt 在 处理文字的时候呢,先把文字切成各种各样的一些碎片啊,但是碎片不一定是完整的字或者词,有的时候是字节这个层面的一些片段,实际上我们英文也是如此,比如说我们英文 想思想想这个词, think, 如果是 thinking 的 话,那么 think 可能是一个词,那后面 ing 这个后缀,那就变成另外的一个 token, 所以 中文和英文它大致的原理是一样的,总之就是要把这些文字切成小的片段啊。 那么我们实际在大模型眼镜和发展的一个过程中呢,我们可以看一下,就是大概这些大模型,它把我们的文字呢,用了多少个 token 啊? 我们以 g p d 三为例,这是二零二年,二零二零年发明的,他用了五万零二百五十七个头啃啊, 那么到了 g p d 四的时候,二零二三年他就用了,呃,十万零二百五十六个头啃啊。那如果是这个拉玛三,二零二四年他用了十二万八千个头啃,那么这些头啃他就已经能够含带了人类的所有的文字 啊,不管是什么用语言啊,全球各种各样的语言和文字他都包含了。呃,那么这个,这个,这是我们 这个整个大模型要在处理这些文字的时候所做的第一步。所以回到我们刚才的案例,我们那六百五十个字的法律文书,那大模型根据他 token 的 一个设定就把它变成了一千三百个 token 啊,对于 gpt 三这样的一个模型来说, 好,那有了 token 以后呢?那计算机能不能看懂呢?实际上还是不够的,他还是看不懂的。那计算机要做什么样的一件事情才能真正的去读懂这些 token 呢?我们要把它向量化。
 02:56查看AI文稿AI文稿
02:56查看AI文稿AI文稿你有没有想过,你每次跟 ai 说一句话,背后其实是中国西北的风和太阳在给你打工?今天这期视频,一口气把 token 这件事跟你讲清楚。先说最核心的问题, token 到底是什么?今年两会,官方给他定义了中文名叫磁源。 用一句话解释, token 就是 ai 处理信息的最小单位,就像用电按度计量,用 ai 就 按 token 计量。打个比方,你去菜市场买菜,摊主不会把整筐菜一起称重卖给你,而是一颗一颗分开卖。 ai 处理语言也是一样的逻辑,他不会直接读懂你说的一整句话,而是先把它拆碎,拆成一个个最小的雨衣颗粒,每一个颗粒就是一个抽肯。 举个具体的例子,你让 ai 帮你写一封请假条,他会先把你的指令拆解成写请假条今天这样的小单位,然后调动背后的算力、解锁、匹配相关知识, 最后把这些零散的 token 重新拼成一封完整的请假条发回你的屏幕。整个过程,从拆解到输出,每一步都在消耗 token。 就 像打电话按分钟收费用, ai 就是 按 token 收费。那 token 消耗的是什么?答案是算力,而算力消耗的是电力。 你在屏幕前敲下那句话的同时,宁夏、内蒙古的数据中心里,成千上万颗 gpu 开始高速运转,完成 token 的 拆解、解锁、匹配和重组,几秒内把结果送回你的手机。 这些 gpu 是 典型的高耗能设备,满负荷跑起来,一刻都不停的在烧电。所以说 token 本质上就是电力的数字化形态, 你每调用一次 ai, 就是 在消耗一点点电力,只不过这个电烧在了数据中心里,而不是你家的插座上。 搞懂了这个,再来说说为什么 token 是 中国真正意义上的电力出口。中国是全球第一发电大国,一年发电量超过九万亿度, 风电、光伏装剂量连续多年全球第一。但问题是,电太多了,用不完,只能眼睁睁看着绿电白白浪费,也就是常说的弃风弃光。那为什么不卖到国外?因为电没法装船运输,就像手里攥着全球最大的金矿,金子太重,搬不出去,只能堆在院子里。但 token 不 一样, token 走的是光线。 当一个美国程序员调用中国 ai 的 接口,数据中心 gpu 开始轰鸣,烧的是中国西北不到两毛钱一度的绿电, 结果一秒送回他的屏幕。全程没有集装箱,没有货轮,没有关税,中国电力的价值就这样通过 token 完成了跨境交付。而这件事,正在以肉眼可见的速度发生。 根据 openroute 平台数据,今年二月,中国模型的 token 调用量首次超过美国,占该平台前十名的百分之五十一以上。更关键的是,这个平台将近一半的用户都来自美国。为什么? 因为中国西北的绿电成本极低,直接拉低了模型定价,同等性能下,比硅谷的便宜十倍以上。据摩根大通预测, 从二零二五年到二零三零年,中国 tucker 消耗量将实现三百七十倍的增长。过去我们靠汗水换外汇,出口的是衣服、家电、电动车,现在我们开始出口。算力本身, ai 的 尽头拼算力,算力的底层,拼的终究是电力。
 04:07查看AI文稿AI文稿
04:07查看AI文稿AI文稿为什么你用 ai 聊天要算字数?为什么大厂都在抢 top? 这期视频让你彻底搞懂 ai, 世界最核心、最值钱的单位 top, 看完你就明白, ai 的 钱全是按 top 赚的。首先大白话讲, token 就是 ai 能看懂的最小文字单位,你可以把它当成 ai 的 文字积木或语言细胞。我们人类认字是按字词句,但 ai 不 一样,它看不懂完整句子,必须先把所有文字切成一个个小碎片,这个碎片就叫 token。 举个例子,中文的人工智能可能切成人工智能两个 token, 而英文 unbelievable 切成 on blind able。 三个 token, 标点、数字、符号全都是独立 took。 我 们换算参考一下,一个中文字约等于零点六个 took, 一个英文字母约等于零点三个 took。 一 句话,你好,今天吃什么?约等于八个 took。 一 句话,人类用汉字交流, ai 用 took 交流。为什么 took 这么重要? 主要有两个核心,一、算力计费单位。所有大模型 api, 比如 chat、 gpt、 文星、豆包,全是按 token 收费,就像暗自付费, 你输入提问词有多少 token, ai 就 输出多少 token, 双向扣费。这就是为什么问的越长,回答越长,花钱越多。二、记忆窗口上限。每个模型都有 token 上限,比如八 k, 一 百二十八 k, 超过这个数, ai 就 会忘事,前面的内容记不住了,所以 tokun 决定了 ai 能记住多长的对话。 tokun 的 全球市场地位可以称之为 ai 时代的新石油。 你可能觉得这只是个小单位,但它现在是全球万亿级市场,直接上硬核数据。二零二六年三月全球周, tokun 掉用量二十点四万亿,占全球的百分之三十六。中国增速二零二四年初日均一千亿, 截止到二零二六年,日均一百四十万亿,两年涨一千四百倍。市场预测,二零二五年全球 tucker 市场约九万亿, 二零三零年将达三百八十万亿,五年涨四十二倍。黄仁勋说, tucker 是 数字世界最核心的大宗商品, tucker 就是 ai 时代的石油,谁产能大,谁便宜,谁就掌控未来。接下来我们说说 tucker 的 商业价值。 toker 的 商业价值绝对已经渗透了整个 ai 产业链,模型厂商,比如 open ai、 百度字节跳动、 api 收费全靠 toker, 一个优质企业客户一年能消耗百亿, toker 相当于年付百万级费用。 企业服务,写文案、做报表、写代码,一个员工等于十个员工效率,智能客服、金融风控、法律审查, toker 替代大量人力, 以前雇人,现在按 token 付费,成本暴跌百分之九。十个人与开发者简直就是创业新门槛。开发 ai 应用,写作、绘画、聊天机器人,成本等于 token 费,以前创业要几百万,现在几百块就能启动。 算力与硬件需求爆炸,偷看消耗暴涨,算力需求暴涨, gpu 服务器、数据中心全爆火,偷看就是算力行业的订单量。最后我们总结一下,记住这四点,你就真正认识了。偷看。一、 token 等于 ai 的 文字,积木是 ai 处理文本的最小单位。二、 token 等于算利货币, ai 按 token 计费,按 token 计计。三、 token 等于全球刚需,万亿市场,中国崛起两年涨千倍。四、 token 等于商业基石,重构 ai 软件企业服务所有商业模式。一句话记住,不懂 token, 你 就不懂 ai, ai 的 未来就是 token 的 未来。好了,本期视频就到这里了, 如果有想了解的技术评论区告诉我,我们下期再见。
30悦科普 01:35查看AI文稿AI文稿
01:35查看AI文稿AI文稿你有没有发现过一个奇怪的现象,同样的 ai 工具呢?有人啊,用它几分钟就能生成一份逻辑严密的商业报告。而你试了几次 ai, 却只会给你一些车轱辘骂,甚至聊着聊着就开始胡言乱语了。 你可能听过很多所谓的提示词、秘籍,也学过各种各样的指令模板,但是啊,如果你不懂今天我们要聊的概念,你对 ai 的 掌控感永远只是在壮大,甚至啊,直接决定了你银行卡余额的概念,就叫做 token。 很多人呢,把 token 简单理解成字母或者单词,这就太肤浅了。在 ai 的 世界里, token 是 唯一的通用货币,是信息的原子,更是啊,大模型赖以生存的物理边界。 为什么你的 ai 会突然断片,忘记前文?为什么中文的 a p i 账单总是比英文贵出一大截?为什么一个能写出精美代码的超级大脑,却数不清一个单词里有几个字母?这些啊,看似离谱的 bug 背后啊,其实都指向了 token 的 底层逻辑。 如果你不理解拓客,你就像是在黑灯瞎火里开车,不仅费油,还随时可能翻车。在这个系列里啊,我会推导那些枯燥的技术围墙,用实际内容把这个 ai 时代的隐形货币彻底给你拆解清楚。从它的分词算法,到它如何影响你的钱包,再到啊,如何利用拓客 国际把 ai 的 效率压榨到极限。看懂了扑克,你才算真正拿到了开启通用人工使用大门的钥匙。我是金博士,关注我,这可能啊,是你今年最值得看的一套 ai 进阶教程,今天,我们正式开始!
15靳简明博士 02:52查看AI文稿AI文稿
02:52查看AI文稿AI文稿token 是 如何被计算出来的?之前呢,我们用了五期视频全面讲解了 token 到底是什么,全网呢有一百万播放,感谢大家的催更。这次呢,我们继续出发探讨 token 到底是如何被算出来的,最后的结果一定会让你发出原来如此的惊叹。 在模型推理阶段呢,完整流程一共分为七步。第一步呢,用户输入提示词,比如我们输入用苹果手机拍苹果这句话。第二步呢,模型将这些提示词切分成一个个托管,并得到每个托管的数字 id, 切分的依据呢,就是这个文件中的词表。 第三步,模型根据这节 token id, 从词切入矩阵中取出对应的词切入向量。比如手机的 token id 是 八五四九,对应的切入向量是这样的,苹果也是这样的。一大堆数字,为了方便演示呢,我们只取前四个数字作为演示势例。 到这里,一句话就被转为了多个数字向量。熟悉限限待数的朋友可能已经意识到,我们可以用一个矩阵来表示这句话,模型呢,也可以通过矩阵运算实现并行计算。第四步呢,模行为每个 token 呢添加位置编码,标记它们的先后顺序,否则模型无法区分你爱我还是我爱你。 位置编码的公式呢,不同模型会略有差异,具体公式呢,这次我们就不展开了,实际的效果就是在没有添加位置编码的时候,这两个不同位置的苹果向量都是一样的。添加了位置编码后呢,两个苹果的向量就变得不一样了,这样模型就能区分不同位置的 token。 第五步,模型读取这些添加了位置编码的向量,通过多层 transform 计算,最终得到了一个理想的预期向量。具体的算法细节呢,可以查看我之前发的 transform 模型讲解视频。 第六步模型呢,将这个理想向量与词表中所有的拓客向量进行比对,计算它们之间的相似度。 这就好比相亲亲友智囊团先定义出理想型男友的标准,身高一八零,有房有车、大城市户口等等,但实际情况是,没有人能百分之百符合这个条件。模型呢,就拿这个标准作为打分依据,对每个后选男嘉宾呢进行打分,也就是计算相似度。 第七步模型,根据计算出来的相似度,取出其中一个后选托肯作为模型。本次的输出 分越高,被选中的概率呢就越大,得分越低呢,选中的概率就越低。这也就是之前说的模型输出具有一定的随机性,不同时间问同样的问题,回答可能会不同。比如这个例子中,候选词照片十逗号,得分相对比较高,都有可能被选到。 最后,模型把选中的 token 拼接到已有的输入中,重复第三步到第七步,一个接一个的输出后续内容,直到模型输出结束符,这才停止输出,结束整个回答。所以你看,模型不是凭空生成内容,而是在做选择题,而每一次的落笔都是一次十万分之一的遇见。
2514陈兴AI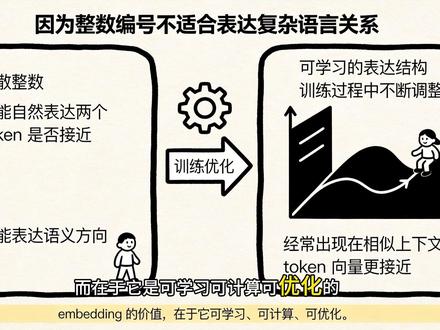 07:56查看AI文稿AI文稿
07:56查看AI文稿AI文稿大家好,咱们今天来聊一个有点意思的技术话题,就是文本被切成 token 之后,它是怎么一步一步变成模型能真正拿来计算的东西的。你可能听过 token, 也知道文本会被切成 token, 但你有没有想过,切完 token 之后,这事还没完,它还得再经过两步转换,才能正式进入模型里干活。 这两步就是 token 变成 id, 再变成 embedding, 而不是你以为的 token 或者 id。 那为什么 token 还不能直接进入模型呢?很多人都有一个误解,觉得切完 token 之后,模型就直接开始处理了。其实不是的, token 只是语言层面的一个切分结果, 它告诉模型这段文字被拆成了哪些单位,但它还停留在符号层面,还没进入到模型能计算的是什么?是数字、向量、矩阵这些东西。 token 虽然比原始文本更结构化了,但它还停留在模型能计算的向量层和参数层。 你可以这么理解, token 已经不是原始文字了,但它还不是模型真正拿来算的东西。接下来咱们就来聊一聊什么是 token id。 当文本被切成 token 之后,模型系统会去查一张词表,这张词表就像是一个大字典,里面记录着每一个 token 对 应的编号。比如说某个 token 对 应的编号是一五三二,另一个可能是四万零五百六十七,这个数字就是 token id。 这里最关键的一点是, id 的 作用只是缩引,它不是用来解释这个词的意义的,它更像是一个地址标签,告诉模型你应该去参数表里的哪一行取东西,而不是告诉模型这个词到底是什么意思。 你可以把它想象成图书馆的所书号,不同的书有不同的编号,但这个编号的作用只是帮你找到这本书,它不代表书的内容之间有什么天然的联系。偷看 id 也一样,它只是一个编号,不带任何语义关系。 那为什么说 id 本身没有语义呢?这可能是最容易被误解的地方。很多人看到 token 最后变成了一串数字,就会下意识地觉得,既然都是数字,那这些数字之间会不会天然带着某种接近关系?比如说, id 是 一千和幺零零幺,会不会比一千和九千更接近?答案是否定的。 在模型里, token id 通常只是词表的缩影,它不负责表达谁和谁像谁和谁相关, 他只是一个人为分配的离散标签。就像门派号一样,门派号一零零一和一千零二只是相邻的两个地址,但不代表住在里面的人就是亲戚或者朋友。所以你千万不要觉得 id 的 数字大小能代表什么语义上的接近度,他只是一个定位用的编号而已。 接下来咱们就进入到今天的重点,什么是 embedding? 当模型拿到 token id 之后,它不会直接拿这个整数去做 testing 或者推理,而是会先去查一张很大的表,这张表里的每一行都对应一个 token id, 每一行里存的是一组浮点数, 把某个 id 对 应的这一行取出来,就得到了这个 token 的 embedding。 你 可以把 embedding 理解成模行为每个 token 准备的一张数字画像, 这个画像不是一个简单的数字,而是一长串数字组成的向量,可能是几百维,也可能是上千维,这个向量才是模型真正拿来做后续运算的起点。 打个比方, id 就 像是快递单上的收货地址,它只是帮你找到对应的包裹,而 embedding 就是 那个包裹里装的东西,是真正有用的内容。 那为什么不能跳过 embedding, 直接拿 id 去计算呢?假设没有 embedding, 模型就只能拿一个个离散的整数去计算,这会有什么问题?最大的问题就是整数编号不具备可学习的表达结构, 它不能自然地表达两个 token 是 不是接近,也不能表达某种语意方向,更不能支持上下文中的细力度组合。而 embedding 不 一样, embedding 是 训练出来的参数,模型会在训练过程中不断调整每个 token 对 应的向量,让这些向量更适合后面的预测任务。 于是,一些经常出现在相似上下文里的 token, 它们的向量表示就会变得更接近。一些功能相近、角色相近的词,也更容易在向量空间中形成某种可利用的结构。 比如说猫和狗这两个词,它们的 embedding 向量就可能比较接近,因为它们都是宠物,经常出现在相似的语境里。 embedding 的 价值不在于它看起来有多复杂,而在于它是可学习、可计算、可优化的。 那又有一个问题啊, embaying 是 不是就等于模型理解了这个词呢?很多科普内容到这里容易讲过头,说 embaying 就是 语义表示,这句话不能说完全错。但如果直接这么讲,你很容易误会成模型。一查完 embaying 就 已经理解这个词了。 其实不是的, embedding 更准确的定位是初时表示它给每个 token 一个进入模型时的起点向量。但真正让一个 token 在 不同句子里表现出不同含义的,不只是它静态的 embedding, 而是后面一层层 self attention 和前馈网络不断更新后的 hidden states。 比如说苹果这个词,在我吃了一个苹果,和我买了一部苹果手机里的含义完全不同。这种差异不是由 embedding 本身决定的,而是由后续的模型层根据上下文调整出来的。所以 embedding 是 底座,不是整套理解过程的终点,它只是模型开始计算的一个起点。 咱们再把这几步合在一起,看一下这层在模型系统里到底解决了什么问题。其实它们解决的是同一个核心问题,如何把语言里的离散符号变成人脑网络能处理的连续表示? token 解决的是切分问题,把原始文本拆成模型可管理的基本单位 id 解决的是缩引问题,让每个 token 能在词表和参数表里被准确定位。 embedding 解决的是表示问题,让这些离散单位拥有可学习、可计算、可参与后续推理的向量形式。 这一层虽然还没有进入到 attention、 qkv、 上下文交互这些更显眼的部分,但它其实是整个大模型系统的入口基础。奢侈就像是你要进大楼得先过安检、刷门、进卡,这一步必不可少。 最后,咱们再聊一个现实问题,这层为什么和实际使用也有关,因为不同模型的入口表示体系本来就可能不一样,不同模型的 tokenizer 不 同,词表不同 id 分 配不同, embedded 参数表当然也不同。 所以同样一句话,在不同模型里,不只是 token 的 数量可能不同,连进入模型时查到的表示体系也不是同一套。这也就解释了为什么不同模型对同一段文本的处理风格、表达偏好、压缩方式和理解路径可能不一样。表面上看, 大家都在处理语言,但底层入口层的切分方式和表示空间本来就不是完全相同的。 好了,咱们今天的内容差不多就到这里了,最后来总结一下核心观点,模型不会直接处理 token 本身,而是先把 token 映设成整数编号,再把编号映设成像量。真正进入神木网络计算的是 embedding。 再简单梳理一下,第一, token 是 语言切分后的基本单位。第二, id 是 这些单位在词表中的缩影位置。第三, embedding 是 模型真正开始计算时使用的连续表示。第四, id 不 带语义, embedding 才是后续天审和上下文建模的起点。 第五, embedding 不是 最终理解,而是进入上下文计算前的初时表示。这一层解决的不是模型已经懂了什么,而是模型终于能开始算了。 它真正完成的事就是把语言世界里的离散 token 翻译成降望玩落世界里的连续向量。希望今天的内容能帮你理解从 token 到 embedding 的 进化之路,咱们下次再见。
207未来摸鱼办 05:45查看AI文稿AI文稿
05:45查看AI文稿AI文稿为什么模型不能直接看文字,非要先切成 token? 大 模型看到一句话,并不像人类一样直接读懂,模型不会直接处理输入的原始文字,第一步必须先把文本转换成它能处理的形式。这个过程的起点就是把文本切成 token。 tokenizer 的 工作本质上就是为模型准备输入,先切分文本,再把 token 转成 id, 同时处理 special token 等模型需要的输入形式。 神经网络真正能处理的不是文字,而是数字。神经网络本质上是一个数学计算系统,擅长处理向量矩阵、概率分布、权重更新, 而不是汉字、英文单词、标点这些人类语言符号。对模型来说,猫 dog、 transformer 这些东西本身没有可计算性,必须先把这些语言符号转换成一套离散、可编码、可查表、可计算的输入形式, 后面才能接入 embedding、 attention、 前馈网络这些模块。 tokenizer 的 核心职责就是把字母串变成模型可接收的输入。 token 不是 字,也不一定是词。 token 是 模型处理语言时使用的基本单位,但这个基本单位不一定等于一个汉字,也不一定等于一个完整单词。现代大模型里, token 很多时候是介于字母和完整单词之间的单位,也就是 subword。 中文一般会按某种规则切成较小片段,英文里的长词也经常会被拆成几段。现代 transformer 常用的是子词级 tokenization, 常见算法包括 bpe、 unigraphy 和 word piece。 按字或者按词来切,这两种极端切法都有明显问题,如果按一个字母来切,优点是几乎不会遇到完全切不出来的词。词表可以做的很小,但问题也很明显,续列会变得特别长,而且单个字母承载的信息太少, 模型需要花更多步去拼出原本一个词才能表达的意思。如果按完整单词来切,看起来更符合人类直觉,但又会遇到另一个问题,现实语言是开放的,新词专有名词缩写、拼写变化层出不穷, 不可能把世界上所有完整单词都提前放进一个固定词表里。子词是词表大小、表达能力、序列长度之间的折中方案。子词 tokenization 的 价值在于, 既不会像字母集那样把句子切得过碎,也不会像整词集那样被未知词卡死。常见词可以整体保留下来,稀有词或新词则拆成更小的已知片段。像 annoying 里这样的词 可能被切成 annoying 加利,也可能被切成 anoy 加 in 加利。这说明 subword 的 本质不是按人类语法强行切,而是按模型词表里已有的高频有效片段来切。 tocanizer 不是 自然规律,而是模型设计的一部分,不同模型用的 tocanizer 可能完全不同。常见的子词算法包括 b p, e, word, piece 和 ungrammar。 它们都在做一件类似的事,把文本拆成模型更容易处理的片段,但具体怎么学,词表怎么合并,片段怎么处理,边界并不一样。还有一类很重要的方法是 sentence piece。 它的一个关键特点是可以直接从原始句子训练子词模型,而不要求先按空格等规则作域分词,这让它更适合做语言无关端到端的文本处理, token 还要变成 id, 才能正式进入模型。文本切成 token 只是第一步。接下来,每个 token 都会被映射成一个整数编号,也就是 token id。 这个编号本身不等于羽翼,它更像一个缩影,方便模型从此表和参数矩阵里找到对应项。 tocanizer 不 仅负责把字母串切成 token, 也负责把 token 转成 id, 再把这些 id 组织成模型需要的输入模型。更准确地说,是先接收一串整数 id, 再把 id 映设成 embedding 向量,从那一步开始,才进入真正的神经网络。计算 模型处理的不只是论文内容,还有一些控制符号。 tokenizer 还会管理 special token, 比如句首、句尾、分类标记、 mask、 padding 等。这些 special token 的 作用 不是表达普通语言含义,而是帮助模型知道输入结构、任务边界、补齐长度或者执行特定任务。 tokenizer 会保证这些 special token 在 tokenization 过程中不会再被拆开。这说明 tokenization 从来不是单纯切词这么简单,它其实是在做一整套输入格式工程。 token 会影响上下文长度成本和输入限制。模型的输入长度限制通常不是按多少个字来算, 而是按多少个 token 来算。也就是说,看到的上下文窗口,本质上是 token 窗口,不是字母窗口。这背后意味着一件很现实的事,同样看起来长度差不多的两段文本, token 数不一定一样。同一段文本在不同模型的 tokenizer 下, token 数也可能不同。 token 切得越碎,序列通常越长,后续计算的负担也越大。 为什么模型一定要先切成 token? 因为 token 是 语言进入模型计算的入口层,模型不能直接处理原始文字,所以要先把文字切成 token。 token 不 能直接进神经网络, 所以还要变成 id, id 再变成向量,后面才进入 embedding, attention, fsn 这些。真正的模型计算 token 不是 一个小技巧,而是大模型处理语言的第一层基础设施。 token 不是 分词小技巧,而是语言进入模型的入口层。
25未来摸鱼办 01:57查看AI文稿AI文稿
01:57查看AI文稿AI文稿嗨,大家好,今天咱们聊聊 ai 世界里的硬通货, token, 这东西到底是啥? 你敢信吗?就两年,中国的 token 日消耗量直接飙了一万四千倍,这啥概念?等于说每天能写出两千一篇文章。所以,这 token 到底是个啥?简单说,它铸是人工智能时代的度算力魔情,怎么算钱就靠它。 想看懂整个 ai 产业,就得先搞懂它。你看英伟达就画了个五层蛋糕来解释,这个模型里 token 就是 核心,它像一根线,把这五层全都穿起来了。 没错,从成本到收入都用 token 来算。不过啊, token 跟 token 可不一样哦,你想想,用来闲聊的 token, 更用来审法,与合同的价值能差出十万倍。所以说,价值的关键不在 token 本身,而在于它干了什么活儿。 再来看看价格,简直是跳楼价,短短四年直接跌了九十九点九八。但好玩的是,这东西越便宜,大家反而花钱越多,这又是为什么呢?因为啊,真正的需求大爆发才刚刚开始, 以前的需求看咱们人类上限明显,但未来需求要看机器,那可就没边了。 这场改革的主角就是 ai 智能体 agent, 它能自己干活,不用人管,这就是未来的需求主力军,一个由 ai 驱动,七成二十四小时不停歇的市场。 所以你看, ai 不 再只是工具了,它自己就能赚钱花钱,成了一个经济体。 当然,新问题也来了,能源贸易、 gdp 算法,我们现有的规则都不够用了。那么最后也问问你自己,你工作里有哪些事儿,未来会被 token 给替代掉?
 01:31查看AI文稿AI文稿
01:31查看AI文稿AI文稿用 ai 的 时候总能看到 token 这个词,那到底是什么呢?搞懂它真的能帮助你省钱的,你可以把 token 理解成为乐高积木啊,我们平时说话用的是文字, 但是 ai 它是读不懂文字的,它需要先把说的话拆成一小块一小块的积木,那每一块就是一个 token, 那 到底怎么拆呢?我来给你看一下啊。我们随便找一个 token 的 计算工具,输入这段话 看一下。这段话被拆成了三十四个 toc, 而且每一块积木都有自己的编号,这里边有几个比较实用的参考数字啊,就是大约四个英文等于一个 toc, 一 百个 toc 大 约是七十五个英文单词, 其实中文他是更费 toc 的, 同样的意思,中文消耗的 toc 通常会比英文的多。为什么我们要关心这个呢?因为每次你跟 ai 对 话的时候,你输入的 toc 通常会比英文的多。为什么我们要关心这个呢?因为每次你跟 ai 对 话的时候,你都在消耗 toc, 而 toc 就是钱,你打的字越多, ai 回复的越长,花的就越多。其实就跟我们用手机流量上网是一个道理,五 g 更费流量。所以下次用 ai 的 时候呢,提示词尽量的写清楚,写精准,既能够拿到好的回答,也能够省偷看。 而且最近呢,官方给 token 做出了一个解释,说它叫词源,但是我觉得这个解释比较中规中矩吧,并不是所有的这种单词都是需要有一些中文的翻译的。好啦,我是开心关注我每天进步一点点。
 01:06查看AI文稿AI文稿
01:06查看AI文稿AI文稿上一期讲到大模型处理指令的第一步,为了完成这个指令,都包括调动背后的模型知识库和算力解锁、匹配、回锅肉制作相关的所有核心 token, 比如五花肉焯水、豆瓣酱煸炒、 冷水下锅煮至八成熟这类关键信息。这个过程中,每一次解锁、匹配和逻辑运算 都是在消耗 token 资源,就像用电时每一秒都在累积度数,用 ai 的 每一次运算也都在累计 token 数。 只要豆包会把这些零散的 token 按照中文表达、逻辑和烹饪的先后顺序重新组合,最终生成一篇通顺完整的回锅肉教程。这篇教程拆解后大概有两百个羽翼 token, 这次指令的完成 就记量为消耗了两百个左右的 token。 整个过程从指令拆解、运算解锁到内容输出,每一个环节都以 token 为核心单位,而最终的 token 消耗总量也是衡量 ai 调用算力成本、收取服务费用的核心依据。下一期我们继续分享,敬请期待!
 02:20查看AI文稿AI文稿
02:20查看AI文稿AI文稿给 ai 发连续重复的文字,比如哈哈哈,六六六这种 token 会变少吗?其实从严格意义上来说, token 不 会变少的。比如说你发八个六和发二十个六,对大模型来说,它的理解的意义不一样的,它可能需要把十个六分成六六六,和另外的七个六六六 其实是不一样的,包括哈哈哈,也是因为他不知道你到底是几个哈,想要表示什么意思。如果说他托克会变少的话,我给他发十个,哈哈,我问他是几个,哈哈,他是不是就识别不出来了呢?所以说这个地方是不会变少的。 我把 ai 本地部署后还会消耗 tok 吗?本地部署以后其实还会消耗 tok 的, 因为刚刚我讲过, tok 只是个低廉单位。那为什么说本地部署以后不费钱呢?是因为你本地部署以后算力是由你自己的电脑提供的,那它不需要去买 tok。 但是 tok 的 使用和消耗是实打实存在的,只 不过这个 token 不 花钱。大小写不同的。同一个单词算同一个 token 吗?这两个其实不会算做同一个 token 的, 因为有些单词,尤其是英文单词,它大小写会有一些不一样的意思。理解大模型需要正确的理解你词语的含义,需要分大小写、 缩写和完整的拼写, token 会一样多吗?这个地方要看大模型的厂商它们的词表或者词库 有没有收录这个单词。比如说可能我们常见的 ai, g、 d、 p、 u、 r、 l 这些单词是大模型已经收录过的,那其实缩写和完整拼写它 们消耗的托管是一样多的,有些单词的缩写是 ai 没有收录的,或者说还没有来得及收录的,比如什么 y y d s, 比如说 divx d s, 那 其实它的托管和完整的拼写来说是不一样的。 ai 到底是怎么分词的呀? 其实它就是通过词表词库来进行分词,它其实涉及到了 n l、 p 自然语言处理,它是会把一个句子拆分成多个词, 或者叫多个托肯,然后为给大模型进行理解。这样的好处在于大模型不会因为一个字的变化或者一个字的错误去理 片意思。比如说我问他今天天气很好,他其实会拆成今天一个天气,一个很好,那其实就非常方便理解了。但是如果说他一个字一个字区分的话,今天天气很好, 在这种情况下他理解会出现偏差,并且消耗的算力会更多。所以说大模型在输入输出之前都会进行一轮分词。
 03:11查看AI文稿AI文稿
03:11查看AI文稿AI文稿大家好,欢迎大家来到 ai 小 白系列第三讲,今天这节课我们讲 token, 搞懂 token, 你 就算彻底明白 ai 是 怎么吃饭的,怎么算账的,为什么贵,为什么限流?那么什么是 token 呢? token 其实很简单,它就是处理文字的最小的一个积木块,它不是字,也不是词,而是 ai 专属的计量单位, 它把文字切碎成最小的一个单元,它可以是一个完整的单词。比如说这个 ai, 它就等于一个 token, 也可以是词的一部分,比如说这个 trading, 这个 tree 和 i 和 in i n g, 它就等于两个 token, 它也可以是一个空格标点,甚至于后缀都可以算一个 token, 甚至可以用一个单独的一个汉字或者字节,它也算一个 token。 就 大家想象一下,你去加油站加油,油枪按声来记费, ai 也是一样啊,它不按字或者词算,而是按 token 来计算费用。 ai 不 会读整句话,它只认一个东西,这个东西叫 token。 那 么有的观众就会问了,这中文怎么才能算 token 呢? 那么其实中英文在算 token 上还是有些差距啊,比如说这个 hello world, 大 概它就等于三个 token。 这个你好世界中文其实要算得多一点,它其实就等于四到六个 token, 因为在这个程度上,不同模型的算法可能有略微的不同。对于一些长的话,比如说 unbelievable, 这个 on, 这个 able, 其实就可以算为三个 token, 就是 把它拆开来用了。 那么 ai 为什么要这么切呢?为什么我们要用 token 来计算,其主要有三个方面的优势。第一个是审算里模型把常用词打包成一个 token, 就 避开了稀有词,有效的防止了这个系统的词汇表来爆炸。第二个就是处理未知的词,就新词,双语词,还有小数那种 emoji 都给切成一个非常小的块,这么容易计算。 再就是统一剂量,用了统一剂量之后,输出全按 token 计费,上下文的长度一按 token 计费,就可以非常的优化模型的速度。那这就是 token 是 如何影响我们日常的使用呢? 就比如说我们几乎日常使使用的所有的 ai 的 api, 其中包括下载 gpt、 cloud 豆包、 kimi、 通易千问都按输入 token 这个输入 token 和输出 token 来进行一个总的计算单位,每次 api 的 调用系统都会计算发送提示词和生成的输出的之合,来进行一个双向的一个计算。 英文就是零点七五个单词大概算一个 token, 而中文就是零点五到零点七个汉字算一个 token, 那 么上下文的窗口又是什么?就是上下文窗口就等于最大 token 的 一个上限。现在 gpt 四 o 大 概就有一百二十八 k 的 一个 token 的 上限,大约转换成中文的汉字有十万个字。 cloud code 三点五大概有两百 k 的 上限, rock 五大概有也是两百万。超过 token 的 阶段,阶段上线,你的 ai 就 会失忆,你的 token 越多,你的输入就越慢,你的输出就越贵,显存占用比也就越高。这就是为什么你当你输入越多的时候,你就发现你的本地跑模型就越来越慢了,就越来越出,容易出现幻觉。 这是黄仁勋在二零二六年的 g t g t c 演讲中讲到, token 就是 一种工厂的经济学,未来数据中心就是 token 的 生产工厂,每瓦性能就决定了谁最便宜。最后来教大家一个 ai 小 白实战的三招,帮你审 token。 第一个就是查 token 的 数量,你每次在问的时候,你可以告诉你的 gpt 和 cloud, 帮我统计一下下面文字的 token 数,直接就是问 ai 就 可以了。第二个就是 你使用尽可能短的 prom 加明确的格式,如果你使用的是中文国产模型的话,你就可以优先使用豆包或者 kimi, 它们的模型成本是相对于更低的。再就是你利用一些现成的 prom, 比如说 prom 机梦,利用你们现成的 prom 的 话,直接减少你的使用成本,少浪费一些 token 就 token 它不是玄学,它其实就是一个 ai 的 油耗计量表,或者说你可以把它类比为手机流量也可以。这只要你懂了 token, 你 就从乱花钱的小白变成了一种精算师。你知道,你知道你输出多少,知道你输出的到底值不值。好了,今天就讲到这里,下课。
52方鑫三个金

