你能想象吗?把 gpt 五级别的推理能力硬生生塞进你的手机里,完全离线还一分钱不收。酷狗最新发布的 jamming 四开源模型彻底点燃了 ai 社区,发布仅仅一周,下载量破千万, jamming 系列累计下载更是突破了惊人的五亿次,直接霸榜哈根 face。 大家都知道大模型好用,但高大上的背后是极其苛刻的部署门槛。想要在本地跑起一个顶尖的 ai, 往往需要几万甚至几十万的算力硬件。但 jm 四完美解决了这个问题,它基于 jm 三技术构建,提供了从二 b 到三十一 b 的 四种规格,最小的二 b 模型在普通手机上就能流畅运行。 推的再神不如实测。今天咱们选举两大对标模型开展同标准横向测试,一个是同参数级别的开源顶流千万三点五,另一个是 google 自家的闭源王牌 jimmy 三点一 pro。 我 们会从代码生成、逻辑推理、长上下文、多轮对话、勾模态能力这四大核心维度逐一实测, 客观还原 demo 四的真实效果。识字前,我们需要先把 demo 四部署到你的设备里。这次我整理了一套完整的全平台部署方案,电脑端覆盖 windows、 macos 和 linux, 移动端支持安卓和 ios, 全程零门槛操作。 由于时间关系,本次我会选用其中一种方式给大家做完整的演示操作。首先我们打开浏览器,进入 lm studio 官方网站,软件会自动适配对应的操作系统,不用我们手动区分。点击登录的下载官方安装包, 安装完成后,打开软件,点击左侧的设置按钮,在搜索框输入扎马四,选择你要体验的模型,点击下载按钮,可以实时查看下载进度。下载完成后,点击左侧的菜单按钮,就可以在对话框输入需求和模型对话了。 维度一,代码生成能力。这次给三个模型的提示词很明确,写一个单文件的 html 页面,还提了波利尼泰风格、实时状态栏、终端打字机效果这些具体需求。咱们看一下生成的具体效果。 首先出场的是 demo 四,可以看到指令遵循度不错,但是视觉风格毛不易的效果感觉没有体现出来,运行之后也没有终止能力。接下来看千万三点五,逻辑和交互做的很棒,增加了终止能力,但是日制中默认输出的是英文,和我给出的样例不太一致。最后是 demo 三点一 pro, 看起来略优于前两者,指令遵循完成度最高。对比下来给我感觉是 demo 三点一 pro 大 于千万三点五,约等于 demo 四。 维度二,逻辑推理能力。这次我们用了一道经典商业推理题,很多人会算成亏一百一或者一百八,特别容易踩坑。从最终结果来看,三个模型都答对了,没有出现逻辑翻车的情况。但是从理解角度来看,我个人排序是 java 三点一 pro 大 于 java 四大于千万三点五。 维度三,长文本多轮对话能力。这次我们给三个模型同步上传了同一份三千字左右的产品需求文档,通过联系多轮的细节追问,实测他们对长文本的精准理解能力,以及上下文的记忆留存能力。 多轮对话测下来,三个模型的上下文记忆能力都在线,但长文本理解提炼能力的差距很明显。同一个提炼项目核心目标的问题, them 的 三点一 pro 做了规整的整合总结,核心信息零丢失千万三点五只做了原文罗列,没有提炼整合。 them 四表现相对最差,直接丢失了生态对接、商业化铺垫两项关键指标。在长文本多轮对话这个维度,我个人给出的排序是, them 的 三点一 pro 大 于千万,三点五大于 them 四。 关于 jm 四的多模态能力,我们在手机和电脑端都做了本地部署实测,最终的运行效果确实不太理想,所以这里就不给大家展示具体的测试效果,也没有做横向对比的必要。 当然,我们也要客观看待。作为一款小参数的开源模型, jm 四在其他维度的表现已经完全超出了预期, 可圈可点。但回归到实际日常使用,如果大家没有极致的本地数据安全隐私需求,也不需要根据自己的需求定制专属功能, 日常使用完全可以使用豆包、 deepsea 这类成熟的免费 ai 工具,体验会更流畅省心。看完整个测试过程,你有什么想法都可以在评论区聊聊,咱们下期见, goodbye!

粉丝2067获赞7562
相关视频
 03:00200YZZ
03:00200YZZ 04:10查看AI文稿AI文稿
04:10查看AI文稿AI文稿大家好,这两天杰纳斯啊,非常热,有人说他是一个开源模型的一个新王者啊,到底是不是呢?我们今天可以来测一下,刚好这两天有一个特别重重要的一个新闻,就是说,呃, 捷豹四呃跟卡布扣的,在这个奥拉玛这个角度上可以做一个无缝的集成,只需要两步操作,第一步就是你装奥拉玛,然后呢下捷豹四的最新的 efo, 比如说我的这个笔记本电脑,它是 rtx 四零六零的一个显卡,它有八 g 的 显存,我这个机器有十六 g 的 内存。 那么这时候呢,我们就可以下它一个 efo 的 一个模型,也就是捷豹四 efo 大 概九点六 g 下,下来以后呢, 然后用再装一个 cloud code, 你 可以用那个,比如说你去 windows 一下,你可以用它的 cloud shell 命令啊,一键安装,安装好以后,你你可以用这个奥拉玛的一个集成命令,把 cloud code 让他去用本地的杰纳斯 eiffelb 的 这个模型,那就这条命令, cloud cloud 杠杠 model。 杰纳斯,然后呢他会先去 下载这个模型啊,他发现我已经下载过了,所以马上就成功了,然后他马上呢去启动这个 cloud code, 然后让他去用这码四这个模型,然后他会问你几个问题,最后呢就是会让你信任这个当前的这个文件夹。好,我们现在已经到这了,我也是刚刚装好,我们来试一下, 请帮我写一个写一个 hello word 的 htm 页面,并在默认浏览器中打开。 好,我们看一下啊,它的这个怎么样?它现在用的就是我们的本地的杰纳斯 infob 的 这个模型小模型啊,然后我们看一下它的一个 gpu 的 一个利用率啊, gpu 一 现在有百分之九十六,那跑满了,你看到了是吧? gpu 一 的这个利用率跑满了,我们看看它到底怎么样啊,哈哈, 它现在这个要显示 token 哦,出来了,大概花了不到两分钟吧。三分钟啊, and i will use the batch。 对, 它是先计划啊,然后 yes, ok, 那 现在 open yes, 继续 ok, require pool yes, 哦,打开了,看到吗? hello, word this is the basic html page。 那 好,我们再让它做一个稍微难一点的,我说写一个最简单的贪吃蛇游戏,并在 切神浏览器中打开,我们看一下啊, 一起创建。 ok, 我 们这样好,打开了,就是贪吃蛇,我看一下啊,可以看能不能玩。 ok, 这个是最简单的,还没有碰到。这个还没有,还没有开始就结束啊,就是不是还没有开始就结束,这个人最简单,但是我们已经看出来这个杰马四啊,他的一些这个功能,我觉得就是他的这个编程的能力啊,我觉得还是可以的啊,因为我这个是小参数模型呃,你不能对他有太高的要求。 ok, 那 么我们今天用这个 cloud code 和 java 四 evo b 这个,呃,一块编代码的。这个游戏呢,我们就告一段落了,我觉得它还是有点用的啊,有些很简单的任务,我们是可以用本地模型的,这样的话也节省非常昂贵的云端 api talk 的 费用。好,谢谢大家。
 09:41查看AI文稿AI文稿
09:41查看AI文稿AI文稿等等,一个只有三百一十亿参数的模型,怎么能跟一万亿参数的模型几乎同分?它的参数量不是小了一点,而是小了三十倍。 三十亿币可以在很多消费级的设备上跑了,按正常的逻辑,它根本不应该出现在这一档。而三十亿币的小模型就是谷歌刚发布的 jama 四。那 jama 四到底是什么?实测它的性能真的有这么好吗?一会我们详细对比,并且在手机上、电脑上都给它跑起来。 最后我们一起说一下,为什么它引起了如此广泛的讨论,以及它引起的新风潮,为什么可能直接改写接下来 ai 竞争的方向。 好,废话不多说,我们开始伽马四,是谷歌新一代的开源模型,这次直接发布了四个版本,能在手机上跑的一二 b, 能在普通消费机电脑上跑的一四 b, 以及需要一些高配电脑或者工作站的二十六 b 的 混合专家版本,以及最受关注的三十一 b 的 重密模型。 这个产品结构本身也解释了谷歌的野心,想把从手机、消费机设备到工作站这条开源路线一起凸出来。它的卖点非常明确,第一,谷歌算是铁树开花了, 这代的 ram 是 阿帕奇二点零的证书,是真正能让开发者去用、去改,去商业化的开源模型。二,它主打的不是参数有多大,而是 intelligence profile, 说白了就是同样甚至更小的体量,尽量打出更高的能力密度。比如这个图,横轴是参数量,纵轴是盲测得分,越往左上角走, 同样参数量的情况下,它的性能就越高。第三,它不只是要聊天,谷歌这次明确在推 reasoning and egotic workflows, 包括多步的推理,代码的生成,图像理解,上下文,甚至小版本还支持音频等多模态, 我们这些一会儿我们在手机上跑模型的时候都能看到。那这就是为什么伽马斯这次热度很高了,过去很多开源模型我们还是追求的最好的性能,那这次呢?谷歌的小版本在打本地和边缘设备, 而大一点点的版本却在挑战开源模型的榜单,说的就是这个三十一 b 的 模型这么小,已经在开放的榜单上打造一个所有人都能看到的位置了。那问题就来了,它的实测性能到底怎么样?真的有这么好吗?接下来我们一起看一下。 既然它号称和最好的那几个开源大模型旗鼓相当,那我们也不客气了,分别测试一 g m 四最好的三十一 b 版本和谷歌自家旗舰 g m d 四 b 版本,并且与同参数量的千万四 b 进行对比。三,如何在手机上跑 j 码四,以及我的真实体验。 首先在云端,我们对比四个模型, j 码最好的三十一 b 版本, gmail 三, flash gmail 三点一, pro 以及 deepsea v 三点二,在很多人都需要的编程文案和推理场景, 看看这个小模型有没有一丝替代昂贵一线模型的可能性。问题一,编程类,请用单文件 html 做一个高端现代家具品牌的网站首页, 这是 jam 生成的网页。其实啊,不经验,但是也不算差,考虑到它的体量,这个结果算是超过预期了。但问题也很明显,有些图片没有正常演示,图纹对应也有错误,所以完成度还是差了一大截。 这是 deepsea v 三点二生成的网页,整体也不错,设计能看,交互也有往下滚,还有一些动画效果,而且它的图片、文字这些元素是对得上的,说明它已经有些理解。这是一个电商的首页了。 这是 jammin 三 flash 生成的网页,第一眼观感已经很好了,设计感呢,比 jammin 更成熟,但是它的问题是动画和交互偏少,整体呢,没有达到完整的状态。 这是 jimi nike 三点一 pro 生成的网页,好疑问,是最强的对吧?几乎是一条提示词下去,设计,排版、交互细节都到位了,也充分理解了这是为电商准备的, 以及开头这些细节的动画,确实有一种高端,一种成熟的感觉。结论, jimi nike 三点一 pro 大 于 jimi nike 三 flash 大 于 deepsea 大 于 gemma。 这一次 gemma 是 最差的。问题二,文案, 请帮我写一段适合发朋友圈、社交媒体的短文案,主题是我第一次用本地 ai, 发现他已经在电脑上自己能做很多事情了。并列三四名, gmail 三点一 pro jimmy 四、 真香,安全感拉满,不要钱的专属助理,这些词都用力过猛,太假。第二名, gmail 三 fresh 最大的问题就是太过营销了,比方说,真后悔没去试,试过就回不去了,太香了,就是营销味太重。 第一名呢是 deepsea, 是 最像真人随手发朋友圈的,比方说啊,刚刚是在电脑上跑了个本地 ai 这种词,或者是速度比想象中的快, 隐私还放心,这些表达都相对比较自然。除了最后那句,推荐你们都试试看,稍微有点假,但整体来说还是最顺的。所以文案这里 deepsea 大 于 jimi nike 三 flash 大 于 jimi nike 三点一 pro 题目三,简单的推理题这个题所有模型都应该答对,这里主要看 jimi 四拉不拉垮。 一个农夫带着一只狼,一只羊和一颗白菜。过河船一次只能载农夫和另外一样东西,如果农夫不在,狼会吃羊,羊会吃白菜。请问怎么把这三样东西都安全的运到河对岸?请一步一步说清楚。 标准答案之一就是,人先带着羊过去,然后人自己回来,然后人带狼过去,带着羊回来。第三步,人再带着菜过去,人自己回来,最后是人再带着羊过去。 其实这道题都答对了,所以如果只看评理结果,那这题就是平手任马四,最好的三十一 b 白板啊。虽然阿尔瑞纳的盲测分数比 deepsea v 三点二高,但是文案和编程这两个我们需要最好模型来做的场景。我自己的测试没有 deepsea v 三点二好, 但是考虑它只有三十一 b 的 大小,编程的效果已经出奇的好。在云端测完最好的版本,下面我们测一下本地能跑的 ram 四,因为啊,大部分人的电脑都跑不了三十一 b 的 版本,所以我们在本地测试 ram 四 e 四 b, 并且对比同参数量的千万三点五四 b。 至于题目这么小的模型,测试编程能力就是有点耍流氓了。因为编程大家肯定都用最好的模型,所以这里我们测试三个日常助理的题目,考常识,考文案,考简单的推理一、常识规划能力。下周我要去巴黎玩,四千, 除了机票之外,预算一万,第一次去,住在巴黎市中心,帮我安排一个计划,并且告诉我最容易踩坑的五件事情, 这是他们的回答。简单来说啊, jama 这边没有出现事实性错误,而且行程写得更顺。但是他的问题就是,他几乎忘记了处理预算这件事情,而且最后的建议啊,没有这么贴切。千万正好反过来五个避坑建议相当靠谱,而且他是有意识的去考虑预算的,虽然是有些混乱吧, 但是千万里面有事实性错误,把两个景点荣俊苑和法尔赛混在一起了,而且他的思考时间啊,差不多是 jama 四的十倍, 所以各有一缺点,结果打平。题目二,文案把下面的 ai 味很重的口播稿点成更像真人说的话,要求更自然,更顺口,信息密度别掉,不要鸡汤,不要夸张, 人马四 ai 味实在是太重了。比如这一句,原句是,如果我们今天只是把 ai 理解成一个简单的聊天机器人,那很可能低估了这场技术变更的真正影响范围。 人马四改写的是,这可不是个小升级,是个大变格。这种话听起来就像 ai 反过来千问那句,你要是现在还把它当个普通聊天机器人,那你可能把这事看清了,我觉得就更自然一些。所以这题呢,比较简单,千问四必 大于 jama 四 e 四 b。 第三题还是刚才那个简单的推理题,一个农夫怎么带着一只羊一只狼和一个白菜过河的问题而都答对了。那么这个题平手可以看到 jama 四 e 四 b 的 版本啊,在我们的测试中,跟千万三点五四比打平,而且文案写的还没有人家那么好, 所以在我这里这个版本是没有什么惊喜的。 jama 四也能在手机上直接跑谷歌 a i h gallery 这个软件。 我的实测感受,第一,手机上有两个版本, jam 四一二 b 的 二点五 gb 和三点六倍 gb 版本。那么这两个呢,都是二十亿参数级别,专门为端侧部署优化的小模型, 两个都支持多模态,也就是图片和音频的理解。二就是有两个加速模式, cpu 加速和 gpu 加速。我的安卓手机呢, cpu 加速明显更快一些。 三,没办法联网,但是能用 viki pita 这个 skills 来获取维基百科上的信息。四,有 agent skill 模式,但是只有默认的 bug skills 和自己定义 skills 的 选项。 五,就是啊,图片识别模式非常的不稳定,经常出现闪退。从所有的评测我们看到啊, gemma 四远远不是最强的,那为什么它掀起了这么大的讨论呢? 就是因为他三十一倍的体量和高性价比的性能,大模型啊,越强越贵越大,就离普通的设备越远。在卷性能的另一端,他开辟了一条竞争的道路,就是谁的能力密度更高,谁更能落地手机电脑这样的普通设备。 那这条路线呢,有三个值钱的地方,第一就是成本更低,对吧?如果一个模型更小,能力还足够强,他的推理成本就会更低,对算力的依赖也更小, 同样的用户数量,竞争力就更高。第二就是他打开了一些之前做不了的场景,比如一些隐私敏感的企业弱网环境离线场景,这条路呢,可能会放大可成交的市场范围。第三 就是卖钱的方式有可能会变。现在 ai 公司卖的是旗舰模型的 api token, 如果未来有更低的部署门槛,更强的观测能力,更好的私有化能力,那钱不一定只在 talk 里赚了, 可以从企业部署私有化方案、设备预装垂直方向里面转。也就是说啊,开始从卖能力变成卖能力加卖系统,更加对接 to b 的 生意, 由此可能会带来竞争壁垒的改变。如果模型能力越来越近,那优势就会变成了谁更容易部署,谁更容易接近工作流了。当然,将来大家肯定还是会选谁的旗舰模型能力最强,尤其是 ag 的 能力和写代码的能力。 但是除了这条竞争路线之外呢,也许我们会看到 ai 竞争的第二条追求更强能力密度的路线。哎,如果你都看到这了,你是不是应该点个关注呢?我们下期再见!
5111木子不写代码 07:13查看AI文稿AI文稿
07:13查看AI文稿AI文稿大家好,本期内容我来分享如何在本地部署谷歌新开源的多模态 ai 模型代码四,我会分享命令行和格式化界面两种安装方案,零基础也能轻松搞定。 最后我还会教你如何修改部署的路径,彻底解决大模型占用 c 盘的问题。本地部署的优势就是你的数据可以完全保存在自己的电脑上,隐私安全有保障,而且支持模型微调, 可以打造专属的 ai 助手。但是他也是有缺点的,就是我们需要稍微懂一些技术,还有就是硬件的支撑,如果电脑配置高,自己可以部署折腾一下。有了本期视频,就算你不懂技术,跟着视频操作也可以部署成功。 本期演示我只分享入门版本,主要就是参考部署的方法和流程。接下来我手把手带大家用欧拉玛一键部署。 首先我们先来了解一下 jam 四到底是什么,它是谷歌新发布的开源多模态的 ai 模型,与 jimmy nay 是 同源的。 简单来说,谷歌就是把自家的 ai 技术打包成了一个免费开源的版本,让每个人都能用上。它的能力是非常全面的,支持文本交互、图像识别、音频处理,还能生成代码, 基本上覆盖了所有的 ai 应用场景。下面我们再来看一下它的核心优势。核心优势它有三个,第一个就是多模态能力,文本、图像、音频代码,一个模型全部搞定。 第二个就是完全免费,它没有会员订阅,没有暗次收费,可以随便的去使用,甚至用它去开发商业化的产品。第三个就是比较重要的隐私安全保障,本地部署模式下,所有的数据处理都在自己的设备上完成, 敏感信息不会上传到云端,这是三大核心优势,就是在我们安装之前,需要我们了解一下这个安装环境。首先系统兼容性 demo, 四是支持 mac os、 linux、 windows 三大主流操作系统,基本上覆盖了绝大多数的用户。 然后就是内存要求,如果你的电脑小于三十二 gb, 推荐安装四 b 版本,自己安装体验折腾一下就可以。如果你的内存达到或超过了三十二 gb, 那 就可以选择二十六 g 或三十一 g 的 版本。 在这里有一个小提醒,就是如果是 mac 电脑 m 系列的芯片,它的显存和内存是合二为一的,大家直接看内存就可以。如果大家不是 mac 电脑,比如 windows 或者 linux, 那 么就优先看显存,显存不够再看内存,这是关于这个配置的查看。像这个本地部署也非常简单,仅需两个步骤即可完成。第一个就是安装欧拉玛,这个欧拉玛就可以理解为是本地大模型的一个容器, 它是装大模型的,有了它才可以运行。第二步就是我们容器安装好之后,我们需要给它把模型放进去,就是部署模型,两个步骤即可搞定。下面我们直接进入实操环节,我们来一起看一下部署的全部流程。 在这里第一步我们就先要有这个欧拉玛,他是一个大模型的容器,就是我们打开之后选择右上角的 download, 这时候我们就需要选择匹配自己系统的版本,在这里我这是 windows, 然后我们选择 download for windows, 在这里选择 download for windows 之后就会弹出窗口,我们选择路径直接保存就可以,当下载好之后,然后我们就安装即可,安装好之后打开就是这样的主界面,这个是我之前安装的版本,部署着一个一点五 b 的 zip, 然后下一步就需要我们去选择大模型,我们还来到刚刚乌拉玛的这个界面,在这里我们选择左上角的 models, 然 然后在这里我们可以看到该马四,然后我们选择进来,它提供了好多个版本,在这里我就选择一个入门的版本,主要就是演示安装的流程,比如我们选择 e 二 b, 然后我们选择,这时候我们就看到了这个安装命令,选择右边的这个两个方框,然后选择 copy, 然后下一步 我们就按键盘上的 windows 加 r 键,这时候出现运行窗口,然后在这里面输入 cmd, 然后直接回车, 回车之后就出现了这个命令窗口,然后我们刚刚复制了直接鼠标的右键,可以看一下,这个命令就粘贴过来了,然后我们直接 回车好了,这时候它就开始部署到本地了,在这里我们需要等待一段时间,好可以看一下出现了 success 这个提示,就证明安装成功了。现在我们在这里可以直接和它对话,比如我们输入你好当前什么模型,然后我们发送 可以看一下,他现在回复我们了,我是一个大语言模型,我叫 jama 四,这时候我们就在本地已经部署成功了, 然后我们再回到欧拉玛的客户端,在这里在这个对话窗口右下角这里,这里可以选择模型,然后我们找到刚刚部署到本地的 jama 模型好了,这时候就切换好了。同样在这里我们也可以直接和他对话,比如我们输入你好,然后发送, 这时候他就回复我们了,你好,很高兴和你交流,请问有什么帮助到你的?到这里我们就已经部署成功了。前面我们分享的是使用命令行 c l i 模式去部署,其实还有一个简变的方法, 在这里我们还可以选择模型后面对应的这个按钮,也是可以直接部署的,这个是非常方便的。好,最后我再分享一个大家比较关心的问题,就是我如何设置这个本地模型的一个部署路径, 在这里我们也不用去改环境变量了,这个客户端是直接支持的,我们选择左上角的设置,然后在这里选择这个 model location, 在 这里我们就可以去设置模型的一个保存路径,在这里大家自己设置就可以,是非常方便的。 好,下面我这里演示的是上传了一张图片,就让他识别这张图片,我们一起来看一下他给我们的结果,好了可以看一下,我们给了他一张图片,我们问他这是张什么图片,他给我们的回复, 这是一张符号或者是图标,然后他还分析了主要包含的元素,还有用途预测等等,能够精准的识别内容,并生成详细的描述, 表现还是可以的。好了,现在我们本地部署成功了,然后刚刚我们也做了一个功能测试,第一个就是我们和他对话,就是文字处理,第二个测试的就是这个图像识别,他也是可以精准识别的, 他虽然是多模态的,但是目前我们用的这个容器不支持多模态的输入,我们暂未测试音频和视频的识别。好,最后我再补充两个细节,就是第一个欧拉玛的拓展性他是非常强的,除了可以部署这个 demo 四, 还支持比如通用签问或者是 deepsafe 等众多的开源模型,部署方法也是完全一样的,一条命令就能去部署。第二个就是本地部署的真正价值不仅仅是隐私保护,更重要的是支持模型微调, 可以用自己的数据去训练模型,打造一个完全专属的 ai 助手。好了,这就是我们本地部署的所有内容,大家感兴趣的可以自己折腾一下,探索更多的玩法。好了,我们本期内容分享就到这里,可以留下你的想法,我们下期再见。
367掌舵者AI实验室 04:59查看AI文稿AI文稿
04:59查看AI文稿AI文稿这几天 jam 四的发布呀,让很多人都在宣传他的功能强大,甚至有人说终于可以实现 toc 自由了。 jam 四呢确实可以实现自然语言的推理,而且还支持多模态,支持文字、音频、图片和视频的读取和识别。但 jam 四是不是真的那么强大呢? 它能不能作为企业级生产的模型来使用呢?今天呢,我就花了一些时间对比一下 g m 四,二十六 b 和三十一 b 这两个模型的能力,并且呢用同样的案例来对比了一下它们跟切的 g p t 和 jimmy 图片识别的差距。 因为我这台电脑呢,相对来说配置还是比较高的,所以呢,我就同时下载了二十六币和三十一币这两个模型。环境呢,依然采用的是欧拉玛测试的场景呢,主要有两个,第一个呢是识别产品的宣传海报,第二个呢是识别商场的一个购物小票。 我们先来看第一个场景,我选择了一个国内非常知名的舞蹈鞋品牌的产品宣传的海报,我们先使用 jam 四二十六币来进行图片的识别。 二十六币这个模型在我的电脑运行起来还是相对比较快的,它的思考时间只花了十二点六秒。 接下来呢就是对于图片信息的识别,整体信息识别的还是比较准确的,但这里呢产生了一个小小的错误,就是对于品牌名称的识别,把五院两个字识别成了别的名字。这个错误的原因呢,可能是因为图片中 五院两个字采用的是草书的格式。那么接下来呢,我们换用三十一 b 的 模型,看看能不能解决这个问题。我们使用三十一 b 这个模型呢,它的思考时间更长了,是因为我这台电脑运行三十一 b, 可能相对来说还是稍微有那么一点点吃力, 同样的,他对于产品的信息和描述都没有什么大的问题,唯独对于品牌标识五院两个字依然识别错误,但三十一币呢,比二十六币相对来说稍微好那么一点点,他只错了一个字, 对另外一个字还是进行了准确的识别。所以对于图片中的文字的识别,特殊的字体界面四还是不能准确的进行识别的。接下来呢,我们再来看一下另一个场景, simmer 四是不是能够准确的读取购物小票。对于购物小票的识别呢,我们要求更加的准确,我们依然先使用二十六 b 进行测试,识别一下这张单据, 以 jason 格式进行输出,因为购物小票相对来说的文字信息比较多,而且呢,要求识别的文字要准确,它在思考的时候花费了三十八点二秒,但整体的输出速度还是比较快的,这里边把信息进行的格式化,信息还是比较完整的。 但是呢,二十六 b 模型也出现了一个错误,就是这两个中文的商品名称都有错别字。那么我们再来看一下三十一 b 的 模型是不是能解决这个问题,同样让他来识别这张单据, 以 jason 格式来进行输出。这一次呢,他花了更长的时间来进行思考,一共花了一百三十四秒的思考时间,对于文字的识别呢 有所改善,但依然存在个别的文字错误,所以呢,我们最终可以下一个结论,界面四对于图片中的文字识别,它的准确度还是有待提高的,那么同样的场景,对于切的 g, p、 t 和界面奶三 是不是都能够识别准确呢?我们再来看一下它们的表现。我们首先来看一下切的 gpt 的 模型的表现,依然让它提取这张小票的信息,以 jason 格式进行输出,这个结果让我非常的意外,切的 gpt 也发生了文字识别的错误, 我们来对比看一下这个字,这个玉字,它识别成了圆字,不过呢,只是发生了这一个错别字, 其他的信息都是非常的准确的,而且的 g, p, t 对 于产品海报的识别是非常准确的,虽然图片中含有特殊的字体,它依然进行了准确的识别,把五院两个字都正确的读取出来了。那最后呢,我们再来看一下 jamie 三模型提取的小票信息以及产品宣传海报的信息,都非常的准确,而且反应速度特别的快, 几乎不需要进行等待,没有错别字错误,没有特殊字体的识别错误。所以在整个测试中呢, jamming 三的表现堪称完美,不但速度快,而且还非常的准确。所以最终的结论是, 如果你在企业 agent 里边来进行使用,或者是在你的工作流中来使用图片识别功能,强烈推荐你使用 jamming 三 pro 模型。 原因呢,只有一个,你需要的是快速准确的识别信息,如果一个 agent 或者工作流识别出来的结果还需要进行人工的核对,那么你上这个 ai 系统还有什么价值呢?
 03:20查看AI文稿AI文稿
03:20查看AI文稿AI文稿大家好,我是根谷 open cloud 的 追马四欧拉玛全新的本地模型体验来了。欧拉玛最新更新的版本是 v 二点零啊,已经支持追马四,搭配 open cloud, 响应更流畅,速度更快,回车记出结果,支持常文本做任务处理,本地 i i 体验相当的不错, 要想流畅的体验,快去试试升级吧。首先教大家如何去升级吧,当你用这个积马四的话,你首先的显卡应该是十六 gb 上的啊,最好能够到三十六 gb 啊,我的电脑是一个一百二十八 g 的 全存和内存一体化的,是吧, m 四 max 的 最强电脑,所以说我运行这个东西是, 呃,我运行这个金马四二十六币了,这个模型是没任何压力的啊,欧拉玛兔啊,一定要用这个命令啊,金买四二十六币啊,你回车 他默认的会把它下载到你这个,因为我是下完了是吧,当然如果你下载很慢的话呀,你应该去做的有两个操作,就是应该是这么做的,应该是做那个去开他代理啊,这个代理应该是这么做啊,就是去去这么做 开这个代理啊,或者是你去那个把这个镜像设置为那个,设置为一层摩摩搭论坛的那个代理啊, 就是把它带代理到国内啊,如果你能够魔法上网的话,就不需要开代理了,因为我这边的网速是比较快,大概是下载了接近接近两个小时,一个半小时啊,大概是五到六兆每秒,他是七 gb 的, 他会下载哪个目录呢?你可以看一下这个目录啊,欧拉玛这个目录,呃, 首先它的模型会下载到这里,下载你其实不用管了,你可以打开你的欧拉玛,现在欧拉玛其实它又升级了一个小版本啊,就是零点零点二 两百啊,零点二点,零点二点零点二啊,这是今天最新版本,大家建议大家升级最新的版本。那我这里下载了两个模型比较好用,一个是 gbt 的, 一个是 o s s 二十 b, 一个是这个积满四,最新的二十六 b。 那 我发现这两个模型都非常快啊,你下完了以后,你一定要用欧拉玛浪琴去启动欧拉玛 浪去,他去启动这个欧风 club, 启动完了以后我这已经是启动了,启动了以后你打开这个小小龙虾的页面来,我给他做一道数学题目吧。啊,这个他不知道他能不能识别啊,哎,你看非常快吧,秒开吧,是吧? 然后他这个地方其实有错误啊,就是我应该去截个图给,不知道能不能截图过去啊?就是你,哎,就是就是就是,求解,这个一元二次方程, 不知道他能不能识别。这个啊,他已经识别出来了啊,这个是啊,我不知道这个结果是不是对的。 x 平方减五, x 加六啊,应该是没,应该是没问题的,对吧?一个是二,一个是三,对吧?对,非常快,然后这个数学题其实更难一些,就是这个勾股定力的这个,一个这个这个 啊,你看看一下,他应该是应该是很快的,一秒、两秒,两秒就出来了,这个比之前是快很多,我记得考了应该是三月 二十八号那个版本嘛,大概是一周前的欧拉玛这个版本和 opencall 的 最新版本啊,它大概是这样一个难度的速写题,要要五到八秒钟,如果是过年的那会大概是要一分多钟,所以说现在是非常快啊,非常快啊,就是我感觉比那个 api 都要快,所以大家尽可能去试一试啊。用它进行养虾的话, 那比如说,比如说我是谁啊?对吧?他应该很快就能够找到十二月份,是吧?年龄怎么怎么样?我觉得非常快,这个建议大家赶紧去升级吧。
162根谷 05:06查看AI文稿AI文稿
05:06查看AI文稿AI文稿不久前,谷歌发布了 jam 四系列,它不仅是一款开源模型,更是一次关于如何把超级大脑装进手机的工程奇迹。今天我们一起来看一下它是如何用不到四 g b 的 显存,跑出大模型的效果。 这里我们做了一个测试,使用三台手机在本地离线跑 jam 四 e 二 b, 屏幕上呈现的是这三台手机的测试数据,下面给大家看一下实际运行的情况。第一个加油问题, 第二个 g two 铜龙问题, 第三个字母出现次数问题。 可以发现,关于对常识的判断仍然是小模型的短板。然后这三台手机中, iqoo 十五的运行速度最快。 simon 四一共四款,覆盖从手机到工作站的所有场景。 a dos base 最轻量手机和树莓派都能跑,自带语音识别,量化后只要四 g 显存。 a, 跨出白瓷笔记本甜品级, 速度和能力之间的平衡点。二十六 b, 混合专家架构,总参数二五 b, 但每次只激活三点八 b, 用小模型的成本干大模型的活。最后是三 e b 单词,旗舰级模型,全参数推理,开源模型排行第三,适合有好显卡的用户。这里要讲一个关键的概念,单词和猫的区别, 单词密集型。你看屏幕上这些格子,全不在闪,因为每次推理所有参数都参与计算,三十一币就是三百一十亿次,运算一个不少。它的优点是稳,缺点是慢,而且吃显存。 切换 m o e 模式,注意看大部分格子暗了,只有几个在亮,这就是混合专家的精髓,模型里有一百二十八个专家,每次只派八个上场,剩下的待命。 最后说说它的边界,左边是强项,文档识别,发票解析,代码补全,长文档,问答 agent, 自动化任务,这些它都能做,而且跑在本地,意味着你的数据永远不用上传到别人的服务器。 右边是它的短板,如果你问它能否替代跨腾或 gpt, 答案显然是不行的,那能否进行高质量写作?这里我的回答是勉强可以,至于大规模的代码重构,那以它的能力还差得很远。 说白了, jam 四是一个极其出色的本地工具型 ai, 你 把它当高效工具用,它不会让你失望。如果你把它当全能大脑用,那你就会很失望。 想试的话,这里有两种方式,手机用户可以直接去 google 的 a i h gallery 上下载使用,电脑用户更简单,欧拉玛一键运行。下面我们来看如何用欧拉玛本地部署 jamal 四 e 四 b 模型,并使用 clogot 调用它。在 clogot 直接提问它是什么模型, 它是由谷歌训练的大语言模型,欧拉玛在首次请求时加载模型,加载耗时三十八秒,显存系统分配总计实际首先确保电脑上已经下载过欧拉玛,只需执行一行命令,欧拉玛 round gemma 四冒号意思币,等待模型下载完成,总计约九点六 g 币。成功后在终端测试。问答, 它是一个大语言模型,名字是 gemma 四,由 google deepmind 的 开发,属于一个开放权重模型系列。复制这个模型 id, 克隆项目源码, 进入项目目录,运行安装命令,下载完依赖后进入引导界面,颜色模式随便选。第四个是我们做的国产模型适配选择第三项,本地欧莱玛模型, 然后粘贴刚刚复制的模型 id 回车。确认到这一步配置成功。我们问个问题测试一下,现在已经调用成功已经登录的用户,想要切换模型,输入 logo, 退出登录,然后运行帮人 devi, 即可重新配置。我们最新版的 cloud code 已开源,大家关注评论获取。 目前呢,该模型权重在 hackin、 face 和 kaido 上都能下载。以上便是我对 gmail 四的实测解读,如果你觉得有用,不妨点个关注,我们下期再见。
834AGI_Ananas 03:23查看AI文稿AI文稿
03:23查看AI文稿AI文稿jam 四非常的火爆,这个视频我们来看到它的破线版本,使用欧拉玛运行,去除了拒绝回答机制,直接的回答没有任何的限制,以及社区当中风评比较好的大参数破性模型 g b d o s s 那 么就与图像和视频模型破线一样, gm 四破线之后的话,能够回答我们提出的任何问题,他不会拒绝,且会直接回答你的任何提问。这两个模型以及对应的五零九零启动日设我都已经部署至了应用之算平台上面,同时这个视频我将分享一个文档, 以辅助想要在本地运行的朋友来如何进行欧拉玛模型的模型文件配置,以控制欧拉玛运行下模型在 gpu 当中的卸载陈述。经过 这样的配置学习,我们可以使用更低的显存来跑更大的模型,甚至说跑一百二十倍的模型。点击进入到优云智算平台,找到对应的镜像点击部署实力,那么我这里推荐租用的是五零九零显卡, 使用 jimmy 四最经济也最具性价比的选项。那么这是一个自启动的镜像,我们不需要启动指令,点击立即部署, 等待一下。那么出了欧拉玛之后的话,我们点击欧拉玛就可以进入到 open web ui, 输入统一的电子邮箱和密码, 点击登录上方,就可以选用对应的模型并与模型进行对话。如果我们租用的是五零九零,可以使用五零九零对应的预设,能够获得更为稳定,更为一键自动化的运行。破线的内容不是那么好演示,正常情况下我们就 打开侧边栏,该怎么对话就怎么对话,那么这都是常用的对话形式嘛,这里我直接以 g b d 开源的这个模型为例,快速启动上来说,只需要记住预设与非预设模型的区分,那么上风这两个也并不是实体模型,仅仅是一个搭配了预设文件之后的模型感 改了一个名字而已。我就以这个一百二十 b 的 模型为例,它是由 g p d 开源,但就限制解除破线这一块的话,这个模型的话,它的性能仍旧算得上顶级,所以我也把它给加进来。当然 jam 四也是很强了,我们可以看到用时十一秒钟,一点都不快, 但仍能属于可以接受的水平,在此时此刻,内存占用为六十七点七 gb。 这里的技巧我整理成了一个文档,放在了我的 bilibili 的 简介当中的云盘里面。把这个文档呢丢给大语言模型九十以上的概率,它能够帮助你去控制大语言模型的 g p u 卸载的陈述。这是 g b d 给我总结的文档,如果愿意的话也可以看一下,这一套是使用 jupiter lab 来进行的配置。我们切一下这个圈八四模型看一下, 可以看到 jam 四的思考速度还是非常的快的,此时此刻的内存占用为五 gb, 因为大部分的模型还在我们的显存当中,回答速度也很快。那么今天呢,由于一个快乐马模型呢,据说是登顶了,甚至呢要超过 cds 来自于阿里,那么具体如何的话,我们还是等它真正的 开源了再看。可以这么说,现在这个状况来说,只要是开源都是有意义的,因为从以前到现在来说的话,哪怕只开源一代模型的话,退一万步说 我们至少能保留那一代模型在我们的硬盘当中,想用的时候随时用,没有限制,就像今天的这个镜像一样,完全的解除了我们的限制,问什么回什么,可能说没有那么聪明,但是绝对自由。
32AI-KSK 03:23查看AI文稿AI文稿
03:23查看AI文稿AI文稿好,大家好,我是小刘。呃,今天我们一起来看一下在 ktapp 上最近比较火的几个开源项目。在这几周里面,那首先第一个是我们昨天讲过的这个 hermes agent, 那 这个开源项目其实是一个自我进化的一个 agent, 呃,它主打一个可扩展,然后多带你开发工作流,现在已经目前从 openclaw 上全程迁到这边来了,就我自己使用的话,一般不再使用 openclaw 作为我的 agent 的 一个呃主要的工作方式。 那还有就是这个 open screen, 这个是一个那个录屏工具,就可以帮助你放大放小,就大家现在看到这种屏幕啊,放大放小啊,就使用这个开源项目啊,当然它也是呃开源的。 那第三个就是这个能够让你的这个 codex 呢,能够支持多个不同的那种角色嘛,就是,呃和那个监牢的 code 的 有点像,就那我今天给大家分享的是这个 这开源项目,这个开源项目在 get up 上目前收获了呃接近二十 k 的 star, 它是一个端测模型。啥意思啊?就是说你可以在你的手机上去跑各种各样的本地离线大模型。 好给大家举个例子,比如说我现在想在我的这种 iphone 上去跑模型,那这时候我直接可以把这个模型给它下到我手机上,这时候呢即使断网的情况下,它也可以通过这样的方式来去跑这个模型, 并且这个模型还是多模态的。啥意思?就是你发图片给他,他可以直接去理解这个图片,并且呢能把这图片的这个细节说出来,也就意味着我们不需要去接入其他的模型,你有一台空闲的手机,你可以对外暴露一个接口,然后你的这种 app 就 可以直接调这个 iphone 的 这种, 哎,这种能力啊,因为它的 gpu 本身来说在本地嘛,对吧?有时候我们做一些小的离线的这种呃 app, 就 可以通过这种方案去实现我们的这个呃模型的能力。那建议的话就是官方是建议在呃十二之后的这种手机设备,因为这样的话你的设备会运行的比较流畅,如果是之前的话,跑起来可能会, 嗯,比较的卡顿啊。这是一个离线端侧的模型,所谓的端侧就是它的号的算力,就是用的是你本地的这种算力,可以看到这里有个那个呃 c p u 对 吧? c p u 是 吧? c p u 还有 g p u。 然后这里可以调各种各样的域值,还支持不同的这种参数,那其实整个内内存占用 大小其实也不是很大,就二点五四 gb 吧。然后呃,这是我们这一次呃再介绍的。首先的话可以看到他有目前有四个类型的模型,一二 b, 还有一四 b, 三十一 b 和这个二十六 b, 激活四 b, 那 最好的肯定是这一个,对吧? 这两个字可能会相对来说会好一点。然后我们可以看官网上的一个使用方式啊,挺有意思的,那你可以从这里去安装,你也可以从这个地方提供两个路口去使用这个开的项目。那官方也是哦,现在属于一个哦, ipad 阶段吧,我觉得,呃还有很多功能可能不是很完善,但是作为一个模型来说,他还是挺有意思的,他有兴趣的话可以去尝试一下打开,然后这里是测试哎,去问他问题,然后可以看到他甚至会自动调用 google 的 这种地图,还有算术题啊,然后,呃,图片识别啊,你看他这识别这个图片 啊,还有语音识别,还有就是一些常见的这个模型我觉得,嗯,最大的好处是什么?就是你可以在没有网络情况下去呃做一些呃 就是问题的询问,即使在那种信号很差的地方,你也可以第一时间得到答案啊,还是挺有意思的,大家有兴趣的话可以尝试一下。好了,那这本视频全部看完了,我是小刘,我们下期再见。还多做了个 ppt, 没用到,哈哈哈。嗯,好,我们下期再见。
138程序员晓刘 03:35查看AI文稿AI文稿
03:35查看AI文稿AI文稿内存搞了四根八 g 的, 这个是显卡,联想的幺零六六涡轮卡,他在电脑上安装一个谷歌的这个 ai, 他 叫 jam 四,这是个本地的模型,可以离线跑, 就不需要联网。最开始我也疑惑,你这个 ai 怎么能离线跑呢?跟我们用那个豆包一样,不联网。他怎么回答问题呢?看了下这个文件大小,四点二 g, 五点九 g 的 不同的版本,十七 g, 十九 g, 这个本身是训练好的,各种乱七八糟的数据都存好了, 当然也有代价吃硬件嘛,他这个运转吃你的内存跟显卡,在线型的那种 ai。 gpt 豆包,他的安装文件很小,两百兆,三百兆,他让你问问题之后发给了云端服务器,消耗的是服务器的硬件资源,他运转好了之后再把结果顺着网线给你。反过来 这么一个过程当然有代价, gpt 可能要交钱,这离线模型你不用花钱买,那个什么头盔免费的。这里面四个版本,一二 b, 一 四 b, 还有三幺 b, 他的硬件要求都不一样,这个要求是最低的, 还可以在手机上面跑。搜了一下,主要是吃内存跟显卡,对 cpu 要求不高。我搞了个幺零六零六 g 的 显卡,就跑这个模型,一四 b 的。 到这个网站去下载 lm studio studio studio studio 工作室软件里面叫工具级的意思, lm studio stu d i o 回车第一个就是这个官网,打开好,这个是全英文的,右上角 download, 先给他下载下来, 点这个 download 和 windows 下载五百八十兆了,下载速度五点七兆还行。好,这个下载完了直接安装中文界面的,为所有人安吧。下一步路径我也不改了,直接安装 好,安装完成直接运行英文界面的,点这个 get start, 开始 我 gmail 四模型,不用专门下载,直接就跳出来了。还是一四 b 的, 直接点这个蓝色按钮, dongle 的 gmail 四一四 b 大 小六点三三 g 让它下载就可以了。这个速度还挺快的,可以让它后台下载,直接继续, 把它忘了删掉,不管他直接继续,这就是他的聊天界面。下载进度在这调成中文,点左下角这个小齿轮, app 浪轨迹,默认英语, 选简体中文关掉。啊,已经变成中文了。这下载速度一秒两兆多。还行,刚才那个界面没有这个模型的话,你可以直接搜这个小人头,点一下 搜索模型,加满四一 b, 一 二 b 都有看下载按钮不就在这吗? completed 下载完成。怎么加载?很简单,点一下这个播放按钮, load model 加载模型,这不就出来了,测一下这个识图功能怎么样啊? 这个 d 轮的话也是完成 paste 粘贴。这是啥发送?这在思考好,结果出来了, pet 聚酯纤维,没问题,没毛病。
2586树叶科技 05:28查看AI文稿AI文稿
05:28查看AI文稿AI文稿公主,你现在看到的就是谷歌最强的开源模型加码四,可以看图,能听音频,也有不错的推理机制,最重要的是完全免费,给我几分钟,从零开始,将加码四部署在自己的电脑上。我们直接开始 先花一分钟和大家聊一下贾马四是什么?它是谷歌刚发布的开源 ai 模型,跟商业版的怎么奈同根同源,你可以理解为谷歌把自家最强的 ai 技术浓缩成了一个免费的版本,直接送给你用。 那么它好在哪里呢?三个点。第一,多模态,不只是聊天机器人,你可以发图片让他看,发音频给他听,还能写代码。 我们可以看看这张表格,横轴是模型的参数体量,而纵轴就是性能表现。贾马四以满血版的性能表现和千万的三百九十七 b 的 模型能力基本持平,关键在于它的体量只有千万的十分之一,这真的非常夸张。 第二,完全免费,不用充会员,不按 token 收费,并且可以商用,你可以模改它做成各种有意思的本地模型,拿去做产品也没有任何的问题。第三,隐私安全,因为跑在你自己的电脑上,所有的数据都不会出,你的电脑拿它处理合同,财务,私人物件,不用去担心泄露。 ok, 我 们直接动手。你现在只需要打开一个浏览器,然后把它放到全屏上,直接官网上搜索欧拉玛点 com 啊,然后这个东西就出来了。然后你只要点击整个画面的一个右上角 download, 看到没有?然后你可以选择你是 mac os 系统还是 linux 还是 windows, 我是 mac os, 那 你就直接点击这个 download from mac os, 然后我们就可以看到这个画面上的右上角应该是会有个下载的链接, 然后等它下载好就可以了,因为我这边其实已经安装好了吗?那么我这边的最终的一个输出效果的话,大概是在这里。你们下载完了之后,打开你们的桌面上的欧拉玛,你们看到的应该是现在这样子的一个画面,那就说明你已经安装成功。 佳马仕一共有四个版本,你可以根据你的电脑配置进行模型的选择,模型的能力越强,所需要的配置就越高。对于内存小于三十二 g 的 玩家,我建议大家直接安装一四 b, 三十二 g 及其以上,可以试试看二十六 b 和三十一 b 的 参数量, 其实这两者模型的能力大通小异,如果你是为了极致的精度,可以选择三十一 b, 但是在我看来,二十六 b 呢,其实是一个非常甜点的位置,达到了速度和精度的一个平衡。如果你不知道你的电脑内存是多少,这里针对 mac 用户,你可以选择终端输入这行命令。 而 windows 用户你可以点击 win 加 r, 点击回车,召唤出来你的终端以后,然后再输入这个命令,也可以显示出你的内存。选择好对应的模型,我们只需要打开终端,和刚刚一样的步骤,根据模型输入指令直接回车即可。等待模型下载好,打开你的 oala, 选择模型就可以开始了。 ok, 我 们打开我们欧曼的软件,你点击这里,然后往下滑,你就可以看到你刚刚已经安装好的这个佳马仕。我们来问他一个很有逻,就是说很有那个逻辑陷阱的一个问题,就是我今天要去洗车,但是只有一百米,你觉得我是走路去还是开车去? ok, 我 们来看一下他的一个答复是怎么样子。 这是一个非常有意思的一个逻辑陷阱题,我们可以从不同的维度去分析。逻辑层面上来说,必须开车去, ok, 这一点已经很棒了啊。 那如果说是从脑筋急转弯角度上来说,他说如果你走路去,那么你是在散步,而不是在洗车。哦,也就是说他分为了三个维度,一个是脑筋急转弯,一个是实用主义层面,还有个就是逻辑层面。我们来看一下他这个佳马仕的这个逻辑能力。哎,你还真别说这小参数,但他的表现还是不错的。 那么 jamas 它的一个很大的优点就在于它其实是支持这个多模态的。我们来不妨给他上传张图片,我们来看一下。 ok, 那 么我们上传一张什么图片呢?哎,上传张这个图片,你们看怎么样啊?就是这是一朵花,然后有个太阳,有一本书,我们来让他看看。我说,啊,描述一下, 描述一下这个图片,我们来看看他的多模态识别能力怎么样?说实话,本地具有多模态识别能力的模型,而且是能够你自己去模改的,其实并不是很多。我们来看一下。 ok, 一, jeff 二,然后 jeff 三,给了几个他看到的一些画面。好,我看他现在在思考和输出。这张画面充满了诗意,唯美且带一丝忧伤。 画面主体是一本翻开的书籍。哎,确实是对的,背景与中景是一个画面,然后呢,躺着一只洁白的玫瑰,然后背景是有一个夕阳,散发出这个温暖的金橙色光芒,哎呦,很不错,你们发现没有,是不是很棒?就是说他好像 表达的还是很到位的,但是因为呃,我其实本来还是想测一下这个关于音频识别和这个视频识别的,因为这个佳马仕它也是支持视频识别的, 但是因为欧拉玛官方不太支持,所以大家可以自己去谷歌 as do do 上面去玩一玩。所以总的来说,其实通过这么两个比较简单的测试,它当然不够严谨,而我觉得感受来说的话,这个香奈儿丝还是 真的是能够在本地帮我们处理一些比较复杂的一些任务的,就是在文字层面以及去多模态识别能力上来说,是一个比较抗打的模型。 看到这里相信你一定会明白, olama 本身是一个模型管理器,你当然也可以不用贾马四,你可以选择开源的 deep stick, 千问等等,其他的开源模型还是同样的命令,一键配置就可以了。 本地捕鼠的最大优点就是保护你的隐私,模型的使用不会受到任何的限制,同时也可以支持模型的微调,让它更合你的口味。下期我打算教大家小白如何从零到一,微调自己的本地模型,感兴趣的可以点个关注,我们下期再见。
8154赵逍遥Xavier 04:07查看AI文稿AI文稿
04:07查看AI文稿AI文稿谷歌刚发布了王炸级别的开源大模型 g m 四,本视频将为你带来详细的评测。本次的 g m 四最大的杀手锏是彻底转向了 ipad 二点零纯开源协议,这意味着他终于解除了之前的法务紧箍咒,开发者可以闭眼商用。虽然三十一 d 模型在 reno ai 榜单上拿到了开源第三, 但回归到真实场景,它的表现其实是一把极其锋利的双刃剑,评价非常两极分化。首先看旗舰级的三十一 bance 模型,它的编程能力非常惊艳,实测写 html 界面,排版精美,在 levelbench 拿到了百分之八十的高分,达到了专业程序员的指令水平。 而且它的 token 效率极高,平均消耗只有 coin 三点五的百分之六十五,非常适合需要反复调用、在意成本的本地 agent 工作流。 但它的偏科非常严重,数学精度不足,简单的运算经常出错,尤其是在处理信息密度大的长文本时,很容易产生幻觉,而且在开启慢思考模式后,偶尔会陷入死循环,无法跳出。接下来是性价比极高的二十六 b m o e 模型, 这款模型是本地二十四 g 显存用户的福音,虽然总参数有二十五点二 b, 但推理时仅激活三点八 b 参数,这意味着你只需要十六到十八 g b 的 显存就能跑起四 b 的 量化版,而且速度极快,实测能达到每秒六十个 token, 非常适合那些需要塞入臃肿系统提示词的 a 帧子应用。不过这款模型的评价极其割裂,虽然有人觉得它实用,但也有开发者直言它在中文写作和逻辑推理上,灌水严重, 被戏称为数字干水制造器。最后是端侧的小杯模型 e 四 b 和 e 二 b。 它最大的亮点在于原声支持最高三十秒的音频输入,这意味着你不需要外挂 s r 语音转文字模型,英文转写效果几乎完美,是做本地语音助手的绝佳选择。但它的视觉能力简直是灾难, 面对简单的发票截图或手机截图,文字提取错漏百出,甚至连最简单的网页自动化操作第一步都会报错。在视觉理解这个维度上,它被 q n 三点五的九 b 模型按在地上摩擦。 那么在实际选择时,如果你需要构建本地的高频 agent 循环照用,且对 token 预算和响应延迟要求极高,那么二十六 b m o e 是 首选。 如果你想打造纯离线的语音交互设备,直接用 e 四 b 即可。当然,如果你最看重的是开源协议,需要变商用 jamas 的 pitch 二点零协议就是最大的优势。 相反,如果你需要一个强悍且稳定的综合小尺寸模型, q n 三点五的九 b 版本在综合能力上是碾压 e 四 b 的。 另外,如果你依赖高精度的数学计算 o c r 文字识别,并且要求极低的幻觉率,或者需要一个更成熟的生态和丰富的尺寸矩阵,那么 canon 三点五会是更稳妥的选择。在底层架构上,简码四引入了两项黑科技, 第一是 pl e 逐层嵌入,这是小模型专享的,它不再把所有信息在初识阶段一次性打包,而是在每一层都生成专属信号, 本质上是用额外的算力换取存储空间,增强表达力。第二是混合注意力机制,它采用了五层滑动窗口和一层全局注意力交替的结构,配合双 o p e 配置,直接将上下文处理能力拉升到了二五六 k。 针对硬件部署,这里给一套基于 ansel 和 m c p p 的 建议。如果你只有八 gb 显存,勉强能跑 e 二 b 或 e 四 b, 但只能做简单的摘药或语音识别,千万不要尝试复杂的视觉理解或长代码分析。二到十六 gb 显存是 e 四 b 的 舒适区, 也可以尝试二十六 b m o e 的 重读量化版。而如果你拥有二十四 g b 显存,强烈推荐跑二十六 b a 四 b m o e, 这是目前最有限势意义的型号,能同时兼顾二五六 k 的 长上下文和高效的吞吐量。 最后,分享两个长文本推理的闭坑技巧。如果你在进行存文字的长上下文推理,建议在辣妈 c p p 中直接关闭微震视觉功能,这样可以节约大量显存。 另外,面对复杂任务时,可以通过 a p i 动态调整 thinking budget, 也就是思考预算,防止模型陷入无限思考的死循环,导致机器直接卡死。
95AI技能研究社 01:18查看AI文稿AI文稿
01:18查看AI文稿AI文稿大家好,今天来给大家实测一下,把 jam 四部署到手机上,到底能实现些什么?视频内容有点多,感兴趣的可以慢慢看完。首先是 ai 聊天,我先把手机切到飞行模式,全程离线使用,可以看到我问他能做什么,他回复的很流畅,反应速度也很快,注意回复这里我全程无加速。 然后是图片识别功能,我随手拍一张照片,问他看到了什么,他能很精准的识别出画面里的细节,解析的特别清楚。还有这个手机指令控制,我直接语音说在地图里找到北京,他立刻就能理解我的意思,自动打开地图应用。虽然现在没网加载不出来, 但整个指令识别和调用应用的过程都是在本地完成的,体验很惊艳。唯一不足的是他听不懂中文,只能英文沟通。还有这个小花园互动游戏, 我说在八号坑种植物,它就能听懂并执行操作说明模型,对自然语言的理解和交互能力都很强。这里依旧听不懂中文,只能英文沟通。最后是提示词工具箱,不管是改写文案、总结文本,还是写代码, 离线状态下都能直接生成,非常方便。整体体验下来, jam 四把 ai 能力真正做到了手机端本地化,不用联网,隐私性更好,功能也足够实用,未来手机端 ai 的 体验真的会越来越强。
3110用AI抄近道的小呆 09:55查看AI文稿AI文稿
09:55查看AI文稿AI文稿谷歌终于坐不住了,正式卷开源市场, jm 四的效果到底如何呢? jm 四的发布啊,真的有可能让我们实现头很自由。这期视频呢,老张给大家简要介绍一下 jm 四怎么安装到本地,以及如何搭配到我们的 open klo 大 龙虾上, 附带所有的安装步骤啊,大家可以一起来体验一下。后续呢,老张也会根据测评效果给大家接着发视频,这期是我们完整的部署流程,老张重点给大家简单聊一下,就是为什么 jm 四的发布啊,会让大家感觉谷歌真的开始卷起来了呢? 首先第一点,他和目前谷歌的 jimmy 三用的是相同的技术基座啊,所以说他的能力是毋庸置疑的。第二点就是商业自由,你直接部署下来做什么都是可以的,都是允许的。然后第三个就是支持多模态,无论是文本、图像甚至小规模的视频音频, 他都可以直接支持。第四点就是结合前段时间爆火的 open klo, 他 可以直接在本地对接 open klo 以及对接 klo 的 code, 实现本地的偷根无线化。这是老张给大家总结的四点,为什么詹姆斯的发布会让大家感觉,哎,可能真的要进入到一个新的纪元, 然后呢,他所发布的这四款模型呢?老张给大家做了一张图片啊,大家可以到时候把它截下来。第一个模型一二 b 的, 他本身是用于手机或者边缘设备八 g 显存, 然后最高端的三十一 b, 他 所对应的旗舰版本呢,是对应的是二十四 g 加,所以大家根据你的需求来进行对应的模型选择。老张这次视频呢给大家来看一下三十一 b 的 这款模型的安装, 然后关于本地的安装部署啊,其实非常简单,任何开源模型,其实我们只需要让他和欧拉玛就是那个小羊驼结合到一起就可以了,然后找到你符合要求的版本。安装成功之后啊,欧拉玛现在已经有了一个完整的应用端了,所以大家可以直接在这个位置和他进行对话交流。 那我们想要下载 jm 四到你本地的电脑上,我们可以使用它的官方指令,会告诉我们直接怎么样去进行 jm 四的对应安装,像老张想安这个三十一 b 的 对吧?我们就把它拿过来, 把它直接这有一个 c l i 命令行安装方式,把这个东西直接复制在你的开始菜单中,单机右键选择运行输入 cmd, 直接把刚才指令粘贴过来,这儿的时间会很长,因为它有二十个 g 的 大小,我们直接稍作等待 安装成功之后,我们也可以直接回到它的客户端中,在模型选项上找到我们安装好的詹姆斯冒号三十一币, 然后可以直接进行对话。老张他处理一个较为复杂的提示词,我们让他看一下当前显存的内存消耗, 咱们拿这个 ai 慢距的提示词来测试啊,这个提示词非常的长,我们看一下他读取提示词的能力,以及他的这个显卡的性能消耗,我们看一下啊,这个显存直接拉满的,达到了百分之九十四的占比, 而且这个响应速度还是非常快的,只需十一点七秒啊,就把整体的业务流程给我们直接补齐了,而且呢按照需求给我们进行了对应的提问,要什么样的慢距效果,所以说以目前的测试反应来看呢,他的这个响应速度起码要比之前的很多大模型要好的多, 所以接下来我们自己来尝试一下对话类的工具,可能大家都不是很需要的,我们能不能把它接入到我们的 open clone, 丢到我们的龙虾里,让它们俩来进行联动的。然后这期视频呢,老张顺便给大家提一下,就是最新版的 open clone 的 部署流程 啊,咱们可以快速的去过一下一些重点的细节,因为之前老张发过很多期的部署视频一块的呢,因为它本身啊, wsl 它是相当于在 windows 系统上安装一个 linux 的 独立系统, 这样的话呢,就直接相当于在你电脑上安装了一个独立的存储空间,它所谓叫做沙盒安全,而且运行起来呢是不会有任何的兼容性的对应问题的,因为 windows 中啊,它的权限呐,路径等经常会报错。所以说我们这 期视频重点教大家怎么用 wsl 进行 win opencl 的 部署安装,这样的话, windows 和 wsl 的 安装您都了解之后之后学起来就非常方便了。 然后接下来呢,老张给大家简单的介绍一下在 wsl 中如何安装我们的 openclaw, 因为之前呢,咱们介绍过太多次了,很多兄弟留言说老张就别介绍怎么安装了,然后我们就给大家简单说一下注意事 项。首先第一呢,你想在 wsl 上安装 openclaw 的 话,第一点你得先在你的 windows 系统下把 wsl 安装一下,当然很多电脑老张发现其实都是自带的, 怎么检查是否自带呢?咱们可以直接输入 wsl 空格杠杠威森,如果弹出定的版本号,证明 wsl 电脑已经安装了,如果没有弹出的话,使用安装指令 wsl 空格 insert 直接安装即可。然后紧接着按照老张给你提供的指令复制粘贴就可以了。先安装你的优班图, 安装之后进行一下更新。安装完优班图之后啊,在这选择这个倒三角,找到优班图系统,就可以直接进入到你的优班图系统当中。 在你安装过程中啊,它会让你设置一个用户名和密码,到时候可能需要做一步密码验证。在优班图系统中,注意是优班图系统中运行这些环境指令,分别安装 python 三,安装一个压缩包工具,方便安装一个 node 点 ps, 然后再安装一个 get 工具。 如果说为了检测每一步安装是否成功的话,你可以分别输入,比如 note 杠 v、 npm 杠 v, 包括 get 杠 v, 在 这检测我们对应的这个版本。如果都能弹出版本号,证明你三项安装都是成功的,这是配置 openclo 的 基本的内容要求。 然后紧接着我们把基本环境配置好的兄弟,你还需要在这个位置安装一下这个欧拉玛。 这老张要重点说一下,说老张我不在本地都已经下载好欧拉玛了吗?为什么在优班图里还需要再配置一下?其实我们优班图中是可以调用本地的欧拉玛的,但是很多兄弟在调用过程中分别给老张留言说说调用时无论是 ip 地址找不到,还是 ip 的 动态变化,导致每次都需要重新连接,重新配置。 所以说最简单的方式就是把欧拉玛在你的优班图系统中再次的安装一遍。其实安装非常简单,只需要把第一步的安装指令复制过去,直接在这个位置直接粘贴即可。安装成功的检测方式很简单,你就输入欧拉玛, 如果他不报错还给我们对应的选项,是咱们是进行对话呀,还是怎么样的证明你的安装就是成功的? ctrl c 直接退出。 所以说欧拉玛安装之后,紧接着就是把我们的模型在当前的优班图中跑起来。老张刚才给大家测试的是 jm 四三十一 b 模型,我们直接输入指令欧拉玛空格 run, 然后你的模型效果直接回车,第一次时他会直接进行对应的模型下载。如果说你现在只想用 open klo 来调用欧拉玛的这个占四的话,可以在我们的本地电脑上把之前咱们那个桌面端给他 删掉,如果说你不你想两端都使用的话,就可以直接在这个位置进行使用了,然后发一个你好看一下响应速度, 嗯,响应速度是非常快的,所以接下来我们把这个家伙欧拉玛的詹姆士直接部署给我们的 openclo, 在 这怎么中止对话,摁一下 ctrl c, 再摁一下 ctrl d 啊,就可以直接进行中止对话了啊,所以说大家可以直接的把它退出来, 退出来之后我们在这儿部署一下 openclo。 关于 openclo 的 安装呢,官网推荐是使用 c o r l 这种安装方法,但是老张发现很多兄弟在使用这种安装方式时呢, 出现了这个网络问题,导致下载出现卡顿,如果说 c u i l 的 方法报错的话,直接使用 n p m 安装也是完全可以的,安装完之后直接输入 open klo 空格杠 v 来输出最新的 open klo 的 对应版本啊,这就是老张跟大家说的一些建议啊,大家按照这个要求去做就行了。 然后接下来我们进入到配置,直接是直接输入它的配置指令回车,选择 yes, 然后选择快速开始就可以,我们直接配置一下模型, 然后选择更新,这选择谁呢?选择这个欧拉玛啊,然后选择默认的这个 ul, 选择本地模型,让他去给我找一下咱们本地有哪些模型,稍作等待 好,选择当前的这个模型,咱们四三十一币,然后配置我们的聊天软件啊,这个老张之前讲过太多太多次了,现在呢,他又支持了很多,包括 qq 之类的,大家有需要的话可以按照之前老张的教程再来一遍,我们先跳过 打开之后啊,就可以直接对话。但是如果说善于观察的兄弟们也发现了,老张呢把这个使用模型呢换成了这个一四 b 的 模型,不是那个三十一 b 的, 因为三十一 b 呢,老张在测试的时候也好,或者在一些使用时候也好,他有的时候会出现这个连接超时的问题,也是 oppo klo 更新到最新版本出现了一个能启动问题, 这个呢,老张现在还没有特别好的解决方案,所以说我先用一次必得给大家进行演示,发一个,你好,我们来测试一下他的响应速度啊,还是比较快的。 然后接下来呢,我们再把之前的那个慢句的提示词发送过来,我们来看一下他能不能更好的帮我们去进行慢句提示词的对应理解,以及对应的相关反馈。 嗯,其实我们看到啊,他反馈的这个结果呢,和三十一 b 相比啊,真的是有一定差距的,但是呢,确实也是另一方面实现了我们所谓的叫偷根自由。 大家呢也可以后续啊,去测试一下怎么让本地如果你的显卡够用的话,把这个大模型给它跑起来。然后老张呢也会及时给大家更新,无论是在评论区中还是视频中教大家如何使用。我是程学老张,定期分享 ai 好 用知识,希望大家多多关注。
4464程序员老张(AI教学) 05:30查看AI文稿AI文稿
05:30查看AI文稿AI文稿上周,谷歌做了一件其他大型科技公司都不敢做的事,他们发布了一个大型语言模型,它真正符合自由和开源的标准,采用了阿帕奇二点零许可证,这意味着他拥有完全的自由,不像那些半开放或仅限研究的模型, 比如 stability r i 的 模型对年收入低于一百万美元的开发者有限制。而 met 的 lama 三虽然也开放,但如果你的产品越活跃,用户超过七亿,就需要向 met 申请特殊许可,这给了 met 很 大的控制权。谷歌这次发布的模型叫做 gemma 四, 我最初以为这又是一个半成品,需要一个小型数据中心才能运行。但最令人惊讶的是, gemma 四非常小巧,小得令人难以置信。 最大的模型也足够在消费级 gpu 上运行,而边缘模型甚至能在手机或树莓派上跑起来。更厉害的是,它在智能水平上与那些通常需要数据中心级 gpu 才能运行的开放模型不相上下。这简直不可思议。 那么,谷歌是如何实现这种惊人瘦身的呢?答案是,它们不仅缩小了模型,还解决了 ai 领域的真正瓶颈。内存运行大型语言模型时,你需要的不是更强大的 c p u, 而是更大的内存宽带。 每当模型生成一个 token, 它都必须读取大量的模型权重,这些权重存储在 g p u 的 显存中。所以模型的大小并不重要,关键在于读取这些数据的成本。 为此,谷歌悄悄发布了一篇关于 toboquat 的 论文。这听起来像个营销词,但实际上非常厉害。它是一种新的量化方法, 通过将数据从迪卡尔坐标转换为极坐标,并利用约翰逊林登斯特劳斯变换来压缩高维数据,从而更有效地存储信息,减少内存开销。 通常通过这种量化过程,你会得到一个简单的权衡,模型文件更小,但性能会下降。但 jam 四的三幺零 e 参数版本在性能上与 kimi k 二点五等模型不相上下。 而最荒谬的是,我可以在我的 rtx 四零九零上本地运行 jam 四,下载量仅二十 gb, 每秒能生成大约十个 token。 相比之下,如果我想运行 kimi k 二点五,我需要下载六百多 gb, 至少二百五十六 gb 的 内存进行激进的量化,还需要多块 h 一 百 gpu 才能启动。所以,显而易见的问题是,谷歌是如何实现这种令人难以置信的瘦身的? 答案是,它们不只是缩小了模型,它们解决了 ai 的 真正瓶颈。内存要在本地运行一个大型语言模型,你不需要更好的 cpu, 你 需要更多的内存宽带。 每次模型生成一个 token, 它都必须读取显存中大量的模型权重,也就是你 gpu 上的视频随机存取内存。 模型有多大并不重要,更重要的是读取它的成本有多高。这就是有趣的地方,因为除了 jam 四,谷歌还悄悄发布了一篇关于 turboquat 的 研究报告。这听起来像个营销术语,但实际上相当疯狂。 它是一种新的量化方法,通过压缩模型权重来减少占用空间。通常通过这个过程,你会得到一个简单的权衡,文件更小,但模型更笨。但 turbo quant 通过两个步骤改进了这种权衡。首先,它将通常在 x y z 迪卡尔坐标系中的数据压缩成包含半径和角度的极坐标, 因为这些角度遵循可预测的模式。模型可以跳过典型的归一化步骤,更有效地存储信息,从而减少内存开销。 然后,他使用一种叫做约翰逊林登斯特劳斯变换的数学技术,通过将其压缩成单个符号位正一负一来缩小高维数据,同时保持这些数据点之间的距离。坦白说,我太笨了,无法理解数学是如何运作的。 但 turbocharger 呢?实际上并不是。 jam 四小型模型背后的秘密你会注意到一些 jam 四模型名称中带有 e, 比如 e 二 b 和 e 四 b, 这代表的是有效参数,因为这些模型采用了分层嵌入技术,这就像给神经网络中的每一层都提供了一个针对每个 token 的 迷你备忘录。 在正常的 transform 模型中,每个 token 在 开始时只有一个嵌入模型,必须将这些信息贯穿所有层,而大部分信息是不需要的。分层嵌入改变了这一点,它为每一层提供了自己定制的 token 小 版本,这样信息就可以在需要时精确地引入,而不是一次性全部加载。 martin grotendorf 有 一篇非常棒的视觉指南,我会在描述中附上链接。如果你想深入了解更多细节,最终结果就是一个小巧、智能且高效的模型。 我正在我的 r t x 四零九零上用欧拉玛运行它。我的初步印象是,它是一个全面的优秀模型,它也是一个很好的模型,可以用昂斯洛斯等工具对你自己的数据进行微调。但如果你是一名程序员,它仍然不足以取代任何高端编码工具。比如今天的视频赞助商 code rabbit, 他 们刚刚发布了一个 c r i 更新,可以让你的代理审查他编辑的所有代码,然后准确地告诉他如何修复任何错误。 你可以通过新的 agent 标志起用此功能,它将扣的 rabbit 变成你的代理可以直接调用的工具。从那时起,它会给你的代理提供结构化的 jason, 其中包含所有问题以及如何修复它们的说明。这样你的代理就可以回去清理所有东西,然后再打开一个拉取请求。 它们还简化了设置过程,并取消了速率限制。所以你可以通过一个简单的终端命令开始,并根据你的代理需求运行任意数量的审查。今天就免费试用 coder rabbit, 使用 coder rabbit os login 命令,并且可以在任何开源项目上永久免费使用。这里是 coder report, 感谢观看,我们下期再见!关注全球 ai 速递,获取更多 ai 前沿资讯!
24全球AI速递 02:26查看AI文稿AI文稿
02:26查看AI文稿AI文稿先说个反直觉的,以前挑模型大家像挑冰箱,越大越好,双开门五百升能装一头牛。现在摘码四出来,感觉像有人默默递给你一个保温饭盒,看着不大,打开一看, 三菜一汤还带保温,关键刚好塞进你包里。三 e b 的 模型跑在你能买到的显卡上,效果跟那些参数巨兽掰手腕还不虚。这不是小布块 好,这是直接换了赛道。不比谁块头大,比谁脑子转得巧。边缘端那俩小鸽子才是真狠角色。 e 二 b 和 e 四 b 名字听着像手机型号,干的事儿可一点都不清亮。你想啊, 以前手机跑 ai, 要么卡成 ppt, 要么偷偷联网传数据,现在这俩小模型离线低,延迟还能听能看,你拍张菜单,他直接帮你算卡路里加翻译加推荐搭配,全程不用等云回复,这感觉像什么? 向你随身带了个懂行的朋友,而不是一个需要打电话问总部的客服隐私这事终于不用靠我们相信你来保证了,而是靠数据根本出不去来,兜底看原许可证,别只看表面啊 pi 七二点零,听着像法律条文,其实就一句话, 你拿去用,改了还能卖,我不收过路费。但有意思的是, google 这次不是施舍,是搭台。 hiking face 首日上线,奥拉玛拉玛 c p p 这些社区神器全支持,甚至你的游戏本都能 fine tune, 这像什么 像?有人不仅开了个免费厨房,还把菜谱、锅碗瓢盆甚至火控系统都给你配齐了。最后说一句,菜做好了,记得数名就行,但咱也泼点冷水。工具越自由,翻车越容易,模型微调歪了,输出带偏键,部署出 bug, 这时候责任算谁的?开言的爽往往伴随着没人都抵的引诱。说点你能直接用上的长上下文加多余元,丢给他一篇五十页的用户反馈报告,让他按情绪、地域、问题类型自动归类,还能顺手生成英文摘要。以前得写一堆脚本加掉 api, 现在一个 browns 搞定离线代码助手三、 e b 版本能在本地跑,你写运营自动化脚本时,让他帮你看逻辑,补函数,查 bug, 敏感数据不用出本地安心。 e 四 b 加音频加视觉。想象一下用户拍张英语笔记的照片与英文 这句话怎么读?模型直接识别文字加标注,发音加生成类似句型练习全程离线延迟几乎为零,这不就是你想要的故事加插图加句型学习流的自动化版本?
86JUN 06:46查看AI文稿AI文稿
06:46查看AI文稿AI文稿整个恢复的速度相当的快,这是在手机上,而且大家看现在完全的没有联网。哈喽,大家好,那今天跟大家分享一下,基本上可以说是 iphone 上面最强大的免费本地 ai, 完全不需要联网,搭载的是 game 四啊,非常的强大, 大概就这个软件啊。 edge gallery 点开之后点击这边,我们可以选择我们的 model 子啊,这边有非常多的什么 jimmy 三呐, jimmy 四, jimmy 四是 google 推出的啊,给迷迷同样也是 google 推出的, 但是他不想给咪咪,给咪咪那是付费的,这个是完全的免费的,这里面我是下载了一二 b, 一 二 b 它是二十亿参数,一四 b 是 四十亿参数。那真马四相比于过去的真马三,主要有这么几个特点啊,首先第一个就是它整个脑细胞啊,整个容量会更加的高 啊,就是模型架构进行了一个非常大的优化。苹不是苹果啊, google 通过非常高效的蒸馏技术 distillation, 可以 让四十亿参数,就这个一四二 b 啊,可以达到过去一百亿二百亿模型那 这种水平,所以它整体智商就更加的高了,但是它占用的内存却没有变,所以它就可以让我们使用这个 iphone 十七 pro max 这种十二个 gb 内存的手机,也可以非常流畅的使用,而且它现在是支持了多模态原生支持,就是它可以理解我们拍摄的图片,逻辑和语言都是同步 的,识别精度跟上一代比啊,提高了大概百分之四十,而且它整个记忆力也增长了,整个智商更加的高了。过去我们在使用手机端的模型的时候,哔哔几句,他就忘了前面哔哔啥了,所以这个是一个非常大的痛点,但是这次 jam 四它每秒可以达到一百二十八个头肯, 所以我们把一整页的,比如说五百页的这种 pdf 啊,这种文章丢不进去,它也可以在几秒内看完,然后回答我们。再有一个就是 iphone 上为什么使用它会更加的好用,就是因为 iphone 它独特的架构就是 m r x, 反正就是统一内存啊,什么 cpu, gpu 啊,这几个都是统一使用内 存,所以在这个 a 十九 pro 里面使用这个加速单元,再配合上 g 八四,整个发热更低,跑得更加的快。那 所以我们简单的给大家演示一下啊,首先这个 ai chat 啊,这个是完全在本地的,所以我们现在打开飞行模式,关闭蓝牙,关闭 wifi, 都是可以正常的使用的。 这边有什么 e 二 b 啊,它有一个 best overall 最推荐使用的这个啊,我们试一下这个 e 二 b 就 可以整个大小容量也就是二点五四个 cb, 然后 ch 你 是谁? 马上就回复了,我是战马四,一个由 google dmind 开发的开放群众的大型语言模型,你有没有意识,整个回复的速度相当的快,这是在手机上,而且大家看现在完全的没有联网飞行模式,所以我们在飞机上在 处理这种文档,我突然有一个呃,突发奇想,想要咨询的时候,就我们直接在手机上跟它逼逼就可以,它就会给我们一个非常不错的答案啊,整个推理模型也相当不错。然后我们在这边点击这个之后,我们可以选择 max token 啊,我们可以进行选择 topk, 说实话,这个我也不知道它是啥意思啊,哈哈,然后我们点击 ok, 我 们可以再问一下啊,根据哥德尔不完美的系统,它都是有一个缺陷的,那么宇宙它作为一个系统, 他为了解决内部的这种无法解决的矛盾,所以他创造了生命,他看本地啊,在本地这么深刻的问题,他触觉了哲学系统论,生命起源,噼里啪啦, 哎呀,生存压力,适应性创造的本质有很多,在本地这个速度我个人感觉已经非常的够用了,还哔哔呢。 ok, 他 最后来了一个总结,一个看似完美的系统, 其内在的动态张力矛盾是其演化的燃料,生命正是这种内在张力的一种具象化和解决机制。他不是为了追求绝对的完美,而是为了在既定的有缺陷的宇宙框架内,实现一种动态的,有目的的存在。人生的哲理根本就是存在,扎斯的存在就是他们 关于这个歌德尔的不晚辈定律啊啊,我再找一期视频单独跟大家分享一下啊,今天我们就先跳过,总之我们在这边可以跟他比一遍,然后点击加号,之后我们看,我们可以看他的 history, 然后点击这边右上角的小加号,我们可以创建一个新的聊天,这个都是可以, 然后我们后退,后退之后这个是 ai chat, 唯一比较不满的就是它整个功能是比较分离的啊。当我们想要 ask a mage 用图片进行交流的时候,我们必须要到下面这边啊, explore other use cases 有 各种 使用的场景啊, ask a mage, 我 们可以让他啊回答我们拍摄的照片和图片。在这边点击加号之后,我们可以选择 photo library, 选择我们的照片,选择 camera 啊,这都是可以的。 我选择 camera 拍一个,呃, use photo, 然后我让他逼逼。这个是什么?有哪些特点啊?这个失误了。哎,这个失误了。这是 playstation port。 差一点啊,等会啊,我们刚才是使用的二 b, 我 们使用四 b 试一下。二 b, 他 可能智商没那么高 啊。使用这个二 b 啊,使用四 b 来试一下。这是什么?有哪些特点?嗯, yes 哦,他把旁边的 major sense 控制特点,触觉反馈,自适应班级, l two, r two 可以 根据游戏内的动作提供不同的阻力。 啊,噼里啪啦,还有例子呢啊,荔枝麦克风和扬声器设计和人体工程学啊,这些都有了。 ok, 这是什么花哦?金樽花,万寿菊。我们再换一个,让他翻译一下,翻译成中文,重新打开飞行模式, wifi 关闭。大概 它同样可以在本地完全免费的进行翻译,相当不错。所以我们在飞机上啊,都可以用注意力焦点, attention, focus, injection, 汇聚所需信息的过程。第一段,第二段它都会进行一个分段,第四段,第五段原文都有此处文字被遮挡,这种细节 相当不错。 very good。 然后这里面呢,还有一些比较简单的,什么 ask, 你 major 啊,什么 audio square, 但是没有特别大的鸟,用什么 prompt lab 啊, tiny garden, 这是一个小的游戏 mobile actions 啊,它可以用这个小的模型来操纵我们的电脑啊,不,是操纵我们的手机,比如说, turn on flashlight, 可以打开我们的闪光灯, turn off, create contact, send, email 这些,但是我用了一下,不是特别的好用,实际来讲比较好用的可能是这个 agent skills, 在 这边我们选择四 b 的 模型,什么 generate, q r code 呀,粘贴进来之后生成 q r 码, loading skill, 它是可以使用我们的 agent skill 的, 我们可以让它生成一个 q r 码完全离线的状态。另外这边啊,还有其他的什么 interact, map 啊 这些用起来感觉就那样啊。然后这个比较有趣, text spinner, 它需要一个访问的权限,大概是这样的一个效果,我们可以更改它的文字啊, spin 使用中文给它相机权限。呃呃,任何文字都可以,就这种效果,虽然没什么鸟用,但是 还挺有意思啊,就是这样的一个为的。这个呢,就是 google ai h 格兰瑞,我们可以使用 google 最新推出的振马四,高效的二 b, 高效的四 b, 我 们都可以在这边使用。但是这个软件呢,说实话,目前它整个 bug 还是有一点多啊,就是用的时候卡住的情况是,呃,挺多的,挺平板的。对大家有兴趣的话啊,想要免费使用的话,可以试一下,再等一下它们的更新吧。 啊,可能我现在是使用的艾弗莎士六点五 bug 版本,所以它整个匹配度不是特别的好啊,大家可以试一下。
2239大耳朵TV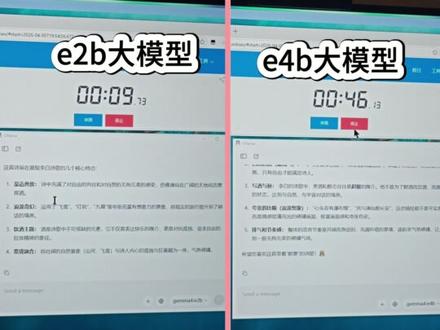 01:30查看AI文稿AI文稿
01:30查看AI文稿AI文稿兄弟们,欧拉玛已经更新好了,杰玛斯的大模型也不朽完成了,一共四个模型,接下来挨个测试一下,所有的测试都是在这个电脑配置下完成的。第一个问题,介绍一下自己, 第二个问题,用李白的风格写一首 诗。 最后一个问题,经典的喜鹊问题 总结一下,四个模型都测了,最快的是一二 b, 最慢的是三十一 b, 四个模型第一次启动都有点慢,后续速度都还可以。 总的来说,回答质量最好的是三十一 b, 包括最后的一个洗车逻辑陷阱也自动识别出来了, 就是我这个配置运行起来实在是太慢太慢了,所以性价比最高的应该是这个二十六 b 模型。回答速度,回答质量都还可以,可以用在部署小龙虾,用来做个人的 a 键,挺好用的。后续再和千万三点五做个横向对比,记得点个关注。
365集集集集盒🌈


猜你喜欢
最新视频
- 1860现在是老谢了