pitstop脚本如何安装

粉丝118获赞1610
相关视频
 01:11查看AI文稿AI文稿
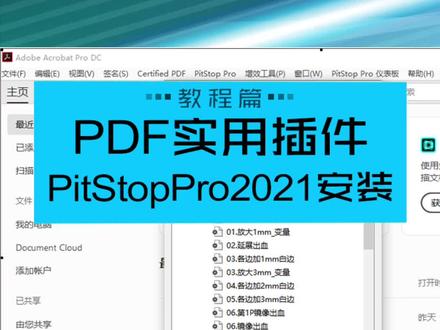
01:11查看AI文稿AI文稿以前用的十点零到十三点零版本的 pick stop 加载自动加出血等其他命令使用不了。今天带来新版二零二一版本插件的安装方法,下载解压好安装包,如需安装包可私信安装前退出三六零电脑管家等杀毒软件。然后鼠标右击, set up e x e 管理员身份运行安装,安装步骤就一直点下一步即可,然后等待安装完成安装。等软件安装好了后,将安装包里面的 crack 文件夹里面的 pit stop pro d l l 文件复制,鼠标右击桌面的 p d f 图标,点打开文件位置找, 找到里面的 plugins 文件夹,打开,再打开里面的 infocus 文件夹,最后再打开里面的 peat stop pro resources 文件夹,粘贴刚刚复制的 peat stop pro d l l 文件 键,点击替换即可。按 ctrl 加 alt 加 g 就可以打开刚刚安装好的插件了。添加好自动命令就可以开始使用了。如果出现了提示需要更新,此事千万不要点, 如果点了更新可能就用不了了,只要点击稍后提醒就可以了。以上就是 pitstop 二零二一的安装教程,希望对你有所帮助。
 01:15查看AI文稿AI文稿
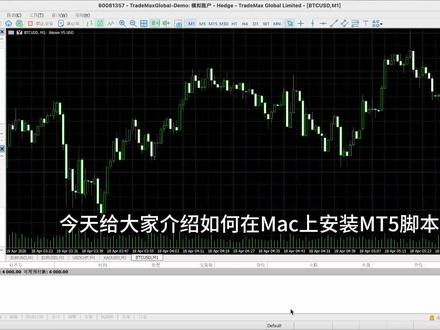
01:15查看AI文稿AI文稿今天给大家介绍如何在 mac 上安装 mt 五脚本,众所周知, mt 五是为 windows 电脑开发的, mac 上实际上是依赖 y 安兼容安装的,那么这就导致我们无法直接使用 mac 的 快捷键。等粘贴进到 mt 五的安装目录,今天主播就教大家如何能够顺利安装脚本。 首先我们点击文件,再点打开数据文件夹,之后点击最下面斜杠的硬盘,如果第一次点击 mac 会提示请求访问权限,我们点击允许即可,这里主包已经用过了,不会再次请求权限。随后点击 users, 找到你的登录名对应的文件夹,然后点击你的脚本储存的位置,这里主播存到了 documents, 在 访打理叫做文稿。点进去后找到你的脚本, 右键复制或者键盘 ctrl 加 c, 注意是 ctrl 而不是 mac 的 command。 然后点开我的电脑 c 盘, program files meta trader five, m q l five, 找到 scripts 粘贴进去即可。这时候我们关闭这个文件选择窗口,就可以在脚本里找到我们的脚本。双击运行脚本,根据脚本说明更改选项。我们这里把允许算法交易勾上,并且到输入里把极速屏仓模式双击改成处,最后再根据你的需要调整脚本就可以了。
341T__MG-_M Max 07:05查看AI文稿AI文稿
07:05查看AI文稿AI文稿大家好,我是山外山,今天我们讲一下 c 加加怎么调用归一插件。 那首先第一步我们要导出内库,打开综合工具,选择帮助文档,在这里找到导出内库,点击 这里可以选择 c 加加一语言, python 和按键精灵,当然其他的没有列出来的,它也是可以调用的, 因为我们插件提供了 dl 还有拍摄模块一语言的内库,那其他语言没有势力,就只能调用 com 接口。我们选择 c 加加导出,在这里选择一个导出的位置,我建议大家选择一个固定的, 固定的位置,每次都导出到这个位置。 那接下来我们创建一个新的工程, 我们就使用一个控制台程序吧,因为 mfc 和 qt 它方法和这个是一样的。选择创建新项目,选择控制台程序, 起个名字叫归一,归一插件入门,点击创建 叉六四程序没有问题,我们这个不用修改,可以给它改成 release 模式。 那接下来我们就要把导出的内裤丢到我们工程里,我们单独给它创建一个文件夹, 选中这三个文件,左键点击拖就行了,拖到这个文件夹里,那现在我们还不能直接使用,如果包含的话,它会提示找不到, 我们右键 在这里找到 vc 加加目录,选择包含目录,给它添加进去, 那现在他就可以了,这是一种方式。还有一种方式呢,我们不添加包含目录,把这三个文件复制到工程里,然后直接直接拖进来就可以用。 但是这样做的缺点是,如果我们有多个工程都使用这个插件,那每一个工程里他都要有这个文件,而且更新插件的时候,这三个内库你还要逐个工程去替换。那这样呢?我们放在固定目录,我们更新一次, 所有工程全部都替换了。那接下来我们看一下怎么去使用它,我们还是创建一个全集变量吧。 呃,单独,我们单独写一个程序, word 类型返回值就加载插件。 首先第一步我们要加载 d l, 我 们做一个判断, 如果它等于假,那我们返回。 else, 这是加载掉登录。 第二, 这里输入我们用户名密码,这个是我的用户名密码,你们登录的时候用我之前发给你们的就可以。 它的返回值是返回剩余点数, 如果它登录成功,它应该返回的剩余点数应该是大于零,所以如果它小于等于零,那就代表失败。 return files, 我 们输出一下吧。 登录失败, 那登录完成之后,我们给它显示一下插件版本号, 在这里我们调用一下 运行,它提示缺少打不开。 p c h, 那 我们双击来到这里,直接把这个删掉就行了。 二六点零四幺幺,这是我们刚才安装的插件版本,它显示插件版本,就代表我们 已经成功调用了插件。那接下来就可以使用插件的所有命令了。那今天视频就到这里,再见。
 07:51查看AI文稿AI文稿
07:51查看AI文稿AI文稿大家好,我是大叔,只说真话,只做实在事,只给干货。大家好,你是不是也遇到过这样的情况,手上只有英特尔显卡,想跑大模型却被告知必须用 nvidia。 但我想告诉你一个真相,英特尔显卡不仅能跑,还能跑得流畅,甚至在某些场景下表现比 nvidia 显卡还要好。别急,今天这个教程就是为你准备的。我先告诉你结论,你的 intel core ultra 处理器加上 openvno 就 能实现高性能本地 ai 推理, 不需要购买昂贵的 nvidia 显卡。这次教程含盖三个核心亮点, c p u g p u n p u 三位一体加速,以验证九款以上模型支持开放 api 接口调用。 咱们直接看内容,你是不是遇到这样的问题,手上只有英特级成显卡或 arc 独显,没有 nvidia gpu 响本地部署大模型,但不知道用什么工具能正常运行,需要开放 api 接口给其他应用调用,但不想花几万块买显卡,想体验 openclock 龙虾助手 hermes zion 的 爱马仕智能体, 担心硬套显卡性能不够,跑不动大模型,使用云服务 a p i 费用高昂,每月几百上千的成本难以承受。如果有以上任何一个问题,请继续往下看,今天这个教程就是为你准备的。解决方案是什么呢? open vino 后端辣妈到 c p p 加上 open vino 等于完美组合, 让 intel cpu、 gpu、 npu 都能流畅运行大模型支持 api 接口开放,轻松集成到你的应用中。它有四个核心优势, one、 intel gpu 加速集成显卡和 arc 独显都能用,无需 nvidia 2 npu 低功耗 core ultra 系列专属 ai 加速器,省电高效。 三、 rest api 开放标准接口如下,应用直接调用四、零额外成本,利用现有硬件,无需购买昂贵显卡。还有一个重要特点,同一份 g g f 模型文件, cpu、 gpu、 npu 无缝切换,无需转换格式,它是如何实现的? 第一,智能图转换,将 g g m l 计算图自动翻译为 open vivo 格式,识别输入输出权重和缓存。第二,翻译后极速运行,首次运行会翻译模型并缓存,后续推理速度提升三到五倍。 第三,算指融合优化,自动合并相邻计算步骤,减少内存访问效率更高。第四,硬件专属优化,针对 cpu、 gpu、 npu 不 同特性,自动选择最佳执行策略。 第五,多种量化精度,支持 q 四、 q 五、 q 六、 q 八等格式,平衡速度与质量显存。第六,设备无缝切换,同一份 g g 二 f 模型文件, cpu、 gpu、 npu 一 键切换,无需转换。简单来说, openwin 就 像一个智能翻译官,把你的大模型翻译成 intel 硬件能听懂的语言, 然后针对你的 cpu、 gpu 或 npu 进行深度优化,让推理速度大幅提升。安装方式有三种可选,根据你的需求选择最适合的方式。第一种,一键脚本,推荐,最简单自动下载翻译配置支持 windows、 mac os、 linux, 如 如果有需要,评论区留言获取脚本。第二种,多客容器很干净,无需配置环境隔离运行不污染系统,适合服务器部署。第三种,手动翻译,很灵活,完全自定义,适合开发者调试。下面详细介绍步骤,手动翻译只需五到十分钟,接下来我们详细讲解手动翻译的三个步骤。 第一步,克隆仓库执行命令, gitcon, 后面跟着开源代码,仓库地址,由于平台限制,完整链接无法显示,需要完整地址请在评论区留言, 然后进入 lama 到 cpp 目录。第二步,编辑 openvino 版本。如果是 linux 系统,先执行 source 命令,加载 openvino 环境变量,然后执行 cmake 命令,指定构建目录和 nintia 生成器,开启 openvino, 支持,最后执行 cmake build 命令,进行并行编译。 如果是 windows 系统,在 exo, 在 native tools command prompt 中执行同样的 cmake 命令,注意路径分幅,使用反斜杠。如果是 macos 系统,先用 blue 安装 openvino, 然后执行 cmake 命令进行编译。 第三步,下载测试模型,创建 model os 目录,从 huggingface 下载测试模型文件到 models 目录,由于平台限制,完整地址无法显示,需要下载地址请在评论区留言,翻译完成,现在可以开始使用了。为什么选择 docker? 无需配置环境,一键启动,隔离运行,不污染系统,特别适合服务器部署和快速体验。步骤一,构建 docker 镜像清亮 call 命令,指定 target 为 light, 标签为 lama puma collin light 使用 open veneno 点 docker file 发来文件。 server veneno dpi 版本,开放接口执行 docker 命令,指定 target 为 server, 标签为 luma pen veneno server。 gpu 容器运行, 执行 docker run 命令,挂在 models 目录,映射 gpu 设备设置环境变量接 gml。 open veneno device 为 gpu 起拥有状态执行运行 luma pen veneno light 镜像 指定上下文长度一千零二十四模型路径 n p u 容器运行,执行 doker run 命令,挂在 models 目录,映设 excel 设备设计环境变量 g g m l ompenvenor 的 device 为 n p u 运行 lompenvenor colonlight 镜像, 指定上下文长度五百一十二。模型路径 server api 模式,开放接口,启动 rest api 服务,执行 docker run 命令。映设端口八零八零挂在 models 目录,运行 low open veno colon server 镜像测试 api 调用,执行 call 命令,向本地服务发送 post 请求,由于平台限制,完整地址无法显示,需要完整命令,请在频讯区留言。设置 content type 为 application json, 发送包含用户消息的 json 数据。 高清儿注意事项,需要预先下载模型到 models 目录。 gpu 或 npu 需要印刷设备文件。 server 模式仅支持单绘画多种运行方式。 gpu 加速模式推荐,日常使用性能最佳,响应最快。设置环境变量 ggml openvio device 为 gpu dot npu 低功耗模式,适合笔记本,省电、高效、续航更长,需限制上下文长度为五百亿二十二。 server api 模式,开放接口 rest api 服务如下,应用直接调用 gpu 加速模式推荐设置环境变量 g g m l open vein device 为 gpu 设置环境变量 g g m l open vein state for execution 为一。运行对话模式,执行 l m c l 命令。指定模型路径上下文长度一千零二十四。 serve api 模式,开放接口,启动 rest api 服务,执行 llama server 命令。指定模型路径端口八零八零上下文长度一千零二十四。测试 api 调用执行客肉命令,向本地服务发送 pos 请 求,由于平台限制,完整地址无法显示,需要完整命令,请在评论区留言。简化配置技巧,将环境变量写入八十二 c 或系统环境变量,避免每次手动设置遇到问题,如何解决?第一个问题, gpu 无状态执行失败 现象是推理报错或崩溃。解决方法是设置环境变量 g g m l open window stay for ex execution 为一。第二个问题, n p u 内存溢出现象是上下文太大导致失败。解决方法是限制上下文长度为五百一十二或更小。第三个问题,首次运行慢,原因是模型变异需要时间,这是正常的,后续运行会非常快。第四个问题, 多 g p u 选择方法是使用 g p u 点零或 g p u 点一指定设备铁技巧技巧查看详细日制级别三、执行 l m c l e 命令,加上 l v 三参数起用性能分析设置环境变量 g g m l open veno profiling 为一 导出计算图用于调试设置环境变量 g g m l open veno dumbed up siggraph 为一。核心要点总结,你现在可以医用 intel 显卡流畅运行大模型,无需 nvidia two 开放 api 接口如下,应用直接调用三零额外成本利用现有硬件。四、部署 openclhermes agent 等智能体。 五、 cpu gpu npu 灵活切换,按需选择推荐场景日常对话用 gpu 模式,低功耗用 npu 模式,大批量用 cpu 模式。关键命令 ggml opengeno device 等于 gpu 到 ggml opengeno stateful execution 等于一、 上下文长度控制用 c 参数我准备了 windows、 mac、 linux 三个平台的一键安装脚本,有需要的在评论区留言获取一键脚本。如果这个教程对你有帮助,欢迎点赞收藏评论,分享你的使用体验。我是大叔大,专注研究 ai acent 与大模型应用,感谢观看,咱们下期再见。
39大书大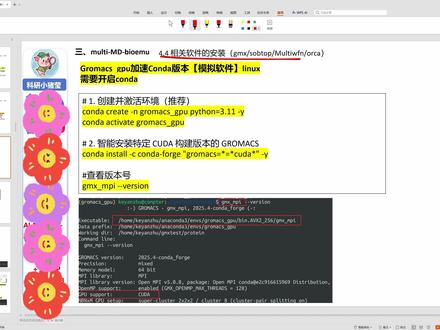 05:47查看AI文稿AI文稿
05:47查看AI文稿AI文稿好,下面给大家讲一下如何去安装, 我们的安装文件给大家放在了一个安装包与安装视频里,这里都是有的,大家不用担心。 gromax 安装脚本, 一般来讲的话,它可以通过两种方式翻译, gopro max, 它其实是有很多版本的,我们可以通过第一个版本, 它有 cpu 版本和 gpu 版本,目前的话我们是肯定安装 gpu 版本, gpu 版本的安装方式有两种,第一种是原码翻译,在之前酷狗里它是没有支持 gpu 加速的, 所以你想用的话就必须进行源码翻译,源码翻译的话,我们之前在九块九的课程以及 b 站上给大家介绍过,这个过程比较复杂, 但是它的指令和我们之前用的有些相似,大家如果感兴趣也可以去试一下源码翻译。源码翻译的话这里我就不讲了,因为对大家的难度可能大一点,它主要包括如下几个方面, 我给大家找一找。 代码的话是在公众号,当然我是指的是是一个源码翻译的方式, 装的是 gpu 加速, 大家可以看一下, 这个的话目前的话就是没有那么推荐大家去做了, 因为它这安装的话还比较麻烦,你需要配置特定的审美和版本安装富力页变换,然后最后嗯特定的库大版本的 gromax 进行翻译,现在库大里面已经有 gpu 翻译的, 所以大家可以通过这种方式直接去实现。 这里的话这里它这里我修改了一下,这里我发现它有一个问题,它虽然能安装上,但有时候会和库达版本不匹配, 这里我给大家大家不要用刻上这个代码了,大家用一个新的储, 我给大家写一下 旧的版本安装库达版本 不匹配新版本匹配度,新版本可以识别。 这里主要涉及到一个问题, 就是说我们安装的时候,我们的安装的 gromax, 它有扩大版本的限制,比如说我之前安装的一个,它的扩大版本要求是十二点八,但是我本地的扩大只有十二点四, 这意味着你新版本的扩大没法在你的电脑上运行,比如说你本地假如说是十二点四, 那你安装了 gmax 版本的要求的扩大必须低于十二点四,如果你按一个十二点八,它就会报错,之前我就是安了一个二五年四月版本的,它要求的版本是十二点八, 然后呢就报错了。然后推荐大家用给大家的补充文件里的新代码,它可以自动检测你的驱动,检测你的支持的最高的一个库大版本, 然后低于这个库大版本还可以你驱动,比如最高支持十二点四,那你 gromax 安装库大版本必须是低于十二点四,如果它支持十二点八,十二点九,那你可以安装十二点八,十二点九,你不能高于这个版本。
 07:26查看AI文稿AI文稿
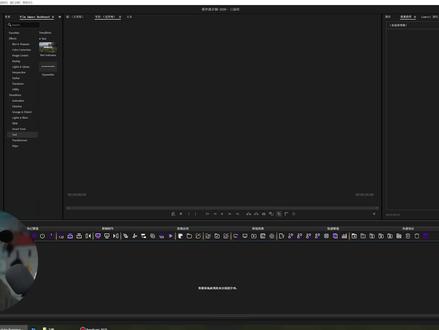
07:26查看AI文稿AI文稿ok, 各位同学,大家有看到我 pr 软件里的这个窗口吗?是不是很多人没见过这个东西是集合了很多剪辑效率的插件脚本,这个脚本呢是这位前辈自己开发的,也在不定时的去更新改进一些功能, 为这位前辈啊点一个赞!接下来大家就跟着我的演示操作,来看一下这个插件脚本到底该如何使用,如果觉得对你有用,记得点赞收藏起来咱们再看。忘记说了,这个插件脚本啊,应前辈的要求,我会把它放在粉丝群,供大家免费去下载使用。 安装的方法这里我就略过,因为在安装包里边它是有安装教程的,可以自行去看。打开 pr 之后在窗口,然后在扩展里边,在这里可以找到它。那这个脚本插件它大概分为了项目管理、标记管理、剪辑制作效果、应用转场管理、轨道管理以及 快速导出。最后还有一个用户自定义,那功能是非常的多,因为时间关系,在这里我就挑选一些比较突出的实用功能给大家做一个演示。项目管理里边可以快速的对帧率 以及项目等进行管理和创建,比如新建一个序列,直接点这里就可以快速的创建序列,序列创建好之后,可以对帧率这些进行快速切换,包括项目的一些关闭和打开,都是可以在这里完成,这些是一些比较基础的功能。 首先是这一个创建分类素材箱,可以快速的创建视频素材、音乐素材或者图片素材的,这种分类素材箱不需要你一个一个去创建,在这里也可以快速的对某段素材进行快速嵌套, 如果我们在剪辑的过程当中有图片素材或者视频素材导入到了项目里边,没有去做剪辑分类的情况下,那这个脚本里边有一个快速整理视频素材, 他会把里边所有的视频素材快速的整理到视频素材文件夹里边,像这个图片也是可以的,点击这一个整理图片素材,他就会自动的把图片素材整理到这个图片文件夹里面去, 是不是一下咱们的项目栏就非常的清晰干净了。接下来切换到剪辑制作这个标记管理,因为比较简单啊,里面的很多功能都是非常快捷的,大家拿到这个脚本之后,可以自己去试一下切换到剪辑制作, 那比如现在我有两段素材,我们需要去调整他的一个顺序,那我们现在只需要点一下这个水平互换, 哎,他就可以把这两段素材进行互换,若是两段叠起来的,我们可以点击这个上下互换。接下来是轨道的一个精准变速功能,比如现在我选择的这段素材,我想让它快速的变速到四十秒,那我只需要将时间向快速的定位到四十秒,然后点击这个变速结尾, 就立马根据你设置的时间啊设置一个变速结尾啊,不需要这样去设置速度与持续时间,然后再去慢慢的去设置这一个倍率,那他还有就是可以快速的对轨道的正放和倒放快速切换,比如现在这个视频是正放的, 我点击这一个快速倒放,看到没有,这样就快速的切换倒放。接下来要讲的这一个功能啊,对大家来说都是比较实用的,比如现在轨道上有很多段素材,我们需要对这些轨道剪辑成同样时长,那么很多人做法可能是一段一段这样去剪, 现在不需要啊,你只需要选中所有的片段,他是以第一段的轨道长度点击这一个等长剪辑, 他会把所有的轨道剪辑成同样的时长。特别是我们在做一些图片素材的时候,经常会把图片素材呀裁剪成相同的时长片段。现在不用手动去操作了,一键点击就可以搞定。里边很多功能很小众,但是很实用,比如选中轨道,点击这个向上移动轨道,或者选中某些轨道向下移动, 再来看效果,应用里边还可以快速对画面大小进行控制,比如放大,缩小, 增加宽度,减少宽度,或者适配填充,像翻转这些啊都是有的,想要恢复直接点击前边一键恢复,像这个裁剪圆角,它也是适配了二六版本的新的效果, 添加了这些效果之后,也可以一键把它删掉。不透明度可以直接点击这一个狂点,狂点他的不透明度就直接剪下去了,想要恢复直接点这个就可以了。镜像垂直翻转,如果需要添加变换,直接点这个,就可以自动的在你效果里面添加一个变换效果, 像超级键、轨道遮罩键这些都是在里边,它还可以快速的设置色彩空间,只需要输入相应的序号就可以改变色彩空间,比如二可以快速的切换锐化或者动画蒙版。 好,接下来讲转场效果里边转场效果做了单独的面板管理,可以快速的添加转场,或者选中两段添加中间 选中添加转场的轨道,可以快速的删掉所有转场,选中两段可以做交叉缩放,在这里可以快速的添加五帧的调整图层,那么我们添加之前一定要在新建一个调整图层,那选中这个轨道,可以点击添加五帧的调整图层, 他就会快速的在上边添加一个做转场用的调整图层。如果是想快速的对轨道添加对应的调整图层,我们可以选中轨道,在这里选择批量添加调整图层,他会直接按照轨道的长度给你添加调整图层,而且是独立的,那特别适合用来做调色用。 在后边可以快速的对视频做一个电影开场,也可以快速的对这个视频做一个电影遮浮 声音的调整,在这里也是有的,这里我就不做演示。轨道管理里边有两个功能是相当好用,我相信很多人都是需要他的,比如现在我们选中一个轨道,这里有一个叫等分切割,我们点一下 这个轨道,我们需要同时切成几段,比如五段,在这里输入五,我们点击 ok, 他 会把同一段素材均等分的分成五段,你也可以按照帧数来进行切割。接下来是在选择上有一个非常便捷的功能, 比如现在我的这个轨道比较多,我需要隔一段把这些轨道选出来的时候,以前是通过手动的方式这样去把它选择出来,那现在不需要你选中所有的轨道,点击这个基数片段, 他就会把基数片段直接给你选出来,那如果你想选择偶数片段,他就会把偶数片段给你选出来,而接下来这个功能也是用的挺爽的,比如现在我先把它剪辑成五段,它就是对轨道进行排列,我们点击这一个阶梯偏移,那他这里说了,负向直向前移,正向直向后移, 那我们输入负一,他可以自动的把这个轨道啊进行这样一梯一梯的进行排列,如果你想反向的去排,那么按照他的指令去输入就可以了,加零 可以看到它是这样反向的去排的,像片段、在线、离线、起用、停用、隐藏这些啊,我就不去演示了。接下来讲这个快速导出,比如这个可以快速批量的导出 h 二六四的高质量,选中你需要导出的片段,点击这一个快速批量导出,然后选择你的文件夹,点击保存,它就会自动的批量进行导出, 是不是非常的方便,而且没有用到 m 一 这个辅助软件,直接就在 p r 里面完成了,它在后边也可以快速的导出一些高质量的一些格式,这里 都给你列出来了,包括转达芬奇、转 ps、 转 a e、 转 au 啊,这些都是有的。就讲一下这个脚本插件的功能是比较多,我们如何把自己常用的一些功能给收藏起来呢?接下来就会用到用户自定义这个项目栏了,比如现在这些项目栏里边啊,你觉得这个是你常用的, 你可以在这个图标上用鼠标右键点一下,然后就会直接把这一个脚本功能收藏到用户自定义里边去啊。在这里好了,这期的分享咱们就讲到这个地方,非常感谢这位老师的无私分享,如果觉得对你有用,记得把它分享给你身边有需要的朋友。我是猫叔,咱们下期见。
698猫叔 05:43查看AI文稿AI文稿
05:43查看AI文稿AI文稿打开浏览器百度搜索爱思助手, 点击下载立即下载 双击打开下载好的安装包, 点击同意立即安装,点击开始使用, 点击立即安装, 如果出现安装失败,点击确定,点击连接端口超时点击立即修复 apple marblesys 服务未启动, 按住开始菜单键加二键输入 services, 点击确定, 找到 apple mobile device service, 右键点击属性,点击登录,选择本地系统账户允许服务与桌面交换确定右键点击启动 数据线连接电脑和手机,手机选择信任词电脑,这样就连接成功了。 点击实时屏幕, 开启开发者模式, 打开设置,找到隐私与安全 找到开发者模式, 点击开启,点击重心启动手机点击启动拔插手机数据线,点击重视, 这样就连接上了。打开手机扫码下载打开 qq 浏览器扫码二维码在视频简介 点击安装,点击右上角 close 关闭广告下滑,找到真正的安装按钮, 点击安装,点击允许点击安装,如果没有弹出下载,请点击这里回到桌面这里 ok run, 安装好了, 打开设置,找到通用,找到 vpn 与设备管理, 找到企业级 ip, 未受信任。二 k run, 点击信任,点击允许并重新启动手机,重启后点击安装描述文件,打开二 k run, 允许无线局用于蜂窝网络输入锁屏密码。 第二步,下载激活器下载地址在视频简介点击下载 解压刚刚下载的激活器, 确认实时屏幕能获取到屏幕信息。 打开刚才下载的激活器激活即可。打开 ios exe, 点击更多信息,人要运行打开二 k runner 激活器 exe, 点击更多信息,人要运行,点击激活, 出现 success 行情, ems 代表激活成功。 清理后台, 重新打开二 k runner, 输入密码, 屏幕上出现 automatics 软件,表示激活成功,只要不关机就不用再次激活。打开 ai 办公,点击设置选择激活模式,点击激活模式,这里显示连接成功即可。 good luck。
 00:41一台服务器装开源容器平台 只有一台 Linux 服务器,也别急着劝退自己。先把平台跑起来,能部署、能访问、能进控制台,后面再考虑集群。#Linux #服务器 #开源容器平台 #Rainbond #运维查看AI文稿AI文稿
00:41一台服务器装开源容器平台 只有一台 Linux 服务器,也别急着劝退自己。先把平台跑起来,能部署、能访问、能进控制台,后面再考虑集群。#Linux #服务器 #开源容器平台 #Rainbond #运维查看AI文稿AI文稿一台 linux 服务器,一条命令,能不能直接跑起一套开源容器平台?镜头落到官网,快速安装入口就在这里。文档打开, linux 单机安装命令已经准备好,这条命令被复制下来,准备带到服务器里。命令进入服务器终端,安装开始往前跑, 中间过程需要配置服务器的公网地址,后面 rainbun 的 控制台界面就从这个地址进入。接下来的环境检查组建启动和平台初步化都由脚本连续完成,直到终端出现成功提示, 这说明单机版已经安装成功,从浏览器访问控制台就可以开始使用了。整个过程不到三分钟就能安装完成,快去试试吧!
62Rainbond 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿关于封脚本这个事情,我今天呢就放开了揉碎了,好好的和大家再聊一聊。 之前呢,我确实信誓旦旦的说啊,要尽我所能的去清理掉这些脱机脚本工作室。但是呢,在这段时间处理脚本的过程中啊,我发现了一个非常非常严重的事情,并且呢,这个事情还解决不了 啊,就是呢,会误封掉很多正常的玩家,那最高的时候,我们封十个号里面竟然有三四个都是误封的,这就非常非常可怕了,到时候呢,脚本工作室你没清除,把正常玩家都清理完了, 那我觉得单凭感觉和肉眼来判断是否是脱机脚本其实没有任何意义,反而呢,最后弄巧成拙。 所以说,月底的盛联幺八零火龙二区呢,我们将不再通过玩家举报,然后人工巡查这种笨笨的方法才来检测和处理脚本了。那这个时候肯定很多人呢啊,就会带节奏了, 你不是说一个不留吗?对吧,你怎么现在又又不管不问了?那我告诉你,其实呢,我这样说呢,并不是不管,而是换了一种更为有效和直接的方式。 用人工去对抗科技肯定是不行的,那只有用魔法才能打败魔法,也就是用科技才能限制住科技。 我们会在增加游戏限制方面再下功夫,比如说啊,为了防止部分地图脚本呢,自动小退二区会增加小退后不在本地图的一些设置。 再比如说,为了防止部分脚本自动下图二区也将会根据地图开放时间,然后进行少量的金刚石的收取等等等等,很多很多, 反正不管过程如何,目的都是一样的,而且这样的限制吧,他不会产生任何的误封,对吧?月底的二区呢,将会有很多很多地方的调整,你们心中所想可能就是我调整的方向,二十号,这样就会有内测公测啊,给大家测试的。
135传奇GM陈胖子 04:51查看AI文稿AI文稿
04:51查看AI文稿AI文稿opencurry, 俗称大龙虾,作为二零二六年最火的 ai ai 卷框架,凭借强大的自动化啊执行能力成为开发者标配,随着使用频次提升, tok 消耗成本居高不下,成为开发者 和中小企业核心痛点。那如何来解决这一问题呢?我们也可以通过在本地部署欧莱玛大模型,结合开源的 core x 来实现本地化。接下来我们就一步步演示整个的操作过程。首先我们打开饿了么的官网,在这里我们可以看到安装的脚本,点击复制,然后我们到搜索框里面输入 power, 选择以管理员身份运行, 看到命令窗口和右键将刚刚的代码复制进来,按回车, 这时沃尔玛就会从官网去当下载沃尔玛的安装文件进行安装,我们耐心等待就可以了。 经过一段时间等待以后呢,奥拉玛已经安装完成了。安装完成奥拉玛以后呢,下一步我们去做安装一个模型,这里呢,我们以千万三点五为例,回到奥拉玛的官网,这边选择模型,这边搜索千万 啊,请问三点五这边有不同模型的大小啊,根据自己的显卡型号啊选存的大小,嗯,去选择就可以了。我们这里为了演示,所以我们选择最小的模型,零点八 b 的 点击,然后这里会有一行的命令复制,回到 hello 的 命令行,右键粘贴需要回车, 这时候皇冠会去加载轻微三点五的模型,因为他有六点六个 g, 所以 我们需要等待一段时间。模型的安装完成,这里我们可以简单测试一下, 大家会先思考回答,也就是说明书,到这一步,奥数和清问都已经部署完成了,下一步我们要去做的是去部署 pro x。 打开 corex 的 git 网站,我们可以拉到下方来,可以看到它当前版本是 v 零点三点八,呃,我们以按照 windows 为例,我们下载 这个 corex, 零点三,零点三点八, windows x 六十四的,我们下载这个点击下载就可以了, 因为我之前已经下载过了,所以我就直接安装桌面上点击运行,下载完还点击运行 corex, 安装完成,这边运行就好了。 corex 启动以后呢,会进入一个欢迎使用界面,我们根据提示往下配置即可, 这里我们选择下一步,下一步他会去检查 gmail 的 版本以及 open curl 的 包的版本。现在我们用的是最新的二零二六年四月九号的版本啊,网关端口他是一八七八九啊。我们点选择下一步, 这一步呢?我们选择模型,模型我们是本地模型,所以我们选择奥拉玛,然后端口是这一个模型的 id, 模型的 id, 我 们通过跑过去的命令奥拉玛 list, 我 们可以看到模型的 id 是 这一个,我们复制下来, 来到这边印贴,印贴以后这边有一个 a p i 的 必要,这边显示是不需要,因为我们使用是本地模型,所以就不会消耗到 token 了。选择保存,保存完后下一步 再会安装必要的一些内容。安装完成,配置完成,然后开始使用。
313科技老王 05:37查看AI文稿AI文稿
05:37查看AI文稿AI文稿大家好,我是麦东,昨天我发了 windows 用 wsl 安装 ems 的 视频,很多人都在后台私信我,为什么我的安装脚板卡在某一部不动了?为什么某个命令一运行就报错,为什么报错代码看半天还看不懂。 所以今天我直接换一种更简单的方法,不用丛林折腾环境,直接用 vmware workstation 导入我做好的 emirates ovi 包,快速把 emirates 跑起来。整个安装过程,我们需要用到两个安装包,一个是 vmware workstation 的 安装包,一个是 emirates 的 ovi 包。 这两个文件我也会给到大家,希望对大家有帮助。下面就跟着我一起来看一下这种安装方式到底有多方便。微软 workstation 的 安装我就不给大家演示了,大家双击安装包,一路点下一步默认安装即可。我们直接点开我已经安装好的微软 workstation, 点击文件,点击打开,选择 ems ovi 包,点击打开。接下来配置一下导入的虚拟机的名称以及存储路径。 存储路径大家要注意,尽量不要有中文。配置完成,点击导入, os 的 虚拟机已经开始导入了,我们耐心等待片刻即可。 好了,已经导入完成了,我们可以简单看一下当前虚拟机的配置, cpu 内存分别为四核四 g, 硬盘为五十 g, 一 般来说是够用的。当然,如果你的电脑配置比较充足,你也可以适当调高一些当前配置。网络模式这边我建议用 nat 就 可以了, 大家这边如果不了解的也没关系,保持默认配置就可以了,不要做调整。配置设置好之后,我们点击开启此虚拟机,出现当前页面之后,我们可以什么都不动,默认等三十秒之后就会自动的选择。第一个 可以看到当前的虚拟机已经开始启动了,启动完成,我们输入用户名密码,登录虚拟机, 我们先用鼠标点击一下黑色区域,再输入用户名是 emirates, 密码同样也是 emirates。 输入完成我们就进入到了当前的虚拟机里面了。进入系统之后,你就不需要再去跑 emirates 的 安装命令了,因为我在做这个 ovr 包的时候已经提前把该装的东西都装好了, 我们只要直接配置下模型就可以直接开始使用了。这个地方有一个小技巧要跟大家说一下。在当前 winoverworksstation 界面里面,我们是没有办法进行复制操作的,但是我们可以用本地的 power shell 去连接当前已经启动的这台虚拟机,后续操作就可以在 power shell 里面进行了。 我们首先在虚拟机里面输入 ipa, 全小写的 ipa, 按下回车,可以看到这边输出了两条地址,我们重点看第二个 e n s 三三的这条地址,在这边我们可以看到当前虚拟机的 ip 地址,幺九二点幺六八点二四五点幺三零,记住这个地址。 接下来我们打开本地的 power 线儿,在 power 线儿中输入, s s h armes at 幺九二点幺六八点二四五点幺三零, armes 就是 我们当前虚拟机的用户名,后面这个则是我们当前虚拟机的地址。按下回车,接下来输入密码即可,密码同样也是 armes, 输入完成之后,我们就已经登录到了这台虚拟机里面了,接下来我们就可以把 vmware workstation 缩小放到后台去运行了, 我们直接在 power shell 里面进行后续操作就可以了。运行 emars model 进行模型的配置。模型配置其实我们在前面的两个视频里面都已经讲过了,这边就再给大家讲解一遍。 可以看到当前支持的模型种类也比较多,除了国外的一些模型之外,也支持国内的像小米、千问、 deepsea、 智浦、 kimi、 mini max 等等,但是仍然有很多的模型厂商并没有直接支持,不过也没有关系,我们可以看到在当前模型清单的倒数第二个有一个 customer endpoint, 我们按下回车,只要你所使用的模型是兼容 open ai 格式的,我们在这里面就可以直接配置。我们需要两个参数,一个是 api 的 best url, 一个是 api key, 这两个参数大家自行去你所使用的模型的厂商控制台里面找就可以了。我这边就直接进行配置了。 api bios u r l 输入完成之后,按下回车开始输入 api key。 api key 在 输入的时候是不可见的,所以大家尽量复制粘贴,不要手动去敲,不然很容易敲错,并且你也不知道到底错在什么地方。输入完成之后,继续按下回车, amaz 会自动检测你当前所使用的模型, 我们直接按 y 确认即可。模型确认完成之后,我们还需要配置一下当前的上下文长度,上下文长度我们可以根据当前你所使用的模型支持的最长上下文以及你日常的使用习惯来确定。我这边就输入二十万 按下回车,接下来还可以给当前模型取一个别名,这边大家自行输入即可。好了,模型已经配置完成了,下面我们运行 emulus, 打开对话界面, 可以看到 emulus 的 对话界面已经成功加载出来了。下面我们惯例问他一个最简单的问题,你是谁?你可以帮助我们做什么? 可以看到 emulus 已经开始给我回复了。到了这一步,我们的 emulus 安装基本就完成了。当然,我们后续还可以给 emulus 配置连接多个即时通讯平台,比如飞书、钉钉、企业微信等。 这个我后面会出一只视频,专门用来讲解 amazon 跟各个平台之间的对接。好了,今天的视频到这边就结束了,工具会变,但方法更重要。我是麦冬,下聊继续。
488麦冬AI实验室 03:42查看AI文稿AI文稿
03:42查看AI文稿AI文稿现在给大家完整演示一下,我先从另一台电脑把打包的压缩包发送过来, 我们先解压。然后这里我准备了 windows、 macos、 linux 系统的一键运行脚本和一键停止脚本,帮助不熟悉命令型的小伙伴更便捷。这里因为我之前已经有勾环境,所以脚本运行中没有去安装依赖。 这里自动打开 web 页面,我们输入默认密码,幺二三四五六进入管理台。在配置页面,我们可以自己去修改管理密码和 api 密钥,这里我修改一下, 然后我们点击保存。 ai 提供商,这里是正常 gemine、 opennine、 cloud 等供应商的 a p i。 添加 os 登录才是我们的重头戏。可以看到支持 codex、 anthrax、 gemini、 kimi、 quin 等授权登录, 这里就是可以把它们赠送的免费额度统一封装成 a p i。 我 来演示一下 quin, 点击登录,打开链接 这里。我之前登录过,就直接登录了,没有账户的小伙伴自己注册,就是不需要下载客户端 可以看见。现在认证成功,我们再测试一下 codex 支持的登录方式,很多,方便演示,我就选择 google 登录, 可以看到很简单就认证成功了。 认证文件这里,点击刷新就可以看见额度还剩多少 g p t。 五点四还是太香了,有 pos 会员的用户可以用这个管理账号轮询这里我批量添加了很多 codex 的 账号 功能,很实用,怎么使用?我们进入中心信息页面,可以看见目前添加账号支持的模型,这也是我们配置给 open core 和 hermes 等 ai 工具填写的模型名字。这里演示一下我新安装的 hermes, 打开配置文件, bios u r l 地址就是我们本地端口模型复制中心信息的模型名称密钥。在 f 文件中不会配置的小伙伴直接把 bios 密钥和模型名称给 ai, 让他帮你配置 好了。现在我们测试一下, 可以看到已经成功了, 我们可以去看看可选模型中添加的模型,可以看到 gptf 五点四 基本演示,就这样,我一下午都是跑,目前非常顺畅,然后想结束进程,点击 saf 脚本就一键结束了。需要便捷安装的小伙伴到文章底部用领取口令 自行领取吧。记得点赞关注。至于说如何批量注册账号,看情况反应,我看看下一篇要不要写。
51聿凡与AI








猜你喜欢
- 1.3万声剧工坊