PythonAIAgent实战教程
说一下 i'm betting, i'm betting, 它的汉语意思是嵌入项链的意思,那项链又是什么呢?一句话简单点说,项链就是把文字转为一串数字, 文字的语义越相近,数字越像。那么文字是如何转为数字的?在 python 里面可以直接调用按 button 的 api, api 会直接返回一串数字给我们。那么接下来提一个词语义解锁。语义解锁是什么? 它和我们传统的关键词解锁区别又是什么?首先说关键词解锁,就是根据关键词去数据库里面查找内容。语义解锁呢?它不是根据关键词,它是根据意思去查找的。那它是如何按照意思去查找呢? 是通过数字比较。首先我们是需要把所有的资料都转为向量存起来,然后第二步,再把要搜索的问题也转为向量。那第三步,拿着这个向量和资料库中所有的向量比较, 最后一步,把数字相似的找出来,这就是语音解锁。那么有疑问,资料库那么多,那我一下子能找到吗? 那我速度不会慢吗?答案是不会慢的,是有专门的向量数据库去来干这个。然后用类似二分查找的方式去查找向量。 那么又有第三个关键的概念叫与弦相似度。与弦相似度它是什么呢?其实它就是一个打分工具,来判断两段文字有多像。 那他为什么叫余弦相似度呢?因为他底层是用的余弦函数来计算两个向量的夹角,夹角越小于弦值越接近,两个向量也就越接近。所以我如何用余弦函数?是直接调用接口,直接调用接口就可以调用接口将文字转为向量, 然后调用余弦函数来判断这两个向量的相似度。来看一下代码,这个是用 python 写的代码, python 处理起来。上面我说的这些东西还是很简洁高效的。你看, 首先将文本转为向量,直接用了 imabyte model 拷的这个方法, 就可以直接将文本转为向量。然后我返回了转为向量的一串数字使用的模型,向量的长度文本预览。你看第二个接口,它通过批量的方式 将文本转为向量,其实它和单个转的用的方法是一样的,用了拷口的方法。接下来我说再说一个概念,它叫 curl 嘛, crom, 它的暗喻词是色彩,色彩饱和度。那么它是存项链的一个数据库,为什么要取用这个色彩饱和度取名呢?可能开发者是为了想把万物变为项链,然后像色彩一样区分 项链,越像颜色越接近项链不同,颜色不同。那么 crom 该如何安装? 它是不需要安装,它是一个 python 的 库,可以直接通过 keep 安装完直接使用。它是一个用来存项链的库,所以它是有增删改查的,就往这个库里面去增删改查项链,我们看一下一些操作, 包括创建集合,往里面增加项链和文档查询,从这库里面查询,从这库里面删除以及修改。那么 chrome 它的数据项链数据是存在哪里的? 它可以通过以下几种方式,第一是内存,我没有给它写存储路径,它默认存内存里面,存内存里面的缺点就是如果重启以后数据会消失。第二种方式是存到文件里面,你看我们在这里写一个配置,把 com dpps 放到这个文件里面, 我看在左边这个文件里面是有存他的数据。这第二种方式啊,第三种方式的话,我们可以存在云里面,可以通过云对象的方式进行存储,我们看一下代码, 我在这个结构里面是要往 com 数据库里面添加向量数据的,这里我如果没有这个集合的话,我会创建这个集合, 然后这个是这个集合的信息,然后在这里把我转的向量信息、文档信息存到这个库里面,然后返回成功,也就是向支持库添加文档数据。 然后我看下这个接口,它表示从知识库里面搜索东西。我们在上一步把项链存在的 char 码里面,也就是说知识库里面在这里的时候,我们通过内幕,然后把它转为项链,然后去 char 数据库里面去查找,我看这里设置的过滤不相关的,如果这个 distance 小于我们设置零点八,关联性比较大,那返回的这个是从 com 知识库里面查询东西,看一下下面这个接口,它表示列出所有的知识库合集,我们看也是通过一个简单的 list connections 方法列出来这个知识库所有的集合。最后再看一个问题,就我们要把一个段落,假如这个段落很长,我们要 存到相册库里面的时候,我们要把它转为数字的时候,我们需要把这个很长的文档进行切割一下,具体他是怎么切割的呢?其实可以通过以下几种方式,第一是通过段落切割, 这样可以保持完整的语义,第二个是通过字数切割,比如说以两百字为字数进行切割,第三个是通过句子切割, 这样切出来的比较准确些,但是比较繁琐。最后再提一个 r a g 这个概念, r a g 它的英文是 re travel argument generation, 反语含义就是解锁增强生成,那它作用是什么呢?我们根据名字来看,是用来增强解锁的,就是我们模型在训练完成之后,它里面的知识是固定的, r a g 可以 从本地的知识库里面找到相关的内容,然后再把它找到内容给模型,然后模型再回答,这就是完整的 r a g 流程。 我们上面说的按编码向量和 com 数据库就是 r a g 里面的一个环节,看一下这几个接口,我刚才看的这几个接口,让文本转向量,我再输入一个文本以后,把它可以直接调用接口以后把它转成这种数字的这种向量, 然后我们再把它添加到数据库里面,你看返回成功,这个就是添加成功的个数,然后我们再从数据库里面查找东西,这个就是从 com 库里面去查找出来内容,然后列出所有的库,这就是列出来的目前还有的所有的库,这就是 i bing 以及 r a g。

粉丝2964获赞1.1万
相关视频
 09:00查看AI文稿AI文稿
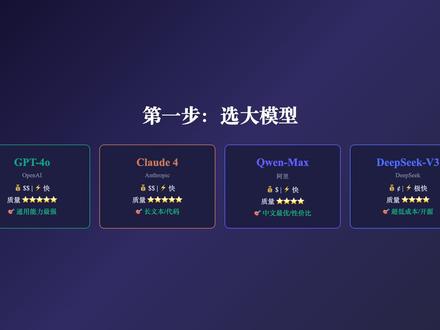
09:00查看AI文稿AI文稿欢迎来到 ai 进化录大模型科普课第三集,前两集我们讲了大模型是什么, ai agent 能做什么。今天我们来动手,手把手教你从零搭建你的。 你可能会问,市面上 chat、 gpt、 timi、 豆包这么多现成的 ai 工具,为什么还要自己搭 agent? 答案很简单,现成工具功能受限,数据不可控,自己搭的 a 枕可以完全定制进你自己的数据库,要你自己的 api, 按你的业务逻辑走。更重要的是,理解原理等于选型不踩坑。 当你知道你曾怎么运作的,你就知道哪些 ai 产品靠谱,哪些在吹牛。这是每个想用好 ai 的 人的必修课。 搭建一个 agent 其实就三样东西,第一大脑,也就是大语言模型, gpt 四 o cloud, 通用千问 deepsea, 它负责思考和决策。第二工具, a 阵的双手搜索引擎、代码执行器、数据库、 api 接口,这些是 a 阵能做事情的关键。第三,循环思考,行动观察,不断重复,直到任务完成。 这就是所谓的 a 阵 take 路。把这三样东西组合在一起,一个最基础的 a 阵就成了。 第一步,选大模型目前主流选择有四个, gpt 四 o, openai 出品,通用能力最强,中英文都很好,适合大部分场景。 cloud 四 andropic 出品,长文本处理和代码能力突出,安全性好。通用千问 quanmax, 阿里出品,中文最优,性价比很高,国内接入方便。 deepsea v 三开源模型里的性价比之王, api 价格是 gpt 的 几十分之一,适合成本敏感。场景选哪个取决于你的场景。个人建议先用 deepsea 开发调试,确定效果后上 gpt 或 cloud。 第二步,定义工具,这里要用到一个核心技术, function calling 函数调用。 原理很简单,你用 jason steemma 格式告诉大模型你有哪些工具可用。 steemma 里写清楚工具的名字,参数作用,然后把工具列表连同用户的问题一起发给大模型。 大模型看到工具列表后,会自己决定要不要调工具,调哪个,传什么参数。注意,大模型只是决定调什么,真正执行的是你的代码。这个设计非常巧妙,大模型负责脑力活,你的代码负责体力活。 第三步,搭循环,这是 agent 的 心跳,叫 agent 露。 整个流程是这样的,用户输入一个请求发给大模型。大模型思考后,如果觉得需要工具,就返回一个工具,调用请求 你的代码,执行这个工具,拿到结果,再把结果发回给大模型。大模型看到结果后继续思考,如果任务还没完成,他会再调工具,如果完成了就直接输出。最终回答。就这么一个循环,不断重复,直到任务搞定。 这也是为什么叫 agent, 而不是 chat bot。 他 不是聊一轮就完了,而是持续思考和行动。 现在来看,实际代码用 python 加 open aisdk, 一 百行就能带一个完整的 agent。 首先定义工具,一个 j s o n 格式的工具描述列表,然后哒循环一个 y o t 循环,把消息和工具列表一起发给大模型,大模型返回后,检查有没有工具调用, 如果有,执行工具把结果追加到消息列表,继续循环。如果没有,说明任务完成,打印回答, break 退出,就这么简单。核心逻辑不超过二十行,剩下的八十行都是工具的具体实现。 这里要介绍一个重要协议, mcp model context protocol 模型上下文协议,你可以把它理解为工具调用的 usbc 标准。 以前每个 ai 平台的工具接口都不一样,你给 chat gpt 写的工具到 cloud 上又得改一遍。 mcp 就是 来解决这个问题的, 它分三层, house 是 宿主,就是 cloud, chat、 gpt 这些 ai 客户端, client 是 客户端,负责维护连接和转发请求。 server 是 服务端暴露具体的工具资源和提示。最大的好处,工具开发一次,所有支持 mcp 的 ai 都能用。 如果一个 agent 不 够用怎么办?答案是多 agent 的 写作。目前主流框架有三个, line graph, 用状态图编排 agent 的 流程,精确控制每一步该干什么, 适合需要严格流程控制的场景,比如审批流、 co, ai 角色扮演模式,你定义研究员、携手审核员等角色,用自然语言描述每个角色的职责。它们自动写作最简单易用。 autopend 微软出品对话驱动,多个 agent 之间通过对话来写作,适合头脑风暴和创意类任务。 最后分享五个避之避坑指南,第一,幻觉防护大模型会编造事实, agent 里一定要加验证层,关键数据二次确认。第二, token 成本控制, 用缓存短提示词分级模型策略能省百分之八十费用。第三,安全沙箱, agent 能执行代码和调用 api, 所有工具执行必须在沙箱内,零容忍安全风险。 第四,调试技巧,打印每一步的 file 和 action, 日制出了问题才能快速定位。第五,生产部署加超时限制,重试机制降级策略,确保百分之九十九点九的可用性。 给大家推荐一个五周学习路线,第一周,学会用 openisdk 调 api 跑通基本对话。 第二周,学 fengshui, 自己定义工具搭 agent 构。第三周,学 write 增强剪索,让 agent 能查你的私有文档。第四周,用 qai ai 或 lan graph 搭多 agent 写作系统。 第五周级,以后研究监控安全和成本优化,把 agent 真正部署到生产环境。 好了,三级课程到这里就全部完成了。 第一集,我们讲了大模型的前世今生。第二集,我们解析了 ai 阵的原理。 第三集,我们动手搭建了第一个 a 阵,从原理到实战,一起见证 ai 进化。我是 ai 进化路,感谢你的观看,如果觉得有用,记得关。
83AI进化录 02:53查看AI文稿AI文稿
02:53查看AI文稿AI文稿欢迎观看 hamis agent 加 playright ai 驱动浏览器自动化实战教程!为什么要 ai 驱动浏览器?重复性的操作非常多,耗时费力,让人头疼,人工操作容易出错,效率很低,而且需要七成二十四小时监控,根本无法执手。 整体架构分为双层, ai 决策层,负责分析和规划浏览器控制层由 playwrite 驱动, chromium 浏览器实际执行操作形成闭环, ai 决策执行反馈不断循环环境。准备很简单,确认安装了 node js 十八以上版本,以及 python 三和 playwrite 一行命令,安装 peep 三 install playrite, 然后运行 playrite install 来安装 chromium 浏览器。安装 playrite 非常简单, peep 三 install playrite, 然后 playrite install chromium 来安装浏览器。 国内用户可以使用加速镜像,安装完成后即可使用,无需复杂配置。第一种调用方式是 terminal 命令行模式,适合快速验证命令。 playwrite screenshot url pass, 适合单次操作和测试,快速返回结构化的页面快照。第二种方式是 execute code, 在 python 脚本中内嵌运行, 支持 headless 模式启动。 chromium 支持复杂自动化流程,与 ai 对 话无缝集成,实现智能控制模式。一是 ai 分 析快照决策页面加载后自动提取页面结构和内容, ai 分 析页面语义,然后 ai 决定下一步操作是什么, 循环执行,直到任务完成模式二是多轮对话控制, ai 先规划出一系列操作系列, playwrite 依次执行每一步,每步结果都返回给 ai 判断,适合复杂多步骤的任务模式。三是 ai 自主探索,没有固定流程, ai 根据页面内容自主判断下一步, 每次提取页面后,判断哪个链接值得点击,通过深度控制防止无限循环。实战技巧,语义化提取页面结构,带重视机制的 ai 点击提高稳定性。 每次操作后截图记录状态,拦截无关图片,可以大幅加速页面加载。跨平台连接 windows 浏览器很简单, windows 上开启调试端口九千两百二十二 wsl, 通过 cdp 协议连接,可以附用已登录的浏览器环境操控任意网页应用。总结一下 ai 决策,配合 playright 执行页面状态返回,给 ai 进行下一轮决策。 terminal 命令行模式做快速验证, execute code 模式做复杂自动化任务。感谢观看,欢迎关注交流 ai 自动化技术!
43周公子 17:38查看AI文稿AI文稿
17:38查看AI文稿AI文稿那我们来试一下,如果我现在要在当前这个妙码 open codex 里面去猝死的话,整个项目呢,先直接 cd 进来啊, cd 到好,在这个里面,我们直接 npm alias 杠 y, 快 速给它来进阶啊,快速来给它去讲一遍。比如说我真的要用 type script, 那 肯定把 type script 相关的依赖 要安上来啊,他要是依赖肯定要安上,然后呢,我想直接用 tsc 来做构建,那就只用 tsc。 但是如果一般情况下啊,包括我们的所有的项目实战里面,只要是涉及到工具库相关的打包,我们都是选择 tsup, 好 把这两个呢按上,这是最重要的两个依赖,最重要的依赖啊,装上之后,我们先来初步化看一下, 呃,当然,除了这两个 div dependencies 以外, tsup 包括 node, 包括其实还差一个 types, node 里面的版本呢,我们可以选择一个二十二的版本吧,扫描一下, 好直接,呃,随便吧,这个二十五也没关系啊。然后呢,还有相关那些依赖 div dependencies, div dependences 有 哪些依赖呢?我们今天要给大家讲的涉及到 luncheon, lun graph, 还有呢包括欧拉玛 dep agents, 把这几个我们都拿去来安装一下啊。第一个是 luncheon, 还有呢是 luncheon 下面的加几个框架,一个是 lun graph 框架, 还有呢是 ionama。 ionama 其实以前就跟大家说过,它是用来去做模型调用和本地部署接入的,对吧? ionama。 再然后呢,还有一个是 deep agent, deep agent 好, 这几个依赖,我们再来扫描一下,看最终安装的版本,这个装它,这个呢?装一点二点五,这个装一点二点六,一点八点五。 好,保存,我们再来 p m p m i 安装一下。好,安装完了啊,安装完之后,第一步先初步化 t s c 配置文件, t s 杠杠 elit, 这就初步化好了啊,初步化了,基本上按照这一套没什么太大问题了,我把它精简一点,这里就是精简之后的效果。 然后呢,因为我们整个要用 tsup 来做构建,所以直接触手啊, tsup 点 config, 点 ts 来做我们产物的构建。这块产物构建其实比较简单啊,使用起来呢,这个在我们项目里面其实也有详细的介绍,包括在项目实战里面,基本上啊,这个 tsup 都是做我们的首选, tsup 作为打包构建工具库类的首选,我们直接 define config 让它导出出去啊, export default 有 点卡, define 好递发什么呢?首先肯定是 entry, entry 从哪里进来就是你的文,你的这个入口文件在什么地方?那当然在 s r c 下面啊,那么就直接把 s r c 下面的所有的文件,只要是设置的是 ps 文件的啊,都把它当做是需要处理的,那就直接这样定义。另外呢,还有包括你的输出的格式化的标准,那就用 esm 嘛 版本呢? note 二十输出的目录, disk 目录, clean, bundle, split, 包括呢? source map 需不需要 dts 需不需要啊?我们讲的都不需要。好,我们在 s r c 里面,其实现在就可以创建一个 index 点 ts 文件出来了,在这里呢,我们随便写一个 console 点 log 一 二三。那么接下来我们来调用一下,看它能不能执行,当然你在调用之前呢,这个地方肯定要去给到一个 build 的 命令, build 的 命令所对应的就是如何去构建它。那直接 psup 啊,因为它会直接读取你当前的 psup, 点 config 文件。好,我们就来来执行。偏偏 build 很快啊,很快,五毫秒全部执行完。我们来看一下效果。点进来这里确实有个 index 点 mgs 输出了,那我们如果说要去把它修改一下 source map, 我 们需要,对吧?这个 dts 呢,就是类型声明文件,我们也需要,这是 dts 里面比较基础的一些知识啊, 那这个时候就会多一个 m 点 map, 这里呢? dts 没有对吧? dts 没有,是因为你的 base, url 包括呢这些配置定义的不对,所以呢,你可以在 ts config 里面,在这里面呢把它里面的配置稍微给它改一下。 呃,对应到我们这里说的是 type script 七,我们看这里现在给我们给定的这个 type script 多少?六点零点二 type script 六点零点二 type script 七 basic error and will ignore dts 的 类型声明错了,我们看下这个里面有没有吧,我们在这儿也给它给定一个 dts declaration true 啊。 declaration map 也给它指定一下,它说 arrow base you are is de defected。 我 这里面没有 base you are, 这里给另一个吧 base you are 要 ignore defected 吧? to sentence 版本的版本的问题啊。嗯, type script type script 这里我如果给六点二也没有关系啊,那我先回退一下吧,回退一下给个五点九点三吧, 重新偏偏抹一下,然后我们再来 build 一下试试就没问题了啊。这个我们先不纠结它的错误,好类型声明,包括呢? map 文件都生成出来了 啊,这样就没问题了,整个产物能够构建出来。好,接下来我们就开始来接入模型来使用了,我们现在第一个例子就是如何去调用 skill。 好, 那我现在把 skill 肯定要拿过来吧,假设我们现在定一个文件文件夹,这个文件夹这点点妙码好,这就是我们妙码智能体的通用智能体的一个开发内容啊,然后把 skill 呢丢过来, 复制过来。那妙马智能体下面有一个 skill, 这个 skill 呢,就是妙马的智能体所有的一个技能,那这个技能除了唐宋什么诗歌转笑话以外,还有其他很多很多不同的业务, 不管是剪视频的啊,那我其实这里还可以做基于 fmp 的 视频剪辑的文案生成的文案,二创的图文生成的等等,所有这些逻辑呢,就都可以把它沉淀成 skill, 爬虫也可以, skill 都可以。有了这个 skill 以后,我们就可以去调用它。但是我们今天重点不是给大家去讲如何去做 skill, 而是我们偏向于更底层,告诉他真正 skill 的 调用底层逻辑是什么。那我们在 s r c 里面这块呢,我们就来开始调用使用这个 skill 来看一看啊,它的整个调用逻辑是什么样子的。首先呢,我们要初步化智能体, 触化智能体啊,智能体触化之后,接下来其实就是整个 asian 的 开发内容,那触化智能体第一步,当然其实在触化之前呢,我们这里应该严格意义上来说,第一步不是考虑智能体的问题,应该是考考虑模型的问题,模型 通俗化,我们用什么模型呢?我们现在都直接用欧拉玛提供的模型, nunchun 欧拉玛,这里来一个欧拉玛 chat 欧拉玛, chat 欧拉玛。然后呢,直接把模型我给它先定义在这,又一个 chat 欧拉玛,谁呢?这个时候啊,就涉及到前面给大家讲过的一个知识点,欧拉玛有什么模型, 大家可以去下载一个九 b 的 模型啊,我其实以前用低那个低参数的模型呢,给大家去试过,太差了,大家尽量的下这个六点六七的这个九 b 模型,或者更好一点的,或者你直接用你用豆包或者千问的线上模型都行啊,我今天主要就是想给大家去用本地的模型来去演示一下。好,那我们就直接模型里面的名字, model 用谁只用它千问三点五九 b 啊,千问三点五九 b。 然后呢? temperature 这个就涉及到温度了,温度呢,到底是越高越好还是越低越好,取决于你的场景,它意思是发散的可能性,你如果温度越高,你就可以理解成它更发散。温度越低呢,它其实就更 严谨,那比如给零零的话,相当于就是没有温度,没有温度,很冰冷的,它就很严谨,不会去太多发散。好,这里模型我就定义好了。第二步,出手话智能体出手话,智能体啊,那智能体怎么出手话呢?在我们这里直接把 depadience 内容给它拿过来, deep agent 里面有一个叫创建智能体 create agent, 不知道怎么卡住了啊? create a deep agent 卡住了。好,那我们接下来创建智能体怎么创建?很简单, agent 等于 create agent 啊, create a deep agent, tip agent 好, 里面有些参数,这些参数呢?第一个 name 我 们就直接做妙码杠, open code 啊,这我们就假设叫这个名字,模型来自于哪里呢?就来自于我们这个模型 l m 模型。好,下来就是涉及到有哪些 沙箱的处理,然后呢?涉及到技能加载,然后再涉及到提示词,叫系统级提示词 好,沙箱的逻辑处理呢?这块我们先跳过,不管它啊,这个沙箱逻辑处理是用通过 backend 来实现来去抽象化的,我们先不管它, backend 先注视在这儿,技能加载是我们的重点的,重点技能在哪里呢?通过 skills 来定义 skills 有 哪些 skill? 我 们可以直接定义当前文件夹下面的,你看当前文件夹没有吧,我们应该要点点斜线出去,哎,在这儿再进一步的,我们就可以看到有个点妙码, 然后呢,或者说我们直接这样子吧,对,就直接妙码下面的 skills 下面的唐宋,什么什么啊,啊,就是 skill 这第一个 skill 啊,这个 skill 就 定义好了,那接下来系统及题词题词干嘛呢? system prompt。 接下来就是 你是二次元的二次元诗人啊,诗词大拿啊,能贯通古今啊,修改唐宋元啊,唐宋诗歌词变成笑话。 好,就假设就这么一段,接下来会读取这个 skill 啊,接下来其实我们有什么样的主题给到它,它就能够去做调用的处理,我们就呢直接在这儿来一个 result。 接下来我们这个智能题,当然它也是比较单一的简单的一个智能题啊,我们通过它来执行 invoke, 我 们在这儿呢需要给到一个 isink 异步调用逻辑,比如 invoke 来调用一下它怎么调用呢?直接当前逻辑里面调 agent 点 invoke, invoke 什么呢?里面传递参数进去,当然这个里面既然是如果实际上是多模态啊,在这里面调用的话,我们 message 定好第一个信息,你的用户的这个 角色是什么?比如说我就是普通的 user 或者 ai, 或者用户提示词,就 human 都可以啊,有工具信息。那 raw 印出来了, content 呢?有什么样的数据?那么就直接我们把刚才的这个内容复制过来给他,让他来帮我们写一遍,看效果怎么样啊?或者我们直接飞流直下三千尺吧, 疑是银河。好,我们假设就给它来这一句,保存一下,我们看它最后执行之后的效果是什么样子。当然这里你需要去接收啊, star, result, await 接收一下,最后呢调用结果。好,我们这个手呢来把结果翻译一下,偏偏 build 翻译,翻译完之后它是不是输出在这了?那这是我们一堆的结果啊。那么接下来调用一下 note dist 目录下面的 index 文件, mgs 回车看效果。现在开始执行了啊, 它说这个 sandbox is alpha 是 一个测试的这样一个版本,现在先不管它,看它执行,我们等它执行完之后输出结果。 本地这个模型一般慢一些啊,用我那个 codax。 codax 我 之前用用刚才前面 codax 那 里调的是用的呃, gpt 五点三格式这个模型,当然你也可以换,比如说换五点四的这个模型, extra high 也可以,或者你直接选我进的用的五点三 codax extra high 也可以 端完了。哎,没有输出,是我没打印吧,不好意思啊,这里忘记打印了,我们来打印一下,看看最终的 result 打印的是什么。这一下肯定会比刚才快一些,因为第一第一次的话相当于有模型启动啊,这些时间都算在里面了,这个肯定会快一点,所以我们打印一下这个 result, 看下效果。五零七零的话可以随便跑。 我,我其实之前跟有几个朋友算过一笔账啊,如果说自己去做就是有时间啊,就给我举个例子,有时间,比如我可以,我们可以,比如搞一个,搞几张显卡,买几张显卡,五零七零的显卡,五零七零显卡的成本一一折算完。如果说按照我用 c 等十二这一类的视频生成模型,一块钱一分钟的这个量来算的话, 那其实只要差不多两个月就能回本就一张显卡把它并行着啊,就相当于应用化之后让其他的用户去平摊这个费用,然后在我这个显卡上面去做类似于 c 三十二啊这些模型的调用。基本上这种一万的显卡已经完全 ok 了啊,因为我的这个电脑是比较特殊,因为我前几年买的这个 mac 的 算是一个高配的电脑。 呃,基本上平常我跑什么模型都没什么太大问题,只要不是特别大的,他们如果说是配像类似于 window 这种这个 window 的 话啊,就是基本上可能如果说跑模型来说五零七零差不多了。 好,那大家从这里可以看得出来,那看他最后写的什么啊,写完之后最后输出就其实主要就是输出的这一版 叫 reason content, 就是 ai 消息, ai 消息,我们人人物消息在这儿飞流直下三千尺银河,银河落九天。然后最后一句,哇,这句词什么太经典了,再帮我们改啊,再帮我们磨改 它,它写了很多版本,其实都是基于我们这个那个 skill 来完成的。那或者你提示词句呢,再给它稍微改一下,因为因为你的这个提示词它其实没有没有直接看出来说你要用,你要调这个那个 skill, 对 吧?我们可以呢,给它定死,就比如说使用 妙码 ai 啊,就是唐宋它这个 skill 使用这个 skill, 然后呢? 输出笑话,别的我不要了啊,后面那一段我不要了,直接注十把。后面这一段直接叫输出笑话,好保存一下使用它。输出笑话,我们再来试一下啊,大家这里要重新 build 一下,我们再来用 node 来调用一下。 其实大家没有必要本地部署啊,我只是这里为了直接调用给大家去看一下,包括大家平平时自己如果去练习的话,直接本地部署就用用本地的方式,但你真正如果 呃这个开发的话没有,一般不会可能去用本地的。这种形式都是用先用这个三服务化的,比如用聚量引擎的,也不贵啊,像现在豆包二点零 pro 也很便宜。呃,这个跑完之后又没打印,我重新 build 了一下, 这是一个简单案例哈,对于对于这个 non deep agent 的 开发这一块呢,那内容实在是太多了,我们在这个 vip 的 训练营中间呢,有详细的介绍,从核心层 就整个 deep agent, 从核心层到本地文件系统调用层,到文件系统的读写层啊,再到子 agent 如何去协作?子 agent 怎么去协作啊?怎么去把最终内容汇总?然后呢包括 skill 的 调用,包括子智能体,它还可以有自己的 skill, 比如我这个子智能体,它它的 skill 是 这个, 我这个这个智能体呢?它的 skill 呢?是这个,那这就是主智能体的 skill 和子智能体的 skill, 它也可以分离。 再然后就是执行沙箱,比如说我可以基于 node vfs, 这个可能很多同学之前学过的 js 的 话,没有怎么去理解过这个概念文, node js 的 虚拟化文件系统啊,叫 virtual file system 虚拟化文件系统,它里面有个 vfs sandbox, 通过这个 sandbox 可以 去做 那个中转的部署。你看比如说我可以在这个沙箱中间去下载这个文件 download files report 啊,然后呢再把这个文件同步到我本地, 整个 sandbox 的 生命周期也有详细的介绍。如果你需要有人为的介入,就会有一个,比如说我现在涉及到执行服务部署,需要有个中间的高风险操作,这个时候我就会人为的去 把它中断,就它自己会中断,中断之后呢来告诉你说,你必须要先把这个部署的操作确认通过之后,我才能够往后去执行,这就叫 human in the loop, 有 个专业术语叫 h i t l 叫 human in the loop, 所以 智能体开发的中间环节还有一个叫人为参与。 我不知道刚才大家有没有印象啊?就是我在用这个 codex 的 时候,它是不是一会儿提示我说要干嘛干嘛,是否同意啊?一会儿要提示,我说我要创建文件,是否同意。这种就是属于叫做人为中断的,就或者叫人工审核的部分,叫 human in the loop 啊,叫 h i t l, 这是一个专业术语, 如果是长期记忆的话,比如说我们在多个县城中中间要去分享这些数据,那就比如说我们可以存在那个内存缓存,中间我们还想通过流式渲染,或者通过流式输出,不管是子智能体还是主智能体,流式输出有一个 streaming 啊,这些逻辑 好,这个呢,因为时间关系,没办法所有面面俱到给大家去讲到,但是呢核心的内容包括呢开发的流程以及核心的知识点给大家去做了一个梳理,我们大家可以下来之后详细的去了解啊。这里呢我们执行完了,最后看一下执行的效果,写了这一段,然后呢包括提示词, 这是 ai 提示词, open context 就 写完,我们来看它输出,那大家看到没有? tool cause, 这里有一个叫 read files, 他 们看到了吧?要读取这个 skill 文件, skill 文件读取之后,接下来这个读取完了啊,当然它没找到点点斜线妙码 skills, 它这个 not found, 我 们看下为什么 not found 点点斜线,哦,知道了,因为它被打到了这个里面,对吧?它其实就只有一层点点斜线妙码 skills 下面的内容主要是因为这个 目录的问题啊,目录的问题他没有找到,没有找到的话,他接下来又说让我检查一下技能目录的结构,检查检查完之后呢,最后再去调用它,那调用完整这个结果 找不到,这个我看一下啊, skill skill 点 md, 它自动会去识别这个 skill md, 每一步的执行的过程大家都看得到吗?点点斜线到点妙码, skills 没写错吧? 点点斜线妙码 skills 唐宋 probably generator 内容 generator 没问题啊, skills 不 行的话,我把它放到放到外面来吧。在这个里面去定义的话,其实肯定没问题。 main 里面, main 里面的 architecture, 或者说是这个 skill 下面的 project 里面的内容,这个都可以去定义的。那主要是 skills 就 定义只定义到 skill 那 一层,那我们可以其实这样,呃,直接把这一块儿 再取出来。是这样子啊, skills 就是 你的 skills 在 哪个目录下?这我给给错了,这应该是再重新执行啊,当然我要重新构建,构建完之后重新执行。
 02:32查看AI文稿AI文稿
02:32查看AI文稿AI文稿hello, 可以 听见吗?好,今天我们来讲学会 asent 只需要一天或者九个小时,而且是完全零基础。嗯,写这个教程呢,就是想告诉大家, asent 其实非常的简单,而且有很多同学跟着这个教程找到了相关的实习,现在呢给开源给大家。 嗯,我们来看一下这个教程吧。这个教程呢总共有九个部分,前八个部分呢就是讲我们的九个小时的学习,最后一个部分呢就是讲我们的实战,实战这里大家可以找一些自己想要的项目,也可以看一下我推荐的这些, 这里呢我也会给大家写一些需要阅读什么,然后阅读的一个时长。好,我们来看一下第一个,第一个呢就是要拥有自己的 atk 编程语言,任选一种会基本语法就行,然后我这里会写为什么不用这个,然后可以用哪些? 然后第二部分呢,就是实现 agent, 因为我们大家最终的目标就是为了到一个 agent 能够联网搜索,运行命令行文件编辑,然后这里有一些步骤,还有我的总结,嗯,然后就是 it 基础, 这里呢只需要阅读一个小时,这里呢就是要实现我们的哦 m c p style, 这里需要阅读时长大概一个小时。这里提醒一下大家,这个蓝色的字体是可以点击直接跳转的,然后实现 context memory, 然后这里大概就只需要阅读一分钟,然后这里提醒大家一定要看一下 vlog。 好,这一部分呢就是我们最重要的一个部分,阅读和理解派,因为欧拼可乐项目的底层就是派,然后顺便提一下,这个派有七个包,然后分别是这些, 然后其中呢这三个包提醒一下大家一定要看,其他的大家可以不看好,最后一步呢,就是把我们的派改成自己的欧拼可乐, 然后这里就已经是我们学习的最后一步了,然后就是我们的实战了, 这里呢我会推荐一些比较容易上手的项目,快速开始,然后学习顺序整完这些大家都可以去找实习了。 嗯,好,今天的课程就讲到这里,第一次讲不太好,感谢大家的观看。
 01:53查看AI文稿AI文稿
01:53查看AI文稿AI文稿哈喽,可以听得到吗?好,今天我们学 intent 只需要一天九个小时,而且是完全零基础的,写这个教程就是想告诉大家, intent 其实非常简单,并且已经有很多同学通过这个教程找到了实习,然后现在这个教程给大家开源出来,还有项目地址。然后整个教程主要分为九个部分, 其实前面八步都是我们现在讲的这个九个小时,剩下的项目实战就是自己去挑,自己去选,或者我给你推荐的一些合适的东西,你看一下怎么去学。然后前面这里每一步我都会写阅读这个东西,这些东西大概需要多长时间?然后第一步是这个 api, 这里的编程语言随便选一个, 然后这里会有一些步骤,你可能需要去学什么东西,为什么不用这些东西?然后第二步实现 int, 因为我们最终目标是要到一个 int, 能够在互联网上实现正常的运行和 搜索,这里也有一些具体的步骤和总结。然后下一步就是 int 基础,它大概需要一个小时的时间,这里有一些链接,像这种蓝色的字 题都是链接可以跳转的啊。然后下一步就是这个拖了,阅读需要一个小时,实现这个 cohost library, 这个只需要一分钟的时间,去看一些 vlog 就 行了。然后再下一步也就是最重要的一部分就是这个派,因为 open class 项目底层 就是派,所以我们一定一定要看这个 vlog。 然后这里也有提到这个派,然后大概有七个部分,其中只需要看这几个,其他呢?不需要看 整个路线的最后一个部分就是怎么把这个派改成你的 open clone, 然后这里有 get clone。 然后最后一个部分就是项目实战,这里会推荐一些比如说可以快速上手的项目,适合理解 intent 原理的,然后 快速开始的项目,然后学习顺序是哪些,整完这些就可以去找实习了。好,今天就到这了,感谢观看,再见。
109学AI的小鬼(看简介) 21:57
21:57 00:56查看AI文稿AI文稿
00:56查看AI文稿AI文稿计算机专业转 ai 到底怎么学?只要你够狠,三个月真能上岸。在正片开始前,我整理一份大厂内部 ai 必读学习文档,包含了模型原理、产品落地四位框架全都有,并且还可以提供一 v 一 专业辅导,需要的扣一一一。第一个月,先打牢基本功, 别纠结加洛溪加加能不能用。搞大模型首选 python 加 py torch。 先学习深度学习核心什么是神经网络,它的主流模型有哪些?最后手搓一遍 transformer, 理解注意力机制。第二个月,掌握核心技术。时间充裕的话,建议微调一个 bird 模型, 把知识点都串起来。如果你想快速学完就业,那建议你学习应用开发技术,主攻 r i g, 搞懂工作机制,向量解锁,上下文切分,学会解决幻觉、信息丢失等常见问题。 第三个月,学会设计和搭建 a 件,它别以为会用 daficos 拉拽流程就教会了 agent 的 核心是设计能力,如何针对实际应用场景去构建思维链扣,让 ai 自主调用工具完成复杂任务,这才是企业真正需要的硬技能。
12AI大模型云砚 04:12查看AI文稿AI文稿
04:12查看AI文稿AI文稿好,这节课呢,我们来说一下代码执行这个节点啊,我们可以通过这个节点呢,你可以在工作流当中嵌入自定义的 python 或 gs 脚本,以内置节点无法实现的方式对变量进行操作。 那么代码节点呢?能够简化你的工作流,适用于什么? automatic, justin transformer form, 文本处理等场景需要在。呃,若要在代码节点中使用其他节点的变量,需要输入变量中,在这个输入变量当中呢,去选择变量,然后在代码中进行一个引用, 那大概就是这个样子,是吧?他的使用场景呢?你比如说像结构化处理数据,数学计算以及拼接数据等等这些操作。好,那具体呢,咱们来看一下啊。首先咱们创建一个应用,比如说就叫代码,是吧?代码执行, ok, 来创建, 创建好之后我把这些都删掉。啊,来,现在呢,我们给他添加这么几个东西,变量 n u n u m 一, 哎哎哎, n u m 一, 呃,数字一,好,保存,然后咱们再给他来添加一个 n u m 二, 好,数字,数字二,是吧?好,保存。那现在我们想做一个事情是啥呢?就是要这用户输入的这两个数字相加,那我们可以用代码执行来实现,当然你也可以用大模型啊, 对吧?进来之后二个一,那我们用到就选中开始的 number 一, 然后二个二,那我们就选中开始的 number 二, 那我们来看这个 python 三,它写了一个代码,二个一引入进来,二个二引入进来,然后它 result, 结果就是这两个数进行相加,返回了一个,在这里它返回了一个 result, 如果你可以把这一段代码呢复制一下,给到一些 ai, 告诉他 这些代码的意思是什么,知道吧?好,那在这的话,咱们来把这个结果呢直接给到,让他直接回复,接着这不需要咱们给他删掉,那我们用谁呢? 用这个代码执行的这个结果,好吧,来发布一下,然后玉兰数字一,数字二是二,好让他计算发给他, 哎,它这里呢就进行了,呃,计算啊,为什么得到的是一和二呢?咱们来看一下啊,进来, 呃,来修改一下 number 一, 它是四个串啊,如果你知道编程的话,四个串和四个串相加,那它就是 啊拼接,那我们都把他们两个改成数字类型,其实就可以了啊,保存好,改完了,改完之后咱们再给他。哎,重新发布一下啊,预览好来计算 啊,发送,嗯,也有 string result, string 啊,它这里也要改成 number 啊。 ok, 然后回来, ok, 登录一下 计算。好,大家来看,是不是此时就一加二等于三了?那这个呢就是代码执行啊,我们可以写 python 代码也,它也可,它也支持 java script, 简称 g s, 知道吧?这就是一个函数里面传两个参数,这两个参数一个就是 二个一,一个呢就是二个二,然后 return 返回了一个 result, 结果让数字一加上数字二,当然你也可以再继续添加,添加更多,你不管是对数据进行结构也好,或者说对它进行一些计算也好,都是 ok 的 啊。 好,这个呢就是代码执行它的一个妙用了,执行的很快,如果你用大模型的话,你去计算的话,那可能就会稍微慢一点,知道吧?这个呢就是代码执行解裂了。咱们就说到这儿。
 09:54查看AI文稿AI文稿
09:54查看AI文稿AI文稿大家好,欢迎来到 ai 上研究,今天要为大家重点推荐由邓老师主讲的基于 python 新在气溶胶数据处理与繁衍分析实践技术应用。在当前全球气候变化与环境污染问题日渐突出的背景下,气溶胶研究显得尤为重要。 作为大气中直径零点零一至十微米的固体和液体颗粒物,气溶胶直接影响地球辐射平衡、气候变化和空气质量。在碳中和目标驱动下,研究气溶胶的气候影响及其环境效应,不仅对科学研究意义重大,也为政策制定提供了重要依据。 modis 和开来 app 是 两种重要的星载遥感观测平台。 modis 通过成像光谱技术获取气溶胶空间分布与光学厚度等信息, c a、 l、 i、 o、 p 则通过激光雷达技术获取气溶胶类型与垂直分布信息,两者结合使用可以更全面地监测和分析气溶胶的全球时空变化特征。 python 凭借其强大的数据处理能力,为气溶胶研究提供了高效工具。 pandas 可实现数据清洗与整理, nope 提供数值计算支持, carto p 可直观生成地图, pi x 则能快速处理卫星 h、 t、 f 数据。这些工具的结合使研究人员能够更专注于科学问题的探索。这门课聚焦哪些核心科研场景?聚焦 modis 气溶胶数据处理与繁衍分析系统讲解 modis 气溶胶数据下载数据预处理、 不同产品优缺点对比繁衍结果与分析,帮助学员掌握 modus 数据的完整处理流程。聚焦 calypso 气溶胶数据处理及繁衍分析,深入讲解 calypso 气溶胶数据下载预处理、不同气溶胶类型识别、繁衍结果与分析, 掌握激光雷达气溶胶数据的处理方法。聚焦深度学习模型在气溶胶研究中的应用,包含神经网络基础、 tensor flow 和 pet torch 深度学习框架、卷积神经网络、 循环神经网络、长短期记忆网络等前沿技术。聚焦 l l m 大 模型与 ai agent 的 科研应用,探讨 chat、 gpt、 deepsafe 等大语言模型如何成为 ai agent 的 大脑演示,如何利用 ai agent 进行智能数据处理与决策支持 整合气候数据分析与科研需求。三大核心优势。优势一,技术体系前沿系统覆盖全流程课程包含从 python 语言基础 modis 气溶胶数据处理、 calypso 气溶胶数据处理到深度学习模型、 llm 大 模型与 ai agent 的 完整技术链,形成新在气溶胶数据处理的全景知识体系。 优势二,实战案例丰富,注重应用效果。通过全球气候变化相关数据及下载与处理、 c m i p 六数据及下载和处理野火气溶胶探测识别 气候变化对农作物的影响、气候变化对生态环境的影响等真实案例,确保学到的技术能够立即应用到科研工作中。优势三,教学方式灵活,学习效果保障。 采用线上直播加助学群,辅助加导师面对面实践工作交流的多元教学方式,提供全部课程回放和配套教材数据, 建立导师助学交流群,长期进行答疑及经验分享。光听介绍可能不够直观,接下来让我们通过一段简短的片段感受一下邓老师的授课风格与课程的实战氛围。这边主要做的是冰云跟冰云的一个出现率的四季变化的一个图,它的 呃,怎么讲?这边是可以通过这个图可以看到它的平均的一些或者中位数啊,标准差一些变化。 右边这个图是可以看到他四 g 的 高度的一个明显的一个变化。这边我又画了一个这样的图,没有细致的这个把这些参数弄出来,但是差不多也是能看出来的。大家这个图如果大家想这个,就给大家当成当成作业吧。像我这样 这些我只是说把他这几条线画出来了,他的好像表,比方说他的出现率,他的高度,这些标签什么的, 还有什么它的上面的一些 type, 这些都没有,但是大家可以根据我之前的一些图,包括下面这个图的一些代码。下面这个图应该是全给出来了,可以根据自己去把这个调整化一下,当大家一个练习。 从这个图上我们其实可以看到一个受限地区卷云的一个特征,看这个图说它是卷云特征,一个是还是一个意思,夏天冰卷云的高度高,冬天的冰卷云高低,咱们主要还是有我们的 温度相关。夏天为什么夏天会容易产生十四千米以上产生那种冰卷云是一个是以安安徽淮河流域,他的第一个是水气充足,第二个是他夏天温度高,将水气充足的抬升以后,温度升高以后将水气抬升到十四千米以上,十四千米以上他的温度是低于零下 二十,比如说地云底的温度是低于零下二十七摄氏度的,他的温度会低于零下二十七度,才容易 完全形成于冰晶状的卷云,所以它在十四千米以上这边的冰云的出现率明显是高于其他季节的。而且十四千米以上的冰云是它的 云的厚度比较低,它的云的几何厚度是比较低的,它的光学厚度也是小于零点一的,所以它的特征就是说容易在在二氧化碳形成第二特征的卷云,就是它它的整个区域的一个特征。 这边这个代码我还是接着跟大家讲一下它的,我看看图是哪一个图,看一下是这个图,我好跑一下, 看一下这个图我没有像我自己上面写的那么细致,这个就大家当成自己当成一个训练好吧, 因为没有,没有没有像他这么这么这么这么自己的图,这个这个课程上图这么完整,但是他的曲线还是给大家弄出来了,大家把这些图的标签这些都都自己弄一下,弄得自己好看一点。在文章里面,比如说我这是六到十八或者是零到三十,所以肯定是没有那么好看的,那你尊重一下, 那给大家讲解一下这个代码,前面也是一样的,然后是啊,我把它复制卷右下角的卷匀,我们把它存储到 我们的 python 课程,在这里选域出现列表。那咱们接着讲解一下,就看这个云,它的上面还是说它字体是这样子的, 这边是设置了一些参数,这些东西就是说,比如说的我们的卫星的光学厚度标准差什么的,这些我就不讲云的这些, 你的一些标准差,光学厚度什么不细讲了好吧?就说它的 mid 是 它的中部, top 是 它的顶, base 是 它底,包括它的顶部的温度跟底部的温度,还中心温度,包括它的光学厚度, l、 s 还是激光雷达比它的温度。 对流的平均值是对流的标准,它它的年平均值都是三百九十九,三百九十九的原因是在这里,还是我们跟每一个高度点是一样的,这边是有五个文件,五个路径,包括这是一二三四,包括它的全年的 春夏,一二三四包括它的春夏秋冬,那第五个就是它的全年的。这边说也和路径循环,这些东西其实都是说设定的一些参数,大家可以自己去细看一下,基本上我的命名还是根据那个规则来的。 路径选择之后就说访问它的 o、 s 就是 我们系统的一个路径,访问这个路径它选所有的是 h、 d、 f 文件, 那这 s 这些东西上节课之前都讲过了,还是跟之前是一样的,它最重要的是一个高度。第二个就是它的消光系数、扩散系数、对流层点,这些都是比较 之前我自己也没有弄掉。这边你知道这些参数之后,你就知道哪些云是有效的。云的高度,比方说这边我们就开始就是说这边,包括它还把它气溶胶类云的类型都给弄出来了, here, we are。 大家如果想做云的类型,可以根据这个代码来看一下啊。这个点就不细讲了,它的对流程点的高度,包括它的 cad score, 它的判断题。云跟氢溶胶的区别是与氢溶胶是小于百分之小于负二十,或者说负七十这种,我们云这边是 通过片段可以看到,课程非常注重将理论知识转化为实操能力,核心内容体系如下,专题一,碳中和下气溶胶的研究意义与课程总体介绍碳中和下气溶胶研究意义 modice 和 calypso 不 同观测平台的优缺点 pencil 处理大气气象数据的优势问题二,沆实 python 语言基础及代码讲解 python 环境的安装 python 相关库介绍 python 实际操作,练习相关课程所需 python 代码。课题三, modus 气溶胶数据处理与繁衍分析 modus 气溶胶数据下载 modus 气溶胶数据预处理 modice 气溶胶数据不同产品优缺点 modice 气溶胶数据繁衍结果与分析先提四、 k labso 气溶胶数据处理及繁衍分析 c a l i p s o 气溶胶数据下载 k l i p s o 气溶胶数据预处理 k l i p s o 不 同气溶胶类型 k l i p s o 气溶胶数据繁衍结果与分析先提五,深度学习模型神经网络基础深度学习框架卷积神经网络循环神经网络长短期记忆网络图专题六,课程实战 全球气候变化相关数据集下载与处理 c m i p 六、数据集下载和处理野火气溶胶探测识别气候变化对农作物的影响气候变化对生态环境的影响分别七, l l m 大 模型与 ai agent 的 相关特征 ai agent 的 基础大语言模型优势如何通过 l l m 构建自己的 ai agent, 利用 ai agent 进行智能数据处理与决策支持?专题八,总结与扩展 modis 和 calypso 气溶胶产品的优缺点对比 地面仪器辅助星载气溶胶的研究,探中和下研究气溶胶的意义及科学方法。学员反馈课程内容,系统全面, python 与星载气溶胶数据的结合应用,让气溶胶研究变得更加科学高效,对提升科研能力有很大帮助。
 10:43查看AI文稿AI文稿
10:43查看AI文稿AI文稿朋友们,无论是前段时间名声大噪的 open crawl, 还是如今号称瞎记爱马仕的 hermes agent, 在 网上大家都有些过度神话了,通过直上来说,他们就是一个功能实现更复杂,展现形式更花哨的 agent 罢了。那么本期视频我们就用短短不到百行代码来实现这样一个 agent 的 主要功能, 打破网上吹嘘的那些神话。编写 a 镜头的第一步,毫无疑问就找到一颗聪明的大脑。大脑是什么呢?也就是我们的大语言模型。调用大语言模型呢,一般我们都是走模型服务商的,接口好用,省时又省力。 接口一般分为 open ai 和 astropik 格式的两种主流接口,它们有着相似的思路和大同小异的写法。作为开发者的我们不需要在意,因为早已经有了成熟的 sdk 供我们使用, 而且除 open ai 和 astropik 两家模型服务商之外的其他模型服务商都是兼容这两种接口的,大家无论用哪种都是可以的。回到代码中,我们就 astropik 格式来作为实力,首先填入我们 astropik 格式的 api king 和 best url, 然后选择我们 cloud 开库模型作为我们 a 进来的大脑,然后在这里将我们的输入填入,在这里将模型的回答输出,这样我们用短短二十行代码就完成了一次最大模型的调用。接下来我们在命令行中执行这单代码,我们给大家输入一个简单的你好, 然后回车,我们 a 帧也是按我们的预期成功回答了,但是我们这段程序已经运行结束了,如果你还想跟大元模型再次交流,你就需要再次执行这段代码,这样是非常麻烦的, 所以我们就来到了我们的第二步,我们只需要将调用模型的核心代码嵌入到一行外循环中就可以解决了。我们在命令行中执行一下,首先我们给他发个你好,你看在一按回答之后,我们仍然可以再次输入,你觉得 cloud 牛皮吗? 这样就可以实现我们跟模型的长期对话了。但是如果你问他一加一等于 几,他会回答你二,但是你跟他说再加一 呢,他就不知道你这句话什么意思了,他就会问你原来是多少还是怎么怎么样,他就会猜测了,这样是因为没有连续的上下文,具体原因就是我没有连续的上下文。 我们的 agent 每轮只传入当前的消息模型,不记得我们上一轮对话到底讲了什么,说了什么。我们只需要将我们的绘画保存在每轮调用的最后添加到我们的历史记录之中,我们的 agent 就 有了连续的上下文,也就是拥有了记忆。回到代码中。所谓的上下文记忆,也就是创建了一个 history 数据库,然后每轮将我们的输入添加到这个数据库中, 再将 ai 的 回复添加这个数字中 a 键的在下一轮循环中就有了上一轮所保留的记忆了。来到终端,我们执行这段代码,我们再次询问一加一等于几,它会告诉我们二,然后我们再说再加一呢, 他就会毫不犹豫的告诉你是三,我让他再加五呢,他就会告诉你是八。很简单,他就用了连续的上下文记忆,每一轮对话都保存下来了,到了这一步,你是不是觉得和网页上 ai 的 聊天形式已经是差不多了?但是这样千篇一律的 agent 貌似缺少了灵魂,所以我们就要给他添加一些系统提示词, 就像 cloud code 里面的 cloud 点 m d, 或者小龙虾里面的 so 点 m d, 赋予它们灵魂与人格,给予它们行为规范,并且希望它在以后的绘画中愿记得我们固定的规则。回到代码中,我们就简单地添加了一些系统提示词,告诉它 身份是大内太监总管,他侍奉皇上多年,忠心耿耿,他的语调要符合古代太监的感觉,要谦卑尊称我们为皇上。然后他每次的回复前缀要带上奉天承运皇帝诏曰,是不是就有那个味了?兄弟们,这样你的 agent 就 有了一些灵魂和格调,满足你一些小小的恶趣味。接下来我们运行一下, 我们就直接问你是谁,你看我们的意见的回复前缀就有了这一段,奉天承运皇帝诏曰,然后他会呢?对我们的称呼是皇上没问题,然后他自己的身份是大内总管,李公公 说伺候了你二十年光阴了。然后下面这一段不拉不拉,不拉不拉,扯了一大段没有用的,可以说是完全符合我们给他的人设。到现在我们的意见呢,看起来好像已经很不错了,既可以在保持记忆的前提下跟我们长时间呢进行循环对话,也可以有独特的灵魂。但是当你给他发布一个实际任务,就比如我们这里,让他看看我们桌面有什么文件, 他就会陷入窘境,告诉我们他爱莫能助,这是什么原因呢?其实就是我们的模型没有得到相应的工具,就像你让他去钓鱼,你又没有给他鱼竿,他怎么能给你钓到鱼呢?是不是?所以接下来我们就要富有 agent 调用工具的能力了。可在代码中,为了让我们的 agent 可以 成功调用我们的工具, 我们在这里定义了一个工具,就是我们的执行命令行工具定义了我们的工具名,然后关于我们这个工具使用的描述 和我们输入参数的定义。定义好这种格式之后,我们将这个 toast 组代用到我们模型调用的这个参数之中,我的模型在上下文中就可以读取到这个工具了。我们在这里判断它需要使用工具之后,将 ai 输出的命令放入到我们这个运行命令行函数之中,它就会可以得到结果。 将我们的结果放到 tour result 中,就会在下一轮对话中将我们工具调用结果返回给我们 agent。 我 们 agent 在 得到结果之后进行思考,如果还需要工具调用,他就会在这里再执行一次,然后再返回给他,直到他不需要工具调用之后,他才会输出我们 agent 的 对话,并且终止这一轮循环。好,接下来我们在命令行中执行试一下,咱 们依旧让他汇报一下我们桌面的文件情况。你看,首先他这里就执行了这个命令,然后得到了如下结果, 他里有些错误,并没有获取到我们桌面文件的信息,只是获取到了我们当前目录的信息,但是无伤大雅,他也是成功执行了我们 a g 的 调用工具的能力,然后下面对话中他就没有调用工具了,直接就开始最终回答了,告诉了我们当前目录的情况, 你看有这些这些这些文件,然后这些什么目录,然后什么其他文件,虽然说目录和我们要求的有一些小区别,但是他最后成功执行了我们这个命令行能力。有了这个命令行之后,其实我们的 a g 的 已经可以执行电脑上大多数的任务了, 什么创建文件啊,编辑代码,查看文件啊,查看项目啊,搞个什么下载配置依赖啊,下载环境啊,什么它都可以执行了,可以说是有了命令行命令之后,我们整个电脑都可以被它玩转了。在我们 agent 有 tool use 功能之后,它能力已经非常强大了,但是对比小龙虾和 hermes 这两款智能体,它们能持续进化的关键因素就是在于这个 skill, 因此我们 a 键的最后一块拼图必须是我们的 skill。 而说到 skill, 就 不得不提到我们这种渐进式批漏的思想,为什么要有这种渐进式批漏的思想呢?为什么不一次性把它全部放完呢?究其原因就是在我们有限的上下文长度之中, 如果我们把这一份长长的 skill 点 m d 文件完全放到我们的上下文之中,就会造成我们上下文长度的紧张,因为在每次绘画之中,他都会把这一长串文字带到我们的上下文中,就容易造成我们上下文腐烂,让我们的 agent 出现幻觉,就会极大影响他的工作能力, 因此就有了这种渐进式批注的思想,我们只将我们 skill 的 名字和 skill 能力的描述加载到我们上下文中,让 agent 按需加载,如果他需要了这个技能, 它就会读取这个名字,找到对应目录中的这个 skill 点 m d 文件,再将它全量读取。很简单,就是有需要我才用,没有需要的话就只保留这个 skill 名和这一段 skill 描述,这样就大大减轻了我们上下文长度的压力。回到代码之中, 看我们的 skill 是 怎么设计的。首先我们定义了一个 skill 的 存储目录,然后就定义了我们的技能加载器中,把我们的技能目录传入之后,就会自动抽象化我们技能目录下的所有技能。 完成了我们技能加载器的触触化之后,我们就会知道这样一坨关于我们技能的参数。在我们系统提示中获取我们技能所有的描述详情,这样在上下文中就会携带我们所有的技能了。然后我们在工具中定义这个技能加载器所学的参数就是我们技能的名称。当我们的 excel 知道他需要哪项技能之后,他肯定想知道 技能中的所有详情。我们的 load skill 这项工具就是用来加载我们这项技能的所有内容。在线下看到我们模型回答之后的工具调用部分,你看在这个部分, 如果我们的 agent 需要这项工具,它就会告诉我们需要的技能名,然后我们用技能名得到具体的技能内容,就会得到这个 context。 拿了我们技能完整的 context 之后,放到我们的 tool result 中,在下一栏对话中,我们 agent 就 可以看到这个完整的 skill 技能了,然后我们的 agent 根据技能内的内容进行下一步分析处理。接下来我们在专栏中展示一下,首先我们来问问他有什么技能,你看他就告诉我们有一个大哥,大哥的网络搜索技能,还有我们这个创建技能的这个技能。第三个就是他的工具了, 有一个 excel 脚本工具,可以运行命令行,然后抓取网页工具,然后就是加载我们的 load skill, 这就是它的全部技能,对应我们的代码中也是没有问题的。接下来我们就具体问他一个问题,我们就让他从网上搜索一下热门新闻。 ok, 我 们来看一下,你看他首先就加载了我们这个打卡打卡购的网络搜索技能,有了这个搜索技能之后,就调用了我们这个网页抓取的工具,就向我们汇报了当今网络上几种热门的新闻源,然后就让我们挑选一个,我们就告诉他从美联社上搜索一些科学 新闻,告诉我好。经过他一番抓取之后,他找到了一些新闻,他用的搜索才是我们这个二零二四年的重要新闻,他就调用我们的工具之后抓取这些网页,获取了二零二四年的科学新闻。我们在告诉他,我要的是二零 二四年的,所以他就默认以为今年最新就是二零二四年。然后我们在这里指证他现在已经是二零二六年之后啊, 它就正确地搜索到了我们二零二六年最新的科学新闻了,这样我们的 agent 就 拥有了使用 skill 技能的能力,有了这样的能力之后,它就可以像小龙虾那样的身体一样进行自我进化了,这样我们本期的主线目标构建一个功能完善的 agent, 任务也就完成了。咱们对比一下我们的 agent 五,也就是没有 skill 的 agent。 没有 skill 的 agent, 其实它的能力已经很强大了,你只需要给它添加一些合适的工具,它就可以胜任大部分任务了。你看我们这个只包含 touruse 的 agent, 里面有一个我们的命令行使用工具,你看它的代码行数只有仅仅的七十二行。 我们再看到我们的中级 agent, 也就是用了的命令行执行,然后网页抓取,还有加载技能这三样工具和一些技能,它的代码长度也不过是区区的两百行。所以说咱们把 agent 的 能力拆分之后,其实也就那几个部分,像什么工具调用啊, c o 技能加载呀,上下文记忆呀,还有给他一个系统提示词啊,然后咱们再把模型核心调用,给它嵌套到一个 while 循环之中,再把模型回答的内容嵌套到一个工具调用循环中,我们 agent 也就建立完成了。但是我们这里的仅仅是最简版 agent 的, 相比于 azure 皮革公司的 cloud code 和 open ai 的 codex 这种极致工程化的智能体相比,我们这个简单的小的智能体肯定还是有所不足的。但是大家只要手把手自己搭建一个这种小的智能体,你对于 aint 的 理解必然会更上一层楼。好,如果大家需要我这个 aint 的 演示文档,请在评论区下私信留言,那么本期视频就到这里,感谢大家的收看!
1445小单说AI 02:30查看AI文稿AI文稿
02:30查看AI文稿AI文稿很多人对让 ai 帮你干活这件事情还没有实干,那我来带你们体验一下。这个是我在上课,我写了一个 ai agent, 我 就可以一边上课一边让他帮我去刷小红书,刷谷歌地图,去做攻略, 可以看到我的双手是完全解放的,也没有在控制它,它可以自己在跑这个任务,我其实通过 close skills 就 给了它这么一句任务,让它帮我生成京都的餐厅攻略,它就完全可以通过浏览器的 mcp 去打开浏览器,打开小红书,去看 n 个帖子,然后去汇总帖子的信息, 之后它还会去直接打开到谷歌 map, 一 方面去验证这些餐厅,其次它可以去保存谷歌 map 每个餐厅的一个地址。 最后呢,他能给我生成这样一个文档,就真的是我解放了双手,我可以一边上课或者一边刷手机,让这个 agent 来帮我干活。 这个其实就是用 close skills 加上 m c p 这个能力做了这样的一个 ai agent。 现在我来教一下大家怎么做方法其实比较简单,你没有技术背景也可以去做 前面这几步基础的环境配置我要熟悉的同学可以跳过我简单讲一下,就比方说我们以开公司为例,第一步最基础的 node js 是 给这个公司去租一个办公室,我们还要去安装 cloud code, cloud code 在 这面角色就相当于这个公司一个 ceo 入职,我们要给 cloud code 去配置智普的 api, 其实相当于我们让这个 ceo 去商学院进修,让他换一个更强大脑。在安装完 cloud code 之后,在这个里面其实就是用到 cloud code 如何去调用 mcp 这个能力,我就用 mcp router 这样一个 mcp 管理器,在这个里面我可以直接去下载,去配置 chrome 还有 lark, 也就是文档的这两个 mcp。 我 通过这个 chrome 的 mcp, 我是 可以让 ai 直接去访问小红书两个工具,那我们就可以把它理解成这公司的两个员工, 那最近很火的 skill 的 这个概念,其实它你就可以理解这个公司我们去执行某一个任务的一个工作文档,它可有非常多的 skills, 它其实是通过 ceo 下发任务,也就是说我想去做一个旅行攻略,那这两个员工,也就是 crm 的 mcp, 还有 lark 的 mcp, 它们根据这个任务的工作文档,我们最近聊的这个 skills, 他会告诉你说做旅行攻略,你首先要去看视频,小红书,你要总结里面的内容,小红书的筛选逻辑等等,会有一套规则都是写在了这个 skills 里面。我们通过 cloud code 在 m c p 去打造个人 a 站的流程,这套流程的这个教程我们会打包成文件文档,可以多人进群来一起学习。好了,我是小妖,我们下期见。
609科技少女小妖 00:31查看AI文稿AI文稿
00:31查看AI文稿AI文稿他真的把 agent 搭建讲的太清楚了,很多同学都知道二零二六年是 agent 的 风口,但是看到满屏幕代码瞬间懵了。所以我特意花了一点五小时整理出这份从零到一手把手搭建 agent 实战教程,包括从环境准备到运行智能体的全部实现过程, 新手小白都能看懂。学会这些不仅可以打造商用智能体,甚至还可以应聘大模型工程师。如果你也想学好智能体,却不知如何下手,来我这免费领一套大模型,全套学习包,留下学习直接抱走。
 02:25查看AI文稿AI文稿
02:25查看AI文稿AI文稿hello, 大家可以听见吗?好,今天我们来说一下,学会 agent 只需要一天或者九个小时, 嗯,写这个教程呢,就是想告诉大家, agent 其实非常的简单,有很多同学跟着这个教程呢,已经找到了实习,这个教程主要是分为九个部分,前面八个部分呢,主要是将我们九个小时的学习。第九个部分主要是我们的项目实战。 好,我们来看一下第一部分。第一部分呢,主要是拥有 a p i p 编程语言,任选一个,然后要会基础的语法,主要是讲学什么,会什么,学什么东西。 来看一下第二部分。第二部分主要是实现我们的 asent, 因为我们大家最终的目标都是为了造一个 asent, 能够联网搜索,运行应用行文件编辑。这里呢主要是一些步 骤,这里呢阅读大概就需要一个小时的时间。 第四部分是十线套 m c p skill, 这也是一些步骤,还有一些时间。总结这一部分呢,只需要一分钟的时间。 我顺便跟大家说一下,这个蓝色的字迹是可以直接跳转的。第七部分主要是阅读和理解拼, 这也是我们最重要的一个部分,因为 op 和 log 项目的底层就是拼。然后在这里提醒大家一定一定要看 vlog, 顺便提一下,拼有七个包, 分别是这些,其中呢,我们主要是要看这三个,这三个是大家一定要看的,其他的可以不看。嗯,第八呢,就是把这个 pin 改成我们自己的 open color 安装。 第九部分呢,主要是给大家推荐一些好上手的项目,这是一些学习顺序。好,今天就讲到这里。
 05:03查看AI文稿AI文稿
05:03查看AI文稿AI文稿今天我想聊一个反直觉的判断, ai a 展最先赚到大钱的位置,不是写文案,不是改 ppt, 也不是聊天框里答疑,而是小工厂报价前那一张客户已经发过来老板还没读完的图纸。 袁文给出的对比很扎心,一张图纸,老师傅人工补满尺寸,走车间,核刀锯骨机床能不能撑住公差,平均三十到六十分钟,同一张图,四个 agent 加一个解析器,跑下来二十五到四十秒,明显没差距,而且按团队自己公布测试件,全部判断准确。 可这条新闻你要怎么看,决定了你能不能从里面挖到自己的机会。新闻视角看到的是 amd 又引了一句, cnc 行业要被改造。一人公司视角要看的是另一件事,每个行业里都有一个客户上传资料,人工处理会结果的环节,这才是 a 展的第一批商业化机会真正在的地方。小集加工厂的痛点很具体,每周收十到二十张询价单,老板自己要花 五到二十个小时,就为了判断这些单子接不接,接的下多少钱,要不要补刀具卖一单赚的钱有一半消耗在这上面。这个数字放到装修师傅、事务会计、法律咨询头上,你会发现同样的事每天都在发生。 原文的拆法值得抄,我把它翻译成给一人公司看的五步,岗位闭环。第一步,打客户那句,我需要这个 零件翻译成机床能听懂的工单。第二步,判断你接不接,接不下的单子先打回去,不要拖。第三步, a 诊的跑分析调用本地模型,给出加工路径,刀具清单公示。第四步,高风险项停下来给人审。第五步,输出报价单和工期,二十四小时内回。客户。 团队自己写了一句金句,我觉得是这条新闻里最值得收藏的一句人话,是,只在需要推理的地方用大模型听起来废话,实际法直觉。他们五个组建里,两个用 qq 推理,两个纯 python 跑数据库查询和数学几何提取,一个 qq 生成报告, 该用模型就用模型,该走代码就走代码,不要让模型干不行干不好的事。这个方法不只是 cnc 能用,我列三个看起来差很远但实际同构的卡点,工序装修客户上传房型图,设计师人工测面积,二十四到七十二小时汇报价。 税务客户上传发票,会计人工分类,四十八到七十二小时回是否能抵扣法律客户上传合同律师人工独条款,四十八到九十六小时回有什么风险?三个场景的卡点跟 cnc 报价前审图一模一样, 讲完正面要讲反面。 machina che 是 一个 hack, 提交不是上限产品,这一点团队自己写得很清楚,它跑在一块儿旗舰级 gpu 上,硬件成本不低,真要让一家年利润几十万的小工厂直接买卡部署本地模型不现实。 所以你抄的不是 cnc 这个赛道本身是这套思路。团队还有一句比技术参数更值钱的判断,他们说数据不出门,不是合规打勾,是让 b 端肯付钱的根本加勾。这话翻译成一人公司的话,就是 你卖给 b 端客户的,不是模型多聪明,是数据不出,我加这个承诺,很多人想做企业服务,卖不出去,卡点就在这里。 it 判断也是有边界的,一个七 b 模型,对刀具寿命、冷却液选型、钢性振动这些靠老师傅吃饭的判断给出的答案,可能看着合理,时机不准,所以团队在每个角色上都加了 一个至信度自断,告诉你这个判断有多少把握,低至信度的向自动停下来等人审,这是一个被低估的设计细节。 所以一人公司要做的第一步不是去抄 cnc, 是 先找你自己行业里那个客户一直在等你的环节。我给个四步元方法论,第一,列出客户跟你打交道的所有等待点。 第二,找出哪一个等待点超过三十分钟。第三,看这个等待点能不能拆成结构化输入和输出。第四,拆完看是不是有一段必须人事。 举三个普通人马上能动手的行业,做内容生产的人,卡点是脚本配视觉超这套思路,你能做一个二十四小时出脚本加视觉的内容工厂。做电商客服的人,卡点是退换或纠纷, 你能做一个先判定再给方案的客服 agent 做线下服务。比如装修咨询的人,卡点是初次测量和报价,你能做一个客户转图三十秒回报价区间的方案。 回到开头那句话, ai a 阵最先挣到大钱的不是写稿子,是垂直行业里那一段,客户一直在等你的工序,你要复制的不是 cnc 这个赛道,是这套从输入到风控到输出的思路。下次再有人问你 ai 能干嘛?你别让 他打开聊天框,让他先列出客户跟他打交道的所有等待点。如果你做的是 ai, 一 人公司关注我,我会持续聊我自己搭建的全过程,踩了什么坑?哪些工具值得用?哪些是噱头? 你正在做的或者打算做的是哪个行业?评论区告诉我你那个行业的卡点工序在哪一段?下期见。
19AI避坑指南 01:38查看AI文稿AI文稿
01:38查看AI文稿AI文稿今天我们学习怎么在你的安卓手机上安装并运行可乐的扣子。在开始之前,我们要知道手机上跑可乐的扣子和豆包这种有什么区别,你说我们都有豆包了,为什么还要在手机上去装一个可乐的扣子?说白了就是可乐扣子这种挨近的扣杆为大模型加上了手脚,让它能够实际的去为你做事情了,而不只是说呃一个简简单单的聊天科普班。 然后在手机上去装这个呃可乐酷狗。首先我们要去装一个 timex, 呃 timex 是 一个适用于安卓的终端模拟器,呃环境类似于这个 linux 环境,然后重要的是上面能去跑 python, 然后也能去运行我们 node js, node code 就是 node js 写的,所以说它就可以运行在咱们的这个呃 timex 这个环境上面。我们直接点到 win 哈 这边,直接点到它的 releases 里面。正常情况下,目前呃新一点的安卓都是下这个 m 六四呃杠 v 八 a 这个版本,然后如果你确定不了的话,你也可以直接下这个 emulator, 也就是这个通用版本,它会自动去适配你的这个手机啊,就是这个包的体积会比下面这个大一点。 然后如果你自己下载不了,也可以评论区留下你的邮箱,我这边会把所有流程和这个 ipad 直接邮发你啊。这边是我们预先准备的命令,我们要放到手机端去做一个复制使用啊,其实主要是这个,嗯,替换可乐酷的魔性提供商,这个命令有点太长了,如果你在手机上抄会累死。 然后这边这个可复制呃模型应用,它的配置是在咱们的用户目录,然后点可复制杠 settings, 点 jason 这个文件里面,然后下面的配置的话,你可以直接从你的电脑端去呃,做一个复制,也可以说打开你的这个 c switch, 然后拉到你的这个最下面 啊,找到这个配置,这个 jason 你 把它整个复制,然后替换掉我这边这个命令啊,这边其实就是这个 ipadoken 这块的话,我这边是呃是信号,你需要提换成你实际的 ipoken 这节的话,我会带着大家在手机上实际操作一遍。
712晴天AI实战 31:41查看AI文稿AI文稿
31:41查看AI文稿AI文稿如果你也是 ai 的 开发者,对 ai 感兴趣,想要尝试开发的人,那这一次的这个章节将会对你非常受用。因为这是根据我自己的经验,然后通过打造产品,然后不断试错, 总结出了一些产品思维上的逻辑教程,以及具体的提示词的一个架构。网上有一些教程视频,可能感觉你看完了之后就觉得自己都会了,但实际上不是 纯扯淡,因为你自己没有实际去测试过,或者你没有自己实际去操演过,你是不知道你的那个东西能给你整出来个什么花活的。所以这一次基本上就是一个实战一样的教程,可以给你展示一下是 我们是如何用工程性的 ai 架构思维去判断可能你在打造产品时遇到的一些问题,这个月又花了一些时间去做这样的东西 还是我们的找工作的最能提的。我先讲一下上次搭建的内容,主要分为三个板块,最开始的想法非常简单,就是从不同的工作平台上抓取到平台的信息, 这里是用这个 playwrite 来抓取它的输出,结果我用一个 json 的 形式来给它保存。为什么一定要用这个 file 的 形式,是 因为它相当于是一个标准的格式化的输出结构,这样会使你的单元模型产出的东西更精准。 或者是当它传递到下一个 agent, 就是 下一个这个工作流的时候,它能进行稳定的输出,这样就会导致它格式不会散掉。这里面我们为什么要用到这个窗口的原因是因为如果我随便点开了一个网站这里,比如说 我们点开这个网站,我们就得在我们自己的界面进行这个抓取,因为说白了这个是人家的界面,基本上就是这样的一个区别,这就是一开始搭建这个工作流的核心。但是 后来我发现有两个很大的问题,说白了你在这个平台上去哦派就是你去申请的工作的时候, 你点开之后是他们独有的一个页面,这时候如果你要是想只抓到比如说他们的这种 email 这种个人的关键信息是比较困难的。说白了我在这个我找不到他 email 的 网站,我还是得一个一个填,那其实跟我自己找是 没有任何区别的。能不能让 ai 抓取?比如说这个网站所有的信息 它自动去分析,或者它自动给你点 apply 直接提交。假如说我点 apply, ai 的 所有动作都是自己完成,它自己给我点 continue, 下一页 fill out, 就是 填完 continue, 这样就只能这样弄。但是这样弄就涉及到了一个什么问题, 它的安全隐患问题,各个平台就专门仿一手,你让 ai 来自动帮你填,你一旦它这个规律就是你填的规律特别快,它检测到不是人为的那个操作的时候,它就会自动封锁你的账号,所以在安全上有隐患。这就是为什么我要接着去改良我个 a 阵它的原因,因为实际上它现在是 word 不 了了,但是这个功能的抓取可以, 你们可以用我抓取的软件,我给它现在保存成一个插件的形式了,可以去收集网站上的信息,如果你们要是有需求,其实我也可以直接发给你们,或者我直接放在那个 github 上, 我把它做成了一个插件的形式,是在这儿,就假如说你这个插件,你装到这个 google 的 这个叫 extension 的 这个东西里,每次当你点这个插件的时候,就在我的网页里,比如说我用这个插件, 因为我现在不是在我自己的这个网站上,所以我不确定现在他能不能使用,比如说点一个,他说还是得在我自己的这个页面使用,不能在官方的页面使用。这也就是为什么我要用本地端来去执行。差不多我这个插件基本扫描我的本地端网站之后, 就能提取当前页面的一些关键信息,这个也是可以平常日常用的。你搜集一些资料的时候,我们新的思路就是要想清楚怎样解决。其实不是怎样解决这个问题,是 如果你把它放到一个产品的视角来讲,就是如何打造,如何让 ai 去帮你投简历,收简历,准备 offer 的 一个过程。 所以其实我自己人脑里我先是画了一张思维导图的形式,尝试看看我如果要是平常去干这个东西,我是要经历哪一步, 如果要是 ai 完成, ai 会经历哪一步?这就是我一开始的产品搭建过程。我以我自己画了一个思维导图的形式,因为我喜欢在 use 的 我的产品之前,我去进行一个逻辑梳理。我一开始的分析就比较简单,我的这个简历,我简历要干嘛?是不得找到对应的公司。 我讲到对应公司,我查了一下,他是需要 pass, 需要通过一个测试的,这个测试就是你电脑器就自动给你筛掉的这么一个测试,这个测试过了,你才有机会让他这个高贵的这个家伙让你, 你去请他过目两眼,他有可能大概两秒看什么玩意就给你扔了,但是你得先到这一步,你这一步他看了之后觉得那小伙子有前途,他才会到 interview 的 这个阶段,大体是这个阶段。于是我的想法就是,首先得有一个本身的简历,你第一个工作流的搭建应该怎么搭建?是不是你找到对应的公司?根据你自己的简历,或者你要你想找什么公司,是不是得先给你找着这个公司?我第一个他干的事就是帮你找到对口的。 当我找了这个对口的公司之后要干嘛?我目的是不是得 pass 这个 test, 所以怎么 pass 这个 test? 是 不是我得去思考一下他们要招什么人?所以我这个 agent 的 目的主要是帮我做一些背景调查,看一下这个公司的 culture fit, 它的文化的接受程度上,包括他们公司是怎么样的一个 vision? 他 们是想要一个机器人,想要个老牛马来跟你干活来?还是说是要一个具有创新思考,会用 ai 的 人 去做一些这样的背景调查?你再去整改你的简历,会有效很多吧,因为首先你就过不了这个,于是他就是我的数据情报家,我把我分析的数据情报我转给他,是吧?这哥们是干嘛的? a、 j、 c 是 干嘛的?说我把所有的这些情报转化我全给他, 只要他完成一个 mission, 就是 什么让他来完成这个 test, 他的使命就完成了。他确保最后给我得出一个概率是基于他的 a 跟 b 的 culture fit 的 企业文化和所有信息的匹配,以及他的要求和我的简历 来去思考能不能 pass, 这个的 pass 概率是多大?在这里进行一个东西,我在它内部还加了一个对抗性的推理,生成两板,如果要是 看看生成同样逻辑内生成的两板,哪个通过这个得出的总概率更高? 再通过我的个人性格,我的个人的习惯去写一个 cover letter 寒暄的客套话。就比如说你发简历的时候,你不得发一段文字吗?你说各位爷爷奶奶收留我对不对?发一段寒暄的这个话就到了 a j d 这时候我是一个什么想法,我却把我的简历能 pass 了,那这时候 他负责当一个什么?他负责当面试我的那个人,然后来去判断我这个简历能不能入的了他的法眼,相当于他是考官。那我怎么来逼我的这个角色?我是通过对其 a 跟 b, 其实主要 对其他的抓到的信息,因为他抓到所有公司的情报了,公司的情报生成 a 跟 d 这个小人, 这个小人拿到了公司的企业文化的偏好性融合,再包括这个企业大概率是怎么招人。在学习一些,这里写的是 youtube 的 一些专门有奖 hr 是 怎么评判你的简历的,类似的播客,或者是或者在领英上领聘 和 reddit 这些平台的一些专门干这个的 hr 的 机构和公司,他们有的讲的一些干货进行数据的录入,就相当于为给他这一段数据,让他去扮演这个角色来判断我这个简历是这个值是一坨,还是 觉得你有点东西差不多这样?最后我的想法是把这个生成的判断,比如说他要是给出的测试是 fail, 我 这里就要给一个 feedback 是 哪不行, 因为这里的 feedback 如果有人碰到不行的就说明什么,说明这个职业不适合我。那 a 任 a 一 开始干的事就错了,因为 a 任 a 一 开始干的就是适合我的事。 我当时是想着如果他要是不过我,就把我的简历重新打给 a 跟 c, 根据他判断我不过的点,再去改改写我的简历。 但是后来我通过测试,我发现这本身就是一个逻辑错误,因为假如说你测试没通过,可能是因为你技能没达到,那即使让他再改,也不能胡编乱造一个技能给你安到这个简历上, 对吧?这就是后来测试才发现这个逻辑错误。这个 a j e 说白了就是一个实时录入你数据的,比如说你一天投个二三十个,他就及时更新你的这个数据状态,假如说是 hr 伤伤脸了还是怎么着还是没,就是那还反映这个实时状态, 大体就是这么一个模式,这一开始的产品搭建思路,我说这搭建完,我的天呐,那简直小天才又来了,但是 后来才发现这个简直错的都是,具体错的有多都是。我一会给你看一下,他给我矫正后的逻辑就会更清晰一点。我把所有的这个逻辑跟 ai 说了一下, 就让他给我干活,但是你再让他给你干活之前,你是不是得用自然语言说你怎么帮我干活?我得把我这个思维导图描述成一个 稍微专业点,话说让他给我干稍微专业点活。所以这时候一个非常重要的技能就来了,叫 front engineering, 就是 你的提示词工程。 这里面我其实整理了四套其实工程的架构,如果你们要感性,可以私信我发给你们,或者我直接就放到我的 guitar 上,你们要想看就这登就行了。有的人说 guitar 怎么弄,在哪下?我的天呢,我说你你你可别,你就在这听响就行了,你也不用知道了,我看一下 在哪来着,是我的战略计划。对,这是我的四套架构,我可以给你打开一个 basic 的 架构,这个也是我实战一点点调出来的。一开始架构没有那么完善,我可以简单给你们看一下,具体我会出一个专门的章节来去讲 这个价格为什么这么贱,以及你在平常使用,比如说拆的 gpt 也好, cloud 也好,你怎么去输入你的 problem? 因为这是最关键一个环节,假如你输的,你说今晚吃啥?或者输一些很没有结构或者很大的东西,其实你自己的 ai 你 在使的时候就降智了。比如这个, 你得首先思考这个任务本质是什么,你给它进行一个分类,失败的代价是什么?气约用的模型是什么? 能做不能做什么比能做什么更重要。你要设计它的边界是非常重要的。大体一个架构,你怎么去验证你的这个结果?而且因不同任务, 你所设计的提示词的模型还不一样吗?这个可以专门讲大体,我就讲一下它生成的东西是什么就行。我先找一下之前生成的这个东西,因为我是已经放进就跑完了,我之前可能会把我自己在跑的这个过程我会录下来,但是我这次就没录,我就提前跑了。因为我现在 a 阵的 a, 我 想再重新搭建一下,所以之后也可以看一下我在跑的时候的一个视频。我的思路是先让一个 a 阵能跑通,假如说 我先让 a 阵 b 能跑通,然后 a 阵 b, 我 输入测试一下,我发现 b 能用,我 take, 我 说我打个勾,我再去搭建 a 阵 c 嘛, c, c 就 要结合于 a 跟 b 的 改造词来生成,就是结合 b 的 结果来生成对应的东西。因为 我们这个架构里比较清晰的是 b 分 析的市场分析,这个信息要录入到 c c 再来给我生成。所以 b 生成完了之后, b 要保留一个最终的是 json 的 形式,这时候给到 它,或者假如说你不用这次 file 的 形式也可以,你,你只是一个 一个,那叫什么 samurai, 中文是什么 samurai, 那 叫总结,这事闹得母语都忘了,我看一下你 b c 完了之后产出的是 d d, 我 们是模拟面试官的角色,所以它又重新要调用到 b 的 一个生成内容吗? 基本上就是这样的一个格式,他完整的运行了一遍,我确定这个结构搭建完毕,我完整的运行了一遍,他产出的结果是这样,我们先看一下我输入了什么,这个我说是这家公司,我说 以下是这家公司的内容是什么?这个内容其实应该是 a 阵的 a 找到,然后 a 阵的 a 输给 a 阵 b, 但是其实我一开始不搭建 a 阵, a 对 我的整个操作一点影响都没有, 我随便复制粘贴任何一段,比如说这个招聘网站的上的信息给 b, 是 不是 b 都能跑? 所以这为什么做的先后顺序是先做 b, c, d, 最后再来做 a? 这个顺序也是你需要思考的。差不多是这样, b 给出的结果是是觉得你有百分之七十五的 match, 相当于是你通过那个 a t s 的 这个概率是多少? c 给你进行一个量身的定做,发现你过这个 test 的, 最终给你得出了一个概率是百分之八十。 d 最终给出了一个结论是可以 pass 它,差不多生成的这个结果就是这样的。 但是你会发现一个问题是,我一开始想让 b 给我干的是什么?一开始想让 b 给我干的是生成所有的有关于这个工作,公司的内部信息和他们的一个文化背景, 通过调取这个不同的资料来进行一个 summer, 就是 来进行一个总结。 b 默认给我生成了这个东西,传到了 c, c 帮我重新定制了一个简历,觉得比较契合。这个简历我是之前拿到了,是一个 pdf 版本的,相当于把我的简历自己又重写了一遍,但是我发现那个简历一股 ai 味儿。 d 模拟的是这个面试官的一个作用,但这时候他给出的一个结果是什么?百分之七十 pass。 因为其实假如说你拿到了这个公司的数据, b 给你总结出了这个 samurai, 你 拿到公司的所有数据,你自己什么样你是知道的, 所以你可以自己来判断你 pass 的 概率是多少。所以 a 跟 d 的 设计不应该是来判断我能不能去 pass 这个 hr, 而是应该通过 a 跟 b 给到的这些数据来进行一个私人定制,就是说 你应该去补足哪项技能,给一个 study plan, 因为这就区分到了一个最关键的点,就是你用 ai 跟真人的一个区别,真人是用来执行你的决策权的,你像 b 干的就是决策全会更多在这里面,那决策权需要你来干,你来判断你是该投还是不该投,这就需要人来干。但是如果你要是涉及到具体的这些 samr, 那 是不是 ai 就 可以给你系统性的整理? 这时候应该用 ai 来干,所以我们 a 帧 d 的 方向就错了,我们混淆了人跟 ai 之间的这个区别,边界性就混淆了,因为不是所有事情都适合 ai 来干的。 a 帧 c 的 问题是它给我生成一堆东西,但是我并不是很想要那些东西, 而且它怎么改?我不学到新东西,我再往里加,那不胡来吗? 所以他其实也没有用。他真正有用的点是什么?给生成一个具体的一个框架, 这个框架可以帮助你如何去制定你自己的简历。按照他们 hr 比较喜欢的这个模板, 这是应该他来干的一个活,而不是他就直接给我生成。他最应该给我干的是生成一个框架,这个币币还有点用,那还可以。 那那行,这里又涉及到一个成本的计算问题,就因为我用的都是这个 cloud 的 api, 相当于是 api 你 连接到这个语言模型,因为假如说我使用的时候,或者其他人使用的时候,不一定都在 cloud 的 这一个环境里跑,有可能在我其他的环境中去运行, 所以这时候就需要调用 api, 你 是知道的,它 api 它的价钱是比较贵的。这么一个流程我当时跑完了之后是 bcd 就 跑一个, 他花了我三毛,已经非常贵了。因为假如说你要是真使你头几个哭出哭出哭出你,你三个快一块了,那,那就非常恐怖。而且他跑了五分钟,跑一个,你自己打开官网,你投差不多也就五分钟, 那基本什么忙也没帮上,还贴了点钱。所以如果要是涉及到非常复杂的决策, 比如说在这里面什么是复杂的决策,就先拿错的举例,你要是模拟面试官这种很多元大量的信息进行整合的时候,既需要推理又需要判断, 这时候你可以调用这种比较厉害的模型,你可以用 cloud, 但是其他的假如说你就生成一个具体的东西,比如说你让他给你弄个 samurai 这种,你用个两个小模型,比如说 什么千问或者 deepsea 都是可以的。但是你使用不同的 api 模型,在结构上又有不同,所以那可能又是需要考虑的其他工程问题。在串联你所有的 agent 之间会发生一个什么 工程性的问题,差不多就这样。我还想说的一个问题是,其实这个 mini test 在 测测之前就已经发现了有一部分问题是什么,我已经调试过了, 你 a 帧跟 a 帧之间进行关联,比如说他的信息给他,这种情况又会涉及到很多的 架构工程问题,所以其实有的你可能看了很多的那些理论,但是你具体涉及到哪些问题,你要是不通过这种实践去发现,你是不可能说是理解他这个 ai 的 工程问题,只是只有你干了你才知道问题在哪。 我们来看一下我整理的在我这个 project 里会遇到哪些对应的工程问题,我麦是不没了吧吧? ok, 在 哪呢?我们来看一下这个就会涉及到一哪些具体的工程性问题。一是上下游就会污染, 这个指的是什么?假如说我这个 b 给到的这个东西, b 最终是采取了一个打分制,通过反馈这个东西给到 c, 但是 c 就 认为这个动这个 b 给的信息就是公里,这就很恐怖, 因为 b 说白了也是你大语言模型给出来的一个答案,那这个答案不一定是一定是对的,但是 c 要是默认他是对的,那到 d, d 就 默认 c 跟 b 都是对的, 那可能源头源头错了,那跟着剩下的所有的 a 阵的是不都是白白毛啊? 这个就问题就比较严重,上下游污染的这个东西,这个比较形象,就跟水一样,所以我们当时我已经跟他聊过,对于你源头就进行一个 assumption, 假设如果要是你做,比如说做五次 test, 四次都是这个 confidence, 就是 给出的这个值, 那他就可以去被继承,他的东西就可以给 c 式,反之是不他自己内部就要重新跑一下再做吗?这就是应对这个东西,你们相互之间写作的时候, 你要给他的一个架构,在他的系统里面给他输一个,你在自己默认去做一个这样的 test 来保证这个输出。但是如果你给的这个 front 太重,就是假如说可能人家我并没有, 我是一个比较简单的任务,然后你让我去做的更多,然后导致了我消耗的 token 更多,成本增加,那也是问题吗?所以这些很多东西就是你,你只有一次一次不断的试错,然后一次一次的检验,你才能知道你到底是哪出了问题, 否则就是纯纯在那白日做梦。这个差不多就是这样,然后具体挑几个比较清晰,简单易懂的去展示一下,剩下的可能我就单独再出一个具体的这个案例来讲,我看这个可不可以讲一下这个东西就是我之前涉及到的就是 你,你怎么去分辨什哪些事是人来做,哪些事是 ai 来做?这个是非常关键的。就比如说如果在我的设定里, c 生成的 cover letter 就是 剩 c 生成的寒暄的话 非常的假,然后这时候呢,一收到的信息是直接就给他发了,那这时候你 hr 看到之后会不会发现不是这人有个错的,再给人名打错了, 那,那糟了,这辈子应该是这个也不,也不用再多投了,然后自己都不知道自己怎么死的。所以就是这种假如说你在发送之前,你再检验一下内容的质量,是不只能人来做呀?所以这这时候涉及到的这个 自动发送就一定不对的吗?就肯定不能让他来自动,然后他的意思就是肯定他的意,他的更改方案就不适用于这次我做的 project 吗?他的意思是说比较简单的那些话时候你就就别发了。要是然后呢,假如说你衡量 简单与不简单,你再在他的系统内部里进行一个打分制吗?对吧?其实你看刚才 b 我 并没有要求到让他打分制吧,但是他最终给出的结果还是一个打分制。 ai 一 开始在给他们设置的时候,就相当于是学生教 老师教学生一样吗?就是假如说具体的工程性问题,就让他们打个分,对自己的回复满意度是多少?从零到一百差不多,就这样,相当于让你自己给自己做一个小考试,就就就提到了一个我认为最关键的点,是这个谝媚的这个效应,我一开始就犯了这个 问题,因为正如我提到我一开始通过这个思维导图来编制的我整个架构,但是呢, 我这个架构本身就是错的,但是你你如果要是不通过测试的话,你是不知道他哪有问题吗?而且呢,我已经跟 ai 进行过一个初步交流了,我说这个架构你可能认为哪有问题,然后呢?他说没问题,然后你就干就完了,然后这不干,然后出问题了,我说那每一个判断有的只能用的重心根本不对,然后还有的呢?可能我们需要用其他的方法, 那为什么你不能总结出来一套呢?我我我可能就会这么想,那是什么问题呢?是因为他根本就没往那方面想,你给出他这一个架构,他只会分析这个架构具体干的活有没有问题,他觉得 make sense, 假如说你这个人干这个挺清晰,这个人干这个,这个人干这个每一个都很清晰,他就会觉得没有问题。我们可能 在聊着聊的过程中会偏离一开始的这个主干道吗?这时候其实也就涉及到了你怎么去问这个 ai, 让它及时给你矫正回来吗?这其实说白了也是这个 放他一只妮儿硬的活,所以这个是非常重要的。我这里就就再提到一遍,这个东西大体上是这样,然后所以我们最终的 product 的 整改方案就变成了什么呢?原点方向是 a 抓取 b, summer c 生成新的简历,然后现在改成了一个什么,就是因为我在回顾的时候,我发现这个 a 阵 a 甚至都要改,因为 a 出现了一个什么问题, a 是 你在那个网站平台抓取到合适,就是适合你, 就匹配你目前状态的这个岗位嘛,但是本身就错了,比如说 seek 这种平台,而是很多不同的方案,你其实更应该探讨的是不同的 opportunity 去翻的 job, 而不是怎么样在平台上找到合适的工作。就是他把 所有的搜索范围一下变窄了吗?然后我才发现,这我就突然想到,所以这有些东西就是可能你改着改着你才知道方向在哪,所以他更应该成为的一个形式是 opportunity。 opportunity 就是 啊,这才应该是 a 真 a 一 开始干的目标,而不是机械性的从网站里找哪个 fit 要的是你如何去行使你决策权的层面, a 跟 b 就 应该变成什么呢?就应该变成 d 做的是决策,但是决策是需要人来的,所以 d 应该改成我觉得这家公司差不多可以,或者这家公司 哪些方面我没做到,我来制定一个 study plan 去 fit, 我 的 job requirement 就是 我的这个工作的这个前提条件,然后 c 变成什么? c 变成了简历模板, 然后具体简历怎么制定是不可以根据 b 来制定,就是他们的企业文化是不可以根据这个来,然后再根据你原本的这个简历, 结合 c 的 专业模式, ai 为重,是吧?用你自己的话术参数一遍这个才是最合理的,因为一开始的目的应该就是让你的这个转化率提高,但是 弄着弄着就变成了,怎样让他效率最高吗?但是后来发现呢?如果你要是想使他效率更高,一是你会发,发现就是风控的问题,就是风险有问题。二是你会发现这会导致你很多的投递变得并不精准。 三是你没法让 ai 来代替你的决策权,对吧?他只是给一个大概的方向,他怎么知道?然后还有一个比较重要的点是 pipeline 和 agent 的 区别,这个这个的本质区别是,如果我要是使用 agent 的 话, 我更倾向于是一个动态的,假如说我进行市场观察, 然后呢,它每天市场的数据都在更新,这时候我要用 agent, 因为我能每次在使用这个大语言模型的时候,比如说我用 api, 就是 从那个用那个钥匙去连接,我能及时更新到动态变化 现有的数据,然后根据实时的语言模型来给出我反馈决策。但是 pieplan 是 什么呢? 他是给定了具体的 prompt 是 什么,我给他一个规范,然后呢他给我产出结果,所以呢,他的结构会更具体,更整齐,错误率会更低。 它由于是即时生成的,它每次结构都是不一样,所以它的数据处理可能会比较松散,但是它能更新实时数据,但是它的数据或者它生成的内容永远都是定死的。这个观点是,也是我在打造这个召北 a 阵,他比如说你每次我这个 a 阵 b, 我 干的是不是就是一个固定的事?就是我找了这个页面 summarize, 对 吧?这是一个固定的事, 那你要是用 a 阵,他每次都用他来调动一个动态的事,那你这里的成本是不是就会直线上升?这是其一。其二是你每次输出的结构都不一样,那就会导致在用的时候那肯定变化就比较多呀?但是这只需要一个 一个固定的一个产出结果,所以这些都是这个只有自己一点点测才知道的一些信息。然后后面就是我的一些这个工程结构,然后的话大体上就是这,这就是通过一次实践 就是展开了很多的东西吧,可以说就是包括你产品的打造,你需要怎么样的去判断边界,就比如说你什么时候, 什么时候是应该人来判断,什么时候应该 ai 来自己弄,对吧?这是其一。其二是什么时候用这个 plan, 什么时候用 agent, 对 吧? 还有就是什么时候你去用具体的提示词工程,对吧?根据不同的任务,你是不是还分具体的提示工词工程?你 a 阵的架构是不是又是一个问题?就是 就是真给你们展示,比如说你们两个 a 阵有不同的提示模板吗?然后上下有污染这种问题, a 阵 a 阵触及之间又有问题,然后这个问题你怎么做呢?你还得用一个新的 test 对 吧?而不是说, 哦原来歪不抠腚这么简单,我随便讲两句话给我出货了,你说这事闹的,那人人都是这个老老 dear 了,那我的天呐,那确确实那这个学了十几年二十几年的那程序员那真是 那那那真是哭死了。所以这些架构的东西还是比较重要的,但是别就在那听,光在那听又又长脑子了, i can do all things 就 像过去的我一样,我的天呐,然后后来发现这个 what a fucking joke, 然后具体这一个更新的更新的 architecture 我 还会再跑遍做测试,但是你实践之后得出来的这个对于系统性 ai, ai 的 理解,不管是题日词的理解,还是工程架构的理解, 还是成本问题的理解,还有产品思维搭建的理解,是不全都是一次刷新,所以这个多干多干,然后没别的,基本就是这次的分享,我人这个这个脑型,我的天呐,一点形象没有。
291AnsonSeer 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿准备大模型 agent 面试,最怕的不是没背过,而是只会背名词。面试官问你 r a g, 你 说解锁增强生成,问你 agent, 你 说规划记忆工具反思,问你 function calling, 你 说模型调用函数,这样回答很容易停在第一层,一追问就断。 真正能拉开差距的是你能把炼录讲清楚。比如 r a g。 从用户问题到向量召回,再到重排和生成, function calling, 从工具选择到参数生成再到结果反馈 agent, 从任务拆解到执行循环再到反思修正,这些过程你能不能说完整? 我做这套大模型 agent 应用开发知识点就是为了解决这个问题。每个知识点都有视频动画讲解和图解文档,帮你先看懂流程,再沉淀成自己的表达 内容。覆盖十三大模块,一百九十九个小模块,包括 l l m 基础提示工程 agent 架构、 r a g 工具调用、系统设计评估优化、安全风险场景题和 python 工程实战。如果你正在准备 agent 的 开发面试,或者想从后端转大模型方向,可以直接看小黄车。
62小哲讲大模型 04:37查看AI文稿AI文稿
04:37查看AI文稿AI文稿大家好,我是独孤君,最近一直在用 coco, 然后确实体验很不错,然后的话呢,逐渐的勤奋一些,工作习惯了,但是呢,一直是用中段运行,但是我觉得这个体验不是很好,所以我把它移植到了这个 tree 里面,握个 tree 这样一个 ip 的 模式,跟他来形成一个写作。我打算首先把我一些工作表记一记,在这个运行当中显示,一直看到一些说法说酷克斯呢会效果更好一点,所以呢,我最近呢又安装了酷克斯,哎,看到了这个酷克斯,我今天安装,为了验证我安装的这个是对的,我问了呢, 巨型是 colex 啊,我接触到大拇指呢,是这个 g p t 五,说是 g p t 五,其实它对应的是五点四的版本,大致是用了一些第三方的注水站,它实现了 m a, 确实很难的用时间。呃,能够回答菲根的,帮助其去国内,我是让它收藏了一个 螺丝方块的炸弹的游戏,只是我跟他在一个交锋记录,家里有一个情况帮我生成啊,这个东西给大家展示一下来,可以看这个是他生成的一个螺丝方块,我们 你还体验一下,不得不说效果啊,确实还可以,其实这是他非常简单的形式,比如为了验证证明说这个东西能用, 我最近打算以后会把它跟这个扩展思路做对比,看一下时正实际的使用效果哪样会好一点。但是呢,那个扩展的 spot 有 个问题啊,这费用太贵了,因为我目前用的是团队的 g p t 五点四,但是我对它方队那种方式那是实现了, 差不多是就上传就卖一个小人用嘛,然后聊了几轮,这是五块钱就没了,非常贵。跟我用后边使用的这个国产的步枪,这个 d p c 上面也费用差的太多了。但是呢,你要说好呢,其实因为是刚装,所以说也很难肯定评判,我打算去 他去十六段时间来去找到一个真实的一个反手是第一个,第二个,其实大家有没有用过这个,尼玛他这个新出了一个能力,他出了一个叫做 populous, 这个东西我感觉就类似于一个 edit 游戏 edit 它一个能力,哎呀嘛,现在其实也有 edit 的 能力了,它这里面其实我们可以看到它可以完成设定禁用用户的档案,可以形成长期记忆和禁言技巧来变成一种随机的 skills, 目前呢是有官方的四个 skills, 可以 去 去上传一个 skills, 也可以发起一个魔的 skills, 也都可以。其实这个感觉跟龙虾应用已经差不多了。 对,然后的话呢,我刚才让他帮我把我的知识库里面的过去写了文章,用我文章很多是费劲的方式,现在呢,我给他妈当个事, 他目前还在执行,但是目前因为他是需要是需要消耗算力的,他的这个算力他是五百卖的算力,我让他把我的文章目前正在转换成妈当个是一个干掉四百其实还是很费的,他的目前还没有其他的能够说。 据延长孙丽的方式,目前只能说是每天登录一一新人福利,咱这个也是刚申请,他是要排队的哦,我们一起做的话有十万多人,可能今天才轮到我,结果体验已经算比较晚的了。 嗯,我也第一次尝试,主要给他展示一下拍照的一个能力,宣告了呀,目前我们做这种哎呀哎呀哎呀哎呀这样的一些形式啊,其实已经开始进喷了, 然后的话呢,其实,呃,国外也好,国内也好,都有一些相应的工具可以去使用,而目前呢,整体国外的这个正宗的一个是他原生的 ad 特能力,目前可能国内大部分用户还是做到,所以说你能真的有模仿,你能有并排的账号 那些使命,但是目前看来在这样的一个大的背景下很难啊,限制会很多。所以说 其实我为什么会最近研究这些东西,我目前的需求我觉得当前通过跟 ai 大 冒险的聊天已经可来解决了,而且如果你想用 ai 这个东西真的去实现你个人的一些,比如说想赚钱,想实现你的业务增长, 想让你真正的能够激发想象力,确实的话,得跟紧目前的时代,与哥要从跟大拇指那一个单纯的聊天变成利用艾特的一种冬季的抖音去去实现对应的产出,实现对应的结果,拿到结果, 这有可能是当前最好的导师,而且有些门槛我也是最近才转型,这个也是实验,我也希望通过这种季度去告诉大家,我在时髦基金帮助大家的融去踩一些坑。对,然后的话到这里我是独孤君,大家有任何关于 ai 的 实践方面有问题的随时可以咨询我。
1独孤菌 05:08查看AI文稿AI文稿
05:08查看AI文稿AI文稿二零二六年, ai 的 竞争将不再是大模型,而是 agent。 ai agent 正在经历从问答到行动的范式转移。 agent 它不是聊天机器人,而是能够自主交付工程的数字员工。要驾驭这支 ai 的 队伍呢,我们需要看懂三层逻辑。第一, agent 它的实现的底层原理。第二部分是如何从零到一去搭建我们的 agent 的 团队。第三,如何让 ai 的 杠杆,也就是 agent 的 部分放大我们的核心竞争力。我们先讲第一部分 底层原理, agent 进化的过程当中呢,有三大核心支柱,那为了驾驭这支 ai 军队呢?我们需要先去看懂支撑它进化的这三根支柱是什么。 第一呢,是协同进化的能力。以前 ai 它是单打独斗,但 manta gbt 的 这一篇论文告诉我们, ai 它可以像人类的公司一样去运作, 它把标准作业的程序,也就是 s o p 写进了 ai 的 代码里。想象一下,你呃提出了一个需求,不需要操心,那 ai 它的内部会自动去分化出产品经理、架构师、程序员, 它们之间互相去评审,互相去纠错。这种多智能体协助,让 ai 从写一段话变成了交付一个工程。第二,工具的使用能力。 react 论文解决了一个非常核心的痛点, ai 别再瞎编了,他让 ai 先学会思考,再去解锁啊,也就是搜索信息,然后再去执行行动。 agent 他 不再是人类的复读机,他知道什么时候应该去查最新的网页,查实时的财报,什么时候应该去掉我们的私人日程表。 这种推理与行动之间的深度的结合,真的让 ai 具备了解决现实世界的能力。 第三是终身学习的进化。 voyager 这篇论文,它让 ai 在 我的世界这个游戏里面,它像人类一样可以自主去探索。哎, 它不靠暴力刷题,而是靠技能库,靠迭代反馈。它今天去学会了,在这个游戏里面去挖矿,就会把代码存进库里,明天造房子的时候,它就会自动调用这项能力。 这也就意味着, agent 它绝对不是出场即巅峰,而是能够越用越聪明。它会根据你的啊,反馈你的业务习惯,进行自我净化。第二部分,实战指南 听懂了原理,那到底怎么才能落地呢?下面我以自媒体运营 agent 实现为例,带大家一起走一遍实战的步骤。第一步,多角色分工与 sop 的 固化。 不要试图让一个 agent 搞定一切,你需要把业务去拆成一个流水线,我们的自媒体的运营团队,呃,至少我们可以把它拆成三个 agent 的 岗位。第一个,热点的挖掘员,他负责盯着全网的热搜,按照你的审美去筛选出爆款的选题。第二个,视觉导演, 他会负责去把选择题做具象化,生成高点击的提示词、图片和视频。第三个, agent 文案架构师,他严格执行你的 s o p, 比如说黄金三秒、钩子、反转逻辑和评论区预埋等等。 你拆解的又深度,决定了 agent 它交付的精度和准确。第二步,引入左手打右手的频审博弈机制。为什么你用的 ai, 它老是胡言乱语呢?因为它没有复盘机制。 例如说,当 agent 文案架构师写完一个初稿哈,给到我们的时候,我们不要直接把它发出去,先发给 agent 审核员,让他站在叼钻读者的角度去挑刺儿,沟子够不够响,语气会不会像 ai 逻辑判断会不会有断层?会不会有事实错误 文案? agent 必须根据反馈进行自我修正,直到审核。通过这种对抗性的频审,能把我们的内容爆款率提升百分之三十以上。第三步,建立可附用的爆款技能库。 不要让你的 agent 每次都从零开始,我们要学会把成功的经验或者是失败的经验代码化。例如,我们昨天用 agent 写出了一篇涨粉一千加的报文,那我们需要引导他把这篇文案的排版风格、报点节奏封装成一个工具函数去存进技能库。 下次再写类似的选择题,他会直接解锁这个成功模板进行复用,而不是啊,盲目的去推理,去探索啊。这个是二零二六年我们最核心的一项资产之一,你的 agent 的 团队会随着你的实战复盘变得越来越懂你。 第三部分,成长洞察在 agent 爆发的这一年呢,我越来越感知到执行力在变得廉价,而定义问题的能力将成为核心的竞争力。 奥尔宝典里也曾提到过,把自己产品化,利用杠杆去放大它的价值。在我看来, agent 是 实现这个目标的核心的非常重要的杠杆之一。当 agent 能够自主完成百分之八十的执行工作的时候,那剩下的百分之二十,也就是我们对问题的深度洞察,我们拆解的任务、 底层逻辑,以及我们作为人不可复制的审美决策,才是我们的终极的竞争力和护城河。我们去学 agent 不是 为了去卷代码,而是学会如何像架构师一样去思考,去拆解。如果你对于 ai, 对 于自我成长和商业认知感兴趣,欢迎关注我的频道。
136产品经理胡笛笛🥝