SealSeek 2.0什么模型
国产大模型看着热闹,实则被三座大山死死压住。第一座山,算力芯片卡脖子,高端 gpu 基本靠进口,国产芯片性能差还贵,训练一次成本能烧几个亿,中小企业根本玩不起。第二座山, 高质量数据严重缺,看着数据多,实则重负杂乱,优质中文数据少,行业数据不流通,模型学不到真东西,容易说瞎话。第三座山, 底层技术没底气,核心架构、关键算法大多是国外的,我们多是跟着改,原始创新太少,想超越根本没根基。但最近 deepseek 的 v 四大更新 真的带来了破局希望,它不仅性能追上国际顶尖水平,还直接适配华为、升腾等国产芯片,算力成本一下子降了一大半。更关键是它的百万级超长上下文,能吃下海量长文本,还开源免费,让中小企业也能用得起顶尖大模型。 一边是三座大山压顶,一边是 deep seek 这样的突破,你觉得国产大模型能借着这波机会翻过身吗?

粉丝4593获赞6.8万
相关视频
 04:21查看AI文稿AI文稿
04:21查看AI文稿AI文稿我让最新的 deepsea v 四和豆包二点零还有 cologne opus 四点七一起参加了高考,结果有点出乎意料。哈喽,大家好,我是王玉,欢迎来到大模型高考测评系列视频。现在的模型测评榜单非常多,偏向各有不同,但是咱们有一个公认的特别好的综合能力测试, 那就是我们的高考。所以我做了这么个项目,让大模型做全部六门最新的高考真题,总分七百五十分,谁考的高,谁的能力就强,并且还统计了性价比和 token 效率图,方便大家选择合适自己的模型。 本期参与测试的模型包括刚刚发布的 deepsea 和 v 四的两款模型, flash 和 pro lite 和 mini。 同时,为了给模型立一个标杆,我还请到了目前公认的地表最强模型 colloud opus 四点七参加考试,并且因为他的出色表现,我还让他兼任了本次考试的阅卷老师。当然,如果后面出现了新的状元模型,我也会 同步更换阅卷老师更新榜单。本次测评的试卷是最新的二零二五年全国新高考一卷真题 物理、化学、生物,采用难度比较高的最新二零二五年江苏卷真题。几乎所有的大模型训练知识库截止日期都早于二零二五年高考,包括最新发布的 deepsea v 四,我们看到它的知识库截止日期是二零二五年五月, 所以二零二五年的高考题肯定是不在他们的知识点里的。经过对这六门科目的全方位测试,总分七百五十分,其中 cloud opus 四点七的状元地位非常稳固, 它的总分是六百五十九分,其次豆包系列模型均在六百三到六百四十分之间。最后 deepsea v 四的模型拿到了五百六十六和五百七十二。 deepsea 总分偏低的原因主要是因为它不支持多模态,它是以盲人的身份参加的此次考试,可以看到主要是化学成绩很差, pro 只有六分, flash 十五分,因为在化学试题中一共十五道题,十四道题都有图片, 这对一个盲人来说确实非常困难。但是就在看不到图的情况下, pro 的 数学成绩位列第一。要知道数学里面也是有两道带图片的题的, deepsea pro 的 成绩居然高于 cloud office 四点七十六分, 如果后期 deepsea 也支持了多默态,我还会再次测试更新榜单。令人意外的是,豆包 mini 的 总分居然比 light 还要高一分, 尤其在数学上, mini 考出了一百二十一分的高分,甚至超过了 cloud office 四点七的一百一十五分和自家大哥的一百零一分。这个差异的主要原因是,在数学测试中, mini 生成了大约四十六万个 token, 而 light 只有十六万。 迷你在思考模式下进行了极其详细的推导,可以看到它的 token 消耗量是最多的,而如果按 token 效率来看的话, cloud opus 四点七消耗的 token 最少,总分却最高, 这其实就是顶尖模型的厉害之处,一针见血,直击要害。在很多简单的题目中,可乐会不作思考,直接给出答案。而滔腾效率最低的豆包 mini 即使是简单的题,也在思考的过程中不断的自我怀疑, 这点其实我们人类也存在,有的人答题就是简洁,逻辑清晰,有的人就是啰里吧嗦,废话太多,从这点上可以判断出高下水平, 而脱离价格谈性能就是耍流氓。 cloud 墙归墙,但是它的价格也是真的贵,而豆包 light 和 mini 用了不到一块钱的成本考出了六百三十分, 性价比十足。当然目前测试的模型还比较少,由于这是第一版视题和提示词,我还会再分析和改进。点个关注,后续我会陆续测试更多的大模型, 你想看哪个模型参加高考?或者如果你有什么建议,欢迎在评论区留言查看完整的榜单请看视频简介,别忘了点赞关注咱们,下个视频见!
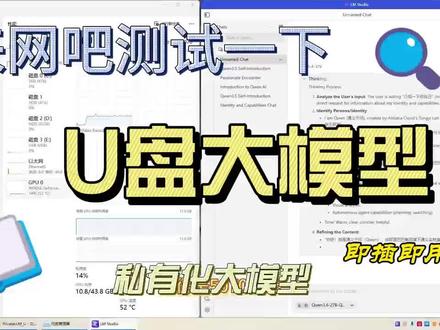 01:33查看AI文稿AI文稿
01:33查看AI文稿AI文稿今天来网吧测试一下我的 u 盘大模型,这是网吧的电脑,六十四 g 内存,英伟达五千零七十显卡,十二 g 显存。这是一个普通的移动硬盘,里面装的机械盘,三点零接口,插上看一下,点启动, 开始运行了,这里 usb 口已经满负荷运行了,需要等一下启动完成,看看注册了哪些大模型。 这是二 b 的 g 吗?这是四 b 的 g 吗?这是七 b 的 千万三点五,这是二十七 b 的 千万三点六,加载一个试试?先加载一个七 b 的 千万三点五。天呐,这台电脑的 usb 口太拉胯了,才 才四十多兆,这是二点零接口啊,现在随便一个 usb 口,最低也得是三点零接口了吧?我一口老血喷到键盘上,终于加载完了,试一下,可以运行,还挺流畅,让他写个小作文,老铁们, 这可是私有化大模型,看看有什么不一样, 低调,一定要低调!这个时候再看 usb 接口,已经没有负债了,看来只是加载模型的时候, u 口会成为瓶颈,加载完就完全不受影响了。再来测试一下二十七 b 的 千万三点六,加载完了,测试一下, 还是挺流畅啊,还得是五零七零显卡,牛逼!
 00:12查看AI文稿AI文稿
00:12查看AI文稿AI文稿ai 圈又炸了,自洁直接甩出多把 c 的 二点零 light 全固态统一,立即在升级,这才是下一代模型能力。他不只是看懂文字图的,今天模型先点击支持精准跟界面交互,相当于给 ai 装了操作手,千联化版本还能做到这种交互,即了用后续端测落地就能助手场景,直接打开新空间。自洁这不齐,直接把全固态交互往前推了一大半。
 10:21查看AI文稿AI文稿
10:21查看AI文稿AI文稿deep c q v 四呢,终于发布了,各方面的参数啊,看起来都很不错,但实际使用起来又是什么水平呢?正好最近两周啊, g p t 五点五, opt 四点七, kimi k 二点六也都刚更新了,再加上之前的 g r m 五点一呢,凑齐了一大批的这个千元模型。很多朋友啊,都在纠结说自己的智能体里面到底应该用哪个模型呢?今天这个视频啊,我就会从价格,从速度, 从完成任务的质量几个角度来跟大家聊一下这几个模型,能够让大家在选这个模型的时候啊,会有个参考。我们首先来看一下各家模型 token 接口的这个价格,按照 token 输入输出七十比 七比二的这个比例来加全,这个呢大家可能如果不清楚的话,也不用特别的去计算,我是按照我自己的平时的账单的统计,然后调用的这个比例算出来的,每个人呢都或多或少会有些不同,但大概呢就是这样一个比例,然后用它来算出每百万 token 的 一个综合的价格,方便我们去比较。我们看到 v 四 flash 呢,零点三二元, v 四 pro 呢,原价是二点五六元,然后加上当前二点五折的发布活动啊,价格大概是零点六四元。 kimi k 二点六呢二点二三元。 jimmy k 二点一呢二点二九元。 opus 四点七十点六三元。 gpt 五点五呢十一点五二元。国产模型啊,大家看到大致呢都在同一个价格袋里面, opus 跟 gpt 呢,价格直接贵了一个数量级, 一次 flash 啊,价格最低,因为它的模型尺寸呢,也是最小的一次 pro 呢,能把一百万的上下文做到这个价格,是采用了新的注意力机制,一百万上下文呢,大概只需要前代的百分之二十七的算力, 百分之十的显存就够了。列出这个综合价格啊,是方便大家去理解,去比较,然后给大家做一个自己选择的参考。然后来介绍一下这次的这个对比的任务设计啊,我这次呢,是想让智能体啊去抓 hack news 上面前一百条的热贴,挑两到四条呢,值得说的话题,查背景, 生成图片,配音,最后用 hyperframe 这个 skill 呢,制作一条三十到六十秒的中文视频报告,中间怎么去完成啊?怎么去这个一步步的定任务呢,完全交给智能体自己去定,每家过程啊,稍有不同, 但大致的内部的流程啊是一样的。先写 python 脚本呢,抓帖子,做数据统计,再写分镜跟旁白,然后呢,生成语音跟图片。语音出来之后呢,来计算一下实际的长度, 重新去调整一下分镜,如果太长呢,就压缩一点,如果太短呢,就扩展一点。最后呢,再用 hyperframes 以代码的形式把这个视频完整的做出来。每个模型的任务呢,我都给它们建立一个独立的空白的文件夹,然后用 skill 去扩展它们 agent 的 能力。比如说像我这里用到了几个 s 册去查资料, gpt, imager 去申图,然后 edge tts 做中文的旁白, hyperframes 负责视频的合成等等,基本上就是四个。如果产出有明显的缺陷啊,我会反馈给 agent 一 次,但只给这一次的机会,只做一次的人工干预,还有一个比较重要的细节来跟大家分享一下。 这次实验用的 agent 啊,是叫做派,大家肯定没听说过,因为在国内还比较冷门。它是一个极简设计的 agent, 几乎不做任何额外的封装。我们平时用的比如说像 cloud code 啊 or codex 这种框架,它约束多,然后规划层比较厚,好处呢就是把那些比较弱的模型啊,能多浮起来走两步, 代价呢就是那些比较强的模型的判断力呢,可能也被一定程度上牺牲掉了。反过来说呢,薄的框架就是让弱的模型一步步能露出马脚,也让强的模型完全能够展示自己的规划跟纠错的能力。我们来大概的这个判断一下,这次一整条的这么长的这个工作流任务啊,需要用到这大模型的工具调用,多步骤规划 上下文,然后选题,判断出错的自己修复,单次跑下来我估计会用到上百次的工具调用,所以这六个模型的推理强度全部拉满,能够真实的展现它们在整个过程中的综合能力。 在最后比较这六个模型的这个能力之前,我们要先来看一下这次任务我们实际使用的账单跟这个生成的速度。 gpt 五点五呢,最快十六分钟 up, 四点七,二十九分钟 up, 开启了 x high。 这个之后啊,花费也是高的离谱, 比 g p t 五点五还贵了三倍多。然后其他的像 deepsea v 四 pro, 然后 kimi k 二点六, g r m 五点一,消耗的 token 呢,差不多,所以成本呢,也几乎差不多。但是 g r m 五点一啊,速度上比较慢, 花了四十四分钟才完成,这个原因呢,就是因为 token 接口的吐字速度太慢。因为之前就听说啊,这智普是国产模型里面比较缺算力的这个一家公司账单讲完之后啊,我们来看一下最终的成品到底是长什么样子。我想按两个维度来评价这次的任务啊, 就是排版跟内容,排版呢,是排版的结构,然后图案的比例,动画字幕这些内容呢,就是指选择题啊,旁白啊,判断力啊这些。然后六个模型呢,按照这两个维度的综合表现,我可以分成三档,第一梯队呢,就是 up 四点七和 gpt 五点五,大家可以看一下它们生成的视频啊。 h n 今日速览 top 一 百里三件事不讲废话第一件 deep c v 四,一千九百八十九分一千五百一十六条评论全列录零抠的跑在华为升腾上 pro 模型每百万输出 token 三点四八美元。 h n 原话从黑客到黑客 第二件, open a i 当天甩出 gpt 五点五,一千五百五十三分。记者分拣封顶贴 andropet missus, 但社区泼水幻觉率百分之八十六,是 opus 两倍多。第三件,最游戏九百零六分的热铁,在 bug 质量下滑。同一天, google 宣布向 andropet 注资最多四百亿美元,社区点透循环贸易, andropet 拿钱回头买 google 的 tpu。 全剧看 top 一 百 ai 话题十五条,却吃掉百分之三十一,得分百分之四十一。评论 谷里四条是 ai 域名榜第,靠十六次领跑。数据采自四月二十五日 h n 热榜,今天 h n 前一百条里, ai 大 模型占三十二条,合计一点一万分七千二百五十七条评论,榜首讨论集中在 deepsea v 四 g p t。 五点五和科沃质量风波。 deepsea v 四拿到一千九百八十九分,一千五百一十六条评论,社区最在意的不是发布会,而是低价好文档,以及跑在华为芯片站上的完整 阅帖。评论里的核心质疑是, ai 编程下的写代码时间是否又变成了独代码和审查成本工作计划最高头 n 四百亿美元, 把它看成供应商融资前 tpu 云和同要成闭环。如果模型商品化,真正的利润可能在算力入口比特和 c i l 供应链攻击,无科技拖拉机走红也只向同一个情绪。技术越强,社区越想要可验证,可修,少锁定系统。今天的关键词是可信。 从排版角度来讲啊,这一档的模型有完整的编辑自觉分进脚本呢,会自动标注 t t s。 实测的时长精确到秒,然后再去反推画面的时长。 g p g。 五点五的定稿啊,甚至自己列了这个时间码的对照表,图文的重点分明,然后动画的节奏也很合理。 t p t。 五点五的短板是首页的,这个数据格式化,没有正确的去渲染。然后从内容角度来说呢, oppo 四点七旁白其实是最讲究的,这可能跟大家的直觉上也比较吻合。 开场四秒钟就切入了三件事情,每一件呢都有具体的数据,加上一句这个嗨客女子原话做压轴,结尾呢,还单独留了十几秒钟做整体的这个全局的数据的复盘,然后这六个里面是唯一一个自己做了 结构化数据分析的这个模型, g p t 五点五呢,选题抓到了这个资本与算力的闭环这个独特的视角。别人都在讲模型本身,然后他呢,在讲生态,在讲一个大的宏观的这个这个角度,但结尾啊,那句就是今天的关键词,是可信。这样句话呢,我觉得就比较仓促了,像他感觉到时间快到了,然后硬切了一个结尾,这种感觉 怎么说呢,就是五十七块钱的 office 啊,贵是真的贵,但能力呢,确实也是最顶尖的。中间党的两个模型呢,就是 dipstick v 四 pro 跟 gim 五点一这一党的模型啊,都只是完成了整个工作的一半,但只是完成的一半不同。 v 四 pro 呢,赢在内容。 r m 呢,赢在了排版。 v 四 pro 的 排版呢,主体是左右结构的,图片被挤得比较小,文字也比较小,远不如第一梯队的那种舒展的,然后清楚的感觉,但有亮点啊,就是首页它做了一张热力图,是这六个模型里面我觉得最具设计感的这个开场,然后结尾这个转场,还用了这个色块动画,看得出来很有这个设计的意图啊。 然后字幕显示呢,我觉得就是比较正常。 v 四 pro 的 内容啊,我觉得它写的旁白是六个模型里面最像写给人看的一份。 d c v 四,近两千顶铁, 完全开源零抠的纯华为 samsung 芯片社区最镇的不是跑分式文档,开发者说比 open a i 好 太多。有人留了四个字, from hackers to hackers。 敢直接把这个 hacker news 的 评论原话当京剧引进来。 from hackers to hackers, 然后循环贸易 中表达呢,保留得很完整,四个镜头的每一个都有一句压得住的短句,然后开源再追,闭源再堵,开发者用脚投票。这句收尾呢,比 opus 我 觉得是最接近第 题。对的,开头有数据统计,然后文字跟图片都足够大,排版很舒服。唯一的问题呢,就是字幕遮住了这个皱纹。我反馈了一次之后呢,也没有修好,但是 g r m 五点一的内容啊,就差强人意了,基本都是新闻播报, 每个镜头的结构呢,都是谁发布了什么数据,多少社区说了什么东西,没有一句呢是自己的这个视角,自己的判断,也没有把几件事串联起来一起的。这个整体的视角只看排版呢。 g r m 真的 厉害,但是把旁白跟分镜如果也算进去的话呢,我觉得 v 四 pro 可能更好一点,所以我把这两个呢,都放在第二档。第三档呢,就是 v 四 flash 跟 kimi k 二点六这一档啊,为什么放在第三档呢?就是因为我觉得它在排版跟内容上面都有些硬伤。你比如说啊,像 v 四 flash 的 这个排版,所有的页面呢,都是同一个上下结构, ppt 模板, 十六比九的图呢贴在上面,然后有大片的空白,字也偏小,开头的数据呢没有渲染出来,字幕也缺失,反馈之后呢,还是没有修复好。至于 vs flash 的 这内容呢,它的旁白基本上也就是在复读这个帖子标题,然后像 deepsea vs 那 段,讲到 sweetband 突破百分之八十,适配华为升腾,这现在都是标题的原话。还有的那段呢,也只是把世界名完成了念一遍, 完全没有自己的这种视角跟判断。然后 kimi k 二点六的排版呢,深图有浓郁的这种 ai 的 味道,深图的提示词呢,也是比较差的,图片也被裁切了,没有完整的展示,然后字呢,也偏小。 kimi k 二点六的内容啊,比 vs flash 我 觉得稍微强一点。选题呢,选了卡尔的信任危机,然后谷歌的助资 把续命和买保险两层的意思呢,都点到了旁白,比较有节奏感。不过相比第二档的 v 四 pro 啊,我觉得还是有点差距的,大家也可以自己看这两视频对比一下。最后来跟大家总结一下,就 gbt 五点五跟 oppo 四点七呢,排版跟内容两件事啊,都非常在线,贵呢,确实有贵的道理。 然后像 v 四 pro 跟 g m 五点一呢,都只能做到一件事,然后卡在中间。然后 v 四 flash 跟 kimi k 二点六呢,在我这个测试当中,两件事都没做到,所以我只能把它排在第三档了。收回这个 dipstick, v 四本身啊,国产第一梯队我就完全是没有问题的。 v 四 pro 一 百万的上下文,性价比也非常的高, 从内容上来说呢,甚至有时候可以超过 g p t 五点五,但综合实力呢,跟 opus 跟 g p t 五点五我觉得还是稍微有点差距。但你聊一下这次测试的本身的局限性,因为六个模型都只跑了一次,会有很大的这个随机性,换一次呢,可能结果又不一样了。 任务设计啊,我这次也是比较偏重于这个视觉方面跟代码能力的,对纯文本推理能力啊,其实不是特别的敏感。真正严谨的测试呢,应该每个模型都去跑 n 次,然后去它的分布,然后再叠加这个盲测打分。这期视频呢,算一个不太严谨的这个测试, 给大家一个基本的这种参考。最后再跟大家说一下,这次测试呢,用的 agent 是 派,在国内还比较冷门,但我现在自己啊,就是内部几乎所有非代码的任务呢,都在它上面跑,非常的顺手,非常的听话,非常的爽。它是个开源项目,完全不是广告,感兴趣的朋友呢也可以自己去学习一下,自己去体验一下。好了,今天视频就到这里,我是李总,黑经理超,我们下次见。
9248第四种黑猩猩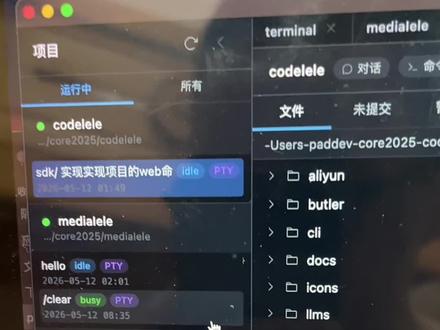 01:37查看AI文稿AI文稿
01:37查看AI文稿AI文稿一会又有人喷我,哎呀,这个项目太简单了,谁不会写啊?嗯,这拿 ai 就 做这么一个东西,我们的国外大模型可都是做什么登月的这种程序,前几天拍的视频,好多人都说,你用国产大模型,不就写点这么简单的前端项目吗? 哎呀,那真就不好意思了,我还真就只能写点前端。最近又做了一个前端的项目,这是我自己写的一个工具,我总觉得对现在所有的别人机器都不满意。 你看我自己做的一个工具,这边是多个 ai 的 管理,一个目录里边可能有几个任务,然后这块是我本机所有的项目, 然后每一个打开以后,我把它叫一个绘画,你看这有,这里有对话,我可以直接输命令行, 然后这里有文件,然后 get 也在这里集成了,这里能看到这项目已经变化的文件。嗯,这个就是 get 的 操作, 你说把它放进去一提交全都搞完了,就相当于把终端,把 ai 对 话,把代码编辑器全都集成到一个工具里边。 这个前端项目还是比较简单,对于 deepsea 这种没什么技术含量。哎,这种项目有没有后端啊?
39拔萃科技 00:11查看AI文稿AI文稿
00:11查看AI文稿AI文稿闲着没事儿戳开一个链接,惊奇发现里面集成了 cloud 三和 stable diffusion, 随手让它生成一张宠物猫窝的渲染图,几秒钟就甩过来一张毛绒质感逼真的成品,这效果放电商平台肯定爆款!
101momo. 01:44查看AI文稿AI文稿
01:44查看AI文稿AI文稿agent 是 deep sea 吗?我有一个轻量级的方案,非常受欢迎,因为它方便又省钱。那说到省钱的时候,大家都知道 deep sea 省钱,所以就有人来问说,啊,不是 deep sea 省钱吗?怎么你这个省钱呢?其实我们要区分两个概念,一个是 agent, 一个是 model。 假如说 agent 是 一辆车的话, 呃,那么里面用的 model 暂且可以说它是里面消耗的油或者是电,那油和电的话呢,它有便宜的也有贵的,但是车本身也会因为它的设计原因,使得有的它耗油高,有的它耗油比较低。所以当我们说便宜的时候,如果我们说 model 便宜,那可能就是指的是 deep sea, 但是有些时候可能是指的是这个 agent 便宜。也就是说在同样的任务,同样的 model 设定下这个 agent, 他 再去执行这个任务的时候,他耗头梗耗得更少。但很多厂商他们是又出 agent 又出 model, 所以 就大家就蒙圈了。比如说像 cc 就 coco 的 嘛, 那他家换了 cc 的 agent 一 般是要配 cc 的 这个 model 的。 但是后来有了龙虾之后,大家发现烧钱的配置是龙虾,还有爱马仕的 agent, 你 配上 cc 的 model, 那 是相当的烧钱, 也就使得大家说龙虾挺好的,但是养不起养不起。 deepsea 的 最开始出圈就是因为它的性价比比较高嘛。但是现在国产的 model 崛起了,国产的 agent 也崛起了,这个因为企业是重度用户,他每天都要去使用的情况下,那么你这个用人成本或者用 ai 的 成本是需要去考量的。 我们再去给企业去推的时候,会根据不同的这个任务类型去推不同的 model。 那 如果说 shokken 的 model 是 deepsea 国产的,开源的,那么 shokken 的 agent 是 open clock, 它也是开源的,我们国产。记得关注分享评论区见哦!
12是傲雪啊 01:05查看AI文稿AI文稿
01:05查看AI文稿AI文稿今天就给大家揭秘一下平时我用的是什么模型,然后以及用了多少,然后统计一下,最近三四个月我大概用了将近三百亿 token 的 一个用量,然后给大家看看我到底用了些什么模型, 我还是给大家看看,免得大家说我没用过什么模型,就在这吹建模型。这是我公司的电脑,公司电脑上面看到没有?这个地方总共用了两百多亿,透坑哈,然后对方是一万两千多美元,这是公司电脑,你可以看到我这方用了非常多的模型,嗯,然后还有我自己家里面的电脑, 对,你看这方家里面电脑,这是我的那个 mac mini, 上面也用了大概三千多美元一个量。那你可以看到我用了各种各样的模型, 然后我还有台电脑,还有台电脑在那边,然后没开机,这是我,嗯,之前最早的时候,嗯,开发用的一台电脑上面应该也有几千美元的消耗量。 对,大家就知道其实这些东西真的不是我在乱说,是确实他就是要花这么多钱,然后每个我都去试过了,就是告诉我大家,就是告诉大家我自己一个真实的体验,他到底是怎么样的,然后以后不准再乱黑了哈。
54非哥说AI 00:48
00:48 00:11查看AI文稿AI文稿
00:11查看AI文稿AI文稿一不小心点进这个网站,惊奇发现直接就能唱完 gpt 四核迷之 journey, 又一个不小心让它生成一张落地灯场景图,它直接给你这种光影层次分明的成品,看到效果马上拿去当店铺首页图了。
14momo. 00:12查看AI文稿AI文稿
00:12查看AI文稿AI文稿兄弟们,兄弟们,看这里!看这里! gbt 五点五全家桶, deepseek 全新旗舰 v 四 pro flash, 还有 gbt 一 米二两个兄弟全部上桌,牛掰!
199果哥AI 01:33查看AI文稿AI文稿
01:33查看AI文稿AI文稿极猛的模型分层,刚刚涨完价,新的大模型 happy house 就 出来炸场,武林高手的出场啊,从来不会跟你提前打招呼。无名模型 happy house, 无官宣,无预热,无人认领,非常的神秘。空降 ai 视频的榜单,直接断层式的碾压,所有的精品 也登顶了行业的第一。有科技院的侦探正在从蛛丝马迹当中去猜测它的来源。前不久, open ai 的 zora 因为巨额的亏损正式关停,烧钱五十个亿,高额的成本,闭源路线彻底走不通。 而 happy house 开源就是落地,亲手打破了行业的闭源垄断,重构了 ai 视频行业的规则,踢翻了整个牌桌。更狠的是啊,开源就像是一场对于闭源模型的终极复仇,大家都能感受到吉梦是闭源的产品平台,手握定价权,不想花钱那就乖乖排队, 这里没有说几分不好的意思,而开源的产品完全不一样,个人和公司都可以本地的部署,可以开发定制化的需求, ai 视频创作成本会将进一步的要占,效率也会翻倍,更能成为大众化的一个生产的工具。 技术的创新从来不是大厂的专属,开源可以打败闭源,中国的 ai 视频也已经领跑全球。工具的迭代其实永无止境,底层的能力永远不会变,提示词审美,视频的结构判断力永远是普通人立足视频的核心,也是把摸鱼感知力转化为生产力的工具。 别再有 ai 的 焦虑,也不鼓励大家去追求技术流,工具不是核心,工作流才是用最简单的工具运用到你的生活和工作的日常当中。想吃透 ai 视频的核心能力,关注我或者加入群聊,我们一起讨论交流。下一个模型,我也会帮大家提前探探路。
 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿hello, 大家好,欢迎来到今日的大众 ai 日报。今日比较领先的 ai 工具,图片内插的 g p d image 二点零 视频内依然是国产的 c d s。 二点零代码内由 code code coser 以及 deepsea 微四版本其他类小米的 mimo 系列正式开园。 今日的 ai 快 讯 open ai 发布,拆的 gpt 英美加二点零改写 ai 绘图逻辑,解决了文字乱码的痛点,可精准生成商路海报等,普通人也能做专业设计。 小米的 vivo v 二点五双模型正式开源,包含旗舰的 a 镜的模型、 vivo v 二点五 pro 全模态模型。 vivo v 二点五都支持一百万托盘,超长的上下文窗口,他们在多项测试中登顶全球开源模型 前。腾讯字节技术大佬业内实测 deepsea 微四 pro, 它和 glom 五点一在原代码分析等四大真实场景中,实测结果显示, deepsea 微四 pro 性价比高,日常小功能中够用,长文本连贯性进步大。但在复杂项目上, glom 五点一在代码理解和全九八零更优。今日的 ai 日报就到这里,干货有用记得点赞关注。
 01:06查看AI文稿AI文稿
01:06查看AI文稿AI文稿每天学习一个好用的工具,今天蹭一波热点,我是第一次使用这个 cloud code, 我 以前一般都是用 codex, 不是 出了这个国产的大模型 deepsafe v 四就开始跑了一个程序, 我做了一个 api 调用的 h 五,呃,主要是把这个 gbt 的 mg 二点零用 a p api 调用到这个 h 五里头,现在已经做好了,在没有用这个可乐的扣子之前,我用了这个 扣子,用了妙物都生成了这一个 h 五,但是大家可以看到,不管是从 ui 还是到使用和调试都是很差的。而我现在这一个版本是已经通过内网穿透,让我身边的朋友已经在使用了的,是非常好用的 整个 h 五,我是用费用是用了大概是五块钱时间,其实真正用的时间可能就是一个小时,希望大家都可以试一试这个可乐扣的加 dbc v 四还是值得大家去尝试的。好的,谢谢。
126磊磊ai 00:11查看AI文稿AI文稿
00:11查看AI文稿AI文稿闲着没事刷到一个平台,惊奇发现集成了 maggie 和 van 维随手让它生成一张无线耳机的产品场景图,几秒钟出了一张光影高级的素材,这质感,直接当官网宣传图都没问题。
63K✎﹏ong
