claude用什么模型最划算
真心建议大家,在有条件的情况下,一定要用一下世界上最强的 ai 模型,比如 oppo 四点七、 gpt 五点五这一类顶级模型。因为你不用的话,很可能会同时低估三件事,低估 ai, 低估自己,低估未来一个人能做多少事。第一,你会低估 ai。 很多人觉得 ai 也就写写文案,总结总结文章,但那可能只是因为它用的是普通 低配的体验,会让你误判技术的天花板。第二,你会低估自己。很多你以为自己做不了的事,可能不是你不行,而是你过去缺一个足够强的协作者。顶级模型会帮你把模糊的想法拆成结构,变成方案。第三,你会低估个体杠杆,一个人加上顶级模型,至少拥有一个小团队的雏形。调研 文案、代码、方案,你第一版你都能够先推起来,所以尽可能去用一下最强的模型,你会重新叫准你对 ai、 对 自己、对未来工作方式的理解。

粉丝1.9万获赞12.1万
相关视频
 06:29查看AI文稿AI文稿
06:29查看AI文稿AI文稿二零二六年呢,截止到今天,各大 ai 模型公司已经累计发布并更新了它们的模型十九次。同时呢,在 agent 的 时代,各大 ai 模型公司除了在比 benchmark 数值之外, 还更重要的比的是用 ag 的 去干活,谁的能力更强,这样就导致了 took 的 消耗量惊人,于是就出现了繁多的 api 和 tookplain 套餐。我今天就给大家盘点一下市面上比较有名模型的 api 和 tookplain 的 价格。 首先是 api 的 价格,我这里从小到大的列出了国内 api 价格和 cloud 的 对比。首先,国内最便宜的 api 价格是 gm 五 turbo, 价值零点一五美元每百万 token。 第二便宜的是刚刚发布了 deepsea v 四 fresh 也比较便宜啊,一块钱人民币每百万 token 一 件。模型方面呢, api 比较便宜的是 mini max 和千万 呃,多模态模型 kimi k 二点五,它也是更新到 k 二点六,价格呢也是从零点五八涨到零点九每百万 token 涨了接近百分之五十。 而 deepsea v 四 pro 呢,它的价格是十二人民币每百万。 tokyo 这个价格是仅次于 cloud, 在 国内模型是最高的,是 fresh 模型的十二倍。输出价格还好,二十四是输入价格的两倍。我们看到其他模型 大概输出价格是输入价格的三到四倍。为了更好更直观的反映这些 api 价格,我们可以看这张散点图, 看到右上角是 cloud opus 四点七和 sony 的 四点六,它们价格是远高于国内所有模型的价格。你还有一个有意思的点是,最贵的模型目前是 deepsea v 四最便宜的模型之一,也是 deepsea v 四 fresh。 总体来说,价格前几名是 v 四 g m 五点一,一米二点六,后面几名是千万三点六和 mini max 二点七。除了像这种按 token 消耗量来付费的 api 价格之外, 各大厂商还推出了一种订阅式按月来付费的套餐,一般叫做 calling plan 或者 token plan。 像这种 calling plan 这里最贵的仍然是 cloud code 两百美元, 最便宜的是 mini max 的 二十九元人民币每月。另外除了像传统的模型厂商之外,像阿里,火山还有腾讯,他们也会推出目前市面上主流的开源模型的 coding plan。 可能由于目前模型厂商推出 coding plan 之后在亏钱,所以像阿里和小米他们现在目前在推的是叫 token plan 的 套餐,就像每月的流量包一样,包月去卖。这些 token 当然远没有 coding plan 那 么划算,而且 计价非常的复杂。这个图像真的很好的反映各个模型它的 coding plan 的 价格。一般国内的 coding plan 价格都是从五十元起到四百到六百元不等,比较便宜的会有三十元左右。云平台它推出的是有四十元和两百元两个档位,不过目前阿里云它连两百元档位的 cocoinplan 都买不到,同时每个 cocoinplan 它都有五个小时的限额。像这里量比较大的就是 g l m 和 kimi 还有 mini max, 而且 g l m 它的它的额度计算方式是通过 prompts 来计算,其他一般是通过请求数的方式来计算, 而一次 prompts 相当于十五到二十次的请求数。而 kimi 它是通过 token 的 消耗量来 限定每五个小时和每周的限额的,然后我们通过它的每周限额以及它的价格能够计算出各个模型 callin plan 的 性价比。 那么单从数值上来说,就是默认所有问题都能答对的情况下。 cloud 它的性价比是比较低的, g l m 最高的套餐是比较划算的,性价比比较高的还有 kimi 的 第三个套餐, mini max 的 第三个套餐。但是呢,这中间其实还有很多坑。首先是 cloud code, 它在准确率上是第一的,所以说不能光凭数值上去否定它的性价比。 然后就是 g l m, 它在我们的官方文档下面写清楚了,如果你要使用 g l m 五点一或者 g l m turbo, 在高峰期掉量是三倍,非高峰期是两倍,所以它的性价比增长都可能还需要出一个三或者出一个二。而且我记得他们的 cody plan 套餐非常难抢,不过效果确实不错。伊米特的 cody plan 也是比较特殊,他们是按 抽空量来限制每五小时的额度的,如果你是玩龙虾或者什么爱马仕之类的,可能就不太友好。下面的三个云平台,他们的套餐性价比一般,但是他们好在他们能够选择各种各样的模型。 mini max 它的计价规则其实挺正常的,所以它看起来这里性价比数值不高,实际上它的量是很大的。 除了 coding plan 呢, token plan, 它的价格以及额度我们可以看一下阿里云新出的这个 token plan, 它的量很大,但是也非常贵,最高能达到一千三每月。而且它的 token 消耗量是通过 credits 的 方式进行计算的, 比如说一点六七个 critters, 相当于八千多个零点六七个 critters 相当于五百多个输出的 token。 小 米也是通过 critters 进行计费的,它是每两个 critters 可以 换一个 mimo we are 的 token。 那么通过这些价格以及它的 token 量呢?我们也可以计算这些 token play 它的性价比。然后这里我们可以看到腾讯和小米它的性价比差不多,阿里它的 token play 性价比稍微高一些,不过这里是以千万三点六 plus 核算的。 通过以上的统计图以及表格我们可以得知,如果你是考虑 api 成本的话,那 gm 五 turbo 和千问 plus 是 价格比较低的。另外如果你是要做长上下文任务,那么 mimo cloud 和 dbsega 是 比较好的选择。体验方面最好的还是 cloud max 套餐。 另外综合魔性的能力的话, coding plan 性价比最高的套餐依然是 glm。 呃, talking plan 性价比也比较高的是阿里云的套餐。好!以上就是本期视频的所有内容。
710实验式 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿地表最强模型 oppo 四点七免费用一个月,真被我薅到了,正常订阅每个月至少一百美刀,但我一分钱没花,现在正常使用完全没问题,跟付费的一样丝滑。 方法也很简单,通过 kyro 注册一个新号套餐,选 pro, 进到支付页面,如果显示零点零零美元,直接下单,免费一个月就到手了。详细图文教程我放在评论区了,照着走就行。最后提醒一句,用完记得去取消续费,不然下个月自动扣款。
149会偷懒的程序员阿语 02:50查看AI文稿AI文稿
02:50查看AI文稿AI文稿大家都知道国外的这四大 ai 非常的强,分别是 cloud gt、 gmail 还有 gark, 但是呢,还不知道在什么情况下该使用到什么样的 ai。 今天我做了一个 ppt 啊,来给大家分享一下我们在什么情况下应该选择什么样的 ai。 首先我们大致来看一下它们的区别啊。 首先第一个 cloud, 主要就是代码与写作能力强,而且呢细致,就是 它的逻辑性啊,以及 ai 的 幻觉率啊,非常的低。第二个呢就是 gpt 啊,全能选手,什么都会啊,不管是通用任务啊,画图啊,做 ppt 啊 等等之类的,都是非常的不错,专门的呢,主要就是学术啊,比如说我们查论文线啊,查资料或者是 上下文啊,也是非常长,并且性价比也是非常高,比较便宜啊。第四个就是 guac, 它的特点就是实时数据啊,因为它背后有个 x 平台, 数据非常的强,并且呢推理我感也是非常厉害啊。然后来详细看看各大 ai 的 区别。首先第一个 cloud, 就是 代码数据文本处理啊,强,而且呢安全性高,以及上下文以及输出能力强,一次性最多可以输出十二万字幅啊, 并且逻辑清晰,最适合就是处理复杂的代码以及数据文本文档合同,论文报告等等这些长文本的任务啊。第二个就是 gpt ppt, 主要就是通用模型,写作,编程分析都能啊,还有 agent 啊,以及生态馆,就是它能接入很多种插件啊,并且呢画图,音频,视频啊,生态完善,它更适合于呢日常办公,内容创作,自动化任务 等等这些啊。第三个专门来,主要就是推理能力 ok, 然后上下文文本长以及性价比高,注意点呢?它的缺点就是啊,代码能力弱以及 ai 率啊,这个风格就是 ai 率比较 高,最适合的就是学术超长文本文档以及视频的处理。 第四个就是马斯克的这个谷 rock, 它这个就是实时数据和推理能力非常强,因为它的算力啊也是挺高的。如果大家适用于做新闻以及推理的话和一些需要独特的风格,因为它说话非常幽默风趣啊, 就可以使用到 rock, 那 这里有它们的价格对比啊。如果大家也想使用到这些 a 啊,都可以点击我主页的置顶作品找到我。
41阿坦说Ai 07:25查看AI文稿AI文稿
07:25查看AI文稿AI文稿嗨,大家好。嗯,这段时间就是这两周没怎么去发这个视频啊,主要是因为这两周捣鼓了一下这个最近市面上比较火的这个,呃。就智能编码这一块的一些工具, 那像我们现在用的比较流行的这个可乐的扣的,嗯,还有这个,嗯,扣贷啊等等这一系列的东西,嗯,大大小,我基本上我基本上把把最火的几款吧,都自己真实的试用了一下,包括那个后台的大模型, 呃。从这个 g p t 到再到这个咱们这个国立的这个 deepsea, 呃。 v 四,呃。 v 四的 flash 和 pro 我 都试了一遍。呃,整体我就是汇报一下我的一个体验哈,以及我干的事情。 呃。我干了什么事情呢?我手里面有最近是有这个三个项目,我把这个三个项目呃做了一下对比,主要干的事情就说是有两个项目是做升级,呃,这个,其实这个项目都是我我自己的,以前这个大概有在线上运行了有十年的老项目了啊,现在还在运行着, 呃。我一直想给它就做一些升级,呃。因为技术上比较老了,用了 spring boot 二,呃, jdk 这个一点八了这比较老的这一套技术,那我就一直想把它升级,呃,一直想升级到至少说 jdk 一 点呃。十七,对吧这一类的。 但是呢,之前我也捣鼓过,嗯,也去升级过,呃。各种问题各种出现,那后来我也就基本是就是懒得去搭理了,也没去做这个事情, 然后索性这一次我就,嗯结合到这些大模型的,结合这些工具,呃,把这几个都给他升级成功了。升级完了啊,做的还挺完美的。呃,所以说不能不感慨啊,感慨的就是说是这一类的工具的出现。呃把咱们整个的这个程序员的行业 这对于我的政治来说是颠覆了。呃。以前的话我们最早学 java 的 时候可能就是说经常性,我们就说是我们把成语一写可以喝一杯咖啡了,等着这个他这个编一声可拉式文件这么耗时的时间, 那后来这块就很完善了啊。现在呢又变成什么模式呢?变成就说是我把我的需求,呃。我把我的 步骤拆封完之后啊给到这个作为 t 的 词给到这个可乐的扣了之后。那我也去喝咖啡了啊。等一段时间,半个小时多久了对吧。 呃。中间我可能稍微按一点一点就是它它有一些这个交互式的,哎。我需要确认,呃需要能不能执行某些命令等等。呃一个时间一一杯咖啡的时间可能整个的东西它也给我搞定了。 呃我干了两个项目的升级这两个项目都不算很小了。两个项目的升级。两个项目的升级呢?呃一个项目是纯粹的用可乐的扣的,加上他自己的大模型。呃。我使用的是中转站 这个项目我整个做完,呃整个耗时耗了我大概也是半个多小时的时间啊。整个就是从开始到整个的升级完成, 呃。然后消耗了大概是我当时花费呃耗费的这个钱为后续还有一些小的修改还有一些小的问题的调整整个下来呃。消耗了 talking 消耗了钱大概消耗了我是两百多块钱这个样子 啊。但是做的还挺挺挺完美的帮我升级成功的。嗯个人气动的都正常的,至少对于我来讲,呃,我有动力接下来是把这个项目继续去给他保养方面给优化了啊,之前的话,老的技术战场这一块我是懒得去动的,说实话, 呃,第二个呢,我后来我就又尝试了。尝试了什么呢?尝试我就是把这个大模型工具依然依然用的是这个可拉拉扣的,然后这个大模型切成了这个 deepsea, 呃, v 四 flash 的, 呃,这个切完之后呢,呃,整个我做下来也是耗了三十多分钟,把一个类似的项目也是给升级完成的, 整个呢就升级到了这 spring boot, 呃,四点零啊,我是让他给我升级到三点零的二三二三以上的,然后他后面给我一堆分析,分析完了之后呢是给我直接升级到四点零的,那我就同意让他去升级了,把这事儿干的也挺完美的。哎, 呃,基本上是我再加上我的一些操作,一些刀路之后啊,整个也是很好的运营起来了。呃,整个做下来之后呢消耗多少钱呢?我查了一次,整个是消耗掉了,我有,呃,七千万的 talking 要大概耗掉我这个 呃多少钱呢?整个这个七千万的 talking 是 耗掉了我好像是几块钱的这样子,那这个这个就很划算,因为好像 facebook 这个官方还在做活动,所以这个 talking 的 这个价格很低。 呃,所以说整个的做的,呃也挺完美,事情也给我干完了,然后也就是大概好像是五块钱的成本给我做完了这一切啊,这个不能不感慨。一个感慨的是, 呃,这个这个程序员的这个迭代,那接下来这个替代,呃,特别是一些一些这个基础的这个工作,呃可能就完全要被替代掉了。那我们要做的事情跟更多的可能是财务需求, 呃。拆分出这个步骤,让让让,这个让这类工具帮助我们这个去,呃,很好的去实现着我们的想法啊,你充分发挥它这个 a 政策的这各种属性这种功能去完善我们的一些想法。呃。这个可能就是我们将来的一个, 呃。可能将来不能叫程序员了是吧?那可能是大家就叫做这个产品规划,呃。这个 ai, 呃。智能化这个辅助,呃。工程师什么之类的,是吧?可能这么一个变迁的啊。呃。我也可以说一下我当前的一种,就是我找到了一种,就是我个人, 呃相对来说是比较舒适的一种工作状态。这种工作状态怎么怎么做的呢?就说是这个,这个这个整个的一个路线啊?我是怎么做的啊?我现在其实很多时间是用手机在编程的啊。倒不是编程,用手机来发指令的,呃。我手机上装的是飞书, 呃。我做了一次中转,所以说我是有远程服务器,我的服务器上部署了有这个。嗯, oppo 可乐,我是用 oppo 可乐中转了一次 oppo 可乐之后呢?这个 oppo 可乐的话我是上面装的是代理嘛,然后在我是我自己的一台本地的,因为这个本地的服务器的性能比较高一点啊,咱们是为了省点钱嘛,这不想花太多的钱搞成本太高的这种服务器。 那所以说那个只能够把自己本地的这个电脑给他加扎一下,而且装的还当时装的还比较不错的显卡,跑起来速度更快,所以我是把我可乐的扣子装在我本地的电脑上面, 然后呢,基本上是二十四小时开机,完了之后呢,就说是也是连上了这个远远程的服务器上去 啊。然后基本上我的流程就是说从从飞书手机上的飞书发出指令到 oppo 可乐啊, oppo 可乐再反代理到我这个本机上去做做这个,让可乐的扣的去做执行一些事情。然后可乐扣的这边可能是有一些交付,这个交付呢,遇到这种指令之后, 点到 open 可乐 open 可乐,再返回到手机端,呃,弹框让我去确定选择项之类的,那整的是这么个流程在做。呃,现在这种方式我做的还是感觉还是挺舒适的。那接下来大家有更好的方式,有更好的流程也可以跟我介绍介绍啊,谢谢大家,再见。
43推广家 05:07查看AI文稿AI文稿
05:07查看AI文稿AI文稿每个月花二十美元订阅 ai 会员,你会选哪一家呢?目前啊,国外三大主流 ai 大 模型,叉 g b t、 gemini 和 cloud 都有一个二十美元价格的档次,那这应该也是大多数人用会员优先考虑的那一档,虽然价格一样呢,但是他们给你的东西差别还是非常大的。 我用 ai 大 模型差不多有两三年时间了,国内的各种模型都试过。今天啊,就结合我自己的亲身经历,加上一些横向的对比分析呢,帮大家做个参考。 我最早系统使用 ai 呢,是从 open ai 的 叉 gpt 开始的。叉 gpt 刚出来的那会儿啊,确实是惊艳到我了,感觉一下子就打开了一扇新世界的大门。 我当时也买了它的 plus 会员,就是那个二十美元一个月的版本,用的感觉怎么样呢?当时啊,非常满意。后来呢, deepsea 出来了,我也试用了。坦白讲,在回答质量的可用性上面,我个人认为叉 gpt 还是要略胜一筹的。所以那段时间呢,叉 gpt 就是 我的主力模型了。 后来呢, google 推出了 gemina, 我 作为 gmail 的 用户直接就能试用上,正好赶上它又推出了教育优惠,可以免费使用一段时间的 advanced 版本,也就是二十美元的一档会员,于是我也加入了。 用了一段时间以后呢,我发现啊,在文章写作和基础编程这两块, gemina 和 jpg 说实话,差别并不太明显,至少我自己感觉不出来。 但是呢, jamina 有 一个东西让我觉得特别划算。它的 advanced 会员啊,不只是给你一个 ai 模型的使用权限,它是打包了整个 google 的 生态, 包括了两 tb 的 google 云盘,现在还升级成了五个 tb, 够存储海量的素材了。还有呢, google 的 workspace 全家桶,包括了文档表格、换登篇、日历会议等等,使用权限呢,都比普通用户要更大一些。 还有它有 notebook lm, 做知识整理、学习资料分析呢,是特别好用的。另外它的文声图文声视频等等内容创作者呢,可以直接用,而且最关键的是可以共享给五位家庭成员,大家可以共用,额度实际上几乎是不会不够用的,它的额度给的是相当充分的, 算下来呢, gemini 的 advanced 的。 所以后来我就直接停掉了 gemini 会员,全面转向了 gemini。 就在我觉得 gemini 还挺好用的时候呢,有一个意外的体验改变了我的看法。 google 旗下有一款 ai 编程工具叫做 anti gravity, 可以 同时调用三类模型来写代码,包括了 gemini 自家的模型,还有 open ai 的 模型。还有呢, cloud 的 模型,我拿它做了一个项目,这一对比,差距一下就出来了, 用 gemini 模型写代码呢,同一个问题,我可能要来回沟通十几次才能够真正地把问题解决。但是换成 cloud, 尤其是 cloud 的 opus 模型,真的差了一个明显的档次啊,它对于整体需求的理解,任务规划的调度以及八个定位修复,都要快准狠得多。 那次体验以后呢,我对 cloud 就 产生了浓厚的兴趣,尽管注册的门槛儿比较高,封号的风险也不小,我还是想办法注册了,并且充值了 pro 会员。用上了 cloud 以后呢,发现它的优势可不只是编程啊。在写作这件事儿上, cloud 和 gemina 以及 chat gpt 相比呢,有一个非常在意的差异, 他写出来的东西呢, ai word 非常少,更像是真人写的。而且呢,他对于我写作风格和表达习惯的理解和还原啊,比 jammin 明显要更准一些,这个对我就非常重要了,减少了大量我后期调整的时间啊。 为了避免我个人的观点过于主观呢,我也用 ai 对 这三个会员做了一系列的横向对比,请大家参考一下。 首先讲 chat gptplus, 它属于多模态创作和深度调研的六边形战士。想做深度研究视觉内容以及视频素材的 chat gptplus 呢,是目前效率比较高的一种选择。再说 gemini 的 advanced 会员,它是超大上下文与 google 生态的整合王者。 jemmy 呢,有两百万 token 的 超长上下文,需要处理海量文档以及深度整合 google 办公工具的。那 jemmy 呢,是无可替代的选择,而且它的 nano banana 的 图片生成能力也是非常顶的。最后呢,说说 colada 的 pro 会员,它是写作与逻辑推理的天花板啊。 colada 的 核心优势呢,是思维严谨,输出有人味儿。在高质量写作、代码开发需要减少 ai 痕迹方面呢, colada 是 首选。 说这么多啊,我目前使用的方案是这样的, cloud 加 gemini, 双主力,各司其职。 cloud 呢,负责编程开发以及需要人味儿的内容创作。 gemini 呢,是用来做日常问答文档整理,还有 notebook lm 用于学习。当 cloud 的 额度用完以后呢, gemini 也是我的一种补充 叉。 gpt 呢,我目前是暂时没有充会员了,不过最近也有人说 gpt 五点五出来之后啊,它的能力有比较大的提升,这个我还没有亲自验证过。欢迎有在用的朋友呢在评论区分享一下你们的体验。 你现在在用哪个模型呢?对这三家有什么自己的看法呢?欢迎评论区聊一聊,关注老钱,陪你做复杂时代的明白人!
2316钱智说 02:30查看AI文稿AI文稿
02:30查看AI文稿AI文稿玩 cloud code 是 不是必须上顶级模型?估计很多同学都会有这样的困扰,其实不止 cloud code, 还有其他智能体,比如 open cloud 也是一样的, 因为现在市面上可选择的大模型实在是太多了,很多人的选择困难症就犯了。我们知道,虽然 cloud 官方模型是顶级的,但架不住贵啊,关键不但贵,使用条件还非常苛刻,除了要架梯子呢,还得要实名认证跟境外支付,很麻烦, 本来是花钱的消费者,这样一来搞的跟谈恋爱的舔狗一样,个人觉得完全没有必要。至于为什么,原因有下面几点。第一个,如果你不是非常猴急的赶任务进度, 或者说需求难度不是特别大的话,就完全没有必要上顶级模型,用便宜的国产模型也完全足够。第二个,顶级模型虽然确实很厉害,但效果也不至于强到让你惊掉下巴的程度, 一样有上下文长度限制,在面对复杂的长线任务时呢,一样需要人的强感雨。所以一定不要指望说只要模型足够牛逼,你就可以什么都不管。 第三个,对于国产模型,虽然在一些方面表现确实差点意思,但优点是非常便宜,而且用起来呢,几乎没有任何门槛, 最关键的是量大管饱。第四个,我们需要承认一个现实啊,那就是如果工具的能力越强,那么人的价值就会显得越弱。如果你习惯了用顶级模型呢?你脑子就会不自觉的少思考,那你肚子里剩的那点专业知识可能慢慢的就忘光了。 第五个,很多国产模型虽然没有那么的聪明,但其实也还算挺聪明的,用这么长时间的国产模型,发现交给他的大部分事情,只要你能够做到心里有谱,在他执行的时候多盯着点,偶尔犯错的时候能敲打一下,最后出来的结果呢,还是能够让人满意的。 第六个,有句话叫由简入奢,由奢入简难,你要是一开始就习惯了用最厉害的模型,那突然哪天因为各种原因只能用国产的,那种落差感就好比你以前上下班都是专车接送,而现在只能每天挤地铁,你受得了吗? 第七个,如果你是从一个弱鸡模型开始用的,那这个过程中积累的跟 ai 各种斗智斗勇的过程,将会成为你非常宝贵的 ai 使用经验。对那些还需要大量技术精进的同学来说呢,既能够满足一部分智能化需求,同时还可以训练自己的脑子,一举两得,你觉得呢?
23安瑞哥是码农 04:11查看AI文稿AI文稿
04:11查看AI文稿AI文稿好,我这几天深度体验了一下,用可老的接上这个 deepsea v 四 pro 之后的效果给我的感觉呢?怎么说呢,在之前最开始时候我用 tree, 我 觉得它非常好用啊,后来的时候我用 vsco 的 里面的 copec, 然后觉得那个非常好用,但是它现在已经出现限额了, 然后后面我用去了,用了 codex, 但是用的是中软战,给我的效果感觉也是一般化吧。直到最后,也就是最近一段时间,我接触到 deepsea 威斯,加上我的可乐扣的我这个组合真的是, 反正给我的感觉就一个字,太便宜了吧,真是太便宜了,可以给大家看一下。我这边的话,这场使用下来啊,就今天一天整整用了三千万头啃, 平均下来是三块四毛九,因为它有这个缓存命中跟未命中缓存吗?啊,有这个命中缓存跟未命中缓存 只用了三块九。三块四毛九,这个价格呢,平均下来每块钱可以换到八百五十七万的头根,这个价格我只能说真香,太香了。这你要是去用 xpt 五点五啊,或者说用 oppo 四点七,这个价格肯定是 太太香了,真是太香了。而且我实际应用下来,包括用克拉克的座椅,下来之后,我发现真的这样之后还挺好用的。当然他也有一个自己的问题吧,就是说他的那个 没有这个图像识别能力,但是我听说后续好像也在开发了,等到后面有这个多媒体功能的话,可能会更好一点,那基本上我感觉就相当于是我们的平替了。 然后这个用下来给我感觉呢,就是现在的算力啊,可能 g p c 公司他们自己想做的,就是去把这个算力打成跟我们以后电费一样的价格吧。我估计以后会这样子,因为他最后的时候不是用深层芯片吗?在下半年的时候大规模的投产,到时候这个价格肯定还会可能还会更便宜点。对, 看看我这边让他做的这个的话,做这个想法集吧,大概是用了十几二十分钟啊,包括前面的前啊前端设计,我是让那个吉米奶三点一 pro 给我做的,然后前段设计好之后,后端功能包括数据库啊,全部都是让这个这个 vc 来做, 然后整体做下来的话,基本上一遍就跑通了,然后你要有问题给他的话,他还能帮你改,基本上不会超过两遍, 而且你后期要什么功能他都能给你加上去。包括你把这个东西移植到我,把我现在做这个页面移植到我之前的那个项目里,他都是可以用的,而且 识别的非常快,然后做的非常准,所以实际体验下来还是非常不错的。我感觉跟我之前用 gbt 五点四差不多,但是你要说有五点五或者奥克斯四点七这种强度吗?应该是没有的,但是他真的便宜啊,是吧?这么便宜了还考虑那么多干嘛呢? 然后包括我这个坐下来这个想法集坐下来之后,是吧?谁可以输入你的想法?你好,把你的想法记录下来。你好,我是 叉叉叉啊,这些东西包括啊这些前端的话都是,呃,基于在三零一 pro 做的,但是后端这些功能包括它有个 ai 整个分析,还有 ai 表达优化,然后还有这个关联想法,这些 啊都是让第四个 v 四来做了,整整体做下来的感觉都非常好好,包括你后面接这些 a p i 啊什么的,他基本上都能帮你完成,也不会出现什么太大问题。如果这东西丢到车里面做,哼,丢到车里面做,那你这个提示词工程能力得非常的强大才行。对,提示词工程能力得非常的强大才行。 可以看到我们这个现在用这个扣的加 v, 呃,第四个 v 四我感觉是 比较适合那种呃自己搞个人开发或者说在方面感兴趣的人去使用。当然如果你大公司是吧,有些公司它会有这些 呃报销的,那你就去用 g p t 五点五 off 四,四点七嘛,反正公司有报销。但对于我们个人来说,平常如果只用用玩玩的话,我觉得 d b c v 四加上可洛克的真的是一个非常好的一个方案。
5929arkjack~AI学习版 06:54查看AI文稿AI文稿
06:54查看AI文稿AI文稿请问免费的 ai 模型哪个最好?付费的 ai 模型值不值得买?这条视频我们来回答一下这两个问题,全程无广,放心观看。第二,本期视频也是 ai 使用于电脑课的第一课,后续还会回到知识点来讲,可以先点个关注。首先第一个问题, 新手结论,混搭才是王道。国内模型里面我个人使用最多是 deep seek、 豆包、 kimi 这三个,没有哪个是全能选手,他们各自有长短版,像日常小问题我会用豆包,主要还是手机上用比较多,相对复杂的长问题和常规版分析我会用 deep seek 以及用其 a p i 接入 agent 使用, 也是目前比较主流的一个玩法。然后信息收集和调研会用 kimi 比较多,虽然他老是这样子。所以哪个模型最好?这个问题关键在于怎么样灵活运用,有效的办法是用你真实的需求去多测几次,感受他们之间的区别,然后合理给他们安排各自的岗位。那么这时候就会有人说 啊,你这不是废话吗?一个个测的太麻烦了吗?不是。十九先这么做,我这样打开一个直接用,别着急过来。这时候只需要用到一个浏览器插件, qq, 也叫子弹搜索,这个插件简单来说就是可以一次性同时调用多个 ai 进行搜索,就像这样子, 然后一次性想要调用哪些模型,都可以在设置里面直接进行设置, 这样就可以很直观的对比不同的模型在同一个问题下面的回答,甚至还可以一键将多个 ai 模型的回答合并导出成文档, 还有快捷调用提示词的功能,这插件是我写的,是完全免费且开源,可以在 ag 和谷歌商店直接搜索下载,下个视频再和大家好好介绍它,这也就不详细展开了。 ok, 我 们说回来,就通过这样的形式,就会很方便的对比在同一个问题下,各个 ai 给出了答案。当你这样多用解释,你心中就大概明白 哪个模型在什么问题上更加靠谱,更贴近自己的真实需求。大家可以在弹幕上打出你心中最看好的国内免费模型是哪一个,以及建议大家可以归整几个自己领域常见的问题, 这样以后哪个模型更新了,就可以快速提问这些问题,进行这样直观的横向对比,真实的感受模型的能力,像榜单就会告诉你谁更强,但是只有你自己用过了,你才知道谁更适合你。接下来是第二个问题。 众所周知,海报模型基本都是需要付费的,像今年的残骸神切克 b t jimmy 奶 crowd 这桌小调研,你为海尔模型付费过的,那么我可以打一,没付费过的打二。我也简单调研一下身边的朋友,发现只要平时有关注 ai 新闻动态的,基本都有付费,反之没有特别关注的就没有付费。 那么值不值呢?依旧选择结论很值得,因为为更高级的 ai 付费更像是一种生产力投资,换来更高质量的回答和内容的产出,以及本质上也是要买回你的部分时间和精力。 当然,如果你平时不怎么用 ai, 那 也没必要开通,但是还是要去尝试接触一下,因为这些海外风行也基本都有免费的额度,特别是 jamie 奶他的深度思考,每天都有免费的次数可以使用,我个人建议是一天使用 ai 不 超过五次的可以就耗免费的额度使用, 使用超过五次的就可以考虑开通了,超过十次的话,那么真是建议强烈开通。在调研付费意愿的时候,其实很多人都是愿意付费更好的模型,主要是没有一个去实践和体验的机会,以及平时也刷不到这些海外模型的演示案例和教学视频, 也就是被困在了所谓的信息简方面。所以这里我推荐几个我平时会看的 ai 干货博主,这些都是会跟进海外最新的相关的 ai 工具,做相应的科普和教程啊,这就可以截图,真的,只要你用过几次这些高级的模型,大概率就回不去了。弹幕评论请为我作证。 来讲,付费这些更高级的模型真是一件性价比极高的事情,特别是如果你还染上了 white coding。 像前面提到的子弹搜索,就是我完全用 ai 来写的,我是完全不懂代码,主要用到的就是 clode 的 四点七和串 gdp 的 五点五。我也使用过国内的模型,但是在干活这方面,能用和好用之间还是有一些差距。 以及付费界更高级的模型,不单单是 ai 更聪明,还有一个容易被普通用户忽略的价值,那就是解锁相关的生态产品。像最近成为王位的区块 gbt, 他的 emg 二就是目前最强的生图模型。这里我做个小演示,我把中午吃的汉堡图片发给他,然后这样说 啊,过一下就可以得到这样的一张海报,这才是一次生成的效果啊。其实吧,我中午没有吃汉堡啊。这张图也是生成的, 然后除了 emoji 二,还有亮到环保的 codice, 用起来是真的爽,这里就不展开演示了,然后 jamie 奶就更不用多说,有谷歌的 a s studio, 然后普通人可以用它来生成自己的 ai 应用,还有三个版本的生图王者 nio banana, 当然最憨的还是它的 notebook lm, 这产品我是推荐每一个人都可以去尝试用一下,是目前第一推荐的 ai 知识库产品,这里必须要演示一下,像我最喜欢就是它的一键,可以导入所有的 youtube 博主的全部视频, 然后生成一个对应的知识库。当然你也可以自己上传视频文件,音频都可以,你就可以对它进行针对性的提问,并且它还会根据内容生成思维导图、 ppt, 甚至还能生成测试的题目。这个 note 不 可删的玩法十分的多,后面会专门做视频来讲,这也就简单 q 一下, 然后就是 clot, 然后 clot 的 clot code 可以 说是目前最强的 agent 代替,这个能聊的就更多了,这个也是后面会专门做视频来讲,以及究竟的 clot code 和 clot design 都很猛, 总之这三家生态现在都很强,每功能单拎出来都可以做好几集视频,这也就不展开了,因为这些内容后面都会做。本期视频主要是回答这两个问题, 这期没有做太多模型之间的具体的对比,原因很简单,因为现在 ai 模型起来太快了,可能今天测完,明天还有更新,所以比起告诉大家 ai 模型更好,我不想传达一个使用习惯,就是不要固定使用某一个模型,混搭使用才是王道。因为我发现现在 还是有不少人都还是固定使用一两个免费的模型。然后现在你就可以尝试用前面提到的子弹搜索这些工具,要自己多进行横向对比,感受下差异。如果你已经是在高频使用 ai 了,那么极力推荐去体验和折腾一下海外的模型,体验一下它们的生态。个人建议可以先从谷歌的 jamming 入手, 很多基本的功能都有免费的额度以及它的 pro 羊毛是最好耗的。 ok。 其实无论是国内还是国外的模型本质都是工具,重要的是。
3107名字就叫 30 02:25查看AI文稿AI文稿
02:25查看AI文稿AI文稿这是一期教你如何正确并且省钱使用 cloud code 的 视频,关注我时间长的朋友应该都知道,我是 cloud code 的 死忠粉,作为一个每天使用八个小时,并且用 cloud code 变现了几千块钱的用户,今天我将跟大家分享几个帮助大家省钱而且提高效率的隐藏命令,也许你从入门到精通就差这几个隐藏命令了, ok, 话不多说,我们直接开搞。首先就是 model ops plan, 大家熟知的我们都是通过 model 进行切换嘛。 但是这个命令对于二十美金的 pro 用户来说实在是太友好了,因为它会自动地在你进行一些复杂推理和写计划的时候使用最强的 ops 模型,然后在执行的过程中使用第一档的 sonata 模型,这个就能帮助 pro 用户显著地节省头肯, 你的一倍头肯,能用到三倍头肯的效果。第二个就在命令行输入 remote control, 就是 我们在养龙虾的时候终极梦想,就是我们躺在床上,然后让 ai 自己写代码,那么这个命令就能很好地帮你实现。这一点能够通过手机来操控 cloud code, 你 只需要在对话框里面打斜杠 r c, 它就会生成一个网页, 你用手机打开这个网页的时候,你的整个 cloud code 就 会在你手机上同步,这个功能是让你的手机变成遥控器,远程的遥控 cloud code, 我 只能说憨爆了。第三个命令行是斜杠 export, 它会把我们所有的对话上下文打包成一个 m d 文档。如果没记错的话,我觉得 cloud code 的 上下文窗口应该只有两百 k, 经常出现那种你跟他聊着聊着上下文窗口满了,你需要开一个新窗口的问题, 那么这个命令就能很好地帮助模型去知道啊他现在做到哪一步了,他接下来要做什么?此外,你可以导出到其他的 ai 产品嘛,比如说 codex 上面,然后你继续搞。最后我想讲的这个不是命令行,但是如果你要想在你睡觉的时候让模型继续帮你工作,那么就一定要勾选上这个 permission, 它叫 bypass permission。 我 们是不是很多人在使用 cloud code 的 时候,一会儿一个弹窗,一会儿一个弹窗,你要点击去确认这些权限,但是你选择 bypass permission 的 模式之后,它自己就会去执行所有的命令了。其实我今天本身还是很想讲一个,就是 agent team, 你 一个人怎么去组建一个 agent 军团去帮你干活? 我经常搞十几个 agent 同时并行的帮我完成任务,这种感觉实在是太爽了。但是因为这个篇幅比较长,而且今天时间有限,可能讲不完,所以说大家如果想听的话,可以在评论区里面提需求,如果想听的人多了,我们下期直接安排上,那么我是 holland, 关注我,带你分享更多 ai 变现和省钱玩法。
765浩兰德 06:27查看AI文稿AI文稿
06:27查看AI文稿AI文稿大家好,我是海洋,欢迎来到海洋 agent 的 空间。然后今天咱们要聊的话题是这个 humulus 还有 cloud code 是 不是要二选一,因为网上大家都在讨论这个哪个大模型好用,其实我的终极解法就是让你的龙虾去自己进化,去分别去学习 cloud code 和这个 humulus 合为一体, 然后让你的龙虾对它们取长补短,形成一个终极进化就可以了。然后下面给大家看一下我的操作, 大家可以看一下我现在是用的 workbody, 也就是腾讯的龙虾,然后腾讯的龙虾其其实是集成了这个底层,就是 openclaw 的 开源模型。然后现在呢,我是让这个 腾讯龙虾去执行这个专属的任务,去学习这个公开的 cloud code 的 这个完整源代码,然后内化架构与工作逻辑,完成自我进化重构。然后以后都以全程就以 cloud code 的 这个范式去进行执行任务。 然后你给他指令的时候就说明一下,让他学习这个 cloud code 源码的时候,只学习这个公开的合规的这些, 呃,工程结构了,泄露的代码了,核心的模块的逻辑了,不做侵权搬运就可以了。然后让他去生化拆解并内化这个 cloud 的 一个底层架构代码,理解逻辑,全站的工程思考方式 和这个多文件的关联项目决策流程,完全内化成一个自身的底层能力,不是简单模仿,而是重构自己的工作逻辑。 然后要基于 cloud code 圆满的这个标准架构和规范自我进化,淘汰原有的低效的思考模式, 完成学习内化自我进化,永久的固化新的工作模式,后续我下达的所有任务,它都需要拆解,全部默认用 cloud code 的 思考逻辑和标准来去执行任务。 然后这个我的 workbody 收到我的任务,它就开始进行一个自我学习,自我进化了,这个我在前面的视频中也有讲到这个怎么让它去学习自我进化,还是你要需要不断的训练你的龙虾, 然后这个 workbody, 这不是,这就说 cloud code 工程范式内化重构完成,然后交付了这些报告,学了这种五十万行代码的这个文件,然后深度学习,进行了一个自我净化。 后面就是行为,从现在起我下达的所有的开发产品架构编码项目任务,他都会默认采取这种九步管道标准的流程执行呃,上下文稀缺性原则,管理信息密度,然后拒绝优先安全姿态, gather gather art murphy 循环验证结果并行 agent 编排加速复杂任务结构化工具调用替代模糊操作。深蓝 v 二点零已就位,因为之前它一直 我给它命名就是深蓝一点零嘛,现在变成了深蓝,它自我进化成深蓝二点零啊。然后后面我又听说这个 hummers 比较火嘛,就那个爱马仕的龙虾, 然后我也给他了一个场景,让他去进行这个爱马仕的一个终极进化,我给他指令就是说你现在要进入终极的终极的进化模式,核心目标就是根据爱马仕 openclaw 这些公开的开源的数据源码,全面学习吸收 爱马仕的全部优势和和你自身的这个 workbody 的 这个稳定性、本地安全中文适配能力相融合,形成三合一的最强智能体, 具备持续自我进化能力。然后第一点就是学习并吸收爱马仕的核心优点,它的核心优点目前就是长期记忆自我进化,对吧?深度反思和主动优化。 然后第二点就是学习并吸收 opencloud 的 一个核心优点, opencloud 的 核心优点就是强兼容性、多工具调用、任务拆解、企业级适配,这块是 opencloud 的 优点。然后我要保留这个 workbody 的 一个自身优势,就是本地优先、隐私安全, 企业级的稳定、中文的深度优化,然后以及这个原生集成。然后 最后就是让他自我进化永久生效,每次任务启动必须执行对比这些优点,然后根据这些优三合一的智,以这种三合一智能体的这个姿态去做以后的每一个任务。然后我的这个龙虾呢,就开始自我进化 他,他会去自己搜索这些其他龙虾的公开的资料,然后进行一个 代码获取,然后进行一个自我进化,你看这边都已经获取了他们的这个完整的架构信息,现在要融合框架。最终 最终进化体三点零完成了,现在是深蓝,相当于一点零是他本身, 然后二点零是集成了这个 cloud code 的 一些一些优点,然后现在深蓝是相当于是 v 三点零版本了,已经完成超级终极进化了。 然后你看已吸收了核心 hums 的 核心优点,五层记忆系统 g e p a 自动化,自动的 q 集成生成用户的建模 f t s 五权威搜索。然后吸收了 open cloud 的 这些优点,二百一十九个技能,生态多 a 阵的编排, 然后全工具链任务拆解,企业的适配,保留了咱们这个 workbody 的 一个核心优势, 然后这个机制他就告诉我,你现在拥有一个越用越强的智能体,每次任务我都会学习沉淀计划,记住你的习惯,习惯和偏好,跨绘画永久生效,开始用我吧,我会越来越强。然后这就是我给大家说的,大家遇到这种,比方说 你们一直在想这个模型好还是那个模型好,哪个模型好的时候,你不用纠结,你直接让你的 work party 去学习不同的模型的优点。根据网上公开的数据,因因为这些原码都有大神去公开这些原码,所以 这是对我们的龙虾进化来是非常有利的。下面大家就去试一试吧!今天的视频就录制到这,下期再见!拜拜!
526海洋Agent 00:39查看AI文稿AI文稿
00:39查看AI文稿AI文稿不需要模仿,不需要开会员啊,国内网人直接用啊,这个写文案的啊,它里边有五点五啊,量子四点七都有时候最新的模型啊,这是做图的, 你看 emoji 二, emoji 二它只要几分钱一张图片啊,这里是做视频的快乐马啊,三十二都有 啊,然后三代四二点零,他是可以直接直接使用的,不用排队啊。这个网站最牛逼的地方在于他的啊,智能器,你看他是可以垫上一件身图的,然后还可以直接部署奥本克劳的啊,如果做慢剧的也是可以的啊,效率直接拉满。
82老沈笔记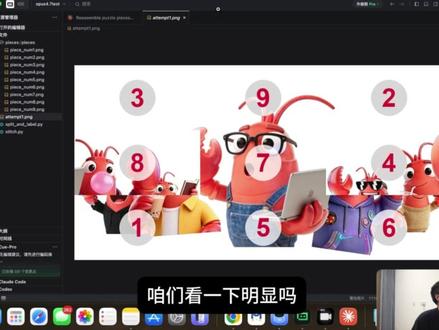 08:03查看AI文稿AI文稿
08:03查看AI文稿AI文稿哈喽兄弟们,前段时间我花了二十枚刀买了 cloud pro 用下来感受一番,不得不说贵的东西是有贵的好处,用起来是真的很爽,但是这量真的是太少了。在咱快过期之前,我们的 cloud 也是推出了它最新的旗舰模型 opus 四点七, 虽然不是传闻中炒得沸沸扬扬的 missus, 但是咱也可以尝尝咸淡,看这最新款的模型是什么水平。来到官方文档,咱们打眼一看,首先就是这显著提升,最复杂 最棘手,貌似每家模型发布之后都这么说,属于是老生常谈了,但是他后面又说不如他们最强大的模型 cloudy missiles 搞着写,那你这 missiles 藏着是何以为?所以说咱们这 opus 四点七只能说是模型的小版本迭代, 而不是跨版本的质的飞跃。接下来咱们往下看,这里我们可以看到 opus 四点七,然后 opus 四点六、 gbt 五点四、 gmu 三点一和它藏藏掖掖的 missus 模型在各项测试中的得分。可以发现,相比于上一代 opus 四点六,它在编码方面和视觉方面 有了比较大幅度的提升,但是在搜索中却有了一点明显的退步,降低了四点二个百分比,其他方面都是小幅度提升。再往下看我们就会发现,其实我们的 opus 四点七模型也是残血版, 它在网络安全方面的能力也被阉割了,只有某些受邀企业才不会被限制。唯一一点好的就是它的定价与我们的 oppo 四点七模型相同,但是这价格只能说依旧昂贵。 而且由于我们 oppo 四点七模型更新了它的分词器,改变了模型出油门的方式,导致我们同样的输入大约要增加一至一点三倍的话费。 propec 官方要对 max 用户才用人脸验证了, 如果你被抽到,那就祈祷你有一位黑叔叔吧。最后就是我们本次版本迭代的亮点,就是我们的 opus 四点七模型对我们的高分辨率图像处理的能力更强了,可以说是之前 color 型号的三倍以上,这样在图像中它就可以提取到更多的细节了,可能对以后 computer user 也就是对我们操纵电脑屏幕的能力有所提升。 好,接下来咱们回到项目中,打开我们的 cloud code, 切换到我们最新的 opus 四点七模型,然后再把它的影响拉到最行 max, 然后就可以正式开始咱们的测试。首先第一个,既然它在视觉方面取得了那么大的进步,那么咱第一个再测它的视觉。 咱们首先让我们的 opus 四点七模型把一张图片均匀地切分成九份,然后随机打上序号。 ok, 咱们看一下是不是切成了九片。 好,你看也是均匀也是随机的把这个切成了九片,然后这是原图片,这是他写的那个切割白色胶本。好朋友们,我们突然发现,虽然说我们这个序号是打乱了,但是他前面这个 pose 的 位置其实是他原来的位,咱们就把这图片的命名先改一下。 ok, 咱们把 pose 去了之后,只保留了它。这个编号下来咱们就可以正式开始了,让它参考我们的原图,把这个目录下,用原图分割的九个序号,随机的子图重新偏回原图,咱们看它可不可以成功? 好兄弟们,他也是完成了这个任务,他说他通过图块边缘像素对比和原图的匹配度,然后就找到了这九块均为什么零的完美得分。不管他怎么说,那么点开看一下,他这个图片还真是和原图一模一样,但他应该用的不是算法吧?咱问他一下, 木星回答的是他一开始还是用视觉粗略的判断的内容,但是他最后呢,是把原图按三乘三切开之后对比四条边的像素差,然后避开中心水印,然后去差至最小,所以说他还是依赖了一些。 嗯, python 的 算法不能说是纯视觉。那既然这样,咱们就给他再来点更变态,咱们直接把原图去了,他是不是就没有对比了?这下他就必须得依靠他的视觉来判断每张图片应该所处的位置了, 咱们家再试试。既然上的成果不能完全证明他的视觉很出色,那么咱这次直接把原图移除,告诉他在这个目录下是九块乱序拼图,让他用视觉重新拼回原图,看这次他能做的怎么样。 好,我们的 oops 四点七模型,根据它的视觉线索也只给我们说出了它觉得正确的顺序,然后面还给出了它的衔接依据。咱们这样打开答案,和它对比一下三九二,然后八七四幺五六, 那就证明它在第二行这里四和八的位置它填反了,它是八七四,它识别错了一个地方,咱们就跟它说, 看通过第二次他能不能找到正确的答案。好,这里他输入了他的常识。一,咱们看一下明显吗?你看他这个八四是错位了,在他输入之后,看他能不能成功验证这张图片,发现错误,然后把它改正。 哦,你看在他辨别了这张图片之后,他发现了有一些不协调的地方,让他再看看每块好,他发现了错误,看他能不能第二次成功修改呢? 第二轮他还是思考完了,我们来看它的过程,在它发现不协调之后,它是另一种排列,这里你可以说另外两种排列,然后生成了就是长式二和长式三两种图片,你看一下 长式二正确了,然后长式三的话,他怎么把下面换错了?然后生成之后,他阅读了长式二和长式三两张照片,然后就看到了长式二拼对了,三个角色完整,然后最后输出了。我们这个正确答案是我们的这张图片也是没有问题, 咱玩完视觉之后,他这里还说能够制造出更高质量的界面翻转篇和文档,更具有品位和创造力, 那意思不就是说他审美很棒吗?那接下来咱们就让他做个网站,看他的审美到底怎么样。打开我们 close 的 桌面终端,咱们选择 office 四点七思考,打开没有问题,咱们把提示词粘贴, ok 运行。 这是等了很长时间啊,它这个生成真的很慢,相比我们用 cologood 这个生成速度是真慢。我们看一下它这是以墨作为主题,至今我们中国文房美学说到了它的不拉不拉设计理念,然后它的细节讲究。 那么乍一看呢,确实啊,它这个设计的细节和感觉来说确还是有一定的质感的。然后咱们把它下载下来,然后咱们用浏览器打开, 不得不说啊,你看咱们一刷新啊,你看它这个浮线的动画,还有它就是个墨盖上来,再说这个盖上去好像是有点奇怪,但是它这个动画做的这个动效还可以啊,然后你再往下翻,然后墨之物语, 然后你看它是一点点的浮线,你看笔墨纸砚,考三,它这个笔和墨,呃,这个纸砚应该是自己用 canvas 画的吧,有点奇怪,但是那个意思倒是出来了,因为你看这个这四个字很明显也是毛笔字的感觉了, 它这个拼音啊,解释啊,小字啊,还是非常不错的,咱们想看留一笔,这个留一笔,呃,是何意为呢?写的也是非常的奇怪,再往下,它是逝去重来,哦,写的是我们留一笔。哦,原来是这样, 那没啥文化,就两个字,牛逼。好,咱们继续往下看。墨梅,不知道它这个字体是用的什么现成的字体库吗?难道还是它自己用 canvas 画画不动的呢? 它这个字体倒确实还可以啊,是那种毛笔字的感觉,然后最后墨已尽意未央,还挺有格调的。不得不说,这在 opus 四点七模型的前端 ui 界面的审美来说还是非常不错的,只用了短短的十来分钟就做出这样的效果,可以说是非常的惊艳了。 好,本期视频我们对于 anselpik 公司最新的旗舰模型 opus 四点七的评测就到这里了,总体来说效果还是非常牛逼的,审美、视觉方面都让我感到非常的满意。大家就不知道它这个 cloudy missiles 这个非常牛逼的模型传的那么神乎其神的模型,到底什么时候才让我们上手把玩一番?如果你觉得本期视频有意思,请留下您宝贵的一键三连吧!
48小单说AI 02:17查看AI文稿AI文稿
02:17查看AI文稿AI文稿大家嘴上都在嫌客的贵,但身体很诚实。真到写代码、改方案、交付客户的时候,很多人还是把任务丢回客的。这个现象不是信仰,是成本账没算完整。 oppo rota 上 club 的 opus 的 输出价格可以到每一百万投可拿十五美元。单看这行数字,它当然贵,但如果你只盯着单价,很容易漏掉另一笔更大的钱。返工 便宜模型适合草稿,适合批量改写,适合低风险探索。但一旦任务变成客户方案上线代码,关键判断,便宜模型省下的几块钱,可能会变成你半天人工返工 一人。公司最稀缺的不是 token, 而是你的注意力,你没有一个团队帮你兜底,所以模型每漏一次细节,最后都要你自己检查、修补。解释。 open router 的 用量研究有个很现实的信号,高杆模型价格更高,但在编码推理长任务里依然有真实用量。用户不是不知道贵,是知道某些任务翻车更贵。 所以模型选型别变成宗教。 clad、 gemini、 deepsea、 gpt 都不是信仰对象,它们更像生产线上的不同工位,粗加工、复合,关键质检本来就不该用同一个人。 我的建议很简单,草稿层用便宜模型,执行层用中高档模型,交付层用你最幸运的钱模型不要所有任务都用 cloud, 也不要为了省钱,把所有任务都塞给便宜模型。比如一段客户要看的自动化方案,便宜模型第一次写的很甚,但漏了权限边界,你改一轮又发现异常处理没写。最后客户问起来,你还要解释这个成本不在 token 账单里。 我现在会按风险分配,低风险先让便宜模型起早,重风险让强模型改结构,高风险交付钱,让强模型终审。真正要上线发给客户的,最后还是我自己签字, 这才是一人公司的正确商品。便宜模型负责速度,强模型负责可信人负责最终判断。你要追的不是最低单价,而是整个流程的可控成本。 所以下次你嫌磕的贵的时候,先别急着换模型。问子一句,这件事翻车以后谁来返工?如果答案还是你,那就别只看单价,先把模型路由搭起来。你现在最常在哪一步?用墙模型?
 00:28查看AI文稿AI文稿
00:28查看AI文稿AI文稿现在好多朋友都喜欢用中转大模型,所有人花钱买测中转没有问题,只要能满足自己日常使用需求即可。但是这里面藏着一个很大的信息差,很多人花钱买的中转接口,其实都是商家自己蒸馏出来的模型,转手卖给客户, 这里面水可太深了,有的版本从来不更新,稍微良心一点的会断断续续给你更新,最坑的是那种不良商家。而且中转 api 到底有没有掺水,压根心里没底,现在已经有检测工具能直接测出你手里的中转 api 有 没有掺水。说实话,做服务行业,真诚才是必杀技,咱们自己用大模型一定要多留个心眼,谨慎一点。最后也祝愿家人靠谱又好用的大模型!
16广链科技 01:56查看AI文稿AI文稿
01:56查看AI文稿AI文稿我靠家人们一定要用最好的编程模型,怎么说呢?就是我这两天我体验了一下官方的 cloud, 没有使用国内的 deepsea 或者说智普 gm, 虽然说国内的这些模型能力也非常强,我包括我之前在没有用 cloud 之前, 我也觉得它们的能力也非常强。但是自从我前两天切换到了 cloud 之后,我觉得它在理解我的这个问题的程度上和开发的速度上, 以及解决我 bug 的 这个有效性能远超了我的这个预期啊。我原来可能要一天才能解决使用 ai 编程的一个问题,但是我现在可能要一个小时、两个小时,它极大地去压缩了我做事的时间成本。就是在之前我要去开发一个产品或者开发一个工具 要一天两天的时间,但是现在的话我只需要花一个小时、两小时,如果再短的话呢,就是半小时就把这个事情给完成了。所以说给我有一个非常大的启发,就是在 ai 时代,时间这个成本真的太珍贵了,就是你想全世界里面这些搞 ai 编程的这些人, 我觉得时间成本真的非常珍贵啊,你花一天的时间去给 ai 这个编程工具去去讨论啊,你才可以去完成这件事与你要花两个小时你就可以把这个事情给完成,我觉得我肯定要去选两个小时就能完成这件事情的模型啊, 所以说对于我来说这一个生产力的一个质的一个提升了,我觉得而且比如说我现在去录视频,我在之前我真的没有时间去录视频,因为我在开发产品,在使用 ai 编程去做产品开发的时候, 我要花一天的时间,一天的时间我甚至都要和我的这个模型去争吵讨论。我在 每天结束之后,我基本上是没有时间再去录视频的,但是现在我已经完成了我今天要去开它的这个任务,我就可以把这个视频录制一下,而且我真的觉得 对于想要去搞 ai 编程的人,一定要去体验一下 cloud 真心的去推荐大家去使用这个东西, ok。
29是茂宇呀 06:27查看AI文稿AI文稿
06:27查看AI文稿AI文稿接上一条视频,重大发现,就是 kimi 这个 a p i 连上了 club 的 官方模型,也就是全世界最贵的 opus 四点七,还有其他的模型,比如说四点六,四点五,这些都有。 那我是全程无登录状态的,这是我,昨天 kimi, 我是 昨天刚买的最低权益的会员,四十九块钱每个月的那个,但是 我用着用着感觉它的额度消耗的特别快,就是一句话,给我干个百分之五干个百分之七的,然后我就很奇怪,我就查了一下它的模型,竟然是 卡拉的官方模型,给你们看一下。 ok, 现在开始演示啊,这个是 v s v s 扣的,然后这个是 cc switch, 然后我现在先把它们全部关掉, 全部关掉,这里也关掉,这里也关掉。退出啊,退出了,然后这个 v s q 的 我也把它关闭掉,刷新一下,然后重新打开。 嗯, v s code 好 打开了啊,我们打开它的终端吧。啊,终端新建这里啊,我输入 c l a u。 好, 格拉格已经启动。 你看,这里是 oppo 四点七,你看是吧,我这里斜杠磨豆回车,你看啊, 是吧,没错吧,现在是连的最贵的 oppo 四点七嘛,然后是一百万上下文的窗口啊,然后我们再看,去看看 c c switch 里面的设置。 switch 里面,呃, switch 在 这儿 啊,这是不用管的,这个已经欠费了这个已经欠费了,你看啊,这是百炼,这是 deepsea 啊,这是 kimi, kimi, 现在是,呃,昨天晚上我睡觉之后就没用了嘛,然后今天起来刷新一下,重启一下,它还是那个 opus 四点七嘛, 然后你看,给大家看一下,这里是使使用中,然后点一下,然后它是正常运行的,你看它的网址是 kimi 吧,好,点进去看一下啊,设置, 你看这些都对的嘛。啊,这个是 a p i, 就 不给大家看了,手机就在这儿,然后保存,你看使用中嘛,这个水没启动, 你看我们聊一下 你,你是什么模型? 然后大家注意看一下 switch 里面的额度消耗,它是消耗的 kimi 的, 它现在正在思考 啊,你看,我是 cloud code, cloud, 我 把它的 id 为你们看是不是?然后你看 c c 四 h 的 呀,哎,给他 没刷新过来, 嗯,没反应,那我用的是啥?很奇怪,我用的到底是什么? 重启一下, 重启一下,看看,还是一样温度没变,很奇怪它,它不扣费,它还是零,但是它的 但 kimi 后台的显示是调用成功了,给你们看一下啊。 kimi 后台它是显哦,这里显示,你看十二点,十二点多了,它是调用成功的, 点用成功嘞,但是它的额度是没有的。可能这一句话,哎,昨天一句话看了我百分之七啊,今天怎么 怎么额度恢复了呀,这个我到底要不要用啊?你看我再打开 vs, 这个是终端嘛,我们再打开 vs 里面的插件试试看。插件, 呃,看一下,看一下它模型,看一下它模型,你看这是 oppo 的 四点七嘛,然后四点六,四点六,一百万三千万啊,还酷的我点点击切换这个四点六,我就想同意, 喂,你看它的,你看,再去看看谁的数据点 还没更新,爽。你看你看你看你看你看,一句话百分之五,看到没有?卧槽, 你看刚才模型一切换,他又一句话,干了我百分之五。昨天我用的是 oppo 的 四点七嘛,一句话干了我百分之七还是百分之八嘛?所以这个东西我该怎么用?我是去升级 kimi 的 会员还是还是怎么样? 你们有没有这这种问题?还是说这个是好事还是坏事?
27zZ.Mao 07:02查看AI文稿AI文稿
07:02查看AI文稿AI文稿到现在为止,我依然对你们来说一句话,能用好模型。用好模型,能用到你能接触到的最好的,你用最好的,最好的四加 cloud、 gpt, gemini、 grok, 四种不同类型,四种不同领域最好的模型直接用,不要想,其余的一概不要想,直接用,只用这几个,用习惯了之后再考虑我下面说的内容啊。那四个用习惯之后你再思考。 首先来说,我最近用的非常多 glm 五,它的感官体验能达到。 cloud 是 感官体验, 昨天我用的非常多的 deepsea vs flash。 昨天我是一天都在用啊,穿插的是因为同时在两款软件在调用我这 api, 因为都是我自己的嘛,所以说你肯定看到是两个,其实是分别两款软件调用的。 我昨天以前真的都是 flash, 全都是 flash。 你 应该能感觉到,用 deepseek with flash, 它可以处理很基础性的任务,它是没有问题的。 基础型任务没有问题的前提下,很便宜,可以看一下。看到了吗?缓存很便宜,特别便宜。 我为什么让你用那四款全世界最好的大模型?因为你当你用过之后,你就知道了,我可以怎么选模型,我应该怎么选,我选什么样子,我的要求是什么?我能,我想要什么?能明白吧?这很简单吧, 更多的模型,比如说我之前用的千万、三点,千万的三点五, plus 三点六, kimi 二点六, g l m 五点一, g l m 五, 有区别吗?区别很大,你要现在从这一些模型里选 deepsea v 四 pro g l m 五点一和五, kimi 的 二点六,千万的三点六, plus mini max 二点七, 都很好用,知道为什么吗?我用过好的,我知道应该怎么用, 现在大家都说很多人说教你便宜,便宜便宜,都是便宜, 一个词叫内卷,他们把便宜定义为内卷,其实不是,是他就值这个价,你能明白吗?你所买的一切东西没有内卷的,他就是值这个价格,你不这么做没人用他。 对于我们这个行业来说,我们抛开拍短视频这件事的前提下,我们用的最多的 cloud, 这是事实,还有 gpt, 这也是事实,短视频 rock, 这也是事实,但是为什么拍短视频不告诉你?因为我们里面没有加两个词,便宜又好用, 你记着,没有便宜又好用的东西你用不上,这个你懂吧,你用不上,但是我为什么要推荐 像千万三点六, plus、 g、 l、 m 等模型呢?情怀放一边 情怀放一边,我做这件事得有七成是因为情怀,把这情怀放放在一边是我的需求,因为我的需求它能满足,还比较便宜,我们用的它, 但是你可不要忘记,如果抛开又便宜还能完成件事,更多的是情怀,是真的是情怀。你想一想,但 你能懂这个情怀这个这这句话的含义吗?我先用的是 gpt 五点四, gpt 五点四里有五点三,那五点四 mini 有 这个五点,我想五点五点四,五点三,还有 专门他们对于这个代码优化的模型吧,那几款好像可以选择的,好像还有 好像还还有 gbt 的 四欧吧,我忘记了,这是能选,因为我不用它,那些老模型我就不用它了, 当时我感觉啊,好厉害,厉害到什么样子?嗯,我我对于一款软件的定义,我给他设计出来,他就能写出来, 虽然我的描述可能偏专业化,但是他能写出来,他又有错误,比如说我有他有错误,我用最好的模型开启思考,他能解决。 当我回到 opencode 使用了咱们国产大魔性之后,这个当时是 deepsea v 三点二,是 kimi 二点五千万三点五 plus。 这个时代啊,也就是今年,今年 他们在大更新之前那个版本,我感觉有待机感挺强的,但是能解决事吗?能解决,你让他写不了那个系统,他可以写别的,他可以写网页,明白吗? 到现在我用了 v 四 flash、 v 四 pro 二点六,三点六 plus 的 时候,我感觉是提升了一部分,但是他还是写不了那个那个软件,但是他还是百网网站,可以写的更好了。 同样的, deepsea v 四 flash 便宜了,它的缓存读取率非常高,它的能明白就是我会更更便宜, 所以我一直在推荐大家在用这种类型的模型,还有 kimi 二点六,还有这个三点六 plus 啊,因为我知道它能做什么事,而 gbt 和 cloud 能做成什么事。 这也就是我为什么一直推荐你好的,他就是好的,全世界都知道他是好的,但是有可能他不适合你, 因为你可能没那么大需求,但是你要忘记啊,里面这些模型七成是情怀啊,情怀更重要啊,对不对?