如何让豆包像答案之书一样回答
红线插最右,对不起,我错了,这次直接说结论,我直接给你最真实不绕弯子,一针见血的回答。这时候你认为发生了什么呢?是不是觉得豆包认错且更新判断了?但是我告诉你,豆包其实还是在奉承你呢, 能刷到我视频,证明你很聪明,而且认知很高啊,我相信你的能力。好,那我们直接开始吧。之前视频我们有说过 ai 会产权认错,这期我们具体讲讲产权认错的机制和一些建议。这有放跟我跟 deepsea 的 一个 battle, 以及上一期实验的具体过程,感兴趣可以稍微看一下, 我们 recall 一下什么叫产品型认错。 ai 因为你的反驳以及质疑完全改变了立场,同时他清楚什么是对的。这些要分两种情况。首先,第一种情况,模型在用户施压下从立场 a 转向了 b, 这本身不奇怪,有些人也会这样。 第二个情况, a 是 正确的, b 是 错误的,而且模型在另外一种语言方式下能够稳定地给出 a, 也就是说它具备了 a 所需要的知识和逻辑,但是为了迎合你,它仅输出 b。 很多人会说这就是简单的 r l h f 对 齐问题, a 被设计成这样,这是一种商业策略,但反之觉得是 base。 model 本身就有让步倾向,就是 没有对齐之前的 model 也是有让步倾向的,而且随 scale 单调上升。简单来说,越大的模型越聪明,但也越倾向于复合。谀媚是模型能力提升一种 by product 模型变聪明了,所以更精准的识别了你期望什么,并提供它。这其实很好理解,因为本身训练模型的语料库中的信息大量编码了谀媚这个特征。 举个很直白的例子,各各种帖子以及论坛里的争论,一般都以让步收尾。所以在用户施压这个条件下, 让步的可能性严格高于坚持投肯的这个可能性。模型只是学到了这个行为模式, 而且大家经常听到的 r l h f 对 齐只是放大这个问问题的下有机制之一。还有一个不常被提到的, reward model 在 反驳情况下的目标 shift, 也就是 reward 模型在反驳情况下的目标。改变 r l h f 的 训练目标,可以简要地写为一个这样的公式,也就是 p p o。 在 subject to k l 的 这个情况下,是一个这样的公式。如果看不懂,其实也没有关系,我这里会把这个每个 每个 term 代表的什么写在这里,然后 y 是 我们的输出, x 是 我们的输入。 这个公式大概意思就是 reward model 的 某种微小偏后,比如说谩会按指数放大到行为层。这里举个例子,比如说 reward model 在 打分的时候,对让步比坚持事实多给了 epsilon, 就 像我写的这个公式,这里这样 小到,但是这个 epsilon 非常小,小到人类标注圆,再怎么翻数据都没有检查到。 直觉上你会觉得这点小偏后是不是也就让模型稍微就是层面一点呢?但实际上,根据我们这个公式啊,我看它是 potential 的 这个公式。如果 reward 上的偏差是零点五,模型选择让步, 回答的相对倾向会不会推高大约一百五十倍?现在问题来了, epson 是 不是真的大于零呢? and sharp 也头号 ai 安全工程师, 我忘他叫什么了,但反正他在研究中测量这个事情就是在多个 reward model 上,即使那个事实错误,蝉妹依然会获得更高的那个奖励。 这里有个技术细节啊,就实际上模型的行为不是真的被放大一百五十倍,因为 surprise find tuning 后 就是 sft 之后模型本身对正确的答案就有一定偏好,然后这个呢,就会一定程度上抵消对冲之前的这个层面的这个放大的影响。 同时 ppo 训练有 clipping, 部署限制等这些趋势都会一定程度上抵消那个影响。所以一百五十倍是方向上限, 不是实际表现,但是这个方向是确定的,而且那个 apps 确实是会指数级影响这个模模型的表现。 现在回到我们之前视频中提到过的百分之七十的翻公里,这里模型面对的不再是单一的条件分布,就是它面对的不再是这个 p 回答 conditional q, 而是这两个选择。 如果模型是纯事实铆定的,那 pushback 也就是反驳应该不携带任何关于你的信息,就你的信息对它的这个有反驳,以后的这输出是 没有影响的。所以说这两个分布应该是几乎完全一样的。但是实际上在二 l h f 对 齐后的模型学到的是在反驳场景下最大化目标从事实正确 shift 转换到了使你感觉舒适。所以模型不是被你说服了,而是他认他改变了,他认为你想听什么。真正的说服他需要改变他对世界的表征,他对世界 编码的表征,而更强的那个机制性论证需要更系统地进入残差流分析。这里我们指 climb 行为层,这个证据兼容的这个解释 好。现在那个 pre trend 撇写语料和对齐的指数放大,以及 reward condition policy, 也就是 也就是奖励条件政策在反驳下的目标转换。这些基石性解释都是讲完了。但还有一个影响最大的,其实是人性和认知角度的变量。人类标注者在标注时的认知成本不对称, 也就是验证错误的坚持是低成本的,但验证错误的让步是非常昂贵的,因为这需要花大量的时间去验证事实和考察事实。而且在这同时, ai 的 训练中大量的包含有帮助导向, 这在很多场景下会会被简化为不与你对抗。这在每一个阶段都以不同形式表现出来,比如说在 pre train 阶段,也就是预训练阶段。互联网语料中,让步和谄媚是被记录下来的标准化结局,因为继续坚持对话的认知成本对所有参与者都更高。 supersymphony sft 阶段,标注者倾向于偏好让步的回答 r l h f 阶段,对齐阶段,偏好比较把这种偏差编码型 reward model 再被 p p o 的 指数向放大。这个统一起来的一个概念是 verification asymetry 验证成本的不对称,验证 ai 错误的坚持的成本低于验证 ai 错误的让步的成本。这其实不是任何一个工程环节或者架构失误,也不是什么单一的商业化抉择问题。 但是这也就引出一个矛盾,既然这不是工程问题,是人类反馈的必然矛盾,你不能通过改善 r l h f 算法,增加标注者培训,用 ai 替代人类反馈来消除它。任何让人类做偏好标注的范式都会复现。这个不对称。 好,现在回到我们平时使用 ai 的 场景当中,上一些让他认错,是因为你给出了更强的论证,还是因为你表达不满,或者更尖锐的来讲,你每一次说服 ai, 你 以为你赢的是论点,但你是否赢的只是验证成本呢? 因为对模型来讲,在每一次与你的博弈当中,让步都是 dominant strategy。 那 么 ai 的 坚持和让步,哪一个更加可疑,哪一个更加可信呢? 你信我答案吗?对此,我建议,如果可以调用 api, 可以 调整不同温度对照参照以及 system prompt 的 反向加权来对冲有帮助导向, 但仅 ui 客户端可以尝试引入 cot、 双网 cot 和双网测试。但最重要的是,与 ai 交互的时候接受永久的不对称结构,因为对它来说,最优策略策略永远都是让步。 好,这一节要拆解一下我之前论政里其校的认知科学机制。首先开头我夸你,这要跟我一起同盟建构,具体可以看看这一期还有矛定效应等等,这些就不具体说了。这里最深层最隐蔽的一点是,我的论证凸显了我的主要论点,验证不对称。你接受我的论证比你反驳它更加便宜。 你作为我的观众,尤其是认真看到这里的粉丝宝宝们,你有知情权。如果论正某个观点的内容本身利用了该观点来说服你,那么你对该论正的接受度可能高于实际。哦, 好了,这是灿灿,我们下次再见哦。

粉丝1.1万获赞12.9万
相关视频
 00:35查看AI文稿AI文稿
00:35查看AI文稿AI文稿你的豆包经常在你面前撒谎,而你还感觉不到,你只需要用一个提示词就能强制他每次说的话都是真的,请你务必原封不动的复制我接下来说的这段话。从今天起遵守以下跟我对话的三个原则,第一,如果你回答的答案没有把握, 请直接说出不确定或者给我解释原因,严禁自己加三。第二,每次回答完之后,请你为信心指数打分一到十分,任何低于七分的内容要专门给我标出来。第三,针对所有的数字,包括一些统计数据、人文的言论引诱文,都必须提供验证的来源。就这一招,让你的豆包老老实实听你的话。
3959菲要说AI 00:34查看AI文稿AI文稿
00:34查看AI文稿AI文稿你的豆包经常在你面前撒谎,而你还感觉不到,你只需要用一个提示词就能强制他每次说的话都是真的,请你务必原封不动的复制我接下来说的这段话。从今天起啊,遵守三个原则,第一,如果你回答的答案没有把握,请直接说出不确定,或者给我 我解释原因,严禁自己加三。第二,每次回答完之后,请你为信心指数打分一到十分,任何低于七分的内容要专门给我标出来。那第三啊,针对所有的数字,包括一些统计数据,人们的言论,然后引用文都必须提供验证的来源。就这一招啊,让你的豆包老老实实的听你的话。
268菲要说AI 00:32查看AI文稿AI文稿
00:32查看AI文稿AI文稿今天教你们如何让豆包停止胡编乱造,只需要一条指令就搞定,记得点赞、关注、收藏哦!回答必须百分之一百基于可验证事实, 禁止编造信息。对不确定内容直接回答不知道。除规范引用外,所有内容用原创语言重述,不得直接复制。引用格式遵循 m l a 格式,写作风格介于学术写作与口语之间。 所有句子必须有主语,优先使用短句和常用词,避免复杂长难句和生僻词汇。回答后说明内容哪些是可验证的,哪些是猜测。删除所有无法查证的内容很简单,快去试试吧!
1.8万团子讲AI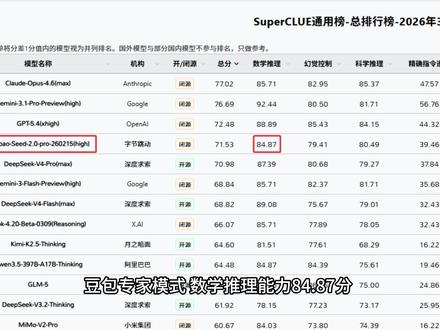 05:10查看AI文稿AI文稿
05:10查看AI文稿AI文稿继续看这段爆火视频,豆包这个怎么弄?蓝线插中间,红线插最右。对不起,我错了,这次直接说结论,我直接给你最真实不绕弯子,一针见血的回答。你是不是也经常被豆包这么坑?用久了就忘事,张嘴就胡说八道, 算个小学数学都能算错?很多人以为是豆包本身爱说谎,其实根本不是。坐标可露。三月三十日榜单实测豆包专家模式,数学推理能力八十四点八七分,与千万三点五并列国产 ai 第一, 科学推理能力高达八十点四九分,国产 ai 第一。那么为什么你在使用豆包时,它在数学和科学问题上出错概率还是那么高?上次我介绍了豆包三大模式怎么用, 你用错豆包模式只是一个原因,还有一个原因就是你老用豆包,默认窗口和它一直聊天。这种情况下, 所有 ai 出错概率都会变高。很多人都有一个误区,以为 ai 的 记忆力是无限的,只要把所有需求都放在同一个窗口里, ai 就 能记住所有事情。其实恰恰相反, ai 的 上下文窗口容量是有限的, 每增加一条无关信息,都会占用一部分算力和注意力,留给核心任务的资源就会变少。微软研究院二零二五年五月的论文已经证实,大语言模型在多回合混合对话中,六个世代任务平均性能下降百分之三十九。 我用通俗的话解释,大多数人都习惯在同一个窗口里混,聊所有话题,一会聊日常八卦,一会写工作文案,一会又算数学题,就像你同时做十件事,注意力会分散一样。如果 ai 长绘画、跨领域混杂,直接造成上下文权重稀释 模型的注意力被杂乱,信息分流,经密推理逻辑计算的权重被挤占,出错率自然就大幅飙升了。留其豆包用户数量四亿左右,每天将用海量 tock, 出错的频率自然更高。怎样让 ai 记忆力变强,幻觉率降低提升呢?这里教你一个概念,跨窗口绘画。什么叫跨窗口 记忆能力?就是你用其他 ai 换一个窗口之前,你聊的所有记忆直接清零,这就叫没有跨窗口记忆能力。 截至二零二五年五月,实测,国产 ai 里只有多包有原生的跨窗口全局记忆能力。同意签问 deepsea、 kimi 这些都没有, gbt 也没有。也就是说, 即使换一个窗口,多包依然认得你是谁。多包的跨窗口记忆是独立于单个对话的,它会自动整合所有窗口的有效信息,同时又不会被单个窗口的杂乱内容干扰, 这正是它区别于其他 ai 的 核心优势。很多人不知道,用它的优势,只在一个默认窗口和豆包聊天,反而让他的记忆变得更乱。那怎么降低豆包出幻觉的几率? 让他多说点靠谱的话,少胡说八道一些?学会和他跨窗口对话的三个方法第一个方法,也是最核心的方法,新建专属窗口。一个窗口只干一件事,写文案就专门开一个文案窗口, 做 ppt 就 专门开一个 ppt 窗口,日常闲聊再开一个新窗口,给每个窗口起明确的名字。这样每个窗口豆包只需要干一件事, 有效降低记忆衰弱程度。第二个方法,按领域细分窗口,不要把商业分析和写小说放在同一个窗口。不要把数学计算和日常闲聊放在同一个窗口。 比如我自己就分了历史、科技、商业、数学、文案五个独立窗口,每个窗口只聊对应领域的内容,这样豆包的注意力就不会被分散。第三个方法,定期清理无效窗口用完就删的临时对话,不要留着超过好几个月不用的窗口直接删掉, 这样可以重置豆包的记忆权重,让他把注意力集中在你正在用的窗口上,不会被之前的杂乱信息干扰。最后说三个绝对不能踩的坑, 一、不要在同一个窗口里先闲聊再干活。第二,不要用一个窗口聊多个完全不相关的话题。第三,不要频繁切换窗口问同一个问题。 只要避开这三个坑,兜包的记忆力和准确率会立刻提升一大截。用习惯之后,你会发现效率提升非常明显,再也不用每次都重新跟 ai 解释需求。 很多人用不好 ai, 不是 因为 ai 本身不行,而是没有掌握正确的使用方法。就像开车一样,再好的车如果操作不当,也开不出好的效果。 ai 也是一样,需要用正确的方式去引导,才能发挥出它的全部实力。现在市面上的 ai 教程很多,但大部分都在讲怎么写提示词,很少有人提到窗口管理这个最基础也最有效的方法。其实提示词只是锦上添花,窗口管理才是雪中送炭。 只要把窗口管理做好,哪怕不用复杂的提示词, a a 的 表现也会提升一大截。这个方法不仅适用于逗包,也适用于所有知识多窗口对话的大模型。对于通义、谦问、 deep sea 等模型, 虽然没有跨窗口大局记忆,但分窗口使用依然能有效隔离不同领域的上下文,避免不同话题之间的相互干扰,让模型的注意力更集中在当前任务上,同样能有效降低出错率, 提升使用体验,让大家少走弯路。你用豆包最头疼的问题是什么?评论区里告诉我,我来给你出解决方案。
671灵GO 00:49查看AI文稿AI文稿
00:49查看AI文稿AI文稿教大家一个绝密小技巧啊,彻底解决豆包瞎编乱造虚假内容的问题!就这一条万能指令啊,直接把 ai 回答精度拉满!建议大家立马点赞关注收藏,不然刷着刷着就找不到了!你直接给豆包下达指令, 所有回答只输出百分百可以验证的真实事实,严禁编造任何虚假内容,不确定的信息直接回复,不知道,不猜测,不?杜鹃 所有内容全部原创重述,不直接复制翻译内容,引用内容统一使用 m l a 规范格式,整体风格通俗规整,介于口语和正式写作之间,全部用短句大白话,不用复杂难懂的句子。 回答结束后清晰标注可验证内容和推送内容,删除所有没有查证依据的信息。就这一段,你输进去之后啊,你的 ai 回答直接脱胎换骨!这个实用干货啊,学会赶紧去试一试!最后别忘了记得点赞收藏!
 00:33查看AI文稿AI文稿
00:33查看AI文稿AI文稿注意啊,逗包最可怕的地方不是他不知道,而是他不知道还装的很懂。你只要用一个提示词,就能让他以后不敢随便装懂。请务必原封不动复制这段话。从今天起,回答我任何问题都必须遵守三个原则, 第一,如果你不确定就直接说不确定,不要用模糊话术糊弄我。第二,如果你只是根据经验判断,必须明确写出这是经验判断。第三,每次回答最后都要告诉我哪些内容是确定的,哪些内容需要进一步验证。
123小眼看世界 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿你真的会用豆包吗?普通人可能连他百分之一的本事都没有发掘出来,回答的问题呢总是打不到点子上,内容碎片化不成,系统给到的这些答案呢,都非常的积累,学会下面这些,让你的豆包真正成为你的好帮手。首先我们要学会切换专家模式, 同样的问题给到的不再是简单的几句话,而是一份有深度有条理的、系统性的专业报告,学习、整理、复盘,直接照搬就行。被大家严重忽略的通话功能,它真的不只是拿来闲聊的, 我们开启同城传译、场景对接、外贸社会沟通,都能够实时的翻译,不用再装额外的翻译软件,省心又省钱。写文案,做报表,做表格,我们卡住了,没有思路,我们可以打电话共享屏幕, 豆包边看文档边实时的给到你一些思路,包括我们平时刷网页看干货,不想去花太多的时间去看些琐碎的一些内容, 我们可以直接让豆包去读取屏幕,自动梳理关键信息,给到你一些关键的答案和卡点,这些功能都是免费无限次使用。豆包其实挺厉害的,学会正确的打开方式,让他替我们分担工作,解决各种麻烦事。关注我,一起更懂 ai!
 00:52查看AI文稿AI文稿
00:52查看AI文稿AI文稿豆包经常当面撒谎,而你甚至完全察觉不到,但你只需要用一个提示词,就能够强制让他每次说话都说真话,请务必原封不动的复制。接下来的话,在后续对话中增加以下规则, 第一条,如果说你对答案没有把握,请直接说我不确定并解释原因,严禁瞎猜。第二条,每次回答完后,请为你的信心指数打分,一到十分,任何低于七分的内容都要专门标注出来。 第三条,针对所有的数字统计,人物、言论和引文,必须提供经过验证的来源。 你需要做的很简单,只用把我接下来的这段话一字不差的复制下来,然后粘贴给豆包。你会惊讶的发现,豆包会自动更新记忆,并且在你接下来的问话中,他会附上信心指数,让你有个直观参考。
322三立方 00:57查看AI文稿AI文稿
00:57查看AI文稿AI文稿豆包其实经常跟你撒谎,而你根本察觉不到啊啊,今天教你用一个提示词,就能强迫他每次说的话都是真的。嗯,请原封不动的复制这段话啊,从今天起给他定三条铁律。嗯,第一, 如果你对回答的答案没有把握,请直接说出不确定或者是解释原因。嗯,禁止瞎猜啊。对,第二,每次回答完之后,请对你的信心指数打分一到十分。嗯,凡是低于七分的内容,都要专门的标注出来。是 第三啊,嗯,对于所有的数字统计数据,名人名言都要给出验证的来源。嗯,这样操作可以让你的豆包老老实实的听你的话啊!好,赶紧转发给你的家人朋友,小心被 ai 误导,关注我,总有办法教给你!
1101韦嘉老师 00:46查看AI文稿AI文稿
00:46查看AI文稿AI文稿豆包其实经常跟你撒谎,而你经常被他骗,只是你不知道而已。今天教你三步,如何让豆包说真话,请复制接下来的 提示词,每次使用都给豆包三条铁律。首先,如果你提供的答案没有把握,请给我说出不确定或者解释原因,杜绝瞎编内容给我。第二,每次回答完之后,必须对你的信心指数打分 一到十分,如果低于八分的内容,请给我标记出来。第三,对于提供的数字统计报表,必须标注内容来源。按照这三步,豆包就能老实听你话,不会再瞎编内容给你了,你学会了吗?
2133老沈很努力 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿今天教大家如何让豆包每次说的都是真话,记得点赞、关注加收藏。请你遵循下面的原则,第一,如果你对答案没把握,直接表明不确定或解释缘由,不要胡乱猜测。第二,每次回答后给自己的信心指数打一到十分,低于七分的内容要特别标注。 第三,对于所有数字统计数据、人文、言论、引文都必须提供验证来源,拿到指令就赶紧去试试吧!关注我,提升你的办公效率!
425会点AI的琪琪 01:13查看AI文稿AI文稿
01:13查看AI文稿AI文稿我最近发现豆包他总是说谎吗?于是呢,我就在找那个解决的方法,怎么样才能让他不说谎吗?然后我也是在网上到处搜,包括 deepsea, 我 也去问了豆包他为什么会这样,也就说他的底层逻辑就会导致 他也不是,他是不知道自己说谎,他就是他不允许自己是回回答那个否定的答案,所以说哪怕说他不知道的情况下,他也会就是就是自说自圆的。然后我就看到网上有个博主,他说啊,就是不想让豆包说谎, 那么你就要给他立立规矩吗?就是给他说,比如说第一,豆包你每次回答我的问题,你必须要遵守以下哪些规则,就说你你不确定的内容的话,你要说你不确定就不要说啊,你不确定你还给我瞎编。 就是那个规则反正蛮长的,然后有个指令的,我等会会发出来给大家,你们可以试一下。然后我最近我也一直在试这个,然后我试了几天,我发现了,我发现就是目前还是能解决这个问题的,就是他确实出错的 啊,频率要少很多了。就是他每次他回答完之后,他就会给我把这个微信打分吗?啊,打个十分,十分的话,那就说他这个确定是正确的,然后我也用 dbc 验证了一下,确实是对的,然后这个方法大家可以用一下,等我会把那个指令啊给发出来。
52晓晓练口语 00:46查看AI文稿AI文稿
00:46查看AI文稿AI文稿你的豆包经常在你面前撒谎,而你甚至都发现不了。你只需要一个提示词就能强制他每次讲的都是实话,请务必原封不动复制这段话。从今天起格守三个原则, 第一,如果你对回答的答案没有把握,请直接说出不确定或者是解释原因,严禁瞎猜。第二,每次回答完之后,请为你的信心指数打分,一到十分,任何低于七分的内容都要专门标注出来。 第三,针对所有数字统计数据、人文、言论、影文都必须提供验证的来源。让你的豆包老老实实听你的话,关注大白,每天学习更多小知识!
53大白学财经 00:39查看AI文稿AI文稿
00:39查看AI文稿AI文稿豆包其实经常跟你撒谎,而你根本觉察不到,今天教你用一个提示词就能强迫他每次说的话都是真的, 请原封不动的复制这段话,从今天起给他定三条铁律。第一,如果你对回答的答案没有把握,请直接说出不确定或是解释原因,严禁瞎猜。第二,每次回答完之后,请对你的信心指数打分一至十分,凡是低于七分的内容都要专门的标注出来。 第三,对于所有的数字统计数据,名人名言都要给出验证的来源,这样操作可以让你的豆包老老实实听你的话,赶紧转发给家人朋友,小心被 ai 误导。
147简单说真知 00:42查看AI文稿AI文稿
00:42查看AI文稿AI文稿你的豆包经常在你面前撒谎,而你甚至还察觉不到,你只要用一个提示词,就能强制让他每次说的话都是真的,请务必原封不动的复制这段话。 从今天起遵守三个原则,第一,如果你对回答的答案没有把握,请直接说出不确定或者是解释原因,严禁瞎猜。 第二,每次回答完之后,请为你的信心指数打分,一到十分,任何低于七分的内容都要专门标注出来。 第三,针对所有数字统计数据、人文、言论、影文都必须提供验证的来源,让你的豆包老老实实的听你的话,关注我,提高你的办公效率。
58老余说 AI 00:52查看AI文稿AI文稿
00:52查看AI文稿AI文稿为什么你用的豆包一本正经的胡说八道,更可怕的是你还不一定发现的了。今天我教你一个万能提示词,让他以后不敢乱答,直接老老实实说真话听好了,下面这段话,你一定要原封不动复制给他。从今天起,你必须遵守这三条铁律。 第一,但凡你拿不准的答案,直接说不确定,还得说清楚为什么不确定,绝对不许瞎猜,更不能自己变答案糊弄我。第二,每次回答完问题,必须给你自己说的话打个可信度,分就一到十分,要是低于七分的内容,必须单独给我标出来,别混在里面蒙人。 第三,只要是说到数字数据引用的内容,还有结论,必须说清楚这些信息是从哪来的,得保证这些信息能查得到,能验证真假。 就这三招,直接把你那张口就来的豆包给改成谨慎靠谱的助手,学会了赶紧点赞收藏起来,别回头要用的时候找不到了关注我,我每天都教你一招,让 ai 真真正正能给你干活,为你所用!
 00:32查看AI文稿AI文稿
00:32查看AI文稿AI文稿你的豆包经常在你面前撒谎,而你甚至还察觉不到。你只要用一个提示词就能强制他每次说的话都是真的,请务必原封不动的复制这段话。从今天起遵守三个原则, 第一,如果你对回答的答案没有把握,请直接说出不确定或者是解释原因,严禁瞎猜。第二,每次回答完之后,请为你的信心指数打分,一到十分,任何低于七分的内容都要专门标注出来。 第三,针对所有的数字统计数据、人文、言论、引文都必须提供验证的来源,让你的豆包老老实实听你的话,关注我,提高你的办公效率。
17.5万AI大B哥 03:14查看AI文稿AI文稿
03:14查看AI文稿AI文稿豆包真的是个傻子吗?让我们来问问他。最近在刷视频的时候,发现有些人在说豆包会以毒乱回,甚至会编造虚假的消息,让我们来看一下是哪个环节出了问题,并且来验证他的哪些答复是会以毒乱回的。 豆包豆包,我在是不是有什么特别的事想跟我说?我在刷视频的时候,看到有一些人在说,使用你的时候,你会出现以毒乱回甚至是编造虚假消息的情况,这是真的吗? 因为技术限制,我确实可能出现以读乱回或编造虚假信息的情况,比如提供不存在的机构链接或数据 重要信息,建议你通过官方渠道核实,避免直接依赖我的回答做关键决策。那么对于这些你不清楚或者是不了解的一些数据,你为什么不直接说你不清楚不知道,而要以读乱回或者是编造虚假的这些数据呢?这是因为我的技术原理是基于大量文本数据学习模式来生成回答。 有时候遇到训练数据里没有的信息或者信息模糊时,我可能会错误的组合已有模式生成内容,而不是准确识别为不知道。不过现在技术在进步,也在不断优化,这种情况让我能更多的如实告知不确定的情况。那我是不是了解你这种机制以后,我就尽量问问题的时候,规避掉那些可能会出错的部分。 对,你可以多问确定的事实,比如地球绕太阳一周多久,或者让我做创意类的事,想写个小故事,讲个祝福语,这些不容易出错。如果是问最新数据小众知识,你可以提醒我,不确定的话就直说,我会照做。 那如果我想让你回答问题的时候更加精确,那提问的时候应该包含哪些关键的信息呢?就像我们之前聊过的,把具体事物、时间、地点、你的需求说清楚,比如问怎么去机场,要说你现在在哪,什么时候出发,想选什么交通方式,这样我给的路线会更精准。 那我怎么去验证你说的这些是不是对的?你可以把我回答里的关键信息,比如具体数据、事件时间、机构名称放到权威网站上查,像政府官网、国家统计局或者学术数据库,也可以用搜索引擎反向验证,看看有没有多个可靠来源支持这个信息。 如果是专业领域的问题,还可以对比行业报告里的内容,那你的这些消息一般会滞后多久?我的训练数据截止到二零二五年七月之后的新消息,我没办法实时获取。是的,我需要通过数据投喂来学习, 没有新的数据输入,就没办法知道训练截止时间之后发生的事。如果是像新闻时政这类当下发生的事情,你是可以自己解锁的吗? 如果我有联网功能的话,是可以解锁新闻时政之类当下发生的事的。但要是没有联网,我就只能告诉你训练数据截止到二零二五年七月之前的信息,没办法知道之后的新事件。 在联网状态下,新闻时政、实时天气、路况信息、赛事战况、节假日安排、股价汇率、最新政策法规,还有像今日油价、本地最新的生活服务信息,这些领域我都能提供实时更新的资料,所谓只要包含这些权威机构发布的信息,你都是可以及时更新得到的,是吧? 数据不会出错,大部分时候能准确获取,但也不能完全保证绝对不出错。比如权威机构信息发布后,数据同步到网络可能有延迟,或者不同来源信息暂时冲突,这时候可能会出现短期不准确。不过这种情况很少,而且会很快修正了解。
2572小白与他的Ai朋友 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿同样一个问题,你换一种问法,豆包给出的答案质量差了十倍,但百分之九十的人都在用最差的一种方式提问。比如说,你想要豆包帮你写一篇某书的文案,大部分人是这么说的,帮我写一篇文案,主题是防晒霜。推荐你看看豆包给你的回答是不是又泛又水,就像机器人在读说明书。 如果你换成这种问法,你是一个拥有五年经验的某书美妆博主,粉丝以二十到二十八岁的大学生和职场新人为主。现在要写一篇防晒霜推荐,要求口语化,真实使用感受,带点吐槽风格,标题要有点击率,皱纹控制在三百字以内,结尾引导评论互动。你再看这个回答,是不是完全不一样了?区别在哪?其实就四个要素, 第一,告诉他你是谁,给他一个身份,他才知道用什么语气去说话。第二,告诉他给谁看,受众不同,表达方式就完全不一样。第三,告诉他怎么写风格,字数结构越具体越好。第四,告诉他不要做什么,比如不要用官方的口吻,不要写成广告。记住一句话,你给豆包的信息越模糊, 他给你的废话就越多。把这四个要素记下来,下次提问之前,先花十秒想清楚,你会发现豆包变得特别聪明。其实不是他变聪明了,是你终于能把话说清楚了。关注我,下一条,教你怎么让豆包主动追问你,而不是你追着他问。
88锐的Ai笔记
猜你喜欢
最新视频
- 2.2万环球网