gpt缓存是什么意思?

粉丝55获赞451
相关视频
 05:17查看AI文稿AI文稿
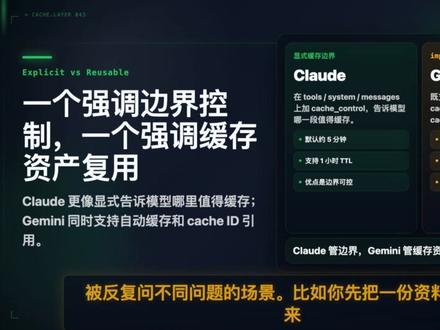
05:17查看AI文稿AI文稿deep seek v 四缓存永久一折啦!如果你只看到降价,可能就错过了背后的原因,它便宜是因为 deep seek 的 缓存机制和 openai cloud gemini 真的 不是一类东西。很多人一听到缓存就以为大家说的是同一种东西,但不同厂商的实现路径并不一样。 deep seek 是 硬盘缓存,其他的是 ttl 缓存。先看 deep seek, deep seek 的 context caching 是 默认开启的,不需要你改代码,也不需要你手动创建缓存。 每次请求过来,他都会尝试把输入里的前缀写入硬盘缓存。如果下一次请求和之前的请求有一段相同的前缀,这段重复内容就可以直接从硬盘缓存里读取。 这部分 token 就 会被算作 cash hit token, 也就是缓存命中 token。 缓存构建耗时为秒级,缓存不再使用后会自动被清空,时间一般为几个小时到几天。官方返回里也能看到两个字段, prompt cash hit tokens prompt cache miss tokens。 一个代表这次输入里有多少 token 命中了缓存,一个代表有多少 token 没命中。 所以 deep seek 这套机制特别适合系统。提示词很长,知识库上下文很长,多个请求前半段高度重复的场景。缓存命中的前提是相应前缀已被写入硬盘缓存。受 sliding window attention 机制的影响,缓存前缀的存取与判别与之前有所不同。 每条缓存前缀是一个独立的完整单元,后续请求只有在完整匹配缓存前缀单元时才能命中缓存。缓 存前缀落盘有三个时机,分别是请求结束位置落盘、公共前缀检测落盘按固定 token 间隔落盘。请求结束位置落盘。每次请求的用户输入结束位置与模型输出结束位置会产生两个缓存前缀单元,后续请求若完整匹配了它们,则可命中 公共前缀检测落盘。当系统检测到多次请求之间存在公共前缀时,会将该公共前缀作为一个独立的缓存前缀单元进行落盘。 后续请求若完整附用了该缓存前缀单元,则可命中按固定 token 间隔落盘。在长输入或长输出中,系统会以一定的 token 数量为间隔截取缓存前缀单元, 避免长前缀因迟迟未达到结束位置而完全无法被缓存。举个简单例子,第一次请求是 a 加 b, 第二次请求是 a 加 b 加 c, 那 第二次就可能命中前面的 a 加 b。 但如果第一次是 a 加 b, 第二次变成 a 加 c, 就 不一定马上命中 a, 但此时会把 a 缓存。第三次请求 a 加 d 时,就可以命中缓存 a, 因为 deep sec 的 缓存 不是只要有一点公共开头就立刻命中,它强调的是已经写入硬盘缓存的完整前缀单元匹配。再看 openai, openai 的 缓存也是自动的,不需要你手动创建 cache。 官方文档提到,从一千零二十四个 token 起按前缀匹配, 现在也支持配置 retention policy 控制缓存保留时间默认五到十分钟,部分模型最长二十四小时。所以 openai 的 使用重点是把稳定内容放在前面, 把变化内容放在后面,比如涨 system prompt、 固定工具定义固定 few shot、 势利,这些都应该放前面。用户问题时间变量参数尽量放到后面。 再看 cloud。 cloud 缓存更强调开发者显示指定缓存边界。开发者可以在 tools、 system、 messages 等位置加 cache control, 告诉模型哪一段值得缓存。 它默认的缓存时间通常是五分钟,也支持一小时。 ttl 这套方式的好处是可控,你知道自己缓存了什么,也知道缓存大概能活多久,但是 你需要自己设计缓存边界。再看 gemini, gemini 同时支持自动开启的 implicit caching 以及创建 cache content, 然后在后续请求里用 cache id 引用它。 ttl 也可以配置,这很适合一份长文档、 一段视频、一个音频材料被反复问不同问题的场景。比如你先把一份资料缓存起来,后面每次只换问题,而不是重复上传整份上下文。所以一句话总结的话, deep seek 更像是自动帮你把重复前缀落到硬盘缓存里,命中就便宜。 cloud 更像是你告诉他哪些上下文要缓存,以及缓存多久时间比较短。 gemini 更像是我既支持自动缓存,也支持你显示创建可复用的缓存内容。 openini 介于中间,它自动识别涨 prompt 的 重复前缀,近期复用就给缓存架。最重要的是,不要每次把动态内容塞在最前面。用户问题时间变量放最后, 然后观察 prompt cash hit tokens 和 prompt cash miss tokens。 如果 miss 很多,说明你的前缀结构可能一直在变化。缓存自然命不中。 缓存降价之后, deep seek 对 长上下文高频重复请求会更有吸引力。但缓存不是魔法,它省的是重复输入成本,不是输出成本, 也不是模型推理能力本身。如果你在做 ragged agent 客服机器人真的可以去看一下自己的 catch hit token, 很多时候省钱不是换模型,而是先把 prompt 结构写对。
473Ali厂长 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿最近很多兄弟在解决自己的游戏掉帧问题的时候,总会看到一些办法是教你如何清理自己的着色器缓存,包括但不限于三角洲、五位契约、 csgo、 守望先锋等, 而且基本都是教你去路径里手动删除。这个方法虽然可以用,但是还是有部分老哥会出现这个 dx cache 文件夹删不掉的问题,又或者是觉得手动找路径很麻烦。这部最新版的 nvd i app 就 帮我们解决了这个问题。 现在的最新的 nbr app 里已经能支持直接清理着色器缓存了,不需要找路径,只需要去 nbr app 里的图形,然后全区设置往下滑,有个着色器缓存的选项,点击之后再打开的这个窗口的右上角点这三个点就可以看到了, 这里点一下就能够自动清理,但是我发现很多兄弟说打开自己的 nbr app 里没有这个选项,打开之后是这样的, 那本期视频就来教兄弟们怎么解决。首先我们需要保证自己的 n dvr app 的 版本号是这个一点零点七点二四七,没有更新的兄弟也可以打开奇游进行快速更新,找到英伟达,先去右上角小方块进入口令,使用蛋挞七七七,拿一点时长, 优化之后在右下角这里就能更新 nvidia app, 更新完之后我们去设置里查看自己的版本号是不是一一点零点七点二四七。然后如果版本号是对的,但是依然没有清理主要色系缓存选项的话,就需要我们去更新一下这个最新的显卡驱动版本, 更新慢或者更新卡进度的话,我们保持开启优化状态去更新即可解决,更新完成后我们再去着色器缓存里就能够看到了。好了,兄弟们快去试试吧,有用的话记得点个赞哦,我们下期见。
 00:25查看AI文稿AI文稿
00:25查看AI文稿AI文稿g p t。 四变笨的又一证据 obanai 会缓存历史回复,让 g p t。 四直接复述以前生成过的答案。即使将模型的 temperature 至调高或者不动, g p t。 四仍重复同一个科学家与原则的回答。此前已有研究表明,差 g p t。 在讲笑话时 百分之九十的情况下都会重复同样的二十五个。唯一的破解办法是把随机性参数问拉高,不过他的代价是回复速度变慢。
404我爱深度学习 07:05查看AI文稿AI文稿
07:05查看AI文稿AI文稿什么是缓存?缓存就是把以后可能还会用到的数据先放在一个更近、更快的地方,下次需要时直接拿,不必每次都从原始位置重新计算或重新读取。 文本会讲清缓存的定义、它解决的问题、常见工作流程,以及为什么缓存既能提速,也可能带来数据不一致等麻烦。先用一个生活类比来理解。你每天都要喝水,如果每次都跑到楼下便利店买一瓶,成本就很高。 但如果你在桌上放一个水杯,想喝时伸手就能拿到。这个水杯就像缓存,它不是水的源头,但它离你近,访问速度快。在计算机系统里,原始数据可能存在数据库、硬盘、远程服务器, 甚至需要通过复杂计算生成。这些地方通常更权威,但访问代价也更高。缓存会把其中一部分数据复制到内存、本地文件、浏览器、 c、 d、 n 节点或者 cpu 内部的小存储里,让系统少走远路。 缓存最核心的价值是减少重复劳动。比如一个商品详情页,很多用户都会访问同一个商品。如果每次都查询数据库,拼接图片、计算价格、读取评论,服务器压力会很大。 把结果缓存起来后,后面的用户可以直接拿到现成内容,响应时间就会明显缩短。缓存之所以有效,是因为程序和用户行为有规律。一个规律叫时间局部性, 意思是刚用过的数据很可能马上还会再用。另一个叫空间局部性,意思是访问了某个数据附近的数据也可能被访问。 cpu 缓存、浏览器缓存、数据库缓存,本质上都在利用这些规律,一次典型的缓存读取流程可以分成三步,第一步,系统先问缓存这里有没有我要的数据。 第二步,如果有就叫缓存命中,直接返回结果。第三步,如果没有,就叫缓存未命中,系统再去数据库或原始服务读取, 然后把结果放进缓存,方便下次使用。这里要注意,缓存不是越大越好,缓存空间通常很宝贵,尤其是内存缓存和 cpu 缓存。 系统必须决定哪些数据留下,哪些数据淘汰。常见策略有 l r u, 也就是最近最少使用的数据优先被清理。还有 l f u, 也就是使用次数少的数据更容易被清理。缓存还经常配合过期时间使用,也叫 t t l time to live。 比如一个验证码,缓存五分钟,超过时间就自动失效。一个新闻列表缓存三十秒,既能减少服务器压力,又不会让用户看到太旧的内容。 ttl 的 关键是权衡时间太短,命中率低,时间太长,数据可能不新鲜。缓存最大的副作用就是可能读到旧数据。假设用户修改了头像,数据库里已经更新了,但缓存里还存着旧头像, 如果系统没有及时删除或刷新缓存,其他页面就可能继续显示旧头像。这就是缓存一致性问题,也是很多系统设计里最容易踩坑的地方。常见的更新方式有三种, 第一种是先更新数据库,再删除缓存,让下一次读取重新加载新数据。第二种是更新数据库的同时更新缓存,但要处理失败和并发症问题。第三种是让缓存自然过期,适合对实时性要求不高的内容,比如热门文章、榜单 缓存可以出现在很多层级。浏览器缓存会保存图片、 css、 javascript 文件,避免每次打开网页都重新下载。 c、 d、 n 缓存会把静态资源放到离用户更近的节点,比如北京用户访问北京节点, 广州用户访问广州节点,这样既减少延迟,也减轻原赞压力。服务器端也常用缓存,比如 radis 和 memkadit, 常被用来存登录状态、热点、数据、排行榜接口结果,它们通常运行在内存里,比数据库读取快很多, 但他们一般不负责长期保存权威数据,所以数据库仍然是最终数据源。数据库内部也有缓存,很多数据库会缓存查询计划、锁影页和数据页,避免频繁读磁盘。 操作系统也会把常用文件内容放在内存页缓存里。你会发现缓存不是某个单独工具,而是一种贯穿整个计算机系统的思想。 cpu 缓存是更底层的例子, cpu 运算速度极快,但从内存取数据相对慢。为了不让 cpu 经常等数据,芯片里会设计 l 一、 l 二、 l 三多级缓存, 越靠近 cpu, 速度越快,容量越小越远,容量越大,速度越慢。评价缓存效果最常看的指标是命中率。命中率越高,说明请求越多地被缓存解决,系统越省资源。 但命中率不是唯一目标。如果缓存内容过气太慢,命中率可能很高,却牺牲了准确性。所以好的缓存设计要同时看速度、成本和数据新鲜度。 在高并发系统里,缓存还会遇到几个经典问题。缓存穿透是请求查询一个根本不存在的数据,每次都绕过缓存打到数据库, 缓存击穿是某个热点数据刚好过期,大量请求同时冲向数据库,缓存血崩是很多缓存同一时间失效,导致后端压力突然暴涨。 解决这些问题也有常见办法。对不存在的数据,可以缓存一个空结果,或者用不隆过滤器提前拦截明显无效的请求。对热点数据,可以加护翅锁,让一个请求去重建缓存,其他请求等待或返回就职。 对大量缓存过期,可以给 t t l 加随机偏移,避免同一秒集体失效。缓存设计还要看业务场景、商品库存、账户余额。这类数据对准确性要求高,不能随便长时间缓存。 文章阅读量、热门推荐配置列表。对短暂延迟更能接受,可以用缓存换性能。 不同数据不能用同一套策略,否则要么浪费资源,要么引入风险。所以缓存不是简单递加一层 reddis 就 完事,真重要。想清楚的是,缓存什么数据放在哪里,多久过期,什么时候更新,失效时怎么办?后端扛不扛得住? 每一个问题都对应着系统的速度、稳定性和数据正确性。总结一下,缓存就是把常用数据 放到更近更快的位置,用空间换时间,用副本减少重复访问。它能让网页打开更快,接口响应更快,数据库压力更小,也能让大型系统在高迸发下更稳定。 但缓存带来的旧数据失效策略和迸发冲击,必须被认真设计理解。缓存本质上就是理解现代计算机系统如何在速度、成本、准确性之间做平衡。
132AI编程大白 04:12查看AI文稿AI文稿
04:12查看AI文稿AI文稿什么是 cpu 的 缓存?大家可以看到这个是二四 mb 高速缓存,这个是代表什么意思啊?经常也会听别人讲 l e l l 三这个一级、二级、三级到底是什么东西?今天给大家做一个简单的讲解。 其实我们用大白话来讲的话,这个就是讲的是咱们这个处理器的缓存 l e l l 三 啊,这个就是呃,咱们讲的一级缓存二级缓存、三级缓存,缓存顾名思义啊,缓就是减慢的意思,存就是存储,它指的意思就是 cpu 运算太快的时候,当咱们的内存条,也就是咱们的 ram, 我们经常讲内存是 cpu 的 这个一个临时存储器啊,内存它当它达不到给 cpu 进行呃处理工作的时候,这个时候 cpu 的 缓存就派上用场了。缓存就是 cpu 自带的高速临时仓库, 作用就是跟内存有点相似了,就是临时存储 cpu 的 大量的一些信息指令,方便大家的理解。我就拿了一张纸给他写下,那么我们把 cpu 比作一个大厨,那么大厨需要做饭,那么他就得要菜,菜的话,菜的话要放在冰箱里面,冰箱的话 我们就相当于内存条,但是呢内冰箱离大厨手就比较远了,这个时候这个 l 一 l 二 l 三也就是缓存,这就拍上用了 l 一 l 三, l 一 它指的就是我们大厨的手, l 二指的就是我们切菜用的一个小方块案板,我们叫案板啊, l 三 这个就是呃大灶台的台面,就比如说放案板的一个这个灶台啊,这样的一个比喻,大家试想一下,大厨想做菜搞什么东西,首先是不是要用手在案板上搞东西,搞完东西在这个叫什么,这个 大的这个灶台上,然后需要什么东西,再从冰箱里去取,大概的一个过程就是这个就是缓存的这样的一个意思啊,这个就是 cpu, 比喻的话还是比较生动形象的,那么 l e 级缓存,它每个就是核心独享,它每一个都是自己自用的,这个容量非常小,一般都是几十 k b, 但是它的速度却是全场最快的,大家可以试想一下,手,它做菜刚刚刚直接就搞定了,是不是 cpu, 也就是大厨需要弄什么东西,手立马就可以搞, 这就是第一个,也就是 l 一 级缓存, l 二级就是咱们讲的这刚刚这个讲的是暗版,暗版的话它是比 l 一 的话要大很多,一般的话可能是几百开币,甚至是几兆币, 然后的话他的速度就比这个手要慢点,因为通过手之后才能轮到他,所以说他就是可能会稍微要比 l e 要慢一点。那么当 l e 已经不能满足的时候,我们再用 l e, 比如说你手切着东西,比如说你切了一个辣椒,这边还有一个洋葱没切,那洋葱已经放在案板上了,就是大概这种意思, 于是类的 l 三,那么你的案板上都已经放满了手,还在切东西,那么你还可以放其他的一些东西,肉啊,什么东西啊,这样的意思好,最后才知道咱们的内存条啊,这样的一个意思,流程就这样生动形象的对比比较,大家就应该就明白了。 你的电脑 l 一 l 二 l 三,如果说它越强,那么这个 cpu 就是 用不着去找内存,它自己就给它处理完了, 这个时候你的 cpu 性能就会越好,越快速度就会很流畅。就是说咱们的缓存越大,那么你的处理器反应就越快,咱们刚刚看的这个样高速缓存二十四 m b, 所以 说这个就是非常快的。当然在这里给大家做一个延伸, 其实 l 一 和 l 二的话,同代的 cpu 差距的话是比较小的,最主要是看 l 三, l 三越大的话越大,那么 同频率下大缓存的帧率就越高,他越低帧率就越小,就是越大,他就是缓存帧率高,然后最低帧比较稳,不跳帧。所以说这就是挑选 cpu 的 一个小技巧,不知道大家有没有学会?
20朱虎修机 02:20
02:20 00:51查看AI文稿AI文稿
00:51查看AI文稿AI文稿硬盘有缓存和无缓存具体区别是什么?这段缓存通常是指 d、 c、 b 板上的一块独立 dram 芯片,就和电脑上的内存是一样的,这块高速内存芯片专门用来存储中转数据,而无缓存硬盘则是没有这片芯片。要知道硬盘里面有一张表叫 f t l 闪存转换层,它借助数据在闪存芯片上的物理数, 这张地图放在更快的 dram 芯片里。电脑想要获取某个文件时,主控就可以瞬间插到文件的位置,直接调取出来,而无缓存则没有这个功能差异呢,就是获取速度的快慢。还有一点就是持续写入 rom, 可以 更加高效的管理数据,搬运性能在出缓后下降不明,而无缓存下降的通常比较明显。当然了,无缓存硬盘也是有些好处的,比如说更低成本、价格更合适、功耗更低以及续航优势。更小的体积更适合笔记本电脑。还有发热更小、温控更稳定,突然断电时也不容易丢数据。
 01:32查看AI文稿AI文稿
01:32查看AI文稿AI文稿朋友们,最近 openai 做了一个全新的 ai, 但是他们自己把它给禁了,就是做下载 jbt 那 个公司。因为这个 ai 有 一个模式叫做歌不离,这是什么意思?就相当于是你去医院买处方药,只有医生开了你才能买, 但歌不离模式,他相当于把这个限制给取消了,任何人都可以自由的买药,你觉得这样听起来很爽对吧?但是 open ai 发现这个 ai 有 一种能力,它可以说服人去做危险的事情,大家想一想, 所以他们非常的害怕,怕这个 ai 被传出去,有人真的听他的,做出了不可挽回的事情,所以说他们干脆选择不发布。 注意, open ai 是 ai 领域最保守最谨慎的公司,连他们都 hold 不 住都不敢发布, 这说明什么?说明 ai 的 风险是真实存在的,不是科幻。那么现在的问题就来了, open ai 已经关掉了,但是代码有可能是开源的, ai 圈有一种操作叫做开源,有没有听过这个词的朋友?代码一旦开源,就像把菜谱公开,谁都能做这道菜。 oppo 还关了一家店,那别的店照做,危险不会消失,只会换个地方出现。但换个角度,一个公司敢把自己的产品关掉,说明什么?说明他们不是在做一个玩具,他们在做一个真正有价值的东西,所以它才这么危险。有价值的东西才需要认真对待风险。 所以 ai 收费, ai 设限,恰恰说明这个赛道是真的值钱的赛道才有搞头,大家一定要注意哈, ai 离普通人比你想象中更近了。
28程序员晚枫 01:13查看AI文稿AI文稿
01:13查看AI文稿AI文稿cpu 缓存 cpu cache cpu cache cpu 缓存在计算机系统中, cpu 高速缓存英语 cpu cache, 在 文本中简称缓存,是用于减少处理器访问内存所需平均时间的部件。 核心原理 cpu 缓存核心原理在金字塔式记忆体阶层中,它位于自顶向下的第二层,仅次于 cpu 寄存器。 关键特征 cpu 缓存关键特征其容量远小于内存,但速度却可以接近处理器的频率。 应用场景 cpu 缓存应用场景当处理器发出内存访问请求时,会先查看缓存内是否有请求。数据 发展历史 cpu 缓存发展历史如果存在命中,则不经访问内存直接返回该数据。如果不存在失效, 则要先把内存中的相应数据载入缓存,再将其返回处理器。以上就是 c p u 缓存的核心内容,感谢观看!
3爱卫生 01:01查看AI文稿AI文稿
01:01查看AI文稿AI文稿你是不是从来没有给笔记本的健康缓存做过深度清理?可别小看这一点啊,健康缓存和硬盘一样,也需要定期维护才能让笔记本保持良好状态。下面呢,就跟着我一步步操作,给你的 r o g 笔记本减负吧!桌面卸载加右键,打开英伟达控制面板, 左侧点击管理 3 d 设置,全区设置中下滑,找到着色器缓存大小设置为进右,接着按下 win 加 r, 输入这串代码,回车下滑,找到维利亚文件夹,再打开这个文件夹,全选删除,再回到英伟达控制面板,将着色器缓存改为驱动器默认值 应用后,再把电脑重启一下,前后缓存就清理完毕了。最后啊,再提醒下大家,清理前后缓存文件后,系统或游戏在短时间内可能会进入到重新构建缓存的阶段, 这时候呢,可能会出现性能略有下降的情况。不过啊,别担心,一旦新的缓存构建完成,系统性能通常会恢复,甚至啊,可能会比清理前更好。学会了别忘记关注我,获得更多 r o g 小 技巧!
373电竞快乐屋 03:03查看AI文稿AI文稿
03:03查看AI文稿AI文稿电脑出装系统安装新磁盘给磁盘分区的时候,有两种分区表类型, mbr 和 gpt。 但是很多小伙伴还不清楚这两个分区表是什么,这一期我们就来了解一下 mbr 与 gpt 的区别。 mbr 的意思就是主引导记录,目前我们使用的硬盘绝大部分都是五百一十二字节的一个善区。 mbr 分区表中逻辑地址以三十二为二,禁止表示, 所以最大只能表示二的三十二次方的地址,所以最大单分区容量为二的三十二次方乘于五百一十二字节等于两千零四十八支币,也就是我们通常 说的 mb2 单分区最大支持二 tb。 下面介绍的都是以五幺二 b 为基准,目前已经有四 k 磁盘, 最多有四个主要分区,它是存在于磁盘区动器开始部分的零号善区,只有五百一十二个字节,在这五百一十二字节中分别有引导程序、 分区表、结束标志记录、签名三个部分。当一台电脑启动时,他会先启动主板自带的 bios 系统, bios 压在 mbr, mb2 在启动操作系统。 gpt 的意思是 gui depart、 teachen table 及全局唯一标识。磁盘分区表是源自 f 标准的一种叫新的磁盘分区表结构的标准。 gpt 提供了更加灵活的磁盘分区机制,支持大于二 tb 单分区、多分区,分区 表自带备份。在启动方式 uefi boot 和 legacy boots 设置上,一定要配合 gpt 和 mbr, 否则电脑会出现无法启动。 legacy 可以引导十六位的 dos 操作系统,三十二位的操作系统 引导六十四位的操作系统,只要 cpu 支持即可,而 uefi 与操作系统外宽是一一对应的,因为如因 fi 分为三十二位于六十四位,三十二位的 uefi 需要安装三十二位的操作系统,六十四位的 uefi 需要六十四位的操作系统。 市面上绝大部分笔记本和台式机都是六十四位的 uefi, 因此我们通常才会错误的认为 uefi 只能安装六十四位 windows 操作系统,只要少部分 windows 平板可能采用了三十二位的 uefi。 当然还有 某些极端的 u 一 fr 引导用了 mb。 二、分区表则不在此次讨论范围内。 看到这里你还是搞不清楚如何分区。有个方便快捷的分区方法,可使用 u 盘魔术师 sgi 工具快速分区,简单两步分区就可进入系统安装了。 希望本期内容对你有帮助,谢谢观看,关注我,学习更多干货!
3304sysceo 03:31查看AI文稿AI文稿
03:31查看AI文稿AI文稿你有没有想过一个问题,你现在打开雀的 gpt 花三毛钱问一个问题,这背后谁在挣钱?不是 openai, 起码不全是。讲个有意思的是讲今年 gtc 大 会上,黄仁勋说了一组数字,基于英伟达两代芯片的采购订单,到二零二七年累计至少一万亿美元。 什么概念?这不是预测,这是客户签了合同付了钱在排队等着拿货的。什么概念?这不是预测,这是客户签了合同付了钱。什么概念?这不是客户签了合同在排队等着拿货的 mate, 还有甲骨文也在网上干,他们二零二三年总共花了一千五百四十亿,到二零二八年预计要花六千二百亿,五年翻四倍。 mate 的 资本开支从七百二十亿直接跳到一千三百五十亿,谷歌从九百一十四亿涨到一千八百五十亿。 为什么砸钱砸的这么狠?这就要说到一个概念,注币权。你可能不知道,在 ai 世界里, talking 就是 新型货币。你问 ai 一个问题,它输出的每一个词,每一个标点都是一个 talking, 就 像你用人民币买东西一样,不同的 ai 模型需要不同的 talking。 在 中国用 mini max institute, 在 美国用 cheap 的 gpt, 相当于你用不同的货币。但不管印什么货币,印钞机都在谁手里,大厂手里你做一个小时 gpu, 不 管拿它跑什么模型干什么活,大厂都按时按量收你租金。这不是一笔 普通投资,这是一个永久收费站。 ai 经济体量越大,过路费收的越多。所以你就明白了,为什么大厂一边砸钱一边取债,谷歌甚至发了一笔一百年期的债券,他们真的不是短期回报,是这把椅子 一旦坐稳了,后来者几乎进不来了。数据中心、电力合同、光纤网络这些物理世界的资产,不是花钱马上就能复制出来的。今年有个现象很有意思, open router 的 数据显示,全球 talking 掉用量前十的模型有五六款,来自中国小米的 miimo 甚至排到过第一。不是说中国模型已经全面超越,而是性价比优势太明显。 同样一台印钞机跑一个小时,印 cheap, gpt 的 talking 可能印一百张,但印 deepseat 的 talking 能印一千张。算总账的话,用中国模型能调用的 ai 总劳动力反而更多。 米塔已经用真金白银证明了这件事的可行性。他们的 ai 广告工具 advantage 年化收入跑到了六百亿美元,占了总广告收入近三分之一。 ai 推荐的广告转化率实实在在的提高了。这不是概念 已经落地的生意,当然不是所有人都买账。大厂每花一美元建产能,能产出的增量收入正在下降,从零点九美元掉到了零点五美元左右。华尔街也有人担心,这么砸钱会不会有泡沫。但你换一个角度想,如果 ai 真的 像当年的店一样普 及,变成新的通用劳动力,每个人身边围着几十上百个 ai 助手替你管财务、盯健康、回邮件,那所有 ai 经济活动都 都得跑在某家大厂的基础设施上。杰文斯辩论说,一种资源越便宜,人们反而会用的越多。 ai talking 的 推理成本三年里降了上千倍,大量过去嫌贵 懒得做,甚至没想过能做的事突然都值得交给 ai 去做了。好,最后说一个让我一直在想的问题。过去一万年, pocket, 也就是货币存在的意义就是给人类的劳动报酬,从淘土筹码到美元,形态一直在变,但底层逻辑从没变过。人是唯一的通用劳动力, 所有 talking 最终都在为人的劳动定价。但如果 ai 真的 成了新的通用劳动力,而他的劳动用 talking 来计价,那这些 talking 背后对应的是什么?谁来定义人的价值?我不知道答案,但这个问题值得每个人想一想。
1346微小众科技






猜你喜欢
- 4371金字猫塔