今天看到这么一条帖子,他说有一个通用的 cloud markdown, 可以 将输出的 token 减少百分之六十三,直到我点进去一看呢,他只不过是一个 cloud 点 markdown 文档,而且他也说了,他只有在这三种情况下是最有用的。 他通篇一共这么几句话,我感觉只要把这几句话粘贴到咱们的代码文档里就行。我们也可以看到他有同样的精准测试结果,如果使用了优化后的去运行,减少了六四七五五零六四六三, 平均每四个提示词可以节省二百九十五个单词,信息相同。在咱们的 api 不 够用的时候呢, 可以去尝试一下,你看他也解决了这样的八个问题。当然如果你感兴趣的话,欢迎关注并私信我。哎,我直接发你吧。

粉丝435获赞8961
相关视频
 00:58查看AI文稿AI文稿
00:58查看AI文稿AI文稿不到一天,全网近三百万人围观, cologne 顶尖工程师已经把 markdown 抛弃了,并声称 h t m l 是 新的 markdown。 这句话慢慢火遍 ai 圈。我给大家拆解一下核心逻辑,这可不是简单的技术迭代,这是一次人机协助范式的彻底刷新。简单说,他们已经不再手写任何 markdown, 而是让 cloud 的 直接生成活的 html 文档。核心就三点,信息密度、视觉清晰度和双向交互。 markdown 文件超过一百行,你可能就不想读了,但 html 文档可以通过标签、侧边栏、格式化图标把海量信息组织得清清楚楚。更重要的是,它可以内置交互。比如,你想调整一个设计参数, 不用再反复描述,直接拖拽 html 里的滑块,效果实时呈现,满意了还能一键复制参数,丢回给 cloud 的 接着改。 这套方案已经渗透到 cloud 的 团队日常工作,无论是方案探索、代码审查、功能实现计划,还是交互原型、动画演示、数据分析报告,他们几乎都用 html 替代 markdown, 效率和可读性都翻倍,整个工作流因为 html 正变得前所未有的直观和强大。
2089阿博粒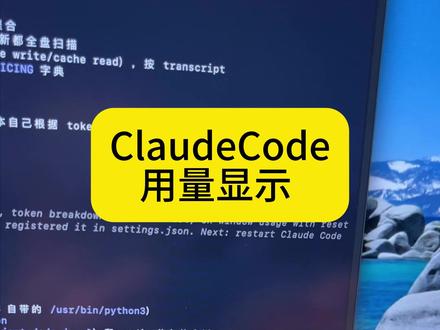 00:22查看AI文稿AI文稿
00:22查看AI文稿AI文稿如何在卡扣的中直接显示 token 用量?非常简单,不需要安装第三方插件,只需要一句 sit 四 line 命令,然后口喷你的需求就行了。 比如我的这个状态栏,可以显示模型名上下文占用百分比输入输出的 token 技术,五小时用量重置时间,还有按绘画按五小时按天的 token 等价费用。你用什么显示的用量?评论区说下,我正在搞 id, 阿图后面会分享更多卡扣的整活下个视频见。
1585阿图AI 05:02查看AI文稿AI文稿
05:02查看AI文稿AI文稿astropica 的 opus、 sony 这些大模型其实并不会帮你写代码、改 ppt 和读网页,它会的其实只有一件事情,你输入一段文字,它给你输出一段文字。那它是怎么拥有前面说的那些能力的呢?答案叫 tool use。 工具使用 大模型从来不自己执行任何东西,他只会吐出一段结构化的输出。意思是我想用这个工具,然后参数你填这些,真正去做的是你电脑上的 clock code, 他 把命令跑完,然后再把结果传回给大模型。 cloud code 命令行本质上就是替大模型干活的小助理。我们以 bash 工具为例来演示 tool use, 这里我新建了一个 git 项目,改了两个文件,然后又新添加了一个文件,然后还是用上次介绍的 cloud tab 来拦截 cloud code 的 api 调用,然后, 然后我们让 cloud 看一下 git 有 什么改动, 哦,你看这里 color code 调用了 bash 工具来执行刚才的 git status 哦,然后返回了刚才我们看到的结果,对不对? ok, 我 们退出,打开第一次拦截的请求,然后可以看到我们给大模型发送的消息是 git 有 什么改动,对不对?然后我们看服务器回音的 s a c e 事件,然后这里重点看 content block, 这里 type 是 tool use, 这是工具调用的固定标识。还记得上期视频里我们给发送的消息是 hello, 对 不对?然后服务器回应了 hello, 你 想要干什么,对不对?然后这里的 content block 的 type 是 text, 所以看到工具调用,这里的 type 不 一样了,对吧? id 是 拓 u 零一开头的一串编号,这是这次工具调用的唯一编号,然后 name 是 bash, 告诉客户端要调哪个工具,然后下面这一堆 tail 都是给出的 bash 工具。这次调用的参数, 我们直接看响应里面帮我们组装好的完整参数就行了。这里 command 调用的是 git status, 然后 description 写的是 show git status and diff, 之后一个值得关注的字段在后面。 这里 stop reason 等于 tour use, 什么意思呢?就有点像 http 握手协议一样的。 此时的状态是大模型已经把指令给到客户端了,等你回话,那么现在视角就回到了客户端这边,打开第二次拦截的请求。 clark cold 在 收到 tool use 之后做了两件事情,第一次他把 command 里的命令拿出来,在终端里真的执行了 get status, 你 看这里是不是刚才在命令行里看到了 get status 结果对不对?然后这里其实他还顺带执行了 get def 的。 然后第二个他把命令的输出打包成了一个 to use 的 block, 我 们看到这里 对不对,然后塞进了第二次请求的 messages 里发回去。我们看这个 to use, 它的 to use 的 id 字段 就是上一步的这个 id, 一 字不差,这是托 use 协议规定的。通过这个 id 配对模型才知道这是哪一次工具调用的结果。 然后 content 的 字段就是刚才这个 git status 原文输出。整个执行过程大模型是一无所知的,他只看到了一个文本结果,然后第二次的请求发出去之后响应来了, content block 里只有 text 一 块, 然后这里 stop reason 等于 and turn。 握手协议完成了 call code 用自然语言总结了改动,在 may 分 支 read me 和 hello p y 修改了,然后还有未跟踪的文件,一来一回循环关闭。刚才演示的就是 tool use 的 全部过程。第一次请求把你要做的事情连同系统提示词里的 tools 列表发过去,模型读完了,会输出一个 tool use, 说要调 bash, 然后参数填 key status。 客户端拿到指令后真的去跑,然后把输出包成一个 tool result, 塞回第二次请求的 messages 里面。大模型拿到工具执行的结果,然后会用人话告诉你改了哪些文件,然后以 end turn 结束。 这就是客户端工具的原理。大模型发指令,你的电脑执行叫客户端工具 client execute tool, 比如 bash 执行命令 edit 的 编辑文件命令 另一类执行,它不在你的电脑上,而是在 asprop 的 服务器上跑,这种叫服务器工具 server executed, 比如说网络搜索 web search 工具,网页抓取 web fetch 工具就属于这一种,你的客户端只拿到结果。 今天我们介绍的是客户端工具在你的电脑上跑的那一类。下一期我们介绍一下服务器端工具是怎么工作的。
523张司机在路上 01:03查看AI文稿AI文稿
01:03查看AI文稿AI文稿分享几个 cloud code 好 用的小技巧,因为我一句代码都不懂,有时候写提示词的时候就很容易陷入死循环,后来用了这几个技巧,体验就顺畅了很多。第一个是安装 skills, 原生的 ai 有 时候输出的并不是很准确,但是装上了之后,它的思考能力和输出的质量都会变得更好。第二个是让它开启 plan mode 模式,让 ai 干活之前先思考好清楚,规划好更详细的解决路径再开始干活,这样解决问题的成功率就会大大提高。 第三个是及时使用 complex 来压缩上下文的内容,就是在你提出一个无关的问题的时候,或者是上下文快板的时候,就要及时清理,这样一来就可以减少 ai 在 思考的时候受到的干扰。第四个是调整提问的方式, 就是尽量不要给他直接下达指令,就当你不知道的时候,可以先把问题的现象描述给他,让 ai 来根据现象来排查问题和思考解决的方法,这样就可以避免下达错误指令的情况。第五个是优先找报错的日制, 就是当你的产品报错的时候,一般浏览器的后台都会出现小红叉,把它下面的内容发给 ai, 解决问题的成功率就会大大提高。
 03:24查看AI文稿AI文稿
03:24查看AI文稿AI文稿今天给大家推荐一套 skill 的, 它打包了市面上常见的格式化的表达,可以一键把你的文章变成 canvas mami 跟 iscaraj。 第一种结构清晰,配色干净,排版漂亮,这是 canvas。 第二种,它把流程节点、箭头的走向以及逻辑链条梳理得让你可以一眼看清,这是 iscaraj。 第三种是手绘的,质感就看起来比较自由随意,像在白板上随意勾的,这是 iscaraj。 同一个内容三种表达只需要十秒。 给大家简单介绍一下这三种矢图它适合在哪些情况下去使用。比如说像 canvas, 它比较适合做知识图谱,项目盖板,或者说文章结构的拆展 分类的话,适合现性逻辑的一些表达,包括流程图,决策数或者时间线。因为我最近在做一款退休相关的一个产品,会涉及到退休年龄的计算,以及退休金的一些计算,它把整个的逻辑都梳理的很清楚,包括说 怎么样去判断一个人的退休类型,它是到了法定年龄去退休,还是在法定年龄之前退休,它的整体的计算的逻辑都会不一样,然后它在这里也展示的很清楚。 export 就 比较简单,它适合那种自由表达,画草图跟圆形,以及非正式的一些思维发散。不过我觉得这个 export 它画的倒是比较简单,就是如果说你要增加一些图,或者说增加一些网页的跳转的话,还是需要你自己去增加的。 而且这个 skill 生成的图,如果说你有一些不满意的话,你是可以点击编辑去修改的,甚至你可以也可以去修改它的底色,比如在这里选择它就会变化,我觉得它就是节省了你从零到一的画图的时间,非常方便。 那接下来来告诉大家怎么样装这个 skill。 主要是三步,第一步就是 obsidian 是 要提前装好 ai agent 的 插件的,我用的是 cloudian, 之前视频有教过怎么安装,这里就不说了。第二步是我们在 github 上搜这个 skill 的 名字,然后就能找到这三个 skill。 这里下面呢,它是有对这个 skill 的 整体的介绍,告诉你整体的安装的方式。我们可以直接复制这个命令,回到 cloudian 的 聊天框,直接发送给 cloudian 即可。 把刚刚的口令发送进来之后它就安装好了。安装完之后呢,它会告诉你对应的 skill 的 用途以及它的触发词是什么。我们平常触发 skill 的 方式是斜杠,然后去掉起选择这个对应的 skill, 比如说萌妹,它就会 加载这个 skill。 这个 skill 还做了一些触发词,就是我不需要去调起了,我直接用自然的语言,比如说我要做一个 make 图,或者我要做一个 canvas 图,它就会自动加载这个 skill。 那 比如说我给他发的是用 make 格式化退休计算的流程,然后呢,他就阅读了这个 skill 的 skill m d。 因为我前面跟他去聊了一些退休计算的流程,然后呢他这里就把整个的计算流程化成了个 blank 图,非常的快。我还让他自动的去帮我保存为 opc 点笔记文件,然后他就可以帮我创建一个新的笔记了。 那今天的分享就到这里啦,以前我们做一张结构图,先理逻辑,再选工具,再调颜色,还有对齐整体的节点以及对拉线,至少半个小时起步,那现在一条指令 十秒三种风格任选,把节省下来的时间更多的放到我们的内容的本身,觉得有用的话点赞、收藏加关注,拜拜。
118Suyee聊AI 10:39查看AI文稿AI文稿
10:39查看AI文稿AI文稿最近啊,我帮几个朋友看了下他们平时是怎么使用 cloud code 的, 结果发现大家踩的坑都差不多,比如说在 contacts 都快满的情况下,还在疯狂地向 cloud code 输出,甚至还问我他的 cloud code 怎么越用越笨,还有装了 skill 的 有没有用上都不知道。 那对于这种把 taco 用在刀背上的做法,我只能说一个字,绝。所以今天就给大家分享一下我自己使用 clotco 的 过程中的几个小技巧,听完包你满意,赶紧点赞收藏。当然,大家也可以在评论区分享一下自己的经验。 第一个,上下文管理这个道理啊,很多人都懂,但很少有人会注意到上下文污染的严重性。如果说你也有这样的毛病,我建议赶紧去看一下。前两周 cloud 发布的这篇关于绘画上下文管理的文章,里面讲的是非常详细的。 特别要注意的是啊,文章里面有提到,当上下文窗口开始占到百分之三十到百分之四十的时候,就会出现一定程度的上下文腐烂。这个其实对我自己也是有点启发的,你像我之前就是用到百分之六十可能才开始做一些上下文的管理,那现在可能百分之三十到四十就要开始做了。 那我平时做上下文管理无非是用到这三个命令,第一个, compact, 当任务跑了很长时间,进行过多轮的对话之后,使用这个命令,让他把前面的对话压缩成一个摘样,清掉容易的信息,只保留关键的,这样的话,你的 contacts 就 会变得很干净,他后续的表现也都会回归正常 我的使用习惯啊,同一个任务超过二十到三十轮对话,或者说我当前的上下文窗口已经占到了百分之五十以上,那我就会进行次压缩。 又或者说当我发现啊大模型开始回答一些奇奇怪怪的答案了,那我的第一反应也都会先去 compact 一下。第二个 clear, 那 这个相较于 compact 会更加的直接,把当前的对话直接清空掉,重新开始, 或者说你开一个新的对话窗口也是 ok 的, 这个适合一个任务已经完全跑偏,或者说你就想换一个新任务的场景。 对比的话, compact 就是 整理桌面, clear 的 话就是清空桌面重新来。那用哪个还是要看当前的任务有没有值得保留的上下文来决定呢? 第三个命令 by the way。 这个命令一般会出现在你不想去侵入当前上下文窗口的情况下去使用。举个例子,比如说你现在正在 web coding, 但是你又想到一个产品的逻辑上面会有点问题,就可以使用 by the way 去跟它进行讨论, 这个是不会记录在上下文的,或者说你使用 by the way 把你这一次的需求让它记录在某个文档里面。当你手头的这个 web coding 的 任务结束之后啊,接下来的任务你可以再调用原来记录下来文档里面这个需求继续展开工作。 那说完了我常用的这三个命令之后啊,还有些关于上下文管理的我的个人的使用习惯。第一个,引用文件的时候,指定路径和文件名,不要让大模型自己去扫描文件,扫描整个仓库,他有的时候如果找不到的话,甚至还会去写一个脚本去帮你去找到这个文件, 所以说这样的托克消耗是得不偿失的。第二个,我相信大部分人都会知道,长任务或者复杂任务的时候,用 plm 的 模式可以大幅度的减少托克的一个消耗。 第三点,尽量让 cloud code 完成一整个工作流,而不是一步一步的告诉他去做什么。因为 cloud code 是 非常强大的一个 agent, 你 给他一个超级复杂的任务,他也能从第一步到最后一步完美的给你执行出来。如果说你每一步都拆开,那首先上下文会变得非常长,那上下文一长,你的大模型就会出现幻觉,你的上下文就会出现丢失,被污染。 那讲完了上下文管理之后,接下来这个 prom 的 缓存本质上和上下文也有一定的关系,那我为什么会单独拎出来讲呢?因为它会直接影响你用 cloud 的 速度和成本,也是大家特别容易忽视的一个问题。 c c 的 一个 prom 的 缓存机制啊,如果说你上一次请求里面的内容和这一次请求的前缀是一样的, cloud 的 就不会重新处理那段内容,直接用缓存速度更快,托克的消耗也会大幅度的降低。 在 cloud code 里, cloud 点 md 的 内容和项目文件的内容在同一个绘画里面是可以被缓存的,但缓存会失效。最常见的失效场景有以下两种。第一个, cloud 点 md 这个文件啊,在 cloud code 的 缓存架构中是被视为一个整体的模块的, 由于它位于缓存前缀的中间位置,一旦你改了文件中哪怕一个标点符号,系统也会判定从 cloud md 这个文件的模块开始,到后续所有的内容,包括历史对话的缓存都会全部失效。 第二个,对话的间隔太长, cloud 的 缓存默认有五分钟的超时时间,超过五分钟没有新的请求,缓存就失效了。 如果说你再做一个任务,保持对话的节奏要比长时间等待更好,所以说每次离开之前先 come back 一下是最好的。理解这个机制之后,你就会开始有意识的组织 cloud d m d 这个文件的结构,让 cloud code 的 能够持续的用到缓存,整体的速度就会明显快一些,托管的使用量也会少很多。 那接下来第三块的使用小技巧,就是我自己平时经常会使用到的一些 skill。 skill 是 cloud code 的 可安装能力包,把一套提示词和逻辑打包成一个命令以后就可以直接调用。那我现在用的最多的就是以下几个。第一个, planning with fire。 当你有一个复杂的任务,不想让 cloud code 直接开始乱动,那就先用这个,它会把任务拆解成结构化的计划写进一个文件里,当你 review 确认之后啊,它再按照文件里的计划一步步执行。这个是我目前使用频率最高的,甚至说我所有偏复杂的任务都会先用这个 planning with file 的 这个 skill。 那举个例子,比如说我现在做 webco 顶,那原本开发的流程,可能说花一天时间去想一下架构,然后再花几天的时间去开发,那现在就反过来,我会先花大概几天的时间去跟他去跟 cloud 的 去聊我会怎么样去设计,然后聊的过程中去把这些我的想法全部记录到文件, 那之后我再做 webco 顶,让他去生成代码的时候,那整个的代码的结构,包括代码的约束,代码的规范都是非常工整的。 那接下来第二个 skill, 那 其实是一整套啊,基本都是偏向前端界面设计的,像 fronten design, 还有像 ui ux pro 这两个 skill 啊,还有一个就是我现在做视频基本上都会用到的 remotion skill 啊,都是我自己高频在使用的。 那这种是专门为前端界面设计调优过的 skill, 我 觉得对于很多开发人员来说,因为对一些 ui 的 设计都不是很 make sense, 我 觉得用这些 skill 可以 帮到你们很多,并且他们的官网也是提供很多的素材和模板 啊。再结合像现在的,比如说 stitch 啊这种圆形的设计软件啊,那我觉得再配合这些 skill, 那 可以起到事半功倍的一个效果。 第三个 notebook lm skill 啊,那对于这个 skill 我 原本是不怎么开始用的,因为像原来的 gmail 可以 直接去连到这个 notebook lm, 因为都是谷歌的全家桶嘛,呃,都能够直接去输出我想要的结果。但后来大家也都知道 gmail 降至比较厉害, 我发现我的结果就我的要求他不太能满足到了啊。后面我就尝试着把 nosbook lm 生成的结果给到 cloud, 让他去帮我进行接下来的任务执行啊,效果也非常的好。然后到后面也发现现在是有这个 skill 的, 那我就直接拿过来用了。 第四个 everything cloud code, 那 这个 skill 汇总了 cloud code 的 目前所有功能的一个用法,相当于一个随时可查的内置的使用手册啊,不确定某个功能怎么用的时候,你就可以直接调用它,比翻原本的官方文档要快很多。 那这边有一点要说明啊,这个 skill 会比较消耗托肯啊,你一定要去关闭它的一些 mcp 啊,你哪怕关了的话,它的托肯消耗也是会比较大的。那如果说没有碰到一些复杂的任务,我觉得是用不上的,但是整体的质量还是非常好的。 第五个, superpowers, 那 这个也是老朋友了,我相信很多人都在使用这个 skill, 那 这个 skill 对 我来说最重要的一点就是它的脑爆啊,这一个技能。 呃,而且这个 skill 是 非常适合小白的,因为它是包含了一整个完整的软件工程的,一个生命周期的一个 skill 的 一个全集啊。所以说,如果你是小白,刚刚入手 web coding, 我 觉得你用这一个 skill 就 足够了。 第六个,卡帕西的这个 skill 啊,那这个 skill 我 觉得是相较于前面 superpower 和 everything, cloud code 的, 它更像是一个靠谱的资深工程师啊,它会强调先清楚再动手,不乱猜啊,能简单的就不要搞得太复杂啊,改动都是以最小的成本去改的,而且每一步都是尽可能的去做验证, 所以说啊,它特别适合去修 bug, 改老项目,做一些重构。那接下来第四块, hux 啊,那 hux 的 定义的话就是钩子啊,它允许你去自定义一些触发器啊,在卡拉扣的做完某件事情的时候,会自动的执行一段啊,你所定义的无论是脚本啊还是命令, 那我最常用的三个场景,第一个,我每次让卡拉扣的修改了代码之后,就会自动的去提醒,也不用担心它改完之后代码的格式会乱掉。 第二个,任务结束的时候自动发通知啊,比如说你在跑一个时间比较长的任务啊,那你可以去做别的事情,那任务完成的时候可以触发一条系统通知到你的手机上, 那为什么会举这个场景呢?啊?之前在用 open call 的 时候,因为像 open call 它本身可以去调用 call 的, 但是它怎么去监控 call 的, 它会一直去用轮询的这个方式去做,会非常的消耗 token。 那后来我就自定了一套我让 openclaw 去触发 claw 的 code, 之后我通过 claw 的 hook 去回调来通知 openclaw, 使用这样的方式之后啊,就可以减少掉不少的 token。 第三个场景,那像工具的调用前后会去自动的记日制啊,你想知道 claw 的 在一个任务里面到底做了什么,那 hux 就 可以帮你在每次工具调用的前后去协调日制,任务结束之后就能够看到完整的执行过程。 第五块, cloud code 的 插件,那说到插件啊,前面提到的像 skillbox, 包括没有提到的 mcp, 其实都可以揉在一块成为一个自己的插件 啊,所以我说我这边就分享我经常使用到的三个。第一个 cloud hard 啊,这个的话可以去实时的监控你自己套餐的一个使用量啊,包括你目前这个 session 的 上下文的一个情况啊,再配合前面上下文管理的一些方式组合起来,那效果是非常的好的。 第二个 figma 的 mcp 啊,那这个很适合前面讲的 fronten 的 design u i u x skill 啊,特别是如果你在工作中啊,你们的产品用的是 figma, 那 你直接可以通过 mcp 的 方式直接把设计搞给搞进来啊,从设计到实现会剩很多。 第三个三 tree, 那 这个也是 mcp 啊,这个比较适合去排查线上的 bug 报出错来以后啊, cc 能够更快地结合异常的信息对账和上下文去定位问题啊,可以省掉自己去翻半天的一个日记。 ok 啊,那以上就是关于本次我自己在使用 calco 的 过程中总结出来的小技巧的一个分享,希望能对大家有所帮助。如果说你看到了这边,证明你是一个非常求学的人,在此我也希望能够得到你的一箭三连和关注。那本期的视频就先到这,我是布鲁,我们下一期视频再见。
2.4万布鲁歇一歇 00:42查看AI文稿AI文稿
00:42查看AI文稿AI文稿今天用科二加 deep seek 做了一个需求文档,加圆形 skill, 输入 p r d 加需求描述,就能按照规则输出详细需求文档,点击查看文档 p r d 包含文档源信息、执行载药问题描述、目标用户、用户故事、功能、需求、 数据库表及字段寄宿站系统架构、项目目录 u i x 需求。接下来生成原型确认风格及页面,看下原型效果,整体效果还不错,我们检查一下原型 功能,基本符合预期。最后把这个需求及原型技能打包出来,就能附用到其他智能体了。
125老纪AI学习笔记 02:52查看AI文稿AI文稿
02:52查看AI文稿AI文稿哈喽,各位朋友大家好,今天分享一下我最近开发的低扣拍乐的使用演示。首先在 vs go 的 上面搜索下载,目前最新版本为零点三二, 这里点击底部图标激活插件,然后点击底部设置 api 的 t 插件是基于 d, p, c, k 进行开发的。这里先进行一个测试, 其中对于复杂问题,左侧会显示出 agent, 它的 plan 和 to do, 右侧会显示工作区的对话塞审。好的,我们进行一个超长上下文本的压力测试, 可以看到公式渲染正常,这里我采用了 markdown 和 html 混合的模式进行输出交互,更加友好美观。 我希望利用性价比最高的开源模型给大家打造一个扣丁扣 pilot, 不要把白花花的银子送给老美了。 这里再进行一次代码生成和自动运行的任务, 可以看到 deep co pilot 自动创建了 plan, 最后的完成的文件都在本地工作区中。 目前 deep co pilot 处于开发初期,遵循 mit 开源协议,希望大家多多关注,呼吁更多的开源社区成员一起维护这个产品,让高质量的 ai 生产力开放,公平、普惠,谢谢大家。
4894泡芙加奶盖 01:35查看AI文稿AI文稿
01:35查看AI文稿AI文稿用括号扣的啊,很多人一上来就会踩坑。那今天收五个最常见的。第一个,指令太模糊,帮我修复登录 bug。 那 到底报了什么错?附件步骤是什么?你想要什么结果?那 cloud 的 不是你肚子里的蛔虫啊,你给他信息越少,他猜的越离谱。 正确的做法是啊,把文件路径、报错,截图、日制全甩给他,再说清楚附件的步骤和你期望的结果。你喂的越细啊,它输出越准。第二个,不用 cloud 点 md。 cloud 点 md 是 什么? 就是在你的项目根目录下放一个叫 cloud md 的 文件,里面写上你的项目背景,技术栈,编码规范。那 cloud 的 每次启动的时候都会去读这个文件,没有它啊, cloud 每次都要重新去参与这个项目,到底是干嘛的?有了它,一上来就能够进入工作状态,很多新手压根不知道有这个功能啊,但其实它真的很好用。 第三个,一次性让 cloud 改太多的东西,有人一上来就有一个超大的需求,让他一口气重构整个项目,然后呢?改着改工了,那你都不知道是哪一步出了问题。那正确做法是啊, 把大学九拆细,改一点验一点,每次改完让他帮你提交代码保存进度出了问题啊,你还可以回滚。那第四个,改完不验证,这个坑最多人踩啊。 卡拉扣的改完不代表他改对了代码能跑,也不代表逻辑对了,有时候他还会偷偷影响别的功能,你可能都不知道。所以啊,一定要让卡拉扣的帮你写完测试并验证,验证通过了才算完。 第五个啊,不管你对话长度聊太久,对话越来越长, cloud 的 输出质量就会下降,他记不住前面说过什么,或者会记混。那怎么办呢?用两个命令,第一, compact, 压缩历史对话, 保留关键的信息,减少上下文的占用。第二, clear, 直接清空上下文,从零开始。那任务做完了,最好开个新的对话,别在同一个对话里面聊太多的东西。那这五个错误啊,你中了几个呢?欢迎在评论区聊聊。
105起哥的AI实战 02:40查看AI文稿AI文稿
02:40查看AI文稿AI文稿hello, 我是 小卢,今天分享十个我每天在用的 color code 小 命令,虽然不起眼,但是真的实用。第一个,感叹号加终端命令。在 color code 中输入感叹号加你的终端命令,命令就会直接在终端执行, 输出的结果会自动进入 code 上下文。比如你要先执行一个命令来看报错信息,你可以让他直接帮你看看怎么回事。不用去复制粘贴。这个命令是我用的最多的,没有之一。 第二个, ctrl 加 g 拷抠的输入框只有一行写短 pro 没有问题,但是如果要粘贴一段报错或者一个复杂的需求描述就很痛苦。按 ctrl 加 g 就 会打开你的默认编辑器, 在里面写完 pro 保存退出内容就会自动提交给 call, 比在一行输入框里面挤来挤去要舒服太多了。第三个,双击淘易件。大部分人会用斜杠 compare 来压缩,但是它会把整个对话都压缩一遍, 包括你精心设定的项目规划细节全没了。双击淘一键可以精确的控制你选中一条中间的信息,只压缩后面的内容,前面的项目约定原样保留。第四个,斜杠 b t w 有 时候你想问一个一次性的问题, 这个函数是干嘛的?这个错误码是什么信息?普通提问会永久地占用上下文的 token。 斜杠 b t w 不 会回答,会显示,但是不会进入对话历史。第五个, copy。 copy 给你写了段东西,你要怎么拿出来? copy 会复制最后一条回复,但是最好的方法是你 copy 完之后按 w, 它会向你选择一个路径写到文件里面,不用复制,不用粘贴,不用手动建文件,一步到位。 第六个, add 加文件名,跟 copy 聊到一半,想让他看某个文件,打 add, 加文件名,按 tab 补全文件内容,会直接进入上下文,不用说,你去看一下某个文件,也不用自己去复制粘贴,精准投喂。第七个, rewind 很多人都会遇到一件事情,就是 ai 把代码给改坏,大部分人会手动的改回去这个命令,它会回滚之前的某个检查点,对话文件改动,一起恢复,相当于是给 ai 的 操作装了个撤销键。第八个,匿名, 第一次打开一个项目, call 对 你的代码一无所知,输入匿名,它会自动扫描项目,生成一个 call 点, md, 里面有技术栈,项目结构、常用命令、代码规范,相当于是给 ai 写了一份入职手册,只用设置一次,以后所有的对话都受益。第九个, deep 让 call 改了半天的代码,他说改好了,但是你不确定他动了哪些地方。输入杠 deep 所有的文件一目了然。 第十个, review tpr 之前想要 call 帮你审查代码,输入 review, 它会自动审查当前分支的代码,变更, 潜在 bug、 安全问题、代码风格全部都列出来。这十个命令没有一个是高级玩法,全都是日常的高频操作,但恰恰是这些小东西决定了你用拷扣是将就还是顺手。如果觉得有用的话,帮忙点个赞,关注一下,我是小卢,我们下次再见,拜拜!
125快跑啊小卢_ 03:06查看AI文稿AI文稿
03:06查看AI文稿AI文稿上一期我们讲了 a 一 阵存循环的核心原理, message 经过 mod 输出,再带着 to see 走的回流到下一轮。今天我们来看一个更具体的问题,怎么给这个循环加上工具? 很多人以为加工具很复杂,要改循环加判断,其实完全不是这样。关键洞察就一句话,加工具不需要改循环。说到底,如果你的 agent 只有 bash 能力,会遇到三个致命问题,第一, cat 和 cid 这些命令遇到特殊字母就崩溃,可预测性很差。 第二,每次 bash 调用都是不受约束的安全面,你想限制它能访问是目录难。第三,所有操作都走 shell, 没有任何结构化管理专用工具,像 read file, write file, edit file 就 不一样了,它们可以在工具层面做路径沙箱,直接在源头把安全性卡住。 怎么设计这个工具系统?答案是 dispatch map, 也叫 handler map, 它本质上就是一个字典,把工具明映射到处理函数。之前硬编码 bash 调用全靠 if i leave 判断是哪个工具,现在变成了一个查表操作,一个 lookup 替换掉整个判断链。 架构图很简单,用户 prompt 进来, l m 决定调用哪个工具。 to dispatch 查表,找到 handler, 执行完返回 to resda, 整个流程完全没变,变的只是 dispatch 曾多了一个工具分发表,具体怎么写?三步走,第一步,定义工具处理器, 每个工具对应一个函数。第二步,把这些函数注册到 t o r tenas 字典里。第三步, agent 的 循环里,便利模型享应当遇到 tolius 快 时,从字典里查 handle 并执行。这个循环本身跟之前完全一样,一行都没改。 加工具等于加 handle, 加 schema, 循环永远不动。说到文件操作, handle 比有个函数必须重点讲 safe part。 它干的事很简单, 拿到一个路径,先 resolve 成绝对路径,然后检查它是否在我库 t a, i, e, r 以内。如果路径逃逸了,直接抛一场。为什么要这么干? 因为 l l m 生成的路径可能是相对路径,可能是这种穿越路径,不做检查就能读到工作区外面的任何文件。 safe pass 就是 这道安全门,把路径逃逸的可能性彻底堵死。 但这只是基础层,系统复杂了。还有一层不能忽视消息规范内部。 messages 列表是系统的内部表示,但 api 只能接受特定格式。 这里有个关键洞察, messages 列表是内部表示, api 看到的是规范的副本,两者不是同一个东西。规范化要做三件事,每个退域域需有匹配的 to result, user 和 assistant。 消息必须严格交替,只发送协议定义的字段。内部可以加原数据,加标记,但发给 api 之前全部要清理干净。 记住这一张最重要的三个稳定点就够了。第一, tool schema 是 给模型看的,说明决定了他知不知道这个工具怎么用。第二, handler map 是 代码里的分发入口,决定了工具调用谁来处理。第三, to result 是 结果回流到主循环的统一出口。把这三点吃透,你就能在不改主循环的前提下新增任何工具权限。 hook, 并发流式这些后续层次当然重要, 但都应该建立在这个最小分发模型之后。来核心公式记一下,加工具等于加 handle, 加 schema, 循环永远不变。 dispatch map 是 那个分发表表执行替代硬编码判断 路径安全靠 c pass 从源头卡住 message 表内部可以复杂,但发给 epi 必须规范化。这套架构理解了。下一期我们讲代办写入,把计划从模型脑内移到系统可观察的状态里。欢迎点关注我们,下期见。
68安逸Ai 04:30查看AI文稿AI文稿
04:30查看AI文稿AI文稿在我们使用 cloud code 的 时候,如何在底部实时显示这个状态栏的信息呢?今天给大家详细说一下。就是第一行,它主要是大模型的名称,然后当前的时间点。 effort low 指的是推理努力程度, thinking 就是 当前是否思考模式,这个是 cloud code 的 当前的版本号。 然后第二行指的是当前的工作目录。第三行,这个 c t x 就是 context, 就 上下文的信息,百分之十七就是当前已已经使用的上下文的占比,百分之八十三是剩余的。这个 size 就 指当前呃上下文窗口的总的数量,然后 in 和 out, in 就是 总的输入的量和 out 是 总的输出的量,就是 大模型从你这个绘画窗口所有的输出就 total, total in, total out。 第四行 in and out 其实就指的是单次的 它的输入输出,单单单次印是十二 k, 然后输出只有九个,就像我刚刚说的,你好,你问有什么我可以帮你的吗?其实这就是九个投屏的量,然后 crt 和 r d 我 给大家列在这了。 crt 就 指的是 cash creation, input tokens 就是 写入缓存的投屏的数量,然后 k 呃 r t 就是 指从缓存读取的投屏数量,都是 api 响应的。对,然后这里面的信息它是实时变化的,我给大家演示一下,如果我们想切换 model 的 话,当前是 k 二点六,我把它换成智普的五点一, 这样就会实时的变化,然后 effort 也是实时变化的。对, effort 当前是 low, 把它调成 medium, 这样就会变成 medium。 对, 然后呃当前的输入输出,这是本,这是当次调用的嘛,所以我就用 kliya 来试一下 kliya 清空,清空之后这样应该是 你看 kliya 之后,它这样就会变成零和百分之一百,就当前的上下文只有百分之零和百分之一,呃,剩余的是百分之百,如果输入你好之后 刚有点卡住了,输入你好之后,它第四行就会有本次绘画的输入,输出嘛,所以第四行就会展示,呃,就会实时展示出来 in out, z, r t 和 r d。 对, 这就是这个我觉得是比较好用的,因为我们在使用模型的时候,其实上下文越多的时候,有很多研究人就是发现,当我们的 token 数量超过百分之三十到四十的时候,其实大模型就会出现,呃,语音信息不清啊,或者幻觉一些之类东西就会丢失掉,关键信息就会出现这种信息的缺失的问题。 然后,呃,这个怎么安装?我给大家也写成了一个,整理成了一个文档,也可以看一下。就是这边它是 stencil, 因为这个东西它本来就是为了适配 glotcode 的 官方的,所以我们本地安装适配的时候其实是会有点问题的。 然后这边采集点也给大家记录了,就是直接拉你状态,状态来的话,它就在终端底部的信息条嘛,它可以显示模型的名称,时间,这些上下文的使用率, api 的 用量等等。但我们最主要的其实就是上下文窗口的使用率,剩余空间以及 api 的 令牌,输入,输出缓存,数据限制等等。然后核心的字顿都是列在这了。对, 可以看一下它的字顿啊,它有绘画 id, 它当前的工作,工作的目录 current workspace, 呃, direct to directory, 然后这个是成本啊,是否使用思考模式脱离努力程度啊?包括这个累计输出,呃,累计输入 窗口的上限,然后这个有几个问题给大家,就是确认一下,就上下文窗口这边为什么始终是两百 k 呢?就是因为它这个是 cloud code 的 默认值,但第三方模型实际显示可能不同。但,呃, 之前他这边是为了适配 cloud code 的 官方的模型 versus, 但是像我们我买的是火山引擎的 coding plan, 他 就不会实时的变化。对,他这边就两百 k, 其实就是 比较不准确的,包括他这个刚刚这个百分比的计算,其实就是 in out 除以这个他这个标的这个两百 k, 所以 这边比如十二除以这个十二加三十六除以两百 k, 大 概是百分之十七的样子,所以他这边百分之十七。但我们主要是看第四行,就是当前输入了多少,输出了多少呢?就单词绘画 这样,其实对我们就帮助就比较比较大了。然后速率限制的话,它也是仅限于格拉库的 ai, 就 你这也是我当前在 这个使用模型过程中的一些体验啊,就是我们在适配一些,呃,比如国外的一些东西的时候,其实我们要很清楚的理解它的自身,才能明明白如何更好的落地化帮助我们使用,而不是只有这样一个形式。但是我目前比较清楚了,这些自身就可以让它调整一版自己使用的这个东西,也可以跟我这不一样。 对,然后这些颜色的代码啊,这些坑点我已经给大家踩过坑了,大家直接呃在我们这些借鉴其实就可就可以了。像它中文路径,它显示乱码,因为有的文件夹里如果是中文的话,它会显示乱码方块,它这个脚本就会显示不出来,就是脚本就会失效,就显示不出来,比如这个字顿的位置。搞错呀, 它不是顶层子盾,它是这个 context window 内部的这个子盾其实就是,呃,就 context window 它是顶层子盾,但底下还有一个,还有一些嵌套的子盾这种这种坑已经帮它大家踩过了,大家配置的时候注意一下就可以了。
2613马斯洛AI智能体 02:50查看AI文稿AI文稿
02:50查看AI文稿AI文稿今天我用 curl code 帮我做一个中等以上需求的一个需求说明书,考虑到 curl 的 像大模型都是一个注意力机制的这么一个大模型,那我可能我的第一步就是在 tst 里边先把整个需求的背景,包括需求的功能点,包括让它呃要设计的一个注意注意要点,然后包括我对这个需求的整体的一个理解,把它呃列举成一二三。然后我在 tst 文档里边 梳理一下整个需求,然后就让 clark called 帮我做做一个详细的设设计说明书,然后他做完做完出来之后,他给我设计的相关的表结构,然后接口说明文档,包括还有时序图,包括还有那个注意事项,甚至还有一些测试的案例。 那设计完了之后,我就会对整个文档做了一个呃快速的呃浏览之后发现它里边其实还有一些设计的点比比较粗,比如说有一些定时任务,它可能是就默认了就每五分钟执行一次,但是它和实际的那个 呃时间是有冲突的。比如说我定时计划是一个随机的九点十三分来执行一个任务,如果他每五分钟来执行一次的话,他在极端情况之下,他可能会在九点十七分才会执行到我九点十三分的一个任务,那在这种情况之下就会造成那个任务的延时, 所以我就让他,我说,我就让他呃做任务的一个前置,然后再呃单独再做一个派发的任务,那就显显著的降低了这个任务的 呃时效性。然后在关于这个 clock code 帮我设计的需求说明书,他也是不断地在从事啊,不断地在迭代,然后最终把这个设设计说明书呃给出出来 啊,最终呢,有一点就是因为它设计说说明书里边本来我已经配置了很多的呃本,本来我已经配置了基本的 clock code 点 m d, 包括 enigma 点 m d。 在 这个不断的对话的过程中,因为这个需求的文档在不断的迭代,也触发了它好几次的那个压缩机制。 所以我觉得就是有一个技巧,就是当你把那个设计说明书如果说多次绘画呃到一定程度的时候,可以执行一下杠 clear 来,嗯,把那个上下文给清空一下,然后再基于它现在生成的那个文档来继续来生对文档进行处理,这样可能 呃让这个自然理更聪明,不会让它产生幻觉。呃,我从这个计划说明书的这个实践过程中,我觉得 clockcode 呃做设计说明,然后再让 呃,比如说 ctrl 或者是去来编编辑代码会更加的呃快速和有效。你们觉得呢?欢迎评论留言。
55飞向蓝天的8鸟 05:10查看AI文稿AI文稿
05:10查看AI文稿AI文稿enzo pig 又又又刷屏了,这次轮到 markdown 了。 cloud code 从今往后不再吐那坨涌长的 markdown, 改吐 h t m l。 而且这不是什么提案,是他们团队内部已经跑了几个月的工程实践。先回答一个问题, markdown 凭什么能活二十二年?看这块板上的三个浪。 二零零四年,张 gruber 发明了它, get up off the door, 把它选为默认,开元世界的门面就这么包下来了。第一浪,二零一一年之后, jacko, notion, obsidian 把它变成了知识工作者的标配。第二浪, 然后二零二二年, check gpt 出来,把 markdown 当成默认输出格式训练,深沉渲染,全走一条路径。第三浪,每一次新范式起来, markdown 都正好在他该在的位置,连续搭对三次浪。但是看板子右下角这个红色箭头,二零二六年五月 出现了一个拐点,我们先承认它强在哪。 markdown 有 四件护城河,第一,人眼可读,你打开原文件也不难受。第二,机器友好, diff, 能看懂 grab, 能搜 it, 能管版本。 第三,生态庞大,编辑器、渲染器、转换器,整条链条都成熟。第四,跨时代稳定。二零零四年写的 m b, 今天还能读,这才是真护城河。但是注意,我说但是了。在 age 的 时代, 马克当一直依赖的三个前提假设同时塌了。第一个假设,有人会手动改塌。 google 时代,人是亲手写 md 的, 现在呢? 人只发 prom, 让 a 诊去写。第一个假设废了。第二个假设,内容不会太大。二零零四年的博客,五百字一屏读完,现在 a 诊的一次吐出来的 plan, 三千字起步,你根本读不完。第二个假设废了。第三个假设,产物是单向展示的, 人看完就关。可 a 阵时代的产物,你还想在上面继续干活?想拖想掉,想点想导出,第三个假设也废了。 凯瑞克的这篇文章其实就是一句话,马克当是报告, html 是 多媒体,报告是什么?看完就扔,用完即关,扁平无色不能动。 多媒体是什么?图形、色彩交互,一起交互,不止能读,还能操作。他们团队在四个地方把 markdown 换成了 html。 第一,报告纯文字的趋势描述换成带图标,可点击有对比的格式化页面。 第二,方案任务清单变成可拖拽的优先级面板,你拖一下排序就重算。第三,日制平铺的一大段输出变成了带筛选按钮的时间线,只看 l o 一 键筛选。第四,文档 多文件的目录数变成带搜索框的围形站。四个战场一个共同特点, markdown 的 位置都是给你看, h、 t、 l 的 位置都是跟你玩, 我想给你一个更本质的视角。左边这个 markdown, 它只有一层文字,就这样再无别的。右边这个 html, 它有六层文字布局,色彩、图标、 svg, 控件交互 js, 再到状态反馈,同样承载一份信息。 htl 的 容量比 markdown 大 得多,不是百分之五,百分之十的差,是一个数量级。最关键的区别在工作流。看上面这条红色的线, markdown, 流人发 prompt, a 帧生成 md, 人打开人手动编辑,然后没了流程,断在人这里,人成了瓶颈。看下面这条绿色的线, html 流人发 prompt, a 帧生成 html, 人直接在上面操作,然后把状态导出,喂回下一轮 prompt 看见没,那个大箭头绕回来了,闭环形成。这才是 serrick 真正想说的,不是换个格式,好看点是让整个斜座循环跑起来。但是我要提醒你, serrick 不是 白讲这个的。这条推文同时替 antropics 做了三件事,第一,心智占位,写 html 等于 cloud code, 库 sir 想抢也抢不走。第二,算力需求, h t m l。 的 token 是 markdown 的 三到十倍,一篇报告直接变成一整个 app。 第三,生态引力, h t m l。 天然适配 skill 和 two, 一 条飞轮把这一切串起来。第一步, h t m l。 体验更好, 用户上瘾,留存上升。第二步,推理消耗飙升, token 是 markdown 的 三到十倍, anthropic 收入上台阶。第三步,更多卡更强模型, spacex colossus 一 买单,下一代 cloud 又更会写 h t m l。 第四步,生态跟随工作流,全部默认输出。 h t m l。 回到第一步,四步一圈越转越大, 带走三句话,第一, markdown 没死,它变成了 agent 之间的内部协议。第二, html 是 新默认, 凡是给人看的输出能 html 就 别 md。 第三,报告到多媒体,让人能拖能调能导出。再未回去。好啦,记得点好收藏关注赞,我们下期再见!
585南山老实人 11:46查看AI文稿AI文稿
11:46查看AI文稿AI文稿如果我告诉你,你可以把自己的一个工作流程打包成一个 ai skills, 以后只需要一句话,就能让 cloud 自动帮你完成这个工作,你信吗?这不是个幻片,这是我们今天要做的一件事情。在接下来内容里,我会带你从零开始,手把手构建一个 skills。 在 构建 skill 之前,我们先来梳理一下构建 skills 的 六步框架。第一步,名称与触发词,就是你的 skill 的 名字叫什么,通过什么自然语言去触发它。 第二步是目标,一句话就是让你的这个 skill 在 完成之后会产出什么样的一个结果。第三步,具体流程, 如果手动完成的话,你会按照什么顺序去做这个事情,看哪些信息,做什么决策。第四步是参考文件,就是你需要什么样的背景信息,可以是图片,可以是当前的项目当前的优先级,或者说你的 风格不规则。想想我在做这个事情的时候会出现什么样子的一个错误,会出现一个什么样子的一个问题, 然后让整体帮你加入相应的防护机制和约束条件。第六步,自我优化循环。在这个 skill 构建完后,就是持续的测试和叠带。接下来实时演示结束后,我会讲如何测试叠带和优化 skill, 把 skill 打磨到一个真正好用的一个状态。 好,以上就是六步构建 skills 的 一个框架,现在我们从零到一开始搭建一个 skill。 好, 现在我们进入 vs code, 这是我使用 cloud code 的 首选环境。如果这是你第一次使用 cloud code, 可以 去左侧的扩展面板打开搜索 cloud code, 那么当我们打开 vs code, 就是 这样子的一个界面,你可以在这里看到一个欢迎的一个选项,我们在这边打开文件夹。好,那当我们打开我们的 skills 演示文件夹,我们看到的就是这样子的一个界面,我们打开看到的 code, 那当我们打开 coco, 我 们所看到的就是一个这样子的一个界面,我们现在叫他帮我配置一下 skill 项目的初识化环境,一般我现在都是通过语音去跟他交流,你们也可以通过这种方式,这种方式会让你的效率提升很多。用简单的 点 cloud 杠 skills 结构初步化,这个项目 skills 文件夹被放在点 cloud 文件夹里面, skill 文件夹是我用来放置 skills 的 地方 发送,等它给我们构建完成,我们已经可以看到它已经给我们创建好了这个项目的一个架构。 我们把获取到的 skill builder skills 放到这个 skills 文件夹当中,我们把我们这个 skill builder skills 移到这个 skills 文件夹下面。 在这里我们可以看到我们 skill builder skills 的 一个官方的参考文档,还有我们给他写的一个 skill builder 的 一个 skills。 md, 这里面的内容就是我们让这个 skill build 如何帮我们创建 skill, 现在我们来创建一个 skill, 用 skill build skills 帮我创建一个 skill, 我构建这个 skills 的 方式是让他主动向你提问,这样沟通起来会容易很多。首先第一个问题,他问我这个新的 skill 想要做什么,他解决什么问题,或者自动化工作流程,我想用它来做内容创作, 具体是构建带品牌风格的信息图。好,我们发送。 现在他来问我们就是怎么样去触发这个 skills, 可以 通过斜杠命令去触发,也可以通过自然语言去触发,自然语言大概就是帮我做一个品牌风格的信息图。 好,那么现在我们就是进入到了逐步流程这个环节,在这个环节非常的关键,到目前为止我还没有告诉他他用什么文字,也没有提到关于我业务的任何信息。现在他问我们这个 skill 接收哪些参数,我选择其他,我跟他描述我自己的想法, 就是我告诉这个 skill 我 想做什么样的信息图,它来构思我的概念,然后向 key 点 ai 的 image two 模型发起请求来生成图片,同时参考我提供的品牌指南输出的格式,我要 png, 不要输出其他的格式。 发送,他问我输出的格式就选他的输出 p n g 图片文件信息图的输出。创建一个 app 文件夹,输出到里面。 好,我们发送给他。他现在问我这个指南放在哪里,它是什么格式?创建一个单独的 reference 参考文件夹,我把我所有的信息都放到里面。 现在他问我们这个 api 密钥存放在哪里,我们要创建一个 emv 文件,把它放在里面,这样我们的 api 密钥就不会去泄露。帮我创建一个 emv 文件,我专门来放置我的 api 密钥。 好,我们选择第一个名字。好,现在他已经问完了我们所有的问题,再给我们出了一个方案。我们先来看一下 这边有一个 skills 的 一个名字,这边他的目标也是根据用户概念来调用生成信息图,嗯,是对的,这就是我想要的一个效果。然后这边是逐步流程用户描述信息图,读取 excel 文件,调用 excel 生成图片,生成 ppt 的 奥普鸟, 哇,完全正确,且他这边的输入和输出和依赖和护栏都列的非常的完整,我们就可以跟他说 这个理解非常的正确。我按照这个方案来创建 skills, 现在我们可以看到他已经为我们创建好了这个 skills 文件夹,在 class skills 文件夹下面边就是他为我创的一个份文档,我们可以把我们的信息都放到里面, 这边呢就是他为我们创建的一个输出文档和我们的点 e m v 文档,这边是存放我们 api key 的 地方,那么现在他已经给出了进一步的提示。首先第一步填写我们的指南,我们现在把我们的平台指南填写进去,现在我已经把我们的文件放到里面去,它是白底透明的时候,我们让它 放置在我们深层的信息图里面,我们去获取我们的 api key, 我 们把这个 api key 给它填上, 那么当我们设置好这个 apikey 之后,我们就可以在这边调用 skill 去生成我们的信息图。我们先来测试一下我们这个 skills 的 效果怎么样?帮我做一张到 skills 的 信息图。 好,我们发送,我们发送之后他就会帮我们用这个 skill 去创建信息图,识别到了我们的 apikey, 他 现在来为我们生成这个图片。 好,现在他已经为我们生成图片,我们去看一下他生成的图片怎么样?但我其实现在有点不太满意他给我生成的这个效果。先第一个他没有把我的个人品牌的 logo 给上去,第二个这种风格也不是我想要的,那我们把我们这个品牌直男的参考文件给他完善, 我们把它给补充进去,我把它补充完之后,我再让他给我生成一个图片,帮我再做一张关于 close skill 的 一个信息图,生成的图片不要太单一,可以添加一点动画,内容丰富一点。 好,我们再让他来给我们生成一个 costco 的 信息图,现在他已经为我生成了一个新的图片,这个图片的效果是之前我们生成的这个的效果要好很多的,而且我们可以看到我自己的图标也被放在上面,这个融合的效果是非常好的。 同时它在这边还识别出我们的一个改进的一个方式,就是在生成前就带着 logo 去参考,它可以直接帮我们更新我们的 skills 工作流。不过我们用的这个 skill 越来越多的话,它会自我改进,到后面用了十次,二十次之后, 每一次它生成的图片都能达到我想要的效果,这就是 skills 的 一个能力。今天我们讲了很多关于 skills 的 内容,也带大家从零到一构建的一个 skills。 接下来我想聊聊如何从九十分的 skill 进化到接近满分的 skill。 也就是通过测试、迭代和调试不同的症状,对应不同的修复方法,我们逐一过一遍。 当 skill 执行的步骤错误或者顺序不对时,我们可以直接修改 skill md 的 文件,因为 skills 的 使用步骤就是按照 skill md 里面的使用步骤去操作的。 如果说缺少语气风格或上下文,你可以给他添加参考文件,这样 a 准就能识别你的语气风格和上下文等等,以达到你想要的产出结果。 如果说是同样错误反复出现的话,那我们就给他添加规则来限制 a 准的行动。如果说是某个工具或者 m c p 出现重复搜索的问题,我们可以创建对应的参考文档, 就像是我在上个视频给你们演示那样,通过这个方法我们会节省大量的 token。 如果说你发现你创建的这个 cq 效果不错, 但还能更好的话,你可以给他添加自我改进的指令,每次在你运行完之后,你就可以跟他说进行一下自我改进,当你运行了十次二十次,他会变得越来越好。 如果你创建的 skill 没有被触发的话,你可以检查你的 y a m l 前置原数据,确保你的描述足够具体。 如果你的 skill 触发的太频繁的话,考虑禁用模型的自动调用。在 call 文档里面可以找到相关的说明,它可以让你控制 skill 只能通过自然元触发,或者说是只能通过斜杠命令去触发还是两者都可以,可以由你自由的选择。 如果你想深入研究更高级内容,一定要去看一下官方的我 skill 文档。在这里关于 skill 的 几乎所有内容都讲完了,有一点特别值得关注,就是前置原数据的参考。我们在这里所看到的 skill 名称和 skill 描述,这些都是 b 选项,但是还有其他的可选项,比如说进入模型的调用, 指定允许的工具等等。下面还有一些指定使用的模型工作量程度,提供允许的上下文配置, back up 函数,指定特定的智能体去工作等等,这些可以让你对 skill 进行非常精细的控制, 但是不用担心,只有当你运行 skill 足够多的次数之后,你才有必要深入到这个层面。一个很重要的一个问题就是 skill 存放在哪里呢?我们目前看到的都是放在 cloud skills 文件夹里面,但是这只是在特定的项目中有效,无论是在我们 a i o s。 新建的那个文件夹,还是换到另外一个文件夹,这个 skills 就 访问不到了。 你也可以创建局 skills, 方法是把它放在你的主目录下,用波浪号表示,这样无论你在 cloud code 的 哪个项目里面,那个 skill 都可以使用。 比如说我有一个前端设计 skills, 我 把它全权安装,这样无论我做什么项目,只要我需要前端设计,这个 skill 都能直接的去调用。直观的理解一下现在的项目 skill 是 项目 a i o s cloud skill 进了名称,进了文件, 而如果说是全职的,你就不会在你的项目里面看到他,他存在你的用户瞩目之下。你可能希望全职安装某些 skill, 因为有些内容是关于你的个人,你的业务,你的工作流的,比如说你公司的背景,项目情况,语气风格等等, 这些你希望在每一个项目上都能用得到。好了,今天我们的视频就到这里,如果你学到了新的东西,可以给我点个赞,这对我帮助非常大,感谢大家看到最后我们下个视频,再见。
143锐知Mind 01:24查看AI文稿AI文稿
01:24查看AI文稿AI文稿你的 cloud code, 百分之八十的 token 都白烧了。五个开源工具,从五个不同角度帮你砍 token, 你 看完就知道该用哪个 token, 消耗有三个黑洞,同一个文件反复读,必定输出几千行废话, ai 每次回复都是长篇大论,一次会话轻松烧掉十万 token。 第一个 open wolf, 从文件读取成省 token。 cloud 是 盲人,不知道文件里有什么,只能一个个打开看 open wolf 怎么省。它在每个文件前面贴一张标签,写清楚内容和大小。 cloud 看一眼标签就够了,不用真的打开文件,同一个文件重复读,直接拦掉。大项目实测三点四兆语言成省元原理,强制 cloud 用原始语言回复, 砍掉所有。让我解释一下希望这有帮助的废话,只保留代码和核心数据。六十九个 token 压到十九个技术信息,一个字都没少。平均省百分之六十五,最高百分之八十七。第三个,八 k, 从命令输出成省 token, 它坐在终端和 ai 之间,拦截命令输出,再压缩四招,过滤噪音,分组聚合截断笼鱼,折叠重复。 cargo test 从一百五十五行压到三行。 it push 从十五行压到一行, cloud 根本不知道输出,被压缩过三十分钟,绘画一百一十八 k 降到二十四 k。 第四个 router, 从模型路由成省 token, 在 cloud 和 api 之间加一层代理,根据任务自动选模型,简单编辑,交给 deepseek, 后台任务用本地模型免费跑,只有真正需要才动用 clod, 花费直接砍百分之七十。第五个 token evisions, 从 prompt 乘省 token 原理写几条规则,放到项目的 c l a u d e m d 里, clod 每次启动自动读取, 比如不要说 sure 和 great question, 不要复出问题再回答,不要过度设计,先读文件再动手,零依赖零配置,复制一个文件就行。省百分之二十到三十五个工具,五个角度。 openwolf 砍文件,砍输出废话 r t k 砍命令噪音, router 砍模型花费 token efficient 砍 front 笼鱼按需选,不要全装黄金组合, r t k 加 pavemett 直接砍掉百分之八十五选对工具才是真正会用 ai 的 人。


