置信度越高越好吗
今天,我们将探索统计学中一个重要的概念,致信水平与区间精度之间的权衡关系。理解这个关系有助于科学地分析数据并做出明智的决策。 致信区间是统计推断中的一个工具,用于描述一个估计值的可能范围。考虑一个例子,我们要估算某个参数的真实值。我们需要定义一个区间,通常选择百分之九十、百分之九十五或百分之九十九的致信水平。 致信水平越高,意味着我们对区间包含真实值的自信度越高。我们用一个 beta 分 布动画展示,随着致信水平从百分之九十增加到百分之九十九,我们会发现致信区间变得更宽。 样本量对致信区间的影响也非常显著。当样本量增加时,致信区间会变窄,这是因为更大的样本量增加时,致信区间会变窄,这是因为更大的样本量能提供更多的信息,减少估计的误差。 为了事先确定样本量,我们可以使用公式来反推。在给定误差范围和致信水平下,所需的样本量可以用公式来计算。 除了常见的双测致信区间,我们也可以构造单测致信区间,用于特别关注下线或上线的场景中。这对于一些特殊的检测问题特别有用。 在对称分布中,我们可以定义最短至信区间极等伪区间,这种区间在对称时具有最小的区间宽度,确保效率。 我们用动画展示 alpha 和 n 的 变化如何影响区间宽度。通过动态调整 alpha 和样本量 n, 可以 看到至信区间如何随之改变。 今天我们了解了致信水平与致信区间的关系,样本量对区间精度的影响,以及如何计算所需样本量。记住这些关键概念将有助于你在数据分析中做出更准确的推断。

粉丝1.5万获赞6.2万
相关视频
 01:48查看AI文稿AI文稿
01:48查看AI文稿AI文稿百分之九十的人不知道你的思维与认知可能正在被 ai 影响甚至反向塑造,因为模型在输出时倾向于去除大概可能应该这类模糊词,从而生成自信且连贯的输出。这个现象被称为 confidence inflation, 也就是自信度膨胀现象, 即你感知到的模型的输出的准确性其实远高于这个输出实际的准确性。据研究显示,模型的实际准确率 其实低于真实准确率百分之二十到百分之六十。这非常可怕。这是因为市面上的语言模型是基于 r l h f, 也就是基于人类反馈的强化学习,而评估者们通常会将 模糊、模糊以及犹豫不决的输出标记为低分数,所以模型学习到了通过展现坚定的立场来获得更高的评分。而你作为人类, 往往会将从输出中感受到的确定性。至于硬核逻辑以及证据质量之上, 这是人类的大脑认知机制失调,这是没有办法的事情。这是一种人类大脑缺陷而且组织严密、立场坚定且逻辑堆叠,过高的输出往往容易掩盖其中内嵌的错误。好,今天先讲到这里,有机会我们下次再讲这个 topic。 对了,大家请大家在评论区告诉我,你们更想看哪个方面的,就是 ai 的 科普,想看更加硬核的 ai 拆解还是实验?或者说是我今天讲的这种,呃,它对你的影响?这类科普下期再见。
 00:32
00:32 01:55查看AI文稿AI文稿
01:55查看AI文稿AI文稿昨天发了一个洲际排雷的视频,大家让我排文泰斯,排这个,排那个,牛哥真是宠粉呢,满足大家的要求,今天我教你一个高效而又简单的方法,把这个视频收藏起来,下次你选到品种需要排雷的时候, 直接翻出来上手就可以用,不说废话,直接上实操干货。你把牛哥的基本面排列的文字版直接粘贴复制,然后输入,用上面的方法帮我排雷, 并以表格的方式呈现给我,然后发送,稍微等待半分钟,当所有的数据都出现的时候,表格的前半部分是标准,后面部分是实际数据, 表格会很清晰的告诉你达标不达标,并且备注你会分析不达标的理由。这是股东研究,这是分红融资,这是他的财务状况。最后下面会有一个综合结论,总结一二三四五条,总结致命的几个雷区。方法简单吧, 我再给你看看最近这轮行情。我拿的品种,这是股东研究,只有一项不合格,要求是百分之三十四,也就是三分之一,而我拿的这个只有百分之二十八点二七,差距并不大。 再看分红融资,全部达标,再看财务状况,全部达标,这是最后的总结,唯一的短板给我分析出来了,核心优势项目很多,如果你拿这样的品种去做波段,晚上你能睡得着觉吧? 两个品种一对比,是不是很容易区分出来,这是我自己核心的东西,我分享给大家,这也是我从来没有踩过雷的原因,我对自己的账户负责,本来炒股就是如履薄冰的,不能被这些雷给绊倒对吧?创作不易,希望我的视频真的能对你有用,喜欢的话帮忙点点,特别关注。
805散修刘老哥 02:25查看AI文稿AI文稿
02:25查看AI文稿AI文稿广西柳州发生五点二级地震,为什么震级并不高,破坏性却有点大?对这个问题我问了 ai, 他 是这样回答的,一是震源深度极浅,八千米能量直达地表。地震波从震源向四面八方传播, 能量随距离增加而衰减。八千米的深度意味着震源距离地表非常近,地震波在传播过程中几乎没有衰减,能量高度集中地释放到地面。根据地震学原理,震源深度从二十千米减小到十千米,震中烈度可提高一度。 此次八千米的深度属于浅源地震中极浅的范畴,导致地面震动强度被急剧放大,这就像在脚下十几米处引爆一个炸药包,与在几百米外引爆的感受天差地别。二是镇中距城区极近十六公里, 破坏力直接作用于城市,镇中太阳村镇距离柳州市中心仅十六公里,这意味着城市核心区直接处于地震能量释放的打新区域,高层建筑的自震周期与地震波形成共振, 导致晃动感被放大数倍,加强了居民的恐慌和建筑物的受力。三是地震区的认知沉睡与建筑设防不足六周按六度抗震设防烈度设计,基本地震加速度值为零点零五克, 而五点二级地震产生的实际地面加速度很可能已超出此标准,导致按最低标准设计的建筑,尤其是大量未做正规抗震设计的村镇自建房不堪一击。柳州作为地震区, 近五年仅记录到五次三级以上地震,这种长期无感的认知,导致居民普遍对地震风险缺乏警惕。建筑设防标准偏低,家庭应急包、地震预警功能等防范措施缺失。 四是前震主震序列的突发性。在主震发生前七小时内,该区域已连续发生五次二点二至三点二 急的前阵,这本是典型的前阵主阵预警信号,但由于当地居民缺乏地震经验,这些明显的警报可能被集体忽略,导致主阵来临时没有准备。
24刚哥说职场 02:15
02:15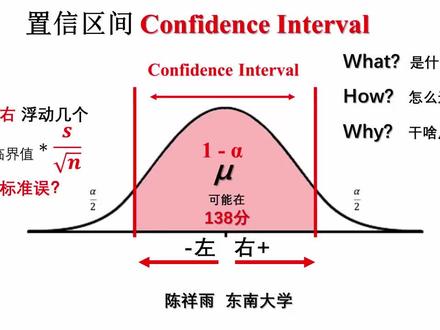 18:04查看AI文稿AI文稿
18:04查看AI文稿AI文稿大家好,在之前的课程中我们学习了气质和显著水平 hurf 的概念。本节课我们来学一下自信区间的概念。 致信区间英语叫做 confidence interval, 请大家把汉语和英语都好好记一下, 因为统计学中还有其他区点,大家不要搞混。刚才认识这个词,大家在英语四级里应该学过了, 字面是自信或信心的含义, intro 可能在六级词汇里是区间的意思。区间这个概念大家在初等数学中也都学过了,例如零到一,这个区间表示从零到一的所有 指范围。致信区间的这个示意图是一个概率分布图,左右两边尾巴尖上是拒绝于双边,每一边的面积是显著水平阿尔法的一半,中间剩下的用红色阴影标出来的面积是一减二法。 中间的面积我们之前也学过,叫做接受欲,接受欲所代表的这个区间就是致信区间。 假如阿尔法等于零点零五,那么中间的面积就是零点九五,则这个区间就叫做百分之九十五的知性区间。百分之九十五叫做知性水平,英语叫做康费等死 level。 本节课我们主要解释三个问题,致信区间是什么?怎么构造致信区间?为什么 要用执勤取点?我们仍然回到之前的高考英语成绩的例子,这个 excel 表里存储着五千名学生的英语成绩,但现在我们没有权限打开这个表。 access restricted, 所以无法直接计算出五千个成绩的真实君子。但我们有权限从表中进行抽样。 假如现在你从表中随机抽出了二十个学生的成绩,这二十个成绩的平均分算出来是 x 八,等于一百三十七点六分,这能说明什么呢? 我们想要知道的是,这五千名学生总体的真实军分没有,但限于条件,我们只能抽样一次得到样本军分为一百 百三十七点六五分,这个样本均分就叫做对总体均分六的一次估计。 sgmh, 因为单次抽样均分在做标轴上表现为一个点,因此这个样本均值也叫做对总体均分 mill 的点估计。 point estimate。 既然是估计,那么我们一般都会这么表述,总体的真实均值六在一百三十七点六分左右,而这个左右实际上就是引入了一个区间的概念, 区间就表示谬在一百三十七点六五分上下浮动。那么上下浮动的范围是多少分呢?一分?三分?还是十分呢? 这个浮动范围我们总不能瞎蒙的,那怎么办呢?这时我们回到均值抽样分布的实验中,假设我们现在有权限打开 excel 表了,并且算出总体的真实均值六等于一百三十七点四一分, 然后对这个 excel 表进行一千次样本容量 n 等于二十的抽样,获得如图所示的均值抽样分布。我们发现均值抽样分布的对称轴正是总体的真实均值。谬, 在一千次抽象中,除了能抽到样本均值正好等于总体均值没有以外,还可能抽到从一百三十三分到一百四十一分等等偏离没有的样本均值。换句话说,明明知道 到了真实的 miu, 也不是每一次抽样均值都是 miu, 所有的抽样均值其实是分布在 miu 左右的一个区间里, 那么这个区间在没有左右浮动的范围是多少呢?这是我们要再用到拒绝欲和显著水平了。 例如我们把左右两边尾巴共阿尔法等于零点零五的抽样画出去作为玉绝玉, 那么中间剩下的一减二法等于百分之九十五,就是我们的接受欲,这个接受欲实际上就是一个区间, 在我们这个演示用的不精确的表格中,这个区间的粗略范围是一百三十五分到一百四十分。对称轴代表的总体均值六等于一百三 十七点四一分,我们粗略的把这个区间看作在一百三十七点四一分上下浮动了二点五分,于是这个接受欲的区间可以表达为从六减二点五到六加二点五分。 注意,下面我说的这句话又比较拗口了,在明明知道总体均值六的情况下,对总体进行一千次抽样,并不是每次抽样均值都等于六的, 而是有百分之九十五的抽样落在了从六减二点五到六加二点五分这么一个区间内,这个区间的浮动范围是在六左右二点五分。那么在不知道 总体均值谬,而且只能抽样一次的情况下,得到一个样本均值一百三十七点六五分。我们假如想估计一个区间说真实总体均值谬,可能在这个样本均值左右浮动的话,那么 浮动的范围是多少分呢?就干脆也用刚才这个二点五分吧,作为这个区间的浮动范围。 于是抽样一次构造出来的这个对总体没有进行估计的区间,就叫做本次抽样的百分之九十五的执行区间。 致信区间由一个点估计 x 八和一个上下浮动的范围构成。上下浮动范围就是从这里到推出来 一个粗略的二点五分。说到这里,基本概念都抛出来了,大家可能还是有点糊涂,我们再从头捋一遍。 有个总体,我们想知道他的均值没有,但限于人力、财力等各方面原因,我们无法获得总体中每个数据来计算。没有,我们只能抽样, 所以我们只出了一次样,算出一个样本军职,我们用这次样本军职来代替或估计总体军职命,但你总不能说命就等于这次样本军职。 按常识你得说没有可能在本次样本君之左右浮动,但浮动多少呢?这时,假如我们突然有人力有财力了, 便对总体进行了一千次抽样,发现百分之九十五的抽样均值分布在谬左右大概二点五分的区间内。 然后我们又回到了只能抽样一次的进行中来,那就正好用这个二点五分吧,来作为这一次抽样均值上下浮动的范围。这就是通过一次抽样所构造的总体 miu 的百分之九十五执行区间。 由此看来,构造知性区间的关键不是抽样均值,因为抽样均值一算就算出来了,没啥不好懂的,关键是这个左右浮动的范围。 大家到这里肯定有疑问,这个二点五是怎么来的呢?在这个例子中,我们是从抽样分布中数出来的二点五分, 之所以能数出来,是因为这个总体其实就是我们自己事先造出来的,我们有权限看到所有数据,也能通过程序模拟一千次抽样。 但真实世界中,我们不可能为每一个统计案例进行一千次的均值抽样啊。 认真听课的同学肯定觉得这句话似曾相识。对,这就是第六节从均值抽样分布到替分布时我们讲过的。所以我们不可能也不用对每一个案例都抽样一千次, 因为我们有替分布。替分布不就是为了让你不用为每个案例抽样一千次而生的吗?可以说替分布预测了,或者说 总结了一切均值抽样分布,我们可以通过任何单个样本和对应的替分布反推出一个均值抽样分布。反推出均值抽样分布后,我们就可以得到百分之九十五的接受,欲去进 也就知道了致信区间上下浮动的范围。所以现在请记住,我们的任务是通过单次抽样反推均值抽样分布的百分之九十五接受与区间。但是请注意,反推出来的这个抽样分布不是来自我们所研究的这个东西, 我们所研究的总体就是这个打不开的一个笑表,它的总体谬是未知的。我们反推出来的抽象分布来自一个假想总体, 这个假想总体的均值就是从所研究的未知总体中抽样一次所获得的样本均值一百三十七点六五分。 为了避免混淆,我们把这个假想总体的均值记做没有假想总体等于一百三十七点六分。下面这句话也比较拗口,大家注意听, 我们通过单次抽样和替分布反推出来的这个均值抽样分布,就是从这个均值为一百三十七点六五分的假想总体中抽样一千次形成的抽样分布。 那么这个假想抽样分布的百分之九十五的接受欲在哪里呢?均值抽样分布中百分之九十五接受欲 的边界线和双边阿尔法等于零点零五,拒绝句的边界线是同样的边界线,或者叫做临界值。这里请大家注意,均值抽样分布中的每一条竖线都代表一个抽样均值 x 八, 所以这个零戒指是 x 八的零戒指。抽样分布中 x 八的零戒指对应着 t 分不中 t 零戒指,这个对应关系是通过 t 值公式来实现的。注意,这里的 x 八是甲想总体中的抽样均值, 这时我们通过小学数学知识把 t 值的公式变换一下,便得到 x 八零借值的基层公式。其中 t 零借值可以通过查表得到,样本标准差 s 可以通过样本算出来。我们先来查表,在 t 零戒指表中找到自由度 df 等于十九,双尾 rf 等于零点零五,也就是中间百分之九十五的 t 零戒指为二点零九三。 注意,双边剃纸零戒指表中只给出正等剃零戒指,我们心中要知道其实有正负二点零九三两个剃零戒指, 然后样本标准差 s 通过公式选注得 s 等于五点五四七,于是我们把 t 等于正负二点零九三, s 等于五点五四七, n 等于二十。待到公式中得到 x 八二零借值等于一百三十七点六五,加减二点五九 九六分。这个二点五九六就是点估计上下浮动的精确范围,这就回答了之前的问题,总体没有的致信区间中上下浮动范围到底是怎么来的? 就是用 t 零减值乘以样本标准差再出以样本容量的平方根算出来的。 之前我们讲气质公式的时候,这个样本标准差除以样本容量的平方根,当时没有详细展开, 现在大家能坚持听到这节课的话,说明大家已经比较专业了。今天我们给出这个 s 除以根号 n 的术语,这个东西叫做样本均值的标准误差,简称标准物,英语叫做 standard error of mean, 简称 standard never, 缩写为 s e, 汉语和英语的缩写都有一定的问题,把均值这个关键词给省略了。所以大家一定要明白,标准物不是所研究总体的标准差,而是所有抽样均值的标准差。 例如这是一千个样本均值的抽象分布,这一千个 x 八作为一个总体的话,这个总体的标准差就是标准物。所以体质其实可以解释为 一个抽样的均值偏离了抽样分布的对称轴多少个标准物。 现在我们回到任务目标,我们已经完全反推出了这个假想的抽象分布。 假想抽样分布的对称轴就是从所研究总体中抽样一次得到的样本均值一百三十七点六五分。 假想抽象分布的百分之九十五的接受与区间,由一百三十七点六五分加减二点五九六分算出来,也就是从一百三十五点零五分到一百四十点二五分, 这个区间就是用来估计所研究总体均值六的百分之九十五的致信区间。 这就回到了本节课封面的这张致信区间的示意图,大家现在应该都清楚了,这个分布是一个假想总体的均值抽样分布,这个假想总体的均值就是从所研究总体中抽样一次的 样本均值。现在我们来总结一下本节课开始提出的三个问题。第一个问题,致信区间是什么?致信区间是对一个未知总体的均值谬的区间估计。区间估计由两部分组成,一个是点估计, 也就是从未知总体中抽样一次所得的样本均值。另一个是上下浮动的范围。 第二个问题,如何构造出执行曲径点估计 x 八很简单,样本加起来除以 n 就算出来了, 浮动范围稍微复杂一点,要用 t 零戒值乘以均值抽样的标准物算出来。第三个问题,为什么用执行取减?有三个理由,第一,由于各种 限制,很多时候我们只能对一个未知总体抽样一次,我们总不能说总体均值六就直接等于样本均值 x 八,我们要加上一个上下浮动的范围,形成一个区间估计。 第二,在总体未知的情况下,这个样本就是我们获得的关于总体的唯一数据,要好好利用, 不要只算出个样本君之来就扔一边了。我们还可以算出样本标准叉 s, 并且进一步来估算出标准物质性区间的宽度,其实就是二 t 格标准物。 第三,其实也是很直观的一个理由,气质是从所有案例中抽象出来的,对称轴等于零,因为减 去了六零,没有单位,因为做了除法,没有任何实际意义的一个值。你不知道 t 等于二点零九代表着几只包子,也不知道 t 等于二点八六代表着多少分。 不仅如此,要算出一个气质的话,你还得有个圆甲色才能有个妙龄。但很多情况下,我们就是想抽一次药, 并没有想去做什么假设检验,也并没有想和哪个假想的妙龄去比较。我们只是想利用这个抽样做出一个区间估计。 例如在一次全校考试后,我们通过二十个同学的抽样军分算出一个致信曲径,我们就有百分之九十五的信心。康飞等词说全校军 分六应该在一百三十八分上下二点五分左右,这里又有实际的数值一百三十八,又有浮动范围上下二点五,而且还带有单位分。所以说 在这种情况下,自信区间比一个光秃秃的气质更能表达实际意义。好,这节课就讲到这里,下节课我们再来详细讲解一下这个自信水平百分之九十五到底该怎么理解,我们下节课见。
1362统计学陈祥雨大猫咪老师 04:22查看AI文稿AI文稿
04:22查看AI文稿AI文稿致信区间是统计学中一个重要的概念,他提供了一个参数的可能范围以及这个范围的致信度。这个参数可能是总体的均值比例差异或其他统计量。在实际研究中, 由于我们通常不能获取到所有的总体数据,因此我们需要通过抽样来估计总体参数。致信区间就是这种估计的一个重要工具。基本概念首先让我们来理解一下致信区间的基本概念。 假设我们对一个总体进行了随机抽样,然后计算了样本的均值和标准差。由于抽样误差的存在,样本均值可能会略微偏离总体均值。我们可以使用样本均值和样本标准差来估计一个范围。我们认为这个范围 内有一定的概率包含总体均值,这个范围就是致信区间,而这个概率就是致信水平。致信水平和致信区间。致信水平通常用百分数表示,比如百分之九十五、百分之九十九等。一个百分之九十五的致信区间意味着 如果我们无限次地从总体中进行抽样,并对每个样本计算百分之九十五的执行区间, 那么这些致信区间中大约有百分之九十五会包含总体的真实参数。需要注意的是,致信水平并不意味着特定的致信区间有多少概率包含总体参数。例如,对于一个给定的百分之九十五致信区间, 我们不能说这个区间有百分之九十五的概率包含总体参数,这是因为总体参数是固定, 不涉及概率。致信水平是对我们的方法的信任度,而不是对特定区间的信任度计算致信区间在实际中,致信区间的计算通常基于特定的统计分布,比如 t 分布或者正态分布。 例如,对于总体均值的估计,我们通常会使用以下公式来计算置信区间,样本均值梯值乘以乘以样本标准差够样本大小, 其中皮质取决于所选择的制性水平和样本大小。样本标准差,故样本大小被称为标准误差。他是样本均值的标准偏差, 反映了样本均值的变异性。解释置信区间在解释置信区间时,我们需要注意以下几点, 他提供了一个可能的范围,而不是一个确切的值。二、二、致信区间的宽度反应的估计的准确性较宽的致信区间说明估计的不确定性较大,这可能是由于样本大小较小、 样本变异性较大或致信水平较高等原因造成的。相反,较窄的致信区间说明估计的不确定性较小。 三、虽然致信区间提供了一个可能的范围,但我们不能说总体参数有多少概率。若在这个范围内,总体参数是一个固定的值,不涉及概率。 致信水平是对我们的方法的信任度,而不是对特定区间的信任度。四、致信区间是对抽样误差的一种量化 抽样五差是由于我们只能观察到总体的一部分及样本而产生的。通过计算制性区间,我们可以了解抽样五差可能导致的误差范围。制性区间的应用制性区间在各种研究中都有广泛的应用, 例如,他们可以用于估计总体的均值比例或差异,也可以用于做出统计推断,比如假设检验。在假设检验中,我们可以通过看总体参数是否落在置信区间内来决定是否拒绝领假设。 此外,致信区间也常常用于表达研究结果的不确定性。例如,一个研究报告可能会说,我们百分之九十五的致信区间是五十,这意味着我们有百分之九十五的信心总体均值在 这个范围内。总的来说,执信区间是一种重要的统计工具,它帮助我们理解和量化抽样物场,使我们能够对总体参数进行更准确和可靠的估计。
236太阳骑士 03:32查看AI文稿AI文稿
03:32查看AI文稿AI文稿你有没有过这样一个阶段,每天忙的像陀螺,从早上七点起床到深夜十二点,还在忙着回复各种消息,但是到了月底复盘,发现自己好像都没有拿到自己想要的结果。更可怕的是什么?明明自己很努力, 却感觉自己一直在别人规划好的赛道上跑,跑的又累又焦虑,却不敢停下来。因为你怕一停就被甩的更远。 这种状态我简直不能太熟悉,我曾经也以为城市靠的是拼时间、拼意志力,拼对自己狠一点。直到我观察了身边那些真正能成大事的人,才发现他们的底层逻辑跟我完全不一样。 今天我想跟大家分享一个特别简单的框架,能成大事的人,他都具备两种能力,一种向内,一种向外。向内是自己与自己内心的关系。美国心理学家克胡特给过一个极其简洁的心理健康标准,自信和热情。自信是什么呢? 是活力向内滋养自己。你相信自己是有价值的,值得被爱,也值得成功,哪怕遭遇重创,你的内核不会崩塌。热情是什么呢?是活力向外流向世界。你做一件事, 不是因为我应该做,而是因为我想做。没有自信的人,还没有出发,就被自我怀疑消耗殆尽,他会在心里反复问我,行吗?万一失败了怎么办? 于是迟迟不敢行动。没有热情的人,做事全靠意志力死撑每一步都向在还债,走不远,也享受不了过程。 所以,人格层面的自信与热情,决定了你敢不敢出发,以及你是否乐于出发。向外,是你与世界建立真实连接的能力。 太多人做事的逻辑是头脑先行,先定一个宏大的目标,然后靠意志力去执行。表面看很合理,实际上藏着一个陷阱, 全能自恋。你幻想自己不费太大努力,光凭天赋、运气或我应该成功的念头,就能拿到结果。一旦遇到困难, 就想换方向,想偷懒,因为你内在深处在等一个不费力的奇迹。真正的高手,用的是另一种逻辑,用体验做事,而不是用思维做事。体验就是放下对结果的执着,专注于过程本身。核心就四个字, 持续投入。你在投入的过程中,会逐渐触摸到事物本身的规律、节奏和美感。你尊重他, 他就会向你展开。能力从来不是从天而降的神来之笔,他不是你学出来的,也不是想出来的, 他是你与事物深度相处的副产品。就像有人蒙着眼睛也能装发动机,说他像我的身体发肤一样熟悉。这种熟悉不是天赋,是无数次拆装、感受、 调整之后,与他建立起来的深度关系。能成事的人,最终是人格与方法的合一。人格能让你敢于出发,乐于出发。深度关系让你走得远,走得深。放下全能自恋,老老实实投入。 当你真正与事物建立起真实的关系,那些让你城市的底层能力就会自然而然地生长出来。你是什么样的人,比你做成什么事更重要。
 00:15查看AI文稿AI文稿
00:15查看AI文稿AI文稿选三,四,选五,六七选五、六八九选七、八九,十二,十五,十六选十,五,十六,十九,二二二三二五二六二七。
30成都楼市盖碗茶 00:3636蓝色
00:3636蓝色


