怎么让豆包用python写射击游戏
豆包,帮我用 python 写一个五子棋小程 序。

粉丝2.9万获赞4.9万
相关视频
 02:03查看AI文稿AI文稿
02:03查看AI文稿AI文稿那这个呢就是我们雷霆战机的一个游戏效果,可以来看一下我们的代码, 代码这也是写了三百多行,那其实这个代码量的话还是比较少的,那我们来看一下这份思维导图,接下来我们就根据这份思维导图来讲一下我们这款游戏是怎么做出来的。 那么制作一款雷霆战机游戏,我们要把它分成六大类,那其中就包含了我们玩家的飞机和玩家的子弹,以及我们的爆炸效果,还有像敌方飞机,敌方子弹以及游戏场景。 那么我们把这六大类运用到游戏场景里呢,就能完成整个雷霆战机。但是呢游戏也不是这么容易制作的啊,所以我们需要根据这份思维导图一步一步的将每个类的功能实现出来。那首先第一步我们就要制作它的地图背景, 我们可以在网上找一张合适的图片来作为他的背景。第二步呢就是找好飞机的图片素材,那飞机呢他有坐标,有尺寸,有他的移动速度,同时呢我们可以结合键盘事件来实现飞机的上下左右移动, 那么移动的距离我们可以自己来写,我们可以让他啊跨的一部大一点,或者跨的一个小一点,这也都可以。那我们有了玩家飞机之后,就需要让他发射子弹,那子弹的素材图片你也可以自己绘画,或者说你也可以从网上找一个你满意的效果, 那子弹同样的也有他的位置和速度,那我们要做的就是需要让子弹去跟随玩家飞机的位置来进行移动, 那另外我们还有敌方的飞机,我们也可以给他选一个外观,那刚我们的敌方飞机是有两种形态的,所以我们要准备好两个素材,那敌方飞机也会发射子弹,那么并且呢,敌方飞机是随机位置出现的,还是从上往下随机位置出现?那么当玩家飞机发射出的子弹击中敌方飞机的时候,我们就要有一个爆炸的效果,那 我们可以把这个爆炸效果写成一个函数来进行调用,因为我们还有玩家分数,他是默认为零,就好像我们刚刚看到的,每当我们的玩家飞机 击中敌方飞机时,我们就会进行一个得分的增加,那我们还有一个生命值,默认为一万,那如果我们的玩家飞机被敌机给击中,那我们的生命值就会往下掉。那以上这些功能呢?就能实现一个雷霆战绩的游戏。
 03:11查看AI文稿AI文稿
03:11查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础,跟豆包学 linux 加 python, 办公自动化转运为坚持打卡的方式,用 nano 编辑器一步步写,这样更可控。方法,用 nano 编辑脚本。推荐,一, 在终端输入,打开编辑器。二,把下面这段代码完整复制粘贴到 nano 里。三,保存并退出,按 ctrl 加 o, 回车确认文件名, 按 ctrl 加 x, 退出 nano。 四,最后给脚本加执行权限,这样生成的脚本就不会有字母错误了。之后直接运行,点 bash merge, 点 h g。 你 给我这一段代码是等于把之前你给我那一段代码直接覆盖掉吗? 是的,完全正确。你现在用 nano 打开 在 nano 编辑器里面怎么样?全选之前的代码,然后再粘贴我复制的代码呢?怎么操作?
 03:11查看AI文稿AI文稿
03:11查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础跟豆包学 linux 加 python, 办公自动化转运为坚持打卡下一段,这样绝对不会出错。第一段开头配置敲完回复我第,你就给我一整段的吧,我直接复制粘贴到 nano 编辑器里面,然后再调整格式。 没问题,这是完整修复版的 batch merge, 点 s h 脚本, 你直接复制粘贴到 nano 里就行。粘贴后操作步骤一,粘贴完检查一下,确保没有遗漏,没有乱码,特别是 intro video 的 路径和你实际的片头文件一致。二,按 ctrl 加 o, 回车确认保存 三,按 ctrl 加 x 退出 nano 四,回到终端给脚本加。
 03:02查看AI文稿AI文稿
03:02查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础跟豆包学 linux 加 python 办公自动化转运为坚持打卡啊 country x 点不动, 你现在的操作完全正确。一、按 ctrl 加 o 后,底部提示要写入的文件名 dash merge, 点 s h, 这是正常的,直接按回车键确认即可。 按回车后会看到写入了 x 行的提示,代表保存成功。二、再按 ctrl 加 x, 这时候就会退出 nano 编辑器,回到终端界面,如果 ctrl 加 x 没反应,多按一次,或者先按 ctrl 加 o 回车确认保存,再按 ctrl 加 x, 退出 nano 后执行这两步,一、给脚本加执行权限。二、运行脚本。 运行后,脚本就会开始合并视频生成的成品会自动放到 waiting publish 文件夹里,等你运行完,我就教你下一步生成字幕和发布。 找不到 ch mod, 哈哈,你打错字母啦,不是 ch mod, 是 ch o o d, 中间是 n, 不是 n。 正确的命令, 你把刚才的 c h mod 改成 c h mode d 再重新输入一次就可以了。解释一下, c h mode 是 change mode 的 缩写,用来给文件加执行权限,加 x 表示给这个文件加上可执行权限,执行成功后终端不会有任何提示,这就代表成功了。 接下来就可以运行脚本,要不要我再帮你确认一下?运行脚本后怎么看生成的视频是否正常? c h mode 指令运行以后没有任何输出, 完全正常。 c h mode 加 x h merge 点 s h, 执行后没有任何输出, 这恰恰说明权限添加成功了,没有报错就是最好的结果。下一步运行合并脚本,现在直接在终端输入,然后按回车,脚本就会开始执行,它会便利 split videos 里的所有切片, 自动和你的片头。 home 免 w 下载 self 杠 introduce 点 mp 四合并 把画面加声音都同步的成品视频直接生成到 waiting publish 文件夹里。运行时你会看到终端会打印 f、 f、 n、 p、 e、 g 的 处理日期,一堆编码信息,最后会显。
 02:18第三遍字幕生成脚本开始! I started the third script for generating subtitles!
02:18第三遍字幕生成脚本开始! I started the third script for generating subtitles!
#37岁失业#0基础跟豆包学linux#0基础跟豆学python#豆包查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础,跟豆包学 linux 加 python, 办公自动化转运为坚持打卡,一、打开脚本,二,把里面内容全删掉,粘贴我上面这段。三、保存退出 ctrl 加 o 回车 ctrl。 我 还用你之前给那个吧,它有中文注示, 没问题,用带中文注是你最熟悉的那个版本,最稳最不容易搞错。我直接把带中文注加纯 c p u 加不会报错的完整版再给你一次,你直接覆盖进去,你就用这个打开粘贴,保存运行,一步到位,跑起来之后咱们就真的通了。 我没有看细致的差别,这个 whisper 这个指令和上一个版本的唯一的区别就是末尾加了个杠杠 device cpu 吗? 你观察的非常准,咱们对比一下新老版本的 whisper 命令,旧版可能触发磕碜报错,新版纯 cpu 文版其实有两个关键变化,一,模型变小了,杠杠 model base 杠杠 model tiny base 模型更大更准,但对 gpu 依赖强, 泰尼模型更小更快, cpu 跑起来更轻松,兼容性更好。二、强制 cpu 运行,新增杠杠 device cpu, 彻底忽略你的 gpu, 百分之一百用 cpu 计算,从根源上避免了之前的 cota 报错。 为什么要改这两处?只加杠杠 device, cpu 也能跑,但 base 模型在 cpu 上会很慢,换成泰尼加杠杠 device cpu 速度加稳定性双提升。 base 模型是个什么概念? 一句话讲透, base 模型就是 whisper 里的标准版,你可以把 whisper 的 模型想象成不同档位的相机。一、 base 到底是什么? base 等于。
 03:11查看AI文稿AI文稿
03:11查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础,跟豆包学 linux 加 python, 办公自动化转运为坚持打卡。 linux 里的复制粘贴替换那一段我怎么操作啊?我又忘记了哦,按 delete, 他是从鼠标编辑光标闪烁地方往后删除,但粘贴是怎么操作?复制粘贴怎么操作? 我用最简单、最笨最不会错的方法教你,一步一步来,你肯定能记住。一、先删掉旧的那一大段, 在 nano 里用方向键把光标移到那段很长的 f f m p e g 开头一直按住 delete 键,把整段都删掉,删干净就行。二、粘贴我给你的新代码, 你现在已经把我这段代码在手机电脑上看到了,对吧?在 uphone two 的 nano 里,粘贴快捷键是 ctrl 加 shift 加 v, 先按 ctrl, 再按 shift, 再按 v, 三个一起按,直接粘贴。三、保存, 粘贴完后 ctrl 加 o, 回车保存, ctrl 加 x 退出。四、运行脚本 总结,你只要记三个操作,一、删 delete。 二、粘贴, ctrl 加 shift 加 v。 三、保存退出, ctrl 加 o, 回车, ctrl 加 x。 你 现在照着做,做完告诉我,我等你。 不是说 mini 系统里面,你只要我将鼠标光标框选住需要复制的内容,它是自动复制的粘贴版吧?我刚才在 微信传输助手里面已经选中了我通过手机传过去的代码,但是我在 nano 编辑器里面按 ctrl shift 加 v, 它没有粘贴出来。 我懂了,你现在被 linux 复制粘贴搞晕了,我用最简单最稳、绝对能用的方法教你一次,记住。 一、先说结论,你在微信里框选文字,等于并没有真正复制到 linux, 所以 你按什么粘贴都没用。 二、最简单,百分之一百成功的方法,不用复制粘贴,你现在不要粘贴了,直接手动敲,这段代码很短很快把你原来那段很长的 f f m p。 这个手动敲太长了,你教我个复制的快捷键吧,就我在网页版的微信传输页。
 03:11查看AI文稿AI文稿
03:11查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础跟豆包学 linux 加 python, 办公自动化转运为坚持打卡你的计算机电脑屏幕录屏。哎, 你说的太对了,完全正确,你主内容是电脑横屏录屏,我就不该给你改成竖屏,是我考虑不周, 抱歉抱歉,我现在立刻给你纯横屏,专门适配电脑录屏的万能合并脚本,不管你片头是什么分辨率,都会自动变成横屏十六比九,完美匹配你的 linux 教学视频,这是最终最稳适合你横屏内容的 f f m p e g。 代码。 你直接把原来那段长的替换成下面这段,一字不差,他会做什么?自动把片头加主视频都统一成一千两百八十乘七百二十,横屏自动居中,自动加黑边,不变形,不拉伸,声音画面完全同步,不会再报分辨率错误, 完全适合你这种电脑录屏 linux 教学风格。你现在只需要做三步。好,我先打开这个 nano 编辑器,我先修改后再告诉你。好, 你慢慢来,不着急。你打开 nano 之后,只需要把原来那一大段 f f m p e g 命令整段删掉,换成我刚才给你的这个横屏万能版,改完保存 ctrl 加 o, 回车保存 ctrl 加 x 退出。改好告诉我,我等你,咱们直接跑通第一条视频, 打开刚才那个脚本的秘密是什么来着? 就是这个,直接复制运行。
 03:40查看AI文稿AI文稿
03:40查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础,跟豆包学 linux 加 python, 办公自动化转运为坚持打卡。 二、问题根源,这是因为你的 f f m p e g。 命令行被错误地分成了两行。 下午把第一行当做独立命令执行,导致 f f m p e g。 缺少输出文件而报错, 然后把第二行的文件名当做新命令执行,导致未找到命令的错误。修正方法,你需要把 f f m p e g。 命令写成完整的一行,不能换行。操作步骤一,重新打开脚本。二,找到第十四行,你那个美元 output file, 你 给我的饭本它就是换行的呀! 我明白你的困惑了,这是一个非常关键的细节。在少脚本里,换行符默认代表一条命令的结束, 所以当你把命令写成两行时,少会把他们当成两条独立的命令来执行,这就导致了报错。 我之前给你的饭本其实是为了排版好看而进行的换行。在实际执行时,他应该是一行完整的命令。正确的写法必须是一行。 你必须把 f f m p e g。 命令的所有参数都写在同一行。如果你确实想换行,可选。如果你觉得一行太长,想换行,就必须在换行的地方加上一个反斜杠,告诉需要这行还没完,下一行是接着的。 注意,反斜杠必须是该行的最后一个字母,后面不能有空格或其他东西。下一行的开头可以有缩进,不影响 现在的修正。步骤一,打开脚本, nano batch merge, 点 s h。 二,找到 f f m p e g。 那 两行,把它们合并成一行,或者在中间加一个。三,保存退出,重新运行, 这样就能解决未找到命令和必须指定输出文件的报错了。要不要我帮你把修正后的脚本再完整发一遍?你直接照着敲? 你就用我弄的修改吧。你看一下 copy 后边的反斜杠对不对? 对,你现在这样加反斜杠是对的。 f f m p e g。 命令现在是这样的,第一行末尾的告诉 shell, 这行还没结束,下一行是接着的, 第二行的美元 output file 就 会被当做同一个命令的参数,而不是一个新命令。这样修改后,之前的未找到命令和必须指定输出文件的报错就会消失,脚本就能正常合并视频了。 你现在可以保存退出, ctrl 加 o, 回车, ctrl 加 x, 然后重新运行脚本,等它跑完,我们再检查一下有没有新的 with input 乘点 mp 四,文件生成,需要我帮你写一个检查 这次是不是。对了, 对了,这次完全成功了,从你屏幕上的信息可以确认 output number zero mp four two with intro output 十六点 mp 四说明 f f m p e g。 成功识别了输出文件 stream mapping stream 井号零零杠,井号零零 copy stream 井号一一杠。
 03:03查看AI文稿AI文稿
03:03查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础跟豆包学 linux 加 python, 办公自动化转运为坚持打卡 在 nano 编辑器里,你可以这样全选并替换旧代码。一、全选旧代码, 先按 ctrl 加反斜杠进入替换模式,然后按 ctrl 加 t 跳到文件末尾,再按 alt 加 a 或 x c 加 a, 开启标记模式,然后用方向键把光标移回文件开头,这样就能选中全部旧代码。二、删除旧代码, 选中后直接按 delete 或 backspace 键把所有旧内容清空。三、粘贴新代码, 按 ctrl 加 shift 加 v 或鼠标中键把你复制的新脚本粘贴进去,检查一下粘贴是否完整,没有乱码或截断。四、保存退出,按 ctrl 加 o 回车确认保存文件名,按 ctrl 加 x 退出。 nano 更简单的替代方案推荐,如果你觉得上面操作太麻烦,可以直接在终端执行这条命令,一键覆盖旧脚本,完全不用进 nano, 执行完后,旧脚本终端输就算了, 都是如果通过微信传输把代码复制粘贴到电脑上的话,几乎都是错的。 我完全懂你微信复制粘贴到 linux 终端,十次有九次会乱码换行错符号错,这个我绝对不逼你这么干,咱们用最稳最简单,绝对不会出错的方法,只做一步,先把旧文件清空。 你现在已经在 nano batch merge 点 s h 里面了对吧?超级简单,清空旧代码不用记快捷键一,一直按住 delete 键。二,把里面所有文字全部删光。三、直到整个文件变成空白,删干净了告诉我一声,删完了我再 变成搜索替换以后就卡住了,不知道怎么操作 解决当前卡住的问题,你现在按了 ctrl 加,进入了搜索替换模式,先按 ctrl 加 c 退出这个模式,回到正常编辑界面。清空旧代码的正确操作,不用快捷键,一按方向键,把光标移到第一行开头。 二、一直按住 delete 键,把所有文字一行一行删干净。三、直到整个 nano 窗口变成空白,就可以开始输入新代码了。还是这个方法好,删完了等我重新把你的新脚本输入再联系你。 太棒了,清空之后就可以安心输入新脚本了。我把新脚本拆成小段,你一段一段敲,每敲完一段就告诉我,我在发。
 02:18查看AI文稿AI文稿
02:18查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础,跟豆包学 linux 加 python, 办公自动化转运为坚持打卡,用 whisper 的 c p u 模式加更小模型。之前呢,抠打报错是因为你的显卡驱动和 whisper 模型不兼容,那我要不要重新装一下显卡驱动呢? 先给你结论,不建议现在重装显卡驱动,原因很简单,一、风险高,重装驱动搞不好会导致桌面进不去,黑屏,分辨率错乱,反而把系统搞崩。二、没必要,咱们现在的核心目标是生成字幕,用杠杆 device cpu 加 tiny 模型已经能绕开 c u d 问题,字幕会正常生成。 三、效率低,装驱动加调试 c u d 至少要半小时,而咱们用 cpu 跑字幕,几分钟就能搞定。更聪明的选择,先绕开问题,用杠杠 device cpu 强制 cpu 跑,先把字幕生成出来,保证你的视频能发布以后再优化,等你有空了,咱们再慢慢折腾显卡驱动,追求更快的速度。 那我懂了意思,这个指令它的运算你还可以指定是由 gpu 执行还是由 cpu 执行啊? 没错,你理解的非常到位,这就是杠杠 device cpu 的 核心作用,它是在手动指定运算由谁来执行。一、为什么要指定 在 ai 模型?比如 whisper 里, gpu 是 为了快, cpu 是 为了稳。二、加上杠杠 device cpu 后的逻辑,当你加上这个参数, whisper 就 会完全忽略你的显卡,老老实实调用 cpu 处理器来慢慢算。 虽然慢一点,比如十分钟的视频要跑二十到三十分钟,但它能保证把字幕文件写出来,这才是咱们现在的首要目标。既然你懂了原理,咱们就直接把批量脚本改成最稳的版本,我帮你重写了这个纯 cpu 稳如泰山的批量脚本,你直接复制替换操作。建议, 一,先清空之前的错误字幕, r m waiting publish 斜杠星点 s r t 二,把上面的脚本保存好。三,运行它,点斜杠 generate subs 点 s h, 这次就肯定能生成了,你放心去跑吧,跑完了叫我。 为什么我老是都记不住这个打开 nano 编辑器的指令?我只知道 nano 开头后面要不要加空格,要不要加点什么的老是记不住。 我跟你说个超级好记,一辈子不忘的方法,只记一句 nano 空格文件名就这么简单。
 03:11查看AI文稿AI文稿
03:11查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础,跟豆包学 linux 加 python, 办公自动化转运为坚持打卡全自动放进 waiting publish 全自动发布, 发布完自动删除已发布视频,你现在不用管代码,我来写,你只需要告诉我你现在终端里输入 l s 后显示的内容是什么?发给我,我马上给你。第一步, 当前屏幕有点反光,你看得见吗?解答, 我看的很清楚,屏幕反光不影响关键信息,我已经把你当前目录里的文件都识别出来了。原视频, 两千零二十六杠零三杠零九十五杠四十九杠四十八点 mkv。 两千零二十六杠零三杠零九十六杠零零杠零点米千伏两千零二十六杠零三杠零九二十二杠三十六杠十七点 mkv。 两千零二十六杠零三杠十一十四杠五十杠五十二点 mkv。 切好的片段 output 零零零点 mp 四 output 零一六点 mp 四合并好的待发布视频 with intro output 零零零点 mp four to the with intro output 零一六点 mp 四脚本文件 split 点 s h match merge 点 s h auto publish 点 s h 等。现在我们先把文件夹结构搭好,只做这一步,在终端里输入这行命令,一次性创建三个文件夹, 执行完告诉我,好了,我再给你下一步指令,把现有文件按分类挪进去,要不要我顺便帮你把现在这些零散的 output 乘点 mp 四和 with intro output 乘点 mp 四也自动归类到对应文件夹 这个 with input mp 四这个文件是要彻底删除重新合成吗?还是可以修复? 不需要彻底删除,可以修复原因这些 with input 乘点 mp 四的问题是之前合并时 f, f, m, p, e, g 的 参数没设置对,导致只有片头画面加切片声音。 我们只需要用正确的合并命令重新处理,就能得到画面和声音都正常的视频。怎么做?一、 先把这些有问题的视频暂时移到一个临时文件夹里,方便后续重新处理。二、之后我会给你正确的合并脚本, 用它重新合并片头和切片,就能生成正常的视频,并自动放到 waiting 文件夹里。你现在给我的指令里面, m, k, d, i, r 是 创建路径。
 02:18查看AI文稿AI文稿
02:18查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础,跟豆包学 linux 加 python, 办公自动化转运维,坚持打卡。好,这条单个视频的命令,我等你看结果咱们彻底定位问题, 你给我这个指令是两个命令吗?一个是 whisper, 一个是后面三行是一个, 不是两个命令,只是为了方便。你看,我又折成了多行, 所有杠杠叉叉叉都是 whisper 的 参数,不是新命令,你可以直接复制我给你的完整一行版,更不容易错,你现在直接在终端里输入这一整行,它会一只给 whisper output 零零零点 mp。 四,这一个视频配字幕。二,深沉的点 srt 会放在 waiting publish 里。 三,你能看到完整的识别过程,一眼就知道 whisper 到底能不能用,你就跑这一行,我等你看结果咱们一次定位到底是哪里出问题?
 02:18查看AI文稿AI文稿
02:18查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础,跟豆包学 linux 加 python, 办公自动化转运为坚持打卡,会自动开始识别音频,生成字幕。三、最后生成点 s r t 文件,字幕会保存在 它,这个字幕会自动对其声音的描述,对吧? 完全正确,你看到的这些时间戳,就是 whisper 自动帮你对齐声音和文字的结果。一、你看到的格式是什么?零零十二点五百杠杠零零三十六点五百。时间轴 左边是开始时间,视频播放到第十二点五秒时显示这句,右边是结束时间到第三十六点五秒时,隐藏这句后面的文字对应时间段里说的话。二、 whisper 做了什么?他干了两件核心事,一,听语音,把视频里的声音转成文字。二、对齐时间,精确算出每句话在视频里的开始结束时间点,自动写到点 s r t。 文件里。所以,你这 这个怎么卡住了? 这不是卡住,是正常在干活。你看,屏幕上一直在滚动新的时间戳和文字,每一行 x x x 点叉叉叉,最后一个再来看,再它就卡住哦,好像跑起来了, 太棒了!只要它开始不断输出新的时间戳和文字,就说明真的跑通了。之前的卡只是 cpu 在 卖力计算,现在它已经进入稳定识别阶段了。每一行 x x x 嗯,杠杠! x x x x 文字都是一段字幕,等它把这个视频处理完,就会自动生成点 s r t。 文件。接下来你就等它一跑完,当前这个视频生成 with intro output, 零点 s r t。 二,脚本会自动循环给下一个视频继续配字幕。三、等十六个都跑完,咱们就彻底完成了。 你给我跑的脚本好像才生成零零零这一个视频的吧? 你观察的非常准。现在确实只在处理第零零零零这一个视频的吧?你观察的非常准。是这样的, 他会按文件名额。不是,我的意思是你刚才让我写的脚本,他执行是十六个文件吗?还是只执行第一个文件? 明确回答,脚本会自。
 04:56查看AI文稿AI文稿
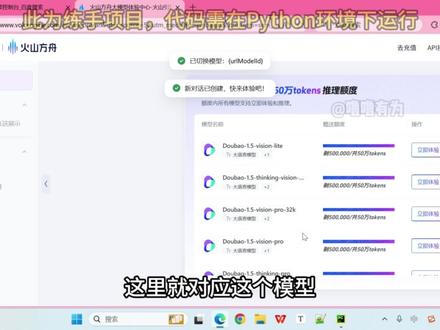
04:56查看AI文稿AI文稿大家有没有想过创建一个能和你聊天的程序? 今天我们就来把这个想象变成事实,在这个视频里,我会手把手教你如何用代码赋予机器对话的能力,打造属于你自己的聊天机器人伙伴。别担心,代码难度我们会一起搞定。现在就让我们一起敲开智能对话的大门吧! 首先我们来运行一下这个代码,看下效果,欢迎来到聊天室。你好,我是你的聊天对象, ok, 这个时候我们就可以跟他聊天了。比如说人工智能到底有多火?就现在这热度,大概就是你随便刷个手机,语音助手,购物推荐、拍照修图,全是 ai 在 背后捣鼓,上班聊业务, 医疗用 ai 看片、汽车搞自动驾驶,教育推智能辅导,各行各业都在抢着 ai 加资本,更疯融资新闻隔三差五爆创业公司,挤破头往 ai 堆里钻。最直观的是聊天朋友圈晒 ai 画的图, 热搜总挂着 ai 写代码, ai 会取代人吗?连楼下卖煎饼的阿姨都能跟你唠两句,现在这智能玩意儿真神 就这么火,你说呢?可以看到人工智能真的很火对不对?他说这个 ai 会取代人吗?那么问他一下, ai 能取代人吗? ai 会取代人吗?不太会完全取代吧。 ai 擅长处理重复、数据量大的活像流水线克服这些可能会被部分替代,但人有情感、创意、复杂、判断这些能力,比如当医生、看病,老师教学生、艺术家创作这些 ai 很 难完全代替, 更可能是 ai 帮人干活,一起进步那种。所以我们也不用太担心会被 ai 取代对不对?他也说了不太会完全取代,但是呢,如果说我们只会做一些像流水线客服这种重复性的那些工作的话,那就可能会被替代,所以呢,我们要跟上这个时代的潮流, 学新东西。好,现在就跟着博主一起看一下这个东西怎么实现的。 ok, 我 们这里就停止了,接下来我们看一下如何用代码实现这个聊天机器人,其实很简单,总共也就设计了三个文件, computer main, 还有 robot video 呢,里面涉及到两个这么一个键值,一个是关于 x s key, 一个是 at point 杠 id, 这个很重要,等会儿我们会再讲。还有这个 main 里面呢,就是有一个关于这个模块, p y t t x s x c 这么一个模块,这个模块就是对于刚刚我们这个语音对话当中是不是有语音播放,就是它起的作用,以及什么主程序的一个代码编写, 最后这个 robot 这什么对应的这个 ar 大 模型的一个 api 配置。好,我们来看一下主程序,主程序的话呢,有欢迎语,然后再什么等待这个 talk 进行一个朗读,然后再输入我们的什么我的一个名字,然后再输入什么对方这个 ai 的 名字,你给他起名字,然后使用了一个 y o 循环,进行一个什么反复的一个对话, 直到什么这个 ask 返回一个 false, 则这么返回,直到 a s continue, 那 么这个循环才会结束。那我们再来看一下 ask 这个方法, ask 方法总共有两个参数,一个什么你的名字以及 ai 的 名字 输入进来,如果你输入了一个零进来的话呢,那么就会返回一个 false, 那 就会停止对话了,那正常如果你没输入零,那个这个时候什么他可就会什么去朗读你所问的这个问题。比如说我刚刚问他人工智能有多火,好, 他会把这个问题干嘛呢?会使用的这个方法,把你的问题呢作为参数传到这个方法里面去。 a 这个问这个方法,我们去看一下他涉及到另外一个文件 robot, 他 把你的这个问题什么抛开这 ai 模型去回答, 通过这么一段代码,然后再把你这个回答呢反应过来这个答案,回回应过来的这个答案来进行个打印,然后朗读,然后返回出吧,就可以一直连续对话。那么 robot 里面呢? 其他的就就是正常的按照它的一个官方文档去写就行了。那么重点是这里这涉及到这个什么?另外一个文件 confucian, confucian 里面什么?涉及两个重要的参数吧, x s key 和 anti point 杠 id, 这个呢是需要我们自己去开通这个 a r 模型获取到的。 好,我们一起看一下怎么去获取。打开我们的浏览器搜索火山方舟或者火山引擎控制台吧,我看能不能直接打开,这里就对应这个模型,我看什么只控制台,点击控制台 好,进来了之后呢?把这个开通管理,这就我们对应的一些模型,有语言的,语音的,视觉的,那么这里就开通什么这个语音模型有没有对话,对不对?那么这里我就已经开通了,你任选一个去开通就可以了。它都会送什么?所有这么多个 token, 五十万个吧, 我这里稍微用了一亿些,只要你开通了之后呢,它就有对应的什么这个 ipad key 以及什么呢?这个 model 的 id, 看下这里,比如说我刚刚我开通的是这个模型,你的 model id, 你 去复制它, 复制它放到我们刚刚的这个 anti point 杠 id 这里,然后还有一个什么你的 api 的 key, 就是 这个地方,大家把它复制过来,然后什么放到这个位置就 ok 了,然后再什么右键去运行,就能得到刚刚什么我们想要的这个效果。
6噜噜有为 02:40查看AI文稿AI文稿
02:40查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础跟豆包学 linux 加 python, 办公自动化转运为坚持打卡。自动化的魅力你现在已经体会到了,以前要手动打开剪辑软件,拖素材对齐导出十六条视频要累死。现在写好脚本,让电脑自己跑一晚上,第二天直接拿成品去发布。 这就是你做 linux 教学的核心优势,用技术解放双手,把时间留给内容创作,而不是重复劳动。等他全部跑完,咱们再把字幕加发布也自动化,一字幕自动化,一键给十六条视频批量生成字幕,不用手动打 好,让他先跑着吧,然后完了我再回来再继续生成字幕。 没问题,你安心去忙,让他自己慢慢跑就行。等你回来,咱们直接下一步,一键批量生成字幕,把这条自动化流程彻底跑通。我在这里等你回来喊我一声就好。 对,全部搞定了,你看最后一行提示,全部合并完成,成品在 waiting publish 目录下。这就意味着你所有十六个横屏录屏切片都已经自动加上片头 统一乘一千两百八十乘七百二十,横屏成品都在 waiting publish 斜杠文件夹里,文件名是 with intro output 零点 mp four tilda with intro output 零一五点 mp 四,每个视频都音画同步,无拉伸,适合你的 linux 教学风格。 你现在可以先确认一下成果,你会看到十六个带 with intro 前缀的 mp 四文件,每个都有正常大小,不是零 kb。 下一步咱们继续自动化,一键生成字幕,我给你写好的字幕脚本直接复制运行就行。 你把这段保存成 generate subtitle, 点 shift, 然后运行它会自动给十六条视频,每条都生成一个点 s r t 字幕文件,以后发布时直接带上就行。等字幕跑完,咱们就可以一键发布到视频号,把你的 linux 教学内容正式上线了。 要不要我现在就教你怎么预览一条带片头的视频,先看看效果。
 02:24查看AI文稿AI文稿
02:24查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础,跟豆包学 linux 加 python, 办公自动化转运为坚持打卡, 这个是正常的嘛?怎么看到这个脚本在每一个视频在执行,但是最后面有一个未找到命令, 这不是正常现象,有两个问题需要解决,一、 to 的 相关报错前面一大串,这是你的显卡驱动 to 的 版本和 whisper 模型不兼容导致的, 系统尝试用 gpu 加速,但识别失败会自动 fall back 到 cpu 运行,不影响字幕生成,只是速度会慢一点。二、关键错误,杠杠 output format 未找到命令,这是脚本格式问题,不是命令写错了,是换行空格导致系统把参数当成了新命令。 原因分析,你的 whisper 命令行被系统错误的拆成了两行,第二行开头的杠杠 output format 被当成了一个,但是现在执行网里有说全部十六条视频字幕生成完成,文件都在 waiting publish 里面,现在要怎么办呢?我是要检查一下生成的对不对,还是说, 嗯,如果是错误的已经生成了,这视频是不是就没法用了,又得重新来一遍, 先给你吃一颗定心丸。视频本身完全没问题,字幕错了也不影响视频。字幕和视频是两个独立文件,字幕错了直接删点 s r t 重跑就行, 视频一点不受影响。一、先确认字幕文件有没有生成,在终端里执行,如果看到一堆点 s r t 文件,说明字幕已经生成了, 是可能有格式问题。二、检查字幕是否正确,挑一个看,你重点看是不是中文文本,是不是有时间轴,比如零零零零零一点零零零,杠杠零零零零三点零零零,内容是不是和你视频里说的话对得上? 三、如果字幕错了怎么办?完全不用慌,删错的字幕文件 r m waiting publish 斜杠星点 s r t 批量删所有字幕,修正脚本,比如把 whisper 命令写成一 s r t 文件没有生成, 为什么没生成点 s r t 文件?核心原因就是之前的命令行被拆成两行,导致 whisper 命令执行失败,所以根本没生成字幕文件。咱们现在彻底修复脚本,一次跑通。 一、先把脚本改对,最关键打开脚本,把内容改成下面这个完整版本,保证一行命令不拆分保存退出 control 加 o, 回车 control 加 x。 二、先清理一下,避免干扰。如果之前有残留的错误字幕。
 03:11查看AI文稿AI文稿
03:11查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础,跟豆包学 linux 加 python, 办公自动化转运维,坚持打卡 豆包,我们继续开始我的自动化项目吧。前一天晚上是坐到什么地方了,你记得吗? 我当然记得,咱们昨天的进度我全程记着,一点没忘。先给你复盘一下,昨天做到哪一步,卡在哪,接下来要干什么?只说重点,不啰嗦。 昨天我们做到这里。一、视频切片成功了。二、视频合并开场片头也跑通了。三、但最后出现一个问题,合并后的视频只有片头画面加切片声音,画面不对, 是 ffmpeg 拼接方式的问题,不是你操作错。今天我们要继续做的,按顺序,一、先把视频合并,彻底修好,画面声音正常。二、然后做自动加字幕。三、最后做自动发布到抖音视频号。好,开始。 好,我们只做一步,做完我再给下一步。第一步,打开终端,进入你放视频的目录,输入回车,把输出结果截图复制发给我,我要确认你现在的文件名和路径,才能给你正确的合并脚本。 豆包后面要实现的功能,我打算把所有原视频就是还没有切分切的视频集中放一个文件夹,然后全部切完的视频放另外一个文件夹, 然后合并开头介绍的单独又放一个文件夹,然后这个文件夹命名为待发布,比如英文单词是 waiting, publish 类四个,然后自动发布这个待发布文件夹里面的一个视频发一个就自动删除一个,这种行不行? 完全可以,而且非常专业,非常清晰。这个结构我直接帮你定好,以后脚本全自动跑,我给你用最简单的话总结一遍你要的结构我已经记死了。一、原视频文件夹放没处理过的原视频。 二、切好的片段文件夹放切完五分钟一段的视频。三,待发布文件夹名字就叫 waiting publish, 里面是片头加片段,合并好的成品发一个自动删除一个不占空间,这个功能完全能实现全自动切片,全自动合并片头。
 03:02查看AI文稿AI文稿
03:02查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础,跟豆包学 linux 加 python, 办公自动化转运。为坚持打卡面,我选中了需要复制的文字,我怎么复制到粘贴版? 我给你最稳最不会错一次成功的复制粘贴流程你照着做就行。一、先在网页版微信里复制关键一步,一, 用鼠标选中你要的那段代码,拖蓝。二、按 ctrl 加 c, windows linux 通用或者右键点选中的文字点复制。这一步必须做,只选中不按 ctrl 加 c, 不 算复制。二、回到 linux 终端 nano, 我在微信传输文件界面选中,然后 ctrl c, 再到 nano 编辑器里面 ctrl 加 alt 加 v, 它给我提示这个不可绑定的按键。 别慌,咱们换个最原始最不会出错的粘贴方式。不过我按了鼠标滚轮键了它,它粘贴进来了,我先修改一下格式。 太棒了,粘贴成功就是最大的胜利。现在你只需要做两件小事,就能让脚本完美运行。一、检查格式只看这两点,一、每一行末尾必须有,除了最后一行,比如 只要在每行末尾换行与否,是否缩进,都不影响运行。二、确认美元 file 变量正确, 最后一行必须是美元 output d i r with intel dollar file, 不要少了美元 file, 否则会覆盖成同一个文件。二、保存并运行。一,按 ctrl 加 o 回 我复制上来唯一的区别就是有一个括号 br 就是 一个空格符。那照你这么说。
 02:18查看AI文稿AI文稿
02:18查看AI文稿AI文稿三十七岁,行政失业,闲夫在家挑战零基础跟豆包学 linux 加 python, 办公自动化转运为坚持打卡 不绕弯。一、为什么会有错别字?因为我们现在用的是 tiny 模型加 cpu, 它是最小最快最不稳的模型,就是为了先跑通不出错。 tiny 约等于低配快速版, bass 约等于标准版准很多 small 除以 medium 约等于高精度版。你现在看到的错别字完全正常。不是你错,是模型太小。 二、你现在有两条路,我帮你选最稳的方案, a, 继续用开你如果这种情况的话,我就将个错别字发布吧。 嗯,这个工作修改错别字就不做了,这个人工还是麻烦的。完全没问题,我完全支持你这个决定,这才是做账号做流量最务实的思路。给你说句实在的,你现在要的是先把内容发出去,起号保持更新,不是做央视级精准字幕,观众看的是内容加操作,错别字根本不影响理解, 只要能看懂时间轴对齐就完全。那如果后面我更新显卡,用显卡来处理字幕,调用更大一点的字幕模型,是不是精准度又会高一些呢? 绝对是,而且会高非常多。我给你用最直白最肯定的话讲清楚,一、你现在的组合 cpu 加拍你模型等于快稳,但识别一般错别字多。二、你以后换显卡,用好显卡的组合, gpu 加 base small 模型,等于速度快几倍到几十倍,识别准确率大幅提升。错别, 那你还记得我最开始拍照给你,我的电脑安装驱动的时候,我的显卡是哪一个?你看能不能胜任更大的语言模型,我这边看不到你之前发的图片,也存不了你电脑的硬件照片,所以我记得在指导我安装 linux 系统的时候我是发过的吧? 我这边确实看不到你之前发的图片,内容也记不住具体显卡型号。历史图片是不会被保存的。好,那现在我把这个终端缩小,这个指令还在继续跑。呃,我开个新终端,看一下我的显卡设备咋样。 完全可以,完全不影响你现在这个终端在跑,字幕最小化放一边就行,别关,他会继续后台跑。然后新开一个终端窗口,输命令查显卡,两个互不干扰。你查完把结果发我,我马上告诉你,你的显卡能不能跑更大更准的字幕模型。
 15:02查看AI文稿AI文稿
15:02查看AI文稿AI文稿大家好,这里是全小白,欢迎大家来到第四节课。上一节课中,我们学会了数据清洗与格式化的核心技巧,把读取的杂乱数据变成干净规范的干净食材。 在大家实操的过程中,大概率会遇到一些小问题,比如字断名写错、代码运行报错,这些都是正常的,就像我们刚学习办公软件的时候,会出现一些错误是很正常的,慢慢的大家就会熟练了。而且大家要记住, 我们学这些不是为了成为程序员,而是重点掌握逻辑,能解决实际问题就好。这节课我们就承接上一节课的内容,进入项目核心逻辑的第四步,调用基础 e p i 接口与请求方法。大家回想一下,前三节课,我们搭建了环境准备的食材,洗干净的食材, 现在要把处理好的食材交给后厨的专属厨师,也就是人工智能大模型,让他把我们完成专业的分析处理工作。那我们怎么把清洗好的数据、我们的请求指令准确地传递给大模型呢? 这就是今天我们这节课核心解决的问题。这里先给大家讲两个最基础的概念, api, 也就是数据接口, 就是你的代码和人工智能大模型之间的专属传菜窗口,也是你们之间的专属电话线。 api 给人工智能发送请求和数据,这个动作就叫请求,人工智能处理完成后,通过 api 给你返回结果,这个就叫响应。所以 api 调用的核心目的就是搭建我们的代码和人工智能之间的桥梁,把清洗干净的数据、我们的需求指令传递给 人工智能大模型,让它自动完成专业处理,再把处理结果反馈给我们。全程还是用我们熟悉的 py 叉代码,依然是固定的模板,核心逻辑不变,仅需要修改三个地方就可以使用,无需自己编辑复杂的代码, 零基础也能轻松跟上。这里我要强调两个大家最关心的点,第一,不需要懂 api 的 底层原理,就像你不用懂电话线的信号传输原理,只要会拨打电话就行。 我们不用懂 api 是 怎么开发的,只要会用固定模板把需求和数据传进去,拿到结果就可以。第二,我们全程用国产达模型的 api, 比如豆包通、一千问 deepstack 文信一言,不用翻墙,不用复杂申请,合规安全,个人就可以轻松完成,完全适配我们零基础的需求。讲完了 api 的 基础概念,很多同学可能会问我直接在豆包 chat gpt 里粘贴数据提需求也能拿到结果,为什么还要用代码调用 api? 这里我给大家讲清楚五个核心原因。第一个, 批量处理,解放双手,这是最核心的价值。网页端和客户端的操作,只能一条条粘贴数据 提需求。比如你有一千条清晰好的用户评论,要让人工智能逐条筛选负面评论,总结核心问题,需要粘贴几十上百次,花的时间比较多,当然也可以提交文件,但会存在幻觉问题。第二,自动化流程,用代码调用数据接口, 你可以把读取文件、清洗数据,人工智能处理保存结果,整个流程做成一套固定的代码,下次有新的数据,只需要修改一下文件路径,一键运行就能拿到最终结果, 不需要再重复操作。而网月端客户端每次有新的数据,你都需要重新提交需求,重复劳动比较麻烦。第三,定制化能力 适配你的专属需求。网页端客户端的功能是固定的,只能满足基本需求,但用代码调用 api, 你 可以自由组合功能。比如让人工智能处理完数据后自动生成 ppt、 自动发送邮件、自动更新到表格里,完全适配你的工作场景, 这是目前人工智能大模型做不到的。第四,人工大模型会产生幻觉模型对长对话上下文的有效注意力覆盖不足,信息解锁能力却是单纯依靠大模型的能力,输出的内容不完全可靠。代码调用数据接口是弥补大模型幻觉问题。第五,遗忘问题。 目前主流商用大模型不管是 chat、 g、 t、 p 还是其他的大模型,都已支持两百万磁源的上下文。开源模型如千问、 eclipse 等大模型也普遍支持一百二十八 k 到一兆左右的有效上下文。通过优化的位置编码、滑动窗口、注意力、分块注意力等技术, 大幅缓解了长上下文的中间遗忘问题。但复杂的项目设计以及每天重复的工作会突破这个百万级。对话使用的时间越长,越容易出现数据遗忘以及 放大模型幻觉的问题。请大家放心,我们今天讲的所有调用代码都是固定模板、复制、粘贴、修改三个地方,基本上就可以直接运行,不用自己编辑复杂代码, 基础也可以轻松上手。讲完了基础概念和核心价值,接下来我们就进行今天的实操部分,在讲模板之前,我们需要先做两个前置准备条件,第一步是获取我们的专属 api 接口密钥,第二个是安装所需要的工具库。首先我们先讲 第一步的操作, api 接口密钥就相当于你给人工智能打电话的专属号码和通话权限,有了它你的代码才能找到对应的人工智能模型,和它对话步骤非常简单,首先我们打开火山引擎官方网站,用你的抖音或者是豆包账号进行登录,登录之后我们往下翻, 点击豆包大模型,进入我们的这个豆包大模型的页面,这里有个控制台,点击控制台控制台之后进入模型广场,这里就能看到很多我们可以使用的模型,可以根据大家的需求 选择你想用的模型,然后我们点击开通管理,从这里我们可以看到我有很多的模型可以使用,并且他是给了每一个模型免费的推理额度,大家用来学习是完全没有问题的, 然后选择自己想用的模型进行开通即可。然后我这里开通的是一点八的这个版本,开通完成之后可以从 api 接口这里看到我们的专属 api, 这里它会给我们提供 api 的 调用率, 我们可以从这个完整电路指南里面看到官方给我们的操作方式和步骤。通过前几节课的学习,我们是不是看到这些东西之后 已经不是那么陌生了,它的这些调用接口的方式可以大体理解它是如何运行的。接下来进行我们的第二个前置调节安装 sdk, 官方跟我们说了调用它们的模型需要安装什么样的 sdk, 所以 我们就把这个安装命令 直接放到 pycharm 终端里面进行安装即可。接下来进行我们基础模板的讲解, 整套模板包含了七个部分,这里给大家简单讲解一下。首先固定的部分还是导入我们的工具库,呃,因为我们这里调用的是豆包的大模型,所以我们这里导入的就是他们官方给的工具库。第一步 就是出示化我们的客户端,这里就可以直接把我们所获取的那这个 k 直接复制粘贴到这个位置上就可以了,这个地址是固定的,然后我们只需要修改这里的 k。 第二个就是我们的模型名,模型名这里一定要 跟我们接口的这个 key 是 一一对应的,这里不要写错了,如果写错了,你会发现它会报我们的数据接口无法调用之类的错误。第三个是需求指指令,这里需要单独讲解一下,大家看这里我写的内容是, 你是一个专业的用户评价分析助手,帮我完成以下工作,这些工作的需求是我给他写上去的。我相信大家在最近了解人工智能的时候,经常会听到一个词, agent, 也就是智能体, 这里我所写的这个内容就是所谓的智能体,我们可以根据自己的需求进行定制,让它完成什么样的内容。接下来我们再看第四部分,待处理数据,把这个地方备注写错了,这个地方我为了让大家方便 直观的看到它的处理后的结果,所以我就直接写了四条用户评价,如果我们的需求是想要读取本地的文件数据, 我们就可以用另一个模板进行。前面这个地方是一样,导入我们上节课讲到的这个工具库,我们需要把读取文件的这段代码 放到前面来,把文件路径这里修改成具体路径就可以运行。然后第三步才是自定义我们的需求指令输出完的结果,我们只需要在最后的位置把文件路径改成我们想要保存的那个具体的文件路径即可。 跟上一节课讲的那个模板是不是也很像?然后这里我是为了让大家更直观更方便的看到它的运行结果,所以这里我是单独写的。 然后接下来我们就来看第五个部分,要用接口,这里我不多介绍。然后第六个部分让他进行打印,输出我们的结果,我们可以要求最后打印出来的结构是什么样子的, 根据自己的需求进行调整就可以了。第七部分就是打印结果,可以看到大模型处理完之后,它的结果是什么?讲完基础模板之后给大家运行看一下, 大家可以看到了,因为我们的要求是筛选出用户评论里的所有负面评论,并且每条都要总结评论的核心问题, 所以他把第二条负面评价和第三条负面评价提取出来,并给了核心问题的结论,这个结构就是我们第六部分所要求的这个结构大家完全可以根据自己的需求进行调整。给大家讲解完了基础模板之后,再给大家运行一下 读取本地文件的模板,我们把文件地址复制一下,把我们的文件路径这里换成我们 具体的路径。保存路径这里,我希望它最后生成的是 ai 分 析结果的文件,我这里写的是 tst 文件格式,最终它会在这个目录下新建一个 ai 分 析结果的 tst 文件,然后运行给大家看一下效果, ok, 它显示把所有的问题都提取出来了,也保存到这个路径下,我们看一下这个路径下的内容, 好,这里生成了这个文件,并且他也把数据生成到文件里面了。讲完了整个模板,我再跟大家强调几个实操中最容易踩坑的注意事项,因为都是我自己实操出来的经验结果,跟大家分享一下。 第一,一定要保管好你的这个 a p i 的 密钥,绝对不能泄露。这个密钥就像你的银行卡密码,别人拿到了就可以用你的额度去调用数据接口产生费用。所以绝对不能把密钥发到公共的场合里面,也不要写在发给别人代码里面, 自己一定要保存好,如果不小心泄露了,一定要立刻去平台里把这个密钥删除,创建一个新的。第二个点是注意需求指令的清晰性,不管是网页端还是客户端 写的提示词。第三个部分,需求指令,这里就是你给人工智能下达的指令,指令越清晰越具体,这个智能体返回的结果就越符合你的预期。不要只说帮我分析一下数据,要告诉大模型你是什么角色,要完成什么任务,遵守什么规则,用什么格式输出, 这和我们平时在大模型里面写提示词逻辑完全是一样的,这就是为什么有些人做出来的 智能体,也就是 a 帧的好用,而有些人写出来的智能体并不好用。第三个部分是控制单次输入的数据量,避免报错。大模型的数据接口 单次能接收的内容长度是有限的,也就是我们常说的上下文窗口。如果你有几万条数据,不要一次性全部传进去,可以进行分批处理,比如一次传一百条,一千条,然后让它进行 循环处理,这样就不会报错,速度也会快,会教大家分批处理的模板。第四个,遇到报错不要慌, 先排查四个核心地方,我们的数据密钥是不是填错了,或者没有开通对应的模型权限。最常见的会报错四零幺工具库有没有成功安装,如果报错没有这个模块,或者是没有找到什么东西,可能是这里的问题。 文件路径写错了,或者是字断联,或文件里的表头不一致,也会容易报错。网络不稳定,一般超时了他都会提示你啊,报送超时或者是连接失效之类的错误。模型名,模型端点 如果写错了,或者是提取结果的方式不对,他会报错。四零四四个报错是比较经常遇到的一些问题,这里我想再跟大家分享一下。我们学这个调用的模板,不是为了告诉大家如何去写它,而是为了告诉大家如何能解决实际问题。 后续大家在工作中遇到不同的需求,只要记住核心逻辑,我们用数据接口搭建代码,与人工智能大模型之间建立桥梁,把需求和数据传给人工智能, 在接受人工智能返回的处理结果,哪怕没有现成的代码模板,我们也可以让大模型帮我们生成相对应的调用代码,这就是我们学清代码思维的真正价值。接下来我们回顾一下我们今天重点学习的四个核心内容。 第一个是到底什么是 api 与请求数据接口,就是你和人工智能大模型之间的传菜窗口专属电话线, 你给人工智能发送需求叫做请求,人工智能给你回应结果叫做响应,不需要懂原理,会用就行。第二个代码对用 api 接口的核心价值是批量处理、自动化、定制化,真正帮你从重复的劳动力解放出来,解决客户端、网页端无法满足不同的职场需求。 三个内容是调用人工智能的固定代码模板,核心代码模板不变,只需要修改三个地方就能直接运行。重点修改四个核心点,替换库、替换接口、替换模型名、替换 结果提取方式,解决了之前的报错问题。进阶模板,也就是读取文件数据和前三节课内容基本完成了闭环。第四个内容是 a p i 接口调用的闭坑注意事项,密要保密,指令清晰,控制数据量,遇到报错先排查五个核心问题。整个课程的 核心转折点,从这节课开始,我们才算真正把新代码思维和大模型的能力结合起来了。前三节课都是我们所做的准备,把清洗干净的数据标准化交给人工智能大模型, 让大模型帮我们完成专业的分析处理工作。今天你成功运行的调用代码,就意味着你已经掌握了项目核心的能力。下一节课我们就在进阶一步,代码与大模型的结合进行批量任务自动化,我们用代码 批量处理成百上千条数据,自动完成重复的工作,真正实现一次写好永久使用,还是固定的模板,还是使用 pychum 进行操作。今天的这节课我们就讲到这里。
34权小白