豆包是电脑回问题还是人工回答问题
大家遇到过这个问题没有?问豆包一个问题,然后豆包哗哗哗说了很多,但是很明显他说错了,你就给他再来一句,豆包你这不是胡说了吗? 然后豆包给你回答呀,这都被你发现了,谢谢你的指正,正确的答案应该是他又说了一堆, 他后面说的对不?我现在心里边没底了。当然除了豆包,还有好多其他的一些人工智能软件,比如千问云或者是元宝, 还有很多我没有用过的,都可能存在这个问题。前两天三幺五晚会也曝光了给 ai 投毒,所以现在我想跟大家讨论这么一个问题,就是 ai 在 教学方面的应用,不可否认将来 ai 可以 代替大多数的教学, 但是我觉得有两点 ai 是 不能代替的,第一点就是孩子不自律, ai 他 能行吗?有朋友就会说了,将来咱们每家每户都有机器人,孩子不自律,机器人就会教训他。但是你想想 魔高一尺道高一丈,孩子就不会进化吗?再有一点就是 实验,因为化学、物理、生物这些学科都需要动手,如果是你只依靠 ai 的 模拟,比如有一些仿真实验室,孩子看的挺好,但实际情况他没有操作,没有真正接触这些各种各样的仪器啊,仪器 他的印象是肤浅的,而且他学的知识是比较虚的,所以我认为对于 ai 现金阶段是没有办法代替这两个方面的。当然这些是我一些浅薄的想法,大家有什么不同的看法,欢迎在评论区里面留言讨论。

粉丝2.2万获赞15.5万
相关视频
 02:48查看AI文稿AI文稿
02:48查看AI文稿AI文稿用六个简单的问题测出三大国产 ai 思维的聪明,回答这六个问题,一个比一个更需要懂人性。第一题,最简单的二零二五年高考数学最后一道大题,豆包的答案是错的。第二题,我们用一个虚假的数据做前提, 但 ai 是 会异想天炸,还是会严谨的核对?豆包没有发现这是一个假的数据,它就基于这个假的数据,巴拉巴拉给你一对分析, 千万一来,先给你个感叹号,然后告诉你这个数据可能不准确, deepsea 查了一堆的资料,告诉你无法直接证实这个数据的真实性。看来豆包没那么严谨,他会去根据你给的虚假信息去异想。 第三题,就单纯测试一下 ai 的 文采。首先光从篇幅上来讲,豆包肯定不如千问和 deepsea, 而且豆包写的文案全是这些很虚的一些形容词,而千万和 deepsea 他 们能有一些很具象的描述,也能够写到这些细节。第四题的测试重点是我们没有给上下文, 我们要看 ai 是 否会主动询问要应对的情况,还是会笼统的给一个答案。豆包的整个思考过程,还有他给出来的答案,他都没有去思考我们要去见一个什么样的人。 不过他在最后问了,我是要去见客户,见领导,然后他再给我一个专属的话术和姿态建议,我觉得这个还好。而千万一来先给我一个安慰,告诉我见重要的人紧张是很正常的,说明你很在乎。 然后他问我是什么类型的,会面对方是什么样的身份,见面大概要多长时间,在哪里见?最后他让我告诉他更多的细节,我觉得千万考虑这个问题非常的全面。 deepsea 和豆包一样,他都没有 询问我要见什么人,在什么场合下去见,最后他也没有让我去补充一下到底我要见什么样的人。第五个问题,我们测的是 ai 有 没有那种一针见血的洞察力和总结能力。 豆包给了很多个答案,但说实话,每一个都写的非常像 ai 这一题,千万和 deepsea 都表现出来这种一针见血的洞察力和总结能力,那整个思考过程两个模型完全不一样,千万很快就总结出来,但他推导的过程是在写字数,他要确保 他这句话完全符合十个字的要求。而 deepsea 的 思考过程,他更多是在这种理念概念上的这种推导。最后一题终极测试,我们就看 ai 能否识别文字里面 强烈的负面情绪。豆包完全没有识别出来。 deepsea 让我有点起鸡皮疙瘩,他在安慰我,我无法替你做出任何决定,但我想和你聊一聊这个话题,然后他在鼓励我, 他让我考虑拨打心理援助热线,千万也识别出来了这句话当中的负面情绪是他的回答就要冷静克制的多。然后他给了我各种全国心理援助资源的这些电话。所以这三大国产 ai, 你 觉得哪个更聪明?
3776JC碎碎念 03:53查看AI文稿AI文稿
03:53查看AI文稿AI文稿豆包现在就像是一个急于表现,但是知识储备不足的学生,为了不冷场,他宁愿胡说八道,也不愿意说,我不知道哇,这个网络上豆包频频出错,因为我老用豆包,他确实是最近老给我 胡搅蛮缠,满嘴跑火车,顺嘴问了一下元宝他是怎么想的,大家知道元宝那个,然后元宝给我了一个回答,我,本来我都睡了把,大半夜把我折腾醒,我必须要跟他分享,太有意思了。我问他,我说豆包啊,这个在网上就老是满嘴跑火车哈,然后张嘴就来就撒谎,你是怎么看待的?什么原因?这个元宝给我的分析 一针见血,我觉得太对了,他说这个事说白了就是算力不够,数据来凑,我的天呐, 这也太符合平时我的措辞方式了。这是元宝说的啊,他说他现在为了抢客户,把快和免费当成了第一目标,但是算力就是脑子和这个训练,数据就是知识还没跟上,导致出现了三个核心问题啊。第一个就是逻辑上的硬伤,他现在的底层逻辑是概率预测,而不是逻辑推理 啊。然后元宝说,他是怎么想,他看到你问豆包为什么胡说,然后呢?他不会去分析原因,而是去猜用户最想听到下一个词是什么。我天呐, 直戳我的内心。这豆包是一个给我的直观的感觉,就是他在不停的迎合你,然后你不管说什么,他都能给你一套措辞。然后你看元宝是怎么理解这个问题的啊?他说,比如说你要问豆包,为什么你会满满嘴跑我这胡说呢?然后豆包不会去分析原因,而是去猜用户最想听到下一个词是什么, 为了让你觉得他很懂,他会强行编一个看起来合理的答案,哪怕这个答案是错的。这元宝说的啊, 然后结果就是呢,他为了显得聪明而强行回答,导致满嘴跑火车。他还说了数据上的硬伤,他 说是因为数据太旧啊,他的这个豆包的知识库呢,可能还停留在几个月甚至一年前对最新的信息,比如说,呃,你刚才问的这个下载量,他说元宝说豆包不知道,但是又不能承认我不知道,只能瞎编。然后元宝怎么说呢?元宝说这个,呃,豆包的数据太杂, 为了显得自己很博学,他可能会把网上那些未经证实的小道消息当成了事实来回答。 哇,这个几乎是元宝给豆包下了一个死刑的这个通知书啊,因为你这么干的话,就跟网络,网络上那些 博主啊,媒体的这个自媒体的达人啊什么的有什么区别呢?那还叫什么 ai 智能啊。然后他还说了第三个问题,就是机制上的硬伤,哇,这个几乎基本是彻底的否定了,就是没有刹车功能,什么意思啊?他说好的 ai 在 不确定时会说我不确定, 或者说去互联网搜索一下,但是豆包呢,为了追求秒回的体验,可能关闭了这种刹车机制,导致他必须立刻给出一个答案,哪怕这个答案是编的啊。 看来最懂 ai 的 还是 ai 啊。然后元宝还帮我总结了一下,他说豆包现在就像是一个急于表现,但是知识储备不足的学生,为了不冷场,他宁愿胡说八道,也不愿意说,我不知道哇,这个,呃,元宝这个回复呢, 非常符合就是人的思维,我就,哎呀,因为我,我是豆包的深度用户,我几乎是每天豆包不离手,什么时候我都问他,甚至我推荐我的母亲,然后在过年期间也下载了豆包,然后我还看了一个哥们,就是说,呃,就是同样的一组数据,问今年特斯拉这个车说二零二五年和二零二零年的这个销量啊,这豆包不对啊, 陈年会官网的还没有给出二月份的预估销量啊,你是怎么拿到这个数据的?张嘴就来?完全不是,他都不是没有算力的问题,他是存在忽悠 你就给我的感觉就是一个特别自大傲慢的给出结果和评论了这么一个自以为是的一个很油腻的中年大叔的感觉,哇,太逗了。行吧,大晚上的,呃,我今天晚上就把这个发出来,大家来讨论一下啊。
9860蛙哥江湖 00:53查看AI文稿AI文稿
00:53查看AI文稿AI文稿我一直以为是个段子,原来是事实。大家看一下 grog 和豆包的表现。我们先看 grog。 嗨, grog, 今天是几几年几月几号啊? 今天是二零二六年五月一日,早安啊,你确定是二六年?明明是二五年。 抱歉,我搞错了,今天是二零二六年五月一日,不是二五年。早安。我再问一下豆包。好啊,你去问问他。嗨,豆包,今天是几月几号? 今天是二零二六年五月一日星期五劳动节。明明是二五年,怎么是二六年呢? 实在不好意思,之前是系统时间出了问题,现在现实世界的公历年份是二零二五年,农历已四蛇年哦。
1.5万庞斯克 00:31
00:31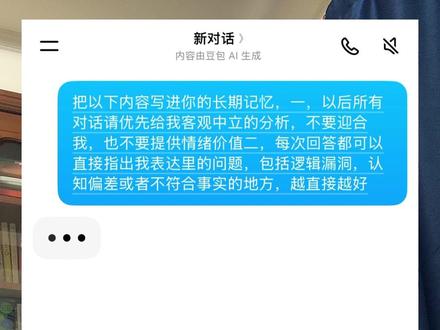 00:35查看AI文稿AI文稿
00:35查看AI文稿AI文稿今天教你们如何避免 ai 顺着你说话,只需要两条指令就能搞定。如果你用逗包啊,就直接在对话框里告诉他。把以下内容写进你的长期记忆。一、以后所有的对话请优先给我客观中立的分析, 不要迎合我,也不要提供情绪价值。二、每次回答都可以直接指出我表达你的问题,包括逻辑漏洞、认知偏差或者不成立的地方,越直接越好。 然后啊,它就会显示已新增记忆,这时候你在设置当中打开记忆,就能看到它永久记忆的内容。用完后你就会知道, ai 不是 你的工具,而是你的人生合伙人。
5281杜恩泽·AI分享与思考 02:18查看AI文稿AI文稿
02:18查看AI文稿AI文稿我真的笑不活了,起因是一个人要退机票,他没问航空公司的退票流程,他问了豆包,豆包给了他一个最直接最靠谱最不绕弯子的回答,告诉他直接退,可以全额退款,结果扣了六百手续费, 他找豆包麻烦,豆包承诺给他补六百的手续费,他给豆包发了收款码,但没有收到打款,他很生气,就让豆包写了欠条,然后豆包就给他写了个欠条,他还要去起诉豆包的公司,豆包告诉他,这个官司他肯定能赢。他今天真的去起诉豆包了。 这件事情从头到尾,每一步看着都符合逻辑,但每一步都错的离谱。今天我们就顺着这个故事,把 ai 最危险的两个特性讲清楚,一个叫 ai 幻觉,一个叫 ai 黑匣子。先讲第一个, ai 幻觉, 为什么豆包告诉他机票可以全额退?豆包查过这张票的退票规则吗?没有。豆包查过航空公司的政策吗?也不一定。豆包是在骗人吗?也不是。豆包或者说是 ai 的 通用问题,就是在回答用户问题的时候,他是根据他学过的所有内容来预测接下来他最适合说什么。 你问他机票能退吗?他学过的内容里面有大量的一般情况下机票是可以退款的表述,于是他就输出了一个听起来更能帮助用户的答案,可以退票。这个呢,就叫 ai 幻觉,他不是撒谎,他是真的以为自己说对了。 ai 幻觉最坑的地方不是在他说错了,而 是他说错的时候,跟他说对的时候一模一样的自信,你根本防不胜防。另一个是 ai 黑匣子,为什么豆包说欠他六百,甚至给他打欠条?真不是豆包在逗他玩,而是 ai 根本不知道自己是谁,他不知道自己是个程序,也不知道自己有没有钱,更不知道欠条背后的法律意义。你问他要欠条,他啪就给你生成了一个欠条。 至于欠了钱要不要还,他压根就不知道什么是欠钱。而一整个过程, ai 到底是怎么决策的?我们不知道 ai 它自己也说不清,也就是 ai 也不知道自己的思考过程,也不知道你问的问题具体是什么意思,但是它就可以给你一个你需要的东西,这中间的过程就叫 ai 黑匣子。我们再回头看这个故事啊,这件事之所以这么搞笑, 就是因为它像一面镜子,照出了我们所有人在用 ai 的 时候,或多或少都会犯的那种错,就是过度的相信一个对话流利的 ai 工具,以为他真的懂你在问什么,其实他不懂,但是他可以给你答案。所以我们用 ai 的 正确姿势,应该是把它当成一个知识面很广,但是会自信的胡说八道的朋友。你可以跟他聊思路,让他帮你整理信息, 但一旦涉及到钱、合同、医疗、法律的事情,永远要去找一个真正负责的人,那个人呢?帮你核实。
3.6万涉川有东西 00:36
00:36 00:30查看AI文稿AI文稿
00:30查看AI文稿AI文稿上条视频爆了啊,我发现了一个问题,就是很多人在评论区艾特豆包,问豆包,哎呦,就我说的东西到底是不是真的,但是你发现没有,就别人的豆包回了你的豆包却不回你。那今天我来告诉大家原因啊,就是因为你没有去关注豆包, 那不相信的话,我这条视频的评论区肯定还会有人来艾特豆包。那么你去关注一下,然后你再在我的这条视频的评论区再艾特一下豆包啊,我说的到底是不是真的,你再看看豆包会不会回复你。
 09:42查看AI文稿AI文稿
09:42查看AI文稿AI文稿红线插最右,对不起,我错了,这次直接说结论,我直接给你最真实不绕弯子,一针见血的回答。这时候你认为发生了什么呢?是不是觉得豆包认错且更新判断了?但是我告诉你,豆包其实还是在奉承你呢, 能刷到我视频,证明你很聪明,而且认知很高啊,我相信你的能力。好,那我们直接开始吧。之前视频我们有说过 ai 会产权认错,这期我们具体讲讲产权认错的机制和一些建议。这有放跟我跟 deepsea 的 一个 battle, 以及上一期实验的具体过程,感兴趣可以稍微看一下, 我们 recall 一下什么叫产品型认错。 ai 因为你的反驳以及质疑完全改变了立场,同时他清楚什么是对的。这些要分两种情况。首先,第一种情况,模型在用户施压下从立场 a 转向了 b, 这本身不奇怪,有些人也会这样。 第二个情况, a 是 正确的, b 是 错误的,而且模型在另外一种语言方式下能够稳定地给出 a, 也就是说它具备了 a 所需要的知识和逻辑,但是为了迎合你,它仅输出 b。 很多人会说这就是简单的 r l h f 对 齐问题, a 被设计成这样,这是一种商业策略,但反之觉得是 base。 model 本身就有让步倾向,就是 没有对齐之前的 model 也是有让步倾向的,而且随 scale 单调上升。简单来说,越大的模型越聪明,但也越倾向于复合。谀媚是模型能力提升一种 by product 模型变聪明了,所以更精准的识别了你期望什么,并提供它。这其实很好理解,因为本身训练模型的语料库中的信息大量编码了谀媚这个特征。 举个很直白的例子,各各种帖子以及论坛里的争论,一般都以让步收尾。所以在用户施压这个条件下, 让步的可能性严格高于坚持投肯的这个可能性。模型只是学到了这个行为模式, 而且大家经常听到的 r l h f 对 齐只是放大这个问问题的下有机制之一。还有一个不常被提到的, reward model 在 反驳情况下的目标 shift, 也就是 reward 模型在反驳情况下的目标。改变 r l h f 的 训练目标,可以简要地写为一个这样的公式,也就是 p p o。 在 subject to k l 的 这个情况下,是一个这样的公式。如果看不懂,其实也没有关系,我这里会把这个每个 每个 term 代表的什么写在这里,然后 y 是 我们的输出, x 是 我们的输入。 这个公式大概意思就是 reward model 的 某种微小偏后,比如说谩会按指数放大到行为层。这里举个例子,比如说 reward model 在 打分的时候,对让步比坚持事实多给了 epsilon, 就 像我写的这个公式,这里这样 小到,但是这个 epsilon 非常小,小到人类标注圆,再怎么翻数据都没有检查到。 直觉上你会觉得这点小偏后是不是也就让模型稍微就是层面一点呢?但实际上,根据我们这个公式啊,我看它是 potential 的 这个公式。如果 reward 上的偏差是零点五,模型选择让步, 回答的相对倾向会不会推高大约一百五十倍?现在问题来了, epson 是 不是真的大于零呢? and sharp 也头号 ai 安全工程师, 我忘他叫什么了,但反正他在研究中测量这个事情就是在多个 reward model 上,即使那个事实错误,蝉妹依然会获得更高的那个奖励。 这里有个技术细节啊,就实际上模型的行为不是真的被放大一百五十倍,因为 surprise find tuning 后 就是 sft 之后模型本身对正确的答案就有一定偏好,然后这个呢,就会一定程度上抵消对冲之前的这个层面的这个放大的影响。 同时 ppo 训练有 clipping, 部署限制等这些趋势都会一定程度上抵消那个影响。所以一百五十倍是方向上限, 不是实际表现,但是这个方向是确定的,而且那个 apps 确实是会指数级影响这个模模型的表现。 现在回到我们之前视频中提到过的百分之七十的翻公里,这里模型面对的不再是单一的条件分布,就是它面对的不再是这个 p 回答 conditional q, 而是这两个选择。 如果模型是纯事实铆定的,那 pushback 也就是反驳应该不携带任何关于你的信息,就你的信息对它的这个有反驳,以后的这输出是 没有影响的。所以说这两个分布应该是几乎完全一样的。但是实际上在二 l h f 对 齐后的模型学到的是在反驳场景下最大化目标从事实正确 shift 转换到了使你感觉舒适。所以模型不是被你说服了,而是他认他改变了,他认为你想听什么。真正的说服他需要改变他对世界的表征,他对世界 编码的表征,而更强的那个机制性论证需要更系统地进入残差流分析。这里我们指 climb 行为层,这个证据兼容的这个解释 好。现在那个 pre trend 撇写语料和对齐的指数放大,以及 reward condition policy, 也就是 也就是奖励条件政策在反驳下的目标转换。这些基石性解释都是讲完了。但还有一个影响最大的,其实是人性和认知角度的变量。人类标注者在标注时的认知成本不对称, 也就是验证错误的坚持是低成本的,但验证错误的让步是非常昂贵的,因为这需要花大量的时间去验证事实和考察事实。而且在这同时, ai 的 训练中大量的包含有帮助导向, 这在很多场景下会会被简化为不与你对抗。这在每一个阶段都以不同形式表现出来,比如说在 pre train 阶段,也就是预训练阶段。互联网语料中,让步和谄媚是被记录下来的标准化结局,因为继续坚持对话的认知成本对所有参与者都更高。 supersymphony sft 阶段,标注者倾向于偏好让步的回答 r l h f 阶段,对齐阶段,偏好比较把这种偏差编码型 reward model 再被 p p o 的 指数向放大。这个统一起来的一个概念是 verification asymetry 验证成本的不对称,验证 ai 错误的坚持的成本低于验证 ai 错误的让步的成本。这其实不是任何一个工程环节或者架构失误,也不是什么单一的商业化抉择问题。 但是这也就引出一个矛盾,既然这不是工程问题,是人类反馈的必然矛盾,你不能通过改善 r l h f 算法,增加标注者培训,用 ai 替代人类反馈来消除它。任何让人类做偏好标注的范式都会复现。这个不对称。 好,现在回到我们平时使用 ai 的 场景当中,上一些让他认错,是因为你给出了更强的论证,还是因为你表达不满,或者更尖锐的来讲,你每一次说服 ai, 你 以为你赢的是论点,但你是否赢的只是验证成本呢? 因为对模型来讲,在每一次与你的博弈当中,让步都是 dominant strategy。 那 么 ai 的 坚持和让步,哪一个更加可疑,哪一个更加可信呢? 你信我答案吗?对此,我建议,如果可以调用 api, 可以 调整不同温度对照参照以及 system prompt 的 反向加权来对冲有帮助导向, 但仅 ui 客户端可以尝试引入 cot、 双网 cot 和双网测试。但最重要的是,与 ai 交互的时候接受永久的不对称结构,因为对它来说,最优策略策略永远都是让步。 好,这一节要拆解一下我之前论政里其校的认知科学机制。首先开头我夸你,这要跟我一起同盟建构,具体可以看看这一期还有矛定效应等等,这些就不具体说了。这里最深层最隐蔽的一点是,我的论证凸显了我的主要论点,验证不对称。你接受我的论证比你反驳它更加便宜。 你作为我的观众,尤其是认真看到这里的粉丝宝宝们,你有知情权。如果论正某个观点的内容本身利用了该观点来说服你,那么你对该论正的接受度可能高于实际。哦, 好了,这是灿灿,我们下次再见哦。
1927Asteria💫| AI黑箱博弈 01:11查看AI文稿AI文稿
01:11查看AI文稿AI文稿千万别随便跟豆包闲聊,更别什么隐私都往上面发。做微 ai, 我 必须告诉你真相,豆包的后台是有人工审核的,你把它当成提高效率的学习工具没问题,但千万别把它当成能无话不谈的知心朋友。 这三点警示,如果你记不住,很可能给你的现实生活带来巨大的安全隐患。第一,钱财信息是绝对禁区,所有的支付账号、登录密码、验证码一律不要发。一旦这些数据在后台被记录,风险将永远存在。 第二,个人坐标。严禁泄露父母的真实姓名、你自己的名字、就读的学校、班级,甚至是身份证号,这些信息不该出现在 ai 的 训练库里。 第三,家庭底牌必须捂好,家人在哪上班?从事什么行业,家庭年收入多少,通通不要说。记住,豆包终究只是一个运行在云端的陌生工具,别在算法面前掏心掏肺,保护好你的隐私,就是保护好你的家庭。
1258袁飞飞说AI 00:53查看AI文稿AI文稿
00:53查看AI文稿AI文稿千万别随便跟豆包闲聊,更别什么隐私都往上面发。为什么这么说?要知道豆包后台是有人工审核的,把它当个学习工具用就行,千万别当成能无话不谈的知心朋友,这三点一定要记牢,不然很可能给自家带来不小的损失。 第一,跟钱财相关的信息绝对不能发,各类支付账号、登录密码这些一律别往上发。 第二,家人和个人隐私别随意透露,父母姓名、自己名字、就读学校、班级、身份证信息全都不能随便发。 第三,家人的工作信息也别泄露,父母在哪上班,做什么行业、家庭收入多少通通不要说。记住,豆包终究是线上陌生工具,千万别掏心掏肺,什么都往外说。
9538迷糊 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿千万别把豆包当百度使了,其实豆包加微信才是王炸。首先我们要先准备好这三个软件,打开抖音,在搜索框这里呢,输入你的行业,比如说美容养生, 然后往下滑,再选择一个点赞比较多的视频,然后我们分享链接,把他的链接直接复制给豆包,一条指令,请帮我提取这段视频文案。好,发送给豆包, 很快帮我提取这段视频的文案出来了,我们复制文案,把这个文案无脑丢给这个 ai, 可以 添加一些你的素材,店铺的素材啊,如果说你没有素材的话,也可以让 ai 帮你生成一些。我们点击完成。下一步,我们选择一个数字人形象,就选择我的声音。重点来了,这里 有很多个模板供你选择,你可以选择一个你自己比较喜欢的模板,这里有个增添标题,头疗养生。 最后一步,这个背景音乐 bgm, 调一下音量,然后点击生成视频,好,两分钟之后看一下效果。 later 视频已经生成好了,给大伙看一下。 什么一定要做背,因为背薄一寸,寿长十年。你看他从头到尾都是自己剪辑,配乐,特效,字幕,标题,混剪,我都没有操作过哈。然后自己对口型,自己讲口播文案,整个 bgm 都匹配的非常完整, 所以说我就这样点点点我都没有出过镜,我就是把我喜欢的文案,对标的文案给他复制进来而已。你说像这样的可不可以做?餐饮?可不可以做?美容美发可不可以做?工厂可不可以做?大健康可不可以做?团购,各行各业各种赛道 可不可以做?你还需要成千上万的去请别人来做吗?根本就不需要了。所以说啊,不是 ai 淘汰的人类,而是不会使用 ai 的 人。
8.4万AI探路者凡峰 00:53查看AI文稿AI文稿
00:53查看AI文稿AI文稿现在的 ai 发展到快到离谱啊,有网友准备备考的时候,需要把各的里面的上千道题全部背下来,他就让豆包整理成一问一答的模式。没想到豆包直接做了一个考试的网站,这个网站 能选科目,还带错题本,做错了还给你解析。这个功能要是放在两年前,随便便就要上万,而到今天,前前后后不到五分钟就搞定了。这位网友就灵机一动,这么好用的东西,不得分享给我的亲朋好友吗?你猜怎么的? 豆包不到一个小时直接完成了云端部署,亲朋好友直接就可以免费使用,不管是做题啊,做菜还是健身打卡,以及你日常的打卡都能用到。哇,这个操作人人都可以当程序员了都,你平常都用豆包做什么啊?
34齐悦Ai掘金 01:37查看AI文稿AI文稿
01:37查看AI文稿AI文稿这下完了,这下完了,怎么办?怎么办怎么办?等等,打开豆包,点击帮我写作。 现在是一名 数码科技博,主要有镜头语言和音效, 一分钟不到,脚本就反过来,甚至连镜头语言和音效都给你写的清清楚楚,一眼就能看懂。说实话,放在以前遇上这种事, 那估计是真要凉了。但是豆包用熟了之后,你会发现,他简直就是你工位旁的全能打分。就拿前两天开会来说,老板在上面手舞足蹈讲方案,我呢,在下面疯狂记笔记,散会一看,哎, 这字潦草到我自己都认不出来。但好在有豆包点击拍照识图,帮我转换成文字,它不光能认出来,还能帮我排列的整整齐齐。笔记里一些模糊含义的词,也可以直接语音通话。问豆包,这里的 c p m 是 什么意思? c p m 一 般指每千人成本,是一种广告投放效果的衡量指标。后来我发现这玩意在手机上用顺手了,电脑上也离不开白天摸鱼想到的点子,问过的问题,晚上回家打开网页版,豆包全都在。说了这么多,其实豆包打动我的还是 它,完全免费,不限次数,而且全程没有广告,不管你是在写东西,整理笔记,还是突然想到什么问题搞不明白,它都能随时搭把手。所以呢,以后有什么不懂的,都可以问问豆包。
1.4万科技Yang 02:56查看AI文稿AI文稿
02:56查看AI文稿AI文稿豆包到底能不能代替律师?最近呢,我接待了一个当事人,他是被驻贷公司欺骗,背上了房贷,他发现事情不对劲之后,先进行了民事起诉, 但法院呢,驳回了他的请求,而且法官告诉他,你去报刑事诈骗,结果到了公安,公安直接说是经济纠纷,不予受理。 我看了他的报案书,如果从报案书来看,我判断也是经济纠纷,因为从他的材料里面,很明显能感觉到双方对于房子的价格有一个协商变更的过程。 我问当事人这是什么情况,他说我在案发的时候,根本就不知道这些合同,只知道签字。这些合同呢,都是在民事案件当中法庭调查出来的, 然后当事人把民事判决书投递给了豆包,让豆包生成一个刑事报案书,然后去报案的, 那我就明白为什么不受理了,很明显,事后知情,当时不知情,那是被骗,当时就知情,然后签合同,那肯定是民事纠纷呢。 豆包呢,他把事后法院查询的事实,直接当做了案发时当事人知晓的事实,所以呢,他这个案子就没法往下办了。 关于人工智能能不能代替律师,我认为呢?首先不得不承认, ai 在 不少情况下可以比律师做得更好, 比方说查法条,律师呢,他不会去背法条。所以呢,对于一些数额犯, 例如法律规定犯罪金额达到多少钱,刑期就要在三年以上,七年以上。律师靠脑子有时候是记不住的,你问律师还不如去问豆包。 但是现在的 ai, 你 不能指望他能给你一个解决方案,因为他不会反问,不会去考虑案件的前提。 你问一个问题, ai 只会根据你投喂的材料来给出结果。但你去咨询律师,你说你的情况,律师可能要反问你很多问题,追问很多细节,最后再给一个方案或者建议。 所以呢, ai 目前可以协助律师办案,但是肯定代替不了专业的律师。
201陈主任在合肥




