sigrelu激活函数图像

粉丝8693获赞2.6万
相关视频
 06:54查看AI文稿AI文稿
06:54查看AI文稿AI文稿大家好,今天我们继续神经网络的讨论。在上期节目中,我们介绍了神经网络的运作激励数据是如何在神经网络模型中正向流经输入层、隐藏层、输出层 得到预测结果。然后在训练中通过逆向传播 back publication 方法对参数进行调整,从而提高模型准确率。在这个过程中,隐藏层输出层的神经元通过激活函数 activation function 将输入端的加权盒转化成神经元的输出值。今天就让我们深入该话题,了解不同类型的计划函数,他们各自的利弊和使用场景。 首先,为什么要使用激活函数呢?我用下面的简单例子进行说明。该模型有单书物质、单 隐藏层、隐藏层、双神经元、单输出值。在没有激活函数的作用下,无论我们怎么调整权重和偏差,其输出值人为限行加入更多的隐藏层本质上也是一样的。 考虑到真实世界的大多数系统是非线性的,如果要模拟复杂的系统,则必须借助非线性的激活函数了。 现在我们使用上期的 simoi 函数,通过调整权重和偏差值,我们就可以模拟非线性的复杂系统。另外,根据通用近似定理, universal approximation steering, 神经网络中至少需要一层隐藏层和足够的神经元,利用非线性的激活函数便可以模拟任何复杂的连续函数。了解了激活函数的必要性后, 现在我们来看看几乎函数的选择。上期节目中使用的 sigmoy 函数,他有以下特点, 一、其输出值落于零到一的连续区间。二、输入值从横坐标左侧移动到右侧的过程中,其输出值呈现从平缓到加速再到平缓的特点。 三、 secamoy 函数的导数值落于零到零点二五的连续区间在神经网络模型中, sickmoy 函数其实有很大的局限性。 在逆向参数调整 back propagation 过程中,使用烈士法则 change 可以推导出下面的公式,并对深度神经网络模型的权重调整幅度进行计算。不清楚的小伙伴可以回看上期节目,其中这里的 中间部分是各层 c m a 激活函数导数的成绩。根据我们之前谈到的 c m a 函数特征的第三点多个小于零点二五的值相乘后会严重影响最终权重调整幅度。 这也就会导致在神经网络模型的训练中,第一层的初始权重之后很难通过 back propagation 再产生变化。这个问题被称为梯度消失。 venice ingredient。 另外,考虑到 sigma 函数在进行指数计算时需要消耗较多的算例资源, 因此在平时的神经网络模型中,他通常不被使用。现在我们介绍一个与 sigmoin 函数相似的激活函数 tenh, 我们对比一下两者的特征,其值落于负一到一的区间内。另外,其导数值落 于零到一区间,大于 sigmoy 零到零点二五的导数区间。因此相比 sigmoy, time h 能够相对缓解剔度消失的问题。在平时激活函数的选择上, tenh 是由于 sigmoy 函数的。 那么是否有更好的激活函数呢?在实际应用中,隐藏层的默认推荐激活函数通常为 radio rectified linear unit。 首先,它是一个非线性函数,其在大于零时展示的线性特征能够很好的解决体度消失的问题。 另外,相较前两者,他也能够带来更高效的计算。最后,根据通用近似定理,其整体的飞线性又能够在神经网络中你和任何复杂的连续函数。比如这个例子中,我们像 搭积木一样组合多个 red 六函数,你和下面的复杂函数。不过当输入值为负数时,其输出值和倒数均为零,这意味着该神经元会处于熄灭状态,且在逆向参数调整过程中不产生梯度调整值。 最后,我们介绍 real 六函数的变形题 leaky realme, 在复数区间内通过添加一个较小斜率的线性部分,使复数区域内也能够产生梯度调整值,完美解决之前的神经元熄灭问题。 以上四种激活函数在隐藏层的选择顺序为,首先考虑 radio 和 leaky radio, 然后 ten h, 最后 segmoi。 那是不是说明 ten h 和 seigmi 函数完全没有作用呢?并不是, seekmoy 和 ten h 在循环神经网络 rnn recurring neural network 及其变种模型中还是有一席之地的。这块内容我们在以后的节目中会详细介绍。隐藏层的数据最终来到了输出层,通过输出层的激活函数转化成业务要求的表达形式, 因此输出层激活函数的选择是以业务要求为导向的。我们用下面的几个简单例子来说明 一二分类问题。如果我们的目标是判断这个图片中的动物是否是猫,我们可以用 c 跟猫一函数返回是猫的概率作为最终数出值。 二、多分类问题在该类问题中,样本只能属于一种类别,当我们希望返回图片中的动物分别是猫、 狗和竹鼠的概率,我们可以使用 soft max 函数返回属于每个类别的概率,其概率总和为一。三、多标签问题, 某个样本可以同时属于多个类别,我们可以计算图片中分别出现猫、狗、竹鼠的概率,这里也可以使用 sig 末函数对每个类别的概率单独进行计算。 四、线性回归问题,当我们面临的问题是要预测绝对的数值时,比如身高、体重、 gdp、 投资额等,那么最后就可以直接使用线性函数作为激活函数。 在介绍完输出层几乎函数的选择后,我们今天的节目也要告一段落了,希望本期节目能够帮助大家更好 的梳理和理解神经网络中激活函数的知识点。下期节目中我们会使用 excel 演示如何利用我们之前两期的内容从零开始构建神经网络模型,那么下期见。
545funincode 02:13查看AI文稿AI文稿
02:13查看AI文稿AI文稿大家好,欢迎来到深度学习词典第十六课本系列视频运用简洁明了的方式介绍人工智能和深度学习的各种常用概念,非常适合零基础的新手入门, 坚持学完,相信你一定会有所收获。今天我们讨论的话题是 sigmal 的激活函数。在神经网络中,激活函数对层的输出进行非线性变换。 有一种激活函数称为 sigmoid, 将其提供的输入映射到零到一之间的一个值。对于某个值, x 传递给 sigmoid 函数, 其输出将是 e 的 x 次方,除以一加一的 x 次方。在神经网络中,我们传递的 x 是曾中某个节点在激活前的输出。通过观察 sigmoid 的图像可以发现它呈 s 型,曲线在曲线底部渐进于零,曲线顶部渐进于一。因此,对正无穷的数作为函数输入,我们得到接近一的输出。相反的,对负无穷的数作为函数输入,我们得到接近于零的输出。 当我们传入接近零的输入时,大概在负三到三之间得到零和一区间之间的某个值不一定,那么接近零或一。当 sigmoid 应用于某层时,层中的每个节点都会应用 sigmoid 函数。 以全连接层为例,当 sigmoid 用作某层的激活函数时,他接受前一层输出的加权和,并将该和转换为零到一之间的值。直观来说,我们可以认为某节点的激活输出 越接近上线一,他就越活,越类似的,他越接近零,他就越不活跃。由于 sigmoid 输出在零和一之间,结合刚刚说的直观感受,我们可以把 sigmoid 的输出看作是某节点的激活概率。 好了,恭喜小伙伴们一直坚持耐心学完这一节,欢迎留言你的建议和想法。使用深度学习词典,你将开始熟悉深度学习领域所需的所有基本概念,开启属于你自己的 ai 之路。
15人工智能学习室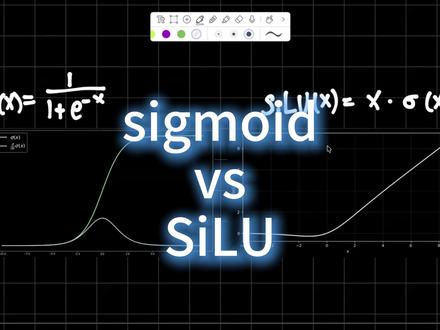 05:51查看AI文稿AI文稿
05:51查看AI文稿AI文稿今天比较 sigma 的 激活函数和 solu 激活函数,现在打个比方,假如说你是一个激活函数,有两份工作可以做,一份是门口的保安大爷,一份是公司主管手下的大厂职员。 先说保安这份工作,你站在炸炸鸡旁边,你的职责是非常简单的回答一个问题,到底这个门是开不开,放不放行,放多少? 那么你输出的就必须是一个通行的概率,范围是在零到一之间的,所以这个时候你就是需要用 sigma 的 这个激活函数。 假如说外面有个人来了,有个 x 来了,这个 x 很 大很正,那你就输出,那你就给他必必须过,然后输出一个零点九九类似的分数。 但假如说外面来的人很富,这个 x 是 很小的,那你就给他几乎不过,比如说给他一个零点零零零一这个分数, 这就是为什么二分类输出层 logit 要过一遍 sigma 的 函数,因为模型最后要的是要不要,是不是 有还是没有?你作为保安大爷,你必须给一个零到一之间的答案,你只负责开门还是关门,这个门开多大,开的概率是多少? 所以这就是 sigma 函数的特点,它的范围是零到一之间,把它把输入的 x 全部会呃划到这个范围里面,然后全部是大于零的,它没办法把 x 划到大于一的这个范围, 它相当于是一个二分类给一个零到一之间的概率或者是答案。好,现在是第二份工作,现在你进大厂了,当职员了, 那你的任务就不再是给人放门了,你的任务就是要在公司内部搬运信息,处理业务,还有传递信号,那么这个时候如果你还用 sigma 的 当激活的话,那就非常尴尬了,因为 sigma 的 一个问题是, 输入的 x 不 管是多大输出,永远会被压扁到零到一之间。那现在假如说你用 sigma, 领导给你一个一百千克的任务,然后你回一句,啊,不行不行,领导,对不起,我只只能输出一千克,那相当于这里面的信息,你你都给 把它扔掉了。而且很多信息它是有正有负的,正的可能表示是加强,负的可能表示是抑制或者是反向修复。但是如果是 sigma 的 话,呃,不管是正的还是负的,你直接会把 整个负方向给干没了,就小于零,小 x, 如果小于零的话,那你输出的一定是大于零的负方向被你给干没了。 这在公司内部传递信息来说,就相当于是把所有文件都压缩成了一个一 kb 的 缩略图,然后只能看得见轮廓,但是信息全没了, 那这个时候就不行了。所以大厂职员更适合用写录或者是 switch 这种激活函数,这个激活函数就相当于是一个员工加一个主管在审批,然后 sigma x 就是 这个主管,然后 x 就是 员工, 也就说 x 是 你本来要提交的工作量,这个工作量很可能可能很大,也可能是负的,要纠错, 那 sigma 的 x 就是 主管给你的通过比例,这个是在零到一之间的,当 x 很 大很正的时候,主管觉得,哎,靠谱。 sigma 的 x 给他给一,给他给约等于一, 那相当于你几乎是全额提交了这个 x, 你 的输出 x 乘以 sigma 的 x 就是 约等于 x 的, 那么这个时候呃传输效率也比较高, 那如果 x 是 负的话,哎,主管觉得,哎,这不靠谱。 sigma 的 x 把它设成约等于零,那么这个时候 你提交的就很少,然后输出的也是接近于零的,因为 x 乘以 sigma x, 然后这个 sigma x 接近于零的话,那么他们的成绩也是接近于零的,相当于这像像是一个噪声,然后主管觉得不靠谱,相当于这个噪声就被抑制了。 那么如果 x 是 有点负的,但是也没有特别离谱,那这个主管也不会一刀切,然后你还他可能留一点点反向修正的力度,这个这个时候 sigma 的 x 他 不是接近于零的,他是有一个负值的, 然后 x 乘以 cy 还是可以传输下去的,比如说啊,六乘以个负零点三,六乘以个负零点四,那这个时候其实还是能留一点点的反向修正的力度的,它它不会就是像 x 很 富的时候造成,是完全被抑制的。所以说写路他的职责就相当于是大厂里当员工,他要在内部传递和处理信息,他要既保留一定的浮值,既 既保留一定的 x, 又要有一个类似于门控的感觉,这个 x 它输出多少有一个门控。 然后如果是 sigma 的 话,就是在门口当保安,输出的相当于是一个概率,从零到一,到底是 过还是不过有还是没有,是还是不是要做决策二分类。所以说如果你的任务是门口的东西,能不能进就用 sigma 的。 如果说是,呃公司里要干多少活,怎么干,怎么传出信息,那就用 si 路或者是 switch。
47老学姐讲AI 01:13查看AI文稿AI文稿
01:13查看AI文稿AI文稿ok, 那 为什么要有记我函数呢?因为在一个深度神经网络中,如果它没有记我函数,其实就相当于是一个限行模型,也就是说,记我函数是为了引入这个非限行能力。那 我们先来讲 sigma, sigma 其实就是压缩,把一个输入压缩到零到一之间,那靠近零或者靠近一很容易梯度消失,而且它的输出恒为正,是均值 为零,所以导致它的收敛比较困难。所以我们引入了 redu, 那 redu 其实就是小于零就按零输出,大于零就按原样输出。这样的好处是呢,它大于零的区间,它都是呃, 它的 t 度都是为一的,就很容易收敛,但是没有 t 度相似,但是在经常落到负区间,容易导致神经元死亡的现象。所以我们呃又引入了 leak redu, 它在负区间引入了一个较小的斜率,让负输入依然有个 t 度。 但是呢,最后发现这个呃这个斜率其实是可以学习的,它是非常重要的。所以我们又引入了这个呃 prel, 最后到了 erel, 那 erel 其实就是在负区间使用这个指数函数,让输出逐渐趋于一个负常数,然后更加稳定地保持单侧饱和。那总的来说,一个理想的几何函数通常具备两个特性,一个是零均值输出,一个是单侧饱和。
6719吃个东西 05:51查看AI文稿AI文稿
05:51查看AI文稿AI文稿大家好,我是你们的老朋友泡泡茶,我们今天来讲就是大模型激活函数的第三代 switch, 更柔和的智能控, 它是为什么叫呃,被称为智智能控的激活函数呢?它的公式看起来有点复杂,其实也不复杂,它 switch x 等于 x 乘以 sigma 的 函数。 这个 moi 的 函数可能有的同学知道不,也同学不太知道,就待会我给大家看长啥样子,其实也比较简单,它是是,它是 switch, 具有上限型和下限型的特点,它的一个自门控机制呢,输入 x 和门控 sigma 的 x 共同决定行为,比圆路和极路看起来更复杂,但是更平滑了。现代大模型中的角色呢, 较少是单独使用,更多的是作为基础主键去构建更复杂的激活函数,就是一般比较少,它是单独去使用的。 然后呢,函数的特性呢?格式化的是一图呢,平滑的曲线过路,不同于锐路,有硬边界。 switch 在 所有点上都具有平滑的导数。 自适应门控输出值呢,受到输入自身的门控机制调节,具备更丰富的表达能力, 可以构建更复杂的主键。它一般不单独出现,它是作为比如说 switch group 等现代激活函数的核心组成部分,提升模型的性能。这个我们后面会讲到啊,然后我们看一下,就是大家看一下这个图,很简单了,这是一个,是一个默认的函数,你看它是长这个样子, 从这就是一个拐角过来这零点,然后这个零点五,这是一个 e 加上这个这样的一个函数,它这个函数呢,就在这个上面乘到 x, 说看起来是不是长得很像刚才的几入是吧?但是它比更柔和更平滑,它没有几入,这这下面几入可能会弯这么多, 而且这个地方极路是这样的,有点有点弯的,但它没有,因为它是个 x, 是 这样的一个一个,然后我们看一下,然后第四,这是它的一个啊,然后第四代呢,就是几个路啊?极路 啊,就是格鲁,格鲁呢,它是带门控的信息过滤器,它呢跟刚才的 switch 长得很像,刚才 switch 不是 x 吗?它是 x 一, 然后去这个地方是一个门控, 乘以 c 个 mo 的 x 二,然后我们看一下它是怎么怎么做的呢?将输入分为内容 x 一 和门控 x 二。门控呢,经 c 个 mo 的 函数激活之后呢向 就是阀门一样动态的控制这个内容的一个通过量智能信息的过滤器,这是一种高级的过滤器,让模型呢自主学习并筛选出关键信息,提升模型的表达能力。就是它有一个门控的一个那个机制,而且它用这个东西来控制这个, 它这两个参数输入不太一样,我们看对比一下它俩长在哪不一样了哈,就是 switch 呢,是单一的激活函数。格入函数呢,它是一个计算单元和结构, 然后它都是接收一个输入向量,输出一个经过变化的向量,然后它是通过内部分路和门控机制输出一个向量。 然后呢,其实呢就是核心思想,它是将限行部分和非限行部分呢,是一个默认的是非限行部分啊,产生了非频发的非限行激活。它是用门,这个呢的机制是用门控的,机制, 是用输入的一部分呢,去控制另外一部分的信息的流通和通过量,就这样的,然后它是一个 x 乘以 sigma 的 beta。 x 刚才我们看到的是没有这个 beta, 是 吧?就是因为通常就为一嘛。然后呢,它是这样的一个函数,其实可以把这个东西它是 x 呢,被分为了两路,一个进行限行变换,限行变换是 x 乘以这个一个限性的一个公式,然后通过 sigma 非限性变换的一个门控,另外一路得到一个非限性变换,最后结果是两者相乘。 我们看一下典型的应用,就是可以替它可以替换神经网中的路由几路等激活函数用于前馈层。然后呢,这个呢,它是作为更复杂的,就是基础模块,特别是在创世 former 模型中的 f f n 前馈神经就是前馈网络中层中其遍体 sweet group 和呃 g group 被广泛应用,提升模型的性能,就说它也是,就是一个一种,就是单元结构,是作为更构造更复杂的一个激活函数的一部分,它也是,其实它俩就还有一定变通,对吧?然后我们看一下 group 的 优势呢,为何成为新宠? 因为它是用门控机制来控制更加智能,不再是简单的呃预执的判断,而是通过学习得到门控的动态的门控能更精准的控制信息流, 有效的减少了参数的溶于 group 的 结构呢,可以在保持甚至提升模型性能的同时,减少所需的参数量,提升训练和推理效率。 他能处理长训练能力更强优秀的信息过滤能能力呢,能使得 groot 在 处理长文本训练时 表现出色,有效有效的缓解了长距离的依赖问题,其实我们看看这几个都还挺简单的,对吧?我们今天这一讲就先讲到这,我们有问题我们评论区留言,拜拜。
21AI闲谈小馆 29:04查看AI文稿AI文稿
29:04查看AI文稿AI文稿我们来看一下给神经网络注入灵魂的激活函数,在之前的视频中已经和大家介绍到了神经网络的架构,有多个神经元组成,每个神经元呢,都和上一层所有的神经元做全连接,他们每个里面都做两个运算, 第一个就是对于输入信息进行加权求和,也就是一个限性组合。第二个呢,对于限性组合的结果 z 呢,做一个通过激活函数做一个非限性的映射,然后得到最终的输出信号,就 送给下一层。在什么叫限性?什么叫非限性啊?限性是一种可叠加成比例的关系啊,在几何上表示就是一条直线,而不是曲线啊,它这个线不是线条的意思,是直线的缩写。 其实这个操作看起来是非常啰嗦的,那我们为什么一定要做这个非限性的变换呢?如果说啊,我们没有非限性的变换,都是做限性组合,每一层呢,做完第一层呢,就把结果作为 输入传给第二层,第二层再算出来的结果再传给第三层的参数,这样是不是就可以了?如果说我们把括号展开之后呢,整体就会退化成一次陷阱变换了,因为计算之后呢,又是 w 一 乘 w, 二乘 w 三 x, 再加上这样一个长数,其实我们可以带成 w 撇加上 b 撇, 这样呢,其实又是一个陷阱层了,也就是说呢,无论我们堆多少层,是没有激活函数的,神经网络始终就是一个简单的陷阱模型, 他画出来的永远是一条直线,对于这样的关系他是表达不了的,只有引入非限性才能让他发生弯曲,模拟一些复杂的情况, 而我们现实世界中啊,大部分规律并不是简单的直线,比如说猫和狗的区分,他就不是一条直线,温度和销量的一些关系呢,也不是一些简单的成比例的关系。所以计算函数在每一层之间呢,插入了一道非限性的弯,这样呢,就让神经网络能够拟合任意复杂的函数了。 那既然非限性这么重要,那我为什么要写 w x 加 b 呢?我在这一步就是把它做成非限性的,比如说 z 就 等于 w x 方加 b。 举个例子啊,这样省我不就是只做一步了吗?就省掉激活函数了,岂不是更简单了吗? 从其实从理论上来讲是可以的,但是从计算机工程上,这是做不到的。主要原因呢,是有两个。第一个呢,其实 w x 加 b 看起来平平平无奇啊,但它背后是几十年的数值运算的积累,它计算机呢,也配合做了各种各样硬件的实现。首先就是硬件加速, 无论是 gpu 或者是谷歌的 tpu, 它都是为矩阵的乘法量身打造的,几毫秒就能完成一级规模的这个运算了。 而且呢是 ws 加 b, 它的梯度是非常简单的,只要直接移除反向,反向传播的时候,一行公式就可以搞定了,一旦把它变成非限性的,那么这些红利就全都没了。 第二呢,我们看一个简单的,我们看起来如果 ws 方加 b 这个盈是非常简单的非限性了,但是如果说我们把它像刚才一样叠加三层来算一下,就会发现它这 x 已经到八次密了,如果说我的神经网络有十层,它就到了一 x 的 幺零二四次密,这是一个非常巨大的数值啊, 无论是说他的,我们在前向传播的时候,一不小心他就会变成一个无穷大,或者是因为比如说三三的一幺零二次次密就已经到了无穷大了,若是零点三,那就会乘上,连乘上十次之后呢,就会变得非常小了,模型就直接瘫痪了。 在反向传播的时候也是一样的,导数的求导数的时候,这也是带着这么多层导数模型几乎是彻底失控就没法运算了。 从数学上来说呢,是没问题的,但是从计算机实现上来说,包括这么大的数值的表示,这些都是做不到的。所以说呢,在工程上的解法呢,就是先做限性变换,把限性变换出来的值呢,然后独立做一次非限限变换,分了两层 这样的,而且我们对于激活函数啊,刻意去挑的一些输入输出,是一些有边界的,或者是导数特别温和的形式,主动来掐断指数这种膨胀的一个传染链。比如说后面我们要介绍的这一些啊,他们的输出呢,有的就是在零到一之间,有的在负一到一之间, 有的呢,正半轴导数横为一,这样求导就非常方便。历史上也确实有这种操作啊,就 mass alt 或者二阶神经元都尝试把非限性的揉进限性运算里面,但是呢,这些尝试的结果是惊人的一致的, 就我们这样做呢,计算的复杂度涨的不止一个数量级,但是效果提升连百分之十都不到,所以说呢,就没必要 当前的用限性变换再加上非限性激活呢,是足够灵活可用的。那么一个好的激活函数有哪些基本素养呢?并不是所有的非限性函数都能当激活函数,我们前向传播的时候也要稳定,反向传播的时候呢,也要让它可计算, 这里面列了六个点。第一个呢,就是非限性的,这个激活函数呢,一定是非限性的函数,这是最基本的门槛了,否则呢,就像我们最开始讲的,它还会让整个网络退化成了一个限性变换, 就成一条直线了。第二呢,因为我们在反向传播的时候是要不停的用导数的,在上个视频反向传播可以给大家讲过,所以说呢,他就要求激活函数呢,最好是处处是可导的,对一些特殊的点不可导,我们规定一些值就可以了。 第三个,梯度的行为良好,梯度不要变得特别大,也不要变得特别的小,因为这也是我们在反向传播的时候,不断的会对梯度进行连成。 如果你特别大,也会把那个数乘的特别大,虽然没有指数命长得那么夸张,但也会形成一个很大的数字,但是如果是一个不停的永远都是小于一的数字,那么每次相乘就渐渐变成零了,所以呢,也不太好 在一个计算起来要特别的便宜,比如说计算机最擅长做什么了?做加法和做加做乘法,如果你非是一些指数运算什么之类的密运算,这些就算起来特别的慢了,所以最好是一些非常简单的计算 输出呢,最好是零中心的。这个到后面我们会讲的,让大家看到这个是什么含义,如果说我们的激活函数是一些单调递增或单调递减,是一些比较平滑的,比较有边界的,那就更好了, 总而言之呢,一个好的记换函数是是在表达能力,梯度传播,计算成本还有数值稳定性之间的取一个平衡,其实就是我们记换函数的一个发展啊,我们来看一下。首先呢,就在第一个记换函数,其实就是我们在讲 mlp 的 时候提到的,对,一九五八年的时候 就是感知机的发明人罗森布拉特呢,其实他就用节约函数搭出了感知机了。节约函数呢,实际上非常简单啊,大概呢一个这种图像,你要是大于零的时候呢,他就永远输出一, 如果小于零的时候就输出零,那么他的导数呢?其实在零这一块是不可导的,其实应该是个无穷大,但你可以把它规定成零这样,其实他的导数呢,整体就全都是零。其实讲到这大家就能看出来,他是一个模拟生物的神经元,你要么就放电, 要么呢就沉默。所以说呢,最开始激活函数的名字就是这么来的,对于一个神经元,你要么激活,要么不激活它抑制它,这是是一个全或者无的开关, 那么它有什么坏处呢?首先呢,它的梯步梯度呢,是无法传播的,就除了 x 零外, x 等于零外呢,导数横为零 就误差信号,一旦碰到节约函数呢,就直接被清零了,多层网络根本就没法训练,这其实也是最开始为什么深度学习,第一次寒冬就是解决不了一或问题,其实呢,多层感知机能,但是呢 无法训练,这是一个很重要的原因啊。第二个呢,实际上是一个隐式的,用它呢,信息的损失是特别大的,为什么呢?比如说无论你输入的值呢,是零点零零一还是一千,它的输出永远是一, 对不对啊,大家看一下,无论你就是这么小还是超级大,它输出永远都是一,只要大于零就输出一。这种时候呢,其实我们整个网络就丧失了对一些数值程度的感知,是特别大还是非常小? 大量的数值信息呢,在激活的瞬间就被永远丢弃掉了,所以信息损失是非常大的,没有平滑的过度,就几乎没有梯度可言,所以说呢,这也直接推动了他不能用,所以说就推动了我们第二个 sigma 的 激活函数的诞生。在一九八六年的时候,我们讲就是新队把反向传播带到了神经网络了,和神经网络做了结合。上个视频我们主要就在讲这个,但这种时候他发现训练的时候呢,就需要一个触处可导的激活函数, 那时候用的就是 sigma 的。 其实这是一个十九世纪就用来描述人口增长的老朋友了,这是在统计学非常呃常用的一个函数了,并不是计算机发明的,它大概的形式呢,就是一加一的负的 x, x 就是 输入嘛分之一, 它的导数是什么呢?它自己在乘上一减它,其实这也是一个非常好算的,对,好算的值啊,它的曲线是这样,是一个 s 型,大概是一个 s。 sigma 的 本身这个词的意思就是这个,而且呢,它是处在一个零到一之间的一个值,它的导数呢,也非常的简单啊, 大概就是这样子,大家看出来在正常这个函数本身呢,如果说你给他中间呢,这就是零点五,如果小于零接近零的时候,他就是输出零点五,小于零的时候就不断的变小,后面呢,再小的时候就永远接近零了,大的时候也是不断不断的接近一, 他的导数也有一个特点,大家记一下,他的导数呢,当然是平滑的,但有一个问题啊,他的最大值就是零点二五左右, ok, 它相对于节约函数呢,是有几个好处的,首先它是处处可导的,这平滑的梯度下降就能工作了。它还有一个额外的好处呢,就是它的输出是在零到一之间,而且 x 等于零的时候就是零点五, 非常适合做二二分类的输出层。所以说从逻辑回归,我们就是用 sigma 的 做输出的,把一个限性的结果给转成一个输出,它大概概率你还是不是的概率呢? 因为等于零的时候就是零点五吗?大概小于零的时候不是,大于零的时候就好了,他还非常的平滑,输入一点五和一点六呢,输出是有一些微小,但是确实是有意义的差异。神经元呢,终于有了一些模拟感了, 这一切看起来都非常的好啊,直到大家把它给放到了一些深层的网络中,可能就是用五层以内还可以,但是一到深层的时候就出问题了。刚才还记得大家让大家看它的导数的图像,就会发现,它的导数最大值是在 x 等于零的时候是零点二五, 但是呢,只要是 x 一 大的时候就饱和了, s 的 绝对值其实就是 x 无论特别大还是特别小,因为它往两边都是零嘛, 它导数无论是特别大还是特别小的时候,导数都基本等于零了,因为后面整个函数不增长了嘛,导数就是在描述函数变化的速度呢,你后面不变化了,肯定导数就接近零了。 那这有什么问题呢?我们在反向传播的时候啊,是过一层梯度就要乘上一下这个导数,因为每一层都有激活函数,所以肯定要乘激活函数的导数的。 所以五层之后呢,即使我们假设理想情况下,每最大值它都是零点二五,经过五个零点二五相乘,就是零点零零一了,就梯度只剩下千分之一了,再往层次一深,几乎梯度就消失了。我们就管这个现象呢,就叫梯度消失, 也就是说外层在做百米冲刺,外层的神经元,但是往内层传的时候呢,几乎在原地踏步了,不再动了。 其实这也是早期的神经网络很难训练的非常深的根本原因啊。早期虽然理论上可以,它不只是计算机硬件计算速度的限制,其实呢,我们在用的算法就不支持它神经网络特别的深,一般五层就差不多到极限了。 sigma 的 还有两个硬伤,第一个呢就是输出是非零中心。 什么叫非输出是非零中心呢?我们刚才看它的输出永远是零到一之间的数字,它也就说永远是正数。 说下一层在反向传播的时候算出来的梯度呢,长期的就保持着相同的符号,要么都是正,要么都是负,就权重的更新就失去了一些灵活性了。我们用优化器呢,就可能 z 字形来回的折线,它不是嘟嘟嘟嘟嘟一点点往下降的,它是来回震荡,就容易形成这种问题。 再一个呢,我们看到啊,这个 mod 的 一一加一的负 x 方分之一嘛,它计算起来是非常贵的,因为它有指数,计算机运算天然是比较贵的, 而且指数级的压缩使两端的斜率呢,渐渐的就变成零了,它是一个把负无穷和正无穷硬给挤到了零和一之间嘛,压缩的代价就会产生饱和,这样其实在两端的时候,斜率就是为零,几乎就是不可用了。 所以说呢,如今我们已经基本上不再用,不再把 sigma 的 用在隐藏层了,基本上都是在做二分类任务的输出层的时候,最后用它一下,那这怎么办呢?在九十年代初啊,杨立坤这个也是 ai 的 三巨头之一了,在贝尔实验室呢,就他去做什么手写数字识别, 当然 cnn 就是 他发明的这个架构,他也是被 sigma 的 非零中心这个训练震荡所困扰。在一九九八年的时候,他写了一个论文,就是高校的反向传播,他在他总结了一下,用了一个函数,就是 th, 它的 th 大 概是什么样子啊,也是又一堆指数啊,但算起来大概就是这样子的一个函数,它的导数呢,就是以减 th 的 平方, 它的输出。相对而言啊,我们可以看一下,这个呢,是 sigma 的, 在零到一之间,它其实就是负一到一之间, 它的导数呢,相对于 sigma 的 它这是比较尖的,是 tanh 啊,就会发现它的导数,你看最大值就比较大了,到一了都已经不再像 sigma 的是零点零,只是零点二五左右。 这个它相对于 sigma 的 做的两个优化,两两者的趋势看起来是特别像的,只是取值范围和导数的这个 快慢不一样。它的最大的改进就是导数最大值是一,比 sigma 的 大了四倍了,所以梯度的衰减就更慢了。而且呢,它是一个零中心,输出的 z 字震荡的明显减轻了,收敛就比较快。可以看到这零是它的中心嘛,既有负数又有正数,它的输出, 但是它依然存在的问题是嘛,它本质上仍然是个 s 型,两端饱和呢,并没有变。无论是它函数本身呢,还是它的导数,在两边都是无限趋近于零的,而且呢,它还是依赖指数,函数的计算成本同样也不低。 虽然说泰 h 也算是大获成功啊。杨立坤呢,发明了。 net, 这是一个 cnn 的 版本啊,在九十年代末呢,都已经开始在美国邮局使用了,但银行也在使用,就美国百分之十到百分之二十 手写支票啊,还有在邮局中的数字,它是零到九十个数字嘛,给你是谁都在用它了,但是呢,还是受限于刚才很难训练超过 五层或超过十层,因为它收敛了一些。但是呢,仍旧有一样的问题,在深层的网络中呢,还是用不了它,因为它本质上是对 simo 的 一次改良,而不是突破。 在直到二零一零年新队,这个就是 ai 三巨头,我们前面已经出现过无数的名字了,和他的同事呢,提出了一个简单的令人发指的激活函数,就是 ray。 ray 是 怎么说的呢,它就取零和 x 之间的最大值,其实意思呢,大概就是这样子,零和 x 之间的最大值嘛,当你小于零的时候呢,我这函数就永远输出零。当你大于零的时候呢,我就输出你自己。 其实它的导数呢,小于零的时候,导数永远为零,因为值不变嘛,大于零的时候呢,因为它就输出自己,所以变化就跟自己一样。那么导数就是一,它的好处是非常之多的啊,但是呢,这个东西看起来过于粗糙了,是不是啊,很多人都怀疑它,甚至怀疑这个东西 reno 到底能不能用。 但是呢,在低位指大赛上,新队和他的两个学生发又推出了 alex night, 在 低位指大赛上呢,一举把错误率给降到了百分之十五。 其实那都前一年的最佳都是百分之二十六啊,每次都是优化百分之一左右每次大赛,但是他呢,直接优化了百分之十左右,而且他领先了第二名,可以看到第二名差不多就是百分之二十五吧,比前一年降了百分之一。 他直接降了这么多,震惊全世界。从那次整个 cba, 就是 计算机视觉圈呢,迅速地就认可了深度学习,迎来了深度学习的第二次热潮了。其实 reno 这个激活函数呢,也可以说是贡献特别大, 那么蕊露是怎么做到这一点的?但是首先它就是能够让深度神经网络终于变深了,不再是受限于五到十层这样子的了。 首先它就大幅的缓解了梯度消失的问题,因为它的正半轴导数横为一,不再是一个小,就是小于一的小数了,便是法则在上面呢,几乎就变成梯度的直通车了,就你原来是多少?因为你梯度是一嘛,乘上一之后还是多少?是这样让深层的网络第一次能够真正的被训练了, 深层的浅层的早就能了。再一个呢,他的计算速度是特别快的,对不对啊?他没有指数,甚至也没有除法,连乘法也没有。在大规模训练的时候啊,如果是上亿次运算的时候,他是非常快的,因为看他这函数啊,首先前向传播的时候,他就要么输出你自己,要么就输出零, 它的导数呢,就要么输出一,要么就输出零,所以它的计算是超级快的。再一个呢,它是有一个天然的稀疏激活,这是什么意思呢?它的负出负输出呢? 负输入的时候直接就至为零了,就任意一次乾象的时候,只有部分神经元才被激活,对吧?只要你输出是小于零的,我就把你给抑制住了, 其实它是自带的一种政策化的效果。到今天,其实我们在看大模型的时候,经常会听说 m o e 模型框架构, m o e 是 什么意思啊?混合专家模型嘛, 大家也会看到,无论是说呃 deepsea 还是千问的时候,都会说它有几千亿参数,其中每次会有多少,几百亿个被激活,几十亿个被激活,是怎么做到的呢? 就识别了,大家叫它混合专家模型,比如说你问的是天气方面的,我就把做菜相关的参数都给抑制掉,其实跟这个的大概原理是一样的,所以说呢,蕊露出现之后呢,它的训练效果是特别好的, 就不只是在 em 大 赛上去获胜了,在各种各样的深度神经网络上都可以胜任,所以说它就迅速取代了 c mode 和 timeh, 成为深度学习时代的最具代表性的激活函数了。到今天,我们在很多日常的训练中也可以直接使用, 但 sigma 在 二分类最后的输出层还是有用的,但是呢, relev 也不是说完美的,它还是有一定缺陷的。首先呢,有一个问题呢,就是打印 relev 的 问题,这是什么意思呢?如果每次更有一次更新之后,它的预期获值呢?为负了,那么它的输出就变成零了, 数也变成零了,那么后面的就彻底都死掉了,因为没法再往后传了,因为他等于小于零的时候,输出就永远为零了嘛,后面的再怎么样也救不回来了,其实这些神经元就相当于彻底死掉了,无论怎么训都没用了。再一个呢,其实他他的输出明显不是一个非零中心的输出,要么是零,要么是正数, 所以说呢,呃,当然它其实因为它的比较简单啊,它是因为相当于有个直通车嘛,所以说它的 z 字震荡是没那么严重的,但总归还是有一些不完美之处的。 再一个呢,我们在讲好的激活函数的基本素养里面也提到,它的输出最好是有边界的,就像 sigma 是 零到一, i h 呢,是负一到一之间,但是呢,我们可以看到路由呢,它的输出可以大到无穷了,你的只要是正数呢,就无限的大,所以说呢,在一些深层加大参数的情况下,激活值可能一路被放大, 引起数值的一些不稳定性,但这个也能解决啊,所以说在蕊露时代呢,就离不开后面我们要经常讲的一些归一化的问题了,批批归一化,层归一化等,为什么要用?其实就在解决蕊露越往后面参数越大,它的放大就越大的问题了, 所以蕊露的伟大之处呢,也可以恰恰说是它的粗糙,所以说它可以说是深度学习历史上一个比较重要的里程碑意义的激活函数了。 针对他有一些问题嘛,其实最主要的就是他后面这两个问题啊,还好就这两个问题,因为他有 t 度直通车,所以说呢, z z 字震荡并不明显,而且虽然说输出无上界呢,但是通过归一化处理呢,还是能把他控住,但只有死亡神经元的问题,这是 问题,实际上是有,在很多情况下是会产生一些不好的现象,让模型难以训练,那后面就会有一些关于 reno 的 改进版,我们先来看一个,第一个就是 lek reno, 它实际上是干什么的,我们可以看一下啊,既然你负的时候容易死嘛,那我就给你一个特别小的斜率就好了,就 lek reno, 它是公式是怎么样子呢? 你大于零的时候呢?我的输出和 re 路是一样的,大家可以看到啊,绿色的这个是 re 路,蓝色的这是 nick re 路,他们在大于零的时候输出是完全一样的,但在小于零的时候不一样,小于零的时候 re 路输出直接是零,而他是给了一个很小的斜率,并不是零, 说你要是一次小也不会变成零,你两次小也不会变成零,如果你每次都是小于零的,我们一成就变成一个零了,这样其实给一些负半轴的导数呢,永永远不为零,让神经元不会彻底的死亡,给他一些机会,如果你连续的小才不行, 但是他有些坏处,一般情况下这个特别小的这个系数是零点零一,但是呢,这是一个超参数,是人工去写的,他不见得是最优的。 所以说在大部分情况下, rio 再加上一些比较好的出手话参数,出手话你不要出手话的成那么大的吗?现在也有各种各样的技巧,后面我们也会介绍到,再加上一些 bashnom 的 话就已经够用了。 它的导数其实在大于零的时候肯定也是一了,在小于零的时候呢,也是一个非常小的数字,非常小,但不是零, 所以他的计算呢,其实也是足够简单的,在很多时候,我们训练的时候,可能用锐路出不来,结果的时候可以用它来做一下尝试。再有一个呢,锐路, 锐路他也在解决,给锐路做一下优化,其实也是解决负半轴的问题。在在锐路呢,其实在 x 等于零的时候是一个硬性的切断,但锐路呢,就想换成一种比较柔和的,比较软的处理方式,就根据输入的大小,有一定的概率来决定放行多少信号。 它的一个典型计算是,它实际上是 g, 是 什么意思啊?其实就是正态分布的那个意思啊,也就是高斯分布了,对吧?所以这个就是高斯的名字了, 然后它就是利用正态分布来积累的一个分布函数,但是在计算机上这个是很难做的,所以我们会用 th 来给他做一个模拟,这就是跟它一个近似的结果,可以看出来这个计算并不简单。所以说呢, 它的大概呢,其实也能看出来啊,它跟 rio 也是特别像的,我们如果在实际训练的时候,如果用的几路 d k, rio 的 时候,甚至我们后面的 swisse 的 时候呢,会发现它们的训练的趋势呢,也特别的像,就因为它们几个的这个函数呢,确实长得也特别的像啊, 就是这个曲线本身就很像,只不过是它真的不是一个尖锐的结果了,是一个平滑的,相对于 rio 这是一个尖而言。 所以说呢,相应的它的导数呢,也是一个比较平滑的导数,这就是它相对于在大大规模训练的时候,它的效果呢,确实是比蕊露会稍微好一小点。 所以说呢,在二零一六年就被提出了。之后呢,二零一八年就是 google 的 bot 的 一个 l p 的 模型呢,就是 bot 就 用了它进入了大众的视野了。从此以后呢,就是无论是 g p t 还是 v i t 等所有几乎主流的 platform 模型呢,都开始跟进了。 比如说呢, g 陆呢,其实在其实是在它的那个最后一层 fnn 层,就是 g 陆在大模型时代的地位呢,就相当于 re 陆在 cnn 时代的地位, 所以它的适用范围也是在 transform 类的模型的前馈前馈神经网络层。但它的代价呢,也比相对于 re 陆而言就比较惨重了,它你可以看到它的公式里面啊, 这么复杂,就知道它的计算肯定不简单,所以它的训练呢,也是比用 re 陆要慢得多的。然后呢,还有一个 也是对于瑞露的优化,但是它并不是针对瑞露优化的,而是在二零一七年的时候, google brain 这个团队呢,他用神经架构搜搜索,让模型呢,自己来挑个激活函数,就挑一个 最有效的,让机器呢,自己来挑认为最有效的激活函数是什么?结果搜出来的结果和 g 六呢,几乎是一模一样的,它其实就是 x, 再乘以 sigma 的, 这个就是 sigma 的, 所以说呢, 大家可以看一下,这两个几乎是一模一样的。所以说呢,为什么就是说几路的效果比较好呢?就是跟模型挑出来的大概也长这个样子,看到他们特别的像啊, 然后呢,但是呢,这个其实并不是那个。呃, google 呢?虽然不知道,但这其实不是 google 首创的。在二零一六年的时候,就有人提出了完全相同的函数了,而而且就给它起的名字呢,叫 sigma mod, 因为它这个就是乘上了一个 sigma mod 嘛,输入输入乘上 sigma mod, 对吧?所以叫 sigma 处理器对吧? part 池中的 n n 点 siu 呢,其实也就是 swiss, 这两个是一回事啊,但它相对于 g 路呢,有一个优势,就是它只需要一个 sigma 的 运算,计算呢,是更清量的,相对而言。 然后呢,它在其实能看出来,它跟 g 路几乎都是一样的,但算起来呢,又比 g 路轻。 所以说呢,它在后面的应用由那个 lama 就是 是最开始 metta 开源的一个模型。呃,最最早的那个年代啊,就是无论是 deepsea 啊,还是就是铅等这些开源的模型呢,都是 好了,还是对借鉴了拉玛,所以拉玛引领了就是在后面呢,在拉玛之后呢,开源的这些模型呢,基本上都用了 c 就是 c 路了。还有呢,因为它的算的比呢 re 路要简单一些嘛,所以在一些比较清亮型的 cnn 上也会呢,用用一下它。 然后呢,对于计算特别敏感的时候呢,但又想比蕊露呢更进一步啊,他也是一个比较高效的替代了。所以说呢,他们两个近似相等啊,但形式更简单,其实是最新的二零二三年之后的大模型呢,可能用它就用的更多一点了。 所以说,让我们来总结一下激活函数八十年的演化,这个呢,大概就是我们所所有的激活函数,刚才涉及到激活函数大概的样子和他们的导数的形式了, 可以看出来,他们眼睛的方向明显也不是越来越复杂,比如说 re 录,这个最常用的其实是最简单的,而是呢,越来越懂得在表达能力和梯度传播及工程效率之间的做一些平衡。 然后每一代都解决了什么问题呢?就是节约函数,其实就是第一代出代目,他解决了要不要激活,但是呢,他实在太硬了,又没法反向传播信息,丢的也特别的厉害,所以说呢,几乎是不可用的。 然后第二代呢,就到了 sigmod 了对吧,它第一次呢,让多层的神经网络可被训练了,但是呢,两端饱和,非零中心深层学不动,各种各样的问题呢。接下来杨立坤呢,就有太 h 在 cnn, 然后收获了一些实际的成功了,邮政局啊,银行都开始用它来识别数字了。 它其实是对 sigma 的 一些改良,但本质上还是个 s 型,所以饱和问题是没有解决的。接下来呢,就是新顿带来了一九八六年带来的 revu, 它呢,用最直接的方式,大于零的时候就等于一 对吧,正半轴横为一就保住了梯度了,又真正的开启了现代深度学习,其实就是真正的深层,深度的神经网络,就是让它的层次呢可以变多了,可以可以 呃,可以模拟更复杂的函数了。然后呢,就是对路由的各种各样的优化了, leaky 路由啊,路由啊, switch 这种,或者是这种对吧?就是把路由呢硬折角可以变成一个平滑过度的,所以在大模型时代呢,用的是非常多的,这个就是每一个代的 激活函数在解决什么问题。那么我们应该怎么做选择呢?其实比较简单,如果在输出层是个二分类的问题,就用 sigma, 如果多分类就用 softmax。 然后如果在普通的隐藏层啊,在大部分场景下,尤其是计算资源有限的情况下, ray 路就已经够用了。 如果在一些大模型的训练,想拿到更加精细的结果呢,可能就是 g 路或 c 路。然后总结而言呢,计算函数是给我们提供非限性,让让模型有了非限性的能力了, 而和他密切相关的就是我们之前也讲神经网络他的训练过程了,先前向传播对吧?然后用损失函数算出损失来,然后呢,反向传播算出梯度来, 然后再干什么?梯度下降就是梯度下降提供的一个学习的能力,让网络呢能够你你和任意的函数了。其实我们在讲反向传播的时候,无论激活函数还是梯度下降都有提到过,没有专门的拿出来讲,我们如果彻底的了解了激活函数, 那么呢在接下来呢,我们就来了解一下梯度下降,它是怎么让一个网络能够优化它的参数,找到最佳的参数是多少的,然后让神经网络呢真正的能够学起来。 同时呢我们出了最经典的梯度下降,我们还会给大家介绍一些优化器,让它呢在优化参数的时候变得更智能。好啊,这节课就介绍到这里。
832谦行AIing 06:00查看AI文稿AI文稿
06:00查看AI文稿AI文稿雷路几何函数的铁拳,我们算是体验了一把啊,相信呢,大家一定是意犹未尽,所以呢,我这里呢,再来一道雷路几何函数的铁拳,同时呢,我们也再次闻一闻啊,深度学习面试当中那股扒骨的味道啊。 好,那么这个题目是怎么样的呢?也就是雷路几何函数,对吧?那么雷路几何函数呢,它为什么容易提度消失? 其次,你怎么去诊断雷路几何函数提度消失的呢?然后第三个,如果说雷路几何函数它的提度消失了,那么你要怎么去解决这个问题呢?听一听这个问题啊,是不是很容易的把谷位, 我们看这个问题啊,这个问题呢,有三问,而且呢三问呢,还是相互递进的关系,说明呢,这个出题的人呢,他是一个思维缜密的人啊,啊,那么呢,这个题目呢,当然也是逻辑呢,非常严密的啊, 好,那么呢,我们看第一问啊,他第一问呢,他是说你这个零度几何函数呢,他为什么容易出现题多消失的问题 啊,那这个问题呢,当然还是一个送分的题目啊,啊,这个呢,也体现了我们出题的人呢,他还有一些人情味的啊, 啊,那么呢,他是这个啊,那么这个问题呢,我们要怎么回答呢?其实呢,我们如果说只要知道这个雷路几何函数它小于零的时候呢啊,它全部都是零,对吧?小于零的时候,它这个神经元呢,它就会死亡啊,死亡之后呢,那么当然 我们的这个无论是输出结果还是输出的提动呢,我们固定都把它写成零啊,这样呢,他的提动就是永远都是零了啊,那么呢第一问呢还是比较简单啊,就是神经元死亡的问题啊,神经元死亡之后呢,当然啊提动呢也就没有了啊 啊,这是个比较简单的问题。好,那么呢我们看第二问啊,第二问呢,他问的是怎么样诊断啊,出现了题多消失的问题啊?也就是你你在验答案的时候是吧? 啊,你在练单或者是啊,当然你是训练模型吗?训练模型的时候呢,出现了提度消失,那你怎么判断他出现了提度消失的问题呢啊,那么这个问题呢知道就知道啊,不知道就没不知道了,这个就没有办法了啊,当然我们 啊这个答案呢,就是我们使用这个 h 基增啊,使用 h 基增,反正这个肯定没有错啊, h 矩阵呢啊,它是一个特殊的矩阵啊啊,它可以呢诊断我们的模型呢,是不是出现了梯度相似的问题? 好,如果说你回答了这个 h 矩阵呢啊,那么呢可能啊这个面试官呢,他又会继续问啊啊,首先呢这个 h 矩阵它为什么可以诊断梯度相似的问题呢啊?其次呢啊这个 h 矩阵呢啊,它的特征值特征向量是怎么一回一回事呢 啊,这是对吧,这是连环的第二位啊,然后呢他还有连环第三位啊,他说这个 h 积分呢啊, 你怎么去把它求出来呢啊?如果说啊,你炼丹,你的炼丹炉啊,你的维度达到几万甚至几十万为对吧?达到,比如说你达到一万为的话,那么你的 h 积分他的这个 啊个数多大呢?就是一万乘以一万个数字对吧?你要求这个数字呢还挺困难的啊,那么你怎么把这个 h 值呢?把它求出来也是一个问题啊,虽然这里的问点很多啊, 那么第三个呢,就是你这个题都消失了怎么办啊?看看人家这题出的啊,非常的严谨啊,对吧?一开始问你为什么会出现啊?怎么判断出现了啊?出现了怎么办是吧?啊,人家这题目出的这个很八股啊, 好的话呢,我们看第三问啊,第三问呢,他是问你这个题都消失了怎么办啊?这个题都消失了 啊,那么这个问题呢,当然提肚消失呢,不仅仅是雷露几乎函数会引起提肚消失,对吧?其实呢还有其他的一些情况呢,会导致这个提肚消失啊,当然我们这里问的话呢,主要是问雷露几乎函数导致的提提这个提肚消失怎么办? 虽然你这也当然你可以结合呢雷路几何函数的一些特点啊,比如说呢,小于零的时候是吧,你不是结束消失,不是主要就是在小于零的时候消失了吗?那你说可以说对吧?我们可以用改进版的雷路几何函数啊,比如说呢,是用全是 form 里面啊,那个几何函数 啊,也就是记录几何函数啊,用那个几何函数呢,可以稍微改进。 那么其次呢啊,你还可以呢,在小于零的时候呢,你可以设置一些可以学习的提督,对吧?就是就是,也就是说呢,不是说单纯的把这个提督呢,就是变成零了啊,声音呢,变成零了,你可以呢小于零的时候给它 给出一些可以学习的空间啊,这也是一个思路啊,好,那么呢,这个是解决啊,累赘结构函数导致提多相思的问题啊。其实呢,我们刚刚说了啊,还有其他的一些情况呢,会导致这个提多相思啊,当然情况很多啊,那么呢,我们有没有一个统一的方法能够解决呢 啊?如果说你能回答这回答到这个地方啊,那么呢,你就这个是相当于是加方向了啊, 你可以这么回答,对吧?比如说我们可以使用长插神经网络啊,你要把这个东西拿出来啊,那你的这个炼丹炉那是啊,足够的深了啊,至少是二十层以上啊,你的神经网络。
15技术王 01:19查看AI文稿AI文稿
01:19查看AI文稿AI文稿还有同学不知道激活函数是做什么的,一分钟咱们解释清楚。咱们传统神经网络就让大家说,我们做限行变换,由输入数据 y 等于 w, y 加 b, 我 们做一个变换,得到中间的一个特征再做变换。你们这么去理解,如果说咱们做了五次变换,如果他都是限行变换, 那我说我干脆用一个限行变换替代这五个不就完事了吗?直接用这一个变换,那结果也是类似的。那为什么还要做多层? 你们这么理解,光做限行变化不够,为啥?因为很多时候我们说咱们要解决的问题也好,还是我们要去分析预测东西也好,一般来说都是限性不可分的,限性可分的,能用限性解决问题太少了。那你要不要让你的模型增加一些非限性? 所以说我们的非限性首先是加载一些神经网络权重,带有权重层之后像全阶层,像是卷梯层之后我们加这些非限变换, 一方面来说能让我们的模型学的东西多加入些非限性,另一方面让模型的时候学的过程当中比较稳定,因为一般的几何函数都带有一些特征筛选的过程,比如说软路的几何函数,它能让你筛选一特征,好的特征保留保持梯度,不好的特征直接杀死掉了。 这就是几何函数本质的作用,让你的模型在学过程当中多兼加非限性。如果你还不知道从何开始,我这里整理了学习路线以及配套视频教程,留下函数打包带走。
29ai算法学习课堂











