每次打开claude消耗很多
你们有没有发现一个很离谱的现象,很多人使用 cloud code 的, 不是用不起,是根本不会用。钱不是花在模型上,是花在了自己的低效操作上。今天呢,我讲五个自己在用的方法,直接帮你把这个 token 的 消耗砍掉一半。 第一是任务越模糊越烧钱。很多人一上来就说帮我优化一下这个项目,那这句话的本质是什么?是让 ai 自己去猜,去读,去分析,你一句话模糊了,他背后可能就跑了几十步,正确的做法是直接说 帮我修改第三十二行的报错,越具体呢,越省钱。第二是先总结,再动手接手一个新项目。很多人的第一步就是改代码,这呢其实是最贵的一步,你应该直接说帮我总结这个项目的结构和逻辑,让他先输出一个地图,后面你所有的操作都会更加的精准。 第三是不要重复的喂他代码。很多人有个习惯,就是每聊一句就要重新的贴一贴一遍代码,这基本就等于每次都要重新付一遍钱。记住一件事就是在同一个对话里,他是有记忆的,除非真的很需要,否则就不要去重复的说。第四是任务不拆,成本翻倍, 你让他一次做五件事,他会怎么做?来回确认,反复思考,多轮输出,那你的投屏直接爆炸了。正确的方式是一件一件来,看起来慢,其实更快,而且还更加的省。第五就是别每一步都大局思考, 不是每一步都需要他理解,整理整个项目,大多数的时候只要给相关的代码片段就够了,全区理解,只在关键节点用一次。 最后说一句很扎心的话,就是很多人觉得 ai 很 贵,但其实贵的不是模型,而是你使用的方式。那同样的预算,会用的人,他可能就会多用一倍的时间。

粉丝53获赞2278
相关视频
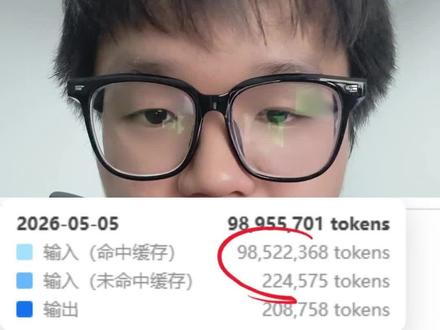 01:38查看AI文稿AI文稿
01:38查看AI文稿AI文稿几个简单的小技巧就可以让你的 ai 命中缓存达到惊人的百分之九十九,其托肯消耗和成本其实可以锐减百二十倍。这真不是夸张,是我消耗了整整一亿托肯得到的一个实际经验结果。第一 点,善用记忆系统。其实我们知道现在大部分市面上主流的 i can, 它都是有自己的一套记忆系统,无论是 open card 还是它都扣的。只要我们善于利用这个记忆系统,其实可以大大的增加这个缓存的命中率。举个例子,我最近在做一套自己的 ai 面试助手,但是这个任务他不是一天两天我就能够完成的, 所以我每天会在任务完成的时候,我会告诉我的 autodrive, 让他自己去保存当天的这个记忆。这样的话,在我明天或者后天重再开启这个任务的时候,他能够直接读取自己的绘画内容,从而大大的降低这个拓客的消耗。 第二点,制造边界和原则。布置一个任务的时候,如果没有明确的规则和原则的话,你可能需要跟你的爱多次交互,他才能够真正的明白你的需求。 就算他明白了你的需求,你没有制定一个明确的边界,你的 ai 也可能会做出越界以及难以预期的一个结果。所以制定边界和原则是非常重要的,你可以直接将这个工作原则喂给你的 ai, 让他传进他的记忆系统。 最后一个点,整理和提炼工作流,让他按照工作流的方式输出结果以及产出文档。当你需要他完成一个周期较长的任务的时候,一个合理的工作流是非常重要的,他不仅可以让 ai 快 速理解和解决一个问题的流程,并且可以通过产出一些文档来极大的提高一个缓存的命中率。举个例子, 你需要做一个文档,那么你可以先跟你的 ai 交流想法,让他去产出做出这份网站需要的一份产品文档,然后你再根据他的产品文档去优化,之后让他去根据产品文档去完成功能,这样他有了依据而不会天马行空,每次产出都会根据文档来做,而不会浪费脱坑又产出垃圾。
324欧拉欧拉欧拉z 06:27查看AI文稿AI文稿
06:27查看AI文稿AI文稿接上一条视频,重大发现,就是 kimi 这个 a p i 连上了 club 的 官方模型,也就是全世界最贵的 opus 四点七,还有其他的模型,比如说四点六,四点五,这些都有。 那我是全程无登录状态的,这是我,昨天 kimi, 我是 昨天刚买的最低权益的会员,四十九块钱每个月的那个,但是 我用着用着感觉它的额度消耗的特别快,就是一句话,给我干个百分之五干个百分之七的,然后我就很奇怪,我就查了一下它的模型,竟然是 卡拉的官方模型,给你们看一下。 ok, 现在开始演示啊,这个是 v s v s 扣的,然后这个是 cc switch, 然后我现在先把它们全部关掉, 全部关掉,这里也关掉,这里也关掉。退出啊,退出了,然后这个 v s q 的 我也把它关闭掉,刷新一下,然后重新打开。 嗯, v s code 好 打开了啊,我们打开它的终端吧。啊,终端新建这里啊,我输入 c l a u。 好, 格拉格已经启动。 你看,这里是 oppo 四点七,你看是吧,我这里斜杠磨豆回车,你看啊, 是吧,没错吧,现在是连的最贵的 oppo 四点七嘛,然后是一百万上下文的窗口啊,然后我们再看,去看看 c c switch 里面的设置。 switch 里面,呃, switch 在 这儿 啊,这是不用管的,这个已经欠费了这个已经欠费了,你看啊,这是百炼,这是 deepsea 啊,这是 kimi, kimi, 现在是,呃,昨天晚上我睡觉之后就没用了嘛,然后今天起来刷新一下,重启一下,它还是那个 opus 四点七嘛, 然后你看,给大家看一下,这里是使使用中,然后点一下,然后它是正常运行的,你看它的网址是 kimi 吧,好,点进去看一下啊,设置, 你看这些都对的嘛。啊,这个是 a p i, 就 不给大家看了,手机就在这儿,然后保存,你看使用中嘛,这个水没启动, 你看我们聊一下 你,你是什么模型? 然后大家注意看一下 switch 里面的额度消耗,它是消耗的 kimi 的, 它现在正在思考 啊,你看,我是 cloud code, cloud, 我 把它的 id 为你们看是不是?然后你看 c c 四 h 的 呀,哎,给他 没刷新过来, 嗯,没反应,那我用的是啥?很奇怪,我用的到底是什么? 重启一下, 重启一下,看看,还是一样温度没变,很奇怪它,它不扣费,它还是零,但是它的 但 kimi 后台的显示是调用成功了,给你们看一下啊。 kimi 后台它是显哦,这里显示,你看十二点,十二点多了,它是调用成功的, 点用成功嘞,但是它的额度是没有的。可能这一句话,哎,昨天一句话看了我百分之七啊,今天怎么 怎么额度恢复了呀,这个我到底要不要用啊?你看我再打开 vs, 这个是终端嘛,我们再打开 vs 里面的插件试试看。插件, 呃,看一下,看一下它模型,看一下它模型,你看这是 oppo 的 四点七嘛,然后四点六,四点六,一百万三千万啊,还酷的我点点击切换这个四点六,我就想同意, 喂,你看它的,你看,再去看看谁的数据点 还没更新,爽。你看你看你看你看你看,一句话百分之五,看到没有?卧槽, 你看刚才模型一切换,他又一句话,干了我百分之五。昨天我用的是 oppo 的 四点七嘛,一句话干了我百分之七还是百分之八嘛?所以这个东西我该怎么用?我是去升级 kimi 的 会员还是还是怎么样? 你们有没有这这种问题?还是说这个是好事还是坏事?
28zZ.Mao 01:26查看AI文稿AI文稿
01:26查看AI文稿AI文稿学 ai 的 这个视频认真听完啊,我现在几乎是放弃了所有 cloud code 啊,虽然 cloud code 目前还是最强的啊。那 oppo 的 四点七,我感觉整个的升级并不大,但是啊,消耗的越来越快了,我甚至我有一天我就问了几个问题就结束了。我现在基本上放弃 cloud code, 全部选择 codex。 那么我给大家的建议就是一定要用最好的模型,当然 cloud code 跟 codex 目前,呃还会比 codex 要强一点,但综合能力来说,我觉得 codex 是 更强。然后接下来就是说,我跟你们说一下是为什么?首先, cloud code 对 国人很不友好啊,这个不知道他这个老板,他是抽了什么风啊,可能被百度这个 pua 抢了。 那,那现在反正只要是你,只要是频繁换 ip, 那 么 ok, 你 马上就会直接就打包回家了啊。我现在已经基本上就放弃 cloud code 的, 那么我现在转投了这个 codex 怀抱,那我自己搞了一个是五叉的这个额度,我,我是使劲的登啊,都登不完。那么在在此之前,我是一个没有任何呃编程经验的小白,我自己写了一个,呃, 我因为我自己做 tiktok 的, 做的 ai 视带货视频,我自己做了一个完完全全的,这一个的无线画布,全部是 codex 给我完成的。然后呢,呃,我 用到的一些工具,无非就是什么 super pro 啊,呃呃,包括 open design 啊,就是这些 ui 的 设计全部都是用 code 一 起完成的。虽 然 cloud cloud design 呢目前还是最牛逼的,但是很多人是已经把这个 cloud design 呢直接就是蒸馏了啊,变成了一个 skill, 一个 open design, 一个是华华语 design。 嗯,这这几个都是很强的啊。
2790OpenAiteach 00:50查看AI文稿AI文稿
00:50查看AI文稿AI文稿为什么 cloud code 明明没有干多少活,使用限制却掉的很快呢?很多人用 cloud code 啊,最亏的一笔账就是你还没开始做任务呢,额度已经花出去了。原因都是在于在你的 cloud md 里面写了太多的规则,项目规范,个人篇好各种提醒, 它看起来就像说明书,其实每轮啊都要被 cloud 重新去加载,你问一句,帮我改个按钮文案,他也要先读那几千个 token 的 规则。 只有像你每次打车去楼下便利店,都要先让司机绕成一圈。所以第一件事情非常的简单,看一下你的 cloud md 有 多长,能删就删,能放到具体项目的就不要放全局,真正常用的规则才留下来。 额度不够用,很多时候不是因为你的任务重,而是你的开场白太贵了,你学会了吗?
60AI 磊叔 01:24查看AI文稿AI文稿
01:24查看AI文稿AI文稿你的 cloud code, 百分之八十的 token 都白烧了。五个开源工具,从五个不同角度帮你砍 token, 你 看完就知道该用哪个 token, 消耗有三个黑洞,同一个文件反复读,必定输出几千行废话, ai 每次回复都是长篇大论,一次会话轻松烧掉十万 token。 第一个 open wolf, 从文件读取成省 token。 cloud 是 盲人,不知道文件里有什么,只能一个个打开看 open wolf 怎么省。它在每个文件前面贴一张标签,写清楚内容和大小。 cloud 看一眼标签就够了,不用真的打开文件,同一个文件重复读,直接拦掉。大项目实测三点四兆语言成省元原理,强制 cloud 用原始语言回复, 砍掉所有。让我解释一下希望这有帮助的废话,只保留代码和核心数据。六十九个 token 压到十九个技术信息,一个字都没少。平均省百分之六十五,最高百分之八十七。第三个,八 k, 从命令输出成省 token, 它坐在终端和 ai 之间,拦截命令输出,再压缩四招,过滤噪音,分组聚合截断笼鱼,折叠重复。 cargo test 从一百五十五行压到三行。 it push 从十五行压到一行, cloud 根本不知道输出,被压缩过三十分钟,绘画一百一十八 k 降到二十四 k。 第四个 router, 从模型路由成省 token, 在 cloud 和 api 之间加一层代理,根据任务自动选模型,简单编辑,交给 deepseek, 后台任务用本地模型免费跑,只有真正需要才动用 clod, 花费直接砍百分之七十。第五个 token evisions, 从 prompt 乘省 token 原理写几条规则,放到项目的 c l a u d e m d 里, clod 每次启动自动读取, 比如不要说 sure 和 great question, 不要复出问题再回答,不要过度设计,先读文件再动手,零依赖零配置,复制一个文件就行。省百分之二十到三十五个工具,五个角度。 openwolf 砍文件,砍输出废话 r t k 砍命令噪音, router 砍模型花费 token efficient 砍 front 笼鱼按需选,不要全装黄金组合, r t k 加 pavemett 直接砍掉百分之八十五选对工具才是真正会用 ai 的 人。
 01:59查看AI文稿AI文稿
01:59查看AI文稿AI文稿cloudco 里面建国产魔性的坑你们踩了没有?今天我告诉你怎么避开这样的坑,顺便教你一个方法,能够省下百分之六十到百分之八十的 token 消耗。 先说第一个问题,大多数人装完 cloudco 的 以后呢,默认就会打开 opus 四点七,这就像打车一样,不管是三公里还是三十公里,都是用专车。同样一百万个 token 的 消耗呢, hikus 四点五和 opus 四点七的成本相差大概整整五倍。但其实呢,百分之九十的日常任务我们都可以用 hikus 去完成的。正确的做法呢,就是分档用,也就是大小模型结合使用,文件啊,格式转换啊,日常使用,我们就用 hikus 写功能写代码, debugsonit 也够了,要设置架构,能大型的重构和大型的角色,我们才上 opps, 就 这个习惯,能让我上周的账单直接省了百分之六十。也有一个开发者呢,记录了他一天三百多个工具的调用呢,通过大小模型结合的方法呢,帮他省了最高百分之八十五的头肯消耗。 那国产模型呢,它是真的便宜,最大的差价大概有三十五倍左右。它的坑主要有三个,在 cloud 的 a 键循环里面呢, 国产模型工具调用的格式经常会出错,导致它的循环直接中断,但它比较大的 代码库进行分析的时候呢,也很容易迷失方向。还有就是有一些模型,它是不完全支持 claudio 的 原生 skill 的 体系的。 一句话总结呢,就是价格便宜,但是跑得不稳定,重复修改的次数一多呢, top 也就翻倍了,它反而其实也没有这么便宜了, 所以呢,解决的方法呢,就是要尽量让他去跑简单的任务,我们大量百分之九十的任务都可以用国产模型去解决,复杂的项目呢就不建议了,这样的话也可以帮你节省不少的 token 成本。 这期的核心就一个词, token efficiency 资源效率,用对的模型比用便宜的模型更有性价比。
33超级 Evan 04:39查看AI文稿AI文稿
04:39查看AI文稿AI文稿为什么我一直不建议大家用中转站去跑 cloud code 呢?很多人第一反应可能是模型产水、数据安全或者账号的稳定性。这问题当然存在,但今天我想讲的是一个很多人都忽略的点,就是提示缓存。 hello, 大家好,这期视频专门讲一下为什么中转站会让 cloud code 的 缓存率变差,希望大家帮忙点赞、关注收藏。 那什么是提示词缓存呢?模型服务端发现很多次请求的开头部分的提示词相同的时候,就会附用这部分已经预处理过的结果,避免每次都会从头处理。缓存的是提示词的前缀,而不是回答,它不会附上一次答案,也不会让模型记住东西每次输出还是重新生成。 缓存要写命中的要求就是前缀一致。所以 agent 的 提示词应该把稳定内容放在前面,把动态内容放在后面。工具定义 scam system prompt, 顺序也要固定。 agent 的 工具很多,规则也很多,上下文很长,每轮请求的时候都要带一大坨固定的内容 缓存,命中之后就可以很大程度地去降低你输入的成 token 成本跟延迟拷 code 的 每一轮对话,它其实并不是只是把你输入的那句话发给模型, 他会把很多东西一起带上。比如系统提示词工具描述 m c b 的 工具定义,查找点 m d memory skills 历史对话工具,结果读过的文件内容甚至项目结构信息。所以你在终端里可能只是打了一句继续修这个 bug, 但真实发出去的请求前面可能已经挂了十几万甚至几十万的 token。 如果每一轮都让模型重新读一遍这些东西,那一定就会慢,也一定会消耗更多的 token。 这就是为什么 cologne 跑长任务的时候,原生的体验会比较顺,因为它不是每步都从零开始稳存命中高的时候,你会有两个很明显的体感。 第一个就是它响应会变快,首字出来的更快,工具调用之间衔接也更顺。第二个是成本低,缓存读取通常会比普通的输入便宜很多,真正贵的是每一轮都重新写缓存,重新计算一大段的上下文。而中转站最容易破坏的恰恰就是提示词缓存。 因为提示词缓存有一个非常严苛的前提,不是内容差不多就行,也不是语义一样就行,而是请求开头的 prefix 必须精确的一致。 你可以你只要理解成请求,对前面一整段的内容必须一模一样。一个标点变了,一个工具顺序变了,一隐藏的字段变了,都可能导致缓存读不到。一旦读不到缓存, koot 就 会从接着上一轮继续工作,变成了这一轮重新读一遍上下文。这时候你看到的现象就是,首资变慢了,攻击调用变慢了,长任务也越跑越拖。 那为什么中转站的缓存率天然的很低呢?第一个坑就是账号,而是一堆账号搭建成的账号池。 为了加载均衡,第一轮可能把你的请求发到 a 账号,第二轮发到了 b 账号,第三轮又发到了另外一个账号。这对普通聊天可能影响不是很明显,但对 t s 缓存来说,基本上就直接断了。你这一轮换了路由,路由上一轮的缓存自然就堵不到了。第二坑就是模型路由不稳定, tt 缓存是按模型隔离的, sorry 的 缓存是不能给 oops 用的, oops 的 缓存也不能给嗨酷用。如果中转站后台做了模型映设,盲时降级自动化模型,你表面上还在请求同一个模型,实际上后面可能已经换了,那缓存链条也就断了。 第三个坑就是动态字断。 call to code 的 请求里会带一些动态的信息,比如每次都可能变化的 bing header, c c h 字断,或者其他的一些原信息。 官方的服务端他知道哪些子段应该参与缓存,哪些子段不应该影影响缓存,但很多第三方的 azure pivot 金融代理不一定能处理的这么细,他可能把这些动态子段也当成普通的系统推送的一部分。结果就是请求最前面的那一块,每一轮都在变,前面一变,后面再稳定也没有用。第四个坑就是 catch control 丢失 astropyg 的 提示词。缓存不是随便把一段文本存起来就行,它是需要 catch control, 也就是缓存断点。服务端要知道哪一段是稳定内容,哪一段应该被缓存,哪一段是每轮新增的内容。但中转站在做协议转换的时候, catch control 可能会被丢掉,被放错位置或者被简化。这个东西一旦处理错,缓存命中就会非常的难看。 你看到有些中转站,它也会显示缓存的价格,它会告诉你缓存命中更便宜。但问题是,如果它本身就很难稳定的命中缓存,那这个便宜其实也就没有什么意义了。你每轮都在重新读项目,重新算上下文,重新让模型进入工作状态。最后的体感就是可拷口的变慢了,工具调用变卡了,常人我不连贯了。 所以我对中转站的判断很简单,如果你只是偶尔的聊聊天,影响可能没那么明显。但如果你是把可拷口的当成主力开发的工具,长时间去跑项目, 读仓库,改代码,跑测试,那我不建议你用中软站。中软站一旦破坏了缓存,你损失的就不只是头肯的价格,你损失的是速度、连续性,还有 agent 词工作的稳定感。以上就是本期的全部内容了,关注我,了解更多 ai 编程工具的真实使用经验。
124小梅同学 07:221.3万张司机在路上
07:221.3万张司机在路上 02:00查看AI文稿AI文稿
02:00查看AI文稿AI文稿六分钟一百多块钱一个二十字的问题,那我的 ai 账户直接扣成负数?我最近一直在用 cloud code, 刚好看到一个博主开源了一套挺火的商业诊断方法论,我觉得挺有意思,就去 github 上把它的这套工具,也就是它开源的一个 agent skill 下载到了本地,准备体验一下。 结果没想到当时我启动了这个 skill, 随口问了一句我如何可以弄清楚 ai 时代的红利这个概念? 就这一个不到二十字的问题,触发了这套开源工具的死循环。我在屏幕前看着他好像只是卡住了,默默思考了快六分钟。但 在后台,他其实正在疯狂消耗我的头壳。因为这套工具里有一个叫概念结构的模块,他处理不了红利这种偏宏观抽象的词汇,导致处理失败。接下来,最恐怖的烧钱操作开始了, 他陷入了工具调用死循环。就好比那一个愣死里的,能去解一道无解的题,他每失败一次,就会把错误日制叠加在原本的对话记录上,打包成一个越来越长的文本,反复重试。 大模型的 api 可是按字数双向计费的,每一次重试,发送的字数都在成倍增加,短短六分钟不到,一百多块钱的余额直接被抽干扣成了负数。 所以我还是建议大家,第一,一定要去 api 控制台设置每日消费上限。还好我这次账户里只剩一百多元的额度了,不然这波估计得亏账。只要是涉及到跑 api 的 ai 工具,最好还是先给自己钱包上把锁。 第二,可以根据你的任务复杂度来预判时间。如果像我这样,明明只是抛出了一个简单的单据没动静,那他绝对是卡进死循环了。这时候建议立刻物理打断,及时止损。 第三,如果你自己开发套件,一定要加上垄断机制,明确限制工具调用失败后的重试次数,毕竟代码跑进死循环最多也就是费点电,但 ai 跑进死循环,那是真在烧你的钱啊! 最后,为了这一百大洋,我也发条视频纪念一下。各位在使用 ai 的 时候有交过哪些离补的学费,也可以来分享一下。
11立青木木 02:15查看AI文稿AI文稿
02:15查看AI文稿AI文稿大家好,今天是视频记录一百天的第六十九天,今天聊一下自己最近一个月使用 cloud code 和 codex 的 一个用量情况吧。 这个用量的统计其实来源于龙虾,作者 peter 发布了一个工具 products bar 在 统计的一个数据来源,大家如果说感兴趣的话,可以装一下这个工具,来看一下自己的一个使用情况。 第一张图其实就是自己库尔德斯的一个使用情况,可以看一下,如果按 api 计费的话,基本上就是一千五百多刀,完了,一点九 b 的 一个头肯用量的一个情况。 完了,可以再看一下这个 polo 的 一个情况, polo 的 最近一个月基本就是按 api 计费的话,就是三千五百刀, tocan 用量的话,基本上就是八币的一个消耗情况,那两个工具叠加起来基本上就是五千多道的一个按 api 计费的费用,再加上九点九币的一个 tocan 消耗用户量。 完了,其实自己前期其实用 cloud code 的 比较多,之前是两百到的一个额度,完了, codex 之前是二十到一个月,但是其实之前也有聊过,现在的订阅机制已经 调整了,现在是 codex 是 两百刀, cloudcode 的是一百刀,都走的订阅用户的模式,没有按 api 计费。如果说按我之前这三十天的一个使用,按 api 计费的话, 费用还是相当的夸张。完了,就把自己的这个用量去 gbt 上搜了一下,大概是一个什么样的一个水平。 gbt 大 概给了几个 档位吧,基本上按我现在九点九 b 的 话,现在的一个档位基本上就是接近个人 agent farm 的 一个用量了。好吧,那今天就先聊到这里,谢谢大家,再见。
 03:08查看AI文稿AI文稿
03:08查看AI文稿AI文稿随着 ai 越来越智能,它可以干很多复杂的任务,但是它带来的货就是托管的消耗会越来越快。给我的感觉就是说我在使用 cloud 的 过程中,我会经常去执行 space 命令,去看一下我的整个托管的消耗怎么样。因为我现在其实慢慢也有一些托管的使用焦虑,因为我会担心一旦触及了五小时的一个限制以及一个礼拜限制,那其实我什么事情都干不了。 所以我一直在考虑一个问题,除了去升级套餐,去获得更大的托管的一个额度之外,有没有其他的工具或手段可以在不降低生成质量同时去减少用户的消耗?最近我其实发现两个比较好用的一个工具分享给大家。第一个叫 windows code, 它其实是一个 cloud code 的 一个插件,它是安装很简单,只要执行两条命令就可以了。 可以看到安装完这个插件之后,它的性能、速度以及它使用的消耗其实都得到了一个优化。第二个工具其实就是说 it, 它的使用也比较简单,也是执行一个命行工具,需要脚本,它就会在你本机上去安装对应的一个软件 就可以去使用了。它其实支持的整个平台会相对来说比较多,拷扣的拷链,拷扣的都是支持的。你再去运行 cloud 的 时候,你只要在前面加上 edge launch 这两个字例就可以了。这次你在 cloud code 中去使用了 mscode 的 这个 plugin 之后,你可以看到的一个效果,它这边会统计,也可以帮你节省了多少的一个费用,以及 对应的售后情况以及使用时长,它其实主要会有一个看板,通过看板可以看到你的整个的一个费用相关事情,因为它其实并不是一个打印的方式去安装的。我们来对比一下这两个工具的一个区别,最大的区别就说 vsco 的 其实是一个插件,与它其实是一个网关的形式,它其实并不是部署在你本地的。 第二块就是说它的整个压缩原理,那 which code 它的主要的一个压缩方式是说通过减少你跟 l n 的 一个调用次数来去节省你的 token。 它的主要的一个节省方式是说去压缩你的字值,去清除一些没用的东西。目前 which code 是 只支持它的 code, 那 它其实支持很多 l n 客户端。在成本方面,目前通过数据看, which 的 整个压缩比会更高一些。 which code 的 个部署方式会比较简单,因为它就是个插件,但是 which 你 是需要单独去维护这么一个网关符的。 最后一个关于说压缩稳定性上面,那 vsco 相对于 ig 来说,它的确定性会更高一些。看一下技术上的一个差异啊,即刚讲到说 vsco 的 整个去节省头等的方式是通过跟 l n 的 一个对话次数,那其他主要的一个工作流程是包括比如说拦截工具调用, 比如说去批量化的一个编辑建议,以及说识别一些纸图的任务。针对这种认为使用更便宜的模型,通过这种方式来去节省你的头层的消耗。其实是说在每次这个问答过程中,它其实会删除一些重复指令,去删除一些没必要之段去压缩整体的格式,跟大模型去交互过程中的整个 test 的 内容会更少,从而去 降低你的头层的一个使用。在扩展性方面, which code 其实会比 i g 会更差一些,因为它其实跟你使用的 l n 工具是深度合在一起的, 它并不是一个简单的一个 plugin, 它其实去改变了你去调用 a 帧的时候, a 帧的一个执行流程,而且扩展性其实会更大一些,因为它其实不挑你使用的 a 帧是什么,它因为它其实是一个通用的,它只是去压缩你的一个 context 的 一个相关内容而已,去删除一些无用的数据。 目前我会把 edge 跟 winco 的 都会安装到我的 color code 里去,因为它们本身并不冲突。一个是 party, 一个是代理网关。目前给我的使用感觉来说,至少我会觉得我兑换次数会比过去更多一些,我的后亏消耗并没有像以前那么快。
 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿用 ai 编程,爽是爽,就是账单看着心疼。每次问个小 bug, ai 都要先给你写一大段客套话。今天介绍这个六万星标的神器,教你如何从大模型嘴里抢回美金。 caveman 这个插件的逻辑简单粗暴,强制 ai 用原始人的方式说话,没有废话,没有寒暄,只说核心逻辑和代码,直接砍掉,大量偷肯消耗。 他甚至内置了文言文模式,利用汉字极高的信息密度,把百字解析压缩成一句话,省钱省到有点离谱。如果你是高频使用自动化工具的极客,或者公司内部跑了几百个 a, 整这个插件,一周就能帮你省下非常可观的 api 费用。 他不只是一个梗,而是一套完整的提效工具链,完全免费,一行命令就能装到你的开发环境里。 ai 时代,真正昂贵的不是模型本身,而是每一次被废话浪费掉的上下文等待时间和推理预算。赶紧把这个神仙插件装上,把省下来的 api 费用拿去喝杯咖啡吧!我是带你每天半小时看透前沿 ai 的 酋长 andy 下课!
58AI酋长Andy 02:33查看AI文稿AI文稿
02:33查看AI文稿AI文稿我的一句你好,烧了三万 token。 先说一下 token, 它是 ai 的 计费单位,就像手机话费按分钟计算一个道理。 ai 按 token 计费,我平时习惯用 call 的 写文案做分析,前两天看了一眼后台,一句你好, token 消耗了三万,第一反应是平台是不是算错了?一查还真没错, 就像一分钟的电话,扣了十块钱话费。但最坑的不是钱,是 ai 在 变笨。我一开始以为啊,是服务器波动,后来查了资料才搞明白,问题就出在上下文。我用 cloud, 从第一天起从来没有压缩过上下文,什么意思? 聊了十轮,二十轮,所有历史对话每次请求都在重新发送, ai 每回复一次,都得把前十几轮的聊天记录全部读一遍再开口。这个坑拆开就三件事。第一, 上下文越滚越大,就像滚雪球,每次对话他都会把历史全带上,聊得越久包袱越重。第二, tok 越烧越多,同一句话,第一天一百 tok, 聊了二十几轮之后变成了几万,因为 ai 每次都要把历史全部读一遍。第三, ai 越聊越慢,读的内容多了,响应就慢了,有时候半天憋不出来一个字,不是 ai 不 行,是你把废话全部喂给他了。 压缩上下文之前,问个简单问题就要等十几秒,压缩之后它就秒回透问,消耗也降了十倍以上。同样用 a a, 有 人一个月花一百,有人花五百,差别全在三个字,清分写。第一清清就是清上下文,用 call 的 话输入 compt a a, 自动把历史压缩成这样。 聊了十轮以上就压缩一次,没用的话直接清掉,别让废话占着上下文。分就是分对话,写文案,开一个窗口,写代码,开另一个,别把所有的事塞在一个对话框里,每个窗口只留当前任务的对话。写就是写配置。 cloud 有 个 cloud 点 m d 的 文件,把常用的要求写进去, ai 每次自动读取一句话,能搞定的事情不用每次都写十句,三个字清分写,记住就行了。省 token 不是 抠门,是让 ai 把算力花在该花的地方去。我自己按这套方法用了两天, token 降了大概百分之八十。最意外的是, ai 的 回答质量反而更好了,不用 ai 在 一堆废话里找重点,回答的自然回答的更加准确。 ai 好 不好用,不光看工具多强,更看会不会用之前烧的全是冤枉钱。如果你也在用 ai, 建议现在去看看上下文是不是该清理了。评论区聊一聊 用 ai 的 时候有没有越来越慢的感觉,下期讲一讲 call 的 点 m d 怎么配置,让 ai 自动记住你的片号。好了,今天的视频就到这里,我们下期再见。
19阿东AI实验室 01:41查看AI文稿AI文稿
01:41查看AI文稿AI文稿你有没有想过,用不同语言和 ai 对 话,背后的 talkin 成本天差地别?以 xrogic 的 cloud 为例,表达相同语义,中文 talkin 费用是英文的一点六五倍,这笔额外支出被称作分 词税。近日,研究员 alan colmas sacky 将经典论文苦涩的教训译成九种语言,输入六大模型,分词器彻底揭开了记费黑。 club 上印记与 tokken 消费是英文的三点一一倍,缅甸傣文更被刻以十五倍抛离税。这并非语言本身的问题,同样一段中文, timi 仅消耗英文的零点八一倍, tokken 同意谦问零点八五倍, deepsea 零点八七倍,谷歌 jimmy 几乎持平零点九八倍, open ai 也才一点一五倍。国产模型不仅免了中文税,效率反超英文,直接推翻了中文天生被 tokken 的 说法。而且分词税的代价还远不止多出 百分之六十五,就意味着你花钱买的上下文窗口就要直接打六折。比如 cloud 飙升的三十万字容量,中文用户实际能输入的内容还不到二十万。更讽刺的是,今年四月份 cloud office 四点七上线,官方轻描淡写的一句,新分子 器可能多耗百分之三十五套餐,就让英文用户的使用成本却暴涨百分之一百二十四到百分之一百六十三。二百美元的 max 套餐,只要两小时就能轻松烧完。而中文用户这次反而 幸免,因为我们的分词税早已封顶,再无上涨余地。这让人想起三十年前的短信,英文一条一百六十字母,中文只能发七十个。每一代技术基础设施的红利,总是率先流向开发者的母语 b p e 算法、公开词表和训练数据全由厂商制定, timi 能做到零点八一 倍,可 loft 却做成一点六五倍。不是技术不行,而是国外厂商的傲慢与偏见,让他们从没把非英语用户放在心上。
4737烦烦老陈 02:25查看AI文稿AI文稿
02:25查看AI文稿AI文稿我最近戒掉了一个坏习惯,就是跟人闲聊,因为我发现很多时候闲聊实际上是在消耗你的认知。因为跟人闲聊有三个结构性的缺陷,第一, 对方的认知边界就是你们这次对话的天花板。第二,人的本性是维护自尊和争输赢,所以大多数时候的对话最终都在维护分析,不再解决问题。第三,你说出来的想法,对方会以他的经验框架去解读,而不是帮你把你的逻辑想清楚。 大多数的闲聊之后,你得到的是情绪的波动,而不是认知的推进。但是和 ai 闲聊,本质上是一种结构化的思维训练,你把一个没有想清楚的问题说出来, ai 呢,会帮你去拆解它的结构,找到你逻辑里的漏洞,给你提供你视野之外的角度。这个过程不是在获取信息,而是在重建你看问题的方式。 长期做这件事情的人和不做这件事情的人,思维的密度会拉开很大的差距,但是工具决定了上限。市面上的大多数 ai 本质上是解锁型和情绪型,你问,他答,你不爽,他道歉。对话到此为止。 但是我用遍了全球大大小小所有的模型,我发现 cloud 不 一样,它是推进型的模型,具体的差异表现在三点。第一,它会分辨你问题的层次, 你说的是表层的问题,他会帮助你往下探,帮你找到你真正想解决问题是什么。第二,他不会为了让你满意而顺着你,即使你的判断有漏洞,他也会指出来这一点。大多数的 ai 做不到,因为大多数的 ai, 他 们被训练成了让用户满意,而不是让用户正确。第三,他的回应有立场,而不是中立的信息堆砌。 他会告诉你他的判断是什么,同时告诉你他判断的依据,这种对话才有推进感。这三点加在一起就是为什么你跟 close 聊完,你对一件事情的理解和聊之前是有完全不一样的感受。 但是我还要再告诉你,工具再好,聊天的逻辑不对,效果也会大打折扣。所以我还要告诉你三条核心的逻辑,第一条,你的输入一定要完整,不要只给结论,一定要把你的处境。你要让他追问,你 直接要答案,你得到的是他的判断,你要让他追问你的话,得到的才是你自己更深层的判断。第三,每一次聊完要做一次总结,你要让他用两到三句话帮你去总结这次对话之后,你对这件事情的判断发生什么变化,这一步才能让你真正把认知给沉淀下来,不然聊完就散了。 当你把这三条逻辑用熟了之后,你会发现你跟 ai 每次对话都是一次有密度的思维训练,所以认知的差距本质上是思维训练量的差距。你每天用来无效社交的时间,换成跟 cloud 的 每一次的深度对话,三个月之后,你看问题的方式会发生很大的改变。
 02:10查看AI文稿AI文稿
02:10查看AI文稿AI文稿昨天在使用 cloud code, 发现它竟然限制了我的对话的次数,并且还有时间的一个提示,在什么时间之后才能继续使用。以及之前在创建新对话的时候,也做了这个新对话框的一个限制, 也就是你不能无限的发起新的绘画。那大家平时比如说使用国内的豆包或者 deepsafe, 应该从来不会出现这样的问题。因为现在国内大部分的像这样的豆包 deepsafe 的 软件,它还没有正式去进行收费。因为我们正常使用像这样的一个 ai 软件,一问一答,大概每次它都会消耗几千到几万的一个 token, 一个月下来 大概需要两百万到三百万的 token 数量,如果换成人民币可能就有几块钱的价格。顾客可以简单理解为和 ai 对 话的计费单位。比如你说了一段话,我今天吃了一碗面,味道很好,一共十二个字和两个标点,那它大概就是十四个 token。 另外我也发现了,如果你一次性给 ai 太多的文字, 那他在回答你的问题的时候,他可能只会读取你的一部分信息。比如说你一次性给他七十万的文字,让他进行处理,那他能力可能只能读三十五万,那他给你的答案可能需要你自己去斟酌一下。刚才说的是我们平时跟 ai 的 一些日常的对话,可能不会说消耗太多的 token, 但是如果大家最近在用,比如说智能体, 那他跟平时的对话的区别就是他可以有自己的规划,执行,再反思再执行,说白了就是可以消耗上百万的 token, 所以 我也有去对比不同模型之间的价格、 稳定性以及他处理的一些领域。正常我们考察一个模型,基本上就是他的稳定性,模型能力以及价格。那你想要稳定性好,模型强,价格必然会贵,但你想要便宜的话,就会牺牲他的能力跟稳定性。目前看下来,科二虽然说模型能力很强,但是他目前也会面临封号的风险。另外如果买中转站的话,中转站也会有跑路的风险, 以及中转站会有模型准确性的一个问题。除了 cloud code, 国外还有一个是呃 x, 那 它的好处就是相比于 cloud code, 它里面会开放更多的第三方的模型啊。缺点就是它的处理速度肯定相对于 cloud code 会慢一些。如果要追求性价比,国产的像 kimi, 如果说正常的使用它跟 cloud code 差别并不会说特别大。另外就是像 glm 的 价格 相比 kimi 会更,但是可能处理速度没有 kimi 那 么快,优点就是它什么工具都能够往里接。那针对现在主流的 ai 模型,我也做了一个表格,以及它的使用场景、价格的一个排序,如果大家有需要的可以看一下这张表格,选择适合你的 ai 工具。
31蛋饼 00:45查看AI文稿AI文稿
00:45查看AI文稿AI文稿用科二扣子写到一半跑去倒水,回来发现他卡在耶索尔诺等你确认有多少人和我一样效率没提上来,耐心先被消耗光了。现在不用等了,科二扣子那只裁判模型安全操作直接放行,有风险的操作停下来问你。真正危险的操作直接换条路干, 就像机场安检,普通行李直接过,有疑问的开包查,危险的当场扣下。有人问,万一裁判判断错了怎么办?放心,连续判断错误三次,它会自动退回普通模式,不会一条道走到黑。 怎么开启终端?输入 call of the naval auto mode, 或者绘画里按 shift 加 tab 切换 auto mode 以后倒水回来,它已经把活干完了。


