怎么清理sdk环境变量
不知道你们电脑出现过这种情况没,你看就是用了英伟达的显卡,但是任务管理器里面占用 cpu 非常的高,达到了百分四十到六十左右,就是这个程序, 你打开右键,打开所在位置,这是一个英伟达的监控程序,教大家如何卸载这个插件,你就点击开始菜单,然后点击设置左侧,我们点击这个应用,然后一直往下拉,英伟达捆绑了好几个插件,占用性能最大的就是这个 video frame view, 点它的更多选项选择卸载。还要再提醒你一遍,我们选择卸载,然后及时卸载完成,我们点马上重启就可以,重启完之后我们再看一下,已经正常了。

粉丝13.0万获赞524.9万
相关视频
 04:13查看AI文稿AI文稿
04:13查看AI文稿AI文稿一天一个计算机知识,今天要讲的是 sdk, sdk 是 什么?它有什么用呢?想象你是一家游戏开发公司的老板,你想开发一款跨平台的角色扮演游戏,游戏要在手机、 电脑等多种设备上运行,但不同的设备系统,像安卓、苹果的 ios 系统,还有 windows、 mac 系统,它们的开发环境和接口都不一样。 如果让你的开发团队从头开始针对每个系统去编辑适配代码,那工作量简直是个无底洞,而且还容易出错,开发周期会变得超级长。这时候问题就来了,有没有一种办法能让开发团队更轻松高效地开发出跨平台的游戏呢?答案就是, s d k。 本地开发工具包我们先从简单的场景说起。假如你只开发一款在安卓系统上运行的小游戏, 安卓系统本身提供了很多功能,比如拍照、访问、通讯录等,但你要使用这些功能,就需要了解安卓系统底层的各种接口和编程规范。这就好比你要去一个陌生的城市, 你得知道这个城市的各种交通规则和道路信息。为了让开发者更方便地使用安卓系统的功能,安卓官方就提供了一套工具包,里面包含了各种开发所需的文档、 视力代码、调试工具等。这个工具包就像是一本详细的城市旅游指南,开发者拿着它就能快速上手调用系统的各种功能。这种针对单个系统或平台,为了方便开发者使用该平台功能而提供的工具包就是本地开发工具包。 有了本地开发工具包,开发者就不用再去深入研究系统底层的复杂细节,开发效率大大提高。通用软件开发工具包当你要开发跨平台的游戏时,本地开发工具包就不够用了, 因为不同平台的本地开发工具包是不一样的,你还是得针对每个平台去做开发,这时候就需要一个更强大的东西,那就是通用的 s d k。 通用 s d k 就 像是一个超级翻译官,它把不同平台的底层接口和功能进行了封装和统一。开发者只需要使用 s d k 提供的统一接口, s d k 就 能自动把这些接口翻译成对应平台能理解的代码。比如你在 s d k 里调用一个拍照的接口, s d k 会根据当前运行的平台, 自动调用安卓或者 ios 系统的拍照功能,这样开发者就可以用一套代码在多个平台上实现相同的功能,大大减少了开发工作量和难度。 s d k 的 功能扩展除了基本的功能封装和统一接口, s d k 还可以有很多扩展功能。 比如有些 sdk 提供了广告功能,在你的游戏里集成这个 sdk 后,它可以自动在合适的位置展示广告,为你带来收益。还有些 sdk 提 供了社交分享功能,玩家可以通过 sdk 把游戏里的精彩瞬间分享到社交媒体上,吸引更多的玩家。这些扩展功能就像是给 sdk 穿上了一层华丽的外衣,让它变得更加实用和强大。 sdk 的 维护随着技术的不断发展和平台的不断更新, s d k 也需要不断的更新和维护。就像你买了一辆车,过一段时间就需要去保养和升级, s d k 的 开发者会不断修复漏洞,优化性能,还会增加新的功能。作为使用 s d k。 的 开发者,你需要及时关注 s d k。 的 更新信, 把你的应用、你的 sdk 升级到最新版本,这样才能保证应用的稳定性和功能的完整性。 sdk 是 什么?好了,到这里我们就知道了, sdk 就是 软件开发工具包,它是一系列开 发工具、文档、势力代码等的集合,它的作用就是让开发者更轻松高效的开发软件,尤其是跨平台的软件。通过 sdk, 开发者可以不用关心底层的复杂细节, 只需要使用统一的接口就能实现各种功能。 s d k 在 很多领域都有广泛的应用,除了游戏开发,像移动应用开发、互联网开发等都离不开 s d k, 现在大家懂了吗?最后遗留一个问题, s d k 虽然好用,但在集成和使用过程中也会遇到一些问题,比如兼容性问题、安全问题等。下期我们聊聊如何解决 s d k。 集成过程中的这些问题,如果你感兴趣,记得持续关注。
371计算机觉授 05:16
05:16 06:25查看AI文稿AI文稿
06:25查看AI文稿AI文稿这个版面当中的知识,你都能够把它补齐的话,基本上要什么题目都可以解决了。说这个免疫系统和神经系统还有内分泌系统一样,他们是共同来维持肌体内环境的稳态的,那么免疫系统他有他自己的功能,他可以抵御外来病源体的侵袭,那体现出来他的什么功能? 对防御 ok, 很好,有一些衰老或者损伤的细胞,他也需要被清理掉,就体现出来免疫系统什么功能?这个是自我的稳定, 除了奸细才是监视,自己,人是不能监视的嘛。那如果说是对待那些异常的细胞,我们才体现出来免疫系统的监视功能。哦, 好,这三个功能呢?它对应的对象是不一样的,之所以免疫调节能够去完成这三个功能,跟它的结构是分不开的,结构和功能是相适应的。对于免疫系统的结构,它介绍的是分了三个层次, 就从大到小,我们必修一的那个生命系统的结构层次是对应的上的,对于个体来说,再往下一个层次就是器官,所以他先介绍了一些免疫器官,那这个比较少考,因为对于这些功能来说,起到最主要的作用的 还是这一个一个免疫的细胞,他完成自己的工作。那免疫细胞有哪些? b 细胞和 t 细胞,它都统称为对淋巴细胞。淋巴细胞是免疫细胞当中一个非常重要的组成部 部分,因为它行使了特异性免疫的功能。那除了淋巴细胞以外,还有一些细胞,比如说一些巨噬细胞、树突状细胞,这个是细胞层次的。在免疫系统当中起作用的 细胞有哪些?就叫免疫细胞,那再往下就到了分子层次的了,只要是能够起到免疫作用的分子,就叫做免疫活性物质。体验免疫的免疫活性物质是什么? 起作用的武器是抗体啊,那这个将细胞它之所以会分泌抗体,是因为 b 细胞接收到信号之后分裂分化而来的。 b 细胞活化有两个信号对,第一个是病源铁和 b 细胞接触,然后第二个跟辅助性 t 细胞接触,其中有一种信号分子是可以促进它的活化的,就是细胞 e 因子。细胞因子它虽然不直接对抗原或病原体起作用,但是它在免疫当中也发挥了一定的作用,那细胞因子也属于一类免疫活性物质。如果免疫系统想要去抵御外来的病原体,其实不是马上就启动特异性免疫的。第一道防线是什么? 对皮肤和淋巴,年字要会写啊。然后第二道防线就是吞,是细胞除了细胞以外还有什么?如果拿溶菌酶是没有分的, 你要打什么?对杀菌物质?因为不是只有溶菌,每一种杀菌物质跟吞食细胞是掉到防线,那溶菌酶也在免疫当中发挥作用,所以溶菌酶也算免疫活性物质。你不用单独去记免疫活性物质是什么,反而你要把这些物质各自有什么作用。搞清楚抗体什么作用,一个是 抑制了病原体的增值,然后第二个呢?抑制了病原体对宿主细胞的黏附。那如果让你去总结细胞因子的作用呢?促进 b 细胞和细胞毒性 t 细胞的分裂和分, 两个都还是要说 ok, 很好,其实对于免疫调节来讲,他要去完成这样的三个功能,不管你是抵御外面的人,还是说对自己的衰老细胞进行一个自我的维护,或者说监视出来异常的细胞,最核心的一个基础就是这些细胞他们之间要具备有 识别的功能,也就是信息传递。那这个细胞之间识别的基础,在课本最一开始他就提到了免疫细胞要识别出来是自己的细胞,还是 我们不是看他长什么模样的,那是靠什么对细胞膜表面的受体,也就是一些蛋白质来进行辨认的。能够去引起免疫系统产生免疫反应的物质,我们都把它叫做抗原,但抗原的种类就很多了,抗原他不一定是蛋白质,只要能够引起免疫反应的都叫做抗原。那这个细胞因子呢,它也成 现出来了另外一个功能。一休一的时候,我们讲细胞膜就讲到了情况,就除开包间连丝啊,有两种情况,一个呢是通过细胞分泌的物质,然后作用于另外一个细胞。一种情况呢就是两个细胞直接接触,而这两种形式呢,在免疫调节里面都有 b 细胞要活化,是要 b 细胞跟 辅助性 t 细胞相互接触,这个接触本质上来说就是什么,对,就是细胞之间通过细胞膜表面的分子进行信号传递,通过细胞因子可以促进 b 细胞的活, 那这个细胞因子就作为信号分子在不同的细胞之间进行信息的传递。所以免疫调节当中是这两种形式都有的。所以我说免疫调节,他如果想考难的话,难就难在这个功能基础细胞之间怎么样相互识别,怎么样信息传递,从分子层面理解透了,那他怎么样的一个情 境都不怕?我们肯定是希望免疫系统这三大功能都正常,他这种功能的失调呢?我们就把它叫做免疫失调,介绍了三种情况。 刚提了一个过敏,还有一个就是自身免疫病,还有最后一个就是免疫缺陷。好,先看自身免疫病吧。自身免疫病的发病原因是什么?很好,那说很好,他是说把自己细胞上面的一些物质当做是抗原,也就是分不清自己和敌人。先看免疫缺陷, hiv 这个病毒主要攻击哪 哪一类细胞?辅助性 t 细胞。那为什么攻击辅助性 t 细胞之后免疫系统会崩溃?哇,非常非常完美化。因为辅助性 t 细胞既在体液免疫当中发挥作用,又在细胞免疫当中发挥作用。 ok。 那 如果说他进一步的问你,辅助性细胞具体的功能是什么?膜化 b 细胞跟细胞,毒性 t 细胞,而且还可以分泌这个细胞因子, 它所有东西都串起来的过敏反应。是不是第一次接触就会过敏?不是啊,是再次接触的时候才会过敏。那为什么第一次接触的时候不过敏,第二次接触才会过敏呢?抗体然后跟过敏原相结合才会引发过敏反应。 为什么他们相结合会引发过敏反应?是抗体依附在肥大细胞表面。过敏原接触了抗体之后,抗体的结构不是会发生变化吗?它就相当于受了个刺激,受刺激之后肥大细胞会分泌什么?分泌组?所以我们很多那些抗过敏的药物就是抗组胺的,那 那阻氨会引起一系列的反应,比如说它可能会使你的气管平滑肌收缩,就哮喘,皮肤的血管舒张,对红肿。那这个阻氨为什么能够使全身都有反应?对,很好,因为阻氨它作为信号分子,调节身体的生命活动,所以这个过敏反应呢,它就比较典型的免疫跟体验。 而最后一个呢,就是我们在了解了所有这些免疫学的原理之后,我们就会想要把它服务于人类,它的应用一个是疫苗,为什么一般情况下器官移植都有排斥作用? 很好就意思的就可以了,因为一般来说那个组织相不考那个词,你只要意识到是因为不同的个体细胞膜表面的蛋白质是不完全相同的,这个就是身份标签,除非是双胞胎,否则一定会有排斥反应。那为了让器官移植成功,我们需要用到什么?免疫抑制这个词就是送分的词。 打疫苗,一般来说我们就,我们就讨论那个抗原疫苗,抗体疫苗我们就不讨论了。为什么二次免疫会更快,因为初次免疫的时候它就产生了记忆细胞和,这就是我们整个免疫调节的所有内容,这个版面当中的知识,你刚刚都能够把它补齐的话,基本上遇到什么题目都可以解决了。
1660懂点儿生物的地瓜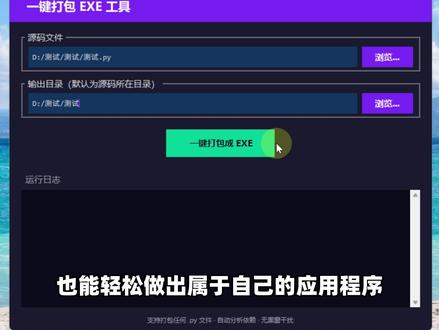 00:31查看AI文稿AI文稿
00:31查看AI文稿AI文稿不用再为写好代码,却不为打包成 excel 而烦恼。这是一款 python 一 键打包 excel 工具,能把你的 python 源码直接打包成可执行的 excel 文件,全程自动完成,包括检测当前开发环境、代码库、环境变量,如果发现缺失也会自动补齐。 操作日制全中文显示,执行过程中不乱码、不闪退、不弹黑窗。而且打包完成后,它会自动清理所有垃圾文件,只留下一个干净的成品。即便是零基础没有开发经验的新手,也能轻松做出属于自己的应用程序。
1220刺客边风(主页等你) 14:12查看AI文稿AI文稿
14:12查看AI文稿AI文稿嗨,朋友们大家好,欢迎收看帽子电子独家赞助的来实战栏目上,帽子电子海量新品授权延期件任你选。本期讲解的是 jetpack 与 sdk manager 是 什么?第二节课为大家讲解 jetpack sdk, manager 是 什么? 基于我们的配套的硬件, jason ajax 六十四及 kit 开发版。我们来详细地去讲解 jetpack sdk 是 什么? 什么是 jitpack, 用一句话总结,它就是 jason 官方完整软件的发行版。大家对发行版有所理解的话,就知道 android 包括树莓派它们都有一些发行版的系统,包括 ubandtwo。 那 jitpack 就是 jason 硬件平台的官方完整的软件发行版。 官方的解释是 luvia techpack, 是 luvia jason 平台的官方软件站,为您提供一套全面的工具和库,用于构建 ai 驱动的边缘应用。那 techpack 它的主要的特点有哪些? 官方统一的软件站,由 luvia 官方维护啊,兼容性强啊,更新一致, 深度硬件的优化,为节省 gpu, dla 和 isp 设计啊,性能发挥最优, 它开箱即用啊,刷机,既具备完整的 ai 环境,无需自行组合各类的库核驱动。 那 jedi 的 主键有哪些?在这里我为大家截取了一张 jedi 官方的截图,大家可以看到,实际上 luida 把 jedi 分 成了三个部分,一个部分就是 ai 的 软件站, 一个部分就是安全体系啊,一个部分就是操作系统。那这样去区分挪威的工程师对机的 pack 的 整理是非常恰当的。 那我们来一个个一个个的总结 ai 的 软件站啊,它包括了 qda, c u d n n t trenton 以及 i i m v l m vision transformer 的 模型支持啊, 它核心的作用就是提供节省上所有 ai 推理与计算的 gpu 加速能力啊,是 jetpack 最关键的 ai 基础层。 相当于来说 jetpack 的 ai 软件站就提供了 jetpack 节省系统需要的 ai 的 基础的 ai 模型, ai 的 架构和 ai 的 算力的组建的工具链。那我们来到了 jetpack 的 第二层 security 啊,安全体系, 这个也是 jason 系列平台硬件的一个非常大的特点,那挪威迪亚,他把 jason 的 安全体系也做了一次革新,让大家用起来更加的安全。这里就包括 secure boot, open t, tms, 内存与存储的加密等机制啊, 它的核心作用啊,就是保护启动链运行时与数据安全,让 jason 能安全地运行 ai 应用,并满足工业级的需求。 那除了 ai 软件这样和安全体系啊,我们也不得不提的就是那系统,如果没有系统的支持,那其他的都是空谈。由 jason, nilix ubox, 优邦 too, 雅克 too 以及 nilix kernel 六点八 r t 内核构成。 提到了这么多可以制作 navigator json 硬件平台的系统,那它的核心作用就是提供驱动内核文件、系统与实时能力,是 jitpack 运行所有 ai 与系统功能的底层基础。 让我们知道了 jitpack 它的主键之后,我们作为初学者,或者作为一个初级的没有接触过 jitpack 的 工程师,怎么去选择 jitpack 的 版本 在哪去选择?我们在这里也为大家归纳总结,为大家节省一些时间,然后去总结 gtepec 各个版本的特性。那 gtepec 的 版本有哪些?它主要是归纳为四点几,五点几和六点几,包括六点一和六点二,然后还有目前的七点几的版本, 那它也是不断的往上在升级革新,我们从它支持的内核和操作系统,包括它的特点和适用的场景,包括推荐的使用的范围来为大家去介绍。那我们最早的就是 gepic 四点几,那它支持的优邦 two 的 版本是四十点零八,内核的版本就是四点九, 这个是稳定,但相对于老旧,它还不支持 qd 乘以 r t, 大 模型几乎无法运行啊。就说 gspec 的 早期的四点几版本是无法运行大模型的, 仅用于老旧的 gs nano 的 和 gx two 的 维护,对于当下来说,我们肯定不会考虑就去用到啊。 gspec 四点几,那 gspec 五点几,它相对于四点几有一定的升级,它支持的优邦 two 二十点零四,内核是五点零的, 它支持 qda 十一, tesla r t, 适合传统的 c v 和 ai, 不 支持最新的 ai 站。相较于适合泽韦尔 orin 早期的项目, 还有 gepic 六点零,支持 uboxtwo 二十点零四的 mix 内核五点一五的, 它引入了部分的 jason 的 缩窄架构特性,支持更高版本的 qda 和 t。 它是属于一个过渡版本,所以不建议新项目使用它。 目前来说选择六点一和六点二是相对于来说最好的,它支持 uwanttwo 的 二十二点零四,内核五点一五,还支持更多的 qdax, 改进多媒体的站,性能稳定了,推荐用于需要稳定加新性能的通用项目。 那还有最新的 gps 七,刚发布不久的 gps 七,那支持浴缸 q 二十四点零四,内核是六点八,它也支持 a m v l m 大 型的 v l a m i g s d s i store 架构。 它的 ai 站相对于较为完整,强烈推荐所有的新项目啊,都使用它,我个人推荐是能选最新的就选最新的。我们来讲一下它怎么去安装它呢? 那努比亚提供了主要的两种方式去安装,一种就是 ios 镜像直接刷机,另外一种就是 sdk manager。 那 sdk manager 对 于初学者来说就是一个非常方便,非常好使的一个工具, 所以啊,推荐大家去使用 sdk manager, 这里也会完整的去讲解怎样通过 sdk manager 去安装努比亚接收的接的 pack, 那官方定义的 st manager, 它是为努比亚的接收 holoscan river, max, deeper, stream, gfx, run time real research, cloud, 以太网交换机 r a p i d s river 和 docker s d k 提供端到端的开发环境设置解决方案,适用于主机和目标设备。 大家可以看到屏幕下方的啊,一个完整的 sdk 的 部署的逻辑图,那 sdk package 是 从 levia 的 云端去下载到你的 development 的 environment, 就是 我们的 host 的 主机上, 通过挪威的 sdk manager, 然后先去 down load 到 host 的 本机之后,然后通过啊 flash s o 和安装你的驱动,包括 sdk 的 组建到你的最终的挪威的设备当中。这一条链路十分清晰,也很简单,就是主机中 down load 的 包括云端的 bsp, 包括 ai 的 模型的组建,这是一个很完整的逻辑。我们接下来去详细的讲解对于初学者来说,怎么去使用 sdk, 下载和使用 sdk manager, 我 们首先要从官方网站去下载安装包, 大家可以看到左边的这个图片啊,这里挪威利亚支持了多个平台的 sdk manager 的 管理器的 package 的 下载, 选择对应主机后,即可一键点击获取 sdk 麦尔杰的安装包。那这里有 david docker ubox, 包括 windows, 包括红帽 这些,你的主机都可以选择相应的版本。然后在这里我也为大家拍了一张图片,在右侧 ppt 的 右侧。这是如何去连接你的开发套件? 通过啊,你的 type c 网线或者你的 d p 这些的连接,完成你的 host 的 主机和设备的连接。准备,你的 sdk manager 将要部署 gepic 的 一个硬件环境,将 jason 连接到主机啊, 并按照要求进入到 recovery 模式啊,即可一键完成系统的刷机啊,驱动的安装以及与 sdk 组件的配置。大家可以看到其实这里硬件的连接非常之简单, 所以这 sdk manager 去安装接着 pack, 对 于初学者或者是刚接触节省平台的学生和工程师是非常合适。那我们在这里也一步步去讲解整个安装的流程。 sdk manager 实战部署的第一步,在连接好接审设备之后, sdk manager 的 step one 主要完成三个内容,选择产品的类型为接审指定目标接审模块的型号。 当你进入到 recovery 模式之后,你的 estate manager 的 step one 的 屏幕界面上会自动弹出你需要选择的节省模块的型号,并选择对应的 jettpack 的 版本。那我们在前面也介绍过了 jettpack 的 版本的选择,根据你的需求去选择 确定系统将以哪一套软件与驱动进行刷写,那这就是我们要部署 jettpack 的 第一步。 那完成第一步之后,我们进入到了 step two 和 step three。 第二步和第三步,我在这里一起讲解。在完成了 step one 的 产品类型, jen 设备型号与 jenpad 版本的选择之后,啊, step two 会让我们进一步选择需要安装的 jennex 运行时主键,如 qda 叉,十 r t, multimedia 以及主机测 sdk 的 工具。确认这些主键后,点击 continue, 系统便自动地进入到了 step three, 也就是步骤三,开始执行实际的下载,制作系统镜像,并对 jason 进行刷机与部署。相信这样的一个我在这里展示的两个图片啊,已经很清楚地描述了这个刷机的流程, 就只有一键,点击或者选择。通过 step two 的 界面去选择你需要的主键和你需要的 ai 的 模型,包括你的架构,包括一系列的软件栈。 实际上这个刷机的流程是非常的方便便捷。所以啊,这也是 louisiana 因为它它能够把 jason 这款产品做的这么成熟,这么 popular 的 一个原因。那完成 jason 的 部署之后,我们还需要去验证。 那在完成了 step one 到 step three 并创建好了节省设备的系统用户之后,啊那 step 四会展示本次刷机与安装的完整的结果,包括节省 linux, qda, 腾讯 rt, multimedia 等组建的安装的状态。 刷写完后,啊通过接收的 d p 接口连接外接的显示器即可进入到优邦 two 的 界面。若能够在显示器上看到 gteck 自动安装的各类应用与工具,就表示啊整套的接收的 linux 系统以 gteck 的 软件已经成功地部署并可以使用了。 在这个 ppt 的 啊下方啊,我给出了 step 四 sdk 软件安装完成之后的一个静态的图, 它就是正确的安装 gigapad 之后应该显示的样子,包括右下角的 ugone two 的 系统的图片啊,大家可以看到这就是安装完后你的节省设备重启起来之后应该看到的系统桌面的样子。如果来到这样的一个图片,那表示你的 gigapad 已经成功的安装完毕, 你可以进入到下一个阶段。那讲完这些,其实本堂课程的内容实际上啊,非常明确,就是讲的 techpack 和 sdk manager, 但是大家也不要小看这两个东西,这是大家学习 jason, 学习英伟达这样强大边缘计算平台的一个基础。那我们来回顾一下本节课程。本节课程系统的讲解了 jitpack 的 完整的概念体系,包括其作为 jason 官方软件站的组建结构, ai 软件栈,安全体系,操作系统层,以及在 ai 推理、 gpu 加速与系统支持中的角色。同时介绍了 the video sdk manager 的 功能定位,安装方式与实际刷写的流程。 通过 step 一 到 step 四,展示了如何为英伟达设备节省平台部署完整的 jitpack 的 环境,并最终在外界显示器上验证 ubox 系统与 jitpack 供应链运行的成功与否。 那本节课的重点还是在于掌握 getpack 各主键之间在系统中的作用,以及 sdk manager 的 四个步骤的逻辑顺序。 难点在于理解主键之间的层次关系,以及刷写过程中版本设备与软件这样一致性的重要性。 我们在后期的学习中,我们会对 java, 包括 java 整个系统会越来越熟悉,大家回过头来再去看这个 java 的 主键和层次关系的时候会越来越清晰。那课程的拓展就在于掌握基础部署流程后,进一步熟悉不同 java 版本的差异与升级的方式, 以便更稳定的管理项目,在 java 的 软件环境的运行中更加得心应手。那本节课程的内容就到此结束。 以上就是我们今天讨论的全部内容,感谢大家收看!由茂泽电子独家赞助播出的来实则栏目下期的内容是 l four t 与 jason 系统架构。
2与非网 13:11查看AI文稿AI文稿
13:11查看AI文稿AI文稿以前很多人喜欢调侃说 open ai 啊,应该叫做 close ai, 说简单点就是 open ai 总是喜欢把一些关键性的东西啊握在自己手里面,对外的开放程度非常不高。 最近他做的一个动作,我觉得大家可能需要用新的眼光来看他了。一直被认为不那么 open 的 open ai 最近做了一件非常 open 的 事情,他把 agent 非常关键的一层能力往外打开了一部分, 它把 ai 真正干活时的工作方式系统性地开放出来了。 open ai 在 四月十五日发布的新版的 agent sdk 里面,明确新增了更强的 hash 和原生的沙箱执行环境,而且开发者可以自带 sandbox, 也可以使用官方内建支持的多家第三方的 provider。 我 们看一下官方的博客怎么说的, 他说更新后的 agent sdk 可以 帮助开发人员在受控的沙箱环境中检查文件、 运行命令、编辑代码,并且处理长期的任务。这句话翻译成人话,其实就是说以前 openai 主要是在卖它的模型能力,一个最强的大脑, 这次他开始把这个大脑怎么进办公室,怎么拿文件,怎么用电脑,怎么把活干完的这一整套工作方法也对外开放。他这里讲的是 s d k 的 又一代的进化方向,我觉得在这个里面啊, s d k 的 升级不是最重要的, 核心还是在于它的 open。 为什么说它 open 呢?因为啊,它明明可以把整个的执行环境锁在自己手里面,如果说它是完全封闭的思路的话,它就可以说你要用我这套的 agent 的 harness, 就 必须跑在我指定的托管环境里面, 但是它没有这么做,它是说给你一套更加成熟的 agent 工作框架,给你原生的 sandbox, 给你 harness, 但是你是可以自己选 provider 的, 也可以自带你的沙箱。你看它这里列出了七家的 provider, 有 大家比较熟悉的 versa, moda, 这些都是可以用的。而且看到这里啊,它这里说 sdk 呢,还专门引入了一个叫做 manifest abstraction, 就是 清单抽象层。这个呢,有一点像 agent 的 工作手册,有了这个 manifest, 新的 agent 可以 在这个框架下更好地运行这个文件,你可以理解它能够让你更好地切换这样不同地 provide 它的不同的。这个 workspace 可以更方便地迁移移植,开发者就可以更好地挂在本地文件去定义输出的目录。而且他这里还说了,开发者能够从 a w s, 谷歌云的存储等等地方去拉取历史的文件,提供了一个非常好的机制, 就是开发者在这个工作空间里面可以很明确地知道在哪里输入,在哪里输出,怎么去运行,这一点非常的重要。实际上它意味着说你不一定必须要用我整套的云服务,它更像是说我把整个的 agent 的 工作方法 开放给你,但是你的执行环境,你的云,你的 provide 不 一定是我的,这个就是它第一个非常 open 的 地方。 第二个它很 open 的 地方是它不只是开放接口,而且开放经验。前面才没过多久, antropic 把第三方的 agent 的 接口全部封了,但是 open ai 走的是 open 的 路线,大家看官网是怎么表达的。它是这样说, 它现在开放的这个 agent s d k 的 框架,它是 kind of like life assistant tools, 这个 s d k 里面它包含了类似 context 的 文件系统工具。我是这么理解的, open ai 正在把 context 里面已经跑出来的那套 ai 工作方式往外抽象,这意味着什么?这意味着 open ai 这一次开放的 s d k, 它的所有的 agent 的 harness 框架是在 codex 这个干活的样板间里面跑过的,就像这个图右边这样子表达的,怎么去处理这个工作空间? workspace 怎么去接文件的?系统 怎么调? shell 怎么做状态的恢复?怎么把任务持续地推进?而现在它是把这一套已经验证过的方法 抽象为一个通用的底座,把它作为一个通用的能力的底座接口,开放给开发者。它这次开放的不是代码能力,而是在它最近这一段时间在 codex 练出来的一整套 ai 的 工作范式,是最近非常热门的点,大家一直在聊各种 computer use, 各种执行能力,各种数字员工,其实 open ai 这一次的升级就是围绕这个展开的, 怎么让 agent 进入一个真正的工作空间?工作场景这里有文件、有依赖、有命令、有目录、有快照、有中断、有恢复。 在这个工作空间里面, agent 能够怎么样读写文件,安装依赖运行代码安全的使用空间,即使中间中断了,那容器也不能丢,工作还能够恢复。其实就是在回答 open call 出来以后,大家非常关注的一个问题,就是 ai 怎么像一个真正能够持续干活的数字员工?这次 openai 开放的内容其实就是似曾一个更强的哈尼斯,大家能想到的 agent 框架的那些内容。 第二个就是一个原生的沙箱执行的环境,这个东西实际上就有一点像 ai 数字员工的工位, 它能不能够在这个数控的环境里面去完成所有的企业交给他的任务。第三个是 workspace, 还有 manifest, 就是 它的整个的工作规范,包括哪些文件你是能看的,哪些目录是你负责写的,数据从哪里来,数据又回到哪里去? 第四层是把 hash 和 compute 分 开,这一点看上去没那么重要,但是其实在企业端非常的关注, 就是我的运行测试环境可以挂,但是我的数据必须保持完整,你可以帮我干活,但是你不能把我内部的数据泄露出去, 甚至你这个活干不成都行。但是数据外泄的这个风险对于企业端是非常要命的。到这里大家应该能够猜出来 openai 的 方式用 codex 来定制业务场景 是什么意思,就是把用 codex 已经跑通的 agent 的 工作模式去占领企业的业务场景。你看官方的博客这里讲得很清楚啊, 他说我们要不断地开发我们的 agent sdk, 然后呢,更容易地将功能更强大的 agent 投入生产。这更强大的 agent 是 谁呢?肯定是他自己的亲儿子 codex, 而且它说减少自定义基础设施的使用,那这基础设施谁来搭建,谁来定义呢?就是 open ai, 这个是 open ai 的 目标和野心。现在 open ai 的 这个动作有没有让你想到最近 antisropic 的 一个动作? antisropic 之前发布了 cloud manage agents, 它和 open i 一 样,两个公司都不只满足于做模型或者 a p i 的 供应商,已经不满足于做最强大脑了,它们都在运行层动起了心思, 当然它们的动作会有一些差别。 anastropic 打法是我给你托管你的 ron thai, open ai 的 打法是我把这个 ron thai 的 关键的规范工作方式,还有 hans 的 设计,还有沙箱的接口,还有 memory, 还有恢复的这种范式都开放出来, 让你按照我的方式去搭。 astropic 更像是托管式的 agent 云, open ai 更像是在做开放式的 agent。 标准层,它不像 astropic 就是 开这种单独的 round tie 的 附加费用的逻辑,它还是更加强调这个 api token 和这个工具使用计费的方式。它把这个沙乡的 provider 的 选择权是交给开发者的,它会相对更加灵活,更加方便企业和开发者去接入到现有的基础设施,也更加有利于它生态的扩张,做更多的用户数。 虽然说 open ai 这样的方式看上去更自由,但是标准是很可怕的。其实 antropic 一 直在定各种标准,现在 mcp 也好, skill 也好,各种的插件的方式也好,其实都是 antropic 做出来的。现在 codex open ai 以新的方式出来定义,它是在抢这种工作方式的利权。一旦你越来越依赖 open ai 所给出的这个 hash, memory, scheme 或者 manifest, 还有 codex 的 这种工作风格和工作方式的话, 后面也会形成一种更软性的锁定,这种是最厉害的。为什么最近苹果出了一个非常便宜的笔记本?我那时候看好像是算上国补,呃,算上学生优惠等等。拿到手一个苹果的笔记本才两千多块钱, 这让那些 windows 笔记本怎么和它 pk? 而且苹果的硬件大家知道,整体的性能是很好的,其实就是软性的竞争。 当你习惯了你的这个桌面的窗口,它的关闭键就是在左边的,所有的这个图标就是圆角的,你再去用 windows 的 系统,你根本就接受不了。 像我们这代人,一开始我们是用 windows 系统,后面用苹果的时候切换起来,真的一开始的时候还是有很高的切换成本的,很多人甚至会在 mac 电脑上面去装一个 windows 系统,这个就是一种软性的束缚。对于 openair 来说,这个事情这个逻辑是一样成立的。 当你选择一个开放的系统,适应了它的工作风格的方式,这种软性的锁定和选择的倾向性往往可能更加恐怖,它的力量可能是更强的。 所以在 agent 的 运行层的争夺上,在未来可能会呈现一个双雄争霸的这么一个局面。 antisorbike, 它会赢。在它的高完成度的托管。 对于那些高价值、长任务重托管的企业场景里面,它一旦站住了脚,它的商业价值是非常清晰的,而且它的产品逻辑也很清晰,那它的整个的收入模式就是 cloud 加 manage agents 再加 round tie 的 收回方式。 open ai, 它的用户群体仍然是最多的,它这样的方式可以在更加广泛的开发者生态里面去铺开, 它可以让更多的人带着现有的云流程和 provider 接入到自己的 age 的 体系。如果大家最近用 codex 用得比较多的话,会 深刻地感知到 codex 已经把 opencloud 的 很多能力已经内化进来了,除了 i m 端没有完全打通,你可以感知到它和小龙虾的能力已经很多地吸收进来了。而且你也可以用 opencloud 去驱动 context, 它不像 episodic 把这个口子给封了,它是开放的,小龙虾可以驱动它。 open ai 是 要赢在生态和广度的,所以它是这么一个态度,这个是一个我认为中期的结果。从长期来看, open ai 后续它也可以出类似像 episodic 这样子的更强的托管层,直接跟 episodic 正面撞上。而且这一次 openai 的 升级,它已经把这些能力都摆上桌的 能力都是具备的,像 sandbox, resume, memory, manifest provider 等等等等。前面走开放,后面去收拢, 相当于做自营的托管的商业城,这是完全可以的,而且非常省。所以啊,这一次 openai 的 sdk 升级,表面上看是工具的升级,但实际上是把 codex 它所练出来的工作方式抽象出来,变成业务的底座。现在 antropica 和 open ai 虽然它们的路径不同,但本质上都在往同一个位置和方向在打。 同时,我也强烈地感知到未来的 ai 数字员工越来越近了。那究竟哪一家会成为未来 ai 员工的基础设施的服务商和提供者呢? 可以在评论区说出你的看法。今天节目就聊到这里,欢迎订阅玲姐说 ai, 给我的节目点赞评论一键三连,我们下期再见,拜拜!
 14:01查看AI文稿AI文稿
14:01查看AI文稿AI文稿那我们发布完了我们的智能体之后呢,我们紧接着就来采用这个 python sdk 啊,调用一下这个智能体,最后的话我们再结合 html 帮着我们生成一个前端前端的界面,最后我们统一的来实现一个外部应用,就说我们将来在外部端啊,也能够实现这个成语接龙的功能啊。 那么这块呢,先先打开拍叉码,就这块我先把配置环境所需要的一些 变量啊,就给它加进去了啊。就这块的话,首先加一下我们的 token 以及我的 bug id 和 user id, 这个 bug id 是 之前用过,查到这个 bug id 怎么看呢?啊?我们通过接口能看啊,那同时的话,我们其实通过它这个网址其实也能看,对不对?你看一下这边是不是就可以拿到一个啊? bug 后面有一长串的这个 id 啊,这个其实就是 bug id 啊。 好,那有了 bot id 之后的话,那我们其实就可以考虑来写一下我们的这个 python 代码,这块的话我们直接来先关掉,先来创建上一个 python 的 文件呀, 好,我就给它叫 app 啊,然后这个 python 的 文件里面,我想在大家想想,我想在这个文件里面去写什么呢?我是不是在这文件里面我将来的逻辑是什么呢?就是说我需要哎,在这里 调用啊,调用一下智能体,智能体啊,然后的话就说我调用智能体之后,因为我将来我跟我直接的这个成语接龙的智能体,是不是就等于是你一言我一语,我说一个字 成语,然后智能体给我个成语,然后我再说一个成语,对不对啊?然后就是把这个整个这个游戏给它进行下去,所以说我们在这里调用智能体啊,同时的话啊,还需要获取智能 能体的结果。哎,就说我需要把智能体返回的这个成语啊,拿到啊,然后的话我在它这个基础上接着再去给它输入成语。那,那所以说这块的话,我们就首先,哎,我们首先需要来先来干什么呢?我们先需要来创建出一个啊应用啊,我就给它叫 a p p 啊, 就说在 python 里面啊,它其实有一个啊这个 flask 应用,就说我其实在做这种 python 的 外部开发的时候呢,我可以加上这个 flask。 啊,那这个呢?其实我们大家知道就行了,我们不需要啊,了解的太多,我看一下这个 flask 好, flask, 然后加上一个 name, 也就说我在这块啊,就先来给它创建上一个 flask 的 应用 cd, 哎,创建一个 flask 的 应用 cd 怎么打开了一个窗了?好关掉个 flask 应用实力啊,好,有了这个应用实力之后啊,我其实就可以考虑来设计一下我的那个什么设计一下我的游戏的逻辑了,对不对啊?也就说我其实因为我整个这个成语接龙,它本来就是个游戏嘛。啊,那所以说我这块可以考虑一下来设计游戏的逻辑,设计 游戏的屁的逻辑啊,我这块这个逻辑怎么去设呢?我先给它创建上一个类啊,我先给它创建一个类叫 class, 这个叫 id, 嗯,这个啊,好,然后把这个游戏的类创建出来之后,我在里面先去创建上一个它的抽象的方法啊,创建 创建抽象的方法,好,然后我们在里面去写我们 define, define 一个 好,我们来创建一个抽象的方法,我们这个抽象方法里面需要什么东西呢?啊?那我是不是需要先把一些这种环境变量相关内容给它加载进来啊?那这个时候呢,我来写上一个 e p i token 啊,捆等于什么呢?我的 a p i 的 token 啊,那其实是写到哪了呢?是不是写到这里来啊?那我是其实是可以靠我的呃,这个获取环境变量给它拿到,对不对啊?那所以说这块我们来加上一个 o s o s o s 的 open 点 get 啊,我可以通过 os 的 open 给它获取,获取到这个属性就好了啊,把它拿过来。好,这个呢,其实就是我们的 api token 啊,那然后我还需要一个什么呢?是不是我的 boot id 啊?也就是我的这个智能体的 id 啊?那它同样的也是可以通过这个 os 来获取到的啊? 获取到就给他叫一个 id 吧。好, id。 好, 有了 id 之后我还需要获取 user id, 因为咱们前面提到啊,就是我们在创就是跟智能体发起对话的时候,我是需要记录这个用户是谁的,对不对? 因为因为我同样一个智能体,它可能有多个用户在同时的访问,那这个时候呢,其实你需要记住是哪个用户发送给你的这个问题啊,对不对?那这个时候呢,我其实需要添加上一个 self 的 user id, 它等于什么呢?等于 us 的 ena, 它的 get 用户 id。 好, 现在的话就说,我想我已经把我需要添加的出口化的那些内容内容都给它写完了, 那我有了这些环境变量相关的一些啊信息之后,那我是不是紧接着需要去来啊,促使化一下我的这个游戏的状态了,也就是我的这个成语接龙的状态啊。那这块的话,我来促使化一下成语接龙。 我这块儿怎么来加他呢?我直接给他叫上一个 self 的 current 啊,就是当前的啊, self self 的 current 的 identity 啊, identity 啊,这个是成语啊。 好,他直接呢,就是就是我要记录当前是哪一个成语,对不对?你比方说像我在这块啊,就是我在这块我跟他聊的时候,但他当前是饱读诗书,那我才能输入,哎,他当前是书声朗朗,我才能输入一个浪子回头,对不对?他当前是头头是道,我才能接着往下面去输,所以说我需要记录一下他的这个当前的这个 成语是谁啊?那这块的话,我们怎么写当前的成语呢?我们直接这样写啊,就是我在这块给他创建上一个方法, 就是因为我想让它的这个当前的成语怎么样呢?就说我当前的这个成语,我想让它在开始的时候啊,给我随机的生成一个啊,那我这样我直接写成一个 get random random 的 一个改灯啊。 好,然后的话在这里面啊,就说我随机的生成上一个啊成语啊,然后我直接来返回上一个 random random 加 choice 啊, 然后我需要干什么呢?我需要在前面啊,给它定义上一点成语,对不对?我给它创建上一部分成语之后,然后呢,让它随机的在这些成语里面去给我选择一个成语,作为它的开始的一个成语,对不对啊?那所以说这块的话,我们直接这么写吧, common, 然后我在这里面给它写上一个一心一意啊, 三七二一,对不对?好,我就先给它写上两个,写上两个之后呢,我其实就可以直接把这个 随机的这个程序给它拿过来,对不对啊?好,这个呢,其实就是获取获取随机的出使程 成语啊,也就是我开始输出的是哪个成语,也就是什么呢?也就是这块我让他开始吧,他输入的这个万紫千红,对不对啊?或者就是后面有一局,我在输了之后,我认输了之后,他再输个风花雪月,那这个其实就是他开始所需要输入的这个成语啊, 那然后呢?我再加上一个开始的成语之后呢,直接就可以来获取当前的成语了啊,然后我还需要一个什么呢?大家是不是记得咱们的这个成语不能重复啊?对不对啊?那所以说我这块儿需要怎么做呢?我需要给它记录上一个记录,哎,也就是说我成语的记录啊,啊,我还要 game 点儿 history 啊。 好,有了这些内容,那我是不是就把整个的这个出土化的一些内啊内容,包括我的一些环境变量,还有我的当前的成语,以及我这块所要将来记录的一个成语的历史记录,哎,就是 的历史记录,哎,有了这些内容,那其实我的这个设计游戏就是我这个游戏的初步化的内容,其实就可以开始了。那同时啊,我在这块再做一个什么动作呢?就说我需要把我的这个扣子的实力给它初步化一下啊,就是初步化 gucci 的 实力这一项啊,也就是说我们实际上在这个,呃,后端调用 sdk 啊,不管是用 sdk 或者 ip api 也好,我们都需要一个扣子,扣端,对不对啊?然后让它去调方法这个形式,去调用它的这个 执行智能体的这个内容,对不对?那所以说这块的话,我来加上一个啊,加上个 self 点扣子啊,扣子等于什么呢?等于我们的扣子,扣子啊, 然后这块需要,应该是需要一个 input 吧,我们把这个 input 给它加一下啊,我们把 input 给它加一下的话,那是一个 from, 不是, 不是 input, from, from 它一个 cos 的 p y cos p y input 扣子,哎,好,把这个扣子给它加上。扣子加上了之后我需要在扣子里面,哎,声明,两个核心的变量,哎,也就是第一个呢,其实就是咱们前面有讲到过,就是这个什么呢?就是它的 token os 啊, token os, token os, 加上它的 token, 哎,等于, 嗯,这块有一个绿线。好,那箭头我们写在下划线的形式啊,好,加上一个 api 的 图标,然后我们的第二个参数呢?其实就差这个 base u l 了。 base u l 等于什么东西呢?等于 a code, 哎, cozy 的 c n c n basis, 哈,也就是咱们需要给它指定上一个将来去访问的域名啊,好,那有了这些内容,其实这个 cozy 的是对象,也就是 cozy 的是对象就有了。那然后我们紧接着就可以写后面的逻辑了,我们写一个。稍等,我想一想, 我们写哪个逻辑呢?我们写添加到这个历史记录里面的这个逻辑啊,就是添加乘余。到哪呢?到历史记录,哎,到历史记录, 我们需要把一个成语给它添加到历史记录,这样来的话就是说我们因为我们为了实现我们这个不重复的能力,对不对?也就是为了实现我们不重复的这个效果啊?那所以说这块我直接这么写啊,我来直接来声明上一个函数 def, 然后 history, 然后我在里面加上一个 else 啊,然后的话我还需要一个用户的成语啊, 这是用户的程序,然后的话我还需要一个什么呢?其实还就需要一个它将来系统生成的成语啊。那注意一下这块系统生成的成语,它是不是是我们将来需要访问 sdk 之后它帮我们生成的成语啊?对不对?啊?那所以说这块我直接给它写成一个 sdk 的 response, sdk 的 response 啊,就是 sdk 的 返回啊, sdk 的 返回好, sdk 的 response 之后,我们其实就可以返回到一个成语,然后我们在这里边的话我们来写上一个模块啊, record 啊, record 等于什么呢?我在这里边给它创建上一个 json 啊,就是第一个就是我们的这个 user, user, user 等于什么呢? user 其实就等于这个 user 来的啊,然后的 下一个我给它叫 ai 啊,就是这个人工智能帮我生成的内容,那他帮我生成的内容呢?其实就是这个 sdk 的 response, 对 不对啊?好,然后呢我给它加上一个时间戳啊,就是说我这块是需要的, 看一下他哪啥时候给我发的对不对?我可能中间啊,比如说到两点,两点整的时候给他发了一个,他到两点零一给我回了一个,那我可能觉得这个比较复杂,我思考一下,我可能到两点一分的时候才给他一个回复,对不对?那这个时候呢,我来给他加上一个时间啊, 好, time stamp。 time stamp 的 话我们直接写上一个 date time 点 now。 哎, date time 点 now, 它有点 no 的 它我们看看这块啊,这块少写了一个冒号啊,这是带不过来了。看一下, 你错了,点 no, no, 然后再给它加上一个啊, str 的 form 啊,然后我们中间加上。 好,这个呢,其实就是咱们的这个十分秒的一个时间戳啊,就是你啥时候发给我的啊?然后的话就说我需要干什么呢?我既然需要说添加成语到一个成语记录啊,那所以说我这块需要在我的成语记录里边把这个成语给它加进来,对不对啊?那我就是这个 game 的 history, 直接来一个 insert 啊。 insert 怎么加呢?我从零开始加,把,直接把这个记录再加进来啊,加进来之后啊,那我其实就可以进行后面的内容了,也就是说我在这块啊,我的这个记录,因为我也不能无限的给它加,就因为我的内存毕竟是有限的啊,那所以说这块我需要对 历史长度,也就是我已经已经知道了这个历史的成语给它记录一个上限,就是历史记录需要有一个长度的上限吧,因为我不能无限的加,对不对?无限加还能把我内存内存给我撑爆了。 继承多少呢?我就给他继承二十吧,二十个,二十个成语基本上够了,基本上我们跟人家这个智能体啊打个几轮基本上就就败下来了。确实是没有人家智能啊,因为这个记录成语也不是我们擅长啊。那这块的话我直接这么写吧,就是 f 上一个 a, f 一个烂烂,它的这个 self 的 game history 啊,它假如说它比二十大啊,也就是说你在你的历史记录里面记录的内容超过了二十,那超过了二十怎么办?我直接把它截一下就好了。啊?那我直接就返回一下它的前二十个,哎,好,这块少了一个冒号啊。加一下。 好,那这样的话其实就是说我们添加这个成语到成语记录,哎,这个逻辑其实就已经 ok 了。
![程序功能:基于Open AI SDK调用大模型的封装类库 程序文件:llm.py
程序主体播报如下:
1、import os
从操作系统模块导入os,用于环境变量访问,确保API密钥安全读取。
2、from openai import OpenAI
引入openai库的核心类OpenAI,用于后续客户端实例化。
3、client = OpenAI(
初始化OpenAI的客户端对象,准备调用兼容的大模型接口。
4、api_key=os.getenv("DASHSCOPE_API_KEY"),
通过os.getenv方法获取环境变量中的DASHSCOPE_API_KEY作为认证密钥,避免硬编码泄露。
5、base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
设置基础URL为阿里云DashScope的兼容模式端点,实现OpenAI SDK与阿里大模型的适配。
6、)
完成客户端配置,确保后续调用指向正确服务。
7、def invoke(user_message, model_name="qwen-plus"):
定义非流式调用函数invoke,默认使用qwen-plus模型,接受用户消息作为输入。
8、completion = client.chat.completions.create(
通过客户端创建聊天完成(即补全)的请求,启动大模型推理过程。
9、model=model_name,
指定使用的模型名称,确保调用正确的预训练模型。
10、messages=[{"role": "user", "content": user_message}]
构建消息列表,仅包含用户角色和内容,实现单轮对话输入。
11、)
结束请求创建,返回完整的响应对象。
12、return completion.choices[0].message.content
提取第一个选择的响应消息内容,作为函数返回值。](https://p3-pc-sign.douyinpic.com/tos-cn-p-0015/osKfGempDIGIQYOgeFkALEofQ62nA6dahCTdnb~tplv-dy-resize-origshort-autoq-75:330.jpeg?lk3s=138a59ce&x-expires=2096830800&x-signature=zVVfWkHFc19E9Qk4vylnq0lg7bY%3D&from=327834062&s=PackSourceEnum_AWEME_DETAIL&se=false&sc=cover&biz_tag=pcweb_cover&l=20260615054334EED780D1AC4E2A9DD26E) 04:07查看AI文稿AI文稿
04:07查看AI文稿AI文稿程序功能基于 open ai s d k 调用大模型的封装内裤程序文件 l l m p。 程序主体播报如下, on import o s 从操作系统模块导入 o s 用于环境变量访问,确保 api 密钥安全读 to from open ai import open ai 引入 open ai 库的核心类 open ai 用于后续客户端实力化。三、 client 等于 open ai 初识化 open ai 的 客户端对象, 准备调用兼容的大模型接口。 for api unders 打 g e t e n v dash scope underscore api undersk e y 通过 os git 封方法获取环境变量中的 dash scope 下划线 api key 作为认证密钥,避免硬编码泄露。 five base underscore url equals h t t p s colon slash slash scope dot a l i y u n c s dot com slash compatible dash mode slash v one 设置基础 elo 为阿里云 dash scope 的 兼容模式端点, 实现 open a i s d k 与阿里大模型的适配。六、完成客户端配置,确保后续调用指向正确服务。 seven def invoke user underscore message model underscore name equals qwe on plus 定义非流式调用函数 invoke 默认使用 quinplus 模型,接受用户消息作为输入。 eight completion equals client dot chat dot completion dot create。 通过客户端创建聊天完成即补全的请求,启动大模型推理过程。 nine model equals model underscore name 指定使用的模型名称,确保调用正确的预训练模型。 ten messages equals role user content user underscore message 构建消息列表,仅包含用户角色和内容,实现单轮对话输入。十一结束请求创建返回完整的响应对象。 twelve return completion choices zero message content 提取第一个选择的响应消息内容作为函数返回值。十三、 def invoke with underscore stream underscore log, user underscore message, model underscore name equals q w e n plus 定义流式调用函数 invoke underscore with underscore stream underscore log。 支持实时输出日制默认模型。宽 plus fourteen completion equals client dot chat dot completion dot create。 发起流式聊天,完成请求起,用增量响应模式来记录日记。 fifteen model equals model underscore name 指定模型名称与非流式函数一致,以保持兼容。 sixteen messages equals role user content, user underscore message 构造相同用户消息列表,确保输入格式统一。 seventeen stream equals true 激活流逝传输,允许响应分块返回,以支持实时处理。十八、完成流逝请求出,使化返回可迭代的响应流。十九、 result 等于 初步化空字浮串 result, 用于累积完整响应内容。 twenty four response in completion, 便利响应流中的每个增量块儿,实现实时数据处理。 twenty one result plus equals response choices zero delta content 将当前增量内容的 delta 追加到 result, 实现响应累积。 twenty two print response choices zero data content and equals 实时打印增量内容而不唤醒模拟流逝日制输出。 twenty three return result, 返回累积的完整结果,确保函数输出可用。关于 openai sdk 调用大模型的封装类库功能播报完毕。 hope you enjoy this wonderful moment see you next time。
 00:31查看AI文稿AI文稿
00:31查看AI文稿AI文稿老铁们给大家分享一款超实用的环境优化工具,可一键规整网络运行环境,快速完成版本适配调试。操作流程简单易懂,一共四步,轻松搞定。首先一键卸载原有运行组件, 无相关程序则自动跳过。接着一键优化重置网络运行环境,短短十几秒即可完成。随后清理系统缓存与残留文件,快速清空 c 盘多余遗留数据。最后完成适配版本部署,仅需三秒左右,操作结束,提示运行就绪,桌面状态栏同步显示对应标识设置完成,就能正常稳定使用。
 00:33查看AI文稿AI文稿
00:33查看AI文稿AI文稿c 盘又红了,别急着重装系统,我做了一个免费工具,一键把 c 盘软件搬到地盘,搬完还能正常用。它会自动扫描你 c 盘所有程序, 告诉你哪些能搬,哪些别动。注册表快捷方式,环境变量全部自动修复,搬不动的还能一键彻底卸载,注册表残留都给你清干净!工具完全免费 gethip 开源链接,在评论区点赞、关注、收藏,评论区留言拿走!
107大刀Ai很大刀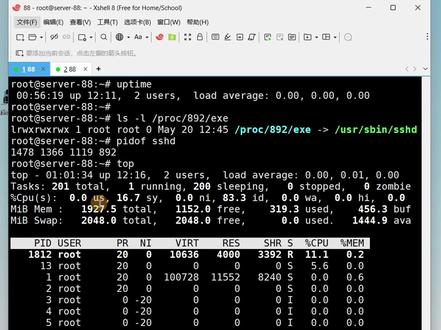 04:31查看AI文稿AI文稿
04:31查看AI文稿AI文稿面试官问生长环境,服务器频繁触发 cpu, 百分之百告警,但登录服务器用拓普命令查看时,所有进城的 cpu 占用率又完全正常,退出服务器没多久,告警又来了。这种现象是怎么回事?你该怎么排查? 如果直接回答找不出来原因,就先 redbox 重启服务器看看。如果重启后还告警,可能是业务流量太高了,给服务器升级配置。这种回答在懂行的面试官眼里是不及格的。这个问题考察的是对恶意程序的对抗机制,以及 linux 内核文件系统的掌握程度。 真正的恶意进程,比如挖矿,木马肯定会写进定时任务或者系统的 system d 服务里做持久化,你前脚刚重启它,后脚就跟着开机自起。 至于盲目加配置,只是让攻击者挖矿挖得更爽,纯属给攻击者送温了。这个问题可以这么回答,这通常是因为恶意进程在后台做了动态躲避和进程名伪装。整体排查思路分两步走。首先,恶意程序会开启一个现成 循环监控系统的进程列表,一旦发现类似 top ps 这种诊断工具启动它就会立刻把自己挂起休眠释放 cpu。 所以 常规排查看不到。一个很常见的绕过办法 是直接把系统自带的 top 命令复制一份重命名后运行。很多简单做进程检测的木马不会识别改名后的工具,所以它还会继续在后台跑,这时候就能直接拿到它真实的进程 pid。 拿到 pid 后,进一步排查会发现它的进程名很可能叫做 enix 或者 mexico。 虽然它的名字显示是 enix, 但它不一定是真的业务进程,可能是木马伪装的。标准的确认做法是直接去查 linux 内核的虚拟文件系统,用 l s 命令查看一下跟目录下的 p r o c 目录里这个 pid 对 应的 exe 文件。 linux 在 进程启动时,会在这里生成一个远链接,直接指向它在磁盘上的真实物理路径, 确认一下这个路径,如果指向的不是正规的 nx 安装目录,那基本就可以确定它有问题,这时候就可以放心的把它 kill 掉,并清理掉对应的持久化文件。下面来看一下实际效果。还是用 c 加加写了一个测试程序,模拟具备伪装和动态躲避能力的恶意程序。 在这里多说一句,本期视频的所有操作和代码纯粹是为了防御掩饰。在网上看到这类测试代码,一定不能放到未经授权的生产服务器上去跑,这东西没授权是违法的。 有测试需求一定在自己本地的虚拟机或者隔离容器里测试。这段代码核心逻辑就干两件事,首先启动的时候直接抹掉真实参数,强行把进程名伪装成 n g x, 然后开个后台线层去便利 p r o c 目录,只要检测到系统运行的 top 或者 ps, 立刻主动休眠释放 cpu。 这里我故意没把 s top 写进黑名单,留着等下演示作对比。当然,现在的木马可能不会只防几个简单的命令,有的会直接去系统底层做内核结识,排查起来会更复杂,但这种绕过检测揪出真身的对抗逻辑是相通的。好,把它翻译一下, 翻译成功了,这个警告不用管,把它放到后台跑起来。现在这个程序已经把所有的 cpu 核心全部放满了。 先来模拟常规运维手段,收到告警后用 top 命令排查一下,可以看到系统总体 cpu 占用看着很低,找不到任何高负荷的进程,但其实是因为木马的哨兵发现了 top 启动,已经主动休眠,把上令释放了,退出来用 htop 看一下真实的情况。因为 htop 不 在刚才说的黑名单里面,所以木马没有暂停, 这个时候就能看到 cpu 确实是满载的状态,百分之百真实的恶意程序肯定不会故意漏掉一个排查工具让你查,所以下面来演示一下常规的排查手段。绕过木马的进程检测机制,把拓普命令复制一份,随便改个名 运行。改名之后的工具,现在就能够抓到 cpu 占用百分之百的进程了。就是这个幺八八三,它占到了百分之九十九点七,这里能看到这个幺八八三,它占到了百分之九点七,这里能看到这个 id。 直接去查底层文件,确认真伪, 看输出结果。这个所谓的 nx 并没有指向标准的 nx 安装路径,暴露了它的真实物理位置,看不下面的黑的 mark, 这就直接把它揪出来了。最后就是标准的清理动作,先把它掐掉,清除恶意程序, 清除之后再来使用 htop 看一下它的载情况,现在 cpu 的 载都恢复正常了。最后还是提个醒,网上找的那些来路不明的二进字执行文件,千万别直接往生长环境里扔, 真需要使用工具,尽量找开源的,自己过一遍源码,然后自己编一运行。今天这个只是个基础的演示,要是真中了深度的木马,不是敲个 q 就 能解决的。这种东西一般都能自己复制在系统里不知道藏了多少个点,根本就清不干净,很多时候只能重装系统。
2854爱睡懒觉 03:21查看AI文稿AI文稿
03:21查看AI文稿AI文稿codex c l i 升级解读,从 v 零点一百三十点零到 v 零点一百三十一点零十天叠带九十个以上 p r 合并五大功能模块,全面增强 tool 终端界面增强状态栏。新增混合 token 用量权限和审批模式显示,支持响应式 markdown 表格渲染。 新增数据驱动的 service tier 命令,可在 priority fast auto 之间切换 chat widget。 大 文件拆分为独立模块,提升可维护性。修复了 url 换行、 tomax 下 shift enter、 浅色主题对比度等多个交互问题。 新增 app 提及搜索,统一的 app 选择器,可一键搜索文件、目录、插件和技能,后端由 app server 插件源数据支撑,搜索更快更准 插件系统,增强插件工作流。新增 marketplace 命令行,支持版本感知分享、 share checkout 共享工作区 bucket 全部就绪,插件 hooks 默认启用。 远程环境重大更新,新增 damon 管理的 codex remote control 命令,运行时支持 enable disable api 和状态读取。支持 registry 配置的远程环境。 x x server 传输超时延长,远程更稳定。 path s d k 重构包明正式迁移到 openai codex 命名空间,固定运行时生成的类型,支持并发 turn 路由审批模式集成覆盖更全面。 新增 codex doctor 诊断命令,一键检测运行时认证终端网络配置和本地状态,方便牌照和技术支持 windows 沙箱全面加固,修复 deny read 规则作用域写入根、防火墙策略失效等问题解决多个 power shell 边缘情况,优化 testkill, 清理输出 状态,持久化修复 app server 守护进程,支持安全重启,保留 sq lite 数据不丢失状态无法打开时 feel closed 新增恢复路径,降低可选原数据同步失败的影响。 get 和认证可信提升。统一使用 word tree root hooks helper 命令,忽略仓库 hook 配置,避免干扰绑定本地 m c p o off 回调自动撤销过期登录 token 架构清理与重构新增 tag extension api tool contracts 格点和 memory 扩展管道, 删除废弃工具路径功能标志配置开关和旧 hogs c i 流水线增强 rust c i 更稳定。 windows bazel 分 片 mac os 签名修复 总结, v 零点一百三十一点零是一个 toe 体验远程工作流插件生态全面升级的大版本。如果你还在 v 零点一百三时,建议立即升级,执行 codex update 即可。感谢观看!
 02:12查看AI文稿AI文稿
02:12查看AI文稿AI文稿如果你们团队还在把数据库密码、 api 密钥写进环境变量文件,或者靠群消息来回传配置,那这个开源项目值得看一下。 它叫 in physical, 在 github 上有两万六千多星,定位是开源的密钥、证书和特权访问管理平台。 它解决的核心问题很直接,把分散在项目服务器、云平台里的敏感配置集中管理,减少密钥泄露,也让开发、测试、生产环境的配置更容易同步。比如一个项目要用数据库账号、云服务密钥、第三方接口密钥, 以前可能每个人本地一份, c i c d 流水线一份。 github vcelaws 里又各配一份。 in physical 可以 通过网页面板管理不同项目和环境的密钥,也可以同步到 github vcelaws, 并支持 terraform、 ansible 等工具。 它还有一个很实用的能力,密钥扫描和泄露预防。官方介绍里提到,可以扫描文件目录和 get 仓库中一百四十多种密钥类型,还能安装提交前钩子,在代码提交前先扫一遍,尽量避免把敏感信息推到仓库里。 如果你们用 cubernetis, 它提供 cubernetis operator, 可以 把密钥送到工作负债里,并自动重新加载部署。 它还有命令行工具和 api, 也支持 node、 python、 go, ruby、 java 点 net 等 sdk, 方便接近本地开发和流水线。 除了密钥, in physical 还覆盖证书管理,比如内部证书机构、外部证书机构、集成证书签发、续期、吊销和过期提醒。 它也支持审计日制,基于角色的访问控制、临时访问和审批流程。部署方面,它既有 in physical cloud, 也支持自托管。官方给了 dakker 本地运行方式,适合想把数据放在自己基础设施里的团队尝试。 一句话总结, in physical 更像是给团队用的敏感配置保险柜,同时兼顾密钥同步扫描、防泄露和证书管理。如果你做后端运维 devops, 或者正在整理团队配置管理,可以收藏一下,找个测试项目试试看。





