cloud code 能多做事,不是因为主循环越来越复杂,真正稳的做法是工具越来越多,循环还是那一条, 如果只有 bash, 所有动作都要走 shell, 读文件靠 cat, 改文件靠 set, 路径安全也很难控制。它看起来万能,但工具边界其实很粗。 解决办法不是改主循环,而是在模型和工具之间加一层分发模型发出 tool use 代码,按工具名查 handler 执行动作,再把结果包装成 tool result。 工具先按三件套理解, schema 是 给模型看的说明书, handler 是 代码里的执行函数, tool result 是 统一回到主循环的结果出口 专用工具还有一个好处,就是能在工具层做安全边界。比如 safepath 会把路径解析到工作区下面,逃出工作区就直接拒绝。 代码形状很简单,一个 toolhandleers 字典,把 bash read file, write file, edit file 这些名字映射到各自的函数,一次查表替代一串 if else。 最关键的是循环体本身和上一张一样,它只是发现 to use, 查 handler 执行输入,然后收集 to result。 新增工具只是新增 schema 和 handler 相对 s 一 s 二变得是工具层。工具从一个 bash 变成四个分发,从硬编码变成 map, 路径安全多了 safe path, 但 agent loop 还是不变。 系统再做大一点,还会遇到消息规范,内部 messages 可能代元数据,也可能缺 tool result, 甚至连续同角色发给 api 之前,要整理成协议能接受的副本。 最后记住一句,工具层是控制面,主循环不要跟着变复杂。 schemer 执行动作 tool result, 把现实结果带回循环。

粉丝69获赞211
相关视频
 03:48查看AI文稿AI文稿
03:48查看AI文稿AI文稿你知道吗? cloud code 其实有四种用法,第一种是 cloud chat, 就是 我们平时用来聊天的那个,比如说打字啊,问他问题啊,有点像 deepsea 或者豆包,你就直接跟他沟通就可以了,然后他回答你就是很简单的。 第二种模式是 cooke, 它可以直接的帮你操控电脑,相当于是个人机协助的一个方式,比如说呃你的文件或者是你的浏览器,很多事情它是可以自动化的去完成的。 第三种就是 color code, 就是 相当于是一个桌面版本,有图形界面,你可以直接写程序,它其实是适合稍微有点基础之后你再去用它,适合想进阶的人去用的。 那第四种就是 color code 命令行,也就是我们说的叫做终端,它是一种纯黑屏的这种敲指令啊的方式,它是比较适合老司机,那新手的话,你其实要去找他还是有点门槛的,他主要是通过指令来操控电脑。这四种难度呢,我是建议是先从聊天开始, 你先把聊天先学好了之后,然后我们就按照这个顺序去呃,一种一种的慢慢的去学。所以第一步的话就是你要先学会怎么去跟 ai 去说话,说话说的好了之后,我们再来学怎么跟 ai 一 起去做事情。 过程中会遇到一些就是比如说需要写程序的这种情况,那么再用 color code 来解决你,你本来就是程序员,那么就可以直接跳到命令行,就是这个版本,我觉得这个更适合你。我们先从 color code 的 聊天模式讲起,我们所有的对话都是在云端进行的,其实不碰我们的电脑的一个本机,我们用它之前要先想清楚三件事情,它能做什么? 做不了什么,可以输出什么,哪些格式,基本上它分两个,能两块能力。第二块叫是连接器,也就是我说的 m c p, 那连接器它其实有点像那种外部拓展,比如说我们像处理这个居妙的邮件或者是日历这些,它是可以跟你连接,就是就是快速的一个操作的,比如说你在日历上定计划这些你都可以用下。光它的一个基本的一些聊天的功能很就已经很强大了, 大部分的问题其实都能够去去处理。那接下来呢?第二种、第三种、第四种呢?基本上我们是要下载一个桌面端才能够去用的,桌面版装好了之后,它界面上有三个功能可以去进行一些切换。 不过我这里要说明一下, callwork 的 话,目前有一些是付费的才能够去解锁,而且大家都知道他在中国地区其实不是特别友好,那我自己用的话是一个免费版,但是没关系, 我们先把能用的先玩透,然后一步步来嘛,而且我们可以通过后期的一个终端也能够实现这个功能,先让你了解是什么 比较重要。 callwork 的 话,他可以直接管理你的电脑里的一些文件夹,不用你手动一个个操作。我们把三十多个 word 文件丢进去,需要整理啊,分类啊,会自己读取,你可以一边跟他聊,然后他一边帮你分析啊,整理报告,然后全程其实都是通过 就是对话去解决。还有像功能,它有排程的功能,就是说你可以设定好每天他做什么,就有点像那个定时任务,比如说他每天早上自动的帮你去整理邮件,整理当天的就是一些行程。我们之前看这个王静林的就是早上凌晨五点钟起来应该做哪些事情,一二三四五六这个他也可以帮你做。还有个是任务 派发的一个功能,就是说你跟他说一件事情,他自己就是去操纵浏览器,然后操控电脑把事情办完,有点像那个我派助理出去了,你自己去办吧,不用一步步你自己盯着。那接下来就是第三种,就 cloud code 桌面版, 你用之前他会提示你保存在固定的位置,之后所有的操作都是在这个目录里去进行,就相当于说, 呃,你有个安全的一个沙盒,那你在这个空间里面他可以随意的操作,这样的话就是有一定的安全,而不是说他直接在你的电脑本地里,对于很多就是有一些有隐私啊,或者是怕是电脑误伤的这种情况的话,这个是比较适合的。对于我们新手来说,我建议是用计划模式,他会先告诉你打算做什么,然后再执行, 就是这样熟练了之后,然后我们就可以可以开自动的一个执行,就直接帮你做那更高级的全开模式就不用被询问,你就直接操作。桌面版的话,我觉得最大的好处就是有图形界面,操作起来比较直观的,出问题也比较容易找到,就是你你在什么地方可以去解决。
244阿呆AI 06:34查看AI文稿AI文稿
06:34查看AI文稿AI文稿大家好,今天我带大家使用 vs code 来安装一下这个 cloud code 的 插件,并且在 cloud code 上面配置两个模型,一个是 deepsea 的 模型,另一个是 cloud 的 模型。首先我们打开 vs code, 在 vs code 的 左侧面板找到扩展,点击扩展,然后在扩展这里面找到 cloud code, 选择第一个 cloud code for vs code, 然后点击安装 好,这个安装很快啊,安装好了 cloud code 之后,我们发现在左侧的面板最下面多了一个 cloud code 的 图标,我们点击 cloud code 好,它现在出现一个这个登录界面,配置 api 的 一个界面,我们现在使用它自带的这几个功能是配置不了 api 的, 因为在国内我们是访问不了这个 cloud 的 官网, 所以我们这里要借助一个其他的工具,我们这里使用的工具是 cc switch, cc switch 呢,大家可以在 github 上面的这个网址去找到并且安装, 我这里使用的是 windows 版本的,它可以支持 macos 还有 linux, 大家在自己的电脑上面找到相应的操作系统的版本去安装就可以了, 我这里已经安装好了,我们打开 cc switch, 在 cc switch 这里面找到 cloud 的 图标,点击 cloud, 然后点击右侧的加号,然后在这个供应商这个界面选择自定义配置,在供应商名称这里输入 deepsea 备注,我们可以不填,官网链接也是可选的,我们可以不填,这里比较重要的一个选项就是 api key, 我 们在 api key 的 网站上面去注册一个,然后在 api keys 这里面来创建一个 api key, 我们把这个 api key 把它复制一下,然后回到 c c switch, 在 api key 这里面把 api key 粘贴进来,看一下这里面请求地址,它这里有个说明,填写兼容 cloud api 的 服务器端地址,不要以斜杠结尾。我们找到这个 这个文档,然后在这个文档里面有一个 s u i, 有 两种格式,一种是 open ai, 一 种是 isnoop, 我 们这里使用 isnoop 的 这种 api 复制粘贴到这个 c c switch 里面来。 好,点开这个高级选项。有五个模型的配置,我们这里可以都配上同一个模型,也可以分开配几种模型,比如现在我们 deepsea 支持的最高版本的微四啊,我们找到这个模型的名称,复制 回到 ccc 去,把这个模型名称填进来, 我们可以使用 seek 微四的 flash 模型填到其中的一个模型里面。好,现在我们点击添加, 这样我们这个模型就已经配置好了。我们回到这个 vs code 的 界面,然后关掉 vs code, 重新打开一下,我们重新点开这个 color code, 此时我们看到 color code 已经出现了这个绘画的界面, 我们打开一个项目,然后点击这里的 cloud code, 或者在这个窗口的右上角也有一个 cloud code 的 这个图标,我们点开,这时候我们就可以对它进行对话了。 比如我们问一下你现在使用的模型是什么 啊?我当前使用的底层模型是 deepsea 维斯 pro, 这样我们就证明到这个模型已经配置成功了。这时候我们也可以在这里面去切换模型, 我们看到这里可以切换这个 deepsea v 四 flash 的 模型。好,这是 deepsea v 四的这个模型的配置,我们接下来再看看怎么样配置一个这个 cloud 模型。配置 cloud 模型,我们使用国内的这个中转商, 我这里使用的是 a p i e, 大家可以在 a p i e 这里面去注册一个,然后我们回到 c c switch 新增一个供应商,同样我们这里选择自定义配置这里的供应商,我们输入 a p i e a p i k 这里面我们回到这个 a p i e 的 这个令牌,这里面把自己的这个令牌复制进来。请求地址,我们这里面也要看一下啊, 我们打开这个 a p i e 的 这个文档,这里面有一个 c c c v 曲的配置, 我们把 api 地址设置成这个,然后点开高级选项,这里设置这个模型名称,我们看一下模型名称啊,找到这个标准模型,还有推理模型,把这个模型名称把它给复制过来, 好,点击添加。现在我们这个 api 的 模型也已经配置过来了, 然后这里已经有了两个模型,我们可以随时去切换模型,我们现在切换到 a p i e 这里面来,点击启动,然后回到 vs code, 我 们关掉,重新起一个绘画。 现在我们来问一下你现在使用的模型是什么? 好,这里我们看到我当前使用的模型是 cloud 双列克四,然后同样的我们也可以在这个模型切换里面去切换相应的模型。好,今天的分享就到这里,谢谢大家。
1505玄鹿AI重构 03:15查看AI文稿AI文稿
03:15查看AI文稿AI文稿教他,让他画的更好一点。期待他后面慢慢进步吧。来装一下,看他有什么用啊?帮我安装一下这个 skills。 好 的,现在说安装完成了,让我们去启动这个浮漂 装一下,直接在它这个高级拓展管理器,然后搜一下这个 wrong, 这个 wrong api gateway 安装一下,然后把这个三个都勾选上, 它现在已经显示已连接了。 然后我们问一下它有什么用啊?这个 skills 能干什么?有什么用? 眼睛哭了,搜索。 嗯,怎么用?我们就让它这个 好,它现在加载出来了。 嗯,它确实能够导入出来。 s t m 三幺幺零三 c 八 t 六, 看它能不能画出来。 画完了,画的其实挺乱的, 期待他后面继续进步吧。他这个确实挺。嗯,看着挺别扭,也可以教他,让他画的更好一点,期待他后面慢慢进步吧。
2421胡昊用 AI 造硬件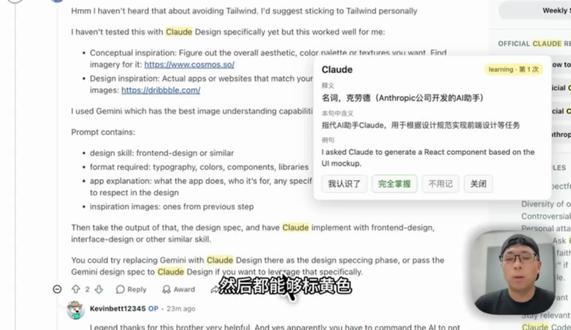 01:41查看AI文稿AI文稿
01:41查看AI文稿AI文稿哈喽,今天我想介绍一下最近我用 cloud code 做的一个 chrome 插件,其实原因就是在于我在看这外网的时候,我发现有些单词我不认识,之前的一些翻译软件我觉得, 呃没有太符合我的需求,所以我干脆就让 cloud 做了一个装上之后,比如说看到不会的单词直接双击, 然后他就能够把这个屏幕上所有的这个单词都能够标记出来,然后都能够标黄色,然后能够他会根据这个上下文来做一个翻译,然后所以更可能更贴合语句一些,然后他这个地方能看到第一次,第几次记, 然后他这里还比如说你学会了之后,你可以点我的,我认识了之后,如果你完全掌握,不想让他显示的话,你就可以点完全掌握,如果你是不小心悟出的话,你就可以点这个不用记,看到三次不会了之后,他这里就会变成一个深色的这个黄色,然后相对于那一个区别, 然后在这个右上角这个地方,它能够看得出来这个词汇有一个统计什么的,然后它语言的话,它是目前默认式对英文翻译中文,但是同时它也能够支持就是七种语言的这种 不停的切换。呃,目前它是一个本地话的,如果它翻译其实调用的是 deepsea with flash, 然后整体的开销都是比较低的,学就是上千个单词,你充个五块十块钱,我觉得都完全够用。 然后我是把它放在了我的这个 github 上面公开出来,然后有兴趣的就可以在这里下载 这个 vocab, vocabulary, vocab rita, 然后或者是在我的这个个人站上面,然后在这个的 chrome 插件这里下载,然后安装的话也是很简单的几个流程就能够实现了, ok。
 01:28查看AI文稿AI文稿
01:28查看AI文稿AI文稿如果你刚开始用 cloud code 或 composer, 千万别一上来装十几个 m c p, 这个视频适合已经会用 ai 写代码,但总觉得他读不懂项目、查不到资料、记不住规则的人。 准备材料很简单,一个 cloud code 或 cursor, 一个测试项目,还有三类 m c p 就 够了。第一步,先配文件类 m c p, 目的不是炫技,而是让 ai 能稳定读取你的项目结构、配置文件和关键代码。你先让他回答这个项目入口在哪儿, 主要模块有哪些,能答对再继续。第二步,配浏览器或网页类 m c p, 它适合查文档,看接口说明,分析网页问题。不要让 ai 乱搜,直接给他明确任务, 比如查这个酷最新版的用法,再改我的代码。第三步,配记忆或规则类 m c p, 把你的代码规范命名习惯、常见 bug 处理方式保存下来,后面改代码就不用每次重复说。第四步,每装一个 m c p, 都用一个真实任务验证,读项目, 查文档,改一个小 bug 跑不通就先别装下一个。常见坑有三个,第一,插件越多不等于越强。第二,不要把密钥、隐私文件随便暴露给工具。第三,别让 ai 自动改一大片代码, 必须先让它解释方案,再小步修改。记住新手 m c p。 顺序就一句话,先文件,再浏览器,最后记忆够用比乱装强。
 05:54查看AI文稿AI文稿
05:54查看AI文稿AI文稿ipc 微四上线之后,哎,我用在 cursor 当中呢,是直接采用它内置的这个 oops 啊, 然后呢,我再又用到了 cursor 当中的一个扩展,呃,在它的扩展当中呢,用到了这样的一个,呃, client code 啊,用 client code 的 这样的一个插件啊,然后去背后用的这个?是啊, dsp 工具四,这样的话呢,就能在 control 当中既用 dsp 啊,也能够用 oops。 然后呢,一边呢享受着 control 这边给人带来的一些相关的服务,同时呢也能够 去使用 code code 啊,它当中的一些的内容,一些的内容,但在这里面呢,就会出现了一个新的问题,那什么新的问题呢啊?就是 啊,就是这个啊,它的技能是不通用的,嗯,课时呢,它会读取它的课时自己下载一个 啊技能,然后 closed code 呢,它会读取 closed 下面的一个技能,同时呢 cursor 呢,它会去啊读里面的一个叫 agent 的 一个 md 啊,在文档里面 agent 的 一个一个叫 agent 的 md, 然后呢而 closed 呢,它会读取一个叫 closed 的 md 啊,这个 closed md。 所以呢,这个就是两者之间啊,都是不一样的啊,两者都都是不一样的,这是两套不同的一个体系。那有的那个同学会说,有的同学会说这个啊, cursor 它是兼容 clode 的, 那你啊,在 cursor 里面,它可以直接读取到 clode 里面的一些的 skill, 但是 clode clode 它又不兼容 cursor 啊, 那这是其一。其二,即便是科索宣称它是兼容 vlog 的, 但是实际我体验下来之后,其实兼容性并不是很好, 因为他说下面有自己的 skill, 那 他更多的是倾向于使用自己的,而不是使用 pro 的, 那在这个时候呢,你如果要想维护,那你就要同时维护两份,那这一点呢,就会比较烦,比较烦,那怎么处理呢?同样我是也是问他啊,问这个 啊,问这个 ops, 然后说你看一下啊,现在都存在啊, clone 和 clone 都存在 skill, 那 怎么让 clone 不 读取 clone 啊? clone 不 读取 clone 之间的一个呢?为什么?因为在这里面它们之中是有不兼容的,比如说像我们之前所说的 safari 等, 要怎么让主 a 阵的去使用三倍阵的去做一些调研嘛?那两套不同的工具肯定是有两套不同的东西,那所以呢,他去做了一系列的一个调研,但是没有什么特别好的一个调研 啊,基本上都是说同一个仓库想一人一套,那同时呢,又是想按照那个幕落的一个颗粒度,有选择的导入第三方的 skill, 而不是全局的一个开关啊等等 啊,都会有各种各样的问题。那在这里面我的一个解决办法呢?是说啊,让它去完整的去分析当前 skill 的 一个体系啊,然后将 skill 啊去裂解为三套啊,分别是 touch 专用的啊, browser 专用的,以及公共信息的。 那在不同的,主要是在不同的 id 或者是说带语言的运行环境下,工具的使用是不同的,比如说 safari 等等。 那相应的在科室里面呢,我主要使用的是 oops, 那 oops 对 于它的对工具的使用和调用,你对它的要求呢?就没有那么死性,可以更加的活泛,更加的宽泛一点,你给目标就可以了,不用过于给一些很详细的一个步骤, 但是呢,在 pro 的 里面,因为我们用的是 deepsea 啊,而 deepsea 在 使用的时候呢,它就没有 deepsea 这么的聪明,它还是要差一些,那同时呢,你要给它一些相对详细的一些的内容。 而 office 呢,在我这边更多的还是方案相关的一些的制定和审核,而 deepsea 更多的是做方案的执行和 相关的制。呃,自动化测试啊,就是做这些的东西,那样的执行和自动化测试啊,验收等等,这些东西包括以及日常的 bug, 那 比较复杂的 bug 再交给这个 os, 那 也就是说这两个有天然的风中,那对应的 skill 也要理解不同的一个情况,那这样的话我们才能够针对不同的主模型去做一个相关的一个测试。那完成了之后啊,完成了之后我们的一个目录就是一个量力, 那首先是 clone 一 套目录,然后 clone 一 套目录,以及这还有一个公共目录。公共目录里面是什么呢?就是一些啊,比如说系统模块介绍啊,然后那个运营知识啊 啊,还有就是这个啊,工具的一些的创建呀,然后一些啊,各种各样的品类啊,然后以及经典案例啊,这些都是公共的,因为它与大模型无关,它都是记录一些事实性的一些东西。 而科室和这个扩展,他都是一些这个啊,非事实性的东西啊,尤其是这个啊瑞的蜜 啊,主要是这个 max 的 瑞啊啊,这一定要读的啊,你在科室里面一定要读啊,这个里面他就介绍了当前的一个技能的一个体系是一个什么样子的,然后呢?扩展那边也是一样的。我们那边也是一样的 啊啊, skill skill 里面也有一个 master rate 啊,其实是一模一样的,一模一样的,只不过都是都是。说一下,介绍一下当前的 skill 的 一个体系,然后你应该怎么去做一个相关的一个加载。 而对于这个 pro 的 里面,它后面背后是 d p c, 所以 你要说的更加的详细一点,更加的详细一点。好了,这就是本期的一个内容,下期见。拜拜。
8破妄-胖 01:51查看AI文稿AI文稿
01:51查看AI文稿AI文稿如何在 vs code 中使用 cloud code, 并且接入最新的 deepsea v 四模型?首先打开 vs code, 点击扩展,搜索 cloud code, 选择第一个,然后点击安装,安装完成后,右上角会出现 cloud code 图标, 点击图标弹出 cloud code 页面,首次打开时会提示登录账号,如果没有账号,可以通过修改配置。绕过登录按键盘 c t r l 键加逗号,弹出菜单,选择 extensions, 选择 cloud code, 点击编辑配置, 粘贴这两段参数,然后保存,这样就不会再提示登录了。那么该如何接入 deepsafe, 打造自己的 agent 呢?我们需要用到一个第三方工具 cc switch, 打开其 github 地址,然后点击 releases, 然后找到安装包下载地址, 这里我们根据电脑的系统版本选择 windows 五 c, 点击后等待下载完成,然后安装即可,因为我之前已经安装过了,就不再重复安装。然后打开 c c switch, 点击右上角添加, 选择 dipstick 下面的信息,默认只需要填入 apikey 即可,也可以根据实际需要修改其他参数,比如模型、版本等。 如何创建 deepsafe 的 apikey, 在 这里就不过多介绍了,很简单,网上教程也很多,登录 deepsafe 官网注册一个就行。然后将 apikey 复制粘贴到 cc switch 中,点击添加即可。这样就全部配置完成,开始使用你的智能题吧。
405十年码上漂 12:30查看AI文稿AI文稿
12:30查看AI文稿AI文稿别再纠结是 codex 还是 cloud code 了,我在实测了数十个 agent 之后发现真正决定生产力上限的不仅仅是 agent 工具,还有你手里的 skill 配置。如果你的 skill 没配对,换再强的 agent 也是在浪费时间。 所以我根据实际开发场景和我的日常使用,筛选出了这四组最核心的顶级 skill, 包含了原能力扩展、工程化开发、前端设计和内容创作。 它们完全不挑平台,不管你以后切换到哪个 agent 装上都能用。先讲最根本的两把钥匙,我称为原 skill。 你 可以把它理解成让 ai 自我进化的能力,它不负责具体的活,而是专门用来扩展 agent 的 能力边界的。不管你用 ai 做什么,这都是你第一天就应该打好的地基。 第一个是 skill creator, 来自 antropica 官方。如果你想把一套成熟的工作流变成一个新的 skill, 便于后续调用,那么选它就对了。以前想自己做个 skill 特别麻烦,得先去研究半天复杂的格式,不然可能写出来的 skill 还会报错。就算写出来了,使用效果也不一定尽如人意。 但现在有了它,你不需要去研究什么复杂的格式,也不用手动改文件,你只需要像给同事交代工作一样,用大白话把你的流程说一遍, 或者直接把你的操作手册丢给它,它就会自动帮你起草测试、反复叠带,在你自己完全不用看开发文档的情况下,一分钟就能写出一个既标准又好用的 skill。 安装和使用方式也很简单,在安装完成后,只需要在 agent 里选中 skill creator, 然后输入你的需求,和它一步步的进行沟通就好, 建议直接全职安装,这样无论你在哪个项目里,都可以随时进行调用。第二个是 find skills, 大家千万别把它当成一个普通的搜索插件, 觉得还得自己手动去查。真正的用法是你直接给 agent 派任务就行了。比如你让他帮你做个 ui 设计,要是他发现自己不会,他就会自动把你的需求拆解成 ui, 点赞你这种关键词,然后自己去全网搬救兵。他在后台连接的是 skill 点 s h 这个平台,他会自己查看哪个 skill 安装量大,哪个作者靠谱, 然后挑出最好的那个供你进行选择。在你选择好之后,他还能直接一行命令帮你安装上 skill。 creator 是 让他能自己造工具, 而 find skills 是 让它能去外面找现成的,这两个配合使用,一定能大大提升你的 agent 的 工作效率。接下来是针对具体场景的 skill。 先说软件开发,我选了这三个, superpowers, j stack 和一个前端大神的 skill, 它们针对的场景略有区别,但核心都在解决同一个问题, 就是终结那种看似逻辑闭环,实则无法落地的代码幻觉,帮你守住工程底线。第一个 superpowers, 他的杀手锏在于他把测试驱动开发这套严苛的工程标准,直接变成了 agent 必须遵守的硬规则。其实很多人刚开始用 ai 编程,最容易上手的场景就是让他写测试,而 superpowers 顺着这个逻辑直接把开发流程给正规化了, 他会强制 agent 进入一套标准的红绿重构循环,先写一个必然失败的测试,证明功能还没实现,然后写最少量的代码,让它变绿,最后再进行优化, 而且它非常稳。 agent 写完之后,它会自动开启两轮内部审计,一轮看代码,实现跟你的需求对不对的上。另一轮则专门盯着代码的质量挑毛病。这种慢思考的模式能帮你抓出很多隐藏的边界问题。 虽然看起来多花了一点点时间,但因为它第一遍就能把代码写到八十分以上,省掉了后面无数次反复抵 bug 的 时间,长期来看,反而更省 token, 也更省钱。 他的整个工作流程大致如下,首先他会拉着你做头脑风暴,把需求细节彻底磨清楚,先出一份整体的设计文档。然后他会把大任务拆成一个个几分钟就能搞定的小碎活,每个活都有明确的验证标准。接着就是让紫 a 着呢,自己去跑, 他自己写,自己查,严禁跳步,你只要在旁边关键节点确认一下就行。最后等测试全部通过了,他会把选项丢给你,是直接合并代码,还是先留着分支或者丢掉?第二个是 j stack, 作者是 y c 的 总裁 gary 谭。如果你还不知道 y c 是 什么,简单说,它就是全球最牛的创业孵化器,像 airbnb、 dropbox 这种巨头都是它孵化出来的。所以这位大佬出的工具,骨子里带的就是那种硅谷创业者的实战基因。这个工具有一点不同, 它不是那种功能单一的 skill, 而是在 agent 里内置了二十三个不同的专家角色,从 ceo、 设计师到发布工程师,你都可以通过斜杠命令直接调用,这相当于给 agent 配齐了一整支团队,让他不再是单兵作战。 为什么要搞这么多角色?因为真正做商业系统,代码行数不值钱,能跑通才值钱。有了这群专家帮你交叉审计, agent 就 能在不同的专业视角下,帮你揪出那些隐藏极深的问题。 我来向你介绍一下他的实战流程。首先,在你动手写第一行代码之前,先跑一下 office hours 命令。这就是 yc 最出名的灵魂拷问。 ai 不 会立刻写代码,而是像个严厉导师一样, 反问你六个最尖锐的问题,把不靠谱的假设先掐死。接着可以用 plan ceo review 命令,让 agent 站在 ceo 的 高度审视计划,看看有没有更优解。到了代码复合阶段, review 命令就是你的资深工程师,他不光找小 bug, 更盯着那些 c i 能过,但一上线就可能爆炸的工程隐患。另一个具有实战特色的是 q a 命令,以前 a 阵呢,只能在代码里纸上谈兵。但这个命令是真的,会打开浏览器,像真人测试员一样去点击验证, 直接把 bug 抓出来修掉。最后活干完了,直接执行 shift 命令,它会自动同步跑测试、推代码、开 pr, 整套发布动作一气呵成。该瑞谭统计过,二零二六年,它的代码产出是二零一三年的二百四十倍。这不是说 ai 写的代码行数多就是厉害,而是同样的需求,它一个人现在能顶一只小团队在干活, 就是角色分工带来的本质变化。第三个是一套前端大神 mod, 自己日常工作用的 skill, 作者是 type script 的 布道者。如果你平时前端开发比较多,那么可以试试这个。 这套工具重点解决的是人与 agent 之间沟通对不起的问题。 mark 总结过,如果没有好的引导规则, agent 写代码很容易陷入几种困境。首先是理解偏差, agent 可能根本没听懂你需要什么,或者写的太啰嗦,废话很多。然后是执行失败,好不容易写出来的代码,结果发现根本跑不通。最后是架构隐患, 虽然代码能跑,但因为缺乏整体规划,后期维护起来会非常痛苦。所以他的这套 skill 核心逻辑很简单,宁可在前期多花几分钟对其需求,也不要在后期花几个小时去处理这套低质量的代码。具体到这套 skill 里面的指令,我建议你重点关注这几个。 首先是 green 系列的命令,这就是刚才提到的拷问模式,当你提了一个模糊的需求,比如说想加个登录功能,他不会马上动手,而是会回过头来不停的拷问你细节。可能问完之后,他发现你真正想要的是 s s o 环境下的多租户登录,这就把隐患消灭在开工之前了。接着是 tree 指令, 也就是一手分诊,他会帮你把所有的任务都过一遍,分清楚轻重缓急,确保你不是在修一些细枝末节的小 bug, 而忽视了真正堵塞进度的核心问题。 最后还有一个 improve 命令,这是代码库的架构急救包,你可以每隔几天就跑一次,让 agent 站在全区的视角审视你的代码库, 找出那些以后可能会越来越难改的地方,并给出重构的建议。接下来是前端页面设计,这是最开始编程 agent 出来时,他做的最差的一个领域之一。 agent 划 u i 出来的永远都是那些固定的套路,固定的字体,蓝紫色的渐变背景、圆角卡片、特定的按钮样式。 你在网上看到的那些 ai 生成的界面,十个里面有十二个长的都一样。解决这个问题的 skill 有 两个,第一个是 fronten 的 design, optropic 官方出品,如果你受够了那种千篇一律的 ai 审美, 那他就是你的救星。以前的 ai 画 ui, 一 眼看过去全是圆角卡片加紫色渐变,就像是在共用一套廉价的模板。而 fronten 的 design 的 核心是帮你洗掉这些 ai 位, 他不是机械的套用部件,而是根据你的产品调性去推敲更有质感的纹理,或者尝试那种更有呼吸感的非对称布局。 比如你给他提一个具体的风格要求,想要一个杂志感带点硬核感的页面,他给出的方案里字体的比例和模块间的留白都会处理的很到位。有了这种对视觉细节的把控,你的 ui 就 从一眼 ai 变成了手作设计,让整个页面从单纯的能看变成了真正意义上的耐看。 第二个是 u i u x pro max, 如果说前面的工具是帮你找灵感,那这个就是直接帮你配了一个设计总监。它的特点在于,它不是在靠直觉画图,而是把专业设计的那些条条框框全部变成了底层的逻辑。比如你要做一个金融或者医疗类的界面,它会非常明确的告诉你 什么样的配色能体现安全感,什么样的字体更显专业,他甚至还会给你列出一份避坑指南,直接点出哪些设计在商业场景里是绝对不能碰的。之所以能这么专业,是因为他后台内置了一百六十多个行业的深度规则, 不管你遇到多冷门的业务,他都能拿出一套成体系的方案,从交互细节到动效走位,都给你安排的明明白白。而且他有一个很实在的功能,就是能帮你生成一套可以持久化附用的设计系统。有了这套规范,你下次再开发新项目, 直接把文件丢给 agent 就 能用,不用每次都从零开始打磨风格。而且他的上手门槛很低,无论是装插件还是用命令行,都能快速跑起来。 这两款工具的分工也很明确, fronten 的 底赞负责把画面画得出彩,而 uix pro max 负责把产品做的更专业。有了它们, ai 的 输出就再也不会有那种廉价感了。最后一类,内容创作。如果你用 agent 做内容创作,那这组宝玉老师的 skill 我 一定要强力推荐给你。 他首先解决的就是内容本身的高质量产出。比如他能帮你生成一张极具审美,完全不输专业设计师的封面图,或者把一大段枯燥的文字直接变成一张高信息密度的格式化信息图。在内容做漂亮之后,他还会顺手帮你搞定后面那些讨厌的碎活, 比如说转格式、做排版,最后还能直接一键发布到各个平台,它把从生产到发布的全流程都打通了,有了它,你就能真正实现生产和发布一体化,把所有的精力都集中在打磨好内容上。宝玉老师的这套工具箱里包含了十几个好用的 skill, 我 这里简单带大家看几个。 首先是用于生成封面图的 cover image skill, 它最强的地方在于有一套五维控制系统,从构图类型、色调方案、渲染风格,到文字排版和情绪基调, 全都能精准调优。这七十七种预设组合,能让封面彻底告别开盲盒的随机感,每一张出来的效果都像是为你的文章量身定制的专业设计。 如果你平时觉得画逻辑图、架构图很头疼,那这个信息图相关的 skill 绝对是神器。它内置了二十一种专业的信息布局,像分析原因的鱼骨图、 做转化的漏斗图、梳理层级的金字塔图应有尽有。更聪明的是,它能自动读懂你文案里的逻辑结构,直接推荐最合适的布局方案。以前要在设计软件里磨半天的信息大图, 现在只需要几秒钟就能产出出版级的可式化成果。如果你经营小红书,那么可以使用小红书 image skill, 它能将长文章自动拆解为一到十张卡通风格的轮播卡片。通过内置的十一种视觉风格和八种排版模式, 如对比、清单、流程等,可以快速生成符合平台排版习惯的图文内容。针对排版环节,这个 markdown to html 的 skill 解决的是一个非常具体的痛点,那就是在微信公众号这种不支持 markdown 的 平台上, 如何保留精致的排版。它内置了多套公众号主题,能自动处理代码、高量和数学公式。最实用的一点是,它能把文中的普通外链自动转为文末的底部引用,彻底解决了公众号里链接打不开或者被截断的尴尬。 如果你平时还有翻译文章或者精读外文资料的需求,那这个翻译 skill 就 派上用场了。它最强的地方在于 提供了一个正式出版级的模式,这个模式不是直接进行翻译,而是会走分析、翻译、校正再到润色这整整四步的流程。而且它有一个非常人性化的功能,就是能让你指定你的读者是谁。比如你告诉他你的读者是资深开发者,他就会自动省略掉那些庸愚的解释, 翻译出来的语气读起来就像是真正的圈内人写的。最后,当你把内容全部准备妥当,可以通过发布微信或者发布微博这两个 skill 来实现一键跨平台分发。 它区分了不同的分发逻辑,你可以发长文形式的文章,也可以选择只发几张图片配一段摘药的贴图模式。它把那些复杂的后台操作全都变成了 agent 里面的一行指令, 从本地草稿到最终发布,整套流程都可以在 agent 里面直接闭环完成。今天分享的这些 skill 只是个开始,其实最关键的是大家要根据自己的工作流程和使用场景,去打磨出真正适合自己的 skill。 如果觉得视频对你有帮助,别忘了点赞和。
102章鱼哥AI助手 30:43查看AI文稿AI文稿
30:43查看AI文稿AI文稿做一人公司呢,必须要有知识库,尤其是在 ai 发展如此快的大环境下。这条内容呢,就讲讲知识库该怎么搭建,包括理念、方法和工具都有哪些。这条内容呢,比较长,大家可以先收藏啊。我看到了很多有关知识库的这个内容啊,我觉得认知都是有偏差的,哎,或者说至少吧,不适合一人公司这个业务场景, 或者说有可能呢,这部分人就不懂商业,他没赚过钱,所以对这个事的理解呢,也是比较浅的。希望我这条内容呢,第一适合一人公司,得有商业变现的价值。 第二呢,就不敢说是最简单的,至少是性价比最高的方案,因为你简单很多的话,还是会牺牲一些效果的。在讲知乎之前,先讲一个看似比较普通的问题啊,就是为什么大家想去用 ai 就 用不好,比如说我想用 ai 去写内容, 或者帮我去做一些咨询的工作,帮我写方案,帮我写脚本,为什么用不好呢?这里个最基本的原因就是 ai 其实他不了解你,他不知道你是谁,他不知道你懂什么,他不知道你卖什么样的产品。所以如果想要把 ai 用好,必须你要先告诉他,你有什么,你是谁,你想怎么去用。 哎,那这个其实就是知识库最重要的意义在这儿,所以你可以理解为你要把知识库建立起来,把知识库做好,你就可以搭建一个你本人和 ai 的 一个沟通和交流的桥梁。那到底什么是知识库呢?我觉得这个事大家理解一定是不一样的,我都不用做调研,在小红书里面,去年很多人靠卖知识库 这个事还是赚到了钱的,对吧?然后能看到很多这样的案例,那小红书里边卖的知识库到底是不是真的我所讲的知识库呢? 呃,你看很多人这个把呃老外的艺人公司的那个网红 danco, 他的内容,或者是纳瓦尔的这些内容把它整理出来,或者是把所谓艺人公司从零到一百万怎么做起来的这些呃内容整理出来,把它呃编好,放到一个非书文档里,或者是把它更好的去呃用更好形式呈现出来吧, 然后放到小红书里去卖。那这个是不是知识库呢?我是这样看的啊。知识库有两个特点,第一,知识库一定是你自己的,像小红书里边,你可能今天举个例子,花九十九块钱买了艺人公司大神单扣的这些内容,有了这样的获得感, 但是有获得感这个知识是不是你真的理解掌握掌握了,这是完全的两回事啊,所以这还是别人的东西,不是你的。哦,那怎么去衡量这个东西是你的呢?有个非常简单的方法,就是在脱稿的情况下,你能不能把它再复述出来, 尤其是在遇到这样应用场景里边。举个例子,比如说有人向你请教一人公司该怎么做,或者是他有些问题,哎,你因为看了别人的这方面的知识库的文档,你能把它给呈现出来, 这叫你的东西,如果不能啊,如果你复述不出来,说明没有吸收它,所以知识库呢,一定是属于你自己的,不是别人的。知识库的第二个特点就是它是用的, 并不是用来收集和收藏的,如果没有应用,知识库就没有价值。很多人我们喜欢去做知识库的原因,就感觉我好像去拥有它, 比如说我把过去的所有沉淀,呃,或者是方法论,呃,文章公式巴拉巴拉把它收集下来,放到这里就大功告成了,对吧?这个完全是不对的,为什么呢?因为就是你没有 应用它的场景,或者你在做这件事的时候,你你的目的性不够,你背后没有商业模式,或者他无用武之地,那么你做这件事他没有意义,他是纯粹浪费时间。所以知识库一定可以被应用,而不是只是用来收集的。那为什么我们觉得知识库这事这么重要呢?比如说你也在关心这条内容,你会去学习它。 原因就是我们做艺人公司其实很重要一个点,其实就是我们的是靠我们知识啊,经验,靠智力、靠脑力劳动来去服务给你的客户来去变现的。 所以在这过程当中我们的沉淀和整合就变得非常重要。对于自己的这种信息知识的这种沉淀,对于每天接收到新的东西的这种整合就变得异常重要了。所以我们经常有感受说,哎呀,我突然想到了一个新的想法,哎,我突然就是在一个这种, 比如读书啊,和跟别人请教交流啊,或者是在跟客户呃交付的过程当中有些新的认知,你就希望说赶紧把它给记录下来,就好像你旁边有一个呃,这个一个桶, 这桶你可以不断的往里扔东西,然后扔了以后你不用担心它会丢掉,对吧?你既然扔了它,你就会知道它一定会帮你啊,很好的把它管理起来。 所以这个其实就是你对知识库里很重要的一个诉求,就是你每天有很多的信息,这些信息不会被丢掉, 然后你有很多的信息,这些信息可以和你现有东西做更好的整合。所以这是我们对知识库这么关心的核心的原因。他有这么重要的魅力的原因就是第一是沉淀,第二是整合, 你可以细想一下,呃,整合这事还是挺麻烦的啊,比如你今天在这个通勤的过程当中有个新的想法,这个想法完全可以融入到或者是和你现有的这个肢体整合起来。但是如果你呃停下来, 或者是你打开电脑,然后把它放在哪里,或者是该怎么去整合,这工作量还是就是还是很复杂的,就事不大,但是非常非常的麻烦,那一旦你没有去做这事,可能就忘掉了。 所以我们希望的这个知识库呢,就是能帮我们做好沉淀和整合的工作。所以对我们一人公司来说,我们一直强调叫做什么?你要做长期的有复利价值的事情, 那既然长期有复利价值,既然我们要做脑力劳动啊,用自己的经验和知识去交付的这个事情,那么知识库就是我们必须要做的,它非常非常的重要。 搭建知识库其实有很多个工具或者流程和方法,所以我在开头时我讲了我希望我的方法性价比是比较高的,以及最适合因人公司的这个应用场景的。我其实试过很多种工具,我包括我一直在迭代我自己的 这个知识库的这种方法,所以我现在综合应用下来,我觉得 cloud 是 非常适合因人公司的知识库的沉淀的,那它需要有一定搭配,所以就会有三个工具,第一个是 cloud, 第二个是这个 flomo, 第三个是飞书,这三个工具把它整合好了,你就可以更好地把你的账簿打印起来了。比如说 cloud, 它的作用在于说它是一个第一帮你去清洗数据,然 然后整合数据,并且记录的这样的一个呃平台。更重要的是它可以通过对话的方式,然后通过智能体的方式,然后呃帮你去解决具体的问题。比如说你要去写篇文章,你可以直接和他对话,呃来去呈现出来,所以它是一个这种交互的场景。同时呢它也可以帮你去记录和吸收, 然后就一整合吧,然后 flow 的 价值在于说,呃,在日常的你有些新的想法,新的这种感受的时候,它可以快速的帮你记录,就是不用等,然后不用去整理思绪,也不用去措辞,快速的把它记录下来,然后把它导出,这个其实会更方便的。那非书的价值在于说把你的这个知识体系知识库, 然后沉淀在这里,方便你去查看和吸收和修改工具讲完了,可能大家会说是不是可以开始去讲怎么去搭建知识库了?还不可以,为什么呢?我,我先跑个题, 我可以跟大家讲,就是搭建知识库的这种操作的方法,呃相对来说比较好学,它甚至不是最重要的,我认为更重要的是就是对于这个事的理解,以及就是你呃能去建知识库的一些前提, 这些前提我认为是能帮助你或者是能让你保证知识库能更好的被应用的一个先决条件。所以我现在跟大家分享一下,就是你要去应用和建立知识库的前提到底应该有什么?第一呢就是建立知识库他必须要有意义,就你做这件事你是为了解决谁的什么问题?你的商业模式是什么? 就这个它是一个工具,它是一个呃,它,你可以理解为它是一个知识体系,那这个知识体系肯定是拿来去做应用的,所以你必须要思考的是,或者是你已经有了这样的一个答案,就是为了谁,然后解决什么的问题,你背后的商业模式吗?商业模式就是你用来去做价值交换, 你可以把你的经验时间付出出去,你你变现对吧?你换来钱,并且这件事能长期持续运转,这个叫做商业模式。其实谈钱不丢人,你会发现在商业这个世界里边,如果说他不能变现或者是长期,至少长期来看他都不能有商业价值的话,你这件事是不值得做的,或者说你要去做也是 怎么说也做不下去,你坚持不了多长时间。第二个前提就是你的知识体系,你知识库啊必须先有个框架,这框架可以是一个呃基本的一个操作流程,或者有几个关键点,呃再简陋一点都没问题。 首先你得有一个最基础的一个框框,这样的话你再去喂给他内容的时候,呃,你才能保证他给出来的东西跟你想要的是一样的,你,你不能说完全塞给他所有的信息,他其实不知道你的主线是什么, 他不知道就是你是怎么去看待这个事的,所以他只能靠他自己的理解。如果你给他很多信息,他靠他自己去理解,呈现出来的话,未必跟你想的是一样的。 我举个非常简单的例子吧,比如说我们在理解一人公司这件事上,我有一个非常简单的一个系统,就首先你要认知到自己的优势什么,然后其次选对赛道,然后设计好你的产品,然后用呃简单的方式做好个人 ip, 然后做好成交,然后成交带来更多客户,然后又会反哺你,更好的去理解你自己的优势。他这五个要素是一个圈, 所以你可以理解我啊,在我的知识体系里面,我至少就分成这五点,那么其他所有的这些信息都可以被安排在这五点里任何的方方面面。那比如说,哎,那这个高客单非标品的这个产品该怎么去设计呢?好,你放到产品里面, 哎,那这个个人 ip 该在拍什么选择题呢?放到个人 ip 里面,对吧?很多人说我不知道我要做什么,我能做什么,擅长做什么,放到个人优势里面,这五个要素就是我的一个最基本的框架。所以对于你来讲的话,你一定要对你做的这个事有一个最基础的认知和理解。如果你完全是一个纯粹是个零的状态下,呃,我觉得他给你的东西, 说实话,呃,你可能很难理解和接受的时候,呃,你就没办法应用,那就违背了知识库的意义了。所以你看 这两个前提,就意味着说我们在做这件事之前还是要能想清楚个大概的。 ai 没有办法在你啥都不懂、啥都不知道、啥都没有积累的时候,帮助你趟出一条路来,对吧?那也不现实,而是说你已经有了个眉目,它能 帮助你做延展,提高你的效率,对吧?然后甚至替代很多的人力的工作,这是 ok 的。 所以你看这两个前提就变得格外重要了。所以可能很多的朋友在看我这条内容的时候, 呃,有有一些想法,但是不够体系,但没关系,你试着把它先做一个非常简单的沉淀,哪怕就刚刚我说的,举个例子,比如说你对一人公司这事你完全不了解,那你能不能总结出三个要点来, 比如说做好产品,然后呃,写好内容,做好成交这三点,哎,这也是一个小框框呀,那你有这小框框以后,你就可以去做延展和推进了, 这个就是我们做知识库里边。呃,在做这件事之前,哈,两个非常重要的前提你必须要具备。好了,接下来就到了搭建这个环节了,其实很简单,你可以跟 cloud 去讲,你要去搭建你自己的知识库,让他去教你一步一步该怎么去操作。你发现这个问题只有 至少在当下啊,只有 cloud 能帮你去解决。基本上问了一圈,呃, cloud 是 最好用或者最清晰的,或者他在过程当中出问题吧,出最少的。 我觉得 glass 很 像一个就是理科,理科直男,他在梳理问题的严谨程度上明显会更好于其他的模型,这是我推荐他的最核心的原因哈,你在这个过程当中出问题的,呃次数是比较少的。比如说我在这个知识库的环节里面,我们已经对话了几十个回合了,没有出现任何的幻觉。可是在其他的模型里面,有的时候他 因为上下文嘛,这是 ai。 目前来说就会遇到一个常见的问题,就是当你的上下文呃次数回合变得很多的时候,他有可能会出现幻觉,他忘了他聊的到哪里了,对吧?他可能忘了之前的这些内容都非常非常正常,但是 cloud 在 这个环节表现的还是 比较好的。所以你就跟他讲你要去搭建你的知识库,他会告诉你要做哪些事情,那我跟他交流的话,他告诉我哈要做五件事。第一呢就是你要告诉他你是谁。 第二个呢,就是你要告诉他你的方法论的库到底是什么?第三就是你要告诉他你有哪些成功的案例,就案例库。第四呢就是你要输入给他你的过去的一些语料,叫做语料库。第五呢就是每日更新的内容,叫做,呃,每日更新的信息库。所以这五点再说一遍, 我是谁?方法论库、案例库、语料库和每日更新这五五个内容。其实这个应该是比较简单的啊,你根据他的要求 呃去回答他的问题就好了,我就不做详细的介绍了。呃,你会发现跟 i 交流就很简单,如果你不知道你接下来要做什么,或者你不知道你的内容全不全,或者是是是不是,呃,是正确的,或者是可不可以优化,你完全可以问他, 你告诉他,呃,你说哪里还需要补充,比如说我再去做提供我是谁这个内容的时候,其实我过去整理了个文档,我就直接给到他了,我就问他,你看还有哪些需要补充,他就告诉我说,呃。你还要告诉我你过去的这二十多年,嗯,都做了,都去哪加工哪些家? 他就告诉我说,嗯,他就说你要告诉我过去的这二十多年里边,然后你去了哪些家,公司是在哪一年,然后做了哪些成绩?这个确实我没有提供,所以他要我去补充这些东西,包括他要让我补充产品的这些信息,我就把他提供给他了。所以当你不知道该怎么做的时候,你就可以去问 ai, 这非常简单的一个事情。 所以这五点里边,我觉得,呃相对来说比较简单。但是我说一下,呃我提供了什么东西吧,我觉得这个是比较重要的,因为发现 他让你去提供这些信息的时候,如果你没有,你发现这知识库照样建立不起来。我们就以方法论库这个事来去讲,就是你的方法论到底是什么,这个还是非常非常重要的。 方法论库其实是一个最呃硬核、最干货的东西,呃,他是代表了你过去的一些经验的沉淀,你可以理解为一些流程啊、方法呃要点,甚至些公式啊等等,或你从实操的这些经验。 呃,这里边有个误区,就是有些朋友把 ai 生成东西过去呃,自己让 ai 生成一些文章,然后把它拿出来喂给 ai, 希望让让 cloud 帮你提炼出这里边的方法论。我觉得这个是有点扯的,为什么呢?就是你拿 ai 生成的东西,然后再喂回给 ai, 让它再去从中去提炼东西,这就是完全浪费时间。 在这个时候方法论库要的是非常干的东西。如果你过去有一些沉淀的呃,比如说工作当中文档,然后 ppt, 然后课件呃,或者是你讲课的这视频音频都可以,那我是怎么做的?跟大家分享一下。我有一个臭毛病,就是会有日常会写文档的毛病,就是当你有一个 呃,研究一个小课题的时候,我会把它写下来,把它沉淀下来。所以当一些很具体的一些场景的问题的时候,我有些比较呃这个深入的思考, 我就会把它给沉沉淀成文字。那么过去的这几年里面,我们沉淀了很多这样的文字,然后甚至我其实已经把它写成了一个十几万字的书稿,那对于我来讲的话,我就把我的书稿 然后拿出来喂给,告诉他这个就是我自己的这个这个知识体系方法论,然后他一下子就把它识别出来了。这时候我发现一个很有意思点,就是你看我喂给他,我就至少有二十万字的东西吧,因为除了书稿以外,还有其他东西,他最终给就是清洗吧,梳理提炼出来的东西非常短 啊,我觉得可能也就几百字吧啊,但是他非常有条理,他把核心的关键环节把他提炼出来,然后就足够了,因为他不需要赘述,也不需要去讲什么前因后果,他只需要把这个要点拿出来就可以了。所以这就我刚才讲的就是当,就是当你如果没有方法论的时候,你把 ai 生成东西再喂给他,这是没有意义和没有价值的, 所以在这一步很重要的点就是你要找到你自己硬核的干货到底是什么?如果这个都没有的话,我说实话咱也不配有这个知识库,对吧? 好,再再给大家举个例子,就是这里边有个叫语料库的,呃,顾名思义,大家知道是什么东西是吧?呃,但是我不知道大家会不会有足够的语料可以提供给他去学习和沉淀,那我是怎么做的?首先就是他也会提示你说如果你有过去你写的这些文章, 然后你这这些文章的这些观点,包括你的表达风格,其实是他需要知道的,所以我就把我过去写的这些公众号的文章呃,打了报给了他。这是第一就是我的公众号内容给他,让他去学习我的这是语料嘛,很重要一点就文字的。然后第二呢,就是我做过很多场直播, 然后我的直播呢,基本上最近的我觉得十几场、二十几场吧,都是和艺人公司相关的,而且都是单口的,而且都是在分享一个很具体的点。然后我卖货的这个环节比例也比较小,所以他都是很具体,余料都是我一晚上可能两三个小时,不拉不拉说这些这些具体的这些话,是吧?所以我就把它直播回放, 然后把它下载下来,转成文字给到他,所以这又是一种语料。那我写的文章的语料和我直播的语料其实又是不一样的,就书面的和口头的表达又是不同的,这是第二种。 然后第三种就是我在呃开会或者是给到客户咨询的时候,其实我会有,有的时候会有录音的这个环节,然后在录音的环节,这个时候他和直播的时候不一样,就他有一个对话 啊的场景,它有这种交流的场景,它有这种,呃案例的背景的场景,那这些东西有的时候,呃,有些客户是允许我们把它沉淀下来的时候,我也把它拿下来, 把它转成了呃这个文字,然后有上下文喂给这 cloud, 这又是另外一种这个语料啊,它它是有对话的,所以它可能有更多的价值, 然后这些其实都是能更加丰富。呃,这个 ai 对 于你的理解,然后 ai 能获取更多的信息, ai 知道你的表达风格、表达思路。我举个例子,你看我,我们做艺人公司,或者我没有会员,然后很多会找我来咨询,然后找我来咨询的时候,呃,我其实最初我理解就是我自己的专业能力,我能帮到他们, 然后我没有所谓使用些什么套路,或者是用什么方法论的东西,我觉得交流其实没有必要,但是我过去这一年里边,我真的数不清我做了多少个咨询。后来你把这些咨询的这些跟用户沟通的方式沉淀下来以后,发现我其实有套路的,这个套路在我脑子里,只不过我没有把它沉淀下来。 但是你把你跟这些学员沟通的这记录喂给 ai 的 时候,其实 ai 就 能帮你整理出来一个你解决你客户问题的一个思路, 对吧?你会怎么去找这个问题的关键点?然后你怎么去这个把这个问题能讲清楚,然后你在应用了哪个模型,你应用了哪个知识体系的方法,其实都在这个里面, 因为人的认知相对来说就是确定的,而且我做的业务呢也比较集中,大家问题呢,说实话也相对来说有一定的类似,所以说我应用的方法,当这个数据积累到足够多的情况下,你会发现它是有规律的。 哎,这个雨料给到呃这个 ai 的 时候,它就能帮你去提炼出来,我觉得这也非常有价值。对于这个雨料收集啊,现在有些硬件呃会让你更方便, 比如说有这个像一个扣一样啊,圆形像小硬币一样,你可以放在身上的,然后也有像手机充电宝一样,可以贴在手机背后的,像你们刷短视频可能都能看到过,它可以帮助你快速去收集这些雨料啊,大家可以 如果你感兴趣的话也可以了解一下,我在这里就不推荐了。再说一下案例库,这个我才可能对大家来说相对是最难的,因为大 大家的案例应该都不会特别多吧,说实话,因为如果案例很多的话,就说明你已经就是已经不是新手了,可能看这个视频或听这个视频的人应该是新手会多一些。所以,呃案例库这个事呢,我觉得是这样的,就是它分成两类,一类呢就是叫做自有案例,一种呢叫做公有案例。什么意思呢?自有案例就是你自己做的 啊,就是比如你自己呃接的客户,交付的客户,然后你完全了解这个背后的很多信息,然后公有案例是指他是这个公开的, 他是别人的,就是你通过在听别人的讲述或者网上的公开信息,你经过收集,然后理解、消化,然后对这个事有一个自己的看待,这个其实就是不是你的客户,然后你对他做了分析和理解,然后面你可能应用他,这叫做工友的案例。如果你自有案例比较少怎么办?第一呢就是把你的注意力放在工友案例上, 这个也是个解决问题方法。第二还有个方法,就是你可以把自己当成案例,那你可能虽然没有服呃,服务过,或者服务好很多的这个客户,但是你自己可能就是一个比较不错的案例, 这个也可以把它看成一个自有的案例,因为你对这里边的细节呢足够了解,能讲的比较细致。呃,所以这里边当然是讲自有案例是最好的,因为你会发现公有案例你讲的时候,你会就像讲别人的事一样,就感觉很多都是书面用于很多就是很粗的东西, 别人听你讲嘛也听不进去,为什么呢?因为细节不够呀,也不够吸引人啊,因为你你自己也没有进去。然后再说一下这个日常更新啊,日常更新是其实这知识库的一个开源的 一个环节,就是它不能是死水一潭呀,那你怎么去收集你的日常的想法呢?就是通过这个日常更新这个库,然后来去完成的。在这个环节我们推荐的产品就是 flomo 嘛,因为它可以快速的让你拿起手机对 他用语音讲,就可以帮助你去记录和整理这信息,做的是非常好的,非常的轻便。然后记记得在这个时候一定要打好标签,比如说这是一个很好的选择题,打个选择题的标签,这个是你的观点,打个观点标签,这个是一个客户的案例思考, 他这个是一个叫做呃这个课程的迭代的一个思维,把它打好标签以后,为什么呢?每过一个星期或者两个星期的时候,你可以通过 flomo 把它导出来,你不需要呃一条条复制, 你把导出来以后,然后把它一下再导入到 cloud 里面,或者导入到你的飞出文档里面去,把它记录和沉淀就 ok 了,所以它还是相对来说非常方便的,因为你有了标签以后,你会更好的去管理它。 我觉得在这个环节大家要注意到一点,就是你在呃用 flomo 或者做日常记录的时候,千万不要去思考,或千万不要去这个去做措辞,或者是去想这事该怎么表达的更严谨。为什么呢?因为我们在日常的呃有想法的时候,它往往就是灵光一现 啊,灵光一现的特点就是可能过了几秒钟你就忘掉他了,所以要抓住这种稍纵即逝的这种感受,而且这种感受往往不会是在你所谓很方便记录的情况下。比如说你坐在办公桌前,你对着一个文档去思考的时候,他其实人的思维是不够发散的, 他其实没有在一个很松弛状态下,他没有办法呃让自己就是把自己过去的这些方方面面的这些案例啊,知识体系啊,或者一些思考能连接起来,他没有办法就他不够发散,他非常的聚焦,越聚焦其实越没有灵感, 就什么时候会比较发散,在你比较放松的时候,比如说刚才我说通勤的状态下,比如上厕所的时候,比如说这个在喝咖啡,然后在那里发呆的时候,比如说你在看一本呃,相对来说没用的一种,一个一本闲书的时候,他会 让你的这个思维啊到处啪啪去连接,这些连接呢会给你带来一些新的思考想法,所以这个时候一个快速能记录的工具就变得啊异常重要了,所以日常 你的信息,然后要通过这种方式把它收集下来,这样你的知识库才不会变成死水一潭。那这个时候大家会说了,哎呀,我我我没有那么多的这个感受,或者一个新鲜东西补充,该怎么办呢?哎,这个就是很重要的点,就是你必须要让自己把自己哈扔进一个叫做信息源更多的环境里 啊,不管是你主动的还是被动的,你只要是想每天有更多的这种启发,或者是更多学习到新的东西的话,你一定要在一个信息源里。我举个例子,如果说你每天呃两点一线,然后的环境呢都非常的封闭, 然后没有信息,然后你每天见的人呢,都是那三四个人,比如你的家人,然后可能公司里就一两个固定的同事,你在如此封闭的情况下,你是很难有更多的去见更多的人, 然后比如说你在你见的客户越多,或者是你接触的这种咨询的学员越多,或者你有更多的合作伙伴交流的时候,他这时候给你的碰撞,你会发现远比你在办公室,你在家里蹲一天两天甚至一周啊收获大的多,这个是非常的关键的,所以这个信息源呢,就是我们要主动去拥抱。 可能你会说,哎呀,韩老师,你说的清楚,我自己现在没有那么多客户,我就是因为没有客户,我才自己在家里或者在公司里边,这个也有办法的,给大家举一个非常小的诀窍,就是你靠你的产品, 靠你的内容去做拓展,就是你可以设计一个产品或者一个内容的栏目,这个产品内容栏目呢,并不是用来变现的,而就是来去拓展你的信息源的,也是 ok 的。 比如说我举个非常简单例子,比如说,呃, 你可能真的需要很多的这种呃这种学员或者咨询,然后来刺激你,可能这个时候你的时间说实话可能没有那么的值钱的时候,你就可以卖非常便宜的一对一咨询,比如九块九, 然后让自己收获更多的信息,对吧?如果说你忙不过来,或者你觉得这个阶段过去,你把这个产品下掉就 ok 了吗?但是你一旦有这个产品,有了九块九的产品,你就会有新的体验, 哪怕说你的体验是,哦,原来低价的确实就换不来好的客户啊,低价的确实这个客户层次不齐啊,这是一种体验和感受啊,他远比你就坐在那里发呆会更好吗?是不是那么像内容也是一样的?比如说你做的个栏目是,哎,我要举办一个播客,这播客我要跟我身边人对谈, 然后我要做到每每周更新一期。那你有了这个目标以后,你就会发现到处去找你微信里边的人,然后你要跟他去约,跟他去交流,你要去, 你要去翻他朋友圈,看他感兴趣什么东西,你要去写这个大纲,写这个主题,然后去做这期内容,然后这一期期内容其实逼着你去跟外界去做交流。所以你看内容和产品其实也可以成为你构建一个信息源的一个杠杆, 或者是推动你去做这件事的工具。不管你是没有信息源,还是说你自己可能是一个不太擅长社交的人,你都可以通过这工具然后来更好去实现,所以这是呃,用好信息源很重要的方法。另外 啊,你也可以去通过读书,然后来去获取。我觉得这个是大家嗯,经常被呃,怎么说呢?经常被忽略的这点,大家都花太多时间在短视频上了,可能大家会说要看长视频行不行?就我不得不说,现在这个视频里有的时候它看似很长的一条视频,它也未必有营养, 就是在这个环节里,呃,如果你不是有针对性的去学习啊, cloud code 该怎么去配置,该怎么去做? 呃,你如果你不是有很明确的目的的话,其实读书真的是一个你必不可少的构建信息的方式,你会发现虽然现在环境日新月异,对吧?这个整个的 ai, 呃,这个发展速度很快,但是很多商业的东西,很多学科类的东西,呃。在过去 五年、十年、二十年、三十年,这些书籍仍然是适用的。比如现在很多人看纳瓦尔宝典就觉得这本书很好,但实际上这本书就是纳瓦尔的一个这个类似推特的一个内容的一个集合, 它里面没有特别的本质的东西,就你看完以后可能觉得有些启发,或者你缓解了一些你的焦虑,但是你去看营销管理这样的这种大步头,虽然很难读,虽然你看里面案例好像都过时了, 过时你可以把跳过吗?你看它这里边的一些核心的一些观点,你会发现到今天仍然没有过时。比如说你看段永平的大道那本书,就他在访谈,他讲的东西,翻来覆去就那些,就把事情做对啊,然后要关心用户的价值啊,其实这么厚一本书,核心观点反复了,就是就是就就就这么几句话, 你看他也推荐的书,他推荐的书也是这个,这个比较老的书,比如说基业长青啊,从优秀到卓越啊,这都是很多年前的书了。所以你会发现读书这件事啊,他可以让你进入到一种状态,这种状态就是,呃,还是修身养性 啊,然后能让你在这个时间段里更聚焦,或者更放松吧,都 ok。 进入到一个读书状态里边, 然后去读这些传统的,看似传统的啊,然后看似可能好像都过时了这些书,但这里面有很多的这些观点,他都是经历过时间的考验的,他都是通过去这些企业或者商业价值,或者从学科的视角,经济学、社会学、心理学啊, 从这里面提炼出来的一些观点,他就能解释。比如说你,你看现在短视频平台里面很多明星啊,大 v 翻车,他为什么翻车呢?如果你读了传播学这里相关这些书籍的时候,你就会知道他为什么会翻车,你知道大众舆论是不容被挑战的,你就会知道谁对谁错,在传播里边,在大众舆论里边是不 重要的,所以这都是你能更好去理解这件事,更好的去获取到新的这种信息和知识,很重要的方式就是读书,读书真的非常非常重要。经常有朋友问我说,哎,你这么忙还能持续的输出,原因是啥?我觉得我我没有什么很性感的答案,就是 读书啊,就是跟你的客户交流开会啊,就思考,拿着笔在纸上划拉呀,就是这些很传统东西,但它就是有用,就是有价值,再加上你对于 ai 的 应用,你有你的工作流,对吧?你用好 cloud, 你 用好这个,呃,各种的这个智能题, 然后你就可以把这个效率提升,这事就很简单。当然说来说去,背后就是你对于你的商业模式,你做哪个人区的生意,他们有什么痛点,对吧?你提供的产品是什么,所有问题都想清楚了以后,哪怕就是阶段性想清楚吧, 你会发现你能做的事,或者是你需要做的事是不多的啊,是不多的。一家公司不应该把自己忙死啊,累死,呃,那是会让你没有感觉,没有创造力,这肯定是不对的。 所以当所有的事情啊,都对了,或者都找到了一个比较好的这种姿势的时候,你没有太多的事需要去做的。我们被自己累死,很多的时候就是因为我们做了我们不该做的事情,没有必要的做的事情,就是我们为了 就是找自己的安全感,然后,呃,每天忙碌的在做这做那,实际上你思考一下你的目标到底是什么?你为了这个目标去做这个事是对的吗?我举个例子,我们有一个学员,他其实是要做弊端的,他是做品牌营销,他是要去服务这些企业的老板。但是在他的日常项目里面,其中有个点叫要成立一个品牌营销的一个社群。 然后我就问他,我说你做这个社群对于你的目标有什么意义吗?因为你的社群进来这些人,他对于你服务的这个你的客户,他完全是两个群体。而且你本身你要做社群这件事,你又是一个人,你要花你比较 不少的时间啊。比如说一天,一周你工作五天的时间,我觉得你要周末组织活动,至少你要花你一天的时间在这个事里面,那五分之一时间在这里面其实也不少了, 他又不能给你带来呃,这个比较多的收入。呃,所以你做这件事完全就是因为这个。我我觉得啊,就是因为没有思考清楚,或者是就是为了自己啊,找到一个所谓的安全感吧。 所以这些事你把它砍掉不做,你会发现你轻松了很多呀。好了,在你把知识库,刚才我们讲这几个模块都建立完成以后,接下来才是最关键的,你就要反复不断的去用它, 你要把你知识库放到实战里面去,比如你要用它去建立一个一个的项目,比如有的项目是帮助你写公众号的,有的项目是帮助你完成你的这个短视频选题和竹子稿的,有的是给你直播大纲的, 有的是给你的客户咨询的一些思路的等等,建立 n 多个这样项目,然后不断去应用它,在应用的过程当中去优化,因为你在你没用的时候,其实你不知道这个知识库它是不是有价值的,这知识库哪里是需要去调优的? 我们之前讲过,知识库建立起来最重要的是应用验证,这个知识库最实际的方法就是看你发布的内容有没有流量,看你跟客户交流的时候,他能不能帮助你,去节省你更多的时间,这个才是知识库的真实价值所在。 说了这么多,我还是想在最后给大家强调一下,知识库呢,只不过是我们的工具,是我们和 ai 交流的时候很重要的一个 桥梁。但是我们在做一人公司的时候,最重要的仍然是你要想清楚你的目标用户是谁,他们有什么需求,你要通过什么方式去满足他们的需求,你会发现只要这些问题想清楚了以后, 你才能去构建你的知识库。这些这些问题如果说你不能很好的回答,其实你不知道要拿什么东西去填到你的知识库里,你不知道该怎么去积累, 对吧?那可能是一个零散的状态,那零散状态你自己都没有想法, ai 没有办法帮你把零散的想法给你找到一个所谓你创业的方向,或者是你破局的方向, 这个事他是做不到的。好了,以上就是我对于用 cloud 该怎么去建立自己知识库的一个思考和方法的描述吧,希望对大家是有帮助的。
139韩叙HanXu 03:29查看AI文稿AI文稿
03:29查看AI文稿AI文稿想在 windows 上同时拥有一个完整的 linux 开发环境,不用装虚拟机,不用双系统,一条命令就能来回切换。这就是我二。 今天这个视频,我带你从零开始,把我二和乌布图二十四点零四装起来,全程大概十分钟。 底部启动 windows 的 握功能,右键开始菜单,选终端管理员,也就是以管理员身份打开 partial, 然后执行两个命令,第一个是启动 windowsop system for linux, 第二个是启动虚拟机平台。这两个命令我都放在评论区里,你直接复制就行。 执行完之后重启电脑,这一步不能省,必须重启。重启回来后,如果你的系统版本比较老,可能会提示需要更新 vivo 内核,去微软官方的下载链接下这个 mc 安装包, 双击运行就完事了。链接我也放在简介里,如果你用的是比较新的 windows, 十一这一步大概率会自动跳过,不用管。 接下来打开一个普通的 passcode 窗口,注意,这次不需要管理员权限了,执行这一行 wsl set of four version two。 这一步是告诉 windows 以后装任何我发行版默认都用我二,而不是老版本的。我已现在正式安装 wooptwo, 同样在 power shell 里执行 wsl install 低于 boot two twenty four point o four, 它会自动下载无 boot two 二十四点零四的镜像并完成安装。等它跑完之后,会自动弹出一个无 boot two 终端窗口,让你设置 linux 用户名和密码。 这里有两点注意,第一,密码输入的时候屏幕上不会显示任何东西,不是卡住了正常输入,然后回车就行。 第二,这个用户名记好,后面配置环境会反复用到,到着 vo 二和 ubo 二十四点零四就已经装好了。如果你虽盘空间比较紧张,可以把 ubo 迁到地盘, 先关掉 vo, 然后在地盘创建一个 vo 目录。先用 export 把 ubo 导出成一个压缩包, 在于 winregist 注销原来的,最后用 import 把它导入到地盘版本,指定为二。导入完之后有一个小问题,默认登录用户会变成 root, 你 需要手动创建一个 wow, 看覆文件, 在里面指定默认用户。具体配置我已经放在评论区里了,退出重进屋补土,一切就恢复正常了。到这里,沃尔沃二合油补土二十四点零四就安装完成了, 下一期我会接着讲怎么在沃里安装 cloud code, 接入 deepsixv 四核配置开发环境。觉得有用的话麻烦点个赞收藏,我们下期见!
27火小狐 02:37查看AI文稿AI文稿
02:37查看AI文稿AI文稿别再往主循环里塞 if 每多一个扩展需求就改主循环最后最核心的代码会变成谁都不敢碰的巨石。 到了权限系统以后,你会发现很多需求不只是允许或拒绝。绘画开始打招呼,工具执行前多检查一次,执行后写审计日记,这些都更适合放进 hook。 hook 可以 理解成预留插口,主系统跑到固定时机,把上下文交出去, hook 返回结果,主系统再决定怎么继续。 最小心智模型就这一条,主循环继续往前跑,到了预留时机,调用 hook runner, 拿到 hook result, 再决定继续阻止还是补。一条说明, 初学者先别做几十种事件,教学版只抓三个 session start 绘画开始 pre to use 工具执行前 post to use 工具执行后 返回。约定先别做复杂,教学版用零一二就够了。零表示继续,一表示阻止当前动作,二表示注入一条补充消息再继续。 这一章先记三个结构, hook event 说明发生了什么。 hook result 说明想不想阻止,或者要不要补充消息。 hook runner 负责统一调度扩展逻辑, 最小实现可以很朴素。准备一个 h o o k s 映射,然后写 run hooks, 逐个执行 handler, 只要返回一或二,就提前交回主循环。 接入主循环时位置要清楚。工具执行前跑 pre two loops, 它可以阻止,也可以补消息。工具真正执行后再跑 post two loops 顾客真正的收益是让扩展长在系统边缘。插件日制首位提示补充都能接入,但主循环还是只负责推进主状态。 最常见的坑是把 hook 做回 if 地狱条件分支到处散落,返回结构每天变一次,再一上来做全市界面,主循环还是会乱。 最后记住一句, hook 不是 主循环的替代品,而是主循环对外暴露的扩展点。下一章记忆系统会看哪些信息应该跨绘画留下?
 05:06查看AI文稿AI文稿
05:06查看AI文稿AI文稿你是不是觉得 cloud 扣已经够好用了,但其实它还能更强?今天咱们就来聊聊怎么给 cloud 扣开挂。从记住你的项目习惯,到一键调用工作流,再到连接外部工具,这些扩展功能用好了,效率直接翻倍。咱们一条一条说清楚,看完你就知道哪些该装,哪些暂时不用管。 先给大家画个地图, cloud code 扩展分好几层,每一层解决不同的问题。最基础的是 cloud 点 md, 它相当于给 cloud 的 长期记忆,每个绘画自动加载。然后是 skills, 你 可以理解为自定义技能包,比如输入斜杠 deploy, 就 能跑一套部署流程。 在网上是 m c p, 这是连接外部服务的桥梁。比如让你的 cloud 直接查数据库,发 slack 消息。还有 sub agents 和 agent teams, 负责把复杂任务拆成小块并行处理。 最后是 hooks, 在 特定事件发生时自动触发脚本,比如每次保存文件后自动跑一遍 e s lint。 这些功能不是让你一次性全配齐的。官方给了一个特别实用的建议,按需添加,别一上来就折腾全套 敲黑板了。这里有个触发器清单,亲测有效。如果你发现 cloud 两次搞错你的项目约定,比如总是用 npm 而不是 pmpm, 那 就该写到 cloud 点 md 里了。 如果你第三次把同一套多步骤流程粘贴进聊天框,赶紧把它封装成 skill。 如果你一直在从浏览器标签页复制数据给 cloud, 那就说明你需要一个 m c p 连接。如果你某个辅助任务的输出把对话窗口刷爆了,用 sub agent 把它隔离出去。如果你希望某件事每次都不用问,就自动发声,比如提交前跑测试,写个 hulk 搞定。 这里有几个容易踩坑的混淆点,我给大家捋一捋。先说 skill 和 sub agent。 skill 是 可附用的知识或工作流,你可以随时调用。 subagent 是 一个隔离的工作县城,适合读大量文件或者做研究,它只返回摘药,不污染你的主对话关键区别, skill 是 知识, subagent 是 劳动力,然后是 cloud 点 m d 和 skill。 如果 cloud 应该永远知道某件事,比如你的构建命令项目结构放 cloud 点 md。 如果只是偶尔,需要参考,比如 a p i 文档部署清单放 skill。 记住一个经验法则, cloud 点 md 保持在两百行以内,长了就拆成 skill 或 rules 文件。还有 sub agent 和 agent team, sub agent 是 在你当前绘画里干活的临时工,干完汇报结果。 agent team 是 多个独立的 cloud 绘画,它们能互相发消息,自己协调。简单来说,一个人能干完的用 sub agent, 需要团队协助的用 agent team。 这里有个黄金组合。要重点说, m c p 给 cloud 的是能力,比如连接数据库,但光有能力不够,你还得教他怎么用好这个能力。这时候 skill 就 派上用场了。 你可以在 skill 里写清楚你们团队的数据库架构,常用查询模式,甚至消息格式规范。 m c p 负责连上工具, skill 负责教会 cloud 怎么用这个工具,两者搭配效果翻倍。 再说说 hook, 很多人容易把它和 skill 搞混。记住一句话, hook 是 不需要 cloud 思考的。自动化 skill 是 需要 cloud 推理的工作流,比如每次保存文件自动格式化代码,这种确定性操作交给 hook, 如果是需要判断和决策的,比如代码审查清单,用 skill 还有一个避坑指南,如果你有一条规则,绝对不能碰点,因为文件别只写在 cloud 点 md 里。当建议用 pre to use hook 直接拦截,这才是真正的强制执行。 这扩展还可以在多个级别定义,用户级、项目级、插件级,甚至子目录里也能嵌套。如果冲突了怎么办? cloud 会自己判断,通常更具体地说明优先。比如子目录里的 cloud 点 md 会覆盖根目录的通用规则, skills 和 sub agents 是 按名称覆盖的, m c p 服务器也有优先级顺序。 hooks 比较特殊,所有注册的 hook 只要匹配事件都会触发,不会互相覆盖。 最后说一个很多人忽略的点上下文成本,你加的每一个功能都会消耗 cloud 的 上下文窗口 东西太多,不仅可能把窗口塞满,还会增加噪音,让 cloud 的 效率下降,甚至触发错 skill, 忘记约定,所以别贪多。 cloud md 每个请求都加载成本最高。 skills 只在调用时加载完整内容,平时只加载描述,成本低。 m c p 工具默认启用搜索,空闲时几乎不占资源。 sub agents 完全隔离,不影响主绘画。 hooks 外部运行零成本。 好了,咱们快速总结一下, cloud code 的 扩展体系可以分成三层, cloud 点 md 管永远要记住的事, skills 管按需调用的知识和工作流。 m c p sub agents hooks 管连接外部,并行计算,自动触发 真实的工作流,通常是组合使用的 cloud 点 m d 定规矩 skill 封装流程, m c p 连外部系统 hulk 做自动化兜底,记住按需添加,别一上来就配全套。当你发现某个操作重复了三次,那就是该把它封装成扩展的信号。关注我们,持续获取实用技巧,让你的开发更高效。
5920AiAppWorks 01:11查看AI文稿AI文稿
01:11查看AI文稿AI文稿讲一下 cloud desktop 在 没有账号也不想装三方插件的情况下,如何接入 deep seek 杠 v 四杠 pro 满写版 em 向下纹首先点击左下方 help, 打开开发者模式,然后就会发现多了个 develop 选项, 点击 configure third 杠 party, 然后输入自己的 api key, 以 d s 的 ur 六翻到下面的模型列表,添加 deepseek 杠 v 四杠 pro em 模型, 然后打开 offer em 杠 contest 这个选项。注意,在 cloud desktop 里,模型名还必须添加 cloud 杠前 j 才能正常使用。最后翻到下面,开启 hide sign 杠 in 这个选项, 最后点击 apply locally cloud 会自动重启应用这些设置,选择由 em 向下玩的 model, 然后就可以用 cloud 直接体验满血 d s 模型了。
2538滑稽🤪 08:51查看AI文稿AI文稿
08:51查看AI文稿AI文稿cloudco 已经在处理数百万行代码的超大规模生产环境中跑起来了,它目前正运行在包含数千名开发者的企业环境里,应对的是百万行级的单体仓库、复杂的微服务架构, 甚至是长达数十年的遗留系统。今天我们直接看 antropolis 总结出的企业级部署指南。我会从底层的导航原理、决定性能上线的 harness 架构,以及最后的组织落地策略这三个维度,带你掌握这套实战方案。 在大规模代码库里,怎么找对代码是核心问题。传统的 ai 工具多用 r a g 技术,靠预先建好的锁影来解锁,但在高速迭代的团队里,锁影经常跟不上代码的变化。比如你刚从命名了一个模块,锁影可能还在指向旧路径,这时候 ai 就 会拿着过时的信息乱写 codecode 避开了这个坑。它用的是 agentec search, 它不依赖静态缩影,而是像真人工程师一样,直接在本地文件系统里工作。它会通过便利目录读取文件,利用 grip 搜索并沿着代码的引用关系进行追踪, 这意味着他看到的永远是当前最新的代码。彻底解决了锁影之后带来的问题,理解了导航原理,接下来看决定 cloud code 性能上线的关键。 harness, 也就是支架生态。很多人有个误区,觉得 cloud code 强不强只看模型指标, 但在企业级应用中,真正决定表现的是围绕模型的这个支架。它有五个扩展点和两个增强能力组成。 扩展点包括 c l a, u d 点、 m d hooks, skills, plugins 以及 m c p。 服务器。增强能力则是 l s p 集成和 sub agents。 简单来说,如果把模型比作引擎,那么 harness 就是 整辆车的底盘和操控系统。 没有这个支架,再强的模型也无法在复杂的工程环境下高效运转。第一个组建是 c o a u d 点 m d。 它是整个系统的上下文底座。它的特点是在每次绘画开始时, cloud 都会自动读取它。在配置上,我们建议采用分层模式, 根目录下的 c o l u d 点 m d 就 像是项目的大纲,用来存放全区规范和最重要的注意事项。而在具体的子目录里,你可以放更细化的文件,专门定义该模块的局部约定。 记住一点,因为这些文件是每次都会加载的,所以一定要保持精简,只放最有价值的信息。千万别写成厚厚的说明书,否则会拖慢性能。 有了静态的知识,我们需要 hooks 来让系统动起来。很多人觉得 hooks 只是用来拦截错误,防止 cloud 做错时的脚本,但这其实是大材小用了。 hooks 真正的威力在于实现持续改进。比如,你可以用 start hook 在 任务开始时自动加载当前模块特有的上下文。 更高级的做法是利用 stophook, 在 任务结束时,让 clout 对 刚才的操作进行反思,并直接提议更新。 c l a u d 点 m d。 另外,对于 link 检查或代码格式化这类极其讲究确定性的任务,直接交给 hoops 去执行,比单纯在 prompt 里求 clout 记得遵守规则要可靠得多。最后,我们来看 skills, 也就是技能。在大型项目中,任务类型非常杂, 如果你试图把所有的专业知识、所有的规范都塞进 c o a u d d 点 m d, 后果就是上下文严重膨胀, cloud 会变得反应迟钝,甚至逻辑混乱。 skills 采用了一种渐进式纰漏的策略,它把各种专项领域的专家知识,比如安全审计、文档处理或者部署流程打包成独立的技能包。 只有当任务真正需要时, cloud 才会按需加载它们。这种方式既保证了它在处理特定任务时的专业深度,又避免了无关信息对上下文空间的挤占,真正实现了用时才现身。 有了基础的支架,我们需要解决如何把这些能力规模化分发的问题。这就是 perkins 插件的作用。在大型组织里,很多优秀的配置往往只存在于某个高手的电脑里,这叫部落知识。为了打破这种局面,插件可以将 skills、 hooks 和 mcp 配置打包成一个单一的可安装包。 这样,当新工程师入职第一天,安装了插件,就能立刻获得和资深开发者完全一样的上下文和能力,实现整个组织能力的标准化。 如果说插线是在组织内部传授经验,那么 m c p。 服务器就是在为 cloud 提供向外延伸的触角。它是 cloud 连接外部工具、私有数据源以及各类 api 的 桥梁。 通过 m c p, cloud 可以 直接调用你们内部的结构化搜索工具,或者接入公司的文档供单系统,甚至是数据分析平台。这让 cloud 不 再只是一个写代码的助手,它真正成为了一个能操作公司整个工程生态的智能体。 在所有的扩展能力里, lsp 集成是提升导航精度的杀手锏。传统的 ai 往往是在做文本层面的模式匹配,这在大规模代码库里很容易出错。比如两个不同模块里有同名的函数, ai 可能会找错地方。 但通过 lsp 集成, cloud 就 拥有了和开发者 ide 完全一样的符号级导航能力,它能精准地追踪不同作用域下的同名符号, 特别是对于 c、 c 加加或者 java 这些强类型语言引入 lsp 是 提升大规模导航可信最有效的投资。 最后,处理特别复杂的任务时,就需要用到 sub agents, 也就是自智能体。在大规模开发中,一个任务通常包含探索和编辑两个阶段。 如果让主智能体同时干这两件事,很容易因为上下文过载而迷失方向。 sub agencies 采用了分治法的思想,它会开启一个拥有独立上下文窗口的 cloud 实力来专门处理子任务。比如,你可以先派出一个只读型的子智能体去扫描整个子系统,把调研结果写成报告, 然后再让主智能体根据这份报告进行精确的代码编辑。这种把探索和编辑分开的模式是处理复杂工程任务的核心逻辑。有了架构基础,接下来看具体的实操。核心目标是让代码库变得可导航。首先是 cloud 点 md 的 分层设计, 不要试图在一个文件里写完所有东西,要把根目录的文件做得尽可能清亮,只放全剧大纲和关键的避坑指南,真正的细节应该放在各个子目录的 clod 点 md 里。另外,建议在具体的子目录里直接出示化 clod, 而不是在仓库根目录,这样能让它的上下文更聚焦。 最后,一定要利用 ignore 文件把生成的代码构建产物和第三方库排除掉,把噪音降到最低。如果你的项目结构非常特殊,或者规模大到目录结构都快理不清了,那就需要进阶手段。 第一,建立代码库地图,再跟目录写一个清单级的 markdown 文件,用一两句话描述每个顶层文件夹的功能,这相当于给 cloud 提供了一份目录锁影。 第二,一定要跑起 lsp 服务,不要只靠文本搜索。 lsp 能让 cloud 通过符号来查找,比如直接找某个函数的定义,而不是在几千个同名字母串里大海捞针。 这两招结合起来,能极大提升它在复杂环境下的导航效率。有一点大家必须注意, cloud code 的 配置绝对不是一劳永逸的。随着 ai 模型能力的不断进化,你以前为了弥补模型缺陷而写的那些指令可能会变成现在的负担。 比如以前你可能需要写很复杂的指令来教他如何进行跨文件重构,但如果新版本的模型已经原生支持的非常好了,这些旧指令反而会变成认知噪音,限制新模型的发挥。 所以建议每隔三到六个月,或者在重大模型版本更新后,都要对配置进行一次彻底的审查和清理。 最后,我们谈谈落地时最关键的组织保障。技术配置做的再好,如果没有人负责,也会变得杂乱无章。 成功的案例表明,企业需要设立专门的角色来管理这个生态,你可以设立一个 d r i, 也就是直接负责人,负责统一配置权限和插件标准, 或者设立专门的 agent manager, 这个角色融合了产品经理和工程师的职能。如果不设专门角色,至少也要有一个核心人员来负责,把散落在各处的部落知识收集起来,转化成标准化的插件和技能,防止团队的 ai 能力陷入碎片化。 那么一个企业该如何开启这个进程呢?我们建议遵循基础设施先行的路线图,不要一上来就全员推广,那样会带来巨大的吃力压力。 最理想的路径是先由 devx 或者开发者体验团队介入,把底层的插件和 mcp 基础设施搭建好, 在基础设施成熟后,再通过跨智能工作组把工程安全和治理部门拉进来,共同制定规范和路线图。这种从工具准备到规范制定再到全员推广的循序渐进方式,是目前最稳妥的落地路径。
36AI信息差 00:18查看AI文稿AI文稿
00:18查看AI文稿AI文稿玩 coco 的 必装的一个插件啊,那必须是 superplus。 目前这个插件已经收获十三万多个 style。 当我刚开始用 coco 的 时候,就感受到它强大之处。首先它能够帮你在编辑代码之前啊,通过提问来完善你的错误想法,探索各种方案啊。所以如果你想做一个完整项目啊,这款插件必不可少。
2899宏哥玩AI【资料在主页】 01:25查看AI文稿AI文稿
01:25查看AI文稿AI文稿嗨,大家好,今天想跟大家分享一个我自己觉得大家在使用 cloud go 的 时候必须去安装的一个工具,它是一个终端管理的系统,叫做 ghost。 那 常用的我们自己苹果自带的这个终端 terminal, 实际上我个人觉得非常的不美观,你可以看到它就是非常古 老的一个界面,你把 cloud 换出来,它也没有什么特别的功能。这个 ghost 有 哪些厉害的点呢?第一点其实是你可以自定义它的界面跟主题,包括它整个的界面的一个风格,还有像我目前做的毛玻璃的这样的一个效果。 第二个我觉得最实用的是它可以让你在开发多个项目的时候去进行左右的分屏,还可以去进行上下的分屏,而且它是无限的,比如说你可以再往再往这个界面的下面再去分一屏,再去分一屏,也就是说你可以在一屏内去管理多个 session, 我 觉得这个是非常好用的,特别是大家涉及到一些多 agent 的 开发的时候, 你也可以把不同的项目直接的加 t, 形成一个新的图标,然后再给它进行无限的去做一个分屏啊,这些都是可以的,我觉得这是第二个点非常有用的功能。第三点就是它自己自带的这种代码股股权跟记的功能,比如说像我之前输入过 cloud code, 我 在两个横线它就会有我上一次使用的这个 u onliefence, 也就是跳过所有所有这种权限审核的这个建议就可以直接打开 那高斯 d 还有个非常有用的功能,就是它可以定死在桌面上,你可以输入 option 加 t, 这样它就会在桌面的全区的最前面的位置,你不管点开什么网页都不会把它给遮掉。所以相对来说,我个人觉得它是我目前使用过配合 call 使用最好的终端管理软 件。如果大家对我的高斯 d 的 配置,比如说像这种它界面的外观呀,还有像毛玻璃啊,还有一些其他的配置,感兴趣的话大家可以私信我。
192Teemo



