comfyui3d漫剧用哪个工作流
四月更新最强工作流,完美解决角色全角度一致性问题,秒杀全网同类型的 ai 功能,只需上传一张人物图片,运行工作流就能自动生成该角色三百六十度无死角全套形象,实现完美的一致性。 生成的图像不仅角度完整,还能轻松转化成真人、三 d、 卡通等任意风格随意切换,大大扩大 ai 绘画的应用场景。 比如生成这样爆款的 ai 动漫、短剧、 ai 电影,都需要保持人物的一致性。那么强大的工作流关键还是免费的,拿到就可以直接使用。如果你也想试试工作流,我都已经整理好在网盘了,暗号拿走开练!

粉丝1685获赞3449
相关视频
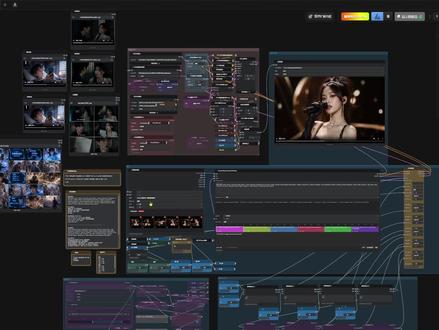 17:17查看AI文稿AI文稿
17:17查看AI文稿AI文稿兄弟们,千呼万唤使出来多图多分镜生成长视频工作流。详姐,他来了!这个工作流一共分为两大板块,第一个板块呢是一个 多图升视频的板块,第二个板块呢是一个多图加音频升视频的一个板块啊,这个工作流我会无偿的分享出来,看完我这个视频的话,基本上拿到手之后就可以使用啊,到时候无论是工作流还有这个模型,我都会放在网盘里去领取啊。我们先展示一下这个工作流做的一些案例啊, 你看我这里我做的分件啊,有一个是一张图片生成二十五分件,这个都是我拿一米纸做的,然后这个是生成了六图,我们先看这个六图了。别走,我知道你恨我。恨你,你也配?我姐死了三年,你手机密码还是他的生日? 你你,你怎么知道?因为我怀了你的孩子。如果你们自己来做的话,你们这些分镜都弄好的话,我这个分镜做的很烂啊。我没,我都没怎么抠啊,正常来说是不能带字幕的,字幕这些东西都是要自己写的提示词啊,所以说你看我这比较烂,所以他出了很多乱码, 然后你们要是自己去做的时候,这些分镜一定要做好,做好之后把那个提示词也写好的话,效果会比我这个好很多倍啊,表哥,我是因为没办法,我没有那么多时间去扣这个东西啊,因为我做教程的话没那么多时间,又是无聊的周末, 嗯,我手机怎么了?你看这乱码都是因为我上传图片有问题。我手机怎么了?细从这什么情况啊?分辨率太低了,我就不上传图片,这什么情况啊? 还有免费的无限出海来吧。怎么给我吸进来。现在这个弄个数字人唱歌。这个啊 好 ok 啊,案例展示完了,本来我这个工作流我测试了极,我测试我这个电脑极限,我的电脑是四零六零泰十六 g 啊,然后三十二 g 内存,然后我测试我这个电脑的极限,我当时 其实理论上来说这个工作流它是可以放无限张图片的,你想放多少张图片都可以,但是我测了最多的,我因为我这就生成二十五张分镜,我就测了最多就二十五张分镜。然后呢,我本来想测两分钟, 两分钟吧,失败了保险存了啊,跑不动,然后呢?后来我又去调调调,最后测着我只能跑得动一分钟,但是一分钟加上二十五个分镜,把二十五个分镜放在一分钟里的话它的效果特别的差啊,特别的差,所以说后来我就把它 变成这个十个分镜啊,这个十张分镜来生成,然后我觉得如果是你们真的是自己在做慢剧的话去把提示词写好,把分镜做好的话,那十个分镜我这个配置啊,先说好是我这个配置啊,是绝对是没有什么压力的,会出来效果不会太差,就是哪怕差无所谓,抽卡就好了是吧,毕竟他的速度还是很快的。你像我现在以这个为例吧,因为那些的话已经生成过了, 哎,看不了了。以这个为例的话现在是十五秒,呃,用了才三百二十九秒啊,并且你们看这个画质也不会太差啊, 如果说不行的话之前我不还发了一个呃,那个高清放大的工作流吗?低的分辨率去跑完,跑完之后再给他放大,不一样的啊,放大速度比较快,对不对啊?这就是工作流这个作品展示,接下来咱们就开始详细的教学啊,详细的一个教学。 首先我们来看看,我把它分成了这几个板块,第一个是模型彩样区啊,第二个是你要输入,要输入东西的,比如图片文那个文本啊,就是题词啊,以及他们的些分辨率啊,这些帧率这些东西。然后呢?还有个数学表达是这个最后讲啊,然后还有就是这个音频这边的输入啊,首先我们先来看这个模型,这边 模型的话这边就是一个大模型搭配了。呃,我这边一共是放了两个 lara, 第一个 lara, 这个 lara 的 话 v b v r 是 一个咱们国内的一个大佬啊,他做的一个 lara, 他 这个 lara 做的就是属于一个物理 lara, 就是 能让你生成的视频更遵循物理效果啊,然后他设置个零点七就行,然后我就把它连到这来了。 这个 logo 是 干嘛?这个 logo 就是 一个过渡转场,我为啥刚才这个视频放这没有动啊?你们看一下区别就知道了。一张分镜和下张分镜的时候,你是把它切开呢?还是说让它自然的转场过去?这个 logo 就是 负责这个的,就是它能让你自然的过度,还是直接切下一个分镜?有一些地方它必须得切分镜才好,你要过渡过去就很生硬。你比如说现在这个案例,就是 你看他没有切分镜就切到这上来了,但是其实有点别扭的啊,有点别扭,特别是如果场景不统一的话,那就更别扭了啊,那就特别的别扭啊,所以说这是他的,如果你需要这种啊,这种自然过渡的话,你就把他这个 logo 直接连到这上面啊,然后把它打开, 选中它, ctrl 加 b, 然后它就开启了啊,可以开启了,然后你要不用它的话, ctrl 加 b, 把它隐藏掉,然后把它忽略掉,然后把这个线连好啊,就 ok 了啊。剩下的这个是可 delete 和 ve。 这边都不要动啊都不要动,我都已经设置好了,到时候我给你们上传的网盘里的时候,这些模型我也会给你们告诉你们该放的什么路径啊,都有的啊, 往下看的话是这是一个加速,如果说你们那有 second 啊,有 second 的 呢,你就用,你要没有的话,直接 ctrl 加 b, 给它忽略掉,照样也能跑啊。 ctrl 加 b 给它忽略掉也能跑,你要有的话就不用忽略了。然后下面这边啊,这边是就是裁样区了啊,就是正常的一个一个 l t s 二点三的一个裁样区啊,主要要讲的是下边这里啊,需要讲解一下啊。首先说这个插件啊,这个插件的话 到时候我也会放在我的网盘里啊,把这个插件我也会放在网盘里的,把它直接复制粘贴到你自己 comui 里的 ctrl u i 里面。 custom models 啊,直接粘贴到这里边,然后重启 ctrl u i, 然后它就出现了啊,它就有了啊,变它特别好用啊,这个这个键啊,上面这些宽度高度你们也不要动啊,下面这些也都不要动,你们只唯一要动就是上传图片,你看 app update 一 枚指向这就是上传图片。 然后这里的话,你比如说,哎,我上传几张图片,我直接一复制夸他就上来了啊,直接就上上这里边来了,你这些图片都是可以调位置的,你想把它放在位什么位置什么位置,你都可以自己手动去调它啊,你想它在前面还是它在前面,都可以,调完之后呢?你会发现之前的时候都是需要一个一个的去把这个线给它连好啊,把这个, 把这个节点的线连好,这边现在这边呢只需要一个点直接连过来,你这边有多少张图片,那你对应的你这边就有多少个可以设置的东西 啊,不像之前你得要手动的去搞这些东西了啊。这里,并且你看我这里应该是十六张图片了,那我这里因为为什么我知道,因为这里显示着十六这个数字啊,我去掉这里一个, 那这边就变成十五了啊,对不对?你看它就变成十五了,这个节点的一个非常好用的一个一个点啊,就是不用再像之前一样那么连了啊,这个节点剪完了就是上传图片,以及你可以摆随便摆你的位置,包括刚才我那个位置,所以他才会有那些比较炫酷的一些运镜啊,一些炫酷的运镜。 然后这个节点说完之后呢,咱们再看这个节点,这个节点还是比较关键的啊,他算是这个工作流里比较关键的一个点,上面这块是输入你的总提示词,就说你这个片子的整体的一个提示词, 就是他的风格,这上面不要写名词,不要写什么人物啊,或者说是建筑物,或者说你什么物品类的东西,这样不要写指定调啊,他只用来定调,下面来写你配合每一张分镜,配合每一张分镜的题词,比如这个分镜啊,比如说我现在第一张,是吧?那现在这里就是第一个,第一个的话,那他就是人物在唱歌, 哎,然后动作自然就完了啊,第二个的话,你需要他干嘛?哎,然后你就这里第二个在写什么,第三个写什么,第四个写什么。那他的这些用法怎么用呢?先输入这里啊,这里是最重要的啊,这里是代表你总帧数,整个视频的总帧数在这里输入啊,这里写三百八十五,那就是三百八十五帧。那这个三百八十五帧从哪得出来的呢?我们在这里看 下面,这里啊,你想生成多少秒?那你这里想输入,我想生成一个十秒的, ok, 你 点这个获取总帧数,这里点一下这个小三角, 然后这边就会获得十秒的总帧数,这里应该是二百四十六啊,二百四十一啊,对,二百四十一,因为是二十四的帧率嘛,然后他也要加一嘛,所有 l t s 二点三也好还是万二点二也好,他们的帧数都是总帧数都要加一的啊,都是要加一的,所以说这是帧率 乘以秒数,这个数学式算完之后他就二百四十一帧啊,你们不会算简易算这个数学表达式的话,你们就直接就按我说的办,这边填秒数帧数,帧数的话尽量不要动,二十四帧就好了。如果说你的电脑配置高的话,你可以加高一点啊, 然后这边就是你这个视频的宽和高,这个你你的电脑配,如果跟我这配置一样的话,可以弄高一点啊,可以弄高,我这为了做教学快一点出视频,所以说我弄的比较低啊,这边的话给你配置的都有啊,都有有哪些分辨率啊?可以选择啊?都可以选择,这里都有。然后这边这个帧数得出来之后,你需要把它复制,复制完之后,哎,把它复制到这,然后点一下回车, 那你这里就变成二百四十帧的一个一个板块了。二百四十你会发现什么?你看这边都被拥挤掉了哈,拥挤把它都变小了啊,你可以点一下直方图的均衡,他们就变成一个平均值了啊,就变成一个平均值了, 然后变成平行值呢?上面这个地方啊,这个地方其实有点和那个 logo 有 点像啊,就这个地方调这个值,现在默认是零点零零一是吧?然后他正常你也可以给他调到零点五,你调到零点五有什么效果呢?其实他和这个 logo 是 有一点相似的效果,就是一个自然过渡,还是说直接切分镜啊?他属于一个这么个东西,这边就 fps 的 针数,这个不要管,这个都已经我已经连好的。 然后这边是干嘛呢?选择你是分针,就是下边这边是以针为单位还是以秒为单位啊?你先这就切换成针 啊,其实如果弄成秒为单位的话也是可以的,那这边也得相应的改啊,那个我就不做过多的一些介绍了,反正你就知道他是这两个是对应的就好了。剪辑的时候发现啊,这段录讲了,然后下边这里啊,这里是可以加啊,可以加这里有多少块,你这里有多少张照片,你这里就要加到多少块。你比如这里有十张照片,那你这里就要一直加,加到十个 啊,就有十个色块,对吧?然后给他平均值一下,然后可以去调,然后这个东西 delete, 就是 减嘛,啊,减掉啊,就是他的英文单词的这个意思啊,减掉啊,你看这都是减掉啊,这个操作不要忘了啊。然后这里的话可以直接设置他的秒数,比如这里我设置一秒啊,他就变成一秒了,你看啊,这里设置五秒啊,六秒啊,他就变成一个六秒啊, 这是他的一个基础操作啊。然后这边切完针之后呢,你要给每一个你的分镜,要计算好,你自己感觉,比如说这里边有台词的话,你自己去念那句台词,自己用嘴去念,念完之后之后你去估算他的秒数,然后给予他多少多少秒或者多少针。你看一开始我像我来做的话,我一开始我会先设置一个他的秒数, 我先试着好他那秒数,之后我根据他那秒数先做好,先把这个东西先做好,做好之后我干嘛呢?我再给他切换成帧,然后这个时候就是秒数那边我已经计算差不多了,是吧?切换完这个帧,这个帧是干嘛用的啊?你把这里对应的每一帧,你比如这里有六张图片,对不对? 输入到下边第一针,那这里是多少?这里是四十二,后边这个括号四十二啊,第二个三十九,那你这里就要输入 三十九啊,然后这里四十,你这就说四十,就以此类推,如果说你的电脑可以的话,你要想跑的图片很多的话,你就根据这个数字往上填, 往上填,往这下边填。我下边预留了很多啊预留很多,你可以根据这个数字往下边这里边去去填。填只动这个啊,不要动这个,这个数学表达式不要动啊,数学表达式我都已经弄好了,不要动。然后你填完之后呢?你要对应的是什么东西啊? 这里是个有点有点小难度啊这有点小难度,一定要仔细听啊一定要仔细听啊,因为有一些我是默认连着的,有一些他没有连着的啊,如果没有连着的,你就需要自己去连一下啊,因为我之前我为了做测试我有些没有给他连上, 因为这里啊,我这里现在到第多少张?第十张了是吧?第十张。 ok, 那 我现在找第十一张,我的第十张在这啊。呃,这里这个整数啊, 连过去连到这个数字这个点这里啊,依次往下连啊,依次往上十,第十张,这这里的十,这里要加一连的,就是加一,就是十一,然后这边呢,你看十一的话连到这边的话就是十二啊,第十二,然后这边 连上,这就是第十三。然后这个地方怎么设置啊?教一下这边怎么设置这边其余的我因为我用过数学表达式了,所以说你们就不用太多的去思考了,但是我给你们讲一下基本的逻辑啊,首先他的第一步前面是零,上面最上面这一张是零针起手,对不对?那最下面这张呢? 那就是负一,那负一就等于是最后一张嘛。啊?中间这些应该是怎么填入啊?正常来说如果不用数学百万式的话应该是怎么填入?比如我把这个线断开, 我把这个线断开,那这里的话就该是零到四十八啊,就是你的第二针就是第四十八啊,零到四十八啊,四十八的时候就切换到这张图片上了 啊,就是四十八针的时候这张图片就该出现了啊,是这个意思啊,所以说那下面是多少呢?那就是四十八加多少, 加上这个四十就是四十八加上三十九,不是应该说是四十二加上三十九啊,就依次往下逆推,就这边有多少针,这边这边应该是填多少数,就第多少针的时候出现,哪张图片就这样一次一次往上加。但是我,我为了你们不太会的话,我做了一个这样的数学表达式,你们只需要把这里对应的数字 填到这些蓝色的框框里就 ok 了,他自己会算好了数,并且填入到这里边啊,并且填入到里就自己不用再去计算他了啊,这是一个我做的一个一个一个数学表达啊, 我会让你们直观的能看懂的,所以说我都把它打开了,要不然的话很多的话我就会把它隐藏起来啊,我就怕你们看不懂,所以说我就直观打开,让你们看到这个东西啊,这就是起到一个这样的作用的。还有这里边啊,还有一个点啊,这个工作留的这个零点七,看到这个零点七了吗?这个零点七干嘛的呢?如果你把它设成一, 那他就会很生硬的夸就切了这张图片可能会很生硬,但如果你把它设置到零点一的话,他会是一个自然的,就是给模型一个发挥想象的空间 啊,让模型发挥想象空间就是不是说直接一刀切的那种推过来啊,然后你上面的手真的是一就好了,然后最下边的这个也是一就好了,中间的话你都可以给它设置成零点七,这样的话它是一个很比较舒服的一个过渡啊,不会切的那么生硬啊,不会切那么生硬,这就是一个多图多分镜生成视频的一个一个一个过程啊, 唯唯一的有点难的难点就是我觉得这个部分提示词的分配与时间的分配,就是你对于每一张分镜,你自己脑海中要有一个大致的一个时间,一个估算,然后你把这个分镜写好,把这个提示词写好,那你一般的话你的效果就会能跟得上啊, 效果就能跟得上。这段已经用法已经讲过了啊,用法已经讲完了,然后咱们就讲第二个板块啊,第二个板块的话只需要改三个点啊,只需要改三个点,怎么让音频配合他?比如说你要做一些慢剧,人物的声音是否要统一啊? 你要是人物声音要统一的话,你就需要自己先把音频做出来,对吧?你把音频做完之后啊,以后我会给你们出一个关于音频制作音频的一个课啊。今天的话主要先讲这里,假如你已经有音频了,你已经做好音频了,你只需要把音频和人物这些分镜对得上就 ok 了啊,好, ok, 现在我们打开它, ctrl 把它全括起来,然后 ctrl 加 b 打开它, 你只需要打开它之后呢要做一件事,第一你先学会这个这个东西的使用,这个东西怎么用啊?你比如我上传这段音频,这个段歌声的音频这个调是从这里设置,你比如我设置二十秒,刚才录制的时候我这里卡了啊,然后这里我重新给大家教一下啊,这里比如说你设置二十秒, 那你这个条就会变成一个二十秒的选举啊,二十秒的选举你任意可以拖动任意位置,然后你从这里呢点一下播放,你看就可以选择选择你要选举的那个那个片段就 ok 了。上面这个,上面这两个啊,你不用管啊,上面这两个不用管啊,你只需要把音乐从这里上传上去啊,点这里啊,点这里上传, 把音乐上传上去啊,或者是把你的音频上传上去,选好了你这段音频之后,你搭配好你自己的这些分镜啊,搭配好你自己的这些分镜,然后你要干什么呢?第一步咱们之前是这边连着这个数学表达式,对不对?哎,点错了,这边连着这个数学表达式,我们只需要把这个描述 连到它这个 a 上啊,把这个描述连到这个 a 之后呢,我们再点这 运算出他的这个总帧数,相当于现在你连了这个东西之后的话,你接下来你这个视频有多少秒,完全取决于你这里选择多少啊,选择多少秒,把它算完之后,把它直接也一样啊,复制粘贴到这里 啊,把它直接粘贴着点回车就 ok 了。还有两个事你要连好的啊,这里有两个点啊,第一,你看这里这里的选择, 你若是音频 latent, 那 就是没有音频输入的,他自己创造 latent 的, 如果你要音频输入的,那把这里切换成音频输入啊,这里要切换成音频输入,然后还有一个点,你要把这个音频参考这个线连到这个音频上,然后他这边就会断开了啊,这边就断开了,然后你把这里 ctrl 加 b 打开啊,打开,那他就是有这个音频参考了,这样的话你就可以做到一个数字人的音频的带音频参考的多分镜了,他的操作方式就是这样的啊,其余的都是一样的啊,其余都是一样的。只有说这三个点啊。第一,你把秒数确定好了,连好了,把这个秒数算出来 放好,放好之后呢?把这里切啊,一个是音频编辑,那个是什么?就是浅空间嘛,噪波嘛,对吧?然后你把噪波不要了,我直接输入了,对吧?我输入一段,然后再把这个下边的那段参考的直接连到连到这个音频上啊,这里就断开了。如果说你想恢复成原样呢,你就把这里还到这个音频编辑,把这里给它连好,然后下边这里呢? 把秒数,哎,直接给他连到这个 a 上啊,把秒数直接连到 a 上,然后把他一一屏蔽好,他又不干活了啊,他又不干活了,然后你就继续从这边做你的啊,就 ok 了啊啊?我再想想还有什么难点吗?啊?后面再啰嗦一嘴啊,就比如说这个工作流啊,他其实也可以做单张的啊,就是单张, 你就是只剩一张图片,剩了一张图片之后呢?你是用这个插件利用这个节点啊,一样用这一个分镜,用一张图片 利用这个插件的,他这些秒数啊,你这段他干嘛这段干嘛这段干嘛这段干嘛啊?也是一样的啊,就是单图也是可以生成视视频的,抖音这边的兄弟们如果需要这个工作流的可以进我的粉丝群啊,然后我的这个一群已经满了,现在还有二群和三群没满,我会把这个工作流和模型还有那个插件放在网盘上分享给大家啊,后天解封之后我会直接发。
1878高尚 13:16查看AI文稿AI文稿
13:16查看AI文稿AI文稿如何用 coffee ui 等开源软件完成一部 ai 短剧的制作?大家好,我是程序,欢迎来到第九期。今天我们详细讲解一下 ltx 二点三的工作流,包括纹身视频、头身视频、音乐声视频和手尾帧等, 同时讲解它对电脑配置的要求,必要插件和工作流优化等内容。内容比较长,请大家先点赞、收藏加关注。好,现在我们来到 coffee ui 的 界面, 还是一样,我们依然是选择官方的工作流。首先我们点击左边的模板,然后点进来以后找到视频。好,第一排最右边这个是他的图声视频,这个是他的音乐声视频,再往下拉,这是纹身视频, 这边这个是首尾针。那么今天我们主要以这个音乐声视频来详细讲解一下,我们点击它的工作流,大家看到左边这里是它的模型文件,包括 check point, 其实这个是颗粒布,这个是他的一个放大模型,他的工作流是采用双彩样,下面这是他的模型文件存放地址。好,我们现在看到这个工作流,他把 所有的工作流全部隐藏了,那么我们只需要把它进行解压出来,先把它拖到边上去,然后在这里右键选择解包工作流,这个时候才是他的整个工作流的真面目。好,我们现在看一下,这是他的一个图像加载区域,这个是他的音频加载区域, 这里整个是他的模型文件加载区域,毕竟他是有音频的,所以说他要比我们平常的工作流要复杂一些。这里可以输入我们的提示词, 这里设置我们的尺寸,包括这是这里是帧数,这里是时长,但是呢他这个工作流啊还是需要改造一下才能用,那么我就不展示我们的改造过程,我们直接展示我们改造结果。好,这就是我们改造的结果。 大家可以看到这个红色的节点要么是替换的,要么是增加的,比如说第一个,第一个这个是我们的音频裁剪,比如说我们输入一整段的音乐,他长达四分钟,实际上我们的视频也只能出二十秒或者三十秒,那么这个裁切工具就特别有意思,比如说我这一段视频结束时间是五十三秒, 那么下一段视频我们可以从五十二秒开始,然后再跑二十秒,然后以此类推,直到把我们这个四分钟的音频全部给他跑完。然后这个节点是预览,是用来展示我们当前所裁切的这个部分,然后这个节点就是图像压缩的节点,它这个节点还是比较好用的。 再来到上面是两个 lra, 第一个 lra 是 vbvr, 它是一个奖励, lra 对 我们视频生成这个动作是有很好的引导作用。然后后面这个 lra 是 一位大佬所开发的,它是专门解决我们 ltx 二点三 在生成视频,当在讲中文的时候,他有可能出现字幕,而且字幕还是乱码,那么这个解决方案有三个。第一个方案就是我们所有的提示词可以用英文来写,再加上我们叫仙侠的这个 lo ra, 然后再加上 k j 的 这个强制负面提示词, 因为我们这个工作流它的 c f g 值是一,所以在当 c f g 为一的时候,它的负面提示词是不生效的,我们加这个节点是强制它负面提示词生效。所以说我们一共用三种方案去解决它带字幕的问题,这里是模型加载区域,然后这里是 参数区域。这两天我在测试过程中,我发现我们尽量用幺二八零乘七二零的这个尺寸去生成我们的视频,这样的话能够保证我们的视频画面不会崩,当它的尺寸越高,它的效果越好。 然后这里是我们的彩样器,我是选择这个 c f g 的, 好像效果还是比较好的。现在我们来看一下之前我测试的时候生成的一段 mv, 就是 这个视频,它是直出七二零 p 的, 我没有进行任何的再次放大,大家先看一下它的效果, 这是一个二十秒的视频,效果还是很不错的。这个二十秒的视频用时是十分钟,过一点六百三十四秒,那么上一段生成他的结束时间是五十三秒,那么我们再生成下一段二十秒的视频,我们可以在这里把它写成五十二, 这里设成一分十二秒,刚好二十秒。那么当我们把整个视频伸出来,我们剪辑的时候,实际上我们要把它的原声关闭,用我们自己加载的原声,这样的话我们能够保证我们的音效不被污染,但是我们可以听一下我们这个原声效果怎么样。好,我们把它拉到三十三秒,然后我们听一下原声的效果是怎么样的, 非常不错,我们原声效果要比他刚才输出的效果是怎么样的,我们再对比下他刚才输出的效果, 音质确实有污染。现在我们在生成下一段的时候,我们再添加一个加速节点,双击,然后这里输入 set 好, 我们添加这个节点,这就是我们之前安装的 set 的 touch 二点二,他对我们的视频加速也是有效果的,但是我之前为什么不用呢?因为我的配置还是够的,所以说任何加速他都有可能对本身的画质有所影响。所以说我之前是没有添加,但是现在为了提速,我们可以尝试用它一下, 然后我们可以选择 cedar tension f p 十六库达的这个,然后我们把线给它连上,它就连到这里, 就连到这里,这样的话我们的连接生效。对了,我们这里还有一个非常重要的节点,就是这个东西,它这个节点就非常厉害了,尤其在这个工作流程链路生成过程中, 当工作里有完成某一段工作的时候,把它的这个模型文件和它所占用的内存显存全部给它卸载掉,然后再进入下一阶段的一个工作,这样的话减少我们的电脑负荷,甚至如果没有它可能到下一段,比如说这个 ve 在 解码分块的时候 有可能就爆掉显存或者爆掉内存。好,现在我们开始运行,看我们加了这个散热器以后,它的运行是多长。在它生成过程中,我来给大家介绍一下我们的内存和显存占用情况。大家可以看到这个内存已经爆到五十三 g, 而它的显存也只是二十二 g, 如果大家内存和显存不够高的情况下,可以适当降低它的分辨率,比如说这里可以设置九六零乘五四四,整个生成完成以后再进行一次高清放大,实际上目前我们直出的七二零 p 也是需要再一次进行放大,发达到幺零八零 p, 然后我们才可以用 好。在它的生成过程中,我们介绍一下它对我们的电脑配置的要求。它这个 f p 八的模型文件接近二十七个 g, 如果选存 小于二十四 g, 基本上是没有办法跑的,但它专门有一个针对五零系显卡的,只有二十个 g, 那 么那个模型文件我们的 十六 g 显存也是能跑的。其实内存我感觉至少要有个六十四 g, 要不然这么多模型文件根本加载不下。那么当我们显存比较低,比如说十六 g 或者十二 g 的 时候,那我们可以选择它的这个 g g u f 量化模型, 只需要在对应的位置输入它的 g g f 模型文件,然后把它的线给它连上,把这个加载器和替换掉就可以了。 包括下面这个克里普加载器也一样,我们可以选择 g g f, 但是无论显存多大,我觉得内存都应该超过三十二 g, 这样的话跑它应该没有什么压力,包括我目前跑这个工作流,我的六十四 g 内存也是勉强够用,如果我去跑三十秒的视频,可能也会包内存 好。生成完毕,我们看到是五百七十六秒,看来加了这个三者胎神,他只是提升了一分钟,比原来六百三十四秒提升了不到六十秒。我们现在看一下它的效果,这是紧接着前面一段音频的,后续的二十秒我们听一下, 大家可以看到我们这个是没有字幕和乱码的,看来我们的策略是行之有效的。好,接下来我们讲一下我们的核心的插件,要想运行这个 ltx 二点三,有几个插件是必须要安装的,我们点开 manager。 好, 现在看一下我们所有安装过的, 这里输入一下 l t x。 好, 这两个插件是必须要安装的, l t x video, 再加上它的这个插件,然后再看一下,我们还会遇到像电脑显存较低的情况下,要用到 g g u f, 这个必须要安装,还有这个 layer style 也是需要安装,包括 k g n l 子。 好,基本上就这些,那么现在这个音乐生成视频我们基本上都讲完了。 ok, 接着我们去看纹身视频,还是一样点模板视频。这里,好,这是我们的纹身视频,我们先把它的这个工作流解压出来,我们直接按照他的默认提示词。好,我们点击运行。好,生成结束,我们看一下效果,用时一百七十秒,不到三分钟, 挺不错,那么我们这样找豆包给我们一段提示词,把时间设置成十秒,它的时间在这里。十,好,我们现在得到了一组提示词,直接给它粘贴进来, 但是生成之前我们这还要加个东西,就是这个东西是防止它报现存给它连接上,然后我们开始运行。 这个工作里,我目前除了他没有进行任何改造,实际上我只是演示给大家看一下效果,这里面要改造无非就是给他夹老软,再就是限制他在输出的时候有这个中文的乱码字幕。这里还有一个细节啊, 当我们直接托官方的,无论是图声视频还是纹身视频,或者是这个音乐转视频的工作流,他不能够直接使用,我们要用的时候,我们要在这里把这个帧率的这根线给他连到这个 b 点上,然后我们的工作流就正常了。 好,出来了一个十秒的视频,我们现在看一下它的效果。 还可以,因为没有加这个 v b v r 这个奖励老软,所以说它的效果好像不是很好。 好,接下来我们看一下我们的图示视频,还是在模板里面找,这是图示视频,我们点进去一样给他工作流程解压出来时间,我们设十秒吧, 加载一张图片,随便输入一段提示词,一个男人在说话,这是他要说的话,然后我们点击生成。好,生成结束,用时是二百八十五秒,我们再看一下它的效果。大家好,我是陈旭,我们是博主的 ai 扎势产, 因为是十秒的视频,我给的话术太短了,然后导致他的语言混乱。好,我们又重新给他写了一些话术,再次运行一下。好,这就结束,我们再听一下它的效果。大家好,我是陈旭,一个 ai 形象,我还有一个搭档,他叫希然, 他这次是动作夸张,还有字幕,不过整体效果还不错,因为他脸一直没有崩,环境也没有崩。好,现在还有一个工作流没有讲,就是我们的首尾针,工作流好,点进来。好,我随便加载了两张图片提示词,我们改一下,他端着咖啡走到窗前, 一样工作流我们就不去更改了,直接用他试乘,这里有做一个十秒吧,五秒太短了。好,试乘完毕,我们看下效果, 这是在没有加任何奖励 lara 情况下跑成这样的一个状态,我觉得也还能接受,而且我们的提示词特别简单,什么都没有,那么真正要跑出好的视频还是需要在提示词下功夫 好。我们今天一共介绍了 ltx 二点三的四套工作流,第一个是纹身视频,第二个是图腾视频,第三个是音乐声震视频,第四个是首尾针视频, 而且他的能力是可以做到三十秒左右的一个视频主要是看我们的电脑配置,其实如果内存够大,我估计跑个一分钟视频应该也是问题不大。然后接下来就是我们的小浅层,用户可以选择把它两个替换成 g g f, 然后再就是我们的生成字幕的一个限制,再加上我们的一些奖励 l r, 让他动作更加连贯 和更加符合逻辑。然后再就是一些细节上的调整,比如加上一些我们清华村的一个节点,还有包括可以裁剪音频的一些小的节点,这些东西都很有用的。我们整个 coffee ui 的 全流程到这里也基本上讲完了。 接下来每一期我会给大家做一些具体的,包括视频呀,包括音频呀,包括图片的一些效果,然后给大家展示,那么今天的演示就到这里感谢大家观看,我们下期见。
4353晨序AI工坊 48:42查看AI文稿AI文稿
48:42查看AI文稿AI文稿五月最新的秋叶 comfyui 整合包已经更新了,不用复杂的环境配置过程,只需三步一下载,二解压,三双击打开即可使用。支持 win mac 和 a 卡,最低幺零六零显卡显存八 gb 即可本地部署运行。和那些花钱还要排队的网站不同, comprise ui 这次的更新诚意拉满,内置三百加模型,工作流,图片和视频直接本地生成,无惧审核压力,不用积分,不用排队,也没有暗此暗月的计费套路。无论是做最近很火的漫剧分镜,还是工作需要的电商产品详情页, 还是创意十足的三 d 建模渲染,都是点一下的事,想试试的。老规矩,验个牌,现在开始教学, 各位同学好,我们这节课呢,来教大家如何第一次搭建工作流。相信大部分来学习 confluence 的 同学都是对 stable diffusion 的 操作有一定理解的,所以我们下面呢,就对比一下 stable diffusion 当中不同的操作模块,来帮助大家更深刻的认识 confluence 的 流程。是这样的, 我们先选择一个大模型文件,选择好之后呢,输入正反面提示词,然后设置输出尺寸。必要的时候呢,我们会选择一个插件模型, 选择好插件模型之后,我们点击生成,最终呢,在右下方就会生成一个我们符合提示词要求的内容。那么其实像大模型 ve 模型正反面提示词,生成图片时所使用的彩样器,以及生成时的输出尺寸插件,还有生成结果 在 confui 当中也是对应有相同功能的节点的,只不过这些节点呢,在 confui 当中,我们可以对其任意的移动位置删减或者复制或者新增一些其他功能的节点,来强化我们生成的结果。 所以相比于 stable diffusion 不 可动的模块, confui 当中的节点呢,它的灵活性会更强。至于在生成效果上,两者并没有特别大的区别,甚至它们使用的模型文件都是相同的。大家可以将 confui 呢理解成开发者版本的 stable diffusion, 它的自由度呢会更高一些。 我们下面来简单的介绍一下 ctrl y 的 基础操作。我们首先点击右下方的清除,将当前默认的工作流呢进行清除。清除之后,我们就得到了一个空白的操作台,我们右键界面当中的任意位置,然后点击新建节点, 就可以从中呢选择我们想要创建的功能节点,例如我们现在点击新建节点当中的彩样,点击创建 k 彩样器节点,那么这样一个具备 k 彩样器功能的节点就被我们创建好了。 相信从这个节点当中呢,大家不难看到在 stable devolution 当中,我们熟悉的参数,例如彩样器选项,提示词,相关性以及迭代部署。 我们在节点当中呢,还能看到很多颜色不同的小圆点,此时我们拖拽其中的一个小圆点,例如拖拽紫色的模型圆点, 拖拽后松开,可以看到此时就弹出了一个选项菜单,其中下方这个区域呢,是我们拖出这个圆点之后经常会创建的节点选项。因为我们拖拽 k 彩样器当中的模型圆点,通常呢会创建一个 checkpoint 加载器,简易的节点, 此时呢, checkpoint 模型加载器与 k 参照器这两个节点就以相同颜色的模型原点进行了相连,其他位置的原点呢,也是相同的逻辑。我们拖拽之后呢,选择我们需要创建的对应节点,那么两个节点当中相同颜色的原点就会进行相连。 此外,我们双击所创建节点的名称,可以看到此时它的名称呢,就变为了可编辑的状态,我们就可以对其名称进行重命名,比如我们给它起一个名字叫模型, 然后回车确定,这样名字就改好了。当然通常是没必要刻意修改这些节点的名称的,但有些时候呢,可能两个节点是相同的节点,只是功能不同, 所以需要对其修改名称。例如在 k 采集器当中,我们拖出正面条件,这个源点会创建一个叫做 clip 文本编码器的节点,这个节点是用来输入正面提示 词的节点,这两个节点是相同的节点,这 是一个连接正面提示词,一个连接负面提示词。所以有时候呢,我们就要对这样的情况对应的节点去修改名称。比如说把连接正面条件的这个节点呢,我们改名为正面提示词。把连接负面条件的这个原点的节点呢,我们改名叫做负面提示词。 不过平时自己用的话,即便是这样的情况,其实也没必要修改。我们点击之后可以选中这个节点, 选中之后呢,这个节点的周围会多出一些白圈来显示我们已经选中了这个节点。选中之后,可以对当前的这个节点呢进行拖拽,或者呢 ctrl 加 c 复制, ctrl 加 v 粘贴,再或者呢按 delete 键删除,跟我们在电脑上操作文件呢是非常类似的。 我们最后来简单介绍一下 confy 右下方的这个操作位置。首先最常用的就是点击添加提示词队列来开始运行工作流。我们创建好完整的工作流之后呢,点击这个位置就可以开始运行当前的工作流,这跟我们在 stable default 当中点击生成是一样的。 我们创建好一个完整的工作流之后,如果确定运行无误,你想保存的话呢,就点击这个模块当中保存的按键。点击之后呢,给这个工作流起一个名字,比如说我们起名叫 abc, 然后点击确认,此时我们这个工作流啊就会作为一个工作流文件下载到本地, 可以看到此时我浏览器的右上方呢,就已经成功的下载了这个工作流文件,拖拽到我们当前的浏览器 comui 的 操作页面就可以了。 另外就是我们刚才演示过的清除当前所有的工作流节点,我们点击清除,点击确认画面就清空了。当然我们同样是可以通过 ctrl 加 z 撤回刚才的操作的,或者呢按 ctrl 加 y 去重新执行刚才的操作。至于其他的功能不是特别常用,我们就不再赘述。 下面话不多说,我们来开始演示如何从零开始搭建一个完整的纹身图。工作流通常呢从原点最多的工作流节点开始搭建, 就是 k 彩样器,我们右键画面当中任意的空白处点击新建节点,点击彩样这个选项,从中呢点击 k 彩样器,我们创建一个 k 彩样器节点, 这个节点上面的原点是最多的,所以我们先创建它,将来创建其他的节点呢,调理会更加的清晰。我们下面拖拽 k 彩样器节点当中的模型原点, 拖出之后呢,松开我们点击创建 checkpoint 加载器简易这个节点,然后我们再次拖拽 k 彩样器当中橙色的正面条件源点,松开之后呢,点击创建 c l i p 文本编码器节点,负面条件源点呢,也重复刚才的操作。拖出之后呢,创建 c l i p 文本编码器节点, 然后我们继续对 k 彩样器这个节点上的源点呢进行拖出操作。首先拖出左侧的这个粉色的 lighten 的 源点, 拖出之后呢,我们点击创建这个叫做空 lighten 的 节点,这个节点呢是用来输入输出图片的尺寸的,那么最后呢,就只剩下一个原点没有拖出了,就是 k 彩样器右侧的这个粉色 lighten 的 原点,我们点击拖出,然后点击选择创建 ve 解码这个选项。 最后呢,我们点击拖拽 ve 解码这个节点当中图像的这个节点拖出之后呢,我们点击创建保存图像这个节点, 这样一来我们纹身图工作流所有的节点呢,就都已经创建完成了,但如果现在我们点击添加提示词队列来运行节点的话,可以看到 ctrl u i 呢会给我们一个十分明显的提示,告诉我们哪些节点是出问题的, 包括这个节点上面的哪些原点是没有进行连接的,所以我们就可以根据提示呢来继续补全我们当前的工作流。首先是两个 c l i p 文本编码器当中左侧的 c l i p 原点, 我们需要将其与 checkpoint 加载器节点当中的 c l i p 原点进行连接,连接好之后呢,我们再将 ve 解码器当中的 ve 这个原点,将其与 checkpoint 加载器当中的 ve 原点进行连接, 这样的连接逻辑其实很好理解,相同颜色的原点连接相同颜色的原点就可以了。最后我们选择一个合适的模型,写下我们需要的内容, 比如说 one go, 我 们点击生成可以看到此时我们就成功的生成了一个符合提示词描述的内容。那么至此呢,我们文生图的工作流就搭建完成了,相信各位同学只要跟着我们的视频一步一步的操作,都是能够搭建成功的。 即便在搭建过程当中出现了原点没有连接全的问题, comui 在 运行之后呢,也会给出一个明显的提示。 那么我们最后呢,来对康飞 y 的 工作流搭建进行一个总结。首先大多数情况下呢,我们从零开始搭建节点,都是要先创建一个 k 彩样器节点的,因为这个节点上面的圆点最多,我们创建好它之后呢, 将 k 彩样器节点上面的圆点拉出之后,往往只需要创建一个节点就可以,所以调理会比较清晰。各 同学可以把 ctrl y 的 操作理解成搭建台式电脑,像左侧的 c l i p 文本编码器, check point 加载器,还有 comlight 的 输入尺寸的节点,就相当于我们的键盘鼠标,我们将它们插在电脑的主机,也就是 k 测量器上面,通过 k 测量器进行运算,最终呢再输出到显示器上面, 这样来类比呢,相信各位同学对 control ui 的 节点连接逻辑就有了更贴近生活的体会。至于我们 stable default 的 操作逻辑非常的相似,也就是先选择模型,再输入提示词,再选择采用方法, 然后设置输出尺寸,最后点击生成,这是一个十分正常且完整的生成顺序。而在 control ui 当中呢,也遵循这样的顺序,例如此时我们更换一个随机种子,然后点击添加提示词队列, 我们可以看到绿色的位置啊,就是标注在生成过程中工作流运行的一个顺序。会先从 checkpoint 模型加载器开始 获取我们使用的模型信息,然后进一步的获取正反面提示词和输出尺寸,最后呢,将它们都集成在 k 彩样器,整合这些信息之后呢,由 ve 解码器进行解码,最后呢留下我们的保存图像这个工作流节点。 不过相信大家第一次接触 cfui 的 话,即便工作流能够搭建完成,其实对工作流运行的逻辑呢,也处在一个比较懵懂的状态。不过根据我的学习经验,大家学习 cfui 最好呢,能够本着先操作后理解的方式来进行学习。 我们前期从零开始教大家搭建工作流,也并非是为了今后你一直从零开始搭建,而是为了在不断的搭建当中愈发的理解 cfui 的 运行机制。 像在将来获取了其他作者所创建的完整工作流之后,我们也可以更加灵活地对其加以改进,使其符合自己的需求。对此呢,我也专门制作了一套课件,上面不仅展示了 stable diffusion 不 同的功能模块去对照 comfy 当中的节点的一个对照图, 同时也包含了我们课上所讲解的 comfy 基础操作知识以及工作流搭建流程,还有最后的总结。各位同学如果需要本节课的课件的话,也非常欢迎在评论区留言,我会尽可能的帮助大家解决在操作过程当中遇到的问题,同时也会发放这套课件。那么以上呢,就是本节课的全部内容, 各位同学如果觉得本节课的内容对你有帮助的话,也不妨点一个免费的一键三连支持一下,我们就下节课再见!各位同学好,我们这节课来讲解 confui 精细化纹身图工作流的第一部分。我们首先来说明一下什么是精细化纹身图工作流。 我们首先打开 stable diffusion, 相信熟悉 s d 的 同学呢都知道 stable diffusion 是 只有一个正反面提示词输入窗口的 们,此时在正面提示词窗口当中输入 one go 还有 right here, 然后选择一个合适的负面提示词模板,点击生成,可以看到此时我们就生成了一个符合提示词描述的结果。那么如果我们想要在画面当中生成两个人物,其中一个是红色头发的少女,一个是蓝色头发的少女, 正常的思路呢就是在提示词当中再追加对于另外一个少女的描述,也就是 one go blue hair。 剪好之后呢,我们再将画布的生成尺寸去拓展一倍,再次点击生成,我们可以看到此时生成的结果呢,并不是十分理想, 我们明明想要生成两个少女,但是画面当中却只有一个,而头发的颜色呢,是以红色和蓝色拼接形成的。 我们现在回到 confui, 打开我们预设好的工作流,也就是精细化纹身图工作流。相信此时部分同学已经猜想到了,既然 confui 相比于 stable default 能够更加灵活地去部署模块儿,也就是节点,那么我们就可以同时部署两个提示词的输入窗口, 来分别描述我们想要生成的两个人物,最后再通过一定的方法呢,将两个人物合并在同一个图像上,以此呢来避免 stable default 当中因为提示词无法做分割 而导致两个人物的特征同时出现在一个人物身上的情况。例如此时我们在 confui 当中,第一个正面提示词输入窗口呢,我们输入红色头发的少女,而第二个提示词输入窗口呢,我们输入蓝色头发的少女。 这些都输入好之后呢,我们点击添加提示词对列,可以看到我们此时生成的结果呢,左侧的人物就是红发的少女,而右侧的人物就是蓝发的少女。 由于这两个人物的提示词都是独立成一个节点的,所以并没有出现颜色之间相互混合,特征之间相互混合的情况,这就是精细化纹身图工作流的优点。 那么话不多说,我们下面就从零开始教大家如何搭建精细化纹身图工作流。我们首先新建一个空白的工作台,点击左上方的文件加图标,点击这个加号,新建好这个默认工作流之后呢,我们清空当前的工作流节点, 下面的操作就与我们之前所讲解的纹身图工作流操作十分类似了,我们依然在任意的空白位置,右键点击新建节点,点 击采样,然后点击 k 采样器。回想起我们上节课所举的类比, k 采样器呢,就好比电脑的主机,我们下面要把键盘,鼠标还有显示器都接到这个主机上,所以我们下一步呢,拖出模型这个圆点 松开之后呢,创建 checkpoint 模型加载器。与基础纹身图工作流不同之处在于,我们这次呢,从 clip 这个圆点上面拖出的内容一共有三个,也就是两个正面提示词输入窗口,以及一个负面提示词输入窗口。 当然如果各位同学想要拖出两个负面提示词输入窗口也是可以的,但通常负面提示词是通用的,所以我们只拖出一个负面提示词窗口就可以。 我们回到 k 彩样器这个节点,从 latent 源点当中呢,我们依然拖出一个节点,叫做空 latent, 用来输入输出图片的尺寸。大家在拖出节点之后呢,最好整理一下它们摆放的位置, 这样将来在拖出其他节点时,调理会更加清晰。然后我们继续从 k 彩样器右侧的 latent 源点当中拖出,选择建立 ve 解码,然后再从 ve 解码这个节点当中拖出图像,选择保存图像这个节点, 然后我们回到 ve 解码这个节点,将 ve 源点与 checkpoint 加载器当中的 ve 源点呢进行相连,这两个是相同的颜色,都是红色的, 我们下面要创建一个之前的课程当中没有提到过的节点,它的名字叫做条件采样区域节点。对于这样的节点呢,我们可以直接双击画面当中的空白区域,打开搜索选项,在搜索选项当中搜索它的名称,我们就搜索条件采样 区域。值得一提的是,旧版的 comui 是 不支持搜索中文的,各位同学需要更新到新版的 comui 才能搜索中文。 我们选择搜索结果当中的条件区域彩样这个选项,这个节点呢,一共要创建两个,所以我们复制当前创建好的条件彩样区域节点, ctrl 加 c, 然后 ctrl 加 v, 粘贴一个一样的, 然后我们分别将条件采纳区域两个节点上面的条件左侧的条件呢,与 clip 文本编码器右侧的条件相连,就连接到两个正面提示词 clip 文本编码器右侧的条件原点上。 连接好之后呢,我们再次双击空白的区域,搜索一个叫做条件合并的节点,搜索到之后呢,我们点击创建,然后我们将两个条件采纳区域右侧的条件一,条件二原点相连,它们的颜色也是一样的。 连接好之后呢,我们的所有节点就都已经创建完毕了,剩下要做的操作就是将那些没有连接好的原点进行相连,逻辑也非常简单,相同颜色的原点连接相同颜色的原点。首先将条件合并当中,右侧的条件原点连接到 k 采集器的正面条件原点上。 最后呢,再将我们要输入负面提示词的 c、 l、 i、 p 文本编码器节点右侧的条件源点连接到负面条件源点上。这样一来我们康复 ui 精细化文声图工作流的第一部分就搭建完成了,我们现在点击添加提示词队列来测试一下, 可以看到我们整个的工作流呢是没有出现报错的,但是生成的结果呢,并非我们一开始所演示的那样的结果,其原因在于我们并没有设置合适的参数。所以我们最后呢来讲解一下如何设置合适的参数,让我们想要生成的内容出现在合适的位置。 首先我们要设置的是最终所生成的图像的宽高,在空 light 的 这个节点上面,我们将生成图片的宽度呢,从五百一十二的默认宽度改为一零二四。当然这个参数呢要根据大家的需求来决定,我们测试的话就设置的稍微小一些。然后我们要设置的是条件参照区域节点上面的参数。 各位同学可以把精细化纹身图工作流理解成我们分别生成的两张图片,生成之后呢,再将这两张图片合并为一张图片,其中传统的 konlighten 这个选项呢,设置的是总图片的尺寸,而两个条件参照区域节点上面设置的尺寸呢,则是合并之前两张图片各自的尺寸。 所以我们首先来设置第一张图片的尺寸,我们就设置为五百一十二乘五百一十二,第二张图片的尺寸呢也是相同的,五百一十二乘五百一十二,这样两张图片加起来的尺寸呢,就可以满足一零二四乘五百一十二的尺寸。 其次我们要设置的是第二张图片在画面当中的坐标,由于第一张图片生成时默认的坐标就是从左到右,从上到下,从零 零开始这样一个坐标,因此第一个按默认的坐标就可以,也就是 x 零 y 零。各位同学可以在脑海中构建一个坐标轴,只有两个方向, x 和 y。 那 么第二张图片呢,就要摆放在第一张图片的顺位位置,与 其相连。那么首先第二张图片在高度上是没有进行移动的,两张图片的关系呢,我们设置的是横向摆放,所以第二张图片的 y 呢,和第一张图片是一样, 都为零。但是第二张图片需要向右平移一个图片一的身位,所以此时第二张图片的条件采用区域 x 值呢,我们就设置为五百一十二, 然后点击确定。这样两张图片呢,就是从左到右依次摆放,横向摆放的关系最终生成后合并在一起。提示词方面呢,我们就套用之前所使用的提示词,也就是第一张图片生成红色头发的少女,我们输入 a girl 还有 red hair。 而第二张图片呢,我们来生成蓝色头发的少女,输入 a girl 还有 blue hair。 写好之后呢,我们再次点击添加提示词队列,可以看到此时我们生成的结果呢,就是一个总尺寸为一零二四乘五幺二,左侧五幺二乘五幺二的尺寸为一个红头发的少女,而右侧五幺二乘五幺二的尺寸为一个蓝头发的少女,他们之间紧密相连的关系了, 并且两张图片的人物造型呢,互不影响,独立存在,这都要归功于我们创建的两个独立的正面提示词窗口。 当然各位同学在创建的时候呢,也不推荐去死记硬背,可以跟着我们的视频一步一步的来创建精细化纹身图的工作流。 我们再次强调,教大家逐步创建工作流的目的并不是为了让你去死记硬背,而是为了让你在不断的练习当中能够理解 comfyui 的 运行机制,能够在将来获取到一些其他作者现成的工作流之后,更善于自己加以改进,为自己所用。 不过话说回来,各位同学可以看到我们当前生成的两个人物,虽然说彼此独立,互不干涉,但他们的融合程度也非常的低,两个人物呢,并非处在同一个背景上,有着非常强烈的割裂感, 那我们该如何既能保障两个人物的造型相互独立,互不亲染,同时又能保障人物处在同一个背景上,让他们相互融合的自然呢?这个知识就留给各位同学思考,我们在下一个视频当中呢,会详细的讲解如何将精细化纹身图工作流当中人物的背景在生成时变为统一的背景。 同样针对于本节课的知识呢,我也制作了一套完整的课间,这面不仅说明了精细化文生图工作流的逻辑,同时也有详细的精细化文生图工作流搭建的过程, 还有最终搭建好之后的全貌展示。同时本节课的康复 ui 搭建好的工作流文件呢,也会发放给大家,各位同学有任何的问题非常欢迎在评论区留言,我会尽可能的帮助大家解决问题,同时也会发放本节课的相关资料。那么以上呢,就是本节课的全部内容, 各位同学如果觉得本节课的内容对你有帮助的话,也不妨点一个免费的一键三连支持一下,我们就下节课再见。各位同学好,我们这节课呢,来讲解 cfui 精细化纹身图工作流的第二部分。 相信各位同学通过上一节课的学习呢,已经掌握了如何从零开始去创建一个完整的精细化纹身图工作流。通过这个工作流,我们一共创建了两个正向提示词输入节点,这两个节点的提示词内容不同,我们最终生成的结果也通过合适的参数设置, 使得两个提示词输入节点生成的角色出现在了同一幅画面上,同时也在设计上并没有相互的亲染和干扰。 但在我们上一节课的结尾呢,也发现我们生成的这两个人物呢,他们虽然在设计上并没有相互的干扰,但与此同时在背景上也毫无关联。所以我们今天这节课的目的就是来教大家如何去对我们上一节课所设计的工作流加以改进,使得我们的人物在背景打光和氛围上能够更加的和谐统一。 我们下面就来讲解一下如何去对我们上一节课的工作流进行改进,来新增一些节点,使我们获得更加理想的效果。 我们首先在上一节课工作流的基础上,在 check point 加载器这个节点上拖出 c l i p 原点,拖出后松开,我们新建一个 c l i p 文本编码器节点。需要说明的是,我们建立的这个新的 c l i p 文本编码器节点,就是用来负责描述这两个人物同时出现的统一背景的 说,我们希望这两个人物都出现在一个街道上,那我们新增的这个节点内容呢,就填写街道,然后我们复制当前工作流当中的条件合并节点,复制好之后粘贴,然后将我们刚才新增的 c l i p 文本编码器右侧的条件源点连接到我们刚刚复制粘贴的这个条件合并节点当中的条件一源点上。 之后,我们将原本连接在 k 彩样器正面条件的这条线设为取消状态,也就是点击拖拽之后松开,然后将原本的条件合并节点右侧的条件源点连接到我们新增的条件合并节点下方的条件二源点上, 我们稍微调整一下这些节点的位置。那么此时呢,各位同学不难看出,在原先工作流的基础上,我们通过这样增加节点连线的方式, 我们描述红色头发女孩的正面提示词节点与描述蓝色头发女孩的正面提示词节点在进行条件合并之后,并不会直接传输到 k 彩样器,而是先与描述背景的正面提示词节点进行了一次合并。最终呢,我们才将整合后的信息连接到了 k 彩样器的正面条件源点上。 就相当于我们先炒了两盘菜,我们生成的红色头发的少女呢,就好比番茄炒蛋生成的蓝色头发的少女呢,就好比烧茄子。在上一节课我们所创建的工作流当中,我们将番茄炒蛋和烧茄子炒好之后,仅仅是装在了同一个盘子里就端上了桌。而我们今天所创建的工作流 在上一节课的基础上,将番茄炒蛋和烧茄子重新倒回了锅中,加入了新的作料,最终呢才端上了盘子。这样我们的生成结果,两个人物的背景呢就会更加融合。 那么话不多说,我们来尝试一下。现在的工作流呢,已经完全连好了,我们在新创建的正面提示词工作流当中写入街道 street 以及夜晚 night。 写好之后呢,我们点击添加提示词队列。那么此时各位同学可以看到, 我们改造之后的工作流就成功的将两个造型特征不同的少女既进行了造型上的区分,两个人的设计完全独立,同时让他们都出现在了同一个背景当中。当然我们可以追加一些负面提示词,以谋求更好的效果。那这里呢,我就沿用 stable diffusion 当中的负面提示词,我们重新生成一遍, 看到有了更好的负面提示词的加持,我们就获得了生成人物更好的效果,并且两个人物的背景依然是和谐统一的。当然生成的结果是随机的,各位同学可以更改随机种子,以谋求更符合需求的效果。 那么到这里呢,我们的精细化纹身图工作流,它的完全体版本就搭建完成了。当然如果我们想要在画面当中不仅生成两个人,而是要生成三个人,四个人,各位同学可以举一反三,在我们当前的工作流基础上,进一步的去增加描述人物所用的正面提示词节点, 并且用条件采样区域以及条件合并工作流节点去将它们整合,最终连接到 k 采样器上。具体的创建方法呢,我就不再演示了,各位同学自行尝试之后如果遇到问题也非常欢迎在评论区交流,我会尽可能的帮助大家解决在操作过程当中的问题。 我们下面对先前没有提到的康复 ui 的 基础操作知识做一些补充,我们之前只讲解了点击右下方的保存,将当前所操作的工作流保存到电脑本地。 但是各位同学会发现,我们点击左侧的文件夹图标在这里呢,我也创建了很多在 comui 操作界面就可以直接选举的工作流,比如我们选举这个换脸的工作流就可以直接打 开。那我们该如何将当前操作的工作流保存到 comui 上面,让我们直接打开工作台就可以选择自己想要操作的工作流呢? 方法也非常简单,首先我们点击左上方的文件加图标,将其展开,然后我们点击这里的加号键,就可以新建一个工作流。这个工作流呢是默认的纹身图工作流, 如果你不需要的话,可以直接按住 ctrl 键不要松开,然后拖拽工作台,将这些工作流全选,然后按 delete 键删除,再重新从零开始建立或者拖拽新的工作流, 我们撤回一下。就以当前的纹身图工作流为例,例如此时呢,我们已经对当前的纹身图工作流进行了一定的修改,那么此时各位同学可以看到,在这个位置就出现了一个保存图标,叫做 save work flow, 我 们点击这个图标就可以保存当前的工作流。 此时我们再次点击左上角的文件夹图标,展开下拉菜单,可以看到在这个位置呢就出现了一个叫做 united flow two 这样一个名称,这个名称呢就是我们当前正在操作的工作流的名称,我们也可以点击这个名称去进行重命名, 比如说我们给它起一个名字叫做 abc, 然后点击 save, 那 此时我们再次展开左上角的文件夹图标,可以看到当前呢就有一个名为 abc 的 工作流被保存到了我们左上角的展开图当中。那么我们现在先切换到其他工作流,然后再次点击左上角的文件夹展开, 再次点击 abc, 此时我们就可以看到我们刚刚所保存的名为 abc 的 工作流了。除此之外,各位同学可以看到这些工作流当中某一些呢是带有预览效果图的,甚至还有一些是动图,那么这些图片是如何产生的呢? 其实也非常简单,我们选择一个合适的模型,然后直接点击添加提示词队列去生成一张图片,那么生成好之后呢,我们再次点击左上方的保存图标,此时我们再展开左上角的文件夹,可以看到我们当前名为 abc 的 工作流就多出了一个我们现在所生成的预览图。 我们再来补充一下对于工作流节点的相关操作。首先是如何一次性选中多个工作流节点,方法非常简单,我们按住键盘的 ctrl 键不要松开,然后用鼠标点击工作台当中的任意空白位置 进行拖拽,那此时会出现一个白色的选框,选框内所含盖的节点呢?我们在松开手之后都会被选中,可以看到是有选中的效果的, 那么此时呢,我们进行任意的操作,都可以对我们当前选中的工作流节点进行操作,比如按 delete 键可以看到我们当前选中的所有节点呢就都被删除了。 如果我们不想选中相邻的节点,想要跳跃的进行选中的话,就按住键盘的 ctrl 键,不要松开,依次的点击我们想要删除或者操作的节点,因为我们先选择 checkpoint 加载器,再选择保存图像节点,可以看到此时呢,这两个节点也被同时选中了。 我们最后再来讲解一下如何对节点赋与颜色,以及如何对功能相似互相搭配的节点进行分区。想要给节点赋与颜色,我们只需要右键点击这个节点, 点击之后呢,我们在右键菜单当中选择颜色,然后在颜色展开菜单当中,我们选择自己需要赋予的颜色就可以了。例如我们现在点击红色,可以看到此时 checkpoint 加载器这个节点就被变为了红色。当然我们在操作时,由于是多选的状态,所以保存图像这个节点呢也被变为了红色。 我们现在右键工作台当中的空白处,然后点击新建框这个选项,点击之后呢起一个名字,例如这个名字呢,我们就叫提示词,写好之后回车确定,此时可以看到我们新建的这个框,它的名字呢就被改为了提示词。 我们可以通过鼠标拖拽的方式改变这个新键框的位置,通过拖拽其右下角的方式改变它的尺寸,此时我们将这个新键框拖拽到 c l i p 文本编码器的下方,那么当我们再次拖拽这个蓝色的新键框时,各位同学可以看到,但凡是出现在这个新键框上方的节点呢,都会被随着一起 拖动,但如果我们此时所拖动的是节点本身的话,那么这个新键框是不会为之所动的。利用这个特性呢,我们将这个新键框拖拽到合适的大小,以涵盖我们想要的内容。 给我们拖拽到这个大小,再将 c l i p 文本编码器下方的这个框拖拽到合适的位置。这个新建框功能呢,就相当于给我们的工作流当中同类型的节点做了一个区域的划分,让操作者或者说使用者在编辑当前工作流时, 能够更容易的判断这些部分的工作流它的用途是什么。其实并没有什么实质性的功能作用,各位同学平时自己做工作流的话,没有必要做这些。 那么针对于本节课的内容呢,我也制作了一套完整的课件,上面以图文教程的方式讲解了我们本节课所讲解的相关知识点, 同时也包含了我们刚刚所提到的康复 u i 基础操作知识的补充。各位同学如果需要本节课的课件的话,也非常欢迎在评论区留言,我会尽可能的帮助大家解决问题,同时也会分享这节课的课件。那么以上呢,就是本节课的内容,对你有帮助的话,也不妨点一个免费的一键三连支持一下, 那就下节课再见。各位同学好,我们这节课呢,来讲解 confui 当中文声图 controlnet 工作流的搭建。在 stable diffusion 当中,我们使用 controlnet 的 时候,不仅要选择 controlnet 的 模型,同时也要选择对应的 controlnet 与处理器。因此我们在 controlnet 当中,我们要想搭建具备 controlnet 功能的工作流,同 同样要先搭建 controlnet 预处理器的工作流节点,那么我们下面呢就新建一个空白的工作台,新建好之后呢,将默认的工作流进行清除。然后首先呢来搭建一个 controlnet 的 预处理器,方法呢也非常简单,我们双击工作台空白的位置, 然后从中搜索我们想要搭建的预处理器名称。比较熟悉 stable definition 的 同学都知道,我们常用的模型预处理器呢,通常就是 canny 边缘检测、 deep 深度检测以及 line art 线稿检测, 有时做室内设计时呢,还会用到 m l, s d 直线检测。如果记不起这些名字的话,可以回到 stable default 的 ctrl n 的 插件看一眼, 然后我们回到 comui。 比如我们此次呢来建立一个 kenny 线稿检测的预处理器,我们就在搜索栏当中搜索 kenny, 然后选择搜索结果当中的 kenny 细致线预处理器,点击之后呢创建这个节点,创建好之后,我们将左侧的图像源点拖出,然后点击创建加载图像节点, 这个位置呢是我们用来放置现稿参考图的,同时我们将 kenny 细致线域处理器节点右侧的图像源点拖出。我们创建一个保存图像节点,这个节点呢是用来放置提取现稿之后的预览效果图的。 六、此时呢,我们直接点击添加提示词对列,就可以看到在保存图像节点当中出现了左侧我们所上传图像的现稿提取结果 么?创建好了与处理器相关的节点,我们下面就从您开始搭建一个纹身图的 control net 工作流。我们首先搭建一个正常的基础纹身图工作流, 那么就直接双击空白处,然后我们搜索 k 彩样器来创建一个 k 彩样器节点。创建好之后呢,按照我们第一节课所教授的流程, k 彩样器当做主机,我们从上面的圆点当中呢去接触键盘鼠标显示器,拖出模型圆点之后,我们点击创建 checkpoint 模型加载器节点,然后分别拖出正面条件源点,创建 c l i p 文本编码器,拖出负面条件源点,创建 c l i p 文本编码器。 然后左侧的 lighten 的 源点拖出,我们创建空 lighten 的 节点,用来设置输出图片的尺寸。而右侧的 lighten 的 源点我们拖出后呢,创建 ve 解码器节点, 最后再将 ve 解码器节点右侧的图像源点拖出,我们创建保存图像节点。最后呢,将 ve 解码节点当中的 ve 源点与 checkpoint 加载器节点当中的 ve 源点两个相同颜色的源点相连。 最后适当调整一下这些工作流节点的位置,让他们看起来呢更加整洁好看。调整好之后呢,我们基础的纹身图工作流节点就全部创建完成了。我们下面要考虑的事情呢,就是将 control night 以及我们刚刚创建的与处理器相关的节点都融入到我们当前的纹身图工作流节点当中。 这里建议大家不必有过多的思考,跟着我们的视频教程边暂停边做就好,等做完之后呢,我们再去尝试理解其中的逻辑。我们首先双击工作台空白处任意的位置,然后搜索 content 应用,然后点击搜索结果当中的 content 应用这个选项,创建 content 应用节点。 当然 controlnet 应用这个节点呢,有很多种不同的版本,但是其中包含的源点都是相同的,因此各位同学在观看视频教程时,只要保障自己创建的 controlnet 应用这个节点包含了我们视频当中所提及的源点内容,就可以 多出的部分呢,可以暂且不管,我们下面将 controlnet 应用当中左侧的正面条件源点连接到正面提示词的 c l i p 文本编码器节点右侧的条件源点上,而 controlnet 应用节点右侧的正面条件源点,我们则连接到 k 彩样器的正面条件源点上。 此时原本正面提示词 c i p 文本编码器节点当中的条件源点与 k 彩样器正面条件源点的相连关系就断开了。这就意味着我们的内容生成之前,会先经过 controlnet 应用这个节点,使我们的 controlnet 能够发挥效果后再抵达 k 彩样器。 我们下面将 controlnet 应用节点左侧的 controlnet 圆点拖出后松开,然后在弹出的窗口当中,我们点击 defcontrolnet 加载器这个选项,创建 defcontrolnet 加载器这个节点。这个节点的功能呢,就是用来设置 controlnet 模型的,我们点击这个节点的内容后呢,会出现一个下拉菜单 们此次要使用的 control net 功能是线稿检测,所以我们选择 kenny 这个模型。我们下一步呢,将 control net 应用这个节点左侧的图像原点连接到 kenny 与处理器这个节点右侧的图像原点上。这一步操作之后呢,我们的参考图就与 control net 之间发生了关联, 我们的 control 相关的节点能够读取到参考图的内容。我们最后一步呢,就是将 diff control 加载器节点左侧的模型原点拖出之后呢,连接到 checkpoint 加载器节点当中的模型原点上。这样一来,我们的文声图 control 工作流就搭建完成了。 我们现在选择上传一张线稿作为参考图,然后选择一个合适的大模型。因为是二次元的线稿,所以这里呢,我选择一个二次元风格的大模型。提示词方面呢,就尽可能描述贴合线稿的内容,我们就书写 one go 还有狐狸耳朵 fox ear。 对 于负面提示词呢,我们就将 stable diffusion 当中的负面提示词模板直接粘贴过来。全部设置完成之后,我们点击添加提示词队列, 可以看到此时我们的工作流当中呢,出现了一些报错。很明显,我们的正面提示词与负面提示词左侧的 c l i p 并没有与模型这个节点相连, 所以我们现在根据提示呢,将这些缺失连接的原点进行相连。其中负面提示词 c l i p 文本编码器右侧的条件原点与正面 c l i p 文本编码器提示词的右侧条件原点相连的思路是类似的, 我们先将其连接到 controlnet 应用这个节点左侧的负面条件源点上,然后再将 controlnet 应用节点右侧的负面条件源点连接到 k 彩样器的负面条件源点上。最后我们点击添加提示词对列,可以看到此时呢我们就成功的生成了一幅根据我们所上传的现稿参考 而得到的一幅有着狐狸耳朵的二次元动漫风格的人物。这里图片尺寸呢,我们可以设置的稍微高一些,将高度呢设置为六百,然后再次点击添加提示词对列,这样我们就获取了一幅更加完整的生成结果,可以看到效果还是相当不错的。那 那么以上呢,我们的 comui 纹身图, controlnet 相关的工作流就全部搭建完成了,我们最后来补充一些关于下载节点相关的知识。其实从我们上一节课开始呢,我们就用到了一些当前我们所使用的 comui 版本并不具备的插件节点, 那么这些新增的插件节点如何下载呢?这里提供三个下载方式。首先第一个下载方式呢,就是我们打开会事启动器,然后点击版本管理, 在上方的分页当中,我们选择安装新扩展这个选项,在这里呢搜索我们想要下载的节点插件的名称,然后点击安装,就可以在会式启动器当中安装新的插件。不过需要注意的是,某些版本可能会出现异常的 情况,导致我们无法在这个位置加载相应的插件,比如说我当前的版本这个功能就失灵了,各位同学呢,可以尝试更换版本。第二种方式呢,是比较稳妥的方式,我们直接在 github 上面来手动的下载相关的插件节点, 我们抵达对应的页面之后呢,点击绿色的 code 选项,在下拉菜单当中,我们选择 download zip 下载压缩文件,最后解压到 confui 根目录当中的 custom nodes 专门放置节点插件的文件夹当中就可以。不过这个功能呢,需要大家有一个特殊的用网 环境,如果你不了解如何使用特殊的用网环境,也非常欢迎在评论区留言,我会尽可能帮助大家解决这个问题。第三种方式呢,就是在 confui 的 操作页面当中,我们点击右下方的管理器, 在弹出的窗口当中,我们点击节点管理这个选项,然后在左上方的下拉菜单当中,我们选择所有这个选项,这样就可以展示出我们当前所有可下载的插件节点,在这个位置呢,搜索相应的名称便可以获得对应的结果。例如我们搜索 control night, 可以 看到直接呢就蹦出了跟 control night 相关的选项,对于那些没有安装的插件节点,我们直接点击这里的 instyle 即可安装,安装成功之后呢,重启一下就可以使用了。 对于本节课的内容呢,我也制作了一套完整的课件,课件上以图文教程的方式讲解了我们今天课上所讲解的全部知识。各位同学如果需要本节课的课件的话,也非常欢迎在评论区留言,我会尽可能的帮助大家解决问题, 同时会分享本节课的课件。那么以上呢,就是本节课的全部内容,各位同学如果觉得本节课的内容对你有帮助的话,也不妨点一个免费的一键三连支持一下,我们就下节课再见! 各位同学好,我们这节课来讲解 comfui 图生图工作流搭建我们都知道在 stable default 当中是有图生图的功能的, 我们将图片导入到图生图的预备窗口,写上合适的提示词,调整合适的生成尺寸与重绘幅度,然后点击生成。生成的结果呢,就会根据我们当前所书写的提示词以及重绘幅度,根据所选模型的风格 原图为蓝本进行重新生成。生成时我们所选的重绘幅度越高,那么生成的结果呢,就越与原图相去甚远。反之,生成的重绘幅度越低,生成的结果呢,就与原图越相似。 同样在 comui 当中,我们在文生图工作流的基础上,加入图片上传节点 v a e encode 节点、蒙版节点、尺寸设置节点 control net 节点,即可创建一个相对完整的图生图工作流。同时我们本节课也会讲解一下,除了局生成之外,如何在 comui 当中创建局部重绘的工作流, 也就是我们可以通过选区笔选择我们需要重新生成的部分,然后再次点击生成。此时我们生成的结果只有在原图当中所选择的区域会受到影响发生改变,而未选择的部分则会维持原状,与原图保持相同。 那么话不多说,我们下面就来详细的演示一下。首先打开 comui, 我 们新创建一个工作台。由于在先前的课程当中,相信大家已经非常熟悉基础文生图工作流该如何从零创建了,所以我们这次就不再从零开始, 我们以当前默认的纹身图工作流为基础来添加相关的节点创建图生图工作流。首先我们双击工作台的空白处,然后搜索加载图像,点击创建加载图像节点,这是用来专门上传原图的节点。我们将加载图像节点当中的图像原点拖拽后松开,然后点击创建 v a e 编码节点, 然后我们再将 ve 编码节点当中的 laten 的 原点拖出后,连接到 k 彩样器左侧的 laten 的 原点上,这时我们原先的空 laten 的 节点就处在不可用的状态,因为我们此次创建的工作流是一个全局生成,工作流生成的结果在尺寸上将与原图保持一致,因此不需要设置输出尺寸的大小。 我们下面将 ve 编码节点左侧的 ve 原点拖出,连接到 checkpoint 加载器当中的 ve 原点上。这样一来,我们的图生图工作流就创建好了。 我们现在选一个合适的模型,例如原图是写实风格的,我们就选择一个偏二次元风格的模型。选择好之后呢, k 彩样器当中最后一个选项降噪,对应的就是 stable diffusion 当中的重绘幅度,我们通过调整降噪这个属性的大小来控制生成的结果与原图的相似程度。 例如此时我们将降噪调整为零点三,然后点击添加提示词对列,可以看到我们再次将降噪选项调整为零点九, 然后点击确定添加提示词对列,可以看到我们此时生成的结果呢?虽然有原图的影子,但是更多听从了提示词当中的描述,生成了包含有瓶子内容的结果。如果我们在生成的时候想要调节生成的尺寸, 也可以将编辑尺寸的节点添加到我们当前的工作流中,相信经过之前的练习,各位同学对这个 laten 的 节点已经非常熟悉了,通常呢,它就是用来连接设置尺寸的节点的,但是我们可以看到原先的空 laten 的 节点,它只有一个 laten 的 原点,也就是单向的。 而我们加入了加载图像节点之后,需要有一个双向连接的 latent 节点,才可以保证加载图像会经过图片尺寸设置节点再抵达 k 采集器。所以我们此时双击空白的工作台, 然后搜索 latent, 我 们从中选择 latent 的 缩放这个选项,创建 latent 的 缩放节点,可以看到此时 latent 的 缩放节点上面有两个 latent 的 圆点, 我们将左侧的 latent 原点连接到 ve 编码节点当中的 latent 原点上,而右侧的 latent 原点连接到 k 采集器当中左侧的 latent 原点上。 此时我们不难发现,在加载图像这个节点当中的数据抵达 k 采集器之前,会先经过我们创建的 latent 缩放这个节点去进行图片尺寸的分割,最终才会输出对应的结果。我们现在再次点击添加提示词对列, 可以看到此时生成的结果,在尺寸上就是符合 lin 的 缩放节点当中所输入的五幺二乘五幺二的正方形尺寸。我们现在将降噪调整为零点一,然后点击确定,点 击添加提示词对列,可以看到当前对于原图的缩放模式呢,是以拉伸压缩的方式进行缩放的,如果我们需要对原图进行裁剪后输出结果, 我们可以将 laten 的 缩放这个节点最下方的裁剪这个选项,点击之后呢选择中心,然后再次点击添加提示词对列,可以看到我们此时生成的结果就是以裁剪的方式对原图进行分割,并根据参数输出对应结果。那么以上就是我们如何搭建一个图生图全区生成的工作流, 我们下面再来讲解一下如何搭建图生图局部重绘工作流,我们就以当前搭建好的内容为基础进行搭建, 要想在我们当前工作流的基础上加入局部重绘的功能,我们只需要替换当前工作流的一个节点就可以,也就是 ve 编码这个节点,我们双击工作台的空白处,然后搜索 ve, 从中我们点击创建 ve 内部编码器节点,有了这个节点呢,我们就可以对原图进行局部重绘的操作, 具体的连接方式呢,就是将图像这个原点连接到加载图像当中的图像原点中,而内部编码器节点当中的 ve 原点就连接到 checkpoint 加载器当中的 ve 原点上。内部编码器当中的遮照原点我们就连接到加载图像的遮照原点上, 最终 laten 的 原点呢,就连接到 laten 的 缩放左侧的 laten 的 原点上。此时原先的 ve 编码节点我们就可以进行删除了, 我们下面调整一下各个节点的位置,使他们的调理更加清晰。我们下面就来演示一下如何进行局部重绘操作来使用局部重绘工作流。首先右键加载图像节点当中的图像,我们从右键菜单当中选择在遮罩编辑器中打开, 此时会弹出一个新的窗口,而我们的鼠标呢,也会变成一个画笔工具,用来选择需要重绘的区域。在左下方的滑块当中,我们可以选择画笔的大小。 选择好合适的大小之后,我们按下鼠标选择需要重绘的部分,比如我们当前选择人物的脸的部分。选择好之后呢,点击窗口右下方的 save to node。 此时我们加载图像窗口,当中的图像就被替换为了一个有遮照的图像, 选中的区域就是人物脸的部分。我们下面调整合适的重绘幅度,例如调整到零点三左右,然后点击生成。可以看到此时生成的结果呢,就与之前的局生成有了些许区别。但 值得注意的是,我们生成的结果并不理想,这是由于我们当前 k 彩样器的默认重绘方法为浅空间去噪,所以使用局部重绘,重绘幅度呢,需要在零点八到一之间,因此我们将当前的降噪选项改为零点八。然后重新点击添加提示词队列, 可以看到此时我们生成的结果呢,才符合了提示词的描述。我们将提示词更换为我们想要生成的一个女孩的提示词, 然后重新点击生成。可以看到这次生成的内容呢,就更加倾向于一个与人物的身体相契合的脸了。当然这样的结果也并非十分理想,这也得益于浅空间去造的特性,并不会基于原图来生成对应的结果。生成的图像呢,完全是根据周边未选中的环境进行生成的, 所以我们最后来讲解如何在图生图当中加入 control 节点,以此呢来保持生成的结果,即便在浅空间去造的模式下,依然能够维持与原图的高度统一,或者说参考原图, 我们依然以当前的节点作为蓝本,在此基础上创建新的节点。已完成 controlnight 图生图局部重绘工作流。首先双击空白处,我们搜索 controlnight 应用,然后点击创建 controlnight 应用节点, 这个节点在我们之前文生图 controlnight 工作流当中创建过,相信大家还是比较熟悉的。具体的连接方法呢,就是我们将 controlnight 应用节点当中的正面提示词 c l i p 文本编码器右侧的条件源点 连接到负面提示词 c l i p 文本编码器右侧的条件源点上。对应的 controlnet 应用节点右侧的正面条件源点以及负面条件源点均连接到 k 彩样器当中的正面和负面条件源点上。这样一来,正反面提示词在抵达 k 彩样器之前就会先进行 controlnet 的 处理。 我们下面将 ctrl nite 应用节点当中的 ctrl nite 圆点拖出,松开。之后呢,我们创建 def ctrl nite 加载器节点,这个节点是用来选择 ctrl nite 模型的。我们此次使用的模型呢是线稿检测模型,所以选择 line art 或者 kenny 都可以,为 这让生成的结果更加柔和。我们此次选择 line art 创建好之后呢,我们将 diff control net 加载器节点左侧的 model 原点连接到 checkpoint 加载器当中的 model 原点上。我们现在还缺少两个原点没有进行连接,那就是 control net 应用节点当中的图像原点和 v a e 原点 中。图像原点呢,我们连接到加载图像当中的图像原点上,这样我们的参考图呢,就导入了 control net 当中,而 v a e 原点呢,我们就常规的连接到 checkpoint 加载器节点当中的 v a e 原点上。其实到了这一步, control net 节点已经可以发挥其效果了, 但是并不具备输出检测图的功能。如果各位同学想要预览一下是否对原图检测成功,我们还可以加入一个预处理器节点。 我们现在双击工作台的空白处,然后搜索 line art, 点击创建 line art 艺术线预处理器节点,我们将这个节点当中左侧的图像原点连接到加载图像当中的图像原点上。而右侧的图像原点呢,我们可以直接拖出后松开,创建一个预览图像的节点。这个节点呢,是用来放置检测图。 那么我们现在万事俱备,点击添加提示词队列来生成一下,看看效果如何呗。那么此时各位同学可以看到,有了 line in art 现稿检测的加持,我们最终的生成结果,人物的五官特征是相对契合原先的身体的,但生成的效果呢,并不是很明显。 我们可以尝试更换模型以谋求更好的效果。例如,我们将当前的模型呢,更换为一个生成效果较明显的模型。同时为了确保更好的效果,我们将 stable fusion 当中也粘贴到 comui 当中。不, 图片的生成尺寸呢,也尽可能与原图保持一致。我们修改一下输出的尺寸,最后再次点击添加提示词对列。此时各位同学可以看到我们这次生成的结果,人物的面部就根据我们当前所选的模型进行了二次原画风格的转变,而身体的其他部分呢,依然保留了原图的内容。 与此同时,面部的生成与身体之间的契合度呢,也远远高于我们之前未创建 control 的 工作流时的契合度。这就是由于我们添加了一个线稿检测,它会检测原图人物的面部线条,以此来更加规范的生成我们所选区域脸的位置, 以避免我们之前出现的脸生成的方向与身体并不契合的结果。这样一来,即使我们的 k 彩样器使用的是浅 充铅降噪,也不用担心生成的部分与原图的身体毫无关联的情况出现了。针对于本节课的内容呢,我也制作了一套完整的课件,上面以图文教程的方式讲解了我们本节课的相关知识。各位同学如果需要本节课的课件的话,也非常欢迎在评论区留言,我 会尽可能的帮助大家解决在操作过程当中遇到的问题,同时也会分享这套课件。那么以上呢,就是本节课的全部内容,各位同学如果觉得本节课的内容对你有帮助的话,也不妨点一个免费的一键三连支持一下,我们就下节课再见!
3027秋叶aaaki 00:45查看AI文稿AI文稿
00:45查看AI文稿AI文稿我靠, ai 漫剧赛道直接他妈大结局了!这个工作流的出现,直接宣布了比赛结束,操作简单到我想骂街,就把你的破小说往里头一丢,大模型就能自动接管一切推理剧情 脚本直接给你生成好,不用你费半天劲研究啥复杂提示词,不用你绞尽脑汁写什么智能分镜指令,直接给你出连贯到离谱的电影级分镜剧本。最牛逼的来了, 直接把人物不一致的千古难题给干碎了!一键出人物三式图场景全套道具,你家主角从片头到片尾长的半毛钱,不带差的!想换画风一键搞定! 古风、赛璐璐、国风三 d 日系动漫啥风格都有,就问你这成品够不够顶?别太么追着我要工具了,我全给你们整理好了直接甩给你!
116小嫚(没回复👀主页👗) 00:42查看AI文稿AI文稿
00:42查看AI文稿AI文稿四月二十九日大神手搓工作流更新第一个动漫视频制作,极低的显存就能输出视频,把工作流拖进康复以外,就能用自动反推提示词, 支持 n s f w 无限唱完直出视频。工作流打包好了,老规矩,验验排第二个,人物一致性工作流,上传以上女神的照片,点击运行就能生成十五个角度的照片,完美解决了人物一致性的难题。第三个, ai 数字人工作流, 只需要上传一张图片,输入一段提示词,就能生成专属于你的 ai 数字人。话不多说,新手教程和工作流已经打包好了,老规矩,验验牌最后来看看效果。宝子们晚上好啊,提前祝大家假期愉快哦!
654-AIGC教程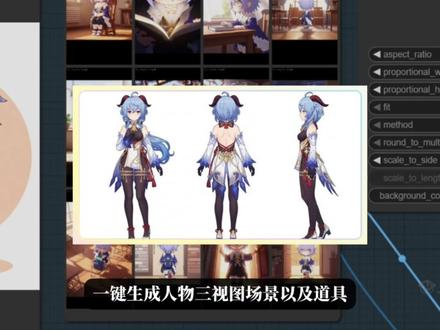 00:45查看AI文稿AI文稿
00:45查看AI文稿AI文稿ai 漫剧赛道的大结局终于来了!康菲又爱这个工作流的出现,直接宣布了比赛结束。只需把小说丢进这里,大模型就能自动接管一切推理剧情, 生成脚本,无需去研究任何复杂的提示词,也无需拽写智能分镜指令,它能直接生成连贯的电影级分镜剧本。最关键的是,它彻底解决了人物一致性的千古难题,一键生成人物三式图、场景以及道具,让主角从片头到片尾长得一模一样, 还能一键使用任何想要画风,古风、赛璐璐、国风三 d 日系动漫全部应有尽有,全程云端运行,不吃电脑配置,每一个镜头的运镜转轴都贴合慢距调型,就算是小白也能制作出像这样的大片效果。工作流教程我已经全部整理好了,赶紧抱走开练!
 00:41查看AI文稿AI文稿
00:41查看AI文稿AI文稿超强人物一次性工作流终于来了!这是一个能搞定角色全角度的 comfyui 工作流,只需上传一张人物图片,运行,工作流就能自动生成该角色三百六十度无死角全套形象,实现完美的一次性 生成的图像。不仅角度完整,还能轻松转化成真人、三 d、 卡通等任意风格随意切换,大大扩大 ai 绘画的应用场景。比如生成这样爆款的 ai 动漫、短剧、 ai 电影,都需要保持人物的一致性。如果你也想试试工作流,我都已经整理好在网盘了, 由于人数太多,私信评论无法及时回复,想要的可以看我主页的介绍,点击 ai 工作室自行获取。
107学会comfyui 00:54查看AI文稿AI文稿
00:54查看AI文稿AI文稿这个超强的 comfy ui 电影级纹身图与图生视频教程终于来了,直接丢工作流就能用!里面不仅含有纹身图和图生视频,而且人物形象超级耐打,不管是服装和饰品,细节 都非常精美,就连光影皮肤和质感处理的都非常自然。先来看看效果,官人,你倒有几日 没来看奴家了,不用找导演,也不用调参数找灵感,小白也能做出电影级大片,上传图片自动反推提示词陈双冷光如薄纱缠绕,人物立于冰晶秘境之巅,侧逆光分层,勾勒出鎏金与冰蓝交织的多层轮廓 光丁达尔笑影子灵雾中透出柔白光,涂成视频效果也是很不错的。动作丝滑,光影细腻,蝶舞纷飞,绝对不输于你看到的任何电影级场景。工作流已经整理好了,需要的小伙伴拿走尝尝。
106七鱼的AI绘画日常 02:10查看AI文稿AI文稿
02:10查看AI文稿AI文稿有款日常高频用的康普 u i 工作流,深图、修图、扩图等全场景覆盖,全是我撕成压箱底的保障工具,重点是操作都超简单,新手闭眼秒上手。第一款,参考深图,在 flux 纹身图工作流里加个图片参考节点就能直接跑, 上传参考图,输入提示时能更好的把控风格点运行图片风格立马切换到位。第二款,高清放大, 这绝对是刚需款,上传要放大的图模型,直接用 flux 一 键运行就行, 是觉得放大后细节太杂,那就调低降噪值,画面瞬间清爽。第三款,智能扩图上传要扩的图设置好上下左右的扩充尺寸,点运行就 ok, 系统将会把沿途说到幺零二四,这里推荐用 plus 模型处理,这个尺寸最稳不过,要注意扩充范围别太大,不然容易翻车。第四款,物体移 上传沿图右键编辑遮罩,圈掉要移除的部分点开始运行这个工作流,先放大遮罩器,再通过那么节点初次重绘,做紧身线稿处理,最后 plus 会二次重绘,比传统的 ps 快 太多了,效果还更自然。第五款,万物迁移,上传要迁移的产品图和目标图, 右键涂好遮罩点运行,这里用的是 flux 的 fedex 和 feel 模式,既能保住物体本身的一次性,又能完美融入目标画面。第六款,局部重绘, 我平常时常用来清画面小瑕疵,操作超简单,上传图片用遮罩涂好要重绘的区域,想改的内容就写 d 字值,不想改就空着。第七款,一键换脸,上传脸部参考图和底图,直接点运行,关键多试几次,调整下参考权重和降噪值,抽卡抽到最自然的效果就搞定了。第 八款人物换装其实就是万物牵引工作流的变底。上传衣服图和模特图,用遮罩涂好模特要换衣的区域,点运行衣 图立马放好。第九款产品精修修珠宝、金属零件这类产品超绝!上传产品图后直接运行工作流,精修完了产品质感拉满更精美。之后再用高清放大工作流处理一下,出来的图直接商用都没有毛病。视频相关的模型和教学课程我都给大家整理好了! 想学 ai 技术?快上电脑,跟着我就行,三天后给你满满惊喜!每天上课都有神秘福利,哪怕你是零基础也完全不用担心! ai 技术我们手把手的教会你,下班后能做的小事业也一定分享给你!点击下方链接,马上报名!报名成功的同学记得查到短信联系数学老师,准时开课!
 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿五月重磅更新,圈内大佬都在用的最强 ai 工具 comfyui 九点五新版本正式来袭!这次升级直接颠覆 ai 创作体验,绿色免安装解压就能用极简中文界面,上手毫无门槛。新版本内置海量精品模型,搭配现成成熟工作流,新手零基础也能 一键跑通流程,轻松就能做出质感拉满的爆款作品。他之所以成为 ai 创作圈主流首选,优势真的太顶了!全程开源零收费,没有会员订阅,没有隐性消费,本地离线运行,既能保护创作数据安全,还能彻底摆脱平台各种限制。 独有的节点式可释化创作模式,顶替死板、固定模板,每一个制作步骤清晰可见,画面、参数、风格、细节全都自由调控,创作自由度直接拉满。 功能更是全能无短版,高清出图、动态视频、慢剧、短剧、创意特效全部轻松拿捏!还没上手新版的朋友别再落伍,完整工具我已整理齐全,带你轻松吃透这款顶级 ai 创作工具!
140AI漫剧入门教程 00:29查看AI文稿AI文稿
00:29查看AI文稿AI文稿这个月带大家死磕这两个工作流,你的下一站,下一站翻身!第一个, ltx 二点三 pro 绿类,目前最顶级的开源视频工作流,免费使用,自动优化提示词和分镜,直接丢给他一大段提示词 自动跑出分镜视频,各个分镜还可以单独调整参数。第二个,三 d 模型工作流,只需一张图片就能变成可编辑可添加材质的模型,直接导入三 d 软件里面。使用工具和教程都在知识库,大家主页低调研究哦!
313秋叶comfyui小助手 00:33查看AI文稿AI文稿
00:33查看AI文稿AI文稿超强 ai 漫剧工作流终于来了!这个工作流的出现,直接宣布了比赛结束。以上效果就是我拿这个工作流生成的。只需将小说丢进这里,大模型就能自动接管一切推理剧情。生成脚本无需去研究任何复杂的提示词,也无需辗写智能分镜指令, 它能直接生成连贯的电影和分镜脚本。最惊喜的是,它彻底解决了人物一致性的难题,一键生成人物场景三式图和场景道具,让主角从头到尾都长得一模一样。工作流和模型参数都调配好了,还没试试的直接抄作业!
28秋叶aaaki







