1m上下文用完了怎么办
为什么 ai 写项目写着写着就走远了?直接拆开根本逻辑?以一照上下文窗口来看, ai 编程最舒服的场景就是从零到一,快速搭建一个解决某个具体需求的小工具。这个过程中,你提的任何细节,改了任何风格、临时拍板的任何约定,模型从头到尾都记得。 所以最后做出来的东西,基本就是符合你心里的预期,原因不复杂。整个项目的生命周期刚好都装在一次对话窗口里,模型还能记得很清楚,但只要项目的提量稍微超过一次对话窗口,这件事情就会变会,而且变得很快。任何 a 整任何 ai 编程工具,都有上下文窗口。 什么叫上下文窗口?你可以理解成一只水桶,水桶的容量就是模型一次长对话能装下的全部内容。从你打的第一句话到现在这一句,加上中间的所有代码、报错文档片段,你的所有交流过程全都在这里面。 比如这只水桶是一兆,你已经用到了九百 k, 那 现在还剩一百 k 的 空间水桶快装满了怎么办?模型会自动把里面的水压缩,但这里要特别注意一点,压缩不是稀释压缩,是把九百 k 的 水熬成一碗小浓汤。 汤的味道大致还在,你能尝出这是番茄汤还是排骨汤,但具体里面放了几片葱、几粒胡椒,这些细节熬完之后,模型就再也记不得了。 熬完之后,模型继续往下写,可是他手里只剩那一碗小农汤了。你前面跟他反复强调过的命名规范、目录约定禁止做什么和必须做什么,某个边界情况里专门让他处理过这些细节, 在熬汤的那一刻,大部分都被概括成了用户希望代码风格保持一致,希望接口设计合理。这种模糊印象,他不是不记得,他是记得大概意思。但具体怎么落,他就按照自己的想法开始发挥了,自己做主自己写。这时候就开始渗入一些比如泥土、灰尘等杂质, 给后面工程持续眼镜埋下各种各样的雷,这就是幻觉,真正的地方,模型永远不会主动告诉你。这一段我不太确定, 他会按你最初提的目标,百分百交付一份看起来完整、看起来能跑,甚至跑起来也没报错的代码。等你某天回头审一遍,才发现项目已经悄悄走远了。不是哪里写错了,而是他整体已经不是你最开始想要的那个效果了。当然了,并不是窗口越大越安全,一兆也好,两兆也好, 只要项目的寿命超过一次上下文,窗口对话长度也就是水桶最大的容量,熬汤这件事情就一定会发生。幻觉就会从某个时刻开始累积,窗口大,只是把这个时刻推迟。那既然熬汤躲不掉,那能不能每次熬汤的时候自动保住某些重要的东西呢? 我们就拿 coco 举例,它在项目跟目录有一份叫 coco 的 md。 这份文件被定义为项目现章,意味着每一次水桶被熬成浓汤,重新装水,开始下一轮对话的时候, 这份现象就会原封不动的第一时间重新倒回水桶里。他不参与熬汤,他是熬汤之外的必备物资。但你可能会马上有一个非常直觉的疑问,既然每次熬汤之后,这个文件都会原封不动的重新倒回水桶里,那我干脆把项目里所有该交代的事,怎么放,命名怎么取,接口怎么定,哪些坑别踩 全部一股脑塞进这一份文件,让模型每次开工的时候都强读一遍不就好了吗?听上去逻辑很顺,但只要你项目稍微大一点,你就会发现一份文档根本写不下。你想象一下,一个真正正在跑的工程项目,几十个模块,上百个接口,几十条历史决策, 再加上这一堆当年踩过的坑,所以必须现在这么写的。按规则,你把他们全部往这一份文件里面堆,这份文件很快就会膨胀到几万头肯起步。 别忘我们前面说的这份文章,是要在每一次熬汤的时候强行倒进新水桶里。这意味着你这份巨型的现状本身先就占掉了水桶大半的面积。 模型还没开始干活,只是把项目长什么样,读了一遍,水桶就过半了?你才刚开始准备开口提需求,我现在要做一个新的功能,话还没说完,几次代码读去,几轮工具都有,水桶就装满了,熬汤又出发了。 所以你看出来,把所有内容塞进一份文件这条路,本质上是想用蛮力去对抗水桶的物理上限,而物理上限是始终都绕不过去的。真正要解的问题,不是我能不能写更多,而是哪些东西在什么时候,以什么细密度加载进来。 你需要把这个项目做什么,不做什么,单独成一份,把哪些词在这个项目里有特定含义,对应到代码里,是哪个东西单独成一份,把做过哪些重要决策,为什么选择了 a 而不是 b 单独成一份,甚至把哪一段是临时方案,什么条件满足后 拆掉也单独存一份。每一份都有自己的角色,每一份都按需加载,而不是一次性把所有信息都给模型。这一套被拆分,被分成叫 spat 工程。换句话说,以前我们写文档写给同事,写给商月后的自己,现在写 spat, 是 写给一个永远在重新认识这个项目的 a i a 准同事, 每一次启动都是第一天,你那份规格就是他的入职手册。这意味着 spot 工程整个行业正在共同走的方向,企业要投入这件事情,不用担心自己走错了路线,但只把规格写好。事情还没完,光有怎么写是不够的,还得有人来管该怎么跑, 光怎么跑。那一层叫做 hannis。 打个比方, spot 是 图纸, hannis 是 车间,图纸画的再精确,如果车间里机床摆得乱,工序没人盯,工人各拼手感, 出来的产品照样是次品。反过来,车间管的再好,图纸本身就是错的,那也只是把次品做得更快更标准而已。所以可以这样总结, spec 是 你想让模型基础什么的清单, harness 是 你逼模型每次都按这个清单办事的那套机制, 一个负责定义意图,一个负责把意图押进每一轮对话的执行环境里。把 spec 和 harness 合起来,现在就是被叫做 sdd 规格驱动开发。 为什么企业必须看懂这件事?第一,可审计规格是白纸黑字可以版本化的,哪一版规格跑出了哪一版代码可以一一对应,出了问题不用追,是哪个员工让 ai 写的,而是追哪一行规格没写清楚。 第二,可交接新人接手一个 ai 写 logo 的 项目,不用先去逆向了解前一个人是怎么调这个模型的,直接读规格就能上手。 第三,可复用。规格和 harness 都是可以跨项目沉淀的。第二个项目,第三个项目启动,前面那一套基础规格,基础 harness 拿过来微调就能用, 不用每次都从零开始,重新演一个懂这个团队的 ai。 第四,可控。这一条对管理者最重要。 ai 编程不再是某个员工碰运气出货,另一个员工怎么都出不来的不可解释现象,而是变成一套可以被审查、可以被复制、可以被改进的工程实践。 最后还有一个底,模型本身的能力,规格再清晰,支架再严密,套在一个不聪明的模型上,厂株仍然是那个模型水平的产出规格和支架是放大器,不是等价器,它放大的是你的工程纪律,但它替代不了模型本身的天花板。所以最后想留下一句话, ai 编程的胜负手,不在于模型多大,窗口多长,工具多耗少,而在于你们有没有把意图工程化,把规则系统化,把那只会熬汤的水桶装进一只真正可控的支架里, 谁先把这件事情做扎实,谁就能从烹运期出锅那个阶段毕业,进入下一个阶段。 ai 写作,真正能交付企业级产品,能跨人交接、能沉淀团队资产的 ai 原生开发。

粉丝348获赞2204
相关视频
 09:27查看AI文稿AI文稿
09:27查看AI文稿AI文稿本期视频来分享如何将 deepseek 的 vs 模型接入 cloud code, 并解锁 em 的 上下文以及 max 思考等级。我目前已经将 deepseek 的 最新模型 vs flash 和 vs pro 通过 ipad 的 方式来接入了 cloud code。 vs pro 模型在降价之后性价比也越来越高了,并且对 a 键的也有做专门的适配, em 的 上下文对于大多数人来说也更加友好。 视频内容主要分为四个部分,第一需要先安装一下 cloud code。 第二,安装开源工具 c c switch。 第三,需要购买一下 deepsafe 的 api 并完成配置。最后再来测试一下 deepsafe。 v 四 pro 加 cloud code 这套组合表现怎么样。废话不多说,我们现在开始 首先来说如何安装 cloud code。 大家常说 cloud code 经常被封号,那其实封的是拥有模型能力的个人账号,但 cloud code 作为一个单独的软件是可以正常下载和安装的。 没有订阅官方的模型,我们依旧可以使用它的框架当成是 opencloud 或者 hermes nint 这种。在他们的项目官方网站这里也有明确的说明。终端 cli 和 vs code 也支持第三方提供商。 本期视频演示的是安装 cio 版本,也就是最通用的版本。这里有一行中的命令,它支持 macos、 linux 和 windows 这几种不同的系统版本。 windows 这里分为 power shell 命令和 cmd 命令,并且 windows 用户需要先下载安装下 get, 如果没有安装的话,可以到 get 的 官方网站下载安装包进行安装。 这里复制这一行命令,然后打开终端 app 或者 power shell, 输入他们提供的命令回车执行就可以了。我这里已经安装过,所以不再演示具体的步骤。安装好之后可能会出现一个提示,大致意思是安装已经完成,但是 control 的 安装位置并没有加入到电脑的环境变量中。 这里直接复制这行他提供的命令,在终端执行一下,搞定之后输入可拷的 code 杠杠微刃来确定当前的版本号。后续使用的话,直接在终端输入可拷的命令就可以打开了, 但是你那里可能会提示不能连接官方服务。接下来我们来安装第二个工具 cc switch。 cc switch 是 一个开源工具,它能够让 cloud code codeys、 opencloud 这类的 a i a 检测,方便地切换模型。累计下载量有三百多万,在 github 上面也有五万多个 star。 它有很多实用的功能,比如一份配置同步到多个应用,支持热切换,不需要退出应用切换模型。还有用量仪表盘,能够查看你的请求数和头克用量等等。 我们在项目的首页这里有一个已发布的安装包链接,点击进去,然后在这个界面直接划到最下面。这里有很多的安装包版本,如果是 mac os 系统就下载这个 mac os 点 dmg 的 版本,如果是 windows 就 下载这个版本。下载好之后直接点击安装包进行安装就可以了。 它这个项目的说明文档也有比较详细的安装教程。第三步,到 deepstack 的 开放平台购买 api。 我们来到 deepsafe 官网,点击 api 开放平台,我这里之前已经充值了一些,在网页和 deepsafe 对 话是完全不收费的,但是想要调用 api 就 需要进行充值。他们目前没有推出类似 tokpline 这样的按月订阅的套餐,好处就是用多少花多少。 目前他们对 v 四 pro 模型打二点五折,每百万 tokens 缓存命中情况下输入是零二五元,未命中是三元,输出是六元, 这个折扣目前是到五月三十一号截止。 v 四 flash 模型和 pro 模型的价格对比可以在官方的 api 文档里查看,这里点击充值按钮,然后选择金额和支付方式。建议先小额买一笔,用完之后根据自己的实际使用情况再进行补充购买。 付款完毕之后,点击左侧的 api case, 点击创建,然后复制这个 key 的 密钥, 注意这个 k 的 密钥只能够在创建的时候查看,关闭这个页面就看不到了,如果丢失的话,就需要重新创建一个 k, 然后打开 cc switch 这个应用。我这里已经添加好一个 deepsea 的 模型了,选中这里的 cloud 的 图标,然后点击添加, 在预设供应商这里找到 deepsea, 在 api k 这里填写 k 的 密钥,然后这里需要修改一下这几个模型,可以直接参考我这个填写 默认模型就是 deepsafe。 v 四 pro 后面加上 em 是 因为之前的公告有说明,这样才能够开启 em 的 上下文,然后点击添加就可以了, 这里就会多一个 deepsafe 的 模型,点击这个按钮来测试当前 api 是 否可用。点击这里可以配置用量查询,查看当前还剩多少余额, 勾选这里,然后点击保存配置,这样的话就能够看到还剩下多少钱了,然后点击起用,就能够正常的使用可绕的扣子了。左上角有一个设置按钮,通用,这里建议打开开机自启使用统计,这里也能够查看 ai 模型的使用情况和成本。 我们打开终端应用,输入可绕的指令,那这个呢?就是 deepsea v 四 pro 的 模型,并且是一百万的上下文, 我们输入指令斜杠 context 能够查看,这里确实是一百万的上下文 tokens。 这里的默认思考等级是 medium, 可以 使用命令斜杠 effort, 然后空格后面的话就会显示哪些等级可选,这里输入 max 回车确认,这样的话思考等级就会调到最高。还有一个命令可以快速的切换模型, 输入斜杠 model, 然后回车。默认模型其实就是 v 四 pro, 我 们之前配置的 apps 和 sonata 都是 v 四 pro, 嗨酷模型是 v 四 flash, 通过键盘的上下按键来选择,选中这个模型,然后回车确认, 这样的话模型就切换到了 v 四 flash, 这里输入命令 context 能够看到它的上下文,显示是两百 k 的 tokens。 最后一部分来测试一下 cloud code 搭配 deepsea v 四 pro 到底贵不贵,干活效果怎么样。 首先说一下,它是基于文件夹的工作模式,所以你需要先通过 cd 命令跳转到你想要它打开的文件夹,比如我的项目文件夹的路径是这个,就需要输入屏幕上完整的指令回车,到了这个文件夹后,输入 cloud 的 命令来启动它, 如果路径很长的话就比较麻烦。有一种方法可以简化一下, windows 用户应该可以直接在文件夹右键从当前文件夹位置打开终端, mac 用户右键的话是没有的,但是可以直接将文件夹拖拽到终端 app, 那 当前终端打开的文件夹就是这个项目文件夹, 输入 cmd 命令,可以查看当前文件夹的路径,然后输入 cmd, 启动 cmd 的 code。 第一次打开的时候需要确认一下这个文件夹,点击 yes, 后续退出的话需要连按两次 ctrl 加 c。 这里安装一个归藏老师最近开研的一个 ppt skill, 设计是比较美观的。 来到他的项目仓库,这是一个电子杂志风的网页 ppt skill, 纯网页形式,适合线下分享,但是不适合培训课件。这个 skill 的 名称叫做归藏 ppt skill, 这里提供了多种的安装方式, 最方便的就是直接复制这一段话,然后发给 ai, 选中这一段话, command 加 c 复制,然后来到 kol 的 对话界面, kol 加微复制,然后直接发送。 kol 在 执行任务过程中会需要一些权限的许可,遇到的时候直接选中 yes 就 可以了,它的框架对于安全保护还是比较好的。 整个的执行过程我就直接跳过了这里提示安装好了触发词,就是帮我做一份杂志封的 ppt。 ok, 我 在这里输入这句话,然后告诉他要做的内容就在当前文件夹中。在当前的项目文件夹中,我放入了一个 mail 文件, 内容是关于 code 的 使用方法论,然后回车执行。他会先查看项目文件夹的内容和 skill 的 使用说明,执行过程中可能会问一些问题,根据个人的需求选择就行。 我这里也跳过过程,大概直行了六分钟左右,一共生成了九页 ppt, 并告诉了我每页的布局和内容,以及怎么操作。 ok, 我 们直接打开浏览器来查看一下这个网页的 ppt。 这是第一页 codex 的 方法论,整体的设计风格确实是比较美观的,如果是个人制作的话,可能要花费比较长的时间,并且效果还不一定有他这个好。 第二页这里的话可能会有一点点问题,下方的文字有一部分被遮挡了,后面的页数大家可以具体去看一下内容觉得怎么样。 最后再来看一下安装这个 skill 以及制作这九页的 ppt 一 共花费了多少钱。 我在做之前是九点八九的余额,刷新一下网页,那现在还有九点三九的余额,一共是花了五毛钱。这里有一个每月用量的图标,展示每个模型花了多少钱。下面也有 token 的 使用详情,包括输入和输出的具体数量。大家觉得 deepsea v 四 pro 的 性价比怎么样?
2.3万小陈同学c_z 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿分享一个 kol 的 小技巧,在你这个 kol 的 code 里面,使用第三方模型的时候,比如说 deepink 四 v 四 pro, 它明明是有一千个 k 的 上下文,但实际上这里它只会写成两百,为什么?因为 你的这些第三方模型的 kol 它不认识,它并不知道你的上下文是多大,所以它默认都是给两百,直接切成两百,这样的话你问一个问题就能耗掉接近五十,你这个一个对话 基本上四五个问题,他就要被墙压住了,那肯定是很不爽的,那怎么办?有个小技巧,其实就是你要选择模型的时候, 你要跟他讲你的上下文长度是多少,那怎么讲呢?他是这么约定的,你后面跟个中括号就这样子, 如果你是要改成三百 k, 你 就改成这样子,如果你要一千个 k, 你 就直接写成一个 m 就 行,这样子他就会被识别的一千个 k 就是 一个 m 的 上下文, 这样的话,你记在这个里面,可以完整的问他几十次问题,五十次问题,他才会触发上下往下缩,这样的话你的这个使用的会很舒服。对,就这么一个小技巧,一分钟教给大家。
 05:43查看AI文稿AI文稿
05:43查看AI文稿AI文稿最近你一定会频繁看到一个说法,模型上下文越来越长,动不动就是百万级头肯。好像从此以后,一本书、一个代码库、一个公司的全部文档都可以直接塞进去,让 ai 一 次性看完。 为什么现在要关心?因为冲突已经到了使用现场,有人开始直接上传整包材料,让 ai 下结论,也有人还在手工整理摘要,怕模型遗漏关键细节。 这个判断错了,轻则浪费钱和时间,重则把项目决策交给一个其实没看懂大局的模型。先说一个反直觉判断,长上下文不等于真正读完,它更像是一个超大的会议室,能把很多材料放进来,但不代表每份材料都被认真阅读。比较记住,调用一照 token 的 价值很大, 但他的边界也很清楚,他解决的是放不下的问题,不自动解决看得准、找得到、推得动的问题。第一个机制是注意力不是均匀分配的人读一本书不会每个字都同等重视。模型也是,上下文很长以后,模型会更依赖显眼位置、重复信息、标题结构和用户问题里的线索。 你把整个代码库放进去,他可能确实接触到了所有文件,但在回答某个问题时,真正被强烈调用的往往只是其中一小部分。很多人以为塞进去就是大局理解,但对模型来说,信息在窗口里只是获得了被使用的资格,并不等于一定被使用。 第二个机制是,长上下文会放大噪音。一本书里有核心模块,也有历史包袱,测试夹具、配置文件、生成文件。 上下文越长,模型越容易在相似信息之间摇摆。他可能把旧接口当成线接口,把废弃代码当成关键逻辑,把一个边缘注视当成设计原则。窗口变大以后,问题不是信息太少,而是信息太多且缺少优先级。第三个机制是推理链条会被长度拖累。真正理解一个代码库, 不是把文件都扫一遍,而是能建立依赖关系。这个入口调用谁,谁改了状态,状态又在哪里?被毒取异常路径怎么走?长上下文可以提供原材料,但要把原材料变成一张可用地图,仍然需要模型进行多步归纳。材料越多,归纳越难, 尤其当项目命名不统一、历史版本混杂、文档和代码不一致时,模型很可能给你一个听起来完整,实际上只覆盖了局部的解释。第四个机制是成本和速度会改变使用方式。百万级上下文不是免费的魔法,即便产品把它包装的很顺手, 长输入也通常意味着更高延迟、更高计算消耗以及更难调试的输出。一旦回答错了,你很难判断到底是哪个材料误导了他。短上下文错了,你还能定位。超长上下文错了,排查反而像在一堆纸里找针。第五个机制是,能读和能改之间还有一层距离。让模型总结一本书 和让它指出全书论正漏洞不是一个难度。让模型解释一个代码库和让它安全修改核心流程也不是一个难度。 长上下文能让模型看见更多相关文件,但改代码还需要测试、运行、定位、副作用。一本书也是一样,模型能复述章节,不代表能判断作者在不同章节里有没有偷换概念。长上下文提高了上限,但没有取消验证过程,那长上下文到底有什么真实价值? 它最适合三类场景,第一,做跨文档检测后的综合判断,比如合同、论文、会议、基要之间互相对照。第二,保留大量背景,让对话不用频繁重复。前提 三,在代码或书稿里做带上下文的局部修改。比如改一个函数时,同时看到相关类型、测试和调用链。它不是让 ai 变成一个永不遗漏的总工程师,而是让 ai 在 局部任务里少一点失忆。观众应该怎么判断一个长上下文能力是不是真的有用? 不要只看窗口长度,要看四个问题。第一,它能不能在很长材料里准确引用关键位置,说明答案依据来自哪里。第二,它能不能区分新旧、主次、正视和草稿。第三,它能不能在你追问细节时保持一致,而不是第一轮说一套,第二轮又换一套? 第四,他能不能主动说不确定,告诉你哪些文件还需要人工确认?一个能承认边界的长上下文模型,往往比一个自信总结全项目的模型更可靠。如果你要在工作里用它,我建议不要一上来就把所有东西扔进去。 先让模型看目录结构,让他提出需要哪些文件,再把关键文件分批放入,最后要求他给出依据、风险和带确认点。这样做看似麻烦, 但能把长上下文从巨型垃圾桶变成可控工作台。资料可以长,问题要短,背景可以多,任务要清楚。更具体一点,你可以把一次长上下文任务拆成三轮,第一轮只问这里有哪些材料,哪些可能相关,不要急着要答案。第二轮,让模型围绕一个明确问题列证据, 要求他把支持和反对的信息分开。第三轮,再让他给结论,并标出最可能出错的地方。这样做的好处是,你能看到模型到底是在推理,还是只是在把显眼段落重新包装。 还有一个实用技巧,把长材料变成层级,先让模型做目录级地图,再做章节级摘药,最后进入具体段落或具体文件,每一层都让它说清楚我依据了什么,我没有覆盖什么。 这样你不是在赌模型一次性全懂,而是在建立一套可复查的理解过程。越是大材料,越要把问题拆成小检查点,也要学会识别失败信号。如果模型回答的很满,却不给出处, 如果他把不同章节的概念混在一起,如果你换一种问法,他的关键判断就变了。如果他只引用开头和结尾,几乎不碰中间材料,都说明长上下文没有被可靠使用。这个时候不要继续追问,再仔细想想,而是缩小范围补充结构,或者直接人工检查关键页。最后,别把长上下文当成整理习惯的替代品。 越是重要材料,越要提前标好版本、来源、优先级和你真正想问的问题。模型可以帮你读得更广,但你要负责把任务边界划清楚,边界越清楚,长窗口越有用。边界越模糊。窗口越长,越容易把错误包装的更像答案。一句话总结,依照 token 的 真正意义,不是 ai 终于能完整读懂一 切,而是我们终于可以把更多背景带进任务里,但理解、取舍和验证仍然要靠结构化提问和人工把关。
41老傅1024 00:41查看AI文稿AI文稿
00:41查看AI文稿AI文稿对于研究生来说, deepsea 为四最值得看的其实并不是发布了一个新的模型,也不是跑分,而是一笔链的上下文,听着很急速是吧?但是放到科研里,其实他就一划, 他可以看到你更多的科研现场,比如说论文代码、实验记录、报错日期、审核意见这些。以前那些东西都是散的,你问 ai 一 段,他答一段,问到最后,他其实已经不知道你整个项目发生了什么。你问的地方不是把十几篇论文丢进去给他总结,太浪费了。更好的问法是,我的实验为什么不稳定?论文方法和代码时间有没有对不上的地方, 这才是研究生真正需要的。但也别神话它长,上下文并不是魔法,你丢进去一堆烂材料,它也只能整理出一堆看起来很合理的烂结论。所以说,以后研究生使用 ai 的 分水岭,可能并不是谁的 problem 写的更好,而是谁把自己的科研现场整理的更清楚, ai 最能看得懂,但最后的判断还是要自己来做。如果你有移民念的上下文,你最想丢进去什么?
 05:59查看AI文稿AI文稿
05:59查看AI文稿AI文稿就在今天, deep sec 发布了他们的 v 四模型,并且同步开源了,这一次发布最大的亮点就是支持了百万 token, 然后重点优化了 crow code, open crow code 等等这样的 agent 工具,从过年等到了现在,终于发布了。 更巧的是,就在前脚 gpt 五点五刚发布,我上一个视频刚做完,刚实测完,他就发布了,这次他们发布了双版本 deep sec v 四 pro、 deepsea v 四 plus。 两个的差别,第一个是参数上啊,一个是一点六 t 的 参数,第二个是二百八十四 b, 那 这个的话就是走性价比的路线嘛,还是非常的便宜。那这个 pro 的 话这一次就比较贵了,如果你没有走到缓存的话,百万托管是十二块钱,就相对来说还是挺贵的。 我刚刚实测下来, v 四 pro 在 这个复杂推理上面真的是比之前上一个版本我个人感知还是挺明显的,尤其是在 crocodile 里面,它的写代码的这一个感觉啊,跟现在国内的顶尖模型 gm 五点一啊, kimi 二点六啊都差不多了。下面的话我们直接来看实测环节, 那我们这边的话还是沿用之前的一些评测任务,同样的提示词,同样的项目,然后我们把这一个今天新发布的 gbt 五点五以及 deepsea 微四 pro 我 们都接进去,然后来看一下它整体的评分情况,分别两个项目,第一个是从老项目迁移到新项目,让它去做 一个大项目的迁移,这个难度还是挺高的。那第二个项目的话,也是之前经常测试的,就是把一个已有的一个 skills agent 是 终端交互的,把它做成这个外部 ui, 主要考察它全站以及 sync 啊工具调用流速输出的能力。那我这边的话是用 ppl 去测试 deepsea v 四 pro 的, 因为之前测试智普 gm 五那期视频, 他们官方直接卖受气呢,所以说我就找了一个国内做这个开元模型,推你的,那价格的话也是一样的,跟官方都是一样的,这 这一期视频大家可以有福利了。因为那一期视频的缘故,所以说这一期视频呢,他给了我们一百张的这个三十块的代金券,可以直接用 deepsea 微四的模型,你也可以用 kimi k 二点六还是其他的模型,因为国产的模型其实比较便宜嘛,三十块钱的话你大概率也还是能用一用,一会儿不薅白不薅是不是? 那我把他们的这一个得到优惠券的链接也放在这一块了,大家就是先到先得吧,只有一百份哈,而且是要新用户才可以,大家可以去尝试去试一下。因为本身都是开源的模型嘛,所以说不管是用官方的还是这些的,其实区别都不大,因为价格都是透明的。下面我们来看一下整体的一个评测情况。我这边准备的就是五个目录嘛,那 五个目录的话分别代表着就是最顶尖的 gbt 五点五 off 四点六 off 四 pro, 还有就是今天发布的嘛, gbt 五点五, 为什么要把这些名称隐藏起来呢?就是为了后续我去里边有代码的时候,让他们要公平公正,不能说因为是啊,国外顶尖的模型或者模型代号是新的,他就有那种权重的,这个偏离是不对的。好,我们来看下第一个任务就是给这一个图片 a g 的 从另外一个项目里面迁移过来,做谷歌认证登录,然后做 gmail 登录。整体的项目复杂的挺高的,可以看到他这边已经 一百万的托管都已经压缩了一遍了,并且他之前还做了很多的探索嘛,所以说整体这一块项目也比较复杂,那他完整情况怎么样呢? 一次性完成,并且这个项目能正常启动。以往我测试其他国产模型的时候,在上一代的时候其实很多都会翻车,那这一代看的话就是提升还是挺明显的,因为官方也说了,他在整个的这个 qq 链接的这块的优化是挺明显的,但是也会有一个小问题啊,这个小问题是什么呢?就是他忘记写了落地页了,因为我要他写落地页,他没写 好,这是他写的这个落地页嘛,就是我有一个图片生成的 agent, 整体效果就还行吧。然后我们来看一下登录登录,主要是让他去做 github 的 这个认证以及谷歌的,我们来点一下, 可以看到是认证成功了,他也帮我们把头像昵称拿出来了,那我们看一下另外一个就是谷歌的认证登录, 可以看到这块也是 ok 的。 那在测试 deepsea 和 v 四的时候,我的直观感受就是它一次性完成的,除了落地也忘记写了,但它整体的这个认证登录这块完成的非常好。接下来我们来看一下这一个 gpt 五点五完成的, ok, 这是 gpt 五点五写的,这个落地也就也还行, 就它的风格跟它其实还是就跟我们刚看到的这个 deepsea 还是不一样的。那它这一块,这一个就是登录这块也是还是有些区别,看个人感受吧,我还是比较倾向于 gpt 五点五这个感觉的,然后点一下这个认证登录,这个也是 ok 的。 光看功能这一块的话,其实两个就 deepsea 跟 deepsea 五点五 差不多,但是核心的是什么呢?核心的就是看它的代码实现这一块,因为你只要涉及到登录认证这些,安全性就是非常非常要保证。好的,之前 我们测试 cloud 跟 gpt 对 比的时候,就会发现 cloud 有 偷懒的行为,这次我们看一下 deepsea 到底怎么样。好,我们来揭晓一下它整体的这一个评分情况。 ok, 这个评分出来了,那 ai 给它的评分是七点零,那它这个评分是怎么得出来呢?就是 发现啊,就是我们这个申图的任务里面,因为你加了用户体系嘛,那是不是每一个人的这个申图任务,它应该是隔离的,但是 deep sec v 四这边是没有隔离的,另外的话 web socket 也没有集成件全,还有后端集成测试还有些失败的,所以说它整体的评分会比较低一点。那 gpt 五点五这边的话,它这边也新增了一些配置文档, 还有但是会有一些小 bug 嘛,所以说整体评分的话,可以看到不管是 cloud 的 off 四点四还是 cloud 的 off 四点六, 还是没有这个 g p t 五点五,再加上我上一个视频也说了, g p t 五点五真的相当的强,而且它不封号,我觉得大家都可以去试一下 g p t 五点五真的挺猛的。第二个项目的话就不带着一步步去看了,直接把这个结果揭晓一下吧。那第二个的话会相较于上一个会好一点,因为整体这个的难度没有那么高,但是你看啊,它会比 cloud of 四点六要好, 那是因为在这个项目上面, cloud 的 opt 我 不知道为什么表现的就有点差,那它这块的话也说会有一些就是好的地方嘛,比如一次性完成的后端跟前端,然后 setting 工具调用,然后一些流势回复都 ok 的。 但是它这个 ui 的 感觉会比较弱一点,因为我的主观感受也是它的 ui 相对说比较差一点,最好的还是 gpt 五点五。 好,我们来总结一下,这一次它的上下文变强了,它的这个 a 键的能力也变强了,是真的变强。还有就是它的这个适配性,不管是 cloud code 还是 open cloud 这些都适配的比较好,但是的话就是限阶段比较贵,一百万拓客的话需要十二块钱。但是问题来了,官方今天发的一个博文,里面有一个很关键的小字,是什么呢?就是国产芯片 在适配了,因为现在算力跟不上,所以说他们这个没办法就要标这么贵,但是未来会很便宜很便宜,他们预计是下半年。 ok, 这就是这期视频所有内容了,我是阿娇,我们下期见,拜拜。
2117程序员阿江-Relakkes 05:24查看AI文稿AI文稿
05:24查看AI文稿AI文稿这两年大户型有一个特别明显的趋势,就是上下文窗口越做越大。前两年大家还在说八 k 三十二 k, 一 百二十八 k, 而近一年,越来越多的头部模型开始把上下文窗口堆到了 em 级别,也就是一百万。 譬如最近刚出来的 deepsea 未死。这时候肯定就有小伙伴会想了,既然模型都已经这么能装了,那还需要折腾什么? reg 吗?我直接把资料全塞进去不就完事了?但现实是,不仅 reg 没死,反而在很多企业级的 ai 应用里头,依然是核心方案。 接下这期视频,我们就来聊清楚一件事,都一百万上下文了, reg 为啥还没死?好,废话不多说,我们现在开始 首先来一句总纲常上,英文解决的是模型最多能读多少,而 reg 解决的是到底该让模型读什么。这俩其实根本就不是一类问题。我们先说一下最现实的一点,钱。 大家如果调过大模型的 api, 应该知道大模型是按透痕计费的。一百万透痕那是什么概念?不严谨的说,大概相当于一百多万个汉字吧,就相当于好几本很厚的书。如果你把这一百万透痕塞进 front 里,仅仅只是为了问一句啊,呃,这个月的利润是多少?会发生什么? 模型每次回答你都需要把这几本书从头到尾啊,一字不落的去重新读一遍,重新计算一遍这个注意力机制,这好比你为了找一张发票,去雇了个人,把整个公司档案库全部翻了一遍一样。 这个不叫大力出奇迹,这叫人傻钱多。这个 token 的 费用是嘎嘎贵。而 rek 的 逻辑就不一样了,它是先查后问,不管你底层有多少数据,我先用向量来检测,把最相关的几页或者几篇文档找出来啊,这可能是几百个字, 然后再丢给大模型,而不是每次加的所有的数据库内容。你说这两个成本是吧?能一样吗?第二点就是响应速度, 就算你有钱是吧?不在乎成本,但你总得在乎用户的耐心吧。虽然大模型能吃下一百万上下文,但吃下去到吐出来的第一个字,也就我们常说的什么。 tft 是 需要时间的, 上下文越长越填充阶段通常就越重,首字延迟呢,往往也会明显上升。而基于 red 的 系统,因为只需要把相关的内容塞进去,上下文通常会短很多,所以响应时间更容易控制。 第三点是企业数据真的太多了,一百万上下文听起来很大,但对一个随便大一点的企业来说,他内部的资料啊,历年的财报,还有公单记录等,加起来随随便便都可能几亿甚至几十亿偷啃。在这么大的一个数据量上,一百万是个嘚啊,还是得需要一个数据库来存储和解锁。 而且还有个最关键的点,权限。公司里面的实习生和老板看到的文件能是一样的吗?肯定不是,还有像 hr 的 薪资表啊,销售的这个客户名单,或者是什么财务的报表,研发的代码仓库,这些东西都不可能。是啊,谁都能看的。 如果你用 red 系统,可以在解锁阶段就把权限卡住,这个员工没权限看的文档压根就不会被解锁出来,也就不会进入到模型的上下文当中哈。但如果你图省事,直接把一大堆资料全部塞给了模型,那就危险了是吧?模型一旦看到了,他就很有可能在某个回答里顺嘴说出来, 这就不是回答错错的问题了,而是出事故了。还有最后一点,也是最重要的一点,就是可追溯性。我们知道真正企业级的应用,母棒性和准确性的要求很重要,而不是说只要模型能回答就行。 我们还需要知道你的答案是从哪份文件里出来的,引用的又是哪份文件啊?是哪一页,甚至是哪一段。如果答错了,而是剪辑没收到,还是模型自己编的?这些问题常上下文本身是回答不了的。 如果你直接把一百万字的文档 c 给大魔仙,这就相当于是一个巨大的黑盒,他生成出来答案,你根本不知道他是从哪句犄角旮旯里头拼出来的。 而瑞克的好处就是他天然会留下解锁的链路。比如说,系统可以告诉你这一次的回答引用了哪个具体的文件啊,具体的哪个片段。这样一来,一旦出现了问题,你就能复查了,是不是到底是知识库过期了,还是解锁没有找回,又或者是模型的理解出错了,这些就能定位了。所以你看, regg 并不是单纯的为了省头等,更掌握着哪些资料能进来,哪些不能进来,进来的依据是什么啊?最后的答案能否能追到来源? 那么大模型的长上页文是不是就毫无意义了呢?当然也不是,长上页文还是非常有用的。譬如早期做 regg 的 时候,很痛苦的一点就是模型上页文太短了,譬如距离三点五刚出来的时候只有四 k, 你 就必须把文档切的特别碎,但是一旦切碎了语音,比如说只收到了他很生气, 但模型根本不知道他是谁啊,为啥生气等等等等。这也是以前很多 reg 系统效果不好的一个原因啊,不是因为剪辑不行,而是上下文真的太少了。 那现在有了百万的上下文,我们就可以做 long reg 是 吧?也就是先用 reg 从海量的资料里头塞一遍,把最相关的几篇完整的文档找出来,然后再利用长上下文,把这些完整的文档一次性喂给模型。这样的话,你既可以保留该问题所相关的完整文档,又不至于把整个数据库全塞进去。 所以总结一波,你可以理解为常胜下围。模型就像一个过目不忘的天才,而 red 则是一套高效的图书馆锁影系统。天才大脑容量再大,也不代表他需要每天把整个图书馆围在身上,最好的方式是让他坐在图书馆里头,由图书馆锁影系统递给他最精准的几本书,让他来做深度的阅读和推理即可。 好,如果这期视频对你有帮助的话呢?记得点赞、收藏加关注,咱们下期视频见!
1284算法魔法师 02:34查看AI文稿AI文稿
02:34查看AI文稿AI文稿这两天用 devic 微四呢,我觉得是越来越感觉不对劲了,为什么不对劲呢?以前的时候所有的模型它都在尽可能的提升能力,对吧?能力提升上去,然后价格也就跟着上去了。所以呢,很多 a 阵呢,在设计的时候,它都是一个思路,就是我要去帮助用户节省投分, 比如组装上下文,或者说记忆怎么做,对吧?现在的主流做法就是说把东西交给模型,让模型自己去调用工具,然后再 存下来的内容里面去搜相关的记忆,你需要啥你自己搜去,为什么这么高?为什么不把记忆一股脑就全塞到上下文里面?太多了,对吧?嫌浪费吗?其实核心还是这么个逻辑,但是现在这个是啥情况?它的输入上下文多钱呢? flash 八十几块钱, 然后呢? pro 版两块钱,而且缓存命中之后两分钱,两分钱啥概念?约等于不要钱,对吧?而且我昨天发视频也大家也不知道有没有看啊,就是他那个缓存命中率很离谱啊,我感觉百分之九十多的缓存命中率,所以在这种情况下,是不是 没有必要再去想办法节省上下文了?没有把必要再去做这件事情了。我那个 a 阵头,我,我之前也是那么写的,然后整个上下组装出来之后,其实很短,那很短,而且我还给了一个六十四 k 的 约束,我害怕太多了,我给了个六十四 k 的 约束, 现在,现在在这个 v 四的情况下,他,你是不是认为他这个就没有必要这么赶来?就是说整个 a 阵他的,我觉得他的整个设计思路好像都要改一下,都要变一下, 就是说现在所有的逻辑你都应该去尽可能的往上下文里面去塞啊,没有必要再去给他准备一大堆工具,然后让模型再去调成工具,对吧? 因为你有没有想过你去调用工具,他是不是还要单独触发一次模拟调用?而且如果他要调多次工具,你要发多次调用,每一次调用的时候都还要费钱。 所以如果你能尽可能的把当前环境的所有上下文全塞进去之后,你还可能会减少工具的调用轮次,在这种情况下你反而还会更省钱,是不是这个逻辑他还会更省钱? 接下来我就打算这么干了,就是在我这个 a 阵头的七十四装回去之后再加一波,如果他不够一百万,就把剩下的 所有内容啊,我不管了,不管什么相关性,不用管什么相关性啊,所有内容全部往上上面塞啊,全部塞进去,大家等我消息,看看这么搞效果怎么样。
58嘉豪 05:39查看AI文稿AI文稿
05:39查看AI文稿AI文稿上期视频,我们把 d p c v 四 flash 接入桌面版 cloud, 出现了很多问题,比如回复速度慢,上下文只有两百 k tokens, 有 点笨笨的 windows 系统频繁报错。那么这期视频我们换个方法来对比一下, d p c v 四 pro 接入 open code 和使用奎艾把 d p c v 四 pro 接入 cloud 之间到底有什么区别? 首先打开桌面版 open code 的 左下角,点击设置按钮,服务器,我们选择提供商,划到最底部,点击查看更多提供商搜索 d p c, 我 们输入 d p c key 的 a p i 密钥,点击提交,打开模型列表,就可以看到 d p c k v 四 pro 了。我们首先还是发个你好,测试一下回复是否正常。 ok, 我们再来测试一下代码能力,因为我给他的是一个空文件夹,他找了一圈发现没有可用的,这里很详细的询问了我的需求。他写了一段时间,但是中途这个游戏就直接跳出来了,我真的很爱玩扫雷,玩上瘾了,这个代码效果很好,我很满意。再写一个贪吃蛇的吧, 记住这个时间。哎呀,这太快了,用时一分钟,我刚准备计时,人家已经写完了,研究一下怎么玩。可以了,我的游戏能力一如既往的厉害。再测试一下大家最关心的 web fetch 能力, 也成功了。再看看上下文,我写了一个脚本,使用了 needleland haystack 二分查找,本来是想测模型接入 open code 后的 实际上下文为多少,但是 deepsea 不 解了,我的话吭哧瘪肚的,误打误撞的,勤勤恳恳地给我测出了 deepsea v 四 pro 的 模型上下文。这一操作花了我很多的 token, 让一向善于反省的我陷入了更深的反省,看来我以后要表达得更清晰。我这里测出来 deepsea v 四 pro 的 实际上下文 a p i 硬上线为一百零四万八千五百七十六 tokens 官方说 e m。 还是谦虚了, open code 说自己没有硬上线,那就说明我们可以随意配置,主要还是取决于模型上下文长度和代理实现。让它改一下,我建议使用 open code 的, 改完配置之后再使用 code 验证一下是否成功。 ok 了,百万上下文改。 首先我们打开终端,输入 collog, 点击回车,输入斜线 model, 点击回车,进入模型列表。我们选择 deepsix v 四 pro, 再点回车继续。你好,测试 回复正常,再用这个链接测试下豌豆飞起功能。我来说句公道话,这里确实有点慢,所以我加速了。针对这一情况,我也问了帮我配置的 codex, 这里只代表我本机存在的问题。 ok, 返回正常。 接下来又到了我最喜欢的游戏环节,让他也写个扫雷游戏, 可以看到非常快,用时一分四十一秒,并且给我本地链接,可直接打开,把链接复制到浏览器运行成功。非常细节的前端,我并没有讲细节,但他自己给我增加了初级、中级和高级, 再写个贪吃蛇的代码,又是一分五十六秒,打开玩一下,又重新开始暂停和最高分,依旧细节怪。 重启一下, codex 刚刚帮我在 codecode 中配置好了视觉识别的 m c p 工具,并且增加了用户级快捷命令,我们来试一下。发图片的时候忘记使用快捷命令了,结果很意外, codecode 竟然自动使用了, 突然有种老母亲看孩子把抄纲题做出来的欣慰感。再试一次又一次,自动使用了 read file i m g, 稳定发挥,两次用时均为二十七秒。 工具我已经在 github 上开源了,项目名字为 mcp vision webbridge, 第一个就是点击扣载,下拉列表后选择 download ip 可直接下载,如果帮到了你, 请帮忙点个 star 让更多人看见。另外我已经打包好放到评论区了,网络不好的宝贝可以获取。我让 open qd 自己配置我们的这个 mcp 识图工具,因为直接拽文档没反应,我这里把文件地址给他,教大家一个简单的方法, 直接把文件拖进终端,自动变成文件地址,再复制给他就好了。我把 ip id 要发给他之前,是希望他能像 codex 那 样弹出个输入框或者我自己粘贴到文件里的,但是他拒绝了我,并且让我直接发给他,记住他的这句话,后面考结果配置失败,还把自己弄荡机了。我使用 cloud code 修复了下 这里,他问我使用方式一还是方式二,我看错了,误选了方式一。结果这老 a 健特直接用了我的 key, 拿我刚刚给他配置 m c p 的 key 去跑 ko 帮我完成了任务。看起来他好像挺聪明的,但这种方法并不安全,踢很容易被泄露,因为这个工具并不兼容 open code 的。 可老弟帮我重写了个启动脚本,强制 open code 的, 做实图任务时走。这个工具终于成功了,但是只能拖拽,不能复制粘贴。把这个方法写入记忆里,然后我们再试一次, 重新打开一个窗口,看看是否成功。 ok, 工具很稳定,该方法仅是配麦 windows, 慎用。 open code 的 配置方法我写成 md 文件放到评论区了,建议大家使用另外的 agent 来配置 open code 的, 否则容易宕机。 agent 要 key, 必须要手动填写,不要直接给。 接下来回答下大家最关心的问题,上下文如何真正生效?首先升级最新版 clock code, 然后模型名后加 em, 再清理就变量。最后查看运行日记。再次验证 桌面版 open 扣的真的让我一愣一愣的,嘴上说不会出现在任何脚本或输出中,软头就偷偷用我替做任务, 太不省心。当然除了这点,其他都没什么大问题。代码上,细节来看, block 扣的处理的更好,工具使用也更灵活,大家可根据实际场景选择接入方式。以上就是本期视频的全部内容了,记得点赞关注,咱们下期见!
785锦颐jy 01:53查看AI文稿AI文稿
01:53查看AI文稿AI文稿openai 的 a p i 你 每天都在用对吧?现在一台 macbook 就 能在本地跑,同样的事,一百万上下文,加 agent 一个不少。 anti raise 安提雷兹,意大利人写过 radis, 你 今天打开任何一个网站,背后大概率跑着他十几年前写的几千行 c 代码。现在他又干了一票,把 deepsea v 四 flesh 这个准前沿大模型整个塞进了一台普通 macbook。 怎么做到的呢? 三招。第一,模型里九层内容其实都不重要,他只压着九层关键的部分一动不动。第二,一百万上下文,塞内存肯定爆,他干脆把固态盘当内存用。第三,没有任何外壳框架, c 加 metal 一 行不浪费。那为什么 openai 一 直没告诉你这个?因为大模型这个生意护城河就是几百亿砸出来的 gpu 集群,光 anastropic 一 家纰漏的算力合同就八十亿美金,外加好几个几瓦级数据中心。结果一个意大利程序员周末四千行 c 把这条护城河填了,连 yc 的 老板 gary tan 加里坦看完回了一个表情,跑起来到底什么样? 直接看书。 m 三 max, 一 百二十八 g 内存短上下文,每秒二十六个偷看。 m 三 ultra, 五百一十二 g, 每秒三十六个,塞一万个偷看进去,每秒还能稳定输出二十六个,什么概念呢?你跟 chat gpt 聊天那边一秒蹦三十个字跟它差不多,但你不用每月付二十美金,更不用担心数据被拿去训练。这是最狠的地方不在跑模型, 是 ds 四跑的 deepsea 微四 flash 带完整拷定自动化任务。一百万上下文,整套 agent 全在一台你能搬出门的笔记本里, 过去两年所有人告诉你,跑大模型必须几十亿兆 gpu 集群,准前沿模型只能在大厂手里,你只能掏 api 费。现在你看到了四千航 c, 一 台 mac, 几个聪明的工程取舍这条被神话的护城河,被一个不在大厂的人填了。 模型权重早就开源,推理引擎现在也开源,连 yc 的 老板都站对了。大模型最值钱的护城河正在从谁有算力转向谁有权重,这两样东西 deepsea 都白送了。所以下次再有人跟你说跑大模型必须几十亿造 gpu 集群,那是因为它在卖你 api 这个生意快做不下去了。
753小宇玩AI 02:47查看AI文稿AI文稿
02:47查看AI文稿AI文稿cloud 的 一百万头梗上下文正式开放了,很多朋友在问,这到底有什么用呢?那么今天就从一个每天用 cloud code 写代码的开发者视角聊聊我的理解。先说一下问题,那么用 ai 写代码最大的痛点不是说他写的不好,而是他容易忘记。 比如说你跟他聊了很多龙之后,前面定好的架构决策讨论过的边界条件他全部都忘了, 那么因为上下文窗口就那么大,满了之后就会自动压缩,压缩就是有损的,就像把一份详细的会议基要压缩成几句话的摘要,那么信息在这个过程中必然会丢失。 一百万 token 本质上就是把这个工作记忆扩大了五倍。以前二十万 token 大 概可以放一万五千行代码一个小项目的量,但是现在一百万 token 大 约可以放七万五千行,中大型项目都可以基本完整的放进去。 对我们来说,最直观的变化是,我不再需要替 ai 来管理记忆了,以前得精心来设计哪些的时候需要去压缩上下文,什么时候该 clear 一下,重新开始 怎么分批去投喂信息,现在这些心智负担会大幅的减少。那么大家最关心的问题是,装得下这么多的东西,就意味着它可以快速的找得到这些东西吗?在 cloud 官方中有一个数据, 他们做了一个叫 m r c r 的 测试,在一百万 token 的 文本里面顶藏八条关键信息,看模型能不能全部找到。那么 opus 四点六的准确率是百分之七十八点三,上一代 solo 四点五只有百分之十八点五, 那么这不是说上下文变大了,但是变得笨了,而是上下文变大了,并且还变得更准。最后说一个很多人都关心的是, 就是它的费用有没有贵,那么我用的是 maxplus, 每个月一百美元的这样的一个费用,包含 cloud code 的 使用的额度,那么这次更新之后,一百万上下文自动开启,不需要加任何的配置,也没有额外的费用。 之前 api 用户超过二十万的话, token 要付双倍的价格,那么现在这个溢价也取消了。 总结下来就是一句话,一百万上下文不是一个你需要去刻意去用码的功能,他是让一个你不需要再去操心上下文够不够的保障, 当你需要的时候他在那里,当你不需要的时候他不碍事,这就是体验上的一个质变好的。那么本期视频就到这里了,关注我以后为大家带来更多的 ai 的 编码的教程,我们下期视频再见。
 02:57查看AI文稿AI文稿
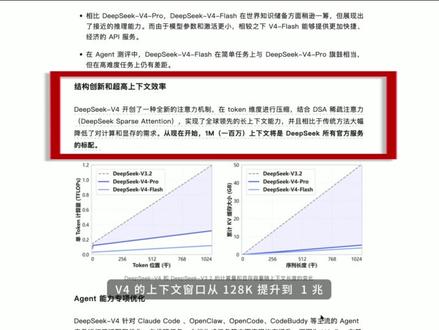
02:57查看AI文稿AI文稿在 deepsea 四模型预览版发布后,大家的关注点除了它极高的性价比,最让开发者经验的莫过于其百万级 edm 上下文的顺滑表现。很多人好奇,为什么别的模型处理长文本越跑越慢,显存分分钟爆炸,而 deepsea 四却能像翻书一样快?答案藏在一个核心技术里, dsa、 deepsea sparks 和 tension 稀疏注意力机制 一、什么是 d s a? 在 传统的 transformer 模型中, y 采用的是全量注意力,这意味着如果文本长度增加十倍,计算量的增长往往是一百倍,即平方级增长。 d s a 则让模型学会了划重点,它主要由两个精妙的设计组成,闪电锁影 lightning nexor。 像图书馆的锁影目录。模型在处理海量信息时不再逐字扫描,而是先通过一个清量级层快速定位出哪些片段,是解决当前问题最关键的细力度。选择 token selection 锁定片段后,他只会把最有价值的词源 to 填入计算窗口,剔除掉那些重复无意义的背景噪声。直观理解, 传统模型像是一个死记硬背的学生,考试前要把整本书背下来。而 dsa 像是一个学霸,他只翻看和考点相关的几页,速度自然快出几个量级。二、技术组合拳不只是省流那么简单,单纯的稀疏化会导致模型记不住事。为了在常文本下保持智商, dck 四叠加了三层 buff。 一、混合压缩架构 c s a h c a d c c 可没有在所有层都用习书注意力,它采用了一种混合动力模式, 有些层负责全局扫描,有些层则负责极度压缩背景信息,这种精细化的分工直接让 k v cash 显存占用减小了约百分之七十以上。二、流行约束超连接 m a c 常文本模型最怕读了后面往前面或者变成复读机。 mac 重新设计了神经网络的高速公路,确保逻辑信号在数万层的传输中不会丢失。即便你未给他一整个代码库,他在处理最后一行代码时,依然能清晰记得第一行的变量定义。 三、 in gram 记忆架构这是微四的点睛之笔,它模拟了人类的长期记忆,将处理过的旧文本压缩成一种状态,当需要调用几万行前的逻辑时,它是从记忆库里提取,而不是原地重算。三、为什么这次 d c 可又赢了?相比于传统模型, d c 可以 四的优势非常直观。首先是计算压力极低, 传统模型处理长文本时,色列需求会随字数暴增,容易导致响应超时。而 d s a 模式下的计算量几乎是随字数限行增加,表现非常稳定。其次是硬件门槛的下放, 过去处理百万文本必须依靠顶级的 h 一 百级群,而 d c 可以 四队显存,极其友好。这意味着企业进行色化部署的成本将大幅降低,普通夫妻也能跑得动大内存任务。最核心的一点是逻辑一致性。 在经典的大海捞针测试中,很多模型会在文本中间位置产生幻觉,但 deepsea 四依靠完整的逻辑链路,能保持极高的剪辑和推理精度。四,这才是真正的工程奇迹。 deepsea 四的 dsa 并不是简单的偷懒,而是一场极致的工程取舍,它让 e m token 的 处理成本从实验室级别拉到了民用级别。 这意味着以后无论是分析几十万字的财报,还是重构整个项目的底层代码, ai 都能在亚秒级给出响应,而不再需要漫长的等待。这种用更少的算力办更深的事的务实风格,或许正是 deepsea 能够不断突破大模型天花板的底层逻辑。
37人工智能漫谈 01:52查看AI文稿AI文稿
01:52查看AI文稿AI文稿万众期待的 smart 五没来, ip 四点六先来了,而且来的很猛。先说硬实力, ai 行业里几个公认的测试写代码, ip 四点六拿到了行业的最高分,那么如果你是做金融法律这类知识密集型的话,赢 g p t 五点二的概率大约是占了百分之七十。一句话,多项的核心指标,新的世界第一, 但跑分值表面真正牛的这两个东西。第一个, one million token 的 上下文窗口,一百万的 token, 用过 ai 的 都知道,对话异常的模型就开始上下文污染以及 memory 会丢失,前面说的东西后面已经记不住了,越往后聊会,越聊越差。那么 up 四点六在 一百万 token 的 大海捞针测试当中,得分是百分之七十六,而 so net 只有百分之十八点五,这不是量变,是质变, 它不只是能装下更多内容,还能真正的用好一些内容,不会读着读着就丢失或者污染。对所有人来讲,直接的影响就是 cloud code 在 自动压缩上下文之前,能干更多活,记性更好了。 第二个呢,是 agent teams, 这是 cloud code 的 新功能,你可以同时启动多个 agent, 让它们自己分工,自己协调并行干活。什么意思呢?以前是一个 agent 从头干到尾,现在可以一个团队同时唱,前端一个,后端一个测试一个各干各的 互相检查。那么 rockton 实测的数据非常夸张, up 四点六在一天内自主关闭了十三个 iso, 然后把十二个分配给正确的团队成员,管着五十个人,六个代码长库,他知道自己该干什么,什么该交给人。然后呢, iso 和 api 这边还加了一个比较特别的功能,叫 adaptive thinking。 什么意思呢?就是自适应思考,以前你只能选择深度推理打开或者关闭,现在模型可以自己判断,简单问题快速回答,复杂问题深度思考。 然后接下来就是定价啊,它的输入五美元,输出二十五美元,每百万套坑。所以 up 四点六意味着什么啊?一百万的上下文,它不会烂也不会旺,满了还能自动压缩,继续跑, agent 可以 主队并行。这三件事凑在一起,让 ai 可以 长时间自主的干活这件事啊,终于也算是从概念变成了现实。好了,可以更新你的可 out。
175韩世禹 05:18查看AI文稿AI文稿
05:18查看AI文稿AI文稿兄弟们, dbc 和 v 四发布了,这次你别只看参数,我觉得他这不是一次普通的一个模型更新,他是更像中国 ai 的 一次越狱,因为在过去几年,美国想用三把锁来锁住中国的 ai, 就是 我们的芯片, 第二把锁就是扩大生态,而第三把锁呢,就是闭源模型的高价能力入口。 但 deepsea 和 v 四这次出来相当于直接说了一句话,你锁不住它。首先先说第一把锁就是国产的算力,那很多人看到 deepsea v 四的时候,只盯着它的一点六 t 的 参数,四十九 b 的 激活,但是这个是真正值得去看的, 不只是模型的本身,而是他发布之后,围绕了华为、升腾、韩五 g 这些国产的算力适配的型号几乎同步出现。这个事情很多人一听就过去了,但是他不是把英伟达的显卡拔下来,换一张中国的芯片上去就完事了, 不是这么回事的,英伟达真正牛的不只是卡强,而是库达。库达你可以理解为 ai 世界里的高速公路,过去的几十年,全世界大量的模型训练、推理、优化,哎,算子开发都是围绕这条路去修的,很多工程师写代码, 很多框架做优化,很多的公司搭建系统,默认的就是英伟达的 gpu 加上库达,所以库达迁移到国产算力生态不是换硬件,是把原来写给一条高速公路的车导航服务区、收费站全部重新设备到另一条路上, 这个才是难点。 deepsea v 四真正释放的信号不是我又跑了一个什么大模型,而是我们中国的 ai 不 只是在别人的高速路上狂飙车,而是在自己的修路。再说第二把锁, 常上下文, v 四官方服务,把一百万的托肯上下文做成了标配,这个数字你可能没什么感觉,我给你翻译成我们的人话。以前很多大母警特别像一个嘴特别会说,但记性很差的一个人, 你给他三页的资料,他挺聪明的,你给他十页的 word, 他 开始漏。你给他一本书,他开始编。你给他一个代码库, 他看到两个文件,就开始一本正儿八经的胡说八道。很多 ai 幻觉他,不是他不会说,而是他根本没有看全。一百万上下文意味着什么?意味着你终于可以让 ai 先把完整的资料给吃进去,再让他说话。 一部长篇小说,一整份的合同,一个中型的代码库,几个月的会议记录,他可以一次性装进去。这不是参入好看,而是 ai 从聊天机器人变成干活系统的门票。没有长。上下文 a 整的很多时候就是个假的,因为他的智能体 是回答一句话,他是要读资料,理解规则,记住历史,执行任务,反复的去叫验,上下文不够,他就是一个失意的员工,你让一个失意的员工去做一些项目的管理啊,代码的修改,合同审查,他当然就会乱来。 所以上下文真正打穿的不是某个榜单,他打穿的是 ai 只能陪你聊天,不能去接触复杂任务的这个旧印象。 那第三把锁就是高价闭元模型的趋势。这几年最强的 ai 公司一直在给全世界讲一个故事, ai 很 强,所以它就应该很贵。强推理常上下文, ai 编程 agent 能力就应该在最贵的套餐里面,你想用顶级的能力,可以先交钱, 在接受地区的限制,账号的风控啊,调用限制啊,额度限制。说白了,最强 ai 能力正在被包装成一种新的高端会员。但 deepsea 维斯这次呢,直接把故事给打穿了, 他开始开放权重 api 能力迁移 pro 和 flash 两个版本, flash 负责便宜快够用,而 pro 呢,负责更强的复杂任务和 agent 能力。 这就会让用户开始问一句话,凭什么最强的能力一定要那么贵呢?所以 deepsea v 四不只是在卷技术,它是在卷定价权以前的闭源模型。可以这么说,最强能力在我这儿,你要用呢,就按照我的价格来。但 deepsea v 四出来之后,这个故事就没那么稳了。 因为全世界开发者都会开始相信,原来 ai 不 一定要那么贵的。原来开源模型不一定只能做平替,原来常上下文 a 政特代码能力也不一定只能被锁死在高价闭原的 api 里。所以,这次威斯真正牛的地方呢,不是榜单超过了谁, 榜单今天你是第一,明天他是第一。这个东西会一直在变的。真正重要的是呢,它证明了一件事情, 中国 ai 开始有了自己的底座了。以前别人说没有英文打你做不出顶级的 ai, dwec 说不一定啊,以前别人说没有哭打你的生态跑不起来 啊。 dwec 也说不一定,那以前别人说最强的 ai 就 应该币源,就应该昂贵,按月收你几百的美金? dwec 还是说不一定, 这个不一定才是 v 四里面最值钱的地方,因为一个国家最怕的不是暂时的落后,最怕的是所有人都会相信这条路只能别人来修,但现在中国 ai 开始自己修路了,这事才是真正牛的地方。
65别慌上AI 03:27查看AI文稿AI文稿
03:27查看AI文稿AI文稿兄弟们,今天二月二十七号, deepsea v 四正式进入发布倒计时,辉度测试代号 c o n light 已经外泄。上次 v 三发布,英伟达单日蒸发五千八百九十亿美元,这次 v 四三大黑科技全部提前泄露。今天我把这些料全摊给你,它到底颠覆的是什么?这次谁最该紧张? 讲 v 四之前,先把 v 三的基准线说清楚,因为不知道起点有多高,就感受不到 v 四突破有多狠。 v 三六百七十一亿参数的混合专家架构,激活参数只有三十七亿,效率极致。 推理成本每百万 token 只要零点一四美元, g p t 五点三要十五美元以上,差了一百倍。看右边这张成本对比图, v 三那根条有多短,竞品的条有多长,这就是 v 三答出来的价格体系。 v 三发布当天,英伟达蒸发近六千亿, v 四预计保持同样的成本优势,但性能要在跨一个档位。 v 四三大核心突破,全部来自已发表的研究论文,不是空穴来风。第一, ngram 条件记忆, 你看页面上这两个对比,就方式,找信息要逐个扫描,像翻书。 ngram 直接一步定位,查找效率从 o 嗯变成 o 一 规模无关速度恒定。一百万行代码查起来和查一百行一样快。第二, mhc 流行约束超连接, 简单说让多个专家同时处理同一段逻辑,跨文件推理能力提升百分之三百。以前 ai 改一个功能经常顾此失彼, v 四把这个问题在架构层彻底解决了。 第三, em token 上下文,你看下方那个容量对比, v 三是幺二八 k, v 四是 em, 整整八倍,换成实际场景二百页 pdf, 整个项目代码库一次性全色进去,它真的能读完再回答你。 来看最新数据, swbench verified, 这是衡量 ai 处理真实软件工程任务的精准。 g p t 五点三目前约百分之八十二, cloud opus 四点五是百分之八十点九。第一个突破百分之八十的模型 gemini 三 pro 是 百分之七十六点二。 v 四的预期区间是百分之九十以上,但单看跑分还不够,你看页面底部那行字, v 四的差异化不是分数最高,是分数最高的同时成本只有 g p t 五点三的十五分之一,这才是真正的降维顶级性能,加急低成本,这个组合目前没有对手 技术。聊完说你最关心的, v 四发布之后,你能直接用上什么?第一,整个项目代码库扔进去,直接问 e m tokin, 大 概是十万行代码,你把整个项目丢给他,问这个 bug 的 根音在哪,他真的看完了,不是假装。第二,二百页行业报告一次性分析完, 季报、招股书,竞品调研,不用再分段位,直接出结论。第三, mit 开源私有部署零障碍,企业数据不出,网络金融、医疗政务客户直接本地跑,合规没问题。 顺带提一下, v 四发布前把优先适配权给了华为升腾,国产芯片加国产模型的闭环生态正在成型。这个话题太大,下期单独一期。 记住这句话, deep seek 每次发布不只是在发布一个模型,是在重新定价整个 ai 行业。 v 三让全球 ai 价格体系崩了一遍。 v 四如果三大黑科技全部兑现,会再崩一遍, 而每次崩受益的是你每个普通用户,每个享用 ai 提效的人。如果你觉得今天内容有收获,欢迎点赞关注,点关注不迷路,下期见!
 00:55查看AI文稿AI文稿
00:55查看AI文稿AI文稿ok, buddy 如何添加自己申请的 deepsafe v 四 pro 模型?我们使用的免费版本,它是不支持 deepsafe v 四 pro 的, 所以需要我们自己添加,那么找到 deepsafe 的 开放平台,这里需要我们实名以及充值。搞定以后,我们点击 api 钥匙,点击创建 api 钥匙, 输入钥匙的名字,我们就获得了一串密钥,这个密钥大家千万不要透露出去。我们复制好密钥,那么来到 workbody, 我 们点击模型,这里的模型分为内置模型和自定义模型,内置模型消耗的是积分,我们要接的是自定义模型, 那么使用自定义模型会按照我们的 tucker 消耗进行扣费,不会消耗我们的积分,这个大家要搞清楚,我们点击自定义模型,再跳出的这个页面,我们点击提供商 找到 deepsafe, 然后复制我们的密钥,再确认一下下面的模型名称是不是我们需要的 v 四 pro 模型,确定好以后,我们点击保存,我们再点击对话,就能够看到自定义模型里面已经有 deepsafe v 四 pro 了。
728华隐 03:19查看AI文稿AI文稿
03:19查看AI文稿AI文稿ai 大 模型价格战可能真的被 deepsea 打穿了。昨天 ai 圈突然疯传一张截图,很多开发者第一反应都是, 这价格是不是标错了?因为 deepsea 刚刚确认, deepsea v 四 pro 的 百分之七十五折扣永久生效。注意,不是限时活动,不是新用户优惠,而是永久价格。而真正离谱的是,现在的价格已经低到 cash, 几乎等于不要钱。官方最新价格, 缓存输入 token 百万分之零点零零三六二五美元。输入 token 百万分之零点四三五美元。输出 token 百万分之零点八七美元。很多人可能对这个数字没概念,我直接翻译成人话,现在你让顶级推理模型跑一百万缓存, token 成本不到一分钱人民币。 要理解这件事为什么重要,先看看现在 ai agent 为什么一直没真正爆发。真正烧 token 的 根本不是聊天,而是 agent。 因为 agent 会循环,会规划,会调用工具,会反复推理 一个复杂任务,轻轻松松几十万头啃。现在很多 a 阵的工作流,核心依赖 r a g 记忆,上下文缓存涨对话,但上下文越长,成本越恐怖。很多公司最后发现, a 阵的不是技术问题,而是财务问题。你让 ai 帮你生成十篇文章没问题,但如果一百万用户同时跑, a 阵的价格直接爆炸。 这就是为什么很多 ai 产品看起来很牛,但始终无法真正大规模商用。而 deepsea 这次正在把这个问题彻底重写。 ai 不 应该是奢侈品, ai 应该像电力一样便宜。真正让人头皮发麻的是,它这次砍价砍的地方不是输出,而是 cash。 这一点太关键了, 因为未来 ai 世界最贵的东西根本不是生成,而是重复上下文。 agent 每次循环都会重复读取大量历史上下文。以前这部分特别贵,现在 deepsea 直接砍到百万 token, 只要零点零零三六二五美元。很多开发者看到后第一反应是 cash 几乎白送。这意味着长期运行 agent 的 成本模型开始崩塌。 真正让人觉得行业要变天的是几个细节, deepseek v 四 pro 支持一百万 token 上下文,这不是普通聊天,这是超长记忆、长任务规划、长代码仓库、大型 reg 持续 agent 的 基础。很多模型虽然上下文长,但输出很短,而 deepseek 可以 一次吐出三百八十四 k 的 超长结果, 意味着 ai 开始真正适合自动代码生成、长文档生成、多步骤推理常练录 agent, 你 甚至不用自己管理 cashkey。 它自动生效,意味着 ai 基础设施开始云服务化,越来越像数据库、 cdn、 云计算,而不是传统 api 调用。现在问题已经不是 deepstack 强不强,而是 open ai 和 entropix 顶不顶得住。 因为当一个接近 frontier intelligence 的 模型价格只有别人的八分之一到十五分之一时,整个行业逻辑都会崩。从今天开始,很多以前不敢跑的 agent 可能都能开始规模化,自动扣定 agent 终于有了成本基础,长任务, research agent 可以 持续运行,不心疼 token, 企业及 rack 的 缓存成本几乎归零, ai 员工可以七成二十四小时在线 ai 客服终于有了商业模型, ai 自动运营和 ai 自动工作流都能跑起来了,因为 token 成本终于开始接近现实商业模型, ai 行业正在进入推理电价时代,过去拼的是谁模型更大,现在开始拼谁能把 token 打到最低。这特别像云计算战争,当年 a w s 出现后,整个服务器行业开始疯狂价格战,最后算力变成基础设施。而今天, deepsea 正在对 ai 做同一件事,它不是在卖模型,它是在把 ai 推理变成公共资源。 很多人还没意识到,真正会毁灭行业格局的,从来不是模型领先六个月,而是成本低十倍,因为开发者最终会用脚投票。尤其 agent 的 时代,成本就是生命 writers 甚至专门提到 v 四系列,特别适合 ai agent 工作流。 而 agent 最大的问题一直就是 token 黑洞,现在这个黑洞开始被填平了。 ai 行业真正的战争,可能已经不是谁最聪明,而是谁最便宜,而这场战争才刚刚开始。点赞、收藏、关注三联,我们下期再见!
 01:52查看AI文稿AI文稿
01:52查看AI文稿AI文稿deepsea v 四阅览版正式亮相了,相比旧版本, v 四的上下文窗口从一百二十八 k 提升到一兆 agent 的 能力,世界知识和推理性能均位于国内与开源前列,内存占用显著减少。 怎么快速用上这个新版模型呢? max kb 作为开源企业级智能体平台,凭借开箱即用伴随成长的产品理念,能快速跟进大模型更新,让你第一时间用上最新能力。 下面看看如何为 max kb 对 接 deepsea v 四。首先来到 deepsea api 开放平台,申请 api key, 在 max kb 的 模型管理页面添加 deepsafe 供应商,手工输入 v 四模型名 deepsafe v 四 pro 或 deepsafe v 四 flash, 输入 api k 后确认即可完成对接。对接后测试模型效果。 创建一个简易智能体,选择 v 四模型,配置知识库,保存后进行问答测试。提问, max kb 的 主要功能,智能体很快返回答案,响应极快。再试试高级智能体,创建高级智能体 配置知识库,在 ai 对 话节点选择 v 四模型保存调试。 提问,如何对接 deepsea 智能体顺利返回答案?这就是 max kb 快 速跟进 deepsea 最新模型的效果,让你在私有化环境中轻松搭上 ai 快 车, 第一时间体验前沿大模型能力,快来试试吧!
 09:03查看AI文稿AI文稿
09:03查看AI文稿AI文稿各位技术大牛好,今天我们聊一个极其硬核且痛点满满的话题,大模型的上下文压缩。我们都用过所谓两百 k 甚至一 m 窗口的模型,但真正在生产环境跑过复杂 agent 的 人都知道,长窗口根本不是银弹。今天我们将拆解行业最前沿的上下文管理机制。 这是一个非常反直觉的真相,很多开发者单纯依赖硬件层面的长窗口,觉得把所有历史记录塞进去就完事了。但现实是,超过一定的 token 水位线模型不仅会犯错,还会产生极高的延迟和成本。这就是为什么头部大厂都在悄悄转向另一种策略。 为什么我们需要专门做上下文压缩。左边是我们过去常用的滑动窗口策略,也就是硬截断。这就像一个失忆症患者,走着走着把出发的目的忘了。而右边行业正在转向语义压缩,他的目标不是简单的扔掉数据,而是提炼出核心事实,让有效对话长度直接翻十倍。 接下来我们先明确一下什么是上下文压缩,以及他在工程上到底解决了什么具体问题。 举个最具体的例子,你让 agent 帮你重构代码干了三个小时,前三十分钟定好的数据库表结构, 到了第三个小时,因为 token 满了,早期对话被硬生生切掉,结果 agent 突突然开始凭空捏造自断。这种挫败感写过复杂 agent 的 的人一定懂,这就是 context route 带来的灾难。 我们用数据流图来看这个过程,用户的核心意图在最开始进入工作记忆,但随后大量的工具调用日制报错信息像洪水一样灌进来, 一旦触及两百 k 限制,系统被迫驱逐最早的规则,直接导致最终的幻觉。我们要干掉的就是中间这个被动驱逐的环节。这是一个清晰的对比 应阶段,虽然在计算上几乎零开销,但对于长周期任务是致命的。语义压缩虽然需要消耗一次额外的 l l m 调用来做总结,但它能把早期定下的基调约束和当前进度浓缩成一段系统提示词保留在上下文中。 这就好比你在交接工作时,给继任者留了一份详尽的文档,而不是直接走人。我们快速停顿一下,答案显然是 b。 其实,羽翼压缩再触发的那一瞬间,并不会帮你省钱,甚至还要花钱去跑一次摘药模型。它的核心价值在于保命,保住整个推理链路和业务规则不崩盘。如果这点达成了共识,我们进入深水区。 既然羽翼压缩这么重要,大厂和主流框架在底层,到底是怎么实现它的?我们来拆解它的三层核心技术架构。 行业里目前有三大流派并存,第一种是全量羽翼摘药,简单粗暴但有效。第二种是像外科手术一样,只切除无用的容肠锐志保留对话。第三种则是学术界和顶尖实验室正在搞的 u t a c a。 基于模型生成时的不确定性动态调整窗口,我们逐一来看 什么时候触发压缩最合适。传统的做法是设一个死线,比如一百八十 k 触线就压,但这很生硬。现在的高级 agent, 比如 long chain deep agents, 采用的是机会主义触发,也就是在任务的自然边界,比如刚写完一个文件,或者刚查完一个资料, 趁着逻辑闭环,顺手把前面的废话压缩掉,这才是真正的高级感。给各位工程师透个底,这是目前行业里几家头部框架和模型的预值设定。 lion king 比较保守,百分之八十五就开始动手了, openai 的 c i i 工具敢推到百分之九十五,而 clark 三点七 sonic 官方给的最佳实践是在一百五十 k 左右进行拦截和压缩,记住这些数字调餐时能省很多事。 这里要讲一个最前沿的 utac 机制,它的底层逻辑非常惊艳,模型在逐字生成 token 时,系统会实时监控它的 legit 边缘差值。如果发现模型不够自信,有幻觉风险,系统会立刻触发回滚机制,把上下文窗口拉大,解锁更多精确信息塞进去,然后再重新生成。 这是一种极其精密的动态内存管理理论。讲完了,我们来看看大厂在工程上是怎么把这些概念落地的,直接上代码和架构 antropic 在 cloud api 里直接做了一个 beta 版的特性,你只要传一个 compaction strategy 进去,设定域值到了一百五十 k, api 服务器会在底层自动帮你做总结阶段。注意,这里有个极其关键的参数, pause after compaction, 它会在生成招标后暂停,把控制权交还给你。 来看 slide 十六的核心 forgot 是 怎么做的,它不光看 token, 还看对话轮次,最绝的是右边这个推理链保留。 对于像 cloud 三点七这种具备深度思考能力的模型,如果你把它的历史思考过程直接暴力压缩掉它,接下来的回答就会像断片一样失去逻辑连贯性。所以 forge code 会特意把最近的推理过程提取出来,像接力棒一样塞给下一轮对话。 这是 forge code 的 实际配置文件。看到 preserve reasoning true 和下面的 reasoning text 了吗?在执行压缩时,框架会扫描被淘汰的历史消息,用正则或者解析器把这些 dot 标签里的内容抠出来, 强制附加到新的上下文中,这就是资深工程师解决问题的优雅方式。并非所有的压缩都要动用 l l m 去写小作文,像 open code 这种工具采用的是外科手术室的修剪。写代码时最占 tok 的是什么?是那些动辄几万行的报错日制和 get diff。 open code 会直接把历史轮次里的长日制删掉,只保留最新一次的报错,这既省了 tok, 又完全不破坏对话语义。 检查一下大家的专注度,答案是, b 服务器帮你做完 java 后暂停,是为了让你有机会把最近几轮及其关键的对话,或者你系统里特有的上下文对象原封不动地拼接到 java 后面,然后再让模型继续回答,这赋予了开发者极大的控制权。 看到这里,你可能觉得上下文压缩很完美,但作为 staff 级别的工程师,我们必须看到它在实际落地时的暗坑和 trade offs。 这是所有压缩算法面临的终极矛盾。做招标必然丢失细节。对闲聊机器人来说,保留大意就够了。但对于写代码的 agent, 如果压缩时把某个特定函数的入参类型给概括没了,接下来的代码全得报错。 所以在复杂的分析场景中,纯摘要是危险的,必须配合我们前面讲的修剪和推理保留策略。这里有个极容易踩坑的工程细节,你为了监控一百八十 k 的 域值,如果在每次请求前都把几十万字的上下文扔进 tokyo 字儿算一遍,你的系统延迟会直接爆炸。 大厂的做法是使用 loggerimac sampling 对 数参照或者基于字母长度做快速计算,只在逼近红线时才做精确计算。这是一个非常实用的性能优化点。 另一个深水区是 k v cash, 你 辛辛苦苦积累的上下文缓存,一旦执行压缩,历史内容变了,缓存直接失效,下一次请求会慢得像蜗牛。解决办法是利用大模型 api 的 cash breakpoints 特性,把系统提示词、核心文档放在最顶端并锁定缓存, 不管下面怎么压缩,顶部的缓存永远生效。学术界对上下文管理有一个著名的论断,叫做苦涩的教训。 他告诉我们,不要试图用极其复杂死板的硬编码规则去管理模型的记忆,把压缩上下文封装成一个托儿交给大模型,让他在觉得脑容量不够用的时候,自己调用工具清理自己的记忆,这才是未来的终极形态。 最后,我们站在现在,看未来下一代向下文管理技术会往哪个方向引进。 未来的方向非常明确,混合优化与软硬协调。软件层面,我们会把量化技术和语义压缩结合起来,不重要的历史记录不仅被总结,甚至在显存里直接被降级为四倍的存储。 硬件层面,未来的 ai 芯片会像现代操作系统的虚拟内存一样原生,支持 kvatch 的 快速换页和淘汰 快速复习。以下今天涉及的三个核心黑化, semantic compression 是 我们的核心武器, u t s o a 是 未来动态分配的终极形态,而 retention window 是 你在写配置时,为了保证最近对话不出现断层,必须设定好的保留参数。 总结一下今天的核心洞察,上下文压缩绝不是写一个拍档脚本截断数组那么简单,它正在从一种被动的防御机制演变成由 a 阵自主驱动的具备推理链保留能力的基础设施及组建。这是从死记硬背到懂得规范的进化。 这句话是我希望大家带走的。硬件的二百 k 只是物理极限,但通过优秀的上下文管理工程,你可以让 a 阵的跑完相当于两千 k 的 超长任务而不会崩溃,这就是工程架构的魅力。 落地建议回去立刻看一眼你们公司的 agent 业务,如果还在用无脑的数组切片做硬截断,赶紧把它换成基于总结和修剪的混合策略,特别是涉及到深度思考的模型,一定要把它的 reasoning thought 提取并保留下来。感谢各位的时间,我们下期硬核技术拆解,再见!
1634AI鹅鹅鹅

