Karpathy加入意义

粉丝2.4万获赞10.9万
相关视频
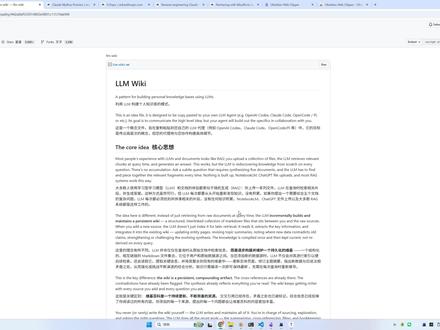 19:22查看AI文稿AI文稿
19:22查看AI文稿AI文稿哈喽,大家好呀。嗯,这周呢,我在公众号上刷到了一个一篇文章,就是这位叫卡帕西的大佬,他聊了一下自己的 r m 构建个人知识库的一个方案,感觉挺有启发的, 因为平时在网页端和 gpt 还有一些其他地方和 ai 聊的一些讨论的一些东西呢,有时候感觉收获挺大的,但是呢没有注意留痕,过段时间也就忘了啊,或者是在浏浏览网页时呢,看到一些好的技术文章,也因为感觉麻烦,也懒得进行存储和整理 啊,他这道方案呢就是解决这些问题的。然后,然后呢,我也看到一些必战其他 up 主实现的这套 r m 的 v k 方案,但是总感觉呃不太适合自己,所以说今天自己手搓了一套,也加了一些自己的想法和改进的方案, 把一些关键的流程分装成了呃 skills 和 comments, 这样呢使用起来也更加的高效,然后我整体试用下来的效果还是不错的,所以说想给大家分享一下啊,这是它的原文章,然后原文章我们就不看,我们直接看经过这个系统提炼后的内容 啊,这是它的原文,然后现在在我的 office 店里,然后我们看一下它经过这套系统,它把这这篇文章提取成了哪些页面呢?首先第一个就是它对它的一些总结, 然后我们来看一下这个总结里介绍了它的三层架构和三个核心操作。你先看一下架构,它有三层,第一层呢是原始资源层, 它存的都是一些你从网上搜集过来,或者是你自己导入了一些不可一些原文档的呃资料素材,然后呢大有缘模型对它呢只有只读的一个权限,它不能对它进行一个编辑修改。然后第二层呢是 vk 层, 就是大圆模型生成的结构化的 markdown 文档,由大 u l m 呢全权维护。呃。第三层呢是模式层,就是存的一些,就是一些配置文件,比如说 cloud 用的 cloud 点 m d, 口袋用的 agent 点 m d, 然后也定义一些呃 vk 的 结构和工作流, 然后对应的三个三种操作呢?第一个操作是 ingest, 其实这个操作有两层含义,第一层,第一层含义呢,代表你添加新来源,就是说你从网上搜集素材这个过程放到这个原始资源层。 然后第二层含义呢代表就是 r m 从原始资源层提取关键信息,整合进现有的 vk。 呃,然后它整合出的结果呢,可能有多个,然后比如说这个是它总结的一个总结,然后呢其他还有比如说这个在 atis 里还有两个文件,一个是呃对它作者的介绍,一个是它呃对比的另一个知识管理系统的一个介绍。 然后呢还有一个关键是概念,然后它总结了两个概念,第一个概念就是也是针对这套 mm vik 的 模式的一个介绍。 然后第二个概念呢是传统的呃 ig 的 方式和这个和它这种 r m v k 的 一个对比,然后有优点和缺点的一个对比和区别的一个介绍, 然后这个文件呢?呃不是它总结出来的,然后我们后面再说,然后它提到它的三种操作。之后还有第二种是查询 query, 就是你问他的时候,问他一些问题的时候,他会综合这些呃智存的 vk 去回答,如果有好的回答呢,他会回填到新的页面,比如说我刚刚说的这个界面,其实就是我问他,你认为,呃,你这套系统和现有的 lg 系统有什么优势, 优势和劣势吗?然后他就是对他的一些优势和劣势进行一个表述 啊,是,这是他这套系统的一个架构和操作流程,然后呢我没有全全部照搬,然后呢我对他进行了一些自己的改造,然后接下来介绍一下我这套系统的一个操作流程。 呃,这个是我项目的 github 地址,我也会放到评论区,然后它的使用也非常简单。呃,这有一个快速开始的一个介绍,但是在使用前呢,你需要安装几个软件?第一个呢就是 office 点这个呃知识库的管理系统, 然后第二个就是你要安装一个 code 编辑,然后可以是 codex, 然后这个视频呢是用 codex 进行演示的。然后第三个呢,你需要安装一个 office 点的 web cleeper, 一个浏览器扩展, 他的安装呢也非常简单,就是在这个呃浏览这个扩展商店里搜一下,然后就叫这个名字,然后直接安装就可以了。 然后安装之后,安装完成之后,这里有一个图标,然后我们点进去,然后这边有个设置,然后可以把它调成中文的,这样就可以了。 然后还有几个插件, office 的 插件需要安装,然后这些插件我也列在了这里。首先第一个呢,如果你使用的是 cloud 呢,你就得安装这个 cloud 点这个插件, 然后其他的插件呢,都是一些非常基础的插件,如果你是一个 office 的 长期使用者,这些插件基本上你都默认默认会安装的。 好,现在我们来做一下实操。首先呢我们把这个项目克隆到本地啊,我这里已经有了。然后呢我们去 office 店里新建一个仓库, 这里点管理仓库有一个创建,然后我们叫做 excel, 我 选一下它的位置,这里我已经选好了,然后点创建, 呃,我们可以把一些我们已经使用的一些呃插件呢直接迁移过去,比如说这是我之前的仓库,然后里面有一个 office 键的一个配种文件,然后我们把它直接移过去,进行一个替换, 可以先把它关掉,然后欢迎也删了,然后回到我们的这个 github 的 项目,就是如果正常来说我们都是,我们是使用中文的嘛,然后如果你使用的是 cloud 的 话,你直接把这三个文件呃复制过来就可以了 啊,这样的话,呃,我们再重新打开一下这个仓库,直接信任,这样的话它的插件也会自动安装过来,就是说比如我们刚刚说的 cloud 点也会自动安装过来。 呃,然后我们介绍一下这个项目的结构啊,首先我们呃通过一个 web code 再打开,因为 office 里只会显示一些呃 md 文件,然后我们看一下 这个目录的结构,是这样的,首先呢它有一个 cloud 在 这里面呢,还有一个 cloud 和一个 agents 的 文件。 呃,主要也是我们刚刚说的,它是属于模式层的文件。呃, cloud 是 给 cloud 用的 agent 点 md 呢,是给口袋子用的。然后它里面分为两个层,一个是肉层,一个是 vk 层, 我们我进行的改进呢,就是说我们这肉层呢,我们分为了三块,首先第一个是 processed 层, processed, 第二个是 enprocessed, 就是 说我们从网上搜集过来的一些内容呢,是直接先放到这个 enprocess 里面的,就说它是一个未处理过的。 呃呃,我们直接来演示一下吧,然后这里有三篇我已经提前找好的文章 用来测试,然后我们通过 office 点进行一个添加,然后这里有有一个添加的目录,这个目录是可以提前设置的,也是在 office 点的插件里, 就是在这个呃 default 里,然后这里面有一个笔记位置,然后我们直接可以填好是我们的 on process 的, 然后在 raw raw 目录下的,我们可以把这文章加进去添加添加, 我们加了三天,然后看这里面已经有了,然后我们的 vs code 里也有,也也是一样的, 这些素材到完 process 里面之后呢,我们可以看一下啊,这里面下面还有两个 index 和这个 readme 文档,这个属于也属于模式层的一部分吧,它记录了一些呃所有的维护, 然后接下来我们就开始进入了这个 index 的 第二部分,就是说从肉层提取知识到 vk 层,然后这个过程呢,我封装成了 skills 啊,也是一个直接可以使用的命令,然后对应的 cloud 呢是这个命令呢,是放在 comment comments 里面,然后 code 呢的话,它是放在 skills 下面的,其实都是都可以使用的。然后现在我们回到这个, 呃,回到 office 点,然后我们这在这里面呢,我们可以直接可以使用这个命令 insert, 你 在 throw, 这是我的第一个命令,然后我们进行一个等待, 嗯,大概用了七分半的时间呢,他完成了这个文件的处理,我们来看一下他的过程啊。首先如果用户没有指定读取哪些文件的时候,他会自动进行全部读取,然后做分类, 可以看一下他,呃,自己做这个分类,他发现这三篇素材的关系不大,所以说他决定单篇处理, 如果你想批量处理的话,你可以直接指定让他读取哪些文章进行处理就可以了。然后这是他的一个默认的一个分组读取的一个策略。然后大家有兴趣可以看一下这个提示词里面这些。呃约束是怎么写的?呃,比如说,哎,读取顺序,对,是这样,对, 好,我们回到刚刚的这个界面啊,它都取完之后做了几个处理,然后它新增了五个页面。这个时候呢,这些这个 raw 文件呢,进入了一个中间态,叫编辑 review。 这个状态呢,也是我事先定义好的,它写在了这个模式层里面。 它在这个状态之后需要进行一个呃人工的一个 review, 就是 我需要看一下它生成这些东西是不是符合我预期的, 如果不符合预期的话,我可以直接在这个写提示词,告诉他啊,我你生成内容我不满意,请进一个回滚,然后回滚完之后你再进行这个 index。 呃, row 的 时候,你可以加一些你自己的提示词,然后你自己对他的一些呃期望和建议,这样的话他可能会进行一些改正和修正。 然后,呃,进行完这一步,如果我们 review 完这些内容之后发现没有问题,符合预期,我们就进行一个 approve index 一个命令的输入,这个命令的意思就是 呃,就是确认,呃就是呃确认无物,呃它可以,它会就会把这些文档正式地从这个按 process 的 文件夹里迁移到这个 process 里面,然后并更新所有文件的呃,这个呃路径的引用, 然后他也会自己检查一下路径的引用是否进行,是否是正确的,然后这时候他还告诉你队列中还有两篇未处理素材,如果我们想继续处理的话,就直接再进行引引在 start 就 可以了,这样的话进行一个就是一个我们的说到提取的一个过程, 嗯,然后花点时间呢,我们把后面两台素材也进行了一个引用,可以看到我这里面是指定了剩余两篇素材,然后它处理的过程呢?是这样的 啊,它批次是两篇,然后用户指名它就会一起进行处理,然后它创建了这些界面, 然后处理完成之后呢产生了这些页面,也是五篇,然后这时候进行了一个待确认状态,就也刚刚说到编辑 review, 然后我这里看完之后呢,我也进行了一个 approve ingest, 就是 进行确认迁移, 然后它进行一个迁移,并且更新缩影可以。然后我们现在看一下它之后的状态是什么样的呢?就是它产生了这 sauce 里面有三篇,然后它们都是一个简对这个文章的一个总结和概括, 然后 intance, intance 里面有产生了四个这个实体概念,这其实这三篇文章主要讲的什么呢?主要讲的呃就是 clove 四点六模型呢?就是 opu 四点六模型呢?对这个发现漏洞,解决漏洞能力 呃提升了很多,就是它解决了很多问题,但是呢它下一代的模型叫 mesos, mesos pro will, 这个模型呢就太强大了, 他解决了很多,能发现很多这个系,世界上系统就是从来没有发现的领域漏洞,这个问题就很严重。如果就是把这个模型发布的话, 就是可能有一些不法分子呢,会利用这个东西去发现漏洞去进行攻击,所以说,呃,这个 s r p k 公司呢?就决定,呃暂时不发布这个模型,先解决安全的问题,这主要讲的这几个事,然后他也总结概念,呃,这个是 啊,大模大语言模型漏洞发现这是刚刚处理过的,我刚才看过了, 然后我们看一下下几个工,下面几个功能啊,就是刚才还有个说功能就是 quarry, 然后我也进行了一个调用,就是 quarry vik, 就是 我问了他一个问题,就是如何才能解决不法分子利用大模型发现有系统漏洞,有系统的漏洞进行攻击的问题呢? 然后他会总结和这些素材,和这个我的 vk 进行一个回答,然后他会说威胁有多严重,然后具体的防御策略, 然后长期的战略, 其实他回答的很长,你也可以告诉他,你可以回答的简短一点,这这都不是问题。 然后我问了他第二问题,就是埃塞雷克将重心啊打错了,重心放在解决安全问题上,是否有利于我们国内模型在性能上进行追赶?这个是不是给了我们一个时间窗口?整体来说对国内大模型的发展是好还是坏呢?啊?我又问了一下他一个这个问题, 他在分析前会先确认几个事实, 然后然后他也是分类讨论,就是短期窗口,短期的时间他认为是对我们的一个优势,就是他 s r vick 将大量的资源投入了这个防御项目,这个叫玻璃之翼的一个项目, 然后还有安全保障措施的开发,这些工作虽然重要,但不直接提升模型的通用能力,所以说短期来说对国内是个利好,但是长期呢,其实是个利空。 可以看到他一个总结,就是短期对国内模型对国内的模型是个利好。窗口中期呢是双刃剑,然后长期呢?嗯,不太确定。如果国内模型只追求性能而不建立安全体系,可能会被排除在全球高端市场之外。 其实这确实也是一个非常现实的一个问题,那如果国内模型建立了同等水平的安全框架和负责任的发布机制,那可以和 i c o v g 在 国际上正面竞争。然后关键的变化就是 安全能力本身是否可以构成互适合,互成合还是可以被快速复制的,就说他们做出来之后我们直接超过来,这也是一个怎么说呢?也是一个弯道超车,也是我们一个比较擅长的一个解决问题的方式吧。 然后我们说到的最后一个命令就是这个 infopro, 这个命令就是做一个知识的一个沉淀和一个对话的沉淀, 就是他会把,呃,就他,他也说了,就是我会把之前两轮的 quora wiki 产生的高价值分析沉淀到这个 wiki 的 这个这个文件夹里, 然后再确认当前的 v v k 状态,然后它在这里面创建了两个页面。第一个就是我刚刚说的对 s o v k 安全优先策略,对国内大模型的长期的发展的影响啊,它也是和我们刚才说的那个东西聊得差不多。 然后就是安全防御的策略,就是也是短期的行动,还有长期的行动。 所以说这就是我刚刚说的,就是如果我们在网上看到一些有价值的文章,就是我们不好存储和留痕的话,其实这就是一个很好的方式。 然后在最后之后我会给大家进行一个 link week, 这就是我们说的健康检查,就是我们可以让它再看一下这些内容里面的链接是否就是正确的缩影,就正确的缩影到了。 哦,我们可以看一下,这个主要是生成关系图不用的,但是这个东西怎么说来说呢?它用处感觉不是很大,如果内容非常多的话,其实它,呃用处不是很大,就非常混乱,其实我是不怎么用的。 嗯,还有一个就是这个 linter week, 也是对一个锁影的一个重构检查,主要是这地方的锁影对它哪些东西,哦,不是,呃,这里对已经处理的素材 排位处理,是这些都会做一个维护和监控,然后还有一个 log, 就 说每你每做一些内容,每做一次就是操作,它也会记录一个日制,这个日制也是一个很好的一个回溯和就是留痕的一个方式嘛。 这个日制我还没有做规档的功能,就是如果他日制很长的话,其实可以做一个规档的功能,这个后面可以考虑一下,所以成一个呃 skill。 然后我们还想我还想说一点,就是 这五个功能,这五 sksk skills 呢,我已经封装好了,大家可以看一下它的提示词,然后在这个,呃,在我准备的这个配轴键当中就是点可拉的和点扩展的当中呢,我还放入了这个 官方推荐安装的几个,五个,呃,五个技能就是这几个,这几个是官方推荐的,就是 o c 店官方推荐的,我觉得还是很有很有必要安装的,它可以提高你的 o c 店处理新车的能力。 好,以上就是这些就是我介绍的内容,大家有兴趣可以试一下,如果觉得可以的话,觉得挺好用的话,可以在 github 上给我点一下 star, 谢谢啊,谢谢大家。
21bald boy 29:4435AI发条橙
29:4435AI发条橙 04:41查看AI文稿AI文稿
04:41查看AI文稿AI文稿大家好,今天我们聊聊 capacity 最近开源的个人知识库方案,以及为什么说这可能改变了我们用 ai 管理知识的方式。前几天,前特斯拉 ai 总监、 open ai 创始人成员之一的 andrew capacity 发了一条推文, 分享了他用 l l m 管理个人知识库的新玩法。他把这个思路整理成了一个 gift, 短短几天就拿到了大几千个 star。 各路开发者反应非常快,已经有人用 go 写了完整的工具,有人做了 cloud code 的 插件,还有人专门为此设计了新的 i d e。 那 capace 到底提出了什么思路,让大家这么兴奋? 核心就一句话,别把 l l m 当搜索引擎用,把它当知识工程师用。大多数人用 l l m 管理文档的方式其实都差不多。你把文件上传,每次提问的时候, l l m。 解锁相关片段,然后深沉回答。这就是大家常说的 rec 方案。 notebook lm chat gpt 文件上传,大部分 reg 系统都是这个套路。 karpsy 觉得这个方式有一个致命问题,没有积累。你问一个需要综合五篇文档的复杂问题, l l m 每次都得从头来,问完了答案就没了, 下次还得重新推导一遍。知识从来没有被真正沉淀下来, karpsy 的 方案完全不一样,他让 l l m 不是 每次从原始文档里解锁,而是持续里 增量试点,构建和维护一个 wiki, 一个结构化的互相链接的 markdown 文件集合。当你往里面添加一个新的资料来源, l l m 不是 简单锁,引进去等着以后被解锁,他会读这个资料,提取关键信息, 然后把信息整合进已有的 wiki 里,他会更新相关实体的页面,修正主题摘要,并标注新数据和旧结论的矛盾之处。用他的话说,知识编一次,然后持续保持最新, 这才是关键区别。 wiki 是 一个持久的、可复利增长的资产,每加一个新来源,每问一个好问题, wiki 都会变得更丰富。那这个系统具体怎么运作? kapi 把它设计成三层,第一层叫 raw sources, 也就是原始资料层, 你收集的论文、文章、图片、数据、文件都放在这里,这层是不可变的, l l m 对 它只读不写。第二层叫 the wiki 知识库层, 这是 l l m。 生成的 markdown 文件目录,包括摘药、实体页面、概念页面、对比分析、综述等等。 这层完全由 l l m。 拥有和维护,你读它, l l m 写它。第三层叫 the schema 规则文件,它告诉 l l m 这个 wiki 怎么组织,用什么约定。对 cloud code 来说就是 cloud md, 对 codex 来说就是 agents md。 整个工作流围绕三个操作展开。第一个是 ingest 录入,你往原始资料目录里丢一个新文件, l l m 会读这个资料,跟你讨论要点。 在 wiki 里写一个摘药页,更新缩影,更新相关的实体和概念页面,一个来源可能牵动十到十五个 wiki 页面的更新。第二个是 query 提问, 你对着 wiki 提问, llm 搜索相关页面后综合回答,好的回答可以回存到 wiki 里,变成新的页面,这样你每次的探索和提问都在持续丰富知识库。第三个是 link 体检,定期让 llm 对 wiki 做健康检查,找页面之间的矛盾。被新资料取代的过时信息, 没有入列的孤儿页面, l l m。 还很擅长,建议你应该去研究什么新问题。 gaapace 的 实际用法很有意思,一边开着 agent, 一 边开着 obsidian。 l l m 根据对话内容编辑 wiki, 他 在 obsidian 里实时浏览,结果跟着链接点点看,看看图谱,试图读读更新后的页面。 他说了一句话,非常精准, obsidian 是 id 一, l l m 是 程序员, wiki 是 代码库。说实话, 维护知识库最烦人的事从来不是阅读和思考,而是那些琐碎的布局工作。更新、交叉引用、保持摘要、最新标注、新旧数据矛盾、 维护几十个页面之间的一致性。这些活,人类做着做着就烦了,然后 wiki 就 慢慢荒废了。但 l l m 不 会厌倦,不会忘记更新, 一个交叉引用可以一次性修改十五个文件,维护成本接近零, wiki 就 能一直保持健康。 carpezee 还提到,这个思路跟一九四五年 vaniva busch 提出的 memex 构想精神上一脉相承。一个个人的精心策划的知识存储,文档之间的关联,和文档本身一样有价值。 故事没解决的问题,是谁来干维护的活? l l m。 把这事搞定了。从这个案例可以看到一个更大的趋势, l l m。 正在从问答工具进化为知识工作伙伴。不是你问他答,而是他帮你把散乱的信息编成结构化的知识网络, 而且这个网络会随着使用不断增长。每一次探索,每一次提问,都在让你的知识库变得更好,这就是复利的力量。好了,如果本期视频对你有启发,欢迎点赞关注我们,下期继续分享!
897AI半月刊 01:17查看AI文稿AI文稿
01:17查看AI文稿AI文稿五月二十二日,乌兹别克斯坦卡拉凯尔帕克斯坦共和国代表团到榆林开展考察交流。代表团先后前往多家化工企业,实地考察金属镁、绿碱化工等产业发展模式, 了解鱼鳞资源转化利用的产业优势,并现场观摩了解鱼鳞、磷、碳能源、清洁能源等重点项目。此外,还走进万亩张子松治沙基地,真切感受沙地变绿洲的生态治理成果。会上, 双方表示,将依靠资源互补优势,在矿产开发、生态防护、绿色能源等领域寻求合作机会,共谋长远发展。ھە سالام مۇرەككەم ھە مەن بۈگۈن بىرىنچى پەندە بىز دىلىگە سازالار مەن يۇنىن شاھرىيە كەلدى ھە ئېرتەلەپتىن بىر ھازىرگىچە بىر قانچە سانازلارنى كۆردۇق ۋە ئۇ بۇ سانازلارنى بىز ئۈچىنچىدە بىر كەتتى بىر ھەكوپېژژژژژژژكەتتى كەتتى ئۆتۈك ئۆتۈكلەردىن بىز كۆزىمىز ئامىن بولدۇق ۋەلىمەنكى ھە كېيىنكى ھەپتە بىز شۇ يولىنى بولاتتى ھەم نەتىجىلەرنى ۋىژژژژژژژژژژژژژژژژژژ。
75榆林国际传播中心 05:41查看AI文稿AI文稿
05:41查看AI文稿AI文稿在卡哇伊看上自己的 viki 构建知识库方法之后呢,我发现大部分博主都在讲这个事情,如何用它构建自己的个人知识库,但很少有博主讲明白 viki 这个东西到底是什么,以及它能在什么情况下使用,你怎么构建啊?那今天我就想给大家用非常简单的方法,任何人都可以理解方法去讲明白 viki 这个概念, 以及你如何用这样一个思维去构建自己的可持续增长的知识库。 ok? 首先 viki 呢,它指的是一组可以快速编辑,互相链接,不断增长的页面,那这三个特性就导致它很适合构建我们的知识库。 首先你可以快速编辑新的内容,然后你不同的文件都是有链接的,所以你不是记住一个一个的单点,你是把不同的概念连成一个网络去记的,这样的话你的联想记忆会帮助你理解所有的相关的概念。那最后呢,它是可以不断增长,因为你不断加了新的东西进来,它的链接会不断的增多,不断增多,它是个指数级增长,那也就是说有点像芒格提到的复利概念,就是你每天增加一点点东西,但其实它内部链接是增加很多的, 那所以时间长了以后呢,你就会发现你的支付非常庞大,并且你可以记得住其中的大棚概念,因为它们是互相链接的。为什么?这一页就是卡巴西的 l m viki md 的 原文框架,首先它分为六部分,就是核心想法是一个构建一个持久化的 viki, 然后架构就是原始资料层、 rock 层、 viki 层和 steam 层,操作流程就先导入,然后用 ai 去查询,再用 ai 去基建, 所以和日期主要是用来记录新增加进来的东西,就是它的 log, 它的时间线啊,然后还有一个就类似于记录更新进度的一个目的,那 c l i 工具就是我们需要用一种 c l i 工具嘛?至少比如说,呃, codex 或者是 cursor 或者是 google, 那 所以 weekend 它不需要工具,它是一个用法。比如说你把卡巴西的 wiki 原文丢给你的 agent agent 就 知道了这样一个 c 模式是什么,它就会以这种 c 模式帮你去构建你的个人知识库。所以你就可以做到是把你的所有相关资料,比如说,呃,你的人生成 相关资料,你的阅读相关资料,你的课程学习相关资料都丢到一个文件夹里,然后他读完之后呢,把这些理解成一些互相关联的文件,这样下次你想从里面提取点什么东西的时候,这个 a 阵就会帮你提取。 那么为什么要构建 wiki 这样一个可持续增长的知识库呢?首先原因就是普通 ai 每次都要从原始教里重新找答案,像你的知识库就没有什么用了。其次呢,这是没有复利的,因为呃,你自己其实也不知道你的知识库里到底是什么,因为都是 ai 帮助你找答案吗?久而久之,那个东西就变成了一个你不会再用的肿鱼的肿瘤啊, 那这知识库的意义就没有了。所以 wiki 解决的事情就是每次你跟该交流,他去剪辑你的知识库,然后对你的知识库产生新的理解,他要把这个理解记录下来,并且整理 wiki 层,更新 wiki 层, 那他你的知识库就会不断的被使用。那么 wiki 具体就是三层结构,第一个就是 raw, 你 放原始资料的地方。第二个呢就是 wiki, 它是 ai 给你的原始资料写的笔记, ai 自己会维护它。那比如说你的原始资料有五十本书,里面有很多的概念,它就会把这些概念都放到一个文件夹里,那这些概念你就是可以附用的, 你不用不需要再去书里去查那些概念,你直接就到 wiki 层让 ai 帮你提取出来就可以了。那 skm 呢?其实就是一组给 ai 的 规则,比如说 cloud md 或者是 colleagues agent md, 这个就比较简单,就是说我要怎么去维护 啊?我的文件里 raw 里面有什么? wiki 里面是什么啊?这个主要是让 ai 可以 看到你的笔记啊,和它们不同文件之间的双向链接啊。然后对于呃它是怎么处理这些文件有一个规则,我们现在如果有了一个这样一个 raw wiki 和 skm 这样一个知识库层级之后,我们来了一份新资料,会有什么变化呢?新资料来了之后,首先你要 叫 ai 读完的资料,他会把里面的一些概念啊,人物啊,工具啊单独建议,这个就是放到 vik 层里面的东西,因为要里面所有资料里面真正有用的就是一些概念,然后一些关系,一些工作流,还有一些使用的工具,那这些东西就是 ai 来维护, ai 去读取,然后提取,提取出来相当于他把这个新资料里面的东西都已经吃透了。那那他提取这些新的概念人物工具之后呢,他会首先检查你的已有的 vik 里面的笔记 是不是有相似的结论,那这个结论是不是错的,他可以去修正。那然后呢,如果你没有的话,他可以补充你的新的观点,以及在你的相关页面之间建立一些新的双向链接。最后他会更新你的总目录,去记录 log 里面,就是今天我改了什么,有点像版本更新记录。对, vicky 大 概就是长这样子。首先他有一个 index, 就是 总目录他的记录 vicky 里面到底有什么, 然后呃 log 呢?就是记录你的这个 vik 知识库网络有什么样的改变,比如今天改了什么,明天改了什么?这些概念人物工作流对比问答,就是 ai 记录的你跟 ai 的 对话,或者是你通过它跟你的知识库呃提取出来的关键概念,这个也就可以作为你自己的语料库。就平时我们在思考,平时我们在交流,或者我们在进行一些内容的产出的时候, 这些概念就可以自然而然的作为一个素材。那这些概念呢?它其实也并不是独立存在的啊,它页面之间用双链会互相链接,双链的意思就是,呃,比如这个文件我可以连接它,但是它同时也知道它在连接它,所以这两个概念是互相链接的。那呃,某一个单独的概念呢?它里面会有一些多的双链引用,就它会引用到别的文件, 所以这个时候你提取出来一个文件的时候,其他文件也会被拉出来。那么具体怎么搭 wiki 呢?其实也很简单,一个是 wiki 文件夹,第三个是 skin 文件夹, skin 和 skin 文件夹呢,都是空的。你让 ai 去自己维护,自己创建, 你就只需要装一个本地的 ai agents, 比如说 code code 把卡帕西的刚才的原文 md 作为 context 复制进去对话框,然后跟他聊你具体想做什么样的主题。比如说我想读本书啊,做一个可持续增长的呃 知识语料库,并且用一个语料库呢去帮助我产出自媒体内容。 ok, 然后呃,聊完这个之后,你再把第一份资料放到 raw 里面,告诉你的 agent 处理一份资料,然后整理进 wiki, 然后你再把第二份资料放进去,就是你不断的放新的资料,那么这个 wiki 呢?它的网络就会越来越大,越来越大,越来越大。 那举个具体的例子就是,假如你想读一本书穷查理宝典,那他有不同的章节,可能你每次就喂他一张,每次喂一张呢,他就会提取出来这种关键概念,比如说芒格说逆向思维能力圈,多元思维模型,然后他会提取关键人物,比如芒格,巴菲特。然后你肯定会在进去的时候去问 a 阵子,比如 说你不太理解为什么芒格反对预测,你就问他,那这个时候 vicky 也会把这个问答记录下来。他这个 index 其实就是记录 vicky 的 缩影表,然后 log 就是 每一次你新加进来一张,它会记录这个 vicky 内容有什么改变,就相当于一个版本更新记录。 skim 其实就是在这里,就是 called md, 就是 called md 呢,它不仅记录你的整个 raw vicky 的 呃结构,它还记录了 vicky 如何根据什么样的规则去改变和增加, 也就说每个人的 wiki 其实不一样的。比如说我的 wiki 可能不光有概念人物,对吧?我可能还有工具和工作流,因为我要做内容产出我的工作流,我要整理我的视频产出工作流,我的视频剪辑工作流,或者是我的图纹生成工作流,以及我对于不同主题的文字长文生成工作流, 可能还需要这个工具呢?我可能是有 office 点啊、 cloud code 啊,或者是有些插件,比如说 cloud 呃 man 啊,或者是呃 cloud design 这种网页端的,它都会记录在我的 wiki 知识库里,也就是 wiki, 它知道我习惯于用这些工具,那也就是说你用的越多,你把东西放的越多,你生产的东西越多,那 wiki 它这个本身就会越来越庞大,它越来越庞大就代表它越来越理解人,就是作者本人。
759YAN 02:05查看AI文稿AI文稿
02:05查看AI文稿AI文稿哈喽,大家好,我是阿黄,上周有朋友问我要怎么样找到自己人生的考点?嗯,这个问题的情景是这样的,在大模型变得越来越强的时代, 执行力呢,已经变得越来越廉价了。这个时候人们应该去提高的能力是自己的判断力,还有能动性。其中能动性是一项关乎你在没有目标的时候怎么生成目标,怎么生成意义的一个能力。那么它相关的问题就是要怎么样找到自己人生的考点。这个问题是一个很大的问题, 就是说很多人写了不同的书,都是为了去回答这个问题,所以一时半会也不可能在一个短视频里面讲清楚。 但是我觉得有一些树是大家可能可以参考的。呃,一个好的判断准则是你的抠理应该长这个样子,就是说它是你热爱的事情,你觉得重要的事情, 还有你擅长的事情,三件事情的交集。那么这个问题又可以继续拆分成,我要怎么判断我是否擅长一件事情?我的观点是这样的,你可以这么看,假设有一个游戏,那么这个游戏里面呢,就会有不同的玩家,不同玩家会有不同的游戏表现,这里面你就可以采纳出一个中位数, 那么怎么判断你是否擅长?就是说大家在获得同样的资源的情况下,你的游戏表现是不是比这个中位数玩家要远远的强? 这里面有两个很重要的前提,一个是资源相同,另一个就是说你的游戏表现最好远超于这个中位数玩家。那么举个例子,比如说打网球,一个优秀的网球运动员,像什么阿卡辛纳给他们同样的训练资源,他们的游戏表现是远超于 中位数玩家的。有一些天才你给他很少的训练资源,他的游戏表现也可以异常的强,那这些人就是特别擅长这个游戏。 嗯,游戏是一个抽象,实际上我们做的很多事情都是游戏。当然剩下两项,比如说热爱或者觉得重要是比较主观的事情,但这个框架至少可以提供你判断一件事是不是你的考量。 那么希望大家都能够找到自己热爱、擅长并且觉得重要的事情坚持做下去。今天就跟大家分享到这,谢谢大家,拜拜。
45Jaybee黄 04:36查看AI文稿AI文稿
04:36查看AI文稿AI文稿ai 五报二零二六年五月二十三日今日十条新闻 entrepreneur 融资三百亿美元估值 google i o 二零二六阿布扎马斯克书要与 oppai 官司,双方达成和 美国二十五个州推进 ai 立法,聚焦透明度余生卡帕西开元 kao m d 工具,引发开五角大楼与亚马逊 歌、微软 space。 欧盟 ai 法案第四条正式生效,企业需提升员 procreate 开放 skills 设计 thinking machines 发布权。美国参议院推出 ai overwatch 第一条 antropig 融资三百亿美元,估值达九千亿。卡帕西宣布加入人工智能公司。 antropig 宣布完成新一轮融资,估值突破九千亿美元大关。 同时,吴恩达弟子、知名 ai 研究者卡帕西 andre carpentier 在 社交平台宣布正式加入 androfei, 引发业界广泛关注。这是继 open ai 之后, ai 领地第二条, google i o 二零二六发布 gemini 安妮的多款 ai 产品。 google 在 i o 二零二六大会上发布了 gemini armi、 gemini 三点五 flash 升级为默认模型 anti gravity i d e 变成助手 gemini spark 以及全新的 agentic search 功能。其中 gem。 第三条,马斯克输掉与 openai 官司,双方达成和解。持续数月的马斯克诉 openai 案落下帷幕,法院裁定马斯克败诉。诉讼期间曝光的内部邮件和推文显示,双方在 a t i 发展方向上存在根本分歧。 消息人士透露,双方目前依旧核心争议达成和解,但具体条款尚未公开。第四条,美国二十五个州推进 ai 立法,聚焦透明度与深度伪造识别。美国各州加速推进 ai 监管立法, 目前已有超过二十五个州正在审议或已通过针对生成式 ai 聊天机器人深度伪造识别、未成年人保护及消费者损害责任等方面的反案,中医院同时提出两党联合反案,预在联邦层面统一规范 ai 安全标准。第五条 卡帕西开源 cloud md 工具引发开发者社区热议前 openai 研究员卡帕西在离开 openai 后迅速行动,开源发布了 cloud md 工具,该工具只在帮助开发者更高效的配置和使用 cloud 系列模型进行编程。 开源社区反应热烈, github 新标识在二十四小时内突破五万。第六条 五角大楼与亚马逊、谷歌、微软、 spacex 等七家公司签署机密 ai 协议美国国防部宣布,已与亚马逊、谷歌、微软、 spacex 及另外三家科技巨头签署协议,在五角大楼机密网络中部署先进 ai 能力。 此举被视为美国打造 ai 优先作战力量的重要一步,但与 angelic 的 共赢争议仍在持续。 第七条欧盟 ai 法案第四条正式生效,企业需提正员工 ai 素养 根据欧盟 ai 法案第四条, ai 系统提供商和部署方需采取措施,确保员工及相关人员具备足够的 ai 素养。这标志着全球首个全面 ai 监管法律进入实质执行阶段。虽然距全面生效还有一年,但相隔合规要求已对企业产生实质影响。 第八条 perplexity 开放 skills 设计核心平台 ai 搜索引擎 perplexity 宣布开放其 skills 设计核心平台,允许第三方开发者在此基础上创建和定制垂直领域的 ai 技能。 该平台被视为 perplexity 从单一搜索工具向 ai 操作系统引进的战略。第九条 thinking machines 发布全双工实时模型 ai 初创公司 linping machines 发布了一款全双工 bodeflex 实时 ai 模型,能够在对话中实现真正的实时双向交互,而非传统的混搭模式。 该技术被认为将大幅提升 ai 对 话的自然融合效率。第十条美国参议院推出 ai overwatch act 确保先进芯片不流向中国 美国两党参议员联合推出 ai openwatch act 法案,要求确保驱动下一代 ai 的 芯片助力美国创新与国家安全。而被中国共产党、军队和监控机构法案只在填补出口管制漏洞,进一步限制中国获取先进 ai 芯片。










