故事版超过15秒即梦怎么生成
最近有朋友问我怎么用即梦生成超过十二秒的视频,其实方法特别简单,我自己一直在用,今天就把这个实用技巧分享给大家。想要做出更长的视频,核心做法就是分两式生成, 但这里有个关键点,一定要让前后两段视频的场景保持恒定不跳变,不然画面衔接会很突兀。 而实现这一点的核心秘诀就是用好参考图,只要把参考图用到位,就能牢牢锁住场景,让两段视频完美衔接,轻松做出超过十二秒的长视频。 是不是超级简单?你学会了吗?记得关注再走哦!

粉丝358获赞1864
相关视频
 04:40查看AI文稿AI文稿
04:40查看AI文稿AI文稿哈喽,大家好,今天我们来聊一聊极梦分身如何突破十五秒。首先原谅我用了标题的我只是想好好的做个教程,因为如果我不这样写的话,我相信这个视频很多人看不到。那其实极梦由于系统的设置,确实是不能突破十五秒的, 准确的说是十二秒,因为后面还有三秒的广告嘛。但是我们是可以通过一些方法把各个片段无缝衔接的拼接到一起。我相信很多人其实也想过做这件事情,奈何自己 每一次做的视频都像是在开盲盒,不是画面对不上,就是衣服不一样,甚至有的时候还会换一个发型,那其实这些问题都非常的普遍,我自己前段时间就尝试了 手搓了一部三十分钟的短剧,我相信目前全网就只有我用急梦分身去做这样的事情。那出来之后呢,就有很多圈内的朋友来问我是怎么做的,那今天我就来结合自己做这个长视频的一个经验,总 总结出来以下的几个方法。那我相信大家掌握了这个方法之后呢,也能够很轻松的去完成自己想要的长句。首先第一个就是要把 ai 去当成摄影师,而不是小说家。我们都知道要写提示词,但是有的人他会写,比如 他内心很震惊,不敢相信眼前发生的这一切,那这就是一个非常典型的小说式的提示词 a i。 在 拿到这种模糊的指令的时候,他可能会跟你生成完全不一样的片段,你真的想要他能够接得上,能够拼接的起来,就得写成镜头可执行的语言。要写谁在画面里面, 要写在什么地方,做什么动作,从哪个视角去拍,所以正确的写法可以是特写。他往后退了半步,眼睛放大,嘴唇微微发抖,在切中景露出惊讶的表情。那这类指令越是具体, 前后的镜头就越容易统一,后期再剪辑的时候就更容易接得上。那第二点就是风格一致,参考图一致。 ai 它是没有记忆的,它不会因为你前面做了多少个视频,它就会记住你想要干什么。现在所有的视频大模型都是没有记忆的, 每一段视频它都是完全独立的,所以你的一段视频是写实拍摄,那么你以后的每一段的提示词, 一句话都要写一个写实拍摄,不然他就有可能会给你其他的风格,那你又得重新抽卡了。另外,在同一个场景发生的故事,一定要放上一张场景参考图, 不然就算你写的提示词再怎么细致,出来的场景也会不太一样。如果场景都不一样,那是不是就完全出戏?那第三个就是拆分镜,这个大家可能都知道, 我的建议呢,就是把一段视频至少能拆成五个镜头以上的画面。比如这个视频,他敲门进来把合同他们已经打款了, 那我是把它拆成这样的片段的,其实十二秒一点都不短了,根据我的经验,十二秒内容在这种短剧上面是可以分成七八个片段的。那如果你实在不知道去怎么写分镜脚本,你可以叫个 ai 啊,让他帮你写,当然也可以关注我,我会发给大家一份我使用过的提示词, 你们可以让 ai 照着这个改就好了,那第四个也很关键,就是不要带字幕和背景音乐。我们首先要认定一个事情,就是即梦,它给你的不是成片, 而是素材。如果多段素材的字幕和 bgm 都不一样,那自然就是有很多问题的。字幕和 bgm 在 后期配起来是非常简单的,用剪映就可以轻松的完成。真正能够把这些素材拼接起来,是我们的结构能力、分镜能力以及剪辑的能力。 第五个呢,就是大家要知道抽卡是一定存在的,因为现在的 ai 就是 没有办法,他就是会偶尔发疯,所以大家一定要认准这个心态,就不会再遇到 参考词明明写的很好的时候,视频还是不是我们想要的,那样心态就崩掉。我们所有的方法都是来降低抽卡率的,我自己这么多的片段,那平均下来每一个视频都是要抽卡两次以上的, 最多的时候我一个视频是抽了差不多有六七次,所以完全不用去担心我每一次的抽卡,每一次的调整,都是我们的进步。 ok, 那 以上就是我总结的一些经验,总结一下积木分身怎么突破十五秒,严格意义上来说,目前确实没有突破的,不, 不是时间上线,而是我们的做法。当你开始把十五秒视频当成最小的单位,当你不再用模糊的文案去碰运气,当你开始用提示词、参考图、分镜去降低你的抽卡率,当你去这样做的时候,那十五秒 就不再是限制。我是蜜蜂,如果大家觉得有用,欢迎大家点赞收藏,也可以关注我,后期我会用更多的视频,用更简单朴实的语言,带大家了解 ai 的 那些事。
630行走的蜜蜂🐝 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿大家好,我是虚拟世界的小新。最近 cds 二点零的强大功能相信很多朋友都体验过了吧,生成十五秒的创意短视频确实方便快捷,但想用它来制作几分钟的剧本剧情时,如何保证每一个十五秒衔接起来的画面连贯、角色一致、情节流畅,就需要点 ai 视频制作的经验了。因为虽然 cds 二点零支持自然语言描述来生成内容, 但如果想要根据你的剧本实现电影级的连贯剧情,确保每一段十五秒视频的镜头语言、人物、动作、场景、细节都高度统一和精准衔接。单纯的自然语言描述是远远不够的,你需要一套系统化的创作方法和一套标准化、能优化细节的指令方案。这个就是 小新在这个新年假期专门为大家做出来的。你只需要先上传你的完整故事概览,让 ai 大 局理解故事背景, 接着按顺序粘贴某个具体情节的文字内容,上传涉及的人物场景、重要物品的参考图片,让 ai 记住他们的视觉特点,点击生成,然后应用就能在瞬间帮你智能拆解本场系内容,并自动融入专业制作思路。 此刻为你生成一系列高度连贯、细节明确的 cds 二点零指令系列。这些指令不仅包含了精确的镜头角度、人物情绪、环境、光线,甚至连物理动态细节都已考量。 你只需将这些指令依次导入 cd bass 二点零进行生成,就能轻松获得一系列画面、人物、情节都高度一致且流畅的十五秒视频片段。将它们简单拼接一段逻辑严谨、蓄势流畅的长篇视觉故事就高效完成了这个能帮你少走弯路,提升效率,优化制作思路的 cd bass 二点零创作辅助应用, 我已经整理到我的资源合集,专为学员提供,赶紧去用我们组合运用这些辅助资源呢!创作了非常多的创意内容,点赞关注,我们会持续更新前沿技术,在各类内容创作中提供实用技巧,用我们的经验帮你少走弯路!
 00:16查看AI文稿AI文稿
00:16查看AI文稿AI文稿这条视频很短,但绝对对你收视频有很大的帮助。真的是二点零一个视频,最多只能生成十五秒,那如果还想无限延长,直接把生成好的视频添加进对话框,然后起始这样写延长。艾特你添加的视频多少秒,之后再按照我上条视频输入起始。
2827Ai 的小鹿 00:55查看AI文稿AI文稿
00:55查看AI文稿AI文稿吉梦做的视频只有十五秒,那怎么样才能让他变得更长一点?这是很多朋友问的一个问题啊,今天来教大家一个方法。 过去我们做的视频呢都在十五秒以内,这个时候呢我们把他的语速可以加快一点,就是在提示词当中,你把这个语速可以调成一点五倍速,或者是更高的语速,也或者说你把这个台词做到一百到一百五十个字, 这样的话他的语速就会非常的快,可以听一下他的视频速度啊。这个时候我们拿到这个原视频,然后导入到剪映当中去, 再把剪映当中这个视频的这个速度呢,我们给它放慢到零点七五或者零点八啊,根据自己的这个语感你来感受一下啊,最后你就能得到一个相对来说正常语速的视频,那么我们就可以通过一样的算力 十五秒的视频,而且你不用去两个视频进行拼接,就能得到一个二十秒甚至是更长时间的视频了。
1359牛大-闪电虎AI创客俱乐部 01:14查看AI文稿AI文稿
01:14查看AI文稿AI文稿如何用这三张人物图做出灵动治愈、分镜切换丝滑的动画剧情短片?今天一个视频教会你从分镜脚本、角色图到最后的成品动画效果轻松搞定。 一步在小梦 agent 用这段神秘指令生成分镜脚本,写清楚视频时长、人物角色设定和对应的大致情节,来仔细看一下。十五秒,四个分镜头,开篇集市买菜、洗菜做饭,最后吃完饭在月下乘凉。成片展示中,每个分镜的细节展示都很不错。 再来生成人物图,在图片生成这里写入这段指令,需要 q 版动画风格生成这样三张简单的人物角色图。然 然后在这里视频生成,把刚刚生成的人物图和脚本放进来,用这个指令告诉他图片中的人物分别是谁。图片四是分镜脚本需要生成一个古代短剧动画小短片,这里选这个二点零全能参考比例三比四, 根据脚本表格选时长十五秒,然后见证奇迹的时刻到了。视频里面的动作、运镜、音效都是直接匹配好的,人物和场景一致性也很好。如果你要做这种古代动画 ai 剧情短剧,跟我一样用小梦就够了。从入门到精通,一站式完成全流程创作,效果真的挺让人惊艳的,效率也是直接拉满。
423小野AI实战日记 01:14查看AI文稿AI文稿
01:14查看AI文稿AI文稿一句话,直出十五秒以上长镜头教程操作简单,拜访老朋友孟老师。 切换视频生成,选择二点零模型,点击参考内容,上传九宫格参考图,比例十六比九,输入分镜指令,时长十五秒,点击生成看效果, 返回首页,选择视频生成,依旧选择二点零视频模型,选择全能参考,把刚才生成好的视频添加进来,输入指令,从最后一帧续写视频看效果,如果不停续写,就能不断加时长。
207云梦楚 00:57查看AI文稿AI文稿
00:57查看AI文稿AI文稿集梦涨价了之后,做一集两分钟的视频要花多少钱?现在是四九九六幺六零的积分,一个十五秒的视频需要两百一十积分,那一分钟是就是四个十五秒乘以四就八百四,然后这个是一积分,是四九九除以六幺六零一积分呢是零点零八毛一这样价格,嗯, 一四个十五秒的一分钟是八百四,这个是百分百的抽卡率。但是你现在集梦的这种抽卡率呢,是要至少要抽四次才能抽到一次有效的视频,就去乘以 八百四,去乘以四次才能得到一次有有效的视频是三三六零一分钟呢,需要用到呃,三千三百六十的积分啊,那两分钟你就直接去乘以二三三二零乘以二,两分钟就要花掉六七二零积分,那一一积分是这个价格去乘以零点零八一, 相当于五百四十四块钱一集。一集两分钟的短视频呢,做下来的价格呢是五百四十四,这是每抽四次卡得到的一个价格,如果你抽的越多,那这个价格呢就会越高。现在你们还认为 ai 用 ai 短视频做出来的视频不要钱了吗?其实它的成本还是挺高的。
5006林漫社 01:07查看AI文稿AI文稿
01:07查看AI文稿AI文稿一张九宫格分镜加提示词,直接生成十五秒广告片,看人物表演、剪辑节奏、配音和 bgm, 已经是专业广告公司大片制作水准,没有什么比乐事吃光了 更可怕!这就是极梦最新的 cds 二点零伸缩模型,用来做广告,呆萌实在是太强了!再来看两个例子,题诗词简单写更, your only limit is you and the only way to fail is to never try so what are you waiting for? 还有经典的士力架广告创意,直接成片,饿货来条士力架 横扫饥饿,做回自己制作,比你想象的还要简单。选择 c dance 二点零模型,可以选择上传九宫格分镜图片,或者直接写提示词, 最多能生成十五秒。点击生成一次,出片的效果就很赞,你学会了吗?
572赛博大福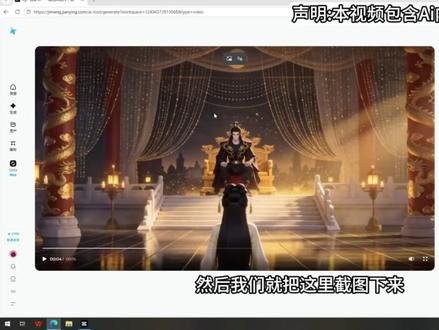 04:41查看AI文稿AI文稿
04:41查看AI文稿AI文稿本期视频我将结合我自身的经验,教大家如何一个人制作 ai 慢剧,并发布对应平台的全流程,哪怕是小白也能利用教程中的免费 ai 软件,轻松制作出 ai 慢剧,相关的制作流程和 ai 工具已经全部打包好了。 同学们好,上一节课呢,我们讲了怎么样去申视频,那我们也是成功地把一段视频给做出来了。那有些同学在后续的这个制作视频的过程中呢,就会遇到一些问题,比如说我们都是十五秒为一段,但是有一些视频它可能 一一两分钟,那他就是有多个十五秒去拼接而成的。那我们如何保持每一个十五秒?他的结束的一个转场就是他最后要跟前面一集那个十五秒是连接起来的,怎么样保持这个一致性呢? 那我们老师今天就给大家讲一个办法,可以让我们的十五秒每一个衔接起来都非常的丝滑。那我们就是如果你不去用这个办法,有可能你这个十五秒结束的时候,在这个地方啊,有可能他下一个十五秒他就是随机生成了人物的站位就会变。 这一集老师就讲怎么样去调整这个人物的这个站位啊?上一集和下一集十五秒是怎么样衔接在一起的啊?这里呢,有些同学就可能他已经知道了,就是在这个视频里面可以用这个首尾针或者用智能多针去参考,比如说手针,我们用一个图片去定下来,比如说我们想要 这个这个地方去,这个作为十五秒啊这个地方去,然后我们就把这里截图下来, 就弄成一个场景放在这里,但是这样呢,我们这个积分其实是很贵的,你看五秒就用了五十多积分,用十五秒的话积分就更多了,那我们吃不有一办法呢,就是我们在这个二点零升视频继续用这个全能参考,但是我们把这一张图的最后一张截下来, 然后截下来之后我们放在这个地方,然后告诉他这一张是手真图、 帧率图,这张图片等于手帧图,那这个后续生成的时候,它就会自动从这个 地方开始去生成视频。那我们不管怎么样去变,至少和上一张上一集十五秒的那个结尾的结束的地方是一致的,包括说人物转场了,比如说我下一个十五秒,我想继续从这个女主的这个角度去升,那我们就把这个地方 斜下来,然后放到这个地方也是一样的,这样我们这个上下十五秒就能衔接在一起了。然后呢有些同学就会说,那我们如何保持这个声音的一致性?就是有可能你做了很多急, 前面的时候你发现男主声音是这个音色,后面发现变掉了,他换了一个音色了,这也是因为这个 ai 它声声音的时候会自动去参考、去脑补,但是它 不一定每一次都是一致的,有可能他生了很多次,有可能在哪一次的环节,他可能把这个音色给变掉了。那怎么样去保持这个音色?就是声音是一个人的声音呢?老师这里也教大家一个办法,比如说你这个水也生出来了,你把他讲话的这个调老师, 然后把他的音频截下来,然后放到桌面上备用啊,这个人就是他的一个专属的一个声音的一个参考,那我们如何去把这段声音使用过来呢?我们就是点这个编, 然后呢我们在这个最前面我们去添加一个,比如说我们这里是备用的一个男主角的声音,然后我们告诉他男主的音色参考 参考这个,那我们他后续不管怎么样去说话,他都会参考这个声音,我们男主就是同一个声音了,我们只需要在台词这里,他每次说话换了一些台词,我们在这里输入就可以了。 包括说有些同学说,那我们声视频除了声音还要有音效,那音效怎么处理?首先第一呢,我们在这个 ai 声视频的时候已经提醒他了要加入这个音效,如果他的音效没有特别丰富,我们还可以后续在这上面点,我们可以点这个 ai 音效,对吧?点了音效之后,它就会生出这些各种各样的音效,我们可以自己去选,包括说如果我们还想要配乐,比如说它自己可能我们自己找不到合适的 bgm 或者配乐,我们点这个 ai 配乐,它也能根据这个画面去配上比较好的一个配乐。 那讲了这个声音,讲了这个手斟图,还讲了这个音色怎么去参考,那我们后续就可以把一个完整的视频从头做到尾,这样都不会出现这个场景的变来变去啊, 也不会出现这个声音不一致啊,也会出,也不会出现这些音效比较少啊,或者说配乐不够好啊,这些都会得到解决了,这样我们也能做出一个完整的一个视频了啊?好了,这节课就讲到这。
 05:01查看AI文稿AI文稿
05:01查看AI文稿AI文稿最近 max two 那 个故事版很火啊,有小伙伴问我怎么做,这东西其实太简单了,晚上能看见的我都做好给你们了,不用你们到处被割韭菜。我做了几款了,给你们先看看, 这款是包含人物的那个三式图的场景四式图,还有那个故事宫格和说明的,就这个样子。第二款是那个打斗和动作专用的,上面会详细的那个标明人物的那个出招的路线, 行走路线的。但用这一款要非常注意啊,给季梦生成视频的时候,要强调那个箭头只作为参考而理解,不要生成在视频里面。 第三款是那个表格来表达那个故事的,这两个都是同一个提示词,只是不同那个宽高,这个是用二比三的,这个是用十六比九的,根据需要选择就可以了。提示词已经全部放在插件的预设里面了。这个对应有三次图的场景的, 这个对应的就是动作的,这个对应的就是表格的。好了,这些就够用了,但你们不要对这个故事版有太大的期望值了,因为这东西一出来时候我们就知道了,但讨论了一下,知道它是噱头大于实际效果的。 v h two 做故事版没问题,做得非常的好。但真正的瓶颈是在纪梦视频生成那里,因为纪梦对图片上的文字给的权重并没有那么高,它不会完全按照你写的东西去做的,我们做个实验就知道了。先来个简单的, 这看起来是不是很完美,跟图片那个情节完全对应上了。其实用个九宫格进去加提示词,完全是可以做到这个一模一样的效果的,这样做的故事版的好处是不用再写一次那个提示词而已, 九宫格就不给你们试试了,百分之百是可以的。好,我们来上点强度,我们来试试这个打斗的。 然后为了测试他,我们分了三个版本来试一下。第一个版本是只有故事版参考的,没有其他提示词。第二个是有故事版还有提示词的。第三个是以前那种方式,三四图场景加分镜那种提示词。 ok, 发车看看效果。 先来看第一种效果吧, 效果确实很不错啊,对吧?但是大家应该看出来了,他其实并没有按照九宫格里面的内容去生成的, 而是自己理解了那个打斗的那个场景,自由安排了很多打斗情节,对吧?但是季梦确实很厉害,打的挺不错的,这里可以看出复杂场景和动作,单纯 看那个故事版是无法精准的控制的。看第二个效果,我先把故事版的分镜提示词从豆包里分离出来,然后提示词加故事版一起生成,看效果。 这次的效果就很明显了,基本上就遵循了故事版的描述了。不相信你们可以倒回去对比一下视频的故事版那个图片,大部分的那个镜头和分镜都是可以对应上的。最后测试一下用以前那种方式, 这个就很离谱很多了,看 这里打着打着键就没了。看我负面提示词强调了,键一定是要一直存在的。上一个视频我就说过了,五月份季梦又降至了, 所以现在基本可以得出结论,做复杂情节或者打斗的话,想要抽卡少,最好的方法是故事版加提示词,目前是比较稳的,用法也非常简单,先写剧本,然后加上这句话, 然后下面加上故事版提示词就可以了。如果是有人物和场景的参考的也进去就可以了。在故事版里面就会帮你们加上 插件,你们自己更新就行了。更新方法上期说了,另外还做了个小优化,这里加了个重复的按钮啊,主要作用就是点击它之后,它会自动插入上次操作过的提示时,减少操作的步骤。今天分享就到这里了,拜拜。
1185飞驰影漫社 01:19查看AI文稿AI文稿
01:19查看AI文稿AI文稿先看成片你有没有发现,很多 ai 打斗视频看第一眼都挺唬人,但一旦想做长一点,问题马上全出来了。尤其超十五秒后,不是动作接不上,就是人物突然变了,再不然就是斗得很激烈,但都是在打空气。 所以很多人不是做不出打斗,而是做不出一段能连续看十五秒以上,还一直在线的打斗。真正难的从来都不是出一帧帅图,而是让他持续打下去,而且越打越难成片。先看到这里,下面直接进教程。首先我们来拜访一下老师,选择视频生成全能,参考 使用这个大模型,然后选择一下时长和尺寸,最后输入这段指令,点击生成,就可以得到第一段打斗视频。 但真正决定上线的,而是后面怎么续,很简单,保留原先的设置,上传第一段视频,写上第二段提示词,再艾特一下视频,搞定。接着看过渡非常流畅,角色场景的一致性几乎没变。 最后在剪辑软件中加入配乐以及简单特效。关注我,带你学习更多 ai 知识!
3312风铃Muse 01:22查看AI文稿AI文稿
01:22查看AI文稿AI文稿即梦作一条十五秒的视频需要四百九十五点数,但我同样是 cds 二点零 vip 和 fast 渠道,不排队,不限制人脸, 而且只需要二点四积分就能生成一零八零 p 的 视频,参考素材全部支持,只需要先生成四百八十的视频,再用二点五积分提升画质,还可以提升至两千或四 k。 你 们可以看一下我生成的效果, 现在点一下画质增强,等一会儿生成途中我们看一下图片生成。这里也可以用最新的 gpt 出图或者 cds 五点零一张图,只要二到四积分,非常便宜。然后我们回来看一下增强后的画面 怎么样,有兴趣直接点我主页进群或者私信。
136XunFuture 00:53查看AI文稿AI文稿
00:53查看AI文稿AI文稿emoji 二点零故事版火了,躺赢的却是极梦。测试了,效果确实没得说,大家自己看一下传统九宫格和故事版生成对比,画面衔接流畅度直接高了一个档次, 就完全是按照你故事版内容一步步执行。但很多人忽略了一个点, emoji 二点零的故事版强在文字理解的精准度, 能把分镜脚本原原本本落地,而吉梦是目前唯一能接住这种精准度并把分镜顺成成片的搭档。换句话说就是吉梦又躺赢了,谁派你来的? 这时有人就说了,我知道吉梦很好用,但是那会员太贵了,我用不起呀。那你为什么不试试吉梦的 api? 不 用会员,用一条付一条。我体验下来,其实很多模型的 api 都很好用,效果不比官网差。所以有时候我也很疑惑,大家为什么不用呢?
 02:01查看AI文稿AI文稿
02:01查看AI文稿AI文稿先声明啊,这绝不是一次抽卡成功的任何这种说法,那多半是麦克老师的套路,因为他们需要你们的情绪价值啊,不然怎么买他的课呢?而我需要的只是流量。来,先来看看成片效果 啊,兄弟。兄弟,这不是意外, 无关人员快点离开,我们需要封锁现场, 不许偷拍。这是魔,我要帮你找死! 怎么样,场景基本没穿帮吧。哎,大家应该看到了我的故事版,对不上我的角色,因为没有充钱,他限制了我上传图片的数量,所以第一步我只好用纹身图,这是我的 提示词。第二步,可以把第一次生成的图片丢给他生成续集。注意看啊,这两张图片是不一样的, 他生成给你的故事版千万不要直接用,你要把不合理的地方把它修正,不然他生成的视频可能还是会很尬。制作最后十五秒故事版的时候呢?呃,考虑到实际生成视频的镜头有所不同,所以我做了一些修改。 但实际上他生成给我的故事版,哈,还是跟我修改的内容关系不大。没有用我的角色啊,但是都没关系啊,这个 s d r 他 能够理解,前两期视频已经实验过了,就算你的 分镜脚本里面的图片场景和人物都错乱,那也没关系。来到视频最关键的一步,一定要告诉模型啊,怎么样来使用你的故事版?
262元风AI分享会 08:29查看AI文稿AI文稿
08:29查看AI文稿AI文稿吉梦有个功能,可以几个积分生成视频啊,还可以十几个积分,二十几个积分,三十几个积分都可以,包括这种长的视频,十六秒的三十多个积分,还有三十多秒的 也只需要六十多个积分,这就是吉梦的一个低积分的一个玩法。我们在前几期已经给大家讲过这种方法,但是有很多人在评论区和私信就问说能不能展开讲一下,详细讲一下,他们也想使用这种方法,毕竟不是每个人都有很多积分,那么我们今天就把这个好的方法分享给大家, 大家如果觉得有用,那么就在关注点赞,我们后续分享更多的好方法给大家,如果觉得哪里不好用,你就在评论区里面留言,也帮同行避避坑啊。 首先我们先教给大家,你们一进来的画面是不是这这样的,都是这样的对吧?然后我们点击视频生成,然后正常情况下你们进来是首尾帧,我们看一下啊,对比一下十五秒的视频大概要多少积分,十五秒的视频是二百一十个积分,如果首尾帧的话,正常情况下全人参考其实也是一样的。 然后我们在这里选择智能多帧,你看见没有,我们可以测一下数啊,这里随便生成几个字, 然后调整一下时间。智能多帧的方法和这个普通的首尾帧肯定不一样啊,我们待会会教给大家怎么来使用,在这里我们已经把时间凑够十五秒,十五秒大家可以看一下,十五秒就三十个积分是吧?所以我们用的其实就是吉梦的一个 二点零模型的一个雏形,就是我们以前用的一个一点零,他也算是现在模型的一个底座吧, 这个模型他也有好的地方,也有不好的地方,待会我们一起来看一下啊,但是他的性价比还是蛮高的,我们可以看一下,我们就找这个三十多秒的一个视频,这个视频比较完整一点,我们可以来看一下,叫这个视频。我们先来看一下画面啊,这个画面就是 我们从一镜到底,然后本来是一个演示视频,只有两个人物说话的时候,你看有近景有远景,然后人物快速走开,一个演示视频,后面的书生跟上来,他也给一个特写,然后说几句话,继续开始生成一个演示视频,算是一个故事内容, 看画面还是挺不错的,是吧?然后我们来看一下我们所做的工作,首先我们的这个画面就需要很多图片, 这是我们的一个故事的一个主体,整个内容他肯定就是说从这个城市里面,我们一张一张看一下,从城市里面的一个远景,如果打不开,我们就看一下小的画面吧。从城市的一个远景,然后到一个近景,一个场景的一个图片,然后到人物的一个特写, 然后最后我们又回到一个远景上面,后面我们书生来了,讲几句话啊,最后又回到一个城市的远景,还深层的一个城市的变迁,我们这里可以看一下,还可以看得到每个镜头运镜,看见没有?他中间可以看得到每个镜头的运镜啊,他人物都有在动,我看一个长一点的 这个方法,所以还是有非常多的好处啊。然后我们当大家刚才看了他还有一些缺点,比如说没有声音,比如说他需要很多图片,那么我们这些图片怎么来呢?我们今天就主要给大家展开讲一下这些问题。首先这个图片它实际上还是一个故事的一个完整性。 跟我们有些有经验的朋友,他之前是做九宫格图,然后把九宫格图往里面一扔,让二点零他自己去理解。而我们的方法就是把九宫图九宫格的图拆出来,拆成每一张,然后只是在中间写一个提示词,我们可以看一下, 继续深层延时摄影视频,人来人往的啊,唐朝时期的百姓参观啊,斗转星移,四季变化怎么怎么样的,后面有一些高清啊,一些,这个叫我们叫条件嘛。 然后我们用两张图片把它连接起来,就像我们的首尾针,其实很多人他之前也在私信问他说首尾针他知道怎么形容,但是这个智能多帧形容太多了,其实也是一样的,我们首尾针形容的不是说他的首帧图片和尾帧图片,它形容的是图片两者中间的关系,你从第一张图片怎么到第二张图片, 所以它中间形容也是一样的。而且这个一点零它也不需要很多字,大家可以看一下,它也不需要很多字,它就能理解你的意思。还有一点零它是不用等的,大家可以试一下啊,不要说高级会员,就是你普通会员你也可以不用等,因为很少有人用,有人用,这个你可以试一下, 一秒钟都不用等,直接就可以生成出来,这是他的一个非常大的一个优势,然后他的缺点就是他没有声音,声音咱们放在最后来解决,好吧?我们先把你的智能多帧的图片先给大家再详细说一下,然后我们这是一个故事的整体,我们给大家生成,我们可以看一下啊,看一下这里 故事版本的一个图片参考图片,我们给大家点开出来,看我们是怎么把这个图片一张一张的来生成, 大家可以看一下我们第一张是近景是吧?然后生成图片也很简单,就我们往后退一点不就行了吗?这也是一个运镜啊,两张图片相当于一首尾声是吧?往后面退一点,然后 我们需要他人来人往,没有人的场景,我们就直接去掉里面的人物就行了。每一张图片就是上一张图片的一个,在同一个场景里面发生,就只需要去掉一些元素,所以从深图上面来说也挺简单的,你看见没有?上一个人啊,仰望着这个高楼,对吧?下一个人我们就回过头来, 就很简单,就没有什么难的。所以别看图片很多,但实际上它就是每一张生成。然后我们看一下这个画面,大家可以看一下这个画面,我们给大家讲一下这个画面,你们就明白了, 就这个人物画面我们可以看一下啊,我们实际上逻辑就这样,比如说这个人我们要作为他一个抬手动作, 当然其实抬手动作一点零也能理解,只是我们比较懒,你看见没有,我们做的是二十多秒的视频,我们想让抬手动作更细致一点,那么我们就在里面加一点,我们大家可以看一下,第一张图他还没有捏拳头,还没有愤怒,然后第二张图他已经开始捏拳头了,看见没有,第三张图 就开始抬手了,第四张图手已经砸到一半的地方了,第五张图已经砸下去了,是吧?当然这个图 其实他就简单做一个抬手动作,一点零也可以,只是我们不想拆开,因为我们长视频做惯了,这种更节约时间,其实对我们来说啊,就是深图,这个我们已经习惯了,这种深图也很简单,其实你就形容就可以看见没有,上一张图啊,还很和悦,还很平静,下一张图就很愤怒,然后捏拳啊,准备砸东西, 再下一张图,保持愤怒,然后把手举高,或者举到多少多少度,就像我的手一样,你现在我如果要打人,我现在就 举到一百八十度,然后你再下一张提示是这样,举到二百七十度,再三百多度就行啊,这种描述来说,对于我们来说很简单。然后我们再给大家说这个声音啊,包括这种声音,你看, 首先我们说他的 bgm 就是 背景音乐,有经验的人,他知道他每一个视频生成出来的背景音乐,无论你是哪个软件,他生成的视频背景音乐都是不一样的,你不可能接得上,所以我们到最后剪辑的那一步,会把所有的背景音乐都是不一样的,你不可能接的上。所以我们到最后剪辑的那一步,会把其他画布里面啊, 我给大家看一下,我们在画布里面也是不需要这个提示词,我们全部都会写,不要背景音乐,不要背景音乐,随便听,看见没有?不要字幕和 bgm, 所以 我们全部都会写, 所以背景音乐是没有用,我们到后面会整体添加一个背景音乐,舒缓的就舒缓的,激动人心就是激动人心的,对吧?然后就是它的一些音效,比如说这个砸东西,嘣嘣嘣砸东西,这里音效 剪辑的都知道,音效就很好找,是吧?然后就是他说话的声音,说话的声音我给大家说一下,首先呃,剪映里面有这个朗读,你可以自己生成一个字朗读,或者我平时喜欢用什么呢?我平时喜欢用这个,我平时喜欢用配音,生成就是一个积分,无论你说多少字都是一个积分,随便打几个字就行, 就是一个积分,然后你把音色扔进去,你想要他模仿谁的音色扔进去就行了,所以他这个还是蛮简单的。然后你们就是合理选择,这个合理选择就像我们自己一样,首先他的画面整体还是不错的,但是他需要一个长图,需要很长的一个图,大家看见没有?需要很多图,但平时我们正常做矩形,他也需要一个分镜图。 然后就是他没有声音,声音需要后期配,这会耽误一点时间,但是对于我们来说,我们前面制作又节约了很多时间,所以各取所需,那他的优势当然就是时间可以长,然后积分也少,还不用等,大家可以随便试一下,就普通会员就不用等,我今天没有没有积分呢?或者说给你们试一下吧, 试一下这种方式他是真不需要的,只需要一分钟,只需要一分钟就可以伸出来这里试一下,我就准备视频就讲完了啊,你们有什么需要了解的就可以回头评论区或者私信都可以啊,我有时间就会给大家解答。看见没有?四个积分啊,就两 就一个视频看见没有?四个积分,我们划到最下面,预计超过一分钟,也就是说虽 他不止一分钟,也就是几分钟的时间他出来了,所以他不用等,你们也可以自己实操一下,所以他有很多的优势,但是有很多的缺点,大家合理选择。好吧,后面我们再给大家分享其他的一些好的方法,或者说一些低积分的一些方法,记得点赞关注哦。
520老钟不老(AIGC) 01:37查看AI文稿AI文稿
01:37查看AI文稿AI文稿你上传正人人脸用 cds 生成视频的时候,是不是总是遇到这样的这样的这样的提示?那我之前分享了,我用我和我女儿的形象做了一个短片,这个短片其实是用了三条十五秒的视频拼到了一起,但是验证了我的方法可以做到让多条视频相对的保持人物的一致性。 很多朋友也在评论区留言,让我去分享一下,那这条视频就是讲一下具体的方法。我先说清楚,极梦的 app 和豆包的 app 我 不懂,我这十几天一直在用的是极梦的网页版和小圆圈,尤其是小圆圈的网页版和 app, 我 觉得他们的模型能力会更加强一点, 用的最多,所以说我讲的仅限是我知道的方法。我先给大家看一下,我今天上午为了做条视频,专门又验证了一下我的方法管不管用,又在疾风网网页版跑了一条视频,他是明确说不让使用真人人脸的。 大家好,今天我给大家带来一个数字,那这条视频我用的就是我的形象,我的声音,怎么做的呢?方法就是把自己的人脸照片生成一个四宫格就可以了,先自己拍几张照片,最好是不同角度的,然后用美图秀秀拼个四宫格 c 单词的题时词就直接说人物形象,参考艾特你的照片就可以了。我女儿呢,用的是三宫格,反正就是两张以上的,应该都都是可以的。目前是极梦的网页版和小园区的网页版,使用下来都是没问题的。 很多人也说用素描,我觉得真人照片效果更加好,素描是 solo 的 玩法,那这个小技巧呢?我也不知道能够管用多久,如果说有其他更好的方法,欢迎各位可以分享一下。
436大麦AI笔记 00:41查看AI文稿AI文稿
00:41查看AI文稿AI文稿把这样一张图片喂给 ai, 就 能得到一段指定动作的视频。不仅可以做这样的偶像跳舞、街头篮球的复杂运球动作,同样也能驾驭三十秒。教你学会用这种分镜版图片制作视 频。首先把这两段提示词喂给 gpt 的 mh 二模型,就能得到完整的分镜版图片。 然后孟老师这里选择视频,生成 cds 二点零模型,全能参考,选择十六比九,时长十五秒。先把分镜版图片放进去,只需要用这句非常简单的提示词, ai 自己就能读懂这张复杂的分镜版图片,然后生成动作复杂的视频。
1581AI珈一 00:47查看AI文稿AI文稿
00:47查看AI文稿AI文稿今天学这个农村大妈吵架,在合适的位置截屏一下,用这个提示词,你就可以给图片高清处理。用这个提示词提取出人物,做成角色图,用这个提示词就可以生成场景图,用这个提示词就可以生成十六宫格故事版。 重点来了,打开我们的老朋友,选择视频生成上传制作好的图片,选择这二点零全能模式,比例选择十六比九,视频时长十五秒。把图片全部艾特到对话框,输入动态提示词,提示词先用我的,也可以修改自己想要的打斗动作,点击生成,静等片刻,视频就生成。好了, 我们下期见。
89527nmAi


猜你喜欢
- 2.6万中道