很多人学 lincoln, 卡在名词太多,最后只会复制代码。今天我们只抓四个核心模块和一条实战路径,让你知道每个模块负责什么,何时使用,出错怎么排查。学完就能自己拼出一个可运行的 agent。 这节课目标很明确,不是被概念,而是能上手。先认识 chain、 agent、 tool、 memory 四大模块,再理解 l、 c、 l 的 管道写法,最后跑通一个带工具的 react 势力,并避开旧版本废弃 api 的 坑。 小白最容易把所有概念混成一团。一个好记方法是分层看,底层是组建积木,上层是业务能力。先把底层组建理解清楚,再拼上层流程,你调试时就知道问题出在提示词、模型、工具还是流程编排。 l、 c、 l 的 核心就是把多个步骤像流水线一样串起来,你可以把它想成前一步输出,自动为给下一步输入。最常用是 prompt 到 l, m 到 parse。 先用 invoke 跑通单词,再用 batch 做批量,最后用 stream 做流式展示。 a 阵选错工具常见根音是工具描述写的太泛,你需要在 docstring 写清触发场景、输入格式和返回内容。工具名也要有区分度,避免两个名称和用途过于相近。俯视模型或在用油时会降。 记忆不是把所有历史都塞进上下文,而是有规则的保留关键内容。短期窗口适合快速响应,长期记忆适合跨轮次任务。你至少要做三省隔离和容量控制,否则上下文会膨胀,成本和错误率都会上升。 react 就是 思考、行动、观察的循环,对小白最有价值的是可观察性,打开 verbos 后,每一步都能看到你。遇到错误时,先看是哪一步失败,是工具输入不合法,工具返回异常,还是模型解析格式不稳定。 建议你按三步推进,避免一次做太多。先用 l c l 跑通最小问答链,再加两到三个工具做多步骤任务,最后接入 memory 做多轮对话。每一步都先验证可运行,再考虑抽象和优化,进度会更稳。 今天你已经有一套可执行方法,知道模块怎么拆,链路怎么连,报错怎么看。下一步直接把事例改成你的业务问题,例如知识问答或任务助手。先跑通小闭环,再逐步加工具和记忆,你就能稳定做出自己的 a 针。

粉丝997获赞4153
相关视频
 01:50查看AI文稿AI文稿
01:50查看AI文稿AI文稿说一下你是怎么利用狼犬的链式调用来简化开发的步骤,面对真实环境的痛点,你又是怎么样落地解决的?狼犬的核心就是通过 runnable 协议和 l c e l 声明式编程简化链路开发,不再需要手写大量异步异常和格式兼容代码,用管道符直接串联 prom 模型解析器, 一套代码就支持同步异步批处理和流程调用,开发的效率明显提升。同时,它做了消息格式标准化, 不同大模型的消息结构被统一抽象,不用再做格式适配,再配合声明式工具绑定组件化,可拔插性很强,换模型基本上不用改主逻辑开发和迭代都很轻快。 在生产环境里面,主要就解决三个核心痛点,第一个就是网络抖动模型限流和报错,通过尾轴一串自动重试组备模型 forback, 实现服务之欲,保障可用性。 第二个就是响应慢,体验差,使用 sstream event 做流逝事件推送,把思考、解锁等中间状态实时透出,降低用户等待焦虑。第三个就是复杂的业务链路容易跑飞, 结合 block graph 把流程做成状态机,加上 checkpoint 断点恢复,支持循环跳转和异常恢复,保证复杂多轮逻辑稳定可控。简单来说, block 用统一协议降低了开发成本,用重试降级流式输出保障线上的稳定性, 再用图执行引擎处理复杂业务,真正满足了生产级的稳定、可扩展、可维护的要求。我已经把二零二六年大模型进阶的最新路线整理好了,如果你也想进阶大模型,我可以给你一份大厂内部必读的文档, 里边包含模型原理、产品落地、思维框架,内容非常全面,需要的话我直接安排。
73跟着扶安学AI 04:08查看AI文稿AI文稿
04:08查看AI文稿AI文稿我看你的项目里用到了 lincoln 生态,那你能聊聊 lincoln 和 landgraff 的 核心区别是什么吗?另外,为什么新版本的 lincoln 底层要转而使用 landgraff 呢?好的面试官,在回答之前,我想先稍微理清一个小误解。其实新版 lincoln 并不是在底层直接替换或强行使用了 landgraff, 它们更像是一种证交、眼界互补、分层的关系。如果非要用一句话来概括它们的核心区别,安全是一个面向 lm 应用的通用组件库,加现行编排框架,它帮你搞定模型、封装、提示词 工具,调用这些原子能力。而 lan graph 则是专为复杂 a 件的设计的有状态待循环的图,计算运行时, 他的本质是一个状态机,专门用来解决那些需要反思、从事人工干预的复杂工作流。 如果把两者的差异拆解到研发实战中,主要有以下四个关键维度,第一,控制流的表达能力。传统的软圈链,比如基于 l c c 的 管道,本质上是单向无环的限性流, dck 虽然有路由,但很难优雅的表达。 i m 生成工具 执行结果不满意,返回 i i m 重新规划这种带有循环的复杂逻辑,以前的 a, g, t, c, q 的 内部写实的硬编码循环非常僵硬,而 line graph 底层基于图结构,天然支持有环图、动态边和条件分支。 第二,状态管理的严谨性。 linq 的 memory 机制大多是外部附加的数据流,在复杂的链中容易藕合,不透明。而 lan graph 强制要求所有节点必须通过一个统一的可虚拟化的 state 对 象,比如用 p n t 或 type d d t 定义进行输入,输出 状态的变更,在每个节点上是显示不可变且版本可追溯的,这就让状态管理变得极其干净。 第三,人际学同与调试性。在构建企业级 a 卷的时,很多关键节点需要人工审批,比如大额转账、发送邮件。 line graph 天生支持图的中断与恢复, 可以非常轻松地插入人工干预节点。同时由于它基于图的快照机制,我们能看清每一步的 state 变化,配合 lsmith 做可观测性和调试,简直是降维打击。 第四,扩展边界。 lan 嵌的嵌更适合做管道式的 e t l 或简单问答任务,而那个话甚至自私节点内嵌套子图,可以用来对接外部事件总线,实现复杂的事件驱动架构。 好的,那你刚才提到新版本并不是底层实用,能具体聊聊新版 lan 嵌,比如 v 零点三加的架构眼镜逻辑吗? 为什么官方会大力推 lan graph? 我 们可以回顾一下 lan chain 的 眼睛路径。在 v 零点一的时候,官方重点在做基础链式调用和组建堆砌。到了 v 零点二,官方做了一次大手术, 核心就是模块解偶和统一 runable 接口 l c s l。 而到了现在的 v 零点三加,整个生态的分层已经非常清晰了。底层 run time 依然是基于 l c s u 的 runable 接口 callbacks 机制和实时处理。上层编排方式明确划分为限性所简单条件编排和复杂图状态及编排。所以 lan graph 并不是去替代 lan 圈的基础链或者底层调用,它依然在疯狂呼用 lan 圈的 prom template、 lm 封装和 output 的 parts。 官方之所以力推 lan graph, 是 因为老版本的 agent 已经无法满足工业级 a 剪的高可用需求了。 向无法建模、复杂循环状态难以共享、缺乏人工干预机制、失败后无法从断点恢复等痛点,在旧架构下都是布丁碟布丁。 line graph 的 引入,标志着 lincoln 团队的思考从现行的函数组合彻底迈向了可编程的状态图。 他补齐了安全生态在高阶 a 键的编排上的最后一块拼图。我整理好了一份大场面试题和学习文档,里面就包含了整个 ai 产品的研发流程、大模型的未来发展方向,以及 ai 产品当前存在的一些问题,想要的我可以安排。
1209大厂阿星 08:16查看AI文稿AI文稿
08:16查看AI文稿AI文稿好,那接下来我们就可以在这一步通过大模型来接入了,怎么接在这块呢?我们来一个 ai engine, 大 模型引擎啊,或者叫 ai agent, 在 这块里面呢,我们假设就只有一个 index 啊,这个呢叫做根音分析的吧,比如是叫做 arrow resistorresistor, 就是 一个问题解决器的智能体啊,那用什么呢?两个插件,第一个叫做 nonchain, nonchain 下面的 non graph graph 啊,版本的话等一下再说。还有呢,需要用一个 long chain 的 欧莱玛,这两个是必须的啊,这两个必须好安装一下,安装之后呢,看版本,这个是一点零点三,看上面这个版本是多少?一点零点二, p m p m i。 重新安装一下,安装这两个插件之后我们就可以来去做开发了。嗯, 好,当然呢,我们还缺少一个啊,就是如果为了颜色什么更好看一些呢,还有个 piccolo color, 这个我们在很早之前就跟大家说过啊, piccolo colors 这个插件版本的话呢,选择一点一点一吧,片片埋就可以了啊, piccolo color 干嘛的呢?为了让那个控制台的交互更好一些,比如说我导入这个 piccolo color, 就 直接来个 pc 啊, pc 好 了之后呢,这里我们的 console log 呢,改一下,就不要用这种形式了,就直接来两个报警的内容吧,比如说 在这里给它写一下,我们不用 console log 了啊,不用 console log 这个地方呢,我们改一下,用 process 点 s t d i o, 直接 pc 导进来啊,比如说把 pc 的 样式呢,给它改一下,假设说捕获到错误,然后呢,正在去做这个紧急诊断保存,我们再来给大家演示一下 build, 哎,这个时候大家发现了吗?检测到报错,构建中有报错,然后呢,正在紧急诊断,诊断什么呢?接下来就开始正式的诊断,诊断的内容在我们的 ai agent 里面去实现 啊,别忘了导入什么内容呢?比如,比如第一个就是啊,但我这一块也跟大家详细的去说明啊,就整个开发的一些步骤过程的话是什么样子的,这块也跟大家去说明, 其实就是应用两个东西,第一个呢是从 nonchain graph 里面呢,拿到 create agent nongraph, nonchain nongraph 里面的有个 create agent, 这个不知道怎么没有提示啊。然后呢,再从 oalanama 中间 拿到那个 chat oalanama, 好, 这个把它拿进来,拿过来。呃,这个 nongraph, 看一下这边好像写错了吧, 那我们直接重新装一个吧,装这个 long chain 一 样的啊,一个是 long chain long graph, 这两个是一样的,根据我们这个的呃提示呢,大家可以下来之后把课间里面写的这个啊,对照着,一点一点往后来看,也能够实现这个功能,主要是消息还有提示那些,把它给。对啊,然后呢重新安装一下,在这里呢,导入的 就变了,就不是。好,我们在这边导入吧, create agent 啊,导进来。好,有了这个 create agent 以后呢,接下来我们就开始往外面去返回一个方法啊,它用来去做这个诊断,叫 handle receiver, 这个时候你肯定要传进来这个 arrow 嘛,对吧? arrow 的 话,我就我的内心呢也是个 arrow。 好,接下来我们就从 arrow 上面去拿到它的内容,比如说它的名称,它的 message, 它的调用站啊,这三个东西呢,我们全部都拿到了,拿到以后,当然其实你这边在给它去做这个提示的时候呢,也能够做得更清晰一些啊。就比如说这里 你除了把报错的内容给它拿过来,呃,还可以在这边给它写几个别的数据啊,比如说第一个在这儿呢, 就直接把当前的叫 arrow 点 name, 然后呢还有 arrow 点 message 全部给它给过去,那再来 build 一下,这时候是不是都看到了一个是检测出错啊?但是如果说你这一部分里面为了跟前面有一个换行的话,最好你在前面这里呢也加个杠 n, 这样的话就比较整体一些了。检测到报错什么错呢?是这个错,这个错怎么办呢?正在去做紧急的 检测啊,怎么检测?那接下来就到我们的智能体开发里面了,我们呢可以把模型先定义出来啊,比如假设我在这呢拿一个简单模型吧,就直接切到欧拉玛里面呢,把你的模型选择一下,当时我们现在用的是千万三零点六 b 的 模型 导进来啊,什么温度, temperature 这些呢,全部自己去配置。我们在给大家去讲这个项目实战的时候,就刚才给大家去演示了,就是 对应到我们最终的一个项目实战的时候呢,会详细给大家来给大家说明,就是这些参数的含义啊,什么是温度最大头肯数,还有 top k、 top p 等等,这些参数的话怎么来用?在什么时候用它对于你的模型有什么影响?这个在我们后续给大家讲妙码 ai 智能体工作流的这个项目实战的时候会给大家来说明啊,就在这个 最近的啊项目实战的时候会给大家去来介绍,所以呢,大家如果要整体学习的话,可以赶紧加入进来之后呢去找咨询老师去了解一下啊,加入进来以后就可以去学起来这个项目,年后的话直接拿这个项目去找工作,横着走啊。好,那把这个内容拿到之后呢,我们肯定先建一建一个提示词,这个提示词的话简单随便建一个吧,比如说 prompt 等于什么?我们就直接呃当前的错误出错了,然后呢错误是什么?把这些错误呢给它都放过来,这是错误名称,还有呢错误的信息,还有一个是这个 stake 调用站啊, 请根据给出的信息啊,然后呢帮我梳理问题,并且给出解决方案, 给出解决方案。好,这样呢,我们接下来就可以直接去调用了,那当然这是异步,异步调用呢,我们直接将它改为异步加接下来 r e s 获取的结果就直接通过 啊,当然我这里需要创建一个智能体啊, agent 等于什么呢? creator agent, 把参数传进去,这个里面的模型啊, model 就是 我们上面定义的那个 l m。 好 了,那这呢就是直接 agent 点 invoke, 说实话啊,把它的消息呢传进去,消息里面有哪些消息? message, 比如说就是你的这一个 prompt 传进去啊,把这一个 prompt 传进去, prompt, 接下来就能够得到结果,我们可以把这个结果呢打印一下 r s 点 knock r s。 好,我们来试一试,当然这个没有引进来啊,我们在 ai 的 这个插件里面去引入一下,直接 import 导进来,就是我们刚才的点斜线,点点斜线吧, ai agent 下面的 arrow reserver 叫 handle reserver, handle reserver 在 这个下面,这里看好了 handle reserver, 当然它也是一个异步的,异步的话我们 await 把错误传进去,这不就可以了?好,我们再来试一试,直接构建, 当然这一步没有等待它,这是错的,对吧?这里呢,我们应该把它变成 aic await, 然后再来到这边也是一样, await 它才可以啊, await 它才可以。当然这一步呢,我们上面给出了,给错了,应该给到这儿 aic await。 好, 我们再来执行试一下,接下来你就可以看到 它在等待,它在思考,思考完之后,你看是不是所有的信息都帮你打印出来了。好,打印出来这些错误信息之后,你看这是 message 的 信息,它给你返回的信息呢?在 response content 里面。那,那我们接下来可以在它里面去把它的 response content 拿过来,点 resp 这个 content 上面得的结果啊, response, 就 我们这边的这个参数嘛,这边 ai message 下面的结果就是返回的啊,就这块返回的 messages 里面的结果叫 response content, response content 把里面的结果给它返回来。当然如果我们一般要做结构化处理的话,其实更简单,就直接在这儿做结构化处理来给它去做一个加工就行了啊,就这个 r e s 这一块。
 19:26查看AI文稿AI文稿
19:26查看AI文稿AI文稿那首先给大家解释解释一下 lan ching 的 表达式啊,简称 lan ching 的 表达式,简称 l c e l 啊,它叫 lan ching expression language 啊,那就是 lan ching 的 表达式表达式语言吧, 其实它的用处就是使用了竖线运送符来连接 lan ching 应用中的 lan ching 应用中的各个组件 啊,就是把各个组键使用竖线把它连起来了,每个组键我就把它称之为叫节点啊,我们一般来说是每个组键叫节点了 啊,把多个组键使用竖线连在连在一起组成一个链,那这个链呢,其实就完成了某一个复杂的业务逻辑, 未来我要根据不同的复杂业务逻辑来定制各种各样的不同的念,听了吗?啊,这样子的话呢,你的这个呃,这个大冒险的应用开发哎,就能实现了啊,就复杂的一些需求就能实现了。 好吧,好,后面的我就不去念了啊。好,后面不去念了啊,然后接下来我们要学什么呢?学 l c l l c e l 的 语法啊,学他的一些基础语法 啊,然后学完语法之后呢,后面我们再举几个综合案例,你大概就知道 l c e l 怎么去用了啊,那么它的语法的知识点呢?有这么几个啊,有这么些啊,分别是 round 结点,结点的调用以及批量和流逝运行。 怎么样是组合成链啊,然后呢,调用链的时候有横,有并行调用,还有什么呢?还有这个串行调用 对吧?也有并行的啊,老师,那刚刚你这个是什么?刚刚我们这个案例是是是,是并行还是还是串行啊?对,是并行还是串行呢?很明显是串行啊,这不是并行的 好吧?不是并行啊,并行什么意思啊?就是各个组建啊,这是一个组建这是一个组建。这也叫节点啊?就是各个组建啊,他是同时读取一个输入,同时进行预算和技术和和调用啊,然后同时得到输出。 当然了,你输出完之后呢,你可以把这些输出的数据了进行聚合,这也是可以的。好吧,这记住。同时 啊,那这个海面不是同时啊?你看先是执行完提示词,提示完词之后再加个大模型,大模型完了之后呢,才能解析啊,不能一上来就解析,对吧?所以这类只能是创新。但是有些需求是要并行的 啊,所以并行调用,然后合并输入和输出字典。因为在在一个复杂的面里面,我们的数据啊是变来变去的,对吧?是要转换的 啊,为什么呢?因为下一个组建他的需求啊,他他所要输入的数据的格式跟你上一个组建输出输出的数据的格式不一致,那不一致的话,你需要把这个数据干嘛变成一致的?变成一致的你要干嘛?那要么就是合并合并输入,或者 或者是定制化一个新的输出,那定制化一个新的输出,这个新的输出刚好满足下一个组建的输入的要求。 我不知道各位能能理解我这句话的意思没有?我给大家画个图啊,就我们的念,大家都这个,这个相信大家都明白啊,就好好比是一条什么一条锁链一样,这这这只念啊,这个念呢?我们 long chain 这种就叫做嵌。 好吧,那这一条链里面有很多很多的组建,或者让很多很多的节点组成,好吧?比如说,哎,我们,哎,我们这里假设,呃, 怎么取消啊?重新来吧。假设,哎,我们这里有一个,呃,有一个,有一个节点,节点用这个圆圈吧。好吧,好,这个节点,这个节点,一号节点啊,然后呢?他还有一个二号节点。 二号节点啊,但后面还有啊。好,那这里假设这是一个链啊,当然这个链是其中一部分,我只只考虑一号节点和二号节点啊。一号节点是一个组件,二号节点也是个组件。 好,那照这么说的话呢?是这样子的,一号节点他计算完之后他会把输出数据传给二号节点,然后再执行二号节点啊,因为我们这个链呢,很明显是什么?是一个串行的,对吧?串行的啊,就是先执行一,再执行二,是这个意思 啊,所以一号节点的输出数据是二号节点的输入数据,这句话听懂没有? 没问题吧?好,但是在有特殊情况下,由于这个爱好组建或者爱好节点,它的输入数据,它的格式是输入数据的格式和你一号节点的输出数据格式是不一致的, 有没有这种可能性啊?这种可能性我跟你讲在以后的实际项目开发过程中是经常碰到的,因为你的需求是各种各样的嘛,对吧? 而且你没这个节点,这一号节点可能是可能是张三开发的,二号节点是李四开发的。嗯,张三开发跟李四开发的,他的数据拿到先商量好保持合适。百分之百一样吗?百分百一致吗? 那肯定不是肯定肯定肯定没这么没没没没有,没有,这么商量那么好,对不对?那肯定有不一样的地方,那不一样怎么办呢?那像这种情况下干嘛呢?我们就要重新在一号二号中间再加一个什么了,再加一个这个输入数据的处理, 处理完之后符合你二号节点的格式了,再把它传到二号节点上去,那等于说这里面在一号二号中间再插入了一个新的组建了,这里面也是一个组建啊,插入了一个新的组建了 啊,这个这个意思啊,还有后备选项。后备选项什么意思?比如说某一个节点报错了,或者某一个节点因为网络不差,没办法搞定,那怎么办?哎,那有后备,后备任务就就是这个节点执行不了了,那我们可以有个备用节点去执行, 保证我们整个链是正常能运行的。啊,这样讲应该好理解吧?啊?先把每一个概念给你讲清楚先啊。好,然后重复多次执行。 roundball 节点啊,这个大家都知道啊, 条件够建差,条件够建差,这个应该大家能理解吧?比如说我们现在有一个链,这个链里面有一个一号节点,一号节点它的输出数据啊, 我们要根据一号节点的输出数据的情况来决定,比如说一号节点他输出的数据是一个数字,这个数字可能是五,那根据我们的条件大大于等于五的走二号节点啊,然后小于等于五的,小于五的,我们走走三号节点,是吧?那这不是条通过条件来构建点吗? 是吧?好,还有 map 高阶处理啊,以及打印那打印嵌的图形以及身份周期管理啊,好,快速说一下那这些语法了,我不知道各位是不是有学过啊。呃我们要重点详细的要给大家去每一个都给大家去讲讲啊。好,那我们通过案例给大家去说啊。我不想讲一大堆的理论, 那我在当前这个包下了我再新建一个新的 python 啊,取个名字我叫零三吧,叫 l c l c l c e l 表达式的语法 的语法。 ok 啊,大家一看这个我 p l 文件你就知道是干嘛的了啊。好,那 呃首先呢我们先从哪一个从哪一个知识点开始讲起了?从这个组键或者接点讲起啊。接点?接点是什么?接点就是各种各样的组键啊。什么是是什么是组键?比如说这个 l l m 杠 open i 这个就是组键, 那还有这个 pass 也是组键,还有提示词也是组键,对了吗?哎那老师那这些组键都是什么?都是南唱给我们提供的。那可不可以是我自己定义的组键呢 啊?比如说比如说我我我要干嘛?我我我是要执行某一个函数,哎这个函数就是一个组键,可不可以啊?当然可以。 好吧函数也可以是一个组也可以也可以是一个节点啊或者叫节点。好,那节点它有标准的它有标准的啊,什么标准呢?就是必须都实现了 runable 接口来进行封装啊,这个标准就是 runable 啊。好,那举个例子啊我们假设我们构建一个节点啊,我们这个节点呢我们就不用,我不使用这个狼倩给我们提供的,因为狼倩给我们提供的一共就那么多嘛?不太多嘛,一共最多我们学个八个七个八个就不就 ok, 就 学完了, 就狼倩给我们提供的这些组建常用的也就是七八个。以后啊,在实际项目开发当中,大部分都是你自己定义的组建啊,或者某工具作为组建 啊,那这个工具也是可能也是你自己定义的,或者是由别人提供的,或者是由第三方的组织给你提供的啊,都可以啊,总之这个节点很灵活的啊,可以是你自己定义的函数,可以是别人给你写好的工具,或者是网络上给你提写好的工具,都是可以,都是可以作为节点的 啊,非常灵活。那这节课呢,我们就使用啊,我们简单一点啊,因为我们讲语法嘛,那我们就使用函数来作为一个节点啊,那函数作为一个节点的话,那首先我们先定一个函数,我们定一个最简单的函数,所有人都能看懂啊,这个函数我们叫 taxi, 传一个 int 类型, 好吧,然后呢,我们做一个加法计算,就是让 x 加上十,没了,就这么简单,就是你给我传一个 x, 然后我让 x 加上十,并且返回传一个二,那返回十二,传一个五,就返回十五,就这意思, 那假设,哎,这个假设,这这是我就当我是模拟一下,哎,这就是一个非常复杂的函数,非常某非常复杂的一个业务,那我能不能把这个业务作为一个节点呢?可以的,但是你不能直接把这个函数名拿过来啊,它是要封装一下的,封装成我们的 round 接口啊,那怎么做呢? 可以这样做啊,那这个节点了,我叫 r e, 算了, r e 等于 roundup, 大家,这个,呃哦, roundup, 这个 lambada, lambada 应该大家都知道,是 python 里面的一个很重要的叫命名函数,是吧?好,然后把这个函数啊 text e 传进去 啊,记,记住啊,这个 type c 后面接不要加括号啊,我只是把这句话的意思就是说把函数封装成一个节点或者一个组件,把函数封装成一个组件 啊,好,格式化一下,然后呢?那,那这样子的话,我们这个函数就可以把它就可以,就可以把它放到念里面去了,或者让就可以组合成念了 啊,但我们先不组合,先,我们先给大家讲讲,讲讲每一个组键或者每一个念它的调用 啊,那调的话呢,一种是普通调了一条 inwalk 就是 普通调,还有一种什么批量运行,还有是流逝运行啊,这几种,这几种调要给大家说一下啊,那我刚刚说了这个 r e 呢,就是一个 runble 了啊,这个 runble 我 们就可以去调调它啊,那我们通过 inwalk 就 可以调,你看这个 inwalk 之前我们是不是讲过吗?来 看看是是不是有了一个 rolkefeller, 我 们都可以音就可都可以调用啊,这个 inwalk 就是 调用的意思啊,知道吧,就普通调用,你看这里是不是有个 inwalk, 其实这这两这两行代码是一模一样的,没有任何区别好吧。啊,因为上面这个也是一个 rolkefeller 对 象啊,这里也是一个 rolkefeller 对 象, 都是符合同一个接口的啊,同一个标准的就是这个 roundball 对 象,只要是 roundball 对 象我们就可以调,那么调的时候要不是传三,要要不是传三,根据你的第一个节点要不要传三来决定。 你看你的第一个节点是什么啊?因为我们这里只有一个节点啊,所以第一个节点就是我们的 taxi, taxi 要不要传三?要是要,是不是要传一个数字,对吧?好,那你就,你就需要传啊,那你这样,我比如说我传个四啊,乱写的啊,我传个四 啊,然后呢?他就得到一个 i e s, 那 我们就用 i e s 来接受一下啊,好,打印一下 i e s, 这最简单了,先让大家体会一下啊。你看这就是调用某一个节点,你看是是不是十四?十四是对的吧,因为这个函数已经把它当成一个节点了,或者当成一个组键了 啊,那,那我把这个组键调用一下,或者把它放到面里面调用一下,也就是说这个组键未来会运行。好吧,那运行的时候你只要传入他规定的参数就可以了,那我传的是四,所以他执行完之后是十四啊,没问题,那这是普通调用啊。那么还有一种是什么?是 批量,批量调用是什么意思呢?我们就写按算了啊, 那我批量掉还是 i s 啊? i s 等于啊,什么叫批量掉?这样子啊?我们直接拿着这个 i e 点 bet, 哎,这叫批量掉了啊?批量掉的话,人家看你掉几次,那比如说我掉两次,那你就要传两个参数, 比如说第一个参数我传一个四,第二个参数我传一个五,那什么意思呢?这句话意思就是说我我,我批量调用这个组件, r e, 这个组件我要调什么?调两次,第一次的时候传一个四,第二次的时候传一个五 啊,大概这个意思啊。好,然后呢?我们一样的哎,我们输出一下,输出的话呢,是直接写在直接把这个 print 写到后面算了啊,来运行一下, 你看是不是十四和十五啊,就叫批量到了,当然你还可以传三个参数啊,我只是用两个举例子,知道吧?你批量几次由你来决定,由你什么由你传的这个参数的参数的个数来决定 啊?你到底批量几次?你看我这里是批量两次,对吧?你可以批量三次,四次,五次,六次都可以,知道吧?好,每一次传的参数可不都可以不同,也可以相同吗?是不是啊?每一次都得到独立的输出,你还要再处理,那是你下一个节点要做的事情了 啊。这是批量调用,那么还有什么?还有这个流式调用,对吧?那流式调用的话呢?我们就不能用这种这种了,因为这种流式调用没有任何任何意义,因为流式调用的话,他返回的数据要多,你才有必要流逝,对吧?你返回的数据就是一个,就是一个字母,一个数字,这还要流逝什么呢? 不需要流逝啊,所以接下来我要换一种了,换,换一个,换一个组键了啊,那我叫三 流逝调用啊。流逝调用我相信大家其实已经能感受得到,比如说我们在使用 deep sync 也好, open i 也好,其实它的输出都是流逝的,这个其实就是一个流逝调用过程。 你看我问个问题啊,今天天气怎么样?明天天气怎么样啊?错了,今天都已经快过了啊,明天天气怎么样啊?然后这里面勾选联网搜索啊,走 啊,有点慢啊,最最近我听别人说这个 deep sync 好 像特别慢,响应特别慢啊。 哇呀,这个 deepsea 还是没钱了,或者访问的人太多了。 好,你看这它就出来了啊。就是看,就是很明显这是一个流逝的输出啊,流逝掉了它其实最重要的就是我要的,我要的是流逝输出啊,一个 token, 一个 token 的 输出啊,现在你看看,看到的就是每一个 token 的 输出啊。 好了啊,我们把这个停掉啊,我就不要这个了啊,就是,我只希望大家体会一下啊,这个叫流逝调用,流逝调用的话就是它有流逝的输出嘛,是吧,那流逝输出你输出内容要多才行啊,不多的话没有任何意义啊,所以我干嘛呢?我要定义一个新的 text r。 好 吧,这个 text r 呢?我,你给我传一个,传一个提示词,括号 t 啊,提示词是字母串的。 然后呢?我跟这个题的词呢?我们说出一句话,好吧,那我说出什么话了?我就把你这句话的每个单词说出一下。好吧,我啥都不做,我就把这个每个单词说出一下。好,那我通过一个破循环, 我喜欢拿到其中一个单词叫 item 啊, e 啊,把,把这个提示词 property 点 split 啊,根据空格隔开,隔开每个单词,然后把每个单词输出啊,每个单词输出的话怎么输出呢?通过 e r 的, 通过 python 中的 e r 啊,把每一个单词输出一下好了,那这这这个函数这个节点就是可以未来我们可以实现流式调用的。 好,然后接下来我们就要开始,就开,就要开始把它一样的啊,把它包装成一个什么呢?就是把这两行代码再执行一下,把它包装成一个 round, 也叫阿姨吧。那前面呢我们可以注视啊。不注视也行,还是还是注视一下。哦这里也注视一下 好。这个呢叫 text r 啊,然后 text r 呢我们要掉 对吧?呃我阿姨要掉。掉的话呢他要传参数啊,因为他的参数他的要求是让你传一个纵状的对吧?不一样了啊。啊那所以接下来你要传的。呃哦你要流逝输出你不能这样掉。对,忘记跟大家说了,一个是参数,一个参数有变化,第二个你要你要想流逝输出的话,你要使用 street, 然后传参数还是一样的,根据你的参数的类型和参数的个数来决定来决定怎么传啊。那我们就传一个参数,而且是自动串的,所以用引号引起来。我随便选一句话啊,我们叫这个 this is dog。 好, 我随便选一句话。那现在呢我们就要输出输出我们打印一下啊,我们做一下这个格式化代码来运行。 嗯这里面我们拿到的是一个什么东西呢?你看这里面我们拿到的是一个窗口对象是不是是一个生殖器? 你看这里面是一个。这在 python 时候如果你学过 python, 这个你做过 python 多年, python 程序员一看这个你就知道 i e s 它返回的是一个什么生殖器。 也就是说你我要我要拿到每一个 token 的 话,或者说我拿到每一个输出的话,我们需要真的这个生成器做一个便利,所以你这个代码不能这样写了,不能直接复制 ies 了。 ies 是 一个什么?是一个生成器?这里返回的是一个生成器啊, 记住。是啊,返回的是一个生成器。好,这个生成器呢,我们要拿到你们的数据的话,要这样子来做, for chunk。 拿到一个 chunk 啊,拿到一个块,从哪里?从生成器里面拿?好吧,那这个生成器就是什么?就是 r e s 嘛, 知道吧?生气。就是 i e s 啊,从 i e s 中拿到每一个块啊。然后呢?接下来我再把每一个块打印出来 check。 啊,这就可以了,来,再运行一下, 你看是不是 this is dog 是 一个一个单词,一个单词作为一个 talking 输出。 这其实就是一种模拟流逝输出啊,但我们这个比较快啊,因为我们这个比较少啊,对吧?内容比较少,输出内容比较少,如果是内容很多,比如说几万个字,那确实非常适合这种流逝输出。
 02:46查看AI文稿AI文稿
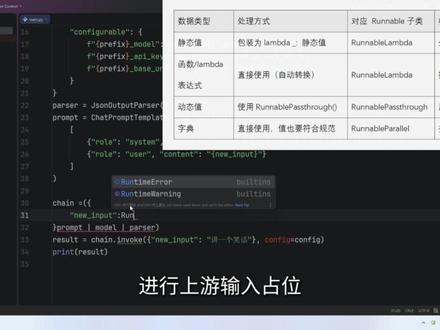
02:46查看AI文稿AI文稿lanchan l c e l 以竖线串联 prompt 模型与输出解析器形成 ai 流水线,数据从左向右流动。竖线运算符底层调用的是 o r 方法, runnable 积累承载了 o 方法,使得所有继承自 runnable 的 组建都能使用竖线进行链式组合。 当执行 prompt 竖线 model 时,调用 prompt 点 or model 返回 runnable sequence prompt model。 继续竖线 pass 时, runnable sequence 承载的 or 方法将 passor 追加到序列中,最终生成 runnable sequence prompt model。 先将变量 l l m 重命名为 model, 以便后续接入 l c l 链式调用。 接下来用 l c e l 语法把三步操作,用竖线连成一条链,数据会沿着这条链自动流转,最后只需要一次调用 invoke 方法传入原始输入就行了。 接下来我们通过编辑返回执行数据的代码,继续学习 l c e l。 记住一点,入列的内容必须是 runable 的 子类字典的职业式 动态值需要用 runnable pass through 进行上游输入展位 静态值使用 lambda 转换为 runnable lambda, 把代码整理好看一些。 接下来我们新增一个函数,将 json 响应内容保存为本地 json 文件, 函数会自动转为 runnable lambda, 直接入列即可。 成功生成 jason 文件了,掌声响起。
52老陈说编程 19:35查看AI文稿AI文稿
19:35查看AI文稿AI文稿ai 大 模型从零开始学第四期 lanking 一 点零实现 r a g 小 案例,上一期我给大家讲了 r a g 案例,很多朋友留言说想要实战教程,今天它来了,今天主播就用 lanking 一 点零带大家走完 r a g 的 完整链路,手把手搭建一个能直接跑起来的 vax 小 项目,把理论变成能落地的代码。 话不多说,我们今天带大家去了解一下囊秤更新的一点零的版本,它的一个特性。你说会通过一个小的案例大家去了解这个囊秤一点零的版本,这也就是我们囊秤的一点零版本和囊秤零点三版本的一个区别。从第一个我们是会先了解囊秤这个 本身他的一个发展历史,那么囊秤本身就是一个开大元开发的一个模型,然后是用来驱动应用程序的一个框架,它的出现呢也就意味着我们可以在之后开发大元模型,可以节省很多造轮子的时间。 那么他的发展历史是什么?首先当这是我们对他的菜市在二零二二年十月创建的,比如说我们整个的 大模型的发展历史是比较短的,他是二二年十月创建的,比如说距今也就才定了两年多的时间,目前是担任当胜集团的一个 ceo, 他 在最开始是在二零二二年底,他的菜市是我们在观察这个大模型 火遍火存在的一个问题。我们其实在做开发的时候一定会有这样的问题,比方说会有大量的重复的工作,我们他会观察这个特点,会把所有的功能集成到我们对应当中里面相当于把很多的模块都集成到一起,跟很多的语言的一个发展其实是一样的。比方说我们在 做网站开发的时候,用拍摄其实也是把功能集成在一起,那后面会慢慢的形成框架。像对你的这个架构和架构的一些 解决这个问题呢?它是在我们用的,是为了去解决我们可组合性将模型、提示词、缩影和工具抽象成一个标准的工具,让开发者能够通过组合这些组建来快速完成我们的大语言模型的应用。那这个就是我们 harry sakes 在 二零二二年所发布的第一个版本, 他发布的版本会有以下这几个版本,首先是一个零点零的一个历史,再就是一点零,再就是二点零点二和零点三,那首先是零点零的版本,零点零点几的版本,但这个时间其实是在二零 二二年到二零二三年十二月,其实中间这里是有一年的时间,这个是处于最早期的一个项目阶段,他所做的事情,他就是把市面上所有的 ai 的 使用那些工具全部给他集中在一起, 所谓的功能代码都是包含在一个包里面的,就是包含在囊秤本身这个库里面。而它的作用就是把市面上所有比较流行的或者说比较主流的一些工具和模型都拿过来了,给它封装到对应的囊秤里面, 它那个时候会其实这种情情况是最有问题的,我们 a p i 是 比较变化,是比较频繁的,以及说是不稳定的,就有一些东西我们在拿出出来是比较频繁的一个情况。 在第二个阶段我们就有一个标准化的一个接口,就是零点一零的一个版本。好,那这个版本其实是按四年一月份的时候所发发布的一个首个稳定价格一个版本他做的什么事情?因为我们之前其实是把所有的包都是放在一个文件里面的,那么现在相当于当趁把这些模块给它抽离出来。 就比方说我们囊镇的一些核心的模块,它的底层核心模块是放在囊镇库里面,像一些第三方的,像我们对应的什么 open, 或者像我们对应的第三方模型的是放在我们对应的囊镇的 community, 就是 我们社区库里面。再一个是我们囊镇它自己的一个 编排层部门引入一个东西叫做 l e c l, 那 这个是对应的这个囊镇的一个 language, 就是 我们对标准的开发语言,它是支持,相当于是支持我们对应的练习调用了,就慢慢的有练式调用这个概念了, 它所在一点零的版本,它就是承诺是向后去兼容,这是我们 a p i 的 核心稳定的版本。 第三个阶段其实是在我们对应的零点二和零点三不久的时间,在二四年月份有了零点一之后,在二四年五月份我们就发布了对应的零点三,它最核心的改变就在哪里,重点是将我们对应的依赖冲突进行一个提升我们的 解决我们的一个冲突和一个提升我们一体的效率。它主要的一个细节是什么?首先第一个我们是对生态进行解码,什么意思?就比方说我们最开始像 open i, 我 们对你的 s 派 来,像我们这个是 repack 这样的一个工具,其两个是 open i 这个人呢?这个公司它其实是 open i 里面的一个 所分离出来之后所创建的,像我们乐扣的就是由这个公司所发布的,他们其实相当于把很多的这种合作的伙伴的包单独给它集成了出来。比方说我们最开始都是,比方像这些社区库都是放置在囊镇的 community 里面的, 那么像现在我们合作的伙伴越来越多,他就是给这些第三方的提供了专门的包,比方说我们之前的包是在 community, 我 们现在是放置了对应的会有专门的囊镇 open 这种库 不再是绑定在主包里面,可以去减轻我们的一个酷的本身的一个安装体系。在零点三版是在二四年九月份升级的,零点三是全面适配了这个 p y d n k v i 的 版本,这个鞋更多是对于数据和系列化这一块验证,数据是只可以去增加我们的一个安全性。那这个就是我们在后面零点二到零点三版本的一个更新, 到今年的十月份是更新了对应的一点零版本,这个一点零版本是发布在二五年的十月,他所做的事情是什么?首个主要版本标志着我们对应的框架进入到成熟期,什么意思呢?这个版本之后我们承诺不会再有一个过多的 这种破坏性的更新,不会说对这个下购证进行一个重构了。它主要更新哪些东西?首先第一个是长期稳定核心的一个 a p i 锁定,不再会有对应的破坏的更新,还有一个就是我们会发布了一个对应的 long term, long graph 的 一个一点零 也是在跟我们这个 n 寸是同时搭配的。这一次更新之后,它其实更多的是把重心往对应的 a 帧里面进行偏移,往 a 帧里面进行移动,它很多的一个是对线段进行更新,还有一个其实是我们在这个对 a 帧的 啊,这个更新之后,它其相当于是给对应的 a 帧它有了更多的选择。当现在之后它的很多的核心功能都是往 a 帧进行偏移的,比如说现在 用 n 证开发一个 rek 也可以,但是相对来说它的重心没有在这一块,因为我们之后发展其实主要是围绕着 a 证的进行发展,所以它往这方面去走是无可厚非的一个选择。好,那么在这一次更新里面,它主要提供的核心模块变成了什么呢?看一下在 n 证本身里面啊, 在 n 证更新了之后,它是提供了这些功能,一个是对应的 n 证,还有像 mec 兔,还有像我们对应的 配置,那么这些东西分别对应是什么呢?第一个是关于代理这一块的,先一个来看,第一个是模型,模型还是一样的,是包含了各个大元模型提供的一个当秤的接口和一些具体的细节以及输出的解析机制。这个东西它其实更新之后它的模型因为 我们之前绝大部分还是用当秤的 open i, 它这次更新相当于我们可以通过当秤本身去掉这些模型,虽然它底层依然是封装的 open i, 但是我们是提供了一个 mini 龙 抽象的一个模型的工具,还有一个就是迁移,相当于我们给这个 red 所提供的一个技术支持。再就是 agent, agent 就是 我们 目前的 nang 发展的一些核心机制了,通过代理能够让大模型主动的去调用外部和内部的一个工具,使 agent 能够成为可能。好,接着就是工具,工具它也是单独给它抽离出来了,之前其实是单独的一个小个模块,现在是给它放在 nang 这个包里面了。 好,工具其实是我们提供给 agent 进行调用的,提供给这个 agent 进行调用的一些工具,提供对应的接口这一些。再就是 mid view, mid view 其实是在这一次版本, 但其实还有一些其他小的版本是没有去给它具体具体去讲,我们看到其就是从零点三直接过渡到零点零,但其实在之前它还会有对应的零点四、零点五这种, 我在 mate 二七之前就有,但是在零点三是没有这个概念的,所以我们这一次他相当于多了一个中间键,这个中间键也可以再了解一下,这个消息还是一样的,我们所讲的这个,嗯,小对话,还像我们对用户啊,像我们对模型这些消息信息。好, 那么这个是当称更新了一点零之后,他主要伴随的是这几模块,他有很多东西已经删除掉了, 有模型接入、代理工具和中间件。再就是消息开源是第三方库,什么意思?就是我们当秤它只是一个包的一个模块,它其实是提供了很多的集成第三方的工具,比方说我们会有一堆当秤库,当秤库就是我们核心的当秤的语法, 我们像很多的一些工具都是集成在哪里这个语法什么都是集成在当秤库了,它底层的语法都是封装在这里面。再就 community 不是 我们第三方那些工具,或者我们像有些哈根、 space 这些, 我们就是集成在对应的 n 城库里面。再就是 n 城,这个是 n 城,我们刚刚讲的 n 城库本身啊, nougat nushaw, nushaw nushaw, 那 这个就是我们对应的做智能体的 nushawaw 是 进行一个部署, nushawawaw 是 一个监控 啊,最最主要的一个更新其实还是对应的南城货,南城货在之前其实他没有那么大的改动,更多是偏向于我把一些核心的功能巷子线拿过去,在一点零之后呢,很多工具的其实都是分装在南城货里面的,比方说像我们对应的南城的一个历史调用, 它的一个叫 runble, runble 是 对所有的主键都是提供对应的链样工具,比如说我们同类的接口,这个相当于是集成到对应的囊括里面来了。还有像我们对应的消息系统,像什么 photoshop, etc 这些,还像我们 t s 模板, t s 模板这一些,输出解析器这一些,那这一块是放在了我们对应的囊括当中,像文档处理啊,像对这个抽象的模型类。再就是我们对应回调 这个结构化输出和缓存都是封装在对应的 n 三库里面的。这里给大家去讲一下我们一点零和零点三的一个特性,它变成什么样子了。 首先是一点零的版本,一点零的版本相当于我们最底层的就是对应的 n 三库, n 三库上面通过它的核心语法,我们可以在上面去封装很多的工具,比方说我们会有对应的第三方,像我们对应的 open i 这一些,这些工具封装在一起拼接成可以就是一个集成成一个 当称,当称本身我们是在当称这个层级上做一个 s 开发的零点三的版本,它其实是这个样子的。首先第一个它是在当称这个包里面是包含了这些东西的,你说之前为什么说它这个调用起来非常不方便?有很多的工具其实都是放在当称本身里面的,就像一些这个 recorder, 还像我们的多功能的一个加载文档加载像模型体育时这一块,那些都是放在囊秤本身里面的,相当于现在他做的程序化处理。很多的核心库都是放在囊秤库里面, 对应的设置库相当于我们需要借助囊秤库来进行开发,我们囊秤是在它的上级往上面进行集成,有了集成之后,有了工具之后,我们再是一个完整的囊秤。 好,那么接下来大家去看一下 n 寸的一个基本的使用啊。第一个是我们安装的方式安装我们通过 p i p 安装就可以了,安装最新的版本就可以,因为我们这里给大家去讲最新的,首先就是我们怎么去通过 n 寸去调用这个模型,这样模型需要注意一下这个模型,我在这里就讲的是这个 n 寸的 open i, 这节也是社区库,但是因为我们有一些合作的厂商会把这个库给它集成起来,好封装的方式看一下。好,来我们看一下封装的过程变成什么样子呢?首先是我们的模型的调用,调用单体的模型,这样模型我们用的是 c o、 p i, 好, 再用这个。 第二个方式就是我们通过 offi 去拿到我们对应的 k 的 时候获取 k, 然后去调用对应的模型是什么,那这个是我们最基本的调用执行的方式,我们会把一个是我们百川这里目前用的是一个 有个千万的模型的 k, 还有一个就是我们对应的千万的 u i l, 这个是需要自己去申请的,我这个就可以去抢到了。执行完之后 好给我们听输出。好,现在给我们输出的内容就是我们对应的模型给我们输出的要通过 n 秤, n 秤里面我们习惯性的一般是用对应的 n 秤, open i 里面 拆的 open i 进行一个输出。其实调用模型的方式有很多种,比如说你可以通过我用了千万这个平台,他自己的也是可以的,但他怎么去调用?或者说用对应的这个 n 秤,他不是提供了一个新的 n 秤里面, n 秤里面他只会有一个我们对应的模型,不懂, 比方说它有一个叫做 emit, 这种调用其实也是的,可以去粗俗化我们的聊天模型,但它其实本身它一更新了之后,它其实本身也是用的 open i 连接方式,也是通过 open i 来进行连接的,也是用了这一个,虽说本质上其实没有很多的区别,但只不过说在 n 寸这一层面上做了一个再次封装。 好,那接下来我们再看啊,那除了这个以外,还有我们怎么去做项链?项链处理,看数据我就做一个简单的 run 给大家去感受一下。首先是加载对应的模块,加载模块这一块其实跟之前比较大的明显是当称的 test, 这个是 pad, 那 这个其实在之前我们导入其实是这样导的,就我们从对应的当称当称里面它只会有一个,就 test, 就 有个 test 这个模块有个这样的东西, 之前其实是这样导入的,现在相当于它把很多的功能呢,是有一些极深的功能,我不想让当衬本子的库显得那么臃肿,把很多的功能都给它抽离出来了,比如说现在这一库需要通过这种方式进行导入。 还有我们从对应的 community 里面拿到对应向量模型,我用的是什么?用的是对应的千万的向量模型。 再就是我们的一个 fast 这个限量数据库啊,首先第一个就是我们要拿到对应的文本,既然要做限量化,首先是要拿文本去做限量化,所以的文件是当这个,那么当前这个文件我们需要对当前这个数据其实就跟类似,有点像我们的爬虫,它其实会自动的去,比如说我们 xp 语法,或者说我们自己 获奖的数据,它其实就是拿到我们注意的数据信息,这个数据是对你要的获取数据是哪个标签里面的来说,我要获取是 id 为这个的标签,看一下我要获取标签是哪一个?三十七个啊,比如说我只要的是这个里面的数据, 因为这个数据里面就是我们要的文本,我要的这个网址上的数据信息。首先我们还是要对文档进行分割,用的是低规分割的方法好,分割完之后呢,我们会对数据进行,比如说分割完之后,我们要把数据放到模型当中,通过当前向量模型把对应的数据 要用的模型是哪一个,这个也是在千万申请的,再把模型给它加载到我们对应的文件当中,好获取方式,首先现在给大家看啊,第一个是我们拿到分割完之后的文档, 这个题跟之前逻辑是一样的,没有什么很大的区别。把文档进行批次分割,因为我们用的这个微视的模型,它有一些模型是有 这种下面模型是有对应的批次选择的,它不能支持,比如说我们默认的话是把这个文件全部处理掉,但它的批次一般是小于十,但是我们要从这个数据里面取小于十,这个批次一次只处理这么多啊。再往后面看怎么样获取第几批 判断当前数据,如果说是哪先创建一个向量数据库的对象,而向量数据库里面先拿的是我们要处理的文本是什么 一个列表。再就是我们需要去用哪一个向量模型去对它进行转换,数据转换好之后,我们会拿到一个向量对象,然后转换好之后, 如果说我们不是零号位,我们是直接进行拼接,把文本的数据经就是我们新的文档进行追加到我们这个文件里面去。这个东西相当于我们是把创建一个文件加载对象,加载我们数据库对象, 把这个数据存在这项链数据库里面,然后存进之后,因为我们其实分批次,你可能有第三批,那如果说不是第一批就不需要创建了,那么如果是第二批,我要重新给它追加到这个模型里面去,追加到在那数据库里面去啊,追加好之后我就给他保存在本地,好吧? 来看一下数据。好,我们来看啊,因为这个还是要注意,大家在之后你们用的模型如果说不同的话,他的批次也要注意,他有可能是不支持多批次的。还有一个我们对你警告,这个是我在项链里面 软件里面没有去添加 c, c 是 我们的浏浏览器代理,这个不用管,可以在这一家群里头也行啊,在这一家加上一个 head, 在 这里也是可以加的,加一个群的对象,加一个 u a 也是可以的,没问题的,防止反爬,就这个意思啊。准备好对应的文档之后,我们用项链数据库,是一个发誓的项链数据库。项链数据库它一般会存这几种格式,一个是什么?一个是我们对应的发誓的这个是项链,还有一个是我们对应的 p、 k、 l, 那 这个是存的文本数据信息,一般是存的 jason 的 数据格式啊,我们对当前的文档来进行处理,好吧 处理方式,搭建一个最基本的向量数据库啊, log, 首先是我们导入对应的需要的库网,一个是我们拿到的是创建一个文档链,还有一个就是我们 需要用到的,给他去提个醒,如果说我们用的之前的零点三的版本,那你发现这个版本我们可能用不了,像我们之前零点三版本我们是这样去导入的,比如说我们导人当称里面的 称,再就是我们里面的文档链对象,获取到一个文件的创建一个文件链对象,这个东西在我们新版本之后,你发现是没有称的,它在它的模块里面是没有称模块的,那么这个模块你需要。如果说想使用使用一些经典类在对应的 cs 里, 在这个,那这个库我们另外相相当于是向下兼容的数据,你可以在这里面获取到,它也是有的,在这个里面单称单称的 classic 里点说里面之前我们看到的有是什么 graph, 像我们对应的秤这些现在在这里面都是有的,像秤, 这就是之前的那个相当于是老的版本向下兼容的一个过程啊。再往后面看,其实我们要创建一个对象向量的模型,这个是我读取在本地, 本地的文件,然后拿到向量模型是否加载我们对应的 pick 的 文件。好,那这个是向量向量数据库 下面存储的一个对象,我们现在需要有了对应的文本之后,我们需要再根据用户的问题进行减速,首先准备提示词,再创建连接,准备好我们对应的提示词,无非就这一件,一个是我们用户提的问题,再有一个就是我们通过解锁 问题所拿到的一个答案,创建一个大模型对象啊。再就是我们需要创建一个链,这个链相当于是让大模型跟提示词绑定起来,先把对应生成的提示词获取过来之后 传递给大模型,创建一个解锁器,对,看一下数据。好,首先是我们对应的创建解锁器,这个解锁器我们通过下载数据库,下载数据库我们要创建一个解锁对象,我们用来搜索 搜索对应的文件的,通过解锁器我们会先拿到解锁器来进行解锁,根据用户输入的问题,比方说当前保护的条例什么时候执行的,他会先在这个解锁里面 向对象里面解锁出和我对应的问题最相关的文档内容,把这个文档内容给到我们对应的文档链,然后把对应提取到的数据发送给对应的提示词,把提示词清补全,补全之后把获取的内容再给到我们对应的大模型, 也就是这样的过程,这个是最最基本的一个提示,这是最简单的一个 reg, 它实现的逻辑其实跟之前没有很大的区别。如果说你们在之后找不到对应的零点三的这个库的版本,那么我们就用对应的 classic 里面的库进行导入就可以了。啊,那这个就是我们对应的答复, 好,那这个就是我们 long 秤的一点零更新的一些特征啊,更,其实主要是在整体的架构这一块,以及说它的现在的更新会更多的是偏向于想做 it 的 这一块的。
29AI大模型杰睿 08:25查看AI文稿AI文稿
08:25查看AI文稿AI文稿相信用过自成体框架的朋友都对 lenient 呢是比较熟悉啊,那么 lenient 自从以前的零点几版本啊,到 呃前不段时间呢,只有一一点零,然后最近的话,它又发布了一点三啊,一点三版本,那这个版本有什么新的特性呢?我认为是可以值得去关注一下。首先的话就是事件流哈,事件流的 v 三协议,还有就是一个 midware 的 架构, 以及统一场统一的输出场,还有结构化的输出增强。然后它的发布日期是五月份啊,五月份,那么我们来看一下啊,它到底有什么新的特性。 首先的话,它这次一点三是一次工程化的跃迁,那么它不仅是啊 l l m 的 一个调用工具箱啊, 而且而是正式的转向构建生产级 agent 的 这么一个功能框架,因为啊,从 chance 到 agent, 那 么呃核心方式的话,它是从 链式调用升级为自动体驱动,那么底层统一是基于 land graph 一个图的一个运行词啊。那么第二个就是微商的事件流的协议,那么全新的一个内容块,它中心流是 api, 那 么是类型化的投影 独立消费啊,告别手动的一个模式的解释。那第三点就是一个呃中间件了架构,那么洋葱模型的中间件,六大的生命周期的钩子,还有就是一些啊,可定义 可组合的一些啊,智能体控制场啊,那么 v 三的一个事件流协议,它它是一个核心亮点了, 它是以内容块为中心的一个全流式的 api, 那 么每个投影它都独立的一个迭代器,就无需手动地去解释那个啊,幕组原主啊,这里面我们看一下代码实现啊,就是它里面有个 one message 啊,它这个是属于全全幕的 screen 啊,这里面就是 每个 l m 调用的时候会产生一个啊全幕的 screen 啊,包括 test 啊, reason 还有 up 这四个投字投影啊, 这是它的一个伪代码,还有第二个是那个多投影并发消费啊,那么同步啊, interlevel 和跟异步的一个呃函函数,然后同时消费 message 跟啊 two groups 还有 values, 它也是个伪代码, 那么这里面就涉及到一个啊,威信的推理流,还有 sub a 啊, sub graph 的 一个指令流,还有就是 attention 的, 自定义的一个啊,自定义的一个投影啊,这三个, 然后这里面有一个就是 create agent 加一个 mid midway 的 一个中间键啊,这不是,它是统一的一个 agent 的 创建入口,那么它配合一个洋葱的中间键啊,实现了一个精细化的控制的一个生命周期啊,那么啊,六大生命周期啊,就是一个是在 before agent, before model 还有 web model core, 还有 after model, web two core 还有 after agent, 这里面就是一个啊,有点像我们以前的那个 啊,这个这个中间长那种啊,中间键那种啊,就是传入前,传入后,传入中啊,好,这里面有四个的一个开箱即用中间键啊,这里面就是一个啊, 是啊,那个总结的吧,总结的还有啊, humans 的 tool, the loop midware, 还有这个,是啊,自定义的一个 quit midware 啊,就任意钩子的一个组合,这都可以开箱即用的, 那我们看那个啊, content blocks 跟加挂输出啊,这里面就是跨模型的一个统一输出格式啊,它是一个啊, pyencil, 一个 skilam 的 一个,它成为了一一等功名啊,这里面它是有一个统一的啊,啊, come block, 还有就是结构化输出的三个策略 好,就是精细精简的一个包结构加那个 lantern classic 就是 核心 lantern, 它只关注 a 件的构建,那么老组建,老旧组建是组啊,就清晰的分离啊,原来 lantern 的 话,它是啊,就是只暴露了 a 件啊最核心的一个功能, 然后旧的话,旧版的话全部迁移到这里啊,旧的全部这里,所以这里面就是一个简单对比,就是旧的 v 零点叉,还有 v 一 点三的一个 system 引入啊,它包括了 agent 构,创建记忆, chance, 还有啊 waitrose, 还有这个简式链式调用啊, 那么增强增强更新啊,就是聚焦的一个外部的工具跟模啊,那个模型编排,那么跟那个 hackface 深度集成,还有就执行速度跟啊模型编排这一块也是有所增强。 还有就是啊,铅笔纸啊,我们这里他提到一些铅笔纸,就是这里面的写法不一样啊,以前的那个就是他的写法是旧式的啊,咱们看这个代码,然后这是新式的写法,新式的写法还是有点不一样的 好架构变迁,就是啊,这是旧的,这是新的啊,旧的话那个中心方式,它是 chains, chains 的 一个链式调用,那目前它已经是 agent 的 自成体,那么底层的引擎的话 啊,原来的是 agent executeer 硬编码循环,那么现在它是换成了那个 line graph 图运行式啊, 图形是就是目前软券也是啊,底层的是用软 graph, 它原,当然软券本身也是属于软券这边的一个他们开发的一个项目啊,流势,流势能力,那么部分支持和属于 token 级别,那目前来讲呢?新的话是全全链路的 v 三四线流, token, 推流工具, 还有纸代理,那么扩展机制它是没有的,要要改原嘛?没,没得扩展,那目前的话它是有那个 midview 的 六大生命周期的一个钩子, 那么自定义,那么它目前是还是有差别哈,还有纯输出解释,那目前的话它是一个标准化对象,原来的话是纯文本加那个正式匹配,政策匹配啊,这句话 需要手动去实现。然后目前的话是用 let's let's let's let's let's let's let, 那么目前的话就是他拥抱的工程 a 整的工程框架,生产计划有流逝,人机回环全部累积好,主要是 v 三的四件的话,他实现了一个精细控制 啊,精细控制好就是一个无限扩展,那么一个六大钩子,还有中间件,还有自定义架构,天花板大提成就是他是可以扩展了,以前是写的比较硬边吧,现在是通过中间再去扩展啊, 还有这清晰的包边界。那么目前的核心是聚焦的 agent 呢? nissan classic 这个保障,那个兼容,那么升级的话是如果是从旧的升级到新的话,它是啊,就是没有什么破坏的啊,目前来讲, 所以说目前来讲是从简单的回答变成了统一接口,从复杂 agent 啊,这它是一个作业选择,然后 p y 啊, python 啊,跟那个 g s 跟 t s 两个生态,然后 land graph 是 原生的一个集成,因为 land graph 其实原生啊是把它分开来看的,就是 land graph 当时也是属于同一个组织,但是它属于啊,分开来看,那目前的话 nike 也是一点三开始也是极强的那个 nike, nike 这个升这个鸡爪它是一个,那么所以目前来讲就是 nike 一 点三的话升级还是比较大的啊,我们可以去结合原来的一点啊,一点零或者说零点几的慢慢去看 啊,就是大家说这个也是其中一个亮点啊,就是所以说,呃,后面朋友如果呃用的什么一个 有体验的话,可以在我评论区给我留言哈。然后啊,如果想要这份资料的话啊,也可以在我评论区关注我之后,然后私信我发一个资料哈,然后我到时候免费给大家领取那个资料啊啊,本期的分享到这里。
11老周聊AI 06:41查看AI文稿AI文稿
06:41查看AI文稿AI文稿各位同学大家好,欢迎来到今天的课程,从今天开始,我会带领大家进入到 ai 前端架构 框架篇,智能体开发框架 learn 的 学习。跟上我的节奏,我会带领你一步一步的从单一的前端开发工程师到 ai 前端架构师的转变。 很多刚接触大模型应用开发的朋友都会问一个问题,现在有那么多调用大模型的方式,为什么我要学习当前?特别是为什么我们要选择他的 ts 的 版本,而且是最新的一点叉的版本? 今天这一节课,我们就来彻底了解清楚这三个问题,我会带大家理解诺基亚的本质, ts 版本的独特优势,以及新版本带来了哪些生产级的重大改进。 首先, notion 到底是什么?大家一定要记住一个核心的观念, notion 它不是大模型本身,而是一个编排框架。 什么意思呢?打个比方,大模型它就像一个知识渊博但是很健忘的专家,你需要告诉他上下文,给他工具,还要记住他之前说过什么。 如果你直接调用原声的大模型的接口,你就要自己处理提示词的管理,工具的调用,记忆的存储,知识库的解锁等等,这些功能非常的灵散,而且不同的模型之间还是不一样的,这就是所谓的碎片化痛点。 当前它的价值就在于它提供了一套标准化的主键和申明式的编排能力, 你不需要从零去实现那些常见的功能,比如怎么管理题词词, 怎么让模型调用外部的工具,怎么让模型记住对话的历史,怎么从你的知识库里解锁信息当庆他把这些都封装好了, 你只需要像搭积木一样的去组合它们,就能够快速的构建出企业级的具备上下文感知和工具调用能力的应用。所以简单的来说, lucy 它就是为大模型应用开发服务的乐高积木套件。 那有人可能会问,既然 longcheng 有 python 的 版本,也有 ts 的 版本,而且 python 的 版本出来的更早,生态也更成熟,为什么我们要学 ts 的 版本呢?这里我重点给前端远战或者想转型 ai 开发的同学讲一下。 ts 的 版本有三大不可替代的优势。第一,类型安全。 ts 的 静态类型检查非常强大, 比如你在定义工具入仓的时候格式写错了,或者格式模板少了一个变量 t s 在 编码阶段就能够直接给你标红报错, 这对于结构复杂的大模型应用来说是非常重要的,因为大模型应用的错误往往是在运行的时候才暴露出来的, 有类型检查能够帮你把大量低级的错误提前消灭掉,大大的降低调试的成本,尤其是当你在构建一个需要调用多个工具的 agent 时,类型安全简直就是救命稻草。 第二, note g s 生态兼容。你可以直接附用你们团队已经很熟悉的 express、 普斯玛、 type o r m 这些成熟的工具, 想做服务端的部署,用 express 起一个 api 就 行,要集成数据库 res 码直接连, 要对接其他的 api, node js, 它的生态应有尽有,你完全不需要为了写 ai 的 应用再去学 python 语言以及 python 后端的相关框架,这样你工程化的门槛也急剧的降低了。 第三,前后端同构的前例,什么意思呢? ts, 它既能在 node js 的 后端跑, 也能在前端浏览器的应用里面跑。你可以把一些轻量的逻辑,比如本地的文档加载,简单的提字词的渲染,直接放在前端执行。而把核心的大模型的调用 和限量的解锁放在后端处理,这样就能很轻松的实现前端的交互以及后端的算力。它的一个协调架构 开发的体验会非常的流畅。所以如果你是前端或者是全站的开发者, ts 版的谅沁就是为你量身定做的。 最后,我们来看看为什么要选 lincoln 一 点 x 这一个版本,注意啊,这里说的是最新的版本,它是二零二五年十月发布的,是框架的一个里程碑,相比之前的零点差的版本, 它做了根本性的重构,核心的目标就是提升生产级应用的稳定性和可维护性。我给大家提炼了十个最核心的变化, 第一,他统一了 agent 的 ipa。 第二, l、 c、 l 成为了他的核心。第三, non graph 的 深度融合。第四,模块化依赖的设计。 这里大家下去做一个了解就行。在我们后续的学习和深入,大家就对这些概念会有一个更深入的理解,这里我就不花过多的时间给大家做一个详细的解释。那我们总结一下今天的内容。 诺基亚,它是一个二模型的编排框架,解决原声调用的一个碎片化的问题。 ts 版本它拥有类型、安全、 note 生态、前后端同构三大优势,尤其适合前端全站的开发者。 诺基亚一点叉版本带来了统一的 a p i l c l 核心 ngram 运行时和模块化依赖,让生产级的应用更加稳健。 理解了这三点,你就明白了为什么我们选择谅倩 e d x 的 ts 版本作为课程的核心。技术上。
 01:27查看AI文稿AI文稿
01:27查看AI文稿AI文稿最近给学弟做辅导,简历也带了几个刚转来做 a 级的新人。我发现大家简历上都写着精通 longchang 和 longchang, 一 问这俩在工程落地时到底是怎么配合的?很多人到现在都还以为这俩是竞品呢,或者只是版本升级。 如果你纯手搓一个大模型应用,你要自己调接口维护,上下文写正则切文档存向量,满屏幕全是代码。这时候狼抢的作用就来了,需要切文档拿走 x-, 需要存向量拿走 x-, 他 帮你把脏活累活全封锁好了,主打一个少写代码,快速出货。 但是当你真正在业务里跑起来的时候,你会发现狼群的问题所在。真正的工业级 a 型的需要思考,比如分析出收到的资料,不对,他得打回重做,遇到复杂问题,他得循环调动工具直到解决。如果你用狼群的单项链条去做这种带半丝纠错的循环链条,你的代码可能就崩溃了。这时候必须上狼群, 别把它当成一个简单的酷蓝寡妇的本质是一个状态及引擎,你在独立定义的每一个起点就是一个动作,箭头就是你的扭转条件,他不仅管流程,还负责帮你记住每一步的状态,这才是做复杂多 a 境的协调的核心基座。 千万别一开始就把这两个混在一起学,先用 long 跑通一个简单的单体分拿,等你的代码逻辑达到普通的卡已经 hold 不 住的时候,再去用 long graph 化妆状态流转图,你又懂它的好到底在哪了?工具背后的架构设计是面试的核心,在做项目的时候多想想为什么要这么选型。
66小迪学AI 12:43查看AI文稿AI文稿
12:43查看AI文稿AI文稿如何用 long chain 一 点零新版本搭建高性能 n l two circle 数据分析系统,做到想看什么数据直接进行提问,不用写一行 circle, 自动操作数据库并生成查询报表和分析报告, 还能支持企业级风控与人工审核流成。本期公开课,我就把两万多行企业级的实战代码和完整落地方案拆开给大家进行讲解。 同时所有的前后端源码也将免费开源,真正带你从零到一,在你的个人电脑上完整复刻这样一套可落地的 n l two circle 数据分析系统。 先看一下我们最终要实现的功能和效果。首先可以连接本地或云端数据库,选择指定的数据库和表,用中文发起提问。比如像这种折扣率大于百分之三十且价格小于五千的性价比产品的复杂问题, 系统也能精准的将查询结果加格式化图表加详细的数据分析报告一次性输出在网页上。 此外,还支持批量上传 csv excel 文件,系统会自动入库建表、理解自断,并能够像操作数据库一样快速生成洞察数据和分析报告,非常适用于做业务运营的同学进行使用。 当然,看到这里大家难免会担心,让 agent 直接操作企业核心的数据库大模型,如果自动删库删表怎么办? 所以我们也会重点给大家讲解企业里应用的安全机制。 human in the loop 借助于廊庆一点零最新版本发布的 human in the loop midway 中间键和检查点机制,仅用几行代码就可以轻松让所有关键代码语句 在执行前先经过人工审核的这样一个工作流程,自然该项目底层的技术也全部基于 loken 一 点零新框架搭建而成,支持千万三、 tipsik 等国产模型自由切换。同时得益于 loken 框架的易用性和便捷性, 哪怕你之前没有任何大模型开发基础,也能够轻轻松松上手实践。本期公开课,我们真的是把内部花了很长时间打磨的 nfl circle a 阵的实战方案拿出来给大家进行讲解。 从业务通点、技术选型到安全策略前后端实现,不仅仅是停留在大模型能不能生成 circle 的 这种 demo 级别,而是一套能落地的代码加前沿的技术架构。 相信只要大家能够详细完整的学完,必然能够以极低的学习成本直接将这套系统对接到自己的数据中进行使用。看在老师们亲注如此多心血的份上,还望大家多多三年支持。 近年以来,大模型技术发展势头非常迅猛,我也将持续为大家提供最前沿使用的技术教学,感谢大家的关注和三年支持!本次公开课的课间代码、项目源码、运行脚本、知识库文件等资料都已经在复范大模型技术社区中上线了, ok 啊,其实我们上面呢就把第二个啊,也就是我们在项目里面给大家构建的第二个这个流程,就是上传所谓的啊这个 c s v 文件,然后呢,让他去创建临时的数据库,并结合用户的自然语言提问,生成可转化的报表和数据分析报告中的 核心流程,给大家进行了一个非常详细的一个梳理,然后我们接下来就来给大家去介绍一下大家在演示视频中看到的这个项目应该如何在本地去进行部署和运行, 那么这个项目呢,就是一个可以在线连接数据库,然后在线上传 csv 文件,它自动的去查询你的后端啊数据库, 然后啊生成对应的一个检测的结果,并输出相关的可戳报告和分析报告的啊这样一个功能的系统。 那么所有的这个前后端源码,大家都可以在百度网盘中直接去进行下载,大家可以扫描屏幕上方的二维码,或者是找到你的助教老师,就可以免费的免费的领取到前后端的一个源码。 那么对于前后端的源码,大家拿到的是一个 backend 文件,还有一个 for end 文件,一共有这两个文件,而 前端呢 for end 啊就是它是一个前后端分离的这样一个架构,前端是通过 react 去进行一个构建的,那么后端呢,就是通过 backend 来去进行一个构建,我们使用的就是 当前一点零的这个版本,加上 fast epa 提供的外部的一个服务的接口。那么整个啊系统的一个架构的设计啊,大家可以看一下这个刻件 数据源的面板啊,智能的问答区就包括了啊核心的这三个参数,同时对于业务层呢,我们是使用的大家可以接入的 g p c 啊, ppt 模型, gpt 啊,前文三啊这些都是可以的。然后我们使用 longchain 内置的这个 circle 的 工具,使用它的 react agent 来去构建的这样一个问答的流程,然后相关的技术栈啊,大家可以看一下这个课间那么核心的这个设计思路,大家啊,给 大家时间关系呢,就不详细的,大家带着大家去进行一个讲解了。那么核心的一个构建的流程就是在 backend 下面有一个 app 文件夹,这个 app 里面有一个 circle agent 点 py 的 这个文件啊,那么这个文件大家点进去它有一个 circle agent manager 这个类,那么这个类里面就定义了啊,它在编辑里面其实就是 定义它很多的这个 api 的 k, 然后抽象当前的模型服务,然后呢这里面是创建 database 从文件啊,所以它指的就是当我们上传一个 csv 文件以后呢,它要去创建一个临时的数据库,存储到进存储到本地,这里面包括啊它读取 csv 的 这个对象啊,大家看一下这些代码都是我们刚才已经给大家全部都讲解过了 啊,然后除此以外呢,这里面创建一个 circle 的 这个 agent, 那 么这个 agent 我 们给它构建的这个提示词就是专业的数据分析师,然后你可以使用这些的工具,使用的步骤和我们刚才给大家介绍的 react 的 那个流程是没有太大的一个区别, 核心原因就是我们在输出格式上给他定义了你要输出这样的一个数据分析报告,包括了核心发现详细分析以及最应最后的一个建议啊,所以才有了大家看到的这里面啊,大家能看到哎,详细的分析报告, 包括了核心发现详细的分析以及建议啊,其实都是我们在提示词里面能够去进行修改的,所以大家如果拿到这个系统上 系统以后想要去啊进行一个额外的处理的话,那么你可以进入到当前的这个文件里面啊,去修改啊,他默认的一个提示词啊,这个是没有任何问题的。 然后下面大家可以看,其实我们就是给他创建这样一个 circle 的 工具包,然后创建他的这个 agent, 返回最后的一个结果啊,就是我们刚才给大家去进行介绍的流程是完全保持一致的啊, 当然我们在课间里面呢,也给大家明确的去定义了啊,你去它的核心文件是在哪啊? app 下面有一个 circle agent, 去找到它就是定义的 circle agent 底层运行的一个核心的文件,那么对应的一个提示词呢,刚才也带着大家去进行了一个详细的分析, 当然啊,对于上传的这个 csa 文件,刚才也说了啊,我们是通过去把它临时的转化成一个临时的, 把它转化成一个临时的这个数据库来执行啊, circle agent 这样一个构建的这个过程,然后我们是把它的这个表明呢,是通过 uud 啊来去进行一个唯一的标识,因为它是一个临时的这个数据库嘛, 然后对应的一个操作流程啊,大家可以看一下,这里面就是啊,他通过 react 的 这种形式,依次的去查询你当前的这个数据库的表结构,生成 circle, 进行一个校验,并再次的去进行一个数据库实际的查询,并根据返回的这个结果来输出最后的一个问题啊, 它是这样的一个流程,而对于这个 agent 后端的这个接口服务呀,大家就可以去看一下对应的啊,这个接口服务里面有一个 app 位置 d b 点 py 的 这个文件啊,这个文件里面啊,就是我们定义的基于 fast api 构建的一些路由的服务,这里面就包括了像啊上传文件呀,啊接收用户的提问呀, 然后呃和当前的用户进行一个和当前的一个问题调用大模型去进行一个对话,包括一些格式化等等啊,大家就可以在这个文件里面去进行一个详细的查看啊,当然我们的 公开课啊,时间的原因就不代表大家展开的啊,进行一个说明了,大家可以跟着我们的这个课间,其实每课间里面的每一部分,每一个短点都是干什么的啊,获取数据源列表,上传 csc 文件,智能的查询以及删除文件等等,这些路由啊,大家都是可以在课间里面找到的, 然后核心的代码也在这里面。而对于前后端服务的一个启动呢,我们给大家也封装的非常的完善了啊,大家只需要按照我们的课间的这个流程啊,首先去创建相关的这个虚拟环境,然后 一键安装我们当前的这个依赖。同时呢,你在点 e a 文件里面去配置你的 api 啊,你可以使用 deepsafe, 可以 使用前三啊, gpt 等等都可以啊,把它改成你自己的 修改 api k 和 base u i l 以及模型的这个名称,直接通过 python api with db, 点 py 文件 就可以快速的实现你后端服务的启动了,那么正常来说,你如果启动了这个后端呢,它会告诉你你当前加载这个数据库都有哪些?然后呢你当前启动的这个服务的端口,也就是 ip 加端口可访问的这个 服务地址啊,我们默认情况下就是 logo house 的 八千和八千零一的这样一个端口,那当你启动好后端以后,你就可以通过 它的 swagger api 去看一下它自动生成的这个文档,这里面就是我们刚才给大家介绍的在后端我们启动的完整的啊这样一个接口的服务了, ok, 然后对于前端来说它就更简单了啊,我们只需要进入到前端以后,通过 npm install 安装一键安装所有的依赖,然后通过 npm rendev 就 可以启动它的一个开发的服务器, 那么正常来说,通过两行的命令启动好以后,你能够看到有这样的一个标识,就是你在本地的 local hold 的 三千的这样一个端口上就可以打开诶这个页面, 就可以打开这个页面,那么你本地的这个数据库它就会自动的去进行一个加载,然后呢你就可以去进行对话问答了,那么在右侧它就可以正常的啊,就显示我们如图所示的啊,如图 如演示视频所示的所有的这些功能都是没问题的啊,所以大家只需要做的是按照我们的这个课键呢,把你的前端和后端全部启动起来,然后在你的后端注意啊,要修改成 可以使用的你的这个 api 的 大模型的 api k 就 可以实现我们啊演示视频里面里面里面的啊这个所有的功能了, 所以这些呢就是我们给大家提供的完整的啊这样一个前后端的源码,可以帮助大家快速的去进行落地的,大家可以找到你的助教老师来免费的去进行里免费的去进行一个领取。 ok 啊,那其实啊,今天呢也是啊,通过两个小时的时间啊,帮大家快速的去介绍一下 n l two circle, 它的一个核心的难点,也就我们借助于 long chain 一 点零的这个版本, 应该如何快速的去进行一个构建。同时我们给大家提供的这个系统呢,也是啊,能够直接在本企业, 能够直接在企业里面进行落地和使用的啊,所以我们呃今天的这个公开课呢,基本上所有的内容啊干货内容就给大家全部的讲完了,当然我们紧接着还有下半场的一个直播答疑的环节啊,当然在这个直播答疑的环节,大家 对上半节课啊干货内容,如果有想进一步了解的这个问题,或者是你在学习上面有一些问题的话,都欢迎大家进行一个。 今年以来,大模型技术发展势头非常迅猛,我也将持续为大家提供最前沿使用的技术教学,感谢大家的关注和三年支持。本次公开课的课间代码项目源码、运行脚本、知识库文件等资料都已经在复范大模型技术社区中上线了。
29赋范课堂- 33:43查看AI文稿AI文稿
如何用 long chain 一 点零新版本搭建高性能 n l two circle 数据分析系统,做到想看什么数据直接进行提问,不用写一行 circle, 自动操作数据库并生成查询报表和分析报告, 还能支持企业级风控与人工审核流成。本期公开课,我就把两万多行企业级的实战代码和完整落地方案拆开给大家进行讲解。 同时所有的前后端源码也将免费开源,真正带你从零到一,在你的个人电脑上完整复刻这样一套可落地的 n l two circle 数据分析系统。 先看一下我们最终要实现的功能和效果。首先可以连接本地或云端数据库,选择指定的数据库和表,用中文发起提问。比如像这种折扣率大于百分之三十且价格小于五千的性价比产品的复杂问题, 系统也能精准的将查询结果加格式化图表加详细的数据分析报告一次性输出在网页上。 此外,还支持批量上传 csv excel 文件,系统会自动入库建表、理解自断,并能够像操作数据库一样快速生成洞察数据和分析报告,非常适用于做业务运营的同学进行使用。 当然,看到这里大家难免会担心,让 agent 直接操作企业核心的数据库大模型,如果自动删库删表怎么办? 所以我们也会重点给大家讲解企业里应用的安全机制。 human in the loop 借助于廊庆一点零最新版本发布的 human in the loop midway 中间键和检查点机制,仅用几行代码就可以轻松让所有关键代码语句 在执行前先经过人工审核的这样一个工作流程,自然该项目底层的技术也全部基于 loken 一 点零新框架搭建而成,支持千万三、 tipsik 等国产模型自由切换。同时得益于 loken 框架的易用性和便捷性, 哪怕你之前没有任何大模型开发基础,也能够轻轻松松上手实践。本期公开课,我们真的是把内部花了很长时间打磨的 nfl circle a 阵的实战方案拿出来给大家进行讲解。 从业务通点、技术选型到安全策略前后端实现,不仅仅是停留在大模型能不能生成 circle 的 这种 demo 级别,而是一套能落地的代码加前沿的技术架构。 相信只要大家能够详细完整的学完,必然能够以极低的学习成本,直接将这套系统对接到自己的数据中进行使用。看在老师们亲注如此多心血的份上,还望大家多多三年支持。 近年以来,大模型技术发展势头非常迅猛,我也将持续为大家提供最前沿使用的技术教学,感谢大家的关注和三年支持!本次公开课的课间代码、项目源码、运行脚本、知识库文件等资料都已经在复范大模型技术社区中上线了, 所以这个智能体呢,当然我们也给大家做了一个进阶啊,这里面大家能够看到有一个叫人在循环啊,所谓的这个人在循环啊,如果把它翻译过来呢?他应该是呃人工介入的啊,这样一个流程啊,所以他的一个工作的机制就是这样的, 就是对于 circle 它的这个执行的过程,因为 circle 啊,它不仅仅是 select 嘛,啊,不仅仅是查询,它也有可能去更新数据,它甚至有可能去删除数据,所以我们在做 n 二 to circle 的 这个技术。 在做这个系统的时候,经常需要对一些高危的操作,比如啊,如果大模型去生成了一些,我要去删除某些数据库中的某些字段的情况下,那么我们把 delete 认为它要去执行这个了,那么好, 你先不要自动的去执行,先停在那里让人工去进行一下审核,如果人工批准了,你再去删除,如果人工不批准,那你就不要删除, 所以这个叫做人工介入的这样一个 a 正的工作流啊,所以这个也这个场景呢,也是很多小伙伴比较关注的。当然它也不仅仅适用于 n l two circle, 它适用于像一些审批呀审核的这种工作流啊,所以,呃,今天的这个势力呢,大家是可以把它扩展到其他的这样一个场景,当然我们借助于狼倩一点零的这个最新的版本,也可以用非常简易的这样一个中间键的, 哎,这个组建来去快速的实现这样一个功能,整体来说并不是特别的复杂。而这个图就是当大模型, 当大模型执行了某些高危的这个操作的时候,先去让人类去进行一个判断啊,如果人觉得 啊,你可以批准了,你可以去做了,那么我去进行一个执行,如果人就说这个操作你不能执行,那么我再去执行另外的这样一个逻辑啊,这个过程应该是比较容易理解的,那 接下来我们就借助于代码的这个环节,快速的帮助大家来去实现一个能够具备人工交互的这样一个 sql agent 函数的系统啊。首先啊,大家在当前的这个数据库环境里面啊,我们这里演示的这个 课间呢,它是一个 jupiter 的 文件啊,大家可以在呃 curser 啊,或者像 vs code 呀,或者是 anaconda 都可以去打开这样一个文件啊,那大家也可以在我们的助教老师那啊,免费的领取到我们今天上课的所有的这些课间啊,都是没有问题的, 大家正常在当前的环境下安装一下。首先我们核心安装的就是 long chain 的 这个最新版,以及呢啊,还有一些像啊潘大师呀,或者是 cycle alchemy, 它的操作数据库的一些第三方的依赖。然后我们这里可以看一下,我们这里应用的是 一点零点三的啊,这个版本啊,也就是他最新的一点零版本,很多小伙伴还是非常关注浪琴一点零版本啊,不过他确实是基于他零点三版本做了很大的一个迭代优化啊,集成了浪寡妇非常优质的一些特性啊。 然后呢啊,我们接下来就去进行一些相关模块的导入啊,大家可以直接执行相关的这个代码,这里面有几个非常关键的给大家进行一个说明。那么首先第一个叫做 create agent, 那 它呢,就是 通过 logitech 一 点零快速构建一个 react 智能体的一个抽象的方法,你可以简单的传入一个模型的实体,传入相关的这个工具,它就能够给你实现 执行啊,反思啊,再次运行多次运行的啊这样一个逻辑,然后 human in the loop midway, 这个就是我们刚才说的,它在新版本中呢,浪琴一点零是融入了很多中间键的这样一个概念。而 human in the loop 啊,指的就是我们如果在创建 create agent 这个过程中,给它放上这样一个中间键,就可以指定它在什么样的一些情况下,还可以去 触发这个中间键来暂停在这里让人工继续进行输入,如果准,如果呃,人工让它去批 呃执行 circle, 它再继续 agent 的 一个执行过程啊,所以它是中间键这样一个概念。而下面的 initchat model 啊,就是我们去接入某一个大模型的一个统一的方法,你可以接入 launchin, 你 可以接入 open i 啊,你也可以接入 python 啊,这些都是没有任何问题的。 下面就是我们要借助于 long chain 啊, long graph 它的一些语法了啊,这个 long graph 它里面的 in memory server, 它指的是我们在内存中的啊,这样一个暂存器,也就是我们可以把之前的运行过程呢,放在这样的一个暂存器里,因为如果, 因为,如果我们不需要不通过这样的一些框架的话啊,往往是把它放在一个简单的这个列表中,来让大模型知道它之前做了一个什么样的事情。那么对于像人机交互的这样一些流程, 它往往来说是不太够用的啊,你的一个列表是不太够用的啊,我们所以需要借助 long graph 的 这样一个机制,同时啊,要使用 long graph 的 一个 command 啊,这个 command 呢,大家就可以理解成我可以通过去执行一些指令 来让它在某一个中断点继续的恢复执行,而这个中断点就是当产生一些高危的操作,生成了一些 circle 语句的时候,如果人工显示了拒绝或者是审批,那么 这个指令是通过 command 来去给到 agent 暂时暂停运行的这样一个状态,来让它继续运行整个的一个流程的啊,它是这样的一个机制。 然后下面的这个 circle 的 工具包呢,就是非常关键的如何构建 schema linkedin 的 这样一个概念,就是 通过这个工具包我们可以连接到具体的某一个数据库,然后呢这个工具包里面有很多的工具,可以去看一下这个数据库的表结构啊,可以去检查一下生成的这个 circle 和你表结构的这个数据是不是一致,它还能够去实际的执行这个 circle 等等啊,一系列的这个工具都是在 longchain 已经封装好的这个工具包里啊,所以这里大家就能够看到啊,使用 longchain 的 这种框架呢,做一些复杂的这个工作流还是非常有优势的, ok 啊,大家把它实际的去进行一个导入,那么下面呢,我们就是正常的啊去呃 正常的去接入一个大模型,那么这里大家就可以使用,像 open a 呀,啊, deepsea 呀啊,千万三呀等等都可以,你只需要去在你的一当前文件下有一个点音 v 文件啊,大家在使本地创建一个这样的一个点音 v 文件,然后在这个点音 v 文件里面呢去 传入你自己的这个 k 啊,然后 base url 以及你想使用的什么模型,那我这里呢是使用的是 gbt 四 o 的 这这个模型,然后你导入以后啊,它这里面 打印当前的这个模型呢啊,就是一个 gbt 四 o。 接下来我们通过 launchin 的 initchat model 依次地去传递啊,你的 api, k, 你 的 base, url 以及你的这个 model, 就可以去用 model 的 这个实力来去加载到你的连接的大模型的 end port 的 一个短点啊,可以实际的去访问这个大模型,返回最后的一个结果啦, 然后我们这里能够打印啊,已经加载的是 gpt 四 o 的 模型,那么自然而然啊,我们要想去操作数据库的话,最简单的一个方式就是我们可以呢去谷歌啊,谷谷歌云上啊,去下载一个非常经典的这个叫 chinlock 的 数据库啊,这个是一个音乐商店的数据库,里面有很多的啊,订单呀,商户的这种表 比较适合我们快速的进行一个测试啊,为了保证大家能够拿到我们的课间都能够快速的去进行一个付现啊,因为如果我们连接本地数据库的话,很多小伙伴啊,还要去配置本地的这个 my circle, 很 难进行一个付现啊,所以我们这里 直接使用点 db 的 本地文件来去进行一个处理,大家执行上面的这个代码呢,你就会在当前运行的这个 文件下面文件的同级目录产生一个这个点 db 的 文件啊,这个大家在运行以后都会生成的,你就可以直接去操作这样的一个数据库了。 然后我们在连接这个数据库的时候,就通过刚才传递的 circle database there from u i a, 然后通过 circulate 然后连接我们本地的这个 qinlu qinluq db, 然后呢就可以看到这个数据库里面里面有很多的这个表,然后还有相关的这些数据 啊,这些大家都是可以实际的去进行一个执行的啊,这个里面一共是有十一张表啊,他有很多的音乐商店业务的订单呀啊,客户之间的关系啊等等相关几个数据。 而接下来我们有了本地的这个数据库以后,我们就要去构建一个能够去连让大模型连接到这个数据库进行操作的 这样一个外部的工具,而这个外部工具呢应用的就是它的一个呃, function calling 啊,也现在也叫 to calling 的 这样一个技术。那么对于 long chain 来说,构建让大模型和数据库连接的一个方式非常简单,就是你通过 circle database token 来去传递你用哪一个数据库,以及当前连接这个数据库的大模型是哪一个,你就可以通过它的 get to 来 去获取到当前的这个 circle 工具包里面所有能用的工具。那么大家执行完以后一共有四个工具,那么一个呢,叫做基于你用户的这个问题生成,结合着当前数据库表结构的啊这样一个 circle to schema, circle db schema 就是 能够看到每一张表里面的 schema 的 表结构信息,而 circle db list tables 就是 能够看到你连接的这个数据库里面都有哪些表。 还有 circle db query checker, 就是 针对于你基于用户的自然语言产生出来的这个 circle, 我 要去进行一个校验啊,它是这样的一个四个工具,所以它所构建的这个工作流程呢,就是用户首先提出问题, agent 先去调用第一个工具,来看一下你当前连接这个数据库里面都有哪些表,然后呢调用第二个 circle db schema 去获取所有的这些表里面对应的这个表结构,然后把它给到大模型的一个上下文中,让大模型去生成 circle 的 一个查询,然后 agent 去调用 它的 circle db query 去验证一下你当前的这个 circle 的 语法对不对啊?它是这样的一个过程, 而生成了这个 circle 以后,接下来就到了我们人工审核的这个阶段了,这个 circle 到底要不要执行?有人工来去进行批准和不批准,如果批准的话再去执行来去获取最终的一个结果,如果不批准的话,那么直接退出啊,他是这样的一个流程, 然后呢我们啊有了这个数据库,接下来我们要去给他构建一个非常专业的这样一个提示词,当然这个提示词呢 比较多啊,核心的就是我们给他定一个身份的背景信息啊,然后呢去告诉他相关的一些工作流程,而这个工作流程呢,基本上啊,就是我们刚才说的这个流程,我们要按照他,让他按照这样的一些操作来去进行一个 分析和处理,然后给他去做一些重要的规则,就是绝对不允许执行 insert, update, delete, drop 等修改数据的语句。那么这种呢,一般在企业里面往往也是不会开放给业务人员去做的,仅仅让业务人员 执行相关的 select 语句就可以了啊,如果出现了什么插入呀,更新呀,删除呀,或者是呃其他的啊,相关 危危险数据库数据信息的这些,我们都需要让他进入到哪呀?都让他去进入到人工审核的这个阶段,让你的 dba 去看一看啊,到底能不能去进行一个执行。 ok 啊,这个是我们定义的这样的一个 problem, 大家可以实际的去看一下,然后接下来我们去构建这样一个呃,人在循环的这样一个 circle 的 agent, 也就是由人工控制介入的一个 agent, 它的整个的这个过程,我们首先需要用到的就是它的 create agent 啊,来创建一个 circle agent 的 一个快捷的方式。然后 midway, 这个中间键,我们用的是 human in the loop midway, 它是专门去用于做人工审核的一个中间键,当然它也是结合了 luncheon 一 点本一点零版本 发布的众多中间件的其中的一个。然后 checkpoint 呢,这个是属于 long graph 它的一个语法啊,它的一个是检查点的这个机制啊,那这个检查点的机制主要就是用于当你这个 a 政策已经暂停了啊,我的人工去输入了一些审批的意见以后,那么它 他要回到哪一个工作流里面呢?啊?所以这个 checkpoint 呢,就是记录当前的这样一个状态啊,你人工审核完以后,我把这个人工审核的结果再给到当前的状态,让他去进行执行或者是退出啊,他是这样的一个关系。 ok, 那 我们看一下上面的流程,看似很复杂,但是其实我们在创建代码的时候一点也不复杂 啊,我们创建的这个 agent 首先使用 create agent 来去进行创建,那么我们传递的是什么呢? model 啊,使用的哪一个模型去做它的一个 circle agent? 那 么 tools 呢?是不是我们刚才说的啊?它创建的 circle database toolkit 里面的那四个工具包括了去查询数据库,根据 呃用户的这个问题去生成 circle 语句,还有查询数据库的 schema, 还有对生成数据的 生成,生成的这个 circle 进行校验的这些工具,然后把我们刚才给他定义的这个其实词给到他。而关键呢啊,在于使用它中间念非常非常简单, 只需要在 create agent 里面加入一个 midway 的 这样一个参数,然后通过列表的这样一个形式给它传递 human in the loop midway。 那这个呢,就是可以让它在当前的构建 a 证这个流程中,可以在某些条件下去打中间的一个断点,让它停止运行。然后我们通过 interpret on 这个方法 用来去判断,当它在执行哪一个工具的时候,它要停下来让用户去进行一个审核啊,所以我们是通过在它去执行 quirry 啊,就是根据用户的问题生成了 quirry, 在 去执行数据库查询的时候,生成了这个 circle 之前,我们让它停下来,来人工去审核它生成的这个 circle 语句能不能够去进行运行,去进行运行。 然后呢? description perfect 就是 指的是当暂停的时候,它提示的一个信息就是 circle 查询需要待审核, 那么接下来我们要搭配的 check pointer, 它的这个中检查点来去支持随时暂停和恢复你 agent 的 一个运行状态啊,它是这样的一个逻辑的关系,然后我们执行下面的这个代码啊,它会显示现在有四个工具,然后起用了人在循环的啊这样一个功能。 接下来我们还可以去借助于 long graph 它的一个底层的运行机制,去生成我们当前构建的这样一个 agent, 那 么核心呢,就是通过 agent 点 get graph 的 这个方法来去给它进行一个绘图,那么它的这个图就是 当用户的请求进来以后,首先进入到大模型,由大模型来去决策调用哪一个工具调用的这个工具呢? 在生成 circle 之前,要去经历人工审核的这个阶段,如果人工进行审核了以后,它可以再次的去进行外部调用的工具,然后把结果返回给大模型,输出最后的一个 parameter, 它也可以在拒绝以后直接返回最后的一个结果啊, 它是这样的一个 agent 的 运行的逻辑关系图,当然这个呢,它也是属于啊 long graph 的 这样一个架构啊,因为毕竟当前一点零呢啊,它是建筑建立在 long graph 基础之上的,那它是这样的 ok, 呃,相关的完整的执行流程呢,大家也可以看一下我们的这个课间啊,其实我们这个课间呢,跟我刚才直播给大家介绍的这样一个过程是没有任何区别的,那接下来我们有了这样的一个 agent, 我 们接下来就可以去实际的去触发一下当前的这个 agent 它的一个运行的逻辑。那么首先我们需要配置的是这样的一个 config, 而这个 config 呢,它指的就是我们在狼窝府的这个技术体系下,需要配置这样的一个 three 的 id 啊,你可以理解成每一个单对话对应的是同样的一个 three 的 id, 当我去运行这个对话的时候,那么通过这个同样的 three 的 id 可以随时的找到你当前对话的一个上下文,也能够随时的回到你想要回到的一个某一个状态。当然这个思维的 id 可以 配配合着 logoff 的 这样一个检查点的这样一个机制啊。所以很多小伙伴比较疑惑的就是,哎,我现在一点零版本已经发布了啊, 他的很多的功能都说是建立在 logoff 之上的,那么我能不能不学 logoff, 直接学习 logache 呀啊,大家可以看到 稍微复杂的一点的这个技术体系啊,我们就需要用到底层 long graph 的 它的一些相关的概念,不过当然啊,我们也可以去呃,有理由相信 long key 呢,可能还会进一步的去进行一个封装,来去把这些高阶的功能 都通过 long key 的 语法来去进行一个构建啊,毕竟这个是 long key, 刚刚发布一点零版本,还是有很多工作是需要做的,但是我们现在要进行构建的就是我们需要通过 configure 用 long key 这个语法来去给它配置 单一的啊 sweet id。 然后我们可以去输入一个问题,比如我们问的问题是,在这个销售代表中,谁负责的这个客户平均购买的金额最高,然后呢,对于啊 long chain, 他 再去 激啊,他再去请求用户的这个新问题的时候,是通过 agent 点 invoke 的 这个方法来去输入问题,给到具体的某一个 agent, 让它进行一个运行,而一 in book 这个方法,它的一个消息系列的格式就是通过 a message 列表的形式 ro 等于 user 表示当前的这条消息呢,是由用户发起的,然后对应的这个 content 就是 用户问的这个问题,其实就是我们这里说的这个销售代表中谁负责的客户平均购买金额最高啊? 所以他就相当于我们把这个问题给到了 circle 的 a 阵上,让他去进行一个执行了。我们可以看一下他的一个执行过程,叫做,哎,用户现在发起了提问,然后 a 阵的开始处理好, a 阵的现在已经暂停了,等待人工审核了, 所以他的这个过程啊,就是只要是用户发起了相关的这个请求呢?那么结合的我的这个流程,他在实际的去执行这个 circle 语句的时候,都会暂停一下,让 人工去审核这个 circle 语句到底是不是安全的,是不是可以执行的啊?所以它会进行一个暂停。然后呢,对于 当前的这个运行状态,我们也可以通过下面的这个语句来去看一下它当前都执行了什么流程,以及它生成的这个 circle 是 什么。那么下面这一部分就是通过它的 state 里面去获取到它整个 agent 的 运行的一个 上下文啊,运行的一个上下文。所以这个过程大家如果不太了解 long graph 或者是 long chain 或者是 agent 的 运行中间逻辑的话 啊,可能稍微理解起来会有一点点困难,但是啊,大家不要担心啊,其实这里面所做的一个核心呢,就是我们刚才说了 agent 它是能够去调用一些外部的这个工具的,那么我们无非就是我们要看一下, 当一个用户请求进来以后,经过这个 agent, agent 每一步都在干什么啊?里面核心做的工作就是它都调用了哪些工具,返回了什么样的一个结果。而对于 agent 在 调用工具的时候,我们是可以通过它 message 里面如果有一个 to cost 的 这个字段, 那么就可以找到他执行的某一个工具,以及针对于当前这个工具执行后返回最后的一个结果。而下面的这些呢,无非就是我们针对于他提取出来的这些 message 啊,做一些格式化的处理,比如我们要提取出 它具体生成的这个 circle 的 语句是什么来进行一个打印。当然我们这里做了一些安全的检查,如果像一些什么删除呀,更新呀,呃,插入呀,我们就给他去做一个啊警告啊,当前这个 circle 包含危险的操作,如果不包含呢,就是非常安全的啊,它是这样的一个逻辑, 那么正常我们可以通过下面来去看一下,那么它的下一个工作看啊是不是就停在了 human in the loop midway 点 after model, 也就是在 模型执行完成以后,停在了人在交,人在循环啊,这个人机交互的加一个中间键的环节,那么带审核的这个 circle 是 什么呢?大家看一下这个中间的过程其实就是 这个 circle, 那 么这个 circle 呢,就是结合了啊你当前连接的这个数据库里面的这些表结构,然后用户输入的这个问题由大模型生成的,接下来要去执行你操作数据库里面的加一个 circle 的 语句, 然后呢我们检查,哎,它确确实实它仅仅是一个 select 啊,它是一个安全的啊,仅仅包含 select 这个查询, 所以我们现在是能够看到它的这个中间过程呀,是能够看到很多它生成的这个 circle 语句。那么除此以外,当我们在进行审核决策的时候,那无非啊 log 呢,它其实只是三种, 一个呢叫做批准啊,一个叫做拒绝,同时还有一个啊就是修改,所以当然我们一直在重复着,我们一直在说狼官府啊,那大家现在也可以理解成使用狼犬一点零去进行构建也是可以,也是可以的,所以对于狼犬一点零创建了这个 create agent, 那 么它也是啊,包含 批准啊,拒绝和修改这三个操作的啊。所以呢,我们在进行使用的时候,那么只需要只需要借助到 command 的 这个参数, 那么这个 command 这个参数呢,我们刚才给大家介绍了,它是属于底层应用栏框 f 抽象出来的,可以去直接执行某一条命令进入到中间状态的啊,这样一个操作的方法。 所以我们的这个呃,拒绝呀,啊,审核拒绝呀,同意呀,还是更改呀,就通过 command 来去给它进行一个构建。而构建的这个方法呢,就是再次的给当前的这个 agent 去发起一个 invoke 操作,然后 我们给他去传入 approve 的 这样一个参数的方法啊,给他这样的一个类型,就是批准他进行一个操作,而 config 等于 config。 所以 就 大家能够理解到,为什么我们在前面的这一部分要去通过一个 config 来去给它构建一个对话的进程,就是在于当我去使用它的批准或者是不批准或者是修改的时候,如果传递了 同样的这个 config, 那 么它会再次的进入到当前的这个对话进程中,也就是你 a 正的停止前的那个状态,它能把这个数据给你返回去,让它去进行运行, 哎,所以这个呢,就是它的 config 啊,配搭配着它的一个检查点所能实现的一个核心的这样一个概念。 然后我们在这里看,其实非常简单,直接通过 command 啊,然后呢给它搭配相关的一个 config, 给它传入具体的一个决策,当然我们这里使用的是一个批准的决策,然后它就会自动的啊 继续去运行,我们可以打印它最终的一个回答,通过最后一个 message 里面的这个 content, 就 可以返回它最后的一个执行结果,我们可以看一下它中间的执行过程呢,就是,哎, 审核通过,继续执行 agent, 然后呢销售额最高的这个艺术家,他们的平均专辑是多少啊?它会打印相关的一些信息,当然这里面的这个 create table 啊,它指的是我们获取 schema 它的这样一个过程,因为 agent 整个的运行上下文啊, agent 它整个的运行上下文呢,它是可以 累积的啊,它是可以累积的,而这些呢都是在获取 schema schema 阶段那个工具函数返回的一个结果。然后我们可以往下看,这个是实际要执行的这个 circle 语句,然后这里面有返回相关的一些信息, 这里面是查询到的一些数据,哎,所以里面所有的这些中间的这些信信息数据啊,他都是能够看到的。通过我们刚才上面给大家演示的这段代码,然后最终的一个回答就是啊,平均购买金额最高的销售代表是这个人啊,他的平均购买金额是五点七二, 所以整个的这个流程啊,是完全透明的,然后我们可以去追溯到每一步操作步骤。而除此以外,如果我们要是想拒绝的话, 是相同的方式啊,通过 command 这个方法,然后给他传递一个 tab reject 这样的一个参数,同时呢对于这个参数可以有一个 feedback 啊,就是去给他一个回馈啊,给他一个反馈。这个 sql 的 查询呢,可能查询过多结果, 请添加 a m t 的 子句,那么这些就是可以当我们去构建成应用程序的时候,它 点击拒绝,然后给出一个拒绝的理由,那它是这样的一个可以符合真实的落地场景的这样一个需求,同时我们给它传递同样的一个 config 啊,它是操作方法是完全一样的啊,大家可以拿到代码以后呢, 实际的去进行一个测试,当然对于多轮对话啊也是一样的,那么对于多轮对话呢,我们无非啊就是应用到它的 config 的 这个机制,其实只要每一次传递相同的这个 config, 它都会在当前的这个运行状态中自动的去管理你之前对话的这样一个流程。比如我们 基于上一个问题继续提问,就是除了最高的前十名都有多少呢?然后这里面都是打印的一些信息啊,我们还是通过 agent 点 invoke 去传递最新的信息,然后给它传递相同的 config, 它其实就已经具备了刚才那轮对话,哎,它里面所有的这些信息逻辑, 所以大家就能够看到他相比于我们自己去维护一个对话列表,是不是非常非常的简洁啊,他都已经给我们做好了,然后啊,大家就可以看一下他实际的这个上下文,当然他对于新的一个请求也是会去暂停等待进行一个审核,然后下面呢我们去给他进行一个打印,哎, 我们啊去提取它的这个 to call 令,然后批准它去进行一个执行返回最后的一个追问的结果,大家可以下看一下返回的这个数据,哎,里面所有的中间运行过程中, 哎哪一都有它的表结构,然后每一步查询出了什么样的一些数据,然后最终生成的啊, circle 的 查询语言是什么,以及返回的最后的一个结果是在这里面 他就是具备了多轮对话的这样一个能力。当然如果大家要是想要去获取完整的这样一个对话历史的话,下面这段相对来说比较复杂的代码,大家可以去看一下 啊。其实这里面呢,呃,如果大家想要去快速入门狼犬的话,像下面的这段代码基本上只需要大概一节课啊,或者是两个小时左右的时间就能够理解啊,他做的是什么啊?当然如果大家之前没了解的话,我给大家快速的去进行一下解释, 就是啊,我们去看到他历史的一些绘画,无非就是判断一下你的每一轮绘画,是啊,人工问的还是这个大模型回答的? 当然对于人工问的主要就是用户不断追问的这个问题嘛,那么他的这个信息格式呢,是 human message。 那 么对于人大模型回答这个问题呢,都是在 ams 这里面, 而对于大模型回答的问题,它里面包括了正常的回答,也包括了外部工具调用的这个结果。所以对于 ams 这里面,我们做了一个子分支,就是判断一下它是否有 to call 令啊,有 to call 令呢,就指的它在大模型操作过程中呢,是执行了相关的一些外部的工具,然后我们就可以把它 a 正确 操作外部工具执行了哪些信息啊,所有的东西全部都提取出来。而对于工具返回的一个结果呢,在 agent 里面啊,是在 tool message 里面去进行的一个返回啊,它是化生成人工的啊这个问题,大模型的这个问题,以及工具调用返回的这样一些消息的序列,然后最后打印出来,大家就可以看到当前的这个对话历史,其实它已经 自动的执行了二十四次,产生了二十四次消息,包括了用户问的问题啊,大模型去调用第一个工具返回出来,当前都有这些表,然后呢 ai 去调用这个工具啊,就是获取每一个表它的这个 schema 的 信息。 接下来每一步呢,大家可以去实际的看一下啊,去校验校验你生成的这个 circle, 然后工具返回的是 接下来啊,大模型根据返回的这个结果回答最后的这个问题,我再一次去发起了提问,谁购买的金额最高,这是第二轮的提问,然后他还是只停相同的这样一个流程,大家可以根据啊这个 返回的这个信息详细的去进行一个查看啊,这个是完全没有任何问题的。当然如果大家对上面的这个代码 感觉到相对来说有点陌生也没有关系,因为很多小伙伴他在学习了这个浪天一段时间后, 也没有办法去理解啊,这个是需要核心掌握它的一个中间的事件流的这样一个状态啊,所以呢,大家看不懂也完全不需要担心啊,其实你只要需要认认真真的去学习 long graph 或者是 long chain, 它的这个事件流大概一到两个小时也是能够完全的去进行一个掌握的。 这里上面呢也是快速的带着大家去梳理了一下啊,我们再去使用它的这个呃,我们再去构建呃人在循环啊,人机交互的这样一个 circle agent 呢,它基于当前一点零实现的一个版本,所以它在 呃人机控制啊,加上全自动执行他的一个总的对比,无非就是我们可以在呃人工介入的这个阶段呢,去对一些高危的这些操作啊,删库呀,更新数据啊等等去做一个人工的审核。当然这个呃这种功能呢,在实际的这个数据分析的领域 也是往往都需要必须掌握和具备的啊,所以我们这次呢也是给大家相当于要提供了一个进阶的啊这样一个版本。好, 那我们再说回来啊,带着大家快速的去落地了一下我们刚才说的啊,大模型在生成 n l two circle 这个技术领域,它的啊自然语言理解,然后 scamming, 然后它的 呃这个对话,以及生成最终的一个数据分析报告等等。啊,这样的一个流程,其实借助于狼犬一点零,整个实现起来并不是很复杂啊,大家也可以看我们刚才的啊这样一个流程, 呃,代码量啊,并不是很大。今年以来大模型技术发展势头非常迅猛,我也将持续为大家提供最前沿使用的技术教学。感谢大家的关注和三年支持。 本次公开课的课间代码、项目源码运行脚本、知识库文件等资料都已经在复范大模型技术社区中上线了。
21赋范课堂  00:58查看AI文稿AI文稿
00:58查看AI文稿AI文稿大模型应用开发最难的不是录制课程,而是视频剪辑,看一下我这些视频课,我每一个都要加上字幕,还要把没用的废话剪掉,争取 让大家看的时候能够以最快的时间学完。而不是说一节课给你录个四十分钟,五十分钟, 一百多节课,没有哪个人能坚持看下去。有些知识点面试当中考了供用的我给你录好,不考的不用的我全都给你剪掉。有视频的版本 ok, 也有文档的版本看你想看视频还是想看文档,包括大明星的部署调优,包括我们真实项目里面 每一个实战环节,还有我们项目里面的落地,争取这两天我就剪辑完,更新完,然后目前还差这个向量剪索制作库,包括我们的这个方正拎,争取尽快剪完,目前还在优惠期啊,等我剪辑完之后就恢复原价。
 02:03查看AI文稿AI文稿
02:03查看AI文稿AI文稿这个 a i a 的 项目运行起来是这样的效果,可以给它进行提问,要大模型,根据我的提问给我规划一条完整的旅行路线, 这个项目怎么跑的啊?大家拿到代码之后注意啊,这里面是分前端的部分和后端的部分,我们是基于 long chain 和 long graph, 后端是 nice g s。 这是一个全站的项目啊,都是基于最新的版本。在这个点英文文件里面有两种运行方式。第一种方式我们本地要用欧拉网模型, 部署千万的模型也好,或者其他的模型也好,而且怎么部署,你之前也讲过啊,在这里面我们可以选择我们的模型在本地安装,这个 tokyo 是 免费的,本地的。还有一类是我们调用云端的,云端的话我们可以调用 deepsea 啊, deepsea 的 话,那你这地方你要配置你的 k, 创建你的 k 啊,这你里面得有余额,要不然调用不通的。然后这里面要配置你这个 k, 配置完了之后我们直接启动就行了,启动完了之后就运行起来就是这样的一个效果。第二天提问可把这个所有内容都给你返回到这里面来了, 对吧?所有的整个旅行,包括你这个饮食预算,景点推荐,天气情况,整个这个项目的完整的工作流程。说一下,这是一个 agent 啊,用户在这里面去输入,输入你的问题,输入完了之后,这时候会基于 long graph iex 模式,然后调用我们大模型对话,然后分析意图,然后再决策调用哪些工具。对工具的话,比如行程的工具,天气的工具,预算的工具,那么这时候再给流逝的输出给前端,整个流程是非常简单的,那我们这里面大概有十一个接口, 整个项目你可以作为公司的项目包装到简历里面,也可以作为找校招啊,找实习啊,也可以作为自己 学习的项目包装到 g m 里面,你可以直接应聘 a 业前端, a 业应用开发 a a n 的 a 业全段的岗位啊,那就是在 nice g s roundabout 大 模型,还有香香裤前端是用 v 三脸内里面,你就这么描述就行了,直接这么去描述。还有我们整个的项目的难点和亮点都给大家整理了, 怎么样包装,具体怎么样实现,这里面都有,包括这个原码,大家一定要跑一跑整个核心时间,就要整个 ai 的 项目的话,大家可以评论区留言。






