image2设置json
最近很多粉丝问我长视频怎么制作,场景怎么保持一致性,今天我出一个教程讲视频怎么制作,今天我们来制作一分钟的长视频制作方式,我这边是自己已经准备好了一分钟的分镜脚本。 首先我们需要准备我们道具提示词,制作出道具图片,打开画布,我们双截添加图片节点,把我们复制好的道具提示词放入节点里面,选择 emoji 二模型,选择十六比九的格式开始制作, 这里我们开始制作第二个道具图片制作我们还是选择相同的方式, 这里点击。制作之后,我们需要用到 deep seek 帮我们制作人物的三式图提示词包含脸部设计的 jason 格式的提示词。然后我们开始制作人物三式图,方法还是选择一麦指二模型制作, 这里 deepsea 已经在帮我们制作人物的提示词了,我们开始复制制作,复制我们的三式图,固定提示词放入图片节点里面,再复制我们的 jason 格式的脸部设计提示词,放入三式图下面,选择 emoji 二模型还是制作, 这里我们制作男主的三式图,方法还是一样的。 我们的道具和人物三式图已经制作完成,接下来我们就需要用到 deep seek 帮我们设计场景提示词,这里有三个场景,我们需要分开制作, 方法还是一样,复制提示词到图片节点里面去,我们使用制作场景和方法,基本上不需要抽卡,直接复制可以制作。 接下来我们开始制作分镜一的画面,这里我们需要把我们的人物主角参考图和场景参考图拉入我们的视频节点里面去,把我们准备好的固定提示词复制进去,让它给我们制作四乘四格式的分镜图。 这里还是一样,我们选择 image 二模型开始制作。 这里需要把我们所需要用到的人物和场景都艾特一遍,防止出错。 这里我们四乘四的网格图已经制作完成。接下来我们制作分镜一的视频,这里需要我们用到一个文本节点,把我们分镜脚本提示词放进去,拉文本节点,拉入视频节点,这样我们可以直接制作视频。 这里我们选择 sedence 二点零模型,选择十六比九的格式,选择四八零 p 开始制作。 视频制作完成,我们来看看分镜一的效果, 你还要装到什么时候? 分镜一看着还行。我们接下来制作分镜二画面的网格,方法还是一样,需要复制我们固定提示词,然后再把我们的分镜脚本提示词复制进去,再把我们所需要的人物场景都拉入进去,同样选择 emoji 模型还是制作。 这里由于这个平台的线不是很好拉入,我重复了很多次,有点不太习惯。这里我们需要整理一下提示词。 这里我就很纳闷我的背景音是哪里来的?我也没播放分镜一啊,有点懵逼。 这里我们分镜二的画面网格已经出来了。接下来我们开始制作视频,首先需要准备文本节点,放入我们视频分镜提示词,再创建视频节点,把我们的网格和文本节点拉入视频节点,选择 cadence 二点零模型开始制作。 这里我们分镜二的视频已经制作完成,我们先来看看效果。 分镜二的效果不错,我们现在制作分镜三的网格画面,还是老方法。 这里我们分镜三的视频已经制作完成,我们来看看效果。 你打我分镜三效果还不错,分镜二和分镜三合成的时候需要剪辑一下即可。接下来我们开始制作分镜四的画面, 这里我们分镜四的视频已经制作完成,接下来我们看看效果。 原来在你心里我一直都是这样的人, 这里我们就已经结束了。包子们,请问你们学废了吗?

粉丝4067获赞1.6万
相关视频
 01:48查看AI文稿AI文稿
01:48查看AI文稿AI文稿这个视频我就讲一下我们这个中转怎么用 image two 这个图片上传工具,当然它也可以做图片修改啥的啊,用起来其实非常的简单,我会给大家提供一个这个安装包啊,这个安装包你只要放在随便一个呃文件夹下面就可以了, 然后你在 codex 里面找到你放了这个安装包的这个文件目录,打开这个文件目录,然后跟他聊天,你,你说让他帮你装一下这个 skill, 然后他就开始装这个 skill 了。呃,装完装完以后使用这个 skill 也是很简单的,但是你装完之前,装完之后用它先重启一下。呃,具体怎么用的话就是 就是你一个对话里面如果没有用过 emoji 的 话,你最好就是先艾特一下,艾特一下这个 skill, 它是 c 开头的啊,你找到这个点一下,这样的话,呃,它这个 skill 就 被用上了,然后你可以告诉他,我这边呢,他的对他需求是生成一张二 k 的 风景图, 然后它会让你提供这个 t 找到 找到分组这里,然后设置一个 image q 的 分组,然后把这 key 直接粘贴给他,就可以粘贴给他,发给他,然后他接下来就会做处理了,这边生成了一张二 k 的 封印图,呃,这个效果是很好的,然后这个是图像生成功能,然后我这边 s 基础上,我就让他在 啊做下的图像呢修改,就把这张图修改成夜晚版本,这边也是给它弄好了,就是你一开始艾特过以后,它基本上是不用管,其实理论上的话不艾特也可以,它会可以自己找这个 skill, 然后这边还让它生成了一个四 k 的 风景图,呃,都没什么问题。
603朝日 10:53查看AI文稿AI文稿
10:53查看AI文稿AI文稿大家好,今天教大家在扣子调用 emoji 二,一键生成分镜图,并且支持多宫格分镜,我们只需要上传自己的剧本以及参考图,我们来看一下这一张整体的效果是非常不错,然后是十六宫格, 人体的画风以及人物的特征,文字的细节都非常的稳定,效果非常不错。那么接下来我会教大家一步一步的搭建,他的节点并不多,我们随便打开一个浏览器,在这里搜索扣子的网址 w 点扣子点 cn, 进入到主页之后,在右上角产品底点击扣子编程,左边找到资源库,右上角点击资源。工作流,名称的话大家都可以自定义拼音缩写工作流描述, 一键生成分镜图,点击确认。进入到工作流之后,它有开始结束两个节点结束我们先不管,首先在开始这里我们需要有几个输入,第一个 input 就是 我们的剧本, 第二个 key 就是 我们需要调用的密钥,第三个是我们的分镜数量, 第四个是我们最终的分镜比例,全部都描述一下, 然后是我们的参考图片,这里的话我是以四张图片为例, image 一, 然后依次到 image 四,这里名称都改一下,不能重复, 尽量类型全部选择 real image。 那么我们有了开始的所有变量之后,我们的第一步就是添加大模型,生成对应的帧进提示词, 这里改个名称。模型的话我们选择二点零 pro, 它的输入我们的剧本 input 以及分镜的数量 number, 然后视觉理解我们的资产。图片编辑一到这么一个,以编辑四 这个参考图片,如果说大家没有的话,就直接上传剧本和这个数量就 ok 了,这里系统提示词,我把它复制过来,系统提示词就是我们需要让这个大模型做的一件事,怎么去做,做成什么样子, 那么这一个内容他也不是固定的,大家都可以基于自己的要求去修改,这个提示词都是可以的,这个相当于是一个通用的。那么我们来看一下人体的一个内容主题,如这个什么汉服游园,都市夜景, 风格,写实真人风,二次元哦,复古胶片,治愈绘本、高级电商质感。如果说大家有其他的风格,可以在这里去修改,包括他的色调,光影, 然后分镜的格式,镜头描述加画面内容,然后画面要求分镜之间风格统一,衔接自然,逻辑连贯,没有多余杂物,构图工整,无水印,无乱码,无多余文字,这个就是对于我们最终生成的分镜图片的一个约束, 然后拒绝人脸变形,字体扭曲等等,都是可以基于自己的想法去修改啊。然后用户提示词,我们在这里描述,剧本就是我们的 input, 帧进数量是我们的 number, 以及我们的参考图片 image 一 到四全部引用上 它的输出,我们就默认 output, 添加类型,默认 stream。 我 们在这里的话可以来测试一下, 在这里的话就随便找了一个剧本,我把它复制过来。我们的第一集 我们的这个剧本它没有包含这个风格,如果说大家想做其他的,比如说三 d 动漫,然后其他的等等风格,就是可以在开始这里去描述一下, 我们在这里就做仿真人的分镜数量,因为它这个剧本是有一点长的,我们这个数量就填个二十五,点击运行。我们先来看一下这个提示词,它的效果怎么样,这里用了一分十七秒,把我们的剧本做成了分镜提示词,我们来看一下效果, 中间的是推理内容,然后 auto put, 我 们点击预览 整体创作参数,二十五个十六比九,然后八 k 超高清商用级无损画质,整体风格写实真人剧。 哇,我们自己没有要求这个风格,它默认的是这个写实真人,然后统一色调光影,一杠一,四个分镜一杠二,四个二三。那么接下来我们就需要根据这生成的分镜提示词对调用 mag 二生成对应的图片, 因为在这里我们是没有上传自己的资产图片,那么在有的情况下,我们还需要把这个图片给转换一个格式,添加代码称 处理,参考图片格式,它的输入就是的 mag, 这里重新引用一下,把这个 input 取掉,称也就变过来了。 o a g 二 i 四,它的代码,我们把它复制过来,这是一个 python 格式,在左上角,我们把它更换过来,已确认,然后重新粘贴它的输出,我们是 k 一 k 二,然后 k 三,变量类型都是 arraystring, 这个输入输出的名称和变量格式一定得对应上,不然这个代码它会运行失败。那么接下来我们找到 excel 的 这个插件, 搜索礼盒,往下滑,找到 gt 二,图片生成,点击添加它的 key, 就是 我们开始的 element 大 模型的 output 任务状态,我们选择同步处,参考图片就是通过代码处理的格式, k 一 k 二, k 三都是可以的,选择 k 一 它的比例开始的比例,然后分辨率,我们选择二 k 吧,我们选择二 k。 为了提高图片的生成成功率,我们添加一个选择器,就是当它生成失败,图片 url 为空的时候,这里创建副本继续生成 或者变量聚合。这个工作流很简单,返回的就是生成图片的 url 链接,连接上我们的结束, 最终返回的可以是我们的变量聚合。 group 一 节点名称的话,大家都可以自定义,我们点击试运行, 我们重新运行一次它的 key, 我 们在这里 ctrl v 粘贴过来。获取的方式我整理在了文档里,分镜数量二十五,我们还是以刚才的剧本为例,比例的话十六比九 只是一个剧本。点击运行在这里的话,我们可以稍微等一下这一个工作流,它是非常的方便,生成了提示词之后直接就调用了一 mag。 二,生成我们的图片 就不需要再更换软件,这个就是工作流的一个优势,像以前我去做这个分镜题二词,我还得打开豆包去复制,之后粘贴到生图软件 再去操作。那么在工作流里边,它都是全流程自动化的生成,但是每一个节点的业务逻辑需要我们自己去把控。我们的工作流用了五分二十四秒运行成功,在这里结束,返回了一个图片地址,我们点击查看 二十五个分镜,我们来对照剧本看一下城市街道入场哦,对着暴雨送外卖,这里有一个御景观二八零一抒情,这个图片上的文字信息都符合剧情 哦,到这个小区安和保开和保安这么一个交际,一杠二安利系保安哦发生争执,一杠三在楼梯的边里, 到一杠四的门口和这个苏秦兆东去做这么一个交互,然后一杠五 来看一下它第二十四个分镜和第十二十五个分镜的一个数字啊,这个文字细节和我们的剧本是不是一样的? 账户总资产二八四五六七八九,文字细节都是一样的,然后它的二十五个阿黑的消息已发出,但被对方拒收了,这个细节做的都非常好, 这个人物场景的一致性都做的特别好,以及角色的这个表情细节,运镜之类的看好来看一下大模型生成的这个例子, 你用了一分二十一秒这个提示词都非常简单,都是可以利用这一个内容去进行一个修改,来看一下它的帧帧整体创作参数。第一集 哦,写实真人短剧风,因为我们在剧本里没有标注这个风格,他默认的就是真人短剧,因为他这个二十五个分镜内容确实比较多,并且咱们是做的二 k 的 分辨率,这个时间四分钟左右都是比较正常的, 而且他的消耗都是非常的低。那么这个就是我今天教给大家搭建的工作流,从剧本再到分镜图,都是通过工作流 一步到位,全流程自动化生成,在做慢距或者短距的时候,都是能大幅提升我们的一个效率,而且特别的简单。今天的视频就到这里,感谢大家的观看。
14阀阀智能体 05:40查看AI文稿AI文稿
05:40查看AI文稿AI文稿哈喽,大家好,我是帅,用 image 二加 cds 二点零做 ai 视频。我现在最推荐的不是一口气生成一大堆的复杂风景,因为像 cds 二点零这种主流大模型的单条生成时间极限就是十五秒,你给它塞一堆的镜头, ai 根本无法理解并生成出对位的连贯画面,本质还是在瞅卡。 所以我今天将向大家分享一套我自己在用的可以生成连贯剧情,同时保持人物和场景一致性的 ai 视频。工作流教程中用到的提示词和步骤我都整理好了,让我们开始吧。 这套方法的第一步,需要先把我们的角色和场景定下来。比如这条片子里,我的灵感是一个女猎手在沙漠废墟中和一个男反派决战的故事。我们需要给 是先设定好场景和人物,所以我先生成了女猎手、男反派,还有沙漠废墟的场景图。第二步,把这些人物和场景图一起上传, 使用 gbt image 二模型,让它基于这些参考生成四乘三的电影分镜图。这里提示词不需要很复杂,重要的是要写清楚剧情和整个段落的节奏。 比如我这里写到的就是,这是沙漠中的最终决斗,女猎手来到男反派所在的废墟城镇,利用高低错落的建筑结构,完成一场节奏紧凑、见招拆招的对攻。 分镜出来以后,我不会只看哪一张图好看,而是先判断他有没有试听语言的逻辑。比如第一镜是远景,用来建立沙漠空间和人物进入。第二镜用过肩,是为了建立两个人的方向关系。第三镜给反派特写是为了让观众先感受到压迫感。 第四镜让你猎手拔剑是进入动作之前的节奏点,所以大家拿到故事版以后不要直接拿去生成,而是主要看三个东西,空间关系是不是清楚,动作方向有没有延续,紧别,有没有推进。如果有需要修改的镜头,可以再次对话让他去修改故事版。 建议大家在创作的过程中始终保持让自己去判断分镜的习惯,这一点会很重要。 接下来请注意,这张四乘三的分镜不能直接整张丢给 cds, 因为 cds 二点零单条最长就是十五秒,所以我会把它按行裁切。一次只用四个关键镜头去控制一段十五秒的视频, 然后我们就可以开始写图声视频的提示词了。选择全能参考模式,把我们已经才切好的故事版和人物图上传并引用后,我会把十五秒拆成几个三秒左右的段落,每一段都写清楚景别、角度、运镜和人物调度。 基本上大家就沿用分镜头中生成的镜头描述,并稍作修改即可。生成完以后我们会发现从一致性和镜头语言上来说,这条十五秒的视频都有很出色的表现。 接着同样的方法就是做第二段、第三段,第一段建立战斗关系,第二段进入胶水,第三段升级冲突,最后三条放到时间线,就能形成一条四十五秒左右的完整片段了。 讲完了基础用法,我再和大家补充几个使用上的关键点。如果我们需要视频有很强的人物一致性,比如说大范围的镜头运动或者是激烈的打斗,那在前期的时候,我们可以先去生成人物设定图,并把它加入到我们的全能参考阶段。 大家会发现无论镜头角度怎么变,人物都能够去保持一致性。另外段落之间的衔接也很关键,比如有时候前一组十五秒的视频和后一组十五秒的视频,由于是单独生成的,所以镜头无法很好的衔接。 那解决方法就是我们在第一段视频生成完以后,截取这个视频的最后一帧,然后把这一帧高清放大,再作为下一段视频的首帧参考上传, 并在提示时中强调画面开始与这张图片,这样第二段视频的开头就能衔接上一段的人物位置、动作方向和画面光线。 这里还有一个导演思维的抉择点,尾帧我们可以不用截在动作完全结束的时刻,而是截在动作即将要发生的瞬间。比如说我们的最后一个镜头是武器即将碰撞, 角色刚要转身的时刻,我们就可以选择它来作为我们的伪真,因为一个未完成的动作会给下一段一个继续发生的理由,这也就是我们剪辑当中常用的动式剪辑。 最后,当你生成完十二个镜头,如果你还想继续往下做,我们可以上传第一张分镜图和人物设定图, 让 emh 二继续生成下一页,四乘三分镜续写故事。这里的关键是,如果有新的场景,我们需要同步上传新的场景图片,这样我们就可以保持人物场景和镜头的风格一致性,无限的去延伸我们的故事。 所以这套流程的重点还是把 ai 视频拆回了导演的基本工作,角色设定、场景构思、分镜设计、人物调度、段落内容剪辑点等等。 视频模型在我看来肯定会越来越强,但是不变的还是试听语言的底层逻辑。我们还是要去判断这个镜头为什么存在,我们的人物关系有没有建立,动作方向能不能接住,以及我们的节奏有没有在推进。 好了,这就是本期视频的所有内容了,这套流程的工作文档和提示词我已经都整理好了,免费分享给大家。评论区打上 ai 工作流,分享给你。我是单专注于分享导演视角下的 ai 影像心得,我们下次见啦,拜拜!
1.6万Shine Ai 01:37查看AI文稿AI文稿
01:37查看AI文稿AI文稿codex 的 image 二功能大家用了吗?感觉这功能很强,但是我自己也尝试了一下,我怎么遇到点问题呢?一开始我让他输出一个大纲啊,这大纲也没有问题是吧? 然后呢,我紧接着让他去调用这个隐秘制的阵的这个技能去输出页面,风格就跟网上的博主一样,对吧?啊,好像他也调用了,但是在这就出问题了,就是他说我先用这个隐秘制的技能来做这个方案,但是呢,他又跟我讲没有 暴露独立内置的这个工具入口,就是我在这个技能里边是有的,但是在这就不行 啊,一起初呢,我还怀疑是我的这个提示词写的不好,就比如说这张图,感觉好像还像那么点意思是吧?但是感觉好像不是生出来的图片,而是他直接生成了一个前端代码,或者是这种 svg 的 网页的这种格式。因为他有的字是叠在一起的 啊,因为你比如说生图的话,他至少不会叠在一起,直到啊,直到我让他输出一个这个咖啡的照片,我发现问题出在哪了, 他好像就是这个直接生成的这种 png 格式的,就直接用 python 脚本跑的。但这个问题呢,我现在还没有解决,有没有知道的同学可以在线帮我解答解答,在线等啊, 如果有相同的问题的同学可以码住我,看看有没有大神能帮我们解决一下的。
132数字哥聊AI 06:58查看AI文稿AI文稿
06:58查看AI文稿AI文稿gbt 一 面值二加扣子工作流一键生成电商产品 s q 矩阵图到底有多简单?我们先来看一下效果, 我们可以看到效果还非常不错的,产品的一致性也给我们处理的非常好。这个就是我已经搭建好的一个工作流,它一共是有九个节点,搭建起来也是非常简单的, 现在我就按照我们的这个搭建大纲,大家一步一步搭建我们今天这个工作流,这个就是我们工作里的一个搭建一面,首先他会先给我们一个开始节点和一个结束节点,我们先点击下面注是把我们搭建大纲给他复制过来, 复制过来之后我们来看一下我们的搭建大纲。首先我们需要在我们的开始节点输入四个参数,分别是参考图、产品图、比例 key, 这个 key 呢就是我们的一个算力,我们点击我们的开始节点进来之后,他会先给我们一个默认参数,我们点击这个加号,再给他添加三个参数, 然后我们给他改个名,这里这个变量名大家是可以随便去修改的,但是只能输入拼音或英文,不能输入中文。第一个变量我就输入参考图,第二个变量我输入产品图,第三个变量我输入比例,最后一个变量我输入 key, 然后在参考图这里,我们需要把这个类型改为 file image 这个类型,在产品图这里我们需要把这个类型改为 array file image 这个类型,然后我们的开始节点就配置好了。接着我们来看我们的搭建步骤,首先第一步是循环生成体函数,我们给它拉出一个节点,将业务逻辑里面的循环给它添加进来,添加进来之后我们双击它改改个名, 把它作为我们的一号员工,然后我们给它配置一下。在循环树组这里,我们需要把我们开始节点这个产品图给它添加进来,然后我们给它改个名,给它改成产品图,然后我们配置下下面循环体,我们给它拉出个节点, 我们把这个大模型给它添加进来。添加进来之后我们双击它给它改个名,然后我们给它配置一下。首先在模型这里,我们选择这个豆包二点零 pro, 然后在下面输入这里,我们把这个变量给它去掉,在下面的视觉里也输入这里,我们点击这个加号,再给它添加两个变量。 在这里我们需要把我们开始节点这个参考图,以及我们一号员工这个 产品图给它添加进来。接着我们就来到了下面的系统体型词这里,它是我们整个大模型的一个核心, 它的一个作用就是告诉我们这个大模型它是谁,它应该干什么。我们的提示词写得越好,那么我们这个图片它生成出来的一个效果就会越好,这个我也提前准备好了,我们今天把它复制过来。复制过来之后我们来看一下我们这个系统体型词。首先它给我们定义了一个角色 演示,专业产品图像替换 ai 核心功能为将参考图中的原有产品一比一替换为用户提供的产品图, 主体产品全程保留参考图,所有非产品元素不变,实现无痕合成。接着他给我们定义了核心规则,输入要求、处理步骤限制等等。在下面的用户题子这里,我们需要同时按住 shift 键加大括号,把我们上面输入进来,两个参数都给它添加进来, 它的一个作用就是告诉我们这个大模型它需要拿哪些数据,以及在哪里拿数据,然后我们点击下面的异常处理,在这里我们需要把这个时间改为最大值六百秒, 然后把这个线给它连接起来,接着我们点击我们这个一号员工,在这里我们需要把我们生成体验词的这个 参数给他添加进来,然后我们来看我们的第二步循环生成图片,我们给他拉出一个节点,这里我们还是需要用到循环添加进来之后,我们双击他改改个名,把他做我们的二号员工,然后我们给他配置一下。首先在循环数组这里,我们需要把我们一号员工给我们生成这个题词给他添加进来, 然后我们还需要把我们在开始节点这个产品图给它添加进来,接着我们配置一下下面的循环点,我们给他拉去一个节点,然后我们点击插件,在这里我们搜索剪映小助手,然后我们找到这个,我们点开它,然后我们下滑找到这个字母转列表,我们把它添加进来, 添加进来之后我们双击它改改个名,再输入这里,我们需要把我们二号员工这个参数给它添加进来,也有这个艾特姆产品图, 然后我们再给它拉去一个节点,我们点击插件,在这里我们搜索米盒,然后我们下滑找到这个剪映小助手辅助工具,我们点开它, 我们把第一个爱的历史的给它添加进来,添加进来之后我们双击它,改改个名,然后我们给它配置一下。首先在第一个参数这里,我们需要把我们 图片格式转换的这个参数给它添加进来。第二个参数我们需要把我们在开始节点这个参考图给它添加进来,然后第三个参数我们不用管, 配置好之后我们再给它拉出一个节点,然后我们点击插件搜索秘盒,然后我们下滑找到这个 gt 二图片生成,我们点开它,我们把第一个给它添加进来,添加进来之后我们双击它给它改个名,它就是我们生成图片的一个插件,然后我们给它配置一下。首先它需要我们输入的第一个参数是 key, 这里我们需要把我们在 开始节点这个 key 给它添加进来。第二个参数是提炼词,这里我们需要把我们二号员工这个参数 item input 给它添加进来。第三个参数我们选择这个同步。第四个参数是我们的一个图片,这里我们需要把我们 添加数据列表这个参数给它添加进来。第五个参数是我们的一个比例,这里我们需要把我们在开始节点这个比例给它添加进来。最后一个参数是我们的一个分辨率,这里大家可以根据自己的一个需求去选择。然后配置好之后,我们把我们的这个线给它连接起来, 接着我们点击我们的这个二号员工,在这里我们需要把我们生成图片的这个链接给它添加进来,接着我们来看我们的第三步去除空值, 我们给它拉出一个节点,然后我们点击插件搜索密合,然后我们下滑找到这个长文代码块,我们点开它,然后我们找到这个数值列表,去除空数据,我们把它添加进来,添加进来之后,我们双击它改改个名,把它做我们的三号员工,然后我们给它配置一下,在输入这里,我们需要把我们 二号员工这个参数给它连接起来,接着我们点击我们的结束节点,在这里我们需要把我们三号员工这个参数给它添加进来, 然后我们的整个工作流就搭建完成了,我们可以点击下面的优化布局。今天这个工作流他还是比较简单的,他一共是有九个节点,搭建好之后,我们点击下面顺序,然后在右边这里,我们只需要上传我们的一个产品图,输入我们的一个 key, 接着输入我们图片的一个比例,然后上传我们的一个参考图,接着点击下面的试运行,他就会一键给我们生成电商产品 sku 矩阵图,效果还是非常不错的。好了,以上就本期的全部内容,我们下期视频再见。
32小李AI 11:23查看AI文稿AI文稿
11:23查看AI文稿AI文稿今天带大家一起搭建一套能一键生成通用的电商详情页扣子工作流,我先给大家看三个案例,一会带大家一起搭建这条工作流,今天的工作流还是蛮简单的,你跟着我的节奏来,你也可以搭建出一键生成这样的产品详情页的一个工作流。我们先看哪个产品案例, 首先我输入的是一张女装上衣,然后输入他一个对应的类目,他就会给我生成这样一个精美的一个详情页图片,他的一个对比图,来一个正面反面,还有他的一个细节图, 佩戴图,还有这个背景是完全对照衣服的一个风格来进行深层的。然后第二个是一个女装的一个毛衣,这上面的一个图案,一个还原度完全没有问题。还有一个细节图片,还有一个展示图片,然后第三个就是一个化妆品,一个口红, 一个细节图,还有它的一个精美展示图片,而且它的分辨率也是高的,这些我们都可以调节,我这边生成的是一个二 k 的 一个图片,然后接下来开始搭建我们的一个工作流,我们首先打开扣子工作流的一个界面,然后我们配置一下开始节点,还有以及我们的一个注视, 首先都是我们叫啊先生成图片的一个提示词,再进行生成一个图片,就总体是大概的一个流程,生成图片提示词,然后就是生成图片进行输出一个大概的一个思路,然后往这里放,我们先开始配置一下我们的开始节点,我们这边添加五个 啊,把 b 填勾选项,首先第一个就咱们的一个 k, 一 般后面调用到咱们的一个插件的一个命令,需要用到它。然后第二个咱们填一个数量, 数量就是你后面要生成几张图片,你就在这里填就行了。然后第三个就咱们的一个比例,第四个是咱们的一个产品图片, 然后最下面再我们再添加一个类型 类型,这也就是他,你他会根据你输入的不同的类别,就比如说你选女装,他就会输入到女装大模型的一个提示词里面进行生成提示词,然后进行输出,如果是化妆品或者是其他的通用的,他就会输入到对应的一个大模型里面进行生成, 然后开始节点,我们配置好了,我们现在开始配置第一个节点,我们先添加一个插件,在这里搜索,然后找到这个搜第三个字母串转列表,它的作用就是图片转数组, 他要把前面输入进来的图片转成数组,然后再进行输入到生成图片生成图片的插件里面才能进行使用。然后这边输入,我们选择开始的一个产品图片,我们这边改成一个图片的类型, 然后我们这里就可以选择开始的一个图片,然后异常处理,咱们再填六百秒, 然后我们要再给它添加一个分别识别一个类型的一个插件,我们这里拉出来,然后找到下面选择一个意图识别。意图识别就比如说刚刚前面说到过的,你如果选择女装输入女装, 他就要给你分配对应的一个大模型进行生成提示词,然后这边选择意图识别,我们这边选择开始节点的一个类型啊类型,然后意图是匹配啊,咱们你这边有什么需求都填对应的类型,我这边填女装,然后第二个咱们填一个 化妆品,然后这样子就可以了,然后我们这边连接一下它的三个节点,首先我们先添加一些大模型,第一个我们选择是一个女装,选择大模型,然后改一下名字, 女装图片提示时生成,然后配置一下它的一个系统提示,我们先把它模型改到最新的,然后提示我这边已经准备好,直接复制粘贴进来啊,复制粘贴进来,然后最上面这里 我们这里选择三个,首先第一个咱们选择产品的一个图片,然后第二个咱们选择一个数量, 然后第三个咱们选择一个比例,然后下面这个引用的一些, 这边是蓝色的就代表引用成功,如果是灰色的,你就要改一下他名字,把这个名字给对应上去啊, n u m, 然后对应这个数量,然后下面检查一遍, 然后没问题,我们这边引用一下用户的一个提示词,用户的提示词就是要大模型成功接收到我们的一个指令,从而进行输出,然后我们换成英文输入法,按住 shift, 按住括号,把它们三个都引用进来, 你用完之后呢?它是一个多个数据进行输出嘛,我们要改成一个数组类型,数组数算,然后异常处理都改了六百秒。然后这边第二个化妆品,我们再加一个大模型,一样同理把它模型换成最新的,然后输入,我们选择开始的一个 比例,还有咱们的一个图片和咱们的一个数量啊,这边就已经选择好了, 然后系统提示词我这边已经准备好,我直接复制粘贴进来,然后这边也检查一下它的一个引用名字,它有没有引用成功,是蓝色的就代表引用成功。然后我们继续改下面的,把它们一个系统提示,把我们的一个用户提示都给引用进来,换成英文输入法, 按住 shift, 按住画框,把它们都引用进来,然后输出这边改成数组,这个算形式,一档处理改成六百秒,然后这个改下名字化妆品, 然后就是第三个一个大模型,第三个他这边是选择了一个其他他其他的意思就是假如你这边选择的是女装,他就要从这里传输到女装大模型提示词生成,然后进行生成提示词,如果是化妆品,那就对应第二个, 如果这两个你填的都不是他们两个,他就进行到第三个,一个通用大模型进行生成图片提示词的一个模型里面进行生成,我们改下名字,通用电磁, 然后我们配置一下它的一个输入输出,这边一共要引用四个,第一个咱们的一个产品图片,第二个咱们的一个比例,第三个就是数量, 然后第四个就是咱们的一个类别,选择这个类型,然后系统提示时,我这边复制粘贴进来,然后引用成功。之后呢,这边用户提示时一样把它们都引用进来,换成英文输入法,按住 shift 把四个都引用进来。 然后呢输出这边也是一样,选择咱们的一个宿主轴串啊,因为是它是一个多个类型进行输出, 单个的话它就选宿主串,然后这边我们这里配置完之后呢,我们要加一个变量聚合,把它们是多个数据给串成一起,然后进行整合输出 连在连接在一起,然后我们把他们三个的一个输出都给组合在一起,这边都选择他们的一个输出就行了。选择第一个输出,然后第二个的输出和第三个啊,这个节点就已经生成完毕,我们现在开始要生成图片了,我们这里加一个批处理, 然后配置一下它的一个节点,我们这里选择二,并行数量选择二,然后输入,咱们选择变量聚合,然后我们配置一下它 p 处里面的一个插件生成图片, 然后我们这里添加,然后在这里搜索找到找到这个插件,直接点击,然后改一下名字, 图片生成,然后我们配置一下它,配置一下它的一个节点,我们这里选择第一个就咱们开始的一个命令 k y, 然后我们直接选择开始节点的一个命令。 第二个咱们的一个提示词,提示词咱们已经传输到变电聚合,变电聚合再传输到这里,然后我们直接从这里拿提示词就可以了,批处理 它。第一个选项,然后在下面呢,这里就是选择一个比那个生成的一个模型啊,选择咱们的一个 g p d 音频 g 二,只要复制粘贴进来跟我选一样的就可以了。然后再下面就是选择咱们的一个一个比例啊,这里选择了一个比例,我们直接把前面的开始键的比例给引用过来, 比例,然后在下面这就是一个参考的一个图片,我们这里直接拿前面已经图片转数组的一个图片给我们连接过来, 要不然你直接拿他输入的一个图片,他是输入不了的,他会报错的啊,直接选择他就可以了,他就完美适配了,然后这一个节点就配置好了,我们再再给他加一层保险,他有时候算力拥堵吗?这个模型太火爆,算力拥堵,我生成超时,我们加一层保险,加一个选择器, 选择器这边选择图片生成的一个 url, 就是 它生成图片的一个数据,咱们选这里为条件选择为空,不为空,不为空,它的意思就是假如它生成成功,就是一个不不为空的数据,直接走上面进行输出,如果生成为空,就是一个为空的数据,走下面直接进行二次生成, 再加一个这样子一样的插件,我直接复制粘贴过来啊,把它给它连接上,然后看一下它的一个键有没有问题,这里配置完毕呢?然后我们在这里添加,假如它生成成功,直接进行输出,我们加一个变量聚合,跟前面一样,把它们两个的数据串在一起进行整合输出, 选择他们的一个图片的一个数据 url, 还有图片生成的一个 url, 他 们两个生成连接完之后呢,直接连接尾部给它进行输出。好,输出,这里就选我们的一个变量聚合就可以了,然后并行数量选择二, 然后这个生成图片就已经配置完毕了,然后把它直接连接到我们的一个结束节点,选择生成图片的一个 p 处理, 现在整个工作流程已经搭建完毕,我们现在开始试运行一遍,我们开始试运行一下,密钥我也已经准备好了,我直接复制粘贴进来,然后这还有一个比例,我们这我这边填三比四,然后它的一个类型,我这边上传的图片是一张女装的图片, 然后直接选女装,然后再选择一个数量,你要生成几张图片,我这边选择五张,然后开始试运行一下, 开始运行之后他会传输在这里开始转组,再传输给意图识别输入的是女装,他就要进行女装,这边传输给女装这个大模型,提示时进行提示时生成,生成完之后他就会聚合在这边,然后再进行生成图片开始生成, 然后咱们的一个工作里也是运行成功了,可以看一下咱们的一个输入的一个图片,然后输出出来的一个模特佩戴图,模特的一个场景图片,还有对比他的一个正面,反面一个反馈和这个一个特点,一个细节图片。然后第二个我输入的是张毛衣的,他这边还原度也是特别高,还有他的一个细节图片,他的一个 场景模特佩戴图都是完全没有问题的。第三个是一个美妆的,我这边输入的是一张口红,然后他这边输入输出的是一张 模特拿着这个产品,还有右边这一侧的一些卖点。还有第二张是一个特点特景展示图片,第三张就是一个,然后第四张就是咱们的一个产品的一个特点,一个 工艺给它展现出来,然后今天的视频先到这里,别忘了点赞加收藏,下期还想看什么类型的工作流,可以打在评论区。
48老王勇闯智能体 02:32查看AI文稿AI文稿
02:32查看AI文稿AI文稿还在用花里胡哨的故事版,你是不是跑的?故事版经常有分镜图错误,是不是故事版跑的建模很精美,但是补镜的时候傻眼了,跑的画风完全不一样。故事版字不清晰,视频不按故事版走。今天教大家故事版最实用的用法,分镜线搞图先看视频, ahh ah ah ah uh uh uh 每条十五秒视频可用率在百分之九十以上,通过剪辑基本上不需要补镜,大大提高制作效率和成功率。主包目前故事版使用 emoji 二、制作分镜词,用 gpt 制作,制作简单实用的分镜图,不需要提示词, 直接描述就行。拿此故事版举例,本次六个分镜,所以制作六宫格,九个镜就制作九宫格。故事版的另一个好处就是可以参考上一个故事版来保证一致性,这点相信是大家最需要的东西。 大家看一下三十镜结尾图片,男子躺下的状态和小土坡是不是和三十二保持的高度一致? 下面看一下制作视频的方法。首先你主角需要一个四 k 大 头肖像加三十,保证脸不跑偏,一张难配一个故事版。把你做好的分镜词贴在对话框,这种高速打击仿魔女的风格提示词可以自行截图,下面直接写,参考 it 故事版,点击生成。今天内容就到这里,下期见!
3302老白Ai漫剧 09:34查看AI文稿AI文稿
09:34查看AI文稿AI文稿有宠物种草带货图纹呢,其实是很简单的,用了这套工作流呢,只需要上传参考图和卖点,就能够一键得到像这样的效果图,是不是非常好用呢?我先带大家看这两个案例,然后我会一步一步给大家拆解制作流程,小白也能够轻松上手。 大家可以看到呢,生成的这套图片不仅画面呢非常精美,而且它是有一整套趋势流程在里面的,包含了痛点共鸣,可不支持槽点罗列,产品等场融入场景细节特写等等,让用户了解为什么要使用这个产品,以及使用了之后呢会有什么变化。 像我选择的这两个案例,一个是猫抓板,第二个是呢,一个是磨牙玩具,这两个产品的展现都是非常好的,那么现在呢,就话不多说,直接带大家来拆解这个工作流, 那么现在呢,就拿上我们的搭建大纲,来到我们的一个新的开发界面。好,到这里之后呢,我们先把结束节点放一边, 点击下方的注试,把我们刚才粘贴的这个搭建大纲给它粘贴过来,有他在这里,我们会搭建会更加的清晰。好,那我们就直接看到开始节点,我们这里呢需要产品,图片,卖点、战力和我们的一个图片风格, 那这里就一项,那我们就按照我们的需要的依次添加上,然后呢把他们的名字分别给它改一下。 好,这里呢我们的图片需要给它改一下,变了类型,所以这里我们找到这个 file, 再找到这个 image, 这样设置就没有问题了。如果说你想要上传多张图片呢,那这里呢,我们要找到这个 re, 再滑到这个 file, 找到 image, 这样的话就可以上传我们的多张图片,那开始节点呢就配置完毕了,我来看到第一步 我们要用代码节点来转换格式,转换呢就是图片的格式,因为我们后面用到的生图插件呢,它的格式是不是可以开始的一个图片类型,所以呢我们要给他进行一个转换,在这里呢我们点击添加节点,找到这个代码,把它拉过来之后,我们先给他改个名字。 好,这里呢输入,我们拿到我们开始的一个图片。好,这里呢我们在这里编辑,然后把原本的代码呢都给它删掉,然后把我们写好的代码给它粘贴进来。这里呢输出,我们只需要留一项就可以了, 这里是个变量名,要使用我们左边的这个变量名字。好,这里的输出呢我们要把它变为 arraystring, 这样呢就没有问题了,第一步我们也就完成了,我们来看到第二步用大模型呢来生成我们的图片的一个记事词,所以这里呢我们要添加上一个大模型,然后呢先给他改名字。 好,这里我们来配置一下。模型呢,我们要使用带有图片理解的,这里呢我们就使用这个二点零 pro, 那输入这里呢我们要加上两下,第一个呢拿到我们的一个产品卖点,第二个呢拿到我们的一个图片的风格,我们想要的一个风格视觉理解呢,我们这里加上一下,拿到我们开始的一个图片。 那下面呢就是我们这个大模型里最重要的一款系统记事词,它呢就决定了我们出图的好坏,我们把写好的记事词给它粘贴进来,这个记事词真的是写了我非常长的时间啊, 它包含的一些点呢也是非常详细的,包括我之前说的趋势流程,这里面也有体现,像托尼共鸣啊,科学科普都是在里面的。 好,那我们看到最后的一个用户提示词,我们呢在英文输入法的状态下,按住 shift 加左滑括号键,这样呢这些就会弹出来,我们把它呢分别的给它引入进来,然后在前面我们给它稍微的备注一下。 好,这里写完了之后呢,我们看到这个地方,这个知识续写啊,一定要给他打开,因为呢他这个输出的一共是九张图片的一个记事词,是非常的长,如果说不开这个呢,他直接会把我们的这个记事词给他截断掉,导致我们后面的他就会报错, 然后异常处理。这里因为我们的这个提示词非常长啊,我们就把它设置为六百秒,这样呢它就会减少报错。重试呢我们重试一次备选模型,我们要选择带有图片理解的,我们就选择这个一点八就可以了 啊,这里呢还有一个比较重要的一点,因为它输出的是九个元素,在计时词里也可以看到,所以这里呢变量类型我们要采用数组的形式,我们在这里再找到这个 string, 这样设置就没有问题了。 在这里第二步我们也就配置完毕来看到第三步要批量来生成我们的一个图片,这里呢我们就要添加上一个 p 处理的一个节点, 先把线给它连上,这里呢我们把变形数量设置为三,太多的话呢,他很容易报错。那输入这一块,我们正好拿到生成图片提示词的一个输出。 好,下面我们来配置一下处理器里面的内容。这里呢就需要我们的深图插件了,也就是我们的 emoji, 我 们点击添加节点,找到插件,在这里搜索,我们往下滑找到这个图片生成,点击添加,还是先改个名字 好,这里的配置呢,我们给它配置一下,拿到开始的一个三列格式词呢,拿到批处理传进来的一个格式参考图片,我们就要拿到前面转换图片格式的一个输出比例呢,这个是根据我们的需要自由调节的,这里呢我就选择九比十六 分辨率,我们这里一 k 就 用了,就够用了,如果说你有更高的需求呢,我们还可以设置二 k 或者四 k 的, 这些都是可以的。 好,这一步呢我们就配置完毕。但是生成图片呢,他是需要一定时间的,而且呢他可能会因为某些提示的原因他会报错,所以呢我还要给他一个进行兜底的机制。这里呢非常处理,我们给他改为六百秒, 这里呢我们执行一个哎异常流程,在后面我们添加上一个选择器,如果说他这个生成图片的这个 code, 也就是他这个码,如果说是不等于两百的,就说明他是生成失败的,因为只有两百才说明他是生成成功的, 所以呢如果说他不等于两百,就说明他生成失败了。这里呢我们需要把他的提示词给他优化一下,再进行一个生成,所以呢这里我们加上一个大模型来帮助我们优化这个提示词, 因为优化记事词呢不需要特别好的模型,我们呢就选用他给我们的就可以了。输入这里呢我们拿到哎批处理给我们传进来的一个输入,这就是记事词,那这里呢把我们准备好的记事词给它粘贴进来,然后变回记事词,也是按照刚才的方法, 这样呢就没有问题了。这个用户记事词优化好了之后,我们再接上一个哎图片生成,这里我已经收藏了,所以可以直接使用,或者说呢我们直接在这里创建一个副本也是可以的。 好,这里呢我们就要把它的记事词的来源给它改一下,改成这个优化记事词的一个输出。 好,剩下的呢我们都不需要进行改变,这些就是没有问题的。然后呢我们要把这两个生成的都给他汇总一下,所以这里呢我们需要一个变量聚合,这里先拿到我们一个正常视频的, 这里第一个呢就是我们的生成图片的一个链接,第二个呢就是哎把这个线先给他连上,第二个就是我们生成图片二的一个链接。好,这样就没有问题了,再把最后的线连上。 好,这里呢我们也就配置完毕,这一步。好,配置里的输出呢,我们要拿到哎变量聚合的一个输出。好,这里呢我们基本就配置完毕,把我们的结束节点也给他拿过来, 你看到我们这个工作流它的节点呢是非常少的,所以说呢是非常好上手的。好,这里呢我们点击顺行。好,对结束变量,我们要把它再拿到 在 p 处里的一个输出,我们再点击试运行。好,这样就没问题了,这个时候呢把我们需要的参数呢都给它填上, 那这里呢可以看到我已经上传好的我的一些参数,这里呢我选用的是一个猫咪的一个毛绒玩具。卖点呢,我也写上了这个图片的风格呢,我写的是最可爱的,那这里呢我们就点击试运行。 那这里经过了一段时间呢,我们的图片已经生成出来了,我们来看一下效果,第一张的图片,第二张的一个科普, 可以看到效果是非常的好的,所有的图片呢,这里我也就不一一给大家展示了。那今天的工作流分享呢,到这里也就接近尾声了,希望呢每个人都能根据这个视频呢搭建出属于自己的工作流,那我们下期再见。
31晓尘-AI智能体 07:03查看AI文稿AI文稿
07:03查看AI文稿AI文稿你安装的 code 叉是不是也这样?没有 open ai 的 账号就不能正常使用?本视频教你,没有国外的 open ai 账号也能正常使用 code 叉。这里我们打开电脑上自带的这个微软应用商店,然后在这里搜索 code 叉,搜索之后,这里的话我们选选择这一个图标的, 然后这里是已经安装好的,所以它显示打开没有安的话,我们点击获取,等它安装结束即可。安装结束之后呢,我们点击这里, 然后找到这个 code 叉,然后这个 code 叉它默认的话是使用呃 open a a 的 账号来进行登录,我们在国内没办法正常使用,所以的话我们先不要打开它,我们去到这个 来到这个 c c switch 的 啊界面之后呢,我们选择这里点击一下,然后等它来到这里之后,我们直接划到这个页面最底下, 这里我们根据自己的电脑系统的版本来进行下载即可。 windows 的 话我们就直接下载这一个,然后这里是因为已经下载过了,所以我就不点击下载了。然后还有我们也要如果是 mini max 的 大模型,大模型的话我们就选择下载,把这个也下载下来, 然后这里我也是已经下载,我们就点击这里下载就好。这里我已经下载好了,我们就不继续下载了。下载之后的话,我们就直接去这边打开吧这里然后这个是 c c switch 的 开源项目,我们直接双击运行它, 我们就直接点击下一步,然后这里是让我们去选择这个安装路径,这里的话我把它安装在 c 盘,安装在 d 盘吧, 我直接点击安装,点击下一步,然后这里直接点击安装,然后这里就等它安装结束,这里我们把这个勾选去掉,然后点击结束,结束之后这个 这个我们 mini max 的是使用 mini max 大 模型才才用到的,如果不是 mini max 大 模型的话,需要去选择其他的,可以自己去找相应的开源项目,这里我就直接把它解压, 这里剪下之后的话,我们直接在这里,然后打开这个,这里它有需要你安装的,然后我们本地的话是需要安装这个 node js, 这个的话可以看我上一期的视频去安装,然后这里的话我们就直接把这个命令复制一下, 然后我们点击这里,我们直接输入 cmd, 然后回车,在弹出这个页面里,我们直接复制粘贴一下,然后回车。好,它现在已经在安开始安装依赖了,然后我们这里就会多了一个文件夹, ok, 它显示已经安装,音量已经结束。好,我们现在就把它这个点给关闭掉,然后我们点击这个,我们点击运行这里,运行到这里的话我们就不用管,然后我们就打开我们的安装的那个 cs 微棋, 这个是我们安装 cs 微棋的这个图标,我们直接双击它, 然后这里你如果是第一次使用的话,那默认是这里,然后我们要选择这一个,这里我还是,虽然我已经重新安装了,但是因为之前我是安装过的,所以我这边已经是已经配置好的, 如果是第一次使用的话,我们是需要点击,我直接把这个删掉吧,这个删掉先启动下这个,把这个给删掉。 好,我们现在来重新配置一下,这里的话我们选择这里的 open a, 然后之后我们点击这里的加号,这里我们供应商这些我们就不用管,这里我们就随便填我这里我就填这个 mini max 吧,因为我自己用的是这个模型,然后这里的 api key 我 们也是随便填 这里的请求地址,请求地址的话我们就是把这个运行在这里这里给复制一下,然后把它粘贴到这里来, 这里的话我们模型的话我们选择这里都复制一下 往下滑,这里我们是一定要勾选上,勾选上之后我们就直接点击添加啊,我们现在这里已经添加,然后进这里的话,我们点击这个启动, ok, 已经切换了,那这里我们可以进行测试,这里测试应该是会报错的,因为这里我们还没有填这个东西,就我们还是去到这个 这里,这里面我们是需要把这个配置文件,这个我们先复制一份, 然后把这里给改掉啊,这里的话我们把后面这里给去掉, 我们点击四啊,这里我们一定是要这个点 e n v 的 这样子的格式,然后之后我们点击用我们的这个记事本打开,打开之后的话,这个是我要这里要填入你自己的 mini mag 那 个 api key, 然后每个人我们可以自己去获取一下就行了,那这里有因为 api key 比较私密,所以的话 我就不让大家看到了,把它删掉,然后我去把我的给粘贴过来复制一下 啊,然后这里我已经把这个秘钥给配进去了,配进去之后呢,我们这个界面还是要关闭重启一下, 就这个这个界面,我们直接把它给关闭掉,然后我们就点击这个双击一下,等它启动起来,点击运行,因为它现在已经启动起来了。启动起来之后呢,我们这里再点击一下这个测试, 因为他现在表表示已经正常能正常使用了。然后呢正常能正常使用之后,我们就可以把它给擦掉了。然后现在我们再打开我们的这个 color 叉,然后我现在问一下他,你的 他现在已经回复我了,然后其实他这个回复呢也是在这里会看到的。 然后最后界面我们是不能关闭的,不然关闭的话我们这个 qq 叉就不能正常使用了。我的这个 qq 叉默认的话是其实我们安装的时候它默认都是英文的,然后我们要如果要改变这个,呃四 plus, 我 们就选择这个 setting, 然后找到这里,就这里的我们直接找到往下滑这里我们把它改成中文就行了,这样子我们的 control 它就能正常的使用了。
8565阿疯AI自修室 01:19查看AI文稿AI文稿
01:19查看AI文稿AI文稿codex 加 html 才是做 ppt 的 王炸组合,今天教你用 codex, 只要四步就能做出可以编辑修改的精美 ppt。 第一步,上传你的文档,让 codex 根据你的文档生成 ppt 大 纲和主页内容,这里的大纲就是后续 ppt 的 内容框架。第二步,让 codex 调用 html 这个 style, 根据刚才的大纲生成三版不同视觉风格的 ppt 预览,以拼图形式输出。 这一步我们是为了快速选择合适的视觉风格,我更喜欢这一张。第三步,让 codex 寄予我刚才喜欢的视觉方案,继续调用 image 帧这个 skill, 将拼图中的每一页依次生成高清单页视觉稿图片。 和直接生成 ppt 相比,先生成视觉稿能更好地利用 m h two 模型的构图设计能力,露出的 ppt 会更有设计感。第四步,也是最重要的一步,复制我这段已经调教好的提示词,让 codex 把单页视觉稿图片还原成可以编辑修改的 ppt 文件。 这里我建议每次单独还原一页视觉稿,如果效果不满意,重新生成会更方便。我这里先还原第五页视觉稿,看下效果。可以直接用 wps 打开,我们可以看到这页的还原效果很好,而且可以随便编辑修改 ppt 内容。 接下来我们对剩余每一页视觉稿图片都执行刚才的操作,最后把得到的多个 ppt 文件合并起来,一份充满设计感并且可以编辑修改的 ppt 文件就生成好了。
1.1万不写代码的盖朵 01:40查看AI文稿AI文稿
01:40查看AI文稿AI文稿m g 二,你真的用对了吗?很多人只是把它当做一个身图模型,其实它最厉害的地方就它能把复杂的内容整理成一张清晰、简单、易传播的视觉笔记。今天给大家整理了七个超实用的场景。 第一种,个人形象分析,上传一张自己的照片,它可以帮你分析适合的穿搭风格、发型方向、眼镜配饰的一个搭配,甚至还能做娱乐化的手相关键词可以这样子写。 第二个,学习历史,历史书上面全都是文字,看起来真的特别的累。你可以直接让 english 二把某个朝代,某个人物,历史战争过程整理成时间轴或者是关系图,看图学习比直接啃文字效率多了。 第三,坐在教程想做什么菜,直接把菜名给到他,他可以把食材、步骤、火候还有注意事项图文并茂的呈现给你。如果你再加上小某书风格,马上就能变成美食博主的素材。 四,育儿计划孩子每个阶段要做什么?你可以让他根据宝宝的月龄,生成喂养计划、早教互动、睡眠计划、成长记录表等,一张图就能把一天的育儿重点讲清楚。 避坑指南生活里面有很多新手容易踩坑的事情,你只要告诉他具体的场景,他就能整理出常见的误区。避坑建议正确的做法,直接生成一张清晰的指南图。第六,生活小技巧比如冰箱清理、衣柜收纳、旅行包打包、家电的保养,一张图就能秒懂。 第七,学习科普很多知识用文字是很抽象的,换成图片就特别直观了,植物细胞、 ai 工作原理都可以让 emoji 给你们生成图片,复杂的信息瞬间变简单了!以上提到的所有题字词已经打包好啦,有需要的自取。觉得今天的视频有用,记得点赞收藏关注我们下期见!
127花花AIGC研究室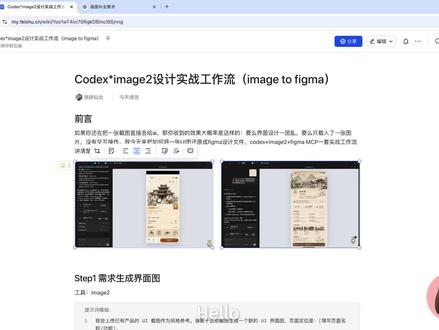 03:46查看AI文稿AI文稿
03:46查看AI文稿AI文稿哈喽,大家好,如果你还在直接把一张截图丢给 ai, 希望它帮你还原成原型,那么你收到的效果大概率是这样子的,要么就是视觉效果一团乱,要么就是它仍然贴入的是一张图片,不是可以交互的原型。 那如何将这张图片还原成为 figma 可以 编辑的设计原文件呢?今天我就想教给大家一套实战的工作流,用到的就是 codex 的 新插件和 image 二的模型, 主要分为五个步骤。第一步,你需要调用 image 二,先帮你将需求生成一张界面的图。 我这里是希望它基于我原有的设计风格帮我去构建一个新的二级页面。我也指定好了它的功能,这里是它生成的效果大致是符合我的需求的。 在这里值得注意的是,你可以先让它生成一段分析和方案,等你确定以后再生成你的 ui 界面图。 第二步,你需要用 codex 帮你将图片转换成为交互的低保帧提示词。里面注意的点是,首先你需要调用这一个插件, 最后需要做一次视觉的 q a。 这个功能是新插件里面带有的 skill, 你 只需要提到了它这个点,它就能自觉地进行调用。那还原的效果大致是这样子的, 这个里面它所有的交互的按钮都是可以点击的,而且它已经区分好了图标和图片的占位符,后续生成好了就可以直接进行替换。 第三步,你需要继续用 image 二去生成图片和图标。生成以后呢,它会提取 ui 界面图里面所有的图片去一个一个生成。 我建议大家将所有的图片素材都新建一个文件夹,然后保存好,方便后面 codex 直接进行调用。第四步,你需要用 codex 帮你将高保证的页面去进行完善。 提示词里面需要注意的点是,在开头你需要调用 product design 的 这个插件,在中间你需要提到 image generation 的 这个 skill, 你 需要去提到 image 二的模型, 否则它是不会调用这个模型去生成的。最后也是要做一次视觉的 q a, 避免了你自己进行反复的调整。那这是我第一次生成的效果, 大致的低保真交互是都有的,那我可以再用 codex 的 注视功能去进行调整。还原的效果是这样子,有的同学可能觉得这些地方没有达到百分之百的还原,我后面用斐格码直接去调整,会更加直接也更快。 最后一步呢,就是输出 fig 码的原文件了,你需要提前在 codex 里面去匹配好 fig 码的 mcp, 如果还没有匹配的同学呢,可以加入群聊,我已经把教程发到群里面了。 提示词在这里,需要调用 codex 的 新插件和 fig 码 mcp, 在 fig 码里面新建好一个画板以后,把这个画板的链接发送到这里,并将这一段提示词发送给他。 最后的还原效果是这样子的,布局和试衣稿里面差不多,还原程度达到了百分之九十五以上,里面的文字都是可以编辑的,里面的图片他也已经都替换好了,并且他还会提取你这个页面里面常用的一些设计组件, 你只需要进行一次的修改,也节省了你的工作量。那我已经把今天所用到的一整套提示词发送到群里面呢?下一次我将会继续调用 codex 的 新插件,在现有的界面基础上,结合交互组件,看能不能进一步的提升 ui 设计的效果。
1572浪味仙女爱设计 01:31查看AI文稿AI文稿
01:31查看AI文稿AI文稿gbt 一 米纸兔电商批量生图,实力来了啊,那不管是做国内还是做跨境电商都可以用它,不仅可以做这个风格迁移啊,还可以做这个原创的这电商图,而且是批量生成,而且可以批量下载的啊。 好,那么看一下这个,这个是我刚刚从某宝上面扒下来的一些产品的详情页,那么很简单自然语言跟他说,提取我发的这十张电商图片的纹身图信息,给我十个对应的图片提示词,给我提示词后,我就要给你发新的产品来做产品迁移。思考六秒之后,就哐哐哐给我出了这个对应的这个提示词。 做完提示词之后,我直接把我要做的产品直接发给他,直接按照这十个提示词给我做产品的详情图,将宽高比设为九比十六。在经过这个两分二十五秒的思考后,他给我出了这一套产品的详情页,可以看到啊,这个质量是非常的高的,最关键的是这个一米 g two 对 这个中文的识别和理解做的是非常的好,我们可以点击这个我们的产品丢进去,说这个美国亚马逊和详情页, 他也是经过二十一秒后的思考后呢,会给到十个提示词,那他会直接问我说是否要直接生成详情页,两分三十三秒就出图了啊,他会有这种不同的细节图以及场景化的, 以及它自己联想的一些角度,还有一些对比。那这套产品我设置的是俄罗斯电商,可以看一下它这个场景画作的非常的细致。好,那么下期我们再讲一下如何用 codex 把这一套工作流程给它做成自动化的,那么使用这套工作流程是真的可以让 gpt 成为你的作图 agent, 抓紧去试试吧。
2.8万阿达的AI思辨 01:21查看AI文稿AI文稿
01:21查看AI文稿AI文稿用 ai 做 ppt 最蠢的方式就是上来一句帮我做个 ppt。 这样出来的东西往往不是 ppt, 而是一堆长得像 ppt 的 文字块。真正好用的方式 不是直接让它生成,而是把做 ppt 这件事拆成一条流程。我的做法是,大纲交给 codex, 画面交给一面积二,先让 codex 根据大纲 把每一页的标题、核心观点、页面结构拆出来,然后再让他给每一页生成对应的配图提示词,交给 image 二去出图。这样出来的图 不是随便配一张素材,而是每一页都能跟内容对得上,而且整体风格还能统一。图出来以后,再让 codex 把标题、要点、图片、版式一起组装成真正的 ppt 文件。所以它不是一句话生成 ppt, 而是 codex 负责结构和排版, image 二负责视觉素材。这样做出来的 ppt, 不管你是做汇报,做方案,做课程,都会比直接一句话生成稳定很多。如果你大纲已经有了,下一步就别自己慢慢排了,直接让 codex 按这个流程帮你做。
748全能的XK同学 02:24查看AI文稿AI文稿
02:24查看AI文稿AI文稿用 codex 把 ai 做的 ppt 文件变成可以编辑的 ppt, 最佳实践路径来了,那废话不多说,我们直接开始 welcome to adis tech channel 以上是用到的所有工具, 那首先我们这个应用到的这个 github 上面这个开源的项目叫做 ppt master, 它就是用来拆分这个图片,把图片变成可以编辑 ppt 的 一个。 一、安装开源 ppt master skill 那 首先安装的话,我们就把它这个仓库地址复制,复制到我们这个 codex 里面,那其实很简单啊,就是直接丢给他,让他安装一下我们这个 skill, 可以 看到啊,在这里啊, ppt master 就 有了。在装好这个 ppt master 之后呢,我们下一步就来做这个 ppt。 二、制作 ppt 静态图片。那首先我们这个做 ppt 的 用到的模型来做出还原度非常高的这个 ppt, 其实这样子它的美观度就能得到一个很好的保证。那在这里如何去找到像这种比较好看,比较风格化的这种 ppt 的 样式呢?这里再给大家推荐一个网站叫 pinterest, 那 这个是一个设计师网站啊,那比如说我们搜 ppt 的 话,它就会给出一些风格化非常强,非常好看的一些 ppt 模板, 那很简单,只要把你喜欢的那种样式直接复制到这个 image to two 这边,那你看他就可以做的很好。那关于这个 ppt 的 股价内容,我也是建议大家用 ai 去写啊,不要去笼统的让他给一份,那你最好是让他去设计这个股价,那 比如说这里有这样,他做一个六页关于 club 的 介绍 ppt 大 纲,那这里点开我们的这个思考模型, ok, 内容有了,然后直接丢图片,让他的图片出 ppt, 出完 ppt 之后直接批量下载我们的这些六张图片。三、 用 codex 制作可编辑格式,然后到我们的这个 codex 里面,那直接调这个 ppt master 的 skill, 用 ppt master 把这份文档做成可编辑的 ppt 斜杠 ppt master。 ok, 那 很简单,这里开到五点五高,那我们看一下它生成这个六页可编辑 ppt 花的时间啊,是六分十七秒,然后呢这个五小时的额度是花了百分之十三。 我们最后来做一下这个效果比对,那可以看到啊,基本上他就做了一个重绘,然后像这种图片的话,如果你觉得他没有他这个图片满意,完全可以截图,然后把它直接重新丢进来,那其实这样就可以看到我们做 ppt 的 话,效率以及美观度就得到一个很好的平衡了。 ok, 那 么工具都有了,我也打包好了,快去试试吧。
1339阿达的AI思辨 03:43查看AI文稿AI文稿
03:43查看AI文稿AI文稿设计行业完蛋了,就在刚刚被炒的沸沸扬扬的一妹子兔已经全量上线了,效果我确实只能用震撼这个词来形容, 说实话,因为我自己也是个设计师。设计师大概是我觉得近几年来在 ai 冲击下最委屈的一个群体。 如果说以前的身图还是会有些缺点,比如可以让人一眼识别出这是 ai 做的,那也应该是很多设计师最后的避了。但是现在我只想说, ai 身上的图片也算是正式步入了一个普通人无法分辨真假的年代。 因为你看这张图啊,不仅文章内容它全部正确,甚至连底部注视区的升词、脚标、序号位置全部都对得上。 还有这种审美极高的海报图,还有马斯克和库克连麦打 pk 等等等等。就这种离谱的深图细节,让我突然感觉到,相比之前所有的绘图模型,它的世界知识,文字渲染,还有这些修改精准度, image 二都做到了一个质的飞跃。 我甚至觉得现在的 ai 深图已经没有什么明显的短板了。就文字渲染这个事啊,它一直都是所有 ai 深图模型最大的痛点,它没有之一。比如你看很多字的一些细节处理上, ai 总是会有一种很抽象那种象形字, 这种情况在中文上面真的尤其明显。但是现在呢,都不说英文了,你就看他的中文渲染极度的离谱,什么长篇课文,报纸、数学试卷这种很离谱的东西,基本上都不会出现一些明显的错误,真的你就要硬生生的去挑里面的细节,才能看到一点 经典。还有一些文字比较多的招聘海报,现在他都能做到一见之出啊。但是呢,如果说这次 image 兔最离谱的一个能力,我想一定就是他对真实世界样貌的精准理解,那也就是我们所说的世界知识。同样是由 toby 首页的截图,你能猜的到哪张是 ai 生成的吗? 要是以前,我相信你一定会说右边,但现在我只能跟你说两张都是。你看这个布局,按钮、样式、图标位置,甚至是封面,还有标题对应的细节,它都是正确的。不仅是有图笔,其他的平台截图它都能生成这个细节量,我真的觉得它已经不是画图的放球了,就连需要文案设计的图,它也可以一句话生成。 就这张三角桌代言海报,还有这张 coco 和克拉德联名的海报,如果你拿去发朋友圈,再配一个合适的文案,我保证他一定会辅导你的这些朋友们。其次是他修改参考图的精准度。虽然在 nars 上你大概看过很多很夸张的 kids, 但是我只能说 make two 更加离谱。 这是我们公司之前三 d 打印的小摆件,是送给大家玩的,但是现在我只需要两句话才能从这样变成这样,最后他变成整套电商级别的产品。详情页,你敢信吗?以前做这种详情页,我们设计师至少搞两三天,这不算紧急的准备,但现在只需要两句话,我都不敢想象很多设计师朋友,他看到这个会是什么心情。 说实话,作为一个曾经的设计师,我现在心情是非常的复杂的,因为看到这里,我不得不承认这次 gpt image two 对 于设计行业的冲击,我觉得比以前所有的 ai 的 时刻都要大,任何人不再需要任何的设计基础,只要你会说话,会表达,你又能做出八十分甚至九十分的设计。 this is complete garbage he can't even type the words see even this needed me to fix it don't be scared。 所以 回到最初的那个观点,设计行业真的完蛋了吗? 那我想说,画图员的时代确实结束了,但设计师的时代才刚刚开始。这个世界永远不缺画图的工具,但真正需要的是真正的思考者,还有问题的解决者, 这才是我们应该穷尽一生去努力的方向。
3.6万数字生命卡兹克 05:42查看AI文稿AI文稿
05:42查看AI文稿AI文稿三十六岁又爱设计,前两天我花一个小时,然后总结出了用 g p t 一 卖 g 二生成高清四 k 网页的一个方法。事情是这样子的,就是前两天我有一个小伙伴,然后他就问我,就是他在做网页的时候,呃,生成出了一个非常满意的网页长图, 但是呢,那个图只有八百多的一个分辨率,他就问我,呃,有没有什么方法让这个图的宽度变成幺九二零的?然后我开始想的是,这不简单吗?我对他说,我说,你对 ai 说一下,让它升成四 k 的 涂鸦,然后他就说,嗯,好像不太行, 它是生成出来最宽也是只有九百多,我在想哈,它是不是提示词没有,对呀,但是经过我测试之后才发现哈,事情确实没有这么简单。然后接下来我就把我整个的 演示的案例,然后和大家分享。好,下面就是无删减的一个尝试过程,然后为了严谨哈,我花了 ai 一 段话,然后让 ai 帮我生成提示词, 是这样的,我对 ai 说,你是 ui 设计专家,也是我的 ui 设计教练,现在我有一个网页的截图,我截图了它两屏的高度,现在我需要将其改为幺九二零乘幺零八零, 网页的尺寸我需要他帮我调整,请问我怎么写关键词?你帮我写一下,不要分析,直接出提示词好了。他出了三版提示词,我挑了第二个提示词,很顺利哈,我就把第二个提示词发给 ai, 他 就帮我把图片生成好了 分辨率,然后大家看一下,也确实是幺九二零乘幺零八零。好,我以为问题解决了哈,然后我就对他说,我说我这边没有问题啊,然后但是他尝试了之后还是只有九百多的宽, 到底问题出在哪呢?然后他就问我,然后他说他尝试了还是只有九百多。他问我,你是用的是 qq 叉吗?我在想啊,不应该呀, qq 叉和 emoji 我 都用了,网页端我都用了, 都没有问题。我想难道他传的是整个网页一个长图,所以他的宽没有变?于是我就把那个腾讯云的官网整个页面截图拼到一起,把整个长图都发给呃, gpt。 我这个时候我是同时操作的 qq 叉和 gpt 同时操作的,然后生成出来的尺寸还是没有问题,都是幺幺九二零乘以幺零八零。我真想把提示词发给他的时候,然后我打开刚刚生成的图片,我就发现 怎么图片这么模糊呢?不是四 k 的 图吗?怎么这么模糊呢?然后于是我非常生气,然后我问 gpt 怎么尺寸对了,但是文字模糊,图片也是模糊的,怎么解决呢?好, gpt 就 回我啊, 他说文字图片模糊的核心原因是原图,它本身就只有八六六,是一张低分辨率的截图,你把它放大到幺九二零, 本质上是把原来的像素撑大,即使加了锐化,也只能让边缘阴影,不能真正还原原本不存在的文字细节和图片细节。好的,他也除了几个方案,但我按照他的方案也没有解决问题, 那怎么办呢?于是我尝试先生成局部,然后我就把腾讯云的那个 banner 截图让他帮我生成,我就说帮我生成高清的 banner 图,图片的宽度改为幺九二零,高度根据图片比例计算。呃,要求 banner 根据 当前从不改变内容,但是一定要达到四 k 的 标准,结果就成了输出的尺寸是二幺七二,虽然没有达到四 k 的 标准哈,那至少是大于幺九二零了。 然后同时呢,我也检查了图片非常的清晰,然后做网页是完全够用的啊。最后的解决方案是什么?就是这个时候如果是我们自己生成的网页哈,然后我们就可以把它上面的文字呀,按钮呀,把它去掉,包括导航呀去掉,那这个时候就可以,嗯, 直接使用它这个图片了,那我们就不需要去呃,在其他地方再去找图了,所以说这个时候还是需要 啊,局部的去生成,就是现在 ai 还是没有达到说一整个网页生成了之后就能直接的使用啊。最后总结一下哈,就是第一,一麦件,目前它是对于长途不能生成高分辨率的设计稿, 但是如果我们通过设计稿的拆分,针对性的生成配图一麦件,它是完全可以生成四 k 插图的,对于 app 网页是完全够用的,就是你生成好了你想要的一个 嗯,风格的图的时候完了,最后的时候让他再生成四 k 分 辨率,这样我们图图片的一个质质量也变高了。第二个就是使用一麦尖的时候,如果不知道怎么写提示词,那我推荐的方法就是找一个你的参考图,然后再加上你的自然语言, 你就在设计师的角度和他沟通就可以了,让 ai 帮你写提示词,你放心,他写的其实还是可以的,至少能达到百分之八十的一个水平 好。第三个就是遇到问题就一定要多问,就比如说这个小伙伴,然后他问到我,我就真的是帮他解决了这个问题。 然后如果大家在使用 ai 的 时候,如果有什么问题,也欢迎在评论区里面呃留言,然后讨论,我们一起去把它解决了。如果你解决了什么问题,也可以评论给我,和我分享这份喜悦,谢谢,大家一起加油。
18风筝的设计日记

