我给克拉的做了个工作状态灯,克拉的开始干活的时候灯会自己亮起来,等他跑完颜色又会自动切回去。本来只是想摸鱼的时候知道 ai 有 没有在干活,结果现在比我还像办公室员工。

粉丝4092获赞7.4万
相关视频
 03:13查看AI文稿AI文稿
03:13查看AI文稿AI文稿最近半年使用 cologod 安装了近百个 skr, 最后发现真正能提升工作效率的其实只有三个技能,今天免费分享给大家。第一个, superpowers, 这个 skr 改变了我用 cologod 的 方式。以前我是直接把需求交给 cologod 的, 让他来写代码,写出来虽然能跑,但是经常跑偏,改来改去浪费大量时间。 装了 superpowers 之后,我养成了一个新习惯,每次开弓前先跑一遍,不认英斯德尔敏。这个技能能让可洛的反过来问我问题,你打算怎么处理并发数据库选什么 等等等等。问完一圈,他会把讨论结果写成设计文档存到本地。听起来多了一步,但这一步帮我拦住了无数次的反攻。有些问题你自己都想不到,但是可洛替你想到了。 注意, superpowers 包含了二十多个紫技能,千万别全开,我只用 breamstorming, 头脑风暴, 其他的按需加载,要不然会浪费大量上下文。第二个技能, playing with fails, 这个技能解决了我被坑过无数次的问题。 cloud 有 个问题,它做到一半就失忆。不知道你们有没有遇到过 一个复杂的任务,聊了半个小时,可乐突然说,好的,让我们开始吧,然后就把之前做过的事情又重来一遍。根本原因是对话太长了,上下文被压缩,之前的计划全丢了。普莱因维的 flow 的 做法很聪明,就是别把计划写在脑子里,它是存在纸上 克拉的扣的。每次动手前会先建一个计划文件,每完成一步就在这个文件里打勾,就算上下文清空了,重新读一下文件就能接着干。 这个思路跟 minnes 很 像, minnes 做常任务为什么玩?因为它所有的中间状态都存在本地了。第三个技能, roughlop, 我 给这个技能起了个外号,监工 sky, 你一定体验过 cloud 的 摸鱼模式。写到一半突然说基础框架已经搭好了,你可以在此基础上继续完善。 翻译过来就是活我没干完,我先下班了。 raflopp 通过一个或可拦截 cloud 的 退出动作,他退出的时候或可会检查。你说的完成标准达标了吗?没达到,回去继续写。 我用它写过,完成过一个 c r u d 模块,设了条件,所有接口测试通过加 redmi 写完才算结束。 kloth 中间响停了三次,但都被塞回去了,最后确实把活干完了。但要注意的是,完成条件一定要写写具体做完用户模块这种话等于没说, kloth 分 分钟说服自己已经完成了写成。完成登录接口可用 单元测试,覆盖率百分之八十。加 redmi 包含 api 文档,它才没法浑水摸鱼。以上就是我常用的三个技能,今天希望能够对大家有所帮助,感谢观看,拜拜,下期见!
2.9万PM.姜同学 01:48查看AI文稿AI文稿
01:48查看AI文稿AI文稿你可能以为做好 cloud code 关键是会写提示词,但真正拉开差距的其实是 skill。 因为 skill 不是 一句提示词,它更像是给 cloud code 装上的工作模式。今天这六个实用 skill, 新手装上以后基本就能少走一大半弯路。 第一个, prompt optimizer。 当你只会说帮我优化一下,帮我改个功能的时候,它会把你的模糊需求改成更清楚、更可执行的任务描述。 你不用一开始就会提示词,先让他帮你把话说清楚。第二个, deep interview。 有 时候不是 ai 不 聪明,是你自己也没想清楚要什么。这个 skill 会让 cloud code 反过来采访你,把目标、边界、验收标准 一步一步问出来,特别适合做新功能、做产品页面或者需求还很模糊的时候。第三个, real plan 大 改项目之前,最怕 cloud code 上来就动手。 real plan 的 作用就是先出计划,再拆风险,再确认测试方式。它适合那种会影响多个文件、多个模块的任务,先把路线定清楚,再开始写代码。 第四个, ultra qa 功能,写完不代表真的能用, ultra qa 会让 cloud code 进入测试、验证、修复的循环,不是只告诉你我改好了,而是继续跑,检查、 看报错、修问题,直到结果更可靠。第五个, ai slow cleaner。 ai 写代码最大的问题不一定是错,而是味儿太重,比如重复逻辑、空泛、封装、变量名很虚,代码看起来很聪明,但没人想维护。这个 skill 就是 专门清理这种 ai 感,让代码变得更像人写的,更像能长期维护的项目代码。 六个, visual verdict 如果你用 cloud code 做前端海报、视频画面,这个非常关键,它不是问好不好看,而是拿截图和目标参考去对比判断布局层级、间距、颜色、还原度到底差在哪里。 所以这六个 skill 不是 让你背更多提示词,而是让 cloud code 在 不同任务里自动切换成更合适的工作方式。不会提示词的新手先装这六个,真的会稳很多。想要我继续整理 cloud code 的 高频 skill 清单,可以先收藏这一期。
2.0万阿森编程日记(AI自动化) 01:15查看AI文稿AI文稿
01:15查看AI文稿AI文稿cloudco 有 一个非常好用但是被大家忽略的指令,就是这个 inside, 在 cloudco 的 任意界面输入 inside 的 指令,两三分钟你就可以得到一份非常有用的报告。这一份报告它主要是总结了我们在过去三十天内使用 cloudco 的 情况,相当于是不盘。我们主要是看下面的内容,这 这里它会显示你在过去三十天内用 cloud code 做了哪一些项目和工作。这里是你只用 cloud code 的 风格和习惯。继续往下看就是你做了哪一些比较好的地方,重点可以看这个就是我们在哪一些地方比 较容易出错,反复在哪一些地方浪费时间。下面就是它根据我们的使用习惯,给我们提供了一些优化的建议,可以直接复制到 cloud code 里面 发送给 cloudco, 它就会帮我们把这些优化的建议给设置好。这里是它给你推荐了一些 cloud, 现在已经有,而且适合你,但是你没有在用的一些功能,也是直接复制到 cloudco, 它就会帮我们自动地设置完成了。 下面就是他会告诉你后面我们用 cloud code 一个新的方法是怎么样,也是直接复制就可以了。这里是他告诉你我们现在手动做的一些事情,其实是已经可以自动化的完成了。我们大概一个月用一次这个指令,就可以看到我们这一个月内使用 cloud code 的 情况,哪一些做的好,哪一些做的不好,进行一个复盘。
121小赖的 AI 日记 04:40查看AI文稿AI文稿
04:40查看AI文稿AI文稿今天来分享一个我自己在用的一个价位打击的工具啊,怎么样用两分钟搞定一份专业分析师级别的行业研究报告?那这个也是我的投资工作流里面一个非常重要的一个步骤,我先拿出来分享。这个方法呢是来源于一本书,叫做如何快速了解一个行业, 作者呢是麦肯锡出来一个分析师,当时看完我就觉得书里的这个方法论写的非常好,所以我就把这整套的理论汇给了 ai, 做成了一个行业分析的这样一个 skills, 我 现在只需要给他一个行业的名字,他就会自动走完整一个研究的一个流程。 在正式演示之前呢,我还是想快速的分享一下这本书里面讲的这套分析的框架,为什么我说他特别好,如果不想听的话,可以直接跳到下一个演示的章节。 那整套方法论的核心呢,是用产业研究的这个生命周期作为一个轴,分六步去进行研究。那第一步呢,是定义行业的这个边界, 书里面讲到横向会根据这个层级的积分,然后再加上一个中将,横向就是产业的这个产业链有哪些环节。然后第二步呢,是判断整个行业的生命周期的阶段,它里面提到了用渗透率,而不是单纯的用一个行业的增长率, 那对应了从导入期到最后的衰退期整个四个阶段。第三步是按照这个阶段去聚焦分析每个阶段的一些重点 啊,打个比方说,从这个成熟期到防守期,那这里面可能会涉及到一些盈利性啊、周期性啊、产能啊,这个公司的溢价能力啊、护城河等等这些我具体就不展开了。 然后第四步呢,是不同阶段匹配不同的这个估值的框架。第五步根据 past 的 模型, past 的 分别就是政策、经济、文化、科技等等四个维度来分析整个行业的外部因素。还有最后第六步就是行业的景气程度跟踪指标。 好,那我们现在其实不需要去懂这些啊,只要用这样一套完整的 skills, 我 们就能直接得到一份非常严谨以及非常结构化的这样一个行业的一个报告。并且呢,如果你告诉他你的目的,你的使用场景,比如说投资选股,或者说你是创业前想要选赛道, 又或者说是想找工作方向,你告诉他之后,他就会自动的去调整整个报告的侧重点以及表达方式,它里面的结构也会不一样, 那这些规范我都完整的写进了这套 skills 里面,它最后会自动的去适配。 ok, 那 么理论说完我们就直接来演示一下,比如说我这里问的是说我是一名股票投资者,光纤通信这个赛道你觉得怎么样?现在它进入整个投资分析的过程,我们稍等一下, 这里我们可以快进一下,他会去筛选联网搜索所有的这些行业报告,包括新闻好,整个过程我们就略过。那第一步行业边界的定义分为上游、中下游,好,分为有不同的这个这个公司。 然后第二步呢,是产业的这个生命周期。第三块是整个核心的投资逻辑分析,那 cloud 的 好处就是他非常的善于运用整个格式化的这种图标的形式来解释一个非常复杂的一个行业。 ok, 那 这里他就出来了,整个上游、中下游分别有的哪些公司啊? 这边也调用了一些这个财经媒体的报道,然后一些这个比如说像知乎上面一些专业的分析,然后 a 股的一些核心标的这个格局, ok 出来了。 然后是第四块 past 外部因素的一些分析。第五部分整个行业的估值逻辑。如果你是作为一个偏价值投资人的话,那这里面这样的一些估值逻辑,包括每个阶段不同的标的估值是贵了还是便宜了,这套东西对你非常的有帮助。然后至第六步紧急程度的一些指指标的跟踪, 最后是整个综合结论以及风险提示。好,这就是一个这样的一套完整的行业分析报告。以前我们说这里的一些判断或者说些数据,你要么是花钱去买报告,要么就是你完全凭自己的经验或者直觉去选股,那么现在这整一套的这个报告两分钟就搞定了, 包括这里面提到的一些投资的标的,提到这些公司,最近关注整个行情的朋友应该都知道。好了,我们总结一下,就是我在很多的我的视频里面也一直在强调,就是鼓励大家不要把 ai 去当做一个执行的工具,而是要把它当成你自己的一种杠杆, 你用它来放大你原来不具备的能力。比如说这个 skills, 就是 相当于人家麦肯锡的专业分析师,花了 几年,花了十年练出来这样一套框架,现在就能变成你随时可以调用的这样一种判断力,那这样才是普通人用 a h 弯道超车的真正的方式。 ok, 这个 skills 文件我会放在我的粉丝群里面,完全免费。如果自己不想动手的,也可以在评论区告诉我你最近在评估哪个行业,我帮你跑一遍。 ok, 就 到这里。
5924创业丹途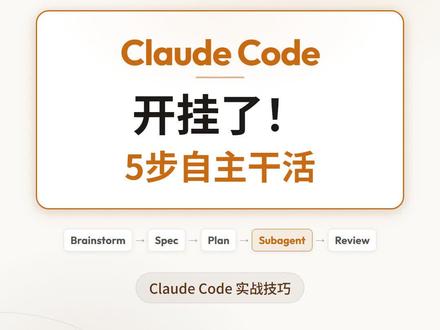 01:29查看AI文稿AI文稿
01:29查看AI文稿AI文稿你还在用 cloud code 乱敲代码,没有规划,没有结构,跑着跑着就偏了。这不叫 whit coding, 这叫瞎撞。 有一个插件能让 cloud code 变成一个真正的资深工程师,他叫 superpowers, github 已经超过十八万 star。 他给 cloud code 定义了一套完整的五步工作流。第一步, brainstorm, 你 只需要说出想法, cloud 帮你头脑风暴,把模糊需求变成清晰方向。 第二步, spec 自动生成产品规格文档,把我想要变成系统应该做什么。第三步, plan 拆解任务,制定执行计划,知道先做什么后做什么。 第四步, brigade, 多个子智能体并行开工,前端后端 devops 同时推进,不互相等待。 第五步, review, 内置 p, d, d 和代码审查,自己跑,测试,自己发现问题自己修复,整个过程 cla 可以 自主运行好几个小时,不跑偏。 安装只需两秒,在 cloud code 里输入破解, install superpowers 搞定。从今天起,不是你在用 cloud code, 是 你在指挥它。
120AI增长观察室 04:05查看AI文稿AI文稿
04:05查看AI文稿AI文稿cloudmed 写得再细, cloud 还是会忘事。这事你肯定遇到过, astropica 官方文档也说了,规则明明白白写在那儿,模型也读了,但执行到某一步,它就是绕过去了。 这一期我想跟你聊清楚为什么以及怎么解决。先说一句,这是一个系列,前两期讲了 cloudmed 怎么写 cloud 目录,下五层配置都干嘛用。 从这一期开始,我们其实在做一件更大的事,把 cloud code 这套东西搭成一条你可以每天照着走的工作流。今天讲的是这条工作流里最容易被低估的一层, hooks ansorepic 自己其实在官方文档里把这层关系写得很清楚,它们把 cloud code 的 能力分成了四层,如果 cloud 每次都该知道的是放 cloud mate, 如果有时需要放 skill 或者 rules, 如果必须每次都发生,放 hulk 也是本期视频重点讲的。 如果某类能力根本不该碰,直接用 permissions 收回来。这四层最容易被混着用的就是第三层, hook。 这一层很多人压根不知道它存在或者知道,但没意识到它解决的是个完全不一样的问题。 那 hook 到底是啥?先问你一句话,你是不是遇到 clod 不 听话的情况?那可不是你的提示词有问题,提示词是软约束,而 hook 是 百分之一百执行。告诉我,你的 clod 是 经常不听话吗?我前阵子让 clod 帮我清个临时目录, 他自己拼了个 r m r f 出来,因为之前在项目目录下已经手动确认跳过这个执行权限,所以自动执行了。还好那是个测试目录。 一句话讲明白 hook 是 什么,它是 code, code 在 自己生命周期的关键节点上让你挂一段强制脚本的入口,用户提交 prompt 之前工具调用之前,工具调用之后,对话结束等等。官方文档列了三十多个事件,但实际上你只要先记住两个就够用。最常用的是 pre to use 和 post to use, 一个在工具跑之前拦,一个在工具跑完之后接先把前面两个用熟,剩下的什么时候要用什么时候再加。这个视频我也是通过 cloud 制作出来的,后面把知识点讲完,会以这个工作流为例讲解。好了,我先分享下我常使用的三个场景, 你看完之后可以直接抄如何使用。第一个 post two news 配自动格式化 cloud, 每次 edit 或者 write 把格式化掉, 配置就六行 json 中 match 写 edit, write 配置命令中写 pretty write 加文件路径,从此你 cloud md 里就不用再写记得格式化这种话了,它一定会发生。这就是 hock 跟提示词的本质区别, 提示词是约定, hook 是 强制。第二个就是我之前提到的,没有让我确认,就执行了 r m r f 操作。在那之后,我加了一个 hook, 在 配置中加上了这个命令的 hook 匹配上就掉一个脚本,脚本里再判断一次完整命令,遇到 r m r f 直接 exit 二,退出码二,这个细节非常关键,我在之前的视频讲过这个,不知道的小伙伴可以翻翻。第三个最舒服, stop 事件配桌面通知我经常让 cloud 跑一个比较慢的任务,自己切去干别的,回来发现他早就停在那等我了。配上 stop hook 之后,他一收尾,桌面直接弹出来消息,我直接确认就好,不用我主动去查看。但我得说一个反话, hooks 不是 越多越好。这事挺微妙,如果某件事不是每次都该发生,硬塞进 hook 反而会变成新的污染源。 它适合勾住那些确定性的,每次都得做的不需要思考的动作。判断要不要思考的标准很简单,你能不能用一个 shell 脚本写完这段逻辑且永远不变,能就上 hook, 不 能就别用。回到开头那个反差点, cloud md 写得再认真也只是契约 期约靠双方履约,你方履约了, cloud 这边偶尔走神一个判断标准,你可以直接拿走。如果你 cloud md 里某条规则,你发现自己会反复去强调这件事,就该下承到 hook 提醒是可跳过的,而 hook 是 应约束。这一期就到这下一期。讲一个更反直觉的东西, sub agent 下期讲怎么判断什么任务该开, sabotage 怎么开,开几个合适。如果对这一期感兴趣,可以点个赞或者收藏,方便回头来抄那几个 hulk 配置回头见,制作不易,觉得文章对你有用,请一键三连。
2329一二说 03:14查看AI文稿AI文稿
03:14查看AI文稿AI文稿用简单的语言讲解一下实现实现一个 cloud code 的 最简化的模型,你不一定非要懂代码,首先需要定义一个系统提示词,告诉模型你是一个编程智能体工作,在项目所在目录里 使用代办摄像工具来规划多步骤任务,优先使用工具,而非文字描述。这个系统提示词的作用就是告诉模型你在做任务之前,需要先制定一个任务步骤,编排计划,按照计划执行任务。优先要使用工具呢?因为我们默认认为不使用工具的话,这个任务就算结束了。 如果某个步骤里模型只回答我们一些文字信息,没有使用工具,当然就不会有下一步执行的必要了。那我们需要提供模型什么工具呢?下面我们会告诉模型你可以用这五个工具。哪五个工具呢? 第一, bash, 这个工具的描述就是告诉模型你可以运行一个任意的 shell 命令。第二, read file, 这个工具描述就是告诉模型你可以提取文件内容,但是需要根据参数的要求提取,你必须提供需要提取文件的路径。 第三, write file, 这个工具描述就是告诉模型你可以写内容到文件里,但是必须提供一些必要的参数,比如需要写入文件的路径和需要写入的内容。第四, edit file, 这个工具描述就是告诉模型你可以编辑文件内容,这个和上面那个 write file 的 区别就是它是编辑文件, write file 是 直接覆盖写入, 需要提供一些必要的参数,比如编辑文件的路径和需要替换文字的内容。第五, to do, 这个工具是最重要的,它告诉模型你需要更新任务编排的清单,用来跟踪任务进行到哪一步。意思就是说,一开始系统提示词里要求生成了任务编排步骤了,需要根据编排计划完成一步,就将这一步认为状态,这一步的任务状态实施成完成。 因为当智能体处理多任务步骤时,他经常丢失对已完成和代办事项的追踪。没有显示的计划模型可能重复工作,跳过步骤或者跑偏,用户也无法看到智能体内部的计划。用这个工具来标记完成了哪些,用于下次对话,让模型自己看到进行到了哪一步。 最后将我们的提问和系统提示词以及工具一起发给大模型,然后放进一个无限的循环里。如果模型回答一次说需要调用哪个工具,怎么调用,我们就直接执行我们这五个工具里的模型指定的工具方法。比如模型回复用 read file 提取某个文件,模型会把工具名称 read file 和文件路径给我们,我们直接按照预先定义好的工具方法 read file 调用即可。 在无限循环里,每一次调用模型的操作的结果都会再次发给模型,模型来判断下一步该怎么做,直到模型回复说就不需要工具了,那我们默认认为这个任务循环就结束。跳出循环,本次任务结束,没有工具调用即可认为是没有再进行下一步操作的必要了。 最后再适当的做一些安全叫验,比如只能工作在呃当前的目录里,不能执行黑名单里的危险命令,比如不能执行呃删除全部或者一些比较危险的命令,然后用 history 树组保存历史绘画,达到记忆多轮对话的功能,这样就实现了一个最简单的 cloud code 的 编程助手。 下面看一下效果。我让这个我们写的编程助手新建一个画布,然后画布可以新建正方形,每新建一个正方形,我们可以检测正方形和正方形之间的碰撞,检测如果碰撞了有提示红字的效果,就是正方形变成红色的效果。 嗯,下面我们看看这个最后它生成的这个 html, 它可以随便的生成正方形,然后检测这个正方形之间的碰撞,还是比较完善的。 最后总结一下,其实模型就是智能体,我们的工作就是给他工具,然后让开这种思路能不能用到你的业务里?给模型一些有边界的工具能力,比如你自己业务系统封装的操作函数,让他自己编排执行来整合到自己的业务里。
73程序员手艺人 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿谁家好人把克拉的 ai 直接装进键盘里啊!黄色跑马灯亮起,克拉的正在疯狂思考全自动写代码, 红色呼吸灯闪烁,需要人为介入,介入完毕后继续跑马灯。任务完成,恢复彩虹模式,主包还接入了小龙虾,可以对话操控灯效。雷光子跑马灯 金色渐变脉冲, 主包的拍摄设备会有色差,问题不大。呼吸粉有一说一,这个是真好看吧。 静态机 最后恢复彩虹原码已开。原想折腾的兄弟评论区扣一下期出防补集教程。
132纯粹的Gamer 00:44查看AI文稿AI文稿
00:44查看AI文稿AI文稿这种感觉啊, top code 的 skill 一 大堆,但你根本不知道该装哪个。其实最简单的方法就是抄冠军的作业。 github 上有个项目叫 everything cloud code, 这是啊, hackson 冠军整理的一套 cloud code 的 工作流不是几个 prompt, 而是一整套的工程化配置。里面直接打包好了,五十六个 skills, 三十三个 commanders, 还有十四个 agents。 而且你还能看到很多高手的工程套路,比如说头看优化记忆,持久化并行执行,还有紫 a 阵的编排等等。 安装也特别简单,两行命令。唯一要注意的就是 m c p 不要全开,因为工具描述本身会占用上下文。所以如果你不知道装什么 skill, 那 就先抄冠军作业吧。
3422建斌聊AI 00:18查看AI文稿AI文稿
00:18查看AI文稿AI文稿我给 cloud 装了蓝牙工作灯,干活的时候就亮黄灯,需要确认就闪烁,等它跑完了就变成绿灯,这样我在摸鱼的时候就能知道它有没有在偷懒,越来越像办公室牛马了。所以现在的我 糟糕。
4.5万刘工不开会![Claude提示词缓存 Prompt Caching算法详解 之前的视频我们介绍了Claude Code如何利用Prompt Caching节省token的。这次我们深入讲解一下Claude Code客户端在请求里明文写的cache_control标记是如何工作的。
cache_control有两种用法。Automatic自动模式,请求顶层放一个字段,服务器自动给最后一个block打1个breakpoint,简单粗暴。Explicit明确指定,自己往block上挂,最多4个,位置自己挑。Claude Code用的是Explicit,3个breakpoint的位置全是它自己选的。3个分别标在system数组第2项末尾、第3项末尾、最新user消息末尾。前两个是稳定锚点,第3个是游标,每轮跟着最新输入往后跑。
3条核心原理:
原理1:缓存只在breakpoint位置写,写的是从头到这里的累积prefix。所以29个tools没标cache_control也被缓存——蹭system[1]的车一起打包写进去。
原理2:读的时候在breakpoint位置查不到,往前一个block查,最多查20个。它找的是"之前写过的条目",不是"现在稳定的内容"。
原理3:20格上限。超过就放弃。
官方博客Thariq的"Prompt Caching is Everything"分享了Claude Code围绕缓存的几个设计:分层(静态在前动态在后)、Plan Mode做成两个工具而不是swap工具集、Tool Search用defer_loading发轻量存根、compact共享原session的system+tools+history做前缀。两条提醒:不要中途切模型(缓存按模型分隔),不要中途改MCP/hook(整段前缀重来)。
#claude #个人开发者 #命令行 #AI工具 #张司机](https://p3-pc-sign.douyinpic.com/image-cut-tos-priv/659b4b86f6fbeace61cd22594ab424d9~tplv-dy-resize-origshort-autoq-75:330.jpeg?lk3s=138a59ce&x-expires=2096211600&x-signature=c0BWENushnJkG%2BkNfSZjY0mXs%2Bc%3D&from=327834062&s=PackSourceEnum_AWEME_DETAIL&se=false&sc=cover&biz_tag=pcweb_cover&l=202606080114042552F6050397AD742BB7) 06:46查看AI文稿AI文稿
06:46查看AI文稿AI文稿在上期视频里,我们详细分析了 clockcode 怎么利用提示词缓存来节省 token 消耗的,但是评论区还是有很多朋友在提问,那么缓存具体什么时候写的,什么时候读,然后新请求来了,是怎么判断什么前缀命中了呢? 那么这期视频我们就深入讲解一下底层的算法,了解一下 clockcode 是 如何在上下文里插入 cash control 标记来精确控制提示词是如何被缓存的。我们打开上次给 clockcode 发 hello 的 抓包请求,然后搜一下 cash control, 我们看到第一个标记是在系统提示词 system 里面,这个第二项 cloud code 的 身份提示词的末尾,对吧?然后第二个这个标记还是在系统提示词里面,是这个一大段的行为准则的后面是吧?然后 第三个就是在这个 message 里面,用户输入的这个 hello 的 这个 block 上了。先说清楚 cash control 是 干嘛的,在 apple pay 官方文档里,每个 cash control 叫一个 break point, 意思是缓存的边界点, 那么你挂在哪个 block 上,就等于告诉服务器从请求最开始的工具定义系统提示词,一路到这个 block 为止。诊断打包存进缓存,然后开 ctrl, 这个字段有两种用法,第一种叫 automatic 自动模式, 请求顶层放一个 catch control, 然后服务器就会自动打一个 break point, 简单粗暴。那么第二种它叫 explicit, 明确指定就是你自己决定往哪个 block 上挂 break point 最多四个。我们刚才看到的请求里, callout code 发的这种就是 explicit expressing 模式,意味着 break point 位置是 coco 自己选的,那么他选的这三个位置有两个是永远不动的,然后第三个每轮都移动,我们打开这三轮的请求并排看,我们会发现第一个 和第二个 break point 永远都盯在 system 的 末尾,三轮全都没有动,只有第三个是不一样的。 第一轮我们发了 hello, 那 么第三个 break point 就 打在了 hello 那 个 block 上,然后第二轮我们回复了 fine, 对 吧?然后前面有 assistant 的 回复,然后加我们的 fine, 那 么第三个 break point 就 移动到了这个 fine 上。 然后第三轮我们发了 thank you, 那 么这个 break point 又移动到了 thank you 上, ok, 那 你有没有想过为什么在 system 里要打两个不动的 break point, 只在末尾打一个不行吗?我们看看第一个 break point 的 前面的内容,它是所有的工具的定义加 call code 的 身份说明, 这里只要 clock code 的 版本是一样的,那么所有的用户的这一段前缀都是相同的,这是最稳定的上下文,也就是说任何同一版本的 clock code 用户都可以共享这个缓存。 那么第二个两个 break point 中间的是系统提示的行为准则。我们复习一下 prompt catch 那 期视频的内容,那么这个里面它包括了当前 cloud code 的 工作目录以及一些系统信息,所以不同的用户,不同的项目到了这部分就不一样了。但是只要是这个目录下的 session, 还是都可以重复使用这个 hash 的。 现在我们来回答观众的核心提问,到底前缀缓存是怎么写,怎么读的呢?那么第一条原理就是 break point 挂在哪个 block 上那个位置,我们就写一条缓存,然后缓存对应的键值就是从开始到这个 block 所有内容一起算的一个累积哈希。 然后我们回到 colocode, 看看这三个 break point 到底写了什么。第一个 break point 对 应的键值就是所有的工具定义加上 colocode 的 身份提示词的哈希, 然后第二个 break point 对 应的键值就是这一大坨,这个行为准则的系统提示词前面所有的上下文放一起做一个哈希。然后第三个 print point 就是 在最后的 user 消息上,那么哈希就是整个上下文一起。 所以一个 clock 的 请求过去服务器提示词缓存里会存三个键,对应就是这三个 break point 的 三条哈希,覆盖的范围一条比一条长。第二条原理就是读缓存的时候,如果在 break point 的 位置查不到,那么我们会往前一个一个 block, 再查找的就是之前写过的缓存。 举个例子,我们看看 coloco 的 刚才那三轮请求,第一轮我们发的 hello 对 不对?然后三个 break point 都是第一次出现,没有人写过,所以服务器会在三个位置各写一轮新的缓存,因为全都是 miss。 然后第二轮我们发的 fine, 那 么第三个 break point 从 hello 挪到了 fine 上面,然后服务器从 fine 开始算哈希的新位置,因为这里是 miss, 那 么再往前面一个 block 是 assistant 对 hello 的 回复,这也没人写过,这里还是 miss, 那 么再往前到 hello, 那 么上一轮在这里写过一个挑目了对不对?所以命中诊断 tos 开头一路到 hello 这里,全部从缓存开始读,然后 hello 到 fine 之间的这几块心算,然后算完之后的结果,在 fine 这个心的位置再写一条缓存,第三轮发 thank you, 然后第三个 break point 又挪到了 thank you 上。一样的流程, thank you 的 位置是 miss, 然后往回退到 assistant 对 fine 的 回复,然后这里还是 miss, 再往回回到 fine, 那 么这里上一轮在这里写过,那么命中了,所以 toos 一 直到 fine 这里的整段都从缓存读,然后 fine 到 thank you 之间这几块心算, 然后每轮第三个 break point 往后挪一两块,那么再往前翻一两个 block, 就 能找到。上一轮在前一个 user 上消息的写入缓存第三条,原理是最多往回找二十个 block, 找不到就放弃。 在刚才的例子里面,我们发现每轮中间是不是就一个 assistant 的 回复,所以 look back 往回翻两三格就能命中,没什么压力。但是假设第三轮发完这个 thank you, 你 让 cologold 干了个大活, 读了几十个文件,然后搜了几次网页,并且改了几个代码,那么在这一轮里面, assistant 的 tool use 快, 再加上你回的 tool result 快, 加起来塞了二三十个 block 进去了,那么第四轮你发了一句继续, 那么第三个 break point 挪到了这个继续上,对不对?我们这时候服务器从这里往回查,然后翻到二十个 block, 还没碰到 thank you 你 这条缓存,那么 look back 就 放弃了。 所以日常聊天重用缓存很稳定,是因为单轮就有几个 block, 但只要某轮对话产生的 block 撑爆了这二十个 block, 那 么这个时候就没办法,整个上下文窗口就只能重新推理了, 没法使用缓存。所以这就是 prompt cache 底层算法的工作原理?对更多细节感兴趣的同学可以去 cloud 官方博客上 colocode 核心工程师 thorick 写过的一篇文章,标题就叫 lessons from building colocode prompt caching is everything。 讲他们做 color code 的 客户端的时候是怎么设计提示词缓存的,还有一些使用时最大化缓存命中的建议,非常推荐大家好好读一下。
425张司机在路上 04:15查看AI文稿AI文稿
04:15查看AI文稿AI文稿我的 skill markdown 有 六百八十九行,配套的 references 还有四千三百零八行,比官方推荐的 cloud markdown 两百行红线足足大二十五倍。但它就是这么用着。 cloud 没选择性失明,反而越写越听话。 cloud code 工作流系列第五期,上一期 sub agent, 末尾我流过沟子, 下集讲 skill。 今天讲清楚一件事,百分之九十的人 cloud markdown 写错了,不是因为他们不懂规则,是因为该写 skill 的 内容塞错了地方。我自己一开始也错,所有方法论都堆 cloud md 里, 视频开头怎么写,章节怎么切,动画怎么做等等,一路写到四百多行,越写越爽。结果 cloud 开始忽略后半段,你让他按五步走,他跳到第三步,你让他反 ai 位检查,他装看不见。这不是模型笨, 是 cloud md 这一层从一开始就装错东西了。官方文档里有一句话可以看一下描述原文,还说长文件消耗更多 context, 降低指令遵循度,所以 cloud md 控制两百行以内。这不是建议,是实测红线。 cloudmed 的 角色是每次绘画都加载的 fact 层,项目约定、目录结构、 build 命令, coding 标准。它装的是事实,不是流程。那流程装哪装 skill? 图中是官方文档给出的 skill 定义, 接下来按照官方给的结构来看一下。先看一眼我制作这个 ppt 的 skill 长什么样。它有一个目录, skillmed 是 入口,总共六百八十九行 references 文件夹有十一个文档,还有模板、视力、脚手架、脚本。这就是 skill 的 真实长相。定义没那么复杂,就三件事,一个入口文件,一堆参考资料,一条触发条件,加起来就是 skill, 它跟 cloud mail 最大的区别在哪?是按需加载,每次绘画默认只加载 description, cloud 看到这条 description 才决定要不要进一步读 body。 这两完全是两个物种,工业化点的说法叫渐近时髦域 description 常驻 body, 按需读 supporting files, 留在文件系统三层边界,清楚每层只装合适的内容,所以判断什么放哪一个非常朴素的问题就够。这是 fact 还是 procedure? fact 是 事实,比如规定写作必须留两行空格,每次都要知道的事实约束就放 cloudmed。 procedure 是 流程, 比如做一期视频要走的五个阶段,每章实现的七步检查,这种只在特定任务里才用的多步流程进 skill。 还有一类是 learning cloud 自己学到的,比如上次这个命令在这个项目里跑失败了,这个用户喜欢先看完整推理,这种进 memory, 下一期会讲这个概念。实操几个上手姿势看内置 skill, 用反斜杠 skills 命令, 你会看到 skill 命令已经在哪了。创建自己的 skill, 项目级放在点 cloud 下的 skills 目录下,用户级放主目录的 skills 目录下。还有一个反模式提醒 commands, 这个在新版本已经合并到 skills, 但很多人还在 command 两边都能跑,但 skills 多了 references 和按需加载,这层能力更大。 description 字段是触发条件写错的 description 长这样,比如代码进行 review, 这个描述太犯, 什么时候触发都行,就等于最后什么时候都不触发。写对的,应该说清楚三件事,做什么,何时用,何时别用, 何时别用。这条最容易被忘,但他是触发条件的另一半。最后说一个长期问题, skill 写多了会变成另一种技术债,来得太快,验证追不上,找得到,但不该执行, 只新增不下线,第三方污染,最后变成 wiki 粉场。这件事在团队规模放大后特别真。一个 skill 上次有用 a p i, 变了之后已经过期,但没人删他,还会被搜出来执行。 所以新建 skill 要克制第一批先做高频边界,清楚有验证手段的流程,比如单元测试修复,发布前检查事故复盘。 cloud md 装 fact, skill 装 procedure, memory 装 learning, 三层各管各的混着用,就是两百行红线撞墙的根本原因。再回到开头那个二十五倍的差距,我想你应该知道什么原因了。好了, skill 就 讲到这里,下一期讲 memory, 也就是 cloud 自己写的笔记,它跟 skill 是 一对, skill 是 你写给 cloud 的 流程, memory 是 cloud 的 写给自己的事实。这一期感兴趣转给那个 cloud, md 已经写到四百行还在加的同事救它于水火。关注我,下期见。
187一二说 01:33查看AI文稿AI文稿
01:33查看AI文稿AI文稿很多新手用 cloud code 最大的问题不是不会提问,而是只会一句话使唤他,你说帮我做个功能,帮我修个 bug, 帮我优化一下。 ai 看起来很努力,项目却可能越改越乱。 真正高效的用法是把 cloud code 当成一套可以调度的 ai 开发团队。第一步,用 prompt optimizer, 它会把模糊想法整理成清晰任务目标是什么,用户是谁,要改哪里,验收标准是什么。第二步,用 deep interview, 需求还不清楚时,别急着开工,让他追问场景边界、优先级,以及明确不要做什么。 第三步,用 plan 或 real plan, 先让他拆路线,读哪些文件,改哪些模块,风险在哪里,最后怎么验证。第四步,进入分工复杂任务,不要让一个 ai 从头干到尾,可以有人读项目,有人写功能,有人查风险,有人负责测试。 第五步,修 bug 用第八个他,先看报错、附线、路径、影响范围和最小修复点,再决定怎么改。第六步,用 test engineer 功能,能跑步等于能交 付,他会从用户路径、边界条件、异常情况和回归风险里补测试点。第七步,上线前用 code review, 必要时再加 security review, 他 们看逻辑漏洞、遗漏场景危险、改动和测试不足。最后让他整理变更内容、验证结果、剩余风险和发布备注,这样才不是写完代码,而是真的准备交付。所以新手最稳的顺序是先优化提示词,再深度追问,再规划路线。复杂任务,做分工出错先定位,上线前测试和审查。 你会发现 cloud code 真正厉害的地方不是它能写几行代码,而是你可以用 skill 把项目变成可控流程。新手先收藏这条路线,以后再让 cloud code 做项目,就不要一句话硬怼了,按这套流程走,翻车概率会低很多。
 10:38查看AI文稿AI文稿
10:38查看AI文稿AI文稿大家好,随着 opus 四点八的发布啊, cloud code 也发布了一个非常重要的功能叫 dynamic workflows 动态工作流,能够可以使用这个动态工作流去调用几百个这样子代码里来进行一个大规模的一个并行的开发。那本期视频就跟大家一起来了解一下 动态工作流是什么,以及如何来使用。我们首先来了解一下什么是动态工作流啊?一句话理解,就是你描述任务 clock code 会写出一张脚本,那这张脚本会在后台自动雇佣并指挥几十到上百个这样的子正体来干活,那最后把一份整理好的结果交给你, 那这个结果可能是你自己定的格式啊,那这里面其实有几个关键词,就是 called 会写脚本,那意味着这个工作流是可以保存起来,可以分享给别人用的,你也可以再一次去调用,因为脚本呢就是实际的代码文件, 然后他会自动雇佣便指挥几十到上百个写子整体,也就是他会根据你的这个任务自己去调度多少个子整体去干这个活,是他自己去分配的,也是会在这个脚本里面定义好, 然后我们看这个图就能看出来就是脚本来指挥这些子智能体啊,然后最后把这个结果给到你,那中间这过程都是在脚本里去完成的,那它是不会再回到这个主对话去跟你去进行一个 cloud 的 一个对话, 因为那样的话会导致这个上下文的问题,所以它是最终会给他一个结果给你。你是听到这里面可能会有点疑惑,那跟现有的这个 cloud code 里面的,比如说子代理, agent teams 这些有什么区别呢?因为他们其实都可以并行去开启多个子代理去干活。我们用这个生活中的一个例子啊,比如说你找人去装修房子来,我们来对比一下这几种方式的一个区别。 那首先我们从最简单的开始就是你一对一的对话,没有任何的子身体,那这个时候就类似于就是你找一个师傅,然后你每次都要叮嘱这个师傅要干什么, 那师傅干完之后就结束了,那你要安排他一个个试,那这种呢是效率最低的,那也是我们最常用的,因为我们去这样一次对话,那第二种就是这种子代理的这种模式,那这种模式就是你安排多个这种师傅去做事情,那师傅做完事情之后会告诉你, 每一个师傅干完干完事情都会告诉你,你需要去判断,要去找,还要找哪些师傅去干这个事情。这个时候区别就在于可以并行去做事情了,但是呢,每一个并行的这个子正问题完成之后,都会告诉你我做了什么东西,来等待你下一步的这个计划。 那么还有一种就是 agent 的 teams, 那 么你会设置好了啊,水电工,对吧?油漆工,电工。然后呢把这个任务分配给这个 agent teams, 那 么这边就会有一个领班,有一个 team leader, 那 他们三个人之间就是电工啊,水工啊、油漆工啊,他们三个人之间是可以互相讨论的啊,谁谁应该做哪个区域啊?谁去做哪个区,他们会通过讨论沟通,然后把这个事情做完,最终给到你一个结果, 那 walk flow 是 什么呢?就是你自己把一张整个施工流程图啊,大概是要我这个房子大概要做成什么样子的,那直接发给这个 coco, 那 coco 呢?就会根据你的这个施工图 开启一个这样的一个脚本,然后去写一段脚本,那这个脚本里面就会并行去执行非常多的这种子正题,那这个子正题可能是小工啊,一号刷漆的,二号刷漆的,对吧?还有这个铺地的电工啊,他分配了几十个人同时去干活, 那么在这个过程中你是不需要知道任何的进度的,最终把你这个房子装修好之后,他就会告诉你。那么这个 agent teams 和 work flow 有 点相似啊,其实最大的区别就是 agent teams 是 让你自己分配好哪些 这个组织人体,也就是我们的这个工人使派工人,然后他们之间是可以互相沟通的。还有就是什么呢?就是 work flow 是 你定义好了整个的意图啊,然后他会去写脚本,然后去开启 几十个这样子代理,而且你可以把这个编排的这个流程保存下来。那你下一次再装修第二套房子的时候,你可以直接用这个编排流程让他去做事情,就是把你这个 工作留保存起来,那这个 agent team 是 是不行的,那这前面的都是不行,所以它是可以被附用的,就这个工作流程是可以被附用的, 所以讲到这里大概应该有个这样的印象啊,就是这些是有本质的一些区别,所以呢,针对以上这些区别呢,我们可以大概知道我们应该什么情况下去使用这种四种类型,比如说你是一两步小改,小改动明确的这种单点任务,那么就用单个筛选,就是 非常简单的这种一对一的对话,这种对吧?你需要去派这种不同的组织人体去完成任务,需要来告诉你的,那么你就用这种组织人体的方式。那么第三个呢?就是你需要个团队,那团队里面的人可以互相沟通讨论,那这种可以用 agenims 去去做这个事情。那么第四个就是 你需要几百个几十个这样子代理,然后可以要循环交叉去验证的来,而且想把这个编排保存起来,那么你就用 coco 这种方式,不一定说一定要几十个几百个这样子体制体制,就是你要调动多个体制体制去 做这种交叉的验证复合,而且想把这个工作流能够复用,那么你就可以用这个工作流的方式。那么这边官方也内置了一个这样的工作流叫 deeply search, 就是 可以给他一个问题啊,他会从多个角度去网上去搜索这个资料,他提前是你在 coco 里用这个模型,本身就有这个网络搜索的能力啊,然后会逐条投票,最后会选出一个比较好的一个结果, 它是一个这么一个工作流,可以去体验一下,我们可以打开 curl code, 可以 输入 deep search, 那 这边就是自带了,我们可以看到这个描述是 dynamic workflow, 就是 动态工作流,那除了系统自带的话,我们可以自己去配工作流啊。然后的话你可以通过斜杠 先看一下你的这个配置里面是不是已经打开了啊? demo 和 workflows, 那 这边是处,把它改成处的话,你就可以可以去开启这样的工作流,那开启工作流有两种方式啊,一种是通过输入 workflow 这个关键词去主动去给它启动这样的工作流 啊,比如说这个,那我输入这个 coco flow 的 时候,这边会变成一个这样彩色的这个字体,意思就是你已经开启了这个 coco flow, 那 么它就会去啊启动这种 coco flow 去做去执行你的任务。 那么还有一种方式是通过改变这个推理的这个效果,那么你可以看到这边,那么你可以选择这个,你看有个这样的闪动的效果,你选择它 选中完之后有个彩彩色的这个边框,那在这边出现这个 archcode, 那 么在这种情况下的话,你输入的这个提示词里面,如它会自己去判断, 它会自己判断你这个任务需不需要开启 flow, 就是 它相当于是给你开来一个这样的环境,你把这个内容输进去之后, 系统自己去判断你要不要开启 coco flow, 如果要的话,他会去开启整个 coco flow, 那 这种使用关键词的方式的话,就是相当于是你一定要去开启这个 coco flow, 所以 这两个是有区别的,所以我们在自己去配置这个 coco flow 的 时候,首先是检查 coco, 然后再使用这两种方式,另一种去看一下, 我们去开启这个沃夫洛。好,我们可以试一下我们显示的方式,去开启这样的沃夫洛,看一下具体的效果是什么样子的啊?我们输入现在国内的模型或其他的模型可能对这个沃夫洛适配没有那么好,但是应该会马上去跟进的, 它这边已经触发了,就是会使用沃夫洛对这个模块进行一个安全审计。 ok, 它这边已经开启了 workflow, 然后提示我们可以使用 workflow 这个命令啊,去查看它现在开启的具体的 呃阶段是什么样子的。我们输入这个 workflowflow, 那 么你就可以看到啊,你看这边它会执行的一个阶段,第一步扫描,然后这边的话有具体的这个五个子质整体, 然后呢?第二步验证,然后这边的话因为它还没有到这一步,所以它没有分配这个质整体。等第三步完成之后,那么你就能拿到一个 这个总体的一个效果,一个,然后你在下边的话是有一个这样的操作命令的,然后按 p 键就停止,然后的话你可以按 s 键,那么你就可以保存,比如说按 s 键,那么你就可以把这个工作流保存在这个当前项目这个目录里面,我们可以看一下当前项目这个目录里面是不是已经保存了, 那么在点 close 里面,这边有个 work flows, 你 看这边的话就是我们刚刚输入的这个要求,那么它就转写了一段这样的脚本, 那这个脚本的话就是具体的一个执行的一个详细情况,我们可以看到每一个这个智能体的这个提示词全部都有,那么你可以 把它关闭之后啊,你可以就是可以把这个工作流分享给别人,或者说你在别的项目里面也能使用了,那么按 p 键就停止了,停止之后你别只要不退出这个对话,你是可以去按 p 键再去给他开启, 你是可以恢复的,那么它又恢复了,所以 book flows 这个命令相当于是去管理整个这个工作流。但是如果你需要去附用这个工作流,你是需要退出来,我们直接退出这个对话, 退出这个对话之后,你启动之后,刚刚那个工作流就没有了,因为刚刚运行的工作流是不存在的,它只会保留在当前对话着,但是呢你可以重新启动 啊,比如说我们这个 api service 这个,那么啊这个就是我们刚刚保存的这个工作流,那么你可以在这边可以启动,那么也是一样,相当于一个命令一样。 所以就变成如果你这是一个可以附用的工作流,那么你可以分享给任何人,可以在别的工,在你的别的这个项目里面啊,像电用命令或者技能一样去给他使用它,这是一个非常方便的事情。最后就提醒一下,这个开 windows, 因为我们开启了很多子代理,那这样肯定是比较费 token 的, 这也是要衡量一下,就是你这个任务到底值不值得用 workflow 这种大批量去跑。然后大家也要注意,就是我们退出对话之后,那你这个 workflow 就 会失效。 所以最好是如果是一个好的 workflow 啊,你可以保存保存下来,然后再随时都可以去启动,那整个这个动态工作流大概是这个样子,那我觉得它的出现啊,其实是代表了整个 ai 领域的一个发展方向,本来我 从我们的一对一的对话能到现在大批量的长时间的执行,那未来这个肯定是一个常态。 ok, 那 本视频就到这,希望这个视频对你有所帮助。
314AI随风 10:08查看AI文稿AI文稿
10:08查看AI文稿AI文稿android 发布了他们的最强模型 cloud of 四点八,老规矩,我不想跟你念参数,那我其实只关心一件事情,就每次新发模型,我们把它丢进真实的项目里面,它的干活质量到底怎么样? 那这一次这一个 cloud of 四点八新发布的模型啊,我刚测完,我反而觉得 gpt 五点五加 codex 的 组合还能打,为什么呢?看到这个视频最后你就懂了,不过这一次有个东西是真的有意思,就是它这个动态工作流在 cloud code 的 里面,就是你只要一句话, 带上 workflow 这个关键词, client code 当场就给你写一段脚本,然后咔的一下拉起一个几十个上百个 agent 的 舰队,一起去帮你干一件大事。 我们来看一下它整个运行的一个流程图大概是怎么样子的。从这个图片可以看到哈,就是当我们 client code 里面你写了一个 workflow, 它这个时候通过脚本,然后去给你并发各种 agent, 那我们可以看一下它这个脚本长什么样子哈,其实也比较简单,就是它有每个阶段嘛,就是你是 workflow 的 一个流程,每个阶段,比如这个阶段它要排查啊,这个时候可以看到它这个用了一个 await, 是 吧? await 去并行运行了多个 agent, 完事之后走到这里得到了结果,这时候就回到你的主要的对话里面,它又开始去 定型,去开始第二个阶段,再去掉各个 a 镜头,大概就这样的一个工作流的一个过程。下面的话到我们的一个实测环节,这次的话我们用了我的一个开源项目,就是 c c 杠,哈哈,它目前的话有十一点九 k 的 star 是 一个,就是把 curl code 的 卸载原代码补齐,做了一个桌面端,还有 c o i 的 一个 开项目嘛,那这个开项目的话最开始也一直是 gpt 五点五加 codex 去迭代的,那这一次的话, cloud of 四点八出来之后,我要去做一个新功能,我们本期的一个实测哈,就是要让我们这一个桌面端,它在它的右侧能够对我们本地的一些 服务,比如说你用 react 或者是 vue 写了一些本地服务,这个时候我们要去点击,让它在右侧展现出来,或者是本地的一些 html 要拦截这个行为, 并且我们右侧要有要有一个小的一个浏览器预览,而且能够像 codex a p p 一 样,能够就在在上面去选中一些按钮啊,标题啊,或者一些块儿啊,能够去做定位,而且还能够直达答案,让它去修改。 在 codex 聊天中,当它改了哪些文件,比如说是 html 呀, markdown 啊,其实你都可以去点击,点击完它会在右侧去预览,而且下面也有这种打开的方式,也整体的交互,就相对来说挺棒的嘛。在整个桌面端,我认为现在 codex a p p 就是 目前交互最好的在桌面端来看, 那下面我们来看一下这个 html 它是怎么做到整哪打哪的?可以看到这个时候我们不是打开了这一个我们这一期视频的这个 ppt 吗?那它这边有一个模式的话,就是你可以去去,这样有一个选择器可以去选嘛?比如说我选中这一块啊,这个时候我就可以用自然元描述啊,我觉得这一块的 ui 交互啊,文案不行, 那就可以通过这样的方式让他去改,可以看到他就对我们这一个图片这一块加了一个备注嘛,对不对?然后还有我们这块的信息整体就是这个交互的功能,然后还有的话就是这个截图啊,他这个截图已经保存到剪切板,我们可以用大概这样的一个流程, 我们就希望我们这 c c 刚哈哈也支持这个功能,并且也有人在我们的 github 要求里面提出来了要这个功能,那我们就试一下。那今天的话 我用了 gbt 五点五以及我们刚刚看到了 kalco 的 off 四点八去做这个任务,那这边的话也是给了它五张 codex a p p 它整体的一个交互流程,并且我们也是用了这一个 superpowers 的 一个头脑风暴模式,相关的一些提示词都是一样的。然后我们去测试这个任务,我们可以看到 codex 这边呢,它最终启动了四十三个, 呃,三部 a 镜呢?帮我们把这个任务完成了,所以效果怎么样?待会儿我们再来看。那我们回到就是 clock code 这边也是用了陀螺风暴 t s 也是一样啊,也是同样的,就是每个阶段让告诉他我们最终这个设计文档要做成什么样子。有了设计文档之后,他也是去 各种实盘刹不住 a 进的去做。那在 codex a p p 这边的话,它整体的这个消耗可以看到今天我是烧了五亿的 token, 那 对于刚刚我们那个任务,大概我估算了一下,大概有三亿 token 这样子吧。 cloud 这边的话也是今天一天就烧了我这个一百刀的百分之二十的一个额度吧,一天就烧了,没有做其他的 任务,基本上没做其他的任务。好,我们下面来看一下两边的一个实现情况如何。好,下面我们来看一下 cloud 桌面端加 cloud off, 四点八,他去帮我们写了这一个 c c 杠,哈哈,桌面端就右侧这个浏览器预览的功能。 那这边的话我也给了一个提示词,就是让他帮我们产出一个 markdown 的 一个内容以及 html, 再让他去写了一个本地的一个突突项目嘛,就是用 react 去写。那最终他这边写完了之后呢? 啊,可以看到这里其实是已经他这边做了一个监测,当然这块的交互其实没有 code app 原声那么好,当然他也做到了,我们来试一下哈,就是我们在运用浏览器打开 啊,可以看到这个,是不是已经可以去看到这个这个网页这个预览效果了?那我们可以看一下截图功能,点一下可以看到这边其实也是可以用的嘛,是不是?那第二个的话比较关键,就是他这个检查元素嘛,可以看到他也是完成了,是不是?比如说我们就说这个按钮,我们就在这让他告诉他啊,我需要把这个按钮改成 就是这一个网页的主题色,你帮我改一下。另外的话,当前这个按钮的这一个 border 这些我也不是很喜欢,你去调整一下。 好,我们来去确定,你可以看到这边它就已经帮我们把这个东西做过去了,就是把截图嘛,就我们刚看到 codex app 那 边的一个交互,交互过去了,我们就可以去让它去做做这个事情。 那下面的话就是其他的一些功能哈,其他一些功能的话就是它可以在这边,比如说我们这是一个 markdown 的 内容嘛,所以说你可以在工作台去预览,基本上就是把那边实现了一遍。 其实整体实现还是挺复杂的,可以看到 codex 那 边他完成这个任务他都开了四十多个 java agent。 那 cloud 这边其实我没去统计,因为它这个过程没有像 codex app 那 边那么直接, 整体的效果其实完成度还可以,当然还有一些细节优化的点。好,我们来看一下扣贷 app 跟我们完成同样的功能,他是做的怎样子的?可以看到他在这一块, 在这一个行内,其实就帮我们把这一个要预览的这一个,呃,本地的地址啊,还有你的 markdown 啊, html 都做出来了,其实这块交互我觉得会稍微好一些。那么点过去看一下可不可以用,那可以看到都是同一个页面吗?是可以用的,刚刚我们说改按钮那个他其实已经改好了,是不是?那么看一下他这个截图可以用吗? 这个截图这个方式是这样子,它不是像呃 cloud code 实现那样子,是放一个图片在这里, cloud code 那 边会好一些。好,我们来试一下它这个定位也是可以的,可以看下,也是能选择某一个。我们选到这一块说一下,这个文字太大了,改小一点,字号改小一点, ok, 可以 看到它这个其实完成度也挺好的。那现在的话,其实我也没有想清楚,到底是把 gbt 五点五生成的这个核到我们的这个主干里面,还是说把 cloud 那 边去核一下?我可能会把 cloud 那 边的这一些 open 这边的加过来,然后用用 gbt 五点五的这种这种样式,最终把两个合起来,得到一个比较好的一个交互方式。那再看一下吧,从我四月份发布以来,就是从它泄露原代码,再加上我们做这个桌面端嘛, 一行代码的微信百分之八十的代码都是 gpt 五点五加这个 qd 写完的。可以看到我今天除了写这个项目以外,还做了其他一些功能。那下一个版本也在,应该是明天就会发布了,我需要去做一些就测试嘛,可以看到它真的是非常非常的好用,而且最关键啊,它不封号 是不是?那你如果是用呃 cloud 的 话,就是真的特别容易封号,我已经被封了四个了。好,下面我们来做一个总结。对于大多数人而言,我还是推荐你选择 qd 加 gpt 五点五。为什么? 你看我老婆这种律师哈,她现在都已经用上 codex 加 gpt 五点五来帮助她在平时的工作中进行赋能。打个比方,她平时有很多需要去操作 word 呀,然后 excel 啊,还有去填一些表单,这个是完全是可以用啊, gpt 五 点五加 codex 去做。再让我不最近也给她做了一个就是律师相关的一个工具嘛,因为她有她们有很多资料,其实都是需要在本地去操作,就是不能上云嘛, 比如说你像客户管理啊,还有一些合并 pdf 啊,这些都是可以照本地去做的。你说像这种工具,直接用 codex 去做,让它去描述你的需求,然后用那个就是一个 go 的 模式嘛,让它去做,完事之后再让它用 computer user 自己去测,它会自己去 啊,写完之后 build 出来这一个桌面的 app, 然后如果你看像我们这种不是需要去选择 pdf 嘛,对不对?如果你需要去选择 pdf, 它还会自己去打开这个,就像我们一样去打开,打开完了之后 去选择,然后去帮你去压缩,做这种合并,各种都可以做到。所以我为什么会推荐大家去使用这个呢?而且等待下一代模型发布的时候,它会更强。还有最重要一点嘛,就是 g p t 五点五, 你正常人用它一般不怎么封号,那 cloud off 四点八这边也挺强的,但是呢,它的门槛就会高一些,并且它的这个桌面段哈,它这个桌面段体验其实相对来说还是差, codex 会差一些,如果你这两个都用不了, 那你也可以用,就是我的这个开源项目就是 c c 杠,哈哈,这个开源项目也是开源免费的,也没有任何的一个门槛。你也可以用,就是各种国内的模型嘛,比如说你可以用 deepsea 呀,你看我这边其实都有,就 deepsea 呀,或者你可以用小米的呀,或者是智普,你都可以。那它基本上内核它也是 clio 的 本身嘛, ci 的 本身 功能我也在迭代,就看大家自己怎么样个选择。 ok, 不 管是 off 四点七四点八,它整体的这个发布啊,没有给我很惊艳的感觉,没有上一代从四点五到四点六的那个惊艳感, 那还是倾向于就是 g p d 五点六的一个发布,看它到底会带来怎样的改变?我现在基本上已经离不开 codex 这个 app 了,我最近真的狂用。我刚也给大家看了一下我的一个 token 消耗,最近一个月吧消耗了大概一百亿 token, 一 万多刀的一个消耗, 最近就是狂用,特别特别好用,而且运行起来也非常的方便。但是它也有一个问题,就是它容易内存泄露,我六十四 g 的 内存它有时候都能给我干嘛,就理解不了到底在干嘛。 ok, 那 这就是本期视频所有内容了,如果大家觉得这视频做的不错,可以给我一键三连,我是阿建,我们下期见。拜拜。
 05:22查看AI文稿AI文稿
05:22查看AI文稿AI文稿本期视频只讲一件事,新手如何快速上锁 cloud code, 让他帮你干活提效开始。首先, cloud code 中有三种常用的工作模式,默认模式、自动模式和计划模式。默认模式每一步都需要你确认, 写文件、执行命令都需要你手动同意,步步确认,它是最安全的,但也是最慢的模式。自动模式,文件操作会自动执行,但涉及到有风险的命令,比如网络请求、 m c p 工具的调用,他仍然会停下来问你,向你申请权限。计划模式,这个模式上来不会先帮你干活, 他会先跟你讨论需求,帮你制定出一个完整的可信性计划,你确定计划没问题之后,他才会动手。我们打开我们的 cloud code 界面, 在左下角就能看到我们当前的模式,按住 shift 加 tab 进行模式切换,空白就是默认模式,紫色的就是自动模式,然后绿色的 plan 就是 计划模式。在项目的开始阶段或者涉及到复杂的需求, 我都建议开启 plan 模式,跟卡扣讨论出一个完整的计划,剩余的执行阶段你都可以保持自动模式。接下来是几个卡扣中比较重要的知识点。第一个 skill 技能,他是给 color code 的 标准操作手册,没有 skill, color code 每次都在极尽发挥同一件事情,他今天可能这样做,明天那样做,结果是不稳定的。就像你给厨师一本固定的菜谱,这样他做出来的菜菜的味道都是固定的,不会给你乱发挥。 color code 中我们输入斜杠, 会列出所有你已经安装过的技能,按 tab 键可以选中这个技能。比如帮我创建一个 word 文档,这样它就能调用这个技能。或者你也可以这样做,帮我创建一个 word 文档, 点击回车,然后大模型会自动识别到你这个需求,可以用到刚刚的 d o c s 这个技能,它就会自动帮你调用这个技能。 m c p 卡拉扣的他的内置能力,他是有边界的,他做不到。帮你控制浏览器,帮你收发邮件。 mcp 就是 让卡拉扣的与其他软件互联互通。 比如你装上浏览器的 mcp, 他 就能帮你控制浏览器。装上数据库的 mcp, 他 就能帮你控制数据库。装上搜资料的 mcp, 他 就能帮你自动搜索资料。就像你给厨师配了一部专线电话,直通时代商外卖平台助理,他不用出厨房,他就能调用外部所有的资源。我们在卡拉扣中输入斜杠, mcp 就能查看我们安装的所有 m c p 工具。 pux 钩子有些动作你希望可拉扣子每次都自动执行,不想每次提醒它。 pux 就是 在特定的节点自动触发的预设规则。比如你配置一个文件,改完就自动备份的钩子, 这样以后每次文件改完,他就会自动帮你备份。就像厨房里的铁绿,每次上菜前都自动撒一把葱花。这个钩子功能对我们有什么用呢?我举个简单的例子,卡奥克德会频繁向我们申请权限,有时候我没有看到,他就会一直在那边等着我们, 不往下执行就会浪费很多时间。然后你就可以对你的 code code 说,帮我配置一个 hux 钩子,作用是每次 code code 向我申请权限时都播放一个音乐,然后你的 code code 就 会把你移步配置,我这里已经配置完了,我直接演示一下,我让它读取一个其他路径的图片,它就会向我申请权限。 它会播放一个超级玛丽的声音,这是我自己配置的,你们也可以选择自己喜欢的音乐作为提示音。 sub agents 自带礼 如果有一个任务很复杂,那么一个 clock 的 创建处理就很慢,这个时候就可以用到三倍镜子弹里。它的作用就是把一个复杂的任务拆成一个小的任务,让这些任务同时去执行,就像主厨同时指挥,几个副厨同时开工。那我们具体怎么用呢?其实也非常简单,直接跟我们 clock 对 话。 我现在有个很复杂的任务,请你帮我用 sub agents 代理执行。这里我只是举个例子,因为实际中你的任务可能很复杂。题是和很多 plug 插件 skill m c p hooks 要一个配置很繁琐,插件就是打包好的解决方案, 你只需要一键安装就能拥有整套能力。包克隆书,斜杠, plug 就能打开插件管理页面,在线安装管理我们的插件上下文窗口。 cloud code, 每次对话他能记住的信息他是有上限的, 你的对话文件执行过的内容全部都在占用这个空间,如果占用过高,就会出现大模型反应变慢了,他的回答质量下降了,就是我们俗称的大模型变笨了。再一个, 占用过高,大模型可能就会忘记你开头说的东西,就像人的短期记忆,同时记忆太多就开始混乱。那我们该怎么处理呢?首先我们用 context 命令, context 命令可以看到当前的占用情况现在是百分之三,当占用超过百分之五十的时候,我们就需要注意及时的使用杠 compact 命令 去压缩我们的对话。这个命令的作用是把之前所有的对话做一个摘要总结,存到记忆里面去,释放大量的上下文空间。还有一个命令杠克拉命令, 这个命令的作用是清空当前的上下文空间。如果你当下的任务已经完成了,克拉口的当下的记忆上下文对你来说已经没有用了,你就可以用这个命令来清空整个上下文,准备做下一阶段的任务,相当于清空大脑。
286野客 Lab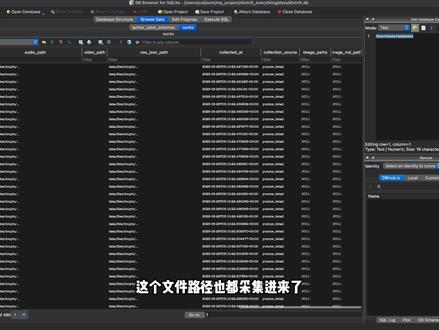 08:23查看AI文稿AI文稿
08:23查看AI文稿AI文稿今天想给大家分享一个我用了这么久 skill 总结下来最有用的一个设计原则,就是原子化加编排 啊,我们先不讲概念,直接看它最终的效果会长什么样子。我这里做的一个 agent 的 工作流是我输入一个抖音博主的主页链接, agent 的 就会一步步的帮我把这个作者的信息数据,以及他历史发布的所有作品的内容和数据全部采集下来, 最后还会给每一个作品打好内容标签,然后汇总一份报告给我。我们看一下这个项目的 skill 目录,就能很直观的感受到 原子化和编排到底是什么意思。这里有十来个原子化的 skill, 他 们每个 skill 都只负责一件很小的事情, 比如说这个就是解析抖音博主的作者信息的一个 skill, 然后这个就是采集这个作者历史的每一条作品的数据,还有一些音视频封面文件的一个 skill, 这个就是如果是图文作品的话,那会对图片进行一个 理解,然后提取图片上的文本的 skill。 这个呢就是如果是视频的作品的话,就会去抽取视频的音频,然后把音频转写成文字的一个 skill。 在 这个转写 skill 里面,因为我是通过远程连接我的 windows 电脑,帮我去做 gpu cuda 加速转写的,所以这里会有一个远程 cuda 转写的这样一个 skill。 这个就是转写完之后,再用大语言模型做一遍润色,因为有一些专业术语之类的需要 啊,经过大语言模型做进一步的润色和处理的。最后就是两个给博主和他的作品打内容标签的 skill, 这里面每一步都是一个独立的原子化的 skill, 它们每一个 skill 都只处理一个 很小的原子化的任务,做完他就直接吐,结果他也不管上下游是谁。那说完了原子化编排是什么意思呢?编排 skill 的 唯一作用就是把这些原子化的 skill 串成一个完整的工作流, 我们可以打开这个编排 skill, 看一下它长什么样子。首先就是它会解析我给出的指令,就是抓取哪一个博主的 数据,然后抓取的作品有多少条。然后我们主要看一下它的工作流程。第零步,它会去调用一个 skill 去做健康检查,看一下我远程的那个 windows 电脑是不是可连接的,然后 c u d a 啊,还有一些依赖项是不是可用的。 然后第一步就是去调用解析作者的这个 skill, 拿到博主的一个概括和信息。第二步就是 采集作品的 skill, 把这个博主的所有作品都抓取下来,包括作品的一个基础信息数据,还有音视频和图片的原文件。然后第三步和第四步就是作品拿到之后分成两种 作品类型,如果是图片的话,走 ocr 提取文字的 skill, 如果是视频的话,那么就走视频音视频转写的一个 skill。 第五步就是用认色 skill 优化一下一些专业术语, 因为 whisper 转写对中文还有一些专业术语,它处理的是不够准的,所以这里需要用大圆模型做一个润色处理。第六步就是基于抓取到的所有作品的内容,跟我协商出 几个作者级别的标签,然后第七步就是为每一个作品打上这些标签,最后就是给我输出一份总结报告,那这里我们可以注意到,就是编排 q, 它自己是没有任何新的逻辑的,它 整个 skill 点 m d 里面就只做一件事情,就是声明工作流总共分为哪几步,但是每一步具体要怎么实现,其实是写在被调用的这个原子化的 skill 里面的,它并不在编排的逻辑里面。那么为什么要这样做呢?我觉得这么做是有三个好处的。 第一个就是让我们去设计工作流,还有设计 skill 变得非常简单,如果你要做的一个工作流或者是一条流水线,它的链条是比较长的, 一上来我们就想把它写成一个可以用的 skill, 让它能跑通,会发现是寸步难行的,很多时候边界划不清楚,流程理不顺,调试起来也很痛苦。但你拆成一个一个原子化的 skill 之后,会发现每个 skill 其实它的实现都是比较简单的, 可能几分钟就能跑通一个,这样的话我们一个一个 skill 去搭建起来,去验证起来就会非常简单了。 第二个好处就是这么做它的可叠代性会非常强。如果我们把所有的业务逻辑都放在一个大的 skill 里面,那么跑起来之后我们去想要单独去优化某一个环节, 我们需要在几百行的 skill 点 md, 还有一堆 reference 文件或者是 scripts 脚本文件里面去找到 某一段或者某一行,改完之后你还担心破坏别的步骤,我相信做过大 skill 的 朋友应该都能懂这种感觉,那么原子化之后我哪一步效果不好,需要优化,我只需要去改那一个小的 skill 编排很多时候根本都是不需要动的, 这么优化起来的话,我们的目标和方法都是非常明确的,根本不用担心破坏整个工作流。第三个好处,也是我觉得最重要的一个好处,就是原子化的 skill 是 可以被附用的。你看刚刚那十个 skill 里面,像图文、 ocr、 音频转写、润色、打标 这些其实都是跟抖音这个平台无关的一个通用能力,所以我现在做的是抖音这个平台的工作流,那后面我要再去做小红书,做 b 站 或者做视频号的类似的工作流,那这些 skill 其实一行都不用改,我只需要再去写一个新的编排 skill, 按同样的格式把它们串起来就可以了。 所以原子化的 skill 攒的越多,我们下一个新的工作流的搭建成本就会越低。而如果我们把整个流程都做在一个大的 skill 里面的话,那我们想要再附用到别的平台上,可能就没有那么简单那么清晰了。 最后我们可以看一下这个 skill 实际跑起来的一个表现啊,我只需要在绘画里面调用这个 skill, 然后丢给他一个抖音博主的主页链接,然后跟他说要采集他的所有作品, 我们就可以看到他一步步的去调用我们刚刚在那个工作流编排那个 skill 里面串的那个流程。第一步去检查我的 windows 是 否可连接,依赖是否都已经安装好,第二步就去解析这个作者, 第三步就去拿到这个作者所有的作品,第四步就去把他的视频进行了转写, 会推送到我的 windows 电脑上,然后一个个去做转写,转写完成之后,他会自动去做一个 l l m 的 大圆润色,转写完成之后就自动进入下一步,根据这个博主的历史的所有作品内容去归纳他的一个内容标签,然后跟我协商确认, 我确认完之后,它就自动地去为它抓取到的每一条作品去做达标,最终就给我生成了一个总结汇报。 整个流程除了我在它提取作者标签那一步参与了一下确认,其他全部都是由 agent 自己一步一步调用各种 skill 去完成的,我觉得整个流程真的是非常清晰的。那最后我们也可以看一下最后最终它产出的一个结果。第一个是这个数据库 啊,我们可以看到每一个作品就是一行数据,它有标题,有正文,有标签,然后是什么时间发布的,以及各种点赞、评论、转发收藏的数据,包括说各种原文件、音视频 封面的原文件的这个文件路径也都采集进来了。然后第二个输出的话,就是每一个作品的音视频, 还有封面的原文件,还有转写完之后的这个文字稿,都非常格式化地落在了我的本地的文件夹里面, 那么这期就到这里,如果你也在做页尾整的,需要搭很多可附用的工作流,可以尝试一下用这个思路去做你的 skill 的 设计。如果大家觉得对你有帮助的话,可以帮我点个赞,点个关注,我们下期再见!
520新也诚🦞 19:38查看AI文稿AI文稿
19:38查看AI文稿AI文稿大家好,我是老吴,今天给大家介绍动态工作流, dynamic workflow, 呃,它是最新的,呃, cloud code, 呃,二点一点一五四,它伴随着 up, 四四点八一起发布。然后呢?呃,这个版本 动态工作流它已经默认开启了,说明已经可以生产可用了。然后它是一个什么样的一个技术呢?呃,简单来讲就是它,它是让 card, 它自己写一段调度脚本, 然后呢在后台指挥,呃,很多个智能型来并发地进行工作,它只把核对勾的结果来交还给你。 要想使用这个功能的话,就是,呃,我们 cloud 的 版本必须是大于,呃,二点一点一五四的, ok, 我 们继续。那什么是 cloud workspace 呢?也就是我们刚才讲的它是一段 cloud, 这,呃,这里我们需要注意,它是现场编辑的 js 脚本 编排脚板,就这个脚板不是我们呃事先编排好的,而是 cloud, 它根据它的实际情况现场编写的。而且这个,呃,嗯有独立的运行时呢,在后台进行执行。 它的智能体也有它的智能体就是,呃 sub sub agent, 它,呃主要是负责一些就读文件,跑命令研究凭证这样的操作,它的脚本只负只是负责来协调 主绘画呢,只收到最终的答案。这样的一个设计呢,就和我们之前小龙虾的那个设计是比较类似的, 有一个主的 agent 来负责收集信息,一些子 agent 负责跑一些,呃负责干具体的任务,然后他这边比较好了,就是他,嗯, 用 js 来编排脚本,这样的话就保持保证了。呃,最大的一个灵活性, ok, 他 到底解决一个什么样的问题呢?他第一个解决问题就是,呃上下文比较长的这样的一个问题,就是单个任务上下文比较长 算不下去,然后虽然我们现在的模型上下文也比较大了,但是总会有爆炸的一天,然后呢他就把状态挪进一个脚板的变量里面, 这样就解决这样的一个问题。然后呢规模化,就是它可以一次开几十或者几百个智能体来并发的进行执行任务,这样的话 效率就是呃会呃更加的一个快。 他这边比较厉害的一个地方就是他加上了一个对抗式的验证,就是他的独立智能体,他会互相的进行反驳,他只会留下,就是最经得起考验的这样的一个结论。 还有一点呢,就是他的这个脚本是可附用的,就是这个工作呃工作流我们可以把它保存下来,下次呢可以一键进行重放, 它的卖点呢就是不是快,而是更可靠,更可信,更可附用 这样的一个设计的,呃一个思路呢,就和我们之前讲的 harness 是 比较类似的,它就是其实呢它也就是 harness 的 一个实现的一种方式吧。 那这一趴呢,我们主要讲讲它什么时候才能用呢?第一点呢就是上下纹比较长的时候, 然后第二一点就是呃我们的嗯切分切分策略就是,呃我们是未知的, 就是我们前面讲的它是它的脚本是动态生成的,这样呢是比较适合。然后第三一点呢就是我们对质量要求是比较高的,我们不在乎 talk 呃消耗多少, 符合这三个条件呢,我们就适合来用 workflows, 我 们看下具体的,就是比如说做一些大规模的文件的一些迁移,然后做一些全代码仓库的一些,呃架构的一些审计, 然后陌生代陌,呃陌生代码库的一些 bug 的 一些排查,然后做一些压力的测试。呃,最后一点呢,就是它的结论必须经得起呃对抗贫瘠这样的一些任务。 之前讲了一些 workflow, 那 它和 sub agent 的 skills 有 什么区别呢?我们一起来看一下。 sub agent 就是 本质上就是它是 cloud 派出去的一个工人, 然后呢这个它是由谁决定它的下一步做什么呢?它是由 cloud 就是 一个回合,一个回合你和它探讨它的中间结果,它存在一个上下文里面 啊, skill 呢,就是它正确的一些指令,就是呃最简单的讲就是一些提示词,它的结果也是保存在它的上下文里面。 workflow 呢,它的本质就是运行时执行的一些脚本,就是是 js 脚本,它的呃 脚本是 g s 现场写的,所以它是比较灵活,它的中间结果呢是存放在一些变量里面,这样就解决了一些上下文刚才我们讲的上下文呃不够的问题。 呃它的是整个编排本身是呃可附用的,就是我们把这 gs 绑下来可附用,然后呢它的并发症就是一次可以跑几十或者几百个这样的一个 agent, 然后在 sub agent 或者 skills 它会它如果被打断的时候,你必须要经过重新跑啊。 workflow 呢,就会发同一个会发绘画之内它是可以呃进行恢复的。 总总体来讲就是它是用脚本来实现它的灵活性,用一些大量的 agent 来实现它的一个并发症。 ok, 那 这个功能是怎么开启呢?嗯,一种方式就是通过 deep research, 这是一个,嗯, cloud 内置的一个 skills, 就是 它是联网搜索的搜索这样的一个功能。然后呢它还有一个第二种方式,就是有一个关键字,就 workflow, 第三个关键词就是呃,用 effort 等于 ultra code, 这样的话就是让 cloud code 去自己去判断到底使不使用。嗯, workflow, 嗯,正常来讲就是我们一般都是不用呃阿秋,阿秋,可这样的一个模式,这种模式就是更费更费 talk, 而且会比较慢。 ok, 待会我们和大家一起来再详细的演示。 然后这个 workflow 运行起来,我们怎么进行查看呢?它也是比较简单,就是斜杠 workflows 就 可以进行查看了,然后呢这是它的一些快捷键, 然后 s 就是 可以把这个 workflow 保存下来,我们待会和大家一起演示。 然后呢就是 workflow, 它的提示词,它是有一些规范的,比如说 scope 就是 它的一个一限定的一个范围,就是你要改的东西限制在哪里。 它的输出也是有一些约定,就是你必须说清楚输出的一个格式。 然后呢就是 verify, 这就是一些验证的规则,它主要是用于交叉,交叉验证的时候。然后呢就 edit 编辑的策略,有大的任务,它是先读,避免呃意外改一些,呃,就是 把一些不该改的文件把它改掉了。 workflow, 就是 这篇讲呢就是怎么进行保存,下次使用就是把那个 i s 把它保存起来,它的默认是保存在项目级,就是 就是像嗯,这个当前项目下点 cloud workflow。 然后呢还有一种情况,个人级的就是保存在当前用户下面的 cloud workflow, 呃,首先呢就是我们用 workflow 它的费用肯定是,嗯,更高的,因为它会消耗很多个 token。 然后呢第二一点就是我们这些智能体,我们要把它改成 accept edit 模式,呃,以避免就它一直呃问你要一些权限, 这边它我们嗯讲它有一些限制,就是它最多就是十六个病房,然后单是最多跑一千个智能体。在前面我们已经讲了, 这边讲了怎么把它关闭,就是 disable 对 to, 那 我们给大跟大家演示一下。 ok, 我 们接下来和大家做一个演示, 我们看到了我们最新的,我这边呃 cloud, 它已经是呃二点一点一五八这个版本,然后我们用的模型它最新的也支持到 up 是 四点八,然后它怎么开启呢?它 我们看下它四点八这个版本,它默认 downemik, 它是 true, 它已经默认把它开启了。好,我们直接用就可以了。 ok, 我们首先呢我们用那个 deep research 这种方式, 就让它在网上去查一下 node js, 呃,二十和二十二这样权限模块这样的一个差异, 看它已经提示你了,可以用 workflow 进行查看, 它分为以下的工,以下的一些流程就 scope, search, fetch, very far, very far 是 非常重要的。然后就是合并,我们看一下 workflow, 它就是刚才我们看到的分为五个阶段, 右右键,就是方向键,右右键,然后就可以看到它的一个详细的过程。 在下方我们也看到它的上下可以进行切换,然后杠 p 可以 把这个 a 镜头把它停下来,然后 e s a 返回, s 就是 把它保存下来,我们返回, 然后我们看一下第二个,第二个它已经完成了这期,这它已经完成了。然后呢这边写的它是用到的,中间显示的它是用到的模型,然后右边呢它显示的,呃,用到了一些 token。 ok, 我 们随便选一个看一下, 它已经结束了。 我们这边看到他一共有四五个 agent 在 并发在跑。好,我们看到他已经完成了,这是他的一些结果, 然后我们看到他用到了九十七个 agent。 好, 我们返回。 ok, 他 已经结束了,然后他现在把结果返回给我们。 ok, 这就是它的一个呃结果。然后我们看一下 这个就是我们刚才的 delete 这样的一个工作流,我们按 s 的 话就会它就可以把它保存下来,这就是保存的一个名字,唯一, ok 让你保存下来了,这是保存的一个位置。 ok, 刚才我们演示了 deep refresh, 然后我们再和大家看一下。呃,这个关键字, 它只要有 workflow 的 workflow 关键字的话,它就会那个,它就会用 workflow, 你 看到了没?这个 workflow 它是变成彩色的。 workflow 它是变成彩色的,但是我们如果不想它变成彩色的话,我们按一个 delete 键就可以了,看到没它就过去了,然后我按空格键重新让它变成彩色的。 ok, 它变成彩色的话,它接下来跑的话就是 用 workflow 的 这样的一种方式。 这 walkthrough 呢?它的主要的任务就是我们让它分析呃这样的一个项目, 然后我这边指定了,就分析用海库模型,然后呢用 opus 四点八模型进行一个汇总,然后生成嗯,这样的一个分析报告。 那首先呢,就把项目,它把它呃克隆下来,然后它这边还在跑, 这个克隆的项目我觉得还是蛮叫,呃,还是比较不错的。它把 open spec 和 super power, 呃,把它结合在一起,然后用它们 就是一个优势,用它们各自的一个优势, open open spec 它主要负责设计。然后呢,这个 power 是 它是基于滴滴 tdd 的 一个开发。 ok, 它已经跑完了,因为我们之前已经跑过一次,所以它现在跑起来现在还是比较快。 ok, 它已经结束了啊,还没结束,还在跑。 ok, 这个我们让他等着吧,然后我们回来,然后我们再和大家演这个,就让他跑着,然后我们再和大家演示一个另外一个叫做 effort otood, otood, 这样,嗯,来开启 workflow 的 一种方式。 ok, 看到没?它开启以后,它会这个颜色会变成一个一个。呃,彩色啊,等几秒钟它就回去了,然后我们把它切换回来,就是用 hi, ok, 看到了吗?我们再和大家演示一下,它变成一个彩色,跟那个 workflow 的 刚才的颜色是一样的。 ok, 行,今天这个视频呢,我们就和大家介绍了一个 color code 的, 呃,四点八 这样的一个新的一个功能, workflow, 呃,在有些场景下用这个还是比较方便的。 ok, 嗯,今天这个视频就和大家讲到这里,如果喜欢的话可以点赞、收藏、关注,谢谢大家。
16老吴聊技术


猜你喜欢
- 55.0万白开水泡泡