spss数据分布特征的描述怎么做
这是一个数据样板,我们可以发现在这有很多的数字类型, 嗯,这个呢是序号,这个下面的 mc h, 他是同期科成绩,嗯,接着是性别,他又分男和女, 这种叫做分类变量教养的方式,还有数学的焦虑,嗯,包括后面的学习态度,他们有什么单亲啊,呃,低焦虑、高焦虑啊、差中粮优秀啊等,他们也都是分类的变量, 那这里的类型数据的类型是比较多的。呃。 spss 这个软件它的容纳程度也非常的广泛,它可以帮助我们去分析 嗯,分类的变量以及等距的数据的这种变量,我们可以发现在这他出现了非常多的数据样本的空间是一共有三百个,如果我单看性别的话,他其实有三百个人,他的性别的一个分类, 其中一代表的是男,二代表的是女。 我们可以看这个数据是非常多的, 我们这个时候就可以进行数据的一个分析,这是属于描述统计的,其中 可以做一个频率的一个分析。我以性别这样的一个变量,他的样本空间是三百个来进行一个分析,我们会出现一个图表,我们可以点一下 右侧的几种。呃,这样的一个设置图表,这个我们一般会选择条形图, 它有点像我们曾经在小学数学当中学过的评书。分布图格式的话一般是不会变的,跟统计一样,样式呢,一般也是不会变化的,我们可以点一下确认,看一下 这正在处理,我们可以发现现在我们得到了许多的表格以及图表。嗯,在这是关于性别的一个分布, 嗯,男的一百四十六,呃,四十六个,女的是一百五十四个,相对应的百分比在这也都有,下面呢就是 是一个性别的一个分布图,我们可以发现男女的比例在这其实相差不大,然后在这其实是我们的女方是更多一些的, 我们可以根据 s p s s 这个软件做一个非常简单的一个描述统计。到后面我们还会有很多种不同的一种假设检验,比如说体检验啊,还有在这是一个相关, 相关的话可以测两个电量,它有一个什么样的关系?是否有这个紧密的联系? 例如说我可以说,呃,男生,嗯,数学成绩与他的家庭教养方式是否有关系,我就可以用相关这样的一个模型来分析。回归的话他就是起到一种预测的作用,可以帮助我们预测。

粉丝243获赞1083
相关视频
 09:19查看AI文稿AI文稿
09:19查看AI文稿AI文稿大家好,今天给大家啊讲一下啊,比如说我们生活中如果会遇到各种各样的呃数据,呃,我们怎么样去处理去分析,比如说我们身高、体重、血压啊,生活平常生活开支数啊等数据 啊,我们怎么对他们特征进描述呢?他比如说他的平均数啊,他的中位数啊,他的种数,他的方差和标准差,这些,我们我们该怎么对他进行分析?现在我们就 啊就用这个,就用十八式这个份数据分析软件,对这个,对这些,对这个数据啊进行分析, 首先我们,哎,首先我们先啊找到这个十八式的分析软件, 我们把它打开。 好,我们现在 spa 是软件打开了啊,我们我们点输入数据, 哎,点确定,好,我们先我们先找到变量,试图,呃先要对他进编辑,比如说我们想要描述一个呃呃一组数据,比如说, 呃每一班的,呃呃每一班的,呃学生的身高啊啊或者或者体重啊或者什么的,那我们写,比如说我们举个例子,比如说描述,呃美,呃描述的身高一个特征, 好,我们先给他进行变量的,呃变量的命令, 那就是一个身高。好,我们进入变量的数据数据师图框, 所以说是不看,我们看的是是身高啊身高。我们这个啊,我们这里啊先输入一组数据,比如说这, 比如说这有十五个人啊,我们从数日十五个数据,假如说有十五个人, 哈哈哈, 好,我们假如说输入一组数据啊,这组数据,是啊十五个人,十五个人身高分为一米六五、一米六六,一米六五啊,这是啊一米七七等,这是数据啊,我们对怎么用?什么是软件对这个数据分析, 首先我们啊点入,呃选选择这个分析,找到这个分析这个,呃菜单啊,找到描述统计啊,这里有描述,我们点击描述, 然后将身高这个,呃这个选项啊,就是我们需要需要分析的这个这个选项,掉入这个变量里面,然后我们选择, 呃选择选项啊,这里有,这里有均值,有标准差,最大值,最小值,有方差 啊,有方叉,这里有,有这些数据我们我们要对他如果进飞行,我们就要点,我们点继续啊,选这些项目,然后点确定就可以了 啊,那么这些接下来这个结果难输出,就会,呃一个描述,呃描述统计量 啊,描述统计量,这里有个也是啊,这里这个是描述的什么是身高,身高我们力数是 a a, 你这个十五带着十五亿,几小时是一几小时,一一六五,一六五就是这一 这一组数据中最小的那个值一六五啊,极大值一九零,是这个数据最大的那个值一六零,然后这个是这一组均值,就是这组数据的平均值,就是这种身高的平均值。然后标准差,就是这组身高的标准差啊,这是方差, 这就是这种数据的一个整体的描述的一个情况啊。如果,呃,如果我们想啊,看一下他的一个呃呃一个正态性,这个数据的是否符合正态,然后呢?是否,呃 嗯是否是一个一个标准的一个分布,我们可以看一下啊,再找到描述统计,我们是可以找到频率,频率这里我们 将身高啊掉入这个变量里面啊,这里有啊,有统计量 啊,比如说我们四选择四分位数啊,啊,或者均均数啊,中位数啊,重数啊, 然后百分位数啊,百分数,你看你选择哪个?选择百分之二十五,我们就选择百分之二十五,就输入百分之二十五啊,不选也没关系,我们暂时不选好,然后我们这里有标准叉,方叉,最小值,最大值,好,我们把它选好, 然后点击继续,然后这里还有图表图表,有啊,有条形图啊,有柄图,有直方图啊,我们我们这组数据,我们选择什么啊?我们把选择选择直方图,直方图在下面一个,在直方图上显示正在曲线,我们把它选上, 点击继续。好,我们现在就 ok 了, ok 了,我们再点击确定 啊,确定之后接下来就会出现三个表格,第一个表格统计量,第二表格身高,第三个表格置换图。好,我们 讲解第一个表格,第一个表格统计量,统计量,均数均数就是这一组,这一组身高平均数平均值一米七三 啊,中数,中,中指,中指就中位数中间位中间的那个数,那个身高是一米七五,中数是什么?中数就是那个那种那种数据中出现次数最多的那个数,一米七五,我们可以回过头来看, 哎,一米七五,哎,一米七五,我们一个两个三个啊,我们一米七五,出现了三个,出现了三次 啊,这是中数,就是走出现数最多的这个,接下来就是标准差,方差,然后几小时就升身高最矮的那一个,几大值就升到最高的那个数,这是百分为数,百分之二十五,百分之五十,百分之七十 啊,像我们身高,身高,你看我们这身高,这里面有这十五个人身高都在这个列的列,这个列这个频率里面,比如说一米六五有两个,哎,啊,一米六六有一个,这写的一啊,一米七五,一米七五这里有三个。 一米七五,我们刚才知道他是种树啊,这里有种树,哎,一米七五他是有三个,他是数数量最多啊,次数最多。一米七五,这里。好,我们接下来看一下他的直放图,这里啊,会会出他的直放图 啊,脂肪图,这里啊,这像这个方块形的,这个条形的就是他的脂肪图。然后我们可以看到这一条曲线,这一条像这一条像,呃,这一条像塔一样的曲线,中型的曲线。我们叫他什么叫他正台曲线, 这个看是他是否符合正常性。我们可以看到他这个数据呢?还是七集中在一米六零到一米八之间,一米九几小数只有一个,这个数据呈现一个什么呈现一个偏太分, 他主要是在啊,如在一米,这个一米七五到一米七五到一米六零,这个这个这个数据段的数据最多。 好,现在给大家讲完了,谢谢大家。
64gzz 14:02查看AI文稿AI文稿
14:02查看AI文稿AI文稿sponse 属于傻瓜式操作,主要应用于问卷调查、医药、人文社科等统计分析领域。它的好处就是我们只需要在软件内点点点菜单就可以生成统计结果。 首先呢,我们看怎么来引入我们的数据,几点击文件,打开数据, 找到我们要的这个数据,打开, 嗯,我们可以看到,嗯,这个数据的左下角是有两个是图,一个是数据是图,一个是变量是图,他默认的是数据是图,数据是图,就有点像 excel 他展示的上面这个是列名, 然后嗯,这个是一行一行的数据,可以看到我们的数据有三十行,然后有呃这样的几列, 嗯,从这个数据试图当中,呃其实是读不懂它的数据含义的。我们点开这个电量试图,电量试图呢,就是有解释这个呃数据的表结构 定义电量类型,比如说他是数值型还是字符串形,嗯,这个是名称,然后这个是他的数据类型, 然后我们看一下,嗯,这个测量这一列他是有三个可以选的,一个叫标度,一个叫有序,一个叫名义。然后他是什么意思呢? 嗯,比如说我们看这个这个 a 指这一列,他就是有序。为什么是有序呢?因为就是有序的含义,就代表着这个变量指服从某种内在级别的类别。比如说从呃 就是十分不满意,到呃十分满意,有一个满意度程满意程度的这样一个呃衡量, 所以他就是,嗯代表着一种递进的这种顺序,那名义的话就代表这个变量值不具有内在等级的类别。比如说是呃公司部门或者是地区编码,它纯粹的是一个就是 呃一个值,比如说这个性别,一代表男性,二代表女性,他是这没有这个数字的这种递进关系的。那标度的话,就代表说这个 数字有具体的含义,比如说薪资的话,比如说七千块钱和两千块钱,他是有这样一个具体数值的含义的, 这个是测量的三个选项。然后我们看这个标签,嗯,在这个名称当中,这个列名是显示在数据仕途当中的,然后我们可以看到其实从这个嗯 他的列名就叫 q 一到 q 七,然后这个数据应该是来自于一个问卷调查的一个数据,然后嗯,这个从 q 一到 q 七,我们是呃不太知道这个列它的具体含义的,所以我们在这里个标签,我们可以去用比较长的文本说明它的含义,我们可以看到就是 q 一代表他的 sx 就是性别,然后呢?呃 q 二代表他的 a 值年龄, q 三代表他的教育程度,然后 q 四代表他喜欢的这个新闻频道,然后 q 五代表一个就是 问题态度类的,就是说呃是否认为就是这个新闻频道的这个服务,然后去传递了重要的新闻。然后 q 六代表 说这个新闻频道是不是嗯放,就是在体育上的报道比较少,然后 q 七 代表说这个新闻频道的主持人是不是真诚的,这个相当于是他的观点态度。然后呢在这个纸里,他如果这个是一个美举类型的,有具体说明,比如说 sx, 这里有说明,就是一代表 meal 就是男性,二代表女性。 那你如果联合这个标签和纸就可以去读懂前面这些,嗯,数据含义相当于是把我们的一个问卷调查去处理成了一个 spass, 哦,可以,就是比较标准化的一个数据。看这里全都是全都是数字嘛,然后 这里是,哎,教育程度的话,他也代表,一代表什么教育程度,二代表什么教育程度,三代表什么教育程度。然后, 嗯,至于那几个态度观点类的,他也是用这个啊。一代表就是, 哦,没有什么态度,二代表同意,三代表不同意,来这样进行一个区分的,那这样的话就可以把一个问卷调查的呃调查结果去很好的做成这种 spass 的数据。 嗯,第三部分呢是一运用这种 spass 来进行简单的分析,然后最常用的就是描述性统计分析,这里呢就是采用分析,然后点击描述统计。呃,点击描述, 然后可以看到这里他让你选择你要的分析的变量,然后,嗯,我们是 嗯把它都选中,然后进行一个分析,然后,呃,点击选项,这里有你就是 你可以勾选,然后他就会就是输出这个你勾选的这个结果,如果你不勾选就不会输出你的这个结果,然后我们按照默认值来做,嗯,点击确定, 可以看到他这里进行了这个描述统计分析,然后,嗯,这个界面呢,他是英文的,我们也调一下,嗯, 语言显示在在这个里面调 编辑选项,然后语言,哦输出,我们也把它调成简体中文应用,确定确定,然后可以看到,嗯,现在的输出还是英文的,然后我们重新操作一下否,嗯, 分析描述统计描述 确定啊,这里我们可以看到他的描述统计是中文的了,嗯, 可以看到这个 n 代表这个列的总数,然后最小值、最大值、均值和标准偏差。然后这样呢就是把我们各个列他的,嗯,就是描述统计的情况分析出来了, 嗯,这样可以帮助我们简单的认识到这个我们各类数据,他的最大值、最小值,平均值,还有一共有多少个?另外呢我们还可以做就是另第二场用的就是频率分析, 然后我们也都去选中,按住 shift, 然后去选中。 嗯,我们点这个图表,这里就是我们可以让他去把图表显示出来,有丙图,呃,直方图,哦,这个是按需选择的,我们选择直方图,然后点 继续确定,嗯,可以看到他这里去 描述了这个统计。首先呢,这个呃观测值,因为它是一个从一到三十的这样一个序号,这个是没有任何意义的。然后我们去从 sex 性别来看,嗯, 可以看到他的麦尔男性出有十二个,然后女性有十八个,一共是三十个。然后这里计算了他的百分比, 就是男性是百分之四十,女性是百分之六十。然后我们再看年龄,呃,在二十一岁以下的,他的百分比是二十三,然后在二十一岁到四十四岁, 呃,中间的是百分之五十,然后四十五岁到六十七岁,六六十四岁之间的是百分之二十六。再看 程度,也有去分别分别类列出来我们这几个教育程度,他的,嗯出现了多少次,然后每个教育程度他的百分比,然后这个是,嗯他喜欢的这个新闻频道, 就是对于每个新闻频道喜欢的分别有多少个人?然后他百分比是多少个?然后这个是态度的百分比。那这样呢?我们就是对,呃,我们数据,这这些数据出现的频率和百分比有一个更强的认识。 然后我们再看这个,哦,赛克斯,这个我们可以看到他这个是频率,然后这个是呃年龄的频率,教育程度的频率,然后嗯, 喜欢频,喜欢频道的,嗯,可以看到我们这里是直方图嘛?然后如果觉得这个直方图不合适,我们可以去选,比如说分析描述统计 频率,然后图表可以去选饼图,看是不是效果更好一些, 这个是没有意义的。然后这个是,嗯,性别、年龄,好像领途更直观一些哈。然后教育程度喜欢的新闻频道,然后他的态度、观点类,然后这个是 很好的让你去快速的认知你的数据特点啊。接下来一个,嗯,是交叉表分析,交叉表分析没有 刚刚说的描述性统计分析和频率分析那样常用,但是呃交叉表也像也是一个非常实用的技能。嗯,什么叫交叉表分析呢?比如说我们去点击这个分析,然后点描述统计,然后点 点交叉表,然后可以看到这里有一个行让我们去拖进来,有一个列让我们去拖进来。嗯,我们想要知道,就是说,嗯,比如说 这个样本当中,他喜欢的这个频道 喜欢哪个新闻频道,跟他的性别就是有没有关系,我们就可以 就是以这两个为研究变量去分析。然后呢我们这里有一些选项可以去选,我们先保持默认,然后点继续,可以看到他输出来的结果, 然后呢?这里是他的,就是 xx, 是他的呃男性和女性,然后这里是他喜欢的这个频道,嗯,是不是这个很像我们 excel 当中的这些,就是 数据透视表,然后嗯,他按照这个嗯喜欢的频频道进行一个统计,再按照性别进行一个 统计,然后交叉出来这样一个表,然后所以他不是一个单一委托的表,那这样的话他就叫交叉表,嗯,再隐身一下。交叉表经常用的有一个是,嗯。 去求呃卡方,还是我们刚刚选的这两个,然后我们去把呃 统计,把卡方给选上,然后我们也可以选一些呃其他的相关性,然后继续这个还是我们刚刚的交叉表,然后 这个是卡方检验,然后我们需要看到看的就是这个皮尔逊卡方的这个渐进显著性,然后它是零点七四三, 这个零点七四三这个叫显著性系数,也就是我们常说的这个 p 值。然后根据统计学的知识,只有当这个 p 值小于零点零五时,才能说明两个组别间 显著性的差异。然后我们这个零点七四三明显是大于零点零五的,所以就是说这个是没有显著性差异的,嗯。
1.4万探数 08:38
08:38 03:32查看AI文稿AI文稿
03:32查看AI文稿AI文稿hello, 大家好,我是 doctor 李,大家呢在接触统计分析的时候呢,经常有很多疑惑,比如说我无从下手分析出来的结果呢,不知道怎么样去解读, 不知道论文当中该如何选择合适的数据分析方法等等等等。接下来呢我们一起来学习 ss 统计分析,一起来解决这些疑惑。首先呢我们学习的是数据的导入, 咱们大多数人呢,大部分都是通过 windows 星来进行数据的收集,那接下来我们来看一下 windows 星收集到的数据如何导入到 spas 软件当中。首先打开 windows, 然后选中自己所所调查到的问卷,然后点击分析下载,点击查看下载答卷,再点击下载答卷数据中的按选项序号下载,由于这个速度比较慢,所以之前已经下载好了一个,大家可以看一下,这就是我们 所收集到的数据啊,这当中呢不需要的一些选项呢,可以提前删除,点击保存, 然后打开我们的 spas 软件,将数据呢导入到 spas 软件当中,点击文件打开数据,然后选择我们保存文件所在的位置桌面, 然后下面选取文件类型。 swats 呢,它兼容性比较强,很多文件类型呢都是可以进行分析的。然后我们保存的是 excel 文件,然后选中我们要分析的数据,点击打开, 然后点击确定,这样的话我们的数据就已经完成 导入到了 spas 软件当中。导入过来的数据呢,我们要进行一些标注,首先呢看变量式橱窗呢名称这一栏,我们需要对这一栏呢进行一个编码, 此次数据的收集呢,主要验证工作排斥,工作创新以及组织自尊以及网络闲逛之间的一个影响关系探究。所以说呢,这些问项呢,都是针对于这四个变量进行提问的。本研究呢,前六个主要针针对的是工作排斥, 后面五个呢,主要是网络闲逛,其次呢是工作创新以及组织自尊这几个变量。所以说呢,我们需要对这些变量呢进行编码, p, h, e, 然后依次呢在我们这些问题上进行编码。 其次呢,需要对每一个变量呢进行复值,因为我们采用的是李克特五分量表,所以说呢,哎,每一分代表什么,我们需要在这里标注,变成一,代表的是 完全不符合,然后点击添加啊,二,标签不符合点击添加。三,一般点击添加四,符合 添加五,完全符合点减六,然后确定剩下的变量呢,也是依次 将它进行复制。现在呢,各个变量的编码以及复制均已完成,接下来呢,就可以进行我们的数据分析。好,今天的课程就讲到这里,下节课呢,我们来讲一下数据的转换。
1.3万小小羊爱分析 04:39查看AI文稿AI文稿
04:39查看AI文稿AI文稿我们这里讲描述性统计,首先我们把仕途窗口切换到变量,仕途来设置变量的属性,我们先设置名称 例行,我们这里选述职, 我们可以选择保留移位, 输入好以后,我们再把窗口切换到数据试图中。 价格我们先输入十组数据,因为前面我们已经输 设置保留意味,即使你输入整数,他也会保留一位小数。我们描述统计 有三个位置,可以把该列数据的一些统计特性全部求出。 首先第一个是描述统计中的频率,我们将价格导入到右侧的边梁框中,我们这里就可以,我们可以点出我们想要求的 一些统计量,这样我们点击确定,我们就可以求出, 包括平均指,中位数等等,这是第一种算法。 第二种我们可以在描述中我们也可以来求出这些这些变量我们只要将我们想求出的值进行打勾 就可以,我们再点击再点确定 他,这种是属于横排的一个排列方式,这是第二种球法。 第三种求法就是我们软件中自带的探索功能,我们这里面也不需要你进 进行打钩,我们软件会自动把它能够求出的所有所有统计量全部求出, 我们只需要将价格放到这个音变量列表中,我们点击确定即可, 这个报告中就已经把所有的描述量已经求出, 还有画出精液图。 接下来我们要输入自辅串型数据,我们还是把仕途窗口切换到 变量试图中, 我们要选择倒数第二个字符串, 我们这里可以哎,不用管他,我们输入好他的名称和类型以后 进入到数据视图中,我们来进行输入, 输入好以后我们再点击分析,我们可以统计出他的, 放到右侧的框中我们来选择,因为我们是输入的这些汉字字符, 所以说我们这些就无法求出 来。进行他的 图表的计算, 我们这里是要统计他的频率,点击确定这里我们就可以看出美中数出现的频率和频率, 这个是它的图形,我们这些图形都可以进行复制粘贴贴到我们。
194深海 04:52查看AI文稿AI文稿
04:52查看AI文稿AI文稿哈喽,大家好,我是 doctor 里,今天呢,我们来学习 spac 当中的频率分析。什么是频率分析呢?它主要利用图表来反映数据的分布特征。我们可以通过频率分析对要分析的数据做出一个初步的了解和判断, 发现隐含在数据背后的信息,为我们后续数据分析呢提供方向和依据。怎么样来理解这句话呢?举一个简单的例子,比如说 a 学者在调研性别,男女和收入之间是否存在差异,结果显示呢,男的收入比女的收入要高,而 b 学者 调研出女的收入比男的收入要高,这种不同的一个结果。通过平均分析呢,发现 a 学者主要是以南方地区为中心,而 b 学者主要以北方地区为中心,所以说会出现这种不同的一个结果。在我们论文的写作过程当中呢,是很有必要标明平均分析的。上 上节课我们学习了数据的类型,分为是大种,定类、定序、定句和定笔。定类和定序呢,数字是没有具体的含义的,而定句和定笔是有具体含义的。我们把数字没有具体含义的呢,分为 分类变量。而有具体含义的呢,分为连续变量。分类变量和连续变量的。频率分析呢,是不同的分类变量,主要考虑的是频率和百分比。 比如说我调研这个数据啊,男生五十人,女生五十人,他们的百分比呢,分别为百分之五十。而连续变量呢,主要考虑的是集中趋势和离散趋势。集中趋势就是反映数据向其中心值聚集的一个程度, 离散趋势呢,反映的是数据远离中心值的一个程度,判断集中趋势呢,主要有平均值和中位数,而离散趋势呢,主要是标准。 那我们什么时候来用平均数或者是中位数来表示集中趋势呢?只要这个我们就要看连续日量差服从什么样一个分布。如果是正态分布,那我们用中位数或者平均值均可以表示集中趋势,因为他们是相同的。 如果是这个是偏态分布呢,我们最好用中位数来表示这个集中趋势。我们来看个例子,好,五个人的收入分别为一千元,两千元,三千,四千,五万, 那他们的工资平均值呢?在一万二,而中位数呢是三千。如果用一万二来表示我们这个工资的一个分布状态,那大家肯定是不乐意的,因为大家的收入很低啊,只有这一个很高。 而如果用中位数三千来表示我们整体的一个工资水平呢?这个大家是可以接受的啊。我们继续来看如何在 spas 当中进行品质分析,打开 spas, 这是我们调研的七十八个人的一个工资收入水平。首先性别呢,它是定类,它是分类变量,而工资呢,数字是有具体行业的,所以它是连续变量。首先我们对分类变量进行平均分析,好,点击分析,描述统计频率, 好,我们点击性别,然后导入到变量当中,点击统计。其实呢,我们在进行这一个分类变量的平均分数呢,这些是可以不需要点的,直接点进去 图表呢,根据自己的研究需要呢,可以让他显示出条形图或者屏状图,对这个调研数据的一个分布呢,更加的直观,我们这里不做选择,持续,然后确定好,我们可以看到男女的频率出现次数分别是三十九人,三十九人各占百分之五十。 接下来我们来看连续变量的一个频率分析,首先点击分析描述统计频率,好,我们导回去,然后把公司导入到变量当中, 点击统计。我们刚才说了连续性变量呢,主要考虑的是集中趋势和离散趋势,集中趋势主要以平均数和中心数为准,而离散呢主要是标准差。 好,这个偏度与风度呢,主要的是这个,我们店这个数据他一个分布情况是如何,一个正态呢还是偏态呢?可以做一个基本判断,我们可以选上 点击继续,然后看图表,图表呢,一般我们要勾选直方图,在直方图当中显示正态曲线,就是我们通过这个图呢可以判断大体判断我们这一份数据它一个分布情况,点击,然后继续,其他的我们可以做选择,然后取消这个评语表即可。点击确定好,我们看 看一下他的一个平均值,中位数啊,都已经出来了,偏度以及风度,我们来看一下这个指方左这个整体一个分布,这个大体上面是服从正态分布的,但是仔细观察的话,他是哎左边的,左边的,左边的尾巴呢,是比右边要长的,所以是有点左偏的。在左偏这种偏态分布当中呢,我们主要看的是中位数, 可以反映我们整体的一个水平。好,这就是我们今天讲的分类变量的频率分析和连续变量的分析。频率分析 一般在学位论文或者期刊论文当中呢,主要体现的是分类辩证的一个频率分析即可。连续性辩证分析呢,很少采用,所以说根据自己的一个研究需要呢,来选择不同的频率分析即可。好,今天的课程就讲到这里。
69小小羊爱分析 01:04查看AI文稿AI文稿
01:04查看AI文稿AI文稿本节内容来介绍 spss 中的描述统计分析,通过 spss 对连续型变量进行描述统计,可以得到最小值、最大值、平均值、方差、标准差等信息。 具体操作如下,先用 spss 打开一个数据集,依次点击分析描述统计描述,随后弹出描述选项卡, 将描述选项卡中左侧的家庭收入变量选入到右侧的变量框中,然后点击最右侧的选项按钮,弹出选项选项卡,勾选平均值、标准差、方差范围、最小值、最大值、标准误差的平均值、风度偏度等,点击继续。 再次返回到描述选项卡,点击确定,这样 spss 就会输出本次描述统计分析的结果。 具体观察输出结果可知,在描述统计表格中,分别列出了家庭收入的个案数、范围、最小和最大值、平均值、标准差、方差、风度偏度等指标。
314追梦吧,少年 16:31
16:31 01:14查看AI文稿AI文稿
01:14查看AI文稿AI文稿在 spss 中可以对数据进行描述性分析,分析方法包括频率分析、描述统计和交叉表分析等。本节内容来介绍一下 spss 中的频率分析。 spss 可以对变量出现的频率进行分析,并给出相应的结果, 具体操作如下,先用 spss 打开一个数据集,依次点击分析描述统计频率,随后弹出频率选项卡。将频率选项卡中左侧教育水平变量选入到右侧的变量中,然后点击右侧统计按钮,弹出统计选项卡。选中四分位数,点击继续 返回到频率选项卡。点击右侧图表按钮,弹出图表选项卡。选中条形图,点击继续再次返回到频率选项卡,点击右侧格式按钮,弹出格式选项卡。 排序方式,按值的升序排序,点击继续返回到频率选项卡后点确定,这样 spss 就会输出本次频率分析的结果。 具体观察输出结果可知,在教育水平表格中分别列出了不同教育水平的频率百分比、有效百分比和累积百分比,同时在教育水平条形图中显示了不同教育水平的频率分布。
264追梦吧,少年 11:38查看AI文稿AI文稿
11:38查看AI文稿AI文稿哈喽,大家好,欢迎继续回来,我是吴松老师,刚才呢,我们已经说了什么?第二个叫描述,我们再来看一下探索,我们探索什么呢?我们再探索一个身高,对不对?我们打破 大哥问到底,我们逮着身高不放,我们点分析秒统计呢?我们再探索一个 spro 探索,点开探索的时候发现他还是一个套路,是不是?那只不过是多了几个锅而已,那么探索什么呢?我们探索身高 啊,探身高,那么在下面怎么办呢?这样子吧,送个增加一个难度,我们探索不同性别的身高到底是什么情况?我们将 性别放入硬字列表,那么后面就会按照男和女的身高分别来进行探索。探索什么呢啊?二级功能窗口永远只干两件事情,一是选变量,我们变量已经选好了,第二个就是设置 参数,摄餐数就是添油加醋, ok, 我们点开统计,点开统计啊,我们先来看一下,在这统计里面,他是 写的是平均值的百分之九十五的咨询区间,我们上课的时候大家还记得吗?我们学过一张总体均数的百分之九十五肯定区间,估计 当时我们花了一定的时间推倒了他的什么百分之九十五可云之间。 gucci 的一个什么公司啊,推的比较烦人,但是 spss 他已经默认了他的 百分之九十五,退到就已经默认的选项就勾选在这地方,如果你此时要想算那百分之九十九的可以去见的话,你只要改就行了,通常默认的有百分之九十五,所以点继续确定,下面就可以进行作图,进行作图,我们点 plot 作图,那么第一个就是相识图 boxplot 默认, 我们把它吗放进去啊,叫做相视图,然后右边还可以描述描述我们数据的,可以做 stem and neaf graph, 就是敬业图和黑色素管理之方图。我们还可以对我们数据是 组织符合正态分布进行同区检验啊,叫含检验的正态图。 ok, 把他们勾选好了之后呢点继续又回到我们爱情功能窗口选项呢,是不需要进行做的,他告诉我们我们如何 感谢我们的数据啊,这是默认的,不用关心他好,自助抽样就不是出来。我们前面也简单的聊了聊了一下,这个呢,嗯,不说啊,不说,不要进行一个了解, 那么等大家读研究生的时候再进行学习吧。 ok, 叫自助抽象法。好,我们设置好了之后, ig 功能窗口选参数,设备量, ok, 点确定, 结果刷刷刷就已经出来了。好,出来好了之后呢,第一个呢叫做更按处理摘药,这个呢,我们简单看一下,他告诉我们什么呢?他告诉我们的数据到底有没有确实值,我们发现确实有没有啊,有,对,男生有三百零三个是有效的,二百八十七是 有效的女生,那么男生有七个缺失,女生呢?有两个缺失的。 ok, 那么缺失的数据是不参加后续分析的。好,我们再来看下面, 下面又分别对了男生和女生来进行一个同学的描述,那么这个描述我相信大家都能看懂。告诉我们男生的身高的均值是多少呢?是一米七 零点零九二,他的标准误差是零点三幺五,是不是他的百分之九十五可以区间?大家注意了,这就是什么?这就是总体三数的百分之九十五的可以区间,是不是他是一六九点四六零到一七零点七二五,而且呢, 真正的总体均速落在这个范围的可能性达到满百分之九十五,下面就是百分之五的修正均值。什么叫百分之五?修正均值是指 我们会把一些特大的、特小的来百分之五的数给他去除掉之后,剩下来的百分之九十五的数据来描述他的均值,我们发现他是一七零点幺五零 和零九二,相差是不大的, ok, 然后这就是他的中位数方差,标准偏差,就是标准差,最小值,最大值极差 四分位数间距偏度,分度啊,老生常谈,和前面都是一样的,下面是女生也是一样的,是不是? ok, 这就带大家看了一个, 你们自己举一反三, ok, 男女生都是一样的。下面就进行了正态音检验,就是 sps 啊,他会用两种方法去告诉我们到底符合不符正态分布。一种叫做,哎呀,这个呢是 翻译成中文的,中文呢,读起来很别扭,不好啊。我们前面这种呢叫做 d 检验啊,叫做 d 检验。后面这种呢叫做 w 检验啊, w 检验, d 检验。一般样板量比较大的时候呢,用 d 检验,样板量比较小的时候呢,用 w 检验,所以叫做大 d 小 w 啊,大 d 小 w, 那何为大,何为小呢?又存在一个困惑,那么何为大呢? 那么在萨斯统计软件认为样本量大于二千的时候才叫大, spss 认为样本量大于五千才叫大。但是我们生物医药领域里面, 我们医学同级学人为出版社这个十周华教授主编的认为,大于五十在生物一样就算大了啊,就算大了,那我们就以就选择一个参考标准吧,就以五十为结吧,我们这个样本来肯定大于五十的,那就那就算大,算大的话,我们看大就是大 递检验发现,男生男生的身高正在检验的批值是零点零零零,小于零点零五的小心意义。有差异和什么有差异啊?失职 男生身高值的分布与正态分布有差异,那么就是说他和正态分布比是有差别的,因此他不符合正态分布。那么女生呢?零点零零零,零点零零九也是小于零点零五的,因此呢,他也是不 符合正在分布的。那为什么不符合正在分布呢?我再往下看一下。哎,有的人说了,老师,这男生不是挺好的吗?男生数据不是挺好的吗?也挺对称的,为什么不符合正在分布呢?是不是然后发现,哎,女生好像也挺好的,为什么不符合正在分布呢? ok, 所以呢,在统计风险的时候,我们很多教材里面都说了,比如说提前要求独立,正在放茶期,虽然 有正态音要求,但是正态音要求不是非常的高,不是非常的高,近似正态也可以啊,近似正态也可以。如果这一题你真正要想知道他为什么不符正态分布,我们就就看偏度系数和风度系数,我们来进行验证,用偏度系数去处于他的标准物,看绝对值是不是大于一点九六。大于那就说明 偏啊,就是说明偏,如果是正的大于一点九六叫正偏态,负的叫负偏态, ok, 如果用风度系数去出一个他的标准物,那么如果大于一点九六,如果是正的话,那叫做奸笑风太尖了,如果是负的了,叫贫苦风, ok, 下面呢就叫做敬业图, stami 的立服 graph, 那么这个敬业图其实就是一个脂肪图,大家看,如果把它逆时针旋转九十度,用数字就用一个纸条,把他们的数字就用一个纸条,给他 拉起来的话,你看是不是就相当于一个脂肪土,是一样的道理,是不是?哎,数字枝条啊,不能拉那么高,是不是就像一个脂肪土的一个道理啊?但是这个怎么看呢?这是告诉我们, 比如说我们以这个为例,这个是四点零,后面是一五七七七,一五七七是指什么呢?有四个人,这地方有四个人,四个人的身高分别是一米五七、一米五七、一米五七、一米五七,四个一米五七,就那样。老师,为什么是四个一米五七呢?这明明是十五点七七七七七啊,那 如果你说四个,那也应该是四个十五点七啊。可是这地方告诉你们什么,这有个主观的看度,主 干的宽度是十,也就说数字要成一个十倍, ok, 而且他说了,每一个叶子代表一个个案,也就说这一个七就代表一个数字七。什么叫做 树敬业图了?大家看一下,十五、十五、十六,这个都叫做树干,在每一个树干上面就长了这么多树叶啊,这有多少个树叶呢?数一数,数一数,前面就是二十四个啊,就是这么一个道理,下面也是一样的,女生也是同样的道理来进行这样干, ok, 这就是正太的 qq 图,用图来进行一个反应,那么数据到底符合不符之乃分布,这怎么看呢?其实大家想想,这就是老北京糖葫芦串,那么中间这一根线呢,就是一个竹签,上面呢就挂着糖葫芦, 如果所有的糖葫芦都在这根线上串着,那就说明什么?说明他符合正在分布。我们看这个图发现总体还是不错的,可是在这个偏小的部分,偏小的部分有些值啊,他已经没有在这个线上了。这是什么数据?这是男生数据,也就说明什么?也就说明在男生里面有几个人啊,身高太矮了点。是这样概念, 下面是女生,我们发现女生总体不错的,可是发现在女生里面有几个人啊?他身高是吧,太高了点点。 ok, 去趋势的,去趋势的,就是我们发现这是这条线,是不是带一定趋势的,如果把他一个趋势给他去掉,是不是变成水平线?变成水平 线怎么看呢?变成水平线就看这些点是不是在这条线的上下对称分布,我们发现总体还行,在这这地方是不是左下角是不是有些直偏小了?哎,到底是一样的啊,女生也是一样的, ok, 最最重要的就是这个 boxplot 叫做相视图, 这个相视图是怎么看的呢?相视图每一个箱子的中间这条线,黑线是代表的中位数,中间这个黑线是代表什么?代表的是中位数啊,黑线是代表的中位数,然后上面这一个呢,是代表的是百分之七十五,下面这个是代表 是百分之二十五,哎,这不就是中位数和四分之一间距吗?然后呢有两条胡须,两条胡须,上面这个胡 须是指这组数据中的什么最大值?最大值 max 啊,最大值 m x 最大值。那么下面这个有东西讲,老师,下面这个胡须是不是最小值啊?下面胡须不是最小值,最小值是谁?是幺幺四啊?是幺幺四,那就告诉我们是什么,如果外面要有值的话, 如果外面要有值的话,那就那这个这个线的位置怎么画?没有值的话,那这个值就是最大值,如果要有值的话,那这个位置是什么呢?这个位置的就这个宽度是我们四分位数间距的多少呢?一点五倍啊,一点五倍,这个箱体 从这里到这里不就是一个 q 吗?四分位数间距吗?那从这里到这里就是乱,就是一点五 q, 哎,也就说在一 一点五倍 q 的时候呢,他画出了他的另外一个胡须,啊,是这样道理,通过这个呢我们可以看出来,男生的身高是比女生要高的,是不是看他的中位数是不是明显比女生要高, ok, 那么到底高不高,我们要经过同学检验是不是啊?但是通过这个图我们可以得到这样的一个主观印象,同时我们可以发现在男生中有三个人身高偏矮了,在女生中有一个人身高偏高了,五百零四号, ok, 如果要身高让他更极端更高,怎么办呢?会不会出现别的情况?我们点开这个身高,这不是,呃,一米七二吗?我们给他改成 两百五十,我们再次调用探索一下点确定,然后我们找到最后一张图,找到最后一张图,哎,我们来看一下他的结果,有没有发现第一号这个人已经不在五行中跳出红尘脉了,他用的 是一个五角星,五角星各位了, sbss, 如果用的是一个圈,表示这是一个可移纸,如果用的一个五角星,那就表示这是一个异常值,那么 以后我们再进行统计分析,如果要发现这么一场值怎么办呢?回到我们的数据来看一下这个人, 一个人啊,他是爱武林,然后去找到这场调查表,或者找到当时的原始测量记录,来看一下到底是不是爱武林,是不是我们录入错了等相关演员,是不是。如果发现录入错了更改,如果发现确实就是爱武林, 那得看你是干什么事情了。如果是调查类的,他确实是这样,那就是这样的,如果是实验人 类的,那有可能他就是实验误差,实验误差要把它进行删除掉的。 ok, 这一小讲时间又有点长了,那么稍后呢?我们再来学另外一个描述方法,稍后再来。
86松哥统计 15:34查看AI文稿AI文稿
15:34查看AI文稿AI文稿今天给大家带来的是问卷分析全流程小白板的讲解,帮助大家快速掌握问卷分析。 我们都知道问卷类分析作为一种最常用的省时省力,能对事物进行比较全面系统的调查方法,无论是在日常工作还是学术研究中都备受青睐,甚至会作为很多同学毕业论文的选题。 本视频以星巴克顾客满意度影响因素为案例,进行问卷全流程的分析讲解,小白也能听懂。 本文的数据是通过问卷网收集到的,我们可以看到一共有四百六十七份数据,点击在线 swat 分析,可以把数据导入到官网, 大家如果是有现成的数据,也可以通过官网上传 excel 一键导入。 在这里是我们顾客填写的问卷的内容,一般包括三个方面,第一种是一般情况调查,也就是人口统计学变量,像性别、年龄、学历这些基本信息。 第二部分是态度,行为认知,比如基本行为或者认知态度相关性。 第三类是满意度调查,本文从七个方面分别是产品质量、口味、包装、价格、服务以及环境方面去研究。满意度 一到五分分别对应着非常不满意、不满意、满意、相对满意以及非常满意。那么我们点击开始分析。 针对满意度影响因素类问卷分析的一个基本的思路一共是分为六大板块,分别是用户画像分析、信度分析、效度分析、指标聚合分析、 样本特征分析以及差异性分析。我将一个一个进行演示。首先是用户画像分析, 一般分为评述分析、描述性分析以及列联表分析,在这里我们使用评述分析, 在描述性分析里的评数分析,我们把用户的一些基本情况拖入到变量框当中,点击开始分析, 我们可以看到评述分析的结果, 从年龄段上来看,女性偏多,二十六到三十五岁的群体偏多。 本身在中商情报榜统计星巴克消费人群比例的时候,当时较高的人群也是二十五到三十四岁,所以和我们问卷调查的结果是一致的。学历上看,本科偏多,婚姻状况已婚偏多, 职业类型多为企业白领,收入范围八千到一万五的居多。 那么第二步我们要进行一个信度分析进行验证。信度指标多以相关系数表示,主要考察问卷的可信度,是数据分析的一个基础。 一般来说,问卷的信度分析只针对量表、性别、年龄等背景信息,是存在较大的差异情况,所以我们一般不纳入信度分析。 衡量信度分析的标准是看这个 alpha 系数越接近于一,表示信度越高。如果问卷的信度如果问卷的 alpha 系数在零点九以上,说明概量表的信度甚加,零点 七到零点八之间可以接受,如果在零点六以下,就要考虑重新编排文卷。我们来看 spas pro 当中 的一个操作,在问卷分析信度分析,我们把满意度的评价指标拖入到变量框当中,选择 alpha 系数,然后点击开始分析。 我们从这个输出结果中可以看到, after 值是零点九,零六是大于零点九的,说明我们该问卷的信度是很好的。 那么问卷通过了信度分析之后,第三步我们要进行一个效度分析,也就是问卷设计的合理步 合理。一般来说,我们基于研究目的会跟会设置多个题目收集意见,按统计学来说,这几个问题的线线性相关会很高,所以通过因子分析之后是会被归纳入一个因子成分的。那么本文 是效度检验,主要使检测问卷评价指标部分的数据以及满意度打分部分将采用因子分析进行验证。因子分析首先要通过 k m o 跟 better 球形检验, 对于 k m o 检验,零点九以上是非常适合做因子分析的,如果系数在零点五以下,就应该放弃。符合 k m o 值检验,说明 变样之间存在相关性,是符合因子分析的要求。那么第二部分要做 better 检验,主要是看 p 值,如果 p 值的显, p 值的显著性小于零点零五,那么拒绝原假设说明可以做因子分析。 具体的操作我们回到 spas pro 当中,点击问卷分析里的效度分析,我们把满意度指标透入到变量框当中,点击开始分析, 我们看到 k m o 的值是零点九一四,同时显著性是小于零点零五的,说明因子分析是有效果的。在问卷通 通过了效读分析之后,我们基于研究目的第四步要进行指标去核分析。我们在题目中会设置多个题目收集意见,多个题目其实线性相关表达的都是同一个看法, 所以通过指标过类归类分析,可以把这几个题目浓缩为一个整体,这时可以采用因子分析或者主成分分析进行因子归类浓缩,以便后续进行回归分析。 理论上如果特征值大于一,同时方差贡献率大于大于百分之九十,就可以提取公共因子变量。一般通过分析方差解释表格和碎实图来确定因子的个数,具体的操作我们来看一下。 在综合评价内,因此分析 我们采用最大方叉法进行,因此分析把满意度指标拖入到变量框当中,主成分个数选为四,因为这里我们已经验证过了点吃鸡开始分析, 我们看方叉解释表格, 四个特征值大于一,同时累积构限率为百分之八十六点六五五,说明问卷评价指标和维度设计比是比较合理的。 那么根据这个表格的显示,筛选之后由七个维度减少到了四个维度。接着在论文当中,我们就需要分析三个维度减少的原因。 在做完了因子分析之后,紧接着到第五步是样本特征分析, 如果研究中涉及样本的特征情况,比如基本行为或者认知态度相关性, 可使用多选分析进行汇总,进一步了解清楚样本特征情况。也可以使用多重响应频率交叉分析,这一步就是给这些数据加上样本背景,例如不同性别对该城市生活满意度的看法。那么首先我们要 进行分析顾客选择星巴克的主要原因,在这里我们使用多选分析, 在问卷分析当中点击多选分析,我们把第七道题的回答拖入到变量框当中, 点击开始分析。通过调查结果可知,顾客选择星巴克首先看中的是店内的舒适环境占比百分之七十一点三, 而产品是其次看中的占比为百分之六十一点六,我们可以结合数据进行进 一步的分析。 第二步是针对星巴克顾客满意度进行一个分析,那么这个分析它主要分为两个方面,第一个方面是具体七个方面的满意度, 我们可以对这七个方面的满意度进行一个评述分析,但是首先要把数据进行处理,在数据处理中点击数据标签,把十到十五题的定量数据转化为定类数据。 具体操作在数据处理的数据标签中 转化为 d 类,逐次进行操作 确认之后,点击数据分析,点击描述性分析里的评数分析,我们把满意度评价指标拖入到变量框当中,点击开始分析, 那么我们可以结合这个表进行进一步的分析以及结果解释。 那么第二个呢,就是总体满意度的分析,在这里我使用模糊综合评价法,因为上面我们已经得到了七个方面的满意度的群体分布, 那么我们根据这个分布的数据去确定模糊综合评价矩阵。 至于权重方面,当没有数据的时候可以采用层次分析法,当有数据的时候可以采取商权法。 点击综合评价类的模糊综合评价, 把标签类拖入到所影像,把评价指标拖入到变量当中,选择商权法以及主因素决定型进行一个分期 输出结果,一是指标权重计算,在这里我们可以看到七个类别的指标权重 输出结果。二是隶属度矩阵计算结果,一般情况下我们会看隶属度过一化的权重 数值,最大的一项即为最后的结果,但是这里我们发现有三项的数据是一样的,那么这个时候我们可以借助第三个结果综合得分进行评判。首先我们需要进行复值 预测,结果显示三点三七是介于一般和满意之间,那么我们得出结果,顾客对星巴克总体的满意程度是介于满意和一般之间的。 最后我们还需要尽尽可能的对比不同人群的 看法,这需要基于第一步的用户画像分析其是否存在差异,验证自己的结果是否具有普世性,可以使用卡方检验、方差分析等等。 那么首先呢,我们来看一下不同特征顾客满意度的分析,也就是不同性别、年龄、学历、婚姻状况、职业、月收入, 他们在顾客满意度上是否存在差异性。本文仅展示不同年龄段的顾客满意度分析,其他方面以此类推。 具体操作,点击非参数检验卡方检验,我们把年龄拖入到 x 当中,把评价指标 标拖入到 y, 点击开始分析。 这里我们主要看 p 值,如果 p 小于零点零五,说明是有差异性的, 那么结果表示不同年龄的客户在口味以及环境上面是有差异的。 同时我们可以结合卡方热力交叉图进行进一步的分析,这个图主要是通过颜色深浅去表示值的大小。 那么按照以上流程的话,整个论文的 数据分析部分就已经全部结束了,大家可以对分析的数据进行一个汇总。 最后给大家推荐一款毕业论文的数据分析神器,并且我今天的讲解都是使用 spac pro 导入一键式生成结果,同时它免费智能,对小白非常友好的数据分析网站, 不限次数,不限时间,不限算法。那么今天的讲解就到这里,感谢大家的聆听。
1235SPSSPRO数据分析 04:35查看AI文稿AI文稿
04:35查看AI文稿AI文稿哈喽,大家好,我是 doctor 里,今天呢我们开始学习方差分析,也就是 r 分析,它也是一种差异分析。我们要进行方差分析呢,要具备两个条件,首先是各个总体呢服从正态分布,一般情况下呢,我们调研到的数据,在随机自然的情况下,它是都是服从正态分布的。 当然了,检验正态分布者也有很多方法,我们这个呢,在以后的课程当中呢,会给大家讲解如何检验正态分布。第二个方叉情性检验, f 检验,也就是说方差要是一致的, 如果说当方叉不一致的时候,我们就没有办法分辨出究竟是控制因素,哎,对这个观测变量产生的影响呢?还是内在波动对这个观测变量产生的影响,所以说方叉一定要保持一致,这是方叉分析的两个基本条件。 方差分析呢,主要有两种,第一种呢是单因素方差分析,第二种是多因素方差分析。今天呢我们注重讲解单因 单元素房产分析的目的呢,就是为了检验某一个控制因素的改变呢,会不会对观测变量带来的显著影响,一定要记住啊,一个控制因素,下面呢可以是两个或以上的主体。好,我们来看个例子, 市场经济不景气呢,闸机店老板想要了解一下分布在不同商圈的三个闸机店的销售额情况,以便根据不同的情况呢制定不一样的营销策略。他这个呢就是一个控制因素商圈,但是这个商圈呢,下面有两或两个以上的主体,所以说我们要进行单因素化妆分析。如何进行单因素化妆分析呢?我们来打开 sports 同学软件, 好,这是我们收集到的商圈呢,它是这个控制因素,我们要了解商圈是否对销售额产生影响,然后商圈下面呢有三个主体哎,中路店啊,江南区以及宏大区这三个店的三个地方的炸鸡店呢, 销售额的统计好了,我们点击分析,在比较平均值当中选择单音算的话,分析好了,我们将商圈呢导入到因子当中,销售额呢导入到音变量列表当中,对比我们不用管。首先我们来看这个选项,首先呢一般进行基本的描述,然后检验方差其性, 好点击继续即可。然后呢我们点击事后比较,就是说如果这个商圈对销售额存在一定的影响呢,我们就要看到底是分布在哪些地方,杂技店对销售额有成影响,这叫事后的比较分析,一般呢我们来选择第一个 l、 s、 d 即可,然后点击继续好确定, 这就是我们这个单元素发展分析的一个分析结果。首先我们来看描述位于宏大的闸机店呢,它的平均销售额为六十八点一四,位于中路区的这个闸机店呢,销售额为五十九点六四, 位于江南区的闸机店呢,他的销售额是六十九点三啊,这是他的一个平均值,我们通过平均值呢也可以大概判断一下,哎,哪几个闸机店的销售额是比较高的呢?但是呢是不具有统计学意义的,对吧,所以我们来看下面。好,我们进行方叉分析呢,就要判断方叉是否齐性, 我们来看这个一般是基于品质的显著性,如果 p 值是大于零点零五的呢,我们就可以认为方叉是一直啊是满足进行方叉分析的一个条件。好看阿罗马分析的结果,他 p 值是也是小于零点零五的,也就是说商圈呢,对这个销售额是存在差异的。 但是我们调查这个商圈是三个商圈,是三个不同地方的杂技店,那到底是所有的杂技店的销售额不一样呢?还是其中两个不一样呢?我们就要进行事后检验,做成比较。这个结果来看,我们来看一下这个 宏大店和中路店,他的显著性是小于零点零五的,也就是说中路和宏大是存在显著差异的。对这个销售额,我们来看,宏大和江南区呢,他是大于零点零五的,所以说他是不显著的,也就是说宏大店和江南店的这个炸鸡店销售额呢,是没有差异的。好,我们看这个中路和宏大店, 是吧?刚才第一个已经判断了,他是有明显差异的,中路和江南呢,我们来看他是小于零点零五的,也是有显著差异的,也就是说中路和江南区呢,他是存在差异的,对这个销售额 好,这个也是一样的,也就说明了呢,这个平均值,恒大和中路呢,看他们的平均销售额是存在形成差异的,而中路和江南呢, 他也是存在系数差异的,而恒大和江南呢,他是几乎是没有差异的,这就是我们这个单元素方向分析的一个过程和结果。那么我们分析出来的这个结果呢,如何进行解读呢?我们一起来看一下。首先呢,我们需要将这个 描述的这个表格呢要放在自己的论文当中,还有这个阿罗马分析的表格,以及我们看到这个多重比较,如果说这个 p 值是大于零点零五的话,也就说商圈对这个销售额是没有影响的呢,也就没有必要进行下一个分析了。 好,我们进行简单一个文字叙述即可,然后道出中路和加蓝区,以及中路和宏大的销售额是存在显著差异的,这就是我们讲的单因素方向分析以及如何解读。好,今天的课程就讲到这里。
825小小羊爱分析 05:49查看AI文稿AI文稿
05:49查看AI文稿AI文稿各位小伙伴们大家好呀,我是努力在处理数据的阿光。嗯,今天是元旦节,祝大家元旦节快乐,新的一年大家健健康康,平平安安,心想事成。嗯,好的,废话不多说,接下来进行我们今天的一个主题内容。 呃,今天主要想分享给大家是如何用 spas 进行剧内分析,绘制它的一个水平普系图 啊,上一期视频他是啊,跟这期视频其实他处理的数据是是一样的,也是进行一个剧烈分析,但是啊,可能主要用的是不同的一个软件进行处理, 今天处理出来的一个图呢,可能不是特别好看,但是呢可能会更加让你清晰的了解剧类分析这个处理过程。好的,接 下来进行的操作,首先打开我们的一个 spa 数据,呃,软件,然后的话,我总共这里有四十三组的一个数据,然后这个是 obs, 对应的是二十五个阶段他不同的一个吸光度。首先我们点击分析, 点击这里的一个分类,点击系统句类,这的话各按标注的一个依据, 主要是代表是我们的一个二十五个阶段的一个不同的一个细弯度,然后我们把它放在 o b s 这里 啊,接下来的就是他的一个变量,就是我们所有的一个组别,然后把它放到这里面变量啊,首先我们看一下统计,这统计呢我们啊,因为你不知道 他剧内的一个个数是多少,一般的话我建议大家可能就可以选择他的一个啊,范围,这的话我一般都是选择二到五, 因为我的这个数据呢,它其实最多只能分到三类,但是为了更为了更加给大家 啊,就是演示我就弄一个范围,其实我可以直接选择单个减,然后设置成一个三就可以了。但是为了更好的一个说明,然后我们就用范围来解决这二到五,要点击继续。这图的话,我们把这个普系图勾选上, 就是他后面就会自动给我们生产一个普系图,然后点击确定,然后方向的话,其实你可以选择啊垂直和水平, 我们刚刚这个他是一个垂直的一个这个方向,那我们就不管他就选择垂直。这方法的话啊,我们主要用的是主肩连肩,然后他的一个区间是平分平方欧式距离,然后其他的就不用管他 啊,可能会有小伙伴问要不要标准的话,其实这个数据他不需要标准的话的,然后点击继续, 然后这里的话点击确定,他就会跳出一个这样的一个处理的一个最后的一个呃,报告表。 首先前面的话啊,他会介绍一下处理的个数是多少啊?这个我们一般都是不需要看的啊,主要看的是这个剧类的一个成员, 因为我们选的一个他的一个处理的一个分类是二到五嘛,我们可以看他第五个的一个句类,可能就是呃,让我们自己就是他就分出来,比如说这个一一跟这个一三他是同一类的,然后他就标一, 然后呃同一个数字的他就是同一类的,这是五个句类,一般的话其实我这个是分为三类就可以了。 嗯,然后这个的话就是让自己看看一下对应的一个呃分的类的一个个数, 具体的话其实你可以根据你的一个因子啊,或者其他的方式就可以把它分类啊,知道他几类,当然你也可以通过他一个组间的一个分类的格式来确定。待会我就给大家看一下怎么看的 这个剧类的数目,一般我们可能啊也不也是不太需要看的。接下来就是我们这张图,这张图就是他的一个水平谱系图啊,其实你在这里可以看得到,你把一条横线看他最大的这这个 因为我们分为,比如说他这个是如果你要分为两类的话,他是啊,这个一十二,跟上面的 所有的一个啊,上面的所有的一个主别都是不同类的,就看看这条线就可以了。 然后你画一条竖线下来,他对应的呃,就是有两个焦点吗?然后这个焦点对应的是这这边所有的数据,然后下面的焦点对应的是一十二。然后 如果我们再看一下,就是如果把它分为三类的话,你看一下在这里画一条线下来,你就可以看得到他就分为三类了,然后这个一二十是一类,一十二是一类,上面的所有是一类。 如果这个想把它分为四类的话,你就在这里画一条线下来,然后一十二是一类,一二十是一类,然后这边这里这部分的数据是一类,然后上面这部分数据是一类, 所以的话啊,基本上看他一个水平普系图的一个,就基本上是这样看把它分为几类的。好的,今天的内容就这么多了,谢谢大家,拜拜。
684想看雪的瓜 09:23查看AI文稿AI文稿
09:23查看AI文稿AI文稿哈喽,小伙伴们,毕业即将至,很多同学拿到数据时重复性的数据,那么要进行一些分叉的分析和显著性的一些分析啊,才能够完成整个的论文。那么这期视频呢,就给大家说一说如何用 spss 进行快速的数据上的分析和处理。 开这个软件呢,首先看下面有一个数据试图和一个变量试图,数据试图呢就像我这样,然后输入两列数据就可以,然后变量数图呢是对 你的呃数据试图的一个定义,或者说是一个属性,那么他的这个零零一,第一列的话是数你的字别量,第二列的话是数你的音变量,看一下第一列在这边,第二列在呃另一边,然后呃这个 类型这一部分你可以改一下他输的数据的一些格式,你可以把它输成呃一些文本啊,或者是数据什么的,你可以自行的改正,然后可以改一下这个小数点的位数, 嗯,这是咱们经常用的呃两个地方,然后甚至可以改一下就是这个表格的宽度。那 那么呃这个第一列式自变量我们应该怎么说?比如说我这个实验是分为五个时期,五个阶段,那么每个阶段做了三个重复性的实验,那么我就把它都标为一, 然后第二个阶段就都变为二啊,比如说你第一个阶段可能是加呃十毫升的用量,或者是说呃是一个呃植物的不同的采收时期, 都可以啊,去自行的定义,只要你呃能够把你的定义和你的实验的这个呃自便量对应上就可以。然后我为了方便呢,就用一二三四五表示, 呃,这第二列呢,就是你在呃每次实验后做出的数据,你可以直接从你平时的实验记录本或者是一个赛欧当中直接粘贴过来,然后 后就开始咱们的呃数据的处理的部分啊,直接可以点击上面的分析,然后这里面有一个比较平均值 以及这个单因素方式分析。呃,注意这个呃音变量的这个列表,一定要输入这个音变量,不要和那个自变量搞反了,然后咱们音变量时第二列,自变量时第一列,然后再选择这个时候比较,然后就像我这样选选择一个 s lsd, 途径 sb, 还有一个沃尔顿坦,嗯,然后咱们的显著性水平设为零点零五,因为零点零一就是极显著了吗?然后选择继续嗯,选项,这边再点击一下,然后把描述和方查其性检验勾选上,然后点击确定,就可以 进入这个数据分析的结果的界面了。嗯,这个单项的话,我一般都是把这个嗯实验的名称就打在这里面,作为一个文件夹的名称吗?然后这一列的描描述,呃, 描述这里的话是有计算这一些数据的平均值,方差这些,呃,你用 excel 做是一样的。呃,所以的话就如果大家 粘贴这个呃描述的话,可以直接右键,然后把它保存为不同的格式,如果说你只想粘贴某一个格的数据,你可以说点击他,然后让他变黑,然后勾选这一区域的数据。 那么这边讲完了之后是比较重点的是这个多重比较啊,多重比较就是在分析你的显著性,这边就是刚才用的啊,咱们勾选的 lsd 吗?然后大家都知道这个星号是表示你这个是 实验是否具有显著性?呃,有一个信号的话,就表示你这个实验是有显著性的。呃,这边实验你看有一个显著性的一个说明,前面这个没有的话, 其实他是零,是显著性,是零点零零,然后后面没有没有算吗?就是其实他已经是极显著的了,咱们已经定义零点零五是显著的。呃,他前面只打了一颗星。如果是说你最后做的数据的表格里面,其实他是可以打两颗星的吗?因为是极限柱。 嗯,然后这边比较难看懂的是,呃,这第一列已经和第一组输血,已经和第二组、第三组、第四组、第五组比较完了,他都是有 信号的话都是显著的,但是这个第二组数据又跟一三四五进行了比较。那么为什么要进行比较呢?呃,这一块的话,一跟二、三四五比较,只能说一跟二、三四五是有显著性的,但你不能说明。呃,二跟三也是有显著性的,是吧?你 跟二比完了是有显著性的,二跟一比完也是有显著性的。一般这个东西都是对称的吗?但是你不能说明啊,二跟三是有 显著性差异的,所以说,呃,就是这一轮比完了之后还要再比一轮。嗯,这边数据的话基本上都是有显著性差异的,说明你的实验数据是比较好的。但是也有这个第四组和第五组数据进行比, 他是显著性这一栏,这一边是。呃大于零点零五的嘛,所以他就没有标星说明第四组数据和第五组数据他们之间是没有显著性差异的。嗯,这个实验的数据只只有你有显著性的。嗯,差异,你才 才能说你这个四面量有影响到一面量吗?不然的话你没有差异其实是没有太大的意义的,也不能说没有意义,也只 比如说你这个自备量没有影响到他,然后,嗯,最后拉,拉到这个。呃,乌罗洞坎这边,这 这边的话就是,呃,你要怎么去标你的建筑性?第一种方法就是标星吗?啊,那个是比较简单,但是也有这种 标字母的。嗯,大家对标字母的这个可能一直不太熟悉。呃,先跟大家说这个文献该怎么看,比如说,呃,这个柱子上面标的是 ab, 这个柱子标的是 a, 这两个柱子有同一个字母 a, 那说明他们俩之间又不显著,但是呃,这个第一个和第三个柱子之间他们之间是没有相同的字母的,那我们开玩笑的时候就知道,呃, 这第一个和第三个是有显著性的差异的。然后除了有这种柱状图的,还有这种,呃,写表格的,写表格的话直接是把它标在呃数据平均值加分叉,然后加减分叉吗?后,然后这个数值的后面。嗯, 判的话也是像我刚才说的,就是看两组数据之间有没有相同的字母就可以了, 现在标的话一般都是用这个字母去标识了,很少会用新号去标识,所以说,呃,大家要把这块就是搞清楚,那咱们自己怎么去标这些呢?嗯, 这就用到了咱们刚才勾选这个涡轮增坎。嗯,这个表格呢,看一个右下 角的数据啊,他是从下到上按照平均值的从大到小去排列的,所以这个七十六点一三,大家看到的是平均值最大的一个数,然后其次是,呃,六十五、二十六, 那么从你的右到左就开始标 abcd 啊,那么大家注意一个规则,就是同意 横行的,有重复就标同一个字母,同一数列,有重复的就标同一字母啊, 我这边的实验数据是非常的简单啊,第四组数据和第五组数据他们在同一个数列,那他们俩就都标的就可以了。还有种情况是同一横行的,可能也会有 在一起的啊,像这种情况一定要先标数列, abcde, 标完了之后再去标你的。很好啊,比如说这个第七组和第八组数据,他们是 没有显著性差异的,因为他们在同一个横行吗?那你可以标西,也可以标地,但是一般情况下都是标西的,因为标那个平均值大的吗?然后这样的话就可以做出那个字母标记法的分析的表格了, 然后这个数据一定不要扔掉,如果是你投稿的话可能会,嗯,杂志社会要你的原始性的数据和一些分析,如果说交 有论文的话啊,这个文件你保存或者是不保存都是啊,无所谓的。嗯,那么今天的视频呢,就到这里了,嗯,喜欢我的小伙伴呢,请一箭三联,爱你们哦。
1.0万雪小板学姐 10:18查看AI文稿AI文稿
10:18查看AI文稿AI文稿大家好,我们继续本讲内容的学习。现在是第六部分,卡放礼盒优度检验。 首先介绍试用类型,卡方礼盒优度检验用于检测数据是否服从某个指定的分布。 h 零,假设为数据符合某种类型分布。 h 一,假设为数据不符合该类型分布, spss 将自动报告其批值。 下面我们举实例加以说明。某病区有五十名患者,研究者 与了解其病种雅型分布是否与已知的长模一致。该研究者已知长模中 a 型病例占百分之十五, b 型病例占百分之二十, c 型病例占百分之六十五。数据库请看截图所示否值情况为 变量是患病类型分为三类,一等于 a 型,二等于 b 型,三等于 c 型。 卡放礼盒优度检验需要满足三个前提条件,假设一存在一个分类变, 在本吏中此条件是满足的。假设二具有相互独立的观测值,不存在互相干扰。 此条件也是满足的。患病类型为 a、 b、 c 的三分类变量并不互相干扰。 假设三预测评数需要大于五。在这里,假设三是需要我们进行验证的,这个验证将同实际检验同时进行, 具体操作如下,卡方礼盒优度检验主要分为等比例检验和自定义比例这两种。 首先介绍等比例分布操作过程请看演示。打开数据库,在任务栏的分析,选择非参数检验, 进一步选择旧对话框,点击卡翻, 将需要检验的患病类型点击放入检验变量列表。 由于是等比例分布,因此期望值中勾选默认的所有类别相等选择完毕,点击确定。请看 这是 spss 给出的等比例分布检验的结果窗口。 首先看第一张表,第一张表的第二列给出了 a、 b、 c 三种疾病雅形的 实际贯彻隶属, a 为十例, b 为二十一例, c 为十九例。 第三列给出相应的预期例数。由于此时是等比例分布检验,意味着三种类型在五十名患者中是同等概率分布的,也就是 a、 a、 b、 c 三种类型分别为十六点七。第四列给出贯彻例数和预期例数的差值分别为负的六点七、四点三和二点三。 接下来将对观测例数和预期例数进行统计学检验,也就是这张表格。首先先要验证,假设三所有的观测 所有的预期例数均大于五,其实在上一张表中可以发现预期例数十六点七都是大于五的。在这张表的备注栏也 同样显示没有表格的预期评数小于五。因此假设三成立的 在卡方检验,这张表格中给出第一行的卡方值为四点一二零,第三行相应的批值是零点一二七。 因此得到结论是某病区五十名患者中疾病分布的类型为 a 型十人、 b 型二十一人、 c 型十九人。 采用卡方礼盒优度检验,判断这些研究对象的疾病类型是否符合等比例分布,最小 七万平数为十六点七,可采用卡方礼盒优度检验,卡方值为四点一二零,批值为零点一二七,大于零点零五, 因此提示研究对象的疾病类型数据符合等比例分布。 接下来介绍自定义比例分布。自定义比例分布的具体过程请看演示。假设 自定义比例为三种疾病类型,分别为百分之十五、百分之二十和百分之六, 请看操作演示。在任务栏分析,选择非常受检验,进一步选择旧对话框像的卡翻窗口, 将患病类型选入检验变量列表,在希望值处点击值,依次输入百分十,点击添加 百分之十五,再次点击添加百分之六十五,同样点击添加。添加完毕,点击确定运行程序, 这是 spss 给出的结果窗口。 同样,第一张表分别给出 a、 b、 c 三种疾病类型的观测例数,分别为十例、二十一例、十九例。 第三列给出相应的预期例数,分别为七点五十 以及三十二点五。第四列给出观测例数和预期例数的差子分别为二点五十一以及负的 十三点五。接下来将对观测例数和预期例数进行自定义比例的分布检验。 首先判断假设三,从备注栏中可知,没有格子的预期平数小于五。同样有上展表可见,最小预期平数是七点五, 也就是说所有的预期评数均大于五。 卡番检验显示卡番值为十八点五四亿, p 值为零点零零零。因此,本研究的结论是, 某病区五十名患者中疾病分布的类型为 a 型十人、 b 型二十一人、 c 型十九人。采用卡方礼盒优度检验判断这些研究对象的疾病类型数据是否符合百分之十五、百分之二十、百分之六十五的比例分布。 最小预期评数为七点五。可采用卡方礼盒优度检验, 卡方值等于十八点五四,一批值等于零点零零零,小于零点零五。因此提示研究对象的疾病类型数据并不符合百分之十五、 百分之二十、百分之六十的比例分布。本讲内容到此结束,这里是二幺幺统计,我是统计师方向,感谢大家的收看,我们下次再见!
 00:27查看AI文稿AI文稿
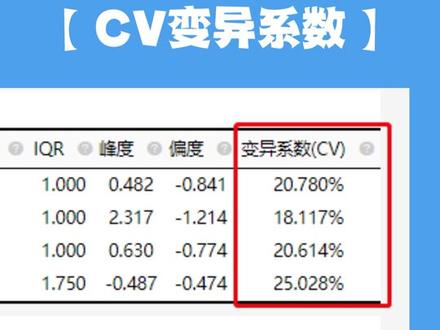
00:27查看AI文稿AI文稿描述分析分析结果怎么看得到描述分析?分析结果需要重点关注 c v 变异系数平均值和标准差。平均值和标准差分别体现数据的集中性特征和波动性特征。 c v 变异系数是原始数据标准差与原始数据平均数的比,通过这些指标可以判断是否有异常值存在。用斯奥作描述分析,各类图表一应俱全,基础指标表格、平均 精致对比图、深入指标表格、百分位数表格,还有智能分析分析建议帮助你理解描述分析,你学会了吗?如有其他疑问,请在评论区告诉我。
196SPSSAU
猜你喜欢
- 1603AI鹅鹅鹅