spss2乘2列联表结果怎么看
相关分析结果怎么看?看这个就会了。第一步,看显著性,查看变量之间是否有显著关系,批只小于零点零五,说明两两变量之间显著相关。第二步,看相关系数, 分析相关关系为正向或负向,也可通过相关系数大小说明相关关系紧密程度。相关系数大于零为正相关,反之为负相关。通常认为相关系数的绝对值大于零点六,表示强相关。 扫相关分析操作如下,拖拽样本至右侧分析框,点击开始分析,你学会了吗?

粉丝3.9万获赞19.6万
相关视频
 11:02查看AI文稿AI文稿
11:02查看AI文稿AI文稿大家好,我是好奇学长这一期呢,因为我电脑连不上网,所以呢就不开始这个头像视频了。呃,那么就用这个录屏软件录屏给大家讲一下, 嗯,单一数方加分析。那么前两节呢,给大家讲了如何把数据录入到 spax 软件当中,然后再 对数据进行描述性统计和这个正态检验。因为单数方差分析是的前提条件是数据要满足正态分布,如果不满足正态分布呢?我们需要用其他的一些分析手段。 那么我们来看分析这个单数方差分析是怎么做呢?我们首先点到分析这里,然后通过均值比比较均值这里这一栏,然后找到最下面就有一个单数二罗瓦分检验,那就是单数方差分析, 我们点进去了之后,这里有一个变量列表和这个因子,这个是什么意思呢?这个下面因子是代表我们的处理变量,但是处理变量因为在这个表当中给到的是一个字符串,这样一个表格一个数值, 那么在统计的时候,他没办法对这个呃制服串进行定量化,所以我们要把这个 处理组用相应的数值数值来代替,比如说对照是零,呃处理一是一,那么我们就用这样的数字来代替,然后我们把这个处理代号放到英子这里来, 然后把我们所测定的所有的观测指标都放到这个嗯,变量力表里面去,然后我们再来看,嗯,除了常规的他的末 认得这些统计结果之外,我们还要做哪些操作啊?嗯,第一个呢是,嗯,这个对比较,这个呢我们通常不是不常用啊。嗯,第二个事后多层比较呢,就是一个说这个比较不同处理之间的这种,嗯, 这种差异性,那么我们常用的呢是有 lsd 和这个邓肯多重比较,那我们科技组呢,通常会要求用邓肯多重比较,所以大家根据自 自己的研究和要求,可以用 i s d l n s n k 这个或者是邓肯,那么其实可以同时多选很多个啊。嗯,但我们因为常用,我们这边常用这个邓肯的话,就用邓肯比较就可以了,勾选一下就行。 那后面这些选项的话描述性统计,因为前节课呢给大家讲过描述性统计,那么这里呢也可以对他进行勾选,他也得到 这个相应的这个标志性统计结果。只有抽象这里我们就可以不管他,跟着选,选定默认值就可以了, 然后直接点确定,然后如果在英文是肯定的是继续,然后就得到了我们这个分析的结果。 好,因为我们选了描述性统计,他会对这些描述性统计得到这样的一个表,我们有一共有呃五个指标,然后每个指标的这个 这个处理的个数有五个,然后比如说这个对照组零代表的是对照组有五个,然后他的均值标准差,标准物上下线最大最小值这些都给出来了,那我们有需要的时候,我们就把它填写进去,填写到自己的文章当中。然后最重要的呢,我们是要来看这个单一数方差分析的结果。呃, 这个可以看到这个每一个指标,我们测定的每一个指标在不同的处理变量下,他得到的这个平方和自由度均方,这个方差值和显著性。那其实我们看这个, 我们做了这个实验,做了这个处理有没有效果呢?我们就来看一看这个最后方差分析的这个显著性是否是显著的。 呃,零点,第一个对指标一是零点零三七是小于零点零五的,这样一个值是显著达到显著的一个影响水平。那么第二个是零点五零 九,这个就是不显著。第三个零点三二四也是不显著的。那么第四个是零点零一,一也是屁值,这个显著性是屁值,呃,是小于零点零五的,那是显著的。 那么第五个呢,是等于零点零零零。那么我们在写文章的时候呢,我们就可以写成小于零点零零零一,然后这样的一个就是两两个零加个一的这样一个方式来表示他, 呃,那么这个是不但小于零点零五,还小于零点零一,那么他就是一个极其显著的这样的一个影响。就是说不同的处理对指标五呢是极其显著的影响。而对这个指标四和指标一呢,都只是一个显著影响。 而对这个指标二和指标三呢,是没有显著影响的,就是说对他的影响是不大的。嗯,下面呢是这个呃邓肯多重比较的这个结果, 这个结果怎么来看呢?呃,这个结果呢,是比如说对指标一,我们首先要看他叫呃 事后多重比较,他是说在这个比较有意义的前提是在前面的这个方差分析,他具有显著性才有意义。那么也就是说指标二和指标三对他进行邓肯多重比较,他得到的这个参数是没有任何意义的,而且得到的应该也是一个,嗯, 同一个级别的啊,你看可以看到他没有分级,然后这个,呃在指标一的话就分成了两级,那么这个级怎么来看呢?我们这个级呢是从后往前看, 然后二,那么就是说这个他是最大的,那么就是从后往前看啊,二这里只有两列呢,二就代表是最大的,如果有三列,有四列,最后一列是最大的,这里呢我们可以看一下他的均值啊,这个给他的均值,那么八点零、八六零,这个, 呃和这个,呃二点零这两个是一样的啊,一样的。那么这两个呢就是比较大的,然后这个他就分在了第一类啊,就是最大的一组当中, 然后对照这一组呢,是既在第二组又在第一组,那么他就是分在了一组,他就是处在一组和二组之间, 那么这个处理一这个这个处理下来他是在第一组,那就说明他是在这个,呃,是在这个低水平这个组。那么待会我再给大家去讲一下这个怎么去看? 好,那么这里就是单一式方叉分析的这个结果。呃,我再给大家看一下这个文章里面,哎,放到文章里面,呃,是要怎么去去应用呢?啊?这个就是已经发 表的土壤学土壤期刊里面,我们课里只需要是发的啊这个这样一篇文章,那么 我们刚才做了描述性同做了这个单式方差分析,得到的结果呢?就是这样一个表,嗯,然后我们把这个表复制到 word 里面进行编辑,把该要的就留下,不该要的就删掉啊,包括了这个,呃, 是这些这个具体的指标,那么这里我在呃讲案例的时候呢,我兄弟指标一,指标二,那么在研究的过程当中,具体是什么指标就写成什么指标,嗯, 然后再把这个自由度和军方这里,嗯,调换一下位置就行了。可以看到这个我们这里是先把这个呃变上来源给了之后,就后面接着就是自由度,然后这个军方,然后方,嗯,我们可以看到 这个是平方和是前面 ss 平方和 s 平方是军方,然后这个方差值和这个显著性 p, 然后在这个呃 这边呢,我们就用屁值,显著性的话就用屁值来表示,你看如果小于零点,呃,比如说这个这里的最后一个的话,我们这里就用这样的形式,屁小于零点零零一这样来表示。那么得到这个结果之后,我们就可以判断 在这个处理之下对哪些指标有显著的影响,然后有这些显著的影响之后,我们再进一步的对他进行画这样一个趋势图,看一下哪个处理更高,哪个处理更低,更显著的去 表现我们数据分析的结果,表现我们这个每一个处理下不同处理下每一个指标的展现形式。 呃,刚才给大家说的这个,呃,这个邓肯多重比较的这样一个结果,但是这个数据对应不起来哈,大家要只要学会去去应用就行了,就以指标五为例来对应这个图,嗯,但这个实际是不对应的哈,就大家去做的时候就区分一下就行了。 那么说这个二和三是在这个三这一组,而且是在最最大的一组里面,那么我们把倒着来标第三组和第二组都标上 a, 从从后往前标哈,这个,嗯, 最大的就是 a, 最小的一字 abc, 这样标下去 a 是最大。那么这里呢要要说一下的,是可以用大写的,也可以用小写的,但是他有规定哈,这个 a 是使平均,呃,这个呃用小写的,这个字母呢,是代表显著 信是在零点零五,如果用大写字母呢,是小屁,是零点零一这样的一个呃,一个概率值, 一个筛选范围,那么我们依次往前标,那么这个呃 d 一和处理一和对照,处理一就应该标为 b, 处理这个对照呢,就标为 c, 就是从高往低这样 abbcdbc 这样的一个趋势。那么这里呃 给了只有三只,分成三组,那么就只用三个字母去标 abc 这一列的,在这一列的标准 a, 在这一列的标准 b, 在这一列的标准 c, 那么像这一个,这一组 呃,他有两个,那就只能一把,这后面的对应的他是处理,处理这个就标准 a, 然后处理一的这个他既在二又在一,那么就标准 ab, 然后 这个三和二二都标识 b, 那么这里可以看一下哦,这里没有 ab 的情况啊。嗯, 这里因为因为在这个研究当中呢,没有涉及到这个跨行分组的这种情况,所以就像如果在同学们在数据分析的时候,遇到 这个跨行的,他既在第二组,又在第一组的情况下,那么就写成标准 ab 这样的形式。当然要看如果他在后面几行,该是 ab 还是 cd, 或者是呃 bc 的,这样的该怎么标就怎么去标就行了。 好,今天呢就先分享到这里,因为视频长度的限制,那么呃,后期呢?给大家讲如何做图。 好,我是豪杰学长,大家对我视频感兴趣的可以点赞、收藏、评论加转发,有什么问题也可以在评论区留言,我可以 针对大家的留言针对性的出一些相应的视频。好,谢谢大家。
586豪吉学长 09:23查看AI文稿AI文稿
09:23查看AI文稿AI文稿哈喽,小伙伴们,毕业即将至,很多同学拿到数据时重复性的数据,那么要进行一些分叉的分析和显著性的一些分析啊,才能够完成整个的论文。那么这期视频呢,就给大家说一说如何用 spss 进行快速的数据上的分析和处理。 开这个软件呢,首先看下面有一个数据试图和一个变量试图,数据试图呢就像我这样,然后输入两列数据就可以,然后变量数图呢是对 你的呃数据试图的一个定义,或者说是一个属性,那么他的这个零零一,第一列的话是数你的字别量,第二列的话是数你的音变量,看一下第一列在这边,第二列在呃另一边,然后呃这个 类型这一部分你可以改一下他输的数据的一些格式,你可以把它输成呃一些文本啊,或者是数据什么的,你可以自行的改正,然后可以改一下这个小数点的位数, 嗯,这是咱们经常用的呃两个地方,然后甚至可以改一下就是这个表格的宽度。那 那么呃这个第一列式自变量我们应该怎么说?比如说我这个实验是分为五个时期,五个阶段,那么每个阶段做了三个重复性的实验,那么我就把它都标为一, 然后第二个阶段就都变为二啊,比如说你第一个阶段可能是加呃十毫升的用量,或者是说呃是一个呃植物的不同的采收时期, 都可以啊,去自行的定义,只要你呃能够把你的定义和你的实验的这个呃自便量对应上就可以。然后我为了方便呢,就用一二三四五表示, 呃,这第二列呢,就是你在呃每次实验后做出的数据,你可以直接从你平时的实验记录本或者是一个赛欧当中直接粘贴过来,然后 后就开始咱们的呃数据的处理的部分啊,直接可以点击上面的分析,然后这里面有一个比较平均值 以及这个单因素方式分析。呃,注意这个呃音变量的这个列表,一定要输入这个音变量,不要和那个自变量搞反了,然后咱们音变量时第二列,自变量时第一列,然后再选择这个时候比较,然后就像我这样选选择一个 s lsd, 途径 sb, 还有一个沃尔顿坦,嗯,然后咱们的显著性水平设为零点零五,因为零点零一就是极显著了吗?然后选择继续嗯,选项,这边再点击一下,然后把描述和方查其性检验勾选上,然后点击确定,就可以 进入这个数据分析的结果的界面了。嗯,这个单项的话,我一般都是把这个嗯实验的名称就打在这里面,作为一个文件夹的名称吗?然后这一列的描描述,呃, 描述这里的话是有计算这一些数据的平均值,方差这些,呃,你用 excel 做是一样的。呃,所以的话就如果大家 粘贴这个呃描述的话,可以直接右键,然后把它保存为不同的格式,如果说你只想粘贴某一个格的数据,你可以说点击他,然后让他变黑,然后勾选这一区域的数据。 那么这边讲完了之后是比较重点的是这个多重比较啊,多重比较就是在分析你的显著性,这边就是刚才用的啊,咱们勾选的 lsd 吗?然后大家都知道这个星号是表示你这个是 实验是否具有显著性?呃,有一个信号的话,就表示你这个实验是有显著性的。呃,这边实验你看有一个显著性的一个说明,前面这个没有的话, 其实他是零,是显著性,是零点零零,然后后面没有没有算吗?就是其实他已经是极显著的了,咱们已经定义零点零五是显著的。呃,他前面只打了一颗星。如果是说你最后做的数据的表格里面,其实他是可以打两颗星的吗?因为是极限柱。 嗯,然后这边比较难看懂的是,呃,这第一列已经和第一组输血,已经和第二组、第三组、第四组、第五组比较完了,他都是有 信号的话都是显著的,但是这个第二组数据又跟一三四五进行了比较。那么为什么要进行比较呢?呃,这一块的话,一跟二、三四五比较,只能说一跟二、三四五是有显著性的,但你不能说明。呃,二跟三也是有显著性的,是吧?你 跟二比完了是有显著性的,二跟一比完也是有显著性的。一般这个东西都是对称的吗?但是你不能说明啊,二跟三是有 显著性差异的,所以说,呃,就是这一轮比完了之后还要再比一轮。嗯,这边数据的话基本上都是有显著性差异的,说明你的实验数据是比较好的。但是也有这个第四组和第五组数据进行比, 他是显著性这一栏,这一边是。呃大于零点零五的嘛,所以他就没有标星说明第四组数据和第五组数据他们之间是没有显著性差异的。嗯,这个实验的数据只只有你有显著性的。嗯,差异,你才 才能说你这个四面量有影响到一面量吗?不然的话你没有差异其实是没有太大的意义的,也不能说没有意义,也只 比如说你这个自备量没有影响到他,然后,嗯,最后拉,拉到这个。呃,乌罗洞坎这边,这 这边的话就是,呃,你要怎么去标你的建筑性?第一种方法就是标星吗?啊,那个是比较简单,但是也有这种 标字母的。嗯,大家对标字母的这个可能一直不太熟悉。呃,先跟大家说这个文献该怎么看,比如说,呃,这个柱子上面标的是 ab, 这个柱子标的是 a, 这两个柱子有同一个字母 a, 那说明他们俩之间又不显著,但是呃,这个第一个和第三个柱子之间他们之间是没有相同的字母的,那我们开玩笑的时候就知道,呃, 这第一个和第三个是有显著性的差异的。然后除了有这种柱状图的,还有这种,呃,写表格的,写表格的话直接是把它标在呃数据平均值加分叉,然后加减分叉吗?后,然后这个数值的后面。嗯, 判的话也是像我刚才说的,就是看两组数据之间有没有相同的字母就可以了, 现在标的话一般都是用这个字母去标识了,很少会用新号去标识,所以说,呃,大家要把这块就是搞清楚,那咱们自己怎么去标这些呢?嗯, 这就用到了咱们刚才勾选这个涡轮增坎。嗯,这个表格呢,看一个右下 角的数据啊,他是从下到上按照平均值的从大到小去排列的,所以这个七十六点一三,大家看到的是平均值最大的一个数,然后其次是,呃,六十五、二十六, 那么从你的右到左就开始标 abcd 啊,那么大家注意一个规则,就是同意 横行的,有重复就标同一个字母,同一数列,有重复的就标同一字母啊, 我这边的实验数据是非常的简单啊,第四组数据和第五组数据他们在同一个数列,那他们俩就都标的就可以了。还有种情况是同一横行的,可能也会有 在一起的啊,像这种情况一定要先标数列, abcde, 标完了之后再去标你的。很好啊,比如说这个第七组和第八组数据,他们是 没有显著性差异的,因为他们在同一个横行吗?那你可以标西,也可以标地,但是一般情况下都是标西的,因为标那个平均值大的吗?然后这样的话就可以做出那个字母标记法的分析的表格了, 然后这个数据一定不要扔掉,如果是你投稿的话可能会,嗯,杂志社会要你的原始性的数据和一些分析,如果说交 有论文的话啊,这个文件你保存或者是不保存都是啊,无所谓的。嗯,那么今天的视频呢,就到这里了,嗯,喜欢我的小伙伴呢,请一箭三联,爱你们哦。
1.0万雪小板学姐 00:33
00:33 03:52查看AI文稿AI文稿
03:52查看AI文稿AI文稿哈喽,大家好,我是武松老师,欢迎继续回来,我们一起学习 spss 同级软件。前面呢,我们已经学了同级学描述的三个功能, 我们再增加一个叫做交叉表,我们点分析秒统计,选择 cros 的过交叉表, ok, 交叉表非常重要,它不仅仅是同级别描述,也可以进行同级学的假设检验。点开交叉表啊,就会出现这样的一个爱机功能窗口。我们现在呢干一件事, 我们要问一个问题,我们想知道不同性别的血型构成到底有没有差别,不同性别的血型构成有没有差别,那么交叉表是干什么事情呢?交叉表主要是进行 分类变量资料,也就说我们当时上课说的技术资料的同学描述的,大家还记得技术资料同学描述指标是不是包括率,过程 相对比是不是啊?但统计分析主要是对绿和构成比来进行一个什么展示的。我们来先来看一下 不同性别的身高,我们把性别放到行变量,把啊不同性别的血型把血型放到一个裂变量,放好了之后呢?按揭功能窗口不就是选变量试参数吗?把变量选好了,开始试参数,我们点统计啊,这时候不能点统计,点统计的话就进行卡房经验了。我们后面会说,我们现在邀请 描述,只要点单元格就可以了,在单元格里面勾选行百分比,勾选行百分比点继续。如果要想做一个图的话,我们可以点一个复式条形图,就是粗壮条形图,点确定, 结果刷就出来了,这立马是不是把一个交叉表做出来了,这个交叉表告诉我们这是性别,男女之血型, abuib 分别里面有多少人?七十八五十二,七十一幺幺零六十 九三六六七幺幺七,然后他们每一个所占的比例,是不是?哎,我们发现他的比例是多少呢?哎, 他是二十五点,二十六点八,二十二点六和三十五点五,加起来正好是百分之百,下面是这么多,加起来是百分之百,哎,各个部分的过程笔之和 永远等于百分之百,是不是这样道理啊?哎,这就是交叉表。所以呢,用交叉表进行分类变量治疗的统计性描述呢,是非常简单的,只要选择行变量和裂变量放入就可以了。 同样呢,下面还可以做出了一个复式的条形图啊,复式条形图反映他们的一个嘛分布过程的啊,这就是交叉表。那么在进行交叉表的过程中, 大家点分析秒数交叉表,那么行变量和裂变量到底怎么进行放呢?建议大家一个规范,就是我们以前上课的时候说过程 实验设计包括三要素是原则,三要素是指什么?肝硬措施、受失对象和实验效应指标。如果你忘掉了,请大家在此时在听,在听课,在看客的过程中,请大家举起你的 右手啊,举起你的右手给自己一嘴巴,三要素就结束了,你的右手就是肝硬措施,你的脸就是收拾对象,打完之后你的脸上红肿肉痛,就是实验效应指标。 ok, 那我们在进行治表的过程中,我们的肝硬措施一般一定要放到行变量,放到行变量,实验效应指标要放 裂变量,这样才对,如果你要放错的话,在单元格里面就不要选行百分比就选裂百分比,如果你放的就是你也不知道自己怎么放的,实在不放心你就行列总计都选,当你总计都选好了之后,点确定 你发现这个表哇,你太复杂,你都不知道怎么开,是不是你都不知道怎么开,里面数据太多了啊?也就说如果你实在不知道的话,你全选选完以后在这地方慢慢去找,找到合适你的,然后再进行一个用啊,就是这么一个过程。 ok, 这一小节非常简单,那么 spss 它的一个 背景的一个铺垫呢?就铺垫到这地方,后面我们就正式来进行开始同居分析了,就开始讲 t 检验、放大分析和卡放检验了。 ok, 稍稍稍后后语我们再继续。
319松哥统计 03:32查看AI文稿AI文稿
03:32查看AI文稿AI文稿hello, 大家好,我是 doctor 李,大家呢在接触统计分析的时候呢,经常有很多疑惑,比如说我无从下手分析出来的结果呢,不知道怎么样去解读, 不知道论文当中该如何选择合适的数据分析方法等等等等。接下来呢我们一起来学习 ss 统计分析,一起来解决这些疑惑。首先呢我们学习的是数据的导入, 咱们大多数人呢,大部分都是通过 windows 星来进行数据的收集,那接下来我们来看一下 windows 星收集到的数据如何导入到 spas 软件当中。首先打开 windows, 然后选中自己所所调查到的问卷,然后点击分析下载,点击查看下载答卷,再点击下载答卷数据中的按选项序号下载,由于这个速度比较慢,所以之前已经下载好了一个,大家可以看一下,这就是我们 所收集到的数据啊,这当中呢不需要的一些选项呢,可以提前删除,点击保存, 然后打开我们的 spas 软件,将数据呢导入到 spas 软件当中,点击文件打开数据,然后选择我们保存文件所在的位置桌面, 然后下面选取文件类型。 swats 呢,它兼容性比较强,很多文件类型呢都是可以进行分析的。然后我们保存的是 excel 文件,然后选中我们要分析的数据,点击打开, 然后点击确定,这样的话我们的数据就已经完成 导入到了 spas 软件当中。导入过来的数据呢,我们要进行一些标注,首先呢看变量式橱窗呢名称这一栏,我们需要对这一栏呢进行一个编码, 此次数据的收集呢,主要验证工作排斥,工作创新以及组织自尊以及网络闲逛之间的一个影响关系探究。所以说呢,这些问项呢,都是针对于这四个变量进行提问的。本研究呢,前六个主要针针对的是工作排斥, 后面五个呢,主要是网络闲逛,其次呢是工作创新以及组织自尊这几个变量。所以说呢,我们需要对这些变量呢进行编码, p, h, e, 然后依次呢在我们这些问题上进行编码。 其次呢,需要对每一个变量呢进行复值,因为我们采用的是李克特五分量表,所以说呢,哎,每一分代表什么,我们需要在这里标注,变成一,代表的是 完全不符合,然后点击添加啊,二,标签不符合点击添加。三,一般点击添加四,符合 添加五,完全符合点减六,然后确定剩下的变量呢,也是依次 将它进行复制。现在呢,各个变量的编码以及复制均已完成,接下来呢,就可以进行我们的数据分析。好,今天的课程就讲到这里,下节课呢,我们来讲一下数据的转换。
1.3万小小羊爱分析 05:04查看AI文稿AI文稿
05:04查看AI文稿AI文稿哈喽,大家好,我是 doctor 里,今天我们一起来学习信度分析。什么是信度分析呢?它是用于判断在我们学位论文、期刊论文以及社会调研当中所使用的这些问项,对测验结果是否有误差,如果信度越高,误差就会越小,测验出来的结果呢就会越来越越稳定,越可靠。 那么如何评价它的信度高低呢?我们就是我们看到的这个克隆巴赫系数,克隆巴赫系数的取值呢,如果在零点八零到零点九零之间呢,它的这个信度效效果是非常好的, 如果在零点七零到零点八零之间呢,信度效度是相当好的,零点六五到零点七零呢,是最小的一个可接受值。如果在零点六零到零点六五之间呢?这个问这个选项呢是最好不要的,这个信度也是不好的,但是呢,根据他不同的这个参考文献呢,其实在这个克隆巴克的取值范围呢,也是有所 区别的,但是呢,最低不能低于零点六,如果低于零点六,就刚才说的一样需要删掉这个问项的,但是常见的标准呢,都是在零点七以上。好了,接下来我们来看一下如何在 spas 当中进行校度分析, 好打开发丝软件,这是上次用到的这个资料。结果品质过程品质信赖,顾客满足之间的一个关系。那么得到这个问证之后呢,我们就要判断他的这个信度如何怎么来弄呢?好,首先点分析, 把它标度可靠性分析好,我们先来检验一下结果品质的性度, 点击之后按照 shift 键不放手,然后点击下一个最后一个结果品质次他就会全选中,然后点击箭头转到向里,点击统计,一般来说呢,选择描述当中的向标度以及删除 向后的标度,然后点击继续,我们也可以在这个刻度标签里呢写上这个结构品质,这样的话呢区别于如果说大家在分析大量的这个变量的这个性度呢,如果写上标签的话呢,是很容易找到我们相对应的这个变量的性度, 结果结果品质好,点击确定好了,这个是标注结果品质,我们主要来看这一项,首先它这个克隆八和阿帕系数呢是零点八十八,是相当好的,这个信度 就是说我们用的这四个分项呢,是完全是可以采用的啊。再一个可以看下这个删除向后的科隆巴和 alpha 系数, 这个意思就是说如果说我们这个可靠性系数是非常低的,比方说是零点六,但是呢如果说结果品质一呢,删除之后 alpha 系数是零点八三四,是高于零点六 以上的,那就意思说我删掉结果品质一呢,他的这个克隆巴和系数呢就会变到零点八三四,就会相应的提高,所以这也是我们如果这个信度系数低呢,这是提高信度的一个方法。好了,我们来看一下过程品质,还有找到分析标度,可靠性分析, 可以点击重置,也可以把他们的四个选中之后呢转移到这边,如果点击重置的话,统计率当中就会没有选中,如果说不重置,直接点击第一个按下 shift 键选中转移到左边这样的话呢,统计当中他还是我们选中的那样的 好,点击过程品质 shift 键,然后点击最后一个全选,点击小箭头他就过来,然后刻度标签呢,改为过程品质,确定好了,这是过程品质的一个新 系数,零点八四六,也是相当好的,然后这个是删除向后的 columbus 二法系数。好了,同样道理,我们来看一下信赖点击分析标度可靠性分析,全选转到左边,然后我们来选择信赖同样的方法, 客服标签呢?改成,改成信赖,点击确定好了,这是信赖的一个,信赖的一个信度系数零点八,计算也是相当高的,也是非常好的一个信度好,柯南八和二十八系数删除后之后的一个值, 好了,再点击分析标度可靠性。我们最后来看一下我们这一次文学调查当中用到的顾客满足的三个问项, 确定好了,这是顾客满足的一个课程八和 alpha 系数零点八五七也是相当好的信度是删除向后的课程八和 alpha 系数。好,我们今天这个信度分析呢,做到这里就已经结束了,但是我们分析完之后,怎样呈现在我们的论文当中呢?如何去解读呢?我们来一起来看一下。 首先需要做一个表格性的分析,分别有变量名称,测量项目,删除项目的科鲁巴赫系数以及科鲁巴赫系数这个,最后这个零点八四八呢?零点八四六,零点八七三以及零点八五七呢,分别的是四个变量的整体的一个信度,整体一个信度, 就这样体现在自己的文章当中即可,然后解读,如何去解读呢?如果不知道怎么写的话呢?可以记下来,截屏都可以, 大体上的是解释一下,我们右边这个表格好好,如果大家呢针对于这个性度分析有任何问题的话呢,也可以评论,也可以私信我。好,下节课我们来讲什么是效度分析。
1290小小羊爱分析 00:31查看AI文稿AI文稿
00:31查看AI文稿AI文稿一招看懂卡方检验分析结果新手小白必看!卡方值和批值是卡方检验结果的重中之重,批值如果此值小于零点零五,说明呈现出差异性,如果大于零点零五,则说明没有差异性产生卡方值。卡方值越大,偏差越大。卡方值越小,偏差越小,越趋于符合 体差异所在。还要对比选择百分比括号内值。用 sto 做卡方检验,各类图表一应俱全。卡方检验分析结果可是画图形。卡方检验统计量过程值深入分析效应量指标,多种比较表格,还有智能分析分析建议帮助你理解卡方检验,你学会了吗?如有其他疑问,请在评论区告诉我。
624SPSSAU 07:01查看AI文稿AI文稿
07:01查看AI文稿AI文稿好,这个呢就是 spss 软件的一个界面, 来看一下这个上面是菜单,这是这个变量,我们要一个一个的录入,首先呢这个 spss 软件他的,嗯,他的这个是数据录入的界面, 但是呢,我们录入这个数据的时候呢,录入每一个变量的时候,变量的名字我们需要在其他的地方设置,我们点左下角的变量,试图对,点了左下角的变量,试图之后呢,我们首先是把变量要录入我们的这个,我们的这个三个变量是, 第一个是性别,性别,注意性别的这个,呃,由于这个性别我们已经把它编码成阿拉伯数字一, 一和二了,所以这个类型这可以是数字。然后呢,小数点可以保留两位,也可以不保留,因为性别都是整数,注意。呃,性别,性别变量,性别变量由于 他是名义的技术的,所以呢,我们进行了一个编码,所以呢,这个编码我们要告诉 sps 软件,我们的编码一代表什么,二代表什么?这个时候我们就是在这个直标签里面录入,一是代表男性,二是代表女性,对, 好,确定。然后呢,注意这个右边什么这个缺失啊,我们等会看看,我们没有录入缺失值,所以这样可以不用管啊,靠右对齐,这个也是可以的。然后呢,这个性别它是属于民意变量,也就是我们常说 说的技术资料。好,这就改成名义,好,性别录入了之后呢,我们第二个变量是年龄,由于年龄它是呃离散型计量资料,所以呢,嗯,这个值标签这儿是不需要进行额外设置的,因为它是一个计量资料,它不存在编码。 然后呢,这个年龄由于是整数,这个小数点可以可以改成两位,也可以是零位,这个没有关系。然后注意这要改一下,因为年龄是计量资料,即便他是离散型计量资料,我们这也要改成一个标度。 好,这个是年龄第三个,第三个就是,嗯,血糖, 血糖,血,血糖呢?啊,这个先关掉。血糖 糖呢,我们刚才已经说了,他是等级变量,他的复制一二三分别表示血糖的低、中高,所以我们这仍然要进行一个复制,一代表低,二代表中,三代表高。对, 刚才我们的这个注意啊,我们这的这个直标签呢,还有什么这个边量的名字呀等等,全部是要按照我们刚才那个 excel 里面的这个原始数据的这个编码来的。 好,注意,这个血糖他是有序的,因为低中高反应了一个等级递增的状况。好,血糖录入完了之后呢,剩下来的就是尿酸,尿酸他是,嗯,剂量资料,离散型剂量资料,我们这不用进行任何 额外的设置,只用把这改成标度就可以,计量资料我们全部使用标度的。然后最后一个是甘油三指,对,甘油三指也是剂量,也是剂量资料,所以呢我们这不需要有负值。然后呢,这个测量改成标度。 好,这个就可以了,注意一边做一边保存好。嗯,一边做一边保存好,保存好了之后呢,这个这个我们再回到,也就是说意味着我们这的这个变量实图已经设置完了。哦,对,还需要插入一个, 就是也可以插入,也可以不插入啊,我们在性别前面插入一个就是这个 id 号,注意这个 id 号,嗯,它是用它是一个,它是一个 名义变量,所以呢,我们一般都用 id 号,他有可能是呃患者的名字,或者是患者的住院号,或者是你自己对患者的编号,所以呢,给予这样,我们习惯的把 id 号选成自付串, 选成了自负串之后呢,嗯,他这默认的就会跟着自负串一起测量的话,这默认的跟着自负串改成名义, 嗯,小数点是没有的,因为他是这幅串,是不存在小数的,注意啊,嗯,有的时候我们这个患者的名字很长,特别是这个少数民族患者的这个名字可能会有八九个字,名字会很长,所以为了避免 名字可能会不被显示,所以呢,我们一定要把这个宽度调到最宽。我啊,陈老师本人的习惯就是习惯把它宽度调到三十,这样 的话呢,嗯,即便在场的少数民族的这个名字或者是住院号都是可以显示的,甚至这个身份证号都是可以显示的。好,一边做一边保存,一定要养成一个好习惯,数据要一边录一边保存 好。然后呢,这个关于变量试图的这么五个变量,我们就已经录入好了,变量录入好了之后,我们再回到数据试图,我们就可以开始录入数据。好,呃,我们根据我们的那个,呃, excel 文件里面, 根据我们的 excel 文件里面录入的 excel 文件。第一个患者,第一个患者是女性,编码二,年龄五十八,血糖是低尿酸两百六十三, 甘油三至两点四。好,这样一个数据我们怎么样?我们怎么样把它直接转入到 spss 软件里面呢? id 就是 number one。 我来看一下啊,没转过来。好,性别是女性,女性的话编码是二。好,注意,这可以把女性和阿拉伯数字在这里切换,实际上这个按钮就是切换编码和汉字的。 好,我们一般来讲的话都是把它切换到阿拉伯数字的界面录入,然后呢?录入好了之后我们再切换回来看看。好,这样是这样演示一下,年龄五十八,血糖十一,然后 这个尿酸两百六十三三幺三至两点四。好,录入好了之后呢,我们看看,我们在这点一 a 就可以切换,性别女血糖低,对, 切换,我们一般是切换成阿拉伯数字的界面来录入,录入好了之后我们再切换回来看看这个数据是一个什么情况。
735杏花开医学统计 05:32查看AI文稿AI文稿
05:32查看AI文稿AI文稿大家好,我是陈老师,欢迎大家收看杏花开医学统计课程,我们的课程在微信公众号中持续更新,帮助大家轻松掌握医学统计学方法和统计软件的操作。我们的微信公众号是 xhk 三四五,欢迎大家关注。 今天我们要讲到的是斯皮尔曼等级相关,等级相关呢,也就是我们常说的智相关,智相关,那个智是智序的智,智序嘛,也就是有序的等级的意思。 好,那么我们什么时候需要用斯皮尔曼相关呢?也就是说,当我的研究对象,我的研究变量是两个等级变量的时候,比如说像今天的这个案案例里面,像这个工作强度,他是表示强度从从弱到强的一种等级,地 灯的一种变量,像这个失眠症状程度,也是反映了这个失眠的严重程度,从轻到重的一种等级性。 所以呢,当我们要研究工作强度、工作强度这样一个等级变量和失眠症状程度这样一个等级变量之间的相关关系的时候,我们一般都会选择斯皮尔曼等级相关,也叫做斯皮尔曼质相关。 好,这个四 pm 制相关呢,很容易和他混淆的就是皮尔逊相关系数。这个呢,陈老师在上一期的微信杏花开医学统计的微信公众号里面,详细给大家讲到了 皮尔逊,它是线性相关,而我们今天讲到的斯皮尔曼呢,则是等级相关。线性相关主要适用于连续数值型的,并且服从正态分布的变量, 因为只有他是连续的数值型的,他才能够取到坐标轴上的任意一个点,这样的话呢,他才可以做一个现行的一种关联分析。 而我们现在要面临的这个,比如说像工作强度,从这个相对紧张,较为紧张等等这样的一种强度的递增和失眠症状的一个从轻到弱的逐步递增的话,他只把他只把数据分成了几个等级, 他无法取到任意一个点,他无法取到任意一个工作强度点,也无法取到任意一种失眠状态,他实际上就是一个粗略的等级划分, 所以对于这样一种数据的话,是绝对不能选择皮尔逊限行相关的,那么我们就必须改用斯皮尔曼等级相关,或者是叫做斯皮尔曼质相关。好,一般来讲,我们上一次, 上一次讲到的皮尔逊线性相关,我们用到的表示的这个相关系数就是一个简单的 r, 小写的 r, 而这个斯皮尔曼智相关,或者是也叫做斯皮尔曼等级相关的相关系数,我们习惯用 r 右下角加一个 s 角标来表示,这个相关系数是等级相关系数, 也就是说呃,线性相关系数,也就是皮尔逊相关系数,它是单纯的一个小小写的 r, 而字相关或者是等级相关,是在呃小写的 r 的右下角加了一个角标,这个角标就是 s, 就是一个 r 右下角加一个小 s, 这个呢,就是现行相关系数和等级相关系数的一个表示方法的区别。好,关于这个等级相关系数的计算计算公式呢,陈老师写在了本期的 杏花开医学统计的微信公众号里面啊,同学可以详细的了解一下这个公式,但是呢,如果你们是非专业,不是学统计学的这个学生的话呢,对于这个公式你们可以可以了解也可以不了解,因为这个公式已经被编进了 spss 的程序, 直接在 spss 里面点击那种现有的对话框进行操作的话呢,我们就会直接得到 rs 这个等级相关系数,所以呢,呃,非专业的同学如果时间比较紧张的话呢,可以不用特别特别弄明白这个。呃等级相关系数的计算公式 好,等级相关系数的这个计的这个这个计算公式他其实也好理解,最简单的就是就是研究智次之间的相关。智次是什么意思?就是排序的意思就是就是同样 一个人就是同样一个人他在工作强度的这种,呃,相对于整体而言他工作强度的排序和他的失眠症状的排序之间有没有关联性?他那个等级相关实际上就是对每一个人不同的进行的一个排序,就是我们常说的致辞 治,治序的治就是排序的意思,通过排序来考察两个变量之间有没有相关关系好。关于这个呢,嗯,这个也好理解啊,就是一种靠这种等级和排序的, 靠等级和排序来运算等级相关系数,而我们的线性相关系数呢,则是直接用原始数据的数值来运算线性相关系数 好,这个呢是他们的一个区别。一般来讲的话呢,对于这种等级相关系数他他的值是介于负一到一之间的, 负一到一之间可以等于负一也可以等于一,一般来讲等级相关系数的绝对值如果大于零点八的话,表示两个变量之间的等级性存在,存在着极强的等级相关。 然后呢?嗯,这个,呃,等级相关系数的绝对值如果在零点六到零点八之间的话呢,一般都是强相关,而这个绝对值在零点四到零点六之间的时候,表示中等相关。一般来讲的话呢,零点四以下的话呢,这个相关的程度就比较弱了。
98杏花开医学统计 05:29查看AI文稿AI文稿
05:29查看AI文稿AI文稿哈喽,大家好,今天分享一下如何用 s p s s 进行二元 logist 回归。二元 logist 回归它主要适用于因变量是二分类变量的数据, 比如说我们现在想看一下患病的影响因素有哪些,那这里的患病就包含了患病和未患病两类, 就是二分类变量,然后它的影响因素也就是自变量,可以是分类型变量,也可以是年龄这样的连续型变量, 这个时候就可以用二元 logist 回归,然后我们来操作一下,点击这个分析回归二元 logist。 然后我们把患病放到音变量框里,把这个性别,年龄, bmi 以及吸烟这四个自变量放到斜变量这个框里, 然后因为这个性别以及 bmi 和吸烟都是分类型的变量,这个时候我们就需要设置一下点这个分类, 然后把性呃性别还有 bmi, 吸烟这三个分类型的变量放到这里面,然后把它们全部选中, 点一下这个参考类别,设置为第一个,然后再点击一下变化量,这个意思也就是说我们 做出来回归的结果,呃进行分析的时候,他参照的就是呃第一个分组,然后点击继续, 然后再点击选项,这里勾选一个 houseman 检验以及 e x p 的百分之九十五执行区间,勾选这两个,然后点击继续,再点击确定, 这样就生成了二元 logist 回归的结果。这里面我们主要需要关注的就是 这个这个检验以及 hosman 检验,还有这个分类表,还有方程中的变量 这四个表吧。我们首先来看一下这个检验,这个表里面我们主要需要关注的是这个 模型这个对应的显著性,这里显著性是小于零点零五,也就是说模型通过了显著性的检验。 然后再来看霍斯曼检验里面他对应的显著性,这个也就是离合优度检验,如果这个显著性大于零点零五,也就是说明这个模型的离合离合优度更好一点。 然后再看这个分类表,这里面有一个正确率,也就是百分之七十五点三,说明这个回归模型的预测准确率为百分 值七十五点三。最后我们再来看一下方程中的变量这个表,这里面主要关注的是每一个影响因素他对应的显著性和 exp 的值。 如果显示性是小于零点零五,也就是说这个因素对患病是有显著影响的,如果他是大于零点零五,就说明这个因素对患病没有显著影响。 这里面性别和吸烟对应的显著性是小零点零五,那也就是说明性别和吸烟这两个因素对患病有显著影响。 然后年龄和 b m i 对应的显著性大于零点零五,说明他两个对患病没有显著影响。然后具体是什么影响,就可以看 这个 e x p 的值。比如说性别,它对应的 e x p 是二点二二七,我们之前不是设置了一下它的参照变量是第一组吗?也就是说性别这个 因素中,我们以女性为参照变量,男性为呃比较的变量。这里面性别对应的 exp 是二点二二七,也就是说与女性相比,男性患病的概率增加一点二二七倍, 这里的一点二七是用这个 e x p 的值减去一得来的,然后这个吸烟它也是参照第一个变量, 那吸烟他的参照组,也就是不吸烟,也就是说这里与不吸烟的人相比,吸烟的人他患病的概率会增加一点八五八倍, 这个一点八五八,也就是用这个 e x p 对应的二点八五八减去一得来的。 以上就是二元 ladiest 回归的操作步骤和结果的解读。
2455spss小师姐 00:21查看AI文稿AI文稿
00:21查看AI文稿AI文稿相关性分析结果怎么看?这是原始数据,这是 spss 的分析结果。 c 值低于零点零五或者零点零一就表示有显著性差异,相关系数绝对值越大,相关程度越高。 算了,太麻烦了,直接用这个。
245SPSSPRO数据分析 05:59查看AI文稿AI文稿
05:59查看AI文稿AI文稿因为因为如果这个数据如果非正态的话,我们就要选择斯皮尔曼相关性分析,但是呢,斯皮尔曼相关性分析的这个结果,斯皮尔曼相关性分析针对于连续变量运,连续非正态变量运算出来的结果 和这个皮尔逊相关性分析的结果其实是一样的,其实只要我们一看这个数据是连续数值型的,无论他是否正态,我们用皮尔逊相关性分析或者是斯皮尔曼相关性分析的结果其实都是差不多的。 所以呢,一般来讲的话呢,呃,同学如果看着,呃,这个我要研究的,我要研究两个连续变量之间的关联性,其实不是那种啊,不是那种很明显的吧,一般这种连续数值性的变量我们都可以用 p 尔区相关性分析。好,这个呢,就是陈老 是讲到的皮尔逊相关性分析的一个前提条件。好,接下来同学可以看一下微信公众号里面陈老师给出来的啊,皮尔逊相关性分析的相关系数 r 的计算公式。 关于这个计算公式呢啊,如果是非专业的,就是说我们仅仅只需要运用啊,我们仅仅只只需要这个,嗯,实践应用实操的话呢,可以不用理解这个公式啊,这个公式的话呢,一般都是像我们这样啊,研究原理的人啊,需要弄明白的。 呃,如果像你们的话,仅仅只需要应用,那么我们可以不用理解这个公式,软件呢,你只要会操作,软件直接会输出皮尔逊相关系数的这个 r 值。好,这个 r 值呢,陈老师需要介绍一下,一般来讲这个 r 值呢,他是在负一到一之间的 b 区间 啊,也就是说这个 r 可以等于负一,也可以等于一,也就是说,如果是两列完完全全一模一样的变量之间的相关关系,那么这个 r 必然就是等于一的。 如果当这个呃 r 等于零的话,实际上就意味着是没有相关关系的。一般来讲,如果 r, 这个呃斯皮尔曼 啊啊,不是一般来讲的话,如果这个皮尔逊相关系数 r 的绝对值,如果在零附近的话,基本上他都是他都是不显著的,就意味着不存在显著的相关关系。 好,嗯,一般来讲的话呢,嗯,这个 r 的他的这个绝对值在零点八到一之间的话呢,表示极强的相关。一般一般来讲的话,零点零点六到零点八之间可能就是强相关,零点四到零点六 就是中等相关。但是呢,关于这个墙相关中等相关的这种呃标准的话呢,呃,可能不一样的专业,他可能会有不一样的界定,但是注意啊,一定是 r 的绝对值, r 的绝对值在零点八以上的时候,才表示一个极强相关。 注意啊,这个微信公众号里面陈老师写到的这个 r 值是指的是他的绝对值在某一种情况下,代表着的是极强还是或者是弱相关。 好,这个是相关系数的一个大小的介绍。现在呢,陈老师就以这样一套案例,这样一个案例数据来演示一下,就是这个年龄、体重指数,收缩压和收张压这么四个指标,来演示一下皮尔逊相关性分析的这个呃,这个操作过程以及运算结果。 好,其实呢,最严谨的理论是应该把这么四个变量先做一个正态性检验,如果呢,他不服从正态分布的话呢,我们应该选择斯皮尔曼相关,就是这样的,点分析相关,这个双变量 双边量就是这个斯皮尔曼相关,如果他是非正态的话,就应该选择斯皮尔曼相关。但是呢,陈老师这个案例数据里面呢?嗯,陈老师已经检验过了,这个数据的偏太不是不是很严重啊,也是可以用皮尔训相关的。 好,现在我们的目的,现在我们的目的是想针对啊,我们看一下啊,本次调研一共搜集了一共搜集了一百三十八名这个患者的年龄, bmi 还有血压的数据,现在我的目的是想研究患者的年龄 b, dmi 还有血压的数据之间有没有关联性,并且这些数据都是连续数值性的变量,且基本上服从正态分布。所以这个时候呢,基于我的目的是为了研究相关,基于我的数据基本上是正态的,所以我就可以选择皮尔逊相关性分析。 好,那么这个操作的过程是这样的啊,点分析分析下面的这个相关相关,然后右边的这个双变量 双变量。好,我们把需要呃研究相关关系的变量全部选到右边的对话框就可以了。 然后呢,这个相关系数是皮尔逊检验的话,就是双尾,我们这个都都选择这个默认的就可以了,然后这其他的可以不用进行额外的勾选,直接点确定就可以了。好,我们来 看一下这个运算结果。 how, 好,这个呢,就是这么几个变量之间的一个相关性分析的一个运算结果。啊,那么这个相关性分析的结果我们应该怎么解读呢?比如说我们以这个 bmi, 嗯,我们以这个年龄和 bmi 也,这个年龄和体重指数之间的关系啊, 这一个部分,这么三个数值就是年龄和体重指数进行了皮尔逊相关性分析的结果。 首先我们来分析第一个就是个案数一百三十八,这个就是展示了我搜集了多少个样本。刚才陈老师已经在呃呃,刚刚的视频里面陈老师说过了, 我们一共搜集了一百三十八名患者的年龄和体重指数的数据,所以呢,这的这个个案数就是一百三十八。好,这个好理解。
149杏花开医学统计 01:44查看AI文稿AI文稿
01:44查看AI文稿AI文稿sbss 操作步骤讲解系列第十九课探索性因子分析 探索性因子分析用于检验量表的结构效度情况,先采用 k 梦和巴特利特球形度检验检验数据是否适合使用探索性因子分析后采用主成分分析提取供音子最大方差法对提取的供音子进行旋转。 第一步,将数据导入 spss 中并复制后点击分析降为因子。 第二步,进入图中对话框后,先将量表提像放入变量框中,点击描述勾选 k 梦和巴特利特球形度检验,点击继续旋转,勾选最大方程 夸法,点击继续选项勾选排除小细数绝对值如下,框中输入零点五,点击继续确定。 然后探索性因子分析的 k 梦和巴特利特球形检验供因子方差,总解释方差成分矩阵,旋转后的成分矩阵结果就出来了。 结果出来后,将旋转后成分举证结果粘贴复制到表格中后,将供应子方差下的提取数据放入表格右侧,再将 k 梦和巴特利特检验结果,即总解释方差中的初始特征值和累积方差百分比放在表格的下方。 观看完记得点赞关注哟,可以带座指导学习交流!
769艾吖法数据 00:35查看AI文稿AI文稿
00:35查看AI文稿AI文稿手把手教你看相关分析结果,比如下图标红的零点六六零六两个星号代表工资与教育程度,在零点零一水平上呈显著相关关系。零点六六零六代表二者之间的 pierce 相关系数为零点六六零六,大于零。综上说明二者之间呈现 显著的正向相关关系,相关系数的取值范围在负一亿之间。一般判断标准如下, 你学会了吗?
292SPSSAU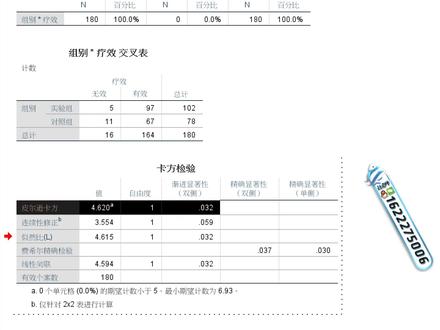 17:17查看AI文稿AI文稿
17:17查看AI文稿AI文稿大家好,我是陈老师,欢迎大家收看杏花开医学统计, 我们将每周在微信公众号中更新最实用的医学统计文章及视频案例教程,帮助大家轻松掌握医学统计学方法和统计软件的操作。我们的微信公众号是 xhk 三四五,欢迎大家关注。 今天我们要讲到的是四格表卡方检验以及四格表卡方检验在医学数据中的应用。首先陈老师要介绍一下什么是卡方检验,卡方检验简单来说就是考察样本值与理论值的偏离程度,在医学应用中我们才我们 常用于我们常用卡房检验来比较不同组别在构成比率上的差异。比如说我们想研究试验组和对照组两个组别的有效率有没有差异,或者是男生组和女生组在治愈率上有没有差异。 卡方检验常用于不同组别在某一种比例上的差异比较好。卡方检验呢,分为四个标,卡方检验和行列卡方检验。 四个表卡房检验一般是指二乘二,也就是两个组别或者是两种情况,也就是二乘二的这么一种交叉表。 而那种 r 乘 c 也叫做行列卡方,一般是指呃组别多于两个组别,组别大于两组或者是呃这个分 类某一种变量的分类大于等于两大于大于或者是等于三类的时候,我们一般会选择行列卡方,有的时候也叫做 r 乘 c 卡方。在今天的这样一个视频里面,陈老师详细的要讲到的是四格表卡方检验。 四个表卡房检验的基本形式已经陈老师刚才已经讲到了是二乘二,第一个二是代表两个组别, 第二个二是代表两种观测结果,每一个组别会有两个观测结果,因此整合在一起就是四种观测结果,也就是二乘二卡方。 二乘二卡方的这个零假设是指两个组别的构成比率不存在显出差异,也就是说第一组的比率派一和第二组的比率 派二是相等的。如果我们卡方检验得出批小于零点零五的话,那就说明两个组别的构成比不存在显著差。如果批小于零点零五,那就说明两个组别的构成比存在显著差异。我们需要拒绝零假设,接受被选假设。 备选假设就意味着两个组别的构成比存在显著差异。好,刚才陈老师讲到的是卡方检验的原理形式,零假设和备选假设。 但是呢,这个卡方检验他不是所有的数据都可以选择的,不是所有的数据都可以进行卡方检验的。卡方检验对数据有一定的要求,四个表卡方检验要求整体的样本量要大于四十,并且那么四个 格子中每一个格子的理论频数必须要大于或者是等于五,不能够小于五。 如果当样本含量大于四十,但是出现了理理论平数在呃大于等于一和小于五,也就是说理论平数在一到五之间的时候,这个时候我们就不能选择普通的卡房检验,这个时候我们要选择连续校正的卡房检验。 这个是一种情况,如果当整体的样本含量小于四十,或者是理论评数有出现零的时候,这个时候我们也不能用普通的卡房检验,而要选择确切概率法, 关于确切概率法或者是啊连续校长的卡方呢?关于这个,陈老师在后期的这个教程,这个医学工 公众号里面会详细的跟大家讲到关于这个统计学方法,关于这种其他的统计学方法,如果想提前了解到的同学呢,可以联系我们。 我们在长期的工作中整整理了一套详细的教程,这套教程包含了大量的医学统计方法分析结果的说明以及详细模板以及这个配套数据,并且持续更新,有需要的朋友可以联系我们的客服进行领取,客服 qq 是三三零幺八八八二零零。 好,刚才我们讲到了,如果样本量嗯大于四十,但是理论评数在一到五之间的时候,我们需要选择连续校正的卡方, 或者是当样本量小于四十,或者是某一个理论评数,某一个单元格的理论评数出现了零的时候,我们就应该选择确切 概率法。好,接下来呢,陈老师就以一套案例数据来跟大家讲解一下我们如何录入卡方四个表,卡方数据的这个数值,并且进行卡方检验的运算。 好这一套案例数据呢,可以看到这个嗯,屏幕右,嗯,屏幕右上方的这个表格。这一套案例数据呢,是以两个组别,一个试验组,一个对照组来进行这个比率的差异的分析。 试验组用到的是这个啊,传统的药物,试验组用的是新药,对照组用的是传统的药物,也就是这个试验组的药物 a, 它是属于一种新开发的药物,而对照组它使用的药物 b 是传统的药物, 我们想看看实验组和对照组他的有效率有没有差异。好,这个可以看到九十七、五六, 十七和十一明显的就是四个格子,四个表,那么我们要把这样一个四个格子的数据进行卡方检验,之前我们要把这种数据录入成 spss 软件承认的卡方检验的格式,这个时候我们怎么做呢? 好,我们先点左下角的变量师图啊,我们要录入的第一个变量应该是组别变量, 组别变量要复职的啊,就是陈老师在上一期的这个新花开医学统计的公众号里面已经详细讲过了变量的编码,这个技术资料的编码复职,我们的一组是试验组, 二组是对照组。 好,一组是试验组,二组是对照对照组。然后呢?这个,呃,然后呢?我们还有一个,这个还要录入一个数据,就是疗效数据。 疗效数据我们在杏花开医学统计的这个公众号里面上一讲已经讲到了,我们一般都是用一来代表有效无效的,这种没有发生的一般都是用零来编码。 好,最后呢我们要录入的一个就是人数,注意这个人数的话呢,他是属于那种 人数,他是属于。陈老师在这个上一讲已经讲到了,人数属于离散型计量资料,他是不需要进行复制的,我们这直接插掉就可以。 好,这么三个变量我们建立好了之后呢,我们就可以开始录入数据了,我们录入数据的界面是数据师图。 好,我们可以详细的看一下,我们是在变量师图里面进行的这个变量名称及编码的输入,然后呢,再然后我们看一下,我们是在这个 数据师徒里面开始录入数据。好,刚才那个组别是, 呃,组别一是代表实验组,二是代表对照组,然后呢疗效呢?一代表有效,零代表无效。那么这个九十七个人,他是什么组的?九十七 七个人,我们先录九十七吧,第一个格子九十七,这个九十七他是什么意思?他是试验组,也就是一疗效是有效的,所以呢,我们横着来看, 试验组有效的九十七个人,那么试验组无效的, 试验组无效的就是五个人。好,我们再来看看对照组,对照组有效的是六十七个人, 对照组无效的是十一个人。好,同学可以仔细的体会一下这个呃,编码的来历啊, 我们可以点这个看一下,你看这个试验组有效的九十七个人,我们横着读,试验组无效的五个人,对照组有效的六十七,对照组无效的十一对,我们就是横着来的。 然后呢,这个人数是标度的,我们可以把这个,这个组别和疗效我们可以改一下,改成那种名义资料啊,一般来讲不改也是可以的,改一下呢,比较规范一点。 好,我们这个数据录入好了之后呢,我们接下来就要进行这个呃,原始这个卡方检验了,然后我们再进行卡方检验的时候,我们实际上检验的是不同的组别在疗效上有没有差异,实际上只用到了组别和疗效数据,但是这个人数呢,它是 累加于组别和疗效上的,我们实际上就是试验组有效的九十七个人,那么九十七个人是需要加权到这个组别和疗效上的,所以呢,我们在做卡房检验之前,需要对数据进行加权,点数据, 点数据加个案加权,对最下面一个个案加权。好, 个案加权,我们是对个案加权的系数,个案加权的系数是什么?就是这个人数直接点确定,好,提示 weight by, 人数就提示我们的这个加权成功了, 好,提示了我们驾驶员成功之后,我们再回到我们刚才的这个界面, 加权成功。加权成功,就意味着 spss 软件已经知道了试验组有效的是九十七个人,他也知道了试验组无效的是五个人,所以人数这一列变量其实我们就可以不要了,我们仅仅只对这么两列 组别他的疗效差异进行一个卡房检验。操作是这样的,点分析描述统计交叉表分析描述交叉表,好,我们把这个, 我们把这个组别选进行疗效选进列,其实这个行列是无所谓的啊,把那个疗效选进行组别选进列,都是可以的啊,这个是无所谓的。注意,我们要点击这的一个统计, 统计点了统计之后呢,自动会弹出这样一个窗口啊, 好,然后呢?我们勾选卡方,然后点继续,然后呢?这个,嗯,关于这个他其他的这个什么单元格,嗯,单元格,还有 单元格里面的这么一些这种统计量,还有这个格式里面的这么一些统计量等等, 关于这样一些呢,陈老师在后期的公众号中会更新对这么一些统计量的一个讲解,在本次的这个视频讲解中,就不详细讲这么一些统计量了,好,购完了之后直接点确定就可以了。 好,这个呢就是卡方检验的运算结果,卡方检验的运算结果呢,会有三张表,第一张表是个案处理表,这个个案处理表实际上就是展示一下参与本次调研一共有多少个人, 然后呢,他实际上就是对照组和试验组整合在一起,一共有一百八十个人,并且是没有缺失的。满足我们卡方检验的第一个前提条件就是总样本量要大于四十。好,这一个条件满足了。 好,满足了之后呢,我们再来看他的运算结果啊,这个呢就是交叉表,基于这样一张交叉表,这个交叉表里面我们可以看一下,这写了零个单元格的期望技术小于五,也就是说这么四个单元格。注意啊,这个是理论, 这个是实际评书啊,理论评书呢,我们没有勾选,所以他就没有展示出来,但是呢,这个没有展示,没有关系,我们只用看,这就行了,没有一个单元格的期望评数小于五,所以呢,并且总样本量是大于四十的,那么 根据这么两个条件,一个是一百八,一个是这个。呃,零个单元格的期望技术小于我,那么满足卡方检验的前提条件,呃,就是,嗯, 我们可以选择这个皮尔逊卡房检验为最终的检验结果,因为啊,样本量大于四十,单元格的这个评数全部都是大于五, 所以呢,我们就可以选择这个卡房检验,我们就不用看其他的了。关于其他的这么一些呢,嗯,如果有同学不懂的话呢,可以在公众号在我们的这个杏花开 医学公众号里面留言给我,我们将针对大家的提问集中进行解答。我们的微信公众号是 xhk 三四五。好,本次的呢,我们就直接选择皮尔逊卡方检验,卡方值是四点六二零, 然后呢他对应的显著性水平是零点零三二小于零点零五,那么这个就意味着,这个就意味着呃试验组和对照组他的疗效,他的这个有效率是存在显著差异的, 那么我们得出来的试验组和对对照组他的有效率是存在显著差异,之后我们一定要判,我们一定要更进一步的判断哪一个组别的疗效更好。那么这个怎么做呢?我们一般都是选择有效的人数除以总人数,这个组别的总人数,比如说 试验组的有效率就等于九十七除以一百零二,他就是等于九十五点一零的,试验组的有效率高达百分之九十五点一零。 而对照组的有效率呢,就是对照组有效人数出六十七除以对照组的总人数七十八,六十七除以七十八等于百分之八十五点九零, 这个呃试验组的有效率是百分之九十五点一,这个对照组是百分之八十五点九,结合这个显著性零点零零点零三二小于零点零五,我们可以最终的肯定试验组的有效率显著高于对照组。 我们再来看看体感试验组,他用的是新药药物 a, 对照组用的是旧药药物 b, 由此我们就可以推测药物 a 的有效率显著 高于要五 b 的有效率。好,这个呢就是卡方检验,卡方检验呢?嗯,不难,但是呢,卡方检验我们尤其是要注意,他必须要求总样本量大于四十,并且呃期望评数小于五的单元格啊,不能, 不能这个超过百分之二十啊,这个的这句话的解释在四个表卡房检验里面,实际上就是不能有任何一个单元格的期望评数小于五, 如果某一个单元格的期望评数,嗯在一到五之间,也就是小于五或者是总样本量小于四十的时候,我们需要选择连续校正的卡方检验。如果呃样本量小于四十,或者是出现了某一个单元格的理论评书为零的话,这个 时候我们应该选择非选确切概率法。好啊,我们会陆续更新更多的卡方检验的医学呃,医学数据的这个案例的应用。 好,今天的课程就讲到这里,我们将持续更新最最嗯最实用的医学统计教程。欢迎大家关注我们的微信公众号, xhk 三四五,品质源于专业,服务源于真心,感谢大家的收看,下期再见!
676杏花开医学统计 00:50查看AI文稿AI文稿
00:50查看AI文稿AI文稿多元线性回归分析结果解读,一、模型拟核优度二方,比如二方为零点三,则说明所有 x 可以解释外百分之三十的变化原因。二、共限性判断通过 wave 或者容忍度判断自变量之间是否存在共限性,容忍度等于 e, wave 值 值大于五,说明有贡献性问题。三、自变量显著性查看 x 对应 t 检验的 p 值, p 值小于零点零五则说明 x 对 y 有显著影响。四、写回归模型公式,构造公式使用非标准化回归系数。五、对比分析 x 对 y 的影响大小, 使用标准化回归系数也可以直接参考 specs 智能分析与分析建议进行结果解读,你学会了吗?
750SPSSAU 14:30查看AI文稿AI文稿
14:30查看AI文稿AI文稿大家好,欢迎来到 spas 课堂,我是宇博士,接下来我跟大家分享的是 spas 里面的量关于量表问题的合并。 呃,也可以叫做呢让表的维度得分计算,这呢是前段时间的一个同学呃问题,然后这里呢来做一个视频来集中处理一下。 好,我们来看一下关于量表维度得分计算。呃,关于量表维度得分计算呢,我们主要是考虑到他这两点,第一点呢就是看量表有没有反向问题,如果有反向问题呢,我们需要把 呃反向问题呢计算,得分的时候呢,需要进行反向积分,然后他呢是通过可以通过转换的重新编码相同变量, 呃,重新把所有反向题目呢一块回到反向得分处理,就可以这样集中处理。第二个呢就是维度或整体得分计算。 呃,这里呢有两种方法,第一种方法呢就是计算得分,就是求和。第二种呢就是计算平均值。呃,通常情况下这是两点都可以。呃,要是有明确量表说明的话呢, 就根据大家的说明就行,有的呢是求总班的,有的呢是求呃得班均职的, 这个都可以。然后呢,我们通过一个焦虑量表达来具体看一下,这是 焦虑自评量表,他呢是有有十五个中奖评分,五个反向评分。我们来看一下呃焦虑。我们来看这个机制,就是我觉得比平时更容易紧张或着急, 这是焦虑焦虑的表现,是吧?然后五呢,你看,我觉得一切都很好,也不会发生不尽,这明显是不焦虑。所以说呢,这五呢就是我们争做 反向体,因为我们白质主要是素质越高,它的腰力程度越高, 像五呢这种呢数值,数值越高呢就交易程度越低,所以说呢,我们就需要把五呢给反向积分处理一下, 就是反向积分题,这五九十三是第十九,反向计算呢,在这里呢就是一百没有过,很少有时间呢,评分是四三二一分,一次是四三二一分, 然后像一这种正讲正讲平分题呢,没有过,很少有一二三四,然后得分越高呢,这个 呃焦虑程度呢就越高。然后再来看他的得分,这些得分呢就与二十个全部相加, 得到一个粗分,然后呢用粗分乘以一点二五,再取整数部分呢就得到标准分, 然后这个标准根呢再跟着呃,跟按照那个长模比较,他看这个临界分值五十迈,然后五十到五十九拿轻度,调六十到六十九拿中度,然后六十九半以上的是重度。 这样呢我们就这两点基本就都设计了,呃,设计到了 一个总分计算,还有一个百降问题处理好,我们根据那个数据呢来具体做一下,这是他这个数据。呃量表问题呢,我们看到是这二十个量表, 然后首先呢把反降问题给标一下,反降问题五九三九 十三十七十九,这样呢把它标注出来呢,再进行反向积分处理啊,这里呢 一呢就是没有时间,四呢就是,呃,绝大部分毛全部时间,这样是对应的是一二三子弹,然后呢我们再给他转化成呢,呃,四三二一转化,中间编码 相同变大, 这五个五九值端直接十九,然后进行就值和金值的一个替换,一呢替换成 c, 然后二 三呢个乘,二四呢个乘 进去, 确定好,这里呢依旧 t 完成四,二就完成三,三 t 完成 二,二就完成一了,然后这里呢就不是这个时间了,我们就可以认为是这个得分了,就不要用这个时间来一就是上到这一分 就转化成一分,二呢就变成二分 这样的。哎,你看这张九呢也是同样的,这里就不做修改了,做完这个之后呢,我们就可以对他进行一个 总分计算,先二十个题目相加,这呢涉及到一个 呃 s p s s 里面的函数计算,我们可以通过计算变量,这里面有个数字表达式。我们来看一下这个, 这里面呢主要是用到了这三个函数,第一个呢就是赞,就多个变量组合,第二个呢就是多个变量就平均值。第三个呢就是 呃账户表达是取整数值,就是去掉小数点部分,整数部分这个 t、 r、 u、 n、 c 这个函数, 然后这个呢咱就跟四舍五入去整是有区别的,你像这个呢 r、 n、 d 呢是去整 四舍五入,这个呢就截掉后面这角度边后的数值,因为我们呢需要先求和,就是对所有变慢的求和,先撒,这就做音量,然后呢再乘上一点二五, 这是一点二五,然后取整个部分就是这个数值了,就写为它。我们复制一下,直接用过来 这个变量呢,因为我们这次取得变量这个 to 呢是从第一个到最后一个, 然后呢我们就这儿还是写个 web 外呢,就是标准分了。呃,我们再来看一下,这呢是这里面这些曲折,然后 sum 是这些球壳乘以一点二五,这呢就是这一部分,然后确定。 好,这样呢,就增加了一列外,增加了一列外呢,我们看到他的描述统计看一下, 最小值呢是二十五,最大值呢是八十五,然后平均值呢是四十九, 然后我们再来根据这个他的临界值呢,来给他分一下,看他是焦虑程度是怎么样的。 登记转换,重新编码为不同编码, 焦虑沉重。 好,我们来再来剪一下。呃,五十分,五十分之内的呢是无了。呃, 也就是从最低到四十九至零,然后五十到五十九,轻度交易 六十到六九, 然后六九以上 啊,不知道 最顶端 再比这个负离还值 零呢?是五一呢,是轻度酒, 中度酒 断桥。 好,这样呢,我们再来描述一下。 好,我们看到了这无奈呢是二百一十一人,然后轻度中度呢?战斗呢都有了,他呢就是增加了。 好,这是关于这个焦虑量表得分得分计算他那个焦虑程度的一个划分情况,还有情况,这是 如果对某个在一些亮条里面呢,有部分题目呢,他是需要划分维度的,比如说一到一个维度,这样的拿出来单独做计算, 比如说一到五吧,一到四吧,一到五,这是维度一,我们就来算一下维度一, 比如说维度一,维度一呢,我们如果先求和的话,可以直接主炸, 然后 一到五,就是说呢,从这个一到二, 这,然后从这一到二,这是维度一求和, 这又增加了一个求和。呃,如果求均值呢,我们直接换一下函数就可以,这叫变量,这呢改成 me 平均值, 然后一到五。 好,我们再来看一下,再来描述一下这两个。 好,我们看到维度一求和呢,就对这五个题目呢进行一架求和均值呢这时,然后 呃求均值呢,均值呢是二点一四五九,这样呢就把维度呃求和或求均值的情况下都计算了,这就是关于呃量表问题的维度的合并或者 计算问题。呃,关于其他问题呢?大家如果有问题呢可以联系我们,这是你的联系方式。呃,这里呢,我们可以呃定制相关的视频,如果有需要可以联系。好,谢谢。
640数据分析李博士 03:42查看AI文稿AI文稿
03:42查看AI文稿AI文稿哈喽,大家好,上一个视频我们聊了什么是性度检验,那这个视频我们就来分享一下效度检验,同样的效度检验也是要和大家聊一下这三个问题。第一个, 那消毒检验是干嘛的?消毒检验它主要是指测量结果与想要考察内容的吻合程度,如果这个吻合度是越高的,那就表明效度也是越高的。 第二个,什么样的数据需要做效度检验?效度检验也是适用于量表型的数据,一般像量表类的数据他都是需要做信度和效度的。 第三个,消毒分析的操作步骤和结果的解读,我们使用的数据也是性质检验的数据,就是 a 一到 b 四, 然后这些都是一些量表型的问题,他主要包括一到五这五个选项,然后我们把这些数据复制到 spss 里面 啊,整理成这样的格式,我们点击这个分析,然后降为因子,把这些量表数据都放到变量这里, 然后点击描述这里面勾选一个 k m o 和 butt later 球形检验,然后点击继续,再点击确定, 这个就是效度检验,我们需要看的表格,然后我们主要需要看这里的 k m o 值和显著性的值,这个是量表整体的效度检验,然后我们也可以测一下氛围 度的性能检验,步骤是一样的,点击这个分析刻度因子, 然后如果需要测 a 的维度,那就可以把 a 的这些变量放到这个框里,然后描述这里,我们已经勾选过了,所以可以不用设置,然后直接点击确定 这个就是 a 维度的消毒检验,再点击分析,降为因子,然后把 b 维度的数据放到变量里面, 然后再点击确定这个就是 b 维度的效果检验。我们把这三个 kmo 的表格,然后放到 excel 里面整理一下,就是这样的格式,它主要包含了 tmo 的值以及这个显著性,我们主要需要关注的也就是这两列。然后可以看一下这里面如果显著性是小于零点零五的,那就说明这个数据是可以做因子分析的。 然后这个 k m o 值它也是有一个取值范围,然后每一个范围对应的它的效度好坏, 如果这个 k m o 值越大,就说明它的效度是越好的,每一个取值范围对应的含义就是在这个表里面了。大家也可以根据自己的数据算出来的 k m o 值,来看一下你的效度情况如何。 然后针对这份数据,我们测出来的效度,他的值可以看到都是大于零点七的,也就是说问卷 整体以及各个维度的效度都是比较好的。然后显著性的值小于零点零五,也就是说这份量表数据是可以继续做因子分析的。 下一个视频我们来讲一下如何做因子分析,以及因子分析的结果怎么看。
1562spss小师姐

