cookie editor教程
哈喽,大家好,我是无知便是罪,专注于收集和分享互联网上不为人知的好东西。今天呢,无知发现了一款超牛叉的浏览器插件,虽然看起来可能会有些蒙插,但是用起来真的爽, 他就是酷 k i d 特啊,执意呢就是可以编辑酷 k 的插件。喜欢研究黑科技的朋友呢,应该都熟悉酷 k 了,或者有时候你打开某些网站也会收到提示是否允许此网站使用酷 k, 说白了就是方便网站记住访客的特定信息, 一般是暂时或者永久的存储在用户的电脑端,你可以在浏览器的设置隐私 pk 中查看电脑都存储了哪些网站的 pk 信息,作用吗?例如记录了你的登录信息,那么你下次再打开此网站,就无需再次输入账号密码了, 或者记录了你的访问位置啊没看完的内容呢?下次打开此网站,会直接定位到未读部分,大家都经历过的必占视频看一半啊,再次打开呢,就会跳转到上次退出的位置,用的也是库 k。 那么了解完酷 k 就更好的理解这个插件是干嘛的了,他可以帮助你访问当前网站上所有酷 k 的列表,创建、修改或者删除酷 k 信息。 你还可以选择导入别人的库 k, 或者将自己的库 k 直接导出共享给别人。没有实际使用场景呢,很多小伙伴可能还是毫无兴趣, 那么就来举例一个重磅的需求,现在我们开某些网站的会员呢,官方管的越来越多了,又限制你的使用设备,又限制使用人数的,有的就直接摊牌了,只能自己用,亲妈也不 能分享,那么结合我们上面说的啊,网站只能通过库 k 辨别你的身份,所以呢,如果你将自己的库 k 信息分享给朋友导入使用,那么网站识别到的还是你在用,所以呢,就没有了各种限制了, 当然缺点也是有的,就是因为是浏览器插件嘛,所以呢,只能在网页端实现, 就别指望在软件中实现了。不过也别灰心,现在很多手机端浏览器也都支持插件脚本了,所以呢,无论是电脑还是手机啊,其实都能做到账号共享,唯一的不足呢,就是网页端的操作体验比不过软件端而已。 好了,就给大家介绍到这里吧,更多使用场景请自行开发插件呢,可在应用商店咨询搜索,找不到的可在支持私信自动回复的平台回复关键字分享,按发布日期获取。如果视频对你有帮助,记得转发支持,我们下期再见!

粉丝4.9万获赞25.0万
相关视频
 02:09查看AI文稿AI文稿
02:09查看AI文稿AI文稿哈喽大家好,今天呢,我们再来聊聊库克埃利特这款浏览器插件。关于库克,我们平常接触最多的就是自己登录的一些网站呢,无需每次都输入账号密码即可自动登录。 而有了这款插件呢,我们则可以无需账号密码,通过导入他人的库存直接登录别人的会员账号,前提呢是你得有他们的会员账号库存。今天呢,我们主要说说手机端如何使用这款插件。 安卓用户呢,直接去安装个支持插件脚本的浏览器即可,如 kv 浏览器。 ios 用户呢,则稍微麻烦点,原理呢都差不多, 首先去外区应用商店搜索库克埃利特下载安装,然后到设置 s 发热浏览器里选择扩展,允许这款插件运行,再打开 s 发热浏览器,点击左下角的 大小,选择管理扩展,也开启这款插件,这样呢,就能像电脑端一样导入库 k 了。不过很多库 k 呢,并不会在手机页面生效,所以呢,我们还需要点击大小,再点击请求桌面网站即可,这样呢,库 k 就会生效了。 不过有一些视频网站呢,你一播放他就会跳转到 app 上,遇到这种情况呢,我只给大家准备了三种方法,大家自己测试,哪个能用就用哪个。一呢就是不要安装相应的 app, 他就跳不动了。二呢是长按内容, 选择在新标签页中打开即可。三呢是通过插件来拦截跳转,如拦截一百就有这个功能,不过支持的网站不多,他的会员功能呢,还支持由后脚本,有条件的可以到 油和脚本里找一些拦截脚本。这些呢,其实主要是针对视频网站的,非视频网站的话,其实装了插件请求下桌面网站就能导入酷 k 了,还是很方便的。吴志呢,也给大家准备了两个会员账号的酷 k, 可自行登录体验,不过时效不补哦。 好了,就给大家介绍到这里吧,可在私信中发送关键字精华,获取本期分享,如果视频对你有帮助,记得转发支持,我们下期再见!
339无知便是罪 00:41查看AI文稿AI文稿
00:41查看AI文稿AI文稿习认稳的小厨房,今天要做的是烤开看,首先加入一百克的黄油,接着加十六克可可粉。哎呀呀,纸巾怎么把糖给吃了?加入五十四克糖后,把二百二十克面粉和一颗蛋倒进去,让它们充分的搅拌均匀。 成团后把面团擀平,用模具按压出空气颗粒形状,一个面团可以做很多份用。最后烤箱烧下火,一百六十度烤二十分钟,后面我画不动了,大概就是饼干烤好后放凉一下,冰淇淋面馅一样是用 油放到晾凉的饼干里,这样一来简单好看又美味的空盆可就大功告成了,大家也去试试做做看吧!
2652阿巴阿巴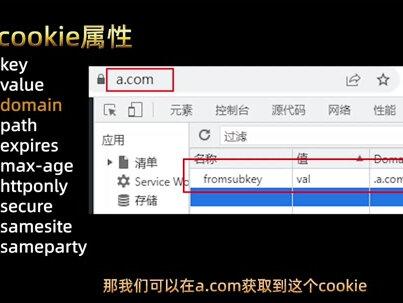 08:53
08:53 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿第一步,把我们要做的音乐给它拖拽进水果软件的播放列表。第二步,打开混音器,在主控上给它加载一个这个插件, 点击向导,他这个里面呢会有很多的模板,他这个位置呢可以输入你要加入进去的文字,例如我给他加一个 dj, 我 们点击这个位置播放,来换一下他的模板, 然后找到你喜欢的。第三步,点击 保存视频,我们把它放在你能找得到的位置就可以,我呢就给他放在这个文件夹里,选择完以后点击确定点击开,然后等待 完成以后,我们找到我们导出的这个视频文件来播放。
203DJ大禹 04:36查看AI文稿AI文稿
04:36查看AI文稿AI文稿python 从零开始学,今天要讲的是 cookie 的 使用。在网站中我们会发现登录之后用户可以看到更多的内容, 比如购物、网站中的购买记录,个人信息等等。这些内容通常需要我们在访问网页发起请求时输入了登录信息才能够获取。每次想要看到新的内容,刷新网站时都会发起一次新的请求,服务器就会像第一次见到你一样要求你重新登录,那也太麻烦了吧。 为了解决这个问题,我们就可以使用上 cookie 了。 cookie 就是 保存了用户信息以及用户的喜好的一串字符。当你使用浏览器第一次登录该网站时,服务器就会创建这个 cookie, 然后响应内容的同时, cookie 就 会被浏览器保存下来, 浏览器在下次向同一个网站的服务器发起请求时,就会携带它。服务器识别了 cookie 之后就知道了用户的身份,就可以避免重复登录,并且能够根据用户的喜好来响应页面内容。 为了更便捷的浏览网站,提升用户的体验感,在浏览器中发起请求时,携带 cookie 就 变得非常重要了。我们怎么才能找到这个 cookie 呢? 首先我们打开浏览器,在网站中我们有两种方式可以进入开发者模式,第一个就是按下键盘中的 f 十二键,第二个我们可以在页面中空白的位置右击点击检查,然后找到网络的选项卡, 刷新一下页面,重新加载数据包。在这里我们可以找到最上面的文档,在请求的标头里面就可以找到这个 cookie, 那么这个 cookie 就是 浏览器保存的 cookie 了。有同学就会发现,这个浏览器中我并没有登录,为什么还会有 cookie 呢?这是因为 cookie 分 为两种,第一种是临时 cookie, 在发起请求时,浏览器会设置一个临时 cookie, 如果你没有登录网站,浏览器也会设置一个临时 cookie, 发送请求时携带给服务器,这个临时 cookie 在 浏览器关闭之后会自动删除。当然这种临时 cookie 也没有保存个人信息和个人账户的作用。 第二种是持久 cookie, 这个持久 cookie 会设置有效的期限,有些网站可能是三到五天,有些可能是半个月或者一个月。大家可以观察一下,我们在浏览器中登录了一个网站之后,过一段时间再次进入的时候,是不是仍旧需要重新登录, 这就是因为 cookie 已经过期了。了解了 cookie 的 类型以及获取方式之后,我们进一步来看在爬虫程序中如何实际应用。 通常来说有这么几种情况,需要在爬虫程序中使用到 cookie。 第一种, 如果需要登录才能访问的页面,例如用户个人中心或者账户信息、会员专属页面、会员专属内容等等,那么我们就需要使用到这个 cookie。 第二种,保持绘画状态。像我们在网站中浏览小说,每一次翻一页或者点击新的下一张,就需要刷新一下页面,那么就要保持这个 cookie 状态的存在, 这时候我们就需要使用到 cookie。 第三种,某些网站通过 cookie 验证请求的合法性,首次访问会设置 cookie, 如果没有检测到 cookie, 那 么就会认定你是爬虫,不返回给你信息,这个时候我们就需要在爬虫程序上携带上 cookie。 如何在爬虫程序中携带上 cookie 呢?有两种方式,第一种是在请求头里面携带 cookie, 这种方式我们可以在爬虫程序中这么写,将 cookie 加入到 headers 里面,然后爬虫发起 get 请求时,携带这个 headers 里面的 cookie 就 可以了。第二种方式就是设置 cookie 参数,我们可以创建一个 cookie 字典,然后将 cookie 里面的属性和值写到里面, 然后在发起 get 请求的时候加上 cookie 这个参数。总的来说, cookie 在 爬虫中是一个非常基础,但重要的部分,无论是模拟登录、保持绘画,还是绕过网站的反爬机制,都离不开它。 掌握了 cookie 的 使用,就能处理很多需要登录状态的网站,也为后面学习更复杂的爬虫技术打下了一个扎实的基础。
137蒲公英的蒲 05:49查看AI文稿AI文稿
05:49查看AI文稿AI文稿pencil 爬虫教程第二章二点八, cookie 使用学 python 我 只看糯米哦,通过上期视频呢,糯米已经讲解了有关 cookie 的 基础知识点,那么本期视频呢,我们就继续深入学习一下爬虫是如何使用 cookie 的。 上节课我们说过, cookie 可以 让一个网站保存你的一些基本用户信息,等你下次重新访问这个页面,就不用再次输入账号密码了。 我们之前用爬虫去爬取网页数据的时候,都是直接在请求头中加了一个 user agent 的 信息,这样可以避免让网站服务器识别出我们是爬虫的请求。但是这些请求都是没有在用户登录的状态下发出的,因此我们无法拿到登录后的一些详细信息。 那么我们该怎么办呢?一个爬虫除了能模拟客户端,能不能也模拟一下用户登录呢? 当然可以了,我们只要在爬虫发出请求前,在请求头中加入我们的 cookie 信息,让网页服务器认为这次的请求是一个真正的用户发出的,这样我们就可以爬取一些登录后的数据信息了。 在莫米实际演示代码前呢,我们还是要先回顾一下 cookie 的 一些基础知识点,这对后续理解爬虫行为起到很大的帮助。 cookie 一 般分为两种类型,一种是临时 cookie, 它没有设置过期时间,只要我们关闭浏览器, cookie 就 会自动删除。 就像你访问一个网站,但是没有登录,这时候网站会给用户浏览器发送一个临时的 cookie 来记录所有的浏览行为,但是用户关闭浏览器再次重新登录这个网站,之前的浏览行为就会丢失。 另一种就是持久 cookie, 它设置了 expires 或者 max edge 属性,这样 cookie 就 会保存在本地硬盘上,直到这个有效期结束才会失效。就好比我们登录了一个网页,我们可能几天甚至半个月都不用重新登录, 直到这个 cookie 失效后,我们才需要重新输入登录信息,这时候服务器会返回一个新的 cookie 供浏览器使用。 我们知道 cookie 这么重要,它是由服务器生成的,那么我们可不可以自己模拟生成一个登录的 cookie 信息呢? 这是当然可以的,但是模拟一个登录可能要涉及到验证码、加密滑块、安全验证等,对于初学者来说难度还是挺大的,因此我们不如直接用 cookie, 这样省时又省力。 当然,如果你的 cookie 过期了,你需要重新登录,重新复制,所以更好的方式是使用 requests session 结合模拟登录。但是今天糯米先把 cookie 的 使用讲透,那么我们怎么去拿到浏览器中的 cookie 呢?糯米这里打开了一个百度页面,并且登录了自己的账号。 接着我们右键选择检查按钮,进入开发者选项页面,或者通过键盘上的 f 十二键也可以进入到当前页面。这里糯米选择了网络选项,也就是 network 选项卡 页面已经提示了我们需要重新加载页面,我们点击这个按钮或者按键盘的 f 五键,刷新一下页面。我们网上翻找主页面的请求,一般是第一个请求, 宝宝们看,这个就是我们想要的请求了,在它的右侧我们可以找到这次 http 请求的请求头以及网站返回的响应, 我们可以在 request headers 里面找到 cookie 一 项,我们可以直接双击它,全选复制这个文本,这样我们就拿到了想要的 cookie。 既然拿到了这个 cookie, 我 们该如何使用它呢?我们回到代码页面,这里糯米已经把这些代码写下来了,我们一步步看。首先我们要导入这 request 库,这里面我们就可以用到它的请求方法。 接下来我们把想要访问的目标网站写下来,用一个 url 变量保存, 这里就是最重要的一步,我们之前会在请求头内放一个 user agent, 就 可以让网站服务器识别不出我们是爬虫发出的请求。 同时呢,我们把刚刚复制的 cookie 也放在这个请求头中。下面的代码呢,就是我们发送一个请求,并且把响应的内容保存下来,写成一个 html 格式,那么我们运行一下看看结果如何。 宝宝们看,我们已经成功请求了百度页面,并且我们在左侧也能看到生成的 html 文件,我们可以在这里右键选择浏览器打开,这样我们就能跳转到百度的页面了,并且这里面已经有了我们的登录信息。 但是呢,有一些信息我们是拿不到的,因为有部分信息他是没有写在 html 文件里。在这里我们还需要关注一下 cookie 使用的注意事项, 我们不要轻易泄露自己的 cookie, 我 们的 cookie 里可能包含了登录凭证信息,别人拿到了你的 cookie 后,可能会冒充你登录页面做一些不好的事。 cookie 里还有 h t t p o n e 属性,有些 cookie 会被标记为 h t t p o n e, 这意味着它无法通过 javascript 读取,这主要是为了防止 x s s 攻击。有一些标记为 secure 的 cookie 只能通过 http 传输,爬虫也要使用 http 网址。 最后, cookie 有 过期时间,一旦过期我们就要重新获取。好啦,以上呢,就是本期的所有内容啦, 相信宝宝们已经掌握了 gucci 的 使用,我们的爬虫也能突破登录限制,抓取到更丰富的数据。下节课呢,糯米继续演示一下爬虫代码,实利用爬虫爬取视频素材,关注糯米,持续带你掌握拍 some!
217糯米姐姐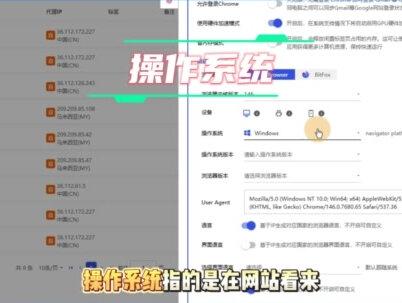 02:38查看AI文稿AI文稿
02:38查看AI文稿AI文稿大家好,本期视频教大家如何快速上手比特浏览器。在客户端左侧点击浏览器窗口页面,点击左上角的创建窗口按钮, 你可以在名称一栏填写环境的名字,也可以将环境创建到分组。在账号平台这里,比特浏览器提供了一些主流平台, 如果没有你想要的,也可以选择其他平台。粘贴网址。选择平台后,可以填写平台的账号与密码。在 q k 这一栏,如果你需要在环境里导入 q k, 可以 将 q k 粘贴到此处, 再填写一些备注内容。接下来填写代理配置,将在第三方购买的信息填写到此处。浏览器内核选择 bit fox 使用的是基于火狐内核的浏览器, 如果你对环境的内核版本有需求,点击此处进行选择。如果没有特殊需求,默认即可。操作系统指的是在网站看来该浏览器环境使用了哪一个操作系统。 比特浏览器已经将其设置为和你电脑相同的操作系统,通常你无需对此修改,默认即可。同时,比特浏览器还提供了移动端的浏览器环境,稍后也会为大家演示路由,指的是在网站看来 浏览器环境体现了哪一个操作系统、浏览器的版本等。如果你对环境的浏览器版本有特别的需求,也可以点击此处选择。下面的指纹设置会为每一个环境生成不同的指纹, 所以这里的选项默认即可。好了,主要的功能就介绍到这儿,下面我们来创建不同内核的浏览器。点击创建窗口按钮, 进入新建浏览器界面之后填写相关信息,选择需要登录的平台。浏览器内核,选择使用谷歌内核的浏览器操作系统,选择默认的 windows。 最后点击确定按钮, 一个新的浏览器环境就创建成功了。来到账号管理界面,我们可以看到刚刚创建的浏览器环境。接下来我们创建一个火狐内核的浏览器环境,重复刚才的步骤,在浏览器内核这里选择 bit fox, 点击确定。 最后再为大家创建一个 android 浏览器环境,继续重复刚才的步骤,在设备这里,选择 android, 完善其他信息,点击确定,创建成功。最后我们来到账号管理界面,勾选这三个浏览器环境并打开。 我们看到在每个环境配置不一样的网络之后,每个环境使用的 ip 都是不一样的,可以有效防止关联,大家可以创建环境试下。
24比特指纹浏览器 02:20查看AI文稿AI文稿
02:20查看AI文稿AI文稿这期视频带你用 cursor 入门 web coding, 从 cursor 的 安装配置到生成你第一个个人主页,手把手带你了解如何进行 web coding。 在 cursor 的 官网就可以直接下载我们对应电脑版本的软件,完成安装以后打开应用,接下来登录 cursor 的 账号就可以进入应用了。 我们先选择 new project, 这里设置一会我们写代码用到的文件夹,我这里就新建了一个 cursor test。 右上角这里的设置按钮可以设置。软件整体的布局有 agent 和 editor, 我 这边选择的就是传统的 editor。 左边这里可以查看文件夹的内容,相当于是文件浏览器。右边这里可以和 ai 对 话,中间可以查看和编辑代码文件 setting 这里有更详细的配置,比如说通用的配置, agents 的 配置和模型的选择。我们现在使用的是免费版,所以模型这里只能选择 auto, 下面这些具体的模型是选不了的, auto 会自动选择模型来平衡他输出的质量和速度。如果后面你有更高的开发要求,或者 auto 模式经常限速,可以考虑选择科四的会员。我们现在就可以在对话框这里输入我们的需求,比如可以试着做一个网页作为个人主页,刚开始可以简单描述一下,然后慢慢优化细节, 那这就是 ctrl 生成的代码文件,还包括了一个 macdunk 格式的说明书,讲解了我们的网页还要配置哪些内容。这些文件可以看到就创建在了我们刚才设置的工程文件夹中,可以直接查看文件中的代码内容,那打开 index html 就 可以看到网页的效果了, 整体看起来更像是一个个人简历。如果你觉得有哪些地方需要修改,就可以在对话框中继续告诉 cursor, 比如把右上角的卡片去掉,等 cursor 修好以后,就可以刷新一下页面,看下新的效果,基本上还是达到了我们的目的的。 那通过 cursor 进行 web coding 大 致就是这么一个流程,后面我也会分享一些更加具体的 web coding 的 技巧。最后我还想分享一下我对 web coding 的 一些看法,我觉得它非常适合我们,将自己一些有意思的想法和创意变成现实,让每个人都拥有创造的权利,那这在 ai 编程以前是很难做到的事情。 对, web 扣定不是一定要做出可以商业化的项目去赚钱,或者 ai 编程去替代程序员制作一个更适合自己的小工具也同样很有意义。那以上就是从 curser 入门 web 扣定的全部内容,如果觉得对你有那么一点帮助,欢迎点赞关注,后面我也会分享实用的 ai 小 技巧和好玩的数码产品,那我们下期视频再见吧!
376李瑞可Lyric 04:16查看AI文稿AI文稿
04:16查看AI文稿AI文稿pencil 爬虫教程第二章二点七 cookie 介绍学 python 我 只看糯米哦,这期视频呢,我们来学习一下爬虫的另一个重要知识点, cookie。 宝宝们有没有遇到这种情况,就是我们在登录一个网站后,关闭掉浏览器,等我们再次打开浏览器登录到相同的网页,会发现我们的登录信息还保存在这里,我们并不用重新输入账号密码。 另外,我们在购物网站也能体会到这一点,我们如果把商品加入到这个购物车里面,在刷新页面后,这些商品还是会存在的,这些都是由网页中的 cookie 完成的。那么到底什么是 cookie 呢?它的具体工作流程是什么呢?我们一个个来看。 在学习 cookie 之前,我们需要知道 http 协议它有一个特点,那就是无状态。什么是无状态? 简单的来说就是服务器会把每一次接收到的请求当做一个全新的独立的请求去处理,服务器不会记得这个请求是哪个用户发的,也不会记得这个用户之前做过什么。 那这么就带来了一个问题,网站应该怎么去记住这个用户,怎么去得知这次请求属于哪个用户的呢? cookie 就是 为了解决 http 无状态的问题而诞生的。 糯米这里写出了 cookie 的 本质,它实际上就是一个小段文本,信息是由服务器生成,然后发送给浏览器,浏览器最终把它保存下来, 等到下一次浏览器再次发送请求的时候,浏览器就会自动把这个 cookie 加入到请求头中。服务器接收到请求后,会检查一下请求中的 cookie, 看看这次请求是属于哪个用户的, 所以 cookie 的 作用就是可以让服务器识别用一个用户,从而维持状态。那么 cookie 到底是怎么工作的呢? 糯米这里就简单地归类为四步。首先呢,用户第一次访问网站,浏览器会向服务器发起一个请求,接着服务器接收到请求后会生成一个 cookie, 这里面包含一些信息,比如用户 id、 登录凭证等。 然后浏览器说到响应后,会把 cookie 保存下来。最后,浏览器每一次访问同一网站时候,都会把这个 cookie 放在请求头中,并且发送给服务器。服务器读取到请求头中的 cookie 后,就会知道本次的请求属于哪个用户的了。 下面呢,糯米再介绍一下 cookie 的 关键属性,宝宝们看,在这里写了这么多属性,我们只要了解一下即可。这里的 domain 就是 指定哪些域名可以接收这个 cookie。 path, 这里就是指定哪些路径可以使用这个 cookie。 还有 expires, 有 些地方会写成 max age, 它可以控制 cookie 的 存活时间,如果设置了过期时间,浏览器就会自动删除它。如果不设置关闭浏览器, cookie 就 失效。 这些属性的存在可以让 cookie 既灵活又安全。最后呢,我们再看下。除了 cookie, 有 时候我们还会接触到 session, session 就是 一个绘画,它们经常一起出现,但却并不是一回事。简单的来说, cookie 存储在浏览器端,它的数据量比较小。 session 呢,它存储在服务器端,可以存储大量的数据。 服务器通常会在 cookie 上添加一个 session id, 浏览器每次请求都会带上这个 id, 服务器就知道去哪个 session 找到该用户的信息了。 举个简单的例子, cookie 就 像我们超市里的会员卡号, session 就是 超市电脑里存储的我们会员的所有信息,包含了积分、优惠券、余额以及用户信息等等,超市可以根据你的卡号找到这些信息。 在爬虫中,我们很多时候只需要处理 cookie, 因为服务器只要通过 cookie 里的赛神 id 就 能识别到。我们 学习完了什么是 cookie? 下一节课,我们会真正动手写一个需要登录的爬虫,用 cookie 来获取个人数据。宝宝们准备好了吗?关注糯米,持续带你掌握 python!
315糯米姐姐 00:48查看AI文稿AI文稿
00:48查看AI文稿AI文稿计算机使用教程,用照片编辑器处理图片,右键点击图片使用照片编辑器照片编辑器的核心操作,旋转亮度调整裁剪旋转用来摆正倾斜的照片,调整画面角度。 亮度调整用来提亮或压暗画面,让照片明暗更舒适。 对比度调整用来增强画面层次,让主体更突出。裁剪用来修正构图,去掉多余内容。
29浩的电脑 00:53查看AI文稿AI文稿
00:53查看AI文稿AI文稿nc 编辑器除了我们自己的对话式编程 hercules 控制支持相同的行业标准,许多其他控件使用的 nc 代码具有完整的红币支持和几乎所有的 g o m 代码, 工程师上手会感觉到非常轻松。编辑 hark 在 n c 模式下,我们强大的颜色编码。 n c 编辑器可以加载最大两千兆的程序,并且是一种非常有效的编程方式,实时提供丰富的信息,代码含义一目了然和高级编辑功能,如查找或放置 和程序导航的工具审查,让您的操作更简单。零件具有各种标准和复杂的功能。 n c 绘画合并选项允许您利用对话调用全部或部分。 n c 程序式编程用于三 d 特征和轮廓。 绘画式和 c 语言的结合是一个非常强大的选项,用于快速编程复杂零件。
19赫克中国 03:46查看AI文稿AI文稿
03:46查看AI文稿AI文稿丘比特安装教程和使用方法来了,三种超简单的使用场景,新手也能一次学会。二屁已经把详细的安装教程整理成文档了,不想看视频的小伙伴直接照着文档一步步来就行,领取方式见主页个人简介,需要的同学快去拿, 下面我来给大家具体演示一下。第一种方法,从命令行窗口进行安装和使用。 win 加二,打开运行窗口,输入 c m d, 打开运行框,输入安装命令 p p install j p t 敲下回车,开始安装, 安装完成后输入 jupiter notebook, 敲下回车,点击右上角 new, 选择 new folder, 创建一个新文件夹,给文件夹起个名字,然后双击打开它, 打开文件夹后点击右上角 new, 选择里面的 python 三,我们来测试一下。输入代码, 点击上方的三角按钮运行,运行成功。第二种方法,在 vs code 中使用,打开 vs code 官网,点击 download, 下载后会弹出提示窗口,点击保留,点击,打开文件,弹出窗口,点击确定, 点击我同意此协议,接着点击下一步,继续点击下一步,再点击下一步,勾选创建快捷方式,点击下一步,点击安装, 安装结束后点击完成,软件会自动打开,在软件左侧点击方块图标搜索栏,输入 python, 点击第一个选项的 install 安装 python, 安装好后,搜索栏输入 jpeg, 点击第一个选项的 install 安装。选择左侧菜单栏第一个图标,点击 open folder, 在 这里建一个新的文件夹, 选中文件夹,点击 select folder, 勾选查询条款,点击 yes, 点击左侧图标新建文件,给文件命名,注意文件的后缀是 ipynb, 输入代码,点击运行符号上方选择 pythonenvironment, 选择第二个 python 三点一二,现在点击三角形运行符号就能运行成功了。接下来是汉画插件的安装, 点击左侧方块图标搜索栏,输入 chinese, 点击第一项 install, 按下键盘, ctrl 加 shift 加 p 搜索框输入 display, 选择第一项 configure display language, 选择中文简体,点击 restart, 重新打开后界面就是中文啦,汉化完成。第三种方法,在 anaconda 中打开 jupiter, 选择一个文件夹进入,点击右上角 new, 选择 notebook, 再弹出窗口,点击 select, 在 界面输入代码, 点击上方三角运行符号就能正常运行了。好了,本次分享就到这里了,有任何问题欢迎关注私信阿鹏!
160四月学长讲科研







