chatgml3如何微调
hello, 各位小伙伴们,大家好,我是 mary 刘。今天来给大家介绍一下 chat glm 三的一个训练的一个过程。在上一期视频呢,我们使用了 long chat chat chat 构建了一个呃包括知识库以及 i 绘画的一个问答。在其中呢,我们使用的 chat g l m 三六 b 的一个模型。今天呢,咱们就在此基础上对模型进行一个训练。 嗯,此次训练呢,也不是一个完整的,包括从数据集,数据集的一个构建,以及到整个训练挑餐的一个过程啊。今天这次呢,只是对训练问题过程进行一个演示展示,去实现了一个一键训练的一个过程。数据集呢,还是采用网上的数据集直接拿来使用。 咱们废话不多说,直接来看一下。在 cat j m 三 d 这个项目中呢,咱们直接打开 cat model demo。 在这目录中呢,我们已经首先放置好了训练所需要格式化的一个数据 t s l 文件。来看一下这次所一键执行的选模型训练的一个脚本。 可以看到这些参数呢,这次的话,大家都可以进行相对应的修改。比如说你如果想用其他的一些参数,一些模型,景区人啊,都可以对其进行修改。首先 get to setpass, 这个是数据级的一个路径 base, model pass 是基准模型的路径。基准模型呢,我是放在整个叉 g m 三登录下 model mode 下面的 啊。这次的话也是采用了 chat g m 三六 b 的一个模型。还有像是的一个长度啊, reading read, 还有像这其他一些参数。在这之中呢,首先需要对这几个参数进行一个简要的一个介绍, 如果你的显存不足不足以完成整个训练的过程,咱们可以适当的考虑去调整一下这几个参数。当显存不足的时候,可以对于这两项啊,最大赛的长度,以及每个设备奔驰的一个大小,把这两项进行一个调机调低,然后调高这一项去依次来看 看一下能不能解决显存不足的问题。但是如果你显存特别低,比如说已经低于六 g 以下,整体 gpo 整体的一个包括专用以及共享内存,它是在 十八 g 或者二十 g 以下的话,我个人认为是不用去考虑训练的一个问题了,可能的硬件是不大支持的。当然啊,这个只是在英美达的显卡之下,其他显卡哈,我并没有显卡去进行实验。 嗯,咱们可调整的部分呢,基本上就是包括这些。这次的话,整个蛋。整个脚本也是这样一种形式。咱们来看一下脚本执行的一个情况。 当出现这个界面的时候呢,他正在加载模型,再拆 point, 然后出现这个界面的时候,他就是把整个数据集的一个内容给加载进来。现在出现这个 worning, worning 可以不用管,这个是正常的。然后现在已经在执行 训练的一个过程,在咱们任务管理器也可以看到啊,我现在用的是三零六零钛一个显卡啊,整体总的一个 gpu 占占用的一个内存也是十八 g 啊。在今天早些时候呢,我也去训练过,训练过一次, 训练过那一次的话,大概整个几个小时的过程中的话, gpo 内内存一直占用都是保持在十八 g 的情况下,嗯,可以预见的是大概二十 g 现存的话是够用的。 这一整个训练一个过程吧,他最终的结果呢,也是会保持保存在啊,住在这个文件夹下啊,包括你设置的这个名称以及日期组成的这个目录下,到时候就可以在这里输出整个模型了。 这也是整个菜 gm 四 gm 三这个模型他微调的一个过程,微调训练的一个过程。嗯,也欢迎各位小伙伴们大家观看。在后续的视频呢,我也会对 咱们个人的有数据集进行一个讲解,如何去构建合适自己的一个数据集,进行模型微调以及模型的一个训练。今天这期视频就这样,感谢各位小伙伴的观看,咱们咱们下期再见。

粉丝37获赞40
相关视频
 07:15查看AI文稿AI文稿
07:15查看AI文稿AI文稿嗯,跟大家今天再介绍一下这个 chat g l m 二代的这个模型怎么进行微调啊?跟大家演示一下啊。那么 chat g l m 的 effective 车令的这个元代码我已经下载下来,下载下来之后的话呢,然后,呃在本机上已经有了,然后 我们只要打一个命令就可以微调了,那么在微调之前的话呢,这个数据啊,数据是比较重要的,就微调的数据,数据是放在这个目录下的啊,我目前进行微调的是这个东西, 是这个数据集啊,这个数据集的话呢,主要是他主要是要调整一下这个自我认知或者自我的那个身份啊,那么微调的话呢,一般的话呢,呃二十四 g 显存就可以了啊,那么他也是一样的呃整个环境还是比较容易做的啊。那主要关注一下的话呢,就是呃我之前呃 微调失败的主要的原因是这个,这个拍 touch 的这个版本啊,不要用二点零点零的这个版本要用最新的二点一点零啊,这个版本啊,用这个版本的话会比较好啊,因为他会报错啊,它里面有一个错误啊,我今天也查了好久,后来发现是有这样一个错误的,那么 那么先呢准备一下这个数据集啊,数据集里面呢,要把这个 name 杠杠的。这个 name 啊,要把它改成啊,我目前改成小工艺啊,它等于是这样啊,然后把那个 chat glm 杠六 b 我改成二啊,它这个数据集,这个数据集改完之后呢,就可以微调了。 微调的指令的话呢,呃,我自己调了一下,用这条指令就可以了,主要的话呢,还要指定这个模型的 pass 啊,他这个是最主要的。然后 bench size 的话,我设置的是一啊,因为我内存不是太大。然后呢,主要是那个 user 杠一二的这个版本啊,这 是比较重要的,然后你就在这个里面回车一下。好,他就开始调整了。呃,首先的话呢,他还是会去装载原始的那个 chat g l m 二代的这个杠六 b 的这个模型有七个文件啊,他先把它给加载起来。嗯, 加载起来之后的话呢,它我目前 frightening 的这个方法的话,我是用 rora 的这个方式去调整的啊,那么一共有十九条数据啊,一共有十九条数据啊,进行调整, 那么它就会装载。然后它 step 的话呢,是九十次,九十次迭代,因为它这个数据量不是非常大,所以它迭代会非常快,很快就,呃,计算完了。那每秒钟的话呢,就迭代三次啊,那么三十秒基本上它就可以跑完了。那跑完之后的话呢,我们再来测测一下啊,它这个认 是否已经改变了?很快啊,三十秒他就跑完了,跑完这个微调就结束了。他这个好,微调完了之后我们测一下,就是说目前的他这个自我认知到底对不对啊?我们打一个命令。 呃,它同样先是装载这个模型。呃,模型装载完了之后,它会加载一个 laura 的那个 friterning 的这样的一个小模型,它会装载起来。嗯, 装载之后他就可以呃进行问答了。呃,因为我现在用的是命令行的。他所有的这个参数的话呢,你可以看到他有一个 march 一个小的模型啊,他已经 mark 进去了,已经成功了,然后他整个一个模型的话一共是六十二个亿啊,他整个参数,呃,那么他就开始欢迎使用什么什么什么啊, 我们就可以问他一下,我让他自我回答一下。 好,你看到他这个地方就是我之前训练告诉他的啊,那么这个就算微调完成了啊?我叫什么什么恰的 g i m, 我室友小公益什么什么的,对,对吧?就我刚才调整了这个两个东西啊,他现在就比较准确的能回答我啊,这就说明调整成功了啊, 那么调整成功之后呢,他还需要还要打一个命令,就是把那个小模型和你的大模型合并起来,然后进行输出啊,那么我们可以打这样的一个命令, 那么这个命令呢呢?它主要是把大的模型跟我前面预训练的模型合并成一个模型,然后存在一个目录 下面啊,它主要是做一个合并的这样一个动作,那么合并完了之后的话呢,你你就可以把这个东西呃放到其他的这个应用里面去,呃就是可以去等于是经过你微调之后的这个模型了。嗯,那我这个模型的话呢,目前是放在这个下面的这个目录下 啊,等一下。好,这个就说明他成功了啊,他放在这个目录下面,我们可以去看一下他合并完的这个模型,他已经完成了,那就在这 那这个就是我刚刚生成的这样的一个模型啊,当然他也会提示你,你要把原来的那些呃 pad 那些要输入进去啊,就是要把原 原来我这个模型里面, 他跟我讲了,呃,要把原来 copy 原来 p y 的文件要到这个目录里面去啊,因为我原来的目录是放在这儿的。 好好,这样的话呢,就是呃, chat glm 二代的这个六 b 的模型,再加上我微调的模型,这个就是我微调之后的模型就可以用了,它等于是这样, 好么?我们也测试一下看看, 主要是这个地方要换一下, 看一下,就这个地方要改一下, 就这个地方要改成,我之前新创建,看看对不对? 我们启动一下, 他在加载 好了,这个说明他加载成功了,我们看一下啊,我们运行一下,访问一下, 好让他介绍一下自己,就是说明这个微调成功了,对吧?他没有任何,这个就是我之前让他微调出来的。好,今天的话呢,那个 chat glm 杠六 b 的这个模型怎么进行微调啊?就跟大家就交流到。
534小工蚁 24:25查看AI文稿AI文稿
24:25查看AI文稿AI文稿各位小伙伴大家好,今天我演示一下用这个 auto d l 去部署一下这个叉 t g l 三的服务。 然后首先呢大家可以注册一下,然后这个就是 auto g l 的这个容器页面,然后我们可以去找一个呃四呃四零九零,然后可以去看看有没有便宜点的,比如说在 呃三零九零也可以啊,就比如说我们申请一个三零九零吧,就比如说在内蒙古 a 区, 然后我们点击创建的话,然后就可以了,然后这个时候要选一下镜像,然后选择拍 touch, 二点零 的就可以 高于这个。哦,那我们还是选四零九零吧, 最高窟的这块显示的是十二,嗯,这个是十一点八。 好,这个费用其实不是特别贵,然后我们只 这个很快就创建起来了。嗯,这边可以采取使用命令行的方式进行登录,然后比 比如说, 然后再输入一下密码,这个时候密码是看不见的 啊,我们可以看一下配置啊,可以看到它是 四零九零,然后大概有二十四集。为什么选这个四零九零呢?因为我们第一步先去演示一下怎么去把这个 叉的 g r m 三在四零九零上跑起来。然后呢其实最重要的就是下载这个项目的模型啊,我们假设创建一个目录,直接就下载个目录吧。 啊,这个下载的特别快,其实没下成功, 需要安装一下这个 get 杠 l f s 先更新一下, 然后再装一下,这个时候再下载一下这个模型,这个 时候大家就会发现这个模型卡住了,这个是正常的,就是他在卡住的时候,呃,就会其实是在下载这个大文件,这个速度还是非常快的,我们再开一个界面, 可以看到已经下载了十四 g, 他这个整个模型的话,呃,大概有二十几个 g, 然后这个时候还可以通过另外一个 drew beat lab 进入进入界面, 我们在这个界面当中的话,再重新把这个呃 chat g, r, m, s and 这个 g 的代码再传上去, 这么着在这个根部路里头就就有两个了啊,我把这个做了一下,做了一下把这个压缩包进行写压缩 in way hmm, 不是个 zip 的格式哦,呃,因为这个还没传完, 我们看到现在十六兆穿完了,然后我们现在再给他减压速, ok, 这个时候这个是两部分,就是第一部分我们先要下载这个模型文件, 然后这个是最重要的,同时我们要去下载一下这个呃叉呃叉的 glm 三的这个项目代码,然后把它都加起来之后,然后我 我们就可以把这个项目进行刨起来了。这个时候还需要安装一下 python 的相关依赖,我们直接 python install 就可以了 啊。我们再看一眼,哎,看这个速度是非常快的,一百六十六兆就可以把这个整个的模型下载下来了 啊,大家可以看到这个模型和这个 g 的项目都放在这了,然后我们进入 呃模型,是在 rot 叉的 g r n 三六 b models, 然后它的这个依赖已经装完了。其实这个项目的启动是在 open api demo 里头, 在我们看一眼是 open a p i v 一点儿 passing 的最后一个修改一下这个模型的路径, 这么着我们就可以把这个模型起起来了。呃,启动模型也是非常简单,然后我们直接 python run, 直接把这 python 就可以起起来, 然后这个时候它会加载这 checkpoint, 一共是七段,然后看可以看到这个启动速度还是挺快的,然后 他端口是八千,然后我们启动之后的话就可以测试访问一下了啊,比如说我们可以访问一下这个,让他推 推荐。呃,介绍一下北京的景点,这个 shell 的话是用来做服务的,然后我们在另开启另外一个终端当中访问一下 啊,可以就用这句吧, ah do you guys? 稍等一下 啊,虽然这边报错了,但是还是收到这个请求,然后他会给你推荐一下北京的故宫或者是呃,圆明岩或者是其他的一些地方啊,证明这个模型已经跑起来了。 然后是跑跑成功的,然后我们使用 nv 的 smi 看一眼,可以看到目前这个模型的话是使用了十二 d, 用了一半,然后这个 cpu 功耗的话在二十瓦 再访问一下, ok, 访问成功,看看,看起来这个四零九零这个性能还是非常好的。 然后第二步我们要进行这个模型的进行微调,这个是讲的,呃,主要进行相关的进行微调啊,当然这波也会有一个拍森的这个测试代码,我们可以把这个代码去加进去, 然后这个代码的话是修改,呃,是从 fast 叉的上面然后找到的,呃,代码进行改了改, 然后我们可以就放放这个母了吧, 我们打带门靠进去, 这个代码大概是起了它,默认的话会访问 一下这个 logo 号字八千,然后起二十个现场横,然后去访问,让他生成这个五十个字的一个故事,然后看看,并且记录一下开始结束时间,然后算的一下 took, 然后我们可以把这个代码再跑一下, 我们再进入这个目录直行一下啊,可以看到这个速度还是非常快的, 然后这么着我们大概能算出这个他呃跑了 token, 然后生成这些字,然后这个看每一次的话 啊,大概是每秒钟五十个 took, 这应该算来说已经可以算不错了,后续的话还可以有一些其他的优化方案,让这个速度更快。 然后下面我们来讲一下如何进行相关的微调。这个微调的话啊,是参考这个叉的 glm 三的一个官方的例子, 这个例子大概分成两部分,第一部分呢是讲他这进行工具的进行微调,比如说他要准备成这个数据集,然后进行 呃,再进行一些相关的处理,然后这个格式里头有这个 tors, 然后包括它的输入输出,然后工具的描述,然后进行角色呀这种呃呃这种 数据源输入,然后同时还有一些工具的转换,然后进行相关的呃工具的微调, 然后可调完了之后可以进行模型的图跟部署。然后呢我们今天来讲一下这种稍微简单的点,就是第二种,就是他只对这种输入输出的方式进行这个微调,然后他这个下载地址可以从清华的 cloud 上面下载, 然后我们再进行操作一下,然后是在这这个地址, 然后我们下载完了之后,可以把这个文件传到传到上面,我们放在 fan fan two 上面, fan two demo 啊,之前已经下过了。好啊,我们看已经到这个文件夹了,我们给他解一下下 啊,这个还是报这个错,因为这个正在上传中,然后我们如果有这个文件夹之后,然后我们可以借压缩,然后再进行运行这个,然后再运行一下这个需要进行安装相关依赖,我们可以一步先把这依赖装上 啊,这个时候可以把这个模型的呃外部端给它关掉, 我们把这个依赖给他装一下。装完依赖之后,我们看这个文件已经上传完了,我们再解压做一下啊,可以看到成功了, 然后这个时候需要做一下转换,这个是原始数据,然后他需要给他进行转换一下,然后我们再执行一下 啊,可以看到速度很快就执行完了。他做了一个什么操作呢?在这个当前目录 刷新一下,会生成一个 format date, 这个 date 里头呢会有一个 overtest 低音的这么个 g c l 的文件,然后它在进行微调的时候就使用了这个文件,然后它的微调的方式呢?直接是执行一下, 呃,执行一下这个返出五 p t 就可以了,然后我们看再看一下, ok, 相关的已经安装完成。呃,为了演示,我们可以把这个小本的微调的时间修改一下,就比如说这个训练的比较多,我们比如说一百四, okay, 好,我们直接执行一下模型的训练,这么着就可以进行 模型的启动,然后他也是第一次启动的话会慢一点,会加载一下。哦,启动报错了,那个忘记修改这个叉的 g r m 六 b 的这个路径了, 然后我们的模型的路径在在这, ok, 我们再运行一下, ok, 这个模型也是在加载,然后他也是进行七个,然后他这么着进行相关的 p 进行训练。 我们也可以再打开另外一个界面看一眼内存啊,我们可以直接从 notebook 上面进行去观看相关的这种视力的监控 啊,可以看到目前那个 cpu gpu 的使用率已经上来了, 他正好在进行相关的运算,然后他的显存占用率的话,目前已经到了二十二个 g, 哎,这个显存最大可以到,呃,可以看到 cpu 的使用率目前看是不是很高。内存的使用率的话,目前也是到了 啊,最高的时候到了二十三级,正常跑的话在十二个级左右。那这进行模型的相关的训练,然后 c gpu 已经是百分百了,然后我们再看一眼 nvida s m i 啊,可以看到这个 gpu 的功耗已经起来了三百九十八左右。 ok, 目前进度百分之六。 呃,感觉还是有点慢, 大概还需要二十多分钟,我可以先停了他, 因为我们可能是只是为了掩饰我们把这些大概不知道是什么的参数再调低点吧, 主要就是给大家演示一下, 大家如果在自己使用的时候可以去再调的精确一点。嗯,主要这个视频的话是给大家进行相关演示,然后咱们让他快速的运行完成就可以。 呃,我们修改了一些参数之后,发现现在就,呃变得很快了,然后就说目前百分之三十四十,然后就可以结束了,结束了之后我们还看官方的这个文档啊,就是说他在进行全量微调之后,他会可以进行本地的一个推理验证, 这么着就可以他会生成一个模型的一个相关路径,然后我们只要把这个模 情路径下面的新创建这个 checkpoint 给它加载进来,就可以本机再验证一下了。 好,我们等他生成这个呃文件,呃,可以看到这个已经生成完了,这个四零九零的速度还是非常快的,我们调整了步数之后,就让他快速的生成一个文件。 ok, 这个就是模型,然后再进行本地推理验证的时候,我们把它再执行一遍。 这块可以看到就是我们通过 web 去看这个项目的话,在当前翻春泳 demo 下面有一个 output, 我们点进 altbook 的话,这会生成,你运行几次的话,它会生成几个临时文件。像最新的一分钟,这个时候是我们生成的这个它运行的这个微调的这个文件,最终的话,它这一个是,就是我们比如说我们刚才设的是, 呃有某一个参数,比如说步数或什么东西,他是呃十,然后所以他这有一个拆空的十,然后同时还有一个拍到这 model 点闭,这个就是他生成的这个微调的这个文件,这个微调的文件和这个模型 模型的这个文件他两个放一块之后,然后这个项目就可以启动起来了。啊,这个这个模型是放在这 啊?没起来。 ok, 我们看到这个速加载速度还是很快,然后现在已经骑起来了,这个时候我他需要让我们去问一些问题, 我们看一眼数据集当中的一些问题, 哎,不是 a d, 我们看这个训练的样本 a d 和 mate data, 看一眼他这 prompt, 他就是运呃需要输入的一些提示,然后同时呢还有一些输出的结果啊,比如说我们输入到,呃这个问题有点长,我们可以给他精剪一下 这个,它实际上是一些标签的集合, 假设我们去问这种类型需要给他, 哎,这个是 时候他就根据这个问题大概回答了一下,然后给你按照这个标签去重新生成了一段文字,这个的意思就是说我们的训练集已经完成了,呃,我们看到没有错误, ok, 这坎就是整个如何进行模型的相关的训练的演示,当然后续,呃 后续的话其实看呃最重要的就是在准备这些数据局,我们看到目前他的话是用的这个网页中的标签与这个文案的关系,然后根据这个学习, 学习完了之后根据你再重新输入一段标签,然后他会给你生成一段相关的这种文案,呃大概是这么个训练, 呃,同时呢这个数据量也是挺多的,我们再看一眼, 呃,这个数据量十有十一万左右,十一万四千五百九十九, 大概有十一万条数据,呃,所以如果要是呃想让模型去学习一些东西的话,那么我们的数据级的准备最好还是呃很多一点,然后这么着,而且都是很相似的一类的这种数据。 我们看他这个实际上是标签的格式写了一些特殊的分隔,然后只要输入这些特殊的分隔,然后他就能大概给你一个什么样的这种文案的生成。好。以上就是今天 天的这个,呃呃呃, chat g r 三的这个在呃四零九零上面的这种部署和这个微调的演示,好,感谢大家。
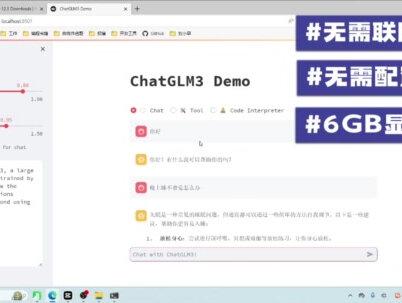 03:22查看AI文稿AI文稿
03:22查看AI文稿AI文稿不用联网,不用付费,家用显卡即可部署全代码开源的大语言模型 chat g l m 三就在本周发布了,本期视频提供 chat g l m 三全网最简单的一键部署包,解压后即可一键运行,无需联网,无需配置六 g b 以上的显存即可流畅使用, 还不受任何约束的随意微调,再也不受 openai 这类 gpd 厂商的限制了。我们的主角 chat jlm 三是由清华大学智普 ai 团队在本周刚刚发布的最新最强的开源大语言模型, 短短几天已经霸榜 get up, 获得了四千家的 star。 官方在八个中英文典型数据集上进行了性能测试,所有指标对比二代模型也有大幅提升,已经超越市面上所有百亿参数以下的 大模型。在轻量级的大语言模型中,瑶瑶李天宇同行部署之前,我先介绍一下电脑的运行环境,我们的电脑必须拥有一个六 gb 以上现存的银微点显卡,虽然此模型可以使用 cpu 运行,但是效果非常的不好,下面我们开始介绍部署方式。 首先第一步,打开 invidia g force experience 控制面板,点击驱动程序,这里找到 n 卡最新版的驱动程序,点击下载并且安装就可以了。我们进行第二步下载扩大,我们进入这个网址,这个网址可以在本期视频的专栏里找到,这里找到我们对应的操作系统,这里我选择 windows x 八六架构,然后选择我的 windows 版本 windows 十一,点击 exe 安装包,这里直接点击下载就可以了,下载好以后我们进行安装, 然后这一步就结束了,我们升级好 n 卡驱动,并且安装完扩大以后就要对电脑进行重启,重启完毕以后进入命令提示服,对刚才的安装进行验证,输入这个命令 in vdr 杠 smi, 这里显示我的扩大版本是十二点三, 如果想要模型运行取得一个比较好的效果的话,我推荐十二版本以上。好,我们进行下一步 下载好本爬爬虾提供的这个一键部署包,我已经将这个安装包打包并且上传到网盘了,需要下载地址的话可以三连后加关注私信我,我们将这个安装包解压好, 解压好以后得到一个这样的目录结构,有三个文件,我们直接点击这个运行脚本,可以看到它自动开启了一个浏览器的窗口,这里显示模型正在加载, 我们需要耐心等待一段时间。模型加载好以后,这里显示出了我的显存大小,由于我使用的是一个笔记本,这里是三零六零的显卡,所以说只有六 gb 大小的显存。这里使用量化 inter 四版本进行运行,我们跟他对话一下,看一下效果。 这里官方提供了三个主要界面,一个是普通对话,第二个是 tools, 这里就可以接入各种第三方工具,比如说查询天气啊,查询股票这种功能。 第三个是 code interpreter, 这个是增强了他的代码功能,也就是说输出代码的一些功能。如果本期视频点赞超过两千,大家对这一块功能感兴趣的话,我会专门出一期视频来讲一。
18在北京打拼的六子 04:32查看AI文稿AI文稿
04:32查看AI文稿AI文稿chat g l m 呃,微调的这样一个项目,它是能够支持 chat g l m 二杠六 b 的这个模型的微调,它已经在六月二十五号这个模型刚公布的时候,它已经能够支持来微调。当然我目前还没有是我估计他们应该是可以的。 他这个项目之前,呃他也能实现的基于 urora 的这样的一个微调啊,之前我也是介绍过的,像那个 qurora 跟 rora 那个微调的差别,之前我也在之前的视频上面跟大家聊过,我这边也就不。 这个项目的话,它还能支持什么监督的微调,就是 s s f 的微调和 r l h f 的这样的一个人类强化学习的这样一些微调 概念,我之前在我之前的视频里面都给大家介绍过,所以我这个就不赘述了。一般大型的浴训类模型完成之后,他还是要经过一些有监督的微调,这是第一步。那么第二步的话呢,还要经 过一个训练,一个奖励,网络在经过人类反馈的强化学习,那这样他的整个一个效果会比较好,他等于是这样。目前这个项目,他这个两种方式都是支持的。类似于恰特基地三点五的这个微调的这个三个阶段,他目前都是支持的。我看了一下这个项目的话是二是今年四月份刚刚把它给 公布出来的,但是我看他的热度还是非常高的。那么在这个项目当中,他也支持了非常多的一些数据集。因为我们清楚,如果你要对数据进行微调呢,你必须要有一些 训练的数据。他目前有有羊驼的英文的数据,也有那个羊驼的中文的数据,包括今第四产生的一些数据,包括中文这个数据集里面有一个比较有名的,就是 标嗯的这样的一个数据,中文的这样的一个数据集,他还是支持的比较多的。还有一个是我记得好像不错的是,应该是那个美国波斯顿大学吧,大概他们公布的 这个叫寡拿口的这样的一个模型,这个模型也是基于 l l m a 的这样一个模型基础上,他们收集了一些这个数据值,然后进行微调。他也是基于这个 qrow 的这样的一个微调,他在六百五十亿参数上面进行调整。 据说这个单块 g p u 四十八级的那个显存就可以调,而且它的性能也是不错的,所以它能够支持非常多的这种 中文的这种中英文的这个数据集还是非常方便。那么微调的方法我前面也讲,它也能够支持 quiro 啊,包括 rura, 包括 p 车零一二的这个版本啊。 p 车零一二的版本的话呢,就是那个原来清华他们开园的这样的一个微调的方式,包括他也能够支持全量的微调,当然他会比较消耗资源。目前他的依赖还是基于这个拍,拍成三点八,那基于拍 touch, 我看了一下,基本上就是我之前介绍过的一些哈登、瑞士 他们开源的这些类。像那个 t r l, 就是做那个人类强化学习的这样的一个内裤,包括 p e f t, 他主要是做那个 q r r 的这个微调,他主要是要用到这个库的分布式,他们会用那个 accelerate 这样一个类,这个类的底层其实就是微软的 deep speed, 对 deeps speed 的这样的一个类。呃,然后他跟那个创始 former 的这个,他们开发的这个类能够很好的整合,这个是最核心的。然后一般微调的话呢,还是要有些强有力的这个 gpu 的,否则的话他会跑的很久。当然他单 gpu 也可以微调,不是的,多 gpu 也是可以微调的。如果是分布式,他一定要装这个内裤,就是 accelerate 啊,这个内裤一定要装一下啊。它这个里面也能支持 r、 l、 h、 f 人类反馈强化学习的这样一个微调。呃,微调完了之后,你要看微调的效果,它也能够支 持的。一个自动的一个评估,他也能跑。我看他他好像也能够支持 c、 l 的这样的一个评测,就是中文的这样一个评测,他也是能够支持的。呃,他这个里面也给大家介绍了一下,如果是用不同的微调的方式来,那么他所需要的 gpu 的显存 大概每秒钟能跑多少的这个数据量。他这个大概讲了一下这个这个项目,他对那个恰是 g、 l、 m 的这个模型会比较友好,因为他这个模型是第一次他就去支持 目前二二代恰特 gim 二的话呢,它也可以通过这个开源的项目进行微调。那下次有机会的话,我可以给大家先尝试一下,然后 看看,给大家检测一下,看看有些什么问题。因为我之前也是用过微调,尝试过,比较花时间。他其实难度不是太大,他这个大方面也比较了一些,他们这个这个项目类似的一些项目他也讲了一下。好,所以这个 项目大概的情况就是这样的,他支持微调的方式还是非常多,而且支持的那个数据员也会非常多,所以的话呢,他用起来还会比较方便。就把各种各样开源的这些东西,脚本啊,什么都已经测试,都已经整合好了。这样的话呢,大家用起来会比较方便。好吧, 所以今天这样一个项目,我就跟大家就聊到这。我回头我可以把这个网址放在我的那个主页上面,大家如果有兴趣的话可以去看一下。好,今天就聊到这。
210小工蚁 01:42查看AI文稿AI文稿
01:42查看AI文稿AI文稿oppo ai 的微调接头普通人真的玩不起,训练起来好贵。这期为了更好演示微调效果,有一位星球粉丝提供原始数据,我来进行微调训练,目的是帮粉丝微调一个铲除高点击转换文案的 gps 模型,大概三百八十度,训练数据视力 直接消耗了我十二米高。话不多说,直接分享微调训练,自己独享 gp 三模型的第三步,也是最后一步,使用 playground 调试自己的微调模型。 我们完成微跳模型的创建后,进入 playground 的页面就是这里。 playground 是 open ai 提供的官方调试工具,页面右侧为调试参数区,左侧区为 prompt 输入和 company 型文本输出的共同区域, 这里默读。我们选择 company 文本填空,这里给大家做个对比。我先用官方提供的模型输入 提示时 prom 点击提交按钮。要经过微调训练,产出的内容是比较通用的,这并不符合粉丝的要求。然后我切换到微调模型,就可以看到输出文案了,内容还是在预期范围内的,已经可以用到实际功能。 调试参数这里先用默认的,如果文本输出不满意,我们再进行不同的设置尝试。这些参数这里不展开讲,我放到保姆教程里,老地方自己去看。那截止到这里,如何微调? gp 三模型分了三期,边摸索边试验,分享完了,是不是很简单? 当然不简单了,直接我调试这些参数,差不多研究了四个多小时,官方文档对数据训练及实际没有讲解数据质量标准或数据治理的方法, 在这种情况下,测试结果非常不可控,所以建议大家还是要多动手多填。我接下来也会分享如何制作我们的训练数据集,有用的话记得点赞收藏。
428暴躁哐哐 02:19查看AI文稿AI文稿
02:19查看AI文稿AI文稿gpt 微调训练数据的视力数量和数据质量有多重要?今天分享一个实战案例,大家来感受一下。上周写作一位星球粉丝,训练一个能够按照给定题目写诗的模型。 一开始粉丝做好的训练数据集是这样的,看得出来是认真阅读了微调数据细节。那一期的教程的 prompt 的分割符和 completion 的空格,起头和结束符都已经按照 open a 的要求进行了,准备点个赞,但是训练完以后,模型完全没法使用,什么也不回复,或者干脆胡言乱语,怎么回事呢?帮粉丝列出了两个原因, 一, prompt 和 completion 关联性差。第二,训练视力太少。先提升关联性,必须要让 gpt 知道训练目标。我们可以在 prompt 中告知 gpt, 你是一位诗人, 你的特点是不拉不拉,不拉不拉。机芯优化后再次训练,效果还是不符合预期。我们进行比如领导争棒为主题写诗,效果确实不好,至少风格上没有达到我们的要求。 然后增加训练实力数量。回忆一下,之前教程有提到, open a 要求内容深层的模型微调至少五百个训练实力,但粉丝竭尽所能只能整理一百个训练实力。唐诗三百首不好找吧?托格莱 cv 四次应酬五百个实力,试了再说。 嗯,这次有很大的进展,虽然还没有完全达标。我试着帮粉丝进行模型的参数调试,因为是内容创作,可以把温度值稍微调高一些,我尝试零点七到零点九左右,再把其他参数也改为, 慢慢的能够进行稳定产出了。比如领导争霸,老板家有春风得意这些主题基本格式都是 ok 的。同样的 prompt 用 chagbt 对比微调模型的写作风格还是很明显的。 但是我认为你完全稳定使用还是有差距的,要在训练数据上继续花时间,毕竟这次案例真实的数据视力只有一百个。 其他粉丝小伙伴开始筹备训练模型前,其实也可以想想你手里的数据质量和视力数量是否能够达到 gpt 的门槛。对于微调训练或者 mbnd 还有其他问题,欢迎粉丝小伙伴留言,有用的话记得点赞收藏。
149暴躁哐哐 11:17查看AI文稿AI文稿
11:17查看AI文稿AI文稿l m 杠六 b 的这样的一个中文中英文双语的这样的一个模型,然后我们怎么对它进行来微调?因为这个模型是中国人研发的,还是有很多人在问说这种模型应该是 英语训练模型,应该是怎么样做一些微调?这个我跟大家一起来交流一下,那么这个模型微调,我们可以看一下大学最近圆的这样的一个比较流行的叫羊驼的这样的一个模型啊,这个模型的话呢,就是目前非常火,可以给大家看一下模型, 看一下就上福大学推出来的这样羊驼的这样的一个模型。简单介绍一下,这个模型的推出,主要是美国的这个学术界就是发现 gpd chat chat gpd 就是非常火, 但是这个项目基本上都是碧源的,学术界的话呢,就比较难去复制他这个模型,所以他们也是要进一步去研究的,所以斯坦福大学的话呢,他们就想方设法要去把 下的 gpd 的这个模型能够在开源的能够复制出来他的,那么他呢就是呃,他们就结合了一些,嗯,然后把呃就推出了这样羊驼啊这样的一个模型啊,那么这个模型,嗯过那个双盲测试啊,他们也测试了一下,就是 啊,然后可以低着去呃模啊,然后呢他们也帮测试啊,那么双方测试测试下是发现的,哎,模型比较小,但是他的能力的话呢,倒也适于恰特 gpg 的这种能力啊,所以的话呢,这个一下子这样的一个开源的这个项目就流行出来了,他等于是这样可以给大家看看啊,他这个项目 星星非常多,对吧?非常非常多,非常热的这样的一个全是在他的话呢,就是目前是对那个这个开原版的恰的 gpt 这个模型是是目前是做的是相对是比较好的他这个这个模型,那么这个模型呢,我们可以给大家看 看一下它它这个模型是怎么训练出来的?它的基础模型呢?它是用了 facebook, 就是 manta 的,它有一个叫 m m a m a 的七 b 的这样的一个基础模型,这个模型的话呢本身也不是太大,是 facebook 开源的, 他在这这个模型基础上,他用了五五点二万调的,然后进行监督的进行叫微调,然后在这个档他就会变成这样的叫 alpaca 的这样的七 b 的这样的一个模型啊,这个的话就是七十亿的这样的一个参数,他有七十亿的这样的一个参数啊,那么这个模型的前面也是讲了,他的这效果还是非常不错的,他的也是这样,那么他在这个当中呢,还是有个创新,这个是一个创新点,他在 五点二万条这个提示指令,它是通过一个,它是通过 chat g p t 自身产生的,它对它是这样来做的,它其实本质上来谈它是有有一百七十五个这样的一个指令,这 个呢是手书的,它有这种指令,通过这个指令通过这个掐的 g p t, 然后自动地产生了五点二万条这个 训练的这个指令,然后再跟这个 l l a m a 这样的一个模型进行监督学习的微调,最后变成了这样的一个模型,这个模型目前在学术界里面是最接近于 chat g p t 就是 g p t 三点五五的这样的一个模型啊,它 还是这样,他们也也找了五个学生做了一些舞台,等于是这样。这个双盲测试的评估啊,发现就是说他的这个能力啊,跟掐的 gpg 类似,很类似。他这个功能上面他们他提供了一个数据,他跟我讲好像是 非常接近,他们做了一个双黄测试,双黄测试里面他们好像是八十九十比八十九这样,他们做了一个看到底这个内容是哪个模型产生的,双黄测试里面 几乎是看不出来到底是哪个模型产生的一些内容。那他当然也是讲了这个模型目前还是有些问题的,这个问题的话跟那个恰的 g b t 是类似的,他的这个问题主要就是还是这就是胡说八道啊,他就是等于是为他录有些模型他不知道的内内容的话呢,他就会逼邪模型,这个叫幻觉啊,他等于是这样。 那个羊驼的这个模型的话呢,在 gitch up 上面也开源了它等于是这样。好,这个模型我就展示给大家,介绍到这儿,我们看看它的代码,看它的代码,看一下它的代码,这个在 git up 上面, 他的这个代码主要是公布了他的五点二万条的条的这个数据集,就是个指令啊,原来也是解释过的,叫提示学习的指令啊,这个是他是把这个数据给公布出来了, 而且他也公布了如何产生这个五点二万条的这个提示指令的这样的一个代码,他也是什么呢?对他有一个创新的方法啊,这个方法的话 看一下他,呃,十年的年底啊,波斯顿大学他们就推荐论文啊,主要是如何自动的产生这个提示的指令啊?他是通过这个模型 怎么自然语言的模型,怎么自动的产生一些提示的指令?他这篇文章里面就讲他有一百七十五个随机的这样的一个任务, 他通过类似的,当然他自然语言的情,他们目前羊驼他们用的是直接掉了欧奔 i 的这个,呃,恰特基的这样的一个指令啊,然后自动的就是问那个恰特 g p t 去产生这样的一个内容,他等于是这样啊,这个五点二万条的这样的一个指令产生的话呢?他的论文上面讲他只花了五百块, 嗯,生成出来的。原来的话呢,那个 chat g p t 的话呢,它是通过人工来收集人工去做的啊,它现在的话呢,就是直接绕过了人工,接通过 他的 gpt 来产生的这种内容啊,成本就更低更快。那他在开源的这样的一个项目里面,他也把这些数据给公布出来。我也看了一下,他这个内容非常多啊,什么早餐的建议啊,他还有一些各种各样的像面试的一些问答,他,他包括一些医医庙的男生,他有很多很多的任务啊,他这个里面 啊,这个就是题指令,当然他也有一些数学题目啊,包括他也有把这个文本 to c 口的这样的一些任务啊,他这个都算是任务,我看了一下,非常多,还有什么 html 的任务,就是你怎么起 html, 他这个里面也有包括还有一些什么 news 的,呃,摘要啊,呃,他做啊,我看了非常基本的啊,其实 一百七十五种吧,一百七十五种看他数据库里啊,对,是一百七十五种,七十五种任务跟大家就聊到这,那么这部分代码也是啊,中文的这些吧,啊,也是有非常好 参考的这种价值,因为他这个数据提示指令是非常重要的,因为这些提示指令你写的好,你才能让这个模型啊。呃,能够压制那个比较重要后呢,他这项里面最后一部分呢,他也提供了个呃,这个么微调的这样的一个。呃, 啊,这个 pad 的话呢,那它也基于这个 hurt and face transformer 的这样的一个内裤啊,的一个 transformer 的一个大型的这样的一个。呃, 处理语言做了一下这个微调啊,他是他产生五点三万条指令的这个指分布啊,他有颜色就是代表词,各种各样的能力啊,各种各样的能力,他有解释的能力啊,他有数学的能力,还有分类的能力等等,还有查找的能力,他有分辨的能力,他是这样的,这个是他微调的具体的参数, 它一 pro 主要是三次,否则多的话它会过离合。它也讲了一下它的整个一个训练,它用了四块 a, 一百的八十 g 的 gpu, 它应该跑大概五个多小时吧,然后它就跑完了,所以的话呢,它是一个比较低成本的 ppt 的这样的一个开源的这样的一个模型啊,那目前它主要是支持的是英文啊,英文它是支持的英文, 当然他这个这个吗是他训练的脚本,训练的脚本这个项目大家要注意的,这个注意的他是不能商用的,因为这个是他日坦福大学,他是声明的,你可以作为学术用途,但是你你可以作为研究,但是你不能利用在啊,因为他是用了那个 ai 的一些呃,诶,通过 obanai 呃的 chat gpg 产生了一些些内容,呃,因为 obanai 里面他也是强调的你,你是不能用 obanai 的内容,然后再去去跟 ai 做商业的竞争,他是等于是这样 看一下,不了给大家解释。那再来看一下就是 chat g l m 六 b 的这个中英文双语的这个模型是如何进行微调的,因为 我们前面就是说就他们羊驼的那个模型啊,这样来进行微调的啊,其实也是可以学他们这个方法论啊,和一些数据,然后看看怎么来微调。我们来一起来看一下,这个是目前微调的这个代码的,也是公布在 git up 上面的,也有 也有人,我们是可以看一下他这个数据集的话呢,他就直接用了他们羊驼产生的这个数据集啊,所以呢,这个数据集的话呢,他是只有那个本的 他,他只有英文的,他中文可能也有,但是会比较少,他等于是这样,他微调这个是他需要的一些硬件,最好的话呢,要超显存,要超过十六 gb, 最好是二十四 gb。 羊驼型的话是四块 a 一百的这样的一个实际的这样的一个 g p u, 它是跑在这儿,那么中国人这个开源的这个项目,它把精度调的更低了,这个我之前也是介绍过的,它是用了哈根 face 里面的叫 p e g f 的这样的一个内裤,它 降低了他的用了一个 rora 的这样的一个模型,他在做那个 transformer 的这样的一个低成本的这样的一个训练。看看啊,我们看看元代码,看一下元代码在这,元代码在这, 主要你还是要先把他的这个微调的代码库,要把它下载下来,不要安装他的依赖还有 requirement, requirement 里面也其实也没啥,主要是用了这个这两个,这个是他跟 face 要做 transform 训练式加速的一个内裤,这个内裤的话呢,主要是用在他是八位整形的这样的一个 模型,训练的时候,他把精度降低,要用到这样的一个内裤。另外他那个 chat g、 b、 l 的这个模型的话呢,他要用到了这几个内裤,他也基于那个拍 touch, 然后基于这个我们看到的 p e、 f t 这样的一个内裤。好,我们看看他是怎么来进行微调的。安装完了之后的话呢,他就把这个羊驼 这个数据进行数据转换,转换成他要的数据。然后的话这句话的话呢,他主要是做一个编码,编码把他的这个英文啊中英文进行编码处理 好,处理完了之后的话呢,他就去加载这个 cat g b l 杠六 b 的这个模型。他在预训练之前的话呢,他在微调之前的话,他先做一些测试,他就是看看他在微调之前他的回答,他的到底是怎么样子的,他就把这些参数,把这些 date tens 给捞了进来, 他去构造这样的一个吹,这样一个训练的这样的一个内裤,这个是具体训练的一些参数,他就去运行这样一个训练就可以了,我看他也是一样的,他跑了这个三个一 pro, 他就训练完了,因为他的那个参数比较低,他的参数精度会比较低,所以的话呢,他用的 g p u 会比较少啊,内存也比较少,他等于是这样训练完了之后,他又做 做了前面一样的那个测试,他会发现测试的结果可能要比前面要好。最后他把这个训练完的这个模型,把它给保存下来,这个是整个他的一个恰特 gbl glm 的这样一个微调的这样一些代码,还是比较简单的,应应该也不难。 那这个微调过程的话呢?探点在我觉得还是在这,你怎么通过一百七十五个任务自动的去产生他这个是五点四万条的预训练的这个指令,这个指令是什么?我觉得是比较重要的,而且你指指令的质量也是比较重要的,那么他们做了一个取巧的方案,直接去问恰的 gpt 要内容, 等于是这样他就呃产生了大量的这些指令,这些指令的话呢,然后再作为一个建度训练的这样微调的这样的一个数据,把最终的这个模型给训练出来,他等于是这样,那么我们看到的是那个 chat g l m 的这个模型,那其实 是类似于这个 gpg two 的这样一个模型,但是他这个模型好的是在于是用那个中英文的语料去进行训练的,他等于是这样,所以的话呢,他相对对中文来讲,他的那个强一点啊,活的这个能力的话,他这个模型呢,是目前主要是英文,所以的话呢,他中文还不支持,所以当然他可能聪明度可能会更高一些。 好,这个就是我今天要跟大家交流的哈,我也欢迎大家能够给我留言。好,今天就介绍到这。
300小工蚁 01:38查看AI文稿AI文稿
01:38查看AI文稿AI文稿超越 tchit gt 三点五还能搭建本地的知识库,直接上传文档帮你阅读文档内容。今天老杨带来文达系统安装教程,可以使用微调版的 tchitglm 模型, 他可以快速的进行相关的生成。还有最为强大的就是他可以具有本地的知识库,自带的三个本地知识文档是咱们关于春秋战国的一些发展史,所以咱们可以根据他本地的知识库选项让他搜索,比方说孔子, 他可以根据咱们中国的历史库来进行孔子的相关搜索去整理,那么这款功能就非常契合,如果你是做电商的, 你完全可以把你电商的所有数据放到这个知识库里,将来根据您公司的产品,他都可以帮你做很好的回答。好的,通过刚才的调试,咱们已经知道这款 ai 已经非常不错了,接下来大家和老张好好的来安装一下,让大家把所有 的坑全部都闭掉。首先第一点呢,咱们需要先安装相关的一些依赖,然后直接双击下一步安装即可。 ok, 直接双击打开对应的文达启动器就可以得到这样的一个界面,他会定期的去进行主程序和 启动器的更新,当然如果在更新的过程中产生报错也是没有任何问题的,大家不用担心。然后在这有一个知识管理好,然后点击 管理文档,在这输入咱们对应的知识库,注意他的默认都是 txt 文件。装成功之后,点击知识库生产,弹出一个对应的进度条,咱们等到这个处理进度走到百分之百,即使安装成功当中选择程序运行, 直接启动 glm 六 b 选项,点击,然后咱们找到这个地址,兄弟们,就是咱们文达的这个首页面了,首页面的话就可以像刚才老张玩法一样任意的去畅玩了。
419程序员老张(AI教学) 02:33查看AI文稿AI文稿
02:33查看AI文稿AI文稿家人们截止到昨天为止下, gpt 已经给所有的四点零用户全部都推送了 dl 一三的绘图功能,那么这款插件呢,它是支持中文绘图的, 那很多小伙伴就说这个插件上了之后呢,已经可以吊打 stable, diffusion 跟 majority 了。那我今天呢就给大家简单介绍一下这款插件应该怎么使用,以及它跟 s d 与 m j 之间的区别。 首先如果你是第一次使用的话,需要点击插件左边的 new chat, 然后直接鼠标移动到 g p t 四上面,然后选择调一三,然后再 这边输入你需要生成的图片,他就会按照你的需求直接给你四张风格不同的图片。那么这个呢,是我用中文让他生成的中国地图图片啊,大家可以看一下四张不同风格的,并且啊看一下一点都没有少,唯有让他生成三只可爱的小猫趴在桌子上,那这也是没有问题的,四个不同的风格,那不同于 s d 跟 mj 的第一点就是它是可以控制图片的,我让他把第三张图片中间的小猫去掉,其他内容不变,他是没有问题的。但是这功能在另外两款软件里面就需要用到非常复杂的插件了,在这边直接跟他对话就可以生成, 那同时呢,他也是可以生成平面图的,我让他生成一个一百三十平的房子,三室两厅两卫都是没有问题的。我再让他把这个平面图 变成 cad, 并且标好尺寸,大家可以看一下,也都是把尺寸标好的,虽然我不知道他有没有瞎标。第二点我觉得非常方便的点呢,就是他是支持中文去修改设置的,什么意思呢?让他把生成图片的随机性改小一点, 他就直接给我改掉了。但如果你在另外两个软件里面要达成这样的功能的话,就需要去改大量的这个设置跟参数,那这个是非常非常方便的。我们来对比一下三款软件生成图片的质量,这边是准备了一个枫叶女生的图片, 这个是他的生成信息,我已经提前把这个生成信息放到软件里面,把图片绑好了,大家看一下啊,这个是 g p t 的生成的图片,这个是 s t 生成的图片,这个呢是 m j 生成的图片。 那总体来讲,我觉得生成图片质量最好的还是米杰尼,大家可以看到米杰尼对于人物的表情,人物的动作以及图片的紧身控制的都是非常非常细节的,整个出图的效果跟质感是要好于另外两个软件的。 那么最后总结一下,我觉得吊一三在功能性、便捷性以及入门门槛方面呢,已经是远远甩开了另外两个软件了。但是在最重要的生成图片功能,我觉得它的出图质量可能还是比不上 s d 跟 m j。 另外呢,他会有的时候会把指令识别错,比如说我让他生成平面图标注尺寸,结果他还是给我的三 d 的图片,但这已经是一个非常非常非常大的进步了。
266星环无限 01:16查看AI文稿AI文稿
01:16查看AI文稿AI文稿有同学说,只要我有一张四零九零卡, nora 在手,天下我有,拥有这样想法的人一定不在少数。如果你打算微调大模型,你会优先考虑是一张二十四 g 以上的卡,你肯定会去查阅 nora 微调训练,你也会去了解 peft 高效参数微调,你甚至还提前预习了 ppo 近端优化策略。 当你热血沸腾看了 r l h f 介绍,你会觉得强化学习人工反馈已经不在话下。以上准备工作已经消耗了你一两个月的时间,接下来才是重点,你将面对如下问题,第一,你可能会发现多人对话没有按照你想象的方式进行,比如自问自答,比如不按套路出牌 和必须按套路出牌,否则他回答的东西和你期望的东西不一样。第二,你可能会发现罗尔微调后,他其他方面的智能丢失了,或者说智能严重下降,而你想要的现象呢?却没有出现。 甚至你开始想其他的微调方案,比方说 peterly 以及这个 problem vitually。 最后,没有办法,只有等模型的二代版本、三代版本再试试,再看看。 第三,当你认为强化学习是自己最后出路的时候,你是不是会发现自己居然没有奖励模型?你甚至不知道什么时候该上强化学习的一种困境,你开始疑惑,强化学习能救我吗?以上这些问题,你遇到过吗?
328野生博士(邪修版)小魔头 04:13查看AI文稿AI文稿
04:13查看AI文稿AI文稿提示工程和微调是自然语言处理和机器学习中的两个重要概念,他们通常用于训练和优化文本生成模型, 两者在自然语言处理中扮演不同的角色。那么,什么是提示工程?其实, 提示工程是一种用于定义或设计,用于与文本生成模型进行交互的提示或问题的技巧。这些提示通常是用户提供的文本,用于引导模型生成所需的文本或回答。良好的提示工程可以显著影响模型的性能,使其生成更准确、 有用和符合期望的文本。另外,提示工程可以包括选择适当的问题类型、设计问题的语法和结构、指导模型关注特定方面的信息等。 再来看一下什么是微调。微调则是在已经进行了预训练的模型基础上的进一步训练过程。 在预训练阶段,模型通常在大规模的文本语料库上进行训练,学会了语言的基本结构和知识,而微调是将预训练模型进一步训练,以适应特定任务或应用领域。微调阶段通常包括使用任务相关的数据,例如问题和答案对, 以调整模型的参数,使其适应于特定任务。通过微调可以提高模型在特定任务上的性能,例如问答、翻译、摘要生成等。 在使用文本生成模型时,我们通常需要进行提示工程来构建输入提示,然后再使用微调 来针对特定任务或应用进行模型优化。这种组合可以使模型更好地满足特定需求,提高生成文本的质量和适用性。 提示工程和微调都是用于训练和优化文本生成模型的重要技术,他们各有优缺点,并在不同的场景中具有不同的适用性。下面再来对比下提示工程和微调的优缺点及适用场景。提示工程的优点,首先是控制性强, 通过设计提示,用户可以精确控制模型生成的内容和风格,以满足特定需求。 其次是灵活性好,用户可以根据任务的不同调整提示,以适应各种应用场景。再者,他易于使用,对于非技术人员来说,构建和调整 提示通常比微调更容易。那提示工程的缺点是什么呢?第一是限制性,他依赖于设计良好的提示,但可能无法处理不在提示范围内的问题或任务。 第二是知识要求,他需要用户具有一定的领域知识和文本生成经验来设计有效的提示。 再来看微调,他的优点,首先是适应性强,我们可以通过微调将通用模型调整为特定任务或领域,具有较高的适应性。 其次他支持多任务学习,允许在一个模型中同时处理多个任务,减少资源和模型复杂性的浪费。再者,微调不受输入提示的格式限制, 可以接受自由文本输入。微调的缺点有以下几点,第一是需要大量数据,微调通常需要大量的任务相关数据,这在某些情况下可能难以获取。 第二是计算成本高,相对于提示工程,微调可能需要更多的计算资源和时间。第三是需要技术专业知识。相对于提示工程,微调通常需要更多的技术专业知识来进行模型训练和调整。 在实际应用中,选择提示工程还是微调取决于任务的性质、可用数据资源和知识水平, 通常二者可以结合使用以获得最佳的文本生成性能。
26凯哥玩AI


猜你喜欢
- 5610MK的鹦鹉