embedding优化方法
大家好,我是圆圆,每天更新干货算法笔记。什么样的未知编码对于时间序列分类问题是最有效的?今天给大家介绍一篇针对时间序列对 transformer 位置编码进行优化的文章。本文分析了 transformer 中各类位置编码的特点, 并提出了一种绝对位置编码和一种相对位置编码方法,适用于时间序列分类任务,并基于这两种编码提出了新的时间序列分类网络架构。本文提出了对绝对位置编码和相对位置编码的改进。针对绝对位置编码, 围兜越高,得到的未知编码越符合期望性质。然而,时间序列数据维度一般较低,使用维度过高的位置编码容易过拟核。因此,文中将模型尺寸和序列长度引入三角函数 静态位置编码的计算逻辑中。针对相对位置编码,文中提出一种高效检索方式,并将位置编码生效位置后移到 attention the softwax 之后达到了更好的效果。最后,基于这两类编码, 文中提出了一种新的时间序列分类模型,并在多个数据集上取得显著效果提升。

粉丝3972获赞1.5万
相关视频
 02:42查看AI文稿AI文稿
02:42查看AI文稿AI文稿嵌入也成为文本反转,是在 stead body fashion 中控制图像风格的一种方法。我们将了解什么是嵌入以及如何使用它们。 有了 inbiding 就不用写一公里的提示词了,用很少的精力就可以大大避免出现错误的人体结构学、令人反感的配色方案、颠倒的空间结构等,亦可以让你提升图像的质量和准确性,生成特定的图像,提高可控性。什么是 inbiding? 在计算机科学中, inbiding 是将高维数据影视到低位空间的过程。 在图像处理中,影百里通常将图像转化为向量表示,以便于继续学习和深度学习任务。在使用 catbody pro 进行绘画时,嵌入定义了新的关键字,描述一个新的概念而不改变模型。 嵌入项量存储在点并或点 pony 的文件中,他的文件非常小,通常不到一百 kb, 是最小成本的一种微调模型的方法。将输入的图像转化为项量后,可以把对应的项量,也就是关键词 字放在图提示中,以便于算法对其进行处理和生成新的图像。简单讲,可以把嵌入理解为一种提前训练好的模型。在模型处理的过程中,告诉模型要如何操作。比如 renbelling 里有玩偶的信息对应一个单词, 像其他提示词一样放在提示里,那么模型生成的图像都会体现出玩偶的特征,但正常作者是你。只是希望不出现令人不适的图片,但想要按照自己的想法生成图片,这时候正向嵌入模型的意义不大,所以反向使用它就有了奇效,毕竟谁也不需要坏的时候和令人反感的内容,除非你想生成可速路。 我用 c 站卸载量最高的地步那个地步。给大家举个例子,这个作者用大量恶心的图片训练的一个文本反转模型就像一个错误集,所以把模型放在负面提示,就自然不会出现你不需要的图片。所以说有些模型作者还是很辛苦的,不仅付出了时间和精力,可能心灵都受到了伤害。 给大家推荐几个最受欢迎的文本反转模型。第一步, negative v 一点七五 t easy negative bed head v 四以 bed head v 四为例,不使用这个牵手模型容易生成换手,使用了引白领出现,换手的几率就大大下降。使用方法很简单,在 c 站或其他站中 点击文本反转选项,并选择你基础版本对应的模型。大部分人使用的都是 v 一点五。然后将以白领文件下载拷贝至根目录下的以白领文目录里,按原名就可以,也可以将文件重命名为您想使用此嵌入的关键字,它必须是你模型中不存在的名字。 然后在文声图中负面提示词里输入文件名。在文文反转选项下点击你要用的模型。注意点,使用嵌入的缺点是有时不清楚他与哪个模型一起使用。一般 cd 的模型作者会告诉你的试用场景和用法,大家看到喜欢的 模型也要看下说明。有些模型是专用的,比如 dream shape 发布的 bed dream, 可以看到以前的版本需要大量的提示词,现在只需要一个线路。感兴趣的关注看,关注我,带你更好地理解 ai 绘画。
888Alex 03:26查看AI文稿AI文稿
03:26查看AI文稿AI文稿三分钟搞懂蓝白定和提示词强度,我们上期学会了利用高清修复来提升出图质量,今天来学习一下两个非常简单的小技巧,来进一步提升我们的出图质量。 一个技巧呢,就是用 inviting 模型,你可以理解为一个打包好的负面词合集,我们点这里啊,来展开扩展模型面板,选中 inviting 模型类别,这里默认就是 inviting 的类别, 我这里已经下载好了。呃,几个模型,我们鼠标单击反向词这里,然后单击选一个模型,这个模型就会自动添加到反向词里面。我们依次点击这几个模型,然后在 这几个词中间加上逗号。 ok, 收起这个面板,然后我们点击生成一下, ok, 生成好了,我们跟刚才那张没加 inviting 模型的来对比一下, 我们看他衣服这里,这个纹理会更加的真实。看一下这个台灯,你会发现刚才的台灯是放在床上的,然后呢,其次右边的台灯看起来也更加真实,再看一下脸部 右边的更像真人一些。那这个 inviting 模型怎么安装呢?我们打开启动器,在模型管理这个页面 选中 in bide 模型类别,点击这个添加模型,就可以添加下载好的模型文件了,需要的同学可以找我,我分享给你。 ok, 我们再学一个小技巧,让图片质量更进一步。这个技巧就是调整提示词强度, c f g 还是这张图,我们只改动提示词强度,给他改到十,别忘了用上一张图片的 c 的值来让 ai 按照上一张图片的画法来画图,点击生成 来感受一下,再给他改到十五试一下。 好,我们来对比一下这三张图。先看面部,呃,对比下来,我会选择十到十五中间的一个值来画图,再看一下物品的细节, 最右边的台灯,你看他整体的质感,还有他的阴影,桌面上反射的这个光,照看一下衣服和手,你觉得哪一张更好? ok, 那到今天为止,我们已经能够画出较高质量的图了,已经能够打败百分之六十九点三的同行了。 但是呢,大家不要骄傲,我们还有很多需要学习的,就比如今天这个 inbiding 模型和提示词强度,就有很多更高级的用法,我们会在后续的课程里都会学到,大家加油!
85金自省AI 06:48查看AI文稿AI文稿
06:48查看AI文稿AI文稿大家好,今天要讲的内容是词嵌入 word inviting 算法。 词嵌入,英文是 word in bedding, 是一种将词汇表中的词或短语映射为固定长度向量的技术。 通过词嵌入,我们可以将弯号的编码表示了高为稀疏向量转为低为且连续的向量。 例如,将 men, woman, king, queen 四个词语映射到一个七维空间中,每个词语都对应了一个七维的像量。 为了进一步说明词语 与词之间的关系,我们可以使用降维算法将词嵌入向量降为至二维,从而在平面上绘制出来。这里可以发现,与相近的词语与异对应的向量位置也更相近。 例如 cat, 猫与 kitten、 小猫的含义接近,它们就聚在一起。 house, dog 与 cat 的语意差异比 kitten 大,所以它们距离 cat 就相对较远。 词嵌入向亮不仅可以表达语意的相似性,还可以通过向亮的数学关系来描述词语之间的语意关联。例如,从图中可以看出,向亮 量 q 减向量 man, 约等于向量 queen 减向量 woman。 因此,总结来说,词嵌入技术能够有效地将自然语言中的词语转换为数值向量,从而表达词语之间的语意关系。 这种技术也为后续更高级的自然源处理任务提供了坚实的基础。 为了实现词嵌入,我们会通过特定的词嵌入算法,例如 word, director, faster, text, love 等等,训练出一个通用的 嵌入矩阵。矩阵中的每一行都代表了一个词像量,这些词像量一旦训练完成,就可以用在不同的 n、 l、 p 任务中。 具体来说,嵌入矩阵的行是语料库中词语的个数,矩阵的列是表示词语的维度。 例如,如果语料库中包括了五千个单词,每个单词都使用一个一百二十八维的向量表示,那么嵌入矩阵就是一个五千乘一百二十八维的矩阵。 下面用英 个具体的例子来说明词嵌入的过程。这词表中包括了五千个单词,每个词使用一个一百二十八为的项量表示,因此嵌入矩阵的大小就是五千乘一百二十八。我们将该矩阵记为 e。 我们要将句子。我喜欢学习数学进行词嵌入。通过词嵌入将句子中的每个词都表示为一个一百二十八围的像量。 首先将句子进行切词,得到四个词语。我喜欢学习数学最初词语使用弯号的进行编码, 每个词是一个五千维的项量,整个句子是四乘五千的矩阵,我们将该矩阵记作 v。 将弯号的矩阵 v 和嵌入矩阵 e 相乘,可以得到一个四乘一百二十八的矩阵,该矩阵记为句子。我喜欢学习数学的嵌入项量。 实际上,磁嵌入矩阵的第一行、第二行、第三行与第五千行 分别代表喜欢我学习数学四个词像量。我们通过将矩阵 v 和矩阵 e 相乘,将这些像量从嵌入矩 圆中取出。 总结来说,嵌入矩阵是词嵌入的关键。通过将弯号的编码表示的词与词嵌入矩阵相乘, 就可以将高为稀疏的矩阵嵌入到一个低为稠密的矩阵中。 相比弯号的编码,词嵌入具有如下优势,一、表达效率的提升词嵌入将文本中的词通过一个低为像量来表达, 相比上万为的弯号的编码效率上有了质的提升。 二、理解词语的语意通过词嵌入表示的词语可以理解词语的语意,并进行词语的推理。语意相似的词在向量空间上也会更相近。 三、嵌入矩阵的通用性弯号的编码不具有通用性,不同语料得到的弯号的编码一般是不同的,而嵌入矩阵是通用的。同一份词像量可以用在不同的 nrp 任务中。 那么到这里,词嵌入 word inviting 算法就讲完了,感谢大家的观看,我们下节课再会。
161小黑黑讲AI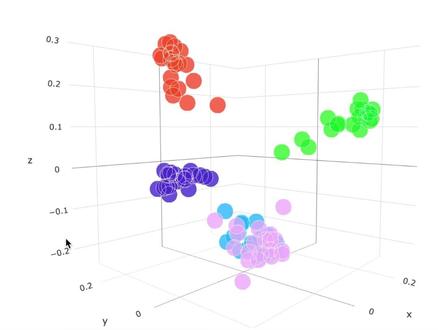 02:28查看AI文稿AI文稿
02:28查看AI文稿AI文稿用亲爱的 g、 p、 t 怎么做类似亲爱的 pdf 的知识顾问的核心原理就在这堆叫做以白点的点上,每个点代表一句话,不同的颜色是不同的类型,比如蓝色都是电影,红色都是动物, 所以含义相近的点,它的距离也会更接近。 inbeding 就是嵌入或者 inbeding vector 嵌入向量, 要得到这些点是用到了嵌入模型,就是给文字提特征的模型。你看左边输入一句话,其中每个单词或者他的指词都可以对应一个像量,这是预先训练并存好的,这些单词的像量就会一起输送给模型, 并计算出整句话的嵌入项量来。编代码也是非常的简单,直接调用 open ai 的一个函数就能够得到 inbiding, 而这个 inbiding 嵌入项量一般其实有几千尾。比如二零四八 八维,你看到在三维空间当中的点,其实是用了 p、 c、 a 组成分分析来降维的,就是为了让普通人能够直观感受。如果你是个超人,能直接想象二零四八维空间,那也没必要来降维了。有了 in bed, 就可以对不同的文本做相似度的计算, 也是调用一句话,计算的是两个向量之间的点击,就是两个向量的长度相乘,再乘以他们夹角的余弦字, 因为这里的像量都被缩放为到长度为一的单位像量,所以点击其实就是余弦指,这也叫做余弦相似度。这是我们对不管是文本、 音频还是图片等常用的度量相似度的方法。你可以理解为在这个三维空间当中,因为每一个点到原点的距离都是一,所以距离越近的两个点,其实夹角就越小,那么夹角的余弦值就会越大, 相似度也就越大。所以当我们要建立自己的知识库问答系统时,本质上就是要将你的文本数据去做分段,每一段都经过模型去生成嵌入特征, 然后呢,把输入的问题也要变成为嵌入特征,这样就可以去做匹配,找到跟你的输入相似度很高的文本片段,再和输入的问题一起去输送给大语言模型, 这样就能够突破对 token 的长度限制。当然在实际使用当中,因为外部的数据可能会非常的多,如果用穷局的方法一个一个去做匹配,耗时会非常长,就不现实,那就可能要去建立,所以 一般会用现成的向量数据库来做操作,比如刚刚融资了一个亿美元的派克问,以后我们再来讲派克问的大致原理。
1561奇笑AI有啥用 01:24查看AI文稿AI文稿
01:24查看AI文稿AI文稿大家好,今天给大家介绍一本由两位大佬编写的书,深入浅出,因 beading 原理解析与应用实践。 这是一本系统全面、理论和实践相结合的引标定技术指南,由资深的 ai 技术专家吴茂桂和高级工高级数据呃科学家王红星撰写,得到了黄铁军、 韦清、张真、周明等中国人工智能领域领军人物的一致好评和推荐。在内容方面,这本书理论与实操相 结合,一方面系统的讲解了以 bid 的基础技术原理、方法和应 核性能优化,一方面列举了引 bary 在机器学习性能提升、中英文翻译推荐系统等六个重要场景的应用实践。在写作上,秉承了复杂问题简单化的原则,尽量避免了复杂的数学公式, 尽量采用可视化的表达方式,旨在降低书的学习门槛,让读者看得完,学得会。
15人工智能研究 02:48查看AI文稿AI文稿
02:48查看AI文稿AI文稿ky 型的问答系统啊,首先我给大家看的是一些典型的使用场景。第二部分给大家看的是典型的使用场景背后我们可以以一个问答系统给大家为例,假设呢, 他其实是基于浪千来做开发,他的整个的业务架构是怎么样的啊?这个其实就是我们浪千的啊开发的 qia 的系统, 有那这样几个步骤。首先假设这个 id 系统已经完了,既然是一个问答系统,这里面其实会有两部分东西,第一部分东西其实就是大模型本身 它其实已经具备的这个能力。另外一部分既然是一个 k v i 系统,比如你的电商的客服,这里边其实还有你自己的一些私有数据,那这个私有数据它最终的承载型是什么?就是你企业内的一个知识库, 那这里面的涉及到企业内部的数据,我们就放在支库里面,外部的数据我们直接和大模型做交付,比如说这大模型什么,就是我们的叉的 gbtc。 这里面假设我问他一个问题,这这个订单能不能退款?这时候怎么办呢?他第一步要先查你的支库,查完你的支库以后,支库会 返回他相关的一些信息,然后他拿到一个信息以后,支库里边他会返回很多信息,你返回信息以后呢? 再加上刚才这个订单能退款吗?再加上这个原来的这个 pront, 这就会组成一个新的 pront, 那组成一个新的 pront, 我其实就会提交给我大模型,这就是他的一个过程。这个快艇其实这个订单他的澳大 id, 比如是等于一,这个订单能不能退款呢?这个问题其实是一个中文,这个中文对于大模型他去理解不了,他其实需要做一个转化,转化的过程其实就是做线量化的过程, 第一步大家看到哈,所以筷子体需要去 inbiding model 去做一次转化,这第一步转化完以后,这个订单二幺等于一的能退款吗?这时候其实已经变成香料语言了,本章呢就是零 一一零,所以这里面他给你的其实是做了这个 cresting 的 vact 啊,一个限量化嘉年华,以后需要我的知识库里面去做一次 cresting 的 query, 这里面去本将是做了一个 query, query 本将是做了一个检索,呃, chroma 这些都是可以的,比如 这个知识库刚刚讲了,其实可以是拼口的,也可以是 redis, 也可以 ice 也是可以。链接里面呢,我们就要支付去查询,查询了我这个订单要不要退款,和我这订单的情况比较类似的,五个订单他就返回给我,和我这个订单状态 比较类似的,以前已经退款或者没有退款的五个订单返给我以后,我接下来就可以继续记其他请求。返回我的过程叫什么?就是取出 top k, k 往往是五个,当然你也可以两个,这个你可以自己设置,因为和我这个订单相关的五个请求。五个请求以后大家看到第六步 pro 呢? to r m v 字的 top k 的 vector 是一个新的 pront, 包含刚才返回 top 五格的数据,再加上 alt id, 等于一的这个店能不能退款,其实就组成一个新的 pront, 组成一个新的 pront 以后,大于研磨小本章做了一个推理,那这个推理比如说你可以使 open ai gb 四, 也可以是 mate 啊,也可以是 google 的啊, bug, 对吧?那 google 是 bug, 对吧?那你当然也可以,其他的东西其实都可以啊。那这里面我们请求大 模型啊,大模型其实就给我一个 ant, 那这个 ant 本站呢?就是这个订单到底能退款还是不能退款?他给我一个一,还是给我零,对吧?一代表能退款啊,零代表不能退款。那最终把这个 ant 呢给到用户,所以这就是 tv 系统机,用当前的架构上实现过程。关注我,你身边需要一个 ai 专家。
28玄姐谈AGI 02:06查看AI文稿AI文稿
02:06查看AI文稿AI文稿兄弟们,近期有粉丝私信,有没有好用的中文 embedding 模型可供选择,下面列举一些常用的中文 embedding 模型。一、 word alpha 中文版中文版 word alpha 是由清华大学自然语言处理与 社会人文计算实验室开发的一款中文词向量模型,支持简体中文和繁体中文。二、 glove 中文版中文版 gobe 是由哈工大社会计算与信息 检索研究中心开发的一款中文词向量模型,支持简体中文和繁体中文。三、 fast text 中文版中文版 fast text 是由 facebook air research 开发的一款中文词向量模型, 支持简体中文和繁体中文。四、 bird 中文版中文版 bird 是由骨骼开发的一款与训练语言模型,支持中文。它可以 用来生成中文文本的词向量表示,并在各种自然语言处理任务中表现出色。对于评测 embedding 模型在语音相似度上的性能,有一些数据及可供选择。一、中文词语相似度评测数据及 chinese world similarity data set 由中科院计算所发布的一系列 中文词语相似度评测数据集,包括此级别短语级别和句子级别的相似度评测。任务二、中文 sps 数据集由中国科学技术大学发布的中文语义文本相似度数据集,包括的文本相似度、 长文本相似度和跨语言文本相似度等。任务三、 cuco 语言相似度数据集由清华大学开发的中文语言相似度数据集,包括词语相似度、短语相似度和句子相似度等。任务四, l c q m c 数据集 large scale chinese question matching corpus 由哈工大社会计算与信息检索研究中心发布的中文问题匹配数据集,用于评估中文文本相似度模型在问答任务中的性能。这些数据集可以帮助您评估不同 in bed 模型在中文语义相似度上的性能,并选择最适合你应用场景的模型。关注我,一起看 ai 圈最前沿资讯!
21彩虹猫 01:48查看AI文稿AI文稿
01:48查看AI文稿AI文稿怎么解决叉 gpt 旧望的问题?当然是给他装一个记忆体。随着 ottgbt 的爆火,在 ai 应用的开发者中, open ai 加拍 com 的组合已经慢慢形成了用户心值。拍 com 作为目前向量数据库的领先者,是大模型记忆的第一选择。 今天分享如何将销量数据上传到派克,话不多说,直接上干货。接下来准备好资料库,为了和之前的视力有对比,这里还是使用之前找到的 tigbt 报告内容做视力。然后不出意外的,我又写了一个派程搅拌, 这个脚本是在之前创建本地所有库脚本技术上修改的,把之前创建 ca 文件的项链数据库替换为使用拍 com 创建项链数据库并上传数据,将报告内容以 report context 这段作为原数据进行上传。 来,咱们运行代码看看。和之前操作一样,输入知识库 word 文件路径以及输入 open a epik。 我这次加入了一个点边电影进度条,提升提升前面效果。下面数据库转化完毕后,我们输入保存好的拍 com 的 apik 和环线值, 给 index 数据库命名。要注意拍 com 的 index 名称只能小写数字和连字复组合,等待一段时间后完成创建和数据上传。甲板会打印向量空间维度向量数据信息, 再进入拍 conconsul 页面,就可以看到已经创建的向量数据库了。 cura 一下就可以看到已上传数据。对于向量数据我们不用关注,在 metadata 这部分就能看到 report context 的字段存出了我们的报告内容了, 这样就搞定了创建和数据上传了。是不是很简单啊,可以开始评论区提问,下一期分享如何使用拍看进行 gpt 问答,觉得有用记得点赞收藏。
427暴躁哐哐 02:12查看AI文稿AI文稿
02:12查看AI文稿AI文稿大家好,我是圆圆,每天更新干货算法笔记。今天给大家介绍一篇华为在人工智能会 aa 二零二三发表的一篇 ct 二预估文章,提出了一种 ct 二预估中医 bread 量化压缩的方法,大幅降低了模型参数量,并保证效果基本无损。 详细的算法笔记也更新到了我的公众号语言的算法笔记中。后台回复 c t 二量化获取。 c t 二预估中占用参数量最大的就会 in bedding table, 尤其 user、 item 等特征的 in bedding 表。由于实体数量很大, 导致这些特征的 inbeding 表非常大,占用了非常巨大的存储开销。因此,对 inbeding table 进行压缩是一个值得研究的领域。目前业内关于 inbeding table the 缩主要有 not space、 in bed、 in dimension、 search in bed、 in pruning。 还使用三种方法。前两者都需要额外的存储和训练步骤来确定最优的 inbedding 维度和减脂方法。 而 hashing 方法由于冲突问题,会严重影响压缩后的模型效果。针对前面方法的不足,华为提出了一种基于量化的端到端 ctr 模型训练方法。量化方法是将模型高精度 los 参数映射到离赛化的纸上,模型结构保持不变,极大节省了存储空间。 本文提出的量化基本的训练框架如下图中的 b 所示。以往的量化压缩方法为图 a, 需要保存全精度的参数,在前向传播过程中对全精度参数量化,基于量化后的参数计算梯度再更新到全精度参数上, 节省了计算资源。而本文提出的避方法,直接在量化后的参数上进行更新,而不用保存全精度的参数,适合本文提出的 invading 存储压缩的场景。 先把量化参数还原成全精度参数,再在全精度参数行梯度反传更新,最后将更新后的参数还原回量化参数,完成一轮训练。在实验阶段,文中对比了不同压缩方法的运行效率和效果,验证了本文提出的方法的优越性。
26圆圆的算法笔记 02:30查看AI文稿AI文稿
02:30查看AI文稿AI文稿刚刚把迈特公司前几天发布的,应该是前几周吧。嗯,发布的那个产品叫做 emigibind。 那篇论文好好的,仔细看了一下啊,我现在才明白什么叫做 emigibidd。 当时看到的说他就是把音频啊,文本,图像,视频,还有 imu, 好像还有个深度,还有热力。 simo 是热力图啊,热力 呃,这几个模态对齐到一个一百零空间里面啊。那这个好处是什么呢?就说我们以前啊,更多的多模态是怎么做呢?一般来说是呃,文本对图像对吧,或者多一点的话,文本对深度图,或者什么什么深度图对啊, rgb 图啊。 那这些多模态呢?其实是更多的像多模态的队。那他怎么办呢?就是 mate 公司就觉得说这个好像都 一对对的啊。那怎么能够跨模态真正的实现多个模态呢?他就用图像作为中间键,不能叫中间键,就是中间物啊,中间对参照物。比如说文本去和图像去啊,一对 对吧。呃,然后图像跟视频其实也是有桥梁属性的,对吧?他们是有那个模态对应关系。然后呃,比如说视频跟 这个 audio, 跟这个声音,它其实也是有配对关系的,对吧?有天然的一种模态对应关系。还比如像,呃,就是热力图,就我们说 simo 热力图,它跟图像其实也是有配对的,这个模态对应关系, 那他就是用这种方式的。甚至还有比如说像他里面提到 video, 就是这个视频里面和就 i 就什么呃, imu, 他也是有关系的啊。因为 为什么呢?因为他这个运动的时候就运动传感,他在呃视频里面是能够感能够能够计算出来的,所以他的模态也是对应的。所以他相当于是用这个图像做一个中间桥梁,他把所有的其他模态 跟图像去对应,做一个桥梁关系。然后大家通过联合训练之后,呃,在 inviting 空间里面去对齐。对齐之后呢,你就说可以做什么呢?通过比如说那这样比如说这个文本就可以直接对应到 video, 呃这个文本可以直接对应到,比如说 audio, 那甚至呃这个这个,嗯,比如他也可以文本直接对应到,比如像那个热力图都是可以做的啊,那这样子就能够做到一米九八一的。而且他啊大量的数据训练能够做到。我们说的那个 zero shot 冷领就比较好用啊。
113Mardin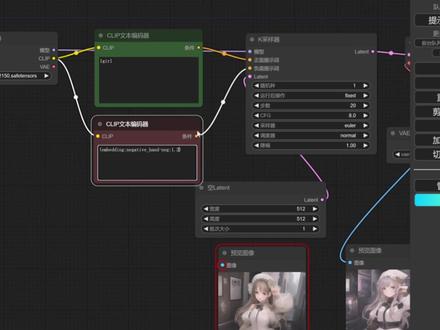 04:25查看AI文稿AI文稿
04:25查看AI文稿AI文稿大家好,今天给大家讲的是 inbending 模型,也就是文本反转。 inbendings 是定义新关键字以生成新人物或者图片风格的小文件。它的体积很小,必须将它们与 title point 模型一起使用。 in bendings 由于训练简单,文件小,所以很受大家的欢迎。它的作用是提示词的打包,意思就是用一个词打包实现 n 个提示词,效果非常的高效。 如果我们需要使用 inbendings 模型的话,我们可以去 c 站或者是 leave 不离不等进行下载 inbendings 模型,然后把它放入 sd 文件夹的康复 ui models inbendings 文件夹内。 下面我们新建一个 clip 文本编码器来帮助我们理解。我们学过 web ui 的同学应该知道,在 web ui 中直接把这个 in 班 dense 模型的名称输入到反面提示词中就可以了,比如说这样。但是在这个 comfort ui 中使用 inbendence 有一些不同,我们需要在这个 inbendence 模型面前加入 inbending 冒号, 注意这里的冒号是英文字符,还有它整个 in bending 的单词一定要小写,大写是无法识别的。我们把这个 clip 的文本编码器作为负面体式词,把它的颜色改为红色。 接下来我们创建一个基础的工作流,然后来看一下有 inbending 和没有 inbending 的生图区别。我们再来创建一个正 面提示词,我们把这个颜色变为绿色,这样的话看起来也比较美观,修改起来也比较方便。 有了正负面提示词之后,我们创建一个采样器,然后把这个条件连入正负面提示词中,接着创建 chat point 加载器,把 clip 连接起来, 模型也连接过来。这里的 lantern 我们连接到空 lantern 上,创造一个前空间画板,创建 v a 一解码,把数值转化为像素图像输出到预览图像。由于这里 的这个动漫大模型自带的 v a 一效果不是很好,所以我们这里需要创建一个 v a 一加载器。这个基础工作流创建之后,我们把这个种子固定一下, 这里的正面提示词输入 a gir 进行申图, 可以看到这个就是有影 banding 模型的预览图, 然后我们把这个 in bending 负面提示词删掉, in bending 模型删掉, 这里由于固定了种子,所以我们直接进行生涂。 我们把两个图进行一下对比,可以看到这个有影 banding 模型的图片效果会更好一点。 同时我们可以对这个负面提示词进行一个权重的控制,我们在这里加上括号, 然后在里面输入冒号,加上权重,这样就完成了对他权重的控制。 我们一定要注意,填写这个 inbend 模型的时候,名称一定要输对,如果电脑里没有这个模型或者名称的话,我们的运行后台会有错误的提示。 另外,我们在使用 inbandings 模型的时候,一定要结合大模型使用,不要把 sd 一点五的 inbandings 模型用在 sdxl 的大模型上,反之易燃。好了,今天内容到这里就结束了,我们下期见。
12峰上智行 16:18【Stable Diffusion】系统课第三课:预设和脚本超详细使用教程和实用技巧 #stablediffusion #stablediffusion教程 #aigc一步之遥 #ai绘画 #ai脚本查看AI文稿AI文稿
16:18【Stable Diffusion】系统课第三课:预设和脚本超详细使用教程和实用技巧 #stablediffusion #stablediffusion教程 #aigc一步之遥 #ai绘画 #ai脚本查看AI文稿AI文稿哈喽,大家好,我是哎小王子,今天给大家讲解一下预设和脚本的使用方式。上次我们在讲纹身图页面参数的时候,我遗漏掉了这个部分啊, 我们先看一下模板预设啊,到这边我们拉下来,你可能这里边什么都没有,因为我之前保存好了几个预设,所以我这里会有这个地方,就是我们关键词的一个预设啊。 假如说我们点击这个基础骑手式,点击之后怎么给他传到这边呢?就是点击这个按钮,你看啊,将所选模板风格应用于当前提示词, 点击 ok, 这边就把提示词给加载过来了。这个一个方便之处就是我们不用在手打,这是模板预测的一个作用,你看我这里还有其他的,然后精美模特关键词我们再导入, 如果不把刚刚导入的删掉的话,再添加,就会两个都保留。所以如果说是不同场景下来预设,建议先把之前先删掉,再导入新的。那么如果说我们想 想保存预设词怎么办呢?我假如说在这里弄个 one girl, pretty cute, 然后 beach background, sunny day, 很简单啊。然后这边就是 nsfw extra arms, 我们输入完这个关键词之后,我们点击这个键,储存为模板风格,点击,然后在这里起名字,我们就叫他测试 好了之后就会在这里出现了。那么说如果我们保存太多模板,有好多我们不想要的怎么办?在哪里删除呢?因为这边没有插件啊,在哪里删除呢?很简单,还是回到我们的 stupid fusionybui 这个界面,打开它,然后往下拉,有一个 styles, 这个我们可以双击直接用 excel 表里边删除啊,直接这样子 插,把它点 delete, 或者我们右键点击打开方式,然后有个记事本打开,这个比较清晰明了啊,因为饲料表比较乱,我们打开看一下,刚刚这个测试的关键词已经出现在这里了,然后把它删掉,整体这一行都删掉, 文件点击保存, ok, 然后回到这个页面我们看,啊,怎么还有啊?啊,怎么办呢?点一下这个刷新按钮, ok 就没有了,所有这边 checkpoint ve 这边都有个刷新按钮,好多刷新按钮是干什么的?当你刚下载了一个大模型, 或者 vae 等等等等,任何东西都可以,你不想关闭这个页面重启的话,你就点击这个刷新键,他就会立即同步到这个页面,你如果你刷新了也没有的话,那就重启重启页面啊,不是重启机子,这个是干嘛?这个我一会再讲。 先讲这个垃圾桶,垃圾桶很简单,就是清理掉你的关键词,点一下,确定吗?啊,确定关键词全部去掉了,然后这个是干嘛?这个左下角箭头就是加载你上一次在这个页面的一些关键词,还有一些预设都会给你同步到这个页面。给大家举个例子啊, 他说我这里是 one girl, 然后这里打 n s f w 采样部署,我打三二六,我选这个 d p m s d e, 然后大小是这 这个样子。 cfc 八九点五,生成次数两个,然后种子选一二三四五六, ok, 我们先生成一下, ok, 这个加载好了,我们记住这个页面啊。假如说我们不小心点了一个刷新键,或者把整个页面给关掉了,因为一刷新之后你这里边全部清零了,全部预设之前写好的都没有了,我们 就点击这个键点一下,哇,全部就出来了。这个箭头就是你把你上一次加载渲染的图片,那些关键词和预设全部加载到这里, 看种子也没有变吧? sept skill 九点五对的宽度高度,这个 dpn fast, 呃,这个生存次数刚刚是二,怎么变成一了?这个无所谓啊,生存次数其实影响不大, 到时候再调就好了,但是这些最基础的预设都已经把你做好了,就有它作用。最后讲中间这个东西啊,就是加载一些模型,比如说我们最熟悉的 checkpoints 大模型,还有 laura, 还有一个就是超网格 hyper networks, 还有 embanding 嵌入式 in bending, 就是把所有关键词打包成一个小模型,然后当你再输入关键词的时候,你就不用再输入几百上千个关键词进去,他把所有几百个上千个关键词汇总到一个小关键词里边。我给大家举个例子,比如说我们想要这种 style, princess 这种有公主风的人 人物怎么办呢?把它点上去,我们这个原本关键词删掉,弯勾我们都不要了。负面关键词我这里有时间下载好了,就是 deep neg 的,我们现在渲染一下。 ok, 我们现在看一下这个是不是一个公主风 风格的一张图。那我回到这个关键词,我就加了一个 embanding 的预设,然后还有一个 n p negative 负面关键词的一个预设就出现了这种图, 但是按理来说这里边会有几十个单词,但是他现在全部汇总成一个单词啊,这种方式呢,大大的提高了我们出速效率,或者有时候我们不知道应该写什么负面关键词,我们直接点他一下就好了,这有他的作用。第二个抄网格,现在用了不多了,还 her networks, 是给模型做一个细小的微调,最初它是 novo ai 发明的,现在已经不怎么用了,它跟嵌入式有点类似,也是把一些关键词给打包变成一种风格, 然后下面这个 checkpoint 大模型,上节课给大家讲的很细啊,然后下一个是 laura, laura 就是我们改变人物风格脸部的一个模型, 我们在调 lora 啊,不管 lora, 抄网格,嵌入式等等等等,就会遇见一个问题啊,你们下载好之后肯定是没有图片的啊,这两个是我做测试加的,肯定是只有 no preview, 那怎么办呢?怎么样才能把这个图片加上去呢? 这个问题问的非常好,我给大家解释一下,我就以 lora 为例子了,因为大部分都是一样的,我们到 models lora, 假如说我们看这个啊, coronal likeness 是没有图片的,那现在我要要给他加图片,怎么加呢?我们首先要找到这张图片,然后我们点击这 coronal likeness, 然后把它复制一下,复制到我们刚刚 这个 lora 页面啊,点击 lora 复制一下,复制过来之后呢,要确保这两个的文件名是一样的,并且是 p n g 格式, g p g 格式也 ok, 也能出现,我们怎么弄呢?点击 f 二,然后 ctrl c, 然后点击 f 二, ctrl v, ok, 后面这个就不用复制了,只用复制这前面这个 safe tensors 就不要加了,点击确定,确定之后我们回到这个页面,点击 refresh, 我们看一下这个图片就加载出来了, 每一个单一的都是要这样加的,他无法直接让你下载好模型之后,就直接会给你一个 preview, 这是我觉得 stupid do you 是应该增加了一些更改细节,这点我相信他未来是一定会改的。这是 lower 模型, 模型不止可以变脸啊,变风格也可以变衣服,假如这个 sweetlot 了,就是把它穿上萝莉塔的衣服,我们看一下,我们看到用这个模型就不是变脸了,就直接把他衣服也穿上去了。下面我给 给大家介绍一个模型下载的网站,我平时除了用 c 站,另外一个用的比较多的模型下载网站就叫做 libliboai, 这个网站的所有模型都是免费下载的,并且他不需要魔法,下载的速度也很快,并且有很多原创的模型作者在这个网站上发布他们的模型。 我们先看下这个页面啊,看一下筛选啊,比如说我们想要 checkpoint, 或者说我们想要一般领就是 textual inversion 一个意思,进去之后假如说我们想要这种风格的建筑物,我们就点击下载 inbending, 文件都很小,大概十到二十 k 左右。然后我们再看一下其他,比如说 checkpoint 大模型也是在这里可以下的,比如说我们想要这个大模型, ok, 进入到这个页面之后,我们可以看一下全部展开,这里有模型的一个介绍。然后如果我们想看这张图片是怎么做出来的话,我们把鼠标碰到这个生成信息里边,就会看到他的正向关键词,负向关键词,还有些采样期用的哪些 步数等等等等。然后如果想要复制过去,直接点击复制生成数据就可以直接用了。我们看一下这个图片的浏览,都是做了很不错的,然后鼠标往下滑,就是其他人用这个模型做的一些图片, 然后都会是在这里展览。如果我们想要这个作为大模型的话,我们直接点这个下载键就 ok 了, ok, 这就是利布利布模型网站的一个介绍, 我会把这个连接放到本视频的简介里面,大家可以去看一下。我们使用罗二的时候可以不止用一个罗二,我们可以用好几个罗二,但有一个问题啊,假如说我用了 japanese corny, 还台湾 door likeness, 如果想三个都用的话,权重一定要改,三个权重全是一,会出现什么问题呢?直接给你出现一个花图, 我们把所有权重变成一的时候,出现图就非常的精美啊,很漂亮,所以我们不要把它调成一,我们要确定所有罗二的权重总和加起来不到一,比如说我们每个配置三分之一 的权重,我们看一下他出来的图片还会不会花了, ok, 出来的图片就不会花了,并且三分之一的基因是日本痘,三分之一的基因是口眼痘, 还有三分之一的基因是台湾斗,这三个基因加起来就是这样的点。如果你想做商图网图的时候,你不想让你的图片看起来和别人做罗尔完全一样,你就去混合就好了, 好比做一个混血儿一样,你把这三个混血,三个国家混血,然后再往下走,就是脚本。脚本其实是一个非常好玩的东西,可以让你看到不同风格、不同采样部署,或者不同采样器的一个对比图。 就像我之前大家可能会好奇我这个图片是怎么做的,我用的就是脚本。我们先看下这边啊,有五个选项,第一个是没有,那就是有四个选项,所以控制网这个就是视频转视频。今天先不讲啊,因为这个,呃,有一个更好的应用去用。我们先讲第一个啊, prompt matrix 提示词 矩阵。这个是怎么用的呢?很简单啊,当我们不知道用什么灯光,用什么风格,用什么关键词去把一个物体或者人物主体做出来。比如说我现在有很多选择,举个很简单例子,渲染一个 an apple on the table, 这个是我的主体,我想做不同灯光,他会在图里边呈现一个什么样的表现,我先弄个 studio lighting, ok, 摄影师,灯光 是什么样子的?再弄一个 cinematic lighting, a soft light, a warm light。 我们可以看一个对比图啊,如果你想使用关键词矩阵看不同风格类型的话,怎么分割呢?就用这个竖线分割啊,这个竖线是在回车下边的那键。先讲一下他出图会什么样子? 会出图像,一个 apple 在桌子上先弄个 studio lighting, 一个 apple 在桌子上 cinematic light, 一个 apple 在桌子上 soft light, 一个 apple 在桌子上 warm light。 他会出现这四种风格,并且像排列组合一样, you use studio lighting, you use cinematic。 迪克拉丁又有这个和这个等等等等,我们看一下这里有几个选项,把变量部分放在提示词文本的开头处,这个勾选的话,就是说这个变成变量了,这个后边的变成那个定量了, 所以我们不用勾选。我们一般先把主体描述好,后边是变亮。下面这个为每张图片使用不同随机风格种子,如果你勾选的话, 这些种子都是随机的,如果你不勾选的话,这些种子都是一个固定的一些种子。我们在做测试的时候尽量不要勾选它,因为勾选它你种子不一样,你看的物品是完全不一样的一个风格, 你无法判定他用哪个灯光是好是坏。然后选择提示词类型,我们是在哪里做矩阵呢?我们在这个 positive prompt 里边做矩阵,所以我们用正面提示词,如果你想看一些反向提示词的一种不同,你就点他就行了。然后选择连接符号,逗号或者空格,这个就默认逗号,就完全没问题。宫格编剧像 速就是一个相框,假如说我之前这个这个图片宫格像素编辑是零啊,你看中间都是贴着的。如果你加一的话,我给大家举个例子,假如说我加到二十六,最后我们看一下效果, 我们看一下是不是我们想要的啊。一个 app on the table, 什么灯光都没有的情况下,有 studio lighting 的灯光下什么样子? 这个是电影灯光,这个是 you 工作室灯光, you 电影灯光的样子,然后下摆,以此类推,并且他们种子是同样的。刚刚这个网格啊网格,就我们看一下中间这个缝隙就是网格, 你要多少像素,就大家想要这个小边框,风格开的话就选它就好了,这就是 prop matrix, 主要看不同风格,不同灯光下,不同任何东西下的一个区别,用它就很好。下一个我们看一下,从文本框或文件载入题, 是词就是 prompt from file or textbox, 这个是干嘛的?假如说现在我是一个 ai 公司,我今天要给客户出图片,我手下的 ai 设计师有五 五十个,每个人给了我两个 prompt, 去把这些图片给生成出来,再就是有一百个的 prompt, 你就用这个方式把所有的关键词放到这里边去。出图, 我们在写的时候每行就是一张图,然后以杠杠 prompt 开头,然后写出不同的参数,不同参数以以杠杠开头,然后空格作为风格。举个例子,杠杠 prompt, 我们要写正向关键词的话,就直接先写一个双引号,然后输入。假如我们想要个 handsome man smoking a cigare, 负面关键词杠杠 negative 下划线, prompt, 然后还是双引号 n s f w, 然后最后我们要什么步数呢?多少步数呢?就刚刚 steps 二十八, ok, 这是第一张图,第二张图我们做一个女士吧,好吧, prompt, 然后还是双引号,加 搭一个山顶雷顶,我们想调节它的宽高比宽就是 waf, 杠杠七六八,高的话杠杠 height, 然后也是七六八,就是一个方形。然后第三呢?男的女的都有了,再弄个狗吧,这个的话,我想要他的种子, 踩洋气,我要,要什么呢?我们就用这原始的 ula 吧。具体这个格式有没有什么表呢?有的,我都整理到我的思维导图里边了,里边有很详细的参数表,具体在这个脚本里边格式怎么写我都放在里面了, 大家可以到我的 discore 里边看啊。第一个就是你每行的随机种子都不一样。第二个就是你每行的随机种子都一样,我们勾选一个就 ok 了啊。这下面还可以上传提示词文件,我们就不用手打或者复制上去了。 我们先看一下他这个图片出来什么样子啊啊,记着啊,如果说你在这里写提示词,他会完全忽略上面所有提示词,加上上面所有参数,就会以你这个为主。我们看一下第一个男生 抽着雪茄, ok 出现了,还挺帅的啊。然后第二个是女生,山林的后,第三个是个 big dog, ok, 都出现了啊,然后我们看一下他们的种子是不是也都不一样,第一个种子说 这个七三三,第二种子多少?这个是固定种子啊,这个是我们提前预设的,一二三四五六七八。第三个种子七七二, ok, 我们看一下他的规律啊,如果我们不填写种子的话,他这个种子会随着第一个出现种子后,每次都加一,每次加一看这个是七七二对不对?下一个是七七三。如果你还有十关键词,并且都没有定好你的种子 的话,下个就是四五六七八九十十一十二,就是这样的出现的, ok, 这个是 prompt prom file or textbox。 我们下一个看 x y z 图表,这个打开之后别看数值很多啊,但是真的是非常简单, 暂时不要管 z, 如果你添加了 x, 又添加了 y, 又添加了 z, 它渲染的时候是非常非常慢,并且图片表示并不是非常清楚。 我们先点 x 轴, x 轴我们就用什么呢?我们假如想看不同采阳器的一个区别,然后 y 轴选什么呢?我们想看不同采阳器在不同引导下的一个效果。这左边选好之后,我们选 x 值啊, x 值就是让我们选采样器,我们具体选哪个采样器? ok, 选这个啊,一个一个点,如果你想全部都看的话,直接点,他就所有采样器都放过来了,我就先选一个 dpm 加加二,然后 active, 然后再弄个 fast, ok, 我们看这三个的区别,然后 cfg scale 这个就要填写值了,这个值怎么写?我们知道 cfg scale 它的预值是多少啊?一到三十对不对?我们上节课讲过,我们想看一二三四五六七八九 十这十步。每个的区别有个很简单快捷方式,如果你想渲染一二三四五六七八九十,每个步数的中间差值为一的话,你就直接写成一杠十,就告诉他一到十 我全都要。那我假如说我想要一三五七九这几个怎么弄呢?那你就写一到九,然后加一个括号,括号里面写什么呢?加二为什么是加二呢?就是每个数字之后我要加个二,这是这个数字,那如果说我想递减着看的呢?那就是九到一, 任何数都可以啊,我只举个例子,不要跟我一样。然后这种减二就是九,减二到七七,减二到五五,减二到三三,减二到一就是九七五三一这五个不同的 cfg skill 的展示方法。 ok, 我们这个选完之后,在图表中包含 轴类星河池是干嘛的?就是是否要加上这些东西,那肯定要加了你,你不加的话,你就不知道他渲染的是什么东西了。然后保持随机种子为负一吗?在做这种对比的时候,一定要是不保持,要所有的种子都是同样的种子。我们先渲染一下看一下啊,我把提前准备好提示词放到这里了, ok, 显卡燃烧完毕,我们打开看一下效果。三个不同采样器,然后不同的 cft scale 指数,我们这个时候就可以做一下对比了。我们大家从这个十五张图里边选一个最好看的吧,我们看一下大家的审美怎么样啊,我觉得这两个不错啊。下边这两个 cfc skill 指数不要用太高啊,太高很容易崩坏的,像这个 dpm, fast 就崩不住了,这俩就崩坏掉了。 ok, 这就是 x yz plot 的用法。我们不止可以用 sumper 和 cfc 指数比啊,我们还可以用什么 checkpoint name 不同大模型去比, 当然这个加载的就比较慢了,因为 s d 每次加载大模型的时候都要花好久好久。你还可以用什么 clip 跳个层做对比啊,然后和一些重绘强度等等。 z 值就是再加一项,具体是怎么用呢?我给大家留个作业啊,大家下去的时候用一个自己想用的三 pro, 比如说 checkpoints, cft scale 啊,或者其他的种子之类的,然后再加一个 z 值,这个 z 值你随便去加啊,最好加我们之前讲过的,没有讲过的,可能你加的不会很好看。记着,如果加 z 值的时候,这些变量啊,不要加太多, 因为非常非常非常的慢,显存不好的话,报显存是轻轻松松的。如果大家觉得我的课程对你的 stabled fusion ai 绘画有帮助的话,希望你们给我一键三连,支持我一下,关注我,让你轻松掌控 ai。
 01:27查看AI文稿AI文稿
01:27查看AI文稿AI文稿好,我们接着来关于打造特定领域的 check g b t。 上几个视频提到两个方法,微调 fire tuning 和封装了 imbedding 的 g p t index。 现在我们来对比一下两个方法的优劣。首先,微调 fi q, 你的底层逻辑是,他在原来的模型上通过你输入了一堆例子, 训练了一个新的模型。相对于他原来的模型而言,你新输入的数据少的可怜,所以 g p t 并没有学到更多新的知识。一般而言,你只能用它来调整 g p t 的输出格式啊, 样式啊,或者做一些分类等等。而且啊,当你有了新的数据想输入的时候,你还得重新训练他,费时费钱。至于 in bed 呢,其实 相当于你首先建立了一个非常聪明的数据库,提问的时候马上到数据库里找到相关的资料片段,然后和问题一起提交给 gpt。 注意哈, in bed 点并没有训练新的模型,所以当你有新的数据的时候,你直接插入到数据库中就可以了,而且 gpt 能根据你提供的资料片段和问题给出比较准确的答案。 有,好了,有了这个 overview, 你再去看看细节,相信你能够迅速判断如何使用 gbt api 打造特定领域的 check gbt。
2142剑哥聊技术(谷歌现役程序员)


