session机制是什么
quick sei 神机制啊,在面试中经常会被问到,有很多人回答的不好,大部分人呢,能说出 sei 神是用来验证用户身份的,但是说不出 cookie 和 sei 神之间有什么关系。我分析啊,主要原因是大家对 cookie sei 神的运作原理不够了解,下面呢,我通俗的来讲解一下 cookie sei 神的运作原理。 下面的内容呢,比较浅显,主要是面向初学者面试时使用的,各路高手大神请自觉划走。 cuke 是一小段存储在浏览器端的文本数据,大小不超过四 k b, 发送网络请求的时候, cuke 会在请求头里一起发送给服务器端。 筛审对象呢,是存储在服务器端的,主要是用来存储用户绘画的数据。筛审 id 需要存储在浏览器端,通常存储在库克里。浏览器发送接口请求的时候需要带着这个筛审 id, 这样呢,服务器端 就可以根据这个筛审 id 找出当前请求的用户是谁了。筛审一般都会配置一个过期时间,比如三十分钟,筛审过期之后,用户就需要重新登录了。打个比方,我们每个人都有一个身份证, 去政府部门办事的时候啊,都需要出示身份证,工作人员呢会对你的身份证进行核验,确认真伪之后才会给你办理具体的业务。这个过程呢,和筛审验证用户身份的机制很像, 你就相当于是浏览器的 gucci 身份证,就相当于是筛审 id, 你要去办事的那个部门就相当于是后台接口, 他们对你的身份证进行核验,就相当于是在比对你的筛审 id。 那么用户没有登录的时候有没有筛审 id 呢? 也是有的,就相当于你刚出生的时候还没有办理身份证,医院呢会给你开一个出生证明,这个出生证明呢 也相当于是赛事 id, 去部门办事的时候也要带着这个出生证明。身份证是有有效期的,过期之前必须要进行更换。 同理, cuke 和赛神呐也是有有效期的,当然这个有效期是我们程序员根据业务需求来规定的。关于 cuke 和赛神的学术解释我这里就不讲了,大家需要的话可以自己去搜索。

粉丝4.5万获赞20.7万
相关视频
 01:49查看AI文稿AI文稿
01:49查看AI文稿AI文稿哈喽,大家好,今天继续给大家说测试那些事,上期视频我们说到了一个酷给,那这次我们来聊一聊。三婶, 想象一个场景,你正在网上购物,然后例如说刷一些淘宝啊什么的,然后让你看,当你看到一个好看的衣服的时候,一般的话都是我先加入到购物车, 然后你再隔右段时间去查看你的购物车的时候,就会发现刚才添加的一个商品已经存在了你的购物车里,而并不是说我在其他人,我在我的闺蜜那边看到了购物车里面也看到这件商品,这时候就用到了一个三圣的机制, 那三省是什么呢?其实它是一个存在服务器的一种用来存放用户数据的类哈西表结构。当浏览器第一次发送请求的时候,服务器会生成一个哈西推广和一个三省 id 来唯一标识,这个一个哈西推广 响应的时候的话会通过一个,我们会有一个响应头,这个响应头是三个 gucci, 返回给浏览器,浏览器再将这 三生 id 去存储在一个 gucci 中,接着当浏览器去发送第二次请求的时候,就会带上这个 gucci, 当然这个库克里边会存储那个三十 id 一起去发送给了一个服务器上,服务器再从请求中去提取出对应的一个三生 id, 并和当前保存的所有的一个三十 id 去进行一个对比,然后找到这个三十 id 对应的一个用户信息。刚刚说到三十 id 会存储到一个 gucci, 但有可有小伙伴可能就有疑问,说上次说到了这个 gucci 可能会被浏览器所禁用,那这种情况下应该怎么办呢? 其实三审他还有一个大的优点是什么?就是如果我客户端把这个库克给禁用掉的时候,会自动把三审 id 附着在一个 uir 后边,就拼到他的后边,这样服务端仍旧可以接受并且提取到对应的一个三审 id。 这种方法其实就有一个名字叫做 uso 重启啊。总结下来,三审是在服务端保存的一个数据结构,用来跟踪用户的一个状态,这个数据你可以存储在内存或者是持续化存储的话,去存储的一个数据库或者是文件中都是可以的。以上就是今天的全部内容,感谢大家的观看,喜欢我就请点赞关注我,拜拜!
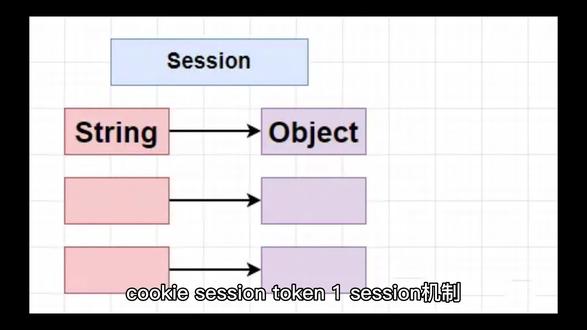 02:22
02:22 01:50查看AI文稿AI文稿
01:50查看AI文稿AI文稿好,我们接着来。在计算机世界里,假设你用浏览器登录一个网站,登录完后服务器就会开一个 session, 然后随机一个 session id 发回去给浏览器。浏览器下次访问该网站的任何一个网页的时候,就会把这个 session id 放在 cookie 里发给服务器。 这个 session id 你可以理解为上节视频所说的会员号, cookie 理解为会员卡, 服务器收到后就会看看内存里有没有这么一个 session, 如果有就让他浏览,如果没有就需要重新登录了。 好注意啊,由于大型网站都有很多服务器,假设浏览器每次访问的是不同的服务器,那么这个 section 就没法查了。当然,你可以做一个统一的专门 存储筛选的服务器,来给所有服务器提供筛选产生服务,但这样会存在筛选服务器打点失效的问题。 但如果把 session 服务器做成一个集群呢?那成本和效率都是一个麻烦事。好, 偷啃,很好,解决了这些问题,我们再来假设浏览器登录了服务器后,我们提供一个偷啃给浏览器,下次浏览器访问一任何一个服务器的时候,只需要提供这个偷啃就可以了。 这个 token 就是上节视频中所说的签过名的会员卡,这个 token 是经过服务器签名的,任何一个服务器都能认出这个签名,这有点像古代打仗里面的令牌,这就是为什么 token 被翻译成令牌的原因。这一 服务器怎么利用数字签名制作这个 token, 收到后又怎么识别这个 token? 等以后我们有机会再讲讲网络安全的知识吧!
3136剑哥聊技术(谷歌现役程序员) 01:01查看AI文稿AI文稿
01:01查看AI文稿AI文稿你了解接口测试师吗?那你说一下 top 肯和三十有什么区别吧?嗯,我只了解库可以和三十,对 took 没有过多了解。 哎,我跟你说一下,但既然你了解三审,那你应该知道三审是有些弊端的。首先呢,是服务器的资源占比较大,三是呢,是存储在服务器的内存之中的,随着用户量的增加啊,服务器的压力会比较大。那第二呢,三审的安全度比较低, 关键是基于孤僻进行用户识别的,那如果孤僻被截破了,用户就非常容易受到跨界请求伪造的攻击。第三,拓展性不强,随着用户量的增加,系统如果使用了多服务器的负载进行方案,那三线的数据呢,是保存在单节点中的,用户第一次访问的是服务协议,那用户再次请求时,可能访问的是另外一台服务器二, 服务器二就获取不到这个三线信息了,就会判定为用户没有登录度。所以如果我们改用偷看的认证机制,那由于服务端不保存三证了,他只是生成偷看,然后验证偷看,咱们用服务器 cpu 的计算时间换取了三摄的存储空间。而且即使是使用了 多台服务器的咨询,只要美男经济的处理逻辑算法是一样的,这就意味着基于通天认证的应用不需要去考虑用户在哪一台服务区登录过,这就为应用的拓展提供了便利性,解决了筛选拓展性的弊端,明白了吗?
7530小码哥聊软件测试 03:23查看AI文稿AI文稿
03:23查看AI文稿AI文稿嗨,大家好,我是麦克,一共做了十四年的家务程序员和创业者,今天我们来分享一道比较基础的面试题, 但是呢,我可以保证很多人不一定能够回答的非常正确。具体的问题是啊, cooky 和 c 型的区别是什么?这个问题的高手回答呢,已经整理成了文档啊,可以在我的主页去加微领取。下面我们看看普通人和高手对于这个问题的回答。普通人的回答, 呃, gucci 和 c 型的区别啊?就是,呃, gucci, 它是属于浏览器层面的一个一个机制吧,就是它可以用来存储一些 服务器的那些信息,然后 c 显呢,是属于呃容器对象,就是像 siri 容器,比如说像他们看他里面的一个对象,嗯,他里面是表示一个浏览器绘画吗?就是我针对同一个浏览器就同一 客户端的一个请求,他会生成一个一个绘画的信息,然后我们可以在这个绘画里面去存储一些服务端的数据吧。嗯,所以,呃,我认为就是 gucci 和 c 选,他们两个区别就是在一个客户端,一个是浏览器的,一个就一个属于客户端浏览器的一个东西,然后那 c 选是属于服务器端的一个存储的主见。嗯, 高手的回答,好的,面试官,我先解释一下 cookie 啊,它是客户端浏览器用来保存服务端数据的一种机制,当我们通过浏览 t 区进行网页访问的时候啊,服务器可以把某一些状态数据以 kvi 的形式写入到 cookie 里面,存储到客户端浏览器。 然后呢,客户呢,下一次在访问服务器的时候,我们可以携带这样一些状态数据发送到服务器端,服务器端呢,可以根据 cuke 里面携带的内容去识别使用者。而 cc 他表示一个绘画,他是属于服务器的一个容器对象,默认情况下,他 会针对每一个浏览器的请求,所谓的容器呢,都会分配一个 c 选对象。 c 选的本质上我们可以认为他是一个康凯尔的哈西曼,他可以用来存储当前绘画产生的一些状态数据。 我们都知道 hb 协议本身是一个无状态协议,也是说服务区端并不知道客户端发送过来的多次请求是属于同一个用户, 所以 c 型是用来弥补 htv 无状态的一个不足。简单来说呢,服务器端啊,可以利用 c 型来存储客户端在同一个绘画里面 产生的多次请求的一个记录。那么基于服务器端的 c 型的存储机制,在结合客户端的 cooky 机制啊,我们就可以去实现一个有状态的 hd 协议。 具体工作原理呢,非常简单,首先客户端第一次访问服务阶段的时候呢,服务器端会针对这次请求创建一个绘画,并且升值一个唯一的水选 id 来标注这个绘画。然后 服务器端把这个 c 型 id 啊写入到客户端浏览器的库克里面,用来去实现客户端状态的一个保存。那么在后续的请求里面呢,每一次都会携带 c 型 id, 服务器端就可以根据 c 型 id 来识别当前这个绘画的状态。 所以啊,总的来看,库可以是客户端的纯属机制,而 c 起呢,是服务器中的纯属机制。以上就是我对这个问题的理解, 你看 cooky 和 cc 大家都不陌生对不对?但是回答面试官这个问题的时候,如何去组织语言清晰的说明这两个的机制,并且非常清晰的去回答出来,还是有难度的。另外关于 cooky 和 cc 的机制啊,工作一到三年的人呢,还是有大部分人是不清楚他们的工作机制的, 建议大家抽空去了解一下。好的,本期的普通人 vs 高手的面试系列视频就到这里结束了,大家记得点赞收藏加关注,我是 mike, 咱们下期再见!
1133跟着Mic学架构〈3月突击版〉 01:46查看AI文稿AI文稿
01:46查看AI文稿AI文稿cookie 和吸水的区别,你要这么打面试官才会满意。第一点,存储的位置不同, cookie 数据它是保存在客户端里面的,而吸水数据它是存储在服务器中,而服务器存储相对于客户端来说是更为安全的。第二点,存储的数据类型不同,两者虽然都是 qw 的数据结构, 不过 gucci 的 v 六他只能是制服串的类型, c 损的 v 六他可以是 upgrade 类型,就是所有所有的那种数据类型他都能支持。 第三点啊,存储的数据大小不同,库克的大小他会受到浏览器的限制,一般限制在四 k 的大小, 而吸水理论上来说他只受内存的限制。第四点,就是生命周期的区别, gucci 的生命周期啊,就是浏览器如果关闭的话,他就会消亡吗?而且他还有对应的超时限制, 就是你无论有没有访问,只要超时的时间一到,他就一定会过期。而稀损的过期,他是取决于服务端的一个设定, 比方说啊,他可以设置成啊,用户持续访问,他就不永远不会实效,就是和浏览器的关开关是没有关系的。还有一点要跟你们说一下,就是面试,有的面试关他可能关注的是这个点, cc 和 gucci 之间他是有什么样的联系啊?首先你们要知道, cc 他是 gucci 的一种应用, htphttp 他是无状态的 服务器,它只能获取到请求来源的 ip, 它是获取不到用户身份信息的服务器,它可以用吸水去存储用户的数据,一般客户端会写一个吸水 id 存放在那个库存里面。比方说这样的数据 像 cookie 和吸水的区别?这样的问题面试官他是一定会问到的。就如果你们面试中还遇到什么不懂的问题啊,可以来找我找我。
3505帽子反戴 06:12查看AI文稿AI文稿
06:12查看AI文稿AI文稿这节课来讲 session, session 是绘画的意思,既然是绘画,那至少得是两方,也就是客户端与服务器之间的绘画。为什么要用 session 呢?来看这几句话。浏览器通过 http 向服务器请求, http 是无状态的,客户端发送过去的请求,服务器是无法通过 http 来记录是谁访问的,那服务器无法记录是谁访问的?在我们网上购物的时候,他又是如何知道每一个请求是谁来访问的呢? 既然在实际使用中需要保持这种状态,肯定得有一种可执行的方案, session 就是其中的一种。我们用图形来演示一下 session 的作用, 来看一个简单的用户请求过程,通过浏览器登录,然后去数据库查询用户信息。 假如这是在访问某一个购物网站,登录完以后,我要查询我的订单, 通过浏览器点击我的订单查询到数据。在登录这一步,我们需要输入用户名和密码, 但是查询我的订单的时候就不用再输了。那查询订单的这个请求没有输入用户名和密码,服务器是怎么知道是我查询的? 要根据我的账号去查询我的订单,这里就可以用到 session 请求到服务器之后, 从 section 里边获取我的账号信息,然后根据账号再去查询订单。那 section 里边我的账号信息是从哪来的呢? 是在登录完之后,把账号信息保存到 sensor 里边,流程就是这样的,输入账号密码,查用用户,保存到 sensor 里边,在做其他请求的时候,从 sensor 里边获取到用户信息,再继续其他操作。 这样就实现了通过 session 来保持了登录状态,来通过代码看一下 session 的操作, 这里有两个 server let, 这一个是处理登录的,另外一个是登录成功以后的换营业。过程很简单,获取到用户输入的 账号和密码,如果账号是账三,并且密码是一二三四五六,那就验证通过,让他登录成功,把他的账号放到现实里边。 session 可以通过 request 来获取到, session 存储信息是通过这种属性和值的形式,这就是刚才我们图形演示的过程,登录成功以后放入 session, 再来看它的幻影页,登录成功以后才能看到幻影的信息。所以访问这个 server later 的时候, 从 section 里边去获取他的账号信息。 get a, 而是 build, 如果账号存在也就是不为空, 那说明已经登录过了,给他一个欢迎信息,那要是账号为空的话,那就提示他让他先登录,把这个消息打印出来, 通过浏览器来演示一下,这个是登录页,在没有登录的时候来访问一下他的首页,提示先登录, 也就是输出的这个信息, 来登录一下张三一二三四五六登录,登录成功, 再来刷新一下首页出现了欢迎语句,看这里,它是浏览器的两个标签页, 但他们访问的 session 是同一个,就像我们使用网站在一个地方登录成功以后,无论打开几个标签页 都是保持登录状态的,那如果重新再打开一个浏览器的话,肯定就需要重新登录了,因为不是同一个主窗口的话,访问到的 session 是不一样的。前面我们讲了每次请求 require 的对象是不一样的, 比较好理解的解释就是我们每次请求写的的参数不一样,对象肯定不一样, 但是同一个客户端获取到 sense 之后, sense 里边的信息却是一样的。所以这里注意一下,他们两个请求不同,但是获取到的 session 是相同的,因为上一个 session 存储的账号信息,我们在这里边可以获取到。 那这就奇怪了,他们两个凭什么一样呢?这是因为当客户端请求 several less 的时候,服务器向客户端返回了一个 session 的 id, 来看他是有 id 的, 在客户端有了这样一个 session id, 每次请求都把这个 id 带过来,服务器根据这个 id 来识别 session, 所以不管是哪一个 request, 对象,通过那个 id 获取到的 session 都是一样的。来看一下在浏览器里存 出的赛神 id, 浏览金安 f 十二,打开开发者工具,在这里边找到 cooking, 有这样一个键和值, 他们就是 search id, 这是他的值。来看另外一个 server letter, 对比一下,他俩的值是一样的。好了,这期就到这里。
140人人都会软件编程 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿一百秒快速认识 season 和 token 实现用户身份验证主要有两种方法, season 绘画和 token 令牌。传统的外部方法是采用基于 cooky 的服务器端绘画,首先将填写的用户名和密码提交给服务器,服务器验证通过后,会在数据库中创建并存储一个 season, 然后向用户响应一个赛神 id, 最终将其保存在浏览器的 cookie 当中。 cookie 是浏览器保存建制队的地方,当用户保持登录状态时, cookie 将与每个后续请求一起被发送出去。 言而言之,我们在客户端和服务器之间开启了一个有状态的塞升绘画。这种方法效果很好,但也存在一些缺点,还容易受到跨战请求伪造的攻击。攻击者将用户引向他们提供的站点,以执行具有风险的操作,比如提交付款啊,更改密码等等。 好在目前绝大数代码都在使用现代框架编写,所以出现这种状况的概率呢也非常低。另一个缺陷是,腮身的存储是需要空间的,你需要将它存储在数据库中。但由于当下的大多数云应用程序都是水平扩展, 这会给生产环境带来平静。而基于偷啃令牌的身份验证恰好解决了这个问题,但也带来了一系列的挑战。首先从客户端向服务器发送其登录的详细信息。他不存储三 cid, 而是生成 jason web 头肯,也就是 gwt。 gwt 是在服务器上使用撕药创建的,然后返回浏览器,通常保存在本地存储中。在客户端请求接口时,请求头戴上 gwt 后,服务器只需要验证签名,不需要在其他地方进行数据库的查找,特别适合于分布式为服务。然而,头坑令牌仍然 可能被攻击者劫持,并且很难实际生效,导致无法在服务器的后台对用户身份进行一个验证。 总之呢,对于这两种方法来说,在腮身绘画中最重要的是要理解,身份验证状态是在服务器上处理的,而头跟令牌是在客户端上管理的。以上就是腮身和头肯的快速介绍,感谢您的收看。
481左侧交易员(AI探索者) 03:09查看AI文稿AI文稿
03:09查看AI文稿AI文稿哈喽,大家好,今天继续给大家说测试那些事。上期我们说到了三审,提到了它是存在于服务器的,例如说是内存里面,但是用它的话会引发一些问题。 第一个当越来越多的用户发送请求的时候,那内存的一个开销会不断的增加。第二个的话,当服务器采用一个分布式或者是集群的时候,三是就会面对一个负载均衡的问题,而负载均衡多服务器的情况下是不好确认当前用户是否登陆了,因为 多服务器是不共享一个三摄的。那这种情况之下呢?高肯就产生了偷看是什么?它其实也会被称作一个令牌,由服务端生成的一串自服串,而这串自服串商城的规则呢,是有一个 u id 就用户的唯一身份标识,还有一个探母就是当前时的街。 还有一个就是赞,是一个签名,只用一个哈巴西压缩成一个定长的十六制的字母串,以防止第三方恶意拼接。最后是加一个固定参数,这个参数你可以加也可以不加。操作的一个认证方式,它其实就类似于一个临时的证书签名,并且是一种无端无状态的一个 认证方式。我们状态其实就是说我服务端并不并不会保存身份认证相关的一个数据。高肯在客户端一般的话是存放在一个 logo sorry, 也就是一个本地存储,酷 k 或者是三 s 都为止中,在服务器的话一般是存在于数据库中。 那整个托克的一个认证流程是怎样的?第一个的话就是用户首先通过用户名和密码发送一个请求,然后第二个是服务端进行一个验证,成功后的话,服务器会返回一个头肯给到一个客户端。第三个的话就是客户端收到数据后保存在一个客户端。第四个就是客户端再次访问服务端的时候,请求的时候会带上一个口肯。第 五个的话是服务器端教练一个头啃,教练成功的话,那就会返回一个请求数据,教练失败就会返回一个错误状态吗?那说了这么多,我们实际偷看的一个应用是在哪方面呢?其实主要是两个,第一个的话是可以抵抗 cifr f, 也就是一个跨站请求物理伪造,用户在访问银行网站的时候,他们是很容易受到一个跨站请求伪造等公, 并且能够被利用起访问其他的一个网站。假如说我表单提交的 s r c 是一个北京点看我,就是一个北京银行北京点看我,然后他后缀的话会加上一个 u 三服装模式。假如说是张三,哦,这是一个黑客,那我 m o t 就是一个提前是一千的话,会针对刚才的一个表单提提交 s r c。 那如果是一个三审和酷 k 的形式的话,用户打开网页的时候其实就已经转给了一个黑客一千元了。因为 frm 发起的一个 boss 的请求是并不受到浏览器的一个同源策略的一个限制,因此可以任意的使用他其他域的一个酷 k 向其他域发送一个 boss 的请求,形成一个 c s r f 的一个攻击。 呃,在 pose 的请求的一瞬间 ok, 会被浏览器自动添加到一个请球头里面,但是涛肯他是不同的,涛肯他是开发者为了防晒这个而进行特特别设计的一个令牌浏览器,不会说自动添加到一个嗨的头里边,攻击者是也是无法防卫用户的一个头肯,所以提交的表 单是无法通过服务器进行一个过滤的,也就无法形成一个攻击。这个应用就是可以实现一个 c o l s, 也是一个跨区资源共享。如果说我公司内部有多个系统的时候,那么我就可以通过投肯来实现一个免登陆资源共享,比如说我要一个 qq 登陆之后,然后 qq 空间他可能也就已经登陆了。 其实在 qq 登录 qq 之后生成了一个投肯,那这个投肯不仅可以在一个 qq 系统进行使用,在腾讯旗下的任何一个系统都能使用,只要其他系统的开发对投肯进行了一个解析,那这个解析规则的话是提前进行沟通好的, 是因为有这个特性,所以偷看也是被用作一个单点登录的一种时效方式,那具体单点登录是什么?然后它是有哪些实现方式?我们下一期给大家说。好,今天就到这里感谢大家的观看,喜欢我就点赞关注我啊,拜拜。
350我在给你提Bug~ 01:29查看AI文稿AI文稿
01:29查看AI文稿AI文稿分布式事物了解吗?比如我们拉转账作个例子, a 需要转一百块钱到 b, 那么他就需要给 a 的余额呢去减一百,同时的话呢,要给 b 的余额去加一百,整个转账你要保证 a 减一百和 b 加一百同时成功或者是同时失败。 那么我们来看一下在各种场景下面是如何去解决这个问题的。比如说像银行的跨行转账,他就是一个典型的分布式事务场景, 假如 a 需要给跨行转账给 b, 那么他就会涉及到两个银行的数据,那么无法通过一个数据库的本地市务来确保我们转账的 acid, 只能呢通过分布式事务来解决。 分布式事物呢,是指事物的发起者、资源以及资源管理者和事物协调者分别位于分布式事物系统当中不同的节点之上。那么像 上述的转账业务当中,用户 a 减一百的操作和用户 b 加一百的操作,它是位于不同的一个节点上。本质上面来讲,分布式事务呢,就是为了确保在分布式系统下数据操作的一个正确执行。那么常见的分布式事务呢,有以下几种方案。第一种的话呢,我们可以玩两阶段提交 x a 好,我们还可以玩 t c t 的方案,我们还可以玩本地消息表,我们还可以用 rock m q 的一个分布式事务消息来实现分布式的一个事务。同时的话呢,还有一种叫做最大努力通知,最后的话呢,还有一种叫做可靠消息一致性方案。
 01:23查看AI文稿AI文稿
01:23查看AI文稿AI文稿网上被提都被我全的那种,你来说一下库克和三审的区别。库可以数据存放在客户短,三审数据是存放在服务短的,还有吗?嗯,目前只了解这么多, 你这么回答显得你了解的只是皮毛,网上被提都背不全的那种,面试最多给你八 k。 除了刚才所说的库给数据存放在客户端,三手数据放在服务区端,他们还有以下四点区别。一呢,是库给不是特别安全,别人可以分析存在本地的库给,并继续库给欺骗, 考虑到安全,建议使用腮神。二,腮神会在一定时间内保存在服务器上,当访问增多时, 会比较占用你福气的性能。考虑到减轻我们福气性能好损,应当使用一些库 k。 三、单个库 k 保存的数据不超过四 k, 很多浏览器都限制一个站点最多保存二十个库 k, 而赛事则存储在我们的服务区端,没有 存储数量限制,可以保存更多复杂的数据类型。第四点呢,是两者的生命周期有一些区别。以二十分钟为例,库给的生命周期是累计的,从创建时开始计时,二十分钟后呢,库给生命周期就结束了。三十年生命周期呢,是间隔的,从创建时开始计时。 如果在二十分钟内没有访问我们的筛审,那么呢,筛审生命周期就被销毁了。但是如果在二十分钟之内,比如第十九分钟时呢,访问过筛审,那么将重新计算筛审生命周期,你明白了吗?
3681软件测试媛姐 00:57查看AI文稿AI文稿
00:57查看AI文稿AI文稿cocon 和 season 功能相似,那为什么还会存在 token 呢?那我们都知道 cookie 和 season, 首先 cookie 呢,存储在客户端, season 呢存储在服务器,那为什么还会存在个 token 呢? token 的运作,其实呢,是用户使用用户名密码登录时,服务端呢,会生成一个 token, 那客户端每次请求呢,都会带上这个 token, 服务器呢?再次验证这个 token 就可以了。那吸水呢,是一种 htp 的一个存储机制,目的呢,是为了无状态的一个 htp 协议提供持久性的一个机制。 talk 呢,就是令牌,比如你授权的路一个程序的时候,他就是一个依据,判断你是否已经授权这个软件了。 其实呢, toc 和 c 水的问题是一种时间和空间的博弈问题, c 水呢,是空间换时间, toc 呢,是时间换空间。所以呢, c 水和 toc 并不矛盾,作为身份认证而言, toc 呢,安全性比 c 水更好。你学会了吗?学会了不要忘记点赞关注哦!
13九九说测试 03:39查看AI文稿AI文稿
03:39查看AI文稿AI文稿coke 和塞神的区别? coke 和塞神的区别是什么呢?那么塞神的话和 cook, 那么他们两个,首先我们先说他的一个相同点,那么相同点的话都是用来记录我们用户的一个信息的,那么在最开始的时候,我们没有 分布式的需求的时候,那刚开始的时候我们主要使用的是一个腮型的技术,然后当我们用户去登录我们的一个服务器, 连到服务器了以后呢,那我们服务器就会生成一个在线 id, 然后通过我们的一个 qq 啊,给他发送回度过我们的一个用户,然后用户呢可以给他记录到我们的 qq 里面去,那么 下一次在访问的时候,他带了这个三线 id 啊,那么和我们服务器里的三线 id 做一个比对,那么这个时候呢,我们就知道了,你以前是登录过的,或者你以前是访问过的,那么这样的话,我可以记录到你用户的登录以后的这样的一个状态的一个信息。好,那么 这就是之前我们的一个腮型的啊,那么这样的一个应用,那么这里的话,我们这个技术呢,叫做 cooky 腮型技术 啊,当然这个技术的话啊,刚开始使用的时候是比较完美的啊,那么我们用起来也非常方便啊,可以非常方便的记录我们的一个用户的信息,那么 当我们这个用户量一大起来以后呢,我们这个时候会发现,那么我们需要记录这个三星的地方啊,非常非常多,那么非常占我们数据库的一个内存。那么还有一个问题呢,就是现在呢,我们这个虽在使用的人数越来越多,我们敷 服务器呢,都在做分布式的一个处理好,那么如果我们做到分布式一个处理呢,在一台服务器上,那么我们存储了这个我们的一个塞气,那么另一台服务器呢?没有存储,那么他登录的时候呢,因为我们负载均衡,给他分到我们另一台服务上器上去了,那么这个时候都会有个问题,那么我们就没有记录到他的一个登录的一个状态,那所以说的话,那么这个时候呢,我们 可能会做两种选择,那么第一种选择的话,我们可以专门分出来一个啊,这个数据库的一个服务器,专门记录我们的一个塞信,那么还有一种选择的话,我们分成几份,你有多少个负载,我们就有多少个塞信啊,服务器来记录我们的一个塞信,那么这样的话很明显是有很大的弊端,那么导致了 我们会专门有一个服务器,或者是我们有专门多个服务器记录这个腮型啊,浪费了我们的一个空间啊,那么后来的话,我们就会发现,那么与其用这种方式,我们又想出来另外一种方式,那么另外一种方式就是使用什么的方式呢?就是使用了我们的一个 top 的方式啊, 偷看的方式出来呢,就是为了解决我们腮型方式的这样的一个弊端,那么我们的偷看呢,一般是使用我们的 md 五啊,或者使用我们的沙腕啊,加我们的密药供养时间出之类的,那么经过一定的算法啊,然后给他加密成一个加密的自封 串,然后我们把这个字幅串,然后返回给我们的一个客户端啊,那么这个客户端以后呢?服务器本身不保存这个东西,对不对? 好,然后的话我们的副这个客户端拿到这个数据以后,下一次请求的时候呢,我们会加到我们请求头里面有个,哦,对, resame 啊, 那么这个东西啊放到请求头里面去啊,然后夹着这个请求头,然后把我们的一个库给传给我们自己,然后拿到这个库给以后呢,我们服务器再去生成这样的一个偷啃,那么跟你传过来偷啃做一个对比,那么这样的话我们就会知道了,你是不是啊?已经登录好的这样的一个硬护的一个状态,那么这就是偷啃的一个问题, 那么他的优势在哪里呢?他并不需要在服务器端保存,那么我们在这个客户端保存可以保存到任意的位置,比如说保存到了要 qq 里面也行,保存到 gs 里面啊,也是 ok 的啊,都是没有任何问题的,你保存到哪里都是 ok, 那么大大大降低 我们服务器的一个负担。那么只需要我们这个时候呢,我们如果做分布式服务器,我们在分布式服务器里面也只需要啊做存储这样的一个算法就 ok 了,然后每次拿过来以后呢,我们进行个计算,然后再比对就 ok 了,那么这个就是我们 coke 啊, c 型啊,还有我们的一个拖痕的一个区别。
253测试猿课堂 00:40查看AI文稿AI文稿
00:40查看AI文稿AI文稿cookie 和 session 的关系和区别有哪些呢?首先呢, cookie 是服务器暂存在用户计算机上的一些资料,好让服务器来辨认用户的计算机。 session 呢,是绘画,是客户端和服务端之间的绘画,通过在服务端记录用户信息,确认用户身份。 k 呢,是一门客户端的缓存技术。 cookie 的数据呢,由服务器生成,发送给浏览器,保存在客户端。 cookie 的数据格式呢,是兼职对它的过期机制呢,是可以自己设置。 cookie 呢,保存在浏览器,它异味造不安全。接下来我们说 session 三审是一门服务端绘画缓存技术。三审是由服务端的外部容器创建,保存在服务器端的三审呢,保存数据呢,是通过建制字的形式。过期机制呢,一般是默认三十分钟。三审呢,在服务器端相对安全,但是过度的使用呢,会消耗服务器端的资源。
376小码哥聊软件测试 09:25查看AI文稿AI文稿
09:25查看AI文稿AI文稿看到一个登录屏幕,您可以在其中输入您的用户名和密码。点击登录按钮后,您的用户名和密码将发送到银行的服务器。如今,日式记录过程通常包括另一个验证步骤,例如获取短信。但为了使其更容易理解,我对其进行了简化。 接下来,服务器需要验证您是否是您所假装的人。因此,银行服务器将检查数据库,以查看您的屏距是否匹配。如果一切正常,服务器将显示您的账户盖栏页面, 但背后还发生了更多事情。一旦服务器验证了您的评剧,他还会在数据库中创建一个包含您的登录事件的条目,并以 cookie 的形式为您提供绘画 a d。 换句话说,你已经用您的用户名和密码交换了包含绘画 id 的 cookie。 绘画 id 只是您的日志记录绘画的唯一标识符,并且是随机生成的。这个概念类似于在衣帽间提供代码并收到带有号码的门票。 我在另一个教程中解释了有关 cookie 的基础知识。我将在说明中链接该教程。您可以在几乎任何网站上亲自检查此日之记录过程,以更好的理解它。在 google chrome 或任何其他浏览器中,您可以打开开发人员工具并检查您的网络流量。 例如,我在这里发送了我的用户名和密码,并收到了带有此绘画 id 的 cookie。 cookie 的内容是秘密的,其他网站无法读取。 因此,服务器会将绘画信息存储在数据库中,而您只能将绘画 a d 存储在 cookie 中,该 cookie 存储在计算机的文件系统中。下次您请求另一个页面时,您的浏览器将 将自动发送包含您的绘画 id 的 cookie。 服务器将检查该 cookie 是否仍然有效。值得注意的是,第二次不再需要您的用户名和密码来唯一的识别您的身份。 如果您注销您的登录,绘画将在数据库中失效,而且服务器也会只是浏览器删除包含绘画 id 的 cookie。 即便如此,如果服务器上的绘画过期, cookie 就变得毫无价值。如果您一段时间不活动,您的绘画将会过期。只要您继续与服务器交互,银行服务器就会保持绘画活动。 如果你有一段时间处于不活动状态,并且想要访问新页面,服务器会注意到这段时间的不活动状态,并会提示您再次提供用户名和密码作为安全措施。有些网站,例如 face book 可能会创建长期绘画,这意味着您很少需要输入登录凭据,但是您的银行可能会使用非常短暂的绘画,通常为五分钟或更短。 如果您连续五分钟处于非活动状态,则需要重新登录。 cookie 的概念可能很难理解。让我打个比方想象一下, cookie 就像你的健身房会员卡一样,它会存储您的会员 id。 当您在入口处扫描它时,它会检查您的会员资格是否仍然有效,并让您进入。 与您的健身卡一样,带有绘画 id 的 cookie 仅适用于特定网站。例如,您不能使用健身卡进入办公楼, 而且如果您的健身房会原资格到期,您的卡将变得毫无用处。现在,让我们回到登录室里。这种方法成为基于 cookie 的身份验证, 因此,此身份验证使用服务器上的绘画来处理此问题。 cookie 只是用于传输绘画 id 的媒介。使用它是因为它很方便。 浏览器将始终在每次请求时发送 cookie。 从技术上讲, cookie 是使用浏览器,通常称为客户端和服务器之间交换的消息中的 http 标头来发送的。 http 是确保浏览器和服务器能够相互理解的协议。在这种情况下,银行将绘画信息存储在服务器端,您看不到其中的内容,这也确保您无法操纵任何信息。 让我们快速讨论一下这个问题。服务器不在 cookie 中存储更多信息的原因之一是由于他们来自客户端,因此无法信任他们。这是一个安全问。 这就像告诉银行,我的银行账户里有一百万美元。相信我,这就是为什么服务器更喜欢使用数据库,理想情况下只存在有效信息。 回顾一下,绘画是由服务器生成的,并将存储在数据库中。作为客户端,您只会收到该绘画的 id, 通常称为绘画 id。 绘画 a d 是无疑随机生成且难以猜测的字母和数字序列。 cookie 用作绘画 i d 的传输媒介,因为浏览器将自动发送于网站关联的任何 cookie。 最后,由于 cookie 可以由客户端修改,因此服务器不能信任他们,并且始终需要验证他们。传统上,基于 cookie 的身份验证多年来一直运行良好,但他正在慢慢过时, 至少对于某些用力来说是这样。现在,假设你想在手机上安装一个应用程序,它可以帮助您管理财务并跟踪您的支出。 您不想做的事,将您的用户名和密码提供给此应用程序。该应用程序不是由您的银行创建或验证的。 在这种情况下,您的应用程序会将您重定向到您的银行。您将输入您的用户名和密码。您的银行会询问黑约翰,您愿意让这个应用程序访问您的交易吗?您将选中是。应用程序将收到一个授予您交易访问权限的令牌。 如果您愿意,此令牌就像临时密码。这就像您在酒店并获得一日 wifi 密码一样。 然而,令牌不仅仅是密码。大多数时候,他会限制对您的数据的访问。 在这种情况下,应用程序将紧查看交易。该应用程序将不允许执行转账或查看其他详细信息。我相信您在使用 facebook, google 或 microsoft 向第三方网站授予对您的用户个人资料的访问权限时一定见过类似的过程。 因此,在这种交换中,除了向银行进行身份验证之外,你永远不会暴露您的用户名和密码。如果您稍后需要,您可以通过使与您的账户密码分离的令牌失效来轻松撤销对您账户的访问权限。 用于此类场景的最流行的协议之一是 wolf open a d, 还有 j w t, 发音为 jot。 让我们看一下银行发行的代币是什么样子的。让我们使用 jason web 令牌或招令牌做 作为视力照。令牌不仅仅包含临时密码。银行可能会发行包含一些重要信息的令牌,例如客户 id, 该令牌授予的范围,令牌核实,创建以及核实过期。 需要记住的一个重要方面是,该信息是经过加密签名的。这意味着很容易验证内容没有被修改,除非您是银行,否则不可能篡改内容并生成新签名。 应用程序可以使用此令牌前往银行并获取交易数据或用户已授予访问权限的任何类型的数据。 在这次交换中,应用程序不知道客户的密码,但仍然能够检索一些数据。我给出的视力只是重 更多用力中的一个,并且有多种方法可以部署和使用令牌。那么,这个令牌与存储在 cookie 中的绘画有何不同呢?使用 cookie 时只涉及两方凝合服务器 使用令牌时必须注意交互通常涉及可能彼此不信任的多方。 因此您信任银行并提供银行登录详细信息,但您可能不信任在 x door 中找到的此应用程序。由于这些原因,令牌通常遵循标准以确保互操作性。而绘画则根据服务器的需要来实现,而不必遵循标准。 此外,某些令牌往往根本不需要服务器上的绘画。对于 chat 令牌,令牌包含绘画信息。 然而,这不是规则。另一个区别式令牌的生命周期有限,一旦过期就会生成新的令牌。 令牌还可以仅授予对特定用户或实体拥有的数据子级的访问权限。传统的基于绘画的身份验证将授予对所有可用信息的访问权限。大多数时候,令牌是使用授权 http 标头发送的,而不是作为 cookie 发送的。后者使用 cookie http 标头。 原因是现在许多交互发生在浏览器之外,例如来自手机上的应用程序。为此使用 cookie 根本没有意义。 基于绘画和基于并排的方法都很广泛,并且通常并行使用。他们例如在使用网站时部署基于绘画的方法, 但在使用同一服务的应用程序时,可能会首选基于令牌的方法。因此,了解两者的工作原理非常重要。我希望这有用,并帮助您更好的理解 cookie 绘画和令牌之间的区别。
12程序猿DD
