sql语句where多个条件

粉丝2551获赞9300
相关视频
 09:26查看AI文稿AI文稿
09:26查看AI文稿AI文稿哈喽,大家好。嗯,今天我们呢接着我们前面一次的那个数据解锁往后讲, 在上一次的内容当中呢,我们讲到了什么呢?讲到了最基本,最基本的数据减税,就是我们的数据查询,我们不再需要从我们的这个 设计器里面去啊右键,然后编辑数据,查看所有,那么我们可以用我们的 tc 口语去去把我们所有的数据检索出来,然后在我们的这个参与分析器里面查看。 我们讲到了最基本的语法,用我们的斯莱克特语句,呃,斯莱克特新芙蓉表明,或者是说斯莱克特列名去查找我们的这个嗯 嗯数据,然后把我们的数据显示出来,我们可以查同时查所有的列,也可以查指定的列。那么今天我们继续往后讲,在我们的这个塞拉塞拉特语句当中呢? 他通常和什么呢? select 语句,通常和我们的以下子句 结合使用,结合使用,那么有哪些呢?第一个是我们的 where 语句, where 子句,也就是我们今天要讲到的,它是干嘛用的呢?它用来指定 我们的这个筛选条件,只有满足 的结果才会被我们 我们查询出来。这第一个 vr 字句,第二个我们的这个 glue goodbye group by 子句。那么 group by 子句它是干嘛用的呢?它是用来分组,分组查询的,它是用来分组查询的,它是只按照 按照一,按照一个或者多个指定的字段对结果进行分组,常常 与我们的这个呃统计函数组合使用, 这是我们的第二个。第三个就是我们这个哈文字句,他是干嘛用的呢?他是用来,通常呢这个是和我们的 group by 这个纸具联合使用的,用来过滤 油。什么呢?用来过滤油,我们的这个这个 group by 子句所返回出来的结果, 这是我们这个嗯,塞拉克的语句,呃,会牵扯到的一些子句, 后面我们会一一讲的,那么今天我们就来讲什么呢?今天我们就来讲这个, 那么威尔他怎么用呢?他的语法是什么呢?他是我们,他的语法是 语法 selector clumas, 也就是我们的这个聂, 或者是叫自断 from, 表明后面跟上我们的这个威尔条件后,后面跟上我们的这个啊,威尔条件, 这个威尔条件他是可以省,可以省略的,你看我们在前面查的时候,我们这个威尔,我们的这个威尔他是他是省略的。比如说 我们现在要做什么呢?我们要做啊学生信息的一些筛选。那么首先我们要定位到啊,我们这已经定位到 student db 了,那如果是别的呢?如果是我们现在定义到 master 数据库当中呢?我们就我们现在去查一下 c frown, 直接等成 info, 然后我们查询一下 他提示什么呢?提示我们的这个对象名 student 的音符无效。这说明呢,我们当前所在的这个库啊,他不是我们啊一直用的这个 student 的这个库。所以说我们需要怎么呢?需要定位到我们的这个我们的这个学生的这个数据库里面去, 然后再去查询,这是我们上次讲到的基本查询,我们现在跟上威尔要查询什么呢?所有 的男生。所以说这个时候我们应该怎么做呢?威尔,我们的这个列名威尔条件,我们把它写好了啊,列名 等于什么?什么威尔,我们的这个或者是说还有更多的威尔,后面我们会讲到那一刻语句,或者是讲了一些特别复杂的,今天我们就讲等号,讲等号固定搜索威尔,我们的这个,嗯, 我们这个性别等于男生等于男,我们来看一下现在我们查到的结果是什么?你看 现在我们查到的结果就是所有的男生信息,这样呢,我们就把别的条件都给都给过滤掉了,拿到的都是男生的信息,那么如果我要 那女的信息呢?女生的信息呢?所以我要把这个,这个时候我就需要把这个男改成女,这样拿到的就是我们的这个啊,女等于我们这个啊,女生的这个信息。那么在我们的数学里面啊, 在我们的这个啊数学符号里面,我们等于是直接是精准的啊,数据精准的等于就是直接等于找找到精准的数据。那么如果我们想还有一种是不等于,那么不等于,在我们的这个啊 circle 里面去是怎么表达的呢?不等于 p。 circle 中的不等于。怎么表示?它应该是什么呢? select 的心 from student info where 不等于。看好了,是一对尖括号尖大鱼和小鱼组成的不等于难, 你看拿到就是女,如果是不等于女呢?他是取相反的一个操作,不等于女,拿到的就是我们的这个男生信息,你看这样的就是男生信息,这个是不等于啊?不是在 不等于,不是这么表示的, 不是这么表示的啊,是两个间,是一个大鱼和小鱼组成的这个啊,大鱼和小鱼的组成的这个叫什么呢?叫做,嗯,叫做不等号,然后这是我们的这个我们还可以查存什么呢? 还可以查询年龄,年龄查询,通过 vr 语句查询年龄 大于十八岁的 select see from student vr a 级大于十八, 你看这是找到大于十八的,那么我们可以也可以得到小于十八的, 你看大于十八和小于十八都拿到了,那么这样而言的话,哎,你说我的等于十八的是不是就没有呢?我们找到等于十八岁的,我们可以直接用等于,那么如果我们想在大于小于里面 都包含十八岁了,那我们就就可以用到什么呢?就可以用到我们的这个,呃,大于等于小于等于, 这样就拿到我们的十八岁了,这样就拿到我们的十八岁,在小,在我们这个啊,小于等于里面呢也也拿到十八岁了,这就是我们啊, 今天要讲的这个,这个内容就是我们的基础基本查询,就是我们这个通过威尔条件去定位到我们想要的一些数据。这个里面呢要注意制服 串了,就是我们的这个制服串的要加引号,去去查制服串类型的这个列,或者是叫自断,需要加引号。然后呢数值型的,我们就可以直接用我们的这个数学符号里面的这个关系运算服去啊,去比较,去查找。 然后呢要注意的是不等号在听说口当中呢,他这个不等号不是用一个叹号,一个等于是用我们的这个 这个,嗯,一个大于符号和小于符号组成的这个不等号,这就是我们今天的内容,就到这里了。
272程序员—路人甲 11:49查看AI文稿AI文稿
11:49查看AI文稿AI文稿大家好,今天我们来聊一下 update 语句,那在之前的视频里面,我们已经简单的介绍过它的用法,那么今天呢, 我们主要介绍他的一些特殊的用法。呃,第一点呢就是分支条件的修改, 那么呃基本的语句结构就这这个样子的,他是其实也是利用了之前我们说过的 case 变这样的一个语句来进行啊,修改的 就分支条件的一个修改方法。那么第二点呢,就是根据查询记录的修改啊,语法呢,就在下面这个地方啊,就是这样的一个语句,结 够了,大家可以看一下,那它的重点呢是在这个地方多了一个缝缝,后面呢是接了一个条呃查询语句。 那好,那我们首先先讲一下分支条件的修改啊,第一点的,那我们看到这里,呃上面有一个表,这个表了跟我们上次的视频的学生成绩表是一样的,只是多了一个字段,一个平和字段, 那么呃我们给他一个值,就是一个空值,平和的字段的值啊, 然后我们先看一下他的,呃,之前的结果就是这样表了,平和字段是空的, 那我们我们要根据什么来修改呢?就是,呃根据我们的学生的成绩啊,修改这张表, 修改什么呢?修改是平和这个字段它的值,那么根据学生成绩呃大于六十,小于八十的,我们就给他一个一般的平和, 然后如果是大于八十,小于等于九十的,我们就给一个呃良好的平和,如果是大于九十的话,我们就给他一个优优秀的平和, 那如果上面的条件都不满足的,就给他一个差评,就是这样的一个修改,那么这个地方就是用, 用到了 case band 一个语句了,我们执行一下看看把先弄上来啊,上面第一个表呢,是我们还没有修改前的表,那么下面这个字就是已经修改后的表,我们看一下 这个就是我们修改就对应一个学生,每个学生的成绩,每一个科目的成绩,应该这样说啊,每个科目的成绩的一个平衡 语句就是这一条了,呃,当然这个地方我们也可以加一个呃条件,就确定他的修改范围, 然后我们加呃,比如说姓名等于张三这样,然后我们再自行看, 再拉上来,那么大家看到了上面还没修改的, 然后再看下面啊,下面张三的平和已经有了,但是李四的还没有,也就说我们这个地方是可以加条件的,而且是其实也就是 a 被语句的一个条件修改范围吗? 所以大家要区分好 vr 条件跟我们的分支条件的一个区别啊。 那好,我们接着说,我们呃第二点,根据查询记录的一个修改, 然后呢我们还是举个例子,呃,这里面呢,大家看一下,有两张表,第一张表呢是呃总成绩表, 就是每一个学生总成绩的一个呃表,他是由四个字段组成的,姓名,总成绩平均分,还有平和四个字段组成啊,我们初始给他一条记录都是零, 然后我们看一下下面这个表,下面这个表就跟我们呃前面说的那个呃学生成绩表是一样的,这个是 我们先执行一下啊,看一下这两张表,没有修改前的两张表啊,这个就是总成绩表,张三的总分跟那个平均分,李四的总分平均分都是零啊, 好了,我们呃下面这条 up day 一句,就是我们需要根据什么根据,呃,学科成绩表, 就是我们这张 t b 这张临时表对应的就是我们的学科成绩表了, 然后我们看一下,我们要得到的是他的总分,就每个学生的总分啊,跟每一个啊,应该是总分的平均分呢?科目平均分, 然后呢他是根据姓名进行 go by 处理的,也就说每个学生啊 go by 出来的一个总分跟一个均分这样的一个查询语句,就找 一条的查询语句,也就说我们要根据这个查询语句得到的结果来进行修改,然后我们给他一个标示是 a, 那么我们的 a 呢?呃,对应的就总分在这个地方,然后还有均分,总分跟均分这两个字段值 对什么?对总成绩表的平均分跟总成绩进行修改, 然后他有必须要有一个条件,就是总成绩表的姓名必须要等于我们查询这个表的姓名,让我们仔细看看啊,上面是没有修改的两张表是没有修改前的表,那么下面呢,就是已经修改后了,我们看到了 啊,这个就是修改后的得到了张三跟李四的一个总分跟平均分,他是根据张三,你说张三这一二三四五五个科目的啊,总分就是这个了,然后他的平均分就是这个, 那么然后我们把这条语句就是查询啊 from 后面的这条语句, 我们单独拿出来执行一下看看啊, 单独自信看看上面两张表了,是没有修改的, 那么下面这张表是我们单独查询的一张表啊,就是根据这条语句查询出来的结果,下面这条啊,下面这个就是这个结果了。 嗯,大家看到了这里面它的两个列,一个叫总分,一个叫均分,然后总分的值,总分的值呢是付给总成绩, 均分的值呢是付给啊,平均分这两个字端,那后面这个条件是必须要有的。我们看一下张三的姓名, 李氏的姓名,这是啊,就是 a 标示的姓名,必须要等于我们这个总成 记的表这个姓名,然后我们看到总成绩他有一个姓名字段,然后那个学科成绩也有一个姓名字段, 那么这两个字段我前面我们必须要有个标示,给他标示清楚他是属于哪里的啊?如果没有这两个标示会怎么样呢?我们先把两个标示删掉,这两个标示删掉他就报错了。 这个地方一定要有一个标识,我们执行一下啊,他表示不明确,姓名不明确,也就说他不知道这个姓名是哪,属于哪张表的, 所以我们必须要增加上这个标识, 然后啊我们再仔细, 哦,这个地方报错了,我们看一下是什么原因, 哦,对了,我们这个地方临时表没删掉,我们标必须要把它删除掉。 呃,这里要说一下这个临时表,临时表跟我们实际表是不一样的,它前面有一个井号,让大家看到 有个警号,他表示是一张临时表,不是实际表。这个我们在后面有机会也会跟大家介绍一下什么叫临时表。好,我们现在再重新执行,那就可以了, 这个就是我们修改后的结果, 那我们总成绩表不是有个平和字段吗?同样的我们也可以。呃,像刚才说的,我们用一个条件分支语去对他进行一个修改, 也就是 case band 的一个处理方式,给它修改一下。我们现在啊 case band, 然后,呃,用哪个成绩啊?就用总分吧。啊?总分,总分, 同样的总分大于大于六十,小于等于八十,然后我们给他一个一般的评价啊,如此类推了。就是跟我们 前面说的啊一样。 那好,改好之后我们执行一下,看一下结果,好拉下来上面两张是没有修改的,这两张哦,这个地方都是有哦。我们应该用那个啊?应该用平均分的, 用平均分来进行平和。改成改一下吧,改成均分啊,然后执行看看。嗯,好了,现在的结果就 好了。那么,呃,今天的视频就先到这里啊,感谢大家的收看,谢谢。
 05:09查看AI文稿AI文稿
05:09查看AI文稿AI文稿大家好,最近有粉丝朋友私信我,呃,让我说说 s k l 的事物, 但是我个人呢,呃不太建议在 secure 里面去执行事务啊,非不得已的情况下,尽量不要呃使用事务。我们要处理事务的话,尽量在我们的程序代码里面去执行, 因为在 cq 里面执行事务,呃很容易就会导致失锁的情况,一旦出现失锁,那么我们整个系统就会崩溃了。 但是既然有粉丝提出要呃讲一下,那我们就讲一下呗。呃 h q 的事物呢,有三种,一种呢是自动自动提 比较事物,另外一种呢是呃我们要今天要说的显示事物,那第三种呢是影视事物啊, 那我们今天要说的这个就是显示事物,呃,显示事物,我们可以用在之前说过的呃存储过程或者是触发器里面都可以,那么显示事物它必须有一个开始 啊,就是我们这个啊, began the trampression 的这个命令啊,这个命令是提示我们事物开始的一个呃语句, 那么接下来就是输入一些呃我们这个事物要执行的 s k o 语句,那么 呃这里面呢,可以是一批语句,当然也可以是一条语句。那我个人建议在呃 hql 的事物处理里面呢,尽量的少,这个地方尽量的少一些语句,不要太多啊,我们的事物要执行的语句尽量少, 那么接下来呢,就是要判断我们呃上面这些语句,这个上面这些语句有没有发生错误 啊?这里面有一个变量,这个变量是呃系统默认的一个变量,如果他不等于零的情况下,那么也就说出现了错误,那么我们在这个地方要做,要做一个回滚的处理啊,要把这个事物回滚,把这 一批的语句啊全部回滚,如果他等于零的情况下,那么我们就提交上面的这些啊,这个提交提交上面这些事物语句,嗯,让他执行完成, 那这个就是 secure 的事物呃处理的一个方法啊方式,那如果说我们的事物比较复杂,我们就要插入一个事物保存点啊,给他那个点名叫做 save e。 这个 safe 一什么意思?相当于我们,呃,不知道大家有没有接触过很久很久以前的一种呃程序代码,程序叫做 basic 啊, basic 里面它有一个沟通 口语句啊,勾头语句必须要指定一个标示点的,那么这个 safe 一就相当于是呃勾头语句里面的那个标示了啊,那么他怎么使用呢?呃,我们可以结合回滚, 我们可以结合回滚,把它回滚到我们指定的标示啊,这这个就是他的使用的一个方式啊,假如说我们前面还有一些语句的情况下啊,我们就回滚, 我们假如说啊,前面有其他语句,我们一旦执行错误,下面的语句执行错误,那么我们就可以回滚到我们指定的这个点上面去,而下面这一个语句呢,我们就不做回滚的处理了, 那么这个就是呃事物保存点的大概的使用方式了啊。那最后我们总结一下, s q 事物必须要有一个开始啊,然后要么是回滚结束,要么是提交结束, 那这个就是 s q 事物处理的一个形式了。呃使用方法,大概是这样我就不再做实力了,看上去他其实是很简单的,但呃,就像我之前所说的, 呃 sq 事物处理,如果处理不好的话,我们呃执行的语句太多的话,很容易很容易就会导致失锁, 呃,所以这个大家一定要注意。那么今天的视频就先到这里啊,感谢大家的收看,谢谢。
 03:20查看AI文稿AI文稿
03:20查看AI文稿AI文稿学过计算机的人都知道 s q l, 但问你 s q l 是 如何执行的,背后的原理是什么?百分之九十同学就答不上来。今天我们就一起深入了解 s q l 背后的运行逻辑。 我们可以从两个层面来理解 s q l 执行。首先是逻辑执行顺序,我给大家总结了一个方便记忆的口诀,从外群哈斯欧利对应的流程是从 from 开始,经过 join on where, 再到 group by, having, select distinct, 最后是 order by and limit。 然后是物理执行流程,从客户端发起请求开始,依次经过连接器、分析器、优化器、执行器,再到存储引擎,最终返回结果。需要注意的是, mysql 八点零版本已经移除了查询缓存。 接下来我们逐个解析 sql 执行的关键阶段。首先是连接器阶段,它主要负责建立连接,验证我们的登录身份,获取对应的操作权限,同时管理所有的数据库连接 默认的 wait time out 时长是八小时。第二个是分析器阶段,它会对 s q l 语句进行词法分析、语法分析以及语义分析,构建解析术来验证 s q l 语句是否合法。 第三个是优化器阶段,它会为我们选择最优的执行计划,比如决定使用哪些缩影,以及多张表之间的连接顺序。每一个阶段都在 s q l。 执行中承担着不可替代的作用。 在面试中,关于 s q l 执行顺序有几个非常常见的陷阱,我来给大家一一讲解。第一个陷阱是在 where 语句中使用聚合函数,比如写出 where count 大 于一这样的错误语句,正确的做法是使用 having 来代替。 第二个陷阱是在 where 中使用 select 语句的别名,比如 where total 大 于十,我们可以选择重复表达式或者通过子查询来解决这个问题。第三个是给大家一个小知识, order by 中是可以使用别名的, 就像 order by, cntdesk 这样是完全合法的,这是因为 order by 是 在 select 语句执行之后才运行的。 想要优化 s q l 的 执行性能,我们必须掌握执行计划的核心知识点。首先我们来了解 explain 的 输出字段,里面包含了 it、 select、 type、 table type、 possible、 keys、 key、 key、 line、 rows、 filtered 以及 extra。 其次是关键访问类型,它们的效率从高到低分别是 system 大 于 const 大 于 x, ref 大 于 ref 大 于 range 大 于 index 大 于 o。 然后是 extra 字段中的关键信息, 例如 using index 代表使用了覆盖锁瘾, using where 代表会在存储引擎解锁后再进行过滤。 using file sort 和 using temporary 都是我们在优化中需要尽量避免的情况。最后是锁瘾设计的原则,我们要优先为高频查询设计锁瘾,遵循选择性原则,同时牢记最左前缀匹配规则, 学好执行计划,才能真正做好 s q l 性能调优。最后我们来做一个总结,第一点, s q l 是 按照逻辑顺序执行的,而不是我们的书写顺序。第二点, where 语句是在 group by 之前执行,而 having 则在 group by 之后。 第三点, select 的 别名只能够在 order by 和 having 中使用。第四点,理解执行计划是我们进行 s q l 性能调优的关键所在。希望今天的内容能帮助大家更好地掌握 s q l 执行的底层逻辑。
58七贝编程 05:07查看AI文稿AI文稿
05:07查看AI文稿AI文稿最近有一个技术博客非常的牛,他让这些数据分析智能体写 circle 语句的准确率从百分之八十提高到了百分之百,并且他更离谱的是,他减少了百分之八十的工具使用,因为现在很多 java, 它最重要的一个技术就是让大模型怎么样写出准确的 circle 查询语句, 因为现在很多大模型,就算顶级的大模型,它的 circle 语句写出来,它的准确率都非常低,它的准确率最多也就达到百分之九十多, 肯定达不到百分之百。而现在这种恰当 b i 的 数据分析的商业的数据分析项目,它的风险敏感度非常高,只要你不是百分之百,那么你就约定于零,这也就是为什么现在以恰当 b i 很 难做的一些原因。 那么他们就是专门做 circle 这种数据查询工具的,他们第一个版本就是直接使用的这种传统的智能体,给他很多工具,让他去查询了之后写出一个正确的语句,他们给到了非常多的智能体,可以看非常多的工具,可以看到他的工具非常多,但是他们的准确率还是只有百分之八十。 他们用了非常多的专业工具,然后增加了大量的提示词工程,而且上下文管理也做了非常好的操作, 并并且还做了一些手工编码的解锁,各个维度的一些属性,反正乱七八糟的都给这个智能体加上了,但是它准确度还是不高。 他们就有一个新想法,如果他们停下来了,就不要再做这种乱七八糟的操作,而是把信任给到现在的大模型,因为现在的大模型写代码的能力已经非常强了,比如说像 cloud 的 opus 这些模型,它已经非常的强了,为什么不愿意信任这些大模型呢? 然后他们就提出了 v 二版本, v 二版本现在非常火的就是动态上下文,让大模型去探索文件型系统,然后去得到他想要的内容,再去写 circle。 他 们就用了这样的一个方式,他们让现在的大模型去自己读取文件, 去 graph, 去构建自己心里的这种构建自己心里模型,再去编写 circle。 其实这个东西就两个工具,一个是沙河的一些执行工具,就是它去探索这些语句。第二个工具就是这个 circle 的 执行语句,就特别简单,两个工具就结束了, 让大模型自己去探索它想要的东西,自己去了解这个 circle 它的语句,它的结构是什么样的,然后再写 circle 语句, 这样的话它的准确度,准确度提高到了百分之百,而且速度快了三点五倍,托管还减少了三点百分之三十七,这个就非常离谱,而且平均的速度降低了非常多,这是为什么? 他们就总结出来经验教训。首先就是文件系统,像 graph 这种其实已经非常古老了, 而这些模型它训练的数据其实也在训练它使用这些工具,而不是训练直接写一个 circle 语句。不像我们人不可能自己莫名其妙的写个 circle 语句,我们是查询出来的,我们是用的这些很古老的一些工具去查询出来的。 比如说现在的 cloud code, 它为什么工具用那么少?而且它的系统接口也非常简单,不像 coser, coser 它是什么这些嵌入式,像这些嵌入模型,像这种语 语言语语意向量都是做了的, reg 这些全做了,但是它的性能没有 cloud code 强,而 cloud code 就是 一些特别简单的 grab 搜索工具 list, 把这些内容查找到,然后进行编辑。本质上是给到大模型像人一样的思考, 让他像人一样去执行工具,而不是给他一些专属的工具不去相信他。然后他也说了,我们限制了大模型的推理,我们不信任现在的大模型,而现在的大模型到 opus 四零五,其实这一些限制成为了他的负担, 也是我们最近能感受到的。我们告诉模型要怎么样做,告诉这种题要怎么样做,其实你得到的结果不好, 你要告诉他你为什么要这样做,你是怎么样想的,我得到了什么样的内容,我想要得到什么样的结果,所以我想你也帮我出一个什么东西,那么这个结果才是好的,而不是请你帮我出一个。他的结构是什么样的,你限制给他加的条条框框,他加死了,加多了都没用,你要告诉他, 要让他知其然,而且要知其所以然,他的效果才会更好。他的一些文件结构,然后一致,这是搜索的一些内容。 最后他也说了,既然减法即是加法,他们认为现在最好的智能体应该是工具最少的。 还有一个点就是现在的智能体最好都使用这样的方式,模型加文件,系统加目标,也就是最近非常火的 skills 的 方式,而现在很多这种智能体架构都在往这种方式去引导,不管是 lanchen 的 deep analytics 还是说 coser, 他 们都支持了这样的方式。 他们有一句话特别有价值,我觉得只有在你证明必要的时候才加入复杂性。只要这个东西他能用,文件结构能用,文件系统能用最简单的方式去实现,就算他慢一点都是能接受的,因为 不会影响他的一个操作习惯,他跟我们人的习惯是一致的。所以说不要动他,不要额外给他加工具,不要让他觉得,不要让他觉得我有很多其他乱七八糟的工具,而是要让他像我们人一样去操作,去思考。我们要相信现在的模型,因为他的能力已经非常强了。
 01:37查看AI文稿AI文稿
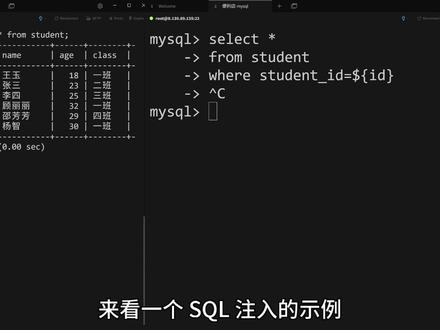
01:37查看AI文稿AI文稿来看一个 c 口输入的事例,怎么通过 c 口输入把学生表里面的信息给删掉。只要你在写 c 口的时候,不小心把简号写成了美元符号,那么这里就会存在一个 c 口输入的问题,下面来看一下效果。 这里本来你查询数据的时候,正常传入的是一一,但是通过 c 口输入,那么他这里就多传入了这一段东西,然后我们来执行一下, 可以看到这个时候你再来查学生表,这里面的数据他一边已经没了,这个就是一个简单的 c 口注入势力,所以大家在写 c 口的时候一定要注意, 要么就是把这个 c 口预编辑一下,要么就是把一些里面该替换的东西,通过拦截器或者其他方式把这些特殊的东西给替换掉。最后给大家推荐一下我的这几份实战手册,手册的价值在于,一可以提高学习效率, 通常来说你跟着手册操作十五分钟左右就可以完成一个实战试炼。二是学习有个兜底的地方,你在遇到问题的时候就不用到处去搜索,有问题你及时问我,我会在第一时间内帮你解决。 这一项目是一个从零开始搭建的微服务项目,除了能学习微服务的搭建,你还能全面了解一个软件的开发流程。 这个项目从需求整理、原型图、绘制设计图、正常的开发一直到项目的部署以及基础运维监控都有,并且项目中的代码都有对应的注示。如果你遇到问题,那么你也是在第一时间就给我打个语音,我会帮你及时的解答。
44编程实战派 01:14查看AI文稿AI文稿
01:14查看AI文稿AI文稿make sql 语句中的 where 和 having 有 什么区别?这是面试高频题目,也是大家测试工作中写 sql 常用的。那 make sql 中呢?它 where 和 having, 它都是筛 选条件,但核心区别是筛选时机和作用对象是不同的啊,一眼就能分清楚。那 where 呢?它是在分组 group by 之前筛选原始的数据号,它只能针对普通的一些字段,比如 id 啊, age 啊, name 啊这些做筛选。它不能用于聚合的一些函数,比如 sum halt average, 那 比如 where h 大 于二十,他先把年龄大于二十的行筛选出来,再进行后续的分组或者计算,这样效率会更高。那 have 呢?它是在分组之后筛选分组的结果,它专门用来过滤聚合函数的。计算结果必须跟 group y 去 配合使用,比如 group y different have 以 sum salary 大 于五万,那他先按部门呢去分组,算出工资总和,再筛选出总和超过五万的这些 部分。如果直接用 where 筛选原始行,再筛选出总和超过五万的这些部分。如果直接用 where 筛选分支,最后 have 以内筛选分组结果。 函数的筛选只能用 having, 普通自断筛选优先用 where, 避免低效。当然,一个查询中两者都可以使用优先使用 where 进行过滤,减少数据,再对分组进行筛选,这能显著提升查询的性能。优化总结就是 where 管分组前的原始行, having 管分组后的聚合数据,这样就能轻松使用。 ok, 你 还想学习更多的内容,欢迎评论或者找我单独交流。
167宇宙AI测试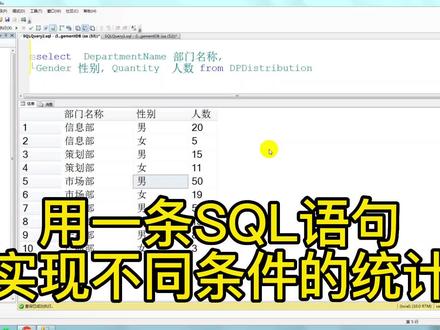 07:34查看AI文稿AI文稿
07:34查看AI文稿AI文稿哈喽,大家好,我是陈秀诺任贾。那么今天呢,给大家分享一个 circle 的一个高级用法,那我个人觉得在呃实际的这个工作当中呢,它的呃用到的频率是非常高的,我们来看一下是什么。 首先呢已知有一个表,那这个表呢,是一个部门的一个人员分布表,它里面记录的信息呢,是每一个部门的男女的这个人数,男性女性的这个人数,那大家可以看到他每一每一个部门他会有两条信息, 那这样我们看起来的话,就是比如说给领导看的时候呢,这个数据看起来就不那么的直观,那我们今天就想一个办法,用 circle 语句来让他展示成这种二维表的格式,就是这种结果,就是每一个部门呢,让他把这个嗯男性 人数和这个女性人数展示在一行数据里面,这样看起来就比较直观一点。然后我们来看一下啊,这个需求呢, 乍一看很简单,是吧?你说你这个其实很简单呢,用我们之前讲到的 group by 其实就可以实现,当然 group by 它是可以拿到这些数据的,但是这些数据呢,可能拿起来一步就没,没有办法一步到位就不能得到我们要的需求。 我们来看一下这个里面三,这个表里面的三个字段就是我们刚刚讲到的名称啊,名称,还有这个啊,性别男的人数, 我们怎么样来得到这个结果呢啊?通常情况下,我们在拿到这种这种需求的时候,我们脑子里第一想到的就是什么呢?想到的是 group by 那 group, 但是我们用的非常非常频率高的一个啊,一个用法,一个知识点,但是呢,有的时候呢,这个 groupby 他也有实现不了的功能,这个时候就需要我们去想办法用这个 groupby。 select 用什么呢? select, group by, 还有我们之前讲到的 case 表达式, case 表达式,共同直线, 共同来完成。那第一种方法我们来看一下,我们这个我们先给它标起来,因为我们后面也要讲这个, 我们来看一下正常情况下我们的我们的思维可能是这个样子,就是怎么样呢?去给他,嗯, group by, 部门,然后性别。我们看一下这样写的时候他得到的结果是什么?这是我们比较常规的 一个想法,看到看到分组求求那个聚合的时候,我们第一想到的就是 google 拜去做一个统计,然后我们来看一下这样得到的结果, 这样得到的结果,那他就是什么呢?那他跟之前的结果是没有什么区别的,没有什么区别的区别就在什么地方呢?他把这个男和女进行了一个排序,是吧?当然这个地方我们也可以直接 select 在在这里,是吧? order by, 用这个什么呢?用这个部门,部门名称进行一个排序, 这样这样,哦,用这个,用这个什么?呃,用这个进行排序,是吧?呃,这个是名称排序,他默认是这个,那我们要应该用这个 gender 来进行排序一下, 然后这样,哎,这样他反复也能达到这里的这样的一个需求,是吧?男,然后女,一共十条数据,两十条数据。男女。 但是呢,他这样就会有一个问题,他并没有达到我们的什么呢?并没有达到我们的呃,刚刚讲到的这种结果,那这种结果怎么样来的?我们依次来往下讲,这是第一种方式。那第二种方式, 第二种方式,那你说我,我一下达不到,我就给他分两条吗?是吧?当然分两条他是可以达到结果的。比如说我们来看第一条数据, 哎,你看得到了啊?策划部,然后呢?这些是男生的是吧?第二条我们把他这个威尔改成这个女女生的,你看这也得到结果了。得到结果之后我们可以 利用一些别的别的啊方法把它数据做一个连和,用 una 或者是说用一些拼接的方法,最终来达到我们的 这个需求。但是呢,我们我们如果用这两条分开写的话,我们会呃减增加这个数据库的这个负担,那他写起来比较繁琐,会用到很多的一些啊,基本的一些算法呀,拼接呀,组合呀等等 才能达到这个结果。那么有没有一种方法能够让他直接一条 soco 语句就拿到这样的结果呢?答案是可以的。那这个时候我们就要什么呢?就要写到就要用到我们刚刚的 什么呢?用 select 加上 group by 加上 case 表达式共同来完成。 我们来看一下怎么做的? kiss 表达是我们之前已经讲过了,用它来,呃可以做好多事情,是吧?之前专门有一直讲,这就不讲了哈。 在这里我们来看一下他第一个不变, select department name, 部门名称不变,然后他变了,在什么地方呢?他在这里面用了 case 语句,用了 case 语句来算的,用了 case 语句,然后我们来看一下第一个,第一个求上, 你看当它等于 case, 问 gender 等于男人,如果它等于男的男生的情况下,那我们就给他显示这个呃 quitty 是吧?就给他显示数量,否则记住 s 不要忘了,然后给他一个零,整个语句结束,整个语句结束。那第二条当他等于女的 时候,也是同样的写法,也是同样的写法,那这样而来呢?我们就可以通过这个 case 的任,然后来达到我们的这个呃 some 的这样的一个结果。最重要的是 最后面这一句 goodbye department name 这句是一定要加上的,因为他核心还是分组嘛?核心还是分组,只是我们用了一个小小的技巧在里面加入了这个 case, 问,认这个 表达式,分支表达式用了什么呢?用了分支表达式来组合使用,已达到 转换成二维表的格式,二维表结构的 结果已达到。嗯,产生我们这个二维表结构的这样的一个结果。这就是我们今天讲到的这个呃,稍微高级一点的,复杂一点,难一点的这个用法。因为我想给大家分享的是,因为 我用的会啊比较多,我在我的实际的工作当中呢啊,这个知识点,就这个知识点我还用的频率还蛮高的, 因为在基础数据的时候,因为在做基础数据的时候,好多数据他在呃做的时候他就没有那么的专业,就是他会呃简单的记录基础信息,而不会考虑到这个呃数据的这个呃,这个叫什么?这个 标准性,很多数据都是它的基础数据,都是,嗯,很凌乱的。那这个时候就需要我们去用我们的强盗 set 把这些数据结组合起来,看起来它,嗯,比较直观一些。那今天的内容我们就到这里。
104程序员—路人甲![[SQL学习Day157]SELECT字段与* #计算机 #面试 #秋招#SQL #数据库](https://p3-pc-sign.douyinpic.com/image-cut-tos-priv/c5b48f958bcf7e9ba588428f7163ee4a~tplv-dy-resize-origshort-autoq-75:330.jpeg?lk3s=138a59ce&x-expires=2086286400&x-signature=0an%2FKiZB5RTBryzDM9NJBxDIUwQ%3D&from=327834062&s=PackSourceEnum_AWEME_DETAIL&se=false&sc=cover&biz_tag=pcweb_cover&l=20260213040820F8B45F18554857A5DEC9) 00:52查看AI文稿AI文稿
00:52查看AI文稿AI文稿呃,我们来看到这道题,它说呢,你要查找所有的列,这里有一张表叫 customers, 对 吧?它里面有两个 colon, 第一个 colon 叫 customer id, 那 第二个 colon 叫 customer 的 一个 name, 分 别表示一个用户的 id 和用户的姓名。呃,然后我的预期是要找什么?我的预期是要找。 呃,解锁所有的列,那不就是 select 这个 cost id, 对 吧?然后还有一个 cost name, 对 吧?然后你 from 一个谁 from 一下这个 table 嘛? from 一下这个 table 的 名字叫 customers, 对 吧? 呃,行吧。那这道题我觉得,呃,你可以从中学到的一个点就是,我们尽量不要使用心,不要用心。我们在工作当中最好还是用这个 colon 把 colon 写出来,对,不是最好,是一定不要用心。对,这个用心是一个很危险的行为。对。
 09:34查看AI文稿AI文稿
09:34查看AI文稿AI文稿哈喽,大家好,在上一次的内容当中呢,我们讲到了这个,嗯,威尔语句的这个基本用法,那么他呢跟在我们这个表明后面,然后加上威尔关键字去使用, 我们讲到了等于符号,然后不等于符号大于小于以及呃,大于等于小于等于这样的一个基本用法。那么今天我们继续把这个大于小于用日期类型再来演示一下呢,接着往后面讲讲什么呢?大于小于 小于符号对日期类型的数据筛选, 怎么筛选呢?现在我们来看我们的数据当中都有什么哈? select 心 from 我们的这个 student efo 表 vir vir 去从什么从从什么什么什么,当什么什么条件的时候,让我们去拿到这个数据 vir。 然后呢我们这个先来看这里面都有哪些哈, 这些是我们现在有的这个数据,是我们现在有的这个数据,你看我加了,我加了两个字段,一个是嗯,我们的这个呃日期,还有一个是电话号码,在这里面呢, 我们要查询九月一号以后入学的学生,我们来怎么做呢? 我们的这个什么呢?二零二一年九月一号这个时候我们来看这个地方,不管了, 爆红线是因为我这个这个 data 这段是我新加的,他的这个 id 还没有识别出来,所以他会给我打一个红线, 然后把它怎么样呢?哎,就出来了,你看这两条数据呢,是在九月一号以后入学的,那么我们再来看一下,如果我把这个大于改成等于,他得到结果是什么呢? 你看他得到的结果就是把九月一号的数据也查询出来的。首先我们来看一下这个日期的,他的这个结构哈,他是由年月日十分秒毫秒数, 他这样构成了一个长日期的这个,嗯,这个,嗯日期格式。那当我们默认的只取到什么呢?只取到这个,呃,年月日 的时候,他默认是给我们取啊,这个时间后面的零时零分零秒的,结果零秒的数据,零时零分零秒的这个数据,这个是我们的这个大于,那如果把这换成小于号呢?同样的道理,把这个大于号换成我们的小于号。 小鱼等于 他拿到的结果就是什么呢?就是你看就是九月一号以前的这个数据,这一条,这一条蛇口,他拿到的是九月一号以前的数据,而我们的这一条呢,他拿到的是什么呢? 包含了九月一号,因为他有取等,有取等的,有取等于的这个这个数据。那么如果你要做精确的时候,要做精确数据查询的时候,你就需要后面跟上十分秒,比如说我们要干 什么呢?把这数据改一下,编编辑前这个。然后呢我把这个数据改成九月一号,九月一号,嗯,中午十二点 二十五分三十秒报名的,那么这个时候,那这样的话我们这个数据改过来了,这个时候我们再用这一段,再用这一段去查,我们来看一下, 你看九月一号的那条数据就不见了,九月一号的那条那条什么呢?那条十二点二十三分三十秒的数据就不见了。那么相反,我们来看一下这条大于等于九月一号的,你看这条数据就出来, 他是零零时零分零秒,这条数据就出来了,那么这有两条是零时零分,那如果是我把这个零时零分改加后面加上一个时间,在早上九点以后,九月一号早上九点 点,九点半,早上九点半以前的这个大于等于。我们来看这个 他得到的是什么呢?你看得到的就是这个,还有一条九月一号的数据他就没有拿到,还有一条九月一号零时零分零秒的这个数据他就没有拿到, 这个就叫做精确的这个数据查询。就是这个日期,他比较特殊啊,日期,因为他呢他是由年月日十分秒构成的,所以说当你的数据精度比较大的时候,你就要注 去取的这个呃十分秒这样的一个数据啊,来做筛选,这样的一个数据来做筛选,然后呃,那么我们的这个大于等于有了 男女,我们再塞一个男女 cir like the 心 flow student info where steal, 他这性别等于男的,你看他拿到的数据是什么呢?拿到的数据是我们的这个所有的男生同学,所有的男生的数据, 这个我们拿到了,那么你说这个这个查询他其实是有呃缺陷的,什么缺陷呢?那你说我如果想多条件查询怎么办呢?我如果想多条件查询怎么办呢?就是我又要想拿到是男生数 数据的,我要想拿到这个男生数据年龄在多少以上的或多少以下的,这个条件我应该怎么来做呢?这就是我们后面要讲到的嗯的 以及嗯的和 or 关键字,嗯的和我们的这个嗯的和我们的这个 or 关键字它是干嘛用的呢?嗯的和 or 或者嗯的 n 的,并且和哦或者这两个关键字有了它呢,就是如虎添翼了,是吧?我既可以查这个 大于小于范围内的,我也可以查男性的,我也可以查啊,多个条件去并列的,这样去啊,这样去做我们的什么呢?这样去做我们的筛选。那我们来看一下这个他的语法是什么呢? 他的语法是什么呢?比如说我们要干嘛呢?查询 end, 取取并集, n 的曲并集,就是你的这个都要符合的并集,这我们在学数学的时候学到过并集,是吧?那么我们现在看一下 seen from student info where? 我们要查询 男生里面 v 二,我们这个性别等于男生, 并且,并且什么呢?并且我们这年龄要在十八岁以上的 a 级大于等于十八岁,那么这个就是什么呢?我们来看一下他得到的结果是什么?你看 性别,性别男年龄都是在十八岁,包含十八岁以上的,包含十八岁以上的,那么这个就是我们的病急,他取病急,如果如果只满足一个条件,另一个条件不满足,他的数据是不被不被筛选出来的。那么第二个我们来 看一下,我们查询女生里面是十八岁以上的,十八岁以上的血色, 这个时候你看他得到了这两个数据,那么我们可以两个两个数字并也可以多个条件。那么我们要查到长于什么呢?男生里面十八岁以上的,并且呢?他还要,他还要在九月一号以前入学的,你在哪个?并且并且 拿下来随 n 的 a, d, d, date, 他呢?小于 年九月一号,在九月一号一号以前入学的 a、 d、 d 对,特偶像 a、 d、 d 少了一个。 对, 你看这就查到,是吧?这两个他是十八岁以上,并且在九月一号以前入学的,这就是我们今天讲的一个小知识,是什么呢?就是嗯, 日期类型在大于小于符号里面的使用,还有就是嗯,关键字 n 的的基本用法,今天就到这里。
84程序员—路人甲









猜你喜欢
最新视频
- 2.1万杰驰电竞