电脑speech是什么文件
本视频讲解 excel 入门第一讲首先我们来讲解第一部分,认识工作簿,工作表以及单元格。 我们在桌面上点击鼠标右键新建 excel 工作表,新建之后,我们可以给它进行重命名,命名为员工表,那么员工表这个文件其实就相当于我们的工作簿。 打开这个工作簿,在这个工作簿里边默认有三个工作表, sheet 一, sheet 二以及 sheet 三。如果你想要添加工作表,按加号就可以了,我们也可以给这些工作表进行重命名,双击 sheet 一, 我们可以命名为员工表。接下来我们讲解单元格, 鼠标点击任意一个格子,那么这个格子就是一个单元格。在 excel 里边,每一个单元格都有它的坐标,比如说当前这个单元格,它的坐标就是第五, 他是地列以及我们的第五行的交叉,所以是第五。接下来我们讲解第二部分,创建和保存工作簿。如果我们想要再创建一个工作簿,我们可以按 ctrl 加 n, 那 么我们又新建了一个工作簿。一 要保存这步我们可以按 ctrl 加 s 进行一个保存,那么我们可以给它存到我们的桌面上,命名为工作布一, 接下来点击保存,在我们的桌面上就多了一个工作布衣。最后我们来讲解制作员工档案表一点零版本,我们观察这个员工档案表目前总共是有三列,所以我们选中第一行三个单元格, 然后点击合并单元格,在上面输入员工档案表,我们可以输入员工的编号,如果要移动到下一个单元格,我们可以按向右的箭头 输入姓名,输入出生日期,可以按 ctrl 加鼠标滚轮,这个单元格会变大。接下来我们可以输入编号,比如说第一个编号,我们输入零零一, 接下来我们的鼠标放到右下角,当它变成一个加号的时候,我们可以往下拉,比如说我们有十个员工,那么我们就可以让他到十,接下来我们来输入姓名这一列,最后我们来输入员工的出生日期, 我们可以点击鼠标的左键,点击这一列进行选中,接下来点击鼠标的右键设置单元格格式,我们设置为日期格式,选择我们想要的日期,比如说这种日期, 接下来我们就可以输入出生日期,比如说我们来输入一九九六, 中间可以用斜杠隔开零九,斜杠零九回车,那么他就变成了出生日期。 第二种输入方法我们可以输入,比如说二零零零年,横杠零八杠零二回车,这是我们输入日期的两种方法。 接下来我们依次输入后面的日期,输入完成之后,我们可以把当前员工档案表一点零版本的格式稍微进行一个整理。 首先我们可以框选到这个表格框,选到表格之后,我们点击所有框线,这个也可以下拉,下拉里边选择所有框线,也可以或者直接点击所有框线, 接下来我们可以选中这个表格,然后选择水平居中,接下来我们可以给他稍微填充一个背景颜色。 下期视频我们来完成员工档案表二点零版本。

粉丝1284获赞3999
相关视频
 01:26查看AI文稿AI文稿
01:26查看AI文稿AI文稿pr 二零二六语音转文字工具 speech to text 的 v 二点一点六更新了哦,只需一键即可将语音轻松转换为精准字幕。需要安装包的看这里哦! 在浏览器搜索这个下载地址,打开后搜索 pr 语音包就找到了。点进去,两种下载方式均可下载。为避免误报拦截,请在安装前暂时关闭杀毒软件。 下载完成后,右键选择解压到当前文件夹,进入解压后的文件夹, 找到 set up, 右键选择以管理员身份运行。安装界面会列出所有支持的语言,取消全选,勾选中文和英文,也可以根据实际需求选择。建议使用默认安装位置开始安装, 整个过程仅需几分钟,安装结束后关闭窗口即可。现在我们启动 pr, 导入需要转换的音频或视频文件,创建字幕,在选项这里选择一下语言 开始识别,稍等片刻,系统将自动生成同步字幕,操作简单,识别准确。好啦,今天的 pr 语音包的安装教程就到这里啦,感谢支持,我们下期再见!
106煲仔饭 01:59查看AI文稿AI文稿
01:59查看AI文稿AI文稿有时候我们装完打印机驱动,我们的打印机并不能打印,这个时候呢,我们就需要看打开控制面板, 找到硬件和声音,下面有一个查看设备和打印机,点开,你会发现我们装完打印机这个所有这个图标它都是发虚的,这个时候呢,我们首先关闭这个框, 点开此电脑,或者是此计算机 c 盘,点开,找到 windows, 双击点开,找到 system 三二,然后再往下翻, 在这个 speech 下面有一个 support, 双击点开,然后找到 printers, 双击点开,首先把这里面的文件全部删除, 点删除,然后关闭这个框,然后在此计算机单机右键点管理点服务和应用程序,点服务到 print splore, 双击点开,点启动 点确定点关闭。这个时候呢,再点开控制面板,点查看设备和打印机,这个时候呢,我们的打印机所有的图标,然后已经变成了正常的,然后黑色, 这时候我们呢然后在打印图标上面点击右键,点打印属性, 点打印测试页已发送到打印机,这时候我们打印就可以操作了。
160浩扬办公 04:37查看AI文稿AI文稿
04:37查看AI文稿AI文稿文字转语音 t t s 视频教程大家好,今天给大家介绍一款我开发的文字转语音工具,它基于微软 h t t s 技术,支持十一种神经网络音色,中英文均可转换,效果好,速度快,支持直接粘贴文字,也可以上传 text pdf docs, md 文件,还可以调节播放速度,从零点五倍到两倍速。最重要的是完全免费,无需联网即可本地运行。 下面我们一起来看具体怎么用。二、环境准备一分钟第一步,安装 python, 打开浏览器,搜索 python 官网,下载 python 三点一一或更高版本,安装时记得勾选 at python to path 验证方法,打开命令行,输入 python version, 看到版本号就说明安装成功。第二步,安装依赖,把项目文件夹下载到本地,进入目录,双击运行与 quote, 双击一键运行 start at 与 quote, 脚本会自动检测 python, 如果没有安装,依赖会自动帮你装好,看到 ok, python detective 就 说明环境准备好了。三、启动服务三十秒 启动方式非常简单,双击运行 be quote, 双击一键运行 start app be quote, 脚本会自动。一、检测开放环境。二、安装缺失的依赖。三、关闭之前运行的服务,避免端口冲突。 四、启动 t t s 服务。五、自动打开浏览器,访问 http, 冒号斜杠斜杠一二七点零点零点幺八千,看到浏览器弹出页面,说明启动成功了。注意,如果端口八千被占用,脚本会自动帮你清理。 四、界面介绍两分钟页面加载完成后,我们看到主界面分为几个区域,顶部标题区显示与 quote, 文字转语音与 quote。 副标题说明使用的是 microsoft h t t s 文本输入区,中间最大的文本框用于粘贴或输入要转换的文字, 下方显示字母。技术上传文件区支持拖拽上传,也可以点击选择。文件支持四种格式, text, pdf, doc 上传后显示文件名和大小,可以清除,重新选择 控制区。音色选择下拉菜单有十一种音色可选,小巧女生、年轻小易女生,童年云夏女生、年轻 云曦男生,年轻云阳男生,中年云剑男生,年轻 arya 美式女生 guy 美式男生 jenny 美式女生 sonia 英式女生 ryan 英式男生播放速度六档可选零点五 x 到二点零 x, 转换按钮 与 quote 转换为语音与 quote 按钮,点击后开始合成音频播放区,转换后出现显示使用的引擎和音色。播放暂停按钮,可拖动的进度条时间显示当前时间总时长。下载 mp。 三、按钮底部状态栏显示服务状态与 quote 服务运行中与 quote 有 关闭服务按钮 五、功能演示三分钟功能一、文字转语音一、在文本框中粘贴一段文字,比如 be quote, 欢迎使用文字转语音工具 be quote。 二、选择一个音色,比如 be quote 小 小女生,年轻 be quote。 三、选择速度保持一点零 x 正常速度。四、点击 be quote 转换为语音 be quote 按钮五、可以看到进度条显示处理进度。六、处理完成后音频播放区出现。 七、点击播放按钮试听八、可以拖动进度条选择播放位置。九、点击与 quote 下载 mp。 三、与 quote 按钮保存文件功能二,上传文件转换一、点击上传区域或直接拖拽文件到区域中。二、选择一个 text 或 pdf 文件。三、文件加载后,文本框会自动填充文件内容。 四、点击与 quote 转换为语音与 quote, 等待合成完成。五、试听并下载。功能三、调整速度一、把速度从一点零 x 改成一点五 x 或二点零 x。 二、重新转换听听加速后的效果。 三、零点五 x 适合听外语文档,放慢听清每个词。功能四、切换音色一、中文内容推荐用中文音色,小巧小一等。二、英文内容推荐用 aria, jennie, sonya lion。 三、不同音色,性别年龄风格都不同,多试试找到喜欢的。功能五、关闭服务一、点击右下角的与 quote 关闭服务与 quote 按钮。二、服务关闭后,页面显示服务已停止。三、需要重新使用时,再次运行 start at 六、技术架构一分钟很多朋友问这个工具是怎么实现的,我简单介绍一下。 前端纯 html 加 css 加 javascript, 没有用任何框架,原声实线,体积小,加载快,支持文件拖拽,音频播放控制。后端 iphone fast api, 高性能 web 框架,支持异步处理,多人同时使用也不会卡。 t t s 引擎三、套引擎自动切换一、首选 microsoft h t t s 效果最好,我们用的这个二,其次 google t t s 备选方案三、最后 y t t s x。 三、完全离线的 windows 本地引擎 文件解析, text 直接读取文本, pdf 用 py pdf 二、提取文字 docx 用 python docx 提取, mb 用 msstring。 解析所有转换后的音频文件保存在 temp 与下划线 audio 文件夹中。 七、常见问题一分钟 q 一、 提示与 quote 服务运行中与 quote, 但页面打不开,检查端口八千是否被占用?在命令行运行 task qf i am uucorn 点 exe, 然后重新启动。 q 二、上传 pdf 乱码。部分 pdf 是 扫描图片转的文字无法提取, 可以先复制 pdf 中的文字粘贴到文本框。 p o 三、转换失败,确保电脑联网 h t t s 和 google t t s 都依赖网络。 p o 四,没有声音,检查电脑音量是否打开播放器是否静音。 p o 五、如何关闭服务?点击右下角与 quote 关闭服务与 quote 按钮,或在命令行按 ctrl 加 c 八、结束语三十秒。
3bob 01:45
01:45 02:51查看AI文稿AI文稿
02:51查看AI文稿AI文稿hello, 和大家分享一个我自己开发的桌面应用,它是一个基于 electron 的 video log 视频日制工具,开发的初衷是我再次意识到自己的沟通表达、 即兴演讲,还有正当下的思考能力非常的差劲,需要提高锻炼,所以又拾起了面对镜头进行即兴演讲的习惯培养。 之前单纯用电脑上的文件夹管理那些自己录的视频总觉得不够,所以 web 抠顶了这个工具, 希望能够更方便的管理我的视频日记们,然后用自己开发的工具来记录 vidoog 也意外的增加了一点坚持的驱动力,下面我来简单演示一下。首先点击这个按钮,可以设置视频的存储目录。 在侧边栏的 gallery 中可以看到往期录制的视频, 我第一个视频是在二零二三年十月份,中间也断断续续的在录制,可以点击预览播放,这样就可以回顾你过去的视频。 现在是二零二三年十月十五日星期三晚上八点四十九分,现在开始我的今日总结。设置页面中就是一些设置,回到录制页面,点击开始录制按钮后,下面还有一个实时的语音识别功能及语音转文字。 因为我本身还习惯用 flomo 来进行复盘,但发现同一天内我就那些想法 类似的内容通过视频说了一遍后,再在 flow 里面用文字再转述一遍的话,短时间内感觉就在重复劳动,降低对这件事的积极性。 所以这个这块语音识别的开发初衷是想在录制视频的同时自动生成一份文字出稿,想的是可以直接将文字出稿或者是通过大模型进行结构化后,能够直接复制粘贴到伏龙蒙里面,直接口头的 直接口头说话来表达我的想法和用文字打字的同时进行思考输出。这两种对内容,对想法的组织对我来说很不一样,前者对我来说很困难, 所以想要坚持练习一下,希望我开发的这个工具能够帮助到我,然后日后再去优化它。 i want you to。
55921世纪与阿吉侬 03:32查看AI文稿AI文稿
03:32查看AI文稿AI文稿好了,我们可以看到现在它显示所有文件已经创建完毕。以下是完整的使用说明,来我们看一下它怎么说。使用步骤。第一步,安装,我们只需要双击运行这个 install, 点 bat 自动安装 play write 和 chromium, 我 也不知道这个 chromium 是 什么东西。第二步,配置话术修改,这个 message template 为实际话术内容。 第三步,只需要登录一次,双击这个 log in, 点 bat 浏览器自动打开,手动点击 continue with google, 完成登录,回到命令行,按 enter, 然后到 session 点 json 自动保存。第四步,手动测试,直接双击 round, 点 bet, 验证脚本是否正常运行,结果写入 i toki bot, 点 lock。 第五步,注册定时任务,右键以管理员身份运行, set up task, 点 bat, 默认每天九点自动执行的有些注意事项,如果这个 session 过期,那么我们需要重新双击 locking, 点 bat 刷新 session idok 改版导致元素找不到,在 may 点 py 的 selectors 字典中更新 css 选择器 三,需要静默运行无浏览器窗口,将 config 点 py 中的 headless 改为 true。 第四个,查看运行记录,打开 idok, 捆绑,点 lock, ok, 那 么我们看到了它的整个的安装使用步骤,我们还是按照它的提示来。第一步,我们先安装这个 install, 点 bat 安装 playwrite 和这个 command 好 了,我们先到文件夹去看一下,我们选的是这个文件夹 iot 这个。好了,这个 install, 点 bat 首次安装,一键安装依赖,我们双击它,按任意键继续 no module named playwrite, 看一下什么意思,他没有找到 playwrite, 那 么我们问一下这个 cloud code 这是什么原因?我们直接在这个模型下面问,双击运行了, 是反馈,这个是不是需要手动下载 play, write 和影的安装文件?我已经发送给他了,他正在思考。他给我们的步骤是手动安装,像是 cloud code 自己在帮我们进行安装 play, write, 他 自己在帮我进行 bug 的 修复。 这些所有的 bug。 其实因为我不是 it 背景,我也不明白到底什么意思,我们直接点 allow, 所以 你看 cloud code, 它是可以帮助你进行代码的编辑,同时进行 bug 的 修复。 好了,现在他已经通过了四个,不会出现乱码解析的问题,他又给了我们重新的操作步骤,重新双击进行安装。 第二步,第三步,第四步。好的,我们先进行第一步,返回,重新点击。他应该是在下载成功了, 我们这里能够看到一些关于 playwrite 的 文字,这个地方在 installing playwrite chromium browser, 应该是装这个 chromium 的 一个浏览器,我们现在看到它正在安装这个浏览器,我们看一下,百分之百了。好了,安装成功了,下一步是运行 login 点 bat, 我 们第一次登录谷歌账号。好了,我们接着点击这个 login, 点 bat 登录页,请手动点击看停留位 哦,打开了。好的,打开了,手动点击 continue with google。 等一下,我要看一下这里,它显示的是四零四,现在有个错误,我要发给 boss, 让他帮我看一下。这是什么原因?我点击了点 b a t, 浏览器打开了,但是显示了这个错误页面,请分析修正。为了老,你看它,这里发现了 i toky 的 教室后台是独立的,域名 teach 点 i toky 点 com, 所以 有可能是刚才的域名错误了, 现在他正在修复。你看所有的修复 bug 的 过程都是他自己在进行,我没有进行手动的操作。好了,我们让他自己进行 bug 修复,记得点赞关注哦。
 46:39查看AI文稿AI文稿
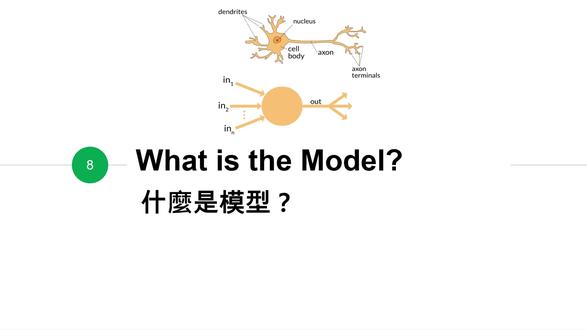
46:39查看AI文稿AI文稿那我们就先从第一个部分讲起,模型是什么?什么是模型呢? 好,那在这里面我们会讲三个部分,那我们就先从最简单的分类问题开始讲起,那这是刚刚一直看看到的很多很多重复的例子,就是 sentiment analysis, 给一个句子,我们要判断它是正面还是负面, 那语音的封顶的 recognition 要判断它是哪一个神,呃,哪一个封顶的讯号,然后手写字便是。这个都是分类问题嘛,因为最终你的凹凸就是一个类别。正还负跟封顶的所有可能性,跟 digit 的 所有可能性。 那如果我们分正跟负,这是不是就是分二分法?我如果只分正跟负,那这就是一个 binary 的 classification。 那如果是下面这种,我有所有可能的封顶可能好几好几百个,好几千个,那 delete 的 数量可能有十个零到九,那我们就称它叫做 multi class 的 分类,也就是你的 class 的 数量不是只有两个,是多个, 所以就分成 binary 跟 multi class, 那 binary 其实就是 yes 跟 no, 就这样就是音符的东西,我们最终希望它能够欧普,说到底是耶还是 no, 那 如果是 multi class, 这比较实际,大部分的应用其实都是 multi class 比较多,就是我们要分辨说它到底是 class a, class b 还是 class c 好,那这其实是比较简单的一些例子,那其实还蛮多 case 没有那么容易直接把它变成是就是这么简单的分类问题的,那如果可以的话,你就把它这样子 formulate, 那 你就会比较好去设计你的模型。 那假设现在我们的任务就是这个分类的任务,所以我们就会有这个方式嘛,这是我们想要 learn 的 这个方式,那这是我们的 input 的 data x, 这是我们 opp 的 label y, 所以假设说我们要做嗯 object 的 一个判断,它是哪一个类别,我们的 input 就是 它的那个 object, 不 管你是影像一张或者是一句话都可以,反正就是一个 input object, 那 你的 y 就是 你的那个类别的 class, 或者我们也可以称它为 label, 或者叫它 label 的 原因就是因为它是需要用人去标记的。对,你比如说这个影像是猫,你是人就要去看,诶,它是猫,然后就标记成猫嘛, 那你要人去看,它是复频标记成 negative, 所以 这个呢,就叫做 label, 那 它其实也是这一个 input, 它的那个类别就是 class。 好, 那我们可以把它想象成它是以这个方式,它是从 n 的 dimension 把它 matting 到一个 m dimension 的 一个 matting, 那 这个 n 跟 n 各自是什么呢? n 呢?其实就是你的 input object, 它有多少维就是 n, 那 n 是 什么呢? n 就是 你的 output 有 多少维,有多少个可能的 class, 那 就是 m 维,所以你的 f 这个 function, 它就是 可能会从 n 的 dimension 把你的 input matching 到一个 n 的 dimension 的 一个向量, 所以 n 跟 n 都是根据你的任务去定义的。哦,你看你的音符,如果是影像,然后它可能是十六乘以十六,所以总共有两百五十六个 digit, 呃,两百五十六个 pixel, 所以 可能是 n, 就是 二五六。以举例来说,那 m 可能你想要把它分成十个不同的,比如说动物好了,那 m 可能就是十,这样, 好,那我们在这边呢,都会先假设说我们的 x 跟 y 是 固定的 vector, 所以 说假如你的 input 的 假如说你的影像好了,或是你的文字长度不一样,或者是影像大小不一样,你就是要想办法把它变成是同样的一个维度引入进去。因为我们的 model 是 不调整我们的 input 的 这个 n 的, 所以 我就是比如说我 n 已经设成一千,你就是一定要给我一千维的 data 进来,那如果 超过我就是没办法处理,所以我们都会这个模型,它不 handle, 你 的 x 是 有变动状状况,你的 x 的 分辨率是固定的, y 的 分辨率也是固定的,所以你也是没有办法处理。说我现在只有五个类别,然后现,然后我在用的时候突然 或者是我的 training data, 有 的时候是五个类别,有的时候是十个类别,这样子是不行的,就是要固定 好,那怎么把它变成是向量放进去呢?这边举一个很简单的例子,就是用手写字便是当成例子,那手写字便是一张图,那 off 就是 这张图,是哪一个 digit 嘛? 就假设的是一张图,十六乘十六,好,那我们就要把这个东西变成一个两百五十六维的一个向量,怎么变呢?我们就把它想成是两百五十六维,每一个维度当成是里面的一个 pixel, 所以 假设说这边的这个 pixel 有 颜色,我们就把它用 e 来表示,没有颜色就变成就用零来表示,所以我们是不是可以用一个 vector 就 表示这一个 input 的 image? 对, 就这么简单,所以所有图拿进来,我们都可以把它转成是对应的这二五六维的向量,然后当成 input, 当成我们的 chain n beta。 那 y 呢? y 要怎么准备? y 是 不是总共有十个可能的 digit 零到九,所以呢?我们就准备十维,那它是 它如果是一的话,我们就在代表一的这个 dimension 显示一,其他用零。那如果它是二的话,我们就是二的这个 dimension 显示一,其他用零。 那这里面的意思就是在这个维度它的意义是它是一还是不是一?那这边是是二或不是二。所以这边的这种 encoding 的 方式,我们叫它 one heart encoding, one heart 意思其实就是在这整个 vector 里面只有一个 dimension, 是, 就是 hot, 类似这种感觉,就是就是只有一个单面选会是一,其他都是零,类似这样子的概念。对,那这几遍是 oppo 的 label 了,所以其实这边的那个就是 formula 的 方式其实是蛮常见的。 那如果是文字怎么办呢?假如说现在是一个 word, 一个 word 而已,就是说这个 word 就是 符合今天的情人节的 word, 就是 love。 好, 那这个 love 我 们要怎么把它变成这个项链?嗯?怎么做呢?这边的做法呢?就是我们准备一个 dictionary 这个词典,假设说有一千,呃,一千个字好了,就是一千尾的一个 vector, 那 你就看 love 出现在这词典里面第几个字, 那就在第几维显示一,其他显示零。那这就是刚刚说到那个 one heart encoding, 就是 只有一个维度是一,其他是零。 对,所以它的 dimension 就 会是你的这个词典的 size。 那 我们的凹凸是什么?凹凸如果说现在做 sentiment analysis, 是 要判断它是正平负平还是 neutral, 我 们就有三个 dimension, 那 一样就是是正的话就是正的这边是一对, 那这样就可以准备我们的 y 的 这边的 label, 所以 我们就有 x 跟 y 的 这两个 vector, 然后我们就准备很多很多的 x 跟很多很多对应的 y, 然后就准备好我们的 training data, 就 可以做 后续的 chain。 所以 这就是我们怎么把我们的 data 变成是向量的表示方式,放进去那之后我们也可以看到不同的 input, 它可能有一些不同的变成 vector 的 方式,就不一定一定是直接用,像这个 one heart encoding, 这是其中一种而已。 好,那这边就是我们可以把所有的 data 全部 x 都变成同样维度的 vector, y 也变成同样维度的 vector, 然后准备了很多 x 跟 y, 我 们就准备好我们生成 data, 然后希望能够去 learn 我 们这个 function, 那 我们就来看看我们的模型的架构吧。那我们就先从最简单的这一个 single layer 的 model 来开始看齐。那在这里呢,我们就快速看一下刚刚前面我们有提到的单一一个神经元的架构,单一个神经元它做的事情如果还记得的话,它其实就是别人传进来的资讯。传进来资讯,假如说是有 n 维的一个项链, 我们就是传进来的,我们要做一些操作,然后传出去给别人传出去的值以 y 来表示。所以传进来资讯做什么操作呢?就做一个 wait, 上 x one 乘以 w one, 以此类推,全部加总在一起, 再加上 b 这个 bias 得到 z, 得到 z 这个值之后,我们会放进一个 activation function, 然后把它压到零到一之间,然后输出给别人变成 y, 所以 一个神经元就是 别人传进来的座位帖上压到零到一之间,然后输给下一个神经元,就这么简单。好, 那每一个神经元就是一个非常简单的方选嘛,那为什么教它一个简单的方选呢?你看呢?我们先把这边这个 bias 是 什么?这个 bias 怎么想象呢?就是我们把这个 bias 想成它其实也是 weight 的 多一个维度而已。 只是呢,这边的这个 b, 它音符的这个值是 always, 是 e, 所以 它就会是这个 vector, 乘上你这个 vector, 它的那个 weight 上就是这个 dot, 这个嘛, 那这个 bias 我 们就直接把它想成这边有一个 always 会是 e 的 一个 feature, 所以 它是一个 always on 的 feature, 然后它乘上我们这边的这个 weight, 那为什么需要这个 bias 呢?这个 bias 它的为什么需要它?原因是因为这个 bias 其实提供给我们现在这个 input 要有多大程度的差异才能让后面这个 y 超过某一个 zero? 意思就是说它有点像是一个 prior, 比如说你像这个 z 是 不是在这个值的时候,它 match 到的这个 y 会,嗯,会很低,那 大概 z 要到零的时候,它才会到 y 的 值,才会到零点五,可是 z 的 值如果是要到零,它才会到零点五。有的时候有可能我们希望,比如说这个音符,它可能很大一部分都是 希望它能够 out 超过零点五的值,那这时候你的你丢进这个方程,你可能不那么容易让 它直接微点上的结果都是超过零点五,那这时候最简单,那它能够超过零点五的值,就是你给他一个 b, 然后这个 b 可能就是比如说已经零点四或是零点五了,所以它后面你 做一个微点上,你就很容易超过零点五嘛。所以你多加了这个 b, 等于是你给了这个 z 的 起始点一个额外的 prior, 所以可以让这边调整调整你这个切点,让你的 y 的 值可以很容易超过多少,或者是很难超过多少,所以这个 b 等于是以你在 learning 的 过程中,可以让你调整你这个数学后的一个额外的一个 learning 可以 认出来的一个 weight, 所以你就把它想成是一个 prior 就 行了。就是如果很大量的资料你都希望它超过零点五,那你这个 b 值可能就会认出一个比较大的值,类似这样的概念。 那刚刚提到这边这个 b 值,就是为什么需要这个 b 值,所以 因为我们可以透过它来调整这个 z 至少有多少类似的概念。好,那接着我们可以看呢,这边这个 y 把它写成数学公式,就是长这样子,非常简单。这边是什么?就是 w, 就是 我们的这个 weight 的 vector, 然后它的 transpose 乘上这个 x 的 vector, 然后加上这个 b, 然后再放进这 animation function, 这就是我们的 y 嘛,所以这其实就是一个神经元它的公式。 那我们其实可以透过调整 w 跟 b, 就是 这个 vector 跟这个 数值,这 constant 数值能够得到不同的 y, 对 不对?因为 x 是 别人传进来的嘛,那我如果要调整 不同的 y 输出给下一个神经元,我们就是透过调整 w 跟 b 就 行了。所以这为什么说它是一个简单的方式,就是我们可以透过调整 w 跟 b 得到不同的 y, 所以想象中一个超简单的方选可能也可以做一些 learning 的 事情嘛。假设说我们这个超简单的方选就是这个神经元,我们的音库就是这张图,就是刚刚的那个这个二五六维的项链,然后就直接输进来, 那我就透过调整这边 w 跟 b 的 值,让 y 符合。如果说 y 大 于等于零点五的话,这个 就是属于 d g 二,那如果小于零点五的话,它就不是 d g 二。我们可以透过,因为 y 是 一个数值嘛,一个零到一的数值,我们可以透过调整 w 跟 b 的 值,让 y 符合我们的全零比特。 所以我们如果有很多张二,呃,很多张 image, 然后它是二跟不是二的这些标记,我们就可以用这些资讯来找出最适合的这个 w 跟 b, 然后使得后面这一个 成立。所以当我们看到一个新的图的时候,我们甚至就看我们最后 out 的 y 就 可以大概可以推论说它到底是二或不是二。如果 y 的 值大于零点五的话,我们就有很高的信心程度,相信它可能是二,类似这样子,所以这其实是一个简单的方式, 这个简单的方选,他只要拗负一个零到一之间小数,他就可以处理二分类了,这个我就直接把它切在零点五吗?就是高于零点五的话就是。 嗯,第一个分类低于零点五的话就是第二个分类,所以简单的这个二分类,其实你用一个简单的神经元其实就可以 handle, 那 为什么 需要很多个神经元呢?因为我们很多问题都不是只是二分类,我们不只是想知道它是不是二,我们希望知道它是几嘛, 对不对?所以我们如果有十个 class, 我 们就准备十个神经元,第一个神经元去负责去看它到底是不是一,第二个神经元去看它到底是不是二, 以此类推。所以我们最后当我们训练完了之后,我们只要去看最右边的这个凹凸,哪一个 y 的 值最大,是不是代表它最有可能是那个 dj? 因为它有有可能有几个值都大于零五?是有可能的,因为比如说一跟七有点长,或者七跟九长有点像,所以这两个可能都稍微有点大,但是最大的是可能是最有可能是那个 dj 嘛, 所以我们可能就是从最后的这个凹凸去找谁是最大的,那最大的就最有可能是我们的那个这个英文所属的 dj。 好, 所以为什么需要一层?因为我们需要多个神经元去处理多个可能的凹凸,然后我们会从里面挑选最大的那一个,然后当成是我们 predict 的 结果, 那到了目前为止大家就会想说,诶,那好像就是准备一层的好像就可以了嘛,对不对?好像就可以做到你的 learning 的 这个 task 的 事情,其实是没错哦,只是它效果不一定会那么好,但是它的确是可以做到,所以这就是 single layer 的 process 的 那个 model, 就是 就是简单的中间只有一层的 那 single layer 的 这些 neural 就 叫做 perceptron 嘛,那它其实是有一些 limitation 的, 为什么呢?因为你看呢?对于这一个 uni 而言,就是这个神经元而言,它是不是就只有做一次的一个执行的处理?它就是要从这些 feature 上面做一个 weight 上,然后压到你之间,就这样子我就要判断它是不是一了。 这件事情其实蛮难的,而且他判断他是不是二,所用的资讯跟判断是不是一,所用的资讯 就是彼此是 independent 的, 对吧?他们虽然都用到,他们都是用这 n 维的这个 vector, 可是他们怎么操作这些彼此都是独立做操作的。就比如说你,如果你如果看一张图,然后 判断他是不是二的,已经很明显的判断他就很高几率是二。然后如果你是负责判断他是不是七,你会觉得二跟七你知道差很多,所以当他那么 确定它是二,那你就应该不太可能是七嘛。所以你其实你可能可以用别人已经用过的一些资讯,可以帮助你判断的更好。可是现在你是每一个神经员都是独立做这些 operation, 所以 他们并没有设任何的 wait, 那 这样子其实是 不一定能够让模型 learn 的 那么好的,因为等于是每一件事情都独立的做。 那在这里,实际上这 perception 你 把它,呃,我们这边是把它简单地想成,如果你只能调整两个维度,就是 x one 跟 x two, 就是 你有两个参数可以调整啊,就是这边只有两个音符,然后你只有两个边。 好,然后这边是你的 y, 这就是 y 是 零到一之间的一个数值,只要把立体画画给画给看。所以一般的一个神经元做的事情就像是这样子,就是 你可以透过调整你的 x 的, 呃,你可以透过调整你的这两维的位去调整这个图它的这个 位置,就比如说你可以希望他往左边移一点或往右边移一点,然后你也可以调整他的 orientation, 就 他的转向,就比如说现在是这样这个方向吗?你可以把他这样转过来一点,那或者是他的斜度, 就是你可以让他平缓一点呐,或者是更陡一点,这些都是可以透过你的 w 去做调整,所以你在调整些位,其实就在调整这一个坡的皮,呃,这个坡的长相跟他的位置跟他的面相, 所以调整一个神经元,它的参数就在调整这个坡到底长什么样子。你这样想就比较有感觉,所以概念上有点像是你一个音符进来,你就看这个点落在你这个坡的哪一边,如果落在上半边的话,就有可能是 positive, 可能落在下半边是 negative, 类似这种感觉。 所以为什么 perception 它是有有一些限制的,它的表达能力不够。那这边用一个很直接的例子让大家来看,这就是只有两个 input, 就是 x one 跟 x two, 然后你有 w one 跟 w two 可以 调整,那还有个 b 啦,对,然后 就做一个微点上变成是 y, 那 你是不是就是可以调整 w 跟 w one 跟 w two 跟 b, 然后希望能够得到你想要的这个 y 的 值。 假设说现在你的 data point 长这样,这怎么看呢?现在有白点跟黑点,那你现在只做二分类,所以黑点是同一类,白点是同一类。好,那如果你看了你的 data 是 长这样子, 所以你是不是希望这样切,对吧?因为你现在是一个 mini 的 一个方式,这样子就是想象你就是一个切线,这样子就只有两个维度在这边切,那把黑点跟白点切开就切在这,嗯,非常 ok。 那如果黑点这样,三个白点在这,那你就是希望这样切嘛,对不对?那假如说你的 data 长这样怎么办?这是什么?这是 x o r, 就是 x one x two x o r 的 状况,这样子,你有办法这样切吗?用这个方选,你其实是切切不开来的, 因为你想想看哦,这是 o r 跟 and, 非常简单,都可以很容易的做到,但 o r 你 要怎么 就是简单地做到?其实是没有办法只用一个 simple 的 operation 去做到。通常我们在实做 x or 是 怎么实做的,大家应该知道吧?如果是 x or 的 话,是不是可以把它拆开来,变成 就是 a and not b, 然后再 or not a and b, 大家应该知道吧?就是这个东西,所以你要 implement x or, 你 其实就 把它拆解开来,然后让它变成是 and or 跟 not 做一个抗败,然后最后就会模拟出你 x or 的 状况。 所以这里面你是不是做了很多个 operation, 那 原本像 and 跟 or 你 都只是做一个 operation 就 可以结束了,那在这边你想要模拟 x o 这种比较复杂的情况,你就是要做多个 operation, 所以 这就是也说明了为什么单一一个 perception, 它是它的表达能力是不够的,因为你只能做一个 simple 的 operation, 但实际上有很多 data, 它可能是比较复杂,你没有办法用 simple 的 operation 就 可以表达出来,所以你就必须要把这些 simple 的 operation 去做一些组合,然后去模拟出复杂的 情况,那这样子你的表达能力才会变得更强,才会去模拟到你 data 里面可能会呈现这种凹凸的状况。 所以这代表说如果我们可以组合简单的 operation, 用多个 operation, 多个简单的 operation, 我 们就可以模拟出复杂的 auto, 这就是生产线的概念。怎么用 simple 的? 就是简单的这些方程去组合成复杂的一个大方程,所以刚刚我们只有 perception, 因为它没有做组合嘛,所以它当然没有办法模拟复杂的状况, 所以这也是为什么会需要 multi layer 的 perceptive, 让它可以从前面做了第一次 simple operation 之后,然后再多做一次 operation, 就 再做多次。像是这边有一个 神经元,这边有第二个神经元,他这两个神经元还可以再做一次后面神经元的组合,所以这边的资讯跟这边资讯就可以在后面再进行融合,就变得更复杂。但是里面的每一个神经元其实都还是很简单, 那这才是刚刚我们能够可以从心口的方式去模拟出复杂的方式这个基本的的概念。 所以这里中间的这里就会变成我们的 hidden unit, 就是 因为它不是我们最终的这个凹凸可以看得到的,那中间的这些 unit 其实它的 音符跟凹凸其实就会吸的在中间,我们并没有直接给他这个凹凸去让他认这边的这个方选到底长什么样子。 那如果是 multi layered perception, 它的表达能力要怎么去思考呢?那我们就发了我前面我刚说的,先从很简单的 这个图,三 d 图来想象,刚刚是不是一个这样子坡这样啊,就往上这样,那如果你有两个,你可以把这两个东西做一个组合,所以你就可以把 一个往上,然后另外一个往下把它夹在一起,你就可以模拟出一个叫做这有点像是山,所以它叫它 reach, 就是 你把两个,然后就是对对象的把它夹起来,你就可以模拟一个 reach, 所以 这样子你就等于是如果这边有一些黑色点在这边,然后其他地方还是白色点,你就可以这样把它包包下去, 你就可以模拟这种复杂状况。但如果原本是这样,你没原本是这种顺顺的你中,如果原本是这样,你中间 你中间只有一些,比如说黑色的点,你就没有办法让它跟另外这一边分离,所以你一定要把这个跟这样夹在一起,让它中间可以 跟下面融合在一起,但是他又可以跟上左右这两边分开,所以用两两块夹起来,你其实可以模拟比较复杂状况,那这就是两个 layer 的 一个简单的模拟,那这边是只有两个维度去示意给你看了,这样大家应该比较好理解。 那如果再复杂一点变成第三层,刚第一层是这样的,那第二层的话,是不是就是你可以两个就是融合,就变成这个三级的状态? reach 之就是三级的意思,那如果是三层的话,你其实就可以在这边再多做一次的 operation, 所以 三级跟三级你会再把它再夹起来,就会变成这样子。 所以像在这里的话,你这一整条上面是都需要是同一个类别,但在这边就不用,因为你在中间只要有一个可能,比如黑色点在很上面,你就去包住它就可以了,所以你变成三层,你的模拟的状况可以再更加的复杂, 那这件是这个叫做 bug, 就 像是一个凸起来的东西。对,所以你可以把这两个 reach 去做抗败,然后就可以做出这一个,这应该很好想的,就是,呃,叉九十度旋转这九十度吗?九十度的两个这个 reach 夹在一起就可以模拟出这个 bug, 所以你会发现就是你的 layer 的 数量如果越复杂的话,你可以模拟出你可以就是隔开的这些黑点跟白点,你可以隔开,这种复杂的 distribution 可以 更多。 对,那这边的这个棒,你的大小都是可以根据你的参数去做调整,你可以很 胖或者是很瘦,那也可以很高或很低,这些都可以根据你的这些 weight 去做调整,所以你的点不论出现在哪里都很容易去包到它。那当然它有可能有一些缺点,就是你的参数当中太多的时候,你就有可能因为你 data 可能 只是有一个 noise, 然后你就很想要去包它,那这样其实让你的 model 反而没那么就是没那么正确,因为你就是去使用了其实是比较不好的一个 data, 所以当参数太多其实也不一定是好,如果参数太多的时候,你就需要更多的一些 data, 可以 让你的参数不要学歪。 那这边就是 multi layer 它的那个 model 的 可以表示的能力,所以当它的 layer 数量越多,它可以表示越复杂的情境,可以包到越复杂的一些 distribution 嘛。那它就可以 proxima 比较复杂的方选,虽然每一个方选都还是 simple 的 简单的方选,但是你叠加了越多层,它就越复杂嘛。 那第 learning 就是 叠了非常多层的 model, 就是 中间你可以叠 l 层,从 input 到 output 中间 我们只要叠超过一,就是你叠两层,我们就可以说它是一个 deep 的 模型了,如果是一的话,它就是 simple 的 mlp, 那 如果你叠到二,其实就已经是一个 deep model 了。因为传统上只有 应该说在 deep learning 出现之前有这个名词,出现之前大家就是只能叠出一层就叠一层才算得出来,超过一层就没办法算了,那这也就是前前面我忘记讲了,就是通常都会跟大家分享一个小故事,就是为什么会有 deep learning 这个词汇,因为 他既然都代表类神经网络,那为什么要有两个名字,大家不觉得很奇怪吗?他就就直接叫类神经网络就好啦。那原因是因为就是传统上有很多记忆学习的方式嘛, usb 线啊什么什么的类神经网络其中一种。那类神经网络之前的效果都一直不好,因为他就是那时候可能 data 不 够多,计算力不够好,所以他的效果都一直没有像其他的 machine 的 方式来的那么的好。所以 在整个机器学习的领域中,做类神经网路的那些研究者就有点可怜,他们的 paper 有 的时候常常 一写出去,大家看到类神经网路就觉得,哎,这个 paper 一定很烂,然后就很容易就被拒绝,所以他们为了怕这次总算做出一个很好的效果,但是又怕一提到这个人家 review 一 看到又直接拒绝,他更不看内容, 所以就想说这个要取一个新的名字,因为它这是比以以往不同的地方,它叠了比较多层,然后得到很好的效果,所以它就说这是一个 deep learning, deep neural network 等等的,所以看它叫它 deep learning。 那 review 可能一看看到想说,诶,可能是个新东西,然后就会认证,就看它内容才发现,哦,其实就是 new or network 嘛。对,但是因为它效果很好,那你至少不会因为一开始给它一个刻板印象,它就被拒绝,所以才会有这个 deep learning 的。 这个就是说法出现。对,其实是为了就是要扭转, 就是刻板,对 new or network perform 不好的刻板印象所出现的就是一个小小的小故事,跟大家分享,就才会有两个名字,所以目前听到 deep learning 它就是代表内神经网络,是一样的意思。 好,那我们后面其实这应该是就是下个礼拜才会详细讲,那后面我会用到这边会写的这 notation, 那 这边先简单 define 一下给大家,我们后面再讲,到时候还是会在复习,那我们就先从 layer l 减一层到 l 层的这些 note 来定义,所以因为你有很多层嘛,所以这一层假设说是 l 减一层,这一层是 d l 层,那 l 减一层假设说有 n l 减一个 note, d l 层有 n l 的 note, 而这边的 note 数量是都可以自己决定的,所以它们 n l 减一跟 n l 不 一定会是同样的数值,不会,不一定会相等。那我们这边呢,会用 a 当成是一个 new 的 output, 就是 activation function 之后的一个结果。对,那 a 的 上标就是它的, 它在第几个 layer 的 output 就是 l 减一,那下标呢?就是它是第这一个这层的第几个 note, 所以 a l 一 就是 d l 层的第二个 note a l 二就是 l 层第二个 note a l 减一,二就是 d l 减一层第二个 note, 这样子 好,所以这上面的这个就是 layer, 下面这个就是这个 layer 里面的第几个 nero, 所以我们用这个 a 来表示这边的每一个 newer 的 output。 然后如果我们看整整层的 a, 就 会把它写成是一整个 a l 就是 一个 vector, 那 这一整个 a l 里面就会有 n l 个 dimension 嘛, 因为就是有 n l 个 new, 所以呢,这里面这个 a, 我 们就把它想成是一个 layer 的 一 output, 这一个 layer 的 output 传给下一个 layer 是 传出去的这个 vector 叫做 a l, 第二个 layer 传出去的 vector 叫做 a l, 这样子 好。然后这两个层之间是不是会有很多 wait 传递,所以呢,这边我们就用 w i j 来表示 l 就是 d l 减一层到 d l 层的 wait, 然后 i j 呢?就是从 new or j 到 new or i 这反多就是,如果是 i j 的 话,就是这一个到这一个就是这边是 i, 这边是 j, 就是 这一条边是 w l i j ok, 好, 那我们整个 w, 就是 这整个 l 减一到 l 乘里面有多少个 w 是 这个 w 数量是可以变成一个 metric, 因为你是有 i 跟 z 两边都是有 n l 减一或 n l 的 数量嘛,所以这边就是有一整个 metric, 然后这个 metric 就是 n l 减一百 n l, 你仔细回去想一下就知道了。对,然后我们就会把它直接写成 w l 就是 l 减一乘到 d l 乘中间的这个位就是 w l, 接着呢是 bis, bis 就 比较简单,就是因为刚有 w 嘛,我们还有一个 bis, 大家别忘了 bis 就是 一个 always on 的 feature, 对 不对?所以就是 e 层上 b 嘛,那这个 b l 就是 d l 层的这个 d i 个 new 它的 bis, 所以 它一样就是一个 vector b l 就是 layer l 的 这一个 bis。 为什么要定义这么多呢?就是我们要把刚刚那个复杂的东西写成比较简单。所以现在从前一层的 neural 的 凹凸是不是 a l 减一,它会呈上对应的 w, 然后加上 d 会得到这一层。呃,这个 neural 它的 input 嘛,然后再做处理再出去。 所以说它的这个 v t 上中间是不是会变成一个 z? 这个我们用 z l i 来表示。 z l i 就是 我们在引入进 d l 层的这个 new, 还没放进 activation 方选之前的这个值。哦,就是 v t 上过后,还记得 v t 上过后变成 z 嘛,然后放进 activation 方选之后变成 a 这样子。 所以 z 其实就是放进 intv 选方选之前的这个 v 体上的值,所以我们用 zli 来表示,所以 zli 它。其实在这个例子上面我们来看,它就是 d l 乘的 d i 的 new, 它的 v 体上,那它的 v 体上是什么?它的 v 体上就是 a l 减一,一乘上这个 w, 再加上这个乘上,这个加上,这个要加,然后加到一乘上 bios 是 不是会等于 z l i 这边应该没问题嘛?就是 v t 上,以基本的那个神经元的定义, 然后把它整理一下,就是长这样子,它其就是前面有 n l 减一个 note 的 v t 上, 然后它一样,我们也可以把这一整层的所有的 z 变成是一个 vector, 叫做 z l 就是 d l 层的所有的 node 放在一起。 所以这边呢,这个 z 要记得是放进 activation 方选之前的这个 input 哦。所以我们现在有什么?有 a、 有 z, 有 w, 有 b, 这就是我们刚提到的所有的 notation, 这个是单一一个神经元的,这是单层的所有神经元同整出来的这个 vector, 对 吧?然后这是放进 a 呃 find entropy 方程之前的微型上的结果,那这是 vector, 那 这是一个位,这是那一整层所有的微整形,那这是一整层的 bias vector。 所以我们来看 layer 跟 layer 之间的关系是什么? layer 的 这个 d l 层, layer 的 凹铺 a l 跟前一层的 a l 减一, 它们之间有一个 z 它们的关系。首先我们先从 a 到 d, 它是怎么从 a 变成 z 的? 是不是就是坐标上? 你看一下这边的这个 z, 就是 这边的这个 a, 每一个 a 乘上它对应的这个 weight 的 结果, 所以你可以把它直接想成是这个 z 的 vector, 其实就是前一层的 a vector 乘上这个 weight metric 加上这个 b 的 vector 会等于 z, 就写成这样子,这就是这一层从 l 减一到 l 所做的事情就是前一层的凹凸 a l 减一乘上中间那层所有的 weight, 加上 bias factor, 会得到微解上的结果, 那只是变成 duck 的 形式,所以这也就是 z 等于 w, a 加 b。 好, 那这边已经有 z 了之后这一层怎么变成 a 的 呢?就只是放进 intv 选项方选而已,就这样,所以 a l 就是 z l 放减 division 方选特别很简单,所以整个关联就是这样子,就是前一层的 a 乘向 wait, 加上 b 放减 division 方选,会得到下一层的 a, 这就是刚刚我们定义的这些关系,那我们后面会用到这个 notation, 然后去解释实际上里面的所有的 w 跟 b 到底是怎么去学的,那这个你就先记得它们的关系是这样就行了。 对,我们之后再讲怎么学的时候,还是会再重复提到一下。这个式子就很简单, w 乘 a 加 b 放置也可以,像方弦会等于就是这一层的凹凸, 那这边就是一般 new or never formulation, 中间就会有非常多的 a a w 跟非常多的 b, 所以 假设这一层是 layer one 嘛,所以这边就是 w one, 这边是 layer two, layer one 到 layer two, 所以 就是 w two, 所以 它就是非常多非常多层的话,你把它合在一起,它实际上你的最后的 y 其实就会写成这样, 就是你这个 y 是 不是在模拟这个很大的方选,这个大方选到底是什么呢?这个大方选是 你的一开始的音符, x 乘上 w one 加 b activation 方选,再乘 w two, 再加 b two, 再放进 intonation 方选,再乘上 w 三 b b 一 直乘出来,然后一直放进 intonation 方选出来,所以你可以发现你放了越多次,你 越多层,你就是被成了这个 w, 越多个不同的 w, 所以 你可以模拟的这个方选的状况就越多。所以你的这个方选有多复杂,是不是就取决于你这边有多少的 参数可以调整,所以你越深的一个模型就是放了越多的这个 w, 所以 你这个方选就有可能表达能力越好,但是参数要训练的就会越越多,这就是一样的。 那我们前面有提到 sigma 的 这个 function, 但其实有很多不同的 activation function 有 长这样子的,就是这种跟这种简单的限性的。那我们刚看到是这种非限性的嘛,那它也可以,就是不一定是从 零到一压到零到一级,也可以压到就是负负负 k 到 k 之间这样子。对,就有很多不同的 activation 方式可以使用。 那像这种就是 bo 领嘛?是你要买就是负一,要买是一就是或领或一,就是就是没有一个 smooth 的 感觉,那下面就是比较 smooth 的 这种 mapping, 那 中间的是 linear 的, 只是这边是有限制的, 下面是 non linear 的, 所以这是不同的 t v n 方向。那这其实也跟你 任务想要做的有关,所以你选择哪一个 entertainment function 其实的确会影响你的 performance。 那 要怎么选好的 entertainment function? 其实目前也没有一个很好的干扰,所以这 嗯,助教在讲的时候可能也会提示说它通常会有哪一个,可是它可能也不能保证说用这一个一定是最好的,那其实你可能可以试试看用别的,但如果你随便选了一个,可能它很烂,那你肯定会问助教,所以这个 setting 这样有没有正确?好? 对,那这是刚的 sigma, 那 这是 hyperbaric tendon, 那 这也是蛮常用的,就是笔录,那它的概念很简单,就是你就是要是一个大于等于零的数值,这样子就是做一个小调整,避免让你的 书就是传出去的 activation 方选传出去的值太小,就它不希望有负的状况, 然后这是不同的 activation function。 好, 那大部分你看到这边大部分会常用的这三个是很常用的,都是 non linear 的 activation function, 大家是不是会有点疑惑说,哎,为什么这三个会蛮常用的?分别前面不是有看到 linear 的 吗?为什么大家大部分会用这三种?是讲哎,比较是木斯一点的,然后 non linear 的 这种 map, 其实原因是因为 在 deep learning 的 model 上面, deep 的 model 上,其实 non linear 的 这个就是 property, 是 非常重要的,为什么呢? 因为如果你中间没有这个 non linear 的 activation function, 它其实就跟简单的 linear 层缝是差不多的。 怎么说呢,你还记得刚刚我们做的什么事情吗?我们的音符 x 是 不是会乘上一个 matrix w, 然后放进 intvolution 嘛,然后再乘上下一层的 w, 这样是不是?是不是?然后再放进 intvolution 方向,然后再乘下一层 w 类似这样,那如果说你的这个 intvolution 方向不是 non linear 的, 那你是不是就可以把它变成是,就像是一个 linear 的 uh, what metric 在 乘,所以你如果中间所有的 innovation function 都没有 n linear 的 特性,那基本上你就可以把这两个直接乘开,直接用一个 metric 去代替就可以了, 因为这就是一个零限性的转换嘛,对不对?所以你根本就不需要用两个啊, 因为它盛开以后不就是一个,你根本就不需要 double 的 参数。所以如果你中间没有放这个能 linear 的 activation function, 你 的 expression 的 能力其实就跟你用一层是一样的, 所以中间加上这个囊里尼,囊囊里尼的边边的方旋是非常必要的。那这里是为什么要加上这个?这样我们才可以真的去上升这个 def learning model 它的表达能力,不然它其实跟一层的 linear model 其实是差不多的。 对,所以有了这个囊里尼的这个特性之后,我们才可以去模拟这种 y c 扭八的状况,不然就等于是你就一定得切直的。所以这就更好理解嘛,就因为你的 data 比如说一定有可能很混乱,你越想你想要表达这种混乱的状况,你一定是要让它有更强的表达能力,然后可以这样子弯弯地去切它。
 01:08查看AI文稿AI文稿
01:08查看AI文稿AI文稿一口气带你认识 windows 常见的文件扩展名都有什么用?第一个 exe, 中文叫可执行文件,绝大多数 windows 应用的安装程序都是这种格式。第二个点 bet, 这是一种批处理文件的扩展名,你可以在里面写上代码来实现各种功能,然后双击运行即可。比如双击打开浏览器, 或者双击创建一个文件夹,你还可以把它设为定时执行任务,实现每天定时关机。比如你可以写一个弹窗脚本,直到点击正确的按钮才能关闭。 第四个 iso, 这是系统的镜像文件,通常我们用来给电脑重装系统。比如这个是 win 十一的镜像,可以把它部署到 u 盘,然后安装到电脑上。 第五个 r e g 这个是电脑的注册表文件,可以用来快速修改注册表设置,但这个一般不建议普通人碰,因为注册表是 windows 系统的核心配置,修改出错容易导致电脑蓝屏。第六个 d l l, 这个是酷文件,比如某些软件运行时会提示缺少某某 d l l 文件,实际上就是缺少酷文件的意思,需要安装对应的组建才可以运行。 第七个 l in act, 这个是快捷方式的扩展名,比如你可以把某个文件右键创建快捷方式,再把快捷方式放到桌面,就能在桌面上双击它打开文件了。那么问题来了,你还知道有哪些特殊的文件扩展名吗?
505网络安全艾登 02:04查看AI文稿AI文稿
02:04查看AI文稿AI文稿不同的文件格式代表什么?又有什么用处?今天一口气讲清楚常见文件格式。一、文档文件最常见的是 docx, 牛马必备,从九十年代一路升级,现在能搞定简历、报告 甚至带图的复杂排版,是学习办公的得力干将。 pdf 便携式文档格式由阿德 b 设计,它的设计初衷就是在任何设备上都显示一致。 txt 纯文本,简单清亮,常用于编程或临时笔记。 二、图像文件最常见的是 gpec, 是 一种有损压缩图片格式,体积小,质量损失较小,基本看不出来。 png 最大的特色就是支持透明背景,做 logo, 截图保存都是首选。采用无损压缩 gif, 支持动画,常见于表情包和短循环视频。三、音频文件最常见的是 mp。 三,一九九一年被发明,能将音频大幅压缩,且听感无明显下降。 vlog 无损压缩,音质完美保留,没有任何损失,是音乐发烧友的首选。 wav 不 做任何压缩,是最原始的声音底片,音质完美,但体积较大。 四、视频文件几乎无处不在的 mp。 四,是当今视频格式的世界语,兼容性最好,是各大平台和手机录像的默认选择。 mov, 苹果生态的默认格式,常用于视频编辑和播放。 mkv 开源强大,能封装多条音轨和字幕,深受影音爱好者喜爱。 五、压缩文件 zip 已成为行业标准,把文件打包压缩,方便传输和存储。二、压压缩率更高,使用也非常广泛。七、 z 开源免费压缩效率出众。六、可执行文件 exe windows 默认可执行文件, 双击就能打开程序。 msi windows 专用安装程序,用来安装软件。七、系统文件是操作系统的骨架,通常隐藏运行,我们很少接触,常见的有 d, l, s, y, s, i, n, i 等。 最后补充一句,即使世界上的文件格式理论上是无穷无尽的,每一种格式都有它专属的用途,我们只需要记住,不同的文件格式都需要用对应的软件才能正常打开和使用。
1.1万曼波课堂 03:14查看AI文稿AI文稿
03:14查看AI文稿AI文稿打开英美达 app, 会有一个系统错误的弹窗,然后提示找不到这个 d 幺幺文件,无法继续执行代码。下面我来分享一下我是如何解决这个问题的。 这类问题一般常见就是电脑可能中毒了,或者说运行库的问题。呃,先打开这个 windows 安全中心,做一下全版扫描,在这个扫描需要费点时间,这个时候再右键 windows 键, 打开终端管理员这边输入 s f c 空格斜杠 s c a n o w, 做一下整个的系统扫描, 然后把这个弹窗关掉。这里需要用到四个文件,第一个的话是即可。这个卸载工具,我们找到应用达 app, 先把它卸载清理干净。这里遇到问题了,提示必须要先重启电脑,然后才能继续卸载, 点一下关闭,那就重启下电脑吧。呃,等他那个系统扫描扫描完毕以后再重启电脑,再开机以后还是和刚才一样打开这个即可。卸载工具,找到英美达 app, 然后双击卸载, 点一下卸载。呃,等他就顺利的卸载完。卸载完以后做一下这个清理,把清理残留的东西清理干净,然后点关闭。下面这两个文件是运行户的整合包,是从微软官网下的,分别是六十四位和三十二位。先双击打开六十四位的 点一下卸载,把原来的这个老版本的卸载掉,再双击打开六十四位,把老版本也卸载掉,然后点关闭,再把三十二位的双击打开,重新安装,把我同意勾搭上,点安装。 同样的把六十四位的也一样,双击打开,把我同意勾搭上,点安装,然后点关闭,再把这个应用达 app 双击打开, 然后稍等他更新资源,更新完以后,呃,他会提示是不是要同意安装,你就点一下同意并安装, 等他安装完就自己打开了。这边的话玩游戏就选第一项,如果说是呃工作的话就选第二项,然后点下一步这个直接点下一步 这一项的话,如果需要用到这个信息浮窗显示 fps, 或者说用英伟达的录屏,那就把这个对勾,把这个选项打开,如果说不需要的话,把这个选项关闭,然后点完成 进来以后他就是这个界面是正常的,可以点着看一下,功能都是全的。如果说需要更新驱动的话,去右边那边下载一下,是最新的驱动,如果不需要的话就不用管。 然后到设置里面可以考虑把这个更新自动更新关闭掉,或者说先不用动也没关系。 好的,到此为止,这个问题就全部解决完毕了。这类报 dl 问题的原因刚才已经说过了,大概率就是这个运行库出了问题。 呃,我们要做的操作就是给他更新补全运行库,但是在这个做这个操作之前呢,先要判断电脑是不是中毒了, 呃,有可能电脑中毒,或者说呃其他的情况影响了运行库,这个时候我们要排查一下。好的,谢谢观看。我是小张,擅长解决各种电脑问题和游戏问题,再见。
118小章修电脑(可远程) 04:31查看AI文稿AI文稿
04:31查看AI文稿AI文稿文件系统是操作系统用来在硬盘、固态硬盘或 u 盘等存储设备上组织和存储文件的一套规则。它负责记录每个文件的具体位置以及数据的排列方式,从而让电脑能够快速的读取、写入和管理信息。 fat 是 windows 系统中最古老的文件系统之一, 最早的版本最大只能存储三十二 mb 的 文件,一旦超过这个大小就会报错。但在那个年代,这已经完全够用了。随着存储设备容量的飙升,斐特十六诞生了,它极大地提升了上限,让电脑首次能够使用十六 gb 的 硬盘,并支持最大二 gb 的 单文件。之后是斐特三二,这是我们至今仍在广泛使用的版本。它 在 windows 上支持大于三十二 gb 的 卷,在某些其他操作系统上甚至能支持到二 tb。 但它的致命硬伤是,单文件最大只支持四 gb。 在现代系统中,这四 gb 的 限制常常让人崩溃。比如,你想把一个超过四 gb 的 高清电影考进斐特三二格式的 u 盘, 就算 u 盘空间还剩几十个 g, 系统依然会报错。此外,斐特三二无法创建大于二 tb 的 分区。如果你强行格式化一块四 tb 的 硬盘,系统,可能会把它强行 p 成两个 tb 的 分区,那为什么还在用?答案是无敌的兼容性。因为它存在的时间太长了, 几乎能和市面上所有的操作系统与设备完美适配,所以依然是 u 盘和存储卡的最爱。 ntfs ntfs 是 目前 windows 的 绝对主力, 它能支持极其庞大的文件和分区。理论极限,单个文件最大可达十六。 e b 做个概念换算, e e b 等于一百万 tb。 也就是说,在日常使用中,它的容量几乎是没有上限的,彻底打破了 fed 三二的最大枷锁。它是一个日制型文件系统, 这意味着它会默默记录对硬盘进行的每一次修改。如果电脑突然死机或断电,系统可以利用这些日记记录来恢复文件系统,大幅降低数据损坏的概率。另外, n t f s 允许系统控制谁能访问特定的文件或文件夹,比如设置为止读 或仅限特定用户访问。它还支持文件加密、压缩和磁盘配合等高级特性,这让它完美契合现代操作系统的需求。正因如此,现代版本的 windows 必须安装在 n t f s 格式的硬盘上,缺点就是跨平台兼容性差,在非 windows 操作系统上,通常只能读不能写。 x file 它由微软于二零零六年推出。简单来说, xfat 就是 打了鸡血的 fat 三二,它的单文件大小上限同样达到了十六 e b 对 于日常存储超大视频文件、系统镜像和高分辨率录像来说毫无压力。 与 ntfs 相比, x f a t 砍掉了日记记录、文件权限加密和磁盘配合等复杂功能。但正是这种做减法,让它变得极其轻巧,运行速度更快,非常适合便携式存储设备。 现代版本的 windows 和 marcos 都能对它进行完美的原声读写。凭借着支持超大文件加跨平台兼容的完美平衡, xfat 成为了大容量 u 盘、移动硬盘以及相机 s d x c 内存卡的首选标准。 h f s h f s 在 一九八五年由苹果推出, 用于早期的 mac 电脑,它最高支持二 g b 的 文件和二 t b 的 卷。苹果随后推出的升级版 h f s 加,大幅提升了存储上限,并加入了日历记录功能。 在很长一段时间里,它都是 mac 电脑的御用文件系统。到二零一七年,苹果推出了脱胎换骨的全新系统 apfs, 它专为现代固态硬盘和闪存量身定制,包含了强大的加密、快照以及更优秀的空间管理功能。如今, apfs 已经是所有现代 macos 系统的默认标配。 缺点就像 linux 的 x 格式一样,苹果的这些文件系统在 windows 上是水土不服的,如果不借助第三方软件, windows 电脑根本读不出里面的数据。 e x t, 这是为 linux 操作系统量身打造的专属格式。 ext 二是最早的经典版本,非常高效,但不是日制型文件系统。这意味着一旦死机或断电,文件损坏的概率极高。为了解决上述痛点, ext 三它最大的升级就是加入了日制记录,可以通过记录来挽救数据。 ext 四于二零零八年发布,目前 linux 圈子的头牌。它支持巨大的存储设备,单文件最大约十六 tb 卷,上限可达一亿币。因为它极少被用来做移动硬盘, 而是牢牢霸占着 linux 系统盘和服务器领域。 zfs 它最初由 sun microsystems 开发,并于二零零六年发布,堪称文件系统界的企业级航母。它的拿手好戏是数据校验与自愈。它会不断使用校验盒来检查存储的数据, 一旦发现数据损坏并且存在备份副本, zfs 就 会自动进行静默修复。它支持的数据规模达到了泽字节级别。对于普通个人电脑来说,这简直是杀鸡用奸心剑。 正是因为这种近乎偏执的数据可能性, c f s 常常被用于服务器、数据中心以及对数据安全要求极高的企业级存储系统中。如今,你可以通过 open c f s 项目在 linux、 free b s d 等 unix 系统上体验到它。
512哈气黄豆 00:53查看AI文稿AI文稿
00:53查看AI文稿AI文稿遇到 d l l 报错问题,千万别去网上搜 d l l, 然后乱下载,那种网站全是坑,下回来一个 e x c 电脑直接变矿机。不管是英雄联盟、永劫无间还是黑神话,遇到零 x c 零零零零零七币、沃克隆台、米色零 d l l 这种报错 都不是游戏坏了,是你电脑缺了运行库。接下来是我测试下来觉得很好用的一款小工具,用这个 dl 修复工具,点一下扫描,再点一下修复,关掉重开,直接能进游戏,报错问题轻松解决。官方链接我也给你们下次报错,别慌,用它就行, 安全干净,没捆绑。这工具厉害的地方在于,每次修复后都会自动生成一份详细的诊断报告,你电脑到底哪里出了问题,是 d l l 版本冲突,还是运行库缺失,一目了然,让你真正了解自己的电脑健康状况,真正靠谱好用的 d l l 修复工具,不需要你懂任何技术。
 04:29查看AI文稿AI文稿
04:29查看AI文稿AI文稿ntfs 权限与文件系统 ntfs 权限分配了正确的访问权限后,用户才能访问其资源。 设置权限,防止资源被篡改、删除在办公环境中,某些存储在计算机中的文件经常需要被很多人读去访问。为防止这些人中的某人篡改、删除该文件, 计算机程序的开发者设计了文件访问权限。只有分配了修改的权限,访问者才能够修改其内容。只被分配读取权限的访问者只能够读取其内容。 这些权限是分配给用户账户或主账户的。分配给主账户的权限,即自动分配了给主的成员,减少了分配的次数。文件系统、文件系统及在外部存储设备上组织文件的方法 常见的文件系统 f a t n t f s e x t ntfs 文件系统特点,提高磁盘读写性能、安全性加密文件系统访问控制列表磁盘利用率压缩磁盘配合 文件系统与权限。文件权限,用户可以对文件进行读取、写入等访问,控制常见的文件操作权限 读取数据,允许能够查看文件中的数据,拒绝不能够查看文件中的数据。写入数据允许能够对文件进行更改以及覆盖现有内容 拒绝不能够对文件进行更改以及覆盖现有内容。附加数据,允许能够更改文件的末尾,而不是更改、删除或覆盖现有数据, 拒绝不能够更改文件的末尾,而不是更改、删除或覆盖现有数据。删除允许能够删除文件,拒绝不能够删除文件。 执行文件允许能够运行程序文件,拒绝不能够运行程序文件常见文件夹的操作权限,列出文件夹内的文件名、 在文件夹内创建、删除文件等。列出文件夹,允许能够查看文件夹内的文件名和只文件夹名,拒绝 不能够查看文件夹内的文件名和只文件夹名。创建文件,允许能够在文件夹内创建文件,拒绝不能够在文件夹内创建文件。 创建文件夹,允许能够在文件夹内创建文件夹,拒绝不能够在文件夹内创建文件夹。 删除,允许能够删除文件夹,拒绝不能够删除文件夹。删除指文件夹和文件,允许 能够删除子文件夹和文件,拒绝不能够删除子文件夹和文件。 ntfs 权限的划分 ntfs 权限细致划分, 完全控制修改、读取和执行。列出文件夹目录读取写入特别的权限,便利文件夹执行文件。 列出文件夹读取数据读取属性,读取扩展属性。创建文件,写入数据。创建文件夹。附加数据,写入属性,写入扩展属性。 删除指文件夹及文件删除读取权限、更改权限取得所有权。
3左重阳 03:43查看AI文稿AI文稿
03:43查看AI文稿AI文稿windows 系统入门注册表 windows 操作系统使用注册表统一管理用户信息、软件配置、硬件配置等,用来提高系统的稳定性和安全性,同时使我们更容易对系统进行维护和管理。 注册表由多个文件组成,是一个庞大的数据库,包含了应用程序、软硬件的全部配置信息、 初步信息及其他重要数据。操作系统通过注册表编辑器来进行注册表的编辑,重放在系统盘的 windows system 三、二文件夹中。打开方式, 开始菜单,搜索 raggedit 并回车运行。注册表的结构包括指数、值 项。注册表编辑器中显示有五颗指数。 windows 七注册表中的数据按照两颗指数进行组织。 key local machine key users, 其他三颗都是这两颗指数的分支。 key local machine 记录关于本地计算机系统的信息,包括硬件和操作系统数据。 k users 记录关于动态加载的用户配置文件 和默认配置文件的信息。 k current user 当前用户的安全 id, 包括当前已交互式登录的用户的配置文件。 k current config 包含在启动时由本地计算机系统使用的硬件配置文件的相关信息。加载的设备驱动程序显示时要使用的分辨率。 k classes root 包括用于各种 o l e 技术和文件类关联数据的信息值。每个注册表项或关键词都可以包括称为值的数据。有些值存储特定于每个用户的信息, 而其他值则存储应用于计算机所有用户的信息值具有三部分, 名称值的数据类型和该值本身。注册表配置单元是一组存储在独立文件夹中的指向和值注册表编辑器的基本操作,创建指向创建值修改值 删除指向或值重命名指向或值制符串值固定长度的文本制符串。 二进制值原始二进制数据,多数硬件主件信息都以二进制数据存储。 d word 值数据由四字节长的数表示,设备、驱动、程序和服务的很多参数都是这种类型。 q word 值数据由八字节长的数表示。多字母串值,多重字母串包含列表或多值的值, 通常为该类型可扩充字母串值长度可变的数据串,该数据类型包含在程序或服务使用 该数据时解析的变量。注册表编辑器常用功能,禁止用户修改桌面背景、禁用控制面板、禁止修改浏览器主页、禁止修改桌面文件的路径、 禁用鼠标右键、禁用任务管理器、禁用系统搜索、禁用关机重启睡眠、禁用注销账户、禁用远程桌面等。
10左重阳





猜你喜欢
- 2.7万猫机