python怎么打开html路径
好了,康的官方刚刚推出了一个项目,可以让我们在 htm 的网页里边嵌入并且运行拍摄的小本,这是他的官网 passcreeped 点 nice 使用过程也比较简便,我们可以下载一个包,解压出文件,找到 passcrepe 的点 css 以及点键 s 这两个文件嵌入引用的网页里边儿也可以使用 cden 的版本, 这样他会要求你的网络比较通畅才可以。这里我使用 cdn 的版本,我们创建一个新的静态网页,叫做 index htm, 买来了保存的桌面上,然后把刚才的应用粘贴过来,我们先写一个纯静态的 he 的标题,然后右键浏览器打开浏览看一下网页的显示,这个时候跟 pass 没有任何关系。 房间里嵌入的拍摄的脚本是把它放到一个标签拍 guns creep 的里边就可以。这里边我们使用 print 打印行字,跟刚才 h 一的标题的文字内容是一致的,注意代码一定要顶到左边对齐,否则它会爆缩 进一场。好,不然你打印之后呢,我们重新刷新浏览看一下,我们可以看到结果跟我们写的静态内容是一致的,正常显示好通之后呢,我们就可以实现更多的可能,比如说这里我们测试一下,我们导入 tim 模块,然后打印一下当前的时间也没有问题, 然后我们再声明一个列表,比如放一些变成语言的名称,然后再做一个复印便利注意一下刚才我们提到的缩进,一定要提到最左边对齐,然后重新运行一下,我们看到果然就会将我们列表的内容便利打印出来。 由于我们使用了 pat 三零零以后的格式化词不串的语法,所以这样的话我们可以在里边可以加入自己的一些静态内容,比如说在每个语言的后边加上一个汉字杠元项目是刚刚发布,还在阿尔法的阶段,我并没有深入的去研究,有兴趣的同学可以自己上他的官网去看一下。

粉丝7772获赞3.2万
相关视频
 01:03查看AI文稿AI文稿
01:03查看AI文稿AI文稿在 html 中运行拍三出体验,一、认识 pass crepe 官网集中英文切换。 二、在桌面创建文本及编辑保存 with the lock sea cat fall off dedicated right going all night 本本另存为 f 八格式 修改后置 明雷 hpml。 三、双击运行查看效果, 你学废了吗?
138非鱼AI数据分析 11:56查看AI文稿AI文稿
11:56查看AI文稿AI文稿嗨,大家好,今天给大家分享一个比较综合的案例,我们使用潘纳斯,借助潘森的爬虫 先爬取一个网页,然后我们使用潘纳斯呢解析这个网页中的 atm 的表格,然后将表格数据传入到 acr 文件,打开咱们的潘纳斯, 本次的目标呢是实现一个真实的场景,我自己经常看英文文档,然后有很多单词不认识,我就使用网易有道这个词典呢,进单词的查询, 他有个功能,就是可以把差距的单词呢加入到单词本,但是这个工具他本身当前没有导出全部单词列表的功能,而为了复习方便,我自己希望能够得到所有的单词列表,传入一个 文件方便复习。那么本视频我就来演示一下怎样实现这个功能。设计两个技术,第一个潘纳斯, 他是拍摄员最强大的数据处理与数据分析的一个库,而第二个就是拍摄爬虫,爬虫技术简单来说就是把网页数据下载下来,然后解析, 这里比较简单,我们借助以快字库来实现,但有一点需要绕过登录验证,因为查询的是我自己的单词本,所以说我是需要登录了以后才能看到的。首先引入几个内裤,就如快词 用于爬去网页,然后用快速点。酷的意思就是一会用于绕过登录,然后使其他几个酷,包括机身, tom 以及潘纳斯库。我们运行第零步,我 介绍一下处理的流程。首先第一步呢就是输入的一个网页,他是有道词典的一个单词本的网页,我这里给了个截图,一会我们再看一下这个页面呢,他这个网页里面有个表格,这个表格呢是分页的, 就是第一页,第二页,一直到最后一页。而我的目标呢,就是把这些页面中所有的表格给都扒取下来,然后拼接成一个大的表格,传入一下整体的处理流程是这样的,首先呢有一个网页, 他需要登录了以后能看到自己的单词本,然后我就使用派送爬床的技术,借助瑞筷子和库克来下载网页, 不同的分页下载的网页是不一样的。然后呢,我选潘纳斯的 red et 喵的方法来解析网页中的表格,这是潘纳斯一个现成的方法, 解析了之后,我们把这些不同页面的表格拼成一个大的表格,最终呢,把这个大的数据存到给 siri 文件,就是判断字典图给 sir 的方法。我们先看下最终的效果, 就这样的,这是一个 cr 的文件,它里面包含了我自己单词本中所有的单词,包含单词音标解释三列,这个话就很方便,因为我自己的复习,比如说我可以打印下来 进行复习。这三个大的步骤就是这是一个网页,然后爬窗下载和解析,最后存储到 acro 文件,我们来进入具体的实现。首先第一大步, 我们登录网页有道词典的 pc 版,这个时候呢,需要我进行微信扫码登录,为了让我登录验证,这里我介绍一种方法,就是就是我们把 qq 字附着一个文件,然后 爬取的时候呢,带着 ok 就可以绕过登录了,什么意思呢?我们进行演示,首先我打开这个网页,有道此店,他的 pc 版的地址点一下, 点开以后呢是这样一个网页,在这个位置有一个查看单词版,我点一下,然后呢他打开了一个登录的界面,这里我进行登录一下,就点这两个同意,然后点这个微信, 这个时候我拿自己的手机来扫码一下,扫一扫同意,他就进入了我自己的单词本的主页, 我们看到我共计八十六个单词,然后呢分这么几页,下页,下页的话,你们看到总共有六样,这个幼儿呢一直在变化,就是从零到五, 总共六页,这个页面就是我要抓取的目标,而这网页上的表格就是有几息的目标,但是因为我们需要登录验证,方法呢就是我可以复制他的库克,这个页面的库克就可以绕过登录,方法是这样的,我装了个插件,后面的插件叫做 id 的这个库存, 我点一下这个插件,然后点这个这个地方导出亏给色点一下他的提示库,可以呢,已经复制到了剪贴板,回到胶布套,这个插件呢我列在这里了,方法就是 id 的这次库克,大家感兴趣可以自己装一下, 我把这库给子复制了,以后干什么呢?我们回到这个正面的首页,打开这个课程的目录, cos 第二次 点的这个 c 三十二,就是第三十二节,点进去里面有个酷,可以点太子色,这是我之前的内容,把它删了粘贴新的,我们看到这是个金色的形式,我保存一下, 回头交叉这一步呢,我就把这个金色数据读取到一个库存架里面,这个库存架对象可以用一会的爬去,有了它我们的爬虫呢直接可以下载登录后的页面的数据库存架,顶于快速点括号一次点为快死库存架。 然后我们打开刚才的这个文件,就是库克点他的文件金色进行加载,然后对每个库克的支点对象来说,我们给这个估计价赛 他的内幕, y 六刀门 pass, 看下这个估计价。 这就是我们把这个网页的这个酷 k 呢下载到一个对象里面,就是 readys 的酷酷一家,然后我们进入第二大步,将这个一天喵下载下来,传入列表,我出来对象是累死的,就是所有的一天喵,然后呢把这个 ur 复制过来, 里面有个参数,就是这个 p 顶一 idx 是个张音符,代表是第几页放 idx, 因为转你六,就是说我要爬去六页,这个数字呢从零到五, 然后我 cpt 一下就防止这个服务器把我给爬出给禁掉,然后蒲音上爬去了第几页,接下来呢就是用筷子顶盖上进行爬曲爬去的油饵呢, 幺二点方便车把这 idx 就是这个数字给替换成真实的数字,这个时候注意带上这个扣一键,就是酷一次定扣一键,这个爬去,结果我们将阿联太子的给碰到一天没有 s 这个列表里面这个代码,他就实现了六个网页,他在爬去 运行, 我们看到他爬去了第一零第一,第二,第三,一直往后到第五页杠九十六个页面, 然后我们看一下第零个页面长什么样子,运行,我们看到这是一个贴面,在吗往下拉的话会发现里面就是包含了我 自己的单词本里面的单词,但这样一贴描我是没法用的,所以说第三大步我需要解析里面的 表格。首先我们来演示一下单个页面做串的解析方法呢,就是 pd 点 red 贴标,我们把第一个贴面的做串穿进来,然后复制给 df 这个冰量运行。 然后呢,我们看一下这个 df 变量,他的 nice 以及他的 top, 为什么看 nice, 大家看下 top 就知道了, 他那是等于二,他本身是一个类似的,其实我们看判断的文档就知道,这个类似里面每一个元素都是一个 d f, 因此我们看一下 df 零和 d f 一分别是什么? 颠覆零,我们看到,我们看到这刚才我们看到的表格的表头就是列名,然后颠覆一,我们看前三行,这里展示的才是真正 字典的数据,这就说明这个判断是他还是不够的智能,他没有把这两个 df 呢给拼成一个,而是把这个表头给当成了一个单独的 df, 没关系,我们可以自己搞定。 方法是这样的,首先我让 dfccont 等于 df e, 然后呢,我让 dfccon 点克拉姆斯等于 d f 零点克拉姆斯,就是说把第一个 df 他的表头复制给第二个 df, 他的表头 运行,我们再看下这个 df 的前三行运行。哎,这个时候就没问题了,我们把这两个 df 给合并起来了, 这个 df 呢有内容,有表头,这对单个 df 的处理,我们怎么把六个网页的表格给拼起来呢?其实用的方法就是 pt 点慷慨测, 但在这之前我需要实现六个网页表格分给他。解析方法是这样的,首先出示画列表,然后对每个 a, t、 m 字不串,使用 pd 点 redet c, l 进行读取, 然后呢我们让 df clond 的第二个 df 同时把它的靠浪不死等于 df 零点,靠浪不死就是表头,然后呢把这个 df 给判断到这里是里面,这个时候这里面就包含了六个 df 运行, 我们可以使用平行的,慷慨的直接进行多个表格的合并运行。我们再看这个前几行运行 没有问题,数据格式是对的,我们看一下这个是一步就是他的多少行多少列,不运行其实就得到了 他有八十六行,意思就是八十六个单词,跟我们刚才看到的这个网页上共计八十六个单词是对的上的最后一步就是把结构数据呢输入到第三个文件, 方案也简单了,就 df 筛选出这三列,分别是单词,音标和解释,然后点头盔 cr, 第一个变量我们设定一个 excel 的路径,关键是最后这个就是点 xlxx, 就是 excel 后缀, 然后加一个音,那个等于放肆,这样的话我们输出呢就不带这个数字的错印运行,没有报错,我们打开我们的文件夹, 就在这里奥特曼判断四里面有个 costx, 打开里面有一个 c 三十二 red 贴标,打开里面我就看到了生成了一个 exce 软件,我们说 双击打开,打开来给 siri 文件了以后,我们就看到这里面呢就整整齐齐的放了单词,音标,解释这三列,往下拉会发现总共有八十六个单词。 ok, 以上呢,我们实现了我们的目标。回顾一下,回到我们的这个流程图,整流程是这样的,首先我们一个网页,这个网页呢我们需要登录验证才能看到,然后我们借助拍摄爬虫 使用快速的酷 k 下载了登录后看到的网页,对于下载好的网页就有 app 的代码, 我们使用判断字典 red etm 的方法进行表格的解析,然后我们使用批点慷慨的方法把这些表格给拼成一个大的表格, 最后使用 p 点拖给 cr 的方法把它输入到 excel 文件,方便后续的进行复习也好,打印也好 好,总之会更加的方便。本集的这个实力是一个综合的实力,我们只要用到两方面的知识,就是拍摄的爬虫以及拍大指怎样解析文艺的表格。最后进行输出。以上就是本视频的内容,我们下次见,拜拜!
1703Python导师-蚂蚁 00:44查看AI文稿AI文稿
00:44查看AI文稿AI文稿今天继续给大家讲文件,那文件的相对路径和绝对路径,比如说我们这打开 open number 点 txt, 那这个就是我们用的相对路径,因为它是执行当前程序 目录,比如说拍摄入门变成一百粒下面的 number 点 tst, 大家可以看到我们的左下角有这么一个文件,他跟我们这个是在一个目录里面,那这样可以直接查找。那如果我们是在这个目录的下一集,比如说这里面增加了一个 aaa, 那我们可能就需要 aaaa number 点 txt, 通过这种形式来进行,这个就是相对路径,那同样的绝对路径的话,就是当前文件的绝对位置,可以读取系统的任意地主文件。比如说我这个 number 点 txt, 它其实是带 uzer、 抓 box 下面等等这一长串内容,那这个就是我们的相对路径和绝对路径,希望大家不要搞错。
 01:15查看AI文稿AI文稿
01:15查看AI文稿AI文稿只需要先倒入潘的醋才能使用读取文件功能 丑的滚滚方法而使用了。
14Coinmach 02:11
02:11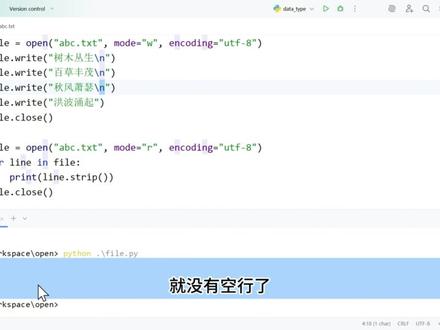 06:45
06:45












