如何用growth函数进行预测
大家好,我是一休哥, 欢迎来到跟一休哥学做表。今天我们来看 wps 的公司第六十四课,就这个公司,我们大概先看一下他的 公司的名词解释,根据现有的数据预测指数伸展值 已知拜词集合满足指数回归礼盒曲线,就是这个 外,是等于这样的一组已知的外置, 好像是这有两个数字,这个 b 乘以这个耳母,然后这上面不知道是一个这个标识是什么意思啊?大家感兴趣可以去查一下, 我们就先把网络上一些参数借来一下,然后把公司套进来,看一下会有什么结果值,行,我们先去,我刚才已经 悄悄的在网络上找了一下这个参数啊,我们把他的参数直接超过来,大家稍等片刻, 行,就这个参数了,我们直接把他公司给他套进来。 椅子外的集合, 我们看他这边是什么套 外的集合是 就这边的利润都是外的,而个是销售额是这个, 老哥是急,这边有一个 b 九啊, 新的 x 级是 b 九,我们看一下外的几何是这个 俄罗斯的鸡蛋是这个, 这个要在英文字,英文底下输啊,然后这底下这个是 第九推车。厉害,没有素质。 销售额等于 哦,这边这有个度啊,利润是多少得出来给你一个销售, 销售啊,这个是 b 九,就这边啊,年度是二零二一年的 四六 五四七四六五五五四七七八四六五七八四五七八四。 好好,就这个意思啊,这样就得出来了,得出这个值根据是上面以前的比例啊,以前这个比例就是根据之前现有的数据指数增长值预测出他的增长值, 这公司我们在这边再来给他插入液,我再给大家演示一遍啊。 选择这个,这个其实翻译过来它也是增长的意思,英文呢?外直是结果,只是这个 就是最终求出的结果。那俄克斯的集合是这个销售额 操作额,然后新的集合就是这个 销售了多少,现在来求他的净利润不强制系数,唯一直接回车一下,结果 按照以前的增长的销售额和他的利率比,最终推断出二零二一年 在这么大的销售额底下,他的利润可能是这个,这相当于也是一个什么礼盒函数,是不是我们把这边给他 清除一下,把这些或者给他删除一下,好,这样就得出来了。那现在我们来看一下啊,我记得当时有个礼盒函数,我们在这里满试验一下,我有点忘了看一下啊, 他当时是也是怎么个操作的?是插入这个吗?哦,好像是这边这个,应该是类似于这个吧。 好,这样就得出来了。数据区域,让这边编辑一下, 选择数据 要做这个, 每一页作为一个数据区,添加一下,取消一二三五个级别, 有点不太对哈,比如说我们这个地方更改一下,把它数据取给它更改,选择一下这个 是吧?然后点个确定 议论是这样变的,销售额, 这个是对五千一的那个,然后再对到这个私底有多少?对的,是这个飞到这边,然后又回来,回来到这底下, 那我们比如说把这个字不是这个,要是这个字给他扩一个,然后回车间看会有什么结果啊? 没什么反应啊,老子再玩一下,好,就变到这里来, 这这边这个应该就是叫礼盒函数啊,还是这种算好的啊?叫礼盒曲线,就是这样计算出来, 但是从这边看也没看出一个什么明显的一个什么规律啊,是吧?从这边变成这样,变成幺幺幺幺,多少开头的 没有看出。如果正常情况底下像有一些有规律的话,他比如说是一个这样的曲线啊,或者是这样的曲线啊,甚至有可能是抛物线啊等等规则曲线,他这种是不规则的,所以说估计只能用这样的公司来计算了,其他也没 怎么折了,是吧?比如说我们这边给他多加个零,肯定他这边也会有硬的变化,哎,像这个数他直接就流到这上面去了,是吧?所以说根本从这图表上没看出什么规律啊,但是他这边结果他是可以推算出来,就这样。 行,今天我们就讲到这边,我是一休哥,拜拜,休息一会我们马上就回来了。

粉丝671获赞6480
相关视频
 01:44查看AI文稿AI文稿
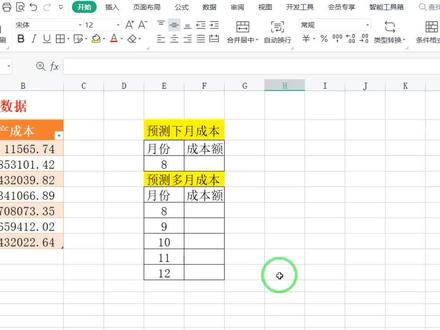
01:44查看AI文稿AI文稿今天我们来学习如何做生产成本预测,如何根据已知的生产成本数据去预测下期的成本或预测多期的一个成本。那么如果我要预测根据这些已知数据去预测八月份的数据, 那应该怎么预测?那我们要用到一个函数,那么在这里如果你对这个函数不了解,我们直接点开 f x, 在这里去输入我们想用的函数 group 函数, 这是一个统计函数,我们点开就可以看到,他是根据现有数据预测指数增长值,那么我们要知道已知的外值集合,已知的 x 值集合,那么外值集合就是已知的生产成本, 已知的 x 值就是月份,那么新 x 值就是这个八月份不强制系数,唯一我们忽略不填,我们点确定 我得到的就能预测出来八月份的一个数值。如果说我要预测多期的一个成本,首先选中整个空白单元格,我们依然是打开 fx 去输入 gross 函数, 已知 y 值的集合,依然是生产成本, x 值的集合,依然是月份 cx 值的集合,我们将月份全部选中, 我们点确定,在这里我们将鼠标放到这里,我们当一个数组来实现,所以我们要同时按住 ctrl shift 加回车三键来实现,按 ctrl e 快捷键 保留两位小数就可以了,那这是我们通过已知的生产成本数据去预测下期的成本和预测多期的一个成本的方法。点赞收藏加关注哦!
201表姐教你学Excel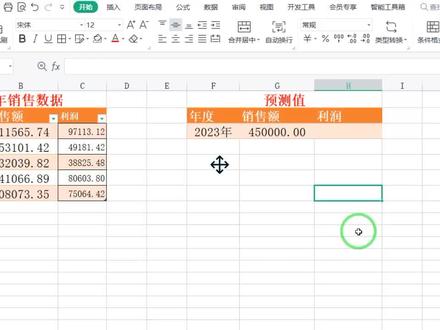 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿今天我们来学习如何根据历年的销售数据,然后去预测我们的一个销售利润,那么在这里呢,我们要用函数, 当我们对某一个函数不太熟练的时候,那么我们直接点开 f x 四,在这里去输入这个函数 gross 函数, 双击点开,那么这里就会有相应的参数,根据它的提示进行相应的选择就可以了。已知的外置集合,那么在这里要知道 gross 函数呢,它是一个统计函数, 它是根据已知数据去预测指数的等比,所以已知外置的几何是 利润。我们将它框卷上以至 x 值的集合销售额给它框卷上新 x 值的集合,就是我们目前预测的二零二三年度的这个销售额, 然后我们点确定,这样的话,我们就直接预测出来了二零二三年的一个利润。点赞收藏加关注哦!
224表姐教你学Excel 00:21查看AI文稿AI文稿
00:21查看AI文稿AI文稿怎么用 excel 做预测分析呢?选中数据,插入一个普通的折线图,右键添加趋势线, 选择符合要求的趋势线,可以显示公式和二平方值。如果需要预测未来四个月的数据,可以在后推周期中输入四,这样就做了一个线性预测分析图了。
3547米小蕉-数据分析 03:28查看AI文稿AI文稿
03:28查看AI文稿AI文稿大家好,欢迎来到奥菲斯课堂,今天我们来给大家讲一下在 excel 表格里如何做数据礼盒。比如说我这里有年龄和身高这两类数据,年龄和身高明显看出他是有关系的 啊,在年龄比较小的一个范围内,是年龄越大身高也是越大,当然年龄到了一定范围他也是不着的了,像后面他一一米八,一直是一米八, 嗯,那么我们想知道说这两列数据具体的一个函数关系是什么?如果我们知道这个关系的话,像这里有七到十七到十三岁之间没有给出,那我想知道八九十到底是年龄是八九十岁的时候到底是多少身高。 如果有这样的函数关系,我就可以直接带进去计算了。如何得到这样的一个关系呢?我们首先把这两类设置, 呃,给选中,选中以后点击插入,插入图表,这里图表这里有个小箭头,点击小箭头,嗯, 就选择第一个趋势线这个长度啊,画一个三点图啊,这是他的整体的一个关系的一个图像,这个图像已经做出来了,那么我们如何得出这个图像对应的一个函数关系呢?这右上角有个加号,我们点击一下,然后有趋势线, 其实是这里有个小箭头,我们点一下,因为他有好多种啊,有更多选项,这就出来了, 这里全世界他的指数啊,谢谢。对手,这个意思就是说我们根据现有的数据观察他,嗯,可能是个什么样的分布啊?比如说我如果认为是谢谢,现在选中, 呃,他这个就是给一个谢谢的故事,我可以这里有显示故事,我点一下,你看他这个谢谢故事,就是一个系数是零点零五六三的一个谢谢故事, 这样的话我就可以根据这个股市计算出年龄等于八九十岁的时候他的身高。但实际上我们看出谢谢你和只能你和一个大概的趋势,他并不一样,因为 十十九岁,二十岁到二十多岁的时候,他年龄年龄变化身高是几乎不变的,说谢谢你们肯定是有问题的。呃,整体来看他反而 更像对手礼盒,试一下对手礼盒,他后边不怎么长了,但前期的幅度还是不一致,我们选个多项式礼盒,多项式礼盒的话就是这个像素可以调,如果 相声越高,他可以理合的曲线越复杂啊。二下的话你说还不是很好,我们可以调节他的下手,结束也就是来个五次的吧。嗯, 点击空白处确定一下。哎,五次的几乎就你合上了,发现他后面也没有怎么变化啊,我们把这个颜色给调一下啊,点击这里,把颜色给他调成红色的,往边看一点。哎,我们看从这个五次,你和他这个呃, 几乎是吻合的,然后他这个股市的话也显示到了这里,这个股市是最高次次五次,然后四次,三次,二次、一次和长寿项是这么一个股市, 这样的话我们就成完成了一个礼盒,我可以根据这个关系计算任意年龄段的身高。谢谢大家,如果喜欢的话可以点赞、关注、收藏。
804又一村博士 05:48查看AI文稿AI文稿
05:48查看AI文稿AI文稿大家好,我是原发教育的伤心老师,今天继续给大家讲解 excel 数据建模与预测分析。今天要讲的是使用散点图和趋势线进行指数方程的长期趋势预测。 上节课讲到了是用二次多项式方程预测,那么针对同一个案例,我这里用指数回归方程来进行预测。首先来介绍一下指数方程预测他的适用场景, 我们有了数据,在随着时间的推移,他会越来越高或者越来越低,呈现出一种指数性的增长或者下降,那么这个时候我们就要考虑用指数回归方程。 需要注意的是,指数回归方程它里面的数据不应该包含零值或者是负值,负数如果有零值或者负数,那么就不能用指数方程,那么就可以要尝试用二次多项式回归方程。 在二四多项式和指数方程之间,如果数据都很类似,那么选哪一种更合适呢?就要看二方直,二方直,谁大就用就用哪一个方法,谁大就用谁。 他的公式是 y 等于 a 一啊,这个是 b, t 就表示什么呢?这个一他是一个自然对数的底数啊,这个不用去深交,他就是类似于这样, y 等于四百七十七点六乘以一, 然后上面是零点一六七三 x, 只要我们求出 a 和 b 就可以了, a 和 b 就可以了, 然后再将未来的时间带入进行预测,他的思路也是一样的,和前面讲到的是一样的,插入三点图和添加趋势线,得到回关方程,观测 监测值二方,然后再计算预测值,那么预测值这个一自然对数转化为函数,就是用一 xp 函数,它是自然对数函数 还是?接着上面的一个案例,上节课讲的是二次多项式,求出来的是 y 等于十二点幺零幺三啊, x 方是这个公式, 那么我们接着来,我们再重新再把它算一遍,插入三点图, 选中三点图,在设计下面添加图表元素,趋势线,先点选一个指数, 然后点线线指数都是可以的。最后要在这个地方我们看一下,首先呢把勾选这两个显示公式和二网址,然后再来看指数和 多项式,这个是多项式的,这是上节课讲到了阿芳指等于零点九七九,指数呢,它是零点九六九,相差 不大,当然二次多项式可能更好一些,那么这个就是指数,点指数。 ok, 那么这个指数我们看一下,这个预测时是指数的预测值, 这个是上次课讲到了二次多项式, 差是等于有一个公式,四七七点六 乘以 e x p 函数,它是返回 自然对数一的 n 次房, 零点幺六七乘以 x 就是 c 二啊,这个是他的一个公式, 就是 y 等于四七七点六一,然后上面是零点幺六七 x 的方回车。 好,这个预测,这种预测和这上面的预测多少有点差距,有差距是非常正常的,因为方法不一样。好,我们来小结一下,什么情况下用非线性的, 非线性的二次多项式。什么情况下用非线性的指数回格方程呢?有两种方法来判断,首先第一个数值不应该包含零或者负数,如果有零或者负数, 不管阿尔方值多大,你就不能用指数回合方程,要用二十多项式,这是第一个判断的标准,第二个判断的标准就是阿方值,阿尔方值越大就用于就用水,但是他的前提是 如果用选择指数,他数据不能有复数啊,就这两个。好,那么关于深入理解趋势线预测法,今天就讲到这里,谢谢大家。
338跟尚西学PowerBI 02:16查看AI文稿AI文稿
02:16查看AI文稿AI文稿今天分享一个在一个赛奥中加密与解密的过程啊,以前你如果知道的话,传情书啊,就没有那么费劲了,我们来看一下,这里有一段话,一个赛奥克代表 master excel 对不对?我需要把加密成一个别人看不懂,但必须要放到一个赛奥中,才能显示出原文的一个过程。 首先我们把这个字符啊进行打闪,等于 mate 夸夸回来,然后里面的选择字符,对吧?后面呢,输入一个 low 夸夸回来,最后一个是一把打闪成单个字符,里面输入 indiana 啊夸夸回来,然后呢,从一个双引号啊,这个常规操作啊, 双引号一比上,后面是一个字符串长度,对吧,加上一个 and, 然后呢是一个 lam 啊,这是一个非常常见的过程,我们之前都讲过好几次了啊,你只要学会这个过程,回车他就把这个字符串啊打散成单个字符了, 对吧?那单个字符呢?我们笑中有一个扣的函数对吧?等于扣的跨过回来,然后呢,选择这个区域,注意看哦,回车, 他把每一个字符文字对应的一个代码,把它变成了代码化了,对不对?那如果代码化之后,我们如何把代码又转成文本呢?那就输入一个恰函数,恰函数跟扣的函数呢?刚好是一正一反的一个逆向过程啊,互利的 选择这个区域,他又可以把它解密成对应的字符,那我再加上一个 contact 啊,速度等于 contact, 看开头呢,就是把某一个区域的字符啊给它连到一起啊。回车,那是不就完成了这个过程啊,这个里面是这个嵌套对不对?是不是可以把复制啊,复制这个对不对?复制,然后呢?把这个替换掉啊,就是我在直播中经常讲的如何写签到公司。 那这个时候第一次呢,相当于这个区域对不对?回车还是一样。最后呢,很转了一步啊,把这个选中,摁一下, f 九 他变成数字了,回车他也是一样。那我们只要把这一串制服复制,然后呢发送给我们想要接受信息的人啊?是啊,是不是没有啊? 然后告诉他,你只要输入一个等号,然后回车就可以得到被加密的明文了。如果你不是 office 二零一六或者以上呢,你可能需要按 ctrl shift 加 anton 啊,也是一样的,可以得到对应的文字,你学会了吗?
635Excel课代表 13:47查看AI文稿AI文稿
13:47查看AI文稿AI文稿大家好,我是研发教育的伤心老师,今天我们一起学习 excel 数据建模与预测分析案例实战。对于预测分析 我们并不陌生,在我们的工作职场当中,都是需要做预测分析的,比如说我们要对销售进行分析,这是最常见的,还有我们的财务预算要分析, 电商、物流、 hr 等等,都是需要做预测分析的。对于我们的工作生活,比如说 股票、基金投资,也是需要进行预测分析,所以所以说预测分析不仅仅对我们的工作有帮助,还能帮我们赚钱。 向投资分析,他就是为我们创造价值的,所以说预测分析需要我们每个人好好的去掌握。对于预测分析,大部分人都有一个误解,就是 拿到一个数据就马上用一个函数,或者是说用一个移动拼接法就把预测求出来了,那么这样的做法是不对的。预测分析相对是一个比较专业的工具模型, 它需要根据你的业务场景来匹配相应的预测工具,不同的数据的特性,不同的业务场景用到的预测分析的工具是不一样的。 概括来说,我把预测分析模型分为两大类,两大业务场景,一类业务场景是没有季节性的数据的分析预测,第二类场景是带有季节性的预测模型, 这两个场景一定要把它分开,如果不区分,那么做出来的预测的结果是不准确的,那么我的整个的课程就是围绕这两大义务场景来分解 讲解的。像非季节性的预测工具,主要有移动平均法、指数平滑法、预测工作表法,还有函数预测、趋势线回归预测、季节性的预测模型 相对来说要复杂一点,主要是三三种方法,第一个是居中移动平原法,第二个是规划求解,第三个是线性回归系数调整法。这两大业务场景都是以案例分析的形式来给大家讲解的,所以 基础一个社会基础比较差的学员不影响预测分析的学习,这个请大家放心。 下面是我的一个介绍,这个图片就是我本人,帅的一塌糊涂。一个 ceo 的培训,我已经 有十二年的经验,包括线上和线下,除此之外,我对 bi 的培训学习也是有一定经验的。预测 分析本质上就是时间序列的预测,我们的预测都是基于时间来的,脱离的时间预测就是没有意义了, 因为我们的预测一定是随着时间的推移来观测我们数据的变化,这个时间可以是连阅日记等等,包括你自定义的其他的时间都是可以的。 时间序列我们做预测的时候一定要清楚它的四种成分,这个是一个我们分析的一个前提和基础, 哪四种成分呢?第一个就是趋势成分,我的一个数据摆在面前,我们要观察 我的这个整个的趋势,随着时间的变化,他的变化趋势是上升还是下降,还是说震荡 平稳,震荡的,还是说是线性的还是非线性的,这就是它的一个趋势成分。它的趋势成分如何去识别呢?很简单, 画一个折线图就可以看出来,这个后面会有讲解。第二个是季节成分,季节成分 它是反映时间系列在一年中有规律的变化,它是由什么引起的?是特殊的季节或者是节假日引起的,每年会重复出现。比如说服装销售,它每年的都有它的一个淡旺季,你像夏装,那么在夏天七八 酒卖的比较好,冬装在冬天卖的比较好。不同的业务场景,它的数据可能会呈现出它的季节成分,这个要结合你的业务场景,也可以通过趋势成分来把它显示出来。 季节成分的预测分析相对来说要懒一些,它主要是要计算它的季节指数,这个在后面的课程也会讲到。 第三个成分是周期成分,周期成分它是反映的时间系列,在超过一年的时间内有规律的变化,大家注意这个周期一定是超过一年的。 如果是说在几个月或者几周里面,你想反映他的周期,这个基本上是很难的周期 他的成分主要是由他的经济状态的变动引起的,有波风和波股。所以这个周期的预测分析啊,往往需要 数据跨度要相对大一些,至少要一年,你不超过一年,你就不用考虑这个周期了。所以周期性分析,预测分析难度相对来说要大一些,复杂一点,因为他需要的数据样本要多一些。第四是不规则成分, 不规的成分它是不归因于上面的三种,并不是所有的数据都是可以预测的,有些数据他是预测不了的,他没有趋势, 也没有周期的成分,也没有季节性的成分,他就是杂乱无章的一个随机的。你如果非有预测,那只有 一个办法,很简单,就是求他的平均值。所以第三个洲际成分和第四个不规则成分, 在我们的商业数据分析当中啊,其实基本上可以把它去忽略,重点要考虑什么呢?重点要考虑它的趋势成分和季节成分,这也是我的整个课程主要要考虑的这两个成分。季节, 季节性因素我们应该怎么去预测?带有非季节性,也就是说趋势性怎么去预测?我们做时间系列的预测 有几步,首先第一步确定时间序列的类型,这个类型是由它的成分决定的,也就是趋势性和季节性。 首先呢,我们看趋势成分,它是根据时间序列的观测词的数据汇一张折线图,下面三张图可以看得出来,第一个就是没有趋势的时间序列, 如果要对他进行预测,那么他的工具方法和后面的是不一样的。第二个是线性趋势的时间系列,那么他的预测方法也是不一样的。第三个是非线性趋势, 它就是一个指数性,一个增长,这三张图表它的预测工具和方法是不一样的。所以我们在拿到数据的时候,第一步就要画这三张图,这个非常重要,包括我后面的课程,有的课程里面可能就 要画这个图,就不代表这个图不考虑,不是的,一定要自己先要把数据把它的趋势来观测出来。第二个季节成分,季节成分 一般需要的数据往往是两年或者两年以上的数据,而且要有一定的间隔,要间隔一年。我们在拿到一个数据的时候,要分析它的季节成分,就是画一张折线图 来观测他的多风多股是否存在季节成分,那如何判断呢?这个时候你不能就数据而论,数据一定要结合你的业务场景,比如说我这个是服装店的一个销售趋势,可以看出六七八,他就有 有一个季节性的因素,它有一个波风,这就说明我拿到这个数据就存在明显的季节成分。那我们在做预测分析的时候,一定要采用非季节性预测模型的三种三种工具。 第二步就要选择合适的方法建立预测模型。我这里做了一个小节, 对于一些数据,他们既没有趋势成分,也没有季节成分,这时呢我们可以用什么方法来移动平均或者指数平滑我的数,我们的数据如果有趋势成分的 上升或者下降,有趋势成分的,根据数据的特性,我们就要用到趋势预算法当中的三种方法其中的 一种,比如说一一元回归,二项式回归,还有指数回归, 这个后面会有讲到。第三个是我们数据如果是有季节成分的,就要用三种方法求出它的季节指数, 要用到季节指数法,我的整个的预测分析的课程都是围绕这些来的,季节性和非季节性的数据场景。 第三步是平价模型的准确性,确定最优的模型参数。我们有的时候用了一些工具方法,一定要评估模型的准确性,比如说我用移动平均或者是植入平滑,中间要求他的阻力系 数或者是间隔数,那么这个时候你就要进行试算,来确定最优的一个参数是什么,这个在后面的课程会详细的讲到。第四步是按要求进行预测,确定的模型参数之后,最后可以通过我们的 公式把它预测值求出来。这个就比较简单,比如说回归方程系数和常数都已经预测好了,那么我们就需要把它直接带入公式,算出来就得到一个预测值。 好,这个就是时间系列的四步。前面讲的四步我把它概括一下,第一就是要识别数据背后的业务 场景,它是季节性还是非季节性,我们通过一张图表能观察,同时你要结合你的业务场景。第二个对于你的数据,你在做图的时候,以及在正式分析之后,你一定要把你不必要的数据进行整理清洗, 来确保数据的准确性。第三步就是要做图发现规律,然后再选择合适的预测方法或模型,这个是关键。最后一步需要注意的是,如果是用回归 礼盒出来的预测,一定要观测他的监控值,他的监控值值就是阿方,这个阿方代表你这个方程的可信度,关于阿方他是如何 合计识别和判断,后面的课程会讲到一个 ceo 的基础,对于学好预算分析, 其实关联性不是很大,你只要学几个函数就可以了,上半数三拍大了,以及预测函数这几个也是非常简单,所以即使是零基础,你把这几个函数在我的课程当中把它消化一下,其实 也是没有没有多大关系的。第二个是规划求解的原理和技能,那么这一个呢?在整个预测分析的课程当中,会专门去讲解他的原理,数据分析工具库,尤其是回归分析, 他的原理在我的课程当中会穿插的给大家去讲解,所以说如果你是一 这个 cl 零,记住对于学习预测分析其实是没有任何障碍的,这个大家也放心 好了,关于预测分析模型,今天就介绍到这里,希望通过整个课程的学习,大家成为预测分析的高手。最后祝大家学习愉快,身体健康,万事如意,谢谢大家!
210跟尚西学PowerBI 18:30查看AI文稿AI文稿
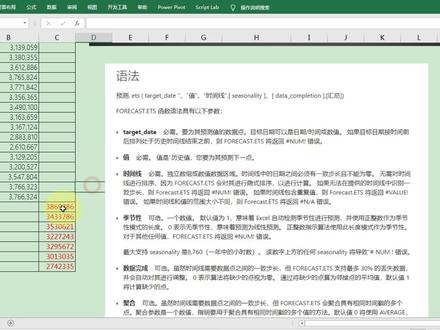
18:30查看AI文稿AI文稿好,各位同学,下面呢,我们一起来看一下这样的一道定的表格题目,请根据题目要求完成下列操作,注意以下的文件呢,必须保存在考生文件加下, 打开工作部文件一个热点 xlsx。 好,那么这个文件呢,我已经打开了啊,那它呢是一个放射性元素的一个测试的数字表啊,我们下面呢,我们来看题目要求。好,首先呢将四个一工作表, 师的一工作表就是 excel 这个工资部文件中的师的一工作表中的 a 一冒号一单元格合并为一个单元格,内容水平居中。好,我们从 a 一呢选到这个一单元格,然后呢在开始功能区里面呢,然后呢再单击一下合并和居中这个按钮就行了 啊,这个题目呢啊,是一个送分题。好,然后呢再往后面看啊,第二个,第二个小问题了啊,这个第一个,第一个文件中的第一个问题中的第二个小问题,叫做计算实测值与预测值之间的这个误差, 注意啊,他是绝对值啊,所以呢,这个地方呢,要需要一个函数,就是一个绝对值函数,他说放置与误差这个绝对值这一列,你觉得放哪一列呢?就放在这一列这里面。 那么做函数题目的时候呢啊,一般情况下,你首先呢选中一个单位格,比如说我当前选中是第三单位格,那么呢,你就要计算一下这个预测值减十册值,就是二十点八减十六点五, 然后得到的结果,然后呢再给他求这个绝对值,那绝对值函数呢,那么这个题目呢,他没有给你,所以呢,大家一定要记住啊,绝对值函数是这个函数啊,你首先选中第三单元格,然后再单击下 fx 这个插入函数按钮,然后呢就弹出了一个插入函数的框,然后呢选哪个函数呢 啊?这个类别啊,如果在常用还说你没有找到的话,那你就选这个啊,就选这个全部啊,这个类别选全部,然后呢选就低含入就 abs, 你看 abs 呢,就返回一个 定数值的绝对值,这地方呢,你说什么叫定数值,你就不需要知道啊,就是说返回一个数的绝对值,比如说负二的绝对值是二,二的绝对值是二,就是不带符号的数值啊,不带符号啊,什么叫不带符号啊?比如负二他中间是不是前面是不是有个负号 啊?就是带符号,那不带符号呢?就比如直接写个二,那直接写个二呢?那个二不就是正数吗?好,等于我们选这个函数就 abs 啊,然后单击确定好,然后呢这个 number 啊,注意,这个 number 呢,你不是一个数,它其实呢相当于公式啊,应该是 二十点八或者是十六点五减二十点八或者二十点八减十六点五,就一样了啊,那要单击一下,用鼠标左键单击一下这个二十点八这个所在的单元狗,就 c 三,然后再写一个减号,然后再单击一下这个十六点五所在的单元狗啊,用鼠标左键单击这个十六点五所在的单元狗,就 b 三。好,然后单据确定,然后下面呢,你就可以从上往下拖动填充笔就行了啊,这很简单对吧?好,接着往后面看题目啊,好,下面这个题目呢啊,稍微呢啊,难一点 啊,他是使用一个衣服函数做什么事呢?他说评估一下这个预测准确度这一列,就这一列,你看预测的一个准确度这一列好做什么事情呢啊?评估规则是这样子的,他说误差呢啊,低于或 等于实测值百分之十的啊,这个不就误差吗?对不对?这不是误差,然后这误差呢是低于这个实测值百分之十的,你看这个四点三啊啊,跟这个实测值二十点八的百分之十进行比较 啊,怎么减比较呢呢啊,低于或等于实在值百分之十的,那么就预测卷度啊,这个准确度呢就是高,那误差呢?大于实在值的呢啊,这个大于实在值百分之十的就是日测的准确度呢?为低 啊,让你使用衣服函数,那这个地方呢,使用衣服函数呢,其实呢用起来呢还是比较简单的一个衣服函数的一个实用啊,用法在后面体温里面呢,我们还会遇到一个啊,比较复杂的 啊,这个条件判断用衣服函数来进行判断的啊,以后入到这样的题目呢,我们再进行详细讲解,那这地方呢,我们首先用基本呢啊,使用一下这个衣服函数,你看他就是,你看他就是呢低于或等于,那就是高,那么大于呢,那就是低,对吧? 好,下面我们怎么做呢?好,下面我们首先选中一个单人狗啊,选中这个 e 三人单人狗,好,我们首先单击啊 fx, 我们找到这个易富函数啊,类别呢,仍然从全部里面进行找啊 啊,衣服函数, 好,我们选中衣服函数啊,那么这个衣服函数呢?大家看一下啊,这个地方有说明,他说判断是否满足某个条件,这个条件就是啊,问题是 这个,呃是误差呢,是低于或等于实在是百分之十呢,还是 高于呢?这个十的,这百分之十的呢?啊,好,这个呢就是他的条件,如果这个条件成立呢,就返回一个值啊,如果条件成立,返回什么值就是高,对吧?条件成立,如果条件不成立呢,就返回另外一个值就低啊,刚好是相反的,是不是? 好,然后再观观察一下啊,这个衣服这个函数呢,他有一对小号,然后这里面呢有参数,有三个参数啊,第一个参数呢叫 logical test, 逗号,第二个参数呢叫维留衣服处逗号。第三个 参数呢叫为留一个负二次。好,就是参数与参数之间的,是用逗号给它分开的。下面我们主要的工作呢,就是给这个三个参数的副职。好,我们单击确定,你看下面是不是给函数参数进行副职。第一个参数呢叫 logic test, 是任何可能被计算为处或者 force 的数值或表达式。就是说你这个数值或者表达式呢啊,要么结果呢是处,就要么为真,要么这个数值或表达式呢,要么是 force, 就是为奖。 方法是相反的啊,要么是成立,要么是不成立哈,这个表达是怎么来写呢?我们首先来写一下,你看这样写,你看误差低于或等于百分之十的,然后我们首先选中的是不是 e 三十单元格,那么我肯定要 啊,判断一下这个四点三,那四点三是不是就是第三?以后大家做函数题目要注意啊,凡是这个单 单元格的内容,比如这个四点三是不是单元格的内容啊?可以用单元格来进行替代。四点三是不是又可以用第三这个单元格来进行替代啊?对吧?就是你看到一个内容可以被单元格来进行替代,那么就用单元格来进行替代,一下子。好,第三,好,第三什么 误差低于或等于,那就是小于等于二,那么小于等于大家一定要会写啊。首先把输入法切换成英文状态,好,首先写个小于号,然后再写一个等号,就这样写,叫小于等于小于等于二。然后什么是 d 三九四点三是小等于什么?二十点八,那二点八这个是不是可以用单元格来进行替代?就是 c 三,那 c 三什么是小等于 c 三的什么 c 三的什么?你看 c 三的百分之十,对吧?那乘以百分之十就行了, 乘以百分之十或者写零点一也可以啊。好,这样写就行了,你看他的结果明显是不就负二四啊?你看第三十四点三,你看二十点八乘以零点一,那么就二点零八,那,那明显这个条件表达是明显是一个不成立,那就负二四。 好,下面呢?我下面是做什么事呢?就 v 六,衣服,处,衣服不就如果的意思吗?处就成立,就如果上面这个 logic test 就是这个逻辑表达式,是成立的时候的一个 v 六, v 六就直,就是这个返回直就是我现在假设上面这个条件是成立的,他的返回局是什么? 是不就高,对吧?好,那就直接写汉字高啊,把输入法切换成这个中文说法高,好,下面呢?我假设对吧?就如果吗?对吧?如果就假设上面这个条件是不成立的, 就 fours 不成立。他的返回指是什么?反回指就是低,那就直接写个低,那么大家注意一下啊,啊,这个高和低,大家有没有发现你高是不是自动的就被一对这个英文的双引号注意啊?这个一的自动的被一对英文的双引号把它引住了啊, 这个你不要自动自己敲啊,自动的就有,你看我就把外面,我放上面,你看这个第一是不是就背上了?就被这个一对英文双引号被这个引住了啊?是双引号引住了啊,好,注意,这个引号是英文状态的双引号。 好,然后呢,我们直接单击确定啊,就好了啊,然后呢,我们再从上往下拖动体重柄就行了,就行了。为为什么可以选?你看你看这个地方是 d 三 c 三,你看从上往下拖动体重柄,从上往下拖动体重柄,你看这是 d 三 c 三, 三是表示什么?第三行,你看我从第三行拖动到第四行,你看就这样就变成第四。 c 四也就三,是不是?变成四也就从上往下拖动填充笔单元格的名称哪一部分在发生变化,是不是?数字部分在发生变化, 也就是说行数在发生变化,是不是?为什么?行数在发生变化?因为我从上往下拖动填充瘾了吧,因为我从第三行拖到第四行,就第三就变成第四,我拖到第五行呢,那么就第五啊,第四就变成了第五,或者五就变啊,四就变成了五,对不对?就这样的一个规律啊。 好,然后呢?接着往下面看啊,好,这一步他说利用条件格式的速度小条件格式下面的这个速度条,那有的同学一看条件格式,是不是觉得就又要用到这个一幅函数啊?不是 这个条件格式啊,是这地方,大家看啊,你看在开着功能区,这地方是不是一个条件格式啊?啊,这是个命令,对不对?好,做什么事啊?渐变填中红色数字点,让你修饰一下 a 三么?好, c 十四这个单个区域啊, a 三 c 十四, a 三 c 十四,那你首先把 a 三 这是 a 三吧, c 十四, a 三 c 十四这个区域呢?给他选中,好吧, a 三 c 十四,好,然后呢,用到竖着条下面的界面,填中 一个红色,填中数数条,对吧?一个红色填中,这是红色填中啊,就行了啊,这很简单,是不是你这样会使用这个命令啊?啊,这个题目其实很简单。好,然后下面呢,这个啊,下面这个道题目就让你做个图啊,首先让你选择这个十字纸 啊,实测值吧,你看实测值还有这个日测值这两列的数据呢,建立一个什么?建立一个带书主标记的一个直线图,那你把对象要选中啊,对象选不中的话,你这个图怎么做的出来?好,首先把实测值 和入册值这个对象选中,也就是从 b 二选到 c 十四啊,从 b 二选到 c 十四。好,建立一个什么带数据标记的直线图,好,在哪座呢?在插入功能处理面,你看这边是不是有个图表, 哎,我这样做啊,单机图表这个命令启动器,然后呢,是不是要弹出的一个插耳图表这个对话框,然后再选中所有图表,这个选样卡好,然后呢,你看这边是不是一个整页图, 然后呢,你看从这边找,你看这边是带输注标记的折线图,好,然后单击确定,你看这个图表就做出来了,是不是很快,对吧?然后呢,再看下面,你看图表标题, 什么叫测试输注对比图,也就是说把这个图有标题啊这几个字改掉,测试数注对比图 好,然后呢?做什么事啊?然后呢?叫居中覆盖标题啊,居中覆盖标题什么意思呢?看看效果就知道了,什么叫居中啊?好,然后呢,你选中啊,随便,你选中这个, 选中这个图表啊,你看这外面是不是有六个小圆圈,对吧?说明你选中的这个图表, 另外的选中这个图表之后,上方是不是出现了一个什么图表工具,是吧?然后有两个功能区,一个叫设计功能区,一个叫格式功能区啊,当然了,我现在用不到这个图表工具啊。好,我就直接这样做啊, 然后这边是不是有个加号,有没有发现这个加号的实际叫添加图表元素,其实跟这个地方一样的啊?在设计功能书里面,你看这地方是不是有一个加号,对吧?你看叫添加图表, 其实这样一样的,我要会计的做啊,会计的做这个叫居中覆盖标题啊,这个命令好,点击这个加号,然后呢,你看这边是不是一个图标标题,对吧?然后点这个 这个箭头啊,这个三角箭头,然后呢,你看这边是不是一个居中覆盖?好,你看一居中覆盖,你看这个标题啊,是跑到这个图表,你看里面,对吧?好,叫居中覆盖好,行了, 好,然后呢再往后面坐啊,他说并将其呢啊移到这个工作表的 a 十七冒号 e 三十七这个去中啊,就移一下嘛。啊, a 十七哎, a 十七还移到下面来,是不是 a 十七 啊?你看 a 十七的吧。好, e 三十七,那你要拉长一点,好吧啊, e 三十七 就好了,对吧?你看 a 十七 e 三十七啊,移到这个区域里面来就行了。好,然后接着往后面看啊,然后下面呢,就是说将这个,嗯,将这个工作表式的一样要更名一下叫测试结果误差表 啊,这个根本呢,其实也很简单,你看就试的一嘛,这个试的一就是试的二,这个试的三的试的试的二和试的三这个空白表,那试的一呢,他是有数据的对吧?好,然后呢试的一上面右击,你看这边是不是有一个重名名啊?重名叫测试数据 误差表的吧。测试数据误差表,没搞错吧,我们检查一下。测试啊,测试结果误差表啊,真的搞错了啊啊 啊,然后最后呢啊,在单,在这个选中任意的选一个单人狗啊,然后呢单击一下保三流啊,然后, 然后呢你可以把它关掉啊,好,把它关掉吧。好,下面呢,我们做下面一道题目啊,他说打开工作部文件一 xc 啊,点 xlsx, 我这个已经打开了啊,好,他呢是一个产品销售的一个情况表啊,他说对,工作表产品销售情况表内的速度清单建立一个速度透着表, 然后呢建立一个数字图书表。后面题目呢?我都不想读了啊,为什么不想读呢?因为我只要把这个数字表这个命令找到 啊,后面呢,我就按照这个题目要求把这个数字图表做出来就行了啊,看我怎么做的啊。好,首先呢,你在这个数字清单里面任意选一个单元格啊,你不是要从 a 一选到这个地方啊,你这样从 a 一选到 g 三七也可以啊。啊,我是不想选,如果不想选的话,我就直接在数字清单里面任意选一个单。 好,然后呢,我们再找到这个输入透露表,这个命令好,输入透露表在哪里呢?在插入功能群里面,你看这边是不是就有一个输入透露表 哈,然后呢,是不是就弹出了一个创建数字图表?好,创建数字图表,我们来看一下啊,这个文字啊, 这个做这个一个四二题吗?一定要首位看这个上面的这个文字啊,他请选择要分析的数据。那对谁要进行分析啊?你看这题目是不是对 输入清单的内容,就是对产品销售情况表里面有输出的内容,建立,建立一个输入透彻表,也就是说这个输入透彻表呢,他的建立前提的对象是这个输入清单,你看这个输入清单对不对?你看产品销售情况表, 不就是这工作表的名字,你看产品销售情况表,不就是这工作表的名字吗?好,这个改单号,他这个分割符相当于汉人那个得这五, 我的数据表的的意思,你就是分析的就是这个的,就是分个符啊,这产品销售情况表中的哪一部分呢? a e 冒号 g 三十七, a e 冒号 g 三七,你看 a g 三十七不是这个吗?三十的吧, a 一不就季度吗? a e 冒号 g 三十七,就是这一块区域。 好,这个区域是明显是对的,所以这一步你就不用改啊,对吧?好,然后下面一个是选择放置输入图书表的位置。好,放在什么位置呢?啊?我们不知道,我们来看看题目啊,我们看一下,他说这地方有这样的一句话, 他说编制于线工作表的二八,这是字母的二啊,不是一啊,二八。冒号 m 二十二,这个单过去好,就是现有的工作表,那就选哪一个现有工作表,对吧?然后这个位置我用水标组建,单击一下,你看这个在这个文本框 往里面一闪一闪的。好,然后呢,我们在这选啊,选一个什么呢?艾巴 m 二十二,艾巴,艾巴在哪里呢?应该在上网的吧,这地方,哎,对了,是吧?艾巴 m 二十二,往下选啊,看变化啊, 二十一了,哎呀,好,你看是不是二八, m 二十二了吧,是不是产品销售情况表的二八吗?好, m 二十二,这个区域内。好,然后呢,你这两步都做完了是吧?分析的数据的一个区域,我,我也搞了,是不是放置数据特表的位置,我也搞对了,然后再单击确定 好,然后呢,你看在右侧是不是就有这个数字特表自断这个窗格了,是不是这样?好,下面我们来看题目啊,好,你看他说行标间是分公司,列标间是基度求和项,是 销售数据,你看列标签是分工资,行标签是分工资,列标签是季度球,好像是销售数量哈,好,然后你看这边是不是有行啊,那就行标间。行标间是什么?是分公司吧,我们再看一下, 行标签是分公司,列标签是季度,把季度按照鼠标,我刚才怎么去的呢?是按照鼠标一拉拉过去的,你看就是把季度拉到这个列区域里面。好,这个值,这个区域是什么值?这个区域是销售数量, 销售数量一拉,你拉到这里面来,你看这样就做完了,是吧?就是做成这样的一个表,这样的一个数字透着表啊。好,然后呢,他说工作表明不变,保存一个事。这个工作部啊,那就直接保存一下 就行了。那么这道题目呢?就做完了。好,那么这个一个色的题目呢?啊,他有两个文件啊,我们都一一做完了啊,希望呢,我们在课后呢要加强练习。好,谢谢大家。
194汪老师的个人课堂 05:01查看AI文稿AI文稿
05:01查看AI文稿AI文稿哈喽,大家好,这里是大表哥。呃,今天呢,同样给大家分享我们的这个 excel 的函数, p 开头的今天的函数叫做吹的,它是属于我们的一个趋势预测类型的一个函数啊,具体看一下它的一个基础跟应用。 我们的函数名称非常简单,叫做脆的,英文的意思呢,也是一个趋势的意思。所以说我们的这个趣的函数呢,它是可以 我们的这个线性趋势来计算并返回我们对应的这个外置的。然后我们看一下他的一个语法构成我们这个趣的函数呢,他主要是由我们的四部分构成,第一个呢,是一个 呃关系表达适中,这个 y 等于 m x 加 b 中的这个 b 有 y 字的这个集合。那么第二个呢 啊,这个系数呢,就是我们的这个公司当中对应的这个 x 轴的 x 值的这个集合区域。第三个数呢叫做 news, 嗯,它是我们这个位需要函数翠的返回对应外值的这个新的 x 值, 然后第最后一个 com testcons 的,然后它是一个逻辑值的一个类型的一个函数,用于指定是否将我们的这个长量币强制为零这样的一个内容 啊,同样我们的这个函数呢,它是有这个一些贵族说明像的。如果说我们在我们的这个 excel 的软件当中,对数据进行直线离合的这个详细信息的话, 我们可以通过这个拉 s 针这个函数来做一个呃输出,跟实线同样。第二点, 以返回结果为数组的公式,那我们必须以数组的公式形式做一个输入,具体是什么意思呢?我们待会看一下案例大家就明白了。最后一点,当为参数输入数组常量时,我们应 使用逗号分格同一行中的这个数据,用分号分格不同行中的数据,这一点一定要牢记啊。我们这个确的函数具体有什么样的一个应用呢?比方说我们可以在这个案例当中可以看一下 月份,我们目前是已知一到五月的这个呃每个月的这个销售的一个件数,那么此时此刻老板就一个需求了,要通过我们一到五月五个月的数据,预测未来一个季度,六七八月三个月份的一个每月的一个 销售件数大致是多少呢?嗯,为什么要预测呢?因为对应的预测出来啊,说明我们的老板或者说我们的这个部门领导,他可以对应做一些策略啊,针对的一些 kpi 啊,一些提成的一些指数啊, 是可以通过我们的预测值来做一个呃细分的对应的一个战略调整的。所以说,呃,我们今天的这个趣的函数就可以实现这样的一个内容,非常简单。具体怎么实现呢?大家可以根据我们的这个趣的一个基本案例,我们自己给大家呈现一下。 首先呃,因为我们的这个是要将三个呃区域的销售件数模拟的销售件数预测同时预测出来,就说他是一个数组类型的一个一个区域,我们直接选中三个区域,然后写入单号,注意等 我们接着来看一下,究竟是怎么通过我们这个去的函数来预测六月、七月、八月的他这个 呃预计的销售件数呢?非常简单,因为我们是六七八月三个宜并做的一个输出计算的,所以说此时要首先选中我们的这三个单元格,选中等号去的, 选中我们的趣队。然后第一个呢是一个已知的外籍和外籍和什么呢啊?就是我们的消食建筑,他此时此刻是一个已知的外籍和选中我们的这个 b 二到 b 六的一个单元格。然后第二个是谁是我们已知的 x 的一个结合,然后 选中我们的一月份到五月份这个区域。第三个就是已知的新的 x 的一个集合,就是我们的六七八月这三个月就 ok 了。 此时此刻我们直接可以做一个输出,因为他是一个数组的形式。什么数组呢?就是我们的六七八月做的一个批量输出,那么此时我们需要用 country shift 加安特尔直接同时按下才能做一个输出的一个计算,我们看一下,那么我们就可以看到我们已经成功输出了未来六月、七月、八月三个月 每个月的一个预计销售件数,这就是我们趣的函数可以实现的一个内容,怎么样,大家都学会了吗?我是大表哥,关注我呦!主页还有更多的其他 excel 函数小知识,记得点赞收藏起来,我们下期课堂再见!
164Excel数据处理大表哥 08:45查看AI文稿AI文稿
08:45查看AI文稿AI文稿我刚才讲的传统循环网络 rn 可以通过记忆题实现短期记忆, 进行连续数据的预测,但是当连续数据的序列变长时,会使展开时间部过长,在反向传播更新参数时,梯度要按时间部连续相乘,会导致梯度消失。 所以在一九九七年,好吃艾特等人提出了长短记忆网络 l s、 t m。 长短记忆网络中引入了三个门线,输入门 it、 遗忘门 ft, 输出门 ot 引入了表征长 长期记忆的细胞台。 ct 引入了等待存入长期记忆的后选台 ct、 波浪号。我分别介绍一下他们的作用。先看三个门线, 他们三个都是当前时刻的输入特征 xt 和上个时刻的短期记忆 ht 减一的函数。 这三个公式中, w i、 w f 和 w o 是带训练参数矩阵, b i bf 和 bo 是代训练偏之项,他们都经过 sigmoe 的几乎函数,是门线的范围在零到一 之间。细胞肽表示长期记忆,细胞肽等于上个时刻的长期记忆乘以遗忘门, 加上当前时刻归纳出的新知识乘以输入门 记忆体,表示短期记忆属于长期记忆的一部分, 是细胞肽过胎泥池激活函数乘以输出门的结果。 后选肽,表示归纳出的带存入细胞肽的新知识是当前时刻的输入特征 xt 和上个时刻的短期记忆 h t 减一的函数 wc 是带训练参数,矩阵, bc 是带训练偏执项。 当明确了这些概念,我们理解一下 lstm, lstm 就是你听我讲课的过程,你现在脑袋里记住的内容 是今天 ppt 第一页到第四十五页的长期记忆 ct, 这个长期记忆 ct 由两部分组成,一部分是 ppt 第一页到第四十四页的内容,也就是上一时刻的长期记忆 ct 减一, 你不可能一字不差的记住全部内容,你会不自觉的忘掉一些,所以上个时刻的长期记忆 ct 减一要乘以遗忘门。 这个成绩象表示留存在你脑中的对过去的记忆。 我现在讲的内容是新知识,是即将存入你脑中的现在的记忆。 现在的记忆有两部分组成,一部分是我正在讲的第四十五页 ppt, 是当前时刻的输入 xt, 还有一部分是第四十四页 ppt 的短期记忆留存,这是上一时刻的短期记忆 ht 减一, 你的脑袋把当前时刻的输入 xt 和上一时刻的短期记忆 ht 减一,归纳形成即将存入你脑中的现在的记忆 ct 布朗号。 现在的记忆 ct 布朗号乘以输入门与过去的记忆一同存储为长期集。 当你把这 讲复数给你的朋友时,你不可能一字不落的讲出来,你讲的是留存在你脑中的长期记忆经过输出门筛选后的内容,这就是记忆题的输出 ht, 当有多层循环网络时,第二层循环网络的输入 xt 就是第一层循环网络的输出 ht, 输入第二层网络的是第一层网络提取出的精华。 你可以认为我现在扮演的就是第一层循环网络,每一页 ppt 都是我从一篇一篇论文中提取出的精华输出给你,作为第二 二层循环网络的,你接收到的数据是我的长期记忆过胎,你是激活函数乘以输出门提取出的短期记忆 ht, 这就是 lstm 的计算过程。如果你还不太清楚,可以回放几遍。这一页的讲解你会豁然开朗。如果你已经懂了 lstm 的计算过程,我们一起看看如何用 tenseflow 实现。 testflow 提供了 lstm 层的计算函数,在这里告知 lstm 中记忆体的个数,在这里告知是否每个时间部都 输出 ht。 如果是处,表示每个时间部输出 ht。 如果是 foss, 表示仅最后一个时间步输出 ht。 一般最后一层用 foss, 中间层用除这个参数的默认选项是 foss。 比如这句话定义了一个具有八十个记忆体的 lstm 层,这一层会在每一个时间部输出 ht。 这句话定义了一个具有一百个记忆体的 lstm 层,这一层仅在最后一个时间部输出 ht。 看一下 lstm 实现股票预测的代码, 代码实现时,只需要把 p 三十八 rn stalk 点 py 中的 rn 层用 lstm 层替代即可。代码改动只有两处, 在这里导入 lstm, 在这里用 lstm 层替换 rn 层, 其余代码与 p 三十八 rnzox 点 py 完全一样。 看一下运行效果, 打开代码 p 四十七 lstm stog 点 py, 右键转运行, 画出了老司徒, 画出了预测效果, print 出了预测效果量化指标。
 06:22查看AI文稿AI文稿
06:22查看AI文稿AI文稿各位亲爱的小伙伴们,大家好,欢迎来到青儿在线视频课堂,今天呢,我们来学习一下如何通过啊,预测函数啊,就是佛里的点 ets 函数进行数据预测啊,我们先来看这个演示啊,呃,我们现在呢有一组实际数据,那就是说记住了二零二零年七月一号啊,每天的值 就是一直到七月三十一号啊,我们现在要预测八月份啊,八月一号到八月七八月七号的这个值啊,我们在这个图表上可以显示就是这个 呃,蓝色的珠子呢,代表就是说我们实际发生的纸,我们可以看到他是有一定的规律性的,那我们需要预测的呢,就是说是八月一号啊,以后的这个纸啊,就 就是说我们需要根据我们的这个规律去预测我们的啊未来要发生的这个值啊。好,那今天呢,我们就来学习如何通过这个函数啊, 呃 forlix 的点 ets 函数去做这样的一个数据预测。好,那我们可以呢在这个呃 c 三十五这个单元格来开始输入我们的公式,我们看一下如何来呃,去进行一个操作。好, 我们把已经写好的这个公式呢,再给他删掉啊,我们在 b 列呢,他是实际制,我们需要在 c 列对他做出一个预测。好,我们在 c 三十五来写入我们的公式。好,我们在这里面呢输入我们的公式就是叫呃 fox, 再点 ets 啊,就是预测啊,预测这样一个函数,我们可以看到他的参数呢比较多啊,第一个参数就是呃目标日期,目标日期就是这个 a 三十五。 好,第二个参数呢就是我们的值啊,这个值呢代表就是说历史的啊,指的是历史值啊,好,历史值呢就是我们的这个 b 四到 b 三十五这个区域就是我们的历史值啊,我们用 f 四锁定这个区域。 好,我们看一下。第三个参数是时间线,也就是,呃,我们的这个七月一号到七月三十一号这个历史的这个时间线啊, a 四到 a 三十四啊,锁定这个 区域, f 四锁定这个区域,然后我们看一下啊,第四个参数是季节性啊,所谓的季节性呢,我们可以看到他实际上就是他这种有没有这种规律的波动的这种特点啊?这个呢叫季节性, 那我们一般呢就是说这个让他自动检测就可以了,那我们输入啊,一默认的话呢是,就是说是 啊,有季节性的啊。好,那接下来呢我们要输入这个下一个参数。第五个这个参数就是 对于这个数据缺失的一个处理啊。啊,那如果是零的话呢,缺少的只能视为零啊一的话呢,自动完成功能啊, 使用线性插纸,也就是他会自动进行一个插纸的计算,我们呢给他输入一就可以了啊,好,这个是一个数据完成, 最后一个参数呢是他的一个聚合,也就是说呢,如果他具有相同时间错啊,相同的这个时间错的话呢,如何来进行一个聚合?默认的话呢,我们就用平均值的方式,也就是输入一就可以了。好, 那这样的话呢,我们就输入好我们的所有的啊,佛瑞 cas 的点 ets 的这样一个参数值啊,我们可以再看一下啊,第一个参数呢就是我们的呃, 需要预测的这个日期值啊。第二个参数呢就是我们历史的这个实际发生的值啊,比四到比三十四。第三个参数呢就是 我们的啊历史的一个时间线 a 四到 a 三十四。好,接下来呢第四个参数呢就是我们的啊季节性啊默认值为一啊,我们输入一就可以了 啊,下一个参数呢就是他的一个对于缺失数据的处理啊,我们就采用插纸的方式进行计算。最后一个参数呢就是我们对于 啊相同时间错的多个点的这样一个聚合方式,那就是我们采用平均的平均值的方式进行处理。好,那这样的话呢,我们就输入好了我们的这个预测函数的所有参数了,确定, 然后向下啊双击这个识字。好,这样就可以获得每个日期的预测值了。好,这样我们回到我们的这个 图表上,我们可以看到这个蓝色的柱子呢,代表我们的时机发生,而红色的柱子呢代表是我们的预测的一个值,我们可以看到他这个跟我们去看到的这种趋势变化还是相对比较符合的。 大家如果我们这里面呢更改我们的这些参数啊,比方说我们在这里面调整我们的这个参数啊,比方说将这个季节性这一块呢,我们如果是修改为零的话,我们看一下 他这个预测呢就会发生变化了,就跟我们就实际的话呢,就是有点不太匹配了啊,所以呢我们对于这个参数 呢,是啊,要根据实际情况我们要去做一些调节调节啊,然后这里面是有季节性的,默认他是按一就可以了,那这样的话他预测出来的值呢,就跟实际的这种发生的值呢,就会比较匹配。 好,那今天我们所讲解的这样一个通过佛雷开始的点 ets 函数做的数据预测方法呢,还是非常的呃,实用的,小伙伴们赶快动手试试看吧,感谢大家收看,再见。
664千万别学Excel 02:17查看AI文稿AI文稿
02:17查看AI文稿AI文稿是我看了很多视频,关于教大家通过单一记住指标或多多记住指标来预测股市的涨跌,这种明显就不靠谱 啊,就是我们做量化眼里这些技术指标都叫因子,但凡有一个因子很有效,他就会被各种团队挖掘,人偷摸赚钱还来不及呢,告诉你们这个有效因子干啥? 什么各种神界几个什么买卖点,这种太多了是吧?你下个某顺啊,有上万个指标都有,但大部分指标都有未来函数。什么叫未来函数? 就是说他通过今天涨停来判断明天怎么怎么样,其实你今天早上开盘,怎么知道今天哪些股涨停呢?啊?这就是未来函数这个陷阱。那么今天我给大家介绍一个十分有效的一个因子, 大家拿小本本记好了啊,欢迎点赞关注加收藏!这个有效因子,他就是市值因子,其实美国早在一九二几年也统计过了,就把一个股市所有股票按照流通市值分成十等份,他就统计出来 啊,一个神奇的规律,就他随着时间的增长,他的收益率越小的股票收益率越高,这是不是有点反常识啊?像某销天天说我们不要买黑五类是吧?当然黑五类他不好 把适应率啊,什么都干掉了。但是其实越小市值的股票盈率越高,要不油资怎么天天打板那二三十一的,大家要想清楚这一点啊。所以大家可以看看这种指数市值的这种分类,比如上周五零一八零呼身三百,中 挣五百,中挣一千,中挣两千,其实越倒小盘他玩的越好,所以 很难平啊,大家其实最简单的策略就是持有那些小盘古做轮动就好了啊,当然要剔出 st 啊,还有即将退市的业绩差的啊,比如说微盘十个以下的流通差的,这种要排除掉,其实这是很简单一个盈利的一个方式啊,还是那句话,股市有风险,投资需谨慎啊,今天说了不代表有投资建议,大家可以做个参。
13股民拉丝 03:00#3分钟话增长如何对现有#销售预测管理流程进行优化与调整,助推企业#营销服务数字化增长?瑞泰信息高科技制造业专家@高宏伟 为您解答!#CRM #数字化转型 #干货分享#专业的事交给专业的人@抖音小助手查看AI文稿AI文稿
03:00#3分钟话增长如何对现有#销售预测管理流程进行优化与调整,助推企业#营销服务数字化增长?瑞泰信息高科技制造业专家@高宏伟 为您解答!#CRM #数字化转型 #干货分享#专业的事交给专业的人@抖音小助手查看AI文稿AI文稿大家好,前一个章节给大家分享的销售过程管理,通过提升销售转化,降低销售培训成本,提升销售预测准确率,实现企业销售过程管理数字化增长与落地。本章节给大家分享高科技企业的销售预测管理, 与众多企业沟通了解到大部分企业销售预测管理现状如下,第一, 销售预测数据不透明,全靠销售团队每个月线下反馈。第二,销售预测准确率低。第三,销售生产与采购流程未完全打通,这些给企业带来了诸多不利的影响,第一, 影响采购与备货的及时性。第二,生产不及时或生产许多呆制库存,想卖的 产品没有卖不掉的产品生产一大堆。第三,交付延期,影响客户产农,导致客户抱怨与投诉。针对这些问题,就需要对现有的销售预测管理流程进行优化与调整, 建立销售预测前、预测中、预测后的管理体系,并通过 cm 平台进行落地。落地的三个步骤,第一,预测前有参考,根据销售预测历史的发货、客户需求等数据进行指导销售团队做预测。 第二,预测中有控制预测提交时,销售领导、计划员可以从客户、人员、区域、产品等纬度进行预测数据汇总,查看与确认,有异常及时的与销售对接处理。第三,预测 后有监控预测之后,可以实时查看与监控预测准确率的执行情况,针对执行一场进行预警与提醒,让销售团队及时的处理。通过销售预测管理体系的落地,可帮助企业数字化增长点可归纳以下三点,第一, 提升销售预测透明化。销售团队及企业领导根据商机数据,实时查看未来的销售趋势,掌握市场需求。 第二,提升销售预测准确率。通过商机预测历史的发货数据,指导销售团队做预测, 提升预测准确率,从而提升库存周转率,提升订单交付效率,最终提升客户满意度。第三,提升产购销的协同效率。将销售预测、采购预测、 生产计划流程与数据进行拉通,实现产购销的协同。综上所述,从三个方面实现销售预测管理数字化增长。第一, 提升销售预测透明化。第二,提升销售预测准确率。第三,提升产购销协同效率。通过三平台将至三方面内容进行实施落地,助推企业营销服务数字化增长的实现。今天分享到这,谢谢!
10瑞泰信息 00:35查看AI文稿AI文稿
00:35查看AI文稿AI文稿excel 预测未来月业绩?现在有了去年一年的月业绩数据,你能预测出未来三个月的大概业绩吗?其实 excel 就有这个功能,只不过都被忽略了。 首先我们选中这些月份和月数据后,点击数据选项卡,然后我们点击预测工作表,再弹出页面中下方,我们可以选择预测结束日期。 选择后我们点击创建,就会新建一个工作表和折线图,还会显示预测的业绩和预测业绩的上下限,你学会了吗?
460齐慧Excel云云 10:20查看AI文稿AI文稿
10:20查看AI文稿AI文稿我的报告题目是基于集成学习的混凝土强度预测分析,我是汇报人杨宇轩。我将从六个方面来进行汇报。 首先是研究背景及意义。混凝土在建筑工程中起着至关重要的作用,是使用量最大的建筑材料。对于混凝土性能的评价指标有混凝土抗压强度、抗腐蚀性、抗冻性等, 其中抗压强度对建筑是否安全有很大影响,因此混凝土强度是否满足设计规范和项目要求是在实际工程中 需要面对的重大问题。同时有效预测混凝土强度可以保证施工安全和运营安全。接下来是我的数据来源,本文采用的数据是来自加州大学机器学习数据库, 包含一千零三十条样本数据,这是我的数据部分截图。由于机器学习是以数据为出发点,一份优秀的数据可以更好的训练出理想的模型,进而对结果的预测更加精准,所以在模型训练前就要对上文提到的数据进行预处理。 由于在该数据集中不含缺失值和重复样本,且绘制镶嵌图后未发现在上届、下届之外的异常值,故无需对数据进行数据清理。 接着是两种规划方式的介绍,接下来是积极学习的算法介绍。首先是随机森林模型,随机森林算法通过 boss try 方法抽取多个样本和特征,将多颗相互没有关联的回归决策术作为积学习器, 通过病情方式获得预测结果。最后将每颗回归决策术的预测结果进行平均,取得最终结果。通过对药本和特征的双重采样,保证了随机性,避免了其他模型常见的过拟核问题,有较好的放化能力。 知识向量计算法能够有效解决二、分类问题知识向量回归算法是知识向量计算法在研究回归问题重情况下的重要应用。知识向量回归算法在实际中多用于解决现行回归问题, 而对于部分非线性回归问题则引入和函数的概念,数据通过和函数被映射到高维空间中。 k 精灵回归算法 k 精灵回归算法在思想上与 k 精灵分类 算法的算法大大体一致,只是将对未知样本属性值的分类转化为,在选取最近的 k 个样本时,我们要选择一个度量来测量未知样本和与之样本之间的一个距离。绝大数多数情况,我们选择欧式距离来对这个距离进行测量, 这是测量的具体公式。叉追 boss 的算法叉追 boss 的算法是 bosting 算法中应用最广范、效果最好的集中学习算法之一,是以提登提登 梯度提升数的思想为基础,将目标函数进行了优化,并利用泰勒公式将目标函数进行近思 使用,可以通过求解 一些偏导和二阶偏导进而求见 目标函数,使目标函数尽可能降低。接下来是本文的关键算法。 stink 荣获算法从上文所提及的随机司令算法和叉 j boss 的算法中分分别体现图了融合算法 bagging 和 boston 的基本思想, 而 stinger 算法的核心思想为堆叠。与其他两种融合算法不同的地方在于,它可以将不同的机学习器作为第一层模型结合起来进行学习, 再将各个机学器器的预测结果的特征矩阵输入到第二层模型,再将第二层模型的预测结果的特征矩阵作为输入矩阵输入到第三层模型,以此类推, 将最后一层模型的输出结果作为最后的预测结果。两层的 sticky 模型的应用是最广泛的,其简要的工作方法如这个 图三点二所示。接下来是实验结果已分析,我们采用随机森林支持销量回归、 k 精灵回归、叉车 boss 的算法,以及以上述四种算法作为原系学习器的 stinger 算法,针对混凝土强度进行回归预测建模的分析, 并选取均方误差和拟和优度作为评价指标,对上述五个模型的预测结果进行比较。 首先是对于随机先令预测的结果分析。图四点一是在未经未经过仓数巡游时,随机先令算法所获得的呃拟和优度和均方误差。由于随机先令函数中 含有多个重要参数,对不同数据及使用不同的参数时,预测的效果也是不同的,我们可以通过调整参 参数寻找到使模型预测效果最好的最优参数。这里我们选择网格搜索的方法进行参数寻优,这是对网格搜索方法原理的介绍。 由于随机森林的模型的参数过多,这里我们选取四个对该实验影响最大的参数进进行调整。图四点三是我们调整后得到的最佳参数,而图四点四是调整后的参数的拟合优度和新英方误差。 可以看出调三过后对方误差由三十六点九八减少到三十四点八一、 由于支持销量回归算法的关键是对距离的计算,所以需要再对数据进行过异化处理来减少亮缸对实验结果的影响。 归一化后的部分实验数据如图四年无所示。 同样我们需要对参数进行寻寻优 图四点八是我们对于知识项链回归模型调整参数后的你和 youtube 的均方误差,可以看出调整参数后模型效果有了显著的提升,均方误差有一百二十九,减少到了三十七 k 金领回归是依靠未知样本与已知样本之间的欧式区域来进行建模的,所以我们也需要在建模前对数据进行过一化处理来消除样亮钢的影响。 由于在建模过程中影响模型预测结果的参数仅有 k, k 表示的是 距离,所以我们采用穷举的方法寻找最优参数。除四点九是不同的。 k 十对应的均方误差由图四点九可以看出, k 等于二十,我们预测后得到的均方误差最小,故选择参数 k 等于二, 当 k 等于二时,所得的你和优度和军方五差如图四点时所示。 叉 j boss 模型是对踢凳低度提升数的改造,所以内部也是由多科决策术共同参与建模。同样我们也选取了 三个对模型影响最大的参数进行巡游。图四点一三是我们巡游后所得到的均方 方误差和拟和优度。从图四点一三可以看出,军方误差由二十五点零七五八减小到了二十一点一零六,这是一个很好的结果。接下来是关键模型, sticking 融合模型。 在对以上四种单一模型及随机森林支持销量机回归、 k 精灵回归和叉 j boss 的进行训练和预测后,本文意图将以上四种单一学习器作为 stinky 融合模型中的鸡学习器, 并且选择较为简单的模型进行回归。模型作为原习序器进行集成学习,有效地减少了过离合的风险,且提高了预测的准确率。实验中采用了 python 中 i k 论中的 staking 进行了建模分析,结合相差验证完成了模型预测。图四点一四是本次本个模型的基本结构。 图四点一五是我们 sticking 模型的你和优度和循环误差。 本次实践最终我们选择均方误差作为比较模型预测的好坏的指标。其中我们将五个模型的均方误差比较可视化,方便我们进行分析。如图四点一六所示。 如图我们可以看出,在四种单一模型和 stinky 融合模型分别都会分别对混凝土抗压强度进行预测后,根据测试及所求的这方误差,本文建立的 stinky 融合 模型所得误差最小。在本文的数据及情况下, speaking 融合模型所预测得到的效果最优。获得到实验所需数据后, 下面对本次本次实验进行总结。在获得实验所需数据后,对数据进行立处理,并且确定了本次数据的检验标准。 接着依次利用随机森林支持香港回归、 k 进里回归和叉 j boss 的模型进行了回归预测。 在模型的训练过程中引入了网格搜索对参数进行了优化,优化参数后的四种模型的预测准确度都有所提升。最后,将以上四种经过参数优化后的性能较好的单一模型作为 steak 融合模型中的机学习器,选取器型,回归模型作为原 信息器,构建出二级融合模型进行预测。经过比较均方误差可知,融合模型的预测效果好于以上四种单一预测模型的预测效果,其该方法实用性强、准确率高,在实际混凝土强度预测中具有比较高的可行性和推广性。
12数苑统计


猜你喜欢
- 1676成路小栈