pandas的vlookup功能
hello, 大家好,今天给大家来一个分享, pandas 怎样实现 excel 的 v look up 功能,并且在指定力的后面进行输出呢? excel 的 v look up, 他是一种将两个 x 表格进行合并的一种功能,其实就按照指定列进行了数据的关联。咱们先来看一下我做了什么事情。首先呢,这两个 x, 这是第一个,这是第二个, 第一个字叫做学生的成绩表,包含这几列班级学号,语文、数学、英语的成绩,其中有一列呢是学号。 我们还有另外一个 style 叫做学生的信息表,他里面就包含学号,姓名、性别、年龄、籍贯等等其他的信息。 这两个 cel 是有关系的,就这个学号的列呢是可以关联起来的。那么我们能不能实现一个功能,给第一个 excel 补充我们学生对应的姓名和性别,两列数据同时直接放到学号这个位置的后面呢? 这就是本节讲的内容,我们先来看一下最终我说了什么内容。这是一个结果的 excel, 我们看到他包含了原来 excel 的班级学号, 语文、数学、英语的成绩,同时他补充了两列包含姓名和性别,并且这两列属于学号的。后面的 这个输出其实有两步的实现,第一步呢,我们给你学号进行关联,第二步,我们需要把姓名和性别呢 放到学号的后面。使用 pass 该怎么做呢? pass 呢? panas 是数据分析领域非常强大的一个工具,我们一般来说是使用 pass 呢就不太容易,不可来进行数据的探索和分析。 怎么启动一个九塔那的不可,就在命令行下面输入九不塔那的不可,然后他会输出一个 ur, 并且自动弹出你的浏览器,打开一个页面,打开页面以后呢就是这样的形式, 大家看到这是我的潘纳斯视频系列,当前我们位于第二十三集,如果打开的话呢就会进入这样的界面,在这个界面里面我们就可以进行 拍摄代码的编写以及输出,甚至可视化。我们来进入北京的内容,标题呢就是拍纳 怎样实现 excel 的 v 六卡普,并且在指定列后面进行输出呢?它是这边的一个背景, 我们有两个 excel, 他们有相同的一个列,我们怎么按照这个列合并成一个大的 excel, 也就是说实现 excel 的 v lucarp 功能,他有一个要求,第一个我们只需要第二个 cel 的少量的列,比如说从四十个列中只需要调出两个列, 比如说刚才的学生信息表,可能我们有很多很多的列,比如四十个列,我们只需要性别和年龄两个列,这是第一个要求,而第二个要求 我们心中的来自第二个小的列呢,需要放到第一个小指定的列的后面,在这个例子中就是放到学号的后面,方便我们的查看这两个要求。 然后第三步,我们将结果输入到一个新的 excel, 这三步怎么实现呢?我分几个大步骤来进行,首先不注意,我们来读取两个数据表,也就是读取两个 excel, 首先我们引入判断词,这个报运行接下来的两步,我们来读取学生成绩表和学生信息表,学生成绩表我们起个名字叫 df grade 成绩等于 p 点 video, 输入这个文件的路径就是 excel 的路径,然后我们看一下前几行运行一下, 我们看到数据被正确的读取了,就包含了这几列班级学号,语文、数学、英语的成绩,潘娜子本身的特性呢,就输出这个样式, 跟表格是一样的。我们再来看读取学生的信息表,方法是一样的,我起个新的变脸名叫 df, 下划线 s 音法等于 pd 点 ready excel 传入我们的 excel 路径, 然后查看前几行运行,我们看到就包含了学号,姓名、性别、年龄、籍贯等列, 这就是我们第一步完成的事情,我们把两个 c 二数据呢给读取到了两个拍摄的变量,那么我们回顾一下自己的目标, 怎样将第二个学生信息表的姓名和性别两列添加到第一个表学生成绩表中,并且放在这个学号的这个列的后面呢?我们先来进行第二步,怎样实现两个表的关联,也就是说怎样实现 效的微录卡补功能,我们看到下方很简单,就这么几毫。在这之前我们回归下有个要求, 就是我们的第二个表呢,他有很多可能的列,比如说有四十个列,这里只是一个简化,我们只需要取到学号的姓名和性别这几列,然后再关联到第一个表,这该怎么做呢?这里我的方法呢就是先内数已经筛选, 我们只筛选所需要的少量的链,方法就是 dfs 银法还是这个边量等于这个 df 进行筛选,筛选出学号,姓名、性别这三列。 通过这种方式我们就把年龄和籍贯给抛弃掉了,我们看一下这个害的前几行运行,我们看到这个 df 呢 就留下了这三类,然后我们就是下一步进行数据的关联,我们将这个关联的结果复个变量叫 df, 墨迹就是墨迹上的结果,钓的语法是 pd, 点墨迹的语法就是数据的关联, 他有这么几个参数, life d f 我们等于 gree 的 write, d f 等于学生信息,然后左边的 k 和右边的 k 分别是学号,这样就实现了一个 v 六卡普,也就是数据观念的功能。 我们一起看一下前几行,我们看到数据呢就被关联了,他多了两个列,姓名和性别, 处于这个新的 df 的最后两列,我们以及时间的关联,怎么把这两列变到学号的后面呢?我们来看步骤三, 怎样调整列的顺序。首先我们来看一下列本身它包含哪些字段,就是 df 点 clams 这个属性运行, 我们看到它的类型呢是银 dix, 包含的就是我们上方的这几列。要完成我们怎么将姓名性别两列放到学号的后面,在这里我们就需要使用拍摄的语法来实现列表的处理, 首先因为这里是一个 index 对象,我们先把它变成一个 list, 语法呢就是这样的, df 点 colomist, 点 to list, 就把这个 index 变成了一个列表, 我们把这个列表进行打印看一下,我们看到这个时候呢,他就不是 enix 对象了,而是一个拍的列表,包含了班级学号, 语文、数学、英语成绩,姓名和性别。我们怎么把姓名和性别变到列表的学号后面呢?这就是拍伞处理的方法了,我们进行一个便利, fall name 音姓名,姓名的列表, 然后我们使用个拍子语法叫做逆向,什么意思呢?先取出性别,再取出姓名,为什么要逆向? 是因为我们的音色的语法,每次呢都在学号这个位置的后面进行添加,所以说我们先添加性别到学校后面,再添加姓名到学校后面,那么他的最终顺序呢?就是学号,姓名,性别, 我便利得到每个名字。首先呢从这历史中移除这个元素,比如说姓名这个就是先移除 姓名这个元素,然后呢我们执行音色的语法,这是拍摄的列表的音色语法, 踏两参数,第一个是一色的位置,第二个颜色的外流,我们看这个位置,这位置怎么取呢?就这个列表,因大 x 学号找到了学号的缩影,然后呢加一代表在他的后面,所以说这句的意思就是把一个元素 给放到了血号这个位置的后面,我们运行,然后重新看一下这个列表, 会发现这个列表就被调整了,包含的是正确的班级学号,后面跟的是姓名和性别,以及三科的成绩。如果我们没有这个逆向的话呢,你会发现最终输出的是学号,性别和性, 这是一个小小的技巧,就是怎样将列表进行逆序,然后我们使用一个语法叫 df 点 rain x 调整我们的锁音,因为我们调整的是列锁音,所以说让 calams 等于我们的这个列表, 等于六克拉姆斯进行所有的重建。然后我们看下前几行运行,我们看到这个数据呢就被正确的排序了,就包含了班级学号,后面跟了姓名,性别,三科的成绩, 我们就把这个数据呢给处理完了。第四步,我们将这个数据进行输出成最终的 s。 二、文件 判断词很简单,就 df, 点 two s r, 写一个 s r 的路径,这个结尾呢就是点 x, l x, 然后加一个参数,加一 next 等于 fouse, 什么意思呢?就这个数字序号,不要添加了,只输出这些有意义的这些列,我们运行, 然后我们打开我们的数据目录,就是我在 gethop 的目录,打开这个 cars, 它里面呢就是 c 二三 cos 二十三呢这个目录,我们打开,这里面呢就多了一个合并后的数据表。打开了以后 就是我们从 df 输出的内容,就是班级学号后面跟的姓名,性别和三科成绩。 ok, 以上就是本节目的演示, 我们学习了怎样将不同的 excel 读取到判断词的 df, 然后实现两个 df 的关联,最后调整我们列的顺序, 出示成最终的领先。最后的最后,欢迎大家关注我的微信公众号,蚂蚁学拍摄,在这个公众号我会发布更多的拍摄基础,数据分析等等视频系列,我们下次见,拜拜。

粉丝18.9万获赞46.9万
相关视频
 04:00查看AI文稿AI文稿
04:00查看AI文稿AI文稿今天讲这个提取某一列的三种方式,还有指定行啊,那么我们现在有一个 dat form 的一个数组啊,复给了 dat, 接受好,我们来提取某一列,比如说提取类目这一列啊, dat 点 name, 哎,直接运行,拿到的就是 name。 什么呀?这一列的所有数据,这种用法呢?叫做点击法,那么你要指定哪一列,你就点哪一列的名字啊,点 name, 那就是把 name 这一列的名字全部拿到,如果是点这个 h, 哎,那就是 age 这一列的啊,所有数据接着走。那么还有一种方式是什么呢?是 data 中括号类目列名放进去,然后 运行,你看一样的,把这一列的所有数据拿到,这种用法呢?它类似于字典的提取, 类似于字典的啊,提取方式还有一种方式是 data, 然后我要提取某一列,那我可以怎么弄点 i look, i l o c 中括号 i 诺克呢?它是什么呢?拿的是序列号啊,也可以把它看成是缩影号。那么逗号风格之前代表行,我们要拿所有的行,所以冒号前后都不取代, 所有都要要啊,所有的字都要取好。逗号后看的是列,我要哪一列呢?我要的是类目这一列,而类目在这个艾洛克的,所以号里面,他在拍摄里面可以把它看的是零嘛,所以号为零嘛, 来,那我们再来运行,哎,就可以拿到,然后提取多列的方式呢?你看这两年拿到了啊, i l o c 诺克啊,它相当于是通过 通过序列号或者叫做什么呢?锁引号的提取啊,通过序列号或者锁引号的提取,哎,这就是 i look 的这个用法。那么如果中国号这儿如果提取多列的话,我们就在这儿 再加一个中括号, 然后提取的是类目,比如说还有一个叫做 six s e x, 照这种方式也是可以的啊,点 ilock, 对吧?那么提取前两行,比如指定的前两行收银号啊,那么就是冒号二,走,你看前两行拿到的,拿到的是所有的列,因为后面列 的这个索取方式,我们去写代表默认所有你也都得要。那么实际上这里呢,还可以用 data 点 lock 的方式,一样的 冒号二啊,他的这个前三行啊,零一二,因为他洛克的话,他拿到的是标题,他不是训练号, 拿到这标题的名字,那你洛克二冒号到二,就从头取到这个行标为二的这一行,他全部提取好,再来三,你看零一二三就拿到,这是哎,洛克和洛克的用法啊, 一样的, ilook 刚才在那写的是通过训练号或者说一号 t 恤,而 look 呢,是通过标题名字,通过的,是 通过的是行标题,或者是列标题,或者是列名。哎,提取啊,是这种意思。好,今天我们就讲到这里。
 08:42查看AI文稿AI文稿
08:42查看AI文稿AI文稿下面我们看对他抚慰这个对象啊,那么这个对象是什么样的数据结构呢啊,他是这样的一个数据结构,所以列,那么这是啊,一行行数据啊,那么这个是啊,构造这个对象的方法, 好了,我们举个例子啊,来说明这个对象怎么构建啊, 那么为了这个简单期间啊,这代码啊,我就是不敲了啊,我们看第一个例子啊, ok, 那么首先呢,我们有有个素阻 这个宿主啊,是个男派宿主的对象啊, 好了,那么我们构建这个对他福瑞啊,我们用潘达斯这个对象的对他福瑞。这个工作方法啊,首先这个数据啊,来自这个数组啊, 是他, 那么这有个裂啊,这个裂啊,来自这个利斯特啊,那么这个锁引呢?来自于啊,这个锁引啊,我们看故造好的对象 列,这是你自定义的列,这是你自定义的,所以啊, 有同学说我这个这东西没有他应该是什么样子的, 没有你,不,你就是没有他默认,明白吧,他给个默认值啊,列零一二,所以零一二, 那么最好啊,你自己来指定啊,不要用他的默认指,明白吧,不要用他默认指啊,就是这个我们来看啊,用字典来构造这个对象啊, 这是个字典气蛙柳,这个蛙柳啊,是个历史的对象啊, 那么 我们呐,这个引带克斯啊,来自于啊,这个引带克斯呢, 是我们自己构造的,不用默认的 啊,这个裂呀,也是我们自己指定的啊,大家注意啊,运行完的结果啊,这是裂,这是你定的缩引啊, 这是这个啊, 那么我们看呢, 他主要用哪些方法啊?首先呢有害的和套显示前几行啊后几行 给大家举个例子啊,你比如说我有这么个 送个雷达福瑞啊 对象啊有这么个对象他这个男派啊就用不上了,大家注意 他这个对象啊用的是历史的啊, 有同学说能利死他也可以直接告状。可以啊 所以说呀你想够到对象啊啊你这块输入历史的是安排宿组都可以是吧 这是我们啊用力死他来构造啊纸巾这个裂 据说啊这个东西啊可以输入不同的数据类型是安排宿舍也可以是利索他也可以啊,现在用利斯的构造的啊 那么所隐之没有他默认啊,歪一歪二歪三三裂 那么他呀有这个 df 啊。 哎我显示前两行啊 显示前两行是吧那显示后两行啊 显示后两行 好了那么我们再再看他还有很多重要方法。那么计算某一列的统计值啊你比如说的 我计算这个 y 一这个列啊 那 df 啊 威这个厉害。 秋总和啊。 一加四加七 加十啊,应该得多少啊应该得二十二是吧 应该得二十二一加四加七加十啊,求平均值啊 他们四个相加再除以四啊二十二除以四 啊,就是得出这个数啊,求最小值 这一列最小值是一啊求最大值这列的最大值是十对吧。十啊, 那么查看数据类型啊啊我就不说了自己查看一下子啊那么查看的数据数目啊 他有个塞子这么个方法 有个塞子他应该是属性啊 数目一共是十二个是吧我们用眼睛瞅他就是个十二个是吧 那么看形状啊 这是个属性啊, 他是个四行三列的是吧?一行两行三行四行四行三列, 返回列数 激烈 两列啊, 有人说不三裂吗? 啊?他是从零开始数的啊。 那么茶 看做个标签名啊, 这是这个对象啊。
11数字化与智能化 01:26查看AI文稿AI文稿
01:26查看AI文稿AI文稿在于造州核对两列数据呢,一般都是在别国中设置为罗卡布卡入公式,然后找出两列的不同, 比如说现在呢有两列姓名呢,我需要找出两列姓名有哪些相同,哪些不相同呢?因为本列呢有相同的姓名,所以说我们不能直接用条形格式的重复值,那么怎么做呢?我们在表格中呢,是维留卡布函数公式,等于维留卡布,然后 a 二,然后再 c 列查找,然后查找第一列,然后呢 第四个是参数零,那么如果查找到呢,他会返回这个姓名,查找不到呢,返回错误值,但是这个呢,有一个问题,就是如果数据非常多的话,我们很难看出,那么查找查找出结果,哪些是相同的,哪些不是相同的,那么今天呢,给大家分享一种比较直观的方法, 怎么做呢?选中第一列,然后呢条件格式在这呢突出显示单规则,然后呢这是啊 等于我们需要把维罗卡布公式呢说到这里面来,等于啊 v look up, 然后呢还是第一个单元格,然后呢选中另外一列啊,逗号一,然后呢逗号零。 接下来呢,我们把这个第一个参数的这个绝对用符号去掉,我们看一下,现在呢已经找出来了,就是两个表的差异,那么现在没有填准颜色呢,就是两个表的数据,这样是不是更简单的呢?
6364excel表格跟我学-兰色幻想 06:08查看AI文稿AI文稿
06:08查看AI文稿AI文稿哈喽,大家好,本节我们进入拍摄数据分析系列课的第二节。使用拍单词怎么读取数据?拍单词本身需要读取表格类型的数据,然后才能进行分析, 这里什么是表格类型的数据呢?我们可以想一下 x 二或者说买次数数据表这样的数据呢,他有行有列,是一个二维的形式,这就是表格类型的数据。因此相应的我们可以读取三种类型的数据, 分别是纯文本的文件,微软的 xl 文件,或者说买色库的数据库表。对于低中类型纯文本文件 csv 呢?是多少分割的文件? ksv 是 top, 也就是刚替分割的文件 tous, 分割符随意。对 这样的文件呢,我们使用潘德斯点 redcsv 进行读取。第二类是微软的 acr, 他使用 xls 或者说 xlxx 格式, 我们使用判断词典瑞的 xl 来读取。而对于第三种,我们也可以从买四个数据库中使用 siri 数据来读取数据表,把它加载到判断。对于买赛后来说,使用的是判断词典 redc 扣的方法。大家如果观察的话,这三种文件呢,都是这种有行有列这么一种二维的形式。 其实一想到数据分析,大家第一个想到的应该是 excel, 而潘纳斯说实话,他其实就是实现了 excel 这种数据分析的功能,当然他不局限于 excel, 他可以读取成本文件,读取麦斯扣,并且也比 excel 本身要强的多。接下来我就来演示一下 plus 怎么读取这三种文件。 打开我们的拍摄交互型开发神器叫布特,本次代办演示呢,我会演示三种文件的读取,第一种就是读取纯文本文件,我会分别演示包含格式的四 s 文件以及随便自定义的太子文件。而第二点 是我会简单的演示判断是怎么读取微软的 xlx 格式的 excel 文件。而第三步我演示判断是怎么读取买字规的数据表。 首先我们引用潘纳斯, spd 就是他的包,然后进入第一个大步骤,就是读取出我们的文件,首先我们来读取一下 csv, 这个 csv 呢,他具有 csv 文件默认的格式,就是有标题行以及列之间呢,使用多少分格服务?这个 csv 我选的是业界开元的一个电影评分数据集, 我们打开看一下这个文件,打开第二次电影平分数据机,我们打开一个 vt 文件,这个文件呢它包含这个标题行,然后所有的列都是用逗号进行分割的,我们设定他的文件路径就是当前的相对路径。然后 我们使用 ptv 的 csv 来读取这个数据,把他的结果呢给复制给一个对象,这样我们就把这个数据呢读取到了判断词,我们就可以对这个数据 进行分析和探索了,比如说我们可以查看这个数据的前几行是有害的方法,他就返回了我们数据的前几行数据,对于这个数据我们看到他有行有列,然后我解释一下判断词的概念, 左侧的这一列呢叫潘纳斯的对象的索引因带克斯,而上面这一行呢叫做这个对象的卡拉姆斯,也就是他的匿名, 而中间的这一部分是他的数据题。然后我们可以看一下这个对象他整体的行数和列数,使用 shift 这个属性来进行查看运行, 我们看到他包含十万零八百三十六行以及撕裂,然后我们看一下他的列名以及他的所以列名列表呢,他就包含这么一个类似特,里面就是撕裂的名字。而所以呢这里是一个 rap, 也就是一个数字序列,从零开始,一直到最后一个数字,最后一个探索呢,我们可以看一下这个对象的数 类型,我们点运行,他就会列出美列他的数据类型,这里看到 u id, 电源 id, 时间拖都是数字类型,平分 分是一个弗罗特负点数类型。第一步我们就做完了,其实我们就演示了判断是怎么读取成本文件,然后对数据进行初步的查看和探索。我们进入一点二级,怎样读取太课的文件,因为大部分情况下我们的数据呢,不是一个 csv 的这种有格式的数据,而是输出成了自己的格式,比如 说这是我自己网站的一个访问的 pvv 的数据,我们来看一下这个数据,这个数据位于丁太子下面的科一赞二称,同时提醒一下这本数据存在于本课程的,给他哈补,大家可以自己下载。在这个目录里面有一个 xs pv 点 tuts, 我们打开,对于 这个数据,首先他没有标记号,第二个他的自断呢是有杠替进行分割,而不是逗号。而对于这个数据,我们就需要使用 v 的四 s v 他的一些参数了。 首先一样的,我们定义这个路径,然后对于瑞的 csv, 我们除了传入无间路径以外,需要指定他的 super, 也就是列的分割符,我们指定为杠替。接下来这个参数,我们告诉判断是这文件没有标题行,所以说这里设为 最后一个参数,我们可以自己设定列名,也就是说数据中没有列名,但是我们可以自己指定,真的好处适用于数据分析的时候,可以根据列名进行筛选。点运行 查看一下,同样呢,他就把这个泰克的文件钢题分格没有标题行给正确的进行解析了。这是第一大步,读取传媒文件,我们就第二步,读 取一个塞尔文件,他使用的方法呢是潘纳斯点瑞的 ecl, 这里我准备了一个塞尔,我们打开看一下,在刚才这个目录,我创建了一个 xspva, 点 xlsx 的文件,我们打开这个文件,我换了一个标题行,就是中文的日期 pv, uv 以及他对应的数据。回到直播间,我们点运行,然后看一下数据,很简单的,他就把 excel 的数据呢给读取成了一个判断死的对象,并且获取了正确的列名,这是第二大步,读取 excel 文件是不是很简单。第三步,我们可以读取 mccout 的数据表, 在这里我是本地的太克特库,创建了数据表,叫做 quezeent 下划线 pvv, 他包含三点,分别是 ppt 的日期 pv 和 uv。 这本思路表我们使用一个方法叫 redc 扣,他有两个参数,第一个是 c 扣与句,我们写成 clax 星 fmm 对应的表明,然后我们需要传入第二个参数,就是数据库的连接 clax, 这里可能是我们可以使用一个内裤,需要买丝扣,点开单词来进行连接,我们运行一下获取连接,执行查询查看这个对象。大家看到我们成功的从买丝扣中也查出了一个二维的表格数据, 就是本节内容的演示,我们学习了判断是怎么读取成本的文件,包含有格式的四 s 文件以及自定义格式的太子文件。我们也演示了判断怎么读取 a 三文件,以及读取百思路数据表。当把数据读取到判断词了以后,我们才能够进行后续的数据分析以及数据的挖掘。
769Python导师-蚂蚁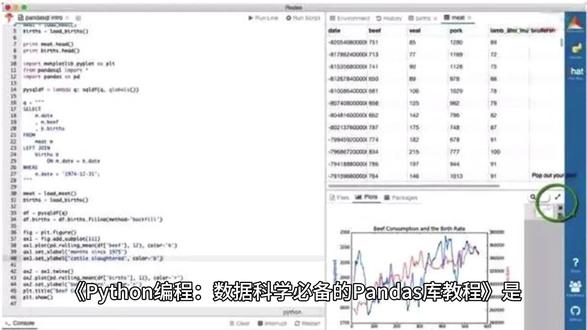 02:12查看AI文稿AI文稿
02:12查看AI文稿AI文稿python 编程数据科学必备的 pandas 库教程是一本深度解析 pandas 在数据科学领域应用的实战指南。 pandas 作为 python 数据分析的核心工具,以其强大的数据结构、 data frame 和 series, 使得数据处理和分析变得轻而易举。 本书首先从基础入门,介绍如何安装和导入 pandas, 让读者对这个库有初步的认识。我们将逐步探索 pandas 的基础操作, 如数据的读取、缩影与切片、数据透视等,这些是数据预处理的重要步骤。 通过实力演示,读者将学会如何高效的操作大量数据,无论是 csv、 excel、 sql 数据库还是网络 api, 获取的数据都能轻松应对。 接下来,我们将深入探讨数据清洗的技巧,包括缺失值处理、异常值检测、重复值剔除等,这些都是确保数据分析结果准确性的关键环节。 此外,还会介绍如何使用 pandas 进行数据转换和重塑,使数据格式适应不同的分析需求。在数据处理部分,我们将学习如何使用 pandas 进行分组、 聚合、排序等高级操作,以及如何利用 pivot 表格进行复杂的数据汇总。这些技能对于构建复杂的分析报告和生成可视化图表至关重要。最后,我们会进入统计分析的篇章, 包括描述性统计、假设检验、相关性分析等,帮助读者理解数据的内在规律和趋势。同时也会 介绍如何使用 pandas 与其他 python 数据分析库如 numpi、 cpi 进行集成,以实现更深层次的数据分析。无论你是刚接触 python 和数据科学的新手,还是已经在数据领域有一定经验的开发者, 这本书都能提供你所需的知识和实践案例,祝你在数据探索和分析的道路上更加得心应手。让我们一起踏上 pandas 的奇妙之旅,用代码解读数据的语言,挖掘数据背后的智慧。
0鹭羽无暇 02:27查看AI文稿AI文稿
02:27查看AI文稿AI文稿使用 pandas 进行复杂的时间序列数据处理和预测分析在 python 的数据分析领域, pandas 库因其强大的数据处理能力和灵活的数据结构,成为了进行时间序列分析的首选工具。 时间序列分析是研究随时间变化的观察值序列,他在金融、经济、社会科学等多个领域都有广泛应用。 pandas 通过其特有的 data frame 和 series 对象 提供了丰富的功能来处理和分析时间序列数据。首先, pandas 的时间序列功能主要体现在 time stomp 和 period 两个类上。 time stomp 用于表示带有时间戳的日期和时间, 而 period 则是在特定频率如日月、季度或年下进行操作。我们可以轻松的将日期、时间数 数据转换为这些类,以便后续处理。对于时间序列数据的预处理, candace 提供了诸如 resample, shift rolling 等函数。 resample 允许我们按指定的时间间隔重新采样数据,这对于生成频率更低的汇总数据或进行季节性调整至关重要。 shift 则可以移动数据点,帮助我们分析趋势和周期性模式。 rolling 函数则可以计算滑动窗口统计如移动平均值或标准差, 这对于捕捉短期波动非常有帮助。对于时间序列预测, pandas 与 stats models 和 seek it learn 等机器学习库无缝集成,支持多种模型的构建。例如,我们可以使用 rima 字回归整合移动平均模型进行趋势和季节性分解,或者利用 profit 库进行复杂的时间序列预测,该库专为飞线性和节假日效应设计。此外, pandas 还提供了可视化工具,如 plus 函数,可以直观的展示时间序列的趋势、周期性和异常值。通过结合 met、 plotly 和 seburine 等可视化库, 我们可以创建专业的实序图、季节性分解图和字相关图,以深入理解数据的动态特性。总的来说, python pandas 在时间序列数据分析中的应用不仅限于基本的数据清洗和可视化,而是涵盖了从数据准备到模型构建的完整流程, 使得复杂的时间序列任务变得简单高效,无论是数据科学家还是业务分析师都能从中受益匪浅。
0鹭羽无暇












