mysql怎么设置输入大于0的限制

粉丝2.7万获赞7.9万
相关视频
 50:32查看AI文稿AI文稿
50:32查看AI文稿AI文稿数据库是按照数据结构来组织、存储和管理数据的仓库,而数据库管理系统主要用于对数据库的操作和管理,是一种软件,比如 mysql 就是一种关系型数据库管理系统。 mysql 的安装方式有很多种,这里主要介绍三种常用的安装方式。 第一个是使用 maxcrow 官方提供的安装程序进行安装, maxcrow 的官网是 maxcrow 点 com, 进入官网之后,在页面顶部就可以看到一个下载的 tabeye, 点击一下就可以进入到下载页面,在页面的最下面有一个开源社区版的链接地址,点进来之后就可以看到各种系统对应的安装包, 右侧这一列是各种语言的驱动程序, a, p, i 和工具等等。当我们点击下载链接之后,他会提示我们登录二狗账户,点击这个不用了,谢谢,就可以直接下载了,也可以使用。第二种安装方式就是使用操作系统自带的包管理工具来安装,只需要在命令行中输入一条 instal 命令就可以了。最后一 种式使用刀口来安装也非常简单,只需要在命令行输入一条刀口, pro max girl 命令就可以自动下载并安装 max girl 了。后面也会为大家演示在 mac, linus 和 windows 上的安装过程,如果你已经安装好了,可以直接跳过这些。本节课内容就到这里,我们下节课再见。 max 系统推荐使用 homebrew 包管理器来安装,打开终端之后直接输入一条 install 命令就可以了。 需要注意的一点是,安装完成之后默认是不会自动启动服务的,需要执行一下下面的命令来启动服务,也可以使用下面的命令来设置为开机自动启动。 启动之后我们就可以使用命令行来连接一下 mysql 的服务,稍微解释一下这一行命令。 mysql 是一个命令行客户端的程序,我们刚刚启动的是服务端,现在我们要使用客户端来连接服务端后面的 杠 u, route 表示使用 route 用户来连接,杠 p 表示使用密码。登录回车之后就会提示我们输入密码。 max 系统中使用 home pro 来安装的 mysql 默认是没有密码的,直接回车就可以了。回车之后可以看到一个 msql 和一个大于号的提示符,就表示我们已经成功连接到了 msql 的服务端了。 这里可以输入一些 skr 语句来测试一下,比如我们可以输入一个用来查看 my skr 中有哪些数据库的语句, show date basis 就可以看到所有的数据库了,这些数据库都是 mysql 安装好之后默认创建的,可以使用 use 命令来切换到某一个数据库,比如我们切换到 mysql 这个数据库,然后再输入一个 show tables 命令,就可以看到数据库中有哪些表。还可以使用 select 命令来查看表中的数据, 比如就来查询一下 tablesprivate 这个表中的数据,回车之后就可以看到结果了。大家先不用关心这些语句的含义,这里 只是为了掩饰 mysql 的安装和使用,来让大家对 mysql 有一个初步的了解。后面我们会详细讲解 skl 语句的各种用法。除了自带的命令行客户端之外, mysql 还提供了一个可视化的图形化 gy 工具 mysql workbox, 它可以帮助我们更加方便的设计、创建和管理数据库表、用户等等。 可以到官网下载对应版本的安装包来安装,安装过程也非常简单, mac 系统的话直接双击安装包,然后把它拖到应用程序里面就可以了, windows 的话一路下一步就可以了。安装完成之后,双击打开 workbang。 左侧是一个导航菜单,包括三个部分,最上面这一个是连接管理器,可以用来创建和管理到不同的 maxcrof 段的连接。 点击加号就可以创建一个新的连接,比如我们来连接一下刚刚安装的 mysql 服务端。第一个字段是连接的名称,可以随意填写,这里就简单填写一个 local house 的,表示连接的 是本地的 msql 服务。连接方法,主机名、端口号和用户名都保什么人就可以了。然后点击一下下面的测试连接按钮,如果弹出成功页面的话,就表示配置没有问题,点击右下角的 ok 按钮之后连接配置就完成了。在页面上也能够看到刚刚添加的这个链接了,点击一下就可以连接到 msql 的服务端。 左侧是一个导航区域,里面有很多功能。最上面的部分是数据库管理,在这里可以查看服务器的状态管理用户和权限,数据导入导出等等。 导航区域的第二部分是实力管理,可以在这里执行服务的启动停止,查看运行日志和配置参数等等操作。 最后一部分是服务器的性能监控,可以查看服务器的运行状态、性能以及资源的使用情况。中间的部分是一个 sql 编辑器,可以在这里输入 sql 语句并执行,下面就会看到执行的结果。左侧菜单栏的第二个选项是一个模型设计工具, 可以用来设计和浏览数据库的压图。比如我们点进来看一下,可以看到它自带了一个 sakila 的数据库模型,这是 max q l 自带的一个演示数据库,用来帮助我们学习 max q l。 这里还有一个非常冷门的小知识点,就是 sakila, 也是 max l 的 logo 里面那个小海豚的名字。我们点击一下这个模型就可以看到数据库的压图了, 可以看到里面有哪些表表之间的关系是怎么样的,这样可以更加直观的了解这个数据库的结构。也可以在设计一个新的数据库的时候,使用这个工具来设计。右键点击某一个表,然后点击一下编辑按钮,就可以看到这个表的详细信息了,包括它的字段、缩影、逐渐等等。 最后一个选项是一个数据迁移工具,可以将其他数据库的数据迁移到 max q 二中,或者将 max q 二的数据迁移到另一个数据库中。除了 work 半句之外,还有很多其他的旧爱工具也非常好用,比如 debut work, navicate 等等,大家可以根据自己的喜好来 来选择。 dpr 是一个免费开源的数据库管理工具,它支持大部分的主流数据库,这个是官网提供的,支持数据库列表,只要你能抢到的数据库基本上都支持。还支持包括 windows、 mac、 linux 在内的多种操作系统,基本上完全可以满足日常的使用了,它的安装也非常简单, 可以使用包管理器来安装,也可以从官网下载安装包来安装。安装的过程这里就不演示了,除了免费开源的社区版之外,也提供了功能更加强大的专业收费版。 最后再介绍一下 navicat, 它是一个收费的数据库管理工具,功能方面和刚刚的两个工具基本相同,支持大部分的主流数据库,但是都是收费的,而且每个数据库都提供了单独的版本,比如你用 mysql 的话,需要单独购买 mysql 的版本, 那过两天你要想用 mongodb 的话,不好意思你还得再重新购买 mongodb 的版本,或者你也可以购买一个更贵的包含所有数据库的专业版。 niket 的安装也非常简单,时间关系 这里就不演示了,大家可以自己去官网下载安装包,然后安装就可以了。 linux 系统上的安装过程和 mac 类似,也是推荐使用包管理工具来安装,不过不同的 linux 发行版的包管理工具不太一样,比如五版图的 a p t center s 的 m, vidora 的 dnf 等等,但是安装命令都是类似的,后面加上 install, 然后加上 messacle gun server 就可以了。 或者也可以到官网下载对应版本的 rpm 包,然后再手动指定这个包来安装也是 ok 的。下面就以无斑图系统作为例子,来演示一下安装的过程。 输入 instal 命令之后会提示我们是否继续安装,输入 y 之后就会开始下载和安装了,这里我们需要稍微等一下,安装完成之后会自动启动 msql 的服务,可以使用下面的命令来查看服务的状态,看到这里显示的 active 就表示服务已经启动成功了,如果没有启动的话,也可以使用下面的命令来手工启动一下 下。这里说一下很多同学经常会遇到的几个问题。第一个就是 note 用户密码的问题,和麦克上不同的是,另一个系统安装完成之后默认是有密码的,如果密码错误的话,当然也就无法连接到 msql 的服务。 乌斑图系统上的话,可以找到这个位置的这个配置文件,它里面记载了一个默认的用户名和密码,那我们就可以使用这个用户名和密码来连接到 msql 的服务。在命令行终端输入 msql 杠 u 后面加上配置文件中的用户名,后面再加上一个杠 p, 然后复制一下密码,回车之后就可以连接到 msql 的服务了。 但是这个用户名和密码都不太好记,如果每次都需要到这个软件里面找一下用户名和密码,也是非常麻烦的。这就是我们的第二个问题,可不可以修改一下 rot 用户的密码,然后直接使用 rot 用户来连接呢?当然是可以的,连接到 msql 的服务之后,就可以使用下面的语句来修改 rot 用户的密码了,这里需要稍微注意一下,修改密码的语句在 不同的 msq 版本上是不同的,如果你使用的是五点七以下的版本,那么使用上面两行命令是可以的。如果你使用的是比较新的五点七点九之后的版本,那么上面这两行语序就不可以了, 因为帕索尔的字段和帕索尔的函数都被废弃了,密码的加密方式也发生了变化,需要换成下面的语句来修改密码。最后不要忘记执行一个 flash 命令来刷新一下权限,然后就可以使用新的密码来登录了。 第三个问题是关于 maxcare 服务的监听地址的,很多时候数据库服务是需要单独安装在远程服务器上的,为了方便,我们一般也会使用 workbench 或者 navycat 这样的可视化的客户端工具来连接到远程的 maxcare 服务,但是在刚刚安装好之后,经常会提示无法连接。 这种情况一般有几个常见的原因。首先第一个就是可能你的福气并没有开放三三零六端口的访问,可以放开三三零六端口的权限,如果在开放环境使用的话,也可以直接关闭防火墙。第二个就是 数据库中的 rot 用户默认是没有开放远程访问的权限的,可以使用下面的语句来查看一下 rot 用户的权限。如果结果中 hot 字段的内容是 local hot 的话,就表示这个用户只能在本地访问。 可以使用下面的语句把耗子的字段的值改成百分号,然后就可以在任何地方访问了,但是这样也会带来一定的安全风险,所以不建议在生产环境中修改成这样的配置。 最后还有一个是关于配置文件中的监听地址的,默认情况下, myscal 服务至监听本地的 ip 地址,这样的话从外部也是无法连接到 myscal 的服务的。不同系统的配置文件位置也会有所不同,详细请参考我们的笔记文档。 使用 vi 打开这个配置文件之后,向下找到一个 bid drives, 也就是绑定地址这个位置。这两行配置是用来设置服务监听的, ip 地址的默认是指监听本机的 ipd 值,这样我们从外部是无法连接到 maxcrow 的服务的。可以把这两行后面的幺二七点、零点零点一 改成四个零,表示监听所有的 ip 地址,然后保存退出,再重启一下 myscal 的服务,然后再到 g u i 工具中修改一下配置,使用 note 用户登录测试一下, 可以看到已经成功登录到了 mysql 的服务端了。最后我们再来看一下 windows 系统上的安装过程, windows 安装过程比较简单,从官网下载好安装包之后,基本上一路下一步就可以了。 首先选择一个安装类型,可以选择默认的开发者类型,这样除了 mysql server 之外,还会帮我们安装图形化界面、 workbench 以及 share 和 rooter 等工具。当然也可以选择只安装 server, 点击执行按钮之后就开始安装了, 然后一路下一步就可以了。和 mac 或者 linux 系统上不同的是,中间会有一部提示我们设置 note 用户的密码,也就是后面我们登录 max k 二服务设 需要使用的密码。安装完成之后会自动启动 mascal 服务,我们可以使用自带的命令行客户端来连接一下,启动之后输入刚刚安装时设置的密码,然后就可以看到熟悉的 mascal 命令行客户端了。 mexico style 是一个交互式的 g s python 和 s g l 的终端,可以用于执行数据库管理任务,它提供了自动语法、高量语法检查、自动完成和上下文的感知的提示,从而提高了开发人员和 dba 的生产力。它的安装非常简单,直接从官网下载对应版本的安装文件,然后一路下一步就可以了。 安装完成之后,可以在命令行中输入 myscls h 命令来启动。看到命令提示符左边变成了这样,带有背景颜色的 myscl 和 gs 就表示启动成功了。 messico shire 的命令都是以反斜线开头的,比如反斜线 help 命令,可以查看帮助信息。反斜线 connect 命令可以连接到 mecco 数据库, 比如来连接本地的 mascal 服务器的话,就可以输入反斜线 connect, 后面加上空格,然后写上 root at locals 就可以了。回车之后会提示我们输入密码。输入之后就可以看到左边的命令提示符多了一个灰色背景的部分,表示已经连接到了本地的 maxcal 服务器了。 连接之后他会提示我们目前并没有选择任何的数据库。可以使用反斜线 usb 命令来选择一个数据库,比如我们就来选择一下 game, 这个数据库就在后面加上库的名字就可以了。回车之后就能够看到左边的命令提示符,又多了一个 game, 表示当前选择的数据库,也就是我们在执行 s 杠语句的时候,都是在 game 这个数据库中执行的。 在 game 的后面还有一个 g s, 表示当前的语言是 javascript。 那之前我们也提到过 mexico shell 是支持 g s, python 和 s l 三种语言的,默认是使用 g s, 如果想要切换到其他语言的话,可以输入一个反斜线,后面直接加上语言的缩写 就可以了。比如反斜线 py 就可以切换到 python 语言,然后就可以在这里直接执行 python 的代码反斜线 sql 就可以切换到 sql 语言,切换到 sql 之后就可以在这里直接执行各种 skl 语句了,后面在终端或者 navicat 中执行 skl 语句的效果是一样的。 r 口官方还提供了一个 bscode mexico shell 插件,可以在 vscod 中直接使用 mecco shell。 打开 vscod 之后,在扩展中搜索 mecco 就可以找到这个插件了,直接安装就可以了。 安装完成之后,在导航栏就多了一个 masco show 的图标,点击这个图标就可以打开 mscoco 的终端来使用了。这个插件有点类似于 python 的猪皮特 notebook, 可以在这里执行 python g s 或者 sk 语句,执行之后的结果就会在下面显示出来。 亮点是所有执行过的语句都会被记录下来。 mexico shell 比较适合用来做一些数据库的管理工作,它可以通过编写一些日常经常重复使用到的脚本来提高工作效率, 比如备份数据库管理集群等等。如果你是一个开发人员,那么一个更加强大和方便的图形化工具可能更加适合你。本节课就到这里,我们下节课再见。 关系型数据库管理系统和非关系型数据库管理系统是两种不同的数据库管理系统。关系型数据库管理系统采用了关系模型来组织数据,借助于集合代数等数据概念和方法来处理数据,通过二维表来表示数据之间的联系, 二维表的每一行表示一条数据,记录每一列表示一个字段,也就是记录的某个属性。不同的表之间通过关联字段来建立联系,这种关联关系就是关系型数据库管理系统的特点。 mythical、 oracle、 host, grace、 xpl 等等都是常见的关系型数据库管理系统的代表。 与之相对的是非关系型数据库管理系统,他是对关系型数据库管理系统的补充和扩展。由于互联网的快速发展,仅仅使用关系型 数据库已经不能满足需求了,比如各种短视频、流媒体、地理位置信息、社交网络等等。这些数据的特点是数据量大,数据结构复杂,数据类型多种多样,这也就决定了关系型数据库管理系统并不能很好的处理这些数据,所以就出现了非关系型数据库管理系统。常见的非关系型数据库有下面这些。 c 口是一种用来操作关系型数据库的语言。在关系型数据库中,数据一般都是以表的形式来存储的, c 口可以用来操作表中的数据。几乎所有的关系型数据库都支持 c 口。 在之前的 mac 口安装以及常见问题那一节,其实你已经接触过一些 c 口语句了,比如更新骆驼用户密码以及防权限时使用的 update 语句,查询用户时使用的 c like 语句。你可以在 mac 口的客户端命令行中直接输入这些语句, 也可以在可视化的旧爱工具,比如 work on 曲或者 narrative cat 中执行这些语句。一般来说, c 口语句并不区分大小写,但是为了提高可读性, 我们一般会把关键字大写,把表名、列名和其他名称小写。按照功能的不同, c 口语句可以分为以下几类。数据定义语言,用来定义数据库对象,比如数据库表列等等。相关的关键字包括 great, job, altar 等等。 数据操作语言,用来对数据库中的记录进行新增、删除或者修改。关键字包括 insert, delete 和 update 等等。数据查询语言,用来查询数据库中的记录。关键字包括 select 和 where 等等。 数据控制语言,用来定义数据库的访问权限和安全级别,以及创建用户等等。关键字包括 grant 和 revok。 下面我们就从创建一个数据库开始,一步一步来学习一下 c 口语句的使用。 可以在 mac c 口的命令行客户端或者 g u i 工具中执行一个 created based 语句来创建一个数据库。比如老杨如果想要开发一款游戏的话,那么首先必须要创建一个数据库,用 用来存储游戏中的各种数据,那我们就来看一下如何操作。首先连接到客户端之后,输入一下 show databases 来查看当前已经存在的数据库,可以看到现在有四个数据库。然后我们来创建一个名字叫做 game 的数据库,在命令行输入 create database, game 回车之后,数据库的创建就完成了,然后再输入 show databases 来查看一下,可以看到现在就多了一个 game 的数据库,如果你不习惯使用命令行的话,也可以在 gui 工具中执行这个语句,结果是一样的。 在之前的课程中,我们介绍了 organg 的使用,为了让大家多接触一些不同的工具,这节课我们就来看一下 navycat, 每个人的喜好也是不同的,这里你可以使用任何你喜欢的工具。 打开 nv 开的之后,先来点击左上角的连加钮来新建一个连接,数据过类型选择 mc 孔,输入连接信息之后点击测试连接,如果没有问题的话就可以保存链接了。然后在左边的连接列表中就可以看到我们刚刚创建的连接, 这样以后就可以直接双击来连接到这个 mc 口的福气了。连接之后就会显示出所有的数据库,包括我们刚刚创建的 game, 这个数据库双击一下就会进入到这个数据库中,能够看到它里面的表视图和存储过程等等内容。 由于这个数据库是刚刚创建的,所以里面还没有任何内容,点击一下左上角的新建查询按钮,可以打开一个新的查询窗口, 在这里我们可以输入各种 c 口语句。和刚刚在命令行中执行一样,我们输入 sodat basis 来查看当前已经存在的数据库,然后点击一下上面的这个执行按钮,快捷键的话是 ctrl 加 r 或者 ctrl 加 r, 在下面就可以看到所有的数据库列表了,和刚刚在命令行中看到的是一样的。 删除数据库也非常简单,可以使用 drop database, 后面加上要删除的数据库的名字就可以了,比如来删除刚刚创建的 game 数据库的话,就可以输入 drop database 后面加上 game。 执行之后再来看一下,可以看 game 数据库已经被删除了,在左侧连接列表中还是能看到这个数据库,是因为界面并没有刷新,右键点击一下,在弹出菜单中选择刷新,刷新之后就看不到这个数据库了。 当然我们也可以使用 gy 工具来创建一个数据库,鼠标右键点击连接之后选择新建数据库,输入数据库的名字之后点击确定就可以了。下面两个选项可以不用填写,他们是用来设置自复题和排序规则的,然后点击确定就可以创建这个数据库了。 再来刷新一下连接列表,就可以看到刚刚新建的这个数据库了。我们也可以通过右键菜单中的选项来编辑或者删除这个数据库,也是非常方便的。时间关系这里就不演示了。 有了数据库之后,我们就可以在数据库中创建表了。在创建表之前,我们需要先使用右词语句来选择一个数据库,比如这里我们就选择使用 game 这个 数据库,那么就输入 use game, 然后点击执行或者使用快捷键来执行一下。执行之后就可以看到左侧的连接列表中 game 数据库被加速显示了,表示我们当前正在使用这个数据库,也可以在上面的下拉列表中直接选择 game 数据库也是一样的。然后就可以使用 create 语句来见表了, create 后面加上一个 table 关键字,然后加上一个表的名称,最后加上一对括号,括号中是字段的名称和数据类型, 字段之间用逗号隔开,最后一个字段后面不需要加逗号。比如我们要做的游戏中需要一个玩家表,表中就需要包含玩家的 id、 名字、等级、经验、金币等等信息, 那么就可以输入 create, 后面加上一个 table 的关键字,然后加上一个表的名称,比如 player 后面加上一对括号。括号中首先是玩家的 id 是一个整数,然后是名字是一个字符串,大小是一百个字符,然后是等级也是一个整数,再加上一个同样是整数的 的经验值,最后是一个时间值,数值类型的金钱。这里就涉及到了 mecco 的数据类型。 mecco 中的数据类型大致可以分为五个大的类别,包括数值类型、日期和时间类型、字符串类型这些常用的传统类型,以及新增的阶层类型和空间类型。这两个新类型 每种类型也都包括一些不同的子类型,我们可以根据需要来选择,比如数值类型包括整数类型和浮点数类型。整数类型根据占用的存储空间的不同,又包括 tenniint、 spawn int, int 和 big int, 分别对应一到八个字节的存储空间,可以存储不同范围的整数。 浮点数类型包括 float 和 double, 分别对应四个字节和八个字节的存储空间,可以存储不同范围的浮点数。日期和时间类型包括 date, time、 day time 和 time。 stamp, 分别对应日期、时间、日期、时间和时间。戳字符串类型包括 chart, what chart, text 和 blob 等等,分别对应定长字符串、变长字符串文本 以及二进制数据。比如刚刚我们定义的 word 叉,括号一百就表示长度为一百的变长字符串,而 dancing mo 十到二二就表示长度为十,并且保留两位小数的十进制数值比较。新版本的麦 c 口还支持接线类型以及点线多边形等几何空间类型。 创建好表之后,我们可以使用 d e s c 语句来查看表的结构。 d e s c 是 describe 的说写,意思是描述用来描述表的结构。 比如如果想查看刚刚创建的 player 表的结构,就可以输入 dfc, 后面加上表明 player, 然后点击执行按钮或者按下快捷键 ctrl 加 r 或者 ctrl 加 r 就可以了。在下面的执行结果中就会显示出表的结构,包括表中每列的名称,数据类型是否允许为空,默认值等等。 如果我们创建表的时候发现表结构有问题需要修改的话,那么就可以使用 alt 语句来修改表结构。比如我们发现文家名字的长度可能不够,需要修改为更长的长 长度,那么就可以使用 alt 语句来修改一下表的结构。 alt 后面跟上 table 关键字和表明,然后跟上 modify column 关键字表示修改列,然后跟上想要修改的列名和新的数据类型。然后执行一下之后,我们再来查看一下新的表结构。可以看到内幕的数据类型已经变成了 warx 两百。 除了数据类型之外,字段的名称也是可以修改的,比如我们可以把 name 这一列改成 nickname 昵称,那么就可以输入 autotable 关键字后面加上表明 player, 然后再加上一个 renamecolom 关键字表示重命名。字段后面加上旧的字段名和一个 to 关键字,最后再加上我们想要修改成的一个新的字段名 nickname, 然后执行一下,再来看一下表结构, 可以看到 name 这一列已经变成了 nickname。 除了修改列的名称和数据类型之外,也可以使用 at com。 我们来添加一个新的字段,比如我们就来添 加一个玩家最后登录的时间,那么就可以输入 auto table player 后面加上一个 atom 关键字,然后加上想要添加的自断名 last login, 最后是一个 day time 的数据类型。执行之后再来查看一下表的结构,可以看到在最后一列多了一个类型是 day time 的 last login, 说明添加已经成功了。 可以添加字段的话,当然也就可以使用 drop column 来删除一个字段,比如我们把刚刚添加的 last login 字段再删除掉,只需要输入 alter table player, 后面加上一个 job column 关键字,最后加上想要删除的字段名称就可以了。 执行之后再来查看一下表结构,可以看到 last login 这一列已经被删除了。最后如果我们想要删除整个表的话,可以使用 droptable 语句,比如来删除刚刚创建的 player 表的话,就可以输入 droptable 后面加上表明 player, 然后执行一下就可以了。执行之后刷新一下数据 库,可以看到 player 表已经不见了。以上就是创建和管理表的一些基本操作,我也非常推荐你自己动手来尝试一下。 到目前为止,我们已经学会了如何创建数据库和表,以及如何来修改他们的结构。这节课我们来看一下如何对表中的数据进行一些常用的操作。首先还是来新建一个玩家表, critable 关键字后面加上表明 player, 然后是 id, 姓名、等级、经验和金钱这几个字段。创建完成之后,我们来向这个表中插入一条数据,可以使用 insert 语句,它的语法结构是这样的, 首先是一个音色的音图,关键字后面跟上表的名称,然后是括号括起来的列的名称,再用 values, 关键字后面加上具体的值就可以了。如果表明后面的括号中包括了所有的列,并且顺序也和表结构保持一致的话,那么这个括号以及它里面的列名就都可以省略掉。直接在 表明后面加上 y 六次关键词,然后加长值就可以了。也可以只写上部分列的名称,只要没有列出来的部分,就会使用我们在键表时设置的默认值来填充。回车之后就可以看到提示我们插入了一条数据,然后可以使用 c like 语句来查看一下数据。 c like 后面跟上要查询的列名,也可以使用一个信号来代替所有的列, 然后跟上一个 form 关键字和想要查询的表的名称,表示从哪个表来查询数据。然后来执行一下这条语句,就可以看到我们刚刚插入的数据了。因斯尔特也可以插入多条数据,直接在 y 六后面加上多组数据就可以了,数据之间用逗号隔开, 比如我们再来插入两条记录,然后来执行一下,这样就可以插入多条数据了。再来使用 c like 查询一下数据,可以看到我们的玩家队伍又扩大了。这里李四和王五同学的等级和经验都是闹,这是因为我们在创建表的时候并没有指定 默认值,那默认就会是一个 not 表示一个空值,这样显然是不太合理的。一般游戏中的玩家等级都是从一级开始,那我们就可以修改一下这个表结构,把等级的默认值改成一。大家还记得怎么来修改表的结构吗?没错,是使用 alt table 关键字后面加上表的名称,然后加上一个 modify, 然后是字段的名称和类型, 在最后加上一个 default, 一,表示默认值是一级,然后再来插入一条数据,执行之后再来查看一下数据,可以看到最后插入的这条记录虽然没有指定他的等级,但是他的等级已经默认为一级了。 我们也可以在建表的时候就直接指定一个默认值。除了默认值之外,还可以使用 now 或者 not now 来指定这个字段是否允许为空值,或者使用 unic 来指定这个字段必须是唯一的。这些都是一种约束,用来保障数据的正确性和完整性。经常用到的约束包括下面几种,除了刚刚我们提到的默认值,非空和唯一约束之外, 还有主见约束和外见约束等等。主见约束用来保证数据的唯一性不为空,并且每个表只能有一个主见,外见约束用来保证数据的一致性,一个表的外见必须是另一个表的主见。这些约束内容大家可以刻下自己尝试一下。 这里有个小问题,我们之前插入的李四和王五同学的等级还是 now, 我们可以使用 update 语句来修改一下他们的等级, update 语句后面跟上表的名称,然后用 set 关键字加上要修改的列名和值,后面跟上一个 y 条件词句,表示要修改哪些数据。比如要把李四同学的等级修改为一级,就可以在 where 后面指定内幕为李四, 这样就可以把李四同学的等级修改为一级了。同样的方法,我们再来修改一下王五同学的等级,然后再来查看一下数据,可以看到现在所有玩家的等级都是一级了,但是后面的经验和金币还是闹,如果也像刚刚那样一条一条修改的话,显然是非常麻烦的,其实是可以一次性修改所有的数据的, 只要把后面的 vr 条件词句去掉就可以了,这样就会把所有的数据都修改掉。比如我们要把所有玩家的经验和金钱都修改为零的话,就可以输入 update, 后面加上表明 player, 然后加上一个赛的关键字,再加上想要设置的自断的名称和值就可以了。如果有多个自断的话,中间可以用逗号格开 再来执行一下,然后再看一下结果,可以看到所有玩家的经验和金钱都已经被修改成零了。这里需要提醒一下各位同学,在实际的开发中不加威尔条件是非常危险的行为,尤其是在执行 update 或者迪丽的语句的时候。 最后再来看一下如何删除表中的数据,我们可以使用 delete 语句后面跟上表明,然后使用外二条件此句来指定要删除哪些数据。比如我们要删除所有金钱为零的玩家,就可以在外二条件后面指定 go 等于零, 然后再来查看一下数据,可以看到所有的玩家都被删除了, 我们需要对数据库执行一些导入或者导出的操作,方便我们对数据进行备份,或者将数据从一个库迁移到另一个库中。比如这里我们就给各位同学准备了一些数据库文件,里面是我们课程中需要使用到的一些数据,方便大家跟着教程一边学习一边实践,以及在后续的课程中来演示一些比较复杂的 c 口语句。 看完这一小节之后,你就可以将这些数据导入到你自己的数据库中了。数据的导入导出可以使用命令来完成,也可以在图情话界面中直接操作。这里我们先来看一下命令行的方式,可以使用 mecco dump 命令来导出数据,输入 mecco dump 之后, 后面加上杠 u 参数,指定一个用户名,然后加上杠 p 参数,指定密码,后面再加上数据库的名称和表的名称,表的名称可以省略,如果省略的话就会导出整个数据库的所有数据,最后加上一个大于号和文件名来表示将数据导出到这个文件中。比如我们来导出一下 game 数据库中的数据,回车之后会提示 是输入密码,输入之后就会将数据导出到 gamersql 这个文件中了。我们来打开一下这个文件,可以看到里面就是一条条的 c 口语句,这些语句就是用来创建表以及插入数据的,这样我们就可以将这个文件分享给其他人,就可以直接导入到自己的数据库中了。 那下面就来看一下如何导入数据。由于后续的课程中会涉及到一些复杂的 c 口语句,会对数据有些要求,这里也提前准备好了一份数据,刚好趁着这个机会来导入一下,这样后面的课程中就可以直接使用了。 数据文件在我们的课程资料中,大家可以自行下载一下。导入数据使用的是 mysco 命令,输入 mysco 之后,后面一样也是跟上杠 u 指定用户名,然后是杠 p 参数指定密码,然后是数据库的名称,最后再加上一个小于号和文件名, 回车之后会提示输入密码,如果没有错误提示的话,导入就完成了。我们打开图形化工具来查询一下,就可以看到我们导入的这些数据, 当然也可以在图形画界面中来操作,这里就不再演示了。下节课开始我们会使用这些数据来讲解和练习 mayor 子句,用来提取那些满足指定标准的记录,它可以同 select, update 和 delete 一起使用,比如查找所有等级为一的玩家,就可以在 where 后面加上条件, level 等于一就可以了。除了等号之外,还有其他的比较运算符都可以使用,比如大于小于大于等于,小于等于不等于等等。 有的时候我们需要查找满足多个条件的数据,比如查找等级大于一并且小于五的玩家,就可以使用 on 来连接这两个条件。为了后面加上第一个条件 level 大于一,然后再加上一个 on, 再加上一个条件 level 小于五。 执行完成之后就可以看到结果中只有等级在一和五之间的玩家了。同样的,如果想要查找经验大于一并且小于五的玩家,就可以把 level 换成 exp, 然后再来执行一下,那就可以看到现在结果中只有经验在一和五之间的玩家了。除了按的以外,还有 alt 和 note 这两个逻辑运算符。需要注意的是,如果同时使用他们的话,是需要注意一下他们之间的优先级的。优先级顺序是 note 大于 on 的大于二。 比如我们想查找等级大于一小于五或者经验大于一小于五的玩家,就可以把上面两条按的语句用二来连接起来,这样就可以把刚刚的两个查询结果合并起来了。执行之后就可以看到结果中有等级大于一小于五的玩家,也有经验大于一小于五的玩家。这里因为按的的优先级要更高一些,所以先执行了两个按的,然后才执行的二。 我们也可以使用括号来改变优先级,比如使用括号把中间的两个条件括起来的话,那么就会先执行中间括号中的偶尔条件,然后再执行两边的按的了,可以看到执行的结果也发生了变化。之前我们使用了等号来查找等级为一的玩家,但 但是如果我们想查找多个不同等级的玩家,就可以使用 in 来指定多个值。比如查找等级为一三五的玩家的话,就可以在第二条件后面加上一个 in, 然后在括号中指定一三五这三个值,中间使用逗号隔开,这样就可以查找等级为一三五的玩家了。印还经常会和此查询一起使用,这个后面我们会详细讲解, 可以使用 betin 和暗的来指定一个连续的范围,比如我们想查找等级在一和十之间的玩家,就可以在威尔条件后面加上一个 level 字段,然后使用 betin 和暗的来指定一个范围,比如一到十,这样就可以查找等级在一和十之间的玩家了,包括一和十。执行之后就可以看到返回了我们想要的结果, 这条语句也等价于 level 大于等于一,并且小于等于十,他们的执行结果是一样的,我们可以在条件语句的前面加上一个 note 来表示取反,比如刚刚的条件前面加上 note 的话, 就表示等级不在一和十之间的玩家了。 note 可以加在任何一个条件语句前面,比如刚刚我们执行过的 in, 或者是各种比较运算服都可以。 有的时候我们需要进行一些模糊查询,比如查找姓王的玩家或者名字中包含王的玩家,这个时候就可以使用 like 来查找 like, 后面加上一个用来匹配的模式,模式中可以使用下面两种通配符,百分号表示任意一个字符,下划线表示任意一个字符。比如查找姓王的玩家的话,就可以在威尔条件后面加上一个 name like, 然后使用一对单元号把王括起来,后面加上一个百分号,表示名字中第一个字是王,后面可以是任意多个字符的玩家。 执行之后可以看到返回了所有姓王的玩家。而如果我们想查找名字中包含王字的玩家,就可以在王的前面也加上一个百分号,表示前面也有可能是任意多个字符,这样就可以查找到名字中包含王的玩家了。 可以看到查询结果中除了刚刚所有姓王的玩家以外,多了一个兰陵王。如果我们想查找姓王并且名字只有两个字的玩家呢?这个时候就可以使用下划线来匹配一个字符,这样结果中就只剩下王五一个,其他三个字的就都被过滤掉了。同样的,如果在后面再加一个下划线的话,就可以查找名字是三个字的王姓玩家了。 有的时候我们需要查找的模式比较复杂,就可以使用 regular expression 来匹配正则表达式,正则表达式中可以使用通配符来定义匹配规则,可以使用的通配符包括下面这些, 点号表示匹配任意一个字符,减小号匹配开头 w 匹配结尾。使用中括号括起来的字符列表表示匹配其中任意一个字符。也可以使用中杠的表示一个范围,比如中括号零杠九就表示匹配零到九之间的任意一个数字。中括号 a 杠 z 就表示匹配任意一个小写字母。竖线表示或者的意思,比如 a 竖线 b 就表示 是匹配 a 或者 b, 还是刚刚的例子,我们想查找姓王并且名字只有两个字的玩家,我们来看一下政策表达式的方式应该怎么写。 vr 后面加上一个字段 name, 然后是表示使用政策表达式的关键字 r 一区 exp 后面加上一个我们想要的政策表达式就可以了。 这里的减角号表示开头, w 表示结尾,点表示匹配任意一个字符,这样就可以查找姓王并且名字只有两个字的玩家了。那如果想查找名字中包含王字的玩家呢?那就只留下王字,其他都去掉就可以了。 注意这里并不需要加上百分号或者下划线,正则表达适中,并没有这两个通配符,他们是在 like 中才有的,大家不要搞混了。如果想查找名字中包含王或者章的玩家,就可以使用中括号把王和章括起来, 表示匹配其中任意一个字符,这样只要名字中包含王或者张的玩家就都可以被查找出来了。我们来执行一下,就可以看到我们想要 的结果了。另外一种方式是使用竖线来表示,或者可以把中括号去掉,然后在王和章之间加上一个竖线,我们来执行一下,可以看到结果是一样的。下面我们来做一些练习,巩固一下刚刚学到的内容,大家可以暂停来自己尝试一下,我们会在下面给出答案。 有的时候我们需要查找某个列的纸是空的数据,这个时候有一个需要注意的地方就是不能使用等号来判断,这也是很多同学最开始的时候容易搞错的地方。 比如想查找邮箱为空的玩家,就不能使用一秒等于 note 来判断,因为 note 值与其他任何值都不相等,包括 note 本身。所以如果我们使用下面的语句来查找没有填写邮箱的玩家的话,就会得到一个空的结果级,而这并不是我们想要的结果。 正确的做法是使用 is now 来判断,这样就可以查找到没有填写邮箱的玩家了。同样的,如果我们想查找填写了邮箱的玩家,就可以使用 is not now 来判断。 myseco 还提供 用一个专门用来比较 note 的比较操作符,就是在等号两边分别加上将括号把它括起来,这样也是可以查找到邮箱是 note 玩家的。但是我还是推荐大家使用 east note 来判断,因为这种写法更加直观,也比较常用,而且在 oracle 等其他数据库中也是通用的。 还有一点需要注意的就是,有的时候数据库中的数据是一个空字符串,表面上看 top 闹都是空,但实际上他们也是不一样的闹需要使用 is not 来判断,而空字符串应该使用等号来判断。看一下下面这个例子,相信大家就能明白了, 还是来查询一下没有填写邮箱的玩家。回车之后可以找到两条记录,这两条记录的邮箱都是空的,然后在后面再加上一个一秒等于空字不串的条件, 然后来执行一下,可以看到查询的结果中多了一条记录,而这条记录的邮箱是一个空字符串,也就是说 no 表示没有值,也就是没有填写邮箱,而空字符串表示填写了一个空的值。这样他们的区别是不是就很明显了呢? 奥特曼用来对查询结果按照某个字段来进行排序,如果不指定的话,默认是升序排序。比如想要按照等级从小到大的顺序来把玩家排列起来的话,就可以在查询语句的后面加上一个奥特曼,然后指定一个列的名称,比如这里就用等级 level, 这样就可以按照等级升序排列了。如果想要降序排列的话,可以在列名后面加上 dsc 再来执行一下,这样就可以按照等级来降序排列了。如果想要按照多个列来进行排序的话,可以在后面加上一个列名,比如我们在等级降序的基础上再加上一个按照经验升序排列,也就是在后面再加上一个 efp 就可以了。后面什么都不加的话,默认就是按升序来排列,当然也可以显示的加上一个 asc 来表示升序, 那我们再来执行一下,这样返回的结果就先按照等级来降序排列,等级相同的话再按照他们的经验来升序排列了。奥特拜后面除了可以使用列名之外,还可以使用列的序号来排序,比如 如果我们想要按照等级降序来排列的话,就可以在后面加上一个五,因为等级 level 是这个表的第五列,然后后面再加上表示降序的 d, e, s, c 来执行一下,可以看到这样结果也是一样的。 聚合函数用来对某个列执行一些计算,比如求和平均值,最大值,最小值等等。常用的聚合函数包括下面这些,比如想知道所有玩家的总人数,就可以使用 cont c like 后面加上一个 com 的星,然后是 freeman 和表明,然后执行一下就可以看到结果了。或者查询所有玩家的平均等级,就可以使用 avg 这个函数括号中指定要计算的列名就可以了,类似的还有求和最大值,最小值等等,大家可以可以下自己尝试一下。 有的时候我们想要统计一下所有玩家中的男女比例,就可以使用分组查询的方式来实现。 globa 用来对查询结果进行分组,后面加上一个或者多个列名,表示按照这些列来分组。然后前面的 c like 语句中就可以使用 我们刚刚学到的 content 或者 some 这些聚合函数来对这个列进行计算了,这样可能还是不太好理解,我们来看一个例子,比如我们想知道所有玩家中每个等级的玩家有多少名,就可以使用 green 来统计, green 后面加上一个 level 表示按照等级来分组。 前面的 select 语句后面加上等级和一个 count 括号 level 来计算每个等级的玩家有多少名,我们来执行一下, 这样就得到了每个等级的玩家数量了。 gruba 还经常和 having 一起使用,用来对分组后的结果进行过滤,比如我们想知道刚刚的结果中数量大于四的等级有哪些,就可以在后面加上一个 having count 括号 level 大于四,这样结果中就会只保留数量大于四的等级了。 另外一个经常同古鲁拜一起使用的是奥德拜来对结果进行排序,比如刚刚的结果并没有一个固定的顺序,如果我们想按照数量来降序排列的话,就可以在后面加上一个奥德拜 count 括号 level, 然后加上一个表示降去的 ds c 就可以了。生活中实际这样的例子也非常多,比如热搜榜,排行榜等等。同样的大家也可以尝试一下其他的聚合函数。 下面来做一个小练习,统计每个姓氏玩家的数量,并将结果按照数量来降去排列,只显示数量大于等于五的姓氏,你可以暂停来自己尝试一下,我们会在下面给出答案, 怎么样,你做出来了吗?这里涉及到一个函数 substrain, 它的作用是截取字符串的一部分,第一个参数是要截取的字符串,第二个参数是开始为止,从一开始。第三个参数是截取的长度。那这里的 substring name e, e 就表示截取 name 字段的第一个字符,也就是姓氏。然后再使用 grouby 来按照姓氏分组,再使用 heavy 来过滤数量大于等于五的 形式。最后使用奥特拜来将序排列。 limit 用来限制查询结果的数量,比如刚刚的练习中,我们得到了所有玩家的姓氏和数量,如果我们只想返回姓氏排行榜的前三名,应该怎么做呢?这个时候就可以在后面加上一个 limit 三就可以了, 来执行一下,这样就只返回了前三名的形式。厘米,他也可以指定一个偏移量,比如我们想返回第四名到第六名的话,就可以在后面再加上一个逗号三,第一个三表示偏移量,表示从第四名开始,第二个三表示返回的数量。 这里有个问题,就是由于我们前面已经限定了数量大于等于五,所以这里只返回了第四名和第五名的姓氏,因为第六名的数量不到五个,所以被过滤掉了。那我们把还用这个条件去掉,再来执行一下,就可以看到返回结果中有第六名的姓氏了, 他只有四个人,所以刚刚被过滤掉了。这种方式其实也是分页查询的原理,也就是我们在各种网站上 常经常看到的分页效果。 distinct 关键字可以用来去除重复的记录,比如我们想知道所有玩家的性别,就可以使用 distinct 来去除重复的记录,这样就可以得到驱虫之后的结果了。 uni 用来合并两个查询的结果, 在之前我们查询过等级为一到三的玩家,来复制一下这条语序,然后再来执行一下,可以看到结果中有三条记录,然后再来查询一下经验为一到三的玩家。 执行之后可以看到结果中有四条记录。那如果想把这两个查询结果合并起来的话,也就是所有等级为一到三以及所有经验为一到三的玩家的话,就可以使用 uni 来合并一下。 合并的方式也非常简单,只需要把两条语句用 uni 连接起来就可以了。我们来执行一下可以看到这样就可以得到所有等级为一到三以及所有经验为一到三的玩家的并级了。需要 注意的是, unny 默认会去除重复的记录,比如刚刚的结果中,第一条语句有三条记录,第二条语句有四条记录。但是如果我们把两条语句合并起来执行的话,结果却只有六条,原因是因为其中一个玩家既满足等级为一到三级,又满足经验为一到三, 所以在合并的时候就被去掉了一条,如果不想去掉的话,可以使用 uni 二来合并,在 uni 的后面加上一个 out 关键字,再来执行一下,就可以看到结果中有七条记录了。 uni 和二有些类似,只不过二是用来合并两个条件的,而 uni 是用来合并两个查询结果的。 uni 用来合并两个查询结果,也就是取两个查询结果的病急,而 intersect 则是用来查找两个结果的交集的。还是刚刚的例子,我们把 uni 换成 intersect 就可以查找这两个结果的交集了。我们来执行一下,可以看到结果中只有刚刚重复的吕秀才这一条记录了。 except 用来查找两个查询结果的差集。 还是刚刚的例子,我们把 intersect 换成 except, 就可以查找这两个结果的差集了。也就是说查找等级为一到三的玩家,但是经验不在一到三之间的玩家,可以看到结果中只有两条记录,刚刚的吕秀才就被过滤掉了。 有的时候我们需要使用一个查询的结果作为另一个查询的条件,这个时候就可以使用此查询了。比如我们想知道所有等级大于平均等级玩家,就可以先查询一下平均等级, 可以使用 avg 喊出来求出所有玩家的平均等级,然后再把这个平均等级作为条件来查询,大于这个平均等级的玩家在前面加上一个 where level 大于就可以了。 此查询除了可以用在威尔词句中之外,还可以用在 slag 语句中,比如我们想知道所有玩家的等级和平均等级的差值,就可以在 slag 语句中使用此查询。我们先来查询一下所有玩家的等级,然后在后面加上一个平均等级。 这里的 select average level from player 就是一个自杀群,可以看到平均等级是一个浮点数,看起来并不是很方便,可以使用 run 函数来做一个四舍五入,这样就得到了一个整数的平均等级了,再用玩家的等级减去这个平均等级, 那就得到了每个玩家的等级,平均等级以及他们之间的差值了。注意看一下结果中每一列的名字,最后两列的名字直接使用了我们刚刚的表达式,这样不太方便阅读。那我们也可以使用一个 x 关键字来给这个列起一个别名,比如平均值这一列,我们可以起一个名字叫做 ivory 曲,最后这个差值的列可以叫做 deep。 再来查询一下,可以看到结果中的列名已经变成了我们刚刚起的别名了,这样看起来就更加人性化,也方便理解了。除了在威尔词句或者 select 语句中使用之外,此查询还可以用在 update 语句, delete 语句, creat 或者 insert 等等各种语句中使用。我们也可以使用此查询来创建一个新的表,比如 可以把所有等级小于五的玩家数据插入到一个新的表中,表明就叫做 new player。 还是先来查询一下所有等级小于五的玩家,然后在前面加上 corry table, 后面加上表明就可以了。执行之后这个新的表就创建完成了。再来查询一下, 可以看到这个新的表被成功的创建了,他的结构和 player 表是完全相同的,里面只有等级小于五的玩家数据。最后再来看一下如何使用此查询来插入数据。 比如刚刚我们创建的新表中只有等级在五级以下的玩家,现在我们想把等级在六到十之间的玩家也插入到这个新的表中,那么就可以使用 inside in two 语句来插入数据。 inside in to 后面加上要插入的表明,然后后面加上自查询的结果就可以了。执行完成之后,可以看到提示我们插入了多少行数据,然后再来查询一下这个新的表, 可以看到等级在六到十之间的玩家也被成功的插入到这个表中了。 exist 用来判断一个查询是否有结果,他的反馈值只有零和一两种,比如 你想知道是否有等级大于一百的玩家,就可以使用 exist 来判断一下。 exist 后面加上一个字,查询,也就是我们想要判断的查询,这里的话就是查询所有等级大于一百的玩家。我们来执行一下,可以看到结果是零,就表示并不存在等级大于一百的玩家。那如果把条件改成等级大于十呢? 再来执行一下,可以看到结果是一就表示存在等级大于十的玩家。 表关联用来查询多个表中的数据,关联的表之间必须有相同的字段,一般会使用表的逐渐和外线来关联。 有关联分为下面几种类型,内连接,只返回两个表中都有的数据。左连接就是返回左表中所有的数据和右表中匹配的数据,右表中没有的数据用 note 填充。相应的右连接就是返回右表中所有的数据和左表中匹配的数据,左表中没有的数据用 note 填充。下面就来看一下这 几种关联的具体用法。游戏中除了玩家之外还需要有装备,我们先来看一下装备表的结构,这个表的结构非常简单,只有三个字段,分别是装备的 id 名称以及所属玩家的 id。 内连接就是使用 inner join 关键字来指定关联的表,然后是 on 关键字和两个表中关联的字段,最后可以加上位尔关键字和查询条件。那我们就来执行一下这条语句, 这样就把玩家表和装备表关联起来了。可以看到我们结果中既包含玩家的信息,也包含了玩家对应装备的信息,他们之间使用玩家 id 这个字段来关联起来。 左连接用来查询左表中所有的数据和右表中匹配的数据,右表中没有匹配数据的话就会使用 note 填充,还是刚刚的例子,我们来使用左连接来查询一下,看看结果是什么样的。直接把 in the drive 换成 left drive 就可以了,然后再来执行一下这条语句, 可以看到结果中包含了玩家表的所有数据,然后是玩家对应的装备信息,有装备的话就会显示装备的信息,如果没有的话就会使用 note 填充。同样的右连接就是用来查询右表中所有的数据和左表中匹配的数据,左表中没有的数据就会使用 note 填充, 还是刚刚的例子,我们来改成右链接,再来查询一下,看看结果是什么样的。直接把 left drawing 改成 right drawing 就可以了。然后再来执行一下,可以看到结果中包含了装备表的所有数据,以及这些装备所对应的玩家的信息,没有对应关系的玩家信息部分就可以使用 note 来填充。 表连接除了使用 joy 和 on 关键词来指定关联的字段之外,还可以使用 where 关键词来制定。还是刚刚的例子,我们可以把 joy 去掉,表明后面加上逗号,然后在 where 后面加上关联的条件,再来执行一下,可以看到结果是一样的。 也可以在表明后面加上别名,然后在外耳关键字后面使用别名来指定关联的条件,再来执行一下,可以看到也是没有问题的。表关联也可以使用多个表,时间关系,这里就不延迟了。数据库中有个技能表 skill, 大家可以刻下自己尝试一下。使用连接的时候需要注意的一点就是迪卡尔奇的问题, 如果连接没有指定条件或者条件不正确的话,就会产生迪卡尔吉,比如如果把上面查询语句的条件去掉的话, 那结果就会是这个样子的。可以看到我们的结果中每一条数据都会和另一个表中的每一条数据进行组合,这样就会产生很多的数据,而一般这并不是我们希望看到的,所以在使用连接的时候一定要注意连接条件是不是正确的。 其实表连接的本质就是 dk 二级,再加上条件过滤,如果不加过滤条件的话,那当然就会把所有的数据都组合起来了。 锁眼是一种用来提高查询效率的数据结构,它可以帮助我们快速的定位到我们想要的数据,如果没有锁眼的话,就只能从头开始便利所有的数据,直到找到满足条件的数据为止。当数据非常少的时候,这样并不会有什么问题,但是如果当数据量非常大的时候,查询效率就会直线下降, 锁眼就是为了解决这个问题而产生的。下面先来看一下如何在买 c 口中创建和使用锁眼。可以在建表的时候直接指定锁眼,也可以在建表之后再来添加一个锁眼。锁眼的创建语法像下面这样, creatinex 是创建锁眼的关键字 音代词,前面可以加上可选的所以类型, uniq 表示唯一,所以 fox 表示全文,所以 special 表示空间,所以再加上一个所以的名称,后面是按关键字和表明表示要在哪张表上创建,所以最后使用括号括起来的一个或者多个字段名,这些字段名就是我们要对哪些字段 来创建锁眼。一般来说,我们会对一张表的逐渐字段或者经常用来查询的字段创建锁眼,也就是威尔后面的查询条件字段,这样可以提高查询的效率。为了让大家最直观的看到锁眼的效果,我们随机生成了两张有两千万条数据的表,这两张表的结构和内容都是完全相同的,他们的结构非常简单,只有四个字段。 再分别来看一下这两张表的数据量,可以看到他们的数据量都是两千万条。下面我们在其中一张表上建立所演,另一张不建立,然后来比较一下他们的查询效率。 我们给 fast 这张表的 email 字段来创建一个索眼, create index, 后面加上索眼的名称,比如这里就叫做 email index, 然后是一个 on 关键字,后面加上表明 fast, 最后是用括号括起来的 email 字段, 然后来执行一下。注意,这里根据数据量的不同,创建所有的时间也会有所不同,这里我们的数据量比较大,所以创建所有的时间会比较长一些,大家耐心等待一下, 等待的过程中,先来介绍一下如何查看锁眼,可以使用 show index from 语句来查询,后面加上表的名称就可以了,可以看到刚刚的锁眼已经创建完成了,再来执行一下这个查询语句, 然后在下面就可以看到所以你的名称,字段的名称,所以你的类型等等清晰了。下面就来比较一下这两张表的查询效率。我们就以查询邮箱以 abcd 开头的数据为例,先来查询一下没有所以你的这张表。为了让两边的结果一样,我们再按照 id 字段来排个序,然后来执行一下, 在下面可以看到语句正在执行,可以看到执行的时间。好的,执行完成了,可以看到执行时间大概是五秒左右。同样的语句,我们再来查询一下有锁眼的这张表 瞬间就完成了,这就是锁眼的一个作用,可以帮助我们快速定位到我们想要的数据,从而来提高查询的效率。删除锁眼,使用照片代词语句后面加上锁眼的名称,然后是 on 关键词和表的名称。比如我们 想要删除刚刚创建的这个锁眼的话,就输入照片 decks, 然后是锁眼的名称 email index, 后面加上 on 关键字和表的名称。 fast 执行之后再来查询一下, 可以看到缩影已经被删除了。除了使用 created index 语句来创建缩影之外,还可以在修改表结构的时候来创建缩影。比如我们想要给 fast 表的内幕字段创建一个缩影的话,那么就可以使用 alter table 语句后面加上表明 fast, 然后是 add index 关键字表示要添加一个缩眼, 后面加上左眼的名称内幕 index, 最后是用括号括起来的内幕字段,也可以在键表语句中直接指定一个左眼时间关系,这里就不延时了,大家可以自己尝试一下。 视图是一种虚拟存在的表,它本身并不包含数据,而是作为一个查询语句保存在数据字典中。当我们查询视图的时候,它会根据查询语句的定义来动态的生成数据。 创建视图使用 crater 语句,比如我们可以创建一个玩家表中等级在前十名的排行榜视图, crater 后面加上视图的名称,然后是 x 关键字后面加上一个想要查询的 club 语序就可以了。这里就是查询玩家表中等级在前十名的数据, 然后来执行一下,这样试图就创建成功了。试图的使用和表是一样的,可以使用正常的 select 语句来查询试图,比如来查询一下刚刚创建的,试图就可以看到试图返回的数据了,而且当表中的数据发生变化的时候,试图中的数据也会随着变化,比如把第一名的等级改成十,执行一下 update 的语句, 然后再来查询一下,试图可以看到试图中的数据也发生了变化,这就是试图的一个特性,试图中的数据是动态的,他会随着表中数据的变化而变化修改。试图使用 auto vivo 语句,后面加上试图的名称,然后是 it 关键字和新的 语句就可以了。比如我们想要把数据改成从小到大排序的话,就可以在 outer view 后面加上视图的名称 top ten, 然后是 s 关键字后面加上一个新的 select 语句,把上面的语句复制一下,然后去掉 d, e, s, c, 再来执行一下,这样试图就修改成功了。然后我们再来重新查询一下,试图可以看到试图中的数据已经变成从小到大排序了,我们可以使用招 vivo 语句来删除,试图后面加上想要删除的试图的名称就可以了。这个非常简单,这里就不再演示了,大家可以自己尝试一下。
2535GeekHour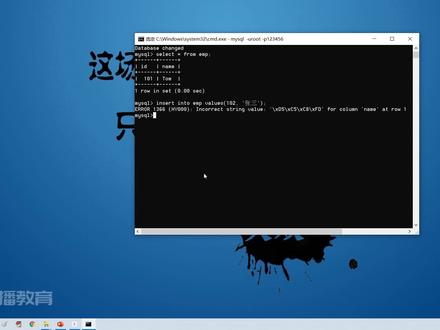 17:38查看AI文稿AI文稿
17:38查看AI文稿AI文稿那么刚刚呢,我们利用这个命令提示服,是不是登录了买 circle 的数据库服务器啊?哎,并且测试了一下,我们买 circle 数据库服务器 安装成功没?成功啊,发现一切都还挺正常。但是呢,后来呢,我们建了一张表,我们在往表中添加这个英文数据的时候,发现没什么问题,但是我们往表中添加中文字符的时候,发现产生了乱码的问题, 那么一旦发生乱码,咱们想都不用想,肯定就是编码方式不一致,咱们之前学过 io, 在讲 io 流的时候是不是讲过编码与解码啊?哎,只要发生乱码,一定是编码不一致,所以说咱们让它编码一致解。 那么咱们在安装买三呃三盒服务器的时候,并没有指定编码,那他默认编码是什么呢?咱们可以先看一眼,通过一个命令叫做授 wherebos, 叫 like, 然后来个叫做 character 啊,大家可以稍微的记一下啊,简单记一下就可以。这个啊,当然并不是特别的常用,看一下 啊,在这个里边呢,我们关注一点就是这个 server, server 指的是不是就是服务器啊?就是你买 server 服务器,他默认的编码是 拉丁码,拉丁指的就是 iso 八八五九杠幺,也就是默认他其实是欧码表。而我现在的客户端 clant 客户端是不是此时 jbk 啊,我们一看, 哎,默认客户端现在是 jbk, 发现编码不一致,因此就产生了这个乱码的问题,所以说呢,我们需要把我们这个服务端呢,把他这个编码给他改一下,对吧?哎,改成 统一的 utf 之前咱们是不是也说了呀,哎,所有的编码就都统一声 utf, 因为 utf 涵盖了世界上所有的字符, 那么改,那么怎么改呢?我们需要改一下买三口服务器的一个配置文件,这个配置文件怎么改啊?在这个文档上都有啊,大家可以按照文档一步步的来, 首先我们要找到这个叫做卖点爱爱的配置文件,这个配置文件在哪呢?大家要注意一下了, 他会在我们买 circle 的安装路径啊,我的买 circle 安装路径在 c 盘下 program files 下有一个叫买 circle, 然后里边有个买 circle server, 五点七打开,其实发现这里边没有,对吧?我要告诉大家,这里没有啊,那么为什么没有呢? 这也是我要给大家强调的一个点,就是什么呢?在买 sco 五点七以前,那个卖点爱爱配置文件呢?实际上是放在这个买 sco 服务器这个路径下的, 那么在 myself 五点七以后呢,实际上那个卖点爱爱就被移动到了 program data, 也就是那个数据文件 myself server, 五点七在这个路径下了,听懂吧。哎,在这个路径下啊,也就是什么意思呢?我们可以过来 之前咱们在安装买 circle 的时候,是不是跟大家说可以指定两个啊,这个指定一个买 circle 的安装路径啊,啊,就是这在咱们安装买 circle 的时候,通过这个选项可以指定买 circle 的安装路径啊,那么有两个,上边这个呢,指的就是买 circle 安装路径, 下边这个呢,就是 myserk 的一个数据文件所存放的路径啊,这个数据文件存放的这个路径就是咱们卸载 myserk 服务器的时候手动删除的那个路径,那么实际上那个卖点爱爱现在在哪啊? 在这个路径下啊,反正一共就两个路径,你是不是就找一下就完事了呀?在哪个里边找到了卖点爱爱,你就改哪个就可以了,这个名字是不会变的, 在 windows 操作系统下,它叫做麦点爱。恩爱,哪怕是在 linux 操作系统下,它也叫麦,只不过后缀名不一样啊。 另一个是操作系统下叫卖点 com 啊,都叫卖,就这两个路径,你去随便找,找到了你改他即可, 懂吧。哎,那么我们在 deta 买 circle, 买 circle server, 五点七以下有一个卖点,恩恩爱,我们把它打开啊,修改即可。怎么改呢?当然都记不住是吧?我也记不住,当然我们会查吗?查文档也好,查百度也好,加上即可, 当然也不不经常改哈,你一旦安装好了以后就改一次,以后一直就用了。那怎么改?大概在这个 imi 的文件当中啊,啊,有个 mysco 命令,大概在六十三行加上这么一条啊,在,哎,在这个路径下, 呃,在这个文件中有个买 sco 命令,在这里边,是不是改一下啊?只不过原来那个命令有注视了,我们把它打开,这里面输入 utf 八,此时大家千万注意买 三口的 utf 八编码啊,就叫 utf 八。以前咱们接触的 utf 八,实际上是不都是 utf 杠八呀,而买三口没有那个杠, 这一点要要注意,如果你加了那个杠,那就错了,那就会出问题,听懂吧。所以说买 circle 就叫 utf 八,而其他的啊,上次是我们这 id 啊,或者其他地方啊,其实都叫 utf 杠八,这一点要注意一下, ok, 然后呢,第二部分还改哪呢?在 myselfd 命令下,大概在七十六行加上这么两条配置,那就加挂上就可以了,这不 myselfd d 吗?在下边加两行 加上即可啊,保存保存保存保存一下,保存好了以后大家注意,还没完,我们需要干嘛呢?需要 重启一下买 coco 的服务,只有重启了买 coco 服务,人家买 coco 服务器才会重新读取卖点爱爱这个配置文件啊,就是才能读取更新好的 配置,听懂吧。那么这个服务在哪来着?此电脑右键有个管理,管理下边有一个服务,在服务这里边去搜 myserk, 这里有个 myco 五七,右键停止再启动也行,或者重新启动即可。 当然,实际上重启服务的这个操作呀,我们通过命令提示服也能完成,只不过这个命令提示服呢,你得右键以管理员的身份运行,然后呢,停止服务,那叫 stop, 比如说后边服务名买 五七,对吧?哎,启动服务呢,那就 netstart 叫买 circle 五七,其实呢,跟刚刚咱们这个操作是一模一样的啊,只不过你要是用命令的话, 是不是略显高大上啊,对吧?哎,略显高大上。 ok, 那么服务重启了之后,我们这个 msrco 是不是也重新登录一下啊?哎,说,命令高大上,我退出 exist 对吧?退出命令提示服, exist 显得高大上,是吧, 少帅? ok, 那么重新登录一下,买 scrow 服务器,这时来个 myscro, 来个杠 you read, 也就是用户名杠 p, 一二三四五六。 那么一输入到这,小伙伴们就就开始迷惑了,说你这密码设了意义不大呀,这不都暴露在外边了吗?一点也不安全,哼,确实是这样,对吧?所以说人家买 sever 给我们提供了一个功能, 你直接一个杠屁,回车,他让你在这个地方输入密码,那这时我们再输入一二三四五六的时候,他是不是用给你覆盖了呀?用星号代替了, 看到吗?给你覆盖就是对密码做了一个保护,此时在回车看到这个页面呢,说明我们买 sko 服务器已经登录成功了,再去柚子我们之前建的那个 test 数据库啊,然后呢,这个编码到底修改成功没成功? 我们是不是再看一下呀,叫 so wearables like, 哎呦哎呦,这还好使吗?不小心按到回车了,呃, like a c t r 百分号分号,呃, 来个单引号,分号回车,嗯,好像不太好使了,是吧?换完了 重来啊, so wearables like, 叫 c h a r a c t 啊, character 百分号,然后呢,来个英文的分号回车啊,我们重点关注一个是哪呢?关注啊,这个 server 他已经变成了 utf, 说明什么呢?说明刚刚咱们这个配置文件生效了,刚才是不是拉丁啊,哎,现在是 utf, 然后呢?大家看,哎,不对呀,你这个客户端这不还是 jbk 吗? 啊,那么这个大家注意,这也是 myserk 给我们提供的一个功能,什么意思呢?这里显示的 j b k 并不是完全说 啊,我们这个客户端就要求是 j b k, 不是这样的,不是说要求我们客户端必须是 j b k, 实际上是什么意思呢?他 这时我们一旦改了这个配置以后啊,这个买时候服务器就有一个功能,他,他会识别你客户端的编码, 然后这里指定的 j b k 指的是买 sky 服务器,他会知道哦,你是以 j b k 的形式发送过来的数据,那么人家服务器会以 j b k 的形式转化成 utf 八,再发送给数据库服务器, 听懂吗?哎,这是他买 circle 服务器的一个小功能,人家给你设计的功能啊,虽然说这里显示的是 jbk, 指的是啊,你这个客户单命令提示服 是 jbk, 什么意思呢?大家注意看,给大家画一下就知道了。比如说这个是我们的客户端客户端,然后呢,这个呢,是我的买 买 style 服务器啊,这个叫做买 style 啊服务器,然后呢紧接着呢,在这里这中间呢,人家买 style 服务器这边呢?人家给你来了个什么呢?来了一个编码的,呃,规范吧,或者什么编码的转换。 那么此时我们现在客户端是不就是我们的命令提示服啊?我们的这个命令提示服,其实此时就作为客户端,他是 gbk, 那他就识别出来你此时的这个客户端呢是 gbk, 那么当我们客户端当然这里呢是 jbk, 然后呢,这个服务端呢,他是 utf 八,是不都限制了编码啊? utf 八,那么此时我们发现客户端这个编码 jbk 服务端是 utf 八, 这也不一致啊,怎么回事?那么接下来他们这个地方显示的是 gbk, 指的是啥意思呢?就是你客户端发送过来的数据, 那么人家买 sl 提供了一个转换的功能,他会知道他将以 j b k 的形式把你来的数据转化成 u t f 八,转成了 u t f 八之后再给你存到服务器当中去, 听懂吧。所以说,那么这边,这个,这个地方对吧?这个 clant 客户端这个地方其实不一定不是固定的,比如说,大家注意,我现在用用另一个客户端登录一下,注意啊, secure 要个,虽然还没讲,我们只需要关注 这个 clant 和 server 它两边的编码就看就就知道了啊,注意蒙圈没蒙圈跟上啊跟上,我们在这里呢,也去叫 so wearable。 为啥? i a b r e wear boss 来个来个叫 c 是 a c t r character 百分号,然后选中执行。哎呦,嗯,太死了吧,然后选中执行 啊,不对,嗯, c h a r a c t r 哎哟, like 拼错了,太激动,卷重直行。注意看这里的 client 是啥? u t f 啊,这里的 sever 也是 u t f, 看到了吧,哎,所以说对吧,这是人家买 circle 提供的一个功能,我们不用 甭管他啊,那此时我们已经限制了编码的话,人家买思考就已经都给我们搞定了, ok, 当然大家看这个 database 这里有个拉丁是吧?这个是什么意思呢?咱们再等一下,马上给大家解释啊。 好的,那既然服务端我们已经改成 udf 啊,那么接下来我们就往里添加中文试试呗。我们先去看一下 slect 星 from emp, 看看他这汤姆是不是还在啊。那么刚才往这个表中添加 这个音词添加中文是不可以的吧,那么这时我们再去尝试添加一下中文试试,叫做张三分号回车 完蛋,翻车不行,对吧?那说为什么不行呢? 哎,因为我们呐,这个表是在我们修改编码以前 创建的,所以说这个表的编码是我们修改编码以前的默认编码,也就是拉丁码,怎么去验证一下呢?也是 so create a table, 看看 emp 表现在它的编码是什么?注意看叉 set 是拉丁 对吧?哎,是我们修改编码以前的拉丁码, iso 八八五九钢窑,所以说当然不行了呀, 听懂吧。啊,不仅是这个表,乃至于我们 test 那个库是不是也是我们修改编码以前创建的呀?啊,比如说 socreate database 叫做 test, 这个库 回车,注意看这个酷的叉二赛的是不是也是拉丁的。哎,所以说他是不行的,因此呢,我们修改了编码,这些呢,我都需要给他,当然我们也可以修改,也可以删除修改,你只需要 outer table 改下编码即可。那咱们这些都没学呢,直接照吧啊。 呃, table 把这个表删掉,当然这个库也给它删掉。 ditbase test 都删掉删掉了,重新创建,听懂吧。那这时在创建叫做 crit database, 重新创建一个数据库叫 past。 然后呢,在这个里边,我们在 use test use 使用这个库再创建一张表, table 叫 emp, 里边有个 id 是 int, 长度为十纯整形的,来个内母弯叉,长度是 二十纯字符的。回车,然后 slak 特星,我们先看看这张表中有没有数据点 p, 发现还没有, 对吧。啊,那此时往里添加一个吧,音色的 in two e m p, 然后来个 y 六四幺零幺添加一个,这回添个杰瑞,这样杰瑞杰瑞呢?回车啊,成功了, carry ok。 然后呢? select 星 from e m p 查询一下, 杰瑞添加进去了啊,这次是不是在添加中文呢?叫做 insert in two emp, 来个 y 六四幺零二,此时来个张张撒就撒吧张撒,然后回车, yeah, query okay, 然后呢,再取 slag, 按上下方形键啊,行,那么张萨 jerry 就都 进来了。那么这个就是买 circle 的一个编码问题,看懂吧?编码问题,那么这个时候呢,刚刚我们说,哎,上面你之前不是有个爹特贝斯是拉丁吗?嗯, 我们看的是哪个队的被子呢?是不是看的是 test 这个数据库他是拉丁呢?其实这刚才已经看到了,这回呢,我们再去看看呢,瘦,呃,这个瘦, vri berry avr i berry verbos like, 然后来个 character 百分号, 此时再看,再看我们当前的这个 database 数据库是不是就是 utfi 呀?看懂吧,哎,然后这个 connection 就是当前的连接是 jbk, 当前的数据库是 utfi 发,当然文件都是二斤制 bannery, 对吧,返回的结果即也是 jbk, 当然它的 把数数据库给我返回的数据数据库服务器返回的数据是不是得返回给我客户端啊?那我客户端收到的结果当然得是 jbk, 当然我用另一个客户端是不是就不一样了呀, 这也是买色可给我们提供的强大功能之一好吧,所以说呢,就是归根结底啊,你出现了乱码问题, 实际上是不按这个步骤改一下即可呀,只不过咱们墨迹的多,更想让大家去尽可能的去理解这个流程啊,实际上呢,你就改一下,其实就搞定了,对吧?先改后改,等等这个问题。然后呢,大家注意之后呢,我们需要写一些命令 都这个命令提示服是不是也太丑了呀?哎,显示写人家命令,这个命令提示服实际上太丑了。我们需要什么呢?需要一个 secure, 我们先把这个视频保存一下吧。
152点播教育 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿回答粉丝问题,如何将某个值呢作为一个限制,比如我模拟量通道的一个数据 a w 四,它采集过来的数据呢,就必然是在零到二千六十八之间,如果超过了这个之间的一个范围,那么我就不取它的一个数据,那么我如何去做呢?我们只需要通过一个指定就可以解决这个问题, 就是这个 limit 指令,这个好,我拖出来放到这里来, 那么这个呢是我们之前讲的模拟量的一个程序,那么我把这个 i w 四这个通道复制到这边输入端,那么最小值呢,我们是零到二七六十八之间,因为这个通道数据的话是零到十伏的,零到十伏的一个信号,所以你的数据呢是零到二七 六十八,超过了这个范围呢,我是取下线的话是取零,上线呢是取二七六十八的,那么我这边数据呢填在一个地址当中,地址 m w 呃 六十,然后 m w 是 ctrl c ctrl v 放到这里来,那这个时候呢,我们来看它的数据是如何进行变化的,我们下载进去, 现在看监控一下这个程序,这个程序值呢在 i w 四呢,它是零的,所以 m w 四呢,它是等于零,那么呃,如果我这个值超过了这个范围,那我们可以在这个强制表章中去强制它 i w 四,我现在强制为负五。好,强制 点击是好,接下来我们来看这个程序,程序这里呢我们可以看到,现在呢它是负五,那么它的一个值呢? m w 六十的值呢?它呢是一个离日状态,因为呢它负五呢是小于零,它也小,对小值呢进行来填写啊,如果我这边数据是三万,好,那我们再强制进, 这时候我们看一下它的一个 m w 六十的值是多少呢?是它的一个上限值二七六十八。那么有了这个指令,我们在实际的工作,工作当中需要对某些数值进行限制的时候呢?就很方便了,对吧?
464工控小飞侠(课程在橱窗) 01:50查看AI文稿AI文稿
01:50查看AI文稿AI文稿my s q l 是一种常用的关系型数据库管理系统,它提供了命令型客户端来与数据库进行交互。以下是使用命令型客户端 my s q l 的基本步骤。打开命令型终端,如 windows 的命令提示符或麦克的终端,输入以下命令来连接到 my s q l。 服务器, i'm y s q l you using the m p。 其中优质内容是你的 mysql 用户名。按下回车后,系统会提示你输入密码。输入密码并按下回车键。 如果密码正确,你将成功连接到 misql 服务器,并看到 misql 的命令型。题四服在命令型中输入 sql 语句来执行相应的操作。例如,可以使用 usb 语句选择要使用的数据库, 使用 select 语句查询数据,使用音色语句插入数据等等。每个 s q i o 语句已分号结尾。以下是一些常见 正的 mysql 命令视力选择要使用的数据库, use database under school name 查询数据 select from table name 插入数据 insert in the table name column 一 column to values value one value to 更新数据 update table under school names psycholome one equals by way you want how long two equals about youtube where condition 删除数据 delete from table and score name where condition。 输入完命令后,按下回车键执行命令。根据命令的不同,你可能会看到相应的结果或提示信息。当完成与 my s q l 服务器的交互后,可以使用以下命令,推出 my s q l 命令型客户端 i exit 或者按下错加系组合键。这些是使用命令型客户端卖 sql 的基本步骤。你可以根据需要使用不同的 sql 语句来操作数据库。记得在执行任何修改数据的命令之前,要谨慎并确保你知道自己在做什么,以免造成数据丢失或损坏。
46华科云商-金木 15:32查看AI文稿AI文稿
15:32查看AI文稿AI文稿当我们遇到性能问题时,首先要确定的是产生问题的原因。我们的目标是缩短响应时间,因此需要了解服务器响应查询需要一定时间的原因。换句话说, 我们需要测量时间的去向。这就引出了一个重要的优化原则,我们无法可靠的优化无法测量的东西,所以首要任务是测量时间都花在了哪里,然后减少或消除任何不必要的工作以取得成果。 麦色口提供了大量的系统,试图允许管理员和开发人员都能更深入的了解系统的实际情况。 如果不先收集必要的数据,提高性能和可靠性就没有参考依据。也就是说,我们只有以事实为依据才能做出明智的决定。当涉及到有关性能查询信息时, performance steam 数据库是一个宝藏,然而 挑战在于如何真正理解这些繁多的数据表格和指标。因此,本视频的目标是如何利用麦色口统计数据,以便让我们更容易利用他的洞察力。 这些表可以让我们获得在实力上执行查询的详细信息。不过最常用的表是 wint statement summary by dejits, 它本质上是自上次重置表以来在实力上执行的所有查询报告。通常重置操作发生在重启麦色口时。现在让我们看看在这个表中能找到什么。 因为该表包含太多字段,无法正确显示在屏幕上,所以我将使用一个参数来垂直显示输出。因此我使用反斜杠大写 g 来代替绊脚分号。 现在可读性更强了,但是有很多干扰项,而且很难理解这些结果。以某种方式对其进行排序会很有用。排序的最佳后选项是查询在服务器上花费的总时间。这通过字段 some timer 未来表示, 它表示查询已执行的次数乘以平均执行时间。那么让我们对这个字段进行排序,同时还将结果限制为前十个查询。 现在我们可以知道哪些查询是最昂贵的了。其中, digest text 字段包含了规范化的查询语句。例如,这两个查询将被规范化为一个通用形式。 tom star 字段表示查询已执行的次数。如前所述, some timer 为字段,显示了执行该查询所花费的总时间。 somelike time 字段显示了等代表所所花费的总时间。 列表中的其他列也可能是寻找优化查询的机会,要诀在于搜索重要的东西。至于什么才是重要的东西,还取决于您的实际情况。例如,如果你从监控中发现大量内部临时表存在问题,其占用了大量内存或次盘,那么这两个字段就是筛选和排序的好对象。 然而,当我们不知道是什么导致了性能问题时,一个好的开始是查询耗时最多的十个查询。 如前所述,在这个试图上使用简单的查询并没有什么帮助。即使相关查询已被标准化,但在服务器 上执行的查询可能会非常多。因此,当我们使用此视图时,应该始终创建一个排序输出,以便能立即看到最相关的信息。为此,我准备了一个查询,并将其复制粘贴到此处。 每行显示了总响应时间和占总响应时间的百分比。查询执行次数,每个查询的平均响应时间以及查询通用语句。 这里显示了按总消耗时间排序的前十个查询,并清楚的说明了每种查询相对于其他查询以及整体查询的代价程度。检查排名前一千位的查询通常不值得花时间优化, 因为他们在总体响应时间中所占比很小。通常情况下,系统的大部分负债都来自于前几个查询。接下来,我们可以检查一个查询的平均执行时间,以便识别该查询的运 运行时间是否高于预期。与此同时,由于测量结果以皮秒为单位,因此输出并不适合人类阅读。该视图的格式化版本已按总耗时降序排列,称为 statement nars 视图。它是 size 数据库的一部分, 可以使用如下语句查询相关信息, select from size statement analysis limits sci 数据库包含了基于 performance camera 数据库构建的预制视图。然而,这些视图的缺点是我们无法通过更改视图来获取更多信息,以便深入了解问题的根本原因。让我们回到 event statement summary by digest 视图。 尽管执行时间分析可以帮助我们确定 哪些类型的活动对运行时间影响最大,但他并不能真正告诉我们背后的真正原因。在实践中,当一个任务占用大量运行时间基本上是花费在 cpu 上的时间时,我们或许可以深入研究这个问题,并发现部分执行时间是在更低级别的等待中花费的。例如, 针对表的 sleek 语句可能会消耗大量时间,但在较低级别,这些时间可能会花在等待 i o 完成上, 比如获取将在稍后阶段被过滤掉的大量数据。要想知道为什么做一个简单的选择,要花费这么多时间,我们必须深入了解该状态及其生成。执行此任务的配置文件。 您可在我们之前的视频中参考该配置文件的工作原理。另一个关键点是,查询是作为预准备语句执行的。也就是说,从客户端库执行的查询不 包含在 event statement summary by digest 表中。通常您需要使用 prepared statement sentences 表。 尽管如此,同样的原则也适用于此。这些都是任务,他们由各种子任务组成,而这些子任务都会消耗时间。 要优化查询,我们必须通过消除此任务,减少此任务发生的次数或加快此任务运行的速度来达到此目的。 一般来说,您可以在头脑中按照查询调用的序列图来思考查询的生命周期。从客户端到服务器,在服务器上进行解析、规划和执行,然后再返回到客户端。执行是查询生命周期中最重要的阶段之一。他涉及对存储引擎的大量调用来检索记录以及检索 记录之后的操作,如分组和排序。在完成所有这些任务时,查询会在网络、 cpu 统计、规划和锁定等操作中花费时间,尤其是调用存储引擎来检索记录。如果数据不在内存中,这些调用会消耗内存 cpu 时间,尤其是 io 时间。在任何情况下都可能因为执行不必要的操作而消耗过多时间, 例如执行的次数过多或运行的速度过慢。优化的目标是通过消除或减少操作或加快操作速度来避免这种情况。接下来,让我们来看看还有哪些情况可以进行优化。 回到 vent statement summary by digest, 试图让我们看一些例子或一些证明。进一步调查合理的条件。与发送回客户端的行数相比,当遇到检查的行数较多时, 这可能表明锁引使用情况并不佳,因为大量记录被发送到客户端前被丢弃了。如果完全连接的数量较多,则表明需要锁引或缺少连接条件。当联合条件没有锁引或者过滤不足时,就会发生全表扫描。如果检查范围的数量很高, 这可能表明我们需要更改表上的锁影。当使用二级锁影,但范围扫描包含了表的大部分数据时,使用二级锁影最终可能比执行全表扫描代价更高。如果在磁盘中创建的内部临时表数量较多, 这可能表明我们需要考虑使用哪些锁引进行排序和分组,以及允许内部临时表使用的内存量写入磁盘仍然比内存更昂贵。最后,如果排序合并的次数较多,这可能表明该查询可以从更大的排序缓冲区中受益。不过,如前所述,哪些指标具有重要意义 还取决于您的具体情况。通常,这些视图与其他视图和表结合使用。例如,您可能会检测到 cpu 使用率非常高。 cpu 使用率高的一个典型原因是大表扫描,因此, 您可以通过查询 steam tables with full table scan 视图来检查。通过全表扫描返回大量记录的一个或多个表, 然后,您可以使用 statements with footable scan 视图找出使用全标扫描而非使用缩影的语句, 让我们安慰使用锁引的技术列 no end excuse call 你降序排序 i o 性能对于卖色口数据库至关重要。数据在不同的地方读取和写入词盘,除了表空间和锁影之外,我们还有重做日志,二进制日志等。 高数量或延迟的增加本身既不是好事,也不是坏事。但是,如果您发现了某个问题,例如,如果确定磁盘还有时瓶颈,因为磁盘的利用率达到了百分之一百, 那么我们就可以使用 i o 表和文件 i o 视图来确定导致 i o 增加的原因。然后我们可以逆向查找相关表。 performance game 数据库中有多个表 包含 io 的延时统计信息,其中 tablely with some rebind exuses 特别有用。 例如,使用此查询代码,我们可以找出特定表。在本例中, reward 数据库中的四 t 表使用或未使用锁引的次数。 此视力显示在表上读取的记录数。首先,我们看到使用锁影读取的记录数,然后是空锁影, 这意味着读取这些记录时没有使用索引。在这里我们可以看到,与没有使用索引的读取相比,使用索引读取的记录数是微不足道的。因此,这可能暗示正在进行大量不必要的 io 读取。如果使用索引,这可能是可以避免的。 花一点时间考虑一下获取,插入,更新和删除计数器核实增加 家是非常有用的。考虑一下 world 数据库的 ct 表,它具有 id 列的主见和 ctrl 列的二级锁引。二级锁引是那些不是主见的锁引?首先,我们将进行一个简单的查询,查询 ct 表中 id 为五的所有内容。 然后,我将使用 performance gamer 数据库表 tableile with summary by index usage 来检查正在发生的 i o 操作数量。 我们有一次读取和一次获取。接下来,我将使用 ctrl 列,它适用于过滤的二级锁引。选择 cd 表中 ctrl 为 nld 的所有内容。 现在我们有二十八行记录。如果我们再次检查统计信息,会得到二十九行读取和二十九行获取。最后,我将按 ct 表的 name 列进行过滤。因此,从 ct 表中选择 name 等于 amsterdam 的所有内容, 我们只得到了一个结果。但如果检查统计信息,会发现读取超过了四千行,并且从数据库中的获取也超过了四千行。这只是因为 name 列上没有锁引, 所以并不奇怪整张表都被读完了。但有趣的是,如果我们进行更新,例如更新四体表,将内列原为 amsterdam 的记录设置为 amsterdam 一。 同样,即使是更新,对数据库的读取和获取也超过了四千行。 现在考虑该表中最后三行中的每个势力获取了多少行记录。同样,我们将 word 语句与 select, update 以及得利语句一起使用。最后再执行 insert 语句。 insert 语句没有 wear 语句,所以有点不同。对于每种类型的语句都会列出读取和写入的次数。 rose 列显示每个语句返回或受影响的行数。这意味着我们可以根据使用或缺少锁影来设置三种类型的过滤器。按主键,按辅助锁影或按无锁影。该表的一个关键要点是更新和删除语句,也是读取语句,即使他们是写 语句,原因是必须先找到记录,然后才能更改他们。另一个观察结果是,当使用二级锁影或不使用锁影来更新或删除记录时,读取的记录多于更新的记录。在我们的视力中,由于表相对较小,因此获取了四千行,但在较大的表上,此问题可能会更加明显。 虽然错误与查询调整没有直接关系,但错误确实表明出现了问题,导致错误的查询仍然会使用资源,但是当错误发生时,所有资源都将白白浪费,因此 错误会给系统增加不必要的负债,从而间接影响查询性能。还有一些与性能更直接相关的错误,比如因无法获取日志导致的错误。当有多个并发请求需要更改某个资源时,例如针对表中的一行, 该行在被单个请求更改时必须被锁定,以避免数据不一致。如果该请求的处理时间过长,将会影响其他所有等待处理的请求。 performance gamer 数据库中有五个表,其按不同类别对遇到的错误进行了分组。例如要检查按账户分组发生死锁的次数,可以使用以下查询, 其中 error name 列等于 reluctant log。 幸运的是,本地主机上的 rose 账户没有出现思索。第一行 user 和 host 未空,表示后台现成。最后总结一下,我们通过浏览 performance scheme 数据库并识别哪些信息可用以及哪些信息最相关来开始了本期视频,特别是在查找可能存在性能问题的查询时, event statement summary bye 这次表是一个非常重要的线索目标。然而 我们不应该局限于仅仅查看查询,还应该考虑表格文件 io 以及查询是否会导致错误。这些错误可能包含锁定、超时和死锁问题。好了,这就是本期视频的主要内容,如果对您有帮助,还请关注我们,感谢您的观看!
35代码坊 05:58查看AI文稿AI文稿
05:58查看AI文稿AI文稿好,这一节我们来讲一下这个 my soccer 啊, my soccer, 它这个创建用户,呃,以及给这个用户赋予权限, 并且如何从远程来访问这个数据库以及远程呢?可以使用这个,呃,用户啊,那我们首先来连接一下 my secure 杠, you root, 我的密码是 you 啊, 密码是一二三四五六。好,那这个时候就说明你的数据库没有开启 start 一下。 好,首先我们来创建一个数据库啊,手 dead base, 那这里面是没有的,我们来创建一个测试库 create dead base, 我们就叫 test trust it tf 二 b 四 use test。 好,那这个时候呢?就,嗯, marry marryer d b, 它是 massacre 的一个开源的一个版本啊, massacre 本身也是开源的,但是,呃, massacre 的 作者考虑到这个美斯科被这个 oracle 收购以后,后面的话,他开源的这个计划会受阻啊,会不会持续的开源下去还是未知数,所以他又出了一个 marryer d b 啊,玛尼亚 d b, 他也是 跟麦斯克内涵什么都是一样的,你可以理解成他就是一个一对孪生兄弟啊,只不过 mary t b, 他是 永远开源的啊。好,那这个我们来创建一个用户啊, great user, 然后我这个 user 是专门针对他给他用的啊,那我就叫 test user, 它是 user 啊,这里面啊, at 你,如果这 你取之是那个 house 的话,那么它就只能在本地使用,也就是说你在那个数据库服务器所在的那个本地使用, i don't divide by, 这个就是一二三四五六,这是给他一个创建的一个用户啊,创建一个用户 grand or where are e g s? 所有的权限 on on 哪里呢? on test test 是数据库的名称, 我们 test 点心啊,把下面的所有的对象 to, 然后喊个用户 to test test user, 那这里的写法还是一样,摆放号表示允许从所有主机来访问,那么 myserker 允许所有主机来访问,它那里有一个 bend 啊,就是 e n d address, 你把这个值设置为零点零点零点零啊,那就可以了。好,那这个权限已经给他了啊。其实如果说你这里面 它这个所有的信息就是放到了这个,我想表达的就是它可以 from, 它可以从这个表里面。 my soccer 对 user 从这个表里面去查询到啊,你看这里面有 管信息 哦,这有点乱了,玩 user, 你看这里就有一个 user 了,这可以过滤一下 test user, 这个就已经参与出来了,并且它的 host 啊,我们可以看它的 host 是百门号,也就是说 你如果最开始创建它的时候,是那个指定的是 local host, 而它后面指定 local host 的,你可以直接 update 它设置这个 host 的这个字段,为这个摆毛也是可以的啊。 好,那这就是在 master 当中如何来创建一个用户,并且给用户负权开启远程访问啊,真心的细节, 但是我们少了一个啊,这个很容易忽略, 刷新权限啊,你这样才会生效。 flash flash privates, 也就是这个,就相当于 flash d b, 跟那个 redis 一样, redis 的所有东西都是在内存当中。呃,你要想把让它持续化,让它写到日志里面去,那这个时候你就要 flash d b, 就把它落盘,这个机制有点类似哈,但是, 呃,这个就主要是把这个权限你写到句台表里面去,把它直接画存起来。好,这就是 my circle 当中如何来创新用户啊?以及现在这个细节。
 34:46
34:46 13:19查看AI文稿AI文稿
13:19查看AI文稿AI文稿大家好,都知道买手后中事务格力级别总共有四种啊,分别是读未提交,读已提交,然后可重复读和串形化, 那这四种事物隔离级别有什么区别呢?以及他会带来哪些这个事物问题呢?今天这节我们就给大家来讲一下。首先讲事物隔离级别之前,那我们先了解一下那事物都有哪些特性啊 啊,事物的特性总共有四个,就是我们常说的 a、 c、 i、 d 啊, a 就是我们的原子性啊,就一个事物,它是一个不可分割的一个工作单元 啊,整个失误下的所有的操作啊,要么全部提交成功啊,要么全部提交失败啊啊,对于一个失误来说,不可能只执行其中的一部分操作啊,就比如说我们在银行 转账啊, a 账户给 b 账户转账的时候,那 a 账户的余额啊,相应的会扣减啊, b 账户的余额会进行一个增加啊,就是说 ab 账户的余额变动啊,是这个事物中不可分割的两个工作单元啊,他要么一起成功,要么一起失败啊, 不会存在说 a 账户的钱扣减了,但是 b 账户啊却没有收到款的一种情况,这就是事物的原则性啊, 那事物的一致性呢,就是说事物开始之前呢,数据库中存储的数据啊,处于一个一致状态啊,那事物完成之后啊, 这个数据啊,就必须再次回到一个已知的一致状态啊,然后除了这个一致性之外啊,还有这个隔离性啊,那隔离性啊,就指的是啊,多个用户啊,多个用户并发访问数据库的时候啊,一个用一个用户的事物啊,不应该被其他用户的事物所干扰啊, 也就是说多个并发事物之间啊,数据要相互隔离啊,如果多个事物操作同一批数据时啊,则需要设置不同的隔离级别啊,否则会产生一些啊,数据问题啊, 比如说 a 给 b 转账啊,不应该受 c 给 b 转账的一个影响,这两个事物啊是相互隔离的,数据不能相互影响啊, 这是事物的隔离性啊,那事物还有一个特性叫持久性,就是说这个事物啊一旦被提交之后啊,他对数据库中数据的这个改变是永久性的, 即使数据库发生故障也不应该啊,进行数据回滚或者其他操作啊。啊,这就是事物的持久性啊,我们先来看一下啊,这个食物格力级别的第一种啊,叫毒味提交,那毒味提交会产生这个脏 赌问题啊,接下来给大家演示一下啊,首先的话我们准备一个叫优色表啊,优色表里面有三条数据啊,其中一条 id 四一,他的名字是张三啊,这条数据, ok, 我们起一个窗口啊,在这个窗口中我们开启一个数,然后将这个 id 四一的这个人的名称啊改成一个老王啊, ok, 我们先执行一下,看下效果啊,我们先启动这个数,然后去做一次这个更新,这个时候因为我们这个数还没有提交,对吧?我们去这边去看这个表里面的数据,他是不会被刷新的啊,然后在这个数没有提交的时候啊,我们再起一个窗口啊,这个窗口我们设置这个 当前的失误格力级别啊,为这个独位提交啊,设置独位提交,然后设置完独位提 提交之后,我们开启一个事务啊,去查一下这个 id 是一的这个英格密码,这个时候我们发现啊,这个别名已经变成了老王啊, 那就说明我们当前事务还没有提交的时候啊,这个事务啊,已经读到了我们未提交的一个数据啊,啊,这个就是形成了一个章读啊, 那假设我们这里的事物啊,进行一次回滚的话,那我们这个啊,数据库啊,事物回滚之后啊,那我们这里再去查询的时候啊, 看他又变成了一个张三了啊,这个就是一个张读的问题啊,就是说一个新事物啊,读取到了另一个失误中还未提交的一个数据啊,这就是张读,那怎么解决张读问题呢?那就是要需要把我们的 数据库的这个失误隔离 gb 啊,改成这个读已提交,它就可以解决这个赃读的问题啊, 怎么操作呢?就是我们同样开一个窗口啊,我们设置这个呃,昵称为老王之后啊,我们还是不提交这个事务啊,然后我们在另一个事务中,我们把这个事务格力级别改成读语提交啊,我们咨询一下, 然后我们开启事务啊,查一下这个昵称,我们会发现啊,这个昵称还是张三啊,也就是说 前一个是我他没有提交的时候,我们读取到的数据啊,还是原先的数据啊,并没有读取到他未提交的这个数据啊,这个就解决了这个赃读的问题啊,通过这个读已提交这种事务隔离级别啊,解决了这个赃读的问题啊, 那这个时候假设我们这条数据进行一个提交的话,假设进行一个提交的话,我们提交试一下,然后看一下我们这个事务里面,再去查询的话,查询出来是不是老王啊? ok, 他已经查询到老王了, 但是他会引入一个新问题啊,叫不可重复读啊,还是刚才的例子啊,我们在这个穿孔里面,我们假设啊,我们这里是把当前这个 id 是一的这个年龄啊,改成三十啊,我们原来是二十五,我们把它改成三十啊,开启这样一个失误啊, 然后我们试一下啊,什么是不可重复读啊?我们先开这个失误之后,我们先开启失误,然后进行一个呃,更新操作啊,更新完之后我们不提交啊, 然后再建一个窗口,之后啊,我们输入隔离疾病还是毒已提交啊,然后我们这里要做什么?我们要去查询啊,查询这个 a 指大约二十五的这个数据啊, 然后我们去查询的时候啊,发现是有两条数据的, ok, 由二六二九啊,然后我们刚才这个 id 是一的这个数据啊,并没有查询出来,因为我们这个事务还没有提交呢。那假设在这个时候啊,我们对这个事务做一个提交, 在这个失误提交之后啊,我们在这个失误里面再去查询的时候啊,哎,这里的数据啊,把这个啊, idc 一的这条数据查出来,那也就是说我们在这个失误里面啊,我们 执行两次 select 的时候啊,就是查询条件一致的时候啊,他先后查询这个结果是不一致的,这就导致了这个叫不可重复读的一个问题啊,因为 啊他两次读渠道的结果是不一致的,所以他这个问题就叫不可重复读啊啊,也就是说我们虽然说事务格立级别改成读与提交了,但是这个不可重复读的这个问题啊是依然存在的。 ok, 那怎么解决这个不可重复读的这个问题呢?这就需要我们将数据库的输入隔离级别啊 啊,改成这个叫可重复读啊,我们来给大家演示一下,首先同样的,我们先把数据进行一次回国,就是改回这个张三二十五啊,然后我们开一个窗口啊,开一个窗口,我们对这个 啊名称做一次修改,我们把名称改成这个老王啊,改成老王的时候,我们先不提交这个事务,我们执行一下, 我们不提交这个事务啊,然后可以看到啊这个名称啊还是张三,因为我们这个事务没有提交啊,然后我们这时候再开启一个事务,我们把这个事务格力级别啊改成这个可重复读啊, repeatable 一个 red, 然后我们跑一下可重复读,然后我们开启一个失误,之后我们要做什么操作呢?我们就是要查询一下这个 id 是一的这条数据啊,我们查询试一下,看它是什么结果 啊,可以看到他还是张三啊,因为我们事务没有提交啊,然后我们这个时候我们在窗口一中进行 进行一个事务提交的一个操作啊,我们执行一下 commate, 提交之后,我们去刷新一下这个列表,发现这个名称已经该变成老王了。但是我们这个事务啊,因为我们先前查的时候是张三啊,我们再次执行这个查询的时候,我们看一下, 哎,可以发现啊,他还是张三啊,这样的话其实就是说我们解决了这个不可重复读的问题啊,因为我们前后两次啊,读取到的结果都是张三都是一致的啊,并没有读取到说前面是张三啊,然后后面又有读取到最新的数据,叫老王了 啊,这样去解决了一个叫不可重复读的一个问题啊,通过这个事物隔离级别改为这个,呃,可重复读, 那不可重复读的问题解决了,但是这个他会引入一个新问题啊,叫做换读啊。什么是换读呢?我们再给大家演示一下啊,首先同样的我们新建一个这个窗口一啊,在窗口一里面啊,我们插入一条啊, id 是这个 啊, id 是四的这个数据啊,我们插入一个 id 是四的数据啊,我们看一下,我们先启动一个四五,然后插入一个 id 是四的数据啊,这个时候我们失误没有提交啊,那这里去查的话,这个 id 是四的,是查不到的, ok, 然后在这个数没有提交的时候,我们同样啊开启一个事物啊,因为这个是可重复读啊,我们开启一个事物之后啊,我们要做什么操作呢?我们就是要给这个先查询一下是 id 是四的数据啊, 首先我们先启动这个数,设置这个格力级别啊,为可重复读,然后开启数, 然后再去查询这个 id 是四的数据啊,这个时候发现我们这个数据是不存在的啊,不存在之后我们要做一个什么操作?我们可能会去做一个插入操作啊,就是我们因为 id 是四的数据不存在啊,这个时候我们可能会就想给他插入一条数据啊, 插入一条数据,在我们在我们插入数据之前呢,我们假设啊,这个 啊,窗口一的这个事物啊,进行了一次提交的时候啊, ok, 我们提交成功,这个时候我们执行这个插入的话,他就会报错啊啊,他报这个主键 id 是四的数据已经存在了 啊,这样就产生了一个幻读啊,因为我这个事物之前查询了一次这个 id 四四的数据啊,并没有查询到啊,那在这个期间如果有事物啊进行一次这个插入的时候啊,我们啊再去做一个插入的时候啊,这个就直接报错了啊 啊,他是一个幻读啊,好像我们之前这个啊读取出来这个空记录好像是假的一样,这就是幻读的一个问题啊 啊,那解决患毒问题,他只需要设置这个数据库隔离级别啊,为串形化啊啊, 串形化是食物隔离级别里面啊,这个呃级别最高的啊,它可以有效的避免我们之前说的这个脏读啊, 不可重复读和换读的问题啊,但是这个串形化啊带来的性能开销也是比较大的,所以一般不推荐使用啊,所以我们买 circle 里面啊,他的这个默认的这个食物隔离级别就是可重复读啊。 ok, 今天给大家介绍一下这个四个啊,数据库的事物隔离级别啊,以及他所能解决的一些问题啊,以及带来的一些新问题啊。 最后我们总结一下,就说章读啊,章读是一个事物啊,读取到了另一个事物还会提交的数据啊,解决章读的话,可以将事物隔离级别改为读以提交。 然后是不可重复读啊,就是说统一事物下使用相同的条件啊,先后多次查询的时候啊,查询的结果却不一 一致啊。那解决不可重复读的话,可以将事物的格力级别改为可重复读啊。最后是这个幻读,幻读的话一般就是我们先查询再插入啊,那查询的时候啊,没有这个记录,但是插入的时候啊,就爆这个组件冲突了, 这就是一种患毒啊。那解决患毒啊,可以将数据库的事务隔离级别改为串形化,当然啊,串形化的这个性能开销比较大,一般也不推荐使用啊。最后我们讲买车后的这个默认的事务隔离级别啊,是可重复读啊。 ok, 今天的这个分享就到这里啊。
44小波聊AI 02:39查看AI文稿AI文稿
02:39查看AI文稿AI文稿没加锁引导致研发和 dba 每人罚了两千块钱啊!大家好,我们知道 myserk 是一个功能强大的关系型数据库,但对于新手来说,在使用初期可能多多少少会犯一些错,这里就来总结一下新手最常犯的错误, 有些甚至产生了严重的后果。首先是不备份数据,他的问题就是数据丢失的风险非常大。解决办法就是我们需要定期进行全备,还需要开启 blog 并且备份 blog。 错误二,就是不加,所以产生的问题就是数据量一上来就会出现大量慢查询。我曾经待过的一家公司, 某个活动刚上线推广不久,就出现大量响应超时,最后原因竟然是某个条件自然没有添加,所以最终这个项目的研发和 dba 每人罚了两千块钱,公司也损失了不少,很多用户看到响应超时就不再继续参加活动了。错误三,就是 是不优化查询,导致的问题就是会有性能下降,还有响应时间变长。解决办法就是我们需要学习怎样去优化收口,还有就是通过执行计划来分析查询语句。错误四,使用弱密码以及不控制权限。他产生的问题就是会导致数据库被攻击勒索。在去年就遇到一个这样的案例,一个朋友 他使用阿里云数据库,临时把密码改成一二三四五六,结果第二天早上一来就发现数据库只剩一条数据了,上面写的是一些勒索信息,还有勒索的联系邮件,其他数据都清空了。解决方法就是我们需要设置复杂的密码,并且增加客户端白名单。错误五,就是不监控数据库, 产生的问题就是不能及时发现,还有解决一些性能上的问题。解决办法自然就是增加监控工具,比如增加 promise。 错误六,不定期清理和优化表,比如某些日字表不去管了, 这样会导致数据库一直膨胀,并且性能会下降。解决办法就是定期清理不再需要的数据,并且清理之后需要重组一下表。错误期,使用迪丽特一次性清空历史数据,它产生的问题就是导致大失误,并且会产生重库延迟。解决方法就是每一条语句删除少量数据,比如一千条 再分多次删除,或者使用归档工具,比如 p t r 卡。如果要清理整张表,建议用川 k 的。错误吧,就是在建表的时候不增加组件,这样产生的问题就是写入数据时很可能会导致数据页频繁分裂, 从而导致写入效率低,还有夜空间浪费。解决办法自然就是增加组件,并且建议是增加自增的组件。错误久就是不增加高可用。他导致的问题就是如果卖烧烤所在的机器一旦荡机,数据库就挂了,业务也就会中断。 解决办法就是增加高可用、高可用的一些方案,比如主从加 keep, nine, m, h, a, m, g, r, 还有 ocostra 等方案。如果有用请点赞加收藏,谢谢!
23马听




