frequency函数统计出现次数

粉丝6.9万获赞6.8万
相关视频
 08:39查看AI文稿AI文稿
08:39查看AI文稿AI文稿啊,各位同学大家好,欢迎继续学习 excel 技巧系列视频教程。这节呢也来解答一个,也是大家经常问的一个问题啊,就是如何去统计,呃,连续达标的最大次数 就是在一个时间段内,或者在一个十七内啊,在一个统计区间内啊,我有些数是达标的,有些数是不达标的,那么我的达标的数里边呢?这个连续的达标七数啊,最大是多少七?呃,这个场景呢,呃,虽然比较小众啊,但是也是经常被提及 啊。今天呢就给大家来讲解一下如何去把这个数据呢啊统计出来。好,我们首先呢来看一组这个数据啊,这是一组模拟的数据,在这里边呢我们要统计一下啊,连续大于等于六十的这个分数 啊,这个最这个最大的出现次数啊,最大次数是多少啊,就连续出现啊,这大于等于六十的这个数,像这个八十九,八十二,九十八,哎,这个就断了,因为五十九了,然后呢六十五,六十一,九十二,哎,这又断了,这五十三了,五十一了。然后这个面呢 啊,这个就比较长了啊,这个就比较长了,然后一直到了这个地方才断啊,所以我们呢在这个数据里边呢,我们其实最终呢就要想知道这个连续的这个次数是多少次啊,最大次数 好,这里边呢我们要用到的是这个 freeconsy 的函数啊,这个里边有一个技巧啊,我们在这里把这个函数一边写一边给大家讲解。等于啊 freeconsy 他呢有两个参数,第一个参数的就是你原始数据啊,原始数据呢,我们来做一个判断啊,做一个判断, 就是我们用 af 来做一个判断,如果啊,就是这个数值,我用一下 f 四把的锁死啊,如果这个数值大于等于六十,六十是我们的标准吗?然后呢,我们就来 输出什么呢?输出一个用肉函数啊,肉函数呢,他会给我们返回这个列行的这个行号啊,还是跟他对应的啊, a 一到 a 二十啊,用肉函数返回这个行行号啊,这个也锁一下吧,往前起点 啊,这样的话呢,我们这个 f 呢,就给我们返回的是一个这个数组啊,我们来看一眼,我们把它选中,然后呢 f 九啊,你可以看 一二三啊,一二三,然后呢,这个一二三,就是说第一个数,第二个数,第三个数都是大于等于六十的啊。 boss 呢,这到第四个数,第四个数就断了,然后第五个,第六个,第七个数呢,又继续,然后第八个第九个数又断了。然后接下来就是我们刚才看到的十十一十二,一直到十七啊,第二又断了, 这样一个数啊。然后呢,砍出自己回去。好,这是 free quincey 的第一个参数。然后呢,我们还要给他做第二个参数,第二个参数跟他正好相反啊。 if 如果 跟那个正好相反,相反的意思就是说前面是大于等于啊,这边呢就是小于小于六十。然后呢,还是用 row 来去取这个行号啊,一 a 二十。 好。然后呢,我们来看一下他的反馈。 f 九 啊,你看他的返回呢,跟刚才这个数呢,正好是这个相反的啊,前面刚才前面这个参数呢,大于等于呢,是这个一二三啊。然后呢, 到第四个时候呢,就是小鱼了,所以这两个就是前面的前面这个 f 产生的值,和现在大家看到这个 a 幅产生的值呢,正好是互补的啊,互补的。然后呢,我们在这个基础值上, 用后边这个 f 产生的这个值呢,去做这个统计区间啊。统计区间,呃,也就是在在 f 九一次啊统计区间,也就是说在零 到四啊,就是这个的,到第四行之前,这是一个区间,然后从第五行开始到第八行之间啊,这是一个区间啊,然后八行在九行是一个区间。然后呢,这个从这个第四行开始 啊,又到了这个第十八号啊,这又是一个区间啊,就是有数字的啊,这是一个区间的分割。那么在这些区间里边 啊,前边的这个 f 这个数啊,就是前面的这个 f 产生这个数所产生的这个频率啊,所产生的这个频次啊,就是在零到四之间啊,这个前面大于等于六十的有多少次 啊,在这个四以后,从这个五开始到八之间啊,大于等于,大于等于这个六十等于多少次啊,以此类推,从第十到第十八之间啊,大于等于六十等于多少 次。这个看到的这个 boss, 你不用管他啊,这个数字呢,就是我们的这个呃笨的分格区间啊,也就是 freecons 以函数的第二个参数啊,分格区间好看出自己的回去。这样的话呢,我们就啊通过这样的手段呢,得到了这个 大于等于六十这个数值呢,连续的在每一个区间他出现的次数啊,这个我们就统计出来了。回来之后呢,因为我们需要这个最大的啊,需要最大的这个次数,这个时候怎么办呢?这个时候我们需要在外边再套一层,我们用这个麦克斯啊,取这个最大的纸就可以了。 好,你看到了没有?这是八次啊,连续出现的八次,一、二、三、四、五、六、七八啊,就是这个,这是最大的,刚才我们已经看到了啊,这是最大的八次。我如果感 改一下啊,比如说把这个改成这个,第一个七十改成五十五啊,这个就变成七次了啊。所以这个就是我们整体的一个实现的逻辑啊,用 freecons 的在里边套两个判断的数组啊,来实现这个互补型的 这个区间统计啊,这个正好得到我们所要需要的这个连续的达标次数啊。这是竖着的,那么横着的怎么办呢?横着的,其实我们需要改一个参数就可以了啊,我们需要改我把这个 啊,不用了,这个我们要重新写啊,横着啊,比如说现在呢,我们这个数字横着的啊,横着的就是从 a 一直到 n 啊,这个数怎么办啊,这个数呢,我们在这里面等于 freeconc 啊,最后再加 max 啊,然后呢,还是 f 啊, 如果这个数啊, f 四,他大于等于六十 啊。然后呢?我们就需要这个地方就不能用肉了,因为它是横着的啊。我们要用什么烤冷啊,用烤冷这个寒水来去产生这个裂号啊,而不是行号啊,还是这样的一个数据, f 四 好,这是第一个 f, 然后第二个 f 啊,如果是这个数, f 四啊,小于六十,然后呢?我们还是用靠了, but i 选中 f 四算四啊,这是这个分配 c 啊,然后外边再套一层 max 就可以了。嗯, max 原理是一样的,只不过方向这个变了啊,方向因为从竖着变成横的,所以我们就不能肉用肉横竖了。我们把肉横竖全部变成了什么,靠,那么横竖啊。唯一的区别就在这个地方。 好,我们来看一下结果三二三。那我们来看一下一二啊,这断了一二,这断了一二,这断了一 看一点又断了啊。然后最后是一二三啊,一二三。好,我们现在把这个地方改一下,改成六十八。我们看一下,改成六十八之后就应该是五个了啊。我们试一下改成 六十八,看这个三是不是能变成五,哎,变成五了。好,大家看到好,这个就是如何利用函数啊,来及动态统计这个连续达标的最大次数啊。这个技巧呢,就给大家分享到这。
36数据分析精选 01:37查看AI文稿AI文稿
01:37查看AI文稿AI文稿用法,亏损一、函数统计这一列数据在不同数据段的出现的次数, 我们把数据呢划分为这么几段,从零到二十,二十到五十,五十到一百,一百到一百五,一百五到两百。划分是几个档次,然后在第一个格里面写等于 括号,选择数据范围,可以这样去选择整个的数据范围,也可以选择整列,如果数据很多的话,可以选择整列,建议呢还是选择数据范围更为稳妥,选择所有的数据 啊,这个数据还是比较多的,有一千多个,选择完以后,第二个参数 就选择这个分界点的数值, 然后右括号回车。旧版本呢,要按住 k, 按住 ctrl 加 shift 调回车啊,我现在是用的三点五个版本,直接挑选回车就可以得到零以下的。没有 啊,零到二十的数据有一百四十个,二十到五十的数据有两百一十个,五十到一百的三百五十三个,一百到一百五的三百五十三个,一百五到两百的三百五十五个,两百以上的是零个。 现在如果我修改这个数据,比如说我把二十交给三十,那相应的数据呢,也会变化,也就说零到三十的呢,是二百一十二个啊,三十到五十的一百三十八个, 我把这个也改成一百二十,那就是从一百到一百二十的是一百三十四个,从一百二十到两百的是五百七十四个。这个数据是可以很灵活的进行统。
274EXCEL助手 05:47查看AI文稿AI文稿
05:47查看AI文稿AI文稿火车爸爸带你玩转数据表,今天我们来分享用两种方式来计算数据的分布。首先呢我们这里假设有一位零售数据,然后是一个啊员工,然后售卖物品数量。 呃,本次呢我们需要用到的两个函数,一个是 freecraftstrotescontaphants 函数啊, freecraftstrot 呢,它其实是直接用用于计算这种数字出现频率的,然后它但是它是实际上是一个数组公式,然后它返回的是一个数字数组, 这里我用红色字体标出了数字公式呢,在输入完成之后,需要按一下 ctrl shift 加回车,然后这个公式才可以生效,这个是需要我们注意的。然后另外一个 comtifs, 这个海叔呢啊,大家可能应用过,他其实更多的是用来条件判断,然后啊可以 进行一个多条件的判断,然后直计算这些符合条件的出现的次数。 然后接下来我们演示一下,首先用第一个本人配词函数来计算一下,在这里呢我们先输入一下啊,先讲解一下这个右侧这些这种码,我们看可以看到售外的最低数量呢是六十一,最高是九十七 啊,我们这里把它分成了一共是五档,是五十九件以下的,然后六十到六十九为一档,七十到七十九,八十到八十九以及九十件以上的,然后一共是五档,我们在这里呢指定了这些分层的数值,这个是一会呃 frequency 和 canapes 都要都需要用到的一个比较条件, 这分布范围呢其实是给我们这个用来看的,然后这个实际的这个分通数值其实才是参与计算,在这里呢我们可以写入这个 函数,然后比较一下,取消我们的数据源,然后并且给他进行一个锁定, 然后比上我们这边我们的这个分档, 这些数字给它锁定之后,摁下回车之后,这里还统计是零,因为它是一个数字公式,在我们没有摁下 快捷键,肯定是这家会车的时候他会生效,这时候选购所有单元格之后,看一下这三个键啊,可以看到这公示后前后呢追加出了这种大括号,这时候表明他是一个速度公式,并且已经生效了。我们可以看到我们统计数的分布,五十九键以下的没有,没有人,然后 六十到六十九这一档呢是只有一个人,然后七十到七十九有六个人,这个应该是人数最多的一档,八十到八十九有三个人,九十分以上的呢,九十件以上的有四个人。另外我们还可以用 ctrl 来统一下数值的分布,在这里呢,我们可以先把这个五十九件以下改成零到六十九, 然后这样的话理解起来会更更加容易。在这里我们可以先说一个公式, 然后可以看到我这个函数的应用格式,然后数据原一,判断条件一,数据二,判断条件二,我们先输入数据原一,然后用 f 四把它锁并上,这时候我们要让它大于零, 首先我们先输入我们的符号,大于用双英文的双引号把它连起来,然后输入一个连接盒,这时候我们希望在相 填充的时候,他能够自动的去啊变化这个单元格的引用,所以我们这边不能输入固定值领,而是需要用一个函数 n 来转化一下它上面一个单元格,比如我们转化成它上面这个 第十一单元格,因为这个这个单元格里边呢,他其实是文本用,恩,这个函数转化之后,他得到的数据上其实就是利用, 所以我们就相当于变变化的,然后变相的用这个一十一获取到了零值。这样在我们向下填充的时候,这个单元格它会自动的填充到一十二,一十三,才能实现我们动态数据的一个统计,然后接下来输入条件,数据为二, 然后还是 nf 四锁定,然后等号,这时候我们第二个判断条件呢,就是要因为眼号引起来要小于 小于等于,然后连接说一十二单元格,也就是刚才我们的五十九,这数完成之后,然后我好回车, 可以看到统计结果是零零到五十九分的呢,这个呃,就零到五十九件的人售卖售量的人是零,然后向下拖动 啊,可以看到这个六十件这个层是一和上面统一是一样的,七十分的呢,七十件的也是十六也是一样的,八十到八十九是三也是一致。但在九十件以上的这时候就出现点问题,我们可以判断一下他的原因在哪。 这里我们打开这个追动器,可以看到他其实统计的范围呢,是要大于八十九,然后小于等于这个这个单元格,这个引用呢,我们这里没有填,他是一个空值,所以导致他统计 来,因为大于八十九小于零的这种这种情况病急他是是没有的。为了解决这个问题,我们在这里直接输入一个一百,其实就可以相应的解决,因为我们这里看到最高的,最高的售卖建设是九十七,所以一百就可以拿过这个情况, 这样就能完美的用 contivs, 然后计算这些数据的分布。这就是今天我们这两用分分司以及 contics 分别计算这种数据分布的情况,然后计算得到这个结果之后,我们都可以分别给插入啊这种顶装图或者是柱状图,然后更直观的去展示这些数据 啊。好的,今天的分享就到这里了,有任何问题欢迎随时私信联系我,再见。
 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿数据分段统计函数之王,飞坤西函数,比如在这里我需要从花名册这一个表格中统计出各个年龄段的人数, 使用飞坤系函数三十秒就可以解决问题。首先框选人数所有的单元格,然后输入公式,等于飞坤系,双击飞坤系函数。第一个参数,一组数值,也就是我们的统计区域, 这里我们是需要统计各个年龄段的人数,那么年龄这一列就是统计区域,我们就选中年龄这一列逗号。 第二个参数,一组间隔值,首先输入一个大括号,然后在大括号里面输入间隔值,我们来看这里的年龄段是分为二十五岁以下的, 然后是二十六到三十五,三十六到四十五,最后是四十五岁以上的,那么我们就输入间隔值,二十五、三十五、四十五, 数字之间分别用分号隔开,再按 ctrl 加 shift 键不松手,再按回车键就完成了统计,你学会了吗?
1569丁当(excel零基础教学)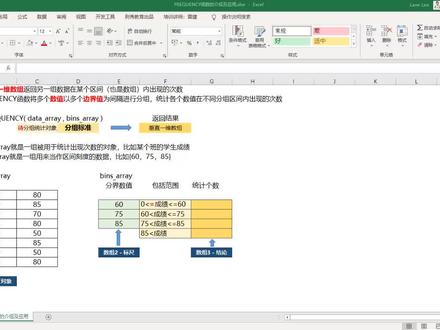 28:11查看AI文稿AI文稿
28:11查看AI文稿AI文稿同学们大家好,今天我们来学习 frequency 函数。 frequency 英文中的意思是频率和次数,那 frequency 函数的概念是以垂直一位数组返回某一组数据,在某个区间内出现的次数。 frequency 函数的作用就相当于把多个数值以多个边界值为间隔进行分组,统计出各个数值在不同分组区间内出现的次数。比如说你手上有一百个苹果,现在要以不同的重量标准进行分组, 分别把它装到不同的篮子里去。比如说我们拿出四个篮子,分别贴上小、中、大、超大,怎样子去确定具体某个苹果该放到哪个篮子里去呢?那四个篮子我们就需要三个边界值,比如说小于十克的 属于小,十克,到二十克的属于中,二十到三十克的属于大,三十克以上的属于超大。那这样子我们就可以把这一百个苹果分别以重量为标准,放到不同的篮子里去。 最后我们在统计每一个篮子里有多少个数量的苹果,这个数量以一个数组的形式呈现出来,这个过程其实就相当于 flick c 的一个作用。再来看一下 flick c 的一个结构, 它的结构并不复杂,只有两个参数,一个是 data 类,相当于是带分组统计的对象,就相当于我们刚刚提到的一百个苹果。 然后宾色类就相当于是一个分组标准。那这个分组标准其实也是以多个边界值构成的一个数组。就像刚刚我们提到的是十二、十三、十三个边界值可以构造出四个 区间,对不对? n 的边界值可以构造出 n 加一个区间,比如说给你一根绳子,你砍三刀,那肯定会出现四段,对不对? 然后做完之后,我们统计出来的数字会一个垂直一位数组的形态展现给我们。好,我们可以再举一个比较常见的例子,某个班级所有学生的成绩,他就相当于是一个带分组的统计对象。 我们要以三个边界值,六十、七十五、八十五为边界值。三个边界值可以划分四个区间, 比如说小于等于六十的啊,一个区间六十到七十五一个区间,七十五到八十五一个区间八十五往上一个区间。那我们就可以来做一下这个演示,让大家更加直观的去明白这个 frequency。 这个是数组一,相当于是带分组统计的对象,这, 这个是边界值构成的一个数组,相当于是一个标尺作用,那这里是一个返回值所构成的垂 c, 因为数组, 那为什么这里的单元格多于这里呢?对吧?刚刚我们也讲过了,三个边界值可以构造四个区间, n 的边界值可以构造 n 加一个区间啊,这里一定是 n 加一,对不对?好,那我们来示范一下,我们先选中这个 n 加一的区间,输入等于 frequency, 然后选择第一个参数 data 类,就是带分组统计的对象,再输入这个分组标准。啊, 好,括号括回来, ctrl shift enter, 我们就可以得到这么一个垂直异位数组,作为我们的 frequency 的返回结果。我们来看一下,零到六十分的有两个啊,一二是吧?只有两个,五十,六十到七十五分 有六个,那我们就数一下七十到底有几个,对吧?好,刚好是六个。同理,七十五到八十五分的,我们要统计一下八十分和八十五分,对吧?一二三四刚好是四个。所以由这个例子我们可以知道, 这个边界值它是归属于上一个区间的,且是该区间的上限, 对吧?就是八十五其实是属于这个七十五到八十五这个区间内的,他是归属于这个区间内的,而且呢,八十五是这个区间的一个上限啊,刚刚我们更新了一下,他的数据有所变化,我们可以再来看一下,八十和八十五这两个数字在这个区间内出现了六次,我们 看一下一二三四五六,对吧?好,那希望这样子大家可以对这个 frequency 的一个函数的结构参数以及它的作用有一个大致的一个了解。 那我们来讲,那我们来讲一下这个函数的特性啊,很多我们已经提到过了,如果提到过我们就简单带过。第一个 frequency 是一个数组函数返回多个值啊,这个没有问题吧? 第二个 frequency 呢,它的返回值一定要比这个 bincelle 的元素多一个,这个也解释过了,三个边界值可以有四个区间, n 的边界值可以有 n 加一个区间,对吧? 然后呢, bean 三六的元素都是取值范围的上限,且包含在该范围之内,就是刚刚我们这里测试过的,我特意写了八十五,那八 八十五它是统计在这个七十五到八十五之间的,对吧?这是它的范围标准,大家可以仔细去看一下。重点是这里有个零啊,零是包含在这个零到六十之间的,这些全是小于号,但是唯独最上面这个零,它是等于号啊。 第四个 frequency 返回的是垂直异位数组,他默认返回的都是垂直异位数组,如有需要,可以用 transpose 进行转制。这个后面我们也会演示。第五个 frequency, 忽略控制和文本,仅对数字处理分布计算, 仅对数字处理分布统计。如果有需要呢,可以将文本转换成数字再去处理。这个我们最后一个例子也会提到好,大家可以暂时先不去管这一条啊。我们讲完第六个 beats 二六的参数可以乱选, 但是呢,他仍然是以声序的规则填入对应位置的对应数量。这一条大家可能理解起来比较困难,我们往第二个例子去看就可以明白了。第七个,如果 bencil 类出现重复值,那么仅在第一次出现该值的对应位置输出相应数量, 其他位置呢?输出为零。比如说这里我们是三个边界值,那我们如果把这个第二个边界值也改成六十,那大家是不是会以为这里也会出现四,其实不然,这里会出现零啊,零到六十之间有六个,那就说明有六个五十,我们数一下,一二三 四五六,对吧?刚好六个,那第二个六十的时候,他其实就会默认啊,这是一个规则,第二次出现重复的一个边界值的时候,那第二个或者第二个往 后的所有重复项,它的一个对应的数量都会出现为零。是这么一个特性,我们后面也会讲到,而且会利用这个特性去做一些啊,统计为一值啊,各种一些技巧。第八个 frequency 输入前一定要选中比宾色类多一个单元格的垂直异位数组区域, 然后输入之后呢,一定要按 c、 s、 e 快捷键完成输入。 好,我们来看案例一,请把下方成绩数据根据对应参数统计及格、不及格、良好、优秀各个区间对应的人数。那我们刚刚也知道了,这个区间是包含数据在零啊,小于等于 x, 小于等于六十,就是六十到零,它都是包含在第一区间内,然后 六十到小于 x, 小于等于七十五,它是包含在这个第二个区间,同理第三个区间它是,它是包含七十五,然后呢,这里是八十五,对不对? 那第四个区间是所包含所有大于八十五的数据,对吧?那这样子,其实我们来看一下,如果我们要针对不及格、及格、良好、优秀来统计的话,我们的这个边界只要做如何修改,比如说我们这里对应的是不及格,这里对应的是及格, 下面对应的是良好,再下面对应的是优秀。那我们再考虑一下,常规情况下不及格这个六十是不是不应该包含在里面?那我们这里要改成五十九对不对?那这里就会相应的 改成五十九,那五十九以及五十九以下的他都属于这个区间范围内。当然啦,有个前提,这里没有什么点五的一个分数啊,都是整数,这个六十我们就改成了五十九,对吧?因为刚刚这个变了之后会影响这两个啊, 那这里呢,我们八十五应该属于优秀,那我们最就应该改成八十四,好,那这里相应的位置改成八十四,这里相应的位置改成八十四,我们把这个七十五改成七十四,分别去做一个调整, 那就七十五,它是属于良好了,对不对?七十五到八十四都属于良好,那这样子才是符合我们常规的一个成绩判断的一个逻辑。那既然边界值我们确定好了,我们就可以去写我们的 frequency 函数了,我们选择这个区域,然后输入等于 frequency, 然, 然后选择这个数据区域,再选择第二个参数,边界值组成的一个数组括号括回来, ctrl shift enter, 大家发现没有?出现问题了,都是五,为什么都是五啊? 因为这个五是垂直一维数组的第一个元素,相当于我们这里输入了四个垂直一维数组,但是呢,每一个格子刚好显示了每一个垂直一维数组的第一个元素, 那这里就出现问题了,那我们通过刚刚的学习,我们应该怎么去完善呢?其实很简单,我们就应该对这个数据进行一个转制,对不对?我们在这个里按 f 二,然后呢外面加一个圈子 pose, 然后再把这个括号括回来, control shift enter, 它就可以返回一个水平异位数组,因为它的结果本来是一个垂直异位数组,现在我经过转制把它 变成了水平异位数组,对吧?他就可以完美的呈现出每一个区间段,每一个评级标准中有多少个数据,对吧?好,我们来检验一下,好,我们来数一下,及格是在六十到七十四,对不对?我们数一下个数一 二三四,对吧?是不对应这四个数据,那好,良好是两个,良好是七十五到八十四,对不对?我们来数一下,一二 就对应这两个数据,对不对?所以说我们这个边界值刚好可以符合我们常规的对成绩的一个判断。那通过这个例子,我希望大家可以理解到,三个边界值决定四个区间,然后呢,我们这个区间怎么设置,让他可以符合我 我们的这个标准,同时要知道这个边界值它到底包含或者不包含于哪一个区域,这个很重要, 接下去就是要接下去就是要理解 transpose 加上这个 frequency, 才可以把这个末日的垂直异位数组转制成水平异位数组呈现在我们的表格中啊,这两个点希望大家可以理解。 那接下去我们来看案例二,案例二,请统计出数据在各个数字区间内出现的次数, 那这里呢,其实我们主要是以乱序排列一个边界值,以及深序排列一个边界值,注意啊,这两个边界值是完全一模一样的, 只是说这里进行了顺序排列,这里是乱序的。那我们来输入一下公式,选择这个 n 加一的区域,输入等于 frequency, 选择这个数据区域 逗号,再选择这个乱序的边界值组成的数组括号括回来。 control shift enter, 同样我们选择这个 n 加一的区域,输入 frequency, 选择相同的数据区域,再选择 声序排列的边界值组成的数组区域。 control shift enter, 我们来看一下,五十对应的是一,这边五十对应的也是一, 四十五对应的是一,这边,四十五对应的也是一,这边八十五对应三,这边八十五也对应了三,对不对?这两边肯定是完全一模一样的,不管你是声序还是乱序, 大家就可以这样子理解 excel, 他默认是把你这个乱序的数据进行了声序,然后把这个对应的数量给他对应上去,之后再给你匹配出来,反馈为一个乱序的结果组。 你不要以为这里是八十到四十五,那上个区间比下个区间大了,那他怎么办呢?其实这个四十五他统计的是零到四十五之间的一个数据,就相当于这里只有一个多少啊?啊?四十五对不对?只有这个数据是符合统计标准的,而不是说四十五到八十,大家一定要清楚啊, 八十的一个下线边界值永远是七十。那我们这里有三步操作,第一步,我们把这个随机函数生成的随机数进行复制,然后呢粘贴作为一个固定。 接下去我们来试验一下文本它到底纳不纳入统计,比如说这里文本我可以输入两个,三个 z、 e、 s、 o w, 对不对? control ant 发现没有,我统计一下这里的数量啊,选中变成十三个了,对不对?那这里明明有十六个数据,为什么这里有十三个呢? 为什么这里少了三个啊?因为我们填入了三个文本,那我们再加入几个空格啊?加入三个空格取消掉,我们再选择这个区域,发现没有,只有十个数据了,说明这里减去了三个文本和三个空格,也就是验证了文本和空值,他是不会作为带统计对象 放入这个边界值构成的区间进行统计数量的,那如果说我们这里输入一个错误值会出现什么情况?我们也来验证一下,等于一除以零, 发现没有,你只要输入一个错误值,那么这个整个函数都会受到波及,返回的结果全部都是错误值。那这个大家也注意一下,我加上去我这里先给他恢复回去啊。那在这个案例中大家掌握什么?第一个结果区域一定是边界值加一 对吧,因为多少 n 的边界值可以区分 n 加一个区间。第二个乱序与声序对这个返回的结果没有影响,但是呢对他的顺序会有影响的。 然后还有一个大家要注意的是,比如说这里六十,他是有两个数量对不对?那我如果再加一个六十呢?那第二个六十这里他就会出现为零。 所以说大家要记住,你的边界值如果有重复,那么 fucking c 函数只会在从上到下第一个边界值的地方反馈出这个边界值所对应的一个统计数量,后面的所有重复的边界值都会显示为零啊,这个特性在我们后面这个例子中就会用到。 好,那我们来看一下案例三,案例三,统计一个数据区域内去重后 存在多少个唯一值,并且将它提取出来。这个案例有几个难点,首先它的数据区域是以文本构成的一个数组, 然后呢我们要去去重后发现文一值,那我们知道 frequency 对文本它是不起作用的,对吧?所以说我们第一步是要构造一个数值去对应这个文本,那我们怎么构造呢?这里我们就想到了用 match 函数来做,我这里输入等于 match, 然后把这个王五给他选中,让他在这个区域内去找他的位置,对不对?绝对引用。 然后呢,用精确匹配,他会返回什么?他会返回一个一啊,这里是变李四了啊,李四是不是一号位?那么如果往下去拖呢?拖到这里为止,我们发现没有, 这个第二个里是,第三个里是,包括这个第四个里是,他对应的都是一啊,他对应的都是一,对不对? 为什么都是一啊?因为精确匹配他是从上往下便利的,找到一号位之后,他就会绑定李四就是一,不管你后面几个李四,他都会反馈为一, 同理,第二个和时他是二,那么所有的和时他所对应的这个数字也是二,那经过这样子之后,我们就可以把文本转换成一个数字来作为代表,对不对? 而且他是一个唯一的,不会说,因为你后面有一个李四,他会变成另外一个数字,那这样子之后我们就有了一个以数字去代替文本的一个操作,对吧?因为这里我是输入单个数据,对不对?我这里要把它改成一个数组公式,我们来修改一下, 选中区域,先删除输入等于 match, 然后第一个参数本来是单个单元格,我给他选中为多个单元格区域,绝对引用, 然后呢,第二个呢?还是这个区域作为他的一个查询的范围,对吧?这样子之后他会把第一个参数中的每一个元素分别放入第二个参数中去查询他的位置,然后呢,返回出 这个数据,在第二个参数中第一次出现的相对序号,作为它的一个结果,也作为一个元素来构成了一个同样大小的一个结果数组啊,然后呢,一定要选择精确匹配, ctrl shift enter, 它就会出现这么一个数组啊, 好,因为后期我们要做什么?我们要做一个 frequency 的函数, frequency 我们需要给它一个边界值,对不对? 那边界时我们怎么来呢?因为这个东西非常特殊,我们的边界值啊,要统计出他的唯一值的话,我们就要用到连续的以一为单位的一个等差数列,我们选择这个区域输入等于 row, 然后里面呢,就用经典的我们之前教程讲过的 indirect, 这里输入一冒号,就是说一行开始到哪里呢?到 rose 就相当于这里有多少行,我就要来制造出从一到这里行数相等的一个等差数列, ctrl shift enter 啊,大家发现没有? 从一到十三的一个常量数组,对吧?好,那我们来看这里李四,他对应的是一,那所有的李四对应的都是一,这个区域相当于是一个带分组处理的对象,那么这个区域呢,就相当于是一个 边界值构成的一个数组。那我们来想象一下,如果一放进这个区域统计,他会出现在这一号位,而且他会有几个啊?他会有一二两个,对不对?那二呢?有几个呢?他会反馈到这个位置,对吧?二, 一二也是两个,对不对?那我们直接写出来看一下好不好?那正常情况下,我们是不是要多选一个单元格,输入等于 frequency, 选择这个区域作为第一参数,绝对引用,再选择这个区域作为边界值组成的一个数组,绝对引用括号括回来, control shift enter, 就可以得到了这么一个结果。数组,那我们来看一下这个数组的意思是什么呢?比如说一,他出现了几次啊?三次,那一二三对吧?二和三分别出现了四次,然后呢?六出现了一次,也就是前 八出现了一次,大家可以这样的横过去对应啊,比如说十三出现了一次对不对?那十三是什么?就是张三,那张三是不是在这个数组里面只出现了一次啊?对吧?那这样子我们再去想如何统计有多少个唯一值呢? 这里有多少个大于零的数字就是有多少个唯一值了,那么就可以等于 count if, 然后选择这个对应的区域, f 四,再加一个条件,大于零对不对? 大于零回车,那他就有六个,对吧?这里是不是有六个不同的一个数字啊?我们再激活一下,五个呢?这里就只有五个了,我们来找一下,少了一个李四,对不对?好,我们再激活一下,变六了,对不对?李四出现了啊,所以说他这里是已经可以正确的统计 多少个唯一值了。刚刚这个思路啊,从这边不断的构思过来,大家一定要跟上节奏,或者是多看几遍好不好? 好,那我们既然到这一步了,我们就往下走,为了让显示更加的清晰,我就把这几列暂时先隐藏掉, 那我现在要做什么呢?根据我们之前学过的一个一反多的经典结构,是不是可以用 index 加 small 加那个 row 来做,对吧?好,那我们先做判断,把这个相对行号给它提取出来,那这里我就可以输入等于 if 这个区域,它大于零,它就返回什么,就返回它的相对行号,对不对?否则就返回什么,返回一个极大值八的八次方都可以啊。 ctrl shift enter, 它是不是返 回来这么一个垂直 e v 数组,对不对?然后我们对这个行号进行一个排序,就是用 small 函数把这个垂直 e v 数组进行一个排序,那我们输入一下这个函数等于 small, 然后这里选择这个区域绝对引用,然后呢?后面我们加一个 row a 一 啊,这个不理解的大家一定要去看我前面那个教程啊,关于自适应产量数组的一个构造啊,也包括你可以看我的直播间或者相应的一个案例去讲一反多的一个结构,里面我讲的比较详细,那这里我就不深入了, 我相当于要对这个数组进行一个从小到大的排序,若 a 一就等于一往下拖的时候,他就会变成若 a 二,那第二行就是二嘛,对吧?好, enter, 然后我往下填充,是不是就对这个行 号进行了一个从小到大的重排,对不对?好,那我现在就可以去提取这个人名了。怎么提取呢?我们可以用 index 函数,我输入等于 index, index 的第一个参数是我的结果所在的区域,绝对应用,不要忘了。然后第二个我们就输入这个对应的行号就可以了啊,比如说这第一个是 l 六七 enter, 那往五就出来了,我们往下填充 啊,他就会有前八和十孙九,王五李四,张三都有,对吧?那张三在几号位?张三他在七号位,我们看一下七号位是第一次出现张三,对不对?那 王五他是四号位第一次出现,对吧?王五是四号位第一次出现,所以他就实现了我们这功能。那么再来看一下美化是什么意思呢?因为这里他有一个极大值, 八的八次方的时候,它是不能返回一个相应的结果,它会出现错误值,那我们经典的一个美化结构就等于 if l, 对吧?如果这个公式是错误值,我就返回为空,对吧?那这个公式我在手中输一下 index, 然后呢选择这个结果所在的区域,绝对引用,加上这个相对应的函号,对吧? enter 往下填充,那这样子我们就实现了一个唯一值的统计个数,加上唯一值的一个提取,我们多激活几次,让它出现一个五,好不好?激活好一次就变成五了,对不对?那这里就是五个了,对不对? 那这里也是五个对应的都是一样的啊,这个逻辑大家一定要去理解清楚,对于如何理解数组公式都是非常有帮助的。好,那我们接下去就把这个公式给它嵌套到一起, 这个过程是比较有意思的,我在直播间也讲过几次了,我们来演示一下。我先把最后一个公式给他复制,然后粘贴到这里,然后一一对里面的一个引用进行替换。 这个引用替换的一个规则是什么呢?我要把所有辅助列的这个区域的一个引用都给他替换成相对应的辅助列第一个单元格的一个公式就可以了, 其实蛮简单的,因为我们理论上啊,这个区域辅助列区域是不应该存在的,最后是要删除掉的,对吧?这个辅助列区域呢,只是说有利于大家去理解这么一个过程, 有助于大家去构思一个解决方案而存在的啊。好,我们来看一下怎么来做。第一个我们看 l 六七, l 六七,我们就要把 l 六七的内容给它复制,然后呢把自己的 l 六七给它 替换掉粘贴啊? enter, 对吧?然后呢我们再来看一下,这里有个 k 六七到 k 七九,那就是 k 六七到 k 七九,就把这个 k 六七的公式复制,然后呢粘贴到这个 k 六七到 k 七九的区域替换掉,好,这样子,对吧?回车, 张三还是在,对吧?好,接下去我们从右往左啊,发现没有 f 六七到 f 七九,那就把 f 六七的这个公式复制, 然后呢粘贴到这里,把这个 f 六七和 f 七九给它替换掉,粘贴。回车啊,前八还在,对不对?好, 再从右往左看 b 了啊, b 没有问题,是我们的数据员。再往前走, h 六七到 h 八零,那我是不是把 h 的这个六七的公式给它复制,然后呢再 粘贴到这里,把这个 h 六七到 h 八零给他替换掉,然后回车,对吧?孙九还在,那我们再从右道左看啊,笔也没有问题,对吧?又到了 f 六七到 f 七九,对吧?那又又同样是操作吧?把这个复制, 然后呢粘贴到这个 f 六七到 f 七九的位置粘贴,然后回车。 接下去往下看,那就这里是有个 d 的,对不对? d 也不属于我们的这个区域,那我就把 d 六七的公式复制, 然后呢粘贴到这个 d 六七和 d d 七九的位置替换掉回车,对吧?好,那这样子之后我们从那边往下看啊,从这边往外看,我们检查一下,除了这个 b 六七到 b 七九已经没有任何的其他区域的引用了,除了这个 low a 一,它是 是一个产量构造,对不对?好,我们给他点上去,然后我们双击这里看一下是否只是引用了这个蓝色区域啊?因为这里的 b 六七和 b 七九有一些我们进行的绝对引用,但是呢,这里我们有个忽略,对吧?我们也要给他加上绝对引用, 否则的话我们往下填充的时候会出现一个错位啊,先给他决定用加起来啊,检查一下。好,这样子 ok 了, 当然了,还有一点啊,这里是数组公式,里面有涉及到了很多数组的计算,相信大家在这里也都看到了,所以说我们一定要激活这个单元格, ctrl shift enter, 然后在这个基础之上,我们去往下拉,就可以得到了我们的一个准确结果,否则的话你可能出现一个错误的结果,所有的结果都是亡五,对不对?大家这里如果遇到问题,一定要去检查一下你的公式最外层有没有这个 象征数组公式的这个大括号好不好?好,那这样之后我们理论上是不是可以把这个都删除啊?删除不影响他的一个计算,对不对? 我们撤销。那这样子我们整个案例就讲完了,我们从文本转换成数字,然后呢给数字构造出一个合理的边界值,通过边界值计算出它的一个啊分布区间, 通过统计非零的分布区间去找出唯一值的个数,同时通过这个非零的分布区间去提取出它相对应的一个行号,用斯莫函数对行号进行一个升序排列,然后根据应带的函数去提取出相对应的一个数据, 再通过 if er 进行美化,最后进行一个公式的嵌套,完成了这么一个复杂公式的一个编写。最 大家一定要注意啊,这个公式往下拖之前一定要 ctrl shift enter, 同时你在欠套公式完之后,一定要看一下这个所有的这个引用区域有没有加绝对引用。 因为这里存在一个问题,我们输入数组公式的时候,因为他是直接选中的他,这个是不需要你去决定用,因为你不存在往下拖拽的情况, 所以说你很容易在输入数组公式的时候不去决定引用,也能得到一个准确结果。但是你如果是盲目的去欠套,你不去思考为什么这里需要决定引用的话,你就可能会出现问题好不好?好,那我们今天就把这个 frequency 的函数讲解完了,我们下次课再见。
219Excel课代表 00:57查看AI文稿AI文稿
00:57查看AI文稿AI文稿求最大连续签到次数,左边是张三的签到表,一表示签到空,表是没有签到,求他最大的连续签到次数。思路,首先先找到空的,没签到的,然后求进两个空值之间一的次数,最后求最大值即可。看一下完整公式和公式解析 分布讲解一下可以看出,辅助列备四五七十三十四十七,切分成若干分就可以想到就可以用 frequency 求断点频次。最大连续签到次数公式, 你学会了吗?关注我,每天学一点 excel 技巧,想学什么评论留言我教你!
 03:21查看AI文稿AI文稿
03:21查看AI文稿AI文稿大家好,这个视频分享 is 要统计函数 flick 写的用法,我们来看一下例子。比如现在我有一个班的成绩表啊,这里有语文成绩,我想统计一下啊, 每个分数段啊,有到个学生,这个时候呢,我们就可以用到动机函数 frequency 这个函数。 我们来看一下,现在我已经把这个分式段的这个要求啊,已经写在这里了啊,这里要分成五个分式段啊。然后呢,在使用这个函数之前呢,我们需要设置一个分段点,这个 分段点呢,需要设置就是这个分数段的最大值啊。比如这里啊,分数小六十的话,我最大值我可以设置成五十九。好,然后呢,这个呢 啊,分数段呢,我可以设置张六十九取到的最大值,这也是一样啊,设置这个分段点的最大值啊, 好,这个最大值就是一百。好,这个分寸点设置好了以后呢,我们就可以开始啊使用这个函数了。这里呢,要特别注意,我们要使用这个函数的时候,比如现在这个啊,我们要 统计每个分支段有导购协商的时候,我们需要用鼠标把这个地方啊都选选起来,然后呢,然后在这里输入这个函数看一下啊, 好,第一个参数是它的数据区域,我们直接用鼠标给写一下。好,这是第一个参数。 然后第二个粘数就是他的这个啊,分段点,分段点我们这里已经设置好了,就在这地方,我们呢用鼠标也把它写一下。好,我们看一下这函数呢,就写好了。 写好完了以后,我们在这个地方要特别注意,我们要同时按住键盘上的 ctrl shift n 的键,这样的时候我们就会看到我们这里统计数据就出来了。我们就会看到啊, 小六十分的学生有十二个人啊,你看这个大一啊,九十分以上的学生有五个人,我们来核对一下, 有这里小六十分的我们看一下啊,确实是十二个人啊,然后上面这个啊,九分以上的 啊,就是五个人。好,本期视频就分享到这,喜欢的话请关注转发,谢谢观看。
9风扬致远 00:34查看AI文稿AI文稿
00:34查看AI文稿AI文稿需要统计不同年龄阶段的人数,可以用频率分布统计 freeconc 函数。首先按照从小到大的顺序依次输入三个零戒指,三个零戒指组成四个区间,因此选中四个单元格输入等于 freeconc。 第一个参数是年龄区域 b 二到 b 三十三,第二个参数是零借值区域一二到一四。最后同时按 ctrl 加 shift 加回车,不同阶段的人数就统计出来啦。
226黑米Office课堂 01:23查看AI文稿AI文稿
01:23查看AI文稿AI文稿宋老师,有没有一个函数专门用来统计数据的频率分布? wps 表格专门提供了一个用来统计数据频率分布的函数,分坤 c, 今天我们来学习一下如何使用分坤 c 函数解决区间段统计问题。 首先根据业绩区间的分割点建立辅助列,输入分割点九十九幺九九 同理,输入其他的分割点,然后选中显示统计结果的区域,输入函数等于 forensive。 第一个参 三数为一组数值,我们选择业绩逗号。第二个参数我们选择一组间隔值,也就是我们的辅助列 g 四到 g 八,然后按一下 ctrl shift 回车三键输入, 那么结果就统计出来了。你学会了吗?点个赞吧!关注我,了解更多办公知识!
184宋老师的WPS办公小课堂 04:32查看AI文稿AI文稿
04:32查看AI文稿AI文稿呃,你好,欢迎你继续跟我学习一下。之前我们学习的啊,目的是求取政府,然后我们进这节课学习一个就是求取频率的函数,就是他在某个条件范围出现了厕所,我们叫 free creams。 free questions 的英文意思其实就是其实就平的意思就是就是他出现的次数。然后这个首先这个是我们要就是我们的一组数据吧,就是在这个数据当中,然后选取,然后这个是我们条件,这个五百,二百,两五百,两千,三千。这个什么意思呢?这是我们条件区域, 代表五百的就代表五百五百以下,然后第二个就是啊,这个就代表五百到两两千之间,然后这个就是代表两千到三千之间,然后这个就是代表三千以上。那我们看一下他那个具体用法。 首先其实我们要先选中对吧,我们这个其实有四个,就是五百,然后五百的两两千之间,三千到两千之间,大于三千的范围。然后我们首先选中,首先选中频率,频率的区域,这边四个就可以了, 然等于 free print, 在上面输入 free print, 然后我们第一个是数据区域,我们把这个数据选择选中啊,第二个条件是第二个参数是条件区域,我们把这个选中就可以了, 然后给它框住,接下来就接下来按住 ctrl 加 shift, 然后加 enter, 然后它自动填充,然后可以看出来,然后这是他们那个频率,就是五百 以下的能有三个,然后五百到两千之间的就是十七个,然后大于三千的四个我们可以我们可以设置一下条件区域看一下。那我们就就简单的看一下啊,那个三千以上的或者五千五百以下的,然后我们用一下简单的条件格式, 然后通过突出显示吧,大于,比如说我们大于三千,我们可以大看一下,大于三千的有四个, 然后这个就是大于三千,比如说我们小于小于,小于五百,那我们可以继续看一下,小于,比如说小于五百,小于五百可以看到他有三个,那当然我们也可以再去验证一下,然后 然后介于你说介于多少,介于五百,五百到两千之间的 也可以看到,我们可以数一下一二三四五六七八九十十一十二十三十四十五十六十七。好,两五百到两天之间等于十七个。然后这个数字就等我们再来看一下,两千到 两千到三千之间的可以看它有十一个,那我们数一下,加上五个,七个,八个,九个,十个,十一个。也就说明频率上我们是没有错误的。这个就是 frequent 啊,一个基本用法 free queens, 然后第一个就是 它,这个就是数据区。 好,第二个就是调进去。 首先第一步我们就是选中,就是频率选中秋季频率的 区域这种第一个先把四个单元格给选中,然后第二步就数据函数 是吧 free queens, 然后调进去,然后数据区。然后第三步是按住 ctrl 加 shift, 加上 enter, 然后就可以填充 频率数据, 这个就是 frequent 求取频率的呃的基本用法。
13买盒火柴烤地瓜 02:53查看AI文稿AI文稿
02:53查看AI文稿AI文稿大家好,今天我们来学习一个函数实例,那么我们来看一下这样一张成绩排名表,我们要对各个同学的总分进行排名啊,前面我们学习过一个函数,好 rank, 那么这个函数呢, 我们来看一下,按下回车往下填充。这时候呢,我们可以看到啊,这二百七十五分呢,有两个第一名,那第二在哪呢?没有直接跳到第三了,第三,这后面第四在哪呢?没有直接跳到第五了啊,那么这时候呢,这个排名结果呢,不符合我们的排名习惯。 那么这时呢,我们要用另外一个函数啊,叫做 frequency, 当他两个参数相同的时候呢,他将会统计数据区域,每个数字对应的数字呢,他出现的次数。好,如果前面有数 数字统计过程的话呢,他将不再重复统计,其统计次数为零。好,我们来看一下他的特点,大家演示一遍。好,选中这块区域 和五号,再选中这一块区域啊,两个参数相同,按下 f 九。这时候我们可以发现,那么第一个三呢,也就是二百五十五出现了次数,他出现了三次。第二个二百五十五呢,他出现了次数呢,他是零次,因为上前面的这已经已经统计过了,他将不再重复统计, 所以他的数字是对应的是零,那么包括下面的,以此类推啊,那么这里不再重复,那么呢这就是 freeconce 的这个特点, 利用这个特点呢,筛选掉我们重复值,在这个基础上,我们先把这个删除啊,等于 free, 然后呢给他做一个判断,大于零啊,这个条件呢, 就相当于筛选掉我们重复之了。好,然后呢,我们把它作为衣服函数的调解。 好,大于零的时候呢,让它返回什么呢?返回,我们现在要找张三,张一大于张一的这个总分的个数,不重复值的个数好,大于 这个一三,好,这个呢就是当大于这个总分一,这个张一的这个同学总分,他总共不重复的个数是多少?在这这个举手呢,我们再加上一个一啊,就是他的排名结果。最外层用求和函数 套用求和函数前面敲两个减号,因为这个参数呢,它是一个逻辑值数组,我们要把它全部转换成一和零来参与计算,然后右括号加上 一。啊,好,这个位置呢,我们要锁住好,三键合一往下填充,这时候呢,就得到我们想要的排名结果了啊,好,这第一,第一到第二,第二到第三,第四第五。好,这样的排名结果呢,才符合我们的习惯,这就是 freecons 函数的特殊用法。
136office远方 01:26查看AI文稿AI文稿
01:26查看AI文稿AI文稿excel 函数 a cross 求频率分布?大家好,今天教给大家 free cross 函数,这个函数呢,它是反映了某些数组的频率分布,那我们来看这个函数具体的使用方法。我们现在呢可以看到这有一列数据年龄, 我们要在这里统计满足这些年龄段的人数各有多少。好,我们来使用 free crunch 函数进行频率分布的统计。来,我们选中 f 列进行插入, 建立辅助列,我们把这列的年龄段中的最大值写到这里,然后我们填充到这个位置,最后一个七十五岁以上的, 那么我们无法确定最大值,那在这里我们就把它空着,选中我们要求的值所在的单元格,输入 frequency 函数,这个函数呢,它一共只有两个词, 参数。第一个参数就是我们要统计的这些年龄,把所有的值全部选中英文条件下的逗号,我们再去选择我们刚才添加的辅助列,也就是说临界点的这个值的范围来选择,然后进行括号,右括号 frequency 这个函数呢,它是一个数组类型的函数,那么我们要返回值的话,我们需要按住 ctrl shift 加回车 这样的一个组合键,我们就把满足这个年龄段的人数给统计出来了。关于 free crunch 函数,你学会了吗?
439对啊网AI技巧蛙 01:00查看AI文稿AI文稿
01:00查看AI文稿AI文稿excel 分段统计人数?我们看这样一个例子,如果教师需要统计成绩的每个分数段的人数,应该如何操作呢?我们之前学过的都是用康的 f 函数来统计,然后呢,今天给大家介绍一个新的函数,分坤 c 函数。 这个函数是以一列垂直数组返回某个区域中数据的频率分布。假如说我们要统计零到五十九分这个分数段的人数, 统计六十到六十九分,统计七十到七十九,统计八十到八十九以及九十分以上的人数。我们首先应该设置这样的分数段,五十九,六十九,七十九和八十九,然后这个人数,我们首先将人数这些 选框选中,在公式插入函数当中,选择弗伦坤 c 函数,点击确定。
20爱办公的小马




